Intro to Load Balancing for Developers – The Algorithms
If you’re new to this series, you can find the complete list of articles in the series on my personal page here If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. Until then! Don.19KViews1like9CommentsX-Forwarded-For Log Filter for Windows Servers
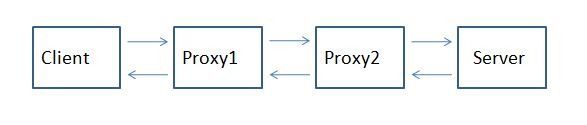
For those that don't know what X-Forwarded-For is, then you might as well close your browser because this post likely will mean nothing to you… A Little Background Now, if you are still reading this, then you likely are having issues with determining the origin client connections to your web servers. When web requests are passed through proxies, load balancers, application delivery controllers, etc, the client no longer has a direct connection with the destination server and all traffic looks like it's coming from the last server in the chain. In the following diagram, Proxy2 is the last hop in the chain before the request hits the destination server. Relying on connection information alone, the server thinks that all connections come from Proxy2, not from the Client that initiated the connection. The only one in the chain here who knows who the client really is (as determined by it's client IP Address, is Proxy1. The problem is that application owners rely on source client information for many reasons ranging from analyzing client demographics to targeting Denial of Service attacks. That's where the X-Forwarded-For header comes in. It is non-RFC standard HTTP request header that is used for identifying the originating IP address of a client connecting to a web server through a proxy. The format of the header is: X-Forwarded-For: client, proxy1, proxy, … X-Forwarded-For header logging is supported in Apache (with mod_proxy) but Microsoft IIS does not have a direct way to support the translation of the X-Forwarded-For value into the client ip (c-ip) header value used in its webserver logging. Back in September, 2005 I wrote an ISAPI filter that can be installed within IIS to perform this transition. This was primarily for F5 customers but I figured that I might as well release it into the wild as others would find value out of it. Recently folks have asked for 64 bit versions (especially with the release of Windows 2008 Server). This gave me the opportunity to brush up on my C skills. In addition to building targets for 64 bit windows, I went ahead and added a few new features that have been asked for. Proxy Chain Support The original implementation did not correctly parse the "client, proxy1, proxy2,…" format and assumed that there was a single IP address following the X-Forwarded-For header. I've added code to tokenize the values and strip out all but the first token in the comma delimited chain for inclusion in the logs. Header Name Override Others have asked to be able to change the header name that the filter looked for from "X-Forwarded-For" to some customized value. In some cases they were using the X-Forwarded-For header for another reason and wanted to use iRules to create a new header that was to be used in the logs. I implemented this by adding a configuration file option for the filter. The filter will look for a file named F5XForwardedFor.ini in the same directory as the filter with the following format: [SETTINGS] HEADER=Alternate-Header-Name The value of "Alternate-Header-Name" can be changed to whatever header you would like to use. Download I've updated the original distribution file so that folks hitting my previous blog post would get the updates. The following zip file includes 32 and 64 bit release versions of the F5XForwardedFor.dll that you can install under IIS6 or IIS7. Installation Follow these steps to install the filter. Download and unzip the F5XForwardedFor.zip distribution. Copy the F5XForwardedFor.dll file from the x86\Release or x64\Release directory (depending on your platform) into a target directory on your system. Let's say C:\ISAPIFilters. Ensure that the containing directory and the F5XForwardedFor.dll file have read permissions by the IIS process. It's easiest to just give full read access to everyone. Open the IIS Admin utility and navigate to the web server you would like to apply it to. For IIS6, Right click on your web server and select Properties. Then select the "ISAPI Filters" tab. From there click the "Add" button and enter "F5XForwardedFor" for the Name and the path to the file "c:\ISAPIFilters\F5XForwardedFor.dll" to the Executable field and click OK enough times to exit the property dialogs. At this point the filter should be working for you. You can go back into the property dialog to determine whether the filter is active or an error occurred. For II7, you'll want to select your website and then double click on the "ISAPI Filters" icon that shows up in the Features View. In the Actions Pane on the right select the "Add" link and enter "F5XForwardedFor" for the name and "C:\ISAPIFilters\F5XForwardedFor.dll" for the Executable. Click OK and you are set to go. I'd love to hear feedback on this and if there are any other feature request, I'm wide open to suggestions. The source code is included in the download distribution so if you make any changes yourself, let me know! Good luck and happy filtering! -Joe13KViews0likes14Comments
F5 Automated Backups - The Right Way
Hi all, Often I've been scouring the devcentral fora and codeshares to find that one piece of handywork that will drastically simplify my automated backup needs on F5 devices. Based on the works of Jason Rahm in his post "Third Time's the Charm: BIG-IP Backups Simplified with iCall" on the 26th of June 2013, I went ahead and created my own iApp that pretty much provides the answers for all my backup-needs. Here's a feature list of this iApp: It allows you to choose between both UCS or SCF as backup-types. (whilst providing ample warnings about SCF not being a very good restore-option due to the incompleteness in some cases) It allows you to provide a passphrase for the UCS archives (the standard GUI also does this, so the iApp should too) It allows you to not include the private keys (same thing: standard GUI does it, so the iApp does it too) It allows you to set a Backup Schedule for every X minutes/hours/days/weeks/months or a custom selection of days in the week It allows you to set the exact time, minute of the hour, day of the week or day of the month when the backup should be performed (depending on the usefulness with regards to the schedule type) It allows you to transfer the backup files to external devices using 4 different protocols, next to providing local storage on the device itself SCP (username/private key without password) SFTP (username/private key without password) FTP (username/password) SMB (using smbclient, with username/password) Local Storage (/var/local/ucs or /var/local/scf) It stores all passwords and private keys in a secure fashion: encrypted by the master key of the unit (f5mku), rendering it safe to store the backups, including the credentials off-box It has a configurable automatic pruning function for the Local Storage option, so the disk doesn't fill up (i.e. keep last X backup files) It allows you to configure the filename using the date/time wildcards from the tcl [clock] command, as well as providing a variable to include the hostname It requires only the WebGUI to establish the configuration you desire It allows you to disable the processes for automated backup, without you having to remove the Application Service or losing any previously entered settings For the external shellscripts it automatically generates, the credentials are stored in encrypted form (using the master key) It allows you to no longer be required to make modifications on the linux command line to get your automated backups running after an RMA or restore operation It cleans up after itself, which means there are no extraneous shellscripts or status files lingering around after the scripts execute I wasn't able to upload the iApp template to this article, so I threw it on pastebin: http://pastebin.com/YbDj3eMN Enjoy! Thomas Schockaert8.4KViews0likes79CommentsTwo-Factor Authentication With Google Authenticator And LDAP
Introduction Earlier this year Google released their time-based one-time password (TOTP) solution named Google Authenticator. A TOTP is a single-use code with a finite lifetime that can be calculated by two parties (client and server) using a shared secret and a synchronized clock (see RFC 4226 for additional information). In the case of Google Authenticator, the TOTP are generated using a software (soft) token on a mobile device. Google currently offers applications for the Apple iPhone, Android-based devices, and Blackberry handsets. A user authenticating with a Google Authenticator-enabled service will require the possession of this software token. In order for the token to be effective, it must not be able to be duplicated and the shared secret should be closely guarded. Google Authenticator’s soft token solution offer a number of advantages over other commercially available solutions. It is free to use (all applications are free to download), the TOTP algorithm is open source, well-known, and well-tested, and finally it does not require a dedicated server for processing tokens. While certain potential weakness in SHA-1 have been identified, none of them can be exploited within the 30-second timeframe of the TOTP’s usability. For all intents and purposes, SHA-1 is reasonably secure, well-tested, and purpose-appropriate for this application. The algorithm however is only as secure as the users and administrators are at protecting the shared secret used in token processing. Calculating The Google Authenticator TOTP The Google Authenticator TOTP is calculated by generating an HMAC-SHA1 token, which uses a 10-byte base32-encoded shared secret as a key and Unix time (epoch) divided into a 30 second interval as inputs. The resulting 80-byte token is converted to a 40-character hexadecimal string, the least significant (last) hex digit is then used to calculate a 0-15 offset. The offset is then used to read the next 8 hex digits from the offset. The resulting 8 hex digits are then AND’d with 0x7FFFFFFF (2,147,483,647), then the modulo of the resultant integer and 1,000,000 is calculated, which produces the correct code for that 30 seconds period. Base32 encoding and decoding were covered in my previous Tech Tip titled Base32 Encoding And Decoding With iRules . The Tech Tip details the process for decoding a user’s base32-encoded key to binary as well as converting a binary key to base32. The HMAC-SHA256 token calculation iRule was originally submitted by Nat to the Codeshare on DevCentral. The iRule was slightly modified to support the SHA-1 algorithm, but is otherwise taken directly from the pseudocode outlined in RFC 2104. These two pieces of code contribute the bulk of the processing of the Google Authenticator code. The rest is done with simple bitwise and arithmetic functions. Google Authenticator Two-Factor Authentication Process Installing Google Authenticator Two-Factor Authentication The installation of Google Authenticator two-factor authentication on your BIG-IP is divided into six sections: creating an LDAP authentication configuration, configuring an LDAP (Active Directory) authentication profile, testing your authentication profile, adding the Google Authenticator iRule and “user_to_google_auth” mapping data group, attaching iRule to the authentication profile, and finally generating soft tokens for your users. The process is broken out into steps as trying to complete all the sections in tandem can be difficult to troubleshoot. Creating An LDAP (Active Directory) Authentication Configuration The LDAP profile we will configure will be extremely basic: no SSL, no Active Directory, etc. A detailed walkthrough for more advanced deployments can be found in our best practices guide: Configuring LDAP remote authentication for Active Directory . 1. Login to your BIG-IP using administrator credentials 2. Navigate to Local Traffic > Profiles > Authentication > Configurations 3. Click “Create” in the upper right-hand corner 4. Select “LDAP” from the “Type” drop-down menu 5. Now fill in the fields with your environment-specific values: Name: ldap.f5test.local Type: LDAP Remote LDAP Tree: dc=f5test, dc=local Host(s): <IP address(es) of LDAP server(s)> Service Port: 389 (default) LDAP Version: 3 (default) Bind DN: cn=ldap_bind_acct, dc=f5test, dc=local (if your LDAP server allows anonymous binds you may not need this option) Bind Password: <admin password> Confirm Bind Password: <admin password> 6. Click “Finished” to save the configuration Configuring An LDAP (Active Directory) Authentication Profile 1. Navigate to Local Traffic > Profiles > Authentication > Profiles 2. Click “Create” in the upper right-hand corner 3. Select “LDAP” from the “Type” drop-down menu 4. Fill in fields with appropriate values: Name: ldap.f5test.local Type: LDAP Configuation: ldap.f5test.local (select previously named configuration from drop-down) Rule: (leave this unchecked and not enabled for now, but this is where we will enable the Google Authenticator iRule shortly) 5. Click “Finished” Test Your Authentication Profile 1. Create a basic HTTP virtual server with your LDAP authentication profile enabled on the virtual 2. Access your