Decrypting TLS traffic on BIG-IP
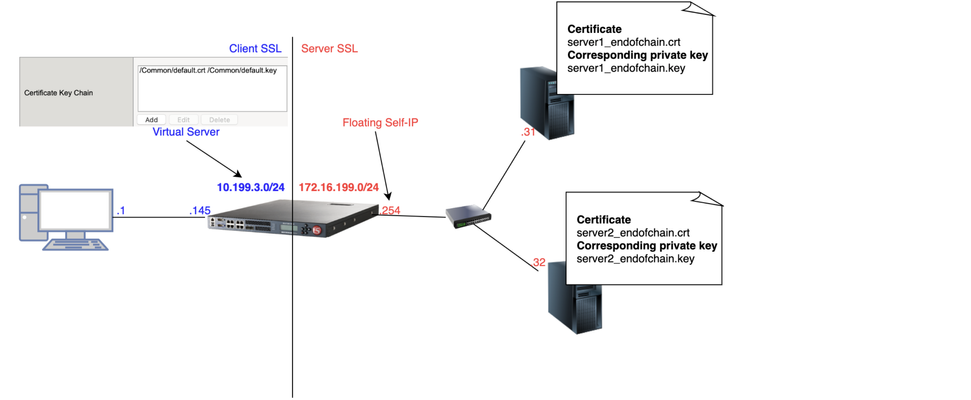
1 Introduction As soon as I joined F5 Support, over 5 years ago, one of the first things I had to learn quickly was to decrypt TLS traffic becausemost of our customers useL7 applications protectedby TLS layer. In this article, I will show 4 ways to decrypt traffic on BIG-IP, including thenew one just release in v15.xthat is ideal for TLS1.3 where TLS handshake is also encrypted. If that's what you want to know just skip totcpdump --f5 ssl optionsection as this new approach is just a parameter added to tcpdump. As this article is very hands-on, I will show my lab topology for the tests I performed and then every possible way I used to decrypt customer's traffic working for Engineering Services at F5. 2 Lab Topology This is the lab topology I used for the lab test where all tests were performed: Also, for every capture I issued the followingcurlcommand: Update: the virtual server's IP address is actually 10.199.3.145/32 2 The 4 ways to decrypt BIG-IP's traffic RSA private key decryption There are 3 constraints here: Full TLS handshake has to be captured CheckAppendix 2to learn how to to disable BIG-IP's cache RSA key exchange has to be used, i.e. no (EC)DHE CheckAppendix1to understand how to check what's key exchange method used in your TLS connection CheckAppendix 2to understandhow to prioritise RSA as key exchange method Private key has to be copied to Wireshark machine (ssldump command solves this problem) Roughly, to accomplish that we can setCache Sizeto 0 on SSL profile and remove (EC)DHE fromCipher Suites(seeAppendix 1for details) I first took a packet capture using :pmodifier to capture only the client and server flows specific to my Client's IP address (10.199.3.1): Note: The0.0interface will capture any forwarding plane traffic (tmm) andnnnis the highest noise to capture as much flow information as possible to be displayed on the F5 dissector header.For more details about tcpdump syntax, please have a look atK13637: Capturing internal TMM information with tcpdumpandK411: Overview of packet tracing with the tcpdump utility. Also,we need to make sure we capture the full TLS handshake. It's perfectly fine to captureresumed TLS sessionsas long as full TLS handshake has been previously captured. Initially, our capture is unencrypted as seen below: On Mac, I clicked onWireshark→Preferences: ThenProtocols→TLS→RSA keys listwhere we see a window where we can reference BIG-IP's (or server if we want to decrypt server SSL side) private key: Once we get there, we need to add any IP address of the flow we want Wireshark to decrypt, the corresponding port and the private key file (default.crtfor Client SSL profile in this particular lab test): Note:For Client SSL profile, this would be the private key onCertificate Chainfield corresponding to the end entity Certificate being served to client machines through the Virtual Server. For Server SSL profile, the private key is located on the back-end server and the key would be the one corresponding to the end entity Certificate sent in the TLSCertificatemessage sent from back-end server to BIG-IP during TLS handshake. Once we clickOK, we can see the HTTP decrypted traffic (in green): In production environment, we would normally avoid copying private keys to different machines soanother option is usessldumpcommand directly on the server we're trying to capture. Again, if we're capturing Client SSL traffic,ssldumpis already installed on BIG-IP. We would follow the same steps as before but instead of copying private key to Wireshark machine, we would simply issue this command on the BIG-IP (or back-end server if it's Server SSL traffic): Syntax:ssldump-r<capture.pcap>-k<private key.key>-M<type a name for your ssldump file here.pms>. For more details, please have a look atK10209: Overview of packet tracing with the ssldump utility. Inssldump-generated.pms, we should find enough information for Wireshark to decrypt the capture: Syntax:ssldump-r<capture.pcap>-k<private key.key>-M<type a name for your ssldump file here.pms>. For more details, please have a look atK10209: Overview of packet tracing with the ssldump utility. Inssldump-generated.pms, we should find enough information for Wireshark to decrypt the capture: After I clickedOK, we indeed see the decrypted http traffic back again: We didn't have to copy BIG-IP's private key to Wireshark machine here. iRules The only constraint here is that we should apply the iRule to the virtual server in question. Sometimes that's not desirable, especially when we're troubleshooting an issue where we want the configuration to be unchanged. Note: there is abugthat affects versions 11.6.x and 12.x that was fixed on 13.x. It records the wrong TLS Session ID to LTM logs. The workaround would be to manually copy the Session ID from tcpdump capture or to use RSA decryption as in previous example. You can also combine bothSSL::clientrandomandSSL::sessionidwhich isthe ideal: Reference: K12783074: Decrypting SSL traffic using the SSL::sessionsecret iRules command (12.x and later) Again, I took a capture usingtcpdumpcommand: After applying above iRule to our HTTPS virtual server and taking tcpdump capture, I see this on /var/log/ltm: To copy this to a *.pms file wecanuseon Wireshark we can use sed command (reference:K12783074): Note:If you don't want to overwrite completely the PMS file make sure youuse >> instead of >. The endresult would be something like this: As both resumed and full TLS sessions have client random value, I only had to copy CLIENT_RANDOM + Master secret to our PMS file because all Wireshark needs is a session reference to apply master secret. To decrypt file on Wireshark just go toWireshark→Preferences→Protocols→TLS→Pre-Master Key logfile namelike we did inssldumpsection and add file we just created: As seen on LTM logs,CLIENTSSL_HANDSHAKEevent captured master secret from our client-side connection andSERVERSSL_HANDSHAKEfrom server side. In this case, we should have both client and server sides decrypted, even though we never had access to back-end server: Notice added anhttpfilter to show you both client and and server traffic were decrypted this time. tcpdump --f5 ssl option This was introduced in 15.x and we don't need to change virtual server configuration by adding iRules. The only thing we need to do is to enabletcpdump.sslproviderdb variable which is disabled by default: After that, when we take tcpdump capture, we just need to add --f5 ssl to the command like this: Notice that we've got a warning message because Master Secret will be copied to tcpdump capture itself, so we need to be careful with who we share such capture with. I had to update my Wireshark to v3.2.+ and clicked onAnalyze→Enabled Protocols: And enable F5 TLS dissector: Once we open the capture, we can find all the information you need to create our PMS file embedded in the capture: Very cool, isn't it? We can then copy the Master Secretand Client Random values by right clicking like this: And then paste it to a blank PMS file. I first pasted the Client Random value followed by Master Secret value like this: Note: I manually typedCLIENT_RANDOMand then pasted both values for both client and server sides directly from tcpdump capture. The last step was to go toWireshark→Preferences→Protocols→TLSand add it toPre-master-Secret log filenameand clickOK: Fair enough! Capture decrypted on both client and server sides: I usedhttpfilter to display only decrypted HTTP packets just like in iRule section. Appendix 1 How do we know which Key Exchange method is being used? RSA private key can only decrypt traffic on Wireshark if RSA is the key exchange method negotiated during TLS handshake. Client side will tell the Server side which ciphers it support and server side will reply with the chosen cipher onServer Hellomessage. With that in mind, on Wireshark, we'd click onServer Helloheader underCipher Suite: Key Exchange and Authentication both come before theWITHkeyword. In above example, because there's only RSA we can say that RSA is used for both Key Exchange and Authentication. In the following example, ECDHE is used for key exchange and RSAfor authentication: Appendix 2 Disabling Session Resumption and Prioritising RSA key exchange We can set Cache Size to 0 to disableTLS session resumptionand change the Cipher Suites to anything that makes BIG-IP pick RSA for Key Exchange:11KViews12likes10CommentsClient SSL Authentication on BIG-IP as in-depth as it can go
Quick Intro In this article, I'm going to explain how SSL client certificate authentication works on BIG-IP and explain what actually happens during client authentication as in-depth as I can, showing the TLS headers on Wireshark. This article is about the client side of BIG-IP (Client SL profile) authenticating a client connecting to BIG-IP. The Topology For reference so we can follow Wireshark output: How to Configure Client Certificate Authentication on Client SSL profile Essentially, what we're doing here is making BIG-IP verify client's credentials before allowing the TLS handshake to proceed. However, such credentials are in the form of a client certificate. The way to do this is to configure BIG-IP by: Adding a CA file to Trusted Certificate Authorities (ca-file in tmsh) to validate client certificate Optionally adding same CA that signed client certificate to Advertised Certificate Authorities Enforcing Client Certificate validation by setting Client Certificate option on BIG-IP to require Optionally setting the Frequency of such checks if we don't want to stick to the defaults. I'll go through each option now. Adding CA file to Trusted Certificate Authorities We should add to Trusted Certificate Authorities a single certificate file (*.crt) with one CA or concatenated file with 2 or more CAs with the purpose of validating client certificate, i.e. confirming client's identity. Upon receiving client certificate, BIG-IP will go through this list of CAs and confirm client's identity. It also has another purpose which is to authenticate BIG-IP to client but it's out of the scope of this article. Optionally add CA file to Advertised Certificate Authorities Trusted Certificate Authoritiesexplicitly tells BIG-IP the CA or chain of CAs it will use to validate client certificate whereasAdvertised Certificate Authorities tells client in advance what kind of CA BIG-IP trusts so that client can make the decision about which certificate to send to BIG-IP: Why would we use Advertised Certificate Authorities? Let's imagine a situation where Client's application has more than one Client Certificate configured. How is it going to figure out which certificate to send to BIG-IP? That's where Advertised Certificate Authorities comes to rescue us! When we add our CA bundle to Advertised Certificate Authorities, we're telling BIG-IP to add it to a header field named Distinguished Names within Certificate Request message. I dedicated the Appendix section to show you more in-depth how changing Advertised Certificate Authority affects Certificate Request header. Configuring BIG-IP to enforce Client Certificate validation To enable client certificate authentication on BIG-IP we change Local Traffic››Profiles : SSL : Client›› Client Certificate to request: The default is set to ignore where client certificate authentication is disabled. If we truly want to enable client certificate validation we need to select require. The reason why is because request makes BIG-IP request a client certificate from the client but BIG-IP will not perform the validation to confirm if the certificate sent is valid in this mode. The following subsections explain each option. Ignore Client Certificate Authentication is disabled (the default). BIG-IP never sends Certificate Request to client and therefore client does not need to send its certificate to BIG-IP. In this case, TLS handshake proceeds successfully without any client authentication: pcap:ssl-sample-peer-cert-mode-ignore.pcap Wireshark filter used:frame.number == 5 or frame.number == 6 Request BIG-IP requests Client Certificate by sending Certificate Request message but does not check whether client certificate is valid which is not really client authentication, is it? This means that ca-file(Trusted Certificate Authorities in the GUI) will not be used to validate client certificate and we will consider any certificate sent to us to be valid. For example, inssl-sample-peer-cert-mode-request-with-no-client-cert-sent.pcapwe now see that BIG-IP sends aCertificate Requestmessage and client responds with aCertificatemessage this time: Because I didn't add any client certificate to my browser, it sent a blank certificate to BIG-IP. Again, BIG-IP did not perform any validation whatsoever, so TLS handshake proceeded successfully. We can then conclude that this setting only makes BIG-IP request client certificate and that's it. Require It behaves just like Request but BIG-IP also performs client certificate validation, i.e. BIG-IP will use CA we hopefully added to ca-file (Trusted Certificate Authorities in the GUI) to confirm if client certificate is valid. This means that if we don't add a CA to Trusted Certificate Authorities (ca-file in tmsh) then validation will fail. Setting the Frequency of Client Certificate Requests This setting specifies the frequency BIG-IP authenticates client by enabling/disabling TLS session resumption. It has only 2 options: once BIG-IP requests client certificate during first handshake and no longer re-authenticates client as long as TLS session is reused and valid. The way BIG-IP does it is by using Session Resumption/Reuse. During first TLS handshake from client, BIG-IP sends a Session ID to Client within Server Hello header and in subsequent TLS connections, assuming session ID is still in BIG-IP's cache and client re-sends it back to BIG-IP, then session will be resumed every time client tries to establish a TLS session (respecting cache timeout). First time client sends Client Hello with blank session ID as it's cache is empty and then it is assigned a Session ID by BIG-IP (409f...): pcap:ssl-sample-clientcert-auth-once-enabled.pcap Wireshark filter used:filter:!ip.addr == 172.16.199.254 and