How to get a F5 BIG-IP VE Developer Lab License
To assist DevOps teams improve their development for the BIG-IP platform, F5 offers a low cost developer lab license.This license can be purchased from your authorized F5 vendor. If you do not have an F5 vendor, you can purchase a lab license online: CDW BIG-IP Virtual Edition Lab License CDW Canada BIG-IP Virtual Edition Lab License Once completed, the order is sent to F5 for fulfillment and your license will be delivered shortly after via e-mail. F5 is investigating ways to improve this process. To download the BIG-IP Virtual Edition, please log into downloads.f5.com (separate login from DevCentral), and navigate to your appropriate virtual edition, example: For VMware Fusion or Workstation or ESX/i:BIGIP-16.1.2-0.0.18.ALL-vmware.ova For Microsoft HyperV:BIGIP-16.1.2-0.0.18.ALL.vhd.zip KVM RHEL/CentoOS: BIGIP-16.1.2-0.0.18.ALL.qcow2.zip Note: There are also 1 Slot versions of the above images where a 2nd boot partition is not needed for in-place upgrades. These images include_1SLOT- to the image name instead of ALL. The below guides will help get you started with F5 BIG-IP Virtual Edition to develop for VMWare Fusion, AWS, Azure, VMware, or Microsoft Hyper-V. These guides follow standard practices for installing in production environments and performance recommendations change based on lower use/non-critical needs fo Dev/Lab environments. Similar to driving a tank, use your best judgement. DeployingF5 BIG-IP Virtual Edition on VMware Fusion Deploying F5 BIG-IP in Microsoft Azure for Developers Deploying F5 BIG-IP in AWS for Developers Deploying F5 BIG-IP in Windows Server Hyper-V for Developers Deploying F5 BIG-IP in VMware vCloud Director and ESX for Developers Note: F5 Support maintains authoritativeAzure, AWS, Hyper-V, and ESX/vCloud installation documentation. VMware Fusion is not an official F5-supported hypervisor so DevCentral publishes the Fusion guide with the help of our Field Systems Engineering teams.73KViews13likes143CommentsImplementing SSL Orchestrator - High Level Considerations
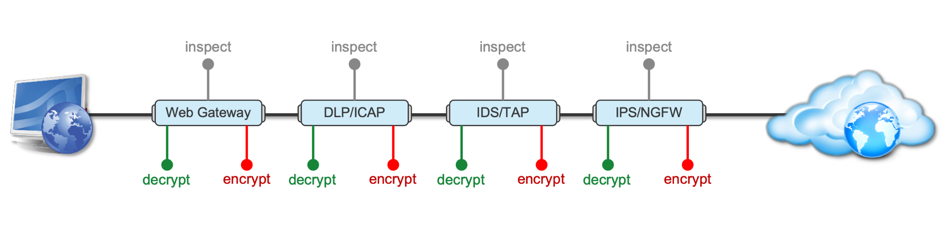
Introduction This article is the beginning of a multi-part series on implementing BIG-IP SSL Orchestrator. It includes high availability and central management with BIG-IQ. Implementing SSL/TLS Decryption is not a trivial task. There are many factors to keep in mind and account for, from the network topology and insertion point, to SSL/TLS keyrings, certificates, ciphersuites and on and on. This article focuses on pre-deployment tasks and preparations for SSL Orchestrator. This article is divided into the following high level sections: Solution Overview Customer Use Case Architecture & Network Topology Please forgive me for using SSL and TLS interchangeably in this article. Software versions used in this article: BIG-IP Version: 14.1.2 SSL Orchestrator Version: 5.5 BIG-IQ Version: 7.0.1 Solution Overview Data transiting between clients (PCs, tablets, phones etc.) and servers is predominantly encrypted with Secure Socket Layer (SSL) and its evolution Transport Layer Security (TLS)(ref. Google Transparency Report). Pervasive encryption means that threats are now predominantly hidden and invisible to security inspection unless traffic is decrypted.The decryption and encryption of data by different devices performing security functions potentially adds overhead and latency.The picture below shows a traditional chaining of security inspection devices such as a filtering web gateway, a data loss prevention (DLP) tool, and intrusion detection system (IDS) and next generation firewall (NGFW). Also, TLS/SSL operations are computationally intensive and stress the security devices’ resources.This leads to a sub-optimal usage of resource where compute time is used to encrypt/decrypt and not inspect. F5’s BIG-IP SSL Orchestrator offers a solution to optimize resource utilization, remove latency, and add resilience to the security inspection infrastructure. F5 SSL Orchestrator ensures encrypted traffic can be decrypted, inspected by security controls, then re-encrypted—delivering enhanced visibility to mitigate threats traversing the network. As a result, you can maximize your security services investment for malware, data loss prevention (DLP), ransomware, and next-generation firewalls (NGFW), thereby preventing inbound and outbound threats, including exploitation, callback, and data exfiltration. The SSL Orchestrator decrypts the traffic and forwards unencrypted traffic to the different security devices for inspection leveraging its optimized and hardware-accelerated SSL/TLS stack.As shown below the BIG-IP SSL Orchestrator classifies traffic and selectively decrypts traffic.It then forwards it to the appropriate security functions for inspection.Finally, once duly inspected the traffic is encrypted and sent on its way to the resource the client is accessing. Deploying F5 and inline security tools together has the following benefits: Traffic Distribution for load sharing Improve the scalability of inline security by distributing the traffic across multiple Security appliances, allowing them to share the load and inspect more traffic. Agile Deployment Add, remove, and/or upgrade Security appliances without disrupting network traffic; converting Security appliances from out-of-band monitoring to inline inspection on the fly without rewiring. Customer Use Case This document focuses on the implementation of BIG-IP SSL Orchestrator to process SSL/TLS encrypted traffic and forward it to a security inspection/enforcement devices. The decryption and forwarding behavior are determined by the security policy. This ensures that only targeted traffic is decrypted in compliance with corporate and regulator policy, data privacy requirements, and other relevant factors. The configuration supports encrypted traffic that originates from within the data center or the corporate network.It also supports traffic originating