How to get a F5 BIG-IP VE Developer Lab License
(applies to BIG-IP TMOS Edition) To assist DevOps teams improve their development for the BIG-IP platform, F5 offers a low cost developer lab license.This license can be purchased from your authorized F5 vendor. If you do not have an F5 vendor, you can purchase a lab license online: CDW BIG-IP Virtual Edition Lab License CDW Canada BIG-IP Virtual Edition Lab License Once completed, the order is sent to F5 for fulfillment and your license will be delivered shortly after via e-mail. F5 is investigating ways to improve this process. To download the BIG-IP Virtual Edition, please log into downloads.f5.com (separate login from DevCentral), and navigate to your appropriate virtual edition, example: For VMware Fusion or Workstation or ESX/i:BIGIP-16.1.2-0.0.18.ALL-vmware.ova For Microsoft HyperV:BIGIP-16.1.2-0.0.18.ALL.vhd.zip KVM RHEL/CentoOS: BIGIP-16.1.2-0.0.18.ALL.qcow2.zip Note: There are also 1 Slot versions of the above images where a 2nd boot partition is not needed for in-place upgrades. These images include_1SLOT- to the image name instead of ALL. The below guides will help get you started with F5 BIG-IP Virtual Edition to develop for VMWare Fusion, AWS, Azure, VMware, or Microsoft Hyper-V. These guides follow standard practices for installing in production environments and performance recommendations change based on lower use/non-critical needs fo Dev/Lab environments. Similar to driving a tank, use your best judgement. DeployingF5 BIG-IP Virtual Edition on VMware Fusion Deploying F5 BIG-IP in Microsoft Azure for Developers Deploying F5 BIG-IP in AWS for Developers Deploying F5 BIG-IP in Windows Server Hyper-V for Developers Deploying F5 BIG-IP in VMware vCloud Director and ESX for Developers Note: F5 Support maintains authoritativeAzure, AWS, Hyper-V, and ESX/vCloud installation documentation. VMware Fusion is not an official F5-supported hypervisor so DevCentral publishes the Fusion guide with the help of our Field Systems Engineering teams.74KViews13likes143CommentsControlling a Pool Members Ratio and Priority Group with iControl
A Little Background A question came in through the iControl forums about controlling a pool members ratio and priority programmatically. The issue really involves how the API’s use multi-dimensional arrays but I thought it would be a good opportunity to talk about ratio and priority groups for those that don’t understand how they work. In the first part of this article, I’ll talk a little about what pool members are and how their ratio and priorities apply to how traffic is assigned to them in a load balancing setup. The details in this article were based on BIG-IP version 11.1, but the concepts can apply to other previous versions as well. Load Balancing In it’s very basic form, a load balancing setup involves a virtual ip address (referred to as a VIP) that virtualized a set of backend servers. The idea is that if your application gets very popular, you don’t want to have to rely on a single server to handle the traffic. A VIP contains an object called a “pool” which is essentially a collection of servers that it can distribute traffic to. The method of distributing traffic is referred to as a “Load Balancing Method”. You may have heard the term “Round Robin” before. In this method, connections are passed one at a time from server to server. In most cases though, this is not the best method due to characteristics of the application you are serving. Here are a list of the available load balancing methods in BIG-IP version 11.1. Load Balancing Methods in BIG-IP version 11.1 Round Robin: Specifies that the system passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. This method works well in most configurations, especially if the equipment that you are load balancing is roughly equal in processing speed and memory. Ratio (member): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine within the pool. Least Connections (member): Specifies that the system passes a new connection to the node that has the least number of current connections in the pool. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. Observed (member): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (member), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (member): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Ratio (node): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine across all pools of which the server is a member. Least Connections (node): Specifies that the system passes a new connection to the node that has the least number of current connections out of all pools of which a node is a member. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node, or the fastest node response time. Fastest (node): Specifies that the system passes a new connection based on the fastest response of all pools of which a server is a member. This method might be particularly useful in environments where nodes are distributed across different logical networks. Observed (node): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (node), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (node): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Dynamic Ratio (node) : This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. Fastest (application): Passes a new connection based on the fastest response of all currently active nodes in a pool. This method might be particularly useful in environments where nodes are distributed across different logical networks. Least Sessions: Specifies that the system passes a new connection to the node that has the least number of current sessions. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current sessions. Dynamic Ratio (member): This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. L3 Address: This method functions in the same way as the Least Connections methods. We are deprecating it, so you should not use it. Weighted Least Connections (member): Specifies that the system uses the value you specify in Connection Limit to establish a proportional algorithm for each pool member. The system bases the load balancing decision on that proportion and the number of current connections to that pool member. For example,member_a has 20 connections and its connection limit is 100, so it is at 20% of capacity. Similarly, member_b has 20 connections and its connection limit is 200, so it is at 10% of capacity. In this case, the system select selects member_b. This algorithm requires all pool members to have a non-zero connection limit specified. Weighted Least Connections (node): Specifies that the system uses the value you specify in the node's Connection Limitand the number of current connections to a node to establish a proportional algorithm. This algorithm requires all nodes used by pool members to have a non-zero connection limit specified. Ratios The ratio is used by the ratio-related load balancing methods to load balance connections. The ratio specifies the ratio weight to assign to the pool member. Valid values range from 1 through 100. The default is 1, which means that each pool member has an equal ratio proportion. So, if you have server1 a with a ratio value of “10” and server2 with a ratio value of “1”, server1 will get served 10 connections for every one that server2 receives. This can be useful when you have different classes of servers with different performance capabilities. Priority Group The priority group is a number that groups pool members together. The default is 0, meaning that the member has no priority. To specify a priority, you must activate priority group usage when you create a new pool or when adding or removing pool members. When activated, the system load balances traffic according to the priority group number assigned to the pool member. The higher the number, the higher the priority, so a member with a priority of 3 has higher priority than a member with a priority of 1. The easiest way to think of priority groups is as if you are creating mini-pools of servers within a single pool. You put members A, B, and C in to priority group 5 and members D, E, and F in priority group 1. Members A, B, and C will be served traffic according to their ratios (assuming you have ratio loadbalancing configured). If all those servers have reached their thresholds, then traffic will be distributed to servers D, E, and F in priority group 1. he default setting for priority group activation is Disabled. Once you enable this setting, you can specify pool member priority when you create a new pool or on a pool member's properties screen. The system treats same-priority pool members as a group. To enable priority group activation in the admin GUI, select Less than from the list, and in the Available Member(s) box, type a number from 0 to 65535 that represents the minimum number of members that must be available in one priority group before the system directs traffic to members in a lower priority group. When a sufficient number of members become available in the higher priority group, the system again directs traffic to the higher priority group. Implementing in Code The two methods to retrieve the priority and ratio values are very similar. They both take two parameters: a list of pools to query, and a 2-D array of members (a list for each pool member passed in). long [] [] get_member_priority( in String [] pool_names, in Common__AddressPort [] [] members ); long [] [] get_member_ratio( in String [] pool_names, in Common__AddressPort [] [] members ); The following PowerShell function (utilizing the iControl PowerShell Library), takes as input a pool and a single