frame.number > 1 and frame.number < 7 Certificate Requestconfirms BIG-IP is trying to authenticate client. Notice Session ID BIG-IP sent to client is 409f7... Then when Client tries to go through another TLS handshake and sends above session ID in Client Hello (packet #70 below). BIG-IP then confirms session is being resumed by sending samesession IDin Server Hello back to client: Wireshark filter used:!ip.addr == 172.16.199.254 and frame.number > 66 and frame.number < 73 This resumed TLS handshake just means we will not go through full handshake and will no longer need to exchange keys, select ciphers or re-authenticate client as we're reusing those already negotiated in the full TLS handshake where we first received Session ID 409f... always BIG-IP requests client certificate, i.e. re-authenticates client at every handshake. On BIG-IP, this is accomplished by disabling session reuse which makes BIG-IP not to sendSession IDback to Client in the beginning and forcing a full TLS handshake every time. pcap:ssl-sample-clientcert-auth-always-enabled.pcap Wireshark filter used: !ip.addr == 172.16.199.254 and ((frame.number > 1 and frame.number < 7) or (frame.number > 74 and frame.number < 80)) Appendix: Understanding how Advertised Certificate Authority field affects Certificate Request header For this test, I've got the following: myCAbundle.crt: concatenation of root_ca.crt and ltm2.crt (signed by root_ca.crt) client_cert.crt: added to Firefox and signed by ltm2.crt I've also added myCAbundle.crt to Trusted Certificate Authorities so BIG-IP is able to verify that client_cert.crt is valid. For each test, I will use change Advertised Certificate Authorities so we can see what happens. We'll go through 3 tests here: Setting Advertised Certificate Authority to None Setting Advertised Certificate Authority to a certificate that didn't sign client cert Setting Advertised Certificate Authority to a bundle that signed client cert Setting Advertised Certificate Authority to None Note that even though no CA was advertised in Certificate Request message, BIG-IP still advertises Certificate typesandSignature Hash Algorithmsso that client knows in advance what kind of certificate (RSA, DSS or ECDSA) and hash algorithms BIG-IP supports in advance. If client certificate had not been signed using any of the certificate types and hashing algorithms listed then handshake would have failed. However, in this case validation is successful as we can see on frame #8 that client certificate is RSA type and hashed with SHA1: pcap: ssl-sample-advcert-none.pcap filter used: !ip.addr == 172.16.199.254 and frame.number > 1 and frame.number < 16 It's worth noting that Distinguished Names is NOT populated and has length of zero because we didn't attach a bundle to Advertised Certificate Authorities. In this case, it worked fine because my client browser had only one certificate attached, so it shouldn't cause a problem anyway. Setting Advertised Certificate Authority to a certificate that didn't sign client cert pcap: ssl-sample-advcert-default-firefox.pcap Wireshark filter used: None I've set Advertised Certificate Authority to default.crt as this is NOT the CA that signed client's certificate: The difference here when compared to None is that now we can see that Distinguished Names is now populated with the certificate I added (default.crt): However, even though I added the correct certificate to my Firefox browser, it sent a blank certificate instead. Why? That's because BIG-IP signalled in Distinguished Names that default.crt is the CA that signed the certificate BIG-IP is looking for and as Firefox doesn't have any certificate signed by default.crt, it just sent a blank certificate back to BIG-IP. Also, because BIG-IP is now performing proper validation, i.e. comparing whatever client certificate is sent to it with the CA list added to Trusted Certificate Authorities, it knows a blank certificate is not valid and terminates the TLS handshake with a Fatal Alert. Setting Advertised Certificate Authority to a bundle that signed client cert pcap: ssl-sample-advcert-ltm2chainedwithrootca.pcap filter used: !ip.addr == 172.16.199.254 and frame.number > 1 Now I've set Advertised Certificate Authority to the correct bundle that signed my client certificate: And indeed handshake succeeds because: BIG-IP advertises myCAbundle.crt in Certificate Request >> Distinguished Names header, as per Advertised Certificate Authority configuration By reading Distinguished Names field, Client correctly sends the correct client certificate back to BIG-IP BIG-IP correctly validates client certificate using myCAbundle configured on Trusted Certificate Authorities Hope this article provides some clarification about these mysterious TLS headers.14KViews10likes8CommentsHow Proxy SSL works on BIG-IP
1. Lab Scenario Lab test results: Client completes 3-way handshake with BIG-IP and BIG-IP immediately opens and completes 3-way handshake with back-end server Upon receiving Client Hello on client-side, BIG-IP immediately sends Client Hello on server-side as it is BIG-IP copies same cipher suite list seen on client-side Client Hello to server-side Client Hello BIG-IP ignores what is configured on both Client SSL or Server SSL profiles. As soon as BIG-IP receives Server Hello it confirms two things: Is RSA the chosen key exchange mechanism in Cipher Suite on Server Hello message sent from back-end server? Does Certificate sent by back-end matches the one configured on Server SSL profile on BIG-IP? ONLY if both conditions above match BIG-IP proceeds with handshake. Otherwise, BIG-IP sends a Handshake Failure (Fatal Alert) to both Server and Client with reset cause ofillegal_parameter BIG-IP copies same Server SSL/Back-end Server certificate to Certificate message sent to Client on client-side BIG-IP completely ignores certificate you configured on Client SSL. It always uses the same server-side certificate. Assuming TLS handshake completes successfully BIG-IP is able to decrypt all client-side as well as server-side data which is the whole purpose of Proxy SSL. 2. How Proxy SSL works When Proxy SSL is enabled,BIG-IP does its best to match client-side to server-side connection in terms of negotiation and traffic to make it as transparent as possible to both client and back-end server and at the same allowing BIG-IP to decrypt traffic. About data transparency BIG-IP achieves transparency by copying whatever client and server sends back and forth. About data decryption BIG-IP has an extra configuration requirement for Proxy SSL configuration (according toK13385) that you should add the same certificate/key present on the back-end server to Certificate/Key fields on Server SSL proxy of BIG-IP. This way BIG-IP can decrypt both client and server sides of connection. In practical terms and to achieve this, BIG-IP completely changes the original purpose of Server SSL Certificate and Key fields. Here's my config: Certificate/Key fields above are no longer used for the purpose described inK14806, i.e. to independently authenticate BIG-IP to back-end server through Client Authentication. Instead, when Proxy SSL is enabled it is used to validate if Certificate sent by back-end server is the same one in this field. If so, BIG-IP also copies this certificate to Certificate message sent to Client on client-side. Noticethat when Proxy SSL is NOT bypassedCertificate configured on Client SSL profile is never used. As soon as I sent first request to Wildcard forwarding VIP BIG-IP establishes TCP connection on client-side first and then immediately on server-side: The next step is to forward exactly the sameClient Hellowe receive from Client on client-side to Server on server-side: Now server sends Server Hello: The first thing BIG-IP checks is key exchange mechanism as Proxy SSL has to use RSA (frame 12): Now BIG-IP checks if Certificate insideCertificatemessage is the same as the one configured on Server SSL. In this case I have used Certificate's unique serial number to confirm this. On BIG-IP: Now on Server's message (frame 12): Now BIG-IP sends this same certificate inServer Hellomessage client-side and we can confirm from Serial number that it is the same: From this moment handshake should complete successfully and BIG-IP is maintaining 2 separate connections using the same certificate/key pair on client and server side with the ability to decrypt both. 3. Troubleshooting Proxy SSL when BIG-IP is the culprit Typically, if BIG-IP is the culprit it either because back-end server selected non-RSA key exchange cipher or because cert/key which are not supported. In another test I used DHE on purpose andBIG-IP resets connection immediately after Server Hello message is received from back-end server which is typical sign of validation error: I confirmed back-end server had selected ECDHE key exchange cipher which is not supported by Proxy SSL (frame 12): In case you don't know yet here's how you work out key exchange cipher: Disabling non-RSA cipher on back-end server did the trick to fix the above error as Proxy SSL only supports RSA key exchange. 4. Setting Up Proxy SSL on BIG-IP I used very minimal configuration for this lab and the only thing I did was to create a wildcard forwarding virtual server using Standard VIP: I enabled proxy-ssl on both Client and Server SSL profiles and added back-end server certificate (ltm3.crt) and key (ltm3.key) to Server SSL profile: I also disabled (EC)DHE and explicitly configured RSA as key exchange mechanism in my back-end server. I also confirmed back-end server was also usingltm3.crt/ltm3.keyas it must match the one configured on Server SSL profile: And it all worked fine:5.5KViews7likes12CommentsAutomate Let's Encrypt Certificates on BIG-IP
To quote the evil emperor Zurg: "We meet again, for the last time!" It's hard to believe it's been six years since my first rodeo with Let's Encrypt and BIG-IP, but (uncompromised) timestamps don't lie. And maybe this won't be my last look at Let's Encrypt, but it will likely be the last time I do so as a standalone effort, which I'll come back to at the end of this article. The first project was a compilation of shell scripts and python scripts and config files and well, this is no different. But it's all updated to meet the acme protocol version requirements for Let's Encrypt. Here's a quick table to connect all the dots: Description What's Out What's In acme client letsencrypt.sh dehydrated python library f5-common-python bigrest BIG-IP functionality creating the SSL profile utilizing an iRule for the HTTP challenge The f5-common-python library has not been maintained or enhanced for at least a year now, and I have an affinity for the good work Leo did with bigrest and I enjoy using it. I opted not to carry the SSL profile configuration forward because that functionality is more app-specific than the certificates themselves. And finally, whereas my initial project used the DNS challenge with the name.com API, in this proof of concept I chose to use an iRule on the BIG-IP to serve the challenge for Let's Encrypt to perform validation against. Whereas my solution is new, the way Let's Encrypt works has not changed, so I've carried forward the process from my previous article that I've now archived. I'll defer to their how it works page for details, but basically the steps are: Define a list of domains you want to secure Your client reaches out to the Let’s Encrypt servers to initiate a challenge for those domains. The servers will issue an http or dns challenge based on your request You need to place a file on your web server or a txt record in the dns zone file with that challenge information The servers will validate your challenge information and notify you You will clean up your challenge files or txt records The servers will issue the certificate and certificate chain to you You now have the key, cert, and chain, and can deploy to your web servers or in our case, to the BIG-IP Before kicking off a validation and generation event, the client registers your account based on your settings in the config file. The files in this project are as follows: /etc/dehydrated/config # Dehydrated configuration file /etc/dehydrated/domains.txt # Domains to sign and generate certs for /etc/dehydrated/dehydrated # acme client /etc/dehydrated/challenge.irule # iRule configured and deployed to BIG-IP by the hook script /etc/dehydrated/hook_script.py # Python script called by dehydrated for special steps in the cert generation process # Environment Variables export F5_HOST=x.x.x.x export F5_USER=admin export F5_PASS=admin You add your domains to the domains.txt file (more work likely if signing a lot of domains, I tested the one I have access to). The dehydrated client, of course is required, and then the hook script that dehydrated interacts with to deploy challenges and certificates. I aptly named that hook_script.py. For my hook, I'm deploying a challenge iRule to be applied only during the challenge; it is modified each time specific to the challenge supplied from the Let's Encrypt service and is cleaned up after the challenge is tested. And finally, there are a few environment variables I set so the information is not in text files. You could also move these into a credential vault. So to recap, you first register your client, then you can kick off a challenge to generate and deploy certificates. On the client side, it looks like this: ./dehydrated --register --accept-terms ./dehydrated -c Now, for testing, make sure you use the Let's Encrypt staging service instead of production. And since I want to force action every request while testing, I run the second command a little differently: ./dehydrated -c --force --force-validation Depicted graphically, here are the moving parts for the http challenge issued by Let's Encrypt at the request of the dehydrated client, deployed to the F5 BIG-IP, and validated by the Let's Encrypt servers. The Let's Encrypt servers then generate and return certs to the dehydrated client, which then, via the hook script, deploys the certs and keys to the F5 BIG-IP to complete the process. And here's the output of the dehydrated client and hook script in action from the CLI: # ./dehydrated -c --force --force-validation # INFO: Using main config file /etc/dehydrated/config Processing example.com + Checking expire date of existing cert... + Valid till Jun 20 02:03:26 2022 GMT (Longer than 30 days). Ignoring because renew was forced! + Signing domains... + Generating private key... + Generating signing request... + Requesting new certificate order from CA... + Received 1 authorizations URLs from the CA + Handling authorization for example.com + A valid authorization has been found but will be ignored + 1 pending challenge(s) + Deploying challenge tokens... + (hook) Deploying Challenge + (hook) Challenge rule added to virtual. + Responding to challenge for example.com authorization... + Challenge is valid! + Cleaning challenge tokens... + (hook) Cleaning Challenge + (hook) Challenge rule removed from virtual. + Requesting certificate... + Checking certificate... + Done! + Creating fullchain.pem... + (hook) Deploying Certs + (hook) Existing Cert/Key updated in transaction. + Done! This results in a deployed certificate/key pair on the F5 BIG-IP, and is modified in a transaction for future updates. This proof of concept is on github in the f5devcentral org if you'd like to take a look. Before closing, however, I'd like to mention a couple things: This is an update to an existing solution from years ago. It works, but probably isn't the best way to automate today if you're just getting started and have already started pursuing a more modern approach to automation. A better path would be something like Ansible. On that note, there are several solutions you can take a look at, posted below in resources. Resources https://github.com/EquateTechnologies/dehydrated-bigip-ansible https://github.com/f5devcentral/ansible-bigip-letsencrypt-http01 https://github.com/s-archer/acme-ansible-f5 https://github.com/s-archer/terraform-modular/tree/master/lets_encrypt_module(Terraform instead of Ansible) https://community.f5.com/t5/technical-forum/let-s-encrypt-with-cloudflare-dns-and-f5-rest-api/m-p/292943(Similar solution to mine, only slightly more robust with OCSP stapling, the DNS instead of HTTP challenge, and with bash instead of python)20KViews6likes18CommentsSSL Profiles Part 1: Handshakes
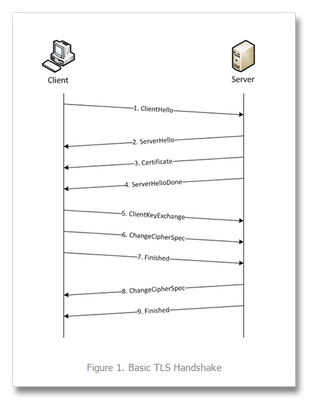
This is the first in a series of tech tips on the F5 BIG-IP LTM SSL profiles. SSL Overview and Handshake SSL Certificates Certificate Chain Implementation Cipher Suites SSL Options SSL Renegotiation Server Name Indication Client Authentication Server Authentication All the "Little" Options SSL, or the Secure Socket Layer, was developed by Netscape back in the ‘90s to secure the transport of web content. While adopted globally, the standards body defined the Transport Layer Security, or TLS 1.0, a few years later. Commonly interchanged in discussions, the final version of SSL (v3) and the initial version of TLS (v1) do not interoperate, though TLS includes the capabality to downgrade to SSLv3 if necessary. Before we dive into the options within the SSL profiles, we’ll start in this installment with a look at the SSL certificate exchanges and take a look at what makes a client versus a server ssl profile. Server-Only Authentication This is the basic TLS handshake, where the only certificate required is on the serverside of the connection. The exchange is shown in Figure 1 below. In the first step. the client sends a ClientHello message containing the cipher suites (I did a tech tip a while back on manipulating profiles that has a good breakdown of the fields in a ClientHello message), a random number, the TLS version it supports (highest), and compression methods. The ServerHello message is then sent by the server with the version, a random number, the ciphersuite, and a compression method from the clients list. The server then sends its Certificate and follows that with the ServerDone message. The client responds with key material (depending on cipher selected) and then begins computing the master secret, as does the server upon receipt of the clients key material. The client then sends the ChangeCipherSpec message informing the server that future messages will be authenticated and encrypted (encryption is optional and dependent on parameters in server certificate, but most implementations include encryption). The client finally sends its Finished message, which the server will decrypt and verify. The server then sends its ChangeCipherSpec and Finished messages, with the client performing the same decryption and verification. The application messages then start flowing and when complete (or there are SSL record errors) the session will be torn down. Question—Is it possible to host multiple domains on a single IP and still protect with SSL/TLS without certificate errors? This question is asked quite often in the forums. The answer is in the details we’ve already discussed, but perhaps this isn’t immediately obvious. Because the application messages—such as an HTTP GET—are not received until AFTER this handshake, there is no ability on the server side to switch profiles, so the default domain will work just fine, but the others will receive certificate errors. There is hope, however. In the TLSv1 standard, there is an option called Server Name Indication, or SNI, which will allow you to extract the server name and switch profiles accordingly. This could work today—if you control the client base. The problem is most browsers don’t default to TLS, but rather SSLv3. Also, TLS SNI is not natively supported in the profiles, so you’ll need to get your hands dirty with some serious iRule-fu (more on this later in the series). Anyway, I digress. Client-Authenticated Handshake The next handshake is the client-authenticated handshake, shown below in Figure 2. This handshake adds a few steps (in bold above), inserting the CertificateRequest by the server in between the Certificate and ServerHelloDone messages, and the client starting off with sending its Certificate and after sending its key material in the ClientKeyExchange message, sends the CertificateVerify message which contains a signature of the previous handshake messages using the client certificate’s private key. The server, upon receipt, verifies using the client’s public key and begins the heavy compute for the master key before both finish out the handshake in like fashion to the basic handshake. Resumed Handshake Figure 3 shows the abbreviated handshake that allows the performance gains of not requiring the recomputing of keys. The steps passed over from the full handshake are greyed out. It’s after step 5 that ordinarily both server and client would be working hard to compute the master key, and as this step is eliminated, bulk encryption of the application messages is far less costly than the full handshake. The resumed session works by the client submitting the existing session ID from previous connections in the ClientHello and the server responding with same session ID (if the ID is different, a full handshake is initiated) in the ServerHello and off they go. Profile Context As with many things, context is everything. There are two SSL profiles on the LTM, clientssl and serverssl. The clientssl profile is for acting as the SSL server, and the serverssl profile is for acting as the SSL client. Not sure why it worked out that way, but there you go. So if you will be offloading SSL for your applications, you’ll need a clientssl profile. If you will be offloading SSL to make decisions/optimizations/inspects, but still require secured transport to your servers, you’ll need a clientssl and a serverssl profile. Figure 4 details the context. Conclusion Hopefully this background on the handshake process and the profile context is beneficial to the profile options we’ll cover in this series. For a deeper dive into the handshakes (and more on TLS), you can check out RFC 2246 and this presentation on SSL and TLS cryptography. Next up, we’ll take a look at Certificates.11KViews6likes6CommentsTLS Stateful vs Stateless Session Resumption
1. Preliminary Information TLS Session Resumption allows caching of TLS session information. There are 2 kinds: stateful and stateless. In stateful session resumption, BIG-IP stores TLS session information locally. In stateless session resumption, such job is delegated to the client. BIG-IP supports both stateful and stateless TLS session resumption. Enabling stateful or stateless session resumption is just a matter of ticking/unticking a tickbox on LTM's Client SSL profile: In this article, I'm going to walk through how session resumption works by performing a lab test. Here's my topology: Do not confuseSession Reuse/Resumption withRenegotiation. Renegotiation uses the same TCP connection to renegotiate security parameters which does not involved Session ID or Session Tickets. For more information please refer to SSL Legacy Renegotiation Secure Renegotiation. 2. How Stateful Session Resumption works Capture used:ssl-sample-session-ticket-disabled.pcap 2.1 New session Statefulmeans BIG-IP will keep storing session information from as many clients its cache allows and TLS handshake will proceed as follows: We can see above that Client sends an empty Session ID field and BIG-IP replies with a new Session ID (filter used:tcp.stream eq 0). After that, full handshake proceeds normally where Certificate and Client Key Exchange are sent and there is also the additional cost CPU-wise to compute the keys: 2.2 Reusing Previous Session Now both Client and Server have Session ID 56bcf9f6ea40ac1bbf05ff7fd209d423da9f96404103226c7f927ad7a2992433 stored in their TLS session cache. The good thing about it is that in the next TLS connection request, client won't need to go through the full TLS handshake again. Here's what we see: Client just sends Session ID (56bcf9f6ea40ac1bbf05ff7fd209d423da9f96404103226c7f927ad7a2992433) it previously learnt from BIG-IP (via Server Hello from previous connection) on its Client Hello message. BIG-IP then confirms this session ID is in its SSL Session cache and they both go through what is known as abbreviated TLS handshake. No certificate or key information is exchanged during abbreviated TLS handshake and previously negotiated keys are re-used. 3. How Stateless Session Resumption works Capture used:ssl-sample-session-ticket-enabled-2.pcap 3.1 New Session Because of the burden on BIG-IP that has to store one session per client,RFC5077suggested a new way of doing session Resumption that offloads the burden of keeping all TLS session information to client and nothing else needs to be stored on BIG-IP. Let's see the magic! Client first signals it supports stateless session resumption by adding SessionTickets TLS extension to its Client Hello message (in green): BIG-IP also signals back to client (in red) it supports SessionTicket TLS by adding empty SessionTicket TLS extension.Notice thatSession IDis NOT used here! The TLS handshake proceeds normally just like in stateful session resumption. However, just before handshake is completed (with Finished message), BIG-IP sends a new TLS message calledNew Session Ticketwhich consists of encrypted session information (e.g. master secret, cipher used, etc) where BIG-IP is able to decrypt later using a unique key it generates only for this purpose: From this point on, client (10.199.3.135) keeps session ticket in its TLS cache until next time it needs to connect to the same server (assuming session ticket did not expire). 3.2 Reusing Previous Session Now, when the same client wants to re-use previous session,it forwards the same session ticket aboveinSessionTicket TLS extensionon its Client Hello message as seen below: As we've noticed, Client also creates a new Session ID used for the following purpose: Server replies back with same session ID: BIG-IP accepted Session Ticket and is going to reuse the session. Server replies with empty/different Session ID: BIG-IP decided to go through full handshake either because Session Ticket expired or it is falling back to stateful session resumption. PS: Such session ID is NOT stored on BIG-IP otherwise it would defeat the purpose of stateless session reuse. It is a one-off usage just to confirm to client BIG-IP accepted session ticket they sent and we're not going to generate new session keys. In our example, BIG-IP successfully accepted and reused TLS session. We can confirm that an abbreviated TLS handshake took place and on Server Hello message BIG-IP replied back with same session ID client sent (to BIG-IP): Now, client This is session resumption in action and BIG-IP doesn't even have to store session information locally, making it a more scalable option when compared to stateful session resumption.6KViews6likes4CommentsSSL Orchestrator Advanced Use Cases: Reducing Complexity with Internal Layered Architecture
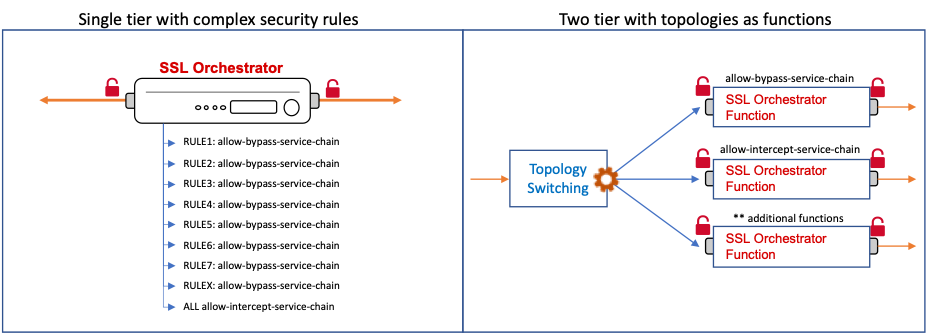
