TACACS+ Remote Role Configuration for BIG-IP
Several years ago (can it really have been 2009?) I wrote up a solution for using tacacs+ as the authentication and authorization source for BIG-IP user management. Much has changed in five years: new roles have been added to the system, tmsh has replaced bigpipe, and unrelated to our end of the solution, my favorite flavor of the free tacacs daemon, tac_plus, is no longer available! This article will cover all the steps necessary to get a tacacs+ installation established on a Ubuntu server, configure tacacs+, configure the BIG-IP to utilize that tacacs+ server, and test the installation. Before that, however, I'll address the role information necessary to make it all work. The tacacs config in this article is dependent on a version that I am no longer able to get installed on a modern linux flavor. Instead, try this Dockerized tacacs+ server for your testing. The details in the rest of the article are still appropriate. BIG-IP Remote Role Details There are quite a few more roles than previously. The table below shows all the roles available as of TMOS version 11.5.1. Role Role Value admin 0 resource-admin 20 user-manager 40 auditor 80 manager 100 application-editor 300 operator 400 certificate-manager 500 irule-manager 510 guest 700 web-application-security-administrator 800 web-application-security-editor 810 acceleration-policy-editor 850 no-access 900 In addition to the role, the console (tmsh or disabled) and partition (all, Common (default) or specified partition) settings need to be addressed. Installing tac_plus First, download the tac_plus package from pro-bono to /var/tmp. I'm assuming you already have gcc installed, if you don't, please check google for installing gcc on your Ubuntu installation. Change directory to /var/tmp and extract the package. cd /var/tmp/ #current file is DEVEL.201407301604.tar.bz2 tar xvf DEVEL.201407301604.tar.bz2 Change directory into PROJECTS, configure the package for tacacs, then compile and install it. Do these steps one at a time (don't copy and paste the group.) cd PROJECTS ./configure tac_plus make sudo make install After a successful installation, copy the sample configuration to the config directory, and copy the init script over to the system init script directory, modify the file attributes and permissions, then apply the init script to the system. sudo cp /usr/local/etc/mavis/sample/tac_plus.cfg /usr/local/etc/ sudo cp /var/tmp/PROJECTS/tac_plus/extra/etc_init.d_tac_plus /etc/init.d/tac_plus sudo chmod 755 /etc/init.d/tac_plus sudo update-rc.d tac_plus defaults Configuring tac_plus Now that the installation is complete, the configuration file needs to be cleaned up and configured. There are many options that can extend the power of the tac_plus daemon, but this article will focus on authentication and authorization specific to the BIG-IP role information described above. Starting with the daemon listener itself, this is contained in the spawnd id. I changed the port to the default tacacs port, which is 49 (tcp). id = spawnd { listen = { port = 49 } spawn = { instances min = 1 instances max = 10 } background = no } Next, the logging locations and host information need to be set. I left the debug values alone, as well as the binding address. Assume all the remaining code snippets from the tac_plus configuration are wrapped in the id = tac_plus { } section. debug = PACKET AUTHEN AUTHOR access log = /var/log/access.log accounting log = /var/log/acct.log host = world { address = ::/0 prompt = "\nAuthorized access only!\nTACACS+ Login\n" key = f5networks } After the host data is configured, the groups need to be configured. For this exercise, the groups will be aligned to the administrator, application editor, user manager, and ops roles, with admins and ops getting console access. Admins will have access to all partitions, ops will have access only to partition1, and the remaining groups will have access to the Common partition. group = adm { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = adm set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 0 set F5-LTM-User-Partition = all } } } group = appEd { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = appEd set F5-LTM-User-Console = 0 set F5-LTM-User-Role = 300 set F5-LTM-User-Partition = Common } } } group = userMgr { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = userMgr set F5-LTM-User-Console = 0 set F5-LTM-User-Role = 40 set F5-LTM-User-Partition = Common } } } group = ops { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = ops set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 400 set F5-LTM-User-Partition = partition1 } } } Finally, map a user to each of those groups for testing the solution. I would not recommend using a clear key (host configuration) or clear passwords in production, these are shown here for demonstration purposes only. Mapping to /etc/password, or even a centralized ldap/ad solution would be far better for operational considerations. user = f5user1 { password = clear letmein member = adm } user = f5user2 { password = clear letmein member = appEd } user = f5user3 { password = clear letmein member = userMgr } user = f5user4 { password = clear letmein member = ops } Save the file, and then start the tac_plus daemon by typing service tac_plus start. Configuring BIG-IP Now that the tacacs configuration is complete and the service is available, the BIG-IP needs to be configured to use it! The remote role configuration is pretty straight forward in tmsh, and note that the role info aligns with the groups configured in tac_plus. auth remote-role { role-info { adm { attribute F5-LTM-User-Info-1=adm console %F5-LTM-User-Console line-order 1 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } appEd { attribute F5-LTM-User-Info-1=appEd console %F5-LTM-User-Console line-order 2 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } ops { attribute F5-LTM-User-Info-1=ops console %F5-LTM-User-Console line-order 4 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } userMgr { attribute F5-LTM-User-Info-1=userMgr console %F5-LTM-User-Console line-order 3 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } } } Note: Because we defined the behaviors for each role in tac_plus, they don't need to be redefined here, which is why the % syntax is used in this configuration for the console, role, and user-partition. However, if it is preferred to define the behaviors on box, that can be done instead and then you can just define the F5-LTM-User-Info-1 attribute on tac_plus. Either way is supported. Here's an example of the alternative on the BIG-IP side for the admin role. adm { attribute F5-LTM-User-Info-1=adm console enabled line-order 1 role administrator user-partition All } Final step is to set the authentication source to tacacs and set the host parameters. auth source { type tacacs } auth tacacs system-auth { debug enabled protocol ip secret $M$2w$jT3pHxY6dqGF1tHKgl4mWw== servers { 192.168.6.10 } service ppp } Testing the Solution It wouldn't be much of a solution if it didn't work, so the following screenshots show the functionality as expected in the GUI and the CLI. F5user1 This user is in the admin group, and should have access to all the partitions, be an administrator, and be able to not only connect to the console, but jump out of tmsh to the advanced shell. You can do this with the run util bash command in tmsh. F5user2 This user is an application editor, and should have access only to the common partition with no access to the console. Notice the failed logins at the CLI, and the partition is firm with no drop down. F5user3 This user has the user manager role and like the application editor has no access to the console. The partition is hard-coded to common as well. F5user4 Finally, the last user is mapped to the ops group, so they will be bound to partition1, and whereas they have console access, they do not have access to the advanced shell as they are not an admin user.4.6KViews1like5Comments
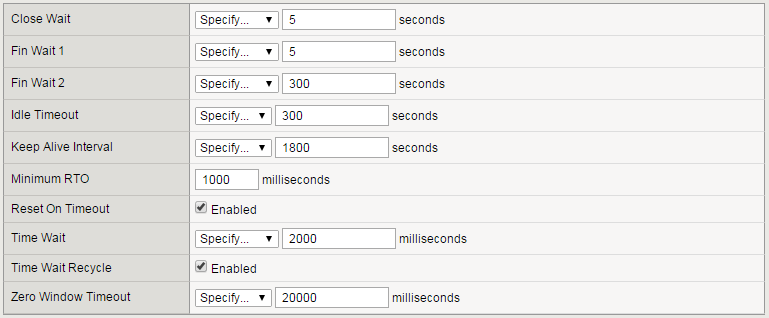
Tuning the TCP Profile, Part One
A few months ago I pointed out some problems with the existing F5-provided TCP profiles, especially the default one. Today I'll begin a pass through the (long) TCP profile to point out the latest thinking on how to get the most performance for your applications. We'll go in the order you see these profile options in the GUI. But first, a note about programmability: in many cases below, I'm going to ask you to generalize about the clients or servers you interact with, and the nature of the paths to those hosts. In a perfect world, we'd detect that stuff automatically and set it for you, and in fact we're rolling that out setting by setting. In the meantime, you can customize your TCP parameters on a per-connection basis using iRules for many of the settings described below, something I'll explain further where applicable. In general, when I refer to "performance" below, I'm referring to the speed at which your customer gets her data. Performance can also refer to the scalability of your application delivery due to CPU and memory limitations, and when that's what I mean, I'll say so. Timer Management The one here with a big performance impact isMinimum RTO. When TCP computes its Retransmission Timeout (RTO), it takes the average measured Round Trip Time (RTT) and adds a few standard deviations to make sure it doesn't falsely detect loss. (False detections have very negative performance implications.) But if RTT is low and stable that RTO may betoolow, and the minimum is designed to catch known fluctuations in RTT that the connection may not have observed. Set Minimum RTO too low, and TCP may improperly enter congestion response and reduce the sending rate all the way down to one packet per round trip. Set it too high, and TCP sits idle when it ought to retransmit lost data. So what's the right value? Obviously, if you have a sense of the maximum RTT to your clients (which you can get with the ping command), that's a floor for your value. Furthermore, many clients and servers will implement some sort of Delayed ACK, which reduces ACK volume by sometimes holding them back for up to 200ms to see if it can aggregate more data in the ACK. RFC 5681 actually allows delays of up to 500ms, but this is less common. So take the maximum RTT and add 200 to 500 ms. Another group of settings aren't really about throughput,but to help clients and servers to close gracefully, at the cost of consuming some system resources. Long Close Wait, Fin Wait 1, Fin Wait 2, and Time Wait timers