member. It then make a call to query the ratio and priority for the specific member and writes it to the console. function Get-PoolMemberDetails() { param( $Pool = $null, $Member = $null ); $AddrPort = Parse-AddressPort $Member; $RatioAofA = (Get-F5.iControl).LocalLBPool.get_member_ratio( @($Pool), @( @($AddrPort) ) ); $PriorityAofA = (Get-F5.iControl).LocalLBPool.get_member_priority( @($Pool), @( @($AddrPort) ) ); $ratio = $RatioAofA[0][0]; $priority = $PriorityAofA[0][0]; "Pool '$Pool' member '$Member' ratio '$ratio' priority '$priority'"; } Setting the values with the set_member_priority and set_member_ratio methods take the same first two parameters as their associated get_* methods, but add a third parameter for the priorities and ratios for the pool members. set_member_priority( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] priorities ); set_member_ratio( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] ratios ); The following Powershell function takes as input the Pool and Member with optional values for the Ratio and Priority. If either of those are set, the function will call the appropriate iControl methods to set their values. function Set-PoolMemberDetails() { param( $Pool = $null, $Member = $null, $Ratio = $null, $Priority = $null ); $AddrPort = Parse-AddressPort $Member; if ( $null -ne $Ratio ) { (Get-F5.iControl).LocalLBPool.set_member_ratio( @($Pool), @( @($AddrPort) ), @($Ratio) ); } if ( $null -ne $Priority ) { (Get-F5.iControl).LocalLBPool.set_member_priority( @($Pool), @( @($AddrPort) ), @($Priority) ); } } In case you were wondering how to create the Common::AddressPort structure for the $AddrPort variables in the above examples, here’s a helper function I wrote to allocate the object and fill in it’s properties. function Parse-AddressPort() { param($Value); $tokens = $Value.Split(":"); $r = New-Object iControl.CommonAddressPort; $r.address = $tokens[0]; $r.port = $tokens[1]; $r; } Download The Source The full source for this example can be found in the iControl CodeShare under PowerShell PoolMember Ratio and Priority.27KViews0likes3Comments
Intro to Load Balancing for Developers – The Algorithms
If you’re new to this series, you can find the complete list of articles in the series on my personal page here If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. Until then! Don.19KViews1like9CommentsDemystifying iControl REST Part 6: Token-Based Authentication
iControl REST. It’s iControl SOAP’s baby, brother, introduced back in TMOS version 11.4 as an early access feature but released fully in version 11.5. Several articles on basic usage have been written on iControl REST so the intent here isn’t basic use, but rather to demystify some of the finer details of using the API. This article will cover the details on how to retrieve and use an authentication token from the BIG-IP using iControl REST and the python programming language. This token is used in place of basic authentication on API calls, which is a requirement for external authentication. Note that for configuration changes, version 12.0 or higher is required as earlier versions will trigger an un-authorized error. The tacacs config in this article is dependent on a version that I am no longer able to get installed on a modern linux flavor. Instead, try this Dockerized tacacs+ server for your testing. The Fine Print The details of the token provider are here in the wiki. We’ll focus on a provider not listed there: tmos. This provider instructs the API interface to use the provider that is configured in tmos. For this article, I’ve configured a tacacs server and the BIG-IP with custom remote roles as shown below to show BIG-IP version 12’s iControl REST support for remote authentication and authorization. Details for how this configuration works can be found in the tacacs+ article I wrote a while back. BIG-IP tacacs+ configuration auth remote-role { role-info { adm { attribute F5-LTM-User-Info-1=adm console %F5-LTM-User-Console line-order 1 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } mgr { attribute F5-LTM-User-Info-1=mgr console %F5-LTM-User-Console line-order 2 role %F5-LTM-User-Role user-partition %F5-LTM-User-Partition } } } auth remote-user { } auth source { type tacacs } auth tacacs system-auth { debug enabled protocol ip secret $M$Zq$T2SNeIqxi29CAfShLLqw8Q== servers { 172.16.44.20 } service ppp } Tacacs+ Server configuration id = tac_plus { debug = PACKET AUTHEN AUTHOR access log = /var/log/access.log accounting log = /var/log/acct.log host = world { address = ::/0 prompt = "\nAuthorized Access Only!\nTACACS+ Login\n" key = devcentral } group = adm { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = adm set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 0 set F5-LTM-User-Partition = all } } } group = mgr { service = ppp { protocol = ip { set F5-LTM-User-Info-1 = mgr set F5-LTM-User-Console = 1 set F5-LTM-User-Role = 100 set F5-LTM-User-Partition = all } } } user = user_admin { password = clear letmein00 member = adm } user = user_mgr { password = clear letmein00 member = mgr } } Basic Requirements Before we look at code, however, let’s take a look at the json payload requirements, followed by response data from a query using Chrome’s Advanced REST Client plugin. First, since we are sending json payload, we need to add the Content-Type: application/json header to the query. The payload we are sending with the post looks like this: { "username": "remote_auth_user", "password": "remote_auth_password", "loginProviderName": "tmos" } You submit the same remote authentication credentials in the initial basic authentication as well, no need to have access to the default admin account credentials. A successful query for a token returns data like this: { username: "user_admin" loginReference: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/login" }- token: { uuid: "4d1bd79f-dca7-406b-8627-3ad262628f31" name: "5C0F982A0BF37CBE5DE2CB8313102A494A4759E5704371B77D7E35ADBE4AAC33184EB3C5117D94FAFA054B7DB7F02539F6550F8D4FA25C4BFF1145287E93F70D" token: "5C0F982A0BF37CBE5DE2CB8313102A494A4759E5704371B77D7E35ADBE4AAC33184EB3C5117D94FAFA054B7DB7F02539F6550F8D4FA25C4BFF1145287E93F70D" userName: "user_admin" user: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/34ba3932-bfa3-4738-9d55-c81a1c783619" }- groupReferences: [1] 0: { link: "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/user-groups/21232f29-7a57-35a7-8389-4a0e4a801fc3" }- - timeout: 1200 startTime: "2015-11-17T19:38:50.415-0800" address: "172.16.44.1" partition: "[All]" generation: 1 lastUpdateMicros: 1447817930414518 expirationMicros: 1447819130415000 kind: "shared:authz:tokens:authtokenitemstate" selfLink: "https://localhost/mgmt/shared/authz/tokens/4d1bd79f-dca7-406b-8627-3ad262628f31" }- generation: 0 lastUpdateMicros: 0 } Among many other fields, you can see the token field with a very long hexadecimal token. That’s what we need to authenticate future API calls. Requesting the token programmatically In order to request the token, you first have to supply basic auth credentials like normal. This is currently required to access the /mgmt/shared/authn/login API location. The basic workflow is as follows (with line numbers from the code below in parentheses): Make a POST request to BIG-IP with basic authentication header and json payload with username, password, and the login provider (9-16, 41-47) Remove the basic authentication (49) Add the token from the post response to the X-F5-Auth-Token header (50) Continue further requests like normal. In this example, we’ll create a pool to verify read/write privileges. (1-6, 52-53) And here’s the code (in python) to make that happen: def create_pool(bigip, url, pool): payload = {} payload['name'] = pool pool_config = bigip.post(url, json.dumps(payload)).json() return pool_config def get_token(bigip, url, creds): payload = {} payload['username'] = creds[0] payload['password'] = creds[1] payload['loginProviderName'] = 'tmos' token = bigip.post(url, json.dumps(payload)).json()['token']['token'] return token if __name__ == "__main__": import os, requests, json, argparse, getpass requests.packages.urllib3.disable_warnings() parser = argparse.ArgumentParser(description='Remote Authentication Test - Create Pool') parser.add_argument("host", help='BIG-IP IP or Hostname', ) parser.add_argument("username", help='BIG-IP Username') parser.add_argument("poolname", help='Key/Cert file names (include the path.)') args = vars(parser.parse_args()) hostname = args['host'] username = args['username'] poolname = args['poolname'] print "%s, enter your password: " % args['username'], password = getpass.getpass() url_base = 'https://%s/mgmt' % hostname url_auth = '%s/shared/authn/login' % url_base url_pool = '%s/tm/ltm/pool' % url_base b = requests.session() b.headers.update({'Content-Type':'application/json'}) b.auth = (username, password) b.verify = False token = get_token(b, url_auth, (username, password)) print '\nToken: %s\n' % token b.auth = None b.headers.update({'X-F5-Auth-Token': token}) response = create_pool(b, url_pool, poolname) print '\nNew Pool: %s\n' % response Running this script from the command line, we get the following response: FLD-ML-RAHM:scripts rahm$ python remoteauth.py 172.16.44.15 user_admin myNewestPool1 Password: user_admin, enter your password: Token: 2C61FE257C7A8B6E49C74864240E8C3D3592FDE9DA3007618CE11915F1183BF9FBAF00D09F61DE15FCE9CAB2DC2ACC165CBA3721362014807A9BF4DEA90BB09F New Pool: {u'generation': 453, u'minActiveMembers': 0, u'ipTosToServer': u'pass-through', u'loadBalancingMode': u'round-robin', u'allowNat': u'yes', u'queueDepthLimit': 0, u'membersReference': {u'isSubcollection': True, u'link': u'https://localhost/mgmt/tm/ltm/pool/~Common~myNewestPool1/members?ver=12.0.0'}, u'minUpMembers': 0, u'slowRampTime': 10, u'minUpMembersAction': u'failover', u'minUpMembersChecking': u'disabled', u'queueTimeLimit': 0, u'linkQosToServer': u'pass-through', u'queueOnConnectionLimit': u'disabled', u'fullPath': u'myNewestPool1', u'kind': u'tm:ltm:pool:poolstate', u'name': u'myNewestPool1', u'allowSnat': u'yes', u'ipTosToClient': u'pass-through', u'reselectTries': 0, u'selfLink': u'https://localhost/mgmt/tm/ltm/pool/myNewestPool1?ver=12.0.0', u'serviceDownAction': u'none', u'ignorePersistedWeight': u'disabled', u'linkQosToClient': u'pass-through'} You can test this out in the Chrome Advanced Rest Client plugin, or from the command line with curl or any other language supporting REST clients as well, I just use python for the examples well, because I like it. I hope you all are digging into iControl REST! What questions do you have? What else would you like clarity on? Drop a comment below.18KViews0likes42Comments