Introduction Sir Isaac Newton said, "Truth is ever to be found in the simplicity, and not in the multiplicity and confusion of things". The world we live in is...complex. No getting around that. But at the very least, we should strive for simplicity where we can achieve it. As IT folk, we often find ourselves mired in the complexity of things until we lose sight of the big picture, the goal. How many times have you created an additional route table entry, or firewall exception, or virtual server, because the alternative meant having a deeper understanding of the existing (complex) architecture? Sure, sometimes it's unavoidable, but this article describes at least one way that you can achieve simplicity in your architecture. SSL Orchestrator sits as an inline point of presence in the network to decrypt, re-encrypt, and dynamically orchestrate that traffic to the security stack. You need rules to govern how to handle specific types of traffic, so you create security policy rules in the SSL Orchestrator configuration to describe and take action on these traffic patterns. It's definitely easy to create a multitude of traffic rules to match discrete conditions, but if you step back and look at the big picture, you may notice that the different traffic patterns basically all perform the same core actions. They allow or deny traffic, intercept or bypass TLS (decrypt/not-decrypt), and send to one or a few service chains. If you were to write down all of the combinations of these actions, you'd very likely discover a small subset of discrete "functions". As usual, F5 BIG-IP and SSL Orchestrator provide some innovative and unique ways to optimize this. And so in this article we will explore SSL Orchestrator topologies "as functions" to reduce complexity. Specifically, you can reduce the complexity of security policy rules, and in doing so, quite likely increase the performance of your SSL Orchestrator architecture. SSL Orchestrator Use Case: Reducing Complexity with Internal Layered Architectures The idea is simple. Instead of a single topology with a multitude of complex traffic pattern matching rules, create small atomic topologies as static functions and steer traffic to the topologies by virtue of "layered" traffic pattern matching. Granted, if your SSL Orchestrator configuration is already pretty simple, then please keep doing what you're doing. You've got this, Tiger. But if your environment is getting complex, and you're not quite convinced yet that topologies as functions is a good idea, here are a few additional benefits you'll get from this topology layering: Dynamic egress selection: topologies as functions can define different egress paths. Dynamic CA selection: topologies as functions can use different local issuing CAs for different traffic flows. Dynamic traffic bypass: certain types of traffic can be challenging to handle internally. For example, mutual TLS traffic can be bypassed globally with the "Bypass on client cert failure" option in the SSL configuration, but bypassing mutual TLS sites by hostname is more complex. A layered architecture can steer traffic (by SNI) through a bypass topology, with a service chain. More flexible pattern recognition: for all of its flexibility, SSL Orchestrator security policy rules cannot catch every possible use case. External traffic pattern recognition, via iRules or CPM (LTM policies) offer near infinite pattern matching options. You could, for example, steer traffic based on incoming tenant VLAN or route domain for multi-tenancy configurations. More flexible automation strategies: as iRules, data groups, and CPM policies are fully automate-able across many AnO platforms (ex. AS3, Ansible, Terraform, etc.), it becomes exceedingly easy to automate SSL Orchestrator traffic processing, and removes the need to manage individual topology security policy rules. Hopefully these benefits give you a pretty clear indication of the value in this architecture strategy. So without further ado, let's get started. Configuration Before we begin, I'd like to make note of the following caveats: While every effort has been made to simplify the layered architecture, there is still a small element of complexity. If you are at all averse to creating virtual servers or modifying iRules, then maybe this isn't for you. But as you are reading this in a forum dedicated to programmability, I'm guessing you the reader are ready for a challenge. This is a "field contributed" solution, so not officially supported by F5. This topology layering architecture is applicable to all modern versions of SSL Orchestrator, from 5.0 to 8.0. While topology layering can be used for inbound topologies, it is most appropriate for outbound. The configuration below also only describes the layer 3 implementation. But layer 2 layering is also possible. With this said, there are just a few core concepts to understand: Basic layered architecture configuration - how the pieces fit together The iRules - how traffic moves through the architecture Or the CPM policies - an alternative to iRules Note again that this is primarily useful in outbound topologies. Inbound topologies are typically more atomic on their own already. I will cover both transparent and explicit forward proxy configurations below. Basic layered architecture configuration A layered architecture takes advantage of a powerful feature of the BIG-IP called "VIP targeting". The idea is that one virtual server calls another with negligible latency between the two VIPs. The "external" virtual server is client-facing. The SSL Orchestrator topology virtual servers are thus "internal". Traffic enters the external VIP and traffic rules pass control to any of a number of internal "topology function" VIPs. You certainly don't have to use the iRule implementation presented here. You just need a client-facing virtual server with an iRule that VIP-targets to one or more SSL Orchestrator topologies. Each outbound topology is represented by a virtual server that includes the application server name. You can see these if you navigate to Local Traffic -> Virtual Servers in the BIG-IP UI. So then the most basic topology layering architecture might just look like this: when CLIENT_ACCEPTED { virtual "/Common/sslo_my_topology.app/sslo_my_topology-in-t-4" } This iRule doesn't do anything interesting, except get traffic flowing across your layered architecture. To be truly useful you'll want to include conditions and evaluations to steer different types of traffic to different topologies (as functions). As the majority of security policy rules are meant to define TLS traffic patterns, the provided iRules match on TLS traffic and pass any non-TLS traffic to a default (intercept/inspection) topology. These iRules are intended to simplify topology switching by moving all of the complexity of traffic pattern matching to a library iRule. You should then only need to modify the "switching" iRule to use the functions in the library, which all return Boolean true or false results. Here are the simple steps to create your layered architecture: Step 1: Build a set of "dummy" VLANs. A topology must be bound to a VLAN. But since the topologies in this architecture won't be listening on client-facing VLANs, you will need to create a separate VLAN for each topology you intend to create. A dummy VLAN is a VLAN with no interface assigned. In the BIG-IP UI, under Network -> VLANs, click Create. Give your VLAN a name and click Finished. It will ask you to confirm since you're not attaching an interface. Repeat this step by creating unique VLAN names for each topology you are planning to use. Step 2: Build a set of static topologies as functions. You'll want to create a normal "intercept" topology and a separate "bypass" topology, though you can create as many as you need to encompass the unique topology functions. Your intercept topology is configured as such: L3 outbound topology configuration, normal topology settings, SSL configuration, services, service chains No security policy rules - just the ALL rule with TLS intercept action (and service chain), and optionally remove the built-in Pinners rule Attach to a dummy VLAN (a VLAN with no assigned interfaces) Your bypass topology should then look like this: L3 outbound topology configuration, skip the SSL Configuration settings, optionally re-use services and service chains No security policy rules - just the ALL rule with TLS bypass action (and service chain) Attach to a separate dummy VLAN (a VLAN with no assigned interfaces) Note the name you use for each topology, as this will be called explicitly in the iRule. For example, if you name the topology "myTopology", that's the name you will use in each "call SSLOLIB::target" function (more on this in a moment) . If you look in the SSL Orchestrator UI, you will see that it prepends "sslo_" (ex. sslo_myTopology). Don't include the "sslo_" portion in the iRule. Step 3: Import the SSLOLIB iRule (attached here). Name it "SSLOLIB". This is the library rule, so no modifications are needed. The functions within (as described below) will return a true or false, so you can mix these together in your switching rule as needed. Step 4: Import the traffic switching iRule (attached here). You will modify this iRule as required, but the SSLOLIB library rule makes this very simple. Step 5: Create your external layered virtual server. This is the client-facing virtual server that will catch the user traffic and pass control to one of the internal SSL Orchestrator topology listeners. Type: Standard Source: 0.0.0.0/0 Destination: 0.0.0.0/0 Service Port: 0 Protocol: TCP VLAN: client-facing VLAN Address Translation: disabled Port Translation: disabled Default Persistence Profile: ssl iRule: the traffic switching iRule Note that the ssl persistence profile is enabled here to allow the iRules to handle client side SSL traffic without SSL profiles attached. Also make sure that Address and Port Translation are disabled before clicking Finished. Step 6: Modify the traffic switching iRule to meet your traffic matching requirements (see below). You have the basic layered architecture created. The only remaining step is to modify the traffic switching iRule as required, and that's pretty easy too. The iRules I'll repeat, there are near infinite options here. At the very least you need to VIP target from the external layered VIP to at least one of the SSL Orchestrator topology VIPs. The iRules provided here have been cultivated to make traffic selection and steering as easy as possible by pushing all of the pattern functions to a library iRule (SSLOLIB). The idea is that you will call a library function for a specific traffic pattern and if true, call a separate library function to steer that flow to the desired topology. All of the build instructions are contained inside the SSLOLIB iRule, with examples. SSLOLIB iRule: https://github.com/f5devcentral/sslo-script-tools/blob/main/internal-layered-architecture/transparent-proxy/SSLOLIB Switching iRule: https://github.com/f5devcentral/sslo-script-tools/blob/main/internal-layered-architecture/transparent-proxy/sslo-layering-rule The function to steer to a topology (SSLOLIB::target) has three parameters: <topology name>: this is the name of the desired topology. Use the basic topology name as defined in the SSL Orchestrator configuration (ex. "intercept"). ${sni}: this is static and should be left alone. It's used to convey the SNI information for logging. <message>: this is a message to send to the logs. In the examples, the message indicates the pattern matched (ex. "SRCIP"). Note, include an optional 'return' statement at the end to cancel any further matching. Without the 'return', the iRule will continue to process matches and settle on the value from the last evaluation. Example (sending to a topology named "bypass"): call SSLOLIB::target "bypass" ${sni} "DSTIP" ; return There are separate traffic matching functions for each pattern: SRCIP IP:<ip/subnet> SRCIP DG:<data group name> (address-type data group) SRCPORT PORT:<port/port-range> SRCPORT DG:<data group name> (integer-type data group) DSTIP IP:<ip/subnet> DSTIP DG:<data group name> (address-type data group) DSTPORT PORT:<port/port-range> DSTPORT DG:<data group name> (integer-type data group) SNI URL:<static url> SNI URLGLOB:<glob match url> (ends_with match) SNI CAT:<category name or list of categories> SNI DG:<data group name> (string-type data group) SNI DGGLOB:<data group name> (ends_with match) Examples: # SOURCE IP if { [call SSLOLIB::SRCIP IP:10.1.0.0/16] } { call SSLOLIB::target "bypass" ${sni} "SRCIP" ; return } if { [call SSLOLIB::SRCIP DG:my-srcip-dg] } { call SSLOLIB::target "bypass" ${sni} "SRCIP" ; return } # SOURCE PORT if { [call SSLOLIB::SRCPORT PORT:5000] } { call SSLOLIB::target "bypass" ${sni} "SRCPORT" ; return } if { [call SSLOLIB::SRCPORT PORT:1000-60000] } { call SSLOLIB::target "bypass" ${sni} "SRCPORT" ; return } # DESTINATION IP if { [call SSLOLIB::DSTIP IP:93.184.216.34] } { call SSLOLIB::target "bypass" ${sni} "DSTIP" ; return } if { [call SSLOLIB::DSTIP DG:my-destip-dg] } { call SSLOLIB::target "bypass" ${sni} "DSTIP" ; return } # DESTINATION PORT if { [call SSLOLIB::DSTPORT PORT:443] } { call SSLOLIB::target "bypass" ${sni} "DSTPORT" ; return } if { [call SSLOLIB::DSTPORT PORT:443-9999] } { call SSLOLIB::target "bypass" ${sni} "DSTPORT" ; return } # SNI URL match if { [call SSLOLIB::SNI URL:www.example.com] } { call SSLOLIB::target "bypass" ${sni} "SNIURLGLOB" ; return } if { [call SSLOLIB::SNI URLGLOB:.example.com] } { call SSLOLIB::target "bypass" ${sni} "SNIURLGLOB" ; return } # SNI CATEGORY match if { [call SSLOLIB::SNI CAT:$static::URLCAT_list] } { call SSLOLIB::target "bypass" ${sni} "SNICAT" ; return } if { [call SSLOLIB::SNI CAT:/Common/Government] } { call SSLOLIB::target "bypass" ${sni} "SNICAT" ; return } # SNI URL DATAGROUP match if { [call SSLOLIB::SNI DG:my-sni-dg] } { call SSLOLIB::target "bypass" ${sni} "SNIDGGLOB" ; return } if { [call SSLOLIB::SNI DGGLOB:my-sniglob-dg] } { call SSLOLIB::target "bypass" ${sni} "SNIDGGLOB" ; return } To combine these, you can use simple AND|OR logic. Example: if { ( [call SSLOLIB::DSTIP DG:my-destip-dg] ) and ( [call SSLOLIB::SRCIP DG:my-srcip-dg] ) } Finally, adjust the static configuration variables in the traffic switching iRule RULE_INIT event: ## User-defined: Default topology if no rules match (the topology name as defined in SSLO) set static::default_topology "intercept" ## User-defined: DEBUG logging flag (1=on, 0=off) set static::SSLODEBUG 0 ## User-defined: URL category list (create as many lists as required) set static::URLCAT_list { /Common/Financial_Data_and_Services /Common/Health_and_Medicine } CPM policies LTM policies (CPM) can work here too, but with the caveat that LTM policies do not support URL category lookups. You'll probably want to either keep the Pinners rule in your intercept topologies, or convert the Pinners URL category to a data group. A "url-to-dg-convert.sh" Bash script can do that for you. url-to-dg-convert.sh: https://github.com/f5devcentral/sslo-script-tools/blob/main/misc-tools/url-to-dg-convert.sh As with iRules, infinite options exist. But again for simplicity here is a good CPM configuration. For this you'll still need a "helper" iRule, but this requires minimal one-time updates. when RULE_INIT { ## Default SSLO topology if no rules match. Enter the name of the topology here set static::SSLO_DEFAULT "intercept" ## Debug flag set static::SSLODEBUG 0 } when CLIENT_ACCEPTED { ## Set default topology (if no rules match) virtual "/Common/sslo_${static::SSLO_DEFAULT}.app/sslo_${static::SSLO_DEFAULT}-in-t-4" } when