What is HTTP?
tl;dr - The Hypertext Transfer Protocol, or HTTP, is the predominant tool in the transferring of resources on the web, and a "must-know" for many application delivery concepts utilized on BIG-IP HTTP defines the structure of messages between web components such as browser or command line clients, servers like Apache or Nginx, and proxies like the BIG-IP. As most of our customers manage, optimize, and secure at least some HTTP traffic on their BIG-IP devices, it’s important to understand the protocol. This introductory article is the first of eleven parts on the HTTP protocol and how BIG-IP supports it. The series will take the following shape: What is HTTP? (this article) HTTP Series Part II - Underlying Protocols HTTP Series Part III - Terminology HTTP Series Part IV - Clients, Proxies, & Servers — Oh My! HTTP Series Part V - Profile Basic Settings HTTP Series Part VI - Profile Enforcement HTTP Series Part VII - Oneconnect HTTP Series Part VIII - Compression & Caching HTTP Series Part IX - Policies & iRules HTTP Series Part X- HTTP/2 A Little History Before the World Wide Web of Hypertext Markup Language (HTML) was pioneered, the internet was alive and well with bulletin boards, ftp, and gopher, among other applications. In fact, by the early 1990’s, ftp accounted for more than 50% of the internet traffic! But with the advent of HTML and HTTP, it only took a few years for the World Wide Web to completely rework the makeup of the internet. By the late 1990’s, more than 75% of the internet traffic belonged to the web. What makes up the web? Well get ready for a little acronym salad. There are three semantic components of the web: URIs, HTML, and HTTP. The URI is the Uniform Resource Identifier. Think of the URI as a pointer. The URI is a simple string and consists of three parts: the protocol, the server, and the resource. Consider https://devcentral.f5.com/s/articles/ . The protocol is https, the server is devcentral.f5.com, and the resources is /articles/. URL, which stands for Uniform Resource Locator, is actually a form of a URI, but for the most part they can be used interchangeably. I will clarify the difference in the terminology article. HTML is short for the HyperText Markup Language. It’s based on the more generic SGML, or Standard Generic Markup Language. HTML allows content creators to provide structure, text, pictures, and links to documents. In our context, this is the HTTP payload that BIG-IP might inspect, block, update, etc. HTTP as declared earlier, is the most common way of transferring resources on the web. It’s core functionality is a request/response relationship where messages are exchanged. An example of a GET message in the HTTP/1.1 version is shown in the image below. This is eye candy for now as we’ll dig in to the underlying protocols and HTTP terminology shown here in the following two articles. But take notice of the components we talked about earlier defined there. The protocol is identified as HTTP. Following the method is our resource /home, and the server is identified in the Host header. Also take note of all those silly carriage returns and new lines. Oh, the CRLF!! If you’ve dealt with monitors, you can feel our collective pain! HTTP Version History Whereas HTTP/2 has been done for more than two years now, current usage is growing but less than 20%, with HTTP/1.1 laboring along as the dominant player. We’ll cover version-specific nuances later in this series, but the major releases throughout the history of the web are: HTTP/0.9 - 1990 HTTP/1.0 - 1996 HTTP/1.1 - 1999 HTTP/2 - 2015 Given the advancements in technology in the last 18 years, the longevity of HTTP/1.1 is a testament to that committee (or an indictment on the HTTP/2 committee, you decide!) Needless-to-say, due to the longevity of HTTP/1.1, most of the industry expertise exists here. We’ll wrap this series with HTTP/2, but up front, know that it’s a pretty major departure from HTTP/1.1, most notably is that it is a binary protocol, whereas earlier versions of HTTP were all textual.1.5KViews4likes7Comments
Tools and facilities to troubleshoot HTTP/3 over QUIC with the BIG-IP system
Introduction This article is for engineers who are troubleshooting issues related to HTTP/3 over QUIC as you deploy this new technology on your BIG-IP system. As you perform your troubleshooting tasks, the BIG-IP system provides you a set of useful tools along with other third party software to identify the root cause of issues and even tune HTTP/3 performance to maximize your system's potential. Overview of HTTP/3 and QUIC HTTP/3 is the next version of the HTTP protocol after HTTP/2. The most significant change in HTTP/3 from its predecessors is that it uses the UDP protocol instead of TCP. HTTP/3 uses a new Internet transport protocol, QUIC uses streams at the transport layer and provides TCP-like congestion control and loss recovery. One major improvement QUIC provides is it combines the typical 3-way TCP handshake with TLS 1.3's handshake. This improves the time required to establish a connection. Hence, you may see QUIC as providing the functions previously provided by TCP, TLS, and HTTP/2 as shown in the following diagram: For an overview of HTTP/3 over QUIC with the BIG-IP system, refer to K60235402: Overview of the BIG-IP HTTP/3 and QUIC profiles. Available tools and facilties Beginning in BIG-IP 15.1.0.1, HTTP/3 over QUIC (client-side only) is available as an experimental feature on the BIG-IP system. Beginning in BIG-IP 16.1.0, BIG-IP supports QUIC and HTTP/3. In addition to that feature, there are tools and facilities that are available to help you troubleshoot issues you might encounter. Install an HTTP/3 command line client Use a browser that supports QUIC Review statistics on your BIG-IP system Enable QUIC debug logging on the BIG-IP system Perform advanced troubleshooting with Packet Tracing Use the NetLog feature from the Chromium Project to capture a NetLog dump. Use the tcpdump command and Wireshark to capture and analyze traffic. Use the qlog trace system database key on the BIG-IP system. Important: For BIG-IP versions prior to 16.1.0 that are in the experimental stages, it is important that you note in your troubleshooting, the version of the ietf draft that your client and server implements. For example, in the Hello packets between the client and server, version negotiation is performed to ensure that client and server agree to a QUIC version that is mutually supported. In BIG-IP 15.1.0.1, the HTTP/3 and QUIC profiles in the BIG-IP system are experimental implementations of draft-ietf-quic-http-24 and draft-ietf-quic-transport-24 respectively. You need to consider this when configuring the Alt-Svc header in HTTP/3 discovery. For some browsers such as those from the Chromium project, Chrome canary, Microsoft Edge canary and Opera, when starting these browsers from the command line, you need to provide the QUIC version it implements. For example, for Chrome canary, you run the following command: chrome.exe --enable-quic --quic-version=h3-25. Only implementations of the final, published RFC can identify themselves ash3. Until such an RFC exists, implementations must not identify themselves using theh3string. 1. Install an HTTP/3 command line client Keep in mind that HTTP/3 over QUIC runs on UDP instead of TCP. By default, browsers always initiate a connection to the server using the traditional TCP handshake which will not work with a QUIC server listening for UDP packets. You therefore need to configure HTTP/3 discovery on your BIG-IP system. This can be done by using the HTTP Alternative Services concept which can be implemented either by inserting the Alt-Svc header or via DNS as a HTTPSVC DNS resource record. To insert the Alt-Svc header, refer to K16240003: Configuring HTTP/3 discovery for BIG-IP virtual server. As you troubleshoot your HTTP/3 discovery implementation, you can use a command line tool that does not come with the overhead of HTTP/3 discovery. Following are two popular tools that you can install on your client system: The picoquic client The curl client where you have the option to use either the ntcp2 or quiche software libraries. 