from clients outside of the security perimeter accessing resources inside the corporate network or demilitarized zone (DMZ) as depicted below. The decrypted traffic transits through different inspection devices for inbound and outbound traffic. As an example, inbound traffic is decrypted and processed by F5’s Advanced Web Application Firewall (F5 Advanced WAF) as shown below. *Can be encrypted or cleartext as needed As an example, outbound traffic is decrypted and sent to a next generation firewall (NGFW) for inspection as shown in the diagram below. The BIG-IP SSL Orchestrator solution offers 5 different configuration templates. The following topologies are discussed in Network Insertion Use Cases. L2 Outbound L2 Inbound L3 Outbound L3 Inbound L3 Explicit Proxy Existing Application In the use case described herein, the BIG-IP is inserted as layer 3 (L3) network device and is configured with an L3 Outbound Topology. Architecture & Network Topology The assumption is that, prior to the insertion of BIG-IP SSL Orchestrator into the network (in a brownfield environment), the network looks like the one depicted below.It is understood that actual networks will vary, that IP addressing, L2 and L3 connectivity will differ, however, this is deemed to be a representative setup. Note: All IP addressing in this document is provided as examples only.Private IP addressing (RFC 1918) is used as in most corporate environments. Note: the management network is not depicted in the picture above.Further discussion about management and visibility is the subject of Centralized Management below. The following is a description of the different reference points shown in the diagram above. a.This is the connection of the border routers that connect to the internet and other WAN and private links. Typically, private IP addressing space is used from the border routers to the firewalls. b.The border switching connects to the corporate/infrastructure firewall.Resilience is built into this switching layer by implementing 2 link aggregates (LAG or Port Channel ®). c.The “demilitarized zone”(DMZ) switches are connected to the firewall.The DMZ network hosts application that are accessible from untrusted networks such as the Internet. d.Application server connect into the DMZ switch fabric. e.Firewalls connect into the switch fabric.Typically core and distribution infrastructure switching will provide L2 and L3 switching to the enterprise (in some case there may be additional L3 routing for larger enterprises/entities that require dynamic routing and other advanced L3 services. f.The connection between the core and distribution layers are represented by a bus on the figure above because the actual connection schema is too intricate to picture.The writer has taken the liberty of drawing a simplified representation.Switches actually interconnect with a mixture of link aggregation and provide differentiated switching using virtualization (e.g. VLAN tagging, 802.1q), and possibly further frame/packet encapsulation (e.g. QinQ, VxLAN). g.The core and distribution switching are used to create 2 broadcast domains. One is the client network, and the other is the internal application network. h.The internal applications are connected to their own subnet. The BIG-IP SSL Orchestrator solution is implemented as depicted below. In the diagram above, new network connections are depicted in orange (vs. blue for existing connections).Similarly to the diagram showing the original network, the switching for the DMZ is depicted using a bus representation to keep the diagram simple. The following discusses the different reference points in the diagram above: a.The BIG-IP SSL Orchestrator is connected to the core switching infrastructure A new VLAN and network are created on the core switching infrastructure to connect to the firewalls (North) to the BIG-IP SSL Orchestrator devices. b.The client network (South) is connected to the BIG-IP via a second VLAN and network. c.The SSL Orchestrator devices are connected to a newly created inspection network.This network is kept separate from the rest of the infrastructure as client traffic transits through the inspection devices unencrypted.As an example, Web Application Firewalls (BIG-IP ASM) are used to filter inbound traffic. d. The LAN configuration for the connection to the BIG-IP ASM is as depicted below. e. The NGFW is connected to the INSPECTION switching network in such a manner that traffic traverses it when the BIG-IP SSL Orchestrator is configured to push traffic for inspection. Summary This article should be a good starting point for planning your initial SSL Orchestrator deployment. We covered the solution overview and use cases. The network topology and architecture was explained with the help of diagrams. Next Steps Click Next to proceed to the next article in the series4.4KViews7likes4Comments
File Uploads and ASM
File Uploads through a WAF Let’s say we have a web application with a form field that permits the upload of arbitrary files. It would appear to the user similar to the below: Aside from photos, the application may permit users to upload Word documents, Excel spreadsheets, PDF’s, and so forth. This can cause many false positives when the web application is protected by ASM, because the uploaded files may: Contain attack signatures. Image files may be parsed as ASCII, and suspicious-looking strings detected; Word or Excel documents may contain XSS tags or SQL injection strings. After all, Mr. ‘Select’ – ‘Union City’ -- is one of our most valuable customers. Contain illegal metacharacters, like XSS tags <> Be so large that the maximum request size (10MB by default) is exceeded Trip other violations It is therefore necessary to inform ASM that a particular parameter on a form field is one that contains a file upload so that checking for attack signatures and metacharacters can be disabled. Why not just disable the signature? Simply, because we do not want to