virtual from a web browser and you should be prompted with an HTTP Basic Authentication credential form 3. Test with known-working credentials, if everything works you’re good to go, if not you’ll need to troubleshoot the authentication issue Adding the Google Authenticator iRule 1. Go to the DevCentral Codeshare and download the Google Authenticator iRule 2. Navigate to Local Traffic > iRules > iRule List 3. Click “Create” in the upper right-hand corner 4. Name your iRule “google_authenticator_plus_ldap_two_factor” and paste the iRule into “Definition” section 5. Click “Finished” when you’re done Attaching The Google Authenticator iRule To Your Authentication Profile 1. Go back to the “Authentication Profile” section by browsing to Local Traffic > Profiles > Authentication > Profiles 2. Select your LDAP profile from the list 3. Now attach select the “google_authenticator_plus_ldap_two_factor” iRule from the “Rule” drop-down 4. Click “Finished” Generating Software Tokens For Users In addition to the Google Authenticator iRule we also wrote a Google Authenticator Soft Token Generator iRule that will generate soft tokens for your users. The iRule can be added directly to an HTTP virtual server without a a pool and accessed directly to create tokens. There are a few available fields in the generator: account, pre-defined secret, and a QR code option. The “account” field defines how to label the soft token within the user’s mobile device and can be useful if the user has multiple soft token on the same device (I have 3 and need to label them to keep them straight). A 10-byte string can be used as a pre-defined secret for conversion to a base32-encoded key. We will advise you against using a pre-defined key because a key known to the user is something they know (as opposed to something they have) and could be potentially regenerate out-of-band thereby nullifying the benefits of two-factor authentication. Lastly, there is an option to generate a QR code by sending an HTTPS request to Google and returning the QR code as an image. While this is convenient, this could be seen as insecure since it may wind up in Google’s logs somewhere. You’ll have to decide if that is a risk you’re willing to take for the convenience it provides. Once the token has been generated, it will need to be added to a data group on the BIG-IP: 1. Navigate to Local Traffic > iRules > Data Group Lists 2. Select “Create” from the upper right-hand corner if the data group does not yet exist. If it exists, just select it from the list. 3. Name the data group “user_to_google_auth” (data group name can be changed in the RULE_INIT section of the Google Authenticator iRule) 4. The type of data group will be “string” 5. Type the “username” into the “string” field and paste the “Google Authenticator key” into the “value” field 6. Click “Add” and you the username/key pair should appear in the list as such: user := ONSWG4TFOQYTEMZU 7. Click “Finished” when all your username/key pairs have been added. Your user can scan the QR code or type it into their device manually. After they scan the QR code, the account name should appear along with the TOTP for the account. The image below is how the soft token appears in the Google Authenticator iPhone application: Once again, do not let the user leave with a copy of the plain text key. Knowing their key value will negate the value of having the token in the first place. Once the key has been added to the BIG-IP, the user’s device, and they’ve tested their access, destroy any reference to the key outside the BIG-IPs data group.If you’re worried about having the keys in plain text on the BIG-IP, they can be encrypted with AES or stored off-box in LDAP and only queried via secure connection. This is beyond the scope of this article, but doable with iRules. Testing and Troubleshooting There are a lot of moving pieces in this iRule so troubleshooting can be a bit daunting at first glance, but because all of the pieces can be separated into their constituents the problem is usually identified quickly. There are five pieces that make up this solution: the LDAP service, the BIG-IP LDAP profile, the Google Authenticator iRule, the “user_to_google_auth” mapping data group, and finally the soft token. Try to separate them from each other to expedite the troubleshooting process. Here are a few helpful hints in troubleshooting potential issues: 1. Are all the clocks synchronized? The BIG-IP and LDAP server can be tested from the command line by running ‘ntpdate –q pool.ntp.org’. If the clocks are more than a few milliseconds off, they’ll need to be adjusted. An NTP server should be configured for all devices. Likewise the user’s mobile device must be configured to use network time or else the calculated value will always be wrong. Remember that timezones do not matter when using Unix time. 2. Is basic LDAP working without the iRule attached? Before ever touching any of the Google Authenticator related iRules, data groups, devices, etc. your LDAP configuration should be in working order. If you’re having problems finding the issue, enable “debug logging” at the bottom of the LDAP authentication configuration page on your BIG-IP and tail the logs on your LDAP server. Revisit the best practices guide if you are still unsure about any configuration options. 3. Turn on (or increase) logging for Google Authenticator iRule. In the RULE_INIT section of the Google Authenticator iRule, there is a debug logging option. Set it to ‘2’ and all actions from the iRule will be logged to /var/log/ltm. If you see one particular area that is consistently hanging, investigate it further. Conclusion With every passing day system security becomes a greater concern. Today’s attacks are far more sophisticated and costly than those of days past. With all the stories of stolen laptops and other devices in the field, it is a little easier to sleep as a systems administrator knowing that a tech-aware thief has one more hurdle to surpass in an effort to compromise your infrastructure. The implementation costs of deploying two-factor authentication with Google Authenticator in an existing F5 infrastructure are very low assuming your employees have company-issued mobile devices. The cost can be deduced to the man hours required to install this iRule and generate tokens for your users. The cost is almost certainly less than that of a single incident of a compromise account. Until next time, batten down the hatches and get that two-factor project underway that’s been on the backburner for two years. Code and References Google Authenticator iRule – Documentation and code for the iRule used in this Tech Tip Google Authenticator Soft Token Generator iRule – iRule for generating soft tokens for users RFC 4226 - HOTP: An HMAC-Based One-Time Password Algorithm RFC 2104 - HMAC: Keyed-Hashing for Message Authentication RFC 4648 - The Base16, Base32, and Base64 Data Encodings SOL11072 - Configuring LDAP remote authentication for Active Directory6.9KViews1like12CommentsMonitoring TCP Applications #01