iControl REST Authentication Token Management
Introduction The Token Authentication (hereinafter "token") is an iControl REST authentication method introduced in BIG-IP v12.0. It allows accesses for not only local users but also remotes users (such as RADIUS or LDAP) unlike the conventional Basic Authentication (uses HTTP's Authorization header) which is only good for local users. This article describes methods for managing tokens. The example calls shown here use curl. The command options used are -s: silent - Do not show the progress meter. -k: insecure - Does not verify the server certificate. -u: user - User name and passwords (e.g., admin:admin). -H: header - Additional HTTP request header. The X-F5-Auth-Token header is used to provide the token. -d: data - The data to POST/PATCH. The following variables embedded in the example calls represents: $HOST - BIG-IP management IP. $TOKEN - A token (e.g., ABCDEFGHIJKLMNOPQRSTUVWXYZ) Things you should know about token When you use tokens, remember the following characteristics: 1. A token expires By default, a token expires after 1,200s (20 min). You can extend the token lifespan by modifying the "timeout" property in the token object. The maximum lifespan is 36,000s (10 hrs). If you attempt to change the timeout property longer than the maximum, you will get the 406 error "Auth-token absolute timeout (36000 seconds) exceeded". 2. Limited number of tokens Each user can request up to 100 tokens at any point in time. Your 101-th token request will be rejected with the 400 error "Bad Request: user xxx has reached maximum active login tokens". You need to either wait for the tokens to expire or explicitly delete them. This limitation applies to all users, irrespective of local/remote and roles (even administrator). The only exception is the "admin" user. 3. You can only manage your own token You cannot view (GET), modify (PATCH) or delete (DELETE) a token generated for somebody else. Such requests will be rejected with the 400 error "Authorization failed". If you need to manage tokens for other users, use the user with an appropriate role (e.g., administrator). Token management 1. Get a token To obtain a token for user foo (and his password is fooPass), run the following call. curl -sk https://$HOST/mgmt/shared/authn/login -X POST -H "Content-Type: application/json" \ -d '{"username":"foo", "password":"fooPass", "loginProviderName":"tmos"}' An example output is shown below: { "generation": 0, "lastUpdateMicros": 0, "loginProviderName": "tmos", "loginReference": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/login" }, "token": { "address": "192.168.184.10", "authProviderName": "tmos", "expirationMicros": 1588199929471000, "generation": 1, "kind": "shared:authz:tokens:authtokenitemstate", "lastUpdateMicros": 1588198729470534, "name": "DCECRMQ66WOSPTSGPR7OAGG5SI", "partition": "[All]", "selfLink": "https://localhost/mgmt/shared/authz/tokens/DCECRMQ66WOSPTSGPR7OAGG5SI", "startTime": "2020-04-30T10:18:49.471+1200", "timeout": 1200, "token": "DCECRMQ66WOSPTSGPR7OAGG5SI", "user": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" }, "userName": "foo" }, "username": "foo" } The "token" or "name" property inside the "token" property shows the token. It is a 26 character long string consisting of uppercase alphabets and numbers. In the above example, it is DCECRMQ66WOSPTSGPR7OAGG5SI. 2. Find the time when your token will expire In the output above, the "timeout" property shows the lifespan of the token in seconds. As shown, the default value is 1200s (20 min). The "expirationMicros" property shows the date/time that the token will expire. The value is a Unix epoch time in GMT with microseconds precision. You can parse the number by using Node.js (preinstalled on any BIG-IP 12.1 and later) as below: # To GMT node -p 'new Date(1588202764161000/1000)' # To your local time node -p 'new Date(1588197991778710/1000).toString()' 3. Use your token Add the X-F5-Auth-Token HTTP request header with the token value to any call you make. For example, to send a GET request to /mgmt/tm/sys/version (equivallent to 'tmsh show sys version'), run below: curl -sk https://$HOST/mgmt/tm/sys/version -H "X-F5-Auth-Token: $TOKEN" 4. Check your token You can check you token by sending the following GET request. curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN -H "X-F5-Auth-Token: $TOKEN" An example output is shown below: { "address": "192.168.184.10", "authProviderName": "tmos", "expirationMicros": 1588217373992000, "generation": 1, "kind": "shared:authz:tokens:authtokenitemstate", "lastUpdateMicros": 1588216173991714, "name": "7CLLGEKL5UZLUI7BO4SE7MUGMI", "partition": "[All]", "selfLink": "https://localhost/mgmt/shared/authz/tokens/7CLLGEKL5UZLUI7BO4SE7MUGMI", "startTime": "2020-04-30T15:09:33.992+1200", "timeout": 1200, "token": "7CLLGEKL5UZLUI7BO4SE7MUGMI", "user": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" }, "userName": "foo" } 5. Modify the timeout value of your token By changing the value of the timeout property (default 1,200), you can extend or shorten the lifespan of the token. You may need to consider: Extending it if your iControl REST session is expected to last long (e.g., a script with hundreds of calls) to avoid timeout in the middle of the session. Shortening it if you successively run multiple iControl REST calls that request tokens each time to avoid running out the tokens. The example below extends the token's lifespan to 4,200s (70 min). curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN \ -X PATCH -H "Content-type: application/json" -H "X-F5-Auth-Token: $TOKEN" \ -d '{"timeout" : 4200}' 6. Delete your token You can explicitly delete your token. curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN -X DELETE -H "X-F5-Auth-Token: $TOKEN" As aforementioned, you can only delete your own token. If you need to remove ALL the tokens in one shot, run the following call from the authorized user such as admin: curl -sku $PASS https://$HOST/mgmt/shared/authz/tokens -X DELETE 7. Fnd the owner of the token from the user reference link As shown in the Merhod 1 and 4, a token object contains the owner (or the requester) of the token (the "userName" property). If it does not contain the readable user information, alternatively, you can send a GET request to the endpoint shown in the "user" property. curl -sk https:/$HOST/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8 \ -H "X-F5-Auth-Token: $TOKEN" The 8-4-4-4-12 format strings are UUIDs computed from the login provider name (the value you provided via the loginProviderName property when you requested your token) and user name. For example, 1f44a60e-11a7-3c51-a49f-82983026b41b in between "tmos" and "users" is from the string "tmos". acbd18db-4cc2-385c-adef-654fccc4a4d8 is from "foo". An UUID (Universally Unique Identifier) is a 128 bits long unique identifier defined in RFC 4122. There are a number of variants and versions in the UUIDs. F5 iControl REST uses version (0011) and variant (10) (represented in binary). See Section 4.1.3 and 4.1.1 of the RFC for details. An example output from the above call is shown below: { "generation": 23, "id": "acbd18db-4cc2-385c-adef-654fccc4a4d8", "kind": "cm:system:authn:providers:tmos:1f44a60e-11a7-3c51-a49f-82983026b41b:users:usersstate", "lastUpdateMicros": 1585693423008243, "name": "foo", "selfLink": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" } References iControl REST User Guide (Clouddocs iControl REST; PDF documents) Auth Token by Login (CloudDocs BIG-IQ API) Demystifying iControl REST Part 6: Token-Based Authentication (DevCentral article) curl man page K04452074: Overview of using the BIG-IQ system authentication token (F5 AskF5 document) Python SDK Cookbook: Working with Auth Tokens (DevCentral article) A Universally Unique IDentifier (UUID) URN Namespace (RFC 4122)17KViews2likes0CommentsAccessing TCP Options from iRules
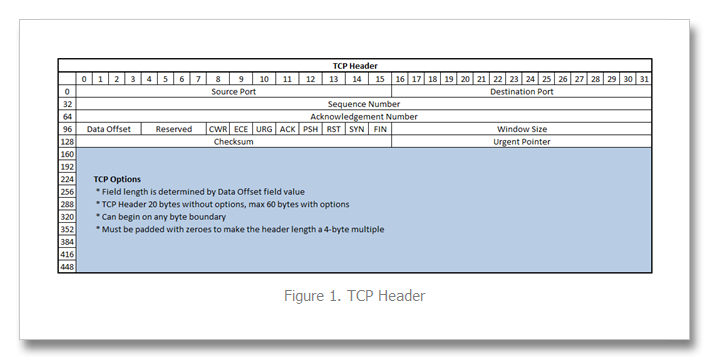