introduce unnecessary exposure into the security policy. Just because a particular signature causes a false positive on the file upload transaction does not mean it should do elsewhere on the web application. At the time of writing, ASM permits attack signatures to be selectively disabled on parameters, but not URLs. Identify the Upload Parameter(s) Use a HTTP inspection tool such as Fiddler, Burp or Developer Tools to determine the name of the upload parameter and URL. In this case, we are uploading a JPG file named DSCF8205.JPG; the parameter used to transfer the file is called ‘filename1’. The URL is /foo.cfm. NOTE: This can also be obtained from the ASM request log; however these do sometimes get truncated making it impossible to determine the parameter name if it occurs more than 5KB into the request. Define the Upload Parameter(s) Assuming the upload is specific to a given URL, create that URL in the ASM policy. Next, create a parameter with the name we discovered earlier, and ensure it is set to type ‘File Upload’. Alternate Configuration Options If file upload is possible in many parts of the site using the same filename, create the parameter globally without defining the URL as we did first here If many file upload parameters are present on a single page with a similar name (e.g. filename1, filename2, filename3…), create a wildcard parameter name filename* ‘Disallow file upload of executables’ is a desirable feature. It checks the magic number of the uploaded file and blocks the upload if it indicates an executable file. As with all ASM configurations, understanding the HTTP fields passed to the application is key The above procedure should work for most cases, and arbitrary file uploads (except executables) should be allowed. However, there are some cases where additional configuration is required. Didn’t Work? Attack signatures have a defined scope, as seen below: Table C.1Attack signature keywords and usage Keyword Usage content Match in the full content. SeeUsing the content rule option, for syntax information. uricontent Match in the URI, including the query string (unless using theobjonlymodifier). SeeUsing the uricontent rule option, for syntax information. headercontent Match in the HTTP headers. SeeUsing the headercontent rule option, for syntax information. valuecontent Matches an alpha-numeric user-input parameter (or an extra-normalizedparameter, if using thenormmodifier); used for parameter values and XML objects. SeeUsing the valuecontent rule option, for syntax information, andScope modifiers for the pcre rule option, for more information on scope modifiers. An XML payload is checked for attack signatures when thevaluecontentkeyword is used in the signature. Note:Thevaluecontentparameter replaces theparamcontentparameter that was used in the Application Security Manager versions earlier than 10.0. reference Provides an external link to documentation and other information for the rule. SeeUsing the reference rule option, for syntax information. This information can be found in ASM under “Attack Signatures List”. As an example, search for ‘Path Traversal’ attack types and expand signature id’s 200007006 and 200007000: A signature with a ‘Request’ scope does not pay any attention to parameter extraction – it just performs a bitwise comparison of the signature to the entire request as a big flat hex blob. So to prevent this signature from being triggered, we can (a) disable it, (b) use an iRule to disable it on these specific requests. Before we can use iRules on an ASM policy, we need to switch on the ‘Trigger ASM iRule Events’ setting on the main policy configuration page. Further information can be found at: https://techdocs.f5.com/kb/en-us/products/big-ip_asm/manuals/product/asm-implementations-11-5-0/27.html. The below is an iRule that will prevent a request meeting the following characteristics from raising an ASM violation: Is a POST URI ends with /foo.cfm Content-Type is ‘multipart/form-data’ Attack Signature violation raised with signature ID 200007000 when ASM_REQUEST_VIOLATION { if {([HTTP::method] equals "POST") and ([string tolower [HTTP::path]] ends_with "/foo.cfm") and ([string tolower [HTTP::header "Content-Type"]] contains "multipart/form-data") } { if {([lindex [ASM::violation_data] 0] contains "VIOLATION_ATTACK_SIGNATURE_DETECTED") and ([ASM::violation details] contains "sig_data.sig_id 200007000") } { ASM::unblock } } } What if you’re getting a lot of false positives and just want to disable attack signatures with Request scope? when ASM_REQUEST_VIOLATION { if {([HTTP::method] equals "POST") and ([string tolower [HTTP::path]] ends_with "/foo.cfm") and ([string tolower [HTTP::header "Content-Type"]] contains "multipart/form-data") } { if {([lindex [ASM::violation_data] 0] contains "VIOLATION_ATTACK_SIGNATURE_DETECTED") and ([ASM::violation details] contains "context request") } { ASM::unblock } } } But it’s not an attack signature… False positives might also be generated by large file uploads exceeding the system-defined maximum size. This value is 10MB by default and can be configured. See https://support.f5.com/csp/article/K7935 for more information. However, this is a system-wide variable, and it may not be desirable to change this globally, nor may it be desirable to disable the violation. Again, we can use an iRule to disable this violation on the file upload: when ASM_REQUEST_VIOLATION { if {([HTTP::method] equals "POST") and ([string tolower [HTTP::path]] ends_with "/foo.cfm") and ([string tolower [HTTP::header "Content-Type"]] contains "multipart/form-data") } { if {([lindex [ASM::violation_data] 0] contains "VIOLATION_REQUEST_TOO_LONG") } { ASM::unblock } } } ASM iRules reference https://clouddocs.f5.com/api/irules/ASM__violation_data.html https://clouddocs.f5.com/api/irules/ASM__violation.html https://clouddocs.f5.com/api/icontrol-soap/ASM__ViolationName.html12KViews3likes7Comments
Is TCP's Nagle Algorithm Right for Me?