2. Use a browser that supports QUIC At this time, browsers by default, still do not support QUIC and do not send the server UDP packets to establish a QUIC connection. The following browsers which are in development support it: Firefox Nightly Chrome Canary (Chromium Project) Microsoft Edge Canary (Chromium Project) Opera (Chromium Project) Note that for browsers from the Chromium project, you need to specify the QUIC ietf version that the browser supports when you launch it. For example, for Chrome, run the following command: chrome.exe --enable-quic --quic-version=h3-25. In most browsers today, you can quickly view the HTTP information exchanged by using the built-in developer tool. To open the tool, select F12 after your browser opens and access any site that supports QUIC. Select the Network tab and under the Protocol column, look at h3-<draft_version> . If the Protocol column is not there, you may have to right click the toolbar to add it. Note: Only implementations of the final, published RFC can identify themselves as h3. Until such an RFC exists, implementations must not identify themselves using the h3 string. Click the name of the HTTP request and you can see that the site returns the Alt-Svc header indicating that it supports HTTP/3 with its ietf draft version. 3. Review statistics on your BIG-IP system The statistics facility on the BIG-IP system displays the system's QUIC traffic processing. On the Configuration utility, go to Local Traffic > Virtual Servers. Select the name of your virtual server and select the Statistics tab. In the Profiles section, select the HTTP/3 and QUIC profiles associated with the virtual server. Alternatively, you can view the statistics from the TMOS shell (tmsh) utility using the following command syntax: tmsh show ltm profile http3 <http3_profile_name> tmsh show ltm profile quic <quic_profile_name> 4. Enable QUIC debug logging on the BIG-IP system You can use the sys db variable tmm.quic.log.level to adjust the verbosity of the QUIC log level to the /var/log/ltm file. Type the following command to see the list of values. tmsh list sys db tmm.quic.log.level value-range sys db tmm.quic.log.level { default-value "Critical" value-range "Critical Error Warning Notice Info Debug" } For example: tmsh modify sys db tmm.quic.log.level value debug 5. Perform advanced troubleshooting with Packet Tracing a. Use the NetLog feature from the Chromium Project to capture a NetLog dump. NetLog is an event logging mechanism for Chrome’s network stack to help debug problems and analyze performance not just for HTTP/3 over QUIC traffic but also HTTP/1.1 and HTTP/2. This feature is available only in browsers from the Chromium project, such as Google Chrome, Opera and Microsoft Edge. The feature provides detailed client side logging including SSL handshake and HTTP content without having to perform decryption or run any commands on your BIG-IP system. To start capturing, open a new tab on your browser and go to, for example, chrome://net-export (Chromium only). For a step by step guide, refer to How to capture a NetLog dump. Once you have your NetLog dump, you can view and analyze it by navigating to netlog-viewer (Chromium only). To analyze QUIC traffic, on the left panel, select Events. In the Description column, identify the URL you requested. For QUIC SSL handshake events, select QUIC_SESSION. For HTTP content, select URL_REQUEST. For example, in the following NetLog dump, the connection failed at the beginning because the client and server could not negotiate a common QUIC version. b. Use the tcpdump command and Wireshark to capture and analyze traffic. The tcpdump command and Wireshark are both essential tools when you need to examine any communication at the packet level. To generate captures and the SSL secrets required to decrypt them, follow the procedure in K05822509: Decrypting HTTP/3 over QUIC with Wireshark. Keep your Wireshark version updated at all times as Wireshark's ability to decode QUIC packets continue to evolve as we speak. c. Use the qlog traces on the BIG-IP system. The BIG-IP qlog trace facility provides you another tool to troubleshoot QUIC communications. By enabling a database variable, the system logs packets and other events to /var/log/trace<TMM_number>.qlog files. qlog is a standardized structured logging format for QUIC and is basically a well-defined JSON file with specified event names and associated data that allows you to use tools like qvis for visualization. Note that the payload is not logged. The qlog trace files are compliant to the IETF schema specified in draft-marx-qlog-main-schema-01. To capture and analyze qlog trace files on your BIG-IP system, perform the following procedure: Capturing qlog trace files on the BIG-IP system Login to the BIG-IP command line. Enable qlogging by typing the following command: tmsh modify sys db quic.qlogging value enable Reproduce the issue you are troubleshooting by initiating QUIC traffic to your virtual server. Disable qlogging by typing the following command: tmsh modify sys db quic.qlogging value disable Note: This step will log required closing json content to the trace files, terminate the trace logging gracefully and is required before you view the files. Sanitizing the qlog trace files Before loading the trace files onto a graphical visualization tool, you first need to sanitize the json content. The tools attempt to fix some common json errors but there may be cases where you need to manually correct some json syntax errors by adding closing braces or commas. Note: Knowledge of different json constructs such as objects, arrays and members may be required when you fix the json files. You can use any of the available online tools such as the following: Json Formatter Fixjson freeformatter Important: Even as the payload information such as IP addresses, or HTTP content are not included in the trace files, you should exercise caution when uploading content to online tools. F5 is not responsible for the privacy and security of your data when you use the third party software listed in this procedure. Alternatively, you can download and install any of the following command line tools on your client device: jsonlint-php jsonlint-py jsonlint-cli Loading and analyzing the qlog trace files with a visualization tool When you have sanitized your json trace files, upload them to a visualization tool for analysis. For example, you can use the following tool available for free. qvis QUIC and HTTP/3 visualization toolsuite The visualization tool can provide you graphical representations of the sequence of messages, congestion information and qlog stats for troubleshooting. For example, the following screenshot, illustrates a sequence diagram of the SSL handshake. Important: Even as payload information such as IP addresses, or HTTP content are not included in the trace files, you should exercise caution when uploading content to online tools. F5 is not responsible for the privacy and security of your data when you use the third party software listed in this procedure. Summary As you use the tools described in this article, you notice that each one helps you troubleshoot issues at the different OSI layers. The built-in developer tools in each browser provide a quick and easy way to view HTTP content but do not let you see the details of the protocol, as do the NetLog tool and Wireshark. However, viewing qlog traces on the qvis graphical tool provides you high level trends and statistics that packet captures do not show. Using the appropriate tool with the right troubleshooting methodology maximizes the potential of HTTP/3 and QUIC for your organization.4.2KViews3likes0Comments
HTTP/2 Protocol in Plain English using Wireshark
1. Quick Intro Some people find it easier to do a "test drive" first to learn how a new protocol works in its simplest form and only then read the RFC. It turns out Wireshark is a perfect tool for me to do just that. It's a simple test and here's the topology: I'll just issue a HEAD request and later on a GET request and we'll see how it looks like on Wireshark. For more info about HTTP/2 profile and HTTP/2 protocol itself you can read the article I published onAskF5andJason's DevCentral article: What is HTTP Part X - HTTP/2. 2. Confirmation of which protocol will be used The packet capture taken below was the result of the following curl command issued from my ubuntu Linux client (I could've used a browser instead): Note: 10.199.3.44 is my virtual server with HTTP/2 profile applied. Here's packet capture (in case you want to follow along): http2-test-v1.zip HTTP/2 is negotiated during SSL handshake in Application Layer Protocol Negotiation (RFC 7301) SSL extension like this: Client says which protocol(s) it supports and server responds whichone it picked (in this case it's HTTP/2!). 3. Negotiation of HTTP/2 Parameters Think of it as something that has to take place like Client Hello and Server Hello in SSL for example. Server side (BIG-IP in this case) sendsSETTINGSframe which counts as confirmation that HTTP/2 is being used plus any flow control configuration we want our peer to honour: Client sendsMagicframe to confirm HTTP/2 is being used and thenSETTINGSwith its requirements for the connection. Yes,Magicframe is always the same. Still curious aboutMagicframe? Readhttps://tools.ietf.org/html/rfc7540#section-3.5. End-points are also supposed to ACK the receipt ofSETTINGSframefrom the other peer and the way they do it is by responding with another emptySETTINGSframewith ACK flag set: 4. Exchanging data Connection-wise we're all set now. For HTTP/2 GET/HEAD requests there is a specific frame type calledHEADERSwhich as the name implies carries HTTP/2 header information. If there was payload it would be carried insideDATAframe type but as this is just aHEADrequest then noDATAframe follows. 