Sharing same VLAN between vCMP guest
Hello, This question is regarding to sharing same VLAN between vCMP guest for F5 viprion platform. lets say, I have a VLAN 10 which is tagged to interface 1.1 at vCMP host level and propagated to Guest A in common partition. -For the guest B can I use same VLAN? -What would be the recommend way to share VLANs between guests? -Can we tag VLAN 10 to 1.2 interface at vCMP host level and share it with Guest B?515Views0likes2Comments
BIG-IP to Cisco via 10Gb SFP+ Direct Attach Copper
Hi, Anybody using Cisco DAC 10G transceiver/copper cables (TwinAx) to connect from a Cisco switch to a BIG-IP? Can't seem to find an answer, suspect it is not supported which is always an issue for DACs between vendors. Cheers1.3KViews0likes14Comments
OCSP With CRL Fallback
Hi all, I've been trying to get my head around OCSP and CRL in a rush. My requirement is relatively simple but without APM (not an option) I'm trying to do this via an iRule. Anyway, the requirement is this; -Use OCSP as the primary method of verifying client certificates (requires an OCSP profile) -Use CRL (not CRLDP) as a fallback should the OCSP responders be unavailable for any reason (requires an SSL profile) According to this, if both are applied (via profiles) then both checks must 'pass' not just one or the other, hence the iRule. I've found examples of using OCSP in an iRule here, here and here (thanks Hoolio) but litle around CRL checking. So, my questions are; -Can I use an iRule to perform the OCSP check and then, if OCSP fails for some reason, switch to an SSL profile that has CRL checking enabled so that CRL checking is performed? -If not, does anyone has any example code for performing a CRL check? -Would it simply be better to use a Pool (or something along these lines) and check it's up rather than do the OCSP check 'manually' in the iRule?831Views0likes6Comments
LDAPS Monitor with Certificate Expiration
Hi Team, I have been working with my AD team trying to resolve a problem where they forget to update a Domain Controller certificate and it expires and ADLDAPS queries fail since they dont bind to expired certificates. They have requested to see if we can drop a member out of the pool if the certificate is expired ( ie, not a valid SSL cert ) I have been messing with the LDAP Health monitor, turning on the Security settings, but I dont believe this would actually check that a certificate is valid or not. I know with server side SSL configuration you can enable SSL authentication but would just stop traffic from flow, not actually drop a member out of the pool. Any ideas ?643Views0likes4Comments
Setting BIG-IP LTM Virtual Server for two SQL Servers nodes
I've created BIG-IP Virtual Edition instance in Amazon EC2 using this tutorial. I've followed this tutorial to configure BIG-IP System as an MS SQL Database Proxy. There were couple things that I didn't get in "Creating a database proxy virtual server" section: For the Destination setting, in the Address field, type the IP address you want to use for the virtual server. The IP address you type must be available and not in the loopback network. In the Service Port field, type 1443. Which IP address should I use in destination field? Public IP, which I use to connect to BIG-IP WEB UI? Why it says set service port to 1443, not 1433, which is default to SQL Server? For now I set public IP and 1443 port and tried to verify connection using UDL file I have two DB nodes and when trying to verify connection directly to their IP addresses - connection succeeds. But when I try BIG-IP public IP - connection fails with the following error message: Test connection failed because of an error in initializing provider. [DBNETLIB][ConnectionOpen (Connect()).]SQL Server does not exist or access denied. Both nodes are enabled and available in LTM (Local Traffic Manager). Any ideas what I'm doing wrong?570Views0likes3Comments
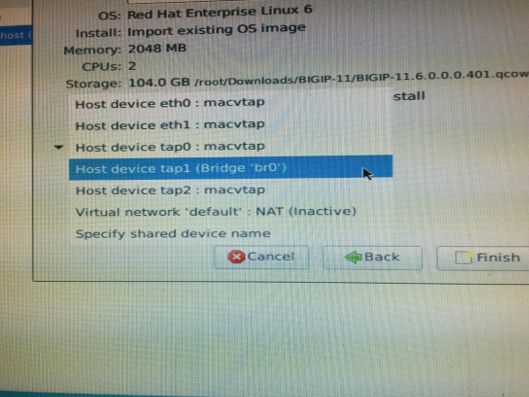
What am I doing wrong with this network configuration for KVM (F5 virtual edition)