CLIENTSSL_CLIENTHELLO { if { ( [POLICY::names matched] ne "" ) and ( [info exists ACTION] ) and ( ${ACTION} ne "" ) } { if { $static::SSLODEBUG } { log -noname local0. "SSLO Switch Log :: [IP::client_addr]:[TCP::client_port] -> [IP::local_addr]:[TCP::local_port] :: [POLICY::rules matched [POLICY::names matched]] :: Sending to $ACTION" } virtual "/Common/sslo_${ACTION}.app/sslo_${ACTION}-in-t-4" } } The only thing you need to do here is update the static::SSLO_DEFAULT variable to indicate the name of the default topology, for any traffic that does not match a traffic rule. For the comparable set of CPM rules, navigate to Local Traffic -> Policies in the BIG-IP UI and create a new CPM policy. Set the strategy as "Execute First matching rule", and give each rule a useful name as the iRule can send this name in the logs. For source IP matches, use the "TCP address" condition at ssl client hello time. For source port matches, use the "TCP port" condition at ssl client hello time. For destination IP matches the "TCP address" condition at ssl client hello time. Click on the Options icon and select "Local" and "External". For destination port matches the "TCP port" condition at ssl client hello time. Click on the Options icon and select "Local" and "External". For SNI matches, use the "SSL Extension server name" condition at ssl client hello time. For each of the conditions, add a simple "Set variable" action as ssl client hello time. Name the variable "ACTION" and give it the name of the desired topology. Apply the helper iRule and CPM policy to the external traffic steering virtual server. The "first" matching rule strategy is applied here, and all rules trigger on ssl client hello, so you can drag them around and re-order as necessary. Note again that all of the above only evaluates TLS traffic. Any non-TLS traffic will flow through the "default" topology that you identify in the iRule. It is possible to re-configure the above to evaluate HTTP traffic, but honestly the only significant use case here might be to allow or drop traffic at the policy. Layered architecture for an explicit forward proxy You can use the same logic to support an explicit proxy configuration. The only difference will be that the frontend layered virtual server will perform the explicit proxy functions. The backend SSL Orchestrator topologies will continue to be in layer 3 outbound (transparent proxy) mode. Normally SSL Orchestrator would build this for you, but it's pretty easy and I'll show you how. You could technically configure all of the SSL Orchestrator topologies as explicit proxies, and configure the client facing virtual server as a layer 3 pass-through, but that adds unnecessary complexity. If you also need to add explicit proxy authentication, that is done in the one frontend explicit proxy configuration. Use the settings below to create an explicit proxy LTM configuration. If not mentioned, settings can be left as defaults. Under SSL Orchestrator -> Configuration in the UI, click on the gear icon in the top right corner. This will expose the DNS resolver configuration. The easiest option here is to select "Local Forwarding Nameserver" and then enter the IP address of the local DNS service. Click "Save & Next" and then "Deploy" when you're done. Under Network -> Tunnels in the UI, click Create. This will create a TCP tunnel for the explicit proxy traffic. Profile: select tcp-forward Under Local Traffic -> Profiles -> Services -> HTTP in the UI, click Create. This will create the HTTP explicit proxy profile. Proxy Mode: Explicit Explicit Proxy: DNS Resolver: select the ssloGS-net-resolver Explicit Proxy: Tunnel Name: select the TCP tunnel created earlier Under Local Traffic -> Virtual Servers, click Create. This will create the client-facing explicit proxy virtual server. Type: Standard Source: 0.0.0.0/0 Destination: enter an IP the client can use to access the explicit proxy interface Service Port: enter the explicit proxy listener port (ex. 3128, 8080) HTTP Profile: HTTP explicit profile created earlier VLANs and Tunnel Traffic: set to "Enable on..." and select the client-facing VLAN Address Translation: enabled Port Translation: enabled Under Local Traffic -> Virtual Servers, click Create again. This will create the TCP tunnel virtual server. Type: Standard Source: 0.0.0.0/0 Destination: 0.0.0.0/0 Service Port: * VLANs and Tunnel Traffic: set to "Enable on..." and select the TCP tunnel created earlier Address Translation: disabled Port Translation: disabled iRule: select the SSLO switching iRule Default Persistence Profile: select ssl Note, make sure that Address and Port Translation are disabled before clicking Finished. Under Local Traffic -> iRules, click Create. This will create a small iRule for the explicit proxy VIP to forward non-HTTPS traffic through the TCP tunnel. Change "<name-of-TCP-tunnel-VIP>" to reflect the name of the TCP tunnel virtual server created in the previous step. when HTTP_REQUEST { virtual "/Common/<name-of-TCP-tunnel-VIP>" [HTTP::proxy addr] [HTTP::proxy port] } Add this new iRule to the explicit proxy virtual server. To test, point your explicit proxy client at the IP and port defined IP:port and give it a go. HTTP and HTTPS explicit proxy traffic arriving at the explicit proxy VIP will flow into the TCP tunnel VIP, where the SSLO switching rule will process traffic patterns and send to the appropriate backend SSL Orchestrator topology-as-function. Testing and Considerations Assuming you have the default topology defined in the switching iRule's RULE_INIT, and no traffic matching rules defined, all traffic from the client should pass effortlessly through that topology. If it does not, Ensure the named defined in the static::default_topology variable is the actual name of the topology, without the prepended "sslo_". Enable debug logging in the iRule and observe the LTM log (/var/log/ltm) for any anomalies. Worst case, remove the client facing VLAN from the frontend switching virtual server and attach it to one of your topologies, effectively bypassing the layered architecture. If traffic does not pass in this configuration, then it cannot in the layered architecture. You need to troubleshoot the SSL Orchestrator topology itself. Once you have that working, put the dummy VLAN back on the topology and add the client facing VLAN to the switching virtual server. Considerations The above provides a unique way to solve for complex architectures. There are however a few minor considerations: This is defined outside of SSL Orchestrator, so would not be included in the internal HA sync process. However, this architecture places very little administrative burden on the topologies directly. It is recommended that you create and sync all of the topologies first, then create the layered virtual server and iRules, and then manually sync the boxes. If you make any changes to the switching iRule (or CPM policy), that should not affect the topologies. You can initiate a manual BIG-IP HA sync to copy the changes to the peer. If upgrading to a new version of SSL Orchestrator (only), no additional changes are required. If upgrading to a new BIG-IP version, it is recommended to break HA (SSL Orchestrator 8.0 and below) before performing the upgrade. The external switching virtual server and iRules should migrate natively. Summary And there you have it. In just a few steps you've been able to reduce complexity and add capabilities, and along the way you have hopefully recognized the immense flexibility at your command.1.6KViews5likes2CommentsSSL Orchestrator Advanced Use Cases: Forward Proxy Authentication
Introduction F5 BIG-IP is synonymous with "flexibility". You likely have few other devices in your architecture that provide the breadth of capabilities that come native with the BIG-IP platform. And for each and every BIG-IP product module, the opportunities to expand functionality are almost limitless.In this article series we examine the flexibility options of the F5 SSL Orchestrator in a set of "advanced" use cases. If you haven't noticed, the world has been steadily moving toward encrypted communications. Everything from web, email, voice, video, chat, and IoT is now wrapped in TLS, and that's a good thing. The problem is, malware - that thing that creates havoc in your organization, that exfiltrates personnel records to the Dark Web - isn't stopped by encryption. TLS 1.3 and multi-factor authentication don't eradicate malware. The only reasonable way to defend against it is to catch it in the act, and an entire industry of security products are designed for just this task. But ironically, encryption makes this hard. You can't protect against what you can't see. F5 SSL Orchestrator simplifies traffic decryption and malware inspection, and dynamically orchestrates traffic to your security stack. But it does much more than that. SSL Orchestrator is built on top of F5's BIG-IP platform, and as stated earlier, is abound with flexibility. SSL Orchestrator Use Case: Forward Proxy Authentication Arguably, authentication is an easy one for BIG-IP, but I'm going to ease into this series slowly. There's no better place to start than with an examination of some of the many ways you can configure an F5 BIG-IP to authenticate user traffic. Forward Proxy Overview Forward proxy authentication isn't exclusive to SSL Orchestrator, but a vital component if you need to authenticate inspected outbound client traffic to the Internet. In this article, we are simply going to explore the act of authenticating in a forward proxy, in general. - how it works, and how it's applied. For detailed instructions on setting up Kerberos and NTLM forward proxy authentication, please see the SSL Orchestrator deployment guide. Let's start with a general characterization of "forward proxy" to level set. The semantics of forward and reverse proxy can change depending on your environment, but generally when we talk about a forward proxy, we're talking about something that controls outbound (usually Internet-bound) traffic. This is typically internal organizational traffic to the Internet. It is an important distinction, because it also implicates the way we handle encryption. In a forward proxy, clients are accessing remote Internet resources (ex. https://www.f5.com). For TLS to work, the client expects to receive a valid certificate from that remote resource, though the inspection device in the middle does not own that certificate and private key. So for decryption to work in an "SSL forward proxy", the middle device must re-issue ("forge") the remote server's certificate to the client using a locally-trusted CA certificate (and key). This is essentially how every SSL visibility product works for outbound traffic, and a native function of the SSL Orchestrator. Now, for any of this to work, traffic must of course be directed through the forward proxy, and there are generally two ways that this is accomplished: Explicit proxy - where the browser is configured to access the Internet through a proxy server. This can also be accomplished through auto-configuration scripts (PAC and WPAD). Transparent proxy - where the client is blissfully unaware of the proxy and simply routes to the Internet through a local gateway. It should be noted here that SSL visibility products that deploy at layer 2 are effectively limited to one traffic flow option, and lack the level of control that a true proxy solution provides, including authentication. Also note, BIG-IP forward proxy authentication requires the Access Policy Manager (APM) module licensed and provisioned. Explicit Forward Proxy Authentication The option you choose for outbound traffic flow will have an impact on how you authenticate that traffic, as each works a bit differently. Again, we're not getting into the details of Kerberos or NTLM here. The goal is to derive an essential understanding of the forward proxy authentication mechanisms, how they work, how traffic flows through them, and ultimately how to build them and apply them to your SSL Orchestrator configurations. And as each is different, let us start with explicit proxy. Explicit forward proxy authentication for HTTP traffic is governed by a "407" authentication model. In this model, the user agent (i.e. a browser) authenticates to the proxy server before passing any user request traffic to the remote server. This is an important distinction from other user-based authentication mechanisms, as the browser is generally limited in the types of authentication it can perform here (on the user's behalf). In fact most modern browsers, with some exceptions, are limited to the set of "Windows Integrated" methods (NTLM, Kerberos, and Basic). Explicit forward proxy authentication will look something like this: Figure: 407-based HTTPS and HTTP authentication The upside here is that the Windows Integrated methods are usually "transparent". That is, silently handled by the browser and invisible to the user. If you're logged into a domain-joined workstation with a domain user account, the browser will use this access to generate an NTLM token or fetch a Kerberos ticket on your behalf. If you build an SSL Orchestrator explicit forward proxy topology, you may notice it builds two virtual servers. One of these is the explicit proxy itself, listening on the defined explicit proxy IP and port. And the other is a TCP tunnel VIP. All client traffic arrives at the explicit proxy VIP, then wraps around through the TCP tunnel VIP. The SSL Orchestrator security policy, SSL configurations, and service chains are all connected to the TCP tunnel VIP. Figure: SSL Orchestrator explicit proxy VIP configuration As explicit proxy authentication is happening at the proxy connection layer, to do authentication you simply need to attach your authentication policy to the explicit proxy VIP. This is actually selected directly inside the topology configuration, Interception Rules page. Figure: SSL Orchestrator explicit proxy authentication policy selection But before you can do this, you must first create the authentication policy. Head on over to Access -> Profiles / Policies -> Access Profiles (Per-session policies), and click the Create button. Settings: Name: provide a unique