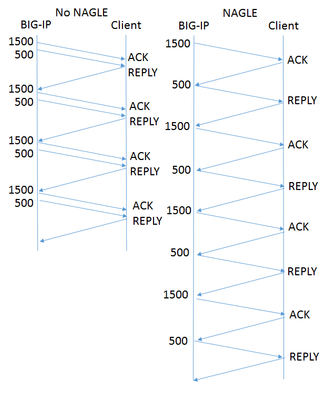
Of all the settings in the TCP profile, the Nagle algorithm may get the most questions. Designed to avoid sending small packets wherever possible, the question of whether it's right for your application rarely has an easy, standard answer. What does Nagle do? Without the Nagle algorithm, in some circumstances TCP might send tiny packets. In the case of BIG-IP®, this would usually happen because the server delivers packets that are small relative to the clientside Maximum Transmission Unit (MTU). If Nagle is disabled, BIG-IP will simply send them, even though waiting for a few milliseconds would allow TCP to aggregate data into larger packets. The result can be pernicious. Every TCP/IP packet has at least 40 bytes of header overhead, and in most cases 52 bytes. If payloads are small enough, most of the your network traffic will be overhead and reduce the effective throughput of your connection. Second, clients with battery limitations really don't appreciate turning on their radios to send and receive packets more frequently than necessary. Lastly, some routers in the field give preferential treatment to smaller packets. If your data has a series of differently-sized packets, and the misfortune to encounter one of these routers, it will experience severe packet reordering, which can trigger unnecessary retransmissions and severely degrade performance. Specified in RFC 896 all the way back in 1984, the Nagle algorithm gets around this problem by holding sub-MTU-sized data until the receiver has acked all outstanding data. In most cases, the next chunk of data is coming up right behind, and the delay is minimal. What are the Drawbacks? The benefits of aggregating data in fewer packets are pretty intuitive. But under certain circumstances, Nagle can cause problems: In a proxy like BIG-IP, rewriting arriving packets in memory into a different, larger, spot in memory taxes the CPU more than simply passing payloads through without modification. If an application is "chatty," with message traffic passing back and forth, the added delay could add up to a lot of time. For example, imagine a network has a 1500 Byte MTU and the application needs a reply from the client after each 2000 Byte message. In the figure at right, the left diagram shows the exchange without Nagle. BIG-IP sends all the data in one shot, and the reply comes in one round trip, allowing it to deliver four messages in four round trips. On the right is the same exchange with Nagle enabled. Nagle withholds the 500 byte packet until the client acks the 1500 byte packet, meaning it takes two round trips to get the reply that allows the application to proceed. Thus sending four messages takes eight round trips. This scenario is a somewhat contrived worst case, but if your application is more like this than not, then Nagle is poor choice. If the client is using delayed acks (RFC 1122), it might not send an acknowledgment until up to 500ms after receipt of the packet. That's time BIG-IP is holding your data, waiting for acknowledgment. This multiplies the effect on chatty applications described above. F5 Has Improved on Nagle The drawbacks described above sound really scary, but I don't want to talk you out of using Nagle at all. The benefits are real, particularly if your application servers deliver data in small pieces and the application isn't very chatty. More importantly, F5® has made a number of enhancements that remove a lot of the pain while keeping the gain: Nagle-aware HTTP Profiles: all TMOS HTTP profiles send a special control message to TCP when they have no more data to send. This tells TCP to send what it has without waiting for more data to fill out a packet. Autonagle:in TMOS v12.0, users can configure Nagle as "autotuned" instead of simply enabling or disabling it in their TCP profile. This mechanism starts out not executing the Nagle algorithm, but uses heuristics to test if the receiver is using delayed acknowledgments on a connection; if not, it applies Nagle for the remainder of the connection. If delayed acks are in use, TCP will not wait to send packets but will still try to concatenate small packets into MSS-size packets when all are available. [UPDATE:v13.0 substantially improves this feature.] One small packet allowed per RTT: beginning with TMOS® v12.0, when in 'auto' mode that has enabled Nagle, TCP will allow one unacknowledged undersize packet at a time, rather than zero. This speeds up sending the sub-MTU tail of any message while not allowing a continuous stream of undersized packets. This averts the nightmare scenario above completely. Given these improvements, the Nagle algorithm is suitable for a wide variety of applications and environments. It's worth looking at both your applications and the behavior of your servers to see if Nagle is right for you.1.2KViews2likes5CommentsBIG-IP Configuration Conversion Scripts
Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP.While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible.Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python)1.6KViews1like13Comments
F5 in AWS Part 4 - Orchestrating BIG-IP Application Services with Open-Source tools
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 The following post references code hosted at F5's Github repository f5networks/aws-deployments. This code provides a demonstration of using open-source tools to configure and orchestrate BIG-IP. Full documentation for F5 BIG-IP cloud work can be found at Cloud Docs: F5 Public Cloud Integrations. So far we have talked above AWS networking basics, how to run BIG-IP in a VPC, and highly-available deployment footprints. In this post, we’ll move on to my favorite topic, orchestration. By this point, you probably have several VMs running in AWS. You’ve lost track of which configuration is setup on which VM, and you have found yourself slowly going mad as you toggle between the AWS web portal and several SSH windows. I call this ‘point-and-click’ purgatory. Let's be blunt, why would you move to cloud without realizing the benefits of automation, of which cloud is a large enabler. If you remember our second article, we mentioned CloudFormation templates as a great way to deploy a standardized set of resources (perhaps BIG-IP + the additional virtualized network resources) in EC2. This is a great start, but we need to configure these resources