5. Appendix A - Other common frame types 5.1 WINDOW_UPDATE There are other common frame types and in my capturethe one that came up wasWINDOW_UPDATE. If you look at section 3 above we see that Client advised BIG-IP that its Initial Window Size was1073741824. WINDOW_UPDATEjust adjusted this value to1073676289: This is HTTP/2 flow control in action. 5.2 DATA in another test (http2-v2.zip) I usedHTTP/2 GETrequest instead ofHEADand requested more data which comes in throughDATAframe type: End Streamflag is false in allDATAmessages except for the last one. It signals when there is more data as well as the lastDATAframe. 5.3 GOAWAY In a subsequent test (http2-connection-idletimeout-1.zip)I set Connection Idle Timeoutin HTTP/2 profile to 1 to force BIG-IP sendingGOAWAYframe to close down connection after 1 second of idle connection. After last piece of data is sent by BIG-IP to client (frame #39), BIG-IP waits 1 second and sendsGOAWAYframewhich initiates the shutdown of HTTP/2 connection. GOAWAYmessages always containsPromised-Stream-IDwhich tells the client what is the lastStream IDit processed. A newStream IDis typically created for every new HTTP request (viaHEADERSmessage). We can see that a new HTTP request slipped in onframe #46but ignored as connection had already been closed on BIG-IP's side.7.1KViews3likes12Comments
Tightening the Security of HTTP Traffic part 1
Summary HTTP is the de facto protocol used to communicate over the internet. The security challenges that exists today was not considered when designing the HTTP protocol. Web browsers are generally used to interact with web applications. However, this interaction is not secured in most deployments, despite the existence of a number of http headers that can be leveraged by application developers to tighten the security of their applications. In this article, I will give an overview of some important headers that can be added to HTTP responses in order to improve the security web applications. I will also provide sample iRules that can be implemented on F5 BigIP to insert those headers in HTTP responses. Content This article has been made in a series of 3 parts to make it easier to read and digest. The following headers will be reviewed in different parts of this article: Part 1: A brief overview of Cross-Site Scripting (XSS) vulnerability X-XSS-Protection HttpOnly flag for cookies Secure flag for cookies Part 2: The X-Frame Options Header HTTP Strict Transport Security X-Content-Type-Options Content-Security-Policy Public Key Pinning Extension for HTTP (HPKP) Part 3: Server and X-Powered-By Cookie encryption Https (SSL/TLS) A brief overview of XSS Attacks Before going further into the details of the headers we need to implement to improve the security of http traffic, it is important to make a quick review of the Cross-Site Scripting (XSS) attack,which is the most prevalent web application security flaw . This is important because any of the security measure we will review may be completely useless if an XSS flaw exist on the application.The security measures proposed in this article rely on the browsernot infected by any kind of malware (including XSS) and working properly. A Cross-Site Scripting (XSS) attack is a type of injection attack where a malicious script is injected into a trusted but vulnerable web applications. The malicious script is send to victim browser as client side script when the user uses a vulnerable web app. XSS are generally caused by poor input validation or encoding by web application developers. An XSS attack can load a malware (JavaScript) into to browser and make it behave in a completely unpredictable manner, thus making all other protection mechanism useless. Cross-Site scripting was ranked third in the last OWASP 2013 top 10 security vulnerabilities. Detailed information on XSS can be found on OWASP website. 1. TheX-XSS-Protection header The X-XSS-Protection header enables the Cross-Site Scripting filter on the browser. When enabled, the XSS Filter operates as a browser component with visibility into all requests / responses flowing through the browser.When the filter detects a likely XSS in a request or response, it prevents the malicious script from executing. The X-XSS-Protection header is supported by most major browsers. Usage: X-XSS-Protection: 0 XSS protection filter is disabled (facebook) X-XSS-Protection: 1 XSS protection filter is enable. Upon XSS attack detection, the browser will sanitize the page. X-XSS-Protection: 1; mode=block If XSS attack is detected, The browser blocks the page in order to stop the attack. (Google, Twitter) Note: If third party scripts are allowed to run on your web application, enabling XSS-Protection might prevents some scripts from working properly. As such, proper considerations should be made before enabling the header. 1.1 Example of how this header is used: the following command can be used to see which http headers are enabled on a web application. This command sends a single http request to the destination application and follows redirection. Therefore it is completely harmless and is only used for educational purposes in this article. I will use the same commandthroughout the article against somes well known sites, that are build with high security standards, in order to demonstrate how the discussed headers are used in real life. curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -sD - https://www.google.com -o /dev/null HTTP/1.1 200 OK Date: Mon, 07 Aug 2017 11:24:08 GMT Expires: -1 Cache-Control: private, max-age=0 Server: gws X-XSS-Protection: 1; mode=block [...] 1.2 iRule to enableXSS-Protection The following iRule can be used to insertXSS-Protection header to all http responses: when HTTP_RESPONSE { if { !([ HTTP::header exists "X-XSS-Protection“ ])} { HTTP::header insert "X-XSS-Protection" "1; mode=block" } } 2.HttpOnly flag for cookies When added to cookies in HTTP responses, the HttpOnly flag prevents client side scripts from accessing cookies. Existing cross-site scripting flaws on the web applicationwill not be exploited by using this cookie. The HttpOnly flag relies on the browser to prevent XSS attacks, when set by the server.This flag is supported by all major browsers in their latest versions. It was Introduced in 2002 by Microsoft in IE6 SP1. Note: Using older browser exposes you to higher security risk as older browsers may not support some of the security headers discussed in this article. 2.1 Example: curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -sD - https://www.google.com -o /dev/null HTTP/1.1 200 OK Date: Wed, 16 Aug 2017 19:34:36 GMT Expires: -1 [..] Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=110=rKlFElgqL3YuhyKtxcIr0PiSE; expires=Thu, 15-Feb-2018 19:34:36 GMT; path=/; domain=.google.com; HttpOnly Alt-Svc: quic=":443"; ma=2592000; v="39,38,37,35" [...] 2.2 iRule to add HttpOnly flag to all cookies for http responses: If added to Big-IP LTM virtual server, the following iRule will add the HttpOnly flag to all cookies in http responses. when HTTP_RESPONSE { foreach mycookie [HTTP::cookie names] { HTTP::cookie httponly $mycookie enable } } 3.Secure flag for cookies The purpose of the secure flag is to prevent cookies from being observed by unauthorized parties due to the transmission of a the cookie in clear text. When a cookie has the secure flag attribute, Browsers that support the secure flag will only send this cookie within a secure session(HTTPS). This means that, if the web application accidentally points to a hard coded http link, the cookie will not be send. Enabling secure flag for cookies is common and recommended 3.1 Example curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -s -D - https://www.f5.com -o /dev/null HTTP/1.1 200 OK Cache-Control: private Content-Type: text/html; charset=utf-8 […] Set-Cookie: BIGipServer=!M+eTuU0mHEu4R8mBiet1HZsOy/41nDC5VnWBAlE5bvU0446qCYN4w/jKbf2+U8d8EVe+BxHFZ5+UJYg=; path=/; Httponly;Secure Strict-Transport-Security: max-age=16070400 […] 3.2 Setting the secure flag with iRule If added to Big-IP LTM virtual server, the following iRule will add the secure flag to all http responses. when HTTP_RESPONSE { foreach mycookie [HTTP::cookie names] { HTTP::cookie secure $mycookie enable } }3.6KViews3likes3CommentsHTTP Explicit Proxy Explained in Plain English
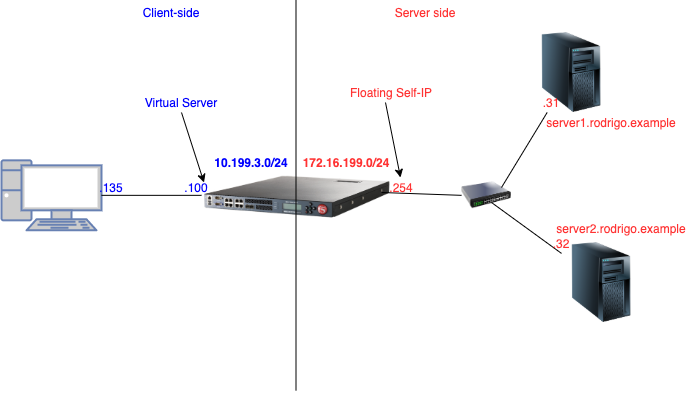