will keep connection state alive to make sure the remote host got all the connection close messages. Enabling Reset On Timeout sends a message that tells the peer to tear down the connection. Similarly, disabling Time Wait Recycle will prevent new connections from using the same address/port combination, making sure that the old connection with that combination gets a full close. The last group of settingskeeps possibly dead connections alive,using system resources to maintain state in case they come back to life. Idle Timeout and Zero Window Timeout commit resources until the timer expires. If you set Keep Alive Interval to a valuelessthan the Idle Timeout, then on the clientside BIG-IP will keep the connection alive as long as the client keeps responding to keepalive and the server doesn't terminate the connection itself. In theory, this could be forever! Memory Management In terms of high throughput performance, you want all of these settings to be as large as possible up to a point. The tradeoff is that setting them too high may waste memory and reduce the number of supportable concurrent connections. I say "may" waste because these are limitson memory use, and BIG-IP doesn't allocate the memory until it needs it for buffered data.Even so, the trick is to set the limits large enough that there are no performance penalties, but no larger. Send Buffer and Receive Window are easy to set in principle, but can be tricky in practice. For both, answer these questions: What is the maximum bandwidth (Bytes/second) that BIG-IP might experience sending or receiving? Out of all paths data might travel, what minimum delay among those paths is the highest? (What is the "maximum of the minimums"?) Then you simply multiply Bytes/second by seconds of delay to get a number of bytes. This is the maximum amount of data that TCP ought to have in flight at any one time, which should be enough to prevent TCP connections from idling for lack of memory. If your application doesn't involve sending or receiving much data on that side of the proxy, you can probably get away with lowering the corresponding buffer size to save on memory. For example, a traditional HTTP proxy's clientside probably can afford to have a smaller receive buffer if memory-constrained. There are three principles to follow in setting Proxy Buffer Limits: Proxy Buffer High should be at least as big as the Send Buffer. Otherwise, if a large ACK clears the send buffer all at once there may be less data available than TCP can send. Proxy Buffer Low should be at least as big as the Receive Window on the peer TCP profile(i.e. for the clientside profile, use the receive window on the serverside profile). If not, when the peer connection exits the zero-window state, new data may not arrive before BIG-IP sends all the data it has. Proxy Buffer High should be significantly larger than Proxy Buffer Low (we like to use a 64 KB gap) to avoid constant flapping to and from the zero-window state on the receive side. Obviously, figuring out bandwidth and delay before a deployment can be tricky. This is a place where some iRule mojo can really come in handy. The TCP::rtt and TCP::bandwidth* commands can give you estimates of both quantities you need, even though the RTT isn't a minimum RTT. Alternatively, if you've enabled cmetrics-cache in the profile, you can also obtain historical data for a destination using the ROUTE::cwnd* command, which is a good (possibly low) guess at the value you should plug into the send and receive buffers. You can then set buffer limits directly usingTCP::sendbuf**,TCP::recvwnd**, and TCP::proxybuffer**. Getting this to work very well will be difficult, and I don't have any examples where someone worked it through and proved a benefit. But if your application travels highly varied paths and you have the inclination to tinker, you could end up with an optimized configuration. If not, set the buffer sizes using conservatively high inputs and carry on. *These iRule commands only supported in TMOS® version 12.0.0 and later. **These iRule commands only supported inTMOS® version 11.6.0and later.3KViews0likes6CommentsF5 Predicts: Education gets personal
The topic of education is taking centre stage today like never before. I think we can all agree that education has come a long way from the days where students and teachers were confined to a classroom with a chalkboard. Technology now underpins virtually every sector and education is no exception. The Internet is now the principal enabling mechanism by which students assemble, spread ideas and sow economic opportunities. Education data has become a hot topic in a quest to transform the manner in which students learn. According to Steven Ross, a professor at the Centre for Research and Reform in Education at Johns Hopkins University, the use of data to customise education for students will be the key driver for learning in the future[1].This technological revolution has resulted in a surge of online learning courses accessible to anyone with a smart device. A two-year assessment of the massive open online courses (MOOCs) created by HarvardX and MITxrevealed that there were 1.7 million course entries in the 68 MOOC [2].This translates to about 1 million unique participants, who on average engage with 1.7 courses each. This equity of education is undoubtedly providing vast opportunities for students around the globe and improving their access to education. With more than half a million apps to choose from on different platforms such as the iOS and Android, both teachers and students can obtain digital resources on any subject. As education progresses in the digital era, here are some considerations for educational institutions to consider: Scale and security The emergence of a smogasborad of MOOC providers, such as Coursera and edX, have challenged the traditional, geographical and technological boundaries of education today. Digital learning will continue to grow driving the demand for seamless and user friendly learning environments. In addition, technological advancements in education offers new opportunities for government and enterprises. It will be most effective if provided these organisations have the ability to rapidly scale and adapt to an all new digital world – having information services easily available, accessible and secured. Many educational institutions have just as many users as those in large multinational corporations and are faced with the issue of scale when delivering applications. The aim now is no longer about how to get fast connection for students, but how quickly content can be provisioned and served and how seamless the user experience can be. No longer can traditional methods provide our customers with the horizontal scaling needed. They require an intelligent and flexible framework to deploy and manage applications and resources. Hence, having an application-centric infrastructure in place to accelerate the roll-out of curriculum to its user base, is critical in addition to securing user access and traffic in the overall environment. Ensuring connectivity We live in a Gen-Y world that demands a high level of convenience and speed from practically everyone and anything. This demand for convenience has brought about reform and revolutionised the way education is delivered to students. Furthermore, the Internet of things (IoT), has introduced a whole new raft of ways in which teachers can educate their students. Whether teaching and learning is via connected devices such as a Smart Board or iPad, seamless access to data and content have never been more pertinent than now. With the increasing reliance on Internet bandwidth, textbooks are no longer the primary means of educating, given that students are becoming more web oriented. The shift helps educational institutes to better personalise the curriculum based on data garnered from students and their work. Duty of care As the cloud continues to test and transform the realms of education around the world, educational institutions are opting for a centralised services model, where they can easily select the services they want delivered to students to enhance their learning experience. Hence, educational institutions have a duty of care around the type of content accessed and how it is obtained by students. They can enforce acceptable use policies by only delivering content that is useful to the curriculum, with strong user identification and access policies in place. By securing the app, malware and viruses can be mitigated from the institute’s environment. From an outbound perspective, educators can be assured that students are only getting the content they are meant to get access to. F5 has the answer BIG-IP LTM acts as the bedrock for educational organisations to provision, optimise and deliver its services. It provides the ability to publish applications out to the Internet in a quickly and timely manner within a controlled and secured environment. F5 crucially provides both the performance and the horizontal scaling required to meet the highest levels of throughput. At the same time, BIG-IP APM provides schools with the ability to leverage virtual desktop infrastructure (VDI) applications downstream, scale up and down and not have to install costly VDI gateways on site, whilst centralising the security decisions that come with it. As part of this, custom iApps can be developed to rapidly and consistently deliver, as well as reconfigure the applications that are published out to the Internet in a secure, seamless and manageable way. BIG-IP Application Security Manager (ASM) provides an application layer security to protect vital educational assets, as well as the applications and content being continuously published. ASM allows educational institutes to tailor security profiles that fit like a glove to wrap seamlessly around every application. It also gives a level of assurance that all applications are delivered in a secure manner. Education tomorrow It is hard not to feel the profound impact that technology has on education. Technology in the digital era has created a new level of personalised learning. The time is ripe for the digitisation of education, but the integrity of the process demands the presence of technology being at the forefront, so as to ensure the security, scalability and delivery of content and data. The equity of education that technology offers, helps with addressing factors such as access to education, language, affordability, distance, and equality. Furthermore, it eliminates geographical boundaries by enabling the mass delivery of quality education with the right policies in place. [1] http://www.wsj.com/articles/SB10001424052702304756104579451241225610478 [2] http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2586847844Views0likes3Comments
