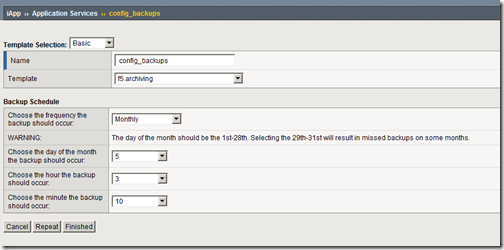
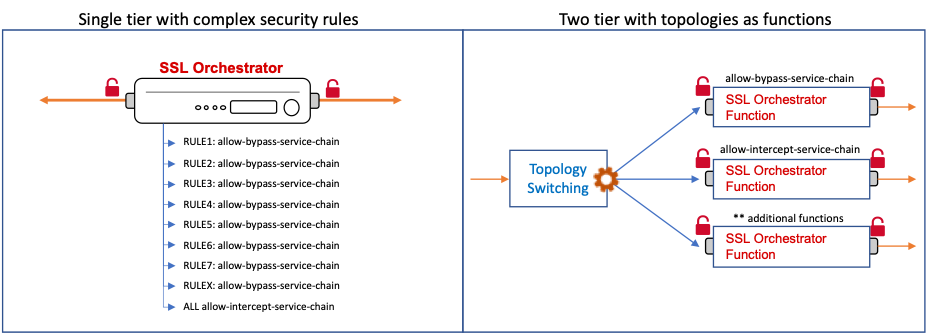
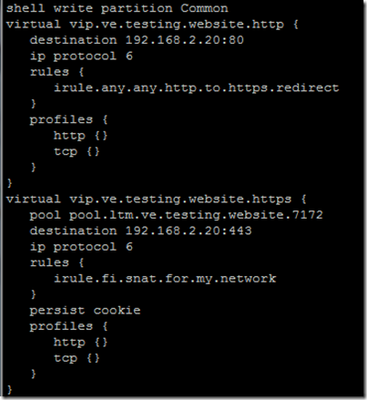
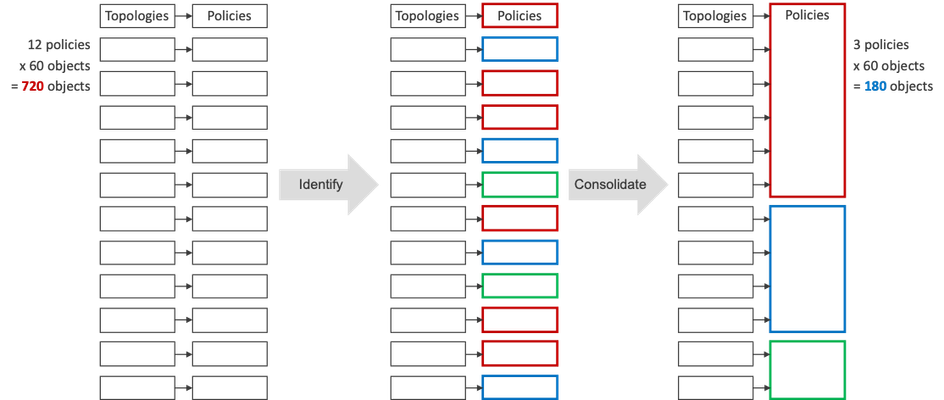
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/configuration\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/configuration\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674562364"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1752674579508":{"__typename":"CachedAsset","id":"pages-1752674579508","value":[{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501733000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1752674563563":{"__typename":"CachedAsset","id":"theme:customTheme1-1752674563563","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1752674562364","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1752674562364","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1752674562364","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674558703":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674558703","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1752674562364","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1752674560769":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1752674560769","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1752674599735","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1752674599735","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1752674599735","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1752674599735","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1752674599735","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1752674562364","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1752674562364","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674562364","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:288036":{"__typename":"Conversation","id":"conversation:288036","topic":{"__typename":"TkbTopicMessage","uid":288036},"lastPostingActivityTime":"2014-08-27T16:20:40.000-07:00","solved":false},"User:user:51154":{"__typename":"User","uid":51154,"login":"JRahm","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS01MTE1NC1uYzdSVFk?image-coordinates=0%2C0%2C1067%2C1067"},"id":"user:51154"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODgwMzYtMTQ0MWkzNDY4MTRDQTQ4RUIyOUJG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODgwMzYtMTQ0MWkzNDY4MTRDQTQ4RUIyOUJG?revision=1","title":"0151T000003d498QAA.png","associationType":"BODY","width":504,"height":250,"altText":null},"TkbTopicMessage:message:288036":{"__typename":"TkbTopicMessage","subject":"Scheduling BIG-IP Configuration Backups via the GUI with an iApp","conversation":{"__ref":"Conversation:conversation:288036"},"id":"message:288036","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:288036","revisionNum":1,"uid":288036,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3127},"postTime":"2011-08-16T14:45:00.000-07:00","lastPublishTime":"2011-08-16T14:45:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Beginning with BIG-IP version 11, the idea of templates has not only changed in amazing and powerful ways, it has been extended to be far more than just templates. The replacement for templates is called iApp TM . But to call the iApp TM just a template would be woefully inaccurate and narrow. It does templates well, and takes the concept further by allowing you to re-enter a templated application and make changes. Previously, deploying an application via a template was sort of like the Ron Popeil rotisserie: “Set it, and forget it!” Once it was executed, the template process was over, it was up to you to track and potentially clean up all those objects. Now, the application service you create based on an iApp TM template effectively “owns” all the objects it created, so any change to the deployment adds/changes/deletes objects as necessary. The other exciting change from the template perspective is the idea of strictness. Once an application service is configured, any object created that is owned by that service cannot be changed outside of the service itself. This means that if you want to add a pool member, it must be done within the application service, not within the pool. You can turn this off, but what a powerful protection of your services! \n Update for v11.2 - https://devcentral.f5.com/s/Tutorials/TechTips/tabid/63/articleType/ArticleView/articleId/1090565/Archiving-BIG-IP-Configurations-with-an-iApp-in-v112.aspx \n The Problem \n I received a request from one of our MVPs that he’d really like to be able to allow his users to schedule configuration backups without dropping to the command line. Knowing that the iApp TM feature was releasing soon with version 11, I started to see how I might be able to coax a command line configuration from the GUI. In training, I was told that “anything you can do in tmsh, you can do with an iApp TM .” This is excellent, and the basis for why I think they are going to be incredibly popular for not only controlling and managing applications, but also for extending CLI functions to the GUI. Anyway, so in order to schedule a configuration backup, I need: \n A backup script A cron job to call said script \n That’s really all there is to it. \n The Solution \n Thankfully, the background work is already done courtesy of a config backup codeshare entry by community user Colin Stubbs in the Advanced Design & Config Wiki. I did have to update the following bigpipe lines from the script: \n \n bigpipe export oneline “${SCF_FILE}” to tmsh save /sys config one-line file “${SCF_FILE}” \n bigpipe export “${SCF_FILE}” to tmsh save /sys config file \"${SCF_FILE}\" \n bigpipe config save “${UCS_FILE}” passphrase “${UCS_PASSPHRASE}” to tmsh save /sys ucs \"${UCS_FILE}\" passphrase \"${UCS_PASSPHRASE}\" \n bigpipe config save “${UCS_FILE}” to tmsh save /sys ucs \"${UCS_FILE}\" \n \n Also, I created (according the script comments from the codeshare entry) a /var/local/bin directory to place the script and a /var/local/backups directory for the script to dump the backup files in. These are optional and can be changed as necessary in your deployment, you’ll just need to update the script to reflect your file system preferences. Now that I have everything I need to support a backup, I can move on to the iApp TM template configuration. \n iApp TM Components \n A template consists of three parts: implementation, presentation, and help. You can create an empty template, or just start with presentation or help if you like. \n The implementation is tmsh script language, based on the Tcl language so loved by all of us iRulers. Please reference the tmsh wiki for the available tmsh extensions to the Tcl language. The presentation is written with the Application Presentation Language, or APL, which is new and custom-built for templates. It is defined on the APL page in the iApp TM wiki. The help is written in HTML, and is used to guide users in the use of the template. \n I’ll focus on the presentation first, and then the implementation. I’ll forego the help section in this article. \n Presentation \n The reason I’m starting with the presentation section of the template is that the implementation section’s Tcl variables reflect the presentation methods naming conventions. I want to accomplish a few things in the template presentation: \n Ask users for the frequency of backups (daily, weekly, monthly) If weekly, ask for the day of the week If monthly, ask for the day of the month and provide a warning about days 29-31 For all frequencies, ask for the hour and minute the backup should occur \n The APL code for this looks like this: \n \n \n \n section time_select { choice day_select display \"large\" { \"Daily\", \"Weekly\", \"Monthly\" } optional ( day_select == \"Weekly\" ) { choice dow_select display \"medium\" { \"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\" } } optional ( day_select == \"Monthly\" ) { message dom_warning \"The day of the month should be the 1st-28th. Selecting the 29th-31st will result in missed backups on some months.\" choice dom_select display \"medium\" tcl { for { set x 1 } { $x < 32 } { incr x } { append dom \"$x\\n\" } return $dom } } choice hr_select display \"medium\" tcl { for { set x 0 } { $x < 24 } { incr x} { append hrs \"$x\\n\" } return $hrs } choice min_select display \"medium\" tcl { for { set x 0 } { $x < 60 } { incr x } { append mins \"$x\\n\" } return $mins } } text { time_select \"Backup Schedule\" time_select.day_select \"Choose the frequency the backup should occur:\" time_select.dow_select \"Choose the day of the week the backup should occur:\" time_select.dom_warning \"WARNING: \" time_select.dom_select \"Choose the day of the month the backup should occur:\" time_select.hr_select \"Choose the hour the backup should occur:\" time_select.min_select \"Choose the minute the backup should occur:\" } \n \n \n A few things to point out. First, the sections (which can’t be nested) provide a way to set apart functional differences in your form. I only needed one here, but it’s very useful if I were to build on and add options for selecting a UCS or SCF format, or specifying a mail address for the backups to be mailed to. Second, order matters. The objects will be displayed in the template as you define them. Third, the optional command allows me to hide questions that wouldn’t make sense given previous answers. If you dig into some of the canned templates shipping with v11, you’ll also see another use case for the optional command. Fourth, you can use Tcl commands to populate fields for you. This can be generated data like I did above, or you can loop through configuration objects to present in the template as well. Finally, the text section is where you define the language you want to appear with each of your objects. The nomenclature here is section.variable. To give you an idea what this looks like, here is a screenshot of a monthly backup configuration: \n \n Once my template (f5.archiving) is saved, I can configure it in the Application Services section by selecting the template. At this point, I have a functioning presentation, but with no implementation, it’s effectively useless. \n Implementation \n Now that the presentation is complete, I can move on to an implementation. I need to do a couple things in the implementation: \n Grab the data entered into the application service Convert the day of week information from long name to the appropriate 0-6 (or 1-7) number for cron Use that data to build a cron file (statically assigned at this point to /etc/cron.d/f5backups) \n Here is the implementation section: \n \n array set dow_map { Sunday 0 Monday 1 Tuesday 2 Wednesday 3 Thursday 4 Friday 5 Saturday 6 } \n set hr $::time_select__hr_select set min $::time_select__min_select \n set infile [open \"/etc/cron.d/f5backups\" \"w\" \"0755\"] \n puts $infile \"SHELL=\\/bin\\/bash\" puts $infile \"PATH=\\/sbin:\\/bin:\\/usr\\/sbin:\\/usr\\/bin\" puts $infile \"#MAILTO=user@somewhere\" puts $infile \"HOME=\\/var\\/tmp\\/\" if { $::time_select__day_select == \"Daily\" } { puts $infile \"$min $hr * * * root \\/bin\\/bash \\/var\\/local\\/bin\\/f5backup.sh 1>\\/var\\/tmp\\/f5backup.log 2>\\&1\" } elseif { $::time_select__day_select == \"Weekly\" } { puts $infile \"$min $hr * * $dow_map($::time_select__dow_select) root \\/bin\\/bash \\/var\\/local\\/bin\\/f5backup.sh 1>\\/var\\/tmp\\/f5backup.log 2>\\&1\" } elseif { $::time_select__day_select == \"Monthly\" } { puts $infile \"$min $hr $::time_select__dom_select * * root \\/bin\\/bash \\/var\\/local\\/bin\\/f5backup.sh 1>\\/var\\/tmp\\/f5backup.log 2>\\&1\" } \n close $infile \n \n A few notes: \n The dow_map array is to convert the selected day (ie, Saturday) to a number for cron (6). The variables in the implementation section reference the data supplied from the presentation like so:\n $::<section>__<presentation variable name> (Note the double underscore between them. As such, DO NOT use double underscores in your presentation variables) \n tmsh special characters need to be escaped if you’re using them for strings. \n A succesful configuration of the application service results in this file configuration for /etc/cron.d/f5backups: \n \n SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin #MAILTO=user@somewhere HOME=/var/tmp/ 54 15 * * * root /bin/bash /var/local/bin/f5backup.sh 1>/var/tmp/f5backup.log 2>&1 \n \n So this backup is scheduled to run daily at 15:54. This is confirmed with this directory listing on my BIG-IP: \n \n [root@golgotha:Active] bin # ls -las /var/local/backups total 2168 8 drwx------ 2 root root 4096 Aug 16 15:54 . 