Introduction If you've ever used the old Linux Squid proxy or F5's Secure Gateway solution, you might be familiar with the existence of HTTP Explicit Proxy. If all you're looking for is to configure it ASAP, there's an iApp available to set things up in no time. This technology is also used by F5's Secure Web Gateway Services (SWG). This article will walk you through the mechanics behind the scenes, i.e. how to manually configure it and understand how it works through a lab test. 1. Lab Scenario Expected result is thatclient (.135) sends HTTP GET request to server2.rodrigo.example using 10.199.3.100/32 as http proxy andBIG-IP queries our DNS server (172.16.199.31) for server2.rodrigo.example's IP address, retrieves web page and passes on to client. 2. How Explicit Proxy works In HTTP Explicit proxy, we configure our client (application) to point to BIG-IP's virtual server which will act as an HTTP proxy for external websites. Once client issues a request, BIG-IP will then open a separate connection with external server the client is trying to connect to and issue the requests on behalf of client passing requests/responses back and forth between client and external server. In order to test HTTP Explicit proxy functionality, I configured my client's browser pointing to BIG-IP's HTTP Explicit proxy virtual server. BIG-IP is supposed to issue the requests on behalf of client and pass them back to client. The client is explicitly configured to use VIP's IP address as a proxy. Here's my config on Firefox (Preferences→ Advanced→ Network): When using any form of unencrypted traffic Firefox forwards request straight to BIG-IP without issuing an HTTP CONNECT request: We can see that BIG-IP just forwards request mostly as it is. The reason forGET /instead ofFQDNon server-side is because BIG-IP performed DNS resolution before that and I filtered it. If request is HTTPS instead of HTTP, things are slightly different. First, Firefox (my browser) tries to establish an HTTP tunnel (using CONNECT HTTP method) tohttps://server2.rodrigo.example, BIG-IP then immediately establishes TCP connection with remote-destination (after DNS lookup of course!). Lastly, once TCP connection is established with remote-destination, BIG-IP responds (to client) with 200 Connected signalling tunnel is successfully established and BIG-IP is ready to forward any requests through recently established tunnel: Now that tunnel is properly established, BIG-IP just forwards whatever Firefox sends. In this case, the SSL handshake Client Hello was the first packet which was captured: It is interesting to note that there is still an HTTP header in the messages between client and BIG-IPwith proxy information sent by firefox (frame 47) that encapsulates SSL message: Now that we understand how HTTP Explicit proxy works under the hood, we're ready to learn how to set up BIG-IP as Explicit proxy. 3. Setting Up Explicit proxy on BIG-IP 3.1 Create Virtual Server with no pool (you can leave http profile for later): 3.2 Create DNS resolver: In the GUI, it would be on Network → DNS Resolvers → Create. Then, we'd click on Forward Zones and add a dot '.' if we want all queries to be sent to this name server. For the purposes of this specific test, I could also have named this zone asrodrigo.example.instead. Note: In my lab test I worked out that forward zone's name is really important! When I named it 'testing' or 'google' BIG-IP did not forward DNS query to 172.16.199.31. However, when I named it either . or rodrigo.example. then DNS resolution worked. 3.3 Create tunnel interface BIG-IP already has a default http-tunnel interface. As long as encapsulation type istcp-forward, we can either stick to default or create a new one. I decided to create a new one for the purpose of this lab test: 3.4. Create http profile using http-explicit as parent and assign it to VIP created previously: Note: When configuring it from GUI just set proxy type to explicit and http-explicit will be set to parent profile. The equivalent in the GUI: 3.5. Testing Connection 3.6 Enabling encrypted requests Initially I did not understand why HTTP traffic worked whendefault-connect-handling was set to deny but HTTPS did not. Below is the summary of my tests: Looking at the packet capture, I noticed that BIG-IP was explicitly denying Firefox's request to establish a tunnel as shown below: Note: For this test I created another Virtual Server called using a different address 10.199.3.101 instead of the one I originally tested just to test default-connect-handling. After reading K40243113: Overview of the HTTP profile, I kind of understood the point: "indicates that outbound requests are delivered only if another virtual server is listening on the tunnel for the requested outbound connection. With this setting, virtual servers are required, and the system processes the outbound traffic before it leaves the device." I then created another VIP withsamedestination IP address and port as back-end server client was trying to connect to just to confirm if this time traffic would go through: And indeed it worked: I also tested with a wildcard virtual server listening on *:443 instead of 172.16.199.32/32 and it worked fine as well. What we have observed so far is that when default-connect-handling is set to deny,in order for encrypted client traffic to be accepted by BIG-IP and proxy tunnel established, the destination address that matches the one on client request has to have a listener on BIG-IP for return traffic. Therefore, we can conclude thatdefault-connect-handlingsetting governs what traffic is accepted by the tunnel interface, but unencrypted requests are not affected. The below picture sums up the explanation: default-connect-handling just adds the extra step to validate whether there is a listener on BIG-IP for destination address:port or not. If not, we deny request. If yes, request goes through.4.8KViews2likes8CommentsIntroducing QUIC and HTTP/3
QUIC [1] is a new transport protocol that provides similar service guarantees to TCP, and then some, operating over a UDP substrate. It has important advantages over TCP: Streams: QUIC provides multiple reliable ordered byte streams, which has several advantages for user experience and loss response over the single stream in TCP. The stream concept was used in HTTP/2, but moving it into the transport further amplifies the benefits. Latency: QUIC can complete the transport and TLS handshakes in a single round trip. Under some conditions, it can complete the application handshake (e.g. HTTP requests) in a single round-trip as well. Privacy and Security: QUIC always uses TLS 1.3, the latest standard in application security, and hides much more data about the connection from prying eyes. Moreover, it is much more resistant than TCP to various attacks on the protocol, because almost all of its packets are authenticated. Mobility: If put in the right sort of data center infrastructure, QUIC seamlessly adjusts to changes in IP address without losing connectivity. [2] Extensibility: Innovation in TCP is frequently hobbled by middleboxes peering into packets and dropping anything that seems non-standard. QUIC’s encryption, authentication, and versioning should make it much easier to evolve the transport as the internet evolves. Google started experimenting with early versions of QUIC in 2012, eventually deploying it on Chrome browsers, their mobile apps, and most of their server applications. Anyone using these tools together has been using QUIC for years! The Internet Engineering Task Force (IETF) has been working to standardize it since 2016, and we expect that work to complete in a series of Internet Requests for Comment (RFCs) standards documents in late 2020. The first application to take advantage of QUIC is HTTP. The HTTP/3 standard will publish at the same time as QUIC, and primarily revises HTTP/2 to move the stream multiplexing down into the transport. F5 has been tracking the development of the internet standard. In TMOS 15.1.0.1, we released clientside support for draft-24 of the standard. That is, BIG-IP can proxy your HTTP/1 and HTTP/2 servers so that they communicate with HTTP/3 clients. We rolled out support for draft-25 in 15.1.0.2 and draft-27 in 15.1.0.3. While earlier drafts are available in Chrome Canary and other experimental browser builds, draft-27 is expected to see wide deployment across the internet. While we won’t support all drafts indefinitely going forward, our policy will be to support two drafts in any given maintenance release. For example, 15.1.0.2 supports both draft-24 and draft-25. If you’re delivering HTTP applications, I hope you take a look at the cutting edge and give HTTP/3 a try! You can learn more about deploying HTTP/3 on BIG-IP on our support page at K60235402: Overview of the BIG-IP HTTP/3 and QUIC profiles. -----[1] Despite rumors to the contrary, QUIC is not an acronym. [2] F5 doesn’t yet support QUIC mobility features. We're still in the midst of rolling out improvements.1.1KViews1like0CommentsWhat is HTTP Part III - Terminology