I’ve written several articles on the TCP profile and enjoy digging into TCP. It’s a beast, and I am constantly re-learning the inner workings. Still etched in my visual memory map, however, is the TCP header format, shown in Figure 1 below. Since 9.0 was released, TCP payload data (that which comes after the header) has been consumable in iRules via the TCP::payload and the port information has been available in the contextual commands TCP::local_port/TCP::remote_port and of course TCP::client_port/TCP::server_port. Options, however, have been inaccessible. But beginning with version 10.2.0-HF2, it is now possible to retrieve data from the options fields. Preparing the BIG-IP Prior to version 11.0, it was necessary to set a bigpipe database key with the option (or options) of interest: bigpipe db Rules.Tcpoption.settings [option, first|last], [option, first|last] In version 11.0 and forward, the DB keys are no more and you need to create a tcp profile with the these options defined, like so: ltm profile tcp tcp_opt { app-service none tcp-options "{option first|last} {option first|last}" } The option is an integer between 2 and 255, and the first/last setting indicates whether the system will retain the first or last instance of the specified option. Once that key is set, you’ll need to do a bigstart restart for it to take (warning: service impacting). Note also that the LTM only collects option data starting with the ACK of a connection. The initial SYN is ignored even if you select the first keyword. This is done to prevent a SYN flood attack (in keeping with SYN-cookies). A New iRules Command: TCP::option The TCP::option command has the following syntax: TCP::option get <option> v11 Additions/Changes: TCP::option set <option number> <value> <next|all> TCP::option noset <option number> Pretty simple, no? So now that you can access them, what fun can be had? Real World Scenario: Akamai In Akamai’s IPA and SXL product lines, they support client IP visibility by embedding a version number (one byte) and an IPv4 address (four bytes) as part of their overlay path feature in tcp option number 28. To access this data, we first set the database key: tmsh create ltm profile tcp tcp_opt tcp-options "{28 first}" Now, the iRule utilizing the TCP::option command: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt28 cH8 ver addr if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { scan $addr "%2x%2x%2x%2x" ip1 ip2 ip3 ip4 set optaddr "$ip1.$ip2.$ip3.$ip4" } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } The Akamai version should be one, so we log if not. Otherwise, we take the address (stored in the variable addr in hex) and scan it to get the decimal equivalents to build the address for inserting in the X-Forwarded-For header. Cool, right? Also cool—along with the new TCP::option command , an extension was made to the IP::addr command to parse binary fields into a dotted decimal IP address. This extension is also available beginning in 10.2.0-HF2, but extended in 11.0. Here’s the syntax: IP::addr parse [-ipv4 | -ipv6 [swap]] <binary field> [<offset>] So for example, if you had an IPv6 address in option 28 with a 1 byte offset, you would parse that like: log local0. "IP::addr parse IPv6 output: [IP::addr parse -ipv6 [TCP::option get 28] 1]" ## Log Result ## May 27 21:51:34 ltm13 info tmm[27207]: Rule /Common/tcpopt_test <CLIENT_ACCEPTED>: IP::addr parse IPv6 output: 2601:1930:bd51:a3e0:20cd:a50b:1cc1:ad13 But in the context of our TCP option, we have 5-bytes of data with the first byte not mattering in the context of an address, so we get at the address with this: set optaddr [IP::addr parse -ipv4 [TCP::option get 28] 1] This cleans up the rule a bit: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } No need to store the address in the first binary scan and no need for the scan command at all so I eliminated those. Setting a forwarding header is not the only thing we can do with this data. It could also be shipped off to a logging server, or used as a snat address (assuming the server had either a default route to the BIG-IP, or specific routes for the customer destinations, which is doubtful). Logging is trivial, shown below with the log command. The HSL commands could be used in lieu of log if sending off-box to a log server. when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "Client IP extracted from Akamai TCP option is $optaddr" } } } If setting the provided IP as a snat address, you’ll want to make sure it’s a valid IP address before doing so. You can use the TCL catch command and IP::addr to perform this check as seen in the iRule below: when CLIENT_ACCEPTED { set addrs [list \ "192.168.1.1" \ "256.168.1.1" \ "192.256.1.1" \ "192.168.256.1" \ "192.168.1.256" \ ] foreach x $addrs { if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "IP $x is invalid" } else { log local0. "IP $x is valid" } } } The output of this iRule: <CLIENT_ACCEPTED>: IP 192.168.1.1 is valid <CLIENT_ACCEPTED>: IP 256.168.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.256.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.256.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.1.256 is invalid Adding this logic into a functional rule with snat: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "$optaddr is not a valid address" snat automap } else { log local0. "Akamai inserted Client IP is $optaddr. Setting as snat address." snat $optaddr } } } Alternative TCP Option Use Cases The Akamai solution shows an application implementation taking advantage of normally unused space in TCP headers. There are, however, defined uses for several option “kind” numbers. The list is available here: http://www.iana.org/assignments/tcp-parameters/tcp-parameters.xml. Some options that might be useful in troubleshooting efforts: Opkind 2 – Max Segment Size Opkind 3 – Window Scaling Opkind 5 – Selective Acknowledgements Opkind 8 – Timestamps Of course, with tcpdump you get all this plus the context of other header information and data, but hey, another tool in the toolbox, right? Addendum I've been working with F5 SE Leonardo Simon on on additional examples I wanted to share here that uses option 28 or 253 to extract an IPv6 address if the version is 34 and otherwise extracts an IPv4 address if the version is 1 or 2. Option 28 when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] binary scan $opt28 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt28 1] log local0. "opt28 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "opt28 ipv4 address: $optaddr" } } Option 253 when CLIENT_ACCEPTED { set opt253 [TCP::option get 253] binary scan $opt253 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt253 1] log local0. "opt253 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt253 1] log local0. "opt253 ipv4 address: $optaddr" } }17KViews2likes10CommentsWhere are F5's archived deployment guides?
Archived F5 Deployment Guides This article contains an index of F5’s archived deployment guides, previously hosted onF5 | Multi-Cloud Security and Application Delivery.They are all now hosted on cdn.f5.com. Archived guides... are no longer supported and no longer being updated -provided for reference only. may refer to products or versions, by F5 or 3rd parties that are end-of-life (EOL) or end-of-support (EOS). may refer to iApp templates that are deprecated. For current/updated iApps and FAST templates see myF5 K13422: F5-supported and F5-contributed iApp templates Current F5 Deployment Guides Deployment Guides (https://www.f5.com/resources/deployment-guides) IMPORTANT:The guidance found in archived guides is no longer supported by F5, Inc. and is supplied for reference only.For assistance configuring F5 devices with 3 rd party applications we recommend contacting F5 Professional Services here:Request Professional Services | F5 Archived Deployment Guide Index Deployment Guide Name (links to off-platform) Written for… CA Bundle Iapp BIG-IP V11.5+, V12.X, V13 Microsoft Internet Information Services 7.0, 7.5, 8.0, 10 BIG-IP V11.4 - V13: LTM, AAM, AFM Microsoft Exchange Server 2016 BIG-IP V11 - V13: LTM, APM, AFM Microsoft Sharepoint 2016 BIG-IP V11.4 - V13: LTM, APM, ASM, AFM, AAM Microsoft Active Directory Federation Services BIG-IP V11 - V13: LTM, APM SAP Netweaver: Erp Central Component BIG-IP V11.4: LTM, AAM, AFM, ASM SAP Netweaver: Enterprise Portal BIG-IP V11.4: LTM, AAM, AFM, ASM Microsoft Dynamics CRM 2013 And 2011 BIG-IP V11 - V13: LTM, APM, AFM IBM Qradar BIG-IP V11.3: LTM Microsoft Dynamics CRM 2016 and 2015 BIG-IP V11 - V13: LTM, APM, AFM SSL Intercept V1.5 BIG-IP V12.0+: LTM IBM Websphere 7 BIG-IP LTM, WEBACCELERATOR, FIREPASS Microsoft Dynamics CRM 4.0 BIG-IP V9.X: LTM SSL Intercept V1.0 BIG-IP V11.4+, V12.0: LTM, AFM SMTP Servers BIG-IP V11.4, V12.X, V13: LTM, AFM Oracle E-Business Suite 12 BIG-IP V11.4 - V13: LTM, AFM, AAM HTTP Applications BIG-IP V11.4 - V13: LTM, AFM, AAM Amazon Web Services Availability Zones BIG-IP LTM VE: V12.1.0 HF2+, V13 Oracle PeopleSoft Enterprise Applications BIG-IP V11.4+: LTM, AAM, AFM, ASM HTTP Applications: Downloadable IApp: BIG-IP V11.4 - V13: LTM, APM, AFM, ASM Oracle Weblogic 12.1, 10.3 BIG-IP V11.4: LTM, AFM, AAM IBM Lotus Sametime BIG-IP V10: LTM Analytics BIG-IP V11.4 - V14.1: LTM, APM, AAM, ASM, AFM Cacti Open Source Network Monitoring System BIG-IP V10: LTM NIST SP-800-53R4 Compliance BIG-IP: V12 Apache HTTP Server BIG-IP V11, V12: LTM, APM, AFM, AAM Diameter Traffic Management BIG-IP V10: LTM Nagios Open Source Network Monitoring System BIG-IP V10: LTM F5 BIG-IP Apm With IBM, Oracle and Microsoft BIG-IP V10: APM Apache Web Server BIG-IP V9.4.X, V10: LTM, WA DNS Traffic Management BIG-IP V10: LTM Diameter Traffic Management BIG-IP V11.4+, V12: LTM Citrix XenDesktop BIG-IP V10: LTM F5 As A SAML 2.0 Identity Provider For Common SaaS Applications BIG-IP V11.3+, V12.0 Apache Tomcat BIG-IP V10: LTM Citrix Presentation Server BIG-IP V9.X: LTM Npath Routing - Direct Server Return BIG-IP V11.4 - V13: LTM Data Center Firewall BIG-IP V11.6+, V12: AFM, LTM Citrix XenApp Or XenDesktop Iapp V2.3.0 BIG-IP V11, V12: LTM, APM, AFM Citrix XenApp Or XenDesktop BIG-IP V10.2.1: APM16KViews0likes0CommentsiControl REST Cookbook - Virtual Server (ltm virtual)