once they have started, and we need a way to define and execute workflows which will run across a set of hosts, perhaps even hosts which are external to the AWS environment. Enter the use of open-source configuration management and workflow tools that have been popularized by the software development community. Open-source configuration management and AWS APIs Lately, I have been playing with Ansible, which is a python-based, agentless workflow engine for IT automation. By agentless, I mean that you don’t need to install an agent on hosts under management. Ansible, like the other tools, provides a number of libraries (or “modules”) which provide the ability to manage a diverse collection of remote systems. These modules are typically implemented through the use of API calls, often over HTTP. Out of the box, Ansible comes with several modules for managing resources in AWS. While the EC2 libraries provided are useful for basic orchestration use cases, we decided it would be easier to atomically manage sets of resources using the CloudFormation module. In doing so, we were able to deploy entire CloudFormation stacks which would include items like VPCs, networking elements, BIG-IP, app servers, etc. Underneath the covers, the CloudFormation: Ansible module and our own project use the python module to interact with AWS service endpoints. Ansible provides some basic modules for managing BIG-IP configuration resources. These along with libraries for similar tools can be found here: Ansible Puppet SaltStack In the rest of this post, I’ll discuss some work colleagues and I have done to automate BIG-IP deployments in AWS using Ansible. While we chose to use Ansible, we readily admit that Puppet, Chef, Salt and whatever else you use are all appropriate choices for implementing deployment and configuration management workflows for your network. Each have their upsides and downsides, and different tools may lend themselves to different use cases for your infrastructure. Browse the web to figure out which tool is right for you. Using Standardized BIG-IP Interfaces Speaking of APIs, for years F5 has provided the ability to programmatically configure BIG-IP using iControlSOAP. As the audiences performing automation work have matured, so have the weapons of choice. The new hot ticket is REST (Representational State Transfer), and guess what, BIG-IP has a REST interface (you can probably figure out what it is called). Together, iControlSOAP and iControlREST give you the power to manage nearly every configuration element and feature of BIG-IP. These interfaces become extremely powerful when you combine them with your favorite open-source configuration management tool and a cloud that allows you to spin up and down compute and networking resources. In the project described below, we have also made use of iApps using iControlRest as a way to create a standard virtual server configuration with the correct policies and profiles. The documentation in Github describes this in detail, but our approach shows how iApps provide a strongly supported approach for managing network policy across engineering teams. For example, imagine that a team of software engineers has written a framework to deploy applications. You can package the network policy into iApps for various types of apps, and pass these to the teams writing the deployment framework. Implementing a Service Catalog To pull the above concepts together, a colleague and I put together the aws-deployments project.The goal was to build a simple service catalog which would enable a user to deploy a containerized application in EC2 with BIG-IP network services sitting in front. This is example code that is not supported by F5 support but is a proof of concept to show how you can fully automate production-like deployments in AWS. Some highlights of the project include: Use of iControlRest and iControlSoap within Ansible playbooks to setup advanced topologies of BIG-IP in AWS. Automated deployment of a basic ASM web application firewall policy to protect a vulnerable web app (Hackazon. Use of iApps to manage virtual server configurations, including the WAF policy mentioned above. Figure 1 - Generic Architecture for automating application deployments in public or private cloud In examination of the code, you will see that we provide the opportunity to provision all the development models outlined in our earlier post (a single standalone VE, standalones BIG-IP VEs striped availability zones, clusters within an availability zone, etc). We used Ansible and the interfaces on BIG-IP to orchestrate the workflows assoiated with these deployment models. To perform the clustering step, we have used the iControlSoap interface on BIG-IP. The final set of technology used is depicted in Figure 3. Figure 2 - Technologies used in the aws-deployments project on Github Read the Code and Test It Yourself All the code I have mentioned is available at f5networks/aws-deployments. We encourage you to download and run the code for yourself. Instructions for setting up a development environment which includes the necessary dependencies is easy. We have packaged all the dependencies for use with either Vagrant or Docker as development tools. The instructions for either of these approaches can be found in the README.md or in the /docs directory. The following video shows an end-to-end usage example. (Keep in mind that the code has been updated since this video was produced). At the end of the day, our goal for this work was to collect customer feedback. Please provide some by leaving a comment below, or by filing ‘pull requests’ or ‘issues’ in Github. In the next few weeks, we will be updating the project to include the Hackazon app mentioned above, show how to cluster BIG-IP across availability zones, and how to deploy an ASM profile with an iApp. Have fun!1.3KViews1like3CommentsF5 in AWS Part 2 - Running BIG-IP in an EC2 Virtual Private Cloud
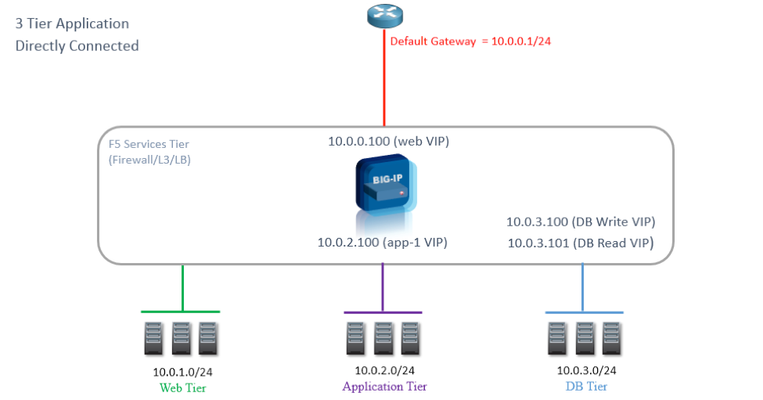
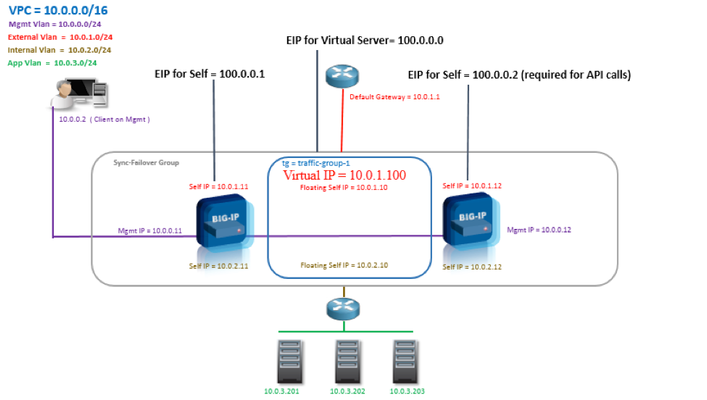