LTM has built-in application health monitor templates for many TCP-based application protocols (FTP, HTTP, HTTPS, IMAP, LDAP, MSSQL, NNTP, POP3, RADIUS, RTSP, RPC, SASP, SIP, SMB, SMTP, SOAP). If you need to monitor an application which depends on an upper layer protocol for which there is not a built-in monitor template, LTM provides a number of options to build a monitor based on the underlying transport layer protocol-- TCP. I'll cover each of those options in a separate article, starting here with the built-in "tcp" and "tcp_half_open" monitor types. Overview: tcp and tcp_half_open Both monitor types attempt to verify the availability of a service by making a TCP connection on the appropriate port. There are only a couple of differences between the tcp and the tcp_half_open monitors: monitor type reverse/transparent connection handling transact with service? tcp ECV yes (optional) full open, full close yes (optional) tcp_half_open EAV no half open, RST close no Both have the same standard monitor configuration options of interval, timeout, and alias address/port (for more on those options, and on reverse & transparent options, see the LTM manual section on Configuring Monitors.) As you will see below, some of the differences are significant and may dictate which monitor is most appropriate for your application. Monitor Type "tcp" The tcp monitor is useful for a couple of different scenarios: Monitoring services that you can't transact with, but want to verify the availability of the socket and close the connection properly (routers, firewalls); or Monitoring services with which you can transact a quick request/response in cleartext after the TCP handshake to verify service availability (telnet is abasic example, but the same concept applies to any other text-based protocol). How it works In summary, a monitor of type tcp attempts to send and/or receive specific content over a TCP connection. The check is successful when the server response contains the Receive String value. A tcp monitor may optionally be configured with a Send String value and a Receive String value. If the Send String value is blank and a connection is successfully established, the service is considered up. A blank Receive String value matches any response. The default tcp monitor, with no Send string or Receive string configured tests a service by establishing a TCP connection with the pool member on the configured service port and then immediately closing the connection without sending any data on the connection. This causes some services such as telnet and ssh to log a connection error, filling up the server logs with unnecessary errors. To eliminate the extraneous logging, you can configure the tcp monitor to send enough data to the service to make it happy, or just use the tcp_half_open monitor. Depending on your monitoring requirements, you may also be able to monitor a service that expects empty connections, such as tcp_echo (by using the default tcp_echo monitor) or daytime (specifying the appropriate alias service port when customizing the tcp monitor template). Here are the details of a tcp monitor in action, including the option for sending data and evaluating the response: 1. The tcp monitor will perform a normal 3-way TCP handshake. 2. If no Send string is configured, the pool member will be marked UP upon successful completion of the 3-way handshake. If a Send string is configured, it will be sent to the server. 3. If the server fails to respond before the timeout, the pool member is marked DOWN. If the server does respond before the timeout, the server response is compared with the Receive string: If no Receive string is configured, the pool member is marked UP; if a Receive string is configured, and the response contains the Receive string, the pool member will be marked UP. If the response does not contain the Receive string, the pool member will be marked DOWN. 4. If the server resets the connection during the handshake or before an expected response is received, the pool member will be marked DOWN and the connection is torn down immediately. In all other cases, the connection will be closed with a normal 4-way close. handshake successful? | | no yes | | DOWN send string configured/sent? | | no yes | | UP server response? | | | close no yes | | DOWN recv string configured? | | | close no yes | | UP recv string match response? | | | close no yes | | DOWN UP | | close close Monitor Type "tcp_half_open" The tcp_half_open monitor is most widely used for gateway monitoring when you just need to ensure the socket is responding to connection requests and desire the lowest overhead on the monitoring target. For example, a busy router would be less impacted by a half open connection request that is immediately reset than a connection that completes the entire open and close handshake sequence. (Although this approach minimizes the impact of monitoring on the monitoring target, it's important to know that the tcp_half_open monitor uses more of LTM's memory than the tcp monitor does, since the tcp_half_open monitor is an EAV that runs a small script outside of TMM, while the tcp monitor is an ECV internal to TMM.) Another common use for the tcp_half_open monitor is to prevent the application from spewing a bunch of log messages indicating connections were opened but not used. For example, one consultant recently told me he uses the tcp_half_open monitor to verify sshd is alive and answering without filling up /var/log/secure. Telnet has similar issues with connections on which no data is sent. It should be noted that some applications cannot gracefully handle the half open connection and subsequent reset, so some testing may be in order before implementing this monitor. How it works The tcp_half_open monitor sends a SYN packet to the pool member, and if a SYN-ACK is received from the server in response, the pool member is marked UP. SYN sent | SYN/ACK rec'd? | | no yes | | DOWN** UP | RST sent **Not fully functional in some versions: SOL7362: The BIG-IP tcp_half_open monitor does not mark the service as DOWN after receiving a RST packet from the pool member More info LTM manual: Configuring Monitors Get the Flash Player to see this player.6.5KViews0likes2CommentsOne Time Passwords via an SMS Gateway with BIG-IP Access Policy Manager
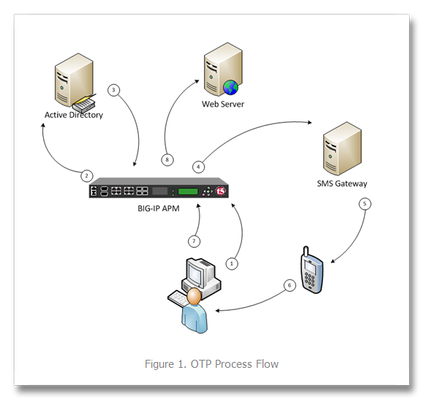