Have you watched the construction of a big building over time? For the first few weeks, the footers and foundation are being prepared to support the building. it seems like not much is happening, but that ground work is vital to the overall success of the project. So it is with this series, so stay with me—the foundation is important. This week, we begin to dig into the HTTP specifications and we’ll start with defining the related terminology. World Wide Web, or WWW, or simply “the web" - The collection of resources accessible amongst the global interconnected system of computers. Resource - An object or service identified by a URI. A Web page is a resource, but images, scripts, and stylesheets for a webpage would also be resources. Web Page - A document accessible on the web by way of a URI. Example - this article. Web Site - A collection of web pages. An example would be this site, accessed by the DNS hostname devcentral.f5.com. Web Client - The software application that requests the resources on a web site by generating, receiving, and processing HTTP messages. A web client is always the initiator. Web Server - The software application that serves the resources a web site by receiving, processing, and generating HTTP messages. A web server does not initiate traffic to a client. Examples would be Apache, NGINX, IIS, or even an F5 BIG-IP iRule! Uniform Resource Identifier, or URI - As made clear in the name, the URI is an identifier, which can mean the resource name, or location, or both. All URLs (locators) and URNs (names) are URIs, but all URLs/URNs are not URIs. Think Venn diagrams here. Consider https://clouddocs.f5.com/api/irules/. The key difference between a URI (which would be /wiki/iRules.HomePage.ashx in this case) and a URL is the URL combines the name of the resource, the location of that resource (devcentral.f5.com,) and the method to access that resource (https://.) In the URL, the port is assumed to be 80 if the request method is http, and assumed to be 443 if the request method is https. If the default ports are not appropriate for a particular location, they will need to be provided by adding immediately after the hostname like https://devcentral.f5.com/s:50443/wiki/iRules.HomePage.ashx. Message - This is the basic HTTP unit of communication Header - This is the control section within an HTTP message Entity - This is the body of an HTTP message User Agent - This is a string of tokens that should beinserted by a web client as a header called User-Agent. The tokens are listed in order of significance. Most web clients perform this on your behalf, but there are browser tools that allow you to manipulate this, which can be good for testing, client statistics, or even client remediation. Keep in mind that bad actors might also manipulate this for nefarious purposes, so any kind of access control based solely on user agents is ill advised. Proxy - Like in the business world, a proxy acts as an intermediary. A server to clients, and a client to servers, proxies must understand HTTP messages. We’ll dig deeper into proxies in the next article. Cache - This is web resource storage that can exist at the server, any number of intermediary proxies, the browser. Or all of the above. The goals of caching are to reduce bandwidth consumption on the networks, reduce compute resource utilization on the servers, and reduce page load latency on the clients. Cookie - Originally added for managing state (since HTTP itself is a stateless protocol,) a cookie is a small piece of data to be stored by the web client as instructed by the web server. Standards Group Language - I won’t dive deep into this, but as you learn a protocol, knowing how to read RFCs would serve you well. As new protocols, or new versions of existing protocols, are released, there are interpretation challenges that companies work through to make sure everyone is adhering to the “standard.” Sometimes this is an agreeable process, other times not so much. Basic understanding of what must, should, or may be done in a request/response can make your troubleshooting efforts go much more smoothly. Basic Message Format Requests The syntax of an HTTP request message has the following format request-line headers CRLF (carriage return / line feed) message body (optional) An example of this is shown below: -----Request Line---- |GET / HTTP/1.1 --------------------- -------Headers------- |Host: roboraiders.net |Connection: keep-alive |User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36 |Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 |Accept-Encoding: gzip, deflate |Accept-Language: en-US,en;q=0.8 ---------------------- The CRLF (present in the tcpdump capture but not seen here) denotes the end of the headers, and there is no body. Notice in the request line, you see the request method, the URI, and the http protocol version of the client. Responses The syntax of an HTTP response message has a very similar format: status-line headers CRLF (carriage return / line feed) message body (optional) An example of this is shown below: -----Request Line---- |HTTP/1.1 200 OK --------------------- -------Headers------- |Server: openresty/1.9.15.1 |Date: Thu, 21 Sep 2017 17:19:01 GMT |Content-Type: text/html; charset=utf-8 |Transfer-Encoding: chunked |Connection: keep-alive |Vary: Accept-Encoding |Content-Encoding: gzip --------------------- ---Zipped Content---- |866 |...........Y.v.....S...;..$7IsH...7.I..I9:..Y.C`....].b....'.7....eEQoZ..~vf.....x..o?^....|[Q.R/..|.ZV.".*..$......$/EZH../..n.._E..W^.. --------------------- Like the request line of an HTTP request, the protocol of the server is stated in the HTTP response status-line. Also stated is the response code, in this case a 200 ok. You’ll notice that the only header in this case that is similar between the request and response is the Connection header. HTTP Request Methods The URI is a resource with which the client is wanting to interact. The request method provides the “how” the client would like to interact with the resource. There are many request methods, but we’ll focus on the few most popular methods for this article. GET - This method is used by a client to retrieve resources from a server. HEAD - Like the GET method, but only retrieves the metadata that would be returned with the payload of a GET, but no payload is returned. This is useful in monitoring and troubleshooting. POST - Used primarily to upload data from a client to a server, by means of creating or updating an object through a process handler on the server. Due to security concerns, there are usually limitations on who can do this, how it’s done, and how big an update will be allowed. PUT - Typically used to replace the contents of a resource. DELETE - This method removes a resource. PATCH - Used to modify but not replace the contents of a resource. If you are at all interested in using iControl REST to perform automation on your BIG-IP infrastructure, all the methods above except HEAD are instrumental in working with the REST interface. HTTP Headers There are general headers that can apply to both requests and responses, and then there are specific headers based on whether it is a request OR a response message. Note that there are differences between supported HTTP/1.0 and HTTP/1.1 headers, but I’ll leave the nuances to the reader to study. We’ll cover HTTP/2 at the end of this series. Examples in parentheses are not complete, and do not denote the actual header names. RFC 2616 has all the HTTP/1.1 define headers documented. General Headers These headers can be present in either requests or responses. Conceptually, they deal with the broader issues of client/server sessions like timing, caching, and connection management. The Connection header in the request and response messages above is an example of a general connection-management header in action. Request Headers These headers are for requests only, and are utilized to inform the server (and intermediaries) on preferred response behavior (acceptable encodings,) constraints for the server (range of content or host definition,) conditional requests (resource modification timestamps,) and client profile (user agent, authorization.)TheHostheader in the request message above is an example of a request header constraining the server to that identity. Response Headers Like with requests, response headers are for responses only, and are utilized for security(authentication challenges,) caching (timing and validation,) information sharing (identification,) and redirection.TheServerheader in the response message above is an example of a response header identifying the