Demystifying iControl REST Part 6: Token-Based Authentication
iControl REST. It’s iControl SOAP’s baby, brother, introduced back in TMOS version 11.4 as an early access feature but released fully in version 11.5. Several articles on basic usage have been written on iControl REST so the intent here isn’t basic use, but rather to demystify some of the finer details of using the API. This article will cover the details on how to retrieve and use an authentication token from the BIG-IP using iControl REST and the python programming language. This token is used in place of basic authentication on API calls, which is a requirement for external authentication. Note that for configuration changes, version 12.0 or higher is required as earlier versions will trigger an un-authorized error. The tacacs config in this article is dependent on a version that I am no longer able to get installed on a modern linux flavor. Instead, try this Dockerized tacacs+ server for your testing. The Fine Print The details of the token provider are here in the wiki. We’ll focus on a provider not listed there: tmos. This provider instructs the API interface to use the provider that is configured in tmos. For this article, I’ve configured a tacacs server and the BIG-IP with custom remote roles as shown below to show BIG-IP version 12’s iControl REST support for remote authentication and authorization. Details for how this configuration works can be found in the tacacs+ article I wrote a while back. BIG-IP tacacs+ configuration auth remote-role { role-info { adm { attribute F5-LTM-User-Info-1=adm console %F5-LTM-User-Console line-order 1 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } mgr { attribute F5-LTM-User-Info-1=mgr console %F5-LTM-User-Console line-order 2 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } } } auth remote-user { } auth source { type tacacs } auth tacacs system-auth { debug enabled protocol ip secret $M$Zq$T2SNeIqxi29CAfShLLqw8Q== servers { 172.16.44.20 } service ppp } Tacacs+ Server configuration id = tac_plus { debug = PACKET AUTHEN AUTHOR access log = /var/log/access.log accounting log = /var/log/acct.log host = world { address = ::/0 prompt = "\nAuthorized Access Only!\nTACACS+ Login\n" key = devcentral } group = adm { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = adm set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 0 set F5-LTM-User-Partition = all } } } group = mgr { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = mgr set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 100 set F5-LTM-User-Partition = all } } } user = user_admin { password = clear letmein00 member = adm } user = user_mgr { password = clear letmein00 member = mgr } } Basic Requirements Before we look at code, however, let’s take a look at the json payload requirements, followed by response data from a query using Chrome’s Advanced REST Client plugin. First, since we are sending json payload, we need to add the Content-Type: application/json header to the query. The payload we are sending with the post looks like this: { "username": "remote_auth_user", "password": "remote_auth_password", "loginProviderName": "tmos" } You submit the same remote authentication credentials in the initial basic authentication as well, no need to have access to the default admin account credentials. A successful query for a token returns data like this: { username: "user_admin" loginReference: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/login" }- token: { uuid: "4d1bd79f-dca7-406b-8627-3ad262628f31" name: "5C0F982A0BF37CBE5DE2CB8313102A494A4759E5704371B77D7E35ADBE4AAC33184EB3C5117D94FAFA054B7DB7F02539F6550F8D4FA25C4BFF1145287E93F70D" token: "5C0F982A0BF37CBE5DE2CB8313102A494A4759E5704371B77D7E35ADBE4AAC33184EB3C5117D94FAFA054B7DB7F02539F6550F8D4FA25C4BFF1145287E93F70D" userName: "user_admin" user: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/34ba3932-bfa3-4738-9d55-c81a1c783619" }- groupReferences: [1] 0: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/user-groups/21232f29-7a57-35a7-8389-4a0e4a801fc3" }- - timeout: 1200 startTime: "2015-11-17T19:38:50.415-0800" address: "172.16.44.1" partition: "[All]" generation: 1 lastUpdateMicros: 1447817930414518 expirationMicros: 1447819130415000 kind: "shared:authz:tokens:authtokenitemstate" selfLink: "https://localhost/mgmt/shared/authz/tokens/4d1bd79f-dca7-406b-8627-3ad262628f31" }- generation: 0 lastUpdateMicros: 0 } Among many other fields, you can see the token field with a very long hexadecimal token. That’s what we need to authenticate future API calls. Requesting the token programmatically In order to request the token, you first have to supply basic auth credentials like normal. This is currently required to access the /mgmt/shared/authn/login API location. The basic workflow is as follows (with line numbers from the code below in parentheses): Make a POST request to BIG-IP with basic authentication header and json payload with username, password, and the login provider (9-16, 41-47) Remove the basic authentication (49) Add the token from the post response to the X-F5-Auth-Token header (50) Continue further requests like normal. In this example, we’ll create a pool to verify read/write privileges. (1-6, 52-53) And here’s the code (in python) to make that happen: def create_pool(bigip, url, pool): payload = {} payload['name'] = pool pool_config = bigip.post(url, json.dumps(payload)).json() return pool_config def get_token(bigip, url, creds): payload = {} payload['username'] = creds[0] payload['password'] = creds[1] payload['loginProviderName'] = 'tmos' token = bigip.post(url, json.dumps(payload)).json()['token']['token'] return token if __name__ == "__main__": import os, requests, json, argparse, getpass requests.packages.urllib3.disable_warnings() parser = argparse.ArgumentParser(description='Remote Authentication Test - Create Pool') parser.add_argument("host", help='BIG-IP IP or Hostname', ) parser.add_argument("username", help='BIG-IP Username') parser.add_argument("poolname", help='Key/Cert file names (include the path.)') args = vars(parser.parse_args()) hostname = args['host'] username = args['username'] poolname = args['poolname'] print "%s, enter your password: " % args['username'], password = getpass.getpass() url_base = 'https://%s/mgmt' % hostname url_auth = '%s/shared/authn/login' % url_base url_pool = '%s/tm/ltm/pool' % url_base b = requests.session() b.headers.update({'Content-Type':'application/json'}) b.auth = (username, password) b.verify = False token = get_token(b, url_auth, (username, password)) print '\nToken: %s\n' % token b.auth = None b.headers.update({'X-F5-Auth-Token': token}) response = create_pool(b, url_pool, poolname) print '\nNew Pool: %s\n' % response Running this script from the command line, we get the following response: FLD-ML-RAHM:scripts rahm$ python remoteauth.py 172.16.44.15 user_admin myNewestPool1 Password: user_admin, enter your password: Token: 2C61FE257C7A8B6E49C74864240E8C3D3592FDE9DA3007618CE11915F1183BF9FBAF00D09F61DE15FCE9CAB2DC2ACC165CBA3721362014807A9BF4DEA90BB09F New Pool: {u'generation': 453, u'minActiveMembers': 0, u'ipTosToServer': u'pass-through', u'loadBalancingMode': u'round-robin', u'allowNat': u'yes', u'queueDepthLimit': 0, u'membersReference': {u'isSubcollection': True, u'link': u'https://localhost/mgmt/tm/ltm/pool/~Common~myNewestPool1/members?ver=12.0.0'}, u'minUpMembers': 0, u'slowRampTime': 10, u'minUpMembersAction': u'failover', u'minUpMembersChecking': u'disabled', u'queueTimeLimit': 0, u'linkQosToServer': u'pass-through', u'queueOnConnectionLimit': u'disabled', u'fullPath': u'myNewestPool1', u'kind': u'tm:ltm:pool:poolstate', u'name': u'myNewestPool1', u'allowSnat': u'yes', u'ipTosToClient': u'pass-through', u'reselectTries': 0, u'selfLink': u'https://localhost/mgmt/tm/ltm/pool/myNewestPool1?ver=12.0.0', u'serviceDownAction': u'none', u'ignorePersistedWeight': u'disabled', u'linkQosToClient': u'pass-through'} You can test this out in the Chrome Advanced Rest Client plugin, or from the command line with curl or any other language supporting REST clients as well, I just use python for the examples well, because I like it. I hope you all are digging into iControl REST! What questions do you have? What else would you like clarity on? Drop a comment below.18KViews0likes42CommentsParsing F5 BIG-IP LTM DNS profile statistics and extracting values with Python