One time passwords, or OTP, are used (as the name indicates) for a single session or transaction. The plus side is a more secure deployment, the downside is two-fold—first, most solutions involve a token system, which is costly in management, dollars, and complexity, and second, people are lousy at remembering things, so a delivery system for that OTP is necessary. The exercise in this tech tip is to employ BIG-IP APM to generate the OTP and pass it to the user via an SMS Gateway, eliminating the need for a token creating server/security appliance while reducing cost and complexity. Getting Started This guide was developed by F5er Per Boe utilizing the newly released BIG-IP version 10.2.1. The “-secure” option for the mcget command is new in this version and is required in one of the steps for this solution. Also, this solution uses the Clickatell SMS Gateway to deliver the OTPs. Their API is documented at http://www.clickatell.com/downloads/http/Clickatell_HTTP.pdf. Other gateway providers with a web-based API could easily be substituted. Also, there are steps at the tail end of this guide to utilize the BIG-IP’s built-in mail capabilities to email the OTP during testing in lieu of SMS. The process in delivering the OTP is shown in Figure 1. First a request is made to the BIG-IP APM. The policy is configured to authenticate the user’s phone number in Active Directory, and if successful, generate a OTP and pass along to the SMS via the HTTP API. The user will then use the OTP to enter into the form updated by APM before allowing the user through to the server resources. BIG-IP APM Configuration Before configuring the policy, an access profile needs to be created, as do a couple authentication servers. First, let’s look at the authentication servers Authentication Servers To create servers used by BIG-IP APM, navigate to Access Policy->AAA Servers and then click create. This profile is simple, supply your domain server, domain name, and admin username and password as shown in Figure 2. The other authentication server is for the SMS Gateway, and since it is an HTTP API we’re using, we need the HTTP type server as shown in Figure 3. Note that the hidden form values highlighted in red will come from your Clickatell account information. Also note that the form method is GET, the form action references the Clickatell API interface, and that the match type is set to look for a specific string. The Clickatell SMS Gateway expects the following format: https://api.clickatell.com/http/sendmsg?api_id=xxxx&user=xxxx&password=xxxx&to=xxxx&text=xxxx Finally, successful logon detection value highlighted in red at the bottom of Figure 3 should be modified to response code returned from SMS Gateway. Now that the authentication servers are configured, let’s take a look at the access profile and create the policy. Access Profile & Policy Before we can create the policy, we need an access profile, shown below in Figure 4 with all default settings. Now that that is done, we click on Edit under the Access Policy column highlighted in red in Figure 5. The default policy is bare bones, or as some call it, empty. We’ll work our way through the objects, taking screen captures as we go and making notes as necessary. To add an object, just click the “+” sign after the Start flag. The first object we’ll add is a Logon Page as shown in Figure 6. No modifications are necessary here, so you can just click save. Next, we’ll configure the Active Directory authentication, so we’ll add an AD Auth object. Only setting here in Figure 7 is selecting the server we created earlier. Following the AD Auth object, we need to add an AD Query object on the AD Auth successful branch as shown in Figures 8 and 9. The server is selected in the properties tab, and then we create an expression in the branch rules tab. To create the expression, click change, and then select the Advanced tab. The expression used in this AD Query branch rule: expr { [mcget {session.ad.last.attr.mobile}] != "" } Next we add an iRule Event object to the AD Query OK branch that will generate the one time password and provide logging. Figure 10 Shows the iRule Event object configuration. The iRule referenced by this event is below. The logging is there for troubleshooting purposes, and should probably be disabled in production. 1: when ACCESS_POLICY_AGENT_EVENT { 2: expr srand([clock clicks]) 3: set otp [string range [format "%08d" [expr int(rand() * 1e9)]] 1 6 ] 4: set mail [ACCESS::session data get "session.ad.last.attr.mail"] 5: set mobile [ACCESS::session data get "session.ad.last.attr.mobile"] 6: set logstring mail,$mail,otp,$otp,mobile,$mobile 7: ACCESS::session data set session.user.otp.pw $otp 8: ACCESS::session data set session.user.otp.mobile $mobile 9: ACCESS::session data set session.user.otp.username [ACCESS::session data get "session.logon.last.username"] 10: log local0.alert "Event [ACCESS::policy agent_id] Log $logstring" 11: } 12: 13: when ACCESS_POLICY_COMPLETED { 14: log local0.alert "Result: [ACCESS::policy result]" 15: } On the fallback path of the iRule Event object, add a Variable Assign object as show in Figure 10b. Note that the first assignment should be set to secure as indicated in image with the [S]. The expressions in Figure 10b are: session.logon.last.password = expr { [mcget {session.user.otp.pw}]} session.logon.last.username = expr { [mcget {session.user.otp.mobile}]} On the fallback path of the AD Query object, add a Message Box object as shown in Figure 11 to alert the user if no mobile number is configured in Active Directory. On the fallback path of the Event OTP object, we need to add the HTTP Auth object. This is where the SMS Gateway we configured in the authentication server is referenced. It is shown in Figure 12. On the fallback path of the HTTP Auth object, we need to add a Message Box as shown in Figure 13 to communicate the error to the client. On the Successful branch of the HTTP Auth object, we need to add a Variable Assign object to store the username. A simple expression and a unique name for this variable object is all that is changed. This is shown in Figure 14. On the fallback branch of the Username Variable Assign object, we’ll configure the OTP Logon page, which requires a Logon Page object (shown in Figure 15). I haven’t mentioned it yet, but the name field of all these objects isn’t a required change, but adding information specific to the object helps with readability. On this form, only one entry field is required, the one time password, so the second password field (enabled by default) is set to none and the initial username field is changed to password. The Input field below is changed to reflect the