server. Entity Headers Entity headers exist not to provide request or response messaging context, but to provide specific insight about the body or payload of the message. The Content-Type header in the response message above for example is instructing the client that the payload of the response is just text and should be rendered as such. A Note on MIME types - web clients/servers are for the most part "dumb" in that they are do not guess at content types based on analysis, they follow the instructions in the message via the Content-Type header. I've experienced this in both directions. For iControl REST development, BIG-IP returns an error if you send json payload but do not specify application/json in the Content-Type header. I also had a bug in an ASM deployment once where the ASM violation response page was set to text/html but should have been application/json, so the browser client never displayed the error, you had to find it buried in browser tools until we corrected that issue. HTTP Response Status Codes We will conclude with a brief discussion on status codes. Before getting into the specifics, there are a couple general things that should make awareness and analysis a regular part of your system management: security and SEO. On security, there are many things one can learn through status codes (and headers for that matter) on server patterns and behavior, as well as information leakage by not slurping application errors before being returned to clients. With SEO, how redirects and missing files are handled can hurt or help your overall impressions and ranking power. Moz has a good best practices article on managing status codes for search engines. But back to the point and hand: status codes. There are five categories and 41 status codes recognized in HTTP/1.1. Informational - 1xx - This category added for HTTP/1.1. Used to inform clients that a request has been received and the initial request (likely a POST of data) can continue Success - 2xx - Used to inform the client that the request was processed successfully. Redirection - 3xx - The request was received but resource needs to be dealt with in a different way. Client Error - 4xx - Something went wrong on the client side (bad resource, bad authentication, etc.) Server Error -5xx - Something went wrong on the server side. Application monitors pay particularly close attention to the 5xx errors. Security practitioners focus in on 4xx/5xx errors, but even 2xx/3xx messages if baseline volume and accessed resources start to skew from normal. Join us next week when we start to talk about clients, proxies, and servers, oh my!1KViews1like3CommentsWhat is HTTP Part VII - OneConnect
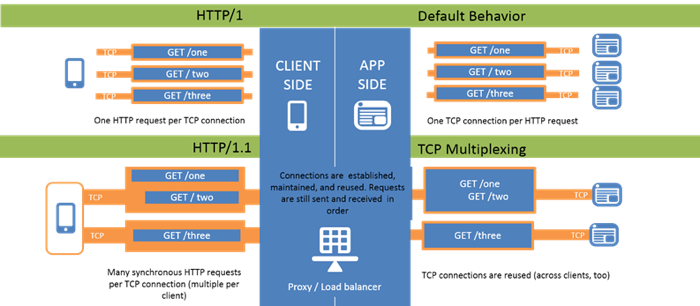
In the last article in this What is HTTP? series we finished covering the settings in the HTTP profile itself. This week, we begin the transition to technologies that support, enhance, optimize, secure, and (insert your descriptive qualifier here…) the HTTP traffic flowing through the BIG-IP, starting with OneConnect. What is OneConnect? What comes to mind when you hear the phrase “Reduce Reuse Recycle”? Does a little green pseudo-triangle with arrows flash before your eyes, or do you think if they really cared about the reduction, the phrase would be “re[duce|use|cycle]”? But I digress. OneConnect reduces the number of server-side connections between the BIG-IP and application servers by reusing the existing server-side connections. So whereas you might be serving thousands of connections on the client-side, there will be a reduced number of server-side connections to offload the overhead of tcp connection setup and teardown. You can see in the image above that before HTTP/1.1, single requests per connection on client and server sides resulted in inefficiencies. With HTTP/1.1, you can multiplex requests on single connections client-side, and as shown below, can multiplex multiple client-side connections onto single server-side connections. This is the power OneConnect offers. Both clients multiple requests in a single tcp connection for each client are pooled together on a single tcp connection between the BIG-IP and the server. There’s even hope for HTTP/1.0 clients via the OneConnect Transformations I mentioned in part five of this series. In this case, the four individual connections on the client-side of the BIG-IP are transformed into a single connection on the server-side thanks to OneConnect. The OneConnect Profile Let’s start with a screen shot of the fields available in the OneConnect profile. As this is the default parent, you don’t have the option to name it and set the parent, but when creating a custom profile, those settings would be available for configuration as well in the General Properties. Source Prefix Length Also known as theSource Maskfield in earlier versions, this is where you specify the mask length for connection reuse. It’s important to understand that this is the contextual source IP of the server-side connection. This means that if you are using a SNAT address, it is applied before the mask length is evaluated for OneConnect reuse eligibility. The masking behavior details by version are maintained on AskF5 in knowledge base articles K5911 (10.x - 11.x) andK85357500 (12.x.) In my current lab version of 12.1.2, the prefix length can be set to IPv4 or IPv6 mask lengths, and are supplied in CIDR notation instead of traditional netmasks. There’s no rocket science to the mask itself, a mask-length of 0 (default) is most efficient as OneConnect will look for any open idle tcp connection on the destination server. A length of /32 for IPv4 or /128 for IPv6 is a host match, so only an open connection between the source host IP (or SNAT) and the destination server would be eligible for reuse. Maximum Size This setting controls the maximum number of idle server-side tcp connections that BIG-IP holds in the connection reuse pool. This value is divided by the number of TMMs on BIG-IP, so for the default of 10,000 on a system with 10 TMMs, the maximum number of idle connections per TMM would be 1,000. This can be tested with an artificially low maximum-size of two, which means one a two TMM system only one idle connection is available per TMM in the connection reuse pool. Let's use this iRule to make it simple to confirm whether connection has been reused or not: when HTTP_REQUEST_RELEASE { log local0. "BIG-IP: [IP::local_addr]:[TCP::local_port] sent [HTTP::method] to [IP::server_addr]:[serverside {TCP::remote_port}]" } If we have two servers and send two requests to them, each request goes to each server respectively (everything except max size here is default with round-robin LB method.) Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38648 sent GET to 172.16.199.31:80 Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38650 sent GET to 172.16.199.32:80 The server2 connection (from second request) is not added to the connection reuse pool because max size is set to 2 (1 per TMM) and server1 is already there. The third request goes to server1 and reuses the connection from the first request (src port 38648): Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38648 sent GET to 172.16.199.31:80 The fourth request goes to server2 and because there are no idle connections open to server2 then a new connection is created: Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38646 sent GET to 172.16.199.32:80 The fifth request again goes to server1 still reusing the idle server1 connection: Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38648 sent GET to 172.16.199.31:80 A sixth request to server2 also creates a new connection because server1 is still occupying the only spot available in the connection reuse pool: Rule /Common/check_oneconnect : BIG-IP: 172.16.199.234:38658 sent GET to 172.16.199.32:80 Maximum Age This is the maximum number of seconds that a connection stays in the connection reuse pool before the BIG-IP marks a connection ineligible for reuse. Two key points on the max age: It is triggered after the first time the connection is reused, not when the connection is used for the initial request. It is only after the first reuse is completed and the connection is idle that the max age countdown begins. The max-age setting does not close connections when expired, it marks connections ineligible for future reuse. They are then closed in one of two ways. The first way is the BIG-IP will close an ineligible idle connection when a new request comes in. The second way is to wait for the server’s HTTP keep alive to time out. Both sides of the connection have the ability to close down the connection. Let’s take a look at the max age behavior by setting it artificially low on the BIG-IP to 5 seconds, and setting the test apache server to 60 seconds to prevent apache from closing