Introduction Hello there! Arvin here from the F5 SIRT. A little while ago, I published F5BIG-IP Advanced Firewall Manager (AFM) DNS NXDOMAIN Query Attack Type Walkthroughpart one and two, where I went through the process of reviewing BIG-IP LTM DNS profile statistics and used it to set BIG-IP AFM DNS NXDOMAIN Query attack type detection and mitigation thresholds with the goal of mitigating DNS NXDOMAIN Floods. In this article, I continue to look atBIG-IP LTM DNS profile statistics, find ways of parsing it and to extract specific values of interest through Python. Python for Network Engineers Python has emerged as a go-to language for network engineers, providing a powerful and accessible toolset for managing and automating network tasks. Known for its simplicity and readability, Python enables network engineers to script routine operations, automate repetitive tasks, and interact with network devices through APIs. With extensive libraries and frameworks tailored to networking, Python empowers engineers to streamline configurations, troubleshoot issues, and enhance network efficiency. Its versatility makes it an invaluable asset for network automation, allowing engineers to adapt to evolving network requirements and efficiently manage complex infrastructures. Whether you're retrieving data, configuring devices, or optimizing network performance, Python simplifies the process for network engineers, making it an essential skill in the modern networking landscape. The Tools ChatGPT3.5 The "Python for Network Engineers" intro came from ChatGPT3.5 [:)]. Throughout this article, the python coding "bumps" avoidance and approaches came from ChatGPT3.5. Instead of googling, I asked ChatGPT "a lot" so I could get the python scripts to get the output I wanted. https://chat.openai.com/ Visual Studio Code UsingVisual Studio Code (VSCode) to build the scripts was very helpful, especially the tooltip / hints which tells me and help make sense of the available options for the modules used and describing the python data structures. Python 3.10 (From ChatGPT)Python 3.10, the latest version of the Python programming language, brings forth new features and optimizations that enhance the language's power and simplicity. With Python's commitment to readability and ease of use, version 3.10 introduces structural pattern matching, allowing developers to express complex logic more concisely. Other improvements include precise types, performance enhancements, and updates to syntax for cleaner code. Python 3.10 continues to be a versatile and accessible language, serving diverse needs from web development to data science and automation. Its vibrant community and extensive ecosystem of libraries make Python 3.10 a top choice for developers seeking both efficiency and clarity in their code. Python Script - extract DNS A requests value from LTM DNS profile statistics iControl REST output This python script will extract DNS A requests value from LTM DNS profile statistics iControl REST output. Python has many modules that can be used to simplify tasks. iControl REST output is in json format, so as expected, I used the json module. I wanted to format the output data in csv format so the extracted data can later be used in other tools that consume csv formatted data, thus, I used the csv module. I also used the os, time/datetime and tabulate modules for working with the filesystem (I used a Windows machine to run Python and VSCode) to write csv files. Create variables with date and time information that will be used in formatting the csv file name, keep track of the "A record requests" value at script execution, and present a tabulated output of the captured time and data when the script is executed. I also used BIGREST module to query/retrieve the "show ltm dns profile <DNS profile> statistics" instead of getting the output from iControl REST request sent through other methods. https://bigrest.readthedocs.io/introduction.html https://bigrest.readthedocs.io/bigip_show.html Here is the sample script output Here is the sample CSV-formatted data in a csv file with timestamp of the script run I created a github repository for the Python script and its sample script output and csv data see https://github.com/arvfopa/scripts/tree/main https://github.com/arvfopa/scripts/blob/main/extractAreq- Python Script "extractAreq" https://github.com/arvfopa/scripts/blob/main/extractAreq_output- "extractAreq" output Bumps along the way BIGREST module I initially encountered an error 'certificate verify failed: self signed certificate' when provided only the IP address and credentials used in the BIGIP class of the bigrest.bigip python module raise SSLError(e, request=request) requests.exceptions.SSLError: HTTPSConnectionPool(host='IP address', port=443): Max retries exceeded with url: /mgmt/shared/echo-query (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate (_ssl.c:1007)'))) This is fixed by setting "session_verify" argument of the BIGIP class to "false" to disables SSL certificate validation device = BIGIP("<IP address>", "<username>", "<password>" , session_verify=False) https://bigrest.readthedocs.io/utils.html I also received this error "TypeError: Object of type RESTObject is not JSON serializable" raise TypeError(f'Object of type {o.__class__.__name__} ' TypeError: Object of type RESTObject is not JSON serializable I reread the BIGREST documentation and found that the output is a python dictionary and can is printed in json format.I rechecked the script and removed the json related syntax and module, and the script runs fine and still gets the same output. I updated the script on github with the simplified changes. https://bigrest.readthedocs.io/restobject.html Here's a sample of the RESTObject properties dictionary values. Plenty of data can be extracted. Example, "clientside.pktsIn" value, a virtual server statistic, can be observed and should detection and mitigation thresholds for AFM, say, UDP protocol DoS attack type, need to be set. This value can be monitored over time to understand how many packets a virtual server receives. ============== {'clientside.bitsIn': {'value': 0}, 'clientside.bitsOut': {'value': 0}, 'clientside.curConns': {'value': 0}, 'clientside.evictedConns': {'value': 0}, 'clientside.maxConns': {'value': 0}, 'clientside.pktsIn': {'value': 0}, 'clientside.pktsOut': {'value': 0}, 'clientside.slowKilled': {'value': 0}, 'clientside.totConns': {'value': 0}, 'cmpEnableMode': {'description': 'all-cpus'}, 'cmpEnabled': {'description': 'enabled'}, 'csMaxConnDur': {'value': 0}, 'csMeanConnDur': {'value': 0}, 'csMinConnDur': {'value': 0}, 'destination': {'description': '10.73.125.137:53'}, 'ephemeral.bitsIn': {'value': 0}, 'ephemeral.bitsOut': {'value': 0}, 'ephemeral.curConns': {'value': 0}, 'ephemeral.evictedConns': {'value': 0}, ============== CSV filename issue I encountered thiserror,"OSError: [Errno 22] Invalid argument: 'dns_stats_2023-12-07_18:01:11.csv". This is related to writing of the output csv file. I asked ChatGPT what this was about andwas providedwith thisanswer. ======================= The error you're encountering, "[Errno 22] Invalid argument," typically suggests an issue with the filename or file path. In this case, it seems to be related to the colon (':') character in the filename. In some operating systems (like Windows), certain characters are not allowed in filenames, and ":" is one of them. Since you're including a timestamp in the filename, it's common to replace such characters with alternatives. You can modify the timestamp format to use underscores or hyphens instead of colons. ==================== The timestamp variable in the script stores the value of the formatted timestamp that will be used in the filename. It initially used a colon (:) as the hour/min/sec separator. It was changed to dash (-) so it would not encounter this error. timestamp = datetime.now().strftime("%Y-%m-%d_%H-%M-%S") Checking the file csv file if it exists The function "write_to_csv" writes the time of collection (formatted_date) andextracted value of DNS A requests count (AReqsvalue). It is called every 10 seconds [time.sleep(10)] for a minute [end_time = time.time() + 60] and writes the output to a file in csv format. The "tabulate" function formats the output of the script. Getting the arrangement of the execution wrong would result in unexpected output. The "file_exists" check to write the "headers" was added to make sure that the "headers" are only written once. "write_to_csv" function ======================== def write_to_csv(formatted_date, AReqsvalue): current_datetime = datetime.now() formatted_date = current_datetime.strftime("%Y-%m-%d %H:%M:%S") csv_filename = f"dns_stats_{timestamp}.csv" headers = ["Date", "DNS A requests"] stats = [[formatted_date, AReqsvalue]] file_exists = os.path.exists(csv_filename) print(tabulate(stats, headers, tablefmt="fancy_grid")) with open(csv_filename, mode='a', newline='') as file: writer = csv.writer(file) if not file_exists: writer.writerow(headers) writer.writerows(stats) end_time = time.time() + 60 while time.time() < end_time: write_to_csv(formatted_date, AReqsvalue) time.sleep(10) ========================== Using ChatGPT In building this script, I usedChatGPT "a lot" and it helped to provide make more sense of the module options, errors and sample scripts. It has been a helpful tool. It tracks your conversation/questions to it and kind of understands the context/topic. "ChatGPT can make mistakes. Consider checking important information." is written at the bottom of the page. The data I used in this article are data from a lab environment.That said, when using public AI/ML systems, we should ensure we do not send any sensitive, proprietary information. Organizations have rolled out their own privacy policies when using AI/ML systems, be sure to follow your own organization's policies. Conclusion Using python to parse and extract values of interest from LTM profile statistics offers flexibility and hopefully simplifying observing and recording these data for further use. In particular, setting values for BIG-IP AFM DoS Detection and Mitigation thresholds will be easier if such data has been observed as it, in my opinion, is the "pulse" of the traffic the BIG-IP processes. As noted in the sample json data output, we can see many statistics that can be reviewed and observed to make configuration changes relevant, for example, mitigating a connection spike by setting a VS connection/rate limit. We can look at the "Conns" values and use the observed values to set a connection limit. Example: 'clientside.curConns': {'value': 0}, 'clientside.evictedConns': {'value': 0}, 'clientside.maxConns': {'value': 0}, 'clientside.totConns':{'value': 0} That's it for now. I hope this article has been educational. The F5 SIRT createssecurity-related content posted here in DevCentral, sharing the team's security mindset and knowledge. Feel free to view the articles that are tagged withthe following: F5 SIRT series-F5SIRT-this-week-in-security TWIS542Views2likes0CommentsDemystifying iControl REST Part 1 - Understanding the request URI
iControl REST. It’s iControl SOAP’s baby brother, introduced back in TMOS version 11.4 as an early access feature but was released fully in version 11.5. Several articles on basic usage have been written on iControl REST (see the resources at the bottom of this article) so the intent here isn’t basic use, but rather to demystify some of the finer details of using the API. This article is the first of a four part series and will cover how the URI path plays a role in how the API functions. Examining the REST interface URI With iControl SOAP, all the interfaces and methods are defined in the WSDLs. With REST, the bulk of the interface and method is part of the URI. Take for example a request to get the list of iRules on a BIG-IP. https://x.x.x.x/mgmt/tm/ltm/rule With a simple get request with the appropriate headers and credentials (see below for curl and python examples,) this breaks down to the Base URI, the Module URI, and the Sub-Module URI. #python example >>> import requests >>> import json >>> b = requests.session() >>> b.auth = ('admin', 'admin') >>> b.verify = False >>> b.headers.update({'Content-Type':'application/json'}) >>> b.get('https://172.16.44.128/mgmt/tm/ltm/rule') #curl example curl -k -u admin:admin -H “Content-Type: application/json” -X GET https://172.16.44.128/mgmt/tm/ltm/rule Beyond the Sub-Module URI is the component URI. https://x.x.x.x/mgmt/tm/ltm/rule/testlog The component URI is the spot that snags most beginners. When creating a new configuration object on an F5, it is fairly obvious which URI to use for the REST call. If you were creating a new virtual server, it would be /mgmt/tm/ltm/virtual, while a new pool would be /mgmt/tm/ltm/pool. Thus a REST call to create a new pool on an LTM with the IP address 172.16.44.128 would look like the following: #python example >>> import requests >>> import json >>> b = requests.session() >>> b.auth = ('admin', 'admin') >>> b.verify = False >>> b.headers.update({'Content-Type':'application/json'}) >>> pm = ['192.168.25.32:80', '192.168.25.33:80'] >>> payload = { } >>> payload['kind'] = 'tm:ltm:pool:poolstate' >>> payload['name'] = 'tcb-pool' >>> payload['members'] = [ {'kind': 'ltm:pool:members', 'name': member } for member in pm] >>> b.post('https://172.16.44.128/mgmt/tm/ltm/pool', data=json.dumps(payload)) #curl example curl -k -u admin:admin -H "Content-Type: \ application/json" -X POST -d \ '{"name":"tcb-pool","members":[ \ {"name":"192.168.25.32:80","description":"first member”}, \ {"name":"192.168.25.33:80","description":"second member”} ] }' \ https://172.16.44.128/mgmt/tm/ltm/pool The call would create the pool “tcb-pool” with members at 192.168.25.32:80 and 192.168.25.33:80. All other aspects of the pool would be the defaults. Thus this pool would be created in the Common partition, have the Round Robin load balancing method, and no monitor.At first glance, some programmers would then modify the pool “tcb-pool” with a command like the following (same payload in python, added the .text attribute to see the error response on the requests object): #python example >>> b.put('https://172.16.44.128/mgmt/tm/ltm/pool', data=json.dumps(payload)).text #return data u'{"code":403,"message":"Operation is not supported on component /ltm/pool.","errorStack":[]}' #curl example curl -k -u admin:admin -H "Content-Type: \ application/json" -X PUT -d \ '{"name":"tcb-pool","members":[ \ {"name":"192.168.25.32:80","description":"first member"} {"name":"192.168.25.33:80","description":"second member"} ] }' \ https://172.16.44.128/mgmt/tm/ltm/pool #return data {"code":403,"message":"Operation is not supported on component /ltm/pool.","errorStack":[]} You can see because they use the sub module URI used to create the pool this returns a 403 error. The command fails because one is trying to modify a specific pool at the generic pool level. Now that the pool exists, one must use the URI that specifies the pool. Thus, the correct command would be: #python example >>> b.put('https://172.16.44.128/mgmt/tm/ltm/pool/~Common~tcb-pool', data=json.dumps(payload)) #curl example curl -k -u admin:admin -H "Content-Type: \ application/json" -X PUT -d \ '{"members":[ \ {"name":"192.168.25.32:80","description":"first member"} {"name":"192.168.25.33:80","description":"second member"} ] }' \ https://172.16.44.128/mgmt/tm/ltm/pool/~Common~tcb-pool We add the ~Common~ in front of the pool name because it is in the Common partition. However, this would also work with https://172.16.44.128/mgmt/tm/ltm/pool/tcb-pool. It is just good practice to explicitly insert the partition name since not all configuration objects will be in the default Common partition. Because we specify the pool in the URI, it is no longer necessary to have the “name” key value pair. In practice, programmers usually correctly modify items such as virtual servers and pools. However, we encounter this confusion much more often in configuration items that are ifiles. This may be because the creation of configuration items that are ifiles is a 3-step process. For instance, in order to create an external data group, one would first scp the file to 172.16.44.128/config/filestore/data_mda_1, then issue 2 Rest commands: curl -sk -u admin:admin -H "Content-Type: application/json" -X POST -d '{"name":"data_mda_1","type":"string","source-path":"file:///config/filestore/data_mda_1"}' https://172.16.44.128/mgmt/tm/sys/file/data-group curl -sk -u admin:admin -H "Content-Type: application/json" -X POST -d '{"name":"dg_mda","external-file-name":"/Common/data_mda_1"}' https://172.16.44.128/mgmt/tm/ltm/data-group/external/ To update the external data group, many programmers first try something like the following: curl -sk -u admin:admin -H "Content-Type: application/json" -X POST -d '{"name":"data_mda_2","type":"string","source-path":"file:///config/filestore/data_mda_2”}’ https://172.16.44.128/mgmt/tm/sys/file/data-group curl -sk -u admin:admin -H "Content-Type: application/json" -X PUT -d '{"name":"dg_mda","external-file-name":"/Common/data_mda_2"}' https://172.16.44.128/mgmt/tm/ltm/data-group/external/ The first command works because we are creating a new ifile object. However, the second command fails because we are trying to modify a specific external data group at the generic external data group level. The proper command is: curl -sk -u admin:admin -H "Content-Type: application/json" -X PUT -d '{"external-file-name":"/Common/data_mda_2"}' https://172.16.44.128/mgmt/tm/ltm/data-group/external/dg_mda The python code gets a little more complex with the data-group examples, so I've uploaded it to the codeshare here. Much thanks to Pat Chang for the bulk of the content in this article. Stay tuned for part 2, where we'll cover sub collections and how to use them.5.3KViews1like8CommentsDemystifying iControl REST Part 7 - Understanding Transactions