type of logon to better queue the user. Finally, we’ll finish off with an Empty Action object where we’ll insert an expression to verify the OTP. The name is configured in properties and the expression in the branch rules, as shown in Figures 16 and 17. Again, you’ll want to click advanced on the branch rules to enter the expression. The expression used in the branch rules above is: expr { [mcget {session.user.otp.pw}] == [mcget -secure {session.logon.last.otp}] } Note again that the –secure option is only available in version 10.2.1 forward. Now that we’re done adding objects to the policy, one final step is to click on the Deny following the OK branch of the OTP Verify Empty Action object and change it from Deny to Allow. Figure 18 shows how it should look in the visual policy editor window. Now that the policy is completed, we can attach the access profile to the virtual server and test it out, as can be seen in Figures 19 and 20 below. Email Option If during testing you’d rather send emails than utilize the SMS Gateway, then configure your BIG-IP for mail support (Solution 3664), keep the Logging object, lose the HTTP Auth object, and configure the system with this script to listen for the messages sent to /var/log/ltm from the configured Logging object: #!/bin/bash while true do tail -n0 -f /var/log/ltm | while read line do var2=`echo $line | grep otp | awk -F'[,]' '{ print $2 }'` var3=`echo $line | grep otp | awk -F'[,]' '{ print $3 }'` var4=`echo $line | grep otp | awk -F'[,]' '{ print $4 }'` if [ "$var3" = "otp" -a -n "$var4" ]; then echo Sending pin $var4 to $var2 echo One Time Password is $var4 | mail -s $var4 $var2 fi done done The log messages look like this: Jan 26 13:37:24 local/bigip1 notice apd[4118]: 01490113:5: b94f603a: session.user.otp.log is mail,user1@home.local,otp,609819,mobile,12345678 The output from the script as configured looks like this: [root@bigip1:Active] config # ./otp_mail.sh Sending pin 239272 to user1@home.local Conclusion The BIG-IP APM is an incredibly powerful tool to add to the LTM toolbox. Whether using the mail system or an SMS gateway, you can take a bite out of your infrastructure complexity by using this solution to eliminate the need for a token management service. Many thanks again to F5er Per Boe for this excellent solution!6.1KViews0likes23CommentsHTTPS SNI Monitoring How-to
Hi, You may or may not already have encountered a webserver that requires the SNI (Server Name Indication) extension in order to know which website it needs to serve you. It comes down to "if you don't tell me what you want, I'll give you a default website or even simply reset the connection". A typical IIS8.5 will do this, even with the 'Require SNI' checkbox unchecked. So you have your F5, with its HTTPS monitors. Those monitors do not yet support SNI, as they have no means of specifying the hostname you want to use for SNI. In comes a litle script, that will do exactly that. Here's a few quick steps to get you started: Download the script from this article (it's posted on pastebin: http://pastebin.com/hQWnkbMg). Import it under 'System' > 'File Management' > 'External Monitor Program File List'. Create a monitor of type 'External' and select the script from the picklist under 'External Program'. Add your specific variables (explanation below). Add the monitor to a pool and you are good to go. A quick explanation of the variables: METHOD (GET, POST, HEAD, OPTIONS, etc. - defaults to 'GET') URI ("the part after the hostname" - defaults to '/') HTTPSTATUS (the status code you want to receive from the server - defaults to '200') HOSTNAME (the hostname to be used for SNI and the Host Header - defaults to the IP of the node being targetted) TARGETIP and TARGETPORT (same functionality as the 'alias' fields in the original monitors - defaults to the IP of the node being targetted and port 443) DEBUG (set to 0 for nothing, set to 1 for logs in /var/log/ltm - defaults to '0') RECEIVESTRING (the string that needs to be present in the server response - default is empty, so not checked) HEADERX (replace the X by a number between 1 and 50, the value for this is a valid HTTP header line, i.e. "User-Agent: Mozilla" - no defaults) EXITSTATUS (set to 0 to make the monitor always mark te pool members as up; it's fairly useless, but hey... - defaults to 1) There is a small thing you need to know though: due to the nature of the openssl binary (more specifically the s_client), we are presented with a "stdin redirection problem". The bottom line is that your F5 cannot be "slow" and by slow I mean that if it requires more than 3 seconds to pipe a string into openssl s_client, the script will always fail. This limit is defined in the variable "monitor_stdin_sleeptime" and defaults to '3'. You can set it to something else by adding a variable named 'STDIN_SLEEPTIME' and giving it a value. From my experience, anything above 3 stalls the "F5 script executer", anything below 2 is too fast for openssl to read the request from stdin, effectively sending nothing and thus yielding 'down'. When you enable debugging (DEBUG=1), you can see what I mean for yourself: no more log entries for the script when STDIN_SLEEPTIME is set too high; always down when you set it too low. I hope this script is useful for you, Kind regards, Thomas Schockaert5.8KViews0likes22CommentsLTM: Configuring IP Forwarding
A basic change in internal routing architecture and functionality between BIG-IP 4.x and LTM 9.x has caused some confusion for customers whose v4.x deployment depended on IP forwarding. Here is an explanation of the change, and the new configuration requirements to support forwarding of IP traffic using LTM. What changed? Both BIG-IP and LTM are default deny devices, which means a specific configuration is required to support every desired traffic flow. In BIG-IP, packets not matching a virtual server or SNAT/NAT would be dropped, unless the BIG-IP v4.x global IP forwarding checkbox feature was enabled. With IP forwarding enabled, packets not matching a virtual or SNAT/NAT would be forwarded intact per the routing table entries. LTM also requires that all traffic must match a defined TMM listener (a virtual server, SNAT or NAT) or be dropped. However, LTM's full application proxy architecture separates routing intelligence from load balancing, and the deprecated IP forwarding feature was intentionally not included in LTM to optimize load balancing performance. The IP forwarding checkbox feature was deprecated early in the BIG-IP 4.x tree. Although F5 has long recommended that IP forwarding be replaced with forwarding virtual servers, forwarding pools, SNATs or NATs, some customers retained their IP forwarding configuration when upgrading to LTM v9.x. Since those various configuration options exist to support traffic previously managed by IP forwarding, the One-Time Conversion Utility (OTCU) that translates v4 configurations to v9 syntax does not presume to configure global forwarding virtual servers in place of global IP forwarding. For those customers and other administrators already familiar with BIG-IP but now using LTM, it isn't obvious how to replicate the forwarding behaviour they require. Configuring forwarding for LTM The recommended replacement for global IP forwarding is a forwarding virtual server configured to listen for all IP protocols, all addresses and all ports on all VLANs. This virtual server would catch all traffic not matching another listener and forward in accordance with LTM's routing table entries. You can configure a wildcard forwarding virtual server that listens for all IP protocols, all addresses and all ports on all VLANs. 