8 drwxr-xr-x 9 root root 4096 Aug 3 14:44 .. 1076 -rw-r--r-- 1 root root 1091639 Aug 15 15:54 f5backup-golgotha.test.local-20110815155401.tar.bz2 1076 -rw-r--r-- 1 root root 1092259 Aug 16 15:54 f5backup-golgotha.test.local-20110816155401.tar.bz2 \n \n Conclusion \n This is just scratching the surface of what can be done with the new iApp TM feature in v11. I didn’t even cover the ability to use presentation and implementation libraries, but that will be covered in due time. If you’re impatient, there are already several examples (including this one here) in the codeshare. \n \n Related Articles \n F5 DevCentral > Community > Group Details - iApp iApp Wiki Home - DevCentral Wiki F5 Agility 2011 - James Hendergart on iApp iApp Codeshare - DevCentral Wiki iApp Lab 5 - Priority Group Activation - DevCentral Wiki iApp Template Development Tips and Techniques - DevCentral Wiki Lori MacVittie - iApp ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"11068","kudosSumWeight":0,"repliesCount":13,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODgwMzYtMTQ0MWkzNDY4MTRDQTQ4RUIyOUJG?revision=1\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282177":{"__typename":"Conversation","id":"conversation:282177","topic":{"__typename":"TkbTopicMessage","uid":282177},"lastPostingActivityTime":"2020-10-29T11:00:29.000-07:00","solved":false},"User:user:106220":{"__typename":"User","uid":106220,"login":"Joe_Pruitt","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0xMDYyMjAtUU1TTFdB?image-coordinates=0%2C0%2C1000%2C1000"},"id":"user:106220"},"TkbTopicMessage:message:282177":{"__typename":"TkbTopicMessage","subject":"Converting a Cisco ACE configuration file to F5 BIG-IP Format","conversation":{"__ref":"Conversation:conversation:282177"},"id":"message:282177","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282177","revisionNum":1,"uid":282177,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:106220"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2541},"postTime":"2012-12-11T08:06:00.000-08:00","lastPublishTime":"2012-12-11T08:06:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n\n In September, Cisco announced that it was ceasing development and pulling back on sales of its Application Control Engine (ACE) load balancing modules. Customers of Cisco’s ACE product line will now have to look for a replacement product to solve their load balancing and application delivery needs. \n\n One of the first questions that will come up when a customer starts looking into replacement products surrounds the issue of upgradability. Will the customer be able to import their current configuration into the new technology or will they have to start with the new product from scratch. For smaller businesses, starting over can be a refreshing way to clean up some of the things you’ve been meaning to but weren’t able to for one reason or another. But, for a large majority of the users out there, starting over from nothing with a new product is a daunting task. \n\n To help with those users considering a move to the F5 universe, DevCentral has included several scripts to assist with the configuration migration process. In our Codeshare section we created some scripts useful in converting ACE configurations into their respective F5 counterparts. \nhttps://devcentral.f5.com/s/articles/cisco-ace-to-f5-big-ip https://devcentral.f5.com/s/articles/Cisco-ACE-to-F5-Conversion-Python-3 https://devcentral.f5.com/s/articles/cisco-ace-to-f5-big-ip-via-tmsh We also have scripts covering Cisco’s CSS (https://devcentral.f5.com/s/articles/cisco-css-to-f5-big-ip ) and CSM products (https://devcentral.f5.com/s/articles/cisco-csm-to-f5-big-ip ) as well.\n\n In this article, I’m going to focus on the ace2f5-tmsh” in the ace2f5.zip script library. \n\n The script takes as input an ACE configuration and creates a TMSH script to create the corresponding F5 BIG-IP objects. \n\n \n\n ace2f5-tmsh.pl \n\n \n$ perl ace2f5-tmsh.pl ace_config > tmsh_script \n\n We could leave it at that, but I’ll use this article to discuss the components of the ACE configuration and how they map to F5 objects. \n\n \n\n ip \n\n The ip object in the ACE configuration is defined like this: \n\n \nip route 0.0.0.0 0.0.0.0 10.211.143.1 \n\n equates to a tmsh “net route” command. \n\n \nnet route 0.0.0.0-0 { network 0.0.0.0/0 gw 10.211.143.1 } \n\n \n\n rserver \n\n An “rserver” is basically a node containing a server address including an optional “inservice” attribute indicating whether it’s active or not. \n\n ACE Configuration \n\n \nrserver host R190-JOEINC0060\n ip address 10.213.240.85\nrserver host R191-JOEINC0061\n ip address 10.213.240.86\n inservice\nrserver host R192-JOEINC0062\n ip address 10.213.240.88\n inservice\nrserver host R193-JOEINC0063\n ip address 10.213.240.89\n inservice \n\n It will be used to find the IP address for a given rserver hostname. \n\n \n\n serverfarm \n\n A serverfarm is a LTM pool except that it doesn’t have a port assigned to it yet. \n\n ACE Configuration \n\n \nserverfarm host MySite-JoeInc\n predictor hash url\n rserver R190-JOEINC0060\n inservice\n rserver R191-JOEINC0061\n inservice\n rserver R192-JOEINC0062\n inservice\n rserver R193-JOEINC0063\n inservice \n\n F5 Configuration \n\n \nltm pool Insiteqa-JoeInc {\n load-balancing-mode predictive-node\n members { 10.213.240.86:any { address 10.213.240.86 }}\n members { 10.213.240.88:any { address 10.213.240.88 }}\n members { 10.213.240.89:any { address 10.213.240.89 }}\n} \n\n \n\n probe \n\n a “probe” is a LTM monitor except that it does not have a port. \n\n ACE Configuration \n\n \nprobe tcp MySite-JoeInc\n interval 5\n faildetect 2\n passdetect interval 10\n passdetect count 2 \n\n will map to the TMSH “ltm monitor” command. \n\n F5 Configuration \n\n \nltm monitor Insiteqa-JoeInc {\n defaults from tcp\n interval 5\n timeout 10\n retry 2\n} \n\n \n\n sticky \n\n The “sticky” object is a way to create a persistence profile. First you tie the serverfarm to the persist profile, then you tie the profile to the Virtual Server. \n\n ACE Configuration \n\n \nsticky ip-netmask 255.255.255.255 address source MySite-JoeInc-sticky\n timeout 60\n replicate sticky\n serverfarm MySite-JoeInc \n\n \n\n class-map \n\n A “class-map” assigns a listener, or Virtual IP address and port number which is used for the clientside and serverside of the connection. \n\n ACE Configuration \n\n \nclass-map match-any vip-MySite-JoeInc-12345\n 2 match virtual-address 10.213.238.140 tcp eq 12345\nclass-map match-any vip-MySite-JoeInc-1433\n 2 match virtual-address 10.213.238.140 tcp eq 1433\nclass-map match-any vip-MySite-JoeInc-31314\n 2 match virtual-address 10.213.238.140 tcp eq 31314\nclass-map match-any vip-MySite-JoeInc-8080\n 2 match virtual-address 10.213.238.140 tcp eq 8080\nclass-map match-any vip-MySite-JoeInc-http\n 2 match virtual-address 10.213.238.140 tcp eq www\nclass-map match-any vip-MySite-JoeInc-https\n 2 match virtual-address 10.213.238.140 tcp eq https \n\n \n\n policy-map \n\n a policy-map of type loadbalance simply ties the persistence profile to the Virtual . the “multi-match” attribute constructs the virtual server by tying a bunch of objects together. \n\n ACE Configuration \n\n \npolicy-map type loadbalance first-match vip-pol-MySite-JoeInc\n class class-default\n sticky-serverfarm MySite-JoeInc-sticky\n\npolicy-map multi-match lb-MySite-JoeInc\n class vip-MySite-JoeInc-http\n loadbalance vip inservice\n loadbalance policy vip-pol-MySite-JoeInc\n loadbalance vip icmp-reply\n class vip-MySite-JoeInc-https\n loadbalance vip inservice\n loadbalance vip icmp-reply\n class vip-MySite-JoeInc-12345\n loadbalance vip inservice\n loadbalance policy vip-pol-MySite-JoeInc\n loadbalance vip icmp-reply\n class vip-MySite-JoeInc-31314\n loadbalance vip inservice\n loadbalance policy vip-pol-MySite-JoeInc\n loadbalance vip icmp-reply\n class vip-MySite-JoeInc-1433\n loadbalance vip inservice\n loadbalance policy vip-pol-MySite-JoeInc\n loadbalance vip icmp-reply\n class reals\n nat dynamic 1 vlan 240\n class vip-MySite-JoeInc-8080\n loadbalance vip inservice\n loadbalance policy vip-pol-MySite-JoeInc\n loadbalance vip icmp-reply \n\n F5 Configuration \n\n \nltm virtual vip-Insiteqa-JoeInc-12345 {\n destination 10.213.238.140:12345\n pool Insiteqa-JoeInc\n persist my_source_addr\n profiles {\n tcp {}\n }\n}\n\nltm virtual vip-Insiteqa-JoeInc-1433 {\n destination 10.213.238.140:1433\n pool Insiteqa-JoeInc\n persist my_source_addr\n profiles {\n tcp {}\n }\n}\n\nltm virtual vip-Insiteqa-JoeInc-31314 {\n destination 10.213.238.140:31314\n pool Insiteqa-JoeInc\n persist my_source_addr\n profiles {\n tcp {}\n }\n}\n\nltm virtual vip-Insiteqa-JoeInc-8080 {\n destination 10.213.238.140:8080\n pool Insiteqa-JoeInc\n persist my_source_addr\n profiles {\n tcp {}\n }\n}\n\nltm virtual vip-Insiteqa-JoeInc-http {\n destination 10.213.238.140:http\n pool Insiteqa-JoeInc\n persist my_source_addr\n profiles {\n tcp {}\n http {}\n }\n}\n\nltm virtual vip-Insiteqa-JoeInc-https {\n destination 10.213.238.140:https\n profiles {\n tcp {}\n} \n\n \n\n Conclusion \n\n If you are considering migrating from Cicso’s ACE to F5, I’d consider you take a look at the Cisco conversion scripts to assist with the conversion. \n\n \n\n \n\n \n\n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7469","kudosSumWeight":0,"repliesCount":6,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286080":{"__typename":"Conversation","id":"conversation:286080","topic":{"__typename":"TkbTopicMessage","uid":286080},"lastPostingActivityTime":"2022-12-05T12:27:33.470-08:00","solved":false},"User:user:130391":{"__typename":"User","uid":130391,"login":"Kevin_Stewart","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0xMzAzOTEtelZmemp2?image-coordinates=0%2C0%2C500%2C500"},"id":"user:130391"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtNjE0Mmk4MDI0OTcxMkRDQUQzNDhB?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtNjE0Mmk4MDI0OTcxMkRDQUQzNDhB?revision=2","title":"0151T000003q1a5QAA.png","associationType":"BODY","width":927,"height":333,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtMzY5OGkyNjNEQkY0RjRFNEM1NDZF?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtMzY5OGkyNjNEQkY0RjRFNEM1NDZF?revision=2","title":"0151T000003q1a9QAA.png","associationType":"BODY","width":1113,"height":465,"altText":null},"TkbTopicMessage:message:286080":{"__typename":"TkbTopicMessage","subject":"SSL Orchestrator Advanced Use Cases: Reducing Complexity with Internal Layered Architecture","conversation":{"__ref":"Conversation:conversation:286080"},"id":"message:286080","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286080","revisionNum":2,"uid":286080,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:130391"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2014},"postTime":"2021-01-04T11:52:07.000-08:00","lastPublishTime":"2022-12-05T12:27:33.470-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Introduction \n Sir Isaac Newton said, \"Truth is ever to be found in the simplicity, and not in the multiplicity and confusion of things\". The world we live in is...complex. No getting around that. But at the very least, we should strive for simplicity where we can achieve it. As IT folk, we often find ourselves mired in the complexity of things until we lose sight of the big picture, the goal. How many times have you created an additional route table entry, or firewall exception, or virtual server, because the alternative meant having a deeper understanding of the existing (complex) architecture? Sure, sometimes it's unavoidable, but this article describes at least one way that you can achieve simplicity in your architecture. SSL Orchestrator sits as an inline point of presence in the network to decrypt, re-encrypt, and dynamically orchestrate that traffic to the security stack. You need rules to govern how to handle specific types of traffic, so you create security policy rules in the SSL Orchestrator configuration to describe and take action on these traffic patterns. It's definitely easy to create a multitude of traffic rules to match discrete conditions, but if you step back and