iControl REST. It’s iControl SOAP’s baby, brother, introduced back in TMOS version 11.4 as an early access feature but released fully in version 11.5. Several articles on basic usage have been written about the rest interface so the intent here isn’t basic use, but rather to demystify some of the finer details of using the API. A few months ago, a question in Q&A from community member spirrello asking how to update a tcp profile on a virtual. He was using bigsuds, the python wrapper for the soap interface. For the rest interface on this particular object, this is easy; just use the put method and supply the payload mapping the updated profile. But for soap, this requires a transaction. There are some changes to BIG-IP via the rest interface, however, like updating an ssl cert or key, that likewise will require a transaction to accomplish. In this article, I’ll show you how to use transactions with the rest interface. The Fine Print From the iControl REST user guide, the life cycle of a transaction progresses through three phases: Creation - This phase occurs when the transaction is created using a POST command. Modification - This phase occurs when commands are added to the transaction, or changes are made to the sequence of commands in the transaction. Commit - This phase occurs when iControl REST runs the transaction. To create a transaction, post to /tm/transaction POST https://192.168.25.42/mgmt/tm/transaction {} Response: { "transId":1389812351, "state":"STARTED", "timeoutSeconds":30, "kind":"tm:transactionstate", "selfLink":"https://localhost/mgmt/tm/transaction/1389812351?ver=11.5.0" } Note the transId, the state, and the timeoutSeconds. You'll need the transId to add or re-sequence commands within the transaction, and the transaction will expire after 30 seconds if no commands are added. You can list all transactions, or the details of a specific transaction with a get request. GET https://192.168.25.42/mgmt/tm/transaction GET https://192.168.25.42/mgmt/tm/transaction/transId To add a command to the transaction, you use the normal method uris, but include the X-F5-REST-Coordination-Id header. This example creates a pool with a single member. POST https://192.168.25.42/mgmt/tm/ltm/pool X-F5-REST-Coordination-Id:1389812351 { "name":"tcb-xact-pool", "members": [ {"name":"192.168.25.32:80","description":"First pool for transactions"} ] } Not a great example because there is no need for a transaction here, but we'll roll with it! There are several other option methods for interrogating the transaction itself, see the user guide for details. Now we can commit the transaction. To do that, you reference the transaction id in the URI, remove the X-F5-REST-Coordination-Id header and use the patch method with payload key/value state: VALIDATING . PATCH https://localhost/mgmt/tm/transaction/1389812351 { "state":"VALIDATING" } That's all there is to it! Now that you've seen the nitty gritty details, let's take a look at some code samples. Roll Your Own In this example, I am needing to update and ssl key and certificate. If you try to update the cert or the key, it will complain that they do not match, so you need to update both at the same time. Assuming you are writing all your code from scratch, this is all it takes in python. Note on line 21 I post with an empty payload, and then on line 23, I add the header with the transaction id. I make my modifications and then in line 31, I remove the header, and finally on line 32, I patch to the transaction id with the appropriate payload. import json import requests btx = requests.session() btx.auth = (f5_user, f5_password) btx.verify = False btx.headers.update({'Content-Type':'application/json'}) urlb = 'https://{0}/mgmt/tm'.format(f5_host) domain = 'mydomain.local_sslobj' chain = 'mychain_sslobj try: key = btx.get('{0}/sys/file/ssl-key/~Common~{1}'.format(urlb, domain)) cert = btx.get('{0}/sys/file/ssl-cert/~Common~{1}'.format(urlb, domain)) chain = btx.get('{0}/sys/file/ssl-cert/~Common~{1}'.format(urlb, 'chain')) if (key.status_code == 200) and (cert.status_code == 200) and (chain.status_code == 200): # use a transaction txid = btx.post('{0}/transaction'.format(urlb), json.dumps({})).json()['transId'] # set the X-F5-REST-Coordination-Id header with the transaction id btx.headers.update({'X-F5-REST-Coordination-Id': txid}) # make modifications modkey = btx.put('{0}/sys/file/ssl-key/~Common~{1}'.format(urlb, domain), json.dumps(keyparams)) modcert = btx.put('{0}/sys/file/ssl-cert/~Common~{1}'.format(urlb, domain), json.dumps(certparams)) modchain = btx.put('{0}/sys/file/ssl-cert/~Common~{1}'.format(urlb, 'le-chain'), json.dumps(chainparams)) # remove header and patch to commit the transaction del btx.headers['X-F5-REST-Coordination-Id'] cresult = btx.patch('{0}/transaction/{1}'.format(urlb, txid), json.dumps({'state':'VALIDATING'})).json() A Little Help from a Friend The f5-common-python library was released a few months ago to relieve you of a lot of the busy work with building requests. This is great, especially for transactions. To simplify the above code just to the transaction steps, consider: # use a transaction txid = btx.post('{0}/transaction'.format(urlb), json.dumps({})).json()['transId'] # set the X-F5-REST-Coordination-Id header with the transaction id btx.headers.update({'X-F5-REST-Coordination-Id': txid}) # do stuff here # remove header and patch to commit the transaction del btx.headers['X-F5-REST-Coordination-Id'] cresult = btx.patch('{0}/transaction/{1}'.format(urlb, txid), json.dumps({'state':'VALIDATING'})).json() With the library, it's simplified to: tx = b.tm.transactions.transaction with TransactionContextManager(tx) as api: # do stuff here api.do_stuff Yep, it's that simple. So if you haven't checked out the f5-common-python library, I highly suggest you do! I'll be writing about how to get started using it next week, and perhaps a follow up on how to contribute to it as well, so stay tuned!2.6KViews1like6CommentsDemystifying iControl REST Part 5: Transferring Files
iControl REST. It’s iControl SOAP’s baby, brother, introduced back in TMOS version 11.4 as an early access feature but released fully in version 11.5. Several articles on basic usage have been written on iControl REST so the intent here isn’t basic use, but rather to demystify some of the finer details of using the API. This article will cover the details on how to transfer files to/from the BIG-IP using iControl REST and the python programming language. (Note: this functionality requires 12.0+.) The REST File Transfer Worker The file transfer worker allows a client to transfer files through a series of GET operations for downloads and POST operations for uploads. The Content-Range header is used for both as a means to chunk the content. For downloads, the worker listens onthe following interfaces. Description Method URI File Location Download a File GET /mgmt/cm/autodeploy/software-image-downloads/ /shared/images/ Upload an Image File POST /mgmt/cm/autodeploy/software-image-uploads/ /shared/images/ Upload a File POST /mgmt/shared/file-transfer/uploads/ /var/config/rest/downloads/ Download a QKView GET /mgmt/shared/file-transfer/qkview-downloads/ /var/tmp/ Download a UCS GET /mgmt/shared/file-transfer/ucs-downloads/ /var/local/ucs/ Upload ASM Policy POST /mgmt/tm/asm/file-transfer/uploads/ /var/ts/var/rest/ Download ASM Policy GET /mgmt/tm/asm/file-transfer/downloads/ /var/ts/var/rest/ Binary and text files are supported. The magic in the transfer is the Content-Range header, which has the following format: Content-Range: start-end/filesize Where start/end are the chunk's delimiters in the file and filesize is well, the file size. Any file larger than 1M needs to be chunked with this header as that limit is enforced by the worker. This is done to avoid potential denial of service attacks and out of memory errors. There are benefits of chunking as well: Accurate progress bars Resuming interrupted downloads Random access to file content possible Uploading a File The function is shown below. Note that whereas normally with the REST API the Content-Type is application/json, with file transfers that changes to application/octet-stream. The workflow for the function works like this (line number in parentheses) : Set the Chunk Size (3) Set the Content-Type header (4-6) Open the file (7) Get