the connection first. If we send one request (frame 10) only the connection is closed 60 seconds later (frame 46) honoring the keep alive we set on apache: The max age did not kick in here as the connection was not reused. However, let’s make another initial request (frame 10.) This time we make a second request (frame 51) 20 seconds later but before the 60 second timeout. Notice the connection has been reused Now that the max age setting has kicked in, we wait another 20 seconds (well after the 5 second expiration we set) and BIG-IP closes the previous connection (frame 77) and opens a new one (frame 92.) One the new connection is established the client-side request is sent to the server (frame 96.) You can also see that after another minute of idleness, the apache server keep alive timeout has expired as well, and it closes the connection (frame 130.) If we had opened a new connection within 5 seconds after frame 115, then the connection would have been reused, and then max-age would kick in again immediately after the connection was idle again. Maximum Reuse This setting controls themaximum number (default: 1,000) of times a particular server connection can be reused before it is closed. So for example, if you set the maximum reuse to two connections, a server-side tcp connection (172.16.199.234:63826 <-> 172.16.199.31:80) would be used for three requests (one initial in frame 10 and two reuses in frames 49 and 90,) and then BIG-IP, unlike with max age in marking a connection ineligible, will immediately close the connection (frame 119.) Idle Timeout Override When enabled (disabled by default,) this setting overrides any timeout set by protocol profiles such as tcp which has a default timeout of 300 seconds. So with the BIG-IP tcp idle timeout at 300 seconds and apache (from earlier) set to 60 seconds on the keep alive, the idle connection will be closed by the server. If we set the keep alive to 301 seconds, BIG-IP would reset the connection. For the sake of testing the idle timeout override, however, let’s enable the idle timeout override in the OneConnect profile by setting it at 30 seconds. You can see in the capture above that after the request is completed (frame 33) and the connection is now idle, it is reset after 30 seconds (frame 44,) occurring before the server timeout and the BIG-IP tcp timeout. You can also set the idle-timeout-override to infinite, which will ignore the other BIG-IP protocol timers but not overcome the settings of the server keep alives. Limit Type This setting controls how connection limits are managed in conjunction with OneConnect. None (default) - OneConnect is not involved with the connection limits. Idle - Specifies that idle connections will be dropped as the tcp connection limit is reached. For short intervals, during the overlap of the idle connection being dropped and the new connection being establish, the tcp connection limit may be exceeded. Strict - Specifies that the tcp connection limit is honored without exception. This means that idle connections will prevent new tcp connections from being made until they expire, even if they could otherwise be reused. This is not a recommended configuration, but might prove useful in exceptional cases with very short expiration timeouts. Understanding OneConnect Behaviors OneConnect does not override load balancing behavior. If there are two pool members (s1 and s2) and we use the round-robin load balancing method with OneConnect applied, the behavior is as follows: First request goes to s1 Second request goes to s2 Third request goes to s1 and reuses idle connection Fourth request goes to s2 and reuses idle connection Applying a OneConnect profile to a virtual server without a layer seven transactional (read: clearly defined requests and responses) protocol like HTTP is generally considered a misconfiguration, and you may see odd behavior when doing so. There may be exceptions, but this configuration should be considered carefully and tested thoroughly before deploying to a production environment. Without OneConnect on a virtual server with HTTP, you will find that persistence data does not appear to be honored. This is because by default, the BIG-IP system performs load balancing for each tcp connection, not each HTTP request, so further requests on the same client-side connection will follow suit from the original decision. By applying OneConnect to the virtual, you effectively detach the server-side from the client-side connection after each request, forcing a new load balancing decision and using persistence information if it available. Resources OneConnect profile overview OneConnect and persistence OneConnect HTTP headers OneConnect and Traffic Distribution OneConnect and Source Mask Thanks to Rodrigo Albuquerque for the fantastic test source material!3.2KViews1like5CommentsWhat is HTTP Part VIII - Compression and Caching
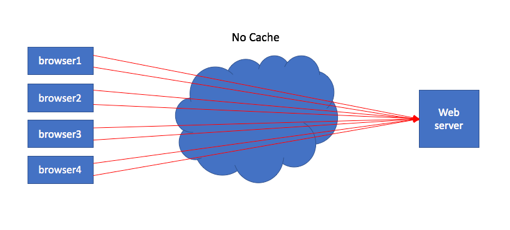
In the last article of this What is HTTP? series we covered the nuances of OneConnect on HTTP traffic through the BIG-IP. In this article, we’ll cover caching and compression. We’ll deal with compression first, and then move on to caching. Compression In the very early days of the internet, much of the content was text based. This meant that the majority of resources were very small in nature. As popularity grew, the desire for more rich content filled with images grew as well, and resource sized began to explode. What had not yet exploded yet, however, was the bandwidth available to handle all that rich content (and you could argue that’s still the case in mobile and remote terrestrial networks as well.) This intersection of more resources without more bandwidth led to HTTP development in a few different areas: Methods for getting or sending partial resources Methods for identifying if resources needed to be retrieved at all Methods for reducing resources during transit that could be successfully reproduced after receipt The various rangeheaders were developed to handle the first case, caching, which we will discuss later in this article, was developed to handle the second case, and compression was developed to handle the third case. The basic definition of data compression is simply reducing the bits necessary to accurately represent the resource. This is done not only to save network bandwidth, but also on storage devices to save space. And of course money in both areas as well. In HTTP/1.0, end-to-end compression was possible, but not hop-by-hop as it does not have a distinguishing mechanism between the two. That is addressed in HTTP/1.1, so intermediaries can use complex algorithms unknown to the server or client to compress data between them and translate accordingly when speaking to the clients and servers respectively. In 11.x forward, compression is managed in its own profile. Prior to 11.x, it was included in the http profile. The httpcompression profile overview on AskF5 is very thorough, so I won’t repeat that information here, but you will want to pay attention to the compression level if you are using gzip (default.) The default of level 1 is fast from the perspective of the act of compressing on BIG-IP, but having done minimal compressing, reaps the least amount of benefit on the wire. If a particular application has great need for less bandwidth utilization toward the clientside of the network footprint, bumping up to level 6 will increase the reduction in bandwidth without overly taxing the BIG-IP to perform the operation. Also, it’s best to avoid compressing data that has already been compressed, like images and pdfs. Compressing them actually makes the resource larger, and wastes BIG-IP resources doing it! SVG format would be an exception to that rule. Also, don’t compress small files. The profile default is 1M for minimum content length. For BIG-IP hardware platforms, compression can be performed in hardware to offload that function. There is a database variable that you can configure to select the data compression strategy via sys modify db compression.strategy . The default value is latency, but there are four other strategies you can employ as covered in the manual. Caching Web caching could (and probably should) be its own multi-part series. The complexities are numerous, and the details plentiful. We did a series called Project Acceleration that covered some of the TCP optimization and compression topics, as well as the larger product we used to call Web Accelerator but is now the Application Acceleration Manager or AAM. AAM is caching and application optimization on steroids and we are not going to dive that deep here. We are going to focus specifically on HTTP caching and how the default functionality of the ramcache works on the BIG-IP. Consider the situation where there is no caching: In this scenario, every