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 Previously in this series, we discussed the networking fundamentals of Virtual Private Clouds (VPC) in Amazon’s Elastic Compute Cloud (EC2). Some of the topics we touched on include the impact of the removal of layer 2 access, limits on network elements like the number of interfaces and publicly routable IP addresses, and how to manage routing within your subnets. Today we’ll cover licensing models and images available in Amazon, sizing requirements, including the number of interfaces assignable to BIG-IP, some basic network topologies, and how you can use Amazon CloudFormation templates to make your life easier when deploying BIG-IP. Licensing Models There are two ways you can run BIG-IP in AWS, at an utility rateor Bring Your Own License (BYOL). Utility Model you pay Amazon both for the compute and disk requirements of the instances AND for the BIG-IP software license at an hourly rate There are two forms: hourly or annual subscriptions. Using annual licenses you can save 37%. Follow the instructions on AWS to purchase an annual subscription. When launching hourly instances, the devices boot into a licensed state and are immediately ready for provisioning BYOL Model You do pay Amazon only for the compute + disk footprint, notfor the F5 software license. Version Plus licenses (like "V12" or "V13") can be reused in Amazon if you have them from previous deployments You must license the device after it launches, either manually or in an orchestration manner. Available as individual licenses, or in volume as license pools. All in all, the utility licensing model offers significant flexibility to scale up your infrastructure to meet demand, while reducing the amount you pay for base traffic throughput. It may be advantagious to use this model if you experience large traffic swings. In contrast, you may be able to achieve this flexibility at a lower cost using BYOL license pools. With volume (pool) licensing, licenses can be reused across devices as you ramp these instances up/down. In addition to choosing between utility and BYOL licenses models, you’ll also need to choose the licensed features and the throughput level. When taking a BYOL approach, the license (which you may have already) will have a max throughput level and will be associated with a Good/Better/Best (GBB) package. For more information on GBB, see Simplified Licensing: Compare our Good, Better, Best product bundles. When deciding on the throughput level, you may license up to 1Gbit/s using hourly AMIs. It is possible to import a 3Gbit/s VE license in AWS, but note that AWS caps the throughput on an instance to 2Gbit/s, so you will be limited by Amazon EC2 restrictions, rather than F5. Driving 2Gbit/s through your virtual instance in AWS will require careful implementation of your configuration in BIG-IP. Also, note that the throughput restrictions on each image include both data plane and management traffic. You can read more about throughput restrictions for virtual instances here: K14810: Overview of BIG-IP VE license and throughput limits. Once you have an chosen a license model, GBB package, and throughput, select the corrosponding AMI in the Amazon Marketplace. Disk and Compute Recommendations: An astute individual will wonder why there exist separate images for each GBB package. In an effort to maintain the smallest footprint possible, each AMI includes just enough disk volume for licensed features. Each GBB package has different disk of requirements which are built into the AMI. For evidence of this, use the AWS CLI to see details on a specific image: aws ec2 describe-images --filter "Name=name,Values=*F5 Networks BYOL BIGIP-13.1.0.2.0.0.6* Truncated output: { "Images": [ { "ProductCodes": [ { "ProductCodeId": "91wwm31qya4s3rkc5bv4jq9b3", "ProductCodeType": "marketplace" } ], "Description": "F5 Networks BYOL BIGIP-13.1.0.2.0.0.6 - Better - Jan 16 2018 10_13_53AM", "VirtualizationType": "hvm", "Hypervisor": "xen", "ImageOwnerAlias": "aws-marketplace", "EnaSupport": true, "SriovNetSupport": "simple", "ImageId": "ami-3bbd0243", "State": "available", "BlockDeviceMappings": [ { "DeviceName": "/dev/xvda", "Ebs": { "Encrypted": false, "DeleteOnTermination": true, "VolumeType": "gp2", "VolumeSize": 82, "SnapshotId": "snap-0c9beaa9345422784" } } ], "Architecture": "x86_64", "ImageLocation": "aws-marketplace/F5 Networks BYOL BIGIP-13.1.0.2.0.0.6 - Better - Jan 16 2018 10_13_53AM-98eb3c1e-ab48-41ff-9c94-d71a5d08e49f-ami-0c93b176.4", "RootDeviceType": "ebs", "OwnerId": "679593333241", "RootDeviceName": "/dev/xvda", "CreationDate": "2018-01-24T19:58:31.000Z", "Public": true, "ImageType": "machine", "Name": "F5 Networks BYOL BIGIP-13.1.0.2.0.0.6 - Better - Jan 16 2018 10_13_53AM-98eb3c1e-ab48-41ff-9c94-d71a5d08e49f-ami-0c93b176.4" }, From the above, you can see that the Good BYOL image configures a single Elastic Block Store (EBS) 31 Gb volume, whereas the Best image comes with two EBS volumes, totaling 124Gb in space. On the discussion of storage, we would like to take a moment to focus on analytics. While the analytics module is licensed in the "Good" package, you may need additional disk space in order to provision this module. See this link (https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/bigip-ve-setup-msft-hyper-v-11-5-0/3.html) for increasing the disk space on a specific volumes. Another option for working around this issue is to use a “Better” AMI. This will ensure you have enough space to provision the analytics module. In addition to storage, running BIG-IP as a compute node in EC2 also requires a minimum number of interfaces, vCPUs and RAM. AskF5's Virtual Edition and Supported Hypervisors Matrix provides a list of recommended instance types although you can choose alternatives as long as they support your architecture's configurations. In short, as you choose higher performance instance types in EC2, you get more RAM and more network interfaces. This will allow you to create more advanced topologies and services. Basic Network Topologies So with a limited number of interfaces, how do you build a successful multi-tier application architecture? Many customers might start with a directly connected architecture like that shown below: In this architecture, 10.0.0.100 is the virtual server. The address matches an EC2 private IP on the external interface, either the first assigned to that interface (the primary private IP) or a secondary private IP. Not shown is the Elastic IP address (EIP) which maps to this private IP. We recommend using the primary private IP as the external self-IP on BIG-IP. An Elastic IP can then be attached to this primary private IP to allow outbound calls. The 1:1 NAT performed by Amazon between the public (elastic) IP and private IP is