the filename (apart from the path) from the absolute path (8) If the extension is an .iso file (image) put it in /shared/images, otherwise it’ll go in /var/config/rest/downloads (9-12) Disable ssl warnings requests (required with my version: 2.8.1. YMMV) (14) Set the total file size for use with the Content-Range header (15) Set the start variable to 0 (17) Begin loop to iterate through the file and upload in chunks (19) Read data from the file and if there is no more data, break the loop (20-22) set the current bytes read, if less than the chunk size, then this is the last chunk, so set the end to the size from step 7. Otherwise, add current bytes length to the start value and set that as the end. (24-28) Set the Content-Range header value and then add that to the header (30-31) Make the POST request, uploading the content chunk (32-36) Increment the start value by the current bytes content length (38) def _upload(host, creds, fp): chunk_size = 512 * 1024 headers = { 'Content-Type': 'application/octet-stream' } fileobj = open(fp, 'rb') filename = os.path.basename(fp) if os.path.splitext(filename)[-1] == '.iso': uri = 'https://%s/mgmt/cm/autodeploy/software-image-uploads/%s' % (host, filename) else: uri = 'https://%s/mgmt/shared/file-transfer/uploads/%s' % (host, filename) requests.packages.urllib3.disable_warnings() size = os.path.getsize(fp) start = 0 while True: file_slice = fileobj.read(chunk_size) if not file_slice: break current_bytes = len(file_slice) if current_bytes < chunk_size: end = size else: end = start + current_bytes content_range = "%s-%s/%s" % (start, end - 1, size) headers['Content-Range'] = content_range requests.post(uri, auth=creds, data=file_slice, headers=headers, verify=False) start += current_bytes Downloading a File Downloading is very similar but there are some differences. Here is the workflow that is different, followed by the code. Note that the local path where the file will be downloaded to is given as part of the filename. URI is set to downloads worker. The only supported download directory at this time is /shared/images. (8) Open the local file so received data can be written to it (11) Make the request (22-26) If response code is 200 and if size is greater than 0, increment the current bytes and write the data to file, otherwise exit the loop (28-40) Set the value of the returned Content-Range header to crange and if initial size (0), set the file size to the size variable (42-46) If the file is smaller than the chunk size, adjust the chunk size down to the total file size and continue (51-55) Do the math to get ready to download the next chunk (57-62) def _download(host, creds, fp): chunk_size = 512 * 1024 headers = { 'Content-Type': 'application/octet-stream' } filename = os.path.basename(fp) uri = 'https://%s/mgmt/cm/autodeploy/software-image-downloads/%s' % (host, filename) requests.packages.urllib3.disable_warnings() with open(fp, 'wb') as f: start = 0 end = chunk_size - 1 size = 0 current_bytes = 0 while True: content_range = "%s-%s/%s" % (start, end, size) headers['Content-Range'] = content_range #print headers resp = requests.get(uri, auth=creds, headers=headers, verify=False, stream=True) if resp.status_code == 200: # If the size is zero, then this is the first time through the # loop and we don't want to write data because we haven't yet # figured out the total size of the file. if size > 0: current_bytes += chunk_size for chunk in resp.iter_content(chunk_size): f.write(chunk) # Once we've downloaded the entire file, we can break out of # the loop if end == size: break crange = resp.headers['Content-Range'] # Determine the total number of bytes to read if size == 0: size = int(crange.split('/')[-1]) - 1 # If the file is smaller than the chunk size, BIG-IP will # return an HTTP 400. So adjust the chunk_size down to the # total file size... if chunk_size > size: end = size # ...and pass on the rest of the code continue start += chunk_size if (current_bytes + chunk_size) > size: end = size else: end = start + chunk_size - 1 Now you know how to upload and download files. Let’s do something with it! A Use Case - Upload Cert & Key to BIG-IP and Create a Clientssl Profile! This whole effort was sparked by a use case in Q&A, so I had to deliver the goods with more than just moving files around. The complete script is linked at the bottom, but there are a few steps required to get to a clientssl certificate: Upload the key & certificate Create the file object for key/cert Create the clientssl profile You know how to do step 1 now. Step 2 is to create the file object for the key and certificate. After a quick test to see which file is the certificate, you set both files, build the payload, then make the POST requests to bind the uploaded files to the file object. def create_cert_obj(bigip, b_url, files): f1 = os.path.basename(files[0]) f2 = os.path.basename(files[1]) if f1.endswith('.crt'): certfilename = f1 keyfilename = f2 else: keyfilename = f1 certfilename = f2 certname = f1.split('.')[0] payload = {} payload['command'] = 'install' payload['name'] = certname # Map Cert to File Object payload['from-local-file'] = '/var/config/rest/downloads/%s' % certfilename bigip.post('%s/sys/crypto/cert' % b_url, json.dumps(payload)) # Map Key to File Object payload['from-local-file'] = '/var/config/rest/downloads/%s' % keyfilename bigip.post('%s/sys/crypto/key' % b_url, json.dumps(payload)) return certfilename, keyfilename Notice we return the key/cert filenames so they can be used for step 3 to establish the clientssl profile. In this example, I name the file object and the clientssl profile to the name of the certfilename (minus the extension) but you can alter this to allow the objects names to be provided. To build the profile, just create the payload with the custom key/cert and make the POST request and you are done! def create_ssl_profile(bigip, b_url, certname, keyname): payload = {} payload['name'] = certname.split('.')[0] payload['cert'] = certname payload['key'] = keyname bigip.post('%s/ltm/profile/client-ssl' % b_url, json.dumps(payload)) Much thanks to Tim Rupp who helped me get across the finish line with some counting and rest worker errors we were troubleshooting on the download function. Get the Code Upload a File Download a File Upload Cert/Key & Build a Clientssl Profile8.2KViews4likes45Comments
BIG-IQ Central Management API automation and programmability - Workflow - Python
Summary In conjunction with the announcement of BIG-IQ 5.0 we are excited to bring the field greater flexibility when centrally managing BIG-IP devices utilizing well defined workflows and the BIG-IQ iControl REST API. We understand that automation and programmability is becoming more the norm these days as the network is evolving into a software defined application aware environment. This article will provide a basic example for first establishing trust while adding a device to inventory, second importing device configuration into BIG-IQ's configuration database and finally adding device to a license pool all utilizing the BIG-IQ rest api uri provided by the interface. Response is parsed in JSON format so there are dependencies required. This is intended to be an introduction to leveraging the API directly. We are in the process of developing a python object abstraction for the BIG-IQ CM REST API to provide even greater simplicity when leveraging automation for central management programmability. But we thought this level of detail may be appropriate to get the ball rolling. The BIG-IQ CM SDK will be structured similar to version 0.1.7 BIG-IP iControl REST API described here: BIGIP SDK - https://devcentral.f5.com/s/articles/f5-friday-python-sdk-for-big-ip-18233 BIGIP SDK Docs - https://f5-sdk.readthedocs.io/en/v0.1.7/ Let's get started ... READY ... SET ... GO ... Here are the API URIs' used as reference for both Python and Perl examples below: Trust:https://'bigiq-ip'/mgmt/cm/global/tasks/device-trust Discovery:https://'bigiq-ip'/mgmt/cm/global/tasks/device-discovery Import: ADC - https://'bigiq-ip'/mgmt/cm/adc-core/tasks/declare-mgmt-authority Import: Firewall - https://'bigiq-ip'/mgmt/cm/firewall/tasks/declare-mgmt-authority License: Pools - https://'bigiq-ip'/mgmt/cm/shared/licensing/pools License: Members: - https://'bigiq-ip'/mgmt/cm/shared/licensing/pools/'member_uuid'/members Using a python class abstraction (libraries can be located in /lib/) for Discovery, Import and Licensing, these tasks are a single call from one place which will provide the flexibility to create scripts defined by workflow. For example, lets - 1. Negotiate trust certificates for a newly deployed BIGIP. 2. Discover the BIGIP device and add to inventory. 