F5 in AWS Part 4 - Orchestrating BIG-IP Application Services with Open-Source tools
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 The following post references code hosted at F5's Github repository f5networks/aws-deployments. This code provides a demonstration of using open-source tools to configure and orchestrate BIG-IP. Full documentation for F5 BIG-IP cloud work can be found at Cloud Docs: F5 Public Cloud Integrations. So far we have talked above AWS networking basics, how to run BIG-IP in a VPC, and highly-available deployment footprints. In this post, we’ll move on to my favorite topic, orchestration. By this point, you probably have several VMs running in AWS. You’ve lost track of which configuration is setup on which VM, and you have found yourself slowly going mad as you toggle between the AWS web portal and several SSH windows. I call this ‘point-and-click’ purgatory. Let's be blunt, why would you move to cloud without realizing the benefits of automation, of which cloud is a large enabler. If you remember our second article, we mentioned CloudFormation templates as a great way to deploy a standardized set of resources (perhaps BIG-IP + the additional virtualized network resources) in EC2. This is a great start, but we need to configure these resources once they have started, and we need a way to define and execute workflows which will run across a set of hosts, perhaps even hosts which are external to the AWS environment. Enter the use of open-source configuration management and workflow tools that have been popularized by the software development community. Open-source configuration management and AWS APIs Lately, I have been playing with Ansible, which is a python-based, agentless workflow engine for IT automation. By agentless, I mean that you don’t need to install an agent on hosts under management. Ansible, like the other tools, provides a number of libraries (or “modules”) which provide the ability to manage a diverse collection of remote systems. These modules are typically implemented through the use of API calls, often over HTTP. Out of the box, Ansible comes with several modules for managing resources in AWS. While the EC2 libraries provided are useful for basic orchestration use cases, we decided it would be easier to atomically manage sets of resources using the CloudFormation module. In doing so, we were able to deploy entire CloudFormation stacks which would include items like VPCs, networking elements, BIG-IP, app servers, etc. Underneath the covers, the CloudFormation: Ansible module and our own project use the python module to interact with AWS service endpoints. Ansible provides some basic modules for managing BIG-IP configuration resources. These along with libraries for similar tools can be found here: Ansible Puppet SaltStack In the rest of this post, I’ll discuss some work colleagues and I have done to automate BIG-IP deployments in AWS using Ansible. While we chose to use Ansible, we readily admit that Puppet, Chef, Salt and whatever else you use are all appropriate choices for implementing deployment and configuration management workflows for your network. Each have their upsides and downsides, and different tools may lend themselves to different use cases for your infrastructure. Browse the web to figure out which tool is right for you. Using Standardized BIG-IP Interfaces Speaking of APIs, for years F5 has provided the ability to programmatically configure BIG-IP using iControlSOAP. As the audiences performing automation work have matured, so have the weapons of choice. The new hot ticket is REST (Representational State Transfer), and guess what, BIG-IP has a REST interface (you can probably figure out what it is called). Together, iControlSOAP and iControlREST give you the power to manage nearly every configuration element and feature of BIG-IP. These interfaces become extremely powerful when you combine them with your favorite open-source configuration management tool and a cloud that allows you to spin up and down compute and networking resources. In the project described below, we have also made use of iApps using iControlRest as a way to create a standard virtual server configuration with the correct policies and profiles. The documentation in Github describes this in detail, but our approach shows how iApps provide a strongly supported approach for managing network policy across engineering teams. For example, imagine that a team of software engineers has written a framework to deploy applications. You can package the network policy into iApps for various types of apps, and pass these to the teams writing the deployment framework. Implementing a Service Catalog To pull the above concepts together, a colleague and I put together the aws-deployments project.The goal was to build a simple service catalog which would enable a user to deploy a containerized application in EC2 with BIG-IP network services sitting in front. This is example code that is not supported by F5 support but is a proof of concept to show how you can fully automate production-like deployments in AWS. Some highlights of the project include: Use of iControlRest and iControlSoap within Ansible playbooks to setup advanced topologies of BIG-IP in AWS. Automated deployment of a basic ASM web application firewall policy to protect a vulnerable web app (Hackazon. Use of iApps to manage virtual server configurations, including the WAF policy mentioned above. Figure 1 - Generic Architecture for automating application deployments in public or private cloud In examination of the code, you will see that we provide the opportunity to provision all the development models outlined in our earlier post (a single standalone VE, standalones BIG-IP VEs striped availability zones, clusters within an availability zone, etc). We used Ansible and the interfaces on BIG-IP to orchestrate the workflows assoiated with these deployment models. To perform the clustering step, we have used the iControlSoap interface on BIG-IP. The final set of technology used is depicted in Figure 3. Figure 2 - Technologies used in the aws-deployments project on Github Read the Code and Test It Yourself All the code I have mentioned is available at f5networks/aws-deployments. We encourage you to download and run the code for yourself. Instructions for setting up a development environment which includes the necessary dependencies is easy. We have packaged all the dependencies for use with either Vagrant or Docker as development tools. The instructions for either of these approaches can be found in the README.md or in the /docs directory. The following video shows an end-to-end usage example. (Keep in mind that the code has been updated since this video was produced). At the end of the day, our goal for this work was to collect customer feedback. Please provide some by leaving a comment below, or by filing ‘pull requests’ or ‘issues’ in Github. In the next few weeks, we will be updating the project to include the Hackazon app mentioned above, show how to cluster BIG-IP across availability zones, and how to deploy an ASM profile with an iApp. Have fun!1.3KViews1like3Comments
F5 in AWS Part 5 - Cloud-init, Single-NIC, and Auto Scale Out in BIG-IP
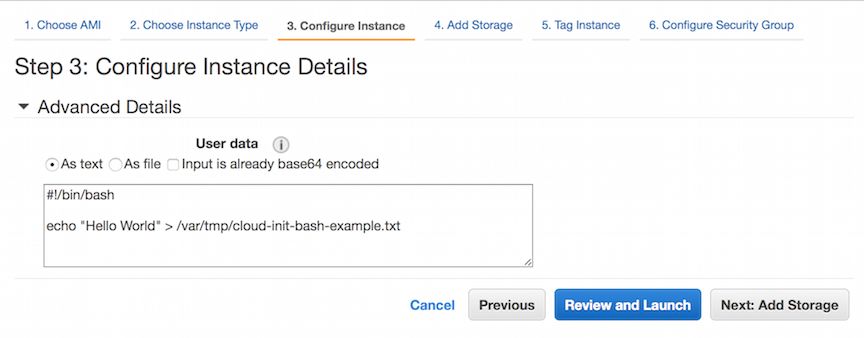
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 The following article covers features and examplesin the 12.1 AWS Marketplace release, discussed in the following documentation: Amazon Web Services: Single NIC BIG-IP VE Amazon Web Services: Auto Scaling BIG-IP VE You can find the BIG-IP Hourly and BYOL releases in the Amazon marketplace here. BIG-IP utility billing images are available, which makes it a great time to talk about some of the functionality. So far in Chris’s series, we have discussed some of the highly-available deployment footprints of BIG-IP in AWS and how these might be orchestrated. Several of these footprints leverage BIG-IP's Device Service Clustering (DSC) technology for configuration management across devices and also lend themselves to multi-app or multi-tenant configurations in a shared-service model. But what if you want to deploy BIG-IP on a per-app or per-tenant basis, in a horizontally scalable footprint that plays well with the concepts of elasticity and immutability in cloud? Today we have just the option for you. Before highlighting these scalable deployment models in AWS, we need to cover cloud-init and single-NIC configurations; two important additions to BIG-IP that enable an Auto Scaling topology. Elasticity Elastiity is obviously one of the biggest promises/benefits of cloud. By leveraging cloud, we are essentially tapping into the "unlimited" (at least relative to our own datacenters) resources large cloud providers have built. In actual practice, this means adopting new methodologies and approaches to truely deliver this. Immutablity In traditional operational model of datacenters, everything was "actively" managed. Physical Infrastructure still tends to lend itself to active management but even virtualized services and applications running on top of the infrastructure were actively managed. For example, servers were patched, code was live upgraded inplace, etc. However, to achieve true elasticity, where things are spinning up or down and more ephemeral in nature, it required a new approach. Instead of trying to patch or upgrade individual instances, the approach was treating them as disposable which meant focusing more on the build process itself. ex. Netflix's famous Building with Legos approach. Yes, the concept of golden images/snapshots existed since virtualization but cloud, with self-service, automation and auto scale functionality, forced this to a new level. Operations focus shifted more towards a consistent and repeatable "build" or "packaging" effort, with final goal of creating instances that didn't need to be touched, logged into, etc. In the specific context of AWS's Auto Scale groups, that means modifying the Auto Scale Group's "launch config". The steps for creating the new instances involve either referencing an entirely new image ID or maybe modification to a cloud-init config. Cloud-init What is it? First, let’s talk about cloud-init as it is used with most Linux distributions. Most of you who are evaluating or operating in the cloud have heard of it. For those who haven’t, cloud-init