invisible to BIG-IP. Keep in mind that a publicly routable self-IP is required to use the BIG-IP failover mechanism, which makes HTTP calls to AWS. We’ll discuss failover in a few moments. Secondary privates IPs and corresponding EIPs on the external interface can then be used for each virtual server. Given this discussion about interfaces and EIPs, be sure to consider that the instance type you choose in Amazon will dictate how many virtual servers you can run on BIG-IP. For example, given a m3.xlarge (allowed three interfaces) and the default account limited of 5 EIPs, you will be limited to 3 virtual servers. In this case, one interface will be used to attach each of the management, external, and internal subnets. On the external interface, you would attach 3 secondary interfaces, each with an EIP. The other two EIPs would be used for the management port and external self-IP. To get more interfaces, move up instance sizes ( -> m3.xxlarge). To get more EIPs, request them from Amazon. If you do use an EIP for the management port, be sure to ACL it appropriately. The benefit of the directly connected architecture shown above, where BIG-IP can serve as the default gateway, is that each node in the tier can communicate with other nodes in the tiers and leverage virtual listeners on BIG-IP without having to be SNATed. This is sometimes preferred as it makes it simpler to implement E-W security & analytics.The problem, as shown below, is that as application or tenant density increases so does the number of required interfaces. Alternatively, routed architectures (shown below) where pool members live on remote networks, are more easily migrated and suitable to situations with limited network interfaces. In the case below, the route table for all pool members must be contain a default route that leads back to BIG-IP. By doing so, you can: leverage BIG-IP for outbound use case (secure outbound traffic) return internet traffic back through the BIG-IP and avoid SNAT’ing your internet facing VIPs . Note: requires disabling SRC/DST Check on your BIG-IP instances/interfaces An alternate, and perhaps more realistic view of the above looks like: Finally, it may make sense to attach an additional interfaces for each application to increase the application density BIG-IP: These routed architectures allow you to reduce the number of interfaces used to connect internal networks, which then enables you to leverage the remaining interfaces to increase application density. Two potential drawbacks include the requirement of SNAT (as BIG-IP is no longer inline to intercept response traffic) and adding an additional network hop. The up/down stream router will generally intercept the return traffic because the client is also on a directly connected or closer network. Elastic IPs = Floating IPs and API Based Failover After you have figured how to incorporate BIG-IP into your network, the final step before deploying applications and network services will be ensuring you can maintain high-availability. One of the challenges in adapting BIG-IP for public clouds was that the availability model of BIG-IP (“Device Service groups”, or DSCs) was tightly coupled to sharing L2/L3 floating addresses in the same L2 segment. An active device made an L2 broadcast (GARP) to take over "Active" ownership of IP addresses and other network listeners. In accordance with the removal of L2, BIG-IP has adapted and replaced the GARP failover method with API calls to Amazon. These API calls toggle ownership of Amazon secondary private-IP addresses between devices. Any EIPs which map to these secondary IP addresses will now point to the new active device. Note here that floating IPs in BIG-IP speak are now equivalent to secondary IPs in the EC2 world. One issue to be aware of with the API-based failover mechanism is the increase in failover time to =~ 10 sec per EIP. This is the time it takes for changes to propagate in AWS’s network. While this downtime is still significantly less than a DNS timeout, it is troublesome as BIG-IP’s Device Service Group (DSC) feature was specifically introduced to provide sub-second failover. Newer applications built for cloud are typically designed to handle these changes in availability concepts, but this makes it more challenging to shift traditional workloads to layer-3-only environments like AWS. Historically, the DSC group feature has also allowed the use of BIG-IP as a highly available default gateway. This was accomplished by directing the default route to the internal floating self-IP on a cluster or by directly connecting application servers. In Amazon, the default route may point to an internet gateway or a device interface, but not a statically named IPaddress. We'll leave the fix for this problem for the next article where we will also talk about other deployment models of BIG-IP in AWS, including those which span availability zones. CloudFormation Templates To close this article, we’ve decided to provide examples of how BIG-IP can be deployed using CloudFormation Templates (CFT) in AWS. CloudFormation is an AWS service that enables you to define a set of EC2 resources that can be automatically and deterministically deployed in your account. These application “stacks” are defined in JSON, making them easier to read and share. F5 provides serveral CFTs with options for licensing model, high availability, and auto-scaling (for LTM and WAF modules). Please review the Github Big-IP Version Matrix for AWS CFT Templates document within our f5-aws-cloudformation repository to determine your deployment requirements. Enjoy!3.3KViews1like3CommentsF5 in AWS Part 3 - Advanced Topologies and More on Highly Available Services