look at the big picture, you may notice that the different traffic patterns basically all perform the same core actions. They allow or deny traffic, intercept or bypass TLS (decrypt/not-decrypt), and send to one or a few service chains. If you were to write down all of the combinations of these actions, you'd very likely discover a small subset of discrete \"functions\". As usual, F5 BIG-IP and SSL Orchestrator provide some innovative and unique ways to optimize this. And so in this article we will explore SSL Orchestrator topologies \"as functions\" to reduce complexity. Specifically, you can reduce the complexity of security policy rules, and in doing so, quite likely increase the performance of your SSL Orchestrator architecture. \n SSL Orchestrator Use Case: Reducing Complexity with Internal Layered Architectures \n The idea is simple. Instead of a single topology with a multitude of complex traffic pattern matching rules, create small atomic topologies as static functions and steer traffic to the topologies by virtue of \"layered\" traffic pattern matching. Granted, if your SSL Orchestrator configuration is already pretty simple, then please keep doing what you're doing. You've got this, Tiger. But if your environment is getting complex, and you're not quite convinced yet that topologies as functions is a good idea, here are a few additional benefits you'll get from this topology layering: \n \n Dynamic egress selection: topologies as functions can define different egress paths. \n Dynamic CA selection: topologies as functions can use different local issuing CAs for different traffic flows. \n Dynamic traffic bypass: certain types of traffic can be challenging to handle internally. For example, mutual TLS traffic can be bypassed globally with the \"Bypass on client cert failure\" option in the SSL configuration, but bypassing mutual TLS sites by hostname is more complex. A layered architecture can steer traffic (by SNI) through a bypass topology, with a service chain. \n More flexible pattern recognition: for all of its flexibility, SSL Orchestrator security policy rules cannot catch every possible use case. External traffic pattern recognition, via iRules or CPM (LTM policies) offer near infinite pattern matching options. You could, for example, steer traffic based on incoming tenant VLAN or route domain for multi-tenancy configurations. \n More flexible automation strategies: as iRules, data groups, and CPM policies are fully automate-able across many AnO platforms (ex. AS3, Ansible, Terraform, etc.), it becomes exceedingly easy to automate SSL Orchestrator traffic processing, and removes the need to manage individual topology security policy rules. \n \n Hopefully these benefits give you a pretty clear indication of the value in this architecture strategy. So without further ado, let's get started. \n Configuration \n Before we begin, I'd like to make note of the following caveats: \n \n While every effort has been made to simplify the layered architecture, there is still a small element of complexity. If you are at all averse to creating virtual servers or modifying iRules, then maybe this isn't for you. But as you are reading this in a forum dedicated to programmability, I'm guessing you the reader are ready for a challenge. \n This is a \"field contributed\" solution, so not officially supported by F5. \n This topology layering architecture is applicable to all modern versions of SSL Orchestrator, from 5.0 to 8.0. \n While topology layering can be used for inbound topologies, it is most appropriate for outbound. The configuration below also only describes the layer 3 implementation. But layer 2 layering is also possible. \n \n With this said, there are just a few core concepts to understand: \n \n Basic layered architecture configuration - how the pieces fit together \n The iRules - how traffic moves through the architecture \n Or the CPM policies - an alternative to iRules \n \n Note again that this is primarily useful in outbound topologies. Inbound topologies are typically more atomic on their own already. I will cover both transparent and explicit forward proxy configurations below. \n Basic layered architecture configuration \n A layered architecture takes advantage of a powerful feature of the BIG-IP called \"VIP targeting\". The idea is that one virtual server calls another with negligible latency between the two VIPs. The \"external\" virtual server is client-facing. The SSL Orchestrator topology virtual servers are thus \"internal\". Traffic enters the external VIP and traffic rules pass control to any of a number of internal \"topology function\" VIPs. \n You certainly don't have to use the iRule implementation presented here. You just need a client-facing virtual server with an iRule that VIP-targets to one or more SSL Orchestrator topologies. Each outbound topology is represented by a virtual server that includes the application server name. You can see these if you navigate to Local Traffic -> Virtual Servers in the BIG-IP UI. So then the most basic topology layering architecture might just look like this: \n when CLIENT_ACCEPTED {\n virtual \"/Common/sslo_my_topology.app/sslo_my_topology-in-t-4\"\n}\n \n This iRule doesn't do anything interesting, except get traffic flowing across your layered architecture. To be truly useful you'll want to include conditions and evaluations to steer different types of traffic to different topologies (as functions). \n As the majority of security policy rules are meant to define TLS traffic patterns, the provided iRules match on TLS traffic and pass any non-TLS traffic to a default (intercept/inspection) topology. These iRules are intended to simplify topology switching by moving all of the complexity of traffic pattern matching to a library iRule. You should then only need to modify the \"switching\" iRule to use the functions in the library, which all return Boolean true or false results. Here are the simple steps to create your layered architecture: \n \n Step 1: Build a set of \"dummy\" VLANs. A topology must be bound to a VLAN. But since the topologies in this architecture won't be listening on client-facing VLANs, you will need to create a separate VLAN for each topology you intend to create. A dummy VLAN is a VLAN with no interface assigned. In the BIG-IP UI, under Network -> VLANs, click Create. Give your VLAN a name and click Finished. It will ask you to confirm since you're not attaching an interface. Repeat this step by creating unique VLAN names for each topology you are planning to use. \n Step 2: Build a set of static topologies as functions. You'll want to create a normal \"intercept\" topology and a separate \"bypass\" topology, though you can create as many as you need to encompass the unique topology functions. Your intercept topology is configured as such:\n \n L3 outbound topology configuration, normal topology settings, SSL configuration, services, service chains \n No security policy rules - just the ALL rule with TLS intercept action (and service chain), and optionally remove the built-in Pinners rule \n Attach to a dummy VLAN (a VLAN with no assigned interfaces) \n \n \n \n Your bypass topology should then look like this: \n \n L3 outbound topology configuration, skip the SSL Configuration settings, optionally re-use services and service chains \n No security policy rules - just the ALL rule with TLS bypass action (and service chain) \n Attach to a separate dummy VLAN (a VLAN with no assigned interfaces) \n \n Note the name you use for each topology, as this will be called explicitly in the iRule. For example, if you name the topology \"myTopology\", that's the name you will use in each \"call SSLOLIB::target\" function (more on this in a moment) . If you look in the SSL Orchestrator UI, you will see that it prepends \"sslo_\" (ex. sslo_myTopology). Don't include the \"sslo_\" portion in the iRule. \n \n Step 3: Import the SSLOLIB iRule (attached here). Name it \"SSLOLIB\". This is the library rule, so no modifications are needed. The functions within (as described below) will return a true or false, so you can mix these together in your switching rule as needed. \n Step 4: Import the traffic switching iRule (attached here). You will modify this iRule as required, but the SSLOLIB library rule makes this very simple. \n Step 5: Create your external layered virtual server. This is the client-facing virtual server that will catch the user traffic and pass control to one of the internal SSL Orchestrator topology listeners.\n \n Type: Standard \n Source: 0.0.0.0/0 \n Destination: 0.0.0.0/0 \n Service Port: 0 \n Protocol: TCP \n VLAN: client-facing VLAN \n Address Translation: disabled \n Port Translation: disabled \n Default Persistence Profile: ssl \n iRule: the traffic switching iRule \n \n \n \n Note that the ssl persistence profile is enabled here to allow the iRules to handle client side SSL traffic without SSL profiles attached. Also make sure that Address and Port Translation are disabled before clicking Finished. \n \n Step 6: Modify the traffic switching iRule to meet your traffic matching requirements (see below). \n \n You have the basic layered architecture created. The only remaining step is to modify the traffic switching iRule as required, and that's pretty easy too. \n The iRules \n I'll repeat, there are near infinite options here. At the very least you need to VIP target from the external layered VIP to at least one of the SSL Orchestrator topology VIPs. The iRules provided here have been cultivated to make traffic selection and steering as easy as possible by pushing all of the pattern functions to a library iRule (SSLOLIB). The idea is that you will call a library function for a specific traffic pattern and if true, call a separate library function to steer that flow to the desired topology. All of the build instructions are contained inside the SSLOLIB iRule, with examples. \n SSLOLIB iRule: https://github.com/f5devcentral/sslo-script-tools/blob/main/internal-layered-architecture/transparent-proxy/SSLOLIB \n Switching iRule: https://github.com/f5devcentral/sslo-script-tools/blob/main/internal-layered-architecture/transparent-proxy/sslo-layering-rule \n The function to steer to a topology (SSLOLIB::target) has three parameters: \n \n <topology name>: this is the name of the desired topology. Use the basic topology name as defined in the SSL Orchestrator configuration (ex. \"intercept\"). \n ${sni}: this is static and should be left alone. It's used to convey the SNI information for logging. \n <message>: this is a message to send to the logs. In the examples, the message indicates the pattern matched (ex. \"SRCIP\"). \n \n Note, include an optional 'return' statement at the end to cancel any further matching. Without the 'return', the iRule will continue to process matches and settle on the value from the last evaluation. \n Example (sending to a topology named \"bypass\"): \n call SSLOLIB::target \"bypass\" ${sni} \"DSTIP\" ; return\n \n There are separate traffic matching functions for each pattern: \n \n SRCIP IP:<ip/subnet> \n SRCIP DG:<data group name> (address-type data group) \n SRCPORT PORT:<port/port-range> \n SRCPORT DG:<data group name> (integer-type data group) \n DSTIP IP:<ip/subnet> \n DSTIP DG:<data group name> (address-type data group) \n DSTPORT PORT:<port/port-range> \n DSTPORT DG:<data group name> (integer-type data group) \n SNI URL:<static url> \n SNI URLGLOB:<glob match url> (ends_with match) \n SNI CAT:<category name or list of categories> \n SNI DG:<data group name> (string-type data group) \n SNI DGGLOB:<data group name> (ends_with match) \n \n Examples: \n # SOURCE IP\nif { [call SSLOLIB::SRCIP IP:10.1.0.0/16] } { call SSLOLIB::target \"bypass\" ${sni} \"SRCIP\" ; return }\nif { [call SSLOLIB::SRCIP DG:my-srcip-dg] } { call SSLOLIB::target \"bypass\" ${sni} \"SRCIP\" ; return }\n\n# SOURCE PORT\nif { [call SSLOLIB::SRCPORT PORT:5000] } { call SSLOLIB::target \"bypass\" ${sni} \"SRCPORT\" ; return }\nif { [call SSLOLIB::SRCPORT PORT:1000-60000] } { call SSLOLIB::target \"bypass\" ${sni} \"SRCPORT\" ; return }\n\n# DESTINATION IP \nif { [call SSLOLIB::DSTIP IP:93.184.216.34] } { call SSLOLIB::target \"bypass\" ${sni} \"DSTIP\" ; return }\nif { [call SSLOLIB::DSTIP DG:my-destip-dg] } { call SSLOLIB::target \"bypass\" ${sni} \"DSTIP\" ; return }\n\n# DESTINATION PORT \nif { [call SSLOLIB::DSTPORT PORT:443] } { call SSLOLIB::target \"bypass\" ${sni} \"DSTPORT\" ; return }\nif { [call SSLOLIB::DSTPORT PORT:443-9999] } { call SSLOLIB::target \"bypass\" ${sni} \"DSTPORT\" ; return }\n\n# SNI URL match \nif { [call SSLOLIB::SNI URL:www.example.com] } { call SSLOLIB::target \"bypass\" ${sni} \"SNIURLGLOB\" ; return }\nif { [call SSLOLIB::SNI URLGLOB:.example.com] } { call SSLOLIB::target \"bypass\" ${sni} \"SNIURLGLOB\" ; return }\n\n# SNI CATEGORY match \nif { [call SSLOLIB::SNI CAT:$static::URLCAT_list] } { call SSLOLIB::target \"bypass\" ${sni} \"SNICAT\" ; return }\nif { [call SSLOLIB::SNI CAT:/Common/Government] } { call SSLOLIB::target \"bypass\" ${sni} \"SNICAT\" ; return }\n\n# SNI URL DATAGROUP match \nif { [call SSLOLIB::SNI DG:my-sni-dg] } { call SSLOLIB::target \"bypass\" ${sni} \"SNIDGGLOB\" ; return }\nif { [call SSLOLIB::SNI DGGLOB:my-sniglob-dg] } { call SSLOLIB::target \"bypass\" ${sni} \"SNIDGGLOB\" ; return }\n\nTo combine these, you can use simple AND|OR logic. Example:\n\nif { ( [call SSLOLIB::DSTIP DG:my-destip-dg] ) and ( [call SSLOLIB::SRCIP DG:my-srcip-dg] ) }\n \n Finally, adjust the static configuration variables in the traffic switching iRule RULE_INIT event: \n ## User-defined: Default topology if no rules match (the topology name as defined in SSLO)\nset static::default_topology \"intercept\"\n\n## User-defined: DEBUG logging flag (1=on, 0=off)\nset static::SSLODEBUG 0\n\n## User-defined: URL category list (create as many lists as required)\nset static::URLCAT_list {\n /Common/Financial_Data_and_Services\n /Common/Health_and_Medicine\n}\n \n CPM policies \n LTM policies (CPM) can work here too, but with the caveat that LTM policies do not support URL category lookups. You'll probably want to either keep the Pinners rule in your intercept topologies, or convert the Pinners URL category to a data group. A \"url-to-dg-convert.sh\" Bash script can do that for you. \n url-to-dg-convert.sh: https://github.com/f5devcentral/sslo-script-tools/blob/main/misc-tools/url-to-dg-convert.sh \n As with iRules, infinite options exist. But again for simplicity here is a good CPM configuration. For this you'll still need a \"helper\" iRule, but this requires minimal one-time updates. \n when RULE_INIT {\n ## Default SSLO topology if no rules match. Enter the name of the topology here\n set static::SSLO_DEFAULT \"intercept\"\n\n ## Debug flag\n set static::SSLODEBUG 0\n}\nwhen CLIENT_ACCEPTED {\n ## Set default topology (if no rules match)\n virtual \"/Common/sslo_${static::SSLO_DEFAULT}.app/sslo_${static::SSLO_DEFAULT}-in-t-4\"\n}\nwhen CLIENTSSL_CLIENTHELLO {\n if { ( [POLICY::names matched] ne \"\" ) and ( [info exists ACTION] ) and ( ${ACTION} ne \"\" ) } {\n if { $static::SSLODEBUG } { log -noname local0. \"SSLO Switch Log :: [IP::client_addr]:[TCP::client_port] -> [IP::local_addr]:[TCP::local_port] :: [POLICY::rules matched [POLICY::names matched]] :: Sending to $ACTION\" }\n virtual \"/Common/sslo_${ACTION}.app/sslo_${ACTION}-in-t-4\"\n }\n}\n \n The only thing you need to do here is update the static::SSLO_DEFAULT variable to indicate the name of the default topology, for any traffic that does not match a traffic rule. For the comparable set of CPM rules, navigate to Local Traffic -> Policies in the BIG-IP UI and create a new CPM policy. Set the strategy as \"Execute First matching rule\", and give each rule a useful name as the iRule can send this name in the logs. \n \n For source IP matches, use the \"TCP address\" condition at ssl client hello time. \n For source port matches, use the \"TCP port\" condition at ssl client hello time. \n For destination IP matches the \"TCP address\" condition at ssl client hello time. Click on the Options icon and select \"Local\" and \"External\". \n For destination port matches the \"TCP port\" condition at ssl client hello time. Click on the Options icon and select \"Local\" and \"External\". \n For SNI matches, use the \"SSL Extension server name\" condition at ssl client hello time. \n \n For each of the conditions, add a simple \"Set variable\" action as ssl client hello time. Name the variable \"ACTION\" and give it the name of the desired topology. \n \n Apply the helper iRule and CPM policy to the external traffic steering virtual server. The \"first\" matching rule strategy is applied here, and all rules trigger on ssl client hello, so you can drag them around and re-order as necessary. \n Note again that all of the above only evaluates TLS traffic. Any non-TLS traffic will flow through the \"default\" topology that you identify in the iRule. It is possible to re-configure the above to evaluate HTTP traffic, but honestly the only significant use case here might be to allow or drop traffic at the policy. \n Layered architecture for an explicit forward proxy \n You can use the same logic to support an explicit proxy configuration. The only difference will be that the frontend layered virtual server will perform the explicit proxy functions. The backend SSL Orchestrator topologies will continue to be in layer 3 outbound (transparent proxy) mode. Normally SSL Orchestrator would build this for you, but it's pretty easy and I'll show you how. You could technically configure all of the SSL Orchestrator topologies as explicit proxies, and configure the client facing virtual server as a layer 3 pass-through, but that adds unnecessary complexity. If you also need to add explicit proxy authentication, that is done in the one frontend explicit proxy configuration. Use the settings below to create an explicit proxy LTM configuration. If not mentioned, settings can be left as defaults. \n \n Under SSL Orchestrator -> Configuration in the UI, click on the gear icon in the top right corner. This will expose the DNS resolver configuration. The easiest option here is to select \"Local Forwarding Nameserver\" and then enter the IP address of the local DNS service. Click \"Save & Next\" and then \"Deploy\" when you're done. \n Under Network -> Tunnels in the UI, click Create. This will create a TCP tunnel for the explicit proxy traffic.\n \n Profile: select tcp-forward \n \n \n \n \n Under Local Traffic -> Profiles -> Services -> HTTP in the UI, click Create. This will create the HTTP explicit proxy profile.\n \n Proxy Mode: Explicit \n Explicit Proxy: DNS Resolver: select the ssloGS-net-resolver \n Explicit Proxy: Tunnel Name: select the TCP tunnel created earlier \n \n \n \n \n Under Local Traffic -> Virtual Servers, click Create. This will create the client-facing explicit proxy virtual server.\n \n Type: Standard \n Source: 0.0.0.0/0 \n Destination: enter an IP the client can use to access the explicit proxy interface \n Service Port: enter the explicit proxy listener port (ex. 3128, 8080) \n HTTP Profile: HTTP explicit profile created earlier \n VLANs and Tunnel Traffic: set to \"Enable on...\" and select the client-facing VLAN \n Address Translation: enabled \n Port Translation: enabled \n \n \n \n \n Under Local Traffic -> Virtual Servers, click Create again. This will create the TCP tunnel virtual server.\n \n Type: Standard \n Source: 0.0.0.0/0 \n Destination: 0.0.0.0/0 \n Service Port: * \n VLANs and Tunnel Traffic: set to \"Enable on...\" and select the TCP tunnel created earlier \n Address Translation: disabled \n Port Translation: disabled \n iRule: select the SSLO switching iRule \n Default Persistence Profile: select ssl \n \n \n \n Note, make sure that Address and Port Translation are disabled before clicking Finished. \n \n Under Local Traffic -> iRules, click Create. This will create a small iRule for the explicit proxy VIP to forward non-HTTPS traffic through the TCP tunnel. Change \"<name-of-TCP-tunnel-VIP>\" to reflect the name of the TCP tunnel virtual server created in the previous step. \n \n when HTTP_REQUEST {\n virtual \"/Common/<name-of-TCP-tunnel-VIP>\" [HTTP::proxy addr] [HTTP::proxy port]\n}\n \n \n Add this new iRule to the explicit proxy virtual server. To test, point your explicit proxy client at the IP and port defined IP:port and give it a go. HTTP and HTTPS explicit proxy traffic arriving at the explicit proxy VIP will flow into the TCP tunnel VIP, where the SSLO switching rule will process traffic patterns and send to the appropriate backend SSL Orchestrator topology-as-function. \n \n Testing and Considerations \n Assuming you have the default topology defined in the switching iRule's RULE_INIT, and no traffic matching rules defined, all traffic from the client should pass effortlessly through that topology. If it does not, \n \n Ensure the named defined in the static::default_topology variable is the actual name of the topology, without the prepended \"sslo_\". \n Enable debug logging in the iRule and observe the LTM log (/var/log/ltm) for any anomalies. \n Worst case, remove the client facing VLAN from the frontend switching virtual server and attach it to one of your topologies, effectively bypassing the layered architecture. If traffic does not pass in this configuration, then it cannot in the layered architecture. You need to troubleshoot the SSL Orchestrator topology itself. Once you have that working, put the dummy VLAN back on the topology and add the client facing VLAN to the switching virtual server. \n \n Considerations \n The above provides a unique way to solve for complex architectures. There are however a few minor considerations: \n \n This is defined outside of SSL Orchestrator, so would not be included in the internal HA sync process. However, this architecture places very little administrative burden on the topologies directly. It is recommended that you create and sync all of the topologies first, then create the layered virtual server and iRules, and then manually sync the boxes. If you make any changes to the switching iRule (or CPM policy), that should not affect the topologies. You can initiate a manual BIG-IP HA sync to copy the changes to the peer. \n If upgrading to a new version of SSL Orchestrator (only), no additional changes are required. If upgrading to a new BIG-IP version, it is recommended to break HA (SSL Orchestrator 8.0 and below) before performing the upgrade. The external switching virtual server and iRules should migrate natively. \n \n Summary \n And there you have it. In just a few steps you've been able to reduce complexity and add capabilities, and along the way you have hopefully recognized the immense flexibility at your command. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"24125","kudosSumWeight":5,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtNjE0Mmk4MDI0OTcxMkRDQUQzNDhB?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODAtMzY5OGkyNjNEQkY0RjRFNEM1NDZF?revision=2\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282744":{"__typename":"Conversation","id":"conversation:282744","topic":{"__typename":"TkbTopicMessage","uid":282744},"lastPostingActivityTime":"2012-08-21T00:01:00.