name Profile Type: SWG-Explicit Profile Scope: leave it at 'Profile' Customization Type: leave it at 'Modern' Don't let the name confuse you. Secure Web Gateway (SWG) is not required to perform explicit forward proxy authentication. Click Finished to complete. You'll be taken back to the profile list. To the right of the new profile, click the Edit link to open a new tab to the Visual Policy Editor (VPE). Now, before we dive into the VPE, let's take a moment to talk about how authentication is going to work here. As previously stated, we are not going to dig into things like Kerberos or NTLM, but we still need something to authenticate to. Once you have something simple working, you can quickly shim in the actual authentication protocol. So let's do basic LocalDB authentication to prove out the configuration. Hop down to Access -> Authentication -> Local User DB -> Instances, and click Create New Instance. Create a simple LocalDB instance: Settings: Name: provide a unique name Leave the remaining settings as is and click OK. Now go to Access -> Authentication -> Local User DB -> Users, and click Create New User. Settings: User Name: provide a unique user name Password: provide a password Instances: selected the LocalDB instance Leave everything else as is and click OK. Now go back to the VPE. You're ready to define your authentication policy. With some exceptions, most explicit forward proxy authentication policies will minimally include a 407 Proxy-Authenticate agent and an authentication agent. The 407 Proxy-Authenticate agent will issue the 407 Proxy-Authenticate response to the client, and pass the user's submitted authentication data (Basic Authorization header, NTLM token, Kerberos ticket) to the auth agent behind it. The auth agent is then responsible for validating that submission and allowing (or denying) access. Since we're using a simple LocalDB to test this, we'll configure this for Basic authentication. Figure: 407-based SWG-Explicit authentication policy 407 HTTP Response Agent Settings: Properties Basic Auth: enter unique text here HTTP Auth Level: select Basic Branch Rules Delete the existing Negotiate Branch Authentication Agent Settings: Type: LocalDB Auth LocalDB Instance: your Local DB instance Note again that this is a simple explicit forward proxy test using a local database for HTTP Basic authentication. Once you have this working, it is super easy to replace the LocalDB method with the authentication protocol you need. Now head back to your SSL Orchestrator explicit proxy configuration. Navigate to the Interception Rules page. On that page you will see a setting for Access Profile. Select your SWG-Explicit access policy here. And that's it. Deploy the configuration and you're done. Configure your browser to point to the SSL Orchestrator explicit proxy IP and port, if you haven't already, and attempt to access an external URL (ex. https://www.f5.com). Since this is configured for HTTP Basic authentication, you should see a popup dialog in the browser requesting username and password. Enter the values you created in the LocalDB user properties. In following articles, I will show you how to configure Kerberos and NTLM for forward proxy authentication. If you want to see what this communication actually looks like on the wire, you can either enable your browser's developer tools, network tab. Or for a cleaner view, head over to a command line on your client and use the cURL command (you'll need cURL installed on your workstation): curl -vk --proxy [PROXY IP:PORT] https://www.example.com --proxy-basic --proxy-user '[username:password]' Figure: cURL explicit proxy output What you see in the output should look pretty close to the explicit proxy diagram from earlier. And if your SSL Orchestrator security policy is defined to intercept TLS, you will see your local CA as the example.com CA issuer. Transparent Forward Proxy Authentication I intentionally started with explicit proxy authentication because it's usually the easiest to get your head around. Transparent forward proxy authentication is a bit different, but you very likely see it all the time. If you've ever connected to hotel, airport/airplane, or coffee shop WiFi, and you were presenting with a webpage or popup screen that asked for username, room number, or asked you to agree to some terms of use, you were using transparent authentication. In this case though, it is commonly referred to as a "Captive Portal". Note that captive portal authentication was introduced to SSL Orchestrator in version 6.0. Captive portal authentication basically works like this: On first time connecting, you navigate to a remote URL (ex. www.f5.com), which passes through a security device (a proxy server, or in the case of hotel/coffee shop WiFi, an access point). The device has never seen you before, so issues an HTTP redirect to a separate URL. This URL will present an authentication point, usually a web page with some form of identity verification, user agreement, etc. You do what you need to do there, and the authentication page redirects you back to the original URL (ex. www.f5.com) and either stores some information about you, or sends something back with you in the redirect (a token). On passing back through the proxy (or access point), you are recognized as an authenticated user and allowed to pass. The token is stored for the life of your sessions so that you are not sent back to the captive portal. Figure: Captive-portal Authentication Process The real beauty here is that you are not at limited in the mechanisms you use to authenticate, like you are in an explicit proxy. The captive portal URL is essentially a webpage, so you could use NTLM, Kerberos, Basic, certificates, federation, OAuth, logon page, basically anything. Configuring this in APM is also super easy. Head on over to Access -> Profiles / Policies -> Access Profiles (Per-session policies), and click the Create button. Settings: Name: provide a unique name Profile Type: SWG-Transparent Profile Scope: leave it at 'Named' Named Scope: enter a unique value here (ex. SSO) Customization Type: set this to 'Standard' Again, don't let the name confuse you. Secure Web Gateway (SWG) is not required to perform transparent forward proxy authentication. Click Finished to complete. You'll be taken back to the profile list. To the right of the new profile, click the Edit link to open a new tab to the Visual Policy Editor (VPE). We are going to continue to use the LocalDB authentication method here to keep the configuration simple. But in this case, you could extend that to do Basic authentication or a logon page. If you do Basic, Kerberos, or NTLM, you'll be using a "401 authentication model". This is very similar to the 407 model, except that 401 interacts directly with the user. And again, this is just an example. Captive portal authentication isn't dependent on browser proxy authentication capabilities, and can support pretty much any user authentication method you can throw at it. Figure: 401-based SWG-Transparent authentication policy 401 Authentication Agent Settings: Properties Basic Auth: enter unique text here HTTP Auth Level: select Basic Branch Rules Delete the existing Negotiate Branch Authentication Agent Settings: Type: LocalDB Auth LocalDB Instance: your Local DB instance Now, there are a few additional things to do here. Transparent proxy (captive portal) authentication actually requires two access profiles. The authentication profile you just created gets applied to the captive port (authentication URL). You need a separate access profile on the proxy listener to redirect the user to the captive if no token exists for that user. As it turns out, an SSL Orchestrator security policy is indeed a type of access profile, so it simply gets modified to point to the captive portal URL. The 'named' profile scope you selected in the above authentication profile defines how the two profiles share user identity information, thus both with have a named profile scope, and must use the same named scope value (ex. SSO). You will now create the second access profile: Settings: Name: provide a unique name Profile Type: SSL Orchestrator Profile Scope: leave it at 'Named' Named Scope: enter a unique value here (ex. SSO) Customization Type: set this to 'Standard' Captive Portals: select 'Enabled' Primary Authentication URI: enter the URL of the captive portal (ex. https://login.f5labs.com) You now need to create a virtual server to hold your captive portal. This is the URL that users are redirected to for authentication (ex. https://login.f5labs.com). The steps are as follows: Create a certificate and private key to enable TLS Create a client SSL profile that contains the certificate and private key Create a virtual server Destination Address/Mask: enter the IP address that the captive portal URL resolves to Service Port: enter 443 HTTP Profle (Client): select 'http' SSL Profile (Client): select your client SSL profile VLANs and Tunnels: enable for your client-facing VLAN Access Profile: select your captive portal access profile Head back into your SSL Orchestrator outbound transparent proxy topology configuration, and go to the Interception Rules page. Under the 'Access Profile' setting, select your new SSL Orchestrator access profile and re-deploy. That's it. Now open a browser and attempt to access a remote resource. Since this is using Basic authentication with LocalDB, you should get prompted for username and password. If you look closely, you will see that you've been redirected to your captive portal URL. 401 Basic authentication is not connection based, so APM stores the user session information by client IP. If you do not get prompted for authentication, it's likely you have an active session already. Navigate to Access -> Overview -> Active Sessions. If you see your LocalDB user account name listed there, delete it and try again (close and re-open the browser). And there you have it. In just a few steps you've configured your SSL Orchestrator outbound topology to perform user authentication, and along the way you have hopefully recognized the immense flexibility at your command. Thanks.2.7KViews4likes10CommentsSSL Profiles Part 2: Certificates
This is part 2 in a series of tech tips on the F5 BIG-IP LTM SSL profiles. SSL Overview and Handshake SSL Certificates Certificate Chain Implementation Cipher Suites SSL Options SSL Renegotiation Server Name Indication Client Authentication Server Authentication All the "Little" Options In part 1, we covered the basics of the TLS handshakes and the context of the client and server ssl profiles. This time we’ll take a look at certficates. What is an SSL Certificate? The certificate is nothing more than a document containing the public key the client will use to compute key material and information about expiration, common and distinguished names, contact information, etc. A certificate can be modified until it is signed. This can be done to itself, which would be a self-signed certificate (all root certificates are self-signed) or a certificate can be signed by a certificate authority (CA). The certificate below in Figure 1 might look familiar. I created this certificate from a private certificate authority I set up when looking at HTTP Strict Transport Security a couple months back. That begs another question: What is a certificate authority? SSL Certificate Authorities The CA is one component within the larger public key infrastructure (PKI). CA’s serve as a trusted 3rd party between server and client, issuing (and revoking) the certificates. The server and optionally the client (owners) request a certificate that is signed by the CA. Both client and server then host the CA’s root and/or intermediate certificates. As shown above, you can be your own CA, but this increases the management burden as you now need to distribute the root/intermediate certificates to your clients in order to gain their trust of your certificates. By using a commercial CA, chances are good their certificates are already in your client trusted stores and thus your certificates will be trusted by the clients. In a corporate network, however, you might want to secure your traffic without forking over the cash for dozens (hundreds?) of certificates. In this case, an internal CA makes a lot of sense, and can be managed somewhat painlessly with active directory or the like. Figure 2 shows the testco CA as installed in my firefox browser. So any certificates I sign with the testco CA will be trusted by my firefox browser, eliminating all the extra clicking I’d need to do for self-signed certificates. Intermediate CAs and the Certificate Chain Best practices with PKI involve creating a number of subordinate CAs. With the testco CA I created, I installed this root certificate into my trust store and I signed the certificate I used for www.testco.com with that CA, and all is well. However, most of the time certificates are signed by Leaf CAs, or subordinate CAs that are created specifically for the purpose of creating certificates for servers, systems, etc. If you reference Figure 1, you’ll notice the issuer section where it informs the client of the certificate signer. In the event this is not the root CA for my www.testco.com, the authentication will fail, because the issuer is not trusted. These trust relationships can chain so that there are multiple levels of trust down from the root certificate to a depth of 10 (openSSL). For example, take the certificate chain in Figure 3. When the client receives the certificate from www.testco.com, it will have a signer (issuer) of Testco Dev CA. My browser doesn’t trust this CA, so it must then validate its signer, which is the Testco CA (root). My browser does trust this CA, so all is good. Now, if I added this intermediate CA to my trust store, validation would stop at that level and would not need to climb to the root CA. This is how most commercial providers work. You get the intermediate CAs from most publishers when you install your system OS. When you connect to an SSL-enabled site, the certificate arrives at the client with it’s signer, and then the certificate chain is climbed until (if) it arrives at a level of trust. In addition to the