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 Thus far in our article series about running BIG-IP in EC2, we’ve talked about some VPC/EC2 routing and network concepts, and we walked through the basics of running and licensing BIG-IP in this environment. It’s time now to discuss some more advanced topologies that will provide highly redundant and highly available network services for your applications. As we touched upon briefly in our last article, failover between BIG-IP devices has typically relied upon L2 networking protocols to reach sub-second failover times. We’ve also hinted over this series of articles as to how your applications might need to change as they move to AWS. We recognize that while some applications will see the benefit of a rewrite, and will perhaps place fewer requirements on the network for failover, other applications will continue to require stateful mechanisms from the network in order to be highly available. Below we will walk through 3 different topologies with BIG-IP that may make sense for your particular needs. We leave a 4th, auto-scale of BIG-IP released in version 12.0, for a future article. Each of the topologies we list has drawbacks and benefits, which may make them more or less useful given your tenancy models, SLAs, and orchestration capabilities. Availability Zones We've mentioned them before, but when discussing application availability in AWS, it would be negligent to skip over the concept of Availability Zones. At a high-level, these are co-located, but physically isolated datacenters (separate power/networking/etc) in which EC2 instances are provisioned. For a more detailed/accurate description, see the official AWS docs: What Is Amazon EC2: Regions and Availability Zones Because availability zones are geographically close in proximity, the latency between them is very low (2~3 ms). Because of this, they can be treated as one logical data center (latency is low enough for DB tier communication). AWS recommends deploying services across at least two AZs for high availability. To distribute services across geographical areas, you can of course leverage AWS Regions with all the caveats that geographically dispersed datacenters present on the application or database tiers. Let's get down to it, and examine our first model for deploying BIG-IP in a highly available fashion in AWS. Our first approach will be very simple: deploy BIG-IP within a single zone in a clustered model. This maps easily to the traditional network environment approach using Device Service Clusters (DSC) we are used seeing with BIG-IP. Note: in the following diagrams we have provided detailed IP and subnet annotations. These are provided for clarity and completeness, but are by no means the only way you may set up your network. In many cases, we recommend dynamically assigning IP addresses via automation, rather than fixing IP address to specific values (this is what the cloud is all about). We will typically use IP addresses in range 10.0.0.0/255.255.244.0 for the first subnet, 10.0.1.0/255.255.244.0 in the second subnet, and so on. 100.x.x.x/255.0.0.0 denote publicly routable IPs (either Elastic IPs or Public IPs in AWS). Option 1: HA Cluster in a single AZ Benefits: Traditional HA. If a BIG-IP fails, service is "preserved". Tradeoffs: No HA across Datacenters/AZs. Like single DC deployment, if the AZ in which your architecture is deployed goes down, the entire service goes down. HA Summary: Single device failure = heartbeat timeout (approx. 3 sec) + API call (7-12 sec) AZ failure = entire deployment As mentioned, this approach provides the closest analogue to a traditional BIG-IP deployment in a datacenter. Because we don’t see the benefits AWS availability zones in this deployment, this architecture might make most sense when your AWS deployment acts as a disaster recovery site. A question when examining this architecture might be: “What if we put a cluster in each AZ?” Option 2: Clusters/HA pair in each AZ Benefits: Smallest service impact for either a device failure or an AZ failure. Shared DB backend but still provides DC/AZ redundancy Similar to multiple DC deployment, generally provides Active/Active capacity. Tradeoffs: Cost: both pairs are located in a single region. Pairs are traditionally reserved for "geo/region" availability Extra dependency and cost of DNS/GSLB. Management overhead of maintaining configurations and policies of two separate systems (although this problem might be easily handled via orchestration) HA Summary: Single device failure = heartbeat timeout (approx. 3 sec) + API call (7-12 sec) for 1/2 Traffic AZ failure = DNS/GSLB timeout for 1/2 traffic The above model provides a very high level of redundancy. For this reason, it seems to make most sense when incorporated into shared-service or multi-tenant models. The model also begs the question, can we continue to scale out across AZs, and can we do so for applications that do not require that the ADC manage state (e.g. no sticky sessions)? This leads us to our next approach. Option 3: Standalones in each AZ Benefits: Cost Leverage availability zone concepts Similar to multiple DC deployment, Active/Active generally adds capacity Easiest to scale Tradeoffs: Management overhead of maintaining configuration and policies across two or more separate systems; application state is not shared across systems within a geo/region Requires DNS/GSLB even though not necessarily "geo-region" HA Best suited for inbound traffic For outbound use case: you have the distributed gateway issue (i.e. who will be the gateway, how will device/instance failure be handled, etc.) SNAT required (return traffic needs to return to originating device). For Internal LB model: DNS required to distribute traffic between each AZ VIP. HA Summary: Single device failure = DNS/GSLB timeout for 1/(N Devices) traffic.. AZ failure = DNS/GSLB timeout for 1/(N Devices) traffic One of the common themes between options 2 and 3 is that orchestration is required to manage the configuration across devices. In general, the problem is that the network objects (which are bound to layer 3 addresses) cannot be shared due to differing underlying subnets. Summary Above, a number of options for deploying BIG-IP in highly available or horizontally-scaled models were discussed. The path you take will depend on your application needs. For example, if you have an application that requires persistent connections, you'll want to leverage one of the architectures which leverage device clustering and an Active/Standby approach. If persistence is managed within your application, you might aim to try one of the horizontally scalable models. Some of the deployment models we discussed are better enabled by the use of configuration management tools to manage the configuration objects across multiple BIG-IPs. In the next article we'll walk through how the lifecycle of BIG-IP and network services can be fully automated using open-source tools in AWS. These examples will show the power of using the iControlSoap and iControlREST APIs to automate your network.3.3KViews1like1Comment