is an industry standard for bootstrapping machines at startup. It provides a simple domain specific language for common infrastructure provisioning tasks. You can read the official docs here. For the average linux or systems engineer, cloud-init is used to perform tasks such as installing a custom package, updating yum repositories or installing certificates to perform final customizations to a "base" or “golden” image. For example, the Security team might create an approved hardened base image and various Dev teams would use cloud-init to customize the image so it booted up with an ‘identity’ if you will – an application server with an Apache webserver running or a database server with MySQL provisioned. Let’s start with the most basic "Hello World" use of cloud-init, passing in User Data (in this case a simple bash script). If launching an instance via the AWS Console, on the Configure Instance page, navigate down the “Advanced Details”: Figure 1: User Data input field - bash However, User Data is limited to < 16KBs and one of the real powers of cloud-init came from extending functionality past this boundry and providing a standardized way to provision, or ah humm, "initialize" instances.Instead of using unwieldy bash scripts that probed whether it was an Ubuntu or a Redhat instance and used this OS method or that OS method (ex. use apt-get vs. rpm) to install a package, configure users, dns settings, mount a drive, etc. you could pass a yaml file starting with #cloud-config file that did a lot of this heavy lifting for you. Figure 2: User Data input field - cloud-config Similar to one of the benefits of Chef, Puppet, Salt or Ansible, it provided a reliable OS or distribution abstraction but where those approaches require external orchestration to configure instances, this was internally orchestrated from the very first boot which was more condusive to the "immutable" workflow. NOTE: cloud-init also compliments and helps boot strap those tools for more advanced or sophisticated workflows (ex. installing Chef/Puppet to keep long running non-immutable services under operation/management and preventing configuration drift). This brings us to another important distinction. Cloud-init originated as a project from Canonical (Ubuntu) and was designed for general purpose OSs. The BIG-IP's OS (TMOS) however is a highly customized, hardened OS so most of the modules don't strictly apply. Much of the Big-IP's configuration is consumed via its APIs (TMSH, iControl REST, etc.) and stored in it's database MCPD. We can still achieve some of the benefits of having cloud-init but instead, we will mostly leverage the simple bash processor. So when Auto Scaling BIG-IPs, there are a couple of approaches. 1) Creating a custom image as described in the official documentation. 2) Providing a cloud-init configuration This is a little lighter weight approach in that it doesn't require the customization work above. 3) Using a combination of the two, creating a custom image and leveraging cloud-init. For example, you may create a custom image with ASM provisioned, SSL certs/keys installed, and use cloud-init to configure additional environment specific elements. Disclaimer: Packaging is an art, just look at the rise of Docker and new operating systems. Ideally, the more you bake into the image upfront, the more predictable it will be and faster it deploys. However, the less you build-in, the more flexible you can be. Things like installing libraries, compiling, etc. are usually worth building in the image upfront. However, the BIG-IP is already a hardened image and things like installing libraries is not something required or recommended so the task is more about addressing the last/lighter weight configuration steps. However, depending on your priorities and objectives,installing sensitive keying material, setting credentials, pre-provisioning modules, etc. might make good candidates for investing in building custom images. Using Cloud-init with CloudFormation templates Remember when we talked about how you could use CloudFormation templates in a previous post to setup BIG-IP in a standard way? Because the CloudFormation service by itself only gave us the ability to lay down the EC2/VPC infrastructure, we were still left with remaining 80% of the work to do; we needed an external agent or service (in our case Ansible) to configure the BIG-IP and application services. Now, with cloud-init on the BIG-IP (using version 12.0 or later), we can perform that last 80% for you. Using Cloud-init with BIG-IP As you can imagine, there’s quite a lot you can do with just that one simple bash script shown above. However, more interestingly, we also installed AWS’s Cloudformation Helper scripts. http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-helper-scripts-reference.html to help extend cloud-init and unlock a larger more powerful set of AWS functionality. So when used with Cloudformation, our User Data simply changes to executing the following AWS Cloudformation helper script instead. "UserData": { "Fn::Base64": { "Fn::Join": [ "", [ "#!/bin/bash\n", "/opt/aws/apitools/cfn-init-1.4-0.amzn1/bin/cfn-init -v -s ", { "Ref": "AWS::StackId" }, " -r ", "Bigip1Instance", " --region ", { "Ref": "AWS::Region" }, "\n" ] ] } } This allows us to do things like obtaining variables passed in from Cloudformation environment, grabbing various information from the metadata service, creating or downloading files, running particular sequence of commands, etc. so once BIG-IP has finishing running, our entire application delivery service is up and running. For more information, this page discusses how meta-data is attached to an instance using CloudFormation templates: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-init.html#aws-resource-init-commands. Example BYOL and Utility CloudFormation Templates We’ve posted several examples on github to get you started. https://github.com/f5networks/f5-aws-cloudformation In just a few short clicks, you can have an entire BIG-IP deployment up and running. The two examples belowwill launch an entire reference stack complete with VPCs, Subnets, Routing Tables, sample webserver, etc. andshow the use of cloud-init to bootstrap a BIG-IP. Cloud-init is used to configure interfaces, Self-IPs, database variables, a simple virtual server, and in the case of of the BYOL instance, to license BIG-IP. Let’s take a closer look at the BIG-IP resource created in one of these to see what’s going on here: "Bigip1Instance ": { "Metadata ": { "AWS::CloudFormation::Init ": { "config ": { "files ": { "/tmp/firstrun.config ": { "content ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", "HOSTNAME=`curl http://169.254.169.254/latest/meta-data/hostname`\n ", "TZ='UTC'\n ", "BIGIP_ADMIN_USERNAME=' ", { "Ref ": "BigipAdminUsername " }, "'\n ", "BIGIP_ADMIN_PASSWORD=' ", { "Ref ": "BigipAdminPassword " }, "'\n ", "MANAGEMENT_GUI_PORT=' ", { "Ref ": "BigipManagementGuiPort " }, "'\n ", "GATEWAY_MAC=`ifconfig eth0 | egrep HWaddr | awk '{print tolower($5)}'`\n ", "GATEWAY_CIDR_BLOCK=`curl http://169.254.169.254/latest/meta-data/network/interfaces/macs/${GATEWAY_MAC}/subnet-ipv4-cidr-block`\n ", "GATEWAY_NET=${GATEWAY_CIDR_BLOCK%/*}\n ", "GATEWAY_PREFIX=${GATEWAY_CIDR_BLOCK#*/}\n ", "GATEWAY=`echo ${GATEWAY_NET} | awk -F. '{ print $1\ ".\ "$2\ ".\ "$3\ ".\ "$4+1 }'`\n ", "VPC_CIDR_BLOCK=`curl http://169.254.169.254/latest/meta-data/network/interfaces/macs/${GATEWAY_MAC}/vpc-ipv4-cidr-block`\n ", "VPC_NET=${VPC_CIDR_BLOCK%/*}\n ", "VPC_PREFIX=${VPC_CIDR_BLOCK#*/}\n ", "NAME_SERVER=`echo ${VPC_NET} | awk -F. '{ print $1\ ".\ "$2\ ".\ "$3\ ".\ "$4+2 }'`\n ", "POOLMEM=' ", { "Fn::GetAtt ": [ "Webserver ", "PrivateIp " ] }, "'\n ", "POOLMEMPORT=80\n ", "APPNAME='demo-app-1'\n ", "VIRTUALSERVERPORT=80\n ", "CRT='default.crt'\n ", "KEY='default.key'\n " ] ] }, "group ": "root ", "mode ": "000755 ", "owner ": "root " }, "/tmp/firstrun.utils ": { "group ": "root ", "mode ": "000755 ", "owner ": "root ", "source ": "http://cdn.f5.com/product/templates/utils/firstrun.utils " } "/tmp/firstrun.sh ": { "content ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", ". /tmp/firstrun.config\n ", ". /tmp/firstrun.utils\n ", "FILE=/tmp/firstrun.log\n ", "if [ ! -e $FILE ]\n ", " then\n ", " touch $FILE\n ", " nohup $0 0<&- &>/dev/null &\n ", " exit\n ", "fi\n ", "exec 1<&-\n ", "exec 2<&-\n ", "exec 1<>$FILE\n ", "exec 2>&1\n ", "date\n ", "checkF5Ready\n ", "echo 'starting tmsh config'\n ", "tmsh modify sys ntp timezone ${TZ}\n ", "tmsh modify sys ntp servers add { 0.pool.ntp.org 1.pool.ntp.org }\n ", "tmsh modify sys dns name-servers add { ${NAME_SERVER} }\n ", "tmsh modify sys global-settings gui-setup disabled\n ", "tmsh modify sys global-settings hostname ${HOSTNAME}\n ", "tmsh modify auth user admin password \ "'${BIGIP_ADMIN_PASSWORD}'\ "\n ", "tmsh save /sys config\n ", "tmsh modify sys httpd ssl-port ${MANAGEMENT_GUI_PORT}\n ", "tmsh modify net self-allow defaults add { tcp:${MANAGEMENT_GUI_PORT} }\n ", "if [[ \ "${MANAGEMENT_GUI_PORT}\ " != \ "443\ " ]]; then tmsh modify net self-allow defaults delete { tcp:443 }; fi \n ", "tmsh mv cm device bigip1 ${HOSTNAME}\n ", "tmsh save /sys config\n ", "checkStatusnoret\n ", "sleep 20 \n ", "tmsh save /sys config\n ", "tmsh create ltm pool ${APPNAME}-pool members add { ${POOLMEM}:${POOLMEMPORT} } monitor http\n ", "tmsh create ltm policy uri-routing-policy controls add { forwarding } requires add { http } strategy first-match legacy\n ", "tmsh modify ltm policy uri-routing-policy rules add { service1.example.com { conditions add { 0 { http-uri host values { service1.example.com } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 1 } }\n ", "tmsh modify ltm policy uri-routing-policy rules add { service2.example.com { conditions add { 0 { http-uri host values { service2.example.com } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 2 } }\n ", "tmsh modify ltm policy uri-routing-policy rules add { apiv2 { conditions add { 0 { http-uri path starts-with values { /apiv2 } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 3 } }\n ", "tmsh create ltm virtual /Common/${APPNAME}-${VIRTUALSERVERPORT} { destination 0.0.0.0:${VIRTUALSERVERPORT} mask any ip-protocol tcp pool /Common/${APPNAME}-pool policies replace-all-with { uri-routing-policy { } } profiles replace-all-with { tcp { } http { } } source 0.0.0.0/0 source-address-translation { type automap } translate-address enabled translate-port enabled }\n ", "tmsh save /sys config\n ", "date\n ", "# typically want to remove firstrun.config after first boot\n ", "# rm /tmp/firstrun.config\n " ] ] }, "group ": "root ", "mode ": "000755 ", "owner ": "root " } }, "commands ": { "b-configure-Bigip ": { "command ": "/tmp/firstrun.sh\n " } } } } }, "Properties ": { "ImageId ": { "Fn::FindInMap ": [ "BigipRegionMap ", { "Ref ": "AWS::Region " }, { "Ref ": "BigipPerformanceType " } ] }, "InstanceType ": { "Ref ": "BigipInstanceType " }, "KeyName ": { "Ref ": "KeyName " }, "NetworkInterfaces ": [ { "Description ": "Public or External Interface ", "DeviceIndex ": "0 ", "NetworkInterfaceId ": { "Ref ": "Bigip1ExternalInterface " } } ], "Tags ": [ { "Key ": "Application ", "Value ": { "Ref ": "AWS::StackName " } }, { "Key ": "Name ", "Value ": { "Fn::Join ": [ " ", [ "BIG-IP: ", { "Ref ": "AWS::StackName " } ] ] } } ], "UserData ": { "Fn::Base64 ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", "/opt/aws/apitools/cfn-init-1.4-0.amzn1/bin/cfn-init -v -s ", { "Ref ": "AWS::StackId " }, " -r ", "Bigip1Instance ", " --region ", { "Ref ": "AWS::Region " }, "\n " ] ] } } }, "Type ": "AWS::EC2::Instance " } Above may look like a lot at first but high level, we start by creating some files "inline" as well as “sourcing” some files from a remote location. /tmp/firstrun.config - Here we create a file inline, laying down variables from the Cloudformation Stack deployment itself and even the metadata service (http://169.254.169.254/latest/meta-data/). Take a look at the “Ref” stanzas. When this file is laid down on the BIG-IP disk itself, those variables will be interpolated and contain the actual contents. The idea here is to try to keep config and execution separate. /tmp/firstrun.utils – These are just some helper functions to help with initial provisioning. We use those to determine when the BIG-IP is ready for this particular configuration (ex. after a licensing or provisioning step). Note that instead of creating the file inline like the config file above, we simply “source” or download the file from a remote location. /tmp/firstrun.sh – This file is created inline as well and where it really all comes together. The first thing we do is load config variables from the firstrun.conf file and load the helper functions from firstrun.utils. We then create separate log file (/tmp/firstrun.log) to capture the output of this particular script. Capturing the output of these various commands just helps with debugging runs. Then we run a function called checkF5Ready (that we loaded from that helper function file) to make sure BIG-IP’s database is up and ready to accept a configuration. The rest may look more familiar and where most of the user customization takes place. We use variables from the config file to configure the BIG-IP using familiar methods like TMSH and iControl REST. Technically, you could lay down an entire config file (like SCF) and load it instead. We use tmsh here for simplicity. The possibilities are endless though. Disclaimer: the specific implementation above will certainly be optimized and evolve but the most important take away is we can now leverage cloud-init and AWS's helper libraries to help bootstrap the BIG-IP into a working configuration from the very first boot! Debugging Cloud-init What if something goes wrong? Where do you look for more information? The first place you might look is in various cloud-init logs in /var/log (cloud-init.log, cfn-init.log, cfn-wire.log): Below is an example for the CFTs below: [admin@ip-10-0-0-205:NO LICENSE:Standalone] log # tail -150 cfn-init.log 2016-01-11 10:47:59,353 [DEBUG] CloudFormation client initialized with endpoint https://cloudformation.us-east-1.amazonaws.com 2016-01-11 10:47:59,353 [DEBUG] Describing resource BigipEc2Instance in stack arn:aws:cloudformation:us-east-1:452013943082:stack/as-testing-byol-bigip/07c962d0-b893-11e5-9174-500c217b4a62 2016-01-11 10:47:59,782 [DEBUG] Not setting a reboot trigger as scheduling support is not available 2016-01-11 10:47:59,790 [INFO] Running configSets: default 2016-01-11 10:47:59,791 [INFO] Running configSet default 2016-01-11 10:47:59,791 [INFO] Running config config 2016-01-11 10:47:59,792 [DEBUG] No packages specified 2016-01-11 10:47:59,792 [DEBUG] No groups specified 2016-01-11 10:47:59,792 [DEBUG] No users specified 2016-01-11 10:47:59,792 [DEBUG] Writing content to /tmp/firstrun.config 2016-01-11 10:47:59,792 [DEBUG] No mode specified for /tmp/firstrun.config 2016-01-11 10:47:59,793 [DEBUG] Writing content to /tmp/firstrun.sh 2016-01-11 10:47:59,793 [DEBUG] Setting mode for /tmp/firstrun.sh to 000755 2016-01-11 10:47:59,793 [DEBUG] Setting owner 0 and group 0 for /tmp/firstrun.sh 2016-01-11 10:47:59,793 [DEBUG] Running command b-configure-BigIP 2016-01-11 10:47:59,793 [DEBUG] No test for command b-configure-BigIP 2016-01-11 10:47:59,840 [INFO] Command b-configure-BigIP succeeded 2016-01-11 10:47:59,841 [DEBUG] Command b-configure-BigIP output: % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 40 0 40 0 0 74211 0 --:--:-- --:--:-- --:--:-- 40000 2016-01-11 10:47:59,841 [DEBUG] No services specified 2016-01-11 10:47:59,844 [INFO] ConfigSets completed 2016-01-11 10:47:59,851 [DEBUG] Not clearing reboot trigger as scheduling support is not available [admin@ip-10-0-0-205:NO LICENSE:Standalone] log # If trying out the example templates above, you can inspect the various files mentioned. Ex. In addition to checking for their general presence: /tmp/firstrun.config= make sure variables were passed as you expected. /tmp/firstrun.utils= Make sure exists and was downloaded /tmp/firstrun.log = See if any obvious errors were outputted. It may also be worth checking AWS Cloudformation Console to make sure you passed the parameters you were expecting. Single-NIC Another one of the important building blocks introduced with 12.0 on AWS and Azure Virtual Editions is the ability to run BIG-IP with just a single network interface. Typically, BIG-IPs were deployed in a multi-interface model, where interfaces were attached to an out-of-band management network and one or more traffic (or "data-plane") networks. But, as we know, cloud architectures scale by requiring simplicity, especially at the network level. To this day, some clouds can only support instances with a single IP on a single NIC. In AWS’s case, although they do support multiple NIC/multiple IP, some of their services like ELB only point to first IP address of the first NIC. So this Single-NIC configuration makes it not only possible but also dramatically easier to deploy in these various architectures. How this works: We can now attach just one interface to the instance and BIG-IP will start up, recognize this, use DHCP to configure the necessary settings on that interface. Underneath the hood, the following DB keys will be set: admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list sys db provision.1nic one-line sys db provision.1nic { value "enable" } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list sys db provision.1nicautoconfig one-line sys db provision.1nicautoconfig { value "enable" } provision.1nic = allows both management and data-plane to use the same interface provision.1nicautoconfig = uses address from DHCP to configure a vlan, Self-IP and default gateway. Ex. network objects automatically configured admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net vlan net vlan internal if-index 112 interfaces { 1.0 { } } tag 4094 } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net self net self self_1nic { address 10.0.1.65/24 allow-service { default } traffic-group traffic-group-local-only vlan internal } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net route net route default { gw 10.0.1.1 network default } Note: Traffic Management Shell and the Configuration Utility (GUI) are still available on ports 22 and 443 respectively. If you want to run the management GUI on a higher port (for instance if you don’t have the BIG-IPs behind a Port Address Translation service (like ELB) and want to run an HTTPS virtual on 443), use the following commands: tmsh modify sys httpd ssl-port 8443 tmsh modify net self-allow defaults add { tcp:8443 } tmsh modify net self-allow defaults delete { tcp:443 } WARNING: Now that management and dataplane run on the same interface, make sure to modify your Security Groups to restrict access to SSH and whatever port you use for the Mgmt GUI port to trusted networks. UPDATE: On Single-Nic, Device Service Clustering currently only supports Configuration Syncing (Network Failover is restricted for now due to BZ-606032). In general, the single-NIC model lends itself better to single-tenant or per-app deployments, where you need the advanced services from BIG-IP like content routing policies, iRules scripting, WAF, etc. but don’t necessarily care for maintaining a management subnet in the deployment and are just optimizing or securing a single application. By single tenant we also mean single management domain as you're typically running everything through a single wildcard virtual (ex. 0.0.0.0/0, 0.0.0.0/80, 0.0.0.0/443, etc.) vs. giving each tenant its own Virtual Server (usually with its own IP and configuration) to manage. However, you can still technically run multiple applications behind this virtual with a policy or iRule, where you make traffic steering decisions based on L4-L7 content (SNI, hostname headers, URIs, etc.). In addition, if the BIG-IPs are sitting behind a Port Address Translation service, it also possible to stack virtual services on ports instead. Ex. 0.0.0.0:444 = Virtual Service 1 0.0.0.0:445 = Virtual Service 2 0.0.0.0:446 = Virtual Service 3 We’ll let you get creative here…. BIG-IP Auto Scale Finally, the last component of Auto Scaling BIG-IPs involves building scaling policies via Cloudwatch Alarms. In addition to the built-in EC2 metrics in CloudWatch, BIG-IP can report its own set of metrics, shown below: Figure 3: Cloudwatch metrics to scale BIG-IPs based on traffic load. This can be configured with the following TMSH commands on any version 12.0 or later build: tmsh modify sys autoscale-group autoscale-group-id ${BIGIP_ASG_NAME} tmsh load sys config merge file /usr/share/aws/metrics/aws-cloudwatch-icall-metrics-config These commands tell BIG-IP to push the above metrics to a custom “Namespace” on which we can roll up data via standard aggregation functions (min, max, average, sum). This namespace (based on Auto Scale group name) will appear as a row under in the “Custom metrics” dropdown on the left side-bar in CloudWatch (left side of Figure 1). Once these BIG-IP or EC2 metrics have been populated, CloudWatch alarms can be built, and these alarms are available for use in Auto Scaling policies for the BIG-IP Auto Scale group. (Amazon provides some nice instructions here). Auto Scaling Pool Members and Service Discovery If you are scaling your ADC tier, you are likely also going to be scaling your application as well. There are two options for discovering pool members in your application's auto scale group. 