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjk4N2lBOTNFM0UwQjc3QkFBOTBD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjk4N2lBOTNFM0UwQjc3QkFBOTBD?revision=1","title":"0151T000003d4DfQAI.jpg","associationType":"BODY","width":90,"height":114,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtNjQ0Nmk0MjlENEExMTY2MTdBMjkw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtNjQ0Nmk0MjlENEExMTY2MTdBMjkw?revision=1","title":"0151T000003d4DgQAI.png","associationType":"BODY","width":184,"height":106,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjc3MWkwMTlEM0VFRDRBNDVDQkY4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjc3MWkwMTlEM0VFRDRBNDVDQkY4?revision=1","title":"0151T000003d4DhQAI.png","associationType":"BODY","width":244,"height":159,"altText":null},"TkbTopicMessage:message:282744":{"__typename":"TkbTopicMessage","subject":"Monitoring Your Network with PRTG - Overview, Installation, and Configuration","conversation":{"__ref":"Conversation:conversation:282744"},"id":"message:282744","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282744","revisionNum":1,"uid":282744,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:106220"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1853},"postTime":"2012-08-21T00:01:00.000-07:00","lastPublishTime":"2012-08-21T00:01:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" A few months back, our team moved DevCentral.f5.com from our corporate datacenter to a cloud service provider. As part of this project, we were required to take over the tasks previously performed by our IT department. One of the tasks that fell into my hands was to look at the monitoring and alerting for the heath of the systems in our environment. These systems included our application tier (application, database, and storage) as well as the F5 network infrastructure (GTM, LTM, ASM, WA, APM, etc). \n After looking at several product offerings, we ended up choosing PRTG Network Monitor from Paessler. We chose PRTG for it’s cost model as well as it’s ability to be customized and extended. \n This is the first in a series of articles covering PRTG and how we use it to monitor the production environment of DevCentral.f5.com. In this article, I’ll go over the features in the product, the installation process, and touch on configuration. In future articles, I’ll talk in more detail about configuration and the development of custom monitoring (to get data from our F5 products) and alerting (sending out customized email/SMS notifications of the monitor results). \n PRTG \n \n The PRTG Network Monitor runs as a service on a Windows machine on your network. It collects statistics from the components in your network (which it can auto-discover) and retains that data for historical performance reporting and analysis. The product has the following features: \n Quick Download, Installation, and Configuration Choose Between 5 Easy To Use User Interfaces Comprehensive Network Monitoring with more than 130 sensor types covering all aspects of network monitoring. Flexible Alerting Support for Clustered configuration of Network Monitors. Distributed Monitoring Using Remote Probes Data Publishing and Maps In-Depth Reporting \n Installation \n Paessler offers a couple of ways for you to test their software and we opted for the 30 day no-limitation trial. They also offer a completely freeware version for 10 sensors. Be careful if you use the network discovery feature as it will easily bypass the 10 sensor limit. Also keep in mind that the commercial product is a separate installation so you will need to re-install the product if you decide to go with a commercial license (meaning you need more sensors). \n You can download the install package from the product website. It consists of a self-contained installer that does it all for you. Since PRTG uses it’s own internal database, no 3rd party products are required to use the software. \n I ran the install with all the defaults and within a few minutes, the software was ready to use. When the install finished, a web browser was opened with the Configuration page. After configuring a few things I was ready to start adding sensors to my network gear. I opted to not do the auto-scanning of my network but went into the Sensors page by clicking on the “Review Results” button. \n Sensor Configuration \n PRTG allows you to build hierarchies of devices. I opted to lay them out in the following device tree \n Root\n Local Probe (I’m only using single probe so everything under this item is monitored locally).\n management server (this is the local machine PRTG is running on. PTRG can monitor itself by the way). DC1\n F5 Devices\n asm-1 (device 1 in our Application Security/Local Traffic HA pair) asm-2 (device 2) egw-1 (device 1 in our Edge Gateway/Web Acceleration HA pair) egw-2 (device 2) gtm-1 (our Global availabililty DNS device) \n Virtuals\n devcentral.f5.com (external virtual for application monitoring) \n Servers - DOMAIN\n adc-1 (windows domain controller #1) adc-2 (#2) \n Servers - APPS\n app-1 (Application server #1) app-2 (Application server #2) … (Application server #n) db-1 (Database server #1) db-2 (Database server #2) fil-1 (Network file storage) \n \n \n \n \n Each of those tree items allows for multiple sensors attached to them. I made use of memory, CPU, disk, Database, and system health checks. \n In the next article in this series, I’ll break down the various health checks I used and cover a few custom ones we developed to determine our application’s health. \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4332","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjk4N2lBOTNFM0UwQjc3QkFBOTBD?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtNjQ0Nmk0MjlENEExMTY2MTdBMjkw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3NDQtMjc3MWkwMTlEM0VFRDRBNDVDQkY4?revision=1\"}"}}],"totalCount":3,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:285547":{"__typename":"Conversation","id":"conversation:285547","topic":{"__typename":"TkbTopicMessage","uid":285547},"lastPostingActivityTime":"2024-04-11T13:58:25.820-07:00","solved":false},"TkbTopicMessage:message:285547":{"__typename":"TkbTopicMessage","subject":"BIG-IP Configuration Conversion Scripts","conversation":{"__ref":"Conversation:conversation:285547"},"id":"message:285547","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:285547","revisionNum":1,"uid":285547,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1799},"postTime":"2011-03-28T09:06:00.000-07:00","lastPublishTime":"2011-03-28T09:06:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP. While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible. Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python) ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"651","kudosSumWeight":1,"repliesCount":13,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:277947":{"__typename":"Conversation","id":"conversation:277947","topic":{"__typename":"TkbTopicMessage","uid":277947},"lastPostingActivityTime":"2016-12-16T06:47:07.000-08:00","solved":false},"User:user:68085":{"__typename":"User","uid":68085,"login":"Michael_Yates_6","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-3.svg?time=0"},"id":"user:68085"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTIzMjNpNzZEODExMDE3NzcxQTFCRQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTIzMjNpNzZEODExMDE3NzcxQTFCRQ?revision=1","title":"0151T000003d47oQAA.png","associationType":"BODY","width":403,"height":439,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTQxNTVpNjM0QkVGNzIxOTQzRTc1Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTQxNTVpNjM0QkVGNzIxOTQzRTc1Mw?revision=1","title":"0151T000003d47pQAA.jpg","associationType":"BODY","width":762,"height":145,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNTQ5OWlDRTRBNEZFNkJENjgyQkUz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNTQ5OWlDRTRBNEZFNkJENjgyQkUz?revision=1","title":"0151T000003d47qQAA.png","associationType":"BODY","width":676,"height":108,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNzk3MGlBMzVFN0JGOTk0Q0NFNTYz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNzk3MGlBMzVFN0JGOTk0Q0NFNTYz?revision=1","title":"0151T000003d47rQAA.png","associationType":"BODY","width":679,"height":288,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctOTQwMmk1NjU2MzQzOEM3OTFGMjQw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctOTQwMmk1NjU2MzQzOEM3OTFGMjQw?revision=1","title":"0151T000003d47sQAA.png","associationType":"BODY","width":689,"height":335,"altText":null},"TkbTopicMessage:message:277947":{"__typename":"TkbTopicMessage","subject":"BIG-IP and Merge File Configuration Changes","conversation":{"__ref":"Conversation:conversation:277947"},"id":"message:277947","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:277947","revisionNum":1,"uid":277947,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:68085"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1799},"postTime":"2011-06-01T08:49:00.000-07:00","lastPublishTime":"2011-06-01T08:49:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Early in my exposure to F5 BIG-IP I was involved in a load balancer migration project from our existing hardware to F5 Load Balancers. This involved the migration of several hundred configurations, so manual configuration of each new configuration was just not an option. \n Direct modification of the configuration file (bigip.conf) was also not an option since it would require a “b load” command to activate any modifications, which is disruptive to active traffic during a reload. \n A merge file on the other hand is non-service disrupting. Meaning that the BIG-IP will not have to reload the entire configuration file and disrupt all other traffic in order to implement your change. It will only make the changes that you specify. If your change is disruptive (removing servers from a pool, putting up a maintenance pages or redirect, etc.) those changes will be disruptive for other reasons and not caused by the merge process. \n The documentation of the command is pretty vague on usage, and it does not appear that very many people in the community are utilizing this feature which I have found immensely useful. \n \n MERGE(1) BIG-IP Manual \n \n NAME merge command - Loads the specified configuration file, which modifies the running configuration. \n \n SYNTAX bigpipe merge (<file> | –) \n DESCRIPTION The bigpipe merge command loads the specified configuration file or data. This modifies the running configuration. After you run the bigpipe merge command, if you want to save the modified running configuration in the stored configuration files, run the bigpipe save all command. \n It is important to note that if you want to replace the running configuration of the BIG-IP system, rather than modify it, you use the bigpipe load command. For more information, see the man page for the bigpipe load command. \n \n Merge files can be utilized to create or modify virtually anything that is contained within the bigip.conf configuration file (Virtual Servers, Pools, Nodes, iRules, Profiles, Classes, etc.). The basic structure of each can be found in the bigip.conf and copied to create a modification merge file (and a back-out merge file to restore the current configuration, so you can adhere to best practices and in compliance with most ITIL change management processes) or act as a template for a new configuration item. \n Commands: \n Merge file verification: bigpipe verify merge <file.name> \n Merge specified file: bigpipe merge <file.name> \n \n Implementation \n I have a new set of Virtual Servers to implement, but none of the supporting pieces have been implemented yet. Below is an example of the merge file followed by an attempted merge with the error that you will receive when verifying a merge file that has missing configurations or errors. The verify command will verify the syntax of the content and the existence of the items called in the merge file. \n NOTE: The top line of the Merge File specifies the target partition. If you have implemented Administrative Domains and Partitions on your BIG-IP, this is where you will specify which partition to place things. You can implement multiple items in different partitions in the same merge file. If you have not implemented Administrative Domains and Partitions you can specify the Common Partition. \n \n \n NOTE: The file extension (.txt) is not necessary. These would actually be .tcl files if you wanted language recognition in an editor like Notepad++. \n \n \n After merging the supporting configuration items the verification will return a good result: \n \n \n Modification with Back-out \n If you have a situation where a modification is necessary, you can retrieve the original (current) configuration from your bigip.conf and place it into a merge file(s). I have discovered that it is a best practice to keep a copy of the original configuration for Back-Out purposes and a second copy to act as a template for a modification. \n \n \n Merge files can also be change management friendly by allowing application configurations to be exported and kept in source control (and even versioned) with the application code providing a more holistic configuration repository or by attaching the configurations to whatever change management processes you may use. \n \n Lastly, merge order matters…. \n The order that you plan to merge files will impact the success or failure of a group of merge files because of the configuration dependencies (Example: You cannot merge a Virtual Server first if it is attempting to utilize a Pool that does not exist yet). \n I have discovered the following order: \n Classes (iRule Data Groups) Pools iRules Virtual Servers \n \n Conclusion \n Merge file implementations are fast. Almost instant and implementations / modifications can be done