3. Import ADC configuration and resolve all differences to BIGIQ’s management database. 4. Import Firewall configuration and resolve all differences to BIGIQ’s management database. 5. Add this newly discovered BIGIP to a provisioned license pool using the base-registration-key as a filter. Using the following python libraries, we can accomplish these tasks defined as methods in each class definition: ## Discovery ../lib/discovery.py: class Discover(object) def device_trust(dev_id): def ltm_discover(modules adc_core, firewall, asm, apm etc..): ## Import ../lib/import.py: class Import(object) def import_ltm(dev_id): def import_security(dev_id, afm=True): ## License ../lib/license.py : class License(object) def license_pool(config): Now it’s just a matter of putting the puzzle together in a script that will accomplish the workflow described above. BIG-IQ and BIG-IP device address and credentials are read in from a configuration file (../config/..) the script first and passed into def workflow for processing. Each method is called with argument <config> dictionary to perform the task required. After completion each will return True or False depending on result from rest response code and some evaluation. ## Import libraries to leverage methods described above from discovery import Discover from import_module import Import from license import License ## main def "workflow" def workflow (Discover, License, Import, config): ## Trust "establish certificate exchange" result_trust = Discover.device_trust(config) ## Discover "add a BIGIP to inventory" result = Discover.ltm_discover(config, result_trust) ## Import ADC "import adc configuration into database" result = Import.import_ltm(config, result_trust) ## Import AFM, ASM, APM "import module configuration into database" result = Import.import_sec(config, result_trust, afm=True) ## Add BIGIP member to license pool result = License.license_pool(config) ## Python main body if __name__ == '__main__': # read config file from ../config/.. config = {} with open (file) as infile: config[str(key)] = val.strip('\n') ## create an instance of each imported class defined in the libraries Discover = Discover(config) Import = Import(config) License = License(config) ## call the main program method "workflow" workflow (Discover, Import, License, config) If you are interested in this code for collaboration or solution, search on key words "bigiq" "api" "python" in code share section on dev central or you can refer to the reference link: Device trust, discovery and import using python requests - supported in Python version 2.7.9 and greater. https://devcentral.f5.com/s/articles/big-iq-trust-discovery-and-import-of-big-ip-using-rest-api-python-oo-973 Grants a license to a BIG-IP from an already-activated purchaced pool. https://devcentral.f5.com/s/articles/big-iq-licensing-of-big-ip-using-rest-api-python-oo-974 We will also be adding to github and will update this article once completed. So please come back and visit us soon and often for additional content.577Views0likes0CommentsGetting Started with the f5-common-python SDK
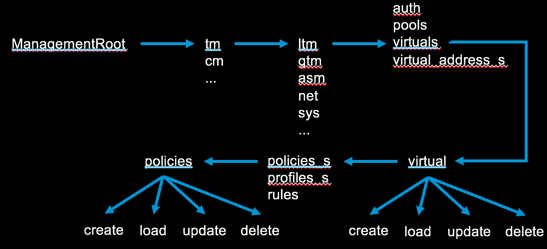
If you have dabbled with python and iControl over the years, you might be familiar with some of my other “Getting Stared with …” articles on python libraries. I started my last, on Bigsuds, this way: I imagine the progression for you, the reader, will be something like this in the first six- or seven-hundred milliseconds after reading the title: Oh cool! Wait, what? Don’t we already have like two libraries for python? Really, a third library for python? It’s past time to update those numbers as the forth library in our python support evolution, the f5-common-python SDK, has been available since March of last year!I still love Bigsuds, but it only supports the iControl SOAP interface. The f5-common-python SDK is under continuous development in support of the iControl REST interface, and like Bigsuds, does a lot of the API heavy lifting for you so you can just focus on the logic of bending BIG-IP configuration to your will. Not all endpoints are supported yet, but please feel free to open an issue on the GitHub repo if there’s something missing you need for your project.In this article, I’ll cover the basics of installing the SDK and how to utilize the core functionality. Installing the SDK This section is going to be really short, as the SDK is uploaded to PyPI after reach release, though you can clone the GitHub project and run the development branch with latest features if you so desire. I'd recommend installing in a virtual environment to keep your system python uncluttered, but YMMV. pip install f5-sdk A simple one-liner and we're done! Moving on... Instantiating BIG-IP The first thing you’ll want to do with your shiny new toy is authenticate to the BIG-IP. You can use basic or token authentication to do so. I disable the certificate security warnings on my test boxes, but the first two lines in the sample code below are not necessary if you are using valid certificates >>> import requests >>> requests.packages.urllib3.disable_warnings() >>> from f5.bigip import ManagementRoot >>> # Basic Authentication >>> b = ManagementRoot('ltm3.test.local', 'admin', 'admin') >>> # Token Authentication >>> b = ManagementRoot('ltm3.test.local', 'admin', 'admin', token=True) >>> b.tmos_version u'12.1.0' The b object has credentials attached and various other attributes as well, such as the tmos_version attribute shown above. This is the root object you’ll use (of course you don’t have to call it b, you can call it plutoWillAlwaysBeAPlanetToMe if you want to, but that’s a lot more typing) for all the modules you might interact with on the system. Nomenclature The method mappings are tied to the tmsh and REST URL ids. Consider the tmsh command tmsh list /ltm pool . In the URL, this would be https://ip/mgmt/tm/ltm/pool. For the SDK, at the collection level the command would be b.tm.ltm.pools . It's plural here because we are signifying the collection. If there is a collection already ending in an s, like the subcollection of a pool in members, it would be addressed as members_s. This will be more clear as we work through examples in later articles, but I wanted to provide a little guidance before moving on. Working with Collections There are two types of collections (well three if you include subcollections, but we’ll cover those in a later article,) organizing collections and collections. An organizing collection is a superset of other collections. For example, the ltm or net module listing would be an organizing collection, whereas ltm/pool or net/vlan would be collections. To retrieve either type, you use the get_collection method as shown below, with abbreviated output. # The LTM Organizing Collection >>> for x in b.tm.ltm.get_collection(): ... print x ... {u'reference': {u'link': u'https://localhost/mgmt/tm/ltm/auth?ver=12.1.0'}} {u'reference': {u'link': u'https://localhost/mgmt/tm/ltm/data-group?ver=12.1.0'}} {u'reference': {u'link': u'https://localhost/mgmt/tm/ltm/dns?ver=12.1.0'}} # The Net/Vlan Collection: >>> vlans = b.tm.net.vlans.get_collection() >>> for vlan in vlans: ... print vlan.name ... vlan10 vlan102 vlan103 Working with Named Resources A named resource, like a pool, vip, or vlan, is a fully configurable object for which the CURDLE methods are supported. These methods are: create() update() refresh() delete() load() exists() Let’s work through all these methods with a pool object. >>> b.tm.ltm.pools.pool.exists(name='mypool2017', partition='Common') False >>> p1 = b.tm.ltm.pools.pool.create(name='mypool2017', partition='Common') >>> p2 = b.tm.ltm.pools.pool.load(name='mypool2017', partition='Common') >>> p1.loadBalancingMode = 'least-connections-member' >>> p1.update() >>> assert p1.loadBalancingMode == p2.loadBalancingMode Traceback (most recent call last): File "", line 1, in AssertionError >>> p2.refresh() >>> assert p1.loadBalancingMode == p2.loadBalancingMode >>> p1.delete() >>> b.tm.ltm.pools.pool.exists(name='mypool2017', partition='Common') False Notice in line 1, I am looking to see if the pool called mypool2017 exists, to which I get a return value of False. So I can go ahead and create that pool as shown in line 3. In line 4, I load the same pool so I have two local python objects (p1, p2) that reference the same BIG-IP pool (mypool2017.) In line 5, I update the load balancing algorithm from the default of round robin to least connections member. But at this point, only the local python object has been updated. To update the BIG-IP, in line 6 I apply that method to the object. Now if I assert the LB algorithm between the local p1 and p2 python objects as shown in line 7, it fails, because we have updated p1, but p2 is still as it was when I initially loaded it. Refreshing p2 as shown in line 11 will update it (the local python object, not the BIG-IP pool.) Now I assert again in line 12, and it does not fail. As this was just an exercise, I delete the new pool (could be done on p1 or p2 since they reference the same BIG-IP object) in line 13, and a quick check to see if it exists in line 14 returns false. The great thing is that even though the endpoints change from pool to virtual to rule and so on, the methods used for them do not. Next Steps This is just the tip of the iceberg! There is much more to cover, so come back for the next installment, where we’ll cover unnamed resources and commands. If you can't wait, feel free to dig into the SDK documentation.12KViews3likes70CommentsGetting started with the python SDK part 4: working with request parameters