1) FQDN Nodes For example, in a typicalsandwichdeployment, your application members might also be sitting behind an internal ELB so you would simply point your FQDN node at the ELB's DNS. For more information, please see: https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/ltm-implementations-12-1-0/25.html?sr=56133323 2) BIG-IP's AWS Auto Scale Pool Member Discovery feature (introduced v12.0) This feature polls the Auto Scale Group via API calls and populates the pool based on its membership. For more information, please see: https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/bigip-ve-autoscaling-amazon-ec2-12-1-0/2.html Putting it all together The high-level steps for Auto Scaling BIG-IP include the following: Optionally* creating an ElasticLoadBalancer group which will direct traffic to BIG-IPs in your Auto Scale group once they become operational. Otherwise, will need Global Server Load Balancing (GSLB). Creating a launch configuration in EC2 (referencing either custom image id and/or using Cloud-init scripts as described above) Creating an Auto Scale group using this launch configuration Creating CloudWatch alarms using the EC2 or custom metrics reported by BIG-IP. Creating scaling policies for your BIG-IP Auto Scale group using the alarms above. You will want to create both scale up and scale down policies. Here are some things to keep in mind when Auto Scaling BIG-IP ● BIG-IP must run in a single-interface configuration with a wildcard listener (as we talked about earlier). This is required because we don't know what IP address the BIG-IP will get. ● Auto Scale Groups themselves consist of utility instances of BIG-IP ● The scale up time for BIG-IP is about 12-20 minutes depending on what is configured or provisioned. While this may seem like a long-time, creating the right scaling policies (polling intervals, thresholds, unit of scale) make this a non-issue. ● This deployment model lends itself toward the themes of stateless, horizontal scalability and immutability embraced by the cloud. Currently, the config on each device is updated once and only once at device startup. The only way to change the config will be through the creation of a new image or modification to the launch configuration. Stay tuned for a clustered deployment which is managed in a more traditional operational approach. If interesting in exploring Auto Scale further, we have put together some examples of scaling the BIG-IP tier here: https://github.com/f5devcentral/f5-aws-autoscale * Above github repository also provides some examples of incorporating BYOL instances in the deployment to help leverage BYOL instances for your static load and using Auto Scale instances for your dynamic load. See the READMEs for more information. CloudFormation templates with Auto Scaled BIG-IP and Application Need some ideas on how you might leverage these solutions? Now that you can completely deploy a solution with a single template, how about building service catalog items for your business units that deploy different BIG-IP services (LB, WAF) or a managed service build on top of AWS that can be easily deployed each time you on-board a new customer?2.6KViews0likes7Comments
5 Years Later: OpenAJAX Who?
Five years ago the OpenAjax Alliance was founded with the intention of providing interoperability between what was quickly becoming a morass of AJAX-based libraries and APIs. Where is it today, and why has it failed to achieve more prominence? I stumbled recently over a nearly five year old article I wrote in 2006 for Network Computing on the OpenAjax initiative. Remember, AJAX and Web 2.0 were just coming of age then, and mentions of Web 2.0 or AJAX were much like that of “cloud” today. You couldn’t turn around without hearing someone promoting their solution by associating with Web 2.0 or AJAX. After reading the opening paragraph I remembered clearly writing the article and being skeptical, even then, of what impact such an alliance would have on the industry. Being a developer by trade I’m well aware of how impactful “standards” and “specifications” really are in the real world, but the problem – interoperability across a growing field of JavaScript libraries – seemed at the time real and imminent, so there was a need for someone to address it before it completely got out of hand. With the OpenAjax Alliance comes the possibility for a unified language, as well as a set of APIs, on which developers could easily implement dynamic Web applications. A unified toolkit would offer consistency in a market that has myriad Ajax-based technologies in play, providing the enterprise with a broader pool of developers able to offer long term support for applications and a stable base on which to build applications. As is the case with many fledgling technologies, one toolkit will become the standard—whether through a standards body or by de facto adoption—and Dojo is one of the favored entrants in the race to become that standard. -- AJAX-based Dojo Toolkit , Network Computing, Oct 2006 The goal was simple: interoperability. The way in which the alliance went about achieving that goal, however, may have something to do with its lackluster performance lo these past five years and its descent into obscurity. 5 YEAR ACCOMPLISHMENTS of the OPENAJAX ALLIANCE The OpenAjax Alliance members have not been idle. They have published several very complete and well-defined specifications including one “industry standard”: OpenAjax Metadata. OpenAjax Hub The OpenAjax Hub is a set of standard JavaScript functionality defined by the OpenAjax Alliance that addresses key interoperability and security issues that arise when multiple Ajax libraries and/or components are used within the same web page. (OpenAjax Hub 2.0 Specification) OpenAjax Metadata OpenAjax Metadata represents a set of industry-standard metadata defined by the OpenAjax Alliance that enhances interoperability across Ajax toolkits and Ajax products (OpenAjax Metadata 1.0 Specification) OpenAjax Metadata defines Ajax industry standards for an XML format that describes the JavaScript APIs and widgets found within Ajax toolkits. (OpenAjax Alliance Recent News) It is interesting to see the calling out of XML as the format of choice on the OpenAjax Metadata (OAM) specification given the recent rise to ascendancy of JSON as the preferred format for developers for APIs. Granted, when the alliance was formed XML was all the rage and it was believed it would be the dominant format for quite some time given the popularity of similar technological models such as SOA, but still – the reliance on XML while the plurality of developers race to JSON may provide some insight on why OpenAjax has received very little notice since its inception. Ignoring the XML factor (which undoubtedly is a fairly impactful one) there is still the matter of how the alliance chose to address run-time interoperability with OpenAjax Hub (OAH) – a hub. A publish-subscribe hub, to be more precise, in which OAH mediates for various toolkits on the same page. Don summed it up nicely during a discussion on the topic: it’s page-level integration. This is a very different approach to the problem than it first appeared the alliance would take. The article on the alliance and its intended purpose five years ago clearly indicate where I thought this was going – and where it should go: an industry standard model and/or set of APIs to which other toolkit developers would design and write such that the interface (the method calls) would be unified across all toolkits while the implementation would remain whatever the toolkit designers desired. I was clearly under the influence of SOA and its decouple everything premise. Come to think of it, I still am, because interoperability assumes such a model – always has, likely always will. Even in the network, at the IP layer, we have standardized interfaces with vendor implementation being decoupled and completely different at the code base. An Ethernet header is always in a specified format, and it is that standardized interface that makes the Net go over, under, around and through the various routers and switches and components that make up the Internets with alacrity. Routing problems today are caused by human error in configuration or failure – never incompatibility in form or function. Neither specification has really taken that direction. OAM – as previously noted – standardizes on XML and is primarily used to describe APIs and components - it isn’t an API or model itself. The Alliance wiki describes the specification: “The primary target consumers of OpenAjax Metadata 1.0 are software products, particularly Web page developer tools targeting Ajax developers.” Very few software products have implemented support for OAM. IBM, a key player in the Alliance, leverages the OpenAjax Hub for secure mashup development and also implements OAM in several of its products, including Rational Application Developer (RAD) and IBM Mashup Center. Eclipse also includes support for OAM, as does Adobe Dreamweaver CS4. The IDE working group has developed an open source set of tools based on OAM, but what appears to be missing is adoption of OAM by producers of favored toolkits such as jQuery, Prototype and MooTools. Doing so would certainly make development of AJAX-based applications within development environments much simpler and more consistent, but it does not appear to gaining widespread support or mindshare despite IBM’s efforts. The focus of the OpenAjax interoperability efforts appears to be on a hub / integration method of interoperability, one that is certainly not in line with reality. While certainly developers may at times combine JavaScript libraries to build the rich, interactive interfaces demanded by consumers of a Web 2.0 application, this is the exception and not the rule and the pub/sub basis of OpenAjax which implements a secondary event-driven framework seems overkill. Conflicts between libraries, performance issues with load-times dragged down by the inclusion of multiple files and simplicity tend to drive developers to a single library when possible (which is most of the time). It appears, simply, that the OpenAJAX Alliance – driven perhaps by active members for