on numerous items at a time. Non-service disruptive to other traffic or configurations Allows for pre-implementation verification Configurations can be exported and kept with an application in source control our used with change management processes \n I hope that everyone finds this ability as useful as I have and that it makes your implementations easier. If anyone has any questions about the merge ability of bigpipe please join the Advanced Design and Configuration group on DevCentral and start a new thread in the forum. . \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5562","kudosSumWeight":0,"repliesCount":4,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTIzMjNpNzZEODExMDE3NzcxQTFCRQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctMTQxNTVpNjM0QkVGNzIxOTQzRTc1Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNTQ5OWlDRTRBNEZFNkJENjgyQkUz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctNzk3MGlBMzVFN0JGOTk0Q0NFNTYz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzc5NDctOTQwMmk1NjU2MzQzOEM3OTFGMjQw?revision=1\"}"}}],"totalCount":5,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:287315":{"__typename":"Conversation","id":"conversation:287315","topic":{"__typename":"TkbTopicMessage","uid":287315},"lastPostingActivityTime":"2023-01-26T14:22:27.122-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3","title":"0151T000003d46KQAQ.jpg","associationType":"BODY","width":800,"height":117,"altText":null},"TkbTopicMessage:message:287315":{"__typename":"TkbTopicMessage","subject":"BIG-IP Configuration Visualizer - iControl Style","conversation":{"__ref":"Conversation:conversation:287315"},"id":"message:287315","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:287315","revisionNum":3,"uid":287315,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1497},"postTime":"2011-01-25T09:01:00.000-08:00","lastPublishTime":"2023-01-26T14:22:27.122-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" I posted almost two years ago to the day on a cool tool called BIG-IP Config Visualizer, or BCV, that one of our field engineers put together that utilizes a BIG-IP config parser and GraphViz to create images visualizing the relationship of configuration objects for a particular virtual server. Well, I’m here to report that another community user, Russell Moore, has taken that work to the next level. Rather than trying to figure out the nuances of configuration objects amongst all the versions of BIG-IP, he converted the script to utilize iControl! In this tech tip, I’ll walk through the installation steps necessary to get this tool off the ground. \n The Setup \n Install a few libraries and GraphViz via apt-get \n \n apt-get install libssl-dev libcrypt-ssleay-perl libio-socket-ssl-perl libgraph-writer-graphviz-perl \n \n Open a CPAN shell and install SOAP::Lite and Net::Netmask \n \n perl –MCPAN –e shell\n \n install SOAP::Lite \n install Net::Netmask \n \n \n \n After installing those libraries and tools, grab the BCV-iControl source from the codeshare, save it as an executable (bcv.pl on my system) and set these variables (I only changed the ones in bold type): \n \n #Declare CLI $vars my $vs1; my $new_dir = 'NO_DIR'; my $extension = 'NO_EXT'; my $ltm_host = \"172.16.99.5\"; my $ltm_port = '443'; my $user_id = \"admin\"; my $req_partition; my $user_password = \"admin\"; my $ltm_protocol = 'https'; my $path; my $dir; \n \n Finally, some command-line options: \n \n root@ubuntu:/home/jrahm# ./bcv.pl -h Thank you for using BIG-IP Configuration Visualizer (BCV 1.16.1-revisited with soap) -v <VS_NAME> this prints the specified virtual server and requires option -c. Default is to print all \n -c Specify the partition/container to look in for option -v \n -t <iControl host LTM> specify ltm_host IP we will connect to \n -d specifies a directory you want the images in. Has to be in Current working Directory: /home/jrahm Default is /img) \n -e Define image format options: svg, png (default is jpg) \n -help for help but you already found it \n \n The Payoff \n Now that all the legwork is complete, we can play! \n \n root@ubuntu:/home/jrahm# ./bcv.pl \n Please wait while we build some maps of your system. Retrieving SelfIPs in Partition: ** Common ** Mapping Partition: ** Common ** routes to gateways Mapping Partition: ** Common ** selfIPs and VLANs.. Mapping Partition: ** Common ** pools and iRule references to pools............ Mapping Partition: ** Common ** virtual servers and properties... Drawing VS: dc.hashtest which is 1 of 3 in Partition: Common Drawing VS: testvip1 which is 2 of 3 in Partition: Common Drawing VS: management_vip which is 3 of 3 in Partition: Common \n All drawings completed! They can be found in: /home/jrahm/img \n \n Taking a look at the virtual server I used for the hashing algorithm distribution tech tip: \n \n Conclusion \n Visual representations of configurations are incredibly helpful in identifying issues quickly. An interesting next step would be to track state of objects from iteration of the drawings, and build a page to include all the images. That would make a nice and cheap dashboard for application owners or operating centers. Any takers? Thanks to community user Russell Moore that took a great contributed tool and made it better with iControl! ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3516","kudosSumWeight":0,"repliesCount":12,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286049":{"__typename":"Conversation","id":"conversation:286049","topic":{"__typename":"TkbTopicMessage","uid":286049},"lastPostingActivityTime":"2021-05-24T06:49:53.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktODMwOWlDQkIwQTE5QTBENzJCQzM4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktODMwOWlDQkIwQTE5QTBENzJCQzM4?revision=1","title":"0151T0000040RduQAE.png","associationType":"BODY","width":1114,"height":472,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTYzaUNBMkQ1RUJERkExMEM3OEI?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTYzaUNBMkQ1RUJERkExMEM3OEI?revision=1","title":"0151T0000040RdvQAE.png","associationType":"BODY","width":1166,"height":491,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTIzMzNpRjFCNEY2MTA4NzY2NEU5Nw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTIzMzNpRjFCNEY2MTA4NzY2NEU5Nw?revision=1","title":"0151T0000040ReEQAU.png","associationType":"BODY","width":562,"height":139,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMzE5NWlBNzg1Njc4QkZBRUY2OTE1?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMzE5NWlBNzg1Njc4QkZBRUY2OTE1?revision=1","title":"0151T0000040RdzQAE.png","associationType":"BODY","width":1160,"height":489,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTk0NWkxRUFEMDI2QkFCQzA3NkU2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTk0NWkxRUFEMDI2QkFCQzA3NkU2?revision=1","title":"0151T0000040Re4QAE.png","associationType":"BODY","width":1152,"height":527,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTExNTdpNzYyRURFQUUxMzhFNENENw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTExNTdpNzYyRURFQUUxMzhFNENENw?revision=1","title":"0151T0000040RdwQAE.png","associationType":"BODY","width":1256,"height":529,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMjAxOGkyMDg5MDI3MzczNUJGRTVG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMjAxOGkyMDg5MDI3MzczNUJGRTVG?revision=1","title":"0151T0000040RdxQAE.png","associationType":"BODY","width":614,"height":431,"altText":null},"TkbTopicMessage:message:286049":{"__typename":"TkbTopicMessage","subject":"SSL Orchestrator Advanced Use Cases: Reducing Complexity","conversation":{"__ref":"Conversation:conversation:286049"},"id":"message:286049","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286049","revisionNum":1,"uid":286049,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:130391"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1346},"postTime":"2021-05-20T13:39:42.000-07:00","lastPublishTime":"2021-05-20T13:39:42.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Introduction Think back to any time in your career where one IT security solution solved all of your problems right out-of-the-box. Go ahead, I'll wait. Chances are you're probably struggling to think of one, or at least more than one. Trust me when I say it doesn't matter how many other industry professions are doing what you do, many of your security challenges are absolutely unique to you. \"Best of breed\" means little if it can't solve all of your problems. That's why an entire ecosystem exists of best-of-breed security solutions...because each is best at a subset of the total problem space. The problem with this inescapable truth is that using multiple solutions to solve for the entire security conundrum also breeds complexity. The spectacular beauty of an F5 SSL Orchestrator solution is that it can drastically reduce that complexity and at the same time, increase manageability, scalability, and proficiency. With great ease and finesse, a sprawl of heavily burdened security products can be transformed into dynamically addressable and independently scalable malware munching monsters, void of the weight of decryption, each focused purely on their strengths. Best of all, SSL Orchestrator sits on top of the F5 BIG-IP, which itself provides unparalleled flexibility. If the SSL Orchestrator itself doesn't meet your every need, it's almost certain there's some configuration or programmatic way to achieve what you're looking for. In this article we will explore some of that immense flexibility. I should note here that the following guidance stands equally as a set of best practices for configuring and managing SSL Orchestrator, and for reducing complexity in an existing environment. Let's go. SSL Orchestrator Use Case: Reducing Complexity We have already solved for the security product complexity of integrating multiple security products, so this article specifically tackles another challenge: what happens when the SSL Orchestrator configuration itself gets to be complicated? The goal is to reduce overall complexity, but as with all other things we tend to think about challenges one at a time, creating separate solutions for each problem as it comes up. This becomes troublesome when we build large numbers of nearly duplicate topologies, or create super-complex security policies. The most important consideration here is that an SSL Orchestrator configuration creates and manages ALL of the objects it needs, and very often that can be a lot. For example, a layer 3 outbound topology with one inline service will create no less than 700 dependent configuration objects. An inbound topology will create about 300 objects. Compare that to a typical LTM virtual server, where common objects are often re-used, and that's around 20. The net result is that creating a ton of SSL Orchestrator configurations can put a strain on the control plane, but also sort of defeats the point of reducing complexity. But fear not, there are a number of really interesting ways to reduce all of this without losing anything, and in some cases even increase capacity and flexibility. The solutions I am about to present are broken down by topology direction: Reducing Complexity for Reverse Proxy Topologies (Inbound) Reducing complexity by using shared security policies Reducing complexity with the Existing Applications topology Reducing complexity with existing applications and shared policies Reducing complexity with gateway mode Reducing complexity with existing application, SNI switching and address lists Reducing Complexity for Forward Proxy Topologies (Outbound) Reducing complexity with layered architectures For the purpose of illustration, I've also extracted the average number of SSL Orchestrator security policy objects for comparison, where a minimal outbound security policy is about 80 objects, and an inbound policy is around 60 objects. I will use these numbers to make basic comparisons throughout, but of course this will always vary per environment. You can find the total number of control plane objects using this command: tmsh -q -c 'cd /; list recursive one-line'|wc -l\n If you don't have access to the BIG-IP command line, but do have a copy of the bigip.conf, you can do this: cat bigip.conf |egrep '^[a-z]' |wc -l\n And the total number of access (security policy) objects using this command: cat bigip.conf |egrep '^apm ' |wc -l\n Reducing Complexity for Reverse Proxy