This cookbook lists selected ready-to-use iControl REST curl commands for virtual-server related resources. Each recipe consists of the curl command, it's tmsh equivalent, and sample output. In this cookbook, the following curl options are used. Option Meaning ______________________________________________________________________________________ -s Suppress progress meter. Handy when you want to pipe the output. ______________________________________________________________________________________ -k Allows "insecure" SSL connections. ______________________________________________________________________________________ -u Specify user ID and password. For the start, you should use the "admin" account that you normally use to access the Configuration Utility. When you specify the password at the same time, concatenate with ":". e.g., admin:admin. ______________________________________________________________________________________ -X <method> Specify the HTTP method. When omitted, the default is GET. In the REST framework, POST means create (tmsh create), PATCH means overwriting the existing resource with the data sent (tmsh modify), and PATCH is for merging (ditto). ______________________________________________________________________________________ -H <Header> Specify the request header. When you send (POST, PATCH, PUT) data, you need to tell the server that the data is in JSON format. i.e., -H "Content-Type: application/json. ______________________________________________________________________________________ -d 'data' The JSON data to send. Note that you need to quote the entire json blob, and each "name":"value" pairs must be quoted. When you have nested quotes, make sure you escape (\) them. Get information of the virtual <vs> tmsh list ltm <vs> curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual/<vs> Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', fullPath: 'vs', generation: 1109, selfLink: 'https://localhost/mgmt/tm/ltm/virtual/vs?ver=12.1.0', addressStatus: 'yes', autoLasthop: 'default', cmpEnabled: 'yes', connectionLimit: 0, description: 'TestData', destination: '/Common/192.168.184.226:80', enabled: true, gtmScore: 0, ipProtocol: 'tcp', mask: '255.255.255.255', mirror: 'disabled', mobileAppTunnel: 'disabled', nat64: 'disabled', pool: '/Common/vs-pool', poolReference: { link: 'https://localhost/mgmt/tm/ltm/pool/~Common~vs-pool?ver=12.1.0' }, rateLimit: 'disabled', rateLimitDstMask: 0, rateLimitMode: 'object', rateLimitSrcMask: 0, serviceDownImmediateAction: 'none', source: '0.0.0.0/0', sourceAddressTranslation: { type: 'automap' }, sourcePort: 'preserve', synCookieStatus: 'not-activated', translateAddress: 'enabled', translatePort: 'enabled', vlansDisabled: true, vsIndex: 4, rules: [ '/Common/irule' ], rulesReference: [ { link: 'https://localhost/mgmt/tm/ltm/rule/~Common~iRuleTest?ver=12.1.0' } ], policiesReference: { link: 'https://localhost/mgmt/tm/ltm/virtual/~Common~vs/policies?ver=12.1.0', isSubcollection: true }, profilesReference: { link: 'https://localhost/mgmt/tm/ltm/virtual/~Common~vs/profiles?ver=12.1.0', isSubcollection: true } } Get only specfic field of the virtual <vs> The naming convension for the parameters is slightly different from the ones on tmsh, so look for the familiar names in the GET response above. The example below queris the Default Pool (pool). tmsh list ltm <vs> pool curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual/<vs>?options=pool Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', fullPath: 'vs', generation: 1, selfLink: 'https://localhost/mgmt/tm/ltm/virtual/vs?options=pool&ver=12.1.1', pool: '/Common/vs-pool', poolReference: { link: 'https://localhost/mgmt/tm/ltm/pool/~Common~vs-pool?ver=12.1.1' } } Get all the information of the virtual <vs> Unlike the tmsh equivalent, iControl REST GET does not return the configuration information of the attached policies and profiles. To see them, use expandSubcollections . tmsh list ltm <vs> curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual/<vs>?expandSubcollections=true Sample Output { "addressStatus": "yes", "autoLasthop": "default", "cmpEnabled": "yes", "connectionLimit": 0, "destination": "/Common/192.168.184.240:80", "enabled": true, "fullPath": "vs", "generation": 291, "gtmScore": 0, "ipProtocol": "tcp", "kind": "tm:ltm:virtual:virtualstate", "mask": "255.255.255.255", "mirror": "disabled", "mobileAppTunnel": "disabled", "name": "vs", "nat64": "disabled", "policiesReference": { "isSubcollection": true, "link": "https://localhost/mgmt/tm/ltm/virtual/~Common~vs/policies?ver=13.1.0" }, "pool": "/Common/CentOS-all80", "poolReference": { "link": "https://localhost/mgmt/tm/ltm/pool/~Common~CentOS-all80?ver=13.1.0" }, "profilesReference": { "isSubcollection": true, "items": [ { "context": "all", "fullPath": "/Common/http", "generation": 291, "kind": "tm:ltm:virtual:profiles:profilesstate", "name": "http", "nameReference": { "link": "https://localhost/mgmt/tm/ltm/profile/http/~Common~http?ver=13.1.0" }, "partition": "Common", "selfLink": "https://localhost/mgmt/tm/ltm/virtual/~Common~vs/profiles/~Common~http?ver=13.1.0" }, { "context": "all", "fullPath": "/Common/tcp", "generation": 287, "kind": "tm:ltm:virtual:profiles:profilesstate", "name": "tcp", "nameReference": { "link": "https://localhost/mgmt/tm/ltm/profile/tcp/~Common~tcp?ver=13.1.0" }, "partition": "Common", "selfLink": "https://localhost/mgmt/tm/ltm/virtual/~Common~vs/profiles/~Common~tcp?ver=13.1.0" } ], "link": "https://localhost/mgmt/tm/ltm/virtual/~Common~vs/profiles?ver=13.1.0" }, "rateLimit": "disabled", "rateLimitDstMask": 0, "rateLimitMode": "object", "rateLimitSrcMask": 0, "selfLink": "https://localhost/mgmt/tm/ltm/virtual/vs?expandSubcollections=true&ver=13.1.0", "serviceDownImmediateAction": "none", "source": "0.0.0.0/0", "sourceAddressTranslation": { "type": "automap" }, "sourcePort": "preserve", "synCookieStatus": "not-activated", "translateAddress": "enabled", "translatePort": "enabled", "vlansDisabled": true, "vsIndex": 2 } Get stats of the virtual <vs> tmsh show ltm <vs> curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual/<vs>/stats Sample Output { kind: 'tm:ltm:virtual:virtualstats', generation: 1109, selfLink: 'https://localhost/mgmt/tm/ltm/virtual/vs/stats?ver=12.1.0', entries: { 'https://localhost/mgmt/tm/ltm/virtual/vs/~Common~vs/stats': { nestedStats: { kind: 'tm:ltm:virtual:virtualstats', selfLink: 'https://localhost/mgmt/tm/ltm/virtual/vs/~Common~vs/stats?ver=12.1.0', entries: { 'clientside.bitsIn': { value: 12880 }, 'clientside.bitsOut': { value: 34592 }, 'clientside.curConns': { value: 0 }, 'clientside.evictedConns': { value: 0 }, 'clientside.maxConns': { value: 2 }, 'clientside.pktsIn': { value: 26 }, 'clientside.pktsOut': { value: 26 }, 'clientside.slowKilled': { value: 0 }, 'clientside.totConns': { value: 6 }, cmpEnableMode: { description: 'all-cpus' }, cmpEnabled: { description: 'enabled' }, csMaxConnDur: { value: 37 }, csMeanConnDur: { value: 29 }, csMinConnDur: { value: 17 }, destination: { description: '192.168.184.226:80' }, 'ephemeral.bitsIn': { value: 0 }, 'ephemeral.bitsOut': { value: 0 }, 'ephemeral.curConns': { value: 0 }, 'ephemeral.evictedConns': { value: 0 }, 'ephemeral.maxConns': { value: 0 }, 'ephemeral.pktsIn': { value: 0 }, 'ephemeral.pktsOut': { value: 0 }, 'ephemeral.slowKilled': { value: 0 }, 'ephemeral.totConns': { value: 0 }, fiveMinAvgUsageRatio: { value: 0 }, fiveSecAvgUsageRatio: { value: 0 }, tmName: { description: '/Common/vs' }, oneMinAvgUsageRatio: { value: 0 }, 'status.availabilityState': { description: 'available' }, 'status.enabledState': { description: 'enabled' }, 'status.statusReason': { description: 'The virtual server is available' }, syncookieStatus: { description: 'not-activated' }, 'syncookie.accepts': { value: 0 }, 'syncookie.hwAccepts': { value: 0 }, 'syncookie.hwSyncookies': { value: 0 }, 'syncookie.hwsyncookieInstance': { value: 0 }, 'syncookie.rejects': { value: 0 }, 'syncookie.swsyncookieInstance': { value: 0 }, 'syncookie.syncacheCurr': { value: 0 }, 'syncookie.syncacheOver': { value: 0 }, 'syncookie.syncookies': { value: 0 }, totRequests: { value: 4 } } } } } } Change one of the configuration options of the virtual <vs> The command below changes the Description field of the virtual ("description" in tmsh and iControl REST). tmsh modify ltm virtual <vs> description "Hello World!" curl -sku admin:admin https://<host>/mgmt/tm/ltm/<vs> \ -X PATCH -H "Content-Type: application/json" \ -d '{"description": "Hello World!"}' Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', ... description: 'Hello World!', <==== Changed. ... } Disable the virtual <vs> The command syntax is same as above: To change the state of a virtual from "enabled" to "disabled", send "disabled":true. For enabling the virtual, use "enabled":true. Note that the Boolean type true/false does not require quotations. tmsh modify ltm virtual <vs> disabled curl -sku admin:admin https://<host>/mgmt/tm/ltm/<vs> \ -X PATCH -H "Content-Type: application/json" \ -d '{"disabled": true}' \ Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', fullPath: 'vs', ... disabled: true, <== Changed ... } Add another iRule to <vs> When the virtual has iRules already attached, you need to send the existing ones too along with the additional one. For example, to add /Common/testRule1 to the virtual with /Common/testRule1, specify both in an array (square brackets). Note that the /Common/testRule2 iRule object should be already created. tmsh modify ltm virtual <vs> rules {testRule1 testRule2} curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual/<vs> \ -X PATCH -H "Content-Type: application/json" \ -d '{"rules": ["/Common/testRule1", "/Common/testRule2"] }' Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', fullPath: 'vs', ... rules: [ '/Common/test1', '/Common/test2' ], <== Changed rulesReference: [ { link: 'https://localhost/mgmt/tm/ltm/rule/~Common~test1?ver=12.1.1' }, { link: 'https://localhost/mgmt/tm/ltm/rule/~Common~test2?ver=12.1.1' } ], ... } Create a new virtual <vs> You can create a skeleton virtual by specifying only Destination Address and Mask. The remaining parameters such as profiles are set to default. You can later modify the parameters by PATCH-ing. tmsh create ltm virtual <vs> destination <ip:port> mask <ip> curl -sku admin:admin -X POST -H "Content-Type: application/json" \ -d '{"name": "vs", "destination":"192.168.184.230:80", "mask":"255.255.255.255"}' \ https://<host>/mgmt/tm/ltm/virtual Sample Output { kind: 'tm:ltm:virtual:virtualstate', name: 'vs', partition: 'Common', fullPath: '/Common/vs', ... destination: '/Common/192.168.184.230:80', <== Created ... mask: '255.255.255.255', <== Created ... } Create a new virtual <vs> with a lot of parameters You can specify all the essential parameters upon creation. This example creates a new virtual with pool, default persistence profile, profiles, iRule, and source address translation. The call fails if any of the parameters conflicts. For example, you cannot specify "Cookie Persistence" without specifying appropriate profiles. If you do not specify any profile, it falls back to the default fastL4 , which is not compatible with Cookie Persistence. tmsh create ltm virtual <vs>destination <ip:port>mask <ip>pool <pool>persist replace-all-with { cookie }profiles add { tcp http clientssl }rules { <rule> }source-address-translation { type automap } curl -sku admin:admin https://<host>/mgmt/tm/ltm/virtual -H "Content-Type: application/json" -X POST -d '{"name": "vs", \ "destination": "10.10.10.10:10", \ "mask": "255.255.255.255", \ "pool": "CentOS-all80", \ "persist": [ {"name": "cookie"} ], \ "profilesReference": {"items": [ {"context": "all", "name": "http"}, {"context": "all", "name": "tcp"}, {"context": "clientside", "name": "clientssl"}] }, \ "rules": [ "ShowVersion" ], \ "sourceAddressTranslation": {"type": "automap"} }' Sample Output { "addressStatus": "yes", "autoLasthop": "default", "cmpEnabled": "yes", "connectionLimit": 0, "destination": "/Common/10.10.10.10:10", "enabled": true, "fullPath": "/Common/test", "generation": 592, "gtmScore": 0, "ipProtocol": "tcp", "kind": "tm:ltm:virtual:virtualstate", "mask": "255.255.255.255", "mirror": "disabled", "mobileAppTunnel": "disabled", "name": "vs", "nat64": "disabled", "partition": "Common", "persist": [ { "name": "cookie", "nameReference": { "link": "https://localhost/mgmt/tm/ltm/persistence/cookie/~Common~cookie?ver=13.1.0" }, "partition": "Common", "tmDefault": "yes" } ], "policiesReference": { "isSubcollection": true, "link": "https://localhost/mgmt/tm/ltm/virtual/~Common~test/policies?ver=13.1.0" }, "pool": "/Common/CentOS-all80", "poolReference": { "link": "https://localhost/mgmt/tm/ltm/pool/~Common~CentOS-all80?ver=13.1.0" }, "profilesReference": { "isSubcollection": true, "link": "https://localhost/mgmt/tm/ltm/virtual/~Common~test/profiles?ver=13.1.0" }, "rateLimit": "disabled", "rateLimitDstMask": 0, "rateLimitMode": "object", "rateLimitSrcMask": 0, "rules": [ "/Common/ShowVersion" ], "rulesReference": [ { "link": "https://localhost/mgmt/tm/ltm/rule/~Common~ShowVersion?ver=13.1.0" } ], "selfLink": "https://localhost/mgmt/tm/ltm/virtual/~Common~test?ver=13.1.0", "serviceDownImmediateAction": "none", "source": "0.0.0.0/0", "sourceAddressTranslation": { "type": "automap" }, "sourcePort": "preserve", "synCookieStatus": "not-activated", "translateAddress": "enabled", "translatePort": "enabled", "vlansDisabled": true, "vsIndex": 52 } Delete a virtual <vs> tmsh delete ltm virtual <vs> curl -sku admin:admin https://192.168.226.55/mgmt/tm/ltm/virtual/<vs> -X DELETE Sample Output No output (just 200 OK and no response body) References curl.1 the man page curl Releases and Downloads ... including the port for Windows Jason Rahm's "Demystifying iControl REST" series(DevCentral) -- This is Part I of 7 at the time of this article. iControl REST API reference (DevCentral) iControl® REST API User Guide (DevCentral) -- Link is for 12.1. Search for the older versions.15KViews3likes7CommentsBuilding an OpenSSL Certificate Authority - Creating Your Root Certificate
Creating Your Root Certificate Authority In our previous article, Introductions and Design Considerations for Eliptical Curveswe covered the design requirements to create a two-tier ECC certificate authority based on NSA Suite B's PKI requirements. We can now begin creating our CA's root configuration. Creating the root CArequires us to generate a certificate and private key,since this is the first certificate we're creating, it will be self-signed. The root CA will not sign client and server certificates, it's job it only to create intermeidary certificates and act as the root of our chain of trust. This is standard practice across the public and private PKI configurations and so too should your lab environments. Create Your Directory Structure Create a directory to store your root CA pair and config files. # sudo bash # mkdir /root/ca Yep, I did that. This is for a test lab and permissions may not match real world requirements. I sudoed into bash and created everything under root; aka playing with fire. This affects ownership down the line if you chmod private key files and directoriesto user access only so determine for yourself what user/permission will be accessing files for certificate creation. I have a small team and trust them with root within a lab environment (snapshots allow me to be this trusting). Create your CA database to keep track of signed certificates # cd /root/ca # mkdir private certs crl # touch index.txt # echo 1000 > serial We begin by creating a working root directory with sub directories for the various files we'll be creating. This will allow you to apply your preferred security practices should you choose to do so. Since this is a test lab and I am operating as root, I won't be chmod'ing anything today. Create Your OpenSSL Config File OpenSSLuses configuration files to simplify/template the components of a certificate. Copy the GIST openssl_root.cnf file to /root/ca/openssl_root.cnf which is already prepared for this demo. For the root CA certificate creation, the [ CA ] section is required and will gather it's configuration from the [ CA_default ] section. [ ca ] # `man ca` default_ca = CA_default The [CA_default] section in the openssl_root.cnf file contains the variables OpenSSL will use for the root CA. If you're using alternate directory names from this demo, update the file accordingly. Note the long values for default days (10 years) as we don't care about renewing the root certificate anytime soon. [ CA_default ] # Directory and file locations. dir = /root/ca certs = $dir/certs crl_dir = $dir/crl new_certs_dir = $dir/certs database = $dir/index.txt serial = $dir/serial RANDFILE = $dir/private/.rand # The root key and root certificate. private_key = $dir/private/ca.cheese.key.pem certificate = $dir/certs/ca.cheese.crt.pem # For certificate revocation lists. crlnumber = $dir/crlnumber crl = $dir/crl/ca.cheese.crl.pem crl_extensions = crl_ext default_crl_days = 3650 # SHA-1 is deprecated, so use SHA-2 or SHA-3 instead. default_md = sha384 name_opt = ca_default cert_opt = ca_default default_days = 3650 preserve = no policy = policy_strict For the root CA, we define [policy_strict] which will later force the intermediary's certificateto match country, state/province, and organization name fields. [ policy_strict ] The root CA should only sign intermediate certificates that match. # See POLICY FORMAT section of `man ca`. countryName = match stateOrProvinceName = match organizationName = match organizationalUnitName = optional commonName = supplied emailAddress = optional The [ req ] section is used for OpenSSL certificate requests. Some of the values listed will not be used since we are manually specifying them during certificate creation. [ req ] # Options for the `req` tool (`man req`). default_bits = 4096 distinguished_name = req_distinguished_name string_mask = utf8only # SHA-1 is deprecated, please use SHA-2 or greater instead. default_md = sha384 # Extension to add when the -x509 option is used. x509_extensions = v3_ca I pre-populate the [ req_distinguished_name ] section with values I'll commonly used to save typing down the road. [ req_distinguished_name ] countryName = Country Name (2 letter code) stateOrProvinceName = State or Province Name localityName = Locality Name 0.organizationName = Organization Name organizationalUnitName = Organizational Unit Name commonName = Common Name emailAddress = Email Address # Optionally, specify some defaults. countryName_default = US stateOrProvinceName_default = WA localityName_default = Seattle 0.organizationName_default = Grilled Cheese Inc. organizationalUnitName_default = Grilled Cheese Root CA emailAddress_default = grilledcheese@yummyinmytummy.us The [ v3_ca ] section will further define the Suite B PKI requirements, namely basicConstraints and acceptable keyUsage values for a CA certificate. This section will be used for creating the root CA's certificate. [ v3_ca ] # Extensions for a typical CA (`man x509v3_config`). subjectKeyIdentifier = hash authorityKeyIdentifier = keyid:always,issuer basicConstraints = critical, CA:true keyUsage = critical, digitalSignature, cRLSign, keyCertSign Selecting the Suite B compliant