whom solutions providing integration and hub-based interoperability is typical (IBM, BEA (now Oracle), Microsoft and other enterprise heavyweights – has chosen a target in another field; one on which developers today are just not playing. It appears OpenAjax tried to bring an enterprise application integration (EAI) solution to a problem that didn’t – and likely won’t ever – exist. So it’s no surprise to discover that references to and activity from OpenAjax are nearly zero since 2009. Given the statistics showing the rise of JQuery – both as a percentage of site usage and developer usage – to the top of the JavaScript library heap, it appears that at least the prediction that “one toolkit will become the standard—whether through a standards body or by de facto adoption” was accurate. Of course, since that’s always the way it works in technology, it was kind of a sure bet, wasn’t it? WHY INFRASTRUCTURE SERVICE PROVIDERS and VENDORS CARE ABOUT DEVELOPER STANDARDS You might notice in the list of members of the OpenAJAX alliance several infrastructure vendors. Folks who produce application delivery controllers, switches and routers and security-focused solutions. This is not uncommon nor should it seem odd to the casual observer. All data flows, ultimately, through the network and thus, every component that might need to act in some way upon that data needs to be aware of and knowledgeable regarding the methods used by developers to perform such data exchanges. In the age of hyper-scalability and über security, it behooves infrastructure vendors – and increasingly cloud computing providers that offer infrastructure services – to be very aware of the methods and toolkits being used by developers to build applications. Applying security policies to JSON-encoded data, for example, requires very different techniques and skills than would be the case for XML-formatted data. AJAX-based applications, a.k.a. Web 2.0, requires different scalability patterns to achieve maximum performance and utilization of resources than is the case for traditional form-based, HTML applications. The type of content as well as the usage patterns for applications can dramatically impact the application delivery policies necessary to achieve operational and business objectives for that application. As developers standardize through selection and implementation of toolkits, vendors and providers can then begin to focus solutions specifically for those choices. Templates and policies geared toward optimizing and accelerating JQuery, for example, is possible and probable. Being able to provide pre-developed and tested security profiles specifically for JQuery, for example, reduces the time to deploy such applications in a production environment by eliminating the test and tweak cycle that occurs when applications are tossed over the wall to operations by developers. For example, the jQuery.ajax() documentation states: By default, Ajax requests are sent using the GET HTTP method. If the POST method is required, the method can be specified by setting a value for the type option. This option affects how the contents of the data option are sent to the server. POST data will always be transmitted to the server using UTF-8 charset, per the W3C XMLHTTPRequest standard. The data option can contain either a query string of the form key1=value1&key2=value2 , or a map of the form {key1: 'value1', key2: 'value2'} . If the latter form is used, the data is converted into a query string using jQuery.param() before it is sent. This processing can be circumvented by setting processData to false . The processing might be undesirable if you wish to send an XML object to the server; in this case, change the contentType option from application/x-www-form-urlencoded to a more appropriate MIME type. Web application firewalls that may be configured to detect exploitation of such data – attempts at SQL injection, for example – must be able to parse this data in order to make a determination regarding the legitimacy of the input. Similarly, application delivery controllers and load balancing services configured to perform application layer switching based on data values or submission URI will also need to be able to parse and act upon that data. That requires an understanding of how jQuery formats its data and what to expect, such that it can be parsed, interpreted and processed. By understanding jQuery – and other developer toolkits and standards used to exchange data – infrastructure service providers and vendors can more readily provide security and delivery policies tailored to those formats natively, which greatly reduces the impact of intermediate processing on performance while ensuring the secure, healthy delivery of applications. API Jabberwocky: You Say Tomay-to and I Say Potah-to OpenAjax Metadata 1.0 and the Adobe Dreamweaver Widget Browser OpenAjax Alliance AJAX-based Dojo Toolkit The Stealthy Ascendancy of JSON JSON Continues its Winning Streak Over XML JSON versus XML: Your Choice Matters More Than You Think I am in your HTTP headers, attacking your application The Web 2.0 API: From collaborating to compromised IT as a Service: A Stateless Infrastructure Architecture Model JSON Activity Streams and the Other Consumerization of IT350Views0likes0CommentsRouting HTTP by request headers
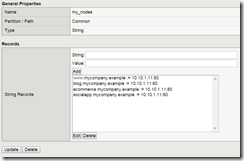
Dynamic network routing protocols, like BGP, allows Internet traffic to go from point A to B. Using iControl REST we can create our own dynamic protocol to route HTTP requests from point 1 to 2. Routing by HTTP request There’s a finite number of IPv4 addresses available and an increasing number of web applications that are being deployed that consume these resources. To help conserve IPv4 resources we’d like to map multiple web applications on a single front-end public IPv4 address while allow multiple separate back-end private IPv4 addresses that are running different web stacks (i.e. PHP for marketing, NodeJS for mobile, IIS for HR, Docker container for IT, etc…). Ideally we can go from an infrastructure that looks like: www.mycompany.example: 192.168.1.10 blog.mycompany.example: 192.168.1.11 ecommerce.mycompany.example: 192.168.1.12 socialapp.mycompany.example: 192.168.1.13 To something like: (www|blog|socialapp|ecommerce).mycompany.example: 192.168.1.10 To accomplish this we need a mechanism to examine the HTTP request (URL) and route to the correct backend server. Tools for routing by HTTP request From a similar article about name-based virtual host we know that we can utilize iRules for processing HTTP requests. Since TMOS 11.4.0 we can also use local traffic policies to do the same. For the following we’ll utilize an iRule for routing, but add a dynamic mechanism to update the routing. The iRule The following iRule looks similar to the original article, but has two differences: 1. Utilizes a data group for extracting the desired configuration 2. Routes to nodes instead of pools when HTTP_REQUEST { set host_hdr [getfield [HTTP::host] ":" 1] set node_addr [class match -value [string tolower $host_hdr] equals my_nodes] if { $node_addr ne "" } { node $node_addr } else { reject } } You could modify the example to route to pools or route by URI, but for today’s example we assume we are routing requests to separate standalone servers. The data group is used as a key/value pair that uses the desired host header as the key (i.e. www.mycompany.example) and the desired backend node address and port as the value (i.e. 10.10.1.10:80). Updating the routing via the GUI Via the TMOS GUI one needs to update the data group to reflect the desired configuration. Updating the routing via iControl REST Now that the configuration is stored in a data group it becomes possible to modify the configuration via iControl REST. Here’s an example utilizing the command line tool curl (note that it requires updating all the data group records each time). % curl -k -H "Content-Type: application/json" \ -u admin:[admin password] \ https://[mgmt host]/mgmt/tm/ltm/data-group/internal/~Common~my_nodes \ -X PUT \ -d '{"records":[{"name":"www.mycompany.example","data":"10.10.1.11:80"},{"name":"blog.mycompany.example","data":"10.10.1.12:80"},{"name":"ecommerce.mycompany.example","data":"10.10.1.13:80"},{"name":"socialapp.mycompany.example","data":"10.10.1.14:80"}]}' One could build on the curl example to create their own utility. I created the "Chen Gateway Protocol" as a Python script. The execution looks like the following: % ./cgp.py add www.mycompany.example 10.10.1.11:80 added: www.mycompany.example % ./cgp.py get www.mycompany.example www.mycompany.example: 10.10.1.11:80 % ./cgp.py update www.mycompany.example 10.10.1.11:8000 updated: www.mycompany.example % ./cgp.py del www.mycompany.example deleted: www.mycompany.example I've posted the code for cgp.py on the DevCentral codeshare. Dealing with HTTPS You can utilize SAN certs, SNI, or wildcard certs to consolidate SSL sites. The pros/cons will be a topic of a separate article. From here The above example illustrates what’s possible with the BIG-IP as a mediator of all things HTTP. Configuration management tools like Puppet, Chef, OpsWorks, SCCM, or a home-grown solution could leverage iControl REST to provide the "dynamic protocol". If you have any questions/suggestions or want to share how you’re routing by HTTP requests please share via the comments or send me a message via DC.1.6KViews0likes2Comments2.5 bad ways to implement a server load balancing architecture