In theprevious article in this series, we looked at how to work with statistics. In this article, we’ll mirror some of the naked query parameters covered in the Demystifying iControl REST part 3 article, but applied through the python sdk. The super secret magic sauce is all in the formatting: requests_params = {‘params’: ‘insert parameters here’} You can read all about the different query parameters in teh demystifying article I linked above. Let's just go through a few examples here that might be helpful. First, consider a pool collection. With no parameters, you get a list of all your pools and their (set) attributes like this (only one pool shown for brevity): >>> from sprint import print as pp >>> pools = b.tm.ltm.pools.get_collection() >>> for pool in pools: ... pp(pool.raw) {u'allowNat': u'yes', u'allowSnat': u'yes', u'fullPath': u'/bc/tp1', u'generation': 94, u'ignorePersistedWeight': u'disabled', u'ipTosToClient': u'pass-through', u'ipTosToServer': u'pass-through', u'kind': u'tm:ltm:pool:poolstate', u'linkQosToClient': u'pass-through', u'linkQosToServer': u'pass-through', u'loadBalancingMode': u'least-connections-node', u'membersReference': {u'isSubcollection': True, u'link': u'https://localhost/mgmt/tm/ltm/pool/~bc~tp1/members?ver=13.1.0.5'}, u'minActiveMembers': 0, u'minUpMembers': 0, u'minUpMembersAction': u'failover', u'minUpMembersChecking': u'disabled', u'name': u'tp1', u'partition': u'bc', u'queueDepthLimit': 0, u'queueOnConnectionLimit': u'disabled', u'queueTimeLimit': 0, u'reselectTries': 0, u'selfLink': u'https://localhost/mgmt/tm/ltm/pool/~bc~tp1?ver=13.1.0.5', u'serviceDownAction': u'none', u'slowRampTime': 10} But wait...there's more! You can get even more data by using the first parameter we'll cover: expandSubcollections. We get the request often on how to get all the pools and pool members in one request, which can be accomplished with this method: pools_w_members = b.tm.ltm.pools.get_collection(requests_params={'params': 'expandSubcollections=true'}) That's great if you are going to use all that data, but what if you only really want to know the pool name and the load balancing method? It seems a tad overkill to pull all that back, doesn't it? That's where the select parameter comes in handy. We pass our requests_params in the get_collection() method and we now get a significantly reduced payload, with only the data we want. >>> pools = b.tm.ltm.pools.get_collection(requests_params={'params': '$select=name,loadBalancingMode'}) >>> pp(pools) [{u'loadBalancingMode': u'round-robin', u'name': u'testpool'}, {u'loadBalancingMode': u'least-connections-node', u'name': u'tp1'}, {u'loadBalancingMode': u'ratio-member', u'name': u'tp2'}, {u'loadBalancingMode': u'ratio-node', u'name': u'tp1'}] This is great, but you'll notice that I have two pools named tp1 there. You'll likely also want the partition to make sure you are manipulating the right pool. This can be done by including that in the select, but a better option might be just to use the filter parameter and return only the pools in the partition of choice. pools = b.tm.ltm.pools.get_collection(requests_params={'params': '$select=name,loadBalancingMode&$filter=partition+eq+bc'}) pp(pools) [{u'loadBalancingMode': u'least-connections-node', u'name': u'tp1'}, {u'loadBalancingMode': u'ratio-member', u'name': u'tp2'}] Like in the browser, you can also just use spaces instead of the + sign on the filter value and it will work just fine. If you had many pools, you could further reduce the data set by using the top parameter. I only have two pools in my bc partition, so for this example I'll take only the top one, but that's ridiculous in a live setting! pools = b.tm.ltm.pools.get_collection(requests_params={'params': '$select=name,loadBalancingMode&$filter=partition eq bc&$top=1'}) pp(pools) [{u'loadBalancingMode': u'least-connections-node', u'name': u'tp1'}] Using top/skip can be very helpful when doing analysis of the active connection table. You can do VERY BAD THINGS to your system by trying to pull the entire table in a single query. The key to the connection table (and other tmsh commands via REST) is to use the options parameter, which for some reason does not have a leading $ like the other parameters. In this case, we are reducing the dataset returned to the server side address matching that IP. You could add a port as well if you had multiple pool members sharing an IP. When combined with top, the query would be built like this: >>> ssconns = b.tm.sys.connection.load(requests_params={'params': '$top=50&options=ss-server-addr+192.168.103.31'}) I say would be built because as I was preparing this article, I noticed that tm/sys/connection is not yet an endpoint in the SDK, so I created issue 1461 for this and I'll try to get it added for the next release. What else would you like to see regarding request parameters via the SDK (or native for that matter)? Drop a comment below. Happy coding!1.3KViews0likes10Comments
Creating a Docker Container to Run AS3 Declarations
This guide will take you through some very basic docker, Python, and F5 AS3 configuration to create a single-function container that will update a pre-determined BIG-IP using an AS3 declaration stored on Github. While it’s far from production ready, it might serve as a basis for more complex configurations, plus it illustrates nicely some technology you can use to automate BIG-IP configuration using AS3, Python and containers. I'm starting with a running BIG-IP - in this case a VE running on theGoogle Cloud Platform, with the AS3 wroker installed and provisioned, plus a couple of webservers listening on different ports. First we’re going to need a host running docker. Fire up an instance in on the platform of your choice – in this example I’m using Ubuntu 18.04 LTS on the Google Cloud platform – that’s purely from familiarity – anything that can run Docker will do. The install process is well documented but looks a bit like this: $ sudo apt-get update $ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common $ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - $sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" $sudo apt-get update $ sudoapt-get install docker-ce docker-ce-cli containerd.io It's worth adding your user to the docker group to avoid repeadly forgetting to type sudo (or is that just me?) $ sudo usermod -aGdocker$USER Next let's test it's all working: $ docker run hello-world Next let’s take a look at the AS3 declaration,as you might expect form me by now, it’s the most basic version – a simple HTTP app, with two pool members. The beauty of the AS3 model, of course, is that it doesn’t matter how complex your declaration is, the implementation is always the same. So you could take a much more involved declaration and just by changing the file the python script uses, get a more complex configuration. { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.0.0", "id": "urn:uuid:33045210-3ab8-4636-9b2a-c98d22ab915d", "label": "Sample 1", "remark": "Simple HTTP Service with Round-Robin Load Balancing", "Sample_01": { "class": "Tenant", "A1": { "class": "Application", "template": "http", "serviceMain": { "class": "Service_HTTP", "virtualAddresses": [ "10.138.0.4" ], "pool": "web_pool" }, "web_pool": { "class": "Pool", "monitors": [ "http" ], "members": [ { "servicePort": 8080, "serverAddresses": [ "10.138.0.3" ] }, { "servicePort": 8081, "serverAddresses": [ "10.138.0.3" ] } ] } } } } } Now we need some python code to fire up our request. The code below is absolutely a minimum viable set that’s been written for simplicity and clarity and does minimal error checking. There are more ways to improve it that lines of code in it, but it will get you