Hello, I have been trying to setup an F5 lab using KVM on debian. I currently have the following network configuration (/etc/network/interfaces - see output pasted at end of post) although whenever I go to create the VM in KVM, only one tap is associated with the bridge (trying to use the taps for management, external, and internal interfaces on the F5 VM). (see screenshot at end of post) Would anyone have any suggestions for configuring networking properly for this setup? I'm open to anything at this point in time. Thanks for your help. source /etc/network/interfaces.d/* auto lo iface lo inet loopback allow-hotplug eth0 iface eth0 inet dhcp iface eth0 inet6 auto auto br0 iface br0 inet dhcp pre-up ip tuntap add dev tap0 mode tap user root pre-up ip tuntap add dev tap1 mode tap user root pre-up ip tuntap add dev tap2 mode tap user root pre-up ip link set tap0 up pre-up ip link set tap1 up pre-up ip link set tap2 up bridge_ports all tap0 tap1 tap2 bridge_stp off bridge_maxwait 0 bridge_fd 0 post-down ip link set tap0 down post-down ip link set tap1 down post-down ip link set tap2 down post-down ip tuntap del dev tap0 mode tap post-down ip tuntap del dev tap1 mode tap post-down ip tuntap del dev tap2 mode tap249Views0likes1CommentAAM IBR and browser conditional GET - expert advice needed
Hi, I am trying to figure out why browser is performing conditional GET instead of imediatelly retrieve object from local cache. Browser is connecting to VS with Web Acceleration AAM enabled profile assigned. IBR is working as I can see hash added to objects, Cache-Control headers are present. Still each time page is reloaded for all objects conditional GET is issued. That makes IBR less than optimal as there is no saving on RTT for conditional GETs. Below transactions for one object First page load, clean cache GET /Portals/0/portal.css;wa42c972a572376dab?cdv=545 HTTP/1.1 Host: www.host.com Accept: text/css,*/*;q=0.1 Accept-Encoding: gzip, deflate, sdch Accept-Language: pl-PL,pl;q=0.8,en-US;q=0.6,en;q=0.4 Cookie: .ASPXANONYMOUS=ksN9_Z2-0AEkAAAAMWU0NGU1M2QtZWYxNy00ZjYzLTllM2UtODBiZTM1ZGRiNWQ40; ASP.NET_SessionId=0qsuljchcmws3rnxe5u1mrh4; _gat=1; _gat_agregate=1; _gat_sklepagregate=1; _ga=GA1.2.2117847018.1430923777; language=pl-PL Referer: http://www.host.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 HTTP/1.1 200 OK Accept-Ranges: none Age: 1718 Cache-Control: public, max-age=864000 Connection: Keep-Alive Content-Encoding: gzip Content-Length: 462 Content-Type: text/css Date: Fri, 08 May 2015 10:20:37 GMT ETag: W/"WA42c972a572376dab" Expires: Mon, 18 May 2015 10:20:37 GMT Last-Modified: Tue, 22 Apr 2014 12:56:40 GMT Server: Vary: Accept-Encoding X-UA-Compatible: IE=Edge X-WA-Info: [V2.S10101.A82290.P94462.N13694.RN0.U947762373].[OT/all.OG/includes] Reload, cache primed GET /Portals/0/portal.css;wa42c972a572376dab?cdv=545 HTTP/1.1 Host: www.host.com Accept: text/css,*/*;q=0.1 Accept-Encoding: gzip, deflate, sdch Accept-Language: pl-PL,pl;q=0.8,en-US;q=0.6,en;q=0.4 Cache-Control: max-age=0 Cookie: .ASPXANONYMOUS=ksN9_Z2-0AEkAAAAMWU0NGU1M2QtZWYxNy00ZjYzLTllM2UtODBiZTM1ZGRiNWQ40; ASP.NET_SessionId=0qsuljchcmws3rnxe5u1mrh4; _gat=1; _gat_agregate=1; _gat_sklepagregate=1; _ga=GA1.2.2117847018.1430923777; language=pl-PL If-Modified-Since: Wed, 08 Oct 2014 09:23:55 GMT Referer: http://www.host.com/ User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 HTTP/1.1 304 Not Modified Accept-Ranges: none Age: 2007 Cache-Control: public, max-age=864000 Connection: Keep-Alive Content-Type: text/css Date: Fri, 08 May 2015 10:25:26 GMT ETag: W/"WA42c972a572376dab" Expires: Mon, 18 May 2015 10:25:26 GMT Last-Modified: Tue, 22 Apr 2014 12:56:40 GMT Server: X-UA-Compatible: IE=Edge X-WA-Info: [V2.S10101.A82290.P94462.N13694.RN0.U947762373].[OT/all.OG/includes] I am not HTTP expert but for me conditional get does not makes any sense. Why it's performed? Tested in both Chrome 42.0.2311.135 and Firefox 37.0.2 (on Win2008 srv). I was reading some post about Chrome behaving like that - sending conditional GET even if object in cache is not expired (seems to be something similar looking at Cache-Control: max-age=0 in reload request). But the same for Firefox as well? Is that kind of bug feature? If so is there any way to modify AAM to force browser not do that? I did additional test (this time using Wireshark not browser plugins) and result was: Browser opened (cache is primed), url entered, only GET for / in Wireshark, no other request Reload used - request for all objects in Wireshark bith OK 200 and 304 Not Modified I am a bit lost what's going on. Piotr266Views0likes2Comments