Topologies There are a number of optimizations that can be done for reverse proxy topologies, but let us start with the simplest and most profound update. Option 1: Reducing complexity by using shared security policies One single topology will create its own security policy, but very often your security policies are all going to be doing basically the same thing. You can make a dramatic impact on complexity and overall object count by simply reducing the total number of security policies and reusing these across your topologies. figure 1: Reducing complexity in a reverse proxy with shared security policies Let's break it down to show the benefit of this approach. We'll illustrate using twelve separate SSL Orchestrator inbound topologies. As I mentioned earlier, a basic inbound layer 3 topology with one inline service will create about 300 control plane objects. Of that, less than half of these are the security policy, service chain and the inline service, around 120. An inline layer 2 service will create around 60 objects, and as there's a finite number of security services to begin with, they'll generally be shared between the security policies so we won't count these. If we then focus just on the security policy and service chain, that's around 60 unique objects. If each of the above twelve topologies creates its own security policy, reducing that down to just 3 unique security policies (for example), can remove over 500 objects, a nearly 75% reduction, and by the way you have also just made overall policy management simpler. Configuration object reuse has tremendous benefit. If you are building a new SSL Orchestrator environment, consider this option if you simply cannot reduce the total number of inbound topologies, but can reasonably reduce security policies down to a smaller set of unique policies that can be shared. If you have an existing environment and need to reduce complexity, setting this up is also very simple: Use the above scripts to get a total object count before taking any action. Identify a set of security policies that perform the same steps, pick one or create a new one, and then under each respective topology replace the existing security policy with this single shared security policy. You can then delete the old unused security policies, then repeat this action for each topology until all duplicate policies are removed. Run the object counts tools one more time and compare the difference. Option 2: Reducing complexity with the Existing Applications topology Shrinking the number of active security policies is an easy win, but even that isn't where the bulk of objects are. Recall again that a minimal inbound topology is about 300 objects, so minus the 120 from the security policy, service chain and inline service objects, 180 remain in the topology and its other dependent configurations. A layer 3 inbound SSL Orchestrator topology is, basically, a reverse proxy virtual server, SSL profiles, security policies, and various other dependent profiles and configurations. If you have LTM licensed on the BIG-IP, you can further reduce this by switching to an Existing Application. The Existing Application topology simplifies the configuration by only building the security policy, service chain and security services. You then attach that security policy to an existing LTM application virtual server. figure 2: Reducing complexity in a reverse proxy with existing application topologies Let's break it down again. Using the same twelve topologies with individual policies, disregarding the security services, you're seeing around 2800 objects. If you were to replace each FULL topology with an LTM application virtual server using an Existing Application security policy, you can see in the image above a pretty significant drop in configuration object count, to about 960 objects. For twelve topologies that's a 77% reduction in configuration objects. Full topology creation is, by design, constrained to the most essential (optimal) elements and thus limits some flexibility of manual configuration. Using a manually defined LTM VIP with an Existing Application topology instead of a full inbound topology will provide the full flexibility of LTM together with security policies and inline services. One caveat, the existing application option requires an LTM license. If you are building a new SSL Orchestrator environment, consider this option if you can see the benefits of deploying existing application virtual servers, where this technique provides additional capabilities and near unlimited customization. If you have an existing environment and need to reduce complexity, putting this one together requires a bit more work in an existing environment, but it's not insurmountable. If this is a new environment, then clearly starting with this configuration approach could be beneficial. To test this configuration, we'll use the virtual server's Source Address parameter. Use the above scripts to get a total object count before taking any action. Create a new Existing Application topology to define your security service(s), service chain and corresponding security policy. Disable strictness on an existing topology. Assuming traffic is flowing to this topology already, we'll need to make a quick switch at the command line so we need strictness to be disabled. Create an LTM application virtual server that matches the topology listener (ie. destination address, port, pool, etc.), but for testing purposes enter just YOUR client IP/mask in the Source Address field. BIG-IP virtual servers follow a \"most specific\" order-of-precedence, so by adding a specific source address, only your traffic will flow to the new VIP and not anything else. Also attach your new Existing Application security policy to this virtual server. Under the Access Policy section, Access Profile setting, select \"ssloDefault_accessProfile\". And then under Per-Request Profile, select your new security policy. figure 3: SSL Orchestrator Existing Application topology selection You should now have an LTM virtual server that matches the topology virtual server, except that it only listens for traffic to your address. You can alternatively apply a source Address List here to allow multiple testers to access the new VIP. Make sure that you are able to access the application and that decrypted traffic is passing to the security service(s). When you are ready to make the switch for all traffic, you'll need to change the Source Address field in the topology listener virtual to something specific, and then change the Source Address field in your new LTM virtual to 0.0.0.0%0/0, again manipulating the order-of-precedence. You can do this manually, or via simple TMSH transaction in a Bash script to switch both services simultaneously: #!/bin/bash\n\ntmsh << EOF\ncreate cli transaction\nmodify ltm virtual sslo_app1.app/sslo_app1 source 10.10.10.10/32\nmodify ltm virtual app1-ea-vip source 0.0.0.0%0/0\nsubmit cli transaction\nEOF\n The first modify command points at the existing topology listener virtual and changes the source to something unique. The second modify command changes your new LTM application virtual source to allow traffic from all (0.0.0.0%0/0). All of this is done inside a transaction, so the change is immediate for both. Perform the steps above for each inbound layer 3 topology that you need to replace with an LTM virtual and Existing Application policy. When you're satisfied that everything is now flowing through your LTM application VIPs, go back and delete the unused topologies, security policies, service chains and SSL configurations. Run the object count tools one more time and compare the difference. Option 3: Reducing complexity with existing applications and shared policies Okay, so far we've separately reduced complexity by either sharing security policies, or using Existing Application topologies with LTM VIPs. What if we actually combined these two methods? figure 4: Reducing complexity in a reverse proxy with existing application topologies and shared policies Again, if we remove the security services from the equation, you should see an absolutely enormous drop in object count. Twelve separate topologies and security policies at around 2800 objects, consolidated to twelve LTM VIPs and three unique security policies is an 86% reduction in configuration objects! Plus, again, you've expanded your flexibility by switching to LTM application VIPs and made SSL Orchestrator policy management much simpler. Migration to this configuration option is more or less the same as the last, except instead of twelve individual Existing Application topologies, you'll only need to create a smaller set of unique policies and share these accordingly. If you are building a new SSL Orchestrator environment, consider this option if you can see the benefits of deploying existing application virtual servers, and you can reasonably reduce security policies down to a smaller set of unique policies that can be shared. Option 4: Reducing complexity with gateway mode At this point, you've now potentially removed 86% of the total configuration objects and made your environment clean, lean, simpler and more flexible. What more could you ask for? Well I'm glad you asked. The following isn't for everyone, but if it makes sense in your environment, it can create a HUGE simplification of resources and management. An SSL Orchestrator inbound \"gateway mode\" topology is intended as a routed path. Conversely what we've been talking about so far are \"application mode\" topologies, where the destination IP:port are configured within the topology, or LTM application virtual server. External clients target this address directly. But in gateway mode, the listener is a network address such as 0.0.0.0/0, so the destination address will actually be behind the BIG-IP, possibly a separate BIG-IP, another load balancer, router, or the application server itself. Traffic is routed through the BIG-IP to get there. You may see this as an advantage if the SSL Orchestrator sits closer to the edge of the network, and/or not owned and managed by the same teams. In any case, by virtue of the single 0.0.0.0/0 listener, you really only need ONE topology and ONE security policy, though your security policy may tend to be a bit more complex. figure 5: Reducing complexity in a reverse proxy with gateway mode If you are building a new SSL Orchestrator environment, consider this option if you can insert the BIG-IP as a routed hop in the application path. If you have an existing environment and need to reduce complexity, we can actually use that most specific order-of-precedence thing again to our advantage. As long as you have a bunch of application mode topologies configured with specific destination addresses, only new traffic flows that don't match one of these will flow to your wildcard gateway mode topology. Create a gateway mode SSL Orchestrator inbound topology by ensuring that the destination address is 0.0.0.0/0 (or other appropriate network address) and no pool is assigned. This will also automatically disable address and port translation so this effectively becomes a forwarding virtual server. You can test this topology by sending a request to a destination address that isn't defined by one of the application mode topologies, but does exist beyond the BIG-IP. When you're ready to move traffic over to the gateway topology, you can either start deleting the application mode topologies (or LTM virtual servers), or simply disable them. Now there's one other thing you have to address in the gateway mode configuration, and that's how to handle server certificates. In inbound application mode, each topology has its own SSL configuration and applied server certificate and key. But what do you do if all HTTPS traffic flows through a single virtual server? There are two options here. In both cases you'll need to create multiple SSL profiles, which you can either do in the SSL Orchestrator UI or manually in the BIG-IP. Certificate selection option 1: Attach multiple SSL profiles to the topology listener You will need to disable strictness on the topology to use this approach, as you'll need to edit the virtual server directly. You're going to add all of the client SSL profiles to the virtual server. The benefit of this method is that it is fast. The downsides are that you have to