usefulness for the ssl profiles, this information is quite handy if you will be installing 3rd party certificates (read: not self-signed) for GTM (Chapter 12 in the Implementations Guide) as certificate depth plays a big role in configuration. Finally, IBM has a great graphic on the chain of trust certificate/signature verification process. Types of Certificates Remember from part 1 where I said that you couldn’t host multiple domains on a single IP without the TLS SNI option? Well, that’s not entirely true. It is true of standard SSL certificates, but certificates have changed over the years to workaround some of these limitations. There are several options when considering certificates. Domain Validated – no company background checking, just a simple comparison to the domain whois information before issuing. $ Organizationally Validated – company background is vetted, site ip/name is validated. $$ Extended Validation – industry standard certificate guidelines. This will turn the browser locator bar green and publish company name as well. Introduced in 2007. $$$ Unified Communications – this certificate takes advantage of the Subject Alternative Name field, so you can secure multiple (specific) domain names on one certificate. Microsoft Exchange is a popular application requiring a UC Certificate, as it supports several names owa.site.com, autodiscover.site.com, cas1.site.com, etc. $$$ Wildcard Certificate – this certificate supports any number of subdomains based on *.site.com, where your subdomain would replace the *. It doesn’t, however, support site.com, so for those lazy users (me) who hate typing the leading www. before hitting enter, the wildcard certificate will not cover that scenario. $$$ Wildcard Plus – This is a combination UCC/Wildcard Certificate in that it will protect at the site.com, *.site.com, and several specified lower-subdomain levels as well. Most modern browsers support the above options, but there are still some questions on the compatibility with the wildcard plus certificates, and some mobile devices have issues with wildcard certificates in general. Make sure you thoroughly vet out your userbase before deciding on a solution. Certificate Formats There are several ways the X.509 certificate structure is packaged. Different platforms require different formats. The LTM uses PEM format. Most of the commercial CAs issue certificates in PEM format. If you are using an internal Windows CA, most likely the certificate, the format is PKCS#7/#12, and prior to version 10.1, needed to be converted to PEM prior to import. The formats used are: PEM – base64 encoded ASCII file with BEGIN CERTIFICATE and END CERTIFICATE statements and can contain the private key DER – binary form of the certificate PKCS#7 – also a base64 encoded ASCII file, though with BEGIN PKCS7 and END PKCS7 statements. Can not contain the private key. PKCS#12 – binary form of the certificate, any intermediates, and the private key. Converting is fairly easy and can be done at the cli of the LTM with the openssl tool. DER to PEM openssl x509 -inform der -in <certname>.der -out <certname>.pem PKCS#7 to PEM openssl pkcs7 -print_certs -in <certname>.p7b -out <certname>.pem PKCS#12 to PEM openssl pkcs12 -in <certname>.pfx -out <certname>.pem -nodes Conclusion There is so much more depth to certificates that we could cover, but hopefully this overview has been informative and provides the foundation necessary for part 3, where we’ll start diving into the profiles themselves.3.6KViews3likes5CommentsTLS Fingerprinting - a method for identifying a TLS client without decrypting
Hello, Kevin Stewart here. A while back someone asked an interesting question in the DevCentral forum about selecting a client SSL profile based on the device (ex. iOS, Android, Windows Phone). Normally you'd use a browser User-Agent HTTP header to identify the client user agent, but in this case, and based on the OSI model, you wouldn't be able to select an SSL profile (OSI layer 6) based on a User-Agent HTTP header (OSI layer 7), because at this point in time you don't yet have the layer 7 data - it's still encrypted. You could, however, use layer 3 or 4 data (IPs and ports), but that's generally not useful for identifying the client user agent. But there might still be a way... Lee Brotherston has discovered that during an SSL handshake, most client user agents (different browsers, Dropbox, Skype, etc.) will initiate an SSL handshake request in an ever-so-unique way. The ordered combination of TLS version, record TLS version, ciphersuites, compression options, list of extensions, elliptic curves and signature algorithms are all specific enough that you can actually build a signature based on that data, and the collection of signatures into a database. From that discovery Lee created a project called "tls-fingerprinting". Please check it out. Now certainly, a client's ClientHello could be modified to support different ciphersuites and other features, the same way you could spoof a User-Agent HTTP header. However this modification will often lower security by re-introducing previously unsupported options, or in many cases modification to the user agent's SSL parameters isn't easy or isn't possible. So given that we now have a new way to identify a user agent based on the client's ClientHello (the first message in the SSL handshake), I decided to re-visit the original DC forum request by integrating Lee's database into an iRules-based solution. The code example in the aforementioned thread just used the client's ciphersuite list, however, so today I'm going to expand on that and use all of the paramaters from the tls-fingerprinting database. Before we get started, I should mention two things: This article is going to be long (sorry about that), and We're going to break it down into a few phases, specifically Defining the values in the tls-fingerprinting signature Exporting and converting the tls-fingerprinting database to a BIG-IP external data group Creating a fingerprintTLS PROC iRule (name this "Library-Rule") Creating the caller iRule So let's get started. Defining the values in the tls-fingerprinting signature Here's an example signature entry in Lee's tls-fingerprinting database (JSON version): {"id": 0, "desc": "ThunderBird (v38.0.1 OS X)", "record_tls_version": "0x0301", "tls_version": "0x0303", "ciphersuite_length": "0x0016", "ciphersuite": "0xC02B 0xC02F 0xC00A 0xC009 0xC013 0xC014 0x0033 0x0039 0x002F 0x0035 0x000A", "compression_length": "1", "compression": "0x00", "extensions": "0x0000 0xFF01 0x000A 0x000B 0x0023 0x0005 0x000D 0x0015" , "e_curves": "0x0017 0x0018 0x0019" , "sig_alg": "0x0401 0x0501 0x0201 0x0403 0x0503 0x0203 0x0402 0x0202" , "ec_point_fmt": "0x00" } Broken down it looks like this: { "id": 0, "desc": "ThunderBird (v38.0.1 OS X)", "record_tls_version": "0x0301", "tls_version": "0x0303", "ciphersuite_length": "0x0016", "ciphersuite": "0xC02B 0xC02F 0xC00A 0xC009 0xC013 0xC014 0x0033 0x0039 0x002F 0x0035 0x000A", "compression_length": "1", "compression": "0x00", "extensions": "0x0000 0xFF01 0x000A 0x000B 0x0023 0x0005 0x000D 0x0015" , "e_curves": "0x0017 0x0018 0x0019" , "sig_alg": "0x0401 0x0501 0x0201 0x0403 0x0503 0x0203 0x0402 0x0202" , "ec_point_fmt": "0x00" } This is a pretty straight forward set of JSON key-value pairs. And if you're curious about what any of these values mean, I urge you to fire up Wireshark, open a browser to some HTTPS site, and then find a ClientHello message in the capture. You'll see all of these values and more, except for the first two, in that message. Our job then is to a) export the set of signatures to a BIG-IP external data group, and b) create an iRule that extracts all of these values from the client's ClientHello and compares those to the set of signatures in the data group. Of course iRules don't natively support JSON parsing, and while yes I could use iRulesLX for this, I decided to simply reformat the signatures in the data group to something more condusive to TCL iRules. Exporting and converting the tls-fingerprinting database to a BIG-IP external data group I don't really care about the "id" value, so I'll leave that out. And the "desc" field will be the value in the data group. The key will be the concatenation of all of the remaining fields. "signature_data" := "ThunderBird (v38.0.1 OS X)", I'm also going to remove the "0x" from the hex values, remove whitespace, and delimit each field with the plus (+) sign, so the resulting key for the above signature will look like this: 0301+0303+0016+C02BC02FC00AC009C013C01400330039002F0035000A+1+00+0000FF01000A000B00230005000D0015+001700180019+04010501020104030503020304020202+00 If any of the values don't exist (ex. the signature doesn't have a sig_alg value), that value is replaced with "@@@@" in the resulting key. Okay, so to convert the tls-fingerprinting database to a BIG-IP external data group, you have to: 1. Download it - the current JSON-based database is here: https://github.com/LeeBrotherston/tls-fingerprinting/blob/master/fingerprints/fingerprints.json. Copy that JSON data in whole to a local text file. The conversion script uses BASH, so you need a Linux or Mac box. I named the file 'fingerprint.db'. 2. Convert it - use the following BASH script to extract each of the fields from each of the signatures. I should warn you now that my sed/awk/grep foo isn't strong, so I borrowed a BASH JSON parser from here: https://gist.github.com/cjus/1047794 #!/bin/bash function jsonval () { ## description desc=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "desc" |awk -F": " '{print $2}'` ## record_tls_version rect=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "record_tls_version" |awk -F": " '{print $2}' |sed 's/0x//g'` if [ -z "$rect" ]; then rect="@@@@"; fi ## tls_version tlsv=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "tls_version" |awk -F": " '{print $2}' |sed 's/0x//g'` if [ -z "$tlsv" ]; then tlsv="@@@@"; fi ## ciphersuite_length cipl=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ciphersuite_length" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$cipl" ]; then cipl="@@@@"; fi ## ciphersuite ciph=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ciphersuite" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ciph" ]; then tlsv="ciph"; fi ## compression_length coml=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "compression_length" |awk -F": " '{print $2}'` if [ -z "$coml" ]; then coml="@@@@"; fi ## compression comp=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "compression" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$comp" ]; then comp="@@@@"; fi ## extensions exte=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "extensions" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$exte" ]; then exte="@@@@"; fi ## e_curves ecur=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "e_curves" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ecur" ]; then ecur="@@@@"; fi ## sig_alg siga=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "sig_alg" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$siga" ]; then siga="@@@@"; fi ## ec_point_fmt ecfp=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ec_point_fmt" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ecfp" ]; then ecfp="@@@@"; fi echo "\"$rect+$tlsv+$cipl+$ciph+$coml+$comp+$exte+$ecur+$siga+$ecfp\" := \"$desc\"," } IFS=} for i in `cat fingerprint.db`; do jsonval $i done Create this BASH script however you like (VI, VIM, Joe, Nano, whatever), save it, chmod it so that it'll execute ('chmod 755 parser.sh'), and then run it ('./parser.sh'). It'll just echo the reformatted signatures to the screen, so you'll want to capture that as a file ('./parser.sh > fingerprint.dg'). It's also be a little slow, again due to my aggregious lack of sed/awk/grep (and regex) foo, but it should still finish in less than a minute. 3. Import it - now go to the BIG-IP management UI, and under System - File Management - Data Group File List, click Import. Choose your reformatted text file, give it a meaningful name (ex. fingerprint_db), select "String" as the File Contents type, and use the same name (ex. fingerprint_db) in the Data Group Name field. On a v12 BIG-IP this will auto-create the local data group. On earlier systems you'll need to go manually create the local data group object that points to this external data group. Creating a fingerprintTLS PROC iRule So now that we've reformatted and imported the fingerprintTLS database, let's build the iRule to parse out the data from the client's ClientHello. I should also warn you that this process requires a lot of binary manipulation, so please don't try to ingest it all at once if you're new to iRules. I'm building this iRule as a separate PROC that other data plane iRules can call. It won't be directly attached to a virtual server. ## Library-Rule ## TLS Fingerprint Procedure ################# ## ## Author: Kevin Stewart, 12/2016 ## Derived from Lee Brotherston's "tls-fingerprinting" project @ https://github.com/LeeBrotherston/tls-fingerprinting ## Purpose: to identify the user agent based on unique characteristics of the TLS ClientHello message ## Input: ## Full TCP payload collected in CLIENT_DATA event of a TLS handshake ClientHello message ## Record length (rlen) ## TLS outer version (outer) ## TLS inner version (inner) ## Client IP ## Server IP ############################################## proc fingerprintTLS { payload rlen outer inner clientip serverip } { ## The first 43 bytes of a ClientHello message are the record type, TLS versions, some length values and the ## handshake type. We should already know this stuff from the calling iRule. We're also going to be walking the ## packet, so the field_offset variable will be used to track where we are. set field_offset 43 ## The first value in the payload after the offset is the session ID, which may be empty. Grab the session ID length ## value and move the field_offset variable that many bytes forward to skip it. binary scan ${payload} @${field_offset}c sessID_len set field_offset [expr {${field_offset} + 1 + ${sessID_len}}] ## The next value in the payload is the ciphersuite list length (how big the ciphersuite list is. We need the binary ## and