I'm in a bit of mood after reading a Javaworld article on server load balancing that presents some fairly poor ideas on architectural implementations. It's not the concepts that are necessarily wrong; they will work. It's the architectures offered as a method of load balancing made me do a double-take and say "What?" I started reading this article because it was part 2 of a series on load balancing and this installment focused on application layer load balancing. You know, layer 7 load balancing. Something we at F5 just might know a thing or two about. But you never know where and from whom you'll learn something new, so I was eager to dive in and learn something. I learned something alright. I learned a couple of bad ways to implement a server load balancing architecture. TWO LOAD BALANCERS? The first indication I wasn't going to be pleased with these suggestions came with the description of a "popular" load-balancing architecture that included two load balancers: one for the transport layer (layer 4) and another for the application layer (layer 7). In contrast to low-level load balancing solutions, application-level server load balancing operates with application knowledge. One popular load-balancing architecture, shown in Figure 1, includes both an application-level load balancer and a transport-level load balancer. Even the most rudimentary, entry level load balancers on the market today - software and hardware, free and commercial - can handle both transport and application layer load balancing. There is absolutely no need to deploy two separate load balancers to handle two different layers in the stack. This is a poor architecture introducing unnecessary management and architectural complexity as well as additional points of failure into the network architecture. It's bad for performance because it introduces additional hops and points of inspection through which application messages must flow. To give the author credit he does recognize this and offers up a second option to counter the negative impact of the "additional network hops." One way to avoid additional network hops is to make use of the HTTP redirect directive. With the help of the redirect directive, the server reroutes a client to another location. Instead of returning the requested object, the server returns a redirect response such as 303. I found it interesting that the author cited an HTTP response code of 303, which is rarely returned in conjunction with redirects. More often a 302 is used. But it is valid, if not a bit odd. That's not the real problem with this one, anyway. The author claims "The HTTP redirect approach has two weaknesses." That's true, it has two weaknesses - and a few more as well. He correctly identifies that this approach does nothing for availability and exposes the infrastructure, which is a security risk. But he fails to mention that using HTTP redirects introduces additional latency because it requires additional requests that must be made by the client (increasing network traffic), and that it is further incapable of providing any other advanced functionality at the load balancing point because it essentially turns the architecture into a variation of a DSR (direct server return) configuration. THAT"S ONLY 2 BAD WAYS, WHERE'S THE .5? The half bad way comes from the fact that the solutions are presented as a Java based solution. They will work in the sense that they do what the author says they'll do, but they won't scale. Consider this: the reason you're implementing load balancing is to scale, because one server can't handle the load. A solution that involves putting a single server - with the same limitations on connections and session tables - in front of two servers with essentially the twice the capacity of the load balancer gains you nothing. The single server may be able to handle 1.5 times (if you're lucky) what the servers serving applications may be capable of due to the fact that the burden of processing application requests has been offloaded to the application servers, but you're still limited in the number of concurrent users and connections you can handle because it's limited by the platform on which you are deploying the solution. An application server acting as a cluster controller or load balancer simply doesn't scale as well as a purpose-built load balancing solution because it isn't optimized to be a load balancer and its resource management is limited to that of a typical application server. That's true whether you're using a software solution like Apache mod_proxy_balancer or hardware solution. So if you're implementing this type of a solution to scale an application, you aren't going to see the benefits you think you are, and in fact you may see a degradation of performance due to the introduction of additional hops, additional processing, and poorly designed network architectures. I'm all for load balancing, obviously, but I'm also all for doing it the right way. And these solutions are just not the right way to implement a load balancing solution unless you're trying to learn the concepts involved or are in a computer science class in college. If you're going to do something, do it right. And doing it right means taking into consideration the goals of the solution you're trying to implement. The goals of a load balancing solution are to provide availability and scale, neither of which the solutions presented in this article will truly achieve.291Views0likes1CommentDevops Proverb: Process Practice Makes Perfect
#devops Tools for automating – and optimizing – processes are a must-have for enabling continuous delivery of application deployments Some idioms are cross-cultural and cross-temporal. They transcend cultures and time, remaining relevant no matter where or when they are spoken. These idioms are often referred to as proverbs, which carries with it a sense of enduring wisdom. One such idiom, “practice makes perfect”, can be found in just about every culture in some form. In Chinese, for example, the idiom is apparently properly read as “familiarity through doing creates high proficiency”, i.e. practice makes perfect. This is a central tenet of devops, particularly where optimization of operational processes is concerned. The more often you execute a process, the more likely you are to get better at it and discover what activities (steps) within that process may need tweaking or changes or improvements. Ergo, optimization. This tenet grows out of the agile methodology adopted by devops: application release cycles should be nearly continuous, with both developers and operations iterating over the same process – develop, test, deploy – with a high level of frequency. Eventually (one hopes) we achieve process perfection – or at least what we might call process perfection: repeatable, consistent deployment success. It is implied that in order to achieve this many processes will be automated, once we have discovered and defined them in such a way as to enable them to be automated. But how does one automate a process such as an application release cycle? Business Process Management (BPM) works well for automating business workflows; such systems include adapters and plug-ins that allow communication between systems as well as people. But these systems are not designed for operations; there are no web servers or databases or Load balancer adapters for even the most widely adopted BPM systems. One such solution can be found in Electric Cloud with its recently announced ElectricDeploy. Process Automation for Operations ElectricDeploy is built upon a more well known product from Electric Cloud (well, more well-known in developer circles, at least) known as ElectricCommander, a build-test-deploy application deployment system. Its interface presents applications in terms of tiers – but extends beyond the traditional three-tiers associated with development to include infrastructure services such as – you guessed it – load balancers (yes, including BIG-IP) and virtual infrastructure. The view enables operators to create the tiers appropriate to applications and then orchestrate deployment processes through fairly predictable phases – test, QA, pre-production and production. What’s hawesome about the tools is the ability to control the process – to rollback, to restore, and even debug. The debugging capabilities enable operators to stop at specified tasks in order to examine output from systems, check log files, etc..to ensure the process is executing properly. While it’s not able to perform “step into” debugging (stepping into the configuration of the load balancer, for example, and manually executing line by line changes) it can perform what developers know as “step over” debugging, which means you can step through a process at the highest layer and pause at break points, but you can’t yet dive into the actual task. Still, the ability to pause an executing process and examine output, as well as rollback or restore specific process versions (yes, it versions the processes as well, just as you’d expect) would certainly be a boon to operations in the quest to adopt tools and methodologies from development that can aid them in improving time and consistency of deployments. The tool also enables operations to determine what is failure during a deployment. For example, you may want to stop and rollback the deployment when a server fails to launch if your deployment only comprises 2 or 3 servers, but when it comprises 1000s it may be acceptable that a few fail to launch. Success and failure of individual tasks as well as the overall process are defined by the organization and allow for flexibility. This is more than just automation, it’s managed automation; it’s agile in action; it’s focusing on the processes, not the plumbing. MANUAL still RULES Electric Cloud recently (June 2012) conducted a survey on the “state of application deployments today” and found some not unexpected but still frustrating results including that 75% of application deployments are still performed manually or with little to no automation. While automation may not be the goal of devops, but it is a tool enabling operations to achieve its goals and thus it should be more broadly considered as standard operating procedure to automate as much of the deployment process as possible. This is particularly true when operations fully adopts not only the premise of devops but the conclusion resulting from its agile roots. Tighter, faster, more frequent release cycles necessarily puts an additional burden on operations to execute the same processes over and over again. Trying to manually accomplish this may be setting operations up for failure and leave operations focused more on simply going through the motions and getting the application into production successfully than on streamlining and optimizing the processes they are executing. Electric Cloud’s ElectricDeploy is one of the ways in which process optimization can be achieved, and justifies its purchase by operations by promising to enable better control over application deployment processes across development and infrastructure. Devops is a Verb 1024 Words: The Devops Butterfly Effect Devops is Not All About Automation Application Security is a Stack Capacity in the Cloud: Concurrency versus Connections Ecosystems are Always in Flux The Pythagorean Theorem of Operational Risk241Views0likes1Comment
Intro to Load Balancing for Developers – The Algorithms
If you’re new to this series, you can find the complete list of articles in the series on my personal page here If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. Until then! Don.19KViews1like9Comments