1. In the LTM GUI, browse to Virtual Servers & click "Create". 2. Configure the following properties: Destination: Network Address=0.0.0.0 Mask=0.0.0.0 Service port: 0 Type: Forwarding (IP) Protocol: *All Protocols VLAN Traffic: All VLANs 3. Click "Finish" to create the virtual server. The resulting configuration snip looks like this: virtual forward_vs { ip forward destination any:any mask none } This will forward all IP traffic as long as there is a matching route in the routing table. (Packets bound for destinations for which there is no route will be dropped with no ICMP notification.) Commonly required modifications You can limit forwarding to only traffic bound for specific subnets by specifying the appropriate subnet and mask. If a different router exists on any directly connected network, you may need to create a custom fastL4 profile with "Loose Initiation" & "Loose Close" enabled to prevent LTM from interfering with forwarded conversations traversing an asymmetrical path. If the forwarding virtual server is intended to allow outbound access for your privately addresses servers, you will need to configure a SNAT to translate the source address of that traffic to a publicly routable address. If you have multiple gateways, you can load balance requests between the routers. To do so, first create a gateway pool containing the routers as members. Then configure the virtual server as above, but selecting Type "Performance (Layer 4)" instead of "Forwarding (IP)", and applying the gateway pool as its resource. Related information SOL7229: Methods of gaining administrative access to nodes through the BIG-IP system If you only need to forward administrative traffic to your servers, and no other forwarding is required, there are several additional options for that detailed in this solution. SOL473: Advantages and disadvantages of using IP forwarding This is an old solution that summarizes the pros and cons of BIG-IP 4.x IP forwarding. I only suggest reading it now to highlight the fact that LTM's approach retains the advantages and overcomes the disadvantages mentioned therein. Get the Flash Player to see this player.5.2KViews0likes5CommentsThe Top 10, Top Predictions for 2012
Around this time of year, almost everyone and their brother put out their annual predictions for the coming year. So instead of coming up with my own, I figured I’d simply regurgitate what many others are expecting to happen. Security Predictions 2012 & 2013 - The Emerging Security Threat – SANS talks Custom Malware, IPv6, ARM hacking and Social Media. Top 7 Cybersecurity Predictions for 2012 - From Stuxnet to Sony, a number of cyberattacks emerged in 2011 that experts have predicted for quite some time. Webroot’s top seven forecasts for the year ahead. Zero-day targets and smartphones are on this list. Top 8 Security Predictions for 2012 – Fortinet’s Security Predictions for 2012. Sponsored attacks and SCADA Under the Scope. Security Predictions for 2012 - With all of the crazy 2011 security breaches, exploits and notorious hacks, what can we expect for 2012? Websense looks at blended attacks, social media identity and SSL. Top 5 Security Predictions For 2012 – The escalating change in the threat landscape is something that drives the need for comprehensive security ever-forward. Firewalls and regulations in this one. Gartner Predicts 2012 – Special report addressing the continuing trend toward the reduction of control IT has over the forces that affect it. Cloud, mobile, data management and context-aware computing. 2012 Cyber Security Predictions – Predicts cybercriminals will use cyber-antics during the U.S. presidential election and will turn cell phones into ATMs. Top Nine Cyber Security Trends for 2012 – Imperva’s predictions for the top cyber security trends for 2012. DDoS, HTML 5 and social media. Internet Predictions for 2012 – QR codes and Flash TOP 15 Internet Marketing Predictions for 2012 – Mobile SEO, Social Media ROI and location based marketing. Certainly not an exhaustive list of all the various 2012 predictions including the doomsday and non-doomsday claims but a good swath of what the experts believe is coming. Wonder if anyone predicted that Targeted attacks increased four-fold in 2011. ps Technorati Tags: F5, cyber security, predictions, 2012, Pete Silva, security, mobile, vulnerabilities, crime, social media, hacks, the tube, internet, identity theft4.7KViews0likes1CommentTACACS+ Remote Role Configuration for BIG-IP
Several years ago (can it really have been 2009?) I wrote up a solution for using tacacs+ as the authentication and authorization source for BIG-IP user management. Much has changed in five years: new roles have been added to the system, tmsh has replaced bigpipe, and unrelated to our end of the solution, my favorite flavor of the free tacacs daemon, tac_plus, is no longer available! This article will cover all the steps necessary to get a tacacs+ installation established on a Ubuntu server, configure tacacs+, configure the BIG-IP to utilize that tacacs+ server, and test the installation. Before that, however, I'll address the role information necessary to make it all work. The tacacs config in this article is dependent on a version that I am no longer able to get installed on a modern linux flavor. Instead, try this Dockerized tacacs+ server for your testing. The details in the rest of the article are still appropriate. BIG-IP Remote Role Details There are quite a few more roles than previously. The table below shows all the roles available as of TMOS version 11.5.1. Role Role Value admin 0 resource-admin 20 user-manager 40 auditor 80 manager 100 application-editor 300 operator 400 certificate-manager 500 irule-manager 510 guest 700 