elliptical curve We're creating a Suite B infrastructure so we'll need to pick an acceptable curve following P-256 or P-384. To do this, run the following OpenSSLcommand: openssl ecparam -list_curves This will give you a long list of options but which one to pick? Let's isolate the suites within the 256 & 384 prime fields; we can grep the results for easier curve identification. openssl ecparam -list_curves | grep '256\|384' And we get the following results (your results may vary depending on the version of OpenSSL running): # openssl ecparam -list_curves | grep '256\|384' secp256k1 : SECG curve over a 256 bit prime field secp384r1 : NIST/SECG curve over a 384 bit prime field prime256v1: X9.62/SECG curve over a 256 bit prime field brainpoolP256r1: RFC 5639 curve over a 256 bit prime field brainpoolP256t1: RFC 5639 curve over a 256 bit prime field brainpoolP384r1: RFC 5639 curve over a 384 bit prime field brainpoolP384t1: RFC 5639 curve over a 384 bit prime field I am going to use secp384r1 as my curve of choice. It's good to mention that RFC5480 notes secp256r1 (not listed) is referred to as prime256v1 for this output's purpose. Why not use something larger than 384? Thank Google. People absolutely were using secp521r1 then Google dropped support for it (read Chromium Bug 478225 for more). The theoryis since NSA Suite B PKI did not explicitly call out anything besides 256 or 384, the Chromium team quietly decided it wasn't needed and dropped support for it. Yea... it kinda annoyed a few people. So to avoid future browser issues, we're sticking with what's defined in public standards. Create the Root CA's Private Key Using the names defined in the openssl_root.cnf's private_key value and our selected secp384r1 ECC curve we will create and encrypt the root certificates private key. # openssl ecparam -genkey -name secp384r1 | openssl ec -aes256 -out private/ca.cheese.key.pem read EC key writing EC key Enter PEM pass phrase: ****** Verifying - Enter PEM pass phrase: ****** Note:The ecparam function within OpenSSL does not encrypt the private key like genrsa/gendsa/gendh does. Instead we combined the private key creation (openssl ecparam) with a secondary encryption command (openssl ec) to encrypt private key before it is written to disk. Keep the password safe. Create the Root CA's Certificate Using the new private key, we can now generate our root'sself-signed certificate. We do this because the root has no authority above it to request trust authority from;it is the absolute source of authority in our certificate chain. # openssl req -config openssl_root.cnf -new -x509 -sha384 -extensions v3_ca -key private/ca.cheese.key.pem -out certs/ca.cheese.crt.pem Enter pass phrase for private/ca.cheese.key.pem: ****** You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [US]: State or Province Name [WA]: Locality Name [Seattle]: Organization Name [Grilled Cheese Inc.]: Organizational Unit Name [Grilled Cheese Root CA]: Common Name []:Grilled Cheese Root Certificate Authority Email Address [grilledcheese@yummyinmytummy.us]: Using OpenSSL we can validate the Certificate contents to ensure we're following the NSA Suite B requirements. # openssl x509 -noout -text -in certs/ca.cheese.crt.pem Certificate: Data: Version: 3 (0x2) Serial Number: ff:bd:f5:2f:c5:0d:3d:02 Signature Algorithm: ecdsa-with-SHA384 Issuer: C = US, ST = WA, L = Seattle, O = Grilled Cheese Inc., OU = Grilled Cheese Root CA, CN = Grilled Cheese Inc. Root Certificate Authority, emailAddress = grilledcheese@yummyinmytummy.us Validity Not Before: Aug 22 23:53:05 2017 GMT Not After : Aug 20 23:53:05 2027 GMT Subject: C = US, ST = WA, L = Seattle, O = Grilled Cheese Inc., OU = Grilled Cheese Root CA, CN = Grilled Cheese Inc. Root Certificate Authority, emailAddress = grilledcheese@yummyinmytummy.us Subject Public Key Info: Public Key Algorithm: id-ecPublicKey Public-Key: (384 bit) pub: 04:a6:b7:eb:8b:9f:fc:95:03:02:20:ea:64:7f:13: ea:b7:75:9b:cd:5e:43:ca:19:70:17:e2:0a:26:79: 0a:23:2f:20:de:02:2d:7c:8f:62:6b:74:7d:82:fe: 04:08:38:77:b7:8c:e0:e4:2b:27:0f:47:01:64:38: cb:15:a8:71:43:b2:d9:ff:ea:0e:d1:c8:f4:8f:99: d3:8e:2b:c1:90:d6:77:ab:0b:31:dd:78:d3:ce:96: b1:a0:c0:1c:b0:31:39 ASN1 OID: secp384r1 NIST CURVE: P-384 X509v3 extensions: X509v3 Subject Key Identifier: 27:C8:F7:34:2F:30:81:97:DE:2E:FC:DD:E2:1D:FD:B6:8F:5A:AF:BB X509v3 Authority Key Identifier: keyid:27:C8:F7:34:2F:30:81:97:DE:2E:FC:DD:E2:1D:FD:B6:8F:5A:AF:BB X509v3 Basic Constraints: critical CA:TRUE X509v3 Key Usage: critical Digital Signature, Certificate Sign, CRL Sign Signature Algorithm: ecdsa-with-SHA384 30:65:02:30:77:a1:f9:e2:ab:3a:5a:4b:ce:8d:6a:2e:30:3f: 01:cf:8e:76:dd:f6:1f:03:d9:b3:5c:a1:3d:6d:36:04:fb:01: f7:33:27:03:85:de:24:56:17:c9:1a:e4:3b:35:c4:a8:02:31: 00:cd:0e:6c:e0:d5:26:d3:fb:88:56:fa:67:9f:e9:be:b4:8f: 94:1c:2c:b7:74:19:ce:ec:15:d2:fe:48:93:0a:5f:ff:eb:b2: d3:ae:5a:68:87:dc:c9:2c:54:8d:04:68:7f Reviewing the above we can verify the certificate details: The Suite B Signature Algorithm: ecdsa-with-SHA384 The certificate date validity when we specificed -days 3650: Not Before: Aug 22 23:53:05 2017 GMT Not After : Aug 20 23:53:05 2027 GMT The Public-Key bit length: (384 bit) The Issuer we defined in the openssl_root.cnf: C = US, ST = WA, L = Seattle, O = Grilled Cheese Inc., OU = Grilled Cheese Root CA, CN = Grilled Cheese Inc. Root Certificate Authority The Certificate Subject, since this is self-signed, refers back to itself: Subject: C = US, ST = WA, L = Seattle, O = Grilled Cheese Inc., OU = Grilled Cheese Root CA, CN = Grilled Cheese Inc. Root Certificate Authority The eliptical curve used when we created the private key: NIST CURVE: P-384 Verify the X.509 v3 extensions we defined within the openssl_root.cnf for a Suite B CA use: X509v3 Basic Constraints: critical CA:TRUE X509v3 Key Usage: critical Digital Signature, Certificate Sign, CRL Sign The root certificate and private key are now compete and we have the first part of our CA complete. Step 1 complete! In our next article we willcreate the intermediary certificate to complete the chain of trust in our two-tier hierarchy.15KViews0likes8CommentsGetting Started with iRules: Variables
If you've been following along in this series, it's time to add another building block to the framework of what iRules are and can do. If you're new, it would behoove you to start at the beginning and catch up. So far we've covered introductions across the board for programming basics and concepts, F5 terminology and basic technology concepts, the core of what iRules are and why you'd use them, as well as a couple of cornerstone iRules concepts like events and priorities. All of these concepts are required to get a proper understanding of the base iRules infrastructure and functionality. Using those concepts as foundations we're going to add to the mix something that's integral to any programming language: variables. We'll cover a bit about what variables are, but also some iRules specific variables functionality and commentary. Things to look for in this article: What is a variable? How do I work with variables in my iRule? What types of variables are available to me in iRules? Is there a performance impact when using variables? When should I use variables? What is a variable? A variable, in simple terms, is a piece of data stored in memory. This is done usually with the notion of using that data again at some point, recalling it to make use of it later in your script. For instance if you want to store the hostname of an incoming connection so that you can reference that hostname on the response, or if you want to store the result of a given command, etc. those things would be stored in a variable. Every scripting language has variables of some form or another, and they're quite important in the grand scheme of things. Without them you'd be building static scripts to perform one off, iterative tasks. Variables are a large part of what allows dynamic programming to account for multiple conditions and use cases. Whether it's storing the data from a math operation to be compared against a desired result, or checking to see if a given condition has been met yet, variables are at the very core of just about everything in programming, and aren't something that we could live without in modern coding. The idea is simple, take a piece of data, whether it's a number or a string or...anything, and store it in memory with a unique name. Then, later, you can recall the value of that data by simply referencing the name you created to represent it. You can, of course, modify, or delete variables at will also. How do I work with variables in my iRule? There are two main functions when it comes to any variable: setting and retrieving. To set a variable in Tcl you simply use the set command and specify the desired value. This can be a static or dynamic value, such as an integer or the result of a command. The desired value is then stored in memory and associated with the variable name supplied. This looks like: #Basic variable creation in Tcl set integer 5 set hostname [HTTP::host] To retrieve the value associated with a given variable you simply reference that variable directly and you will get the resulting value. For instance "$integer" and "$hostname" would reference the values from the above example. Of course calling them by themselves won't do much good. Simple referring to a variable within your code will do pretty much nothing. You'll almost certainly be referencing the variables in relation to something or from another command. I.E.: #Basic variable reference to retrieve and use the value stored in memory if {$integer > 0) { log local0. "Host: $hostname" } What types of variables are available to me in iRules? This topic can creep in scope pretty darn quickly, given that variables are just a simple memory structure, and there are many different types of memory structures available to you via Tcl and iRules. From simple variables to arrays to tables and data groups, there are many ways to manage data in memory. For the purposes of this article, however, we're going to focus on the two main types of actual variables and leave the discussion of other data structures for later. There are two main types of variables in iRules, local and global. Local Variables All variables, unless otherwise specified, are created as local variables within an iRule. What does that mean? Well, a local variable means that it is assigned the same scope as the iRule that created it. All iRules are inherently connection based, and as such all local variables are connection based as well. This means that the connection dictates the memory space for a given iRule's local variables and data. For instance, if connection1 comes in and an iRule executes, creating 5 variables, those variables will only exist until connection1 closes and the connection is terminated on the BIG-IP. At that time the memory allocated to that flow will be freed up, and the variables created while processing that particular connection's iRule(s) will no longer be accessible. This is the case with all iRules and all variables created from within an iRule using the basic set command structure pictured above. Local variables are low cost, easy to use, you never have to worry about memory management with them, as they are automatically cleaned up when the connection terminates. It's important to remember that iRules as a whole, and the variables therein are connection bound. This can cause some confusion when people are expecting a more static state. Local variables will account for the vast majority of your variable usage within iRules. They're efficient, easy to use, and highly useful depending on the situation. These can be set directly as shown above but are also often the result of a command that provides output. There are also multiple ways to reference a variable within iRules. When using a command that directly affects the variable it is usually appropriate to leave the "$" off and reference the name directly, other times braces allow you to more clearly define the beginning and end of a variable name. Some examples would look like: #Standard variable reference log local0. "My host is $host" #Set variable to the output of a particular command using brackets [] set int [expr {5 + 8}] #Directly manipulating a variable's value means no "$", most times incr int #Bracing can allow you to deliniate between variable name and adjacent characters log local0. "Today's date is the ${int}th" Global Variables "Global variables" is a bit of a misnomer, actually. This is the general terminology used within most programming languages, including Tcl, for variables that exist outside of the local memory space. I.E., in the case of iRules, variables that exist beyond the constraints of a single connection. For instance, what if I want to store the IP address of my logging server, and have that always available, to every connection that comes through the BIG-IP, without having to re-set that variable every single time my iRule fires? That would be a global variable. Tcl has a mechanism for handling this, and it's relatively easy to use. Interestingly, though...we aren't using it. The global variable handling within Tcl requires a shared memory space, which in our world does something referred to as "demoting" from CMP. As you'll recall from the "Introduction to F5 Technology & Terms" article, CMP is Clustered Multi-Processing, and is the technology that allows us to distribute tasks within the BIG-IP to multiple cores in an efficient, scalable manner. Because of the requirements of the default Tcl global variable handling, making use of a global variable within Tcl forces any connection going through the Virtual to which the offending iRule is applied to be demoted from CMP, I.E. use only a single processing core, rather than all of them to process the traffic for that Virtual. This is a bad thing, and will severely limit performance. As such, we strongly recommend avoiding global variables in their traditional sense all together. But what about that log server address? There's still a definite need for long lived data to be stored in memory and available at will. It's for this purpose that we've included a new namespace within iRules called the "static" namespace. You can effectively set static global variable data in the static namespace without breaking CMP, and thereby not decreasing performance. To do so simply set up your static::varname variables, likely in RULE_INIT, since that special event only runs once at load time and static variables are global in scope, meaning they stay set until the configuration is reloaded. Once these variables are set you can call them like you would any other variable from within any iRule, and they will always be available. It looks something like this: #Set a static variable value, which will exist until config reload, living outside of the scope of any one particular iRule set static::logserver "10.10.1.145" #Reference that static variable just as you would any other variable from within any iRule log $static::logserver "This is a remote log message" For a more complete look at the different types of memory structures that you can access in iRules, I've included a handy dandy table to show memory structures by type along with some information about each, and an example of using that structure. We'll cover some of these in more detail in later installments of this series, but I want to make you aware of the different types of memory structures available. Note: There is a slight error in the table. It IS possible to unset static variables. Is there a performance impact when using variables? Running any command that isn't cached in any script has some cost associated with it, there's just no way around it. Variables in iRules happen to have a miniscule cost, generally speaking, so long as you're using them appropriately. The cost associated with a variable is in the creation process. It takes resources, albeit a very small amount, to store the desired data in memory and create a reference to that data to be used in the future. Accessing a variable is simply making a call to that reference, and as such doesn't have an additional cost. A common misunderstanding, however, is just what constitutes a variable within iRules, vs. a command or function that will perform a query. Many people see things like "HTTP::host" or "IP::client_addr" and, due to the format, assume it is a command or function and as such will cost CPU cycles to query the value and return it. This is not the case at all. These type of references are cached within TMM, so whether you call "HTTP::host" once or 100 times, you're not going to require more resources, as you're not performing a query to determine the hostname each time, rather just referencing a value that's already stored in memory. Think of these and many other similar commands as pre-populated variable data that you can use at will. When should I use variables? While the cost of creating variables is low, there still is some overhead associated with it. In iRules, due to the exorbitantly high rate of execution in some deployments, we tend to lean towards extreme efficiency mindedness. In this vein we recommend only using variables where they are actually necessary, rather than many programming practices which dictate to use them often as a means of keeping code tidy, even when not truly warranted. For instance, a common practice with many new iRule programmers is to do things like set host [HTTP::host] As I just explained above, however, this is completely unnecessary. Rather, it would be more efficient to simply re-use the HTTP::host command any time you need to reference this information. When it does make sense to use a variable, however, is when you are going to modify the data in some way. For instance log local0. "My lower case URI: [string tolower [HTTP::uri]]" The above will give you an all lowercase representation of the HTTP URI. This is a very common use case, and it is not abnormal to have the need to reference the lowercase version of the URI multiple times in a given iRule. While the HTTP::uri command is cached and will not incur additional overhead regardless of how many times you reference it, the string tolower command is not. As such, it would make sense in this case, assuming you're going to reference the lowercase URI at least 2 or more times, to create a variable and reference that: set loweruri [string tolower [HTTP::uri]] log local0. "My lower case URI: $loweruri" Effectively you want to use variables any time you are going to have to repeat any operation against a value that has a cost associated with it. Rather than repeat that operation multiple times and accumulate extra overhead it's better to perform the operation once, store the result, and reference the variable from there. That covers the basics of variables: What they are, how they work, when to use them and when not, which types you can make use of and how they'll affect your performance, if at all. Hopefully that allows you to approach your iRules with that much more confidence, understanding such a core piece of their makeup. In the next article we'll dig into control structures and operators.14KViews3likes3Comments