disable topology strictness (and leave it disabled), and also keep track of which client SSL profile has the \"Default for SNI\" setting. Create each client SSL profile and specify a unique server certificate and key. You'll also need to edit the \"Server Name\" field and enter the unique SNI hostname. The BIG-IP will select the correct client SSL profile automatically by virtue of the client's TLS ClientHello \"servername\" extension (SNI). In this method you need to select one of the client SSL profiles as \"Default for SNI\". This is the profile the BIG-IP will select in the very rare case that the client does not present an SNI. It's also worth noting here that as of BIG-IP 14.1, SSL profile selection can also be done based on the subject and subject alternative name (SAN) values in the applied certificate, versus a single static \"Server Name\" entry in the client SSL profile. You should still enter a Server Name value in the profile, but profile selection will only use this if the SNI does not match the subject or SAN in the applied certificate. Attach all of the client SSL profiles to the topology listener virtual server. Further detail: K13452: Configure a virtual server to serve multiple HTTPS sites using the TLS Server Name Indication feature Certificate selection option 2: Dynamically assign the SSL profiles via client SNI Using a slightly different approach, we'll employ an iRule on the topology interception rule that dynamically selects the client SSL profile based on the client's ClientHello SNI. The benefits here are that this doesn't require non-strict changes to the topology, and you don't have to set a Server Name value in the SSL profiles or worry about the Default for SNI setting. The disadvantage is that iRule-based dynamic profile selection will generate a small amount of additional runtime overhead. You'll need to weigh these two options against how heavily loaded your system will be. Create each client SSL profile and specify a unique server certificate and key. Create a string datagroup that maps the SNI server name value to the name of the client SSL profile. Example: www1.foo.com := /Common/www1.foo.com-clientssl\n www2.foo.com := /Common/www2.foo.com-clientssl\n www3.foo.com := /Common/www3.foo.com-clientssl\n Navigate over to https://github.com/f5devcentral/sslo-script-tools/tree/main/sni-switching and grab the \"library-rule.tcl\" iRule and import this to your BIG-IP. Name it \"library-rule\". On that same page, also grab and import the \"in-t-rule-datagroup.tcl\" iRule. Modify the data group name on line 23 with the name of your data group. Finally, navigate to the Interception Rules tab in the SSL Orchestrator UI and edit the corresponding interception rule. At the bottom of the page add the new \"in-t-rule-datagroup\" iRule and re-deploy. As TLS traffic enters the gateway mode topology listener, the above iRule will parse the client's ClientHello SNI, lookup the corresponding client SSL profile in the data group, and switch to that profile. Whenever you need to add a new site, simply create a new client SSL profile and add the respective key and value to the data group. Option 5: Reducing complexity with existing application, SNI switching and address lists I've saved this one for last to first introduce you to some of the underlying techniques, specifically address lists and SNI switching. You saw mention of address lists in testing the migration to existing application security policies, and we covered SNI switching in the previous gateway mode solution. If you can't employ a gateway mode (routed path) architecture in your environment, you can still reduce the total number of LTM virtual servers in an Existing Application topology option by using address lists. figure 6: Reducing complexity in a reverse proxy with existing app, SNI switching, and address-lists An LTM virtual server supports either a single static source or destination IP, or an address list that you can define in the UI under Shared Objects >> Address Lists. We use address lists to consolidate multiple LTM virtual servers into a single virtual server using an address list of multiple destination IPs. Since this is an LTM virtual server and not a full topology, you can also easily just add the multiple client SSL profiles without dealing with topology strictness. But you do still need to define one client SSL profile as Default for SNI. In lieu of that you can also use the above SNI switching iRules. If you then also reduce and reuse a unique set of security policies, you can drop control plane configuration objects as low as they can go. I've stated this a few times already, but by using LTM virtual servers instead of full inbound topologies you not only cut down on control plane congestion but also regain some flexibility. And moving to shared security policies means configuration management becomes a breeze. Reducing Complexity for Forward Proxy Topologies Where inbound reverse proxy complexity usually manifests as lots of topologies and lots of security policies, there's usually only one or a small few forward proxy topologies. Most of the complexity in a forward proxy topology is actually in the security policy itself, or in situations where specific environmental requirements necessitate non-strict customization. To solve for this sort of complexity you can employ what is referred to as an \"internal layered architecture.\" This idea is covered in great detail here: https://devcentral.f5.com/s/articles/SSL-Orchestrator-Advanced-Use-Cases-Reducing-Complexity-with-Internal-Layered-Architecture. Essentially this method uses a \"steering\" virtual server positioned in front of a set of SSL Orchestrator topologies (on the same BIG-IP) and directs traffic to one of the topologies via local steering policy decision. figure 7: Reducing complexity in a forward proxy with an internal layered architecture This architecture has some pretty interesting advantages in its own right: The steering policy is simple, flexible and highly automatable. In the absence of policy decisions, the SSL Orchestrator topologies are reduced to essentially static \"functions\", a unique combination of actions (allow/block, TLS intercept/bypass, service chain, egress). Topology objects are re-usable so while creating multiple topology functions, you'll likely re-use most of the underlying objects, like SSL configurations and services. Topology functions support dynamic egress (egress via different paths). Topology functions support dynamic local CA issuer selection (for example, using a different local CA for different \"tenants\"). Topology functions support more flexible traffic bypass options. Topologies as static functions will likely not require any non-strict customization, so makes management and upgrades simpler. The above DevCentral article provides much more insight here and offers a set of helper utilities to make steering policy super simple to deploy. To migrate to an internal layered architecture, we can use the most specific order-of-precedence thing again. Create a set of \"dummy\" VLANs, just an empty VLAN with no assigned interface. SSL Orchestrator topologies require a VLAN, but these are going to be \"internal\". Create your set of SSL Orchestrator topologies. The key idea here is that each will have a very basic security policy. The Pinners rule is actually covered in the helper utility, so you could reduce each security policy to a single \"All Traffic\" rule and apply the unique combination of actions. Last, assign a dummy VLAN to the topology and deploy it. Create your steering VIP as described in the other article but give it a source address filter that matches your local client address or use an address list to let your local team test it. Once you're confident that traffic is flowing through the steering virtual and to the correct internal topologies via policy, you can use the same TMSH transaction technique from the reverse proxy Existing Application use case above. That will move the 0.0.0.0/0 source address filter from your existing forward proxy topology to the steering VIP. Once you've done that, you can delete the unused client-facing topology and any other unused objects. Summary If you are just getting started with SSL Orchestrator, you have a lot of options to choose from. The objective here is to encourage simplicity. For SSL Orchestrator specifically that can mean reducing inbound topologies down to a single gateway mode, or utilizing common BIG-IP capabilities like address lists to reduce the number of existing application virtual servers. Or at the very least, consolidate to a common shared set of unique security policies. In fact, many of the above techniques for reducing and simplifying architectures are useful well beyond just SSL Orchestrator. Any time you have an environment with an enormous number of virtual servers, you can almost always consolidate a lot of these with practices like address lists and SNI switching. That helps by cleaning up the control plane and can simplify configuration, where \"common\" settings can now be managed in one place. This article was long, and for that I sincerely thank you for bearing with me to the end. Hopefully you can use some of this information as a best practice in managing what is easily one of the most flexible application delivery control devices on the planet. And in doing so, also vastly reduce the complexity in your security stack with SSL Orchestrator. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"26599","kudosSumWeight":2,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktODMwOWlDQkIwQTE5QTBENzJCQzM4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTYzaUNBMkQ1RUJERkExMEM3OEI?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTIzMzNpRjFCNEY2MTA4NzY2NEU5Nw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMzE5NWlBNzg1Njc4QkZBRUY2OTE1?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktNTk0NWkxRUFEMDI2QkFCQzA3NkU2?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMTExNTdpNzYyRURFQUUxMzhFNENENw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwNDktMjAxOGkyMDg5MDI3MzczNUJGRTVG?revision=1\"}"}}],"totalCount":7,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286191":{"__typename":"Conversation","id":"conversation:286191","topic":{"__typename":"TkbTopicMessage","uid":286191},"lastPostingActivityTime":"2011-11-28T14:19:02.000-08:00","solved":false},"TkbTopicMessage:message:286191":{"__typename":"TkbTopicMessage","subject":"BIG-IP Configuration Object Naming Conventions","conversation":{"__ref":"Conversation:conversation:286191"},"id":"message:286191","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286191","revisionNum":1,"uid":286191,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1049},"postTime":"2011-11-28T14:19:02.000-08:00","lastPublishTime":"2011-11-28T14:19:02.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" George posted an excellent blog on hostname nomenclature a while back, but something we haven’t discussed much in this space is a naming convention for the BIG-IP configuration objects. Last week, DevCentral community user Deon posted a question on exactly that. Sometimes there are standards just for the sake of having one, but in most cases, and particularly in this case, having standards is a very good thing. Señor Forum, hoolio, and MVP hamish weighed in with some good advice. [app name]_[protocol]_[object type] Examples: www.example.com_http_vs www.example.com_http_pool www.example.com_http_monitor As hoolio pointed out in the forum, each object now has a description field, so the metadata capability is there to establish identifying information (knowledge base IDs, troubleshooting info, application owners), but having an object name that is quickly searchable and identifiable to operational staff is key. Hamish had a slight alternative format for virtuals: [fqdn]_[port] For network virtuals, I’ve always made the network part of the name, as hamish also recommends in his guidance: network VS's tend to be named net-net.num.dot.ed-masklen. e.g. net-0.0.0.0-0 is the default address. Where they conflict (e.g. two defaults depending on src clan, it gets an extra descriptor between net- and the ip address. e.g. net-wireless-0.0.0.0-0 (Default network VS for a wireless VLAN). I don't currently have any network VS's for specific ports. But they'd be something like net-0.0