web-application-security-administrator 800 web-application-security-editor 810 acceleration-policy-editor 850 no-access 900 In addition to the role, the console (tmsh or disabled) and partition (all, Common (default) or specified partition) settings need to be addressed. Installing tac_plus First, download the tac_plus package from pro-bono to /var/tmp. I'm assuming you already have gcc installed, if you don't, please check google for installing gcc on your Ubuntu installation. Change directory to /var/tmp and extract the package. cd /var/tmp/ #current file is DEVEL.201407301604.tar.bz2 tar xvf DEVEL.201407301604.tar.bz2 Change directory into PROJECTS, configure the package for tacacs, then compile and install it. Do these steps one at a time (don't copy and paste the group.) cd PROJECTS ./configure tac_plus make sudo make install After a successful installation, copy the sample configuration to the config directory, and copy the init script over to the system init script directory, modify the file attributes and permissions, then apply the init script to the system. sudo cp /usr/local/etc/mavis/sample/tac_plus.cfg /usr/local/etc/ sudo cp /var/tmp/PROJECTS/tac_plus/extra/etc_init.d_tac_plus /etc/init.d/tac_plus sudo chmod 755 /etc/init.d/tac_plus sudo update-rc.d tac_plus defaults Configuring tac_plus Now that the installation is complete, the configuration file needs to be cleaned up and configured. There are many options that can extend the power of the tac_plus daemon, but this article will focus on authentication and authorization specific to the BIG-IP role information described above. Starting with the daemon listener itself, this is contained in the spawnd id. I changed the port to the default tacacs port, which is 49 (tcp). id = spawnd { listen = { port = 49 } spawn = { instances min = 1 instances max = 10 } background = no } Next, the logging locations and host information need to be set. I left the debug values alone, as well as the binding address. Assume all the remaining code snippets from the tac_plus configuration are wrapped in the id = tac_plus { } section. debug = PACKET AUTHEN AUTHOR access log = /var/log/access.log accounting log = /var/log/acct.log host = world { address = ::/0 prompt = "\nAuthorized access only!\nTACACS+ Login\n" key = f5networks } After the host data is configured, the groups need to be configured. For this exercise, the groups will be aligned to the administrator, application editor, user manager, and ops roles, with admins and ops getting console access. Admins will have access to all partitions, ops will have access only to partition1, and the remaining groups will have access to the Common partition. group = adm { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = adm set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 0 set F5-LTM-User-Partition = all } } } group = appEd { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = appEd set F5-LTM-User-Console = 0 set F5-LTM-User-Role = 300 set F5-LTM-User-Partition = Common } } } group = userMgr { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = userMgr set F5-LTM-User-Console = 0 set F5-LTM-User-Role = 40 set F5-LTM-User-Partition = Common } } } group = ops { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = ops set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 400 set F5-LTM-User-Partition = partition1 } } } Finally, map a user to each of those groups for testing the solution. I would not recommend using a clear key (host configuration) or clear passwords in production, these are shown here for demonstration purposes only. Mapping to /etc/password, or even a centralized ldap/ad solution would be far better for operational considerations. user = f5user1 { password = clear letmein member = adm } user = f5user2 { password = clear letmein member = appEd } user = f5user3 { password = clear letmein member = userMgr } user = f5user4 { password = clear letmein member = ops } Save the file, and then start the tac_plus daemon by typing service tac_plus start. Configuring BIG-IP Now that the tacacs configuration is complete and the service is available, the BIG-IP needs to be configured to use it! The remote role configuration is pretty straight forward in tmsh, and note that the role info aligns with the groups configured in tac_plus. auth remote-role { role-info { adm { attribute F5-LTM-User-Info-1=adm console %F5-LTM-User-Console line-order 1 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } appEd { attribute F5-LTM-User-Info-1=appEd console %F5-LTM-User-Console line-order 2 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } ops { attribute F5-LTM-User-Info-1=ops console %F5-LTM-User-Console line-order 4 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } userMgr { attribute F5-LTM-User-Info-1=userMgr console %F5-LTM-User-Console line-order 3 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } } } Note: Because we defined the behaviors for each role in tac_plus, they don't need to be redefined here, which is why the % syntax is used in this configuration for the console, role, and user-partition. However, if it is preferred to define the behaviors on box, that can be done instead and then you can just define the F5-LTM-User-Info-1 attribute on tac_plus. Either way is supported. Here's an example of the alternative on the BIG-IP side for the admin role. adm { attribute F5-LTM-User-Info-1=adm console enabled line-order 1 role administrator user-partition All } Final step is to set the authentication source to tacacs and set the host parameters. auth source { type tacacs } auth tacacs system-auth { debug enabled protocol ip secret $M$2w$jT3pHxY6dqGF1tHKgl4mWw== servers { 192.168.6.10 } service ppp } Testing the Solution It wouldn't be much of a solution if it didn't work, so the following screenshots show the functionality as expected in the GUI and the CLI. F5user1 This user is in the admin group, and should have access to all the partitions, be an administrator, and be able to not only connect to the console, but jump out of tmsh to the advanced shell. You can do this with the run util bash command in tmsh. F5user2 This user is an application editor, and should have access only to the common partition with no access to the console. Notice the failed logins at the CLI, and the partition is firm with no drop down. F5user3 This user has the user manager role and like the application editor has no access to the console. The partition is hard-coded to common as well. F5user4 Finally, the last user is mapped to the ops group, so they will be bound to partition1, and whereas they have console access, they do not have access to the advanced shell as they are not an admin user.4.6KViews1like5Comments