hex values of this data. binary scan ${payload} @${field_offset}S cipherList_len binary scan ${payload} @${field_offset}H4 cipherList_len_hex set cipherList_len_hex_text ${cipherList_len_hex} ## Now that we have the ciphersuite list length, let's offset the field_offset variable to skip over the length (2) bytes ## and go get the ciphersuite list. Multiple by 2 to get the number of appropriate hex characters. set field_offset [expr {${field_offset} + 2}] set cipherList_len_hex [expr {${cipherList_len} * 2}] binary scan ${payload} @${field_offset}H${cipherList_len_hex} cipherlist ## Next is the compression method length and compression method. First move field_offset to skip past the ciphersuite ## list, then grab the compression method length. Then move field_offset past the length (2) bytes and grab the ## compression method value. Finally, move field_offset past the compression method bytes. set field_offset [expr {${field_offset} + ${cipherList_len}}] binary scan ${payload} @${field_offset}c compression_len #set field_offset [expr {${field_offset} + ${compression_len}}] set field_offset [expr {${field_offset} + 1}] binary scan ${payload} @${field_offset}H[expr {${compression_len} * 2}] compression_type set field_offset [expr {${field_offset} + ${compression_len}}] ## We should be in the extensions section now, so we're going to just run through the remaining data and ## pick out the extensions as we go. But first let's make sure there's more record data left, based on ## the current field_offset vs. rlen. if { [expr {${field_offset} < ${rlen}}] } { ## There's extension data, so let's go get it. Skip the first 2 bytes that are the extensions length set field_offset [expr {${field_offset} + 2}] ## Make a variable to store the extension types we find set extensions_list "" ## Pad rlen by 1 byte set rlen [expr ${rlen} + 1] while { [expr {${field_offset} <= ${rlen}}] } { ## Grab the first 2 bytes to determine the extension type binary scan ${payload} @${field_offset}H4 ext ## Store the extension in the extensions_list variable append extensions_list ${ext} ## Increment field_offset past the 2 bytes of the extension type set field_offset [expr {${field_offset} + 2}] ## Grab the 2 bytes of extension lenth binary scan ${payload} @${field_offset}S ext_len ## Increment field_offset past the 2 bytes of the extension length set field_offset [expr {${field_offset} + 2}] ## Look for specific extension types in case these need to increment the field_offset (and because we need their values) switch $ext { "000b" { ## ec_point_format - there's another 1 byte after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 1}]H[expr {(${ext_len} - 1) * 2}] ext_data set ec_point_format ${ext_data} } "000a" { ## elliptic_curves - there's another 2 bytes after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 2}]H[expr {(${ext_len} - 2) * 2}] ext_data set elliptic_curves ${ext_data} } "000d" { ## sig_alg - there's another 2 bytes after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 2}]H[expr {(${ext_len} - 2) * 2}] ext_data set sig_alg ${ext_data} } default { ## Grab the otherwise unknown extension data binary scan ${payload} @${field_offset}H[expr {${ext_len} * 2}] ext_data } } ## Increment the field_offset past the extension data length. Repeat this loop until we reach rlen (the end of the payload) set field_offset [expr {${field_offset} + ${ext_len}}] } } ## Now let's compile all of that data. set cipl [string toupper ${cipherList_len_hex_text}] set ciph [string toupper ${cipherlist}] set coml ${compression_len} set comp [string toupper ${compression_type}] if { ( [info exists extensions_list] ) and ( ${extensions_list} ne "" ) } { set exte [string toupper ${extensions_list}] } else { set exte "@@@@" } if { ( [info exists elliptic_curves] ) and ( ${elliptic_curves} ne "" ) } { set ecur [string toupper ${elliptic_curves}] } else { set ecur "@@@@" } if { ( [info exists sig_alg] ) and ( ${sig_alg} ne "" ) } { set siga [string toupper ${sig_alg}] } else { set siga "@@@@" } if { ( [info exists ec_point_format] ) and ( ${ec_point_format} ne "" ) } { set ecfp [string toupper ${ec_point_format}] } else { set ecfp "@@@@" } ## Initialize the match variable set match "" ## Now let's build the fingerprint string and search the database set fingerprint_str "${outer}+${inner}+${cipl}+${ciph}+${coml}+${comp}+${exte}+${ecur}+${siga}+${ecfp}" ## Un-comment this line to display the fingerprint string in the LTM log for troubleshooting ## log local0. "${clientip}-${serverip}: fingerprint_str = ${fingerprint_str}" if { [class match ${fingerprint_str} equals fingerprint_db] } { ## Direct match set match [class match -value ${fingerprint_str} equals fingerprint_db] } elseif { not ( ${ciph} starts_with "C0" ) and not ( ${ciph} starts_with "00" ) } { ## Hmm.. there's no direct match, which could either mean a database entry doesn't exist, or Chrome (and Opera) are adding ## special values to the cipherlist, extensions list and elliptic curves list. ## ex. 9A9A, 5A5A, EAEA, BABA, etc. at the beginning of the cipherlist ## Let's strip out these anomalous values and try the match again. ## Substract 2 bytes from cipherlist length set cipl [format %04x [expr [expr 0x${cipl}] - 2]] ## Subtract 2 bytes from the front of the cipher list set ciph [string range ${ciph} 4 end] ## Subtract 2 bytes from the front of the extensions list set exte [string range ${exte} 4 end] ## There might be an additional random set in the string that needs to be removed (pattern is "(.)A\1A") regsub {(.)A\1A} ${exte} "" exte ## If the above regsub doesn't work, try the following: #regsub {(\wA)\1} ${exte} "" exte ## Subtract 2 bytes from the front of the elliptic curves list set ecur [string range ${ecur} 4 end] ## Rebuild the fingerprint string set fingerprint_str "${outer}+${inner}+${cipl}+${ciph}+${coml}+${comp}+${exte}+${ecur}+${siga}+${ecfp}" if { [class match ${fingerprint_str} equals fingerprint_db] } { ## Guess match set match [class match -value ${fingerprint_str} equals fingerprint_db] } else { ## No match set match "" } } ## Return the matching user agent string return ${match} } The PROC requires as input the full TCP payload (of the ClientHello message), the record length (extracted from the ClientHello message), the "outer" record TLS version and "inner" TLS version (also extracted form the ClientHello message). Using these values the PROC basically walks the payload looking for each of the required values (ciphersuite length, ciphersuite list, compression length, compression list, extensions list, elliptic curves, signature algorithms, and ec point formats). If any value doesn't exist in the payload (ex. the ClientHello doesn't contain a Sig_Alg field), that value is replaced with "@@@@". Once all of the values are found, the fingerprint string is created and used to search the data group. If there's a match, the user agent string (ex. ThunderBird (v38.0.1 OS X)) is returned to the caller. While testing this I noticed that newer versions of Chrome and Opera added what looked like "markers" to the ciphersuite list, extensions list, and elliptic curves list (ex. 9A9A, 5A5A, EAEA, BABA - always some alphanumeric value, followed by 'A', and repeated.). A cursory search didn't explain what these are, so maybe someone will know and report back. In the meantime, I added a "guess" function that removed these markers and tried the data group search again. All of the desktop browser testing (including Chrome and Opera) did get an accurate match with either the direct or guessed fingerprint, so I'll leave that in there until I find a better way to handle the markers. Creating the caller iRule The only thing left to do is to create the caller iRule. This iRule only needs to detect an SSL/TLS ClientHello, and then pass that to the fingerprint PROC. This is just a stub iRule to show the proper implementation. Once you've determined a TCP packet is an SSL/TLS handshake ClientHello, call the PROC and then do something useful with the resulting user agent string, like switch the client SSL profile. when CLIENT_ACCEPTED { ## Collect the TCP payload TCP::collect } when CLIENT_DATA { ## Get the TLS packet type and versions if { ! [info exists rlen] } { binary scan [TCP::payload] cH4ScH6H4 rtype outer_sslver rlen hs_type rilen inner_sslver if { ( ${rtype} == 22 ) and ( ${hs_type} == 1 ) } { ## This is a TLS ClientHello message (22 = TLS handshake, 1 = ClientHello) ## Call the fingerprintTLS proc set fingerprint [call Library-Rule::fingerprintTLS [TCP::payload] ${rlen} ${outer_sslver} ${inner_sslver} [IP::client_addr] [IP::local_addr]] ### Do Something here ### log local0. "match = ${fingerprint}" ### Do Something here ### } } # Collect the rest of the record if necessary if { [TCP::payload length] < $rlen } { TCP::collect $rlen } ## Release the paylaod TCP::release } What happens if there's no match? Yes, there are some caveats... It's safe to say that the tls-fingerprinting database isn't all inclusive. In fact it's FAR FROM COMPLETE and not always exact.I found, for example, that my version of Dropbox on a Win7 box (v16.4.30) doesn't make a match. It's nearly impossible to have the signature for every unique user agent every created, and all of the variations and versions of that agent. But what the database does have is the signatures for most browsers, so at the very least it makes for a nice way to whitelist browsers (vs. other agents). It also doesn't technically resolve the question in the original DC forum thread. The question was how to identify the device (ie. iOS, Android, Windows Phone), and for that you'd need some specific agent loaded on the device (not a browser) that could report that information. Mobile device management (MDM) solutions are particularly good at that sort of thing. The browser, Dropbox or other user agent on the mobile device may not specifically report the device (ex. "for iOS"). Some do, but I've found that most don't. At the end of this aticle I've included a few signatures that I found in my testing that aren't in the database. If your curious, uncomment thelog local0. "${clientip}-${serverip}: fingerprint_str = ${fingerprint_str}"line in the fingerprintTLS PROC and then tail the LTM log. The caller iRule is already logging the returned user agent string, so if that is empty, you'll see the empty match in the log (match =), preceded by the unmatched signature. Where this project may be most useful is in outbound traffic management, where you want to decrypt and inspect the Internet-bound traffic, but cannot decrypt some user agents becuase of things like cerificate pinning. Since the pinning decision happens at the client, the only other recourse is to bypass decryption and inspection based on the destination host name or IP address, which can be a tedious thing to manage. TLS fingerprinting might allow you to simply decrypt and inspect for the user agents that you know aren't affected by pinning, specifically browsers. You'll potentially miss some things that you could have decrypted, but you'll save yourself the burden of managing an ever-growing list of pinner exclusions. And on a final note, binary iRule manipulation is a very CPU-intensive thing to do. I could have very simply converted the raw payload to one long hex string (once) and walked that with string tools. I'll update the code when I have some time. Thanks. - Kevin Additional Signatures "0301+0303+0028+C02BC02F009ECC14CC13C00AC009C013C014C007C011003300320039009C002F0035000A00050004+1+00+0000FF01000A000B0023755000050012000D+001700180019+04010501020104030503020304020202+00" := "Dropbox", "0301+0303+0028+C02BC02F009ECC14CC13C00AC009C013C014C007C011003300320039009C002F0035000A00050004+1+00+0000FF01000A000B002300050012000D+001700180019+04010501020104030503020304020202+00" := "Dropbox", "0301+0303+001A+C030C028C014C02FC027C013009F006B0039009E0067003300FF+1+00+0000000B000A0023000D+00170019001C001B0018001A0016000E000D000B000C0009000A+060106020603050105020503040104020403030103020303020102020203+000102" := "Dropbox", "0301+0303+0094+C030C02CC032C02EC02FC02BC031C02D00A500A300A1009F00A400A200A0009EC028C024C014C00AC02AC026C00FC005006B006A006900680039003800370036C027C023C013C009C029C025C00EC00400670040003F003E0033003200310030C012C008C00DC00300880087008600850045004400430042001600130010000D009D009C003D0035003C002F00840041000A00FF+1+00+000B000A0023000D0015+00170019001C001B0018001A0016000E000D000B000C0009000A+060106020603050105020503040104020403030103020303020102020203+000102" := "Dropbox", "0301+0303+0028+C02BC02CC02FC030009E009FC009C00AC013C01400330039C007C011009C009D002F0035000500FF+1+00+0000000B000A0023000D+000E000D0019000B000C00180009000A00160017000800060007001400150004000500120013000100020003000F00100011+060106020603050105020503040104020403030103020303020102020203+000102" := "Android Google API Access", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D0005337400120010000B000A+00170018+0601060305010503040104030301030302010203+00" := "Chrome 47.0.2526.83", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D0005337400120010000B000A+00170018+0601060305010503040104030301030302010203+00" := "Chrome 48.0.2564.97", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D00053374001200107550000B000A0015+00170018+0601060305010503040104030301030302010203+00" := "Chrome 48.0.2564.97", "0301+0303+0022+CCA9CCA8CC14CC13C02BC02FC02CC030C009C013C00AC014009C009D002F0035000A+1+00+FF01000000170023000D0005001200107550000B000A0018+001D00170018+06010603050105030401040302010203+00" := "Android Silk Browser", "0301+0303+0022+CCA9CCA8CC14CC13C02BC02FC02CC030C009C013C00AC014009C009D002F0035000A+1+00+FF01000000170023000D0005001200107550000B000A00180015+001D00170018+06010603050105030401040302010203+00" := "Android Silk Browser" "0303+0303+0038+C02CC02BC030C02F009F009EC024C023C028C027C00AC009C014C01300390033009D009C003D003C0035002F000A006A0040003800320013+1+00+0005000A000B000D0023001000175500FF01+001D00170018+040105010201040305030203020206010603+00" := "Internet Explorer 11.447.14393.0(Win 10)", "0301+0303+0022+C02BC02FC02CC030CCA9CCA8CC14CC13C009C013C00AC014009C009D002F0035000A+1+00+FF0100170023000D0005001200107550000B000A+001D00170018+06010603050105030401040302010203+00" := "Chrome 55.0.2883.87",9.9KViews3likes8Comments