request from the browser communicates with the web server, no matter how infrequently the content changes. This is a wasteful use of resources on the server, the network, and even the client itself. The most important resource to our short attention span end users is time! The more objects and distance from the server, the longer the end user waits for that page to render. One way to help is to allow local caching in the browser: This way, the first request will hit the web server, and repeat requests for that same resource will be pulled from the cache (assuming the resource is still valid, more on that below.) Finally, there is the intermediary cache. This can live immediately in front of the end users like in an enterprise LAN, in a content distribution network, immediately in front of the servers in a datacenter, or all of the above! In this case, the browser1 client requests an object not yet in the cache serving all the browser clients shown. Once the cache has the object from the server, it will serve it to all the browser clients, which offloads the requests to server, saves the time in doing so, and brings the response closer to the browser clients as well. Given the benefits of a caching solution, let’s talk briefly of the risks. If you take the control of what’s served away from the server and put it in the hands of an intermediary, especially an intermediary the administrators of the origin server might not have authority over, how do you control then what content the browsers ultimately are loading? That’s where the HTTP standards on caching control come into play. HTTP/1.0 introduced the Pragma, If-Modified-Since, Last-Modified, and Expires headers for cache control. The Cache-Control and ETag headers along with a slew of “If-“ conditional headers were introduced in HTTP/1.1, but you will see many of the HTTP/1.0 cache headers in responses alongside the HTTP/1.1 headers for backwards compatibility. Rather than try to cover the breadth of caching here, I’ll leave it to the reader to dig into the quite good resources linked at the bottom (start with "Things Caches Do") for detailed understanding. However, there's a lot to glean from your browser developer tools and tools like Fiddler and HttpWatch. Consider this request from my browser for the globe-sm.svg file on f5.com. Near the bottom of the image, I’ve highlighted the request Cache-Control header, which has a value of no-cache. This isn’t a very intuitive name, but what the client is directing the cache is that it must submit the request to the origin server every time, even if the content is fresh. This assures authentication is respected while still allowing for the cache to be utilized for content delivery. In the response, the Cache-Control header has two values: public and max-age. The max-age here is quite large, so this is obviously an asset that is not expected to change much. The public directive means the resource can be stored in a shared cache. Now that we have a basic idea what caching is, how does the BIG-IP handle it? The basic caching available in LTM is handled in the same profile that AAM uses, but there are some features missing when AAM is not provisioned. It used to be called ramcache, but now is the webacceleration profile. Solution K14903 provides the overview of the webacceleration profile but we’ll discuss the cache size briefly. Unlike the Web Accelerator, there is no disk associated with the ramcache. As the name implies, this is “hot” cache in memory. So if you are memory limited on your BIG-IP, 100MB might be a little too large to keep locally. Managing the items in cache can be done via the tmsh command line with the ltm profile ramcache command. tmsh show/delete operations can be used against this method. An example show on my local test box: root@(ltm3)(cfg-sync Standalone)(Active)(/Common)(tmos)# show ltm profile ramcache webacceleration Ltm::Ramcaches /Common/webacceleration Host: 192.168.102.62 URI : / -------------------------------------- Source Slot/TMM 1/1 Owner Slot/TMM 1/1 Rank 1 Size (bytes) 3545 Hits 5 Received 2017-11-30 22:16:47 Last Sent 2017-11-30 22:56:33 Expires 2017-11-30 23:16:47 Vary Type encoding Vary Count 1 Vary User Agent none Vary Encoding gzip,deflate Again, if you have AAM licensed, you can provision it and then additional fields will be shown in the webacceleration profile above to allow for an acceleration policy to be applied against your virtual server. Resources RFC 2616 - The standard fine print. Things Caches Do- Excellent napkin diagrams that provide simple explanations of caching operations. Caching Tutorial - Comprehensive walk through of caching. HTTP Caching - Brief but informative look at caching from a webdev perspective. HTTP Caching - Google develops page with examples, flowcharts, and advice on caching strategies. Project Acceleration - Our 10 part series on web acceleration technology available on the BIG-IP platform in LTM and/or AAM modules. Solution K5157 - BIG-IP caching and the Vary header Make Your Cache Work For You - Article by Dawn Parzych here on DevCentral on tuning techniques2.6KViews1like0CommentsWILS: Virtual Server versus Virtual IP Address
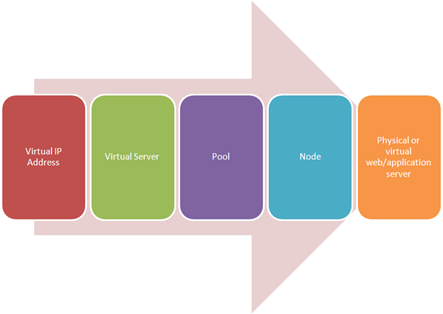
load balancing intermediaries have long used the terms “virtual server” and “virtual IP address”. With the widespread adoption of virtualization these terms have become even more confusing to the uninitiated. Here’s how load balancing and application delivery use the terminology. I often find it easiest to explain the difference between a “virtual server” and a “virtual IP address (VIP)” by walking through the flow of traffic as it is received from the client. When a client queries for “www.yourcompany.com” they get an IP address, of course. In many cases if the site is served by a load balancer or application delivery controller that IP address is a virtual IP address. That simply means the IP address is not tied to a specific host. It’s kind of floating out there, waiting for requests. It’s more like a taxi than a public bus in that a public bus has a predefined route from which it does not deviate. A taxi, however, can take you wherever you want within the confines of its territory. In the case of a virtual IP address that territory is the set of virtual servers and services offered by the organization. The client (the browser, probably) uses the virtual IP address to make a request to “www.yourcompany.com” for a particular resource such as a web application (HTTP) or to send an e-mail (SMTP). Using the VIP and a TCP port appropriate for the resource, the application delivery controller directs the request to a “virtual server”. The virtual server is also an abstraction. It doesn’t really “exist” anywhere but in the application delivery controller’s configuration. The virtual server determines – via myriad options – which pool of resources will best serve to meet the user’s request. That pool of resources contains “nodes”, which ultimately map to one (or more) physical or virtual web/application servers (or mail servers, or X servers). A virtual IP address can represent multiple virtual servers and the correct mapping between them is generally accomplished by further delineating virtual servers by TCP destination port. So a single virtual IP address can point to a virtual “HTTP” server, a virtual “SMTP” server, a virtual “SSH” server, etc… Each virtual “X” server is a separate instantiation, all essentially listening on the same virtual IP address. It is also true, however, that a single virtual server can be represented by multiple virtual IP addresses. So “www1” and “www2” may represent different virtual IP addresses, but they might both use the same virtual server. This allows an application delivery controller to make routing decisions based on the host name, so “images.yourcompany.com” and “content.yourcompany.com” might resolve to the same virtual IP address and the same virtual server, but the “pool” of resources to which requests for images is directed will be different than the “pool” of resources to which content is directed. This allows for greater flexibility in architecture and scalability of resources at the content-type and application level rather than at the server level. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Server Virtualization versus Server Virtualization Architects Need to Better Leverage Virtualization Using "X-Forwarded-For" in Apache or PHP SNAT Translation Overflow WILS: Client IP or Not Client IP, SNAT is the Question WILS: Why Does Load Balancing Improve Application Performance? WILS: The Concise Guide to *-Load Balancing WILS: Network Load Balancing versus Application Load Balancing All WILS Topics on DevCentral If Load Balancers Are Dead Why Do We Keep Talking About Them?2.6KViews1like1Comment