started. #Python Code to run an as3 declaration # import requests import os from requests.auth import HTTPBasicAuth # Get rid of annoying insecure requests waring from requests.packages.urllib3.exceptions import InsecureRequestWarning requests.packages.urllib3.disable_warnings(InsecureRequestWarning) # Declaration location GITDRC = 'https://raw.githubusercontent.com/RuncibleSpoon/as3/master/declarations/payload.json' IP = '10.138.0.4' PORT = '8443' USER = os.environ['XUSER'] PASS = os.environ['XPASS'] URLBASE = 'https://' + IP + ':' + PORT TESTPATH = '/mgmt/shared/appsvcs/info' AS3PATH = '/mgmt/shared/appsvcs/declare' print("########### Fetching Declaration ###########") d = requests.get(GITDRC) # Check we have connectivity and AS3 is installed print('########### Checking that AS3 is running on ', IP ,' #########') url = URLBASE + TESTPATH r = requests.get(url, auth=HTTPBasicAuth(USER, PASS), verify=False) if r.status_code == 200: data = r.json() if data["version"]: print('AS3 version is ', data["version"]) print('########## Runnig Declaration #############') url = URLBASE + AS3PATH headers = { 'content-type': 'application/json', 'accept': 'application/json' } r = requests.post(url, auth=HTTPBasicAuth(USER, PASS), verify=False, data=d.text, headers=headers) print('Status Code:', r.status_code,'\n', r.text) else: print('AS3 test to ',IP, 'failed: ', r.text) This simple python code will pull down an S3 declaration from GitHub using the 'requests' Python library, and the GITDRC variable, connect to a specific BIG-IP, test it’s running AS3 (see here for AS3 setup instructions), and then apply the declaration. It will give you some tracing output, but that’s about it. There are couple of things to note about IP’s, users, and passwords: IP = '10.138.0.4' PORT = '8443' USER = os.environ['XUSER'] PASS = os.environ['XPASS' As you can see, I’ve set the IP and port statically and the username and passwords are pulled in from environment variables in the container. We’ll talk more about the environment variables below, but this is more a way to illustrate your options than design advice. Now we need to build a container to run it in. Containers are relatively easy to build with just a Dockerfile and a few more test files in a directory. Here's the docker file: FROM python:3 WORKDIR /usr/src/app ARG Username=admin ENV XUSER=$Username ARG Password=admin ENV XPASS=$Password # line bleow is not actually used - see comments - but oy probably is a better way ARG DecURL=https://raw.githubusercontent.com/RuncibleSpoon/as3/master/declarations/payload.json ENV Declaration=$DecURL COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt COPY . . ENTRYPOINT [ "python", "./as3.py" ] You can see a couple of ARG and ENV statements , these simple set the environment variables that we’re (somewhat arbitrarily) using in the python script. Further more we’re going to override them in then build command later. It’s worth noting this isn’t a way to obfuscate passwords, they are exposed by a simple $ docker image history command that will expose all sorts of things about the build of the container, including the environment variables passes to it. This can be overcome by a multi-stage build – but proper secret management is something you should explore – and comment below if you’d like some examples. What’s this requirements.txt file mentioned in the Dockerfile it’s just a manifest to the install of the python package we need: # This file is used by pip to install required python packages # Usage: pip install -r requirements.txt # requests package requests==2.21.0 With our Dockerfile, requirements.txt and as3.py files in a directory we're ready to build a container - in this case I'm going to pass some environment variables into the build to be incorporated in the image - and replace the ones we have set in the Dockerfile: $ export XUSER=admin $ export XPASS=admin Build the container (the -t flag names and tags your container, more of which later): $ docker build -t runciblespoon/as3_python:A--build-arg Username=$XUSER --build-arg Password=$XPASS . The first time you do this there will be some lag as files for the python3 source containerare downloaded and cached, but once it has run you should be able to see your image: $ docker image list REPOSITORY TAG IMAGE ID CREATED SIZE runciblespoon/as3_python A 819dfeaad5eb About a minute ago 936MB python 3 954987809e63 42 hours ago 929MB hello-world latest fce289e99eb9 3 months ago 1.84kB Now we are ready to run the container maybe a good time for a 'nothing up my sleeve' moment - here is the state of the BIG-IP before hand Now let's run the container from our image.The -tty flag attached a pseudo terminal for output and --rm deletes the container afterwards: $ docker run --tty --rm runciblespoon/as3_python:A ########### Fetching Declaration ########### ########### Checking that AS3 is running on 10.138.0.4 ######### AS3 version is 3.10.0 ########## Runing Declaration ############# Status Code: 200 {"results":[{"message":"success","lineCount":23,"code":200,"host":"localhost","tenant":"Sample_01","runTime":929}],"declaration":{"class":"ADC","schemaVersion":"3.0.0","id":"urn:uuid:33045210-3ab8-4636-9b2a-c98d22ab915d","label":"Sample 1","remark":"Simple HTTP Service with Round-Robin Load Balancing","Sample_01":{"class":"Tenant","A1":{"class":"Application","template":"http","serviceMain":{"class":"Service_HTTP","virtualAddresses":["10.138.0.4"],"pool":"web_pool"},"web_pool":{"class":"Pool","monitors":["http"],"members":[{"servicePort":8080,"serverAddresses":["10.138.0.3"]},{"servicePort":8081,"serverAddresses":["10.138.0.3"]}]}}},"updateMode":"selective","controls":{"archiveTimestamp":"2019-04-26T18:40:56.861Z"}}} Success, by the looks of things. Let's check the BIG-IP: running our container has pulled down the AS3 declaration, and applied it to the BIG-IP. This same container can now be run repeatedly - and only the AS3 declaration stored in git (or anywhere else your container can get it from) needs to change. So now you have this container running locally you might want ot put it somewhere. Docker hub is a good choice and lets you create one private repository for free. Remember this container image has credentials, so keep it safe and private. Now the reason for the -t runciblespoon/as3_python:A flag earlier. My docker hub user is "runciblespoon" and my private repository is as3_python. So now all i need ot do is login to Docker Hub and push my image there: $ docker login $ docker push runciblespoon/as3_python:B Now I can go to any other host that runs Docker, login to Docker hub and run my container: $ docker login $ docker run --tty --rm runciblespoon/as3_python:A Unable to find image 'runciblespoon/as3_python:A' locally B: Pulling from runciblespoon/as3_python ... ########### Fetching Declaration ########### Docker will pull down my container form my private repo and run it, using the AS3 declaration I've specified. If I want to change my config, I just change the declaration and run it again. Hopefully this article gives you a starting point to develop your own containers, python scripts, or AS3 declarations, I'd be interested in what more you would like to see, please ask away in the comments section.1.4KViews0likes4Comments
Release Announcement: F5 Python SDK v1.0.0
Release Announcement 06 July 2016 We are pleased to announce the release of v1.0.0 of the F5 Python SDK.This is the first stable release of the SDK. Summary This release is not backwards compatible because support for aliased resources has been removed. This means that x = y.create(...) no longer changes both x and y . Instead, xis the created configuration object and y is a creation factory. The release also incorporates several important bug-fixes, noted below. Release Highlights The following bug-fixes are included in this release. Most importantly, the SDK now allows a minimum BIG-IP® version of `11.5.0` and has no maximum version. * #523 Add support for ltm.data_group * #491 allows all versions >= 11.5.0 by default * #492 fix the sys ntp resource * #411 calling `create` and `load` on Resources now returns a new instance of the relevant resource (a factory pattern); this fixes an aliasing bug * #497 New API endpoints for GTM datacenters and iRules * This release fixes multiple type-errors in the concrete subclasses. * #533 Turns off `_check_generation` because it is buggy. * #521 migrate clustering to support non-aliased pattern See the changelog for the full list of changes in this release. Open Issues See the project issues pagefor a full list of open issues in this release. - The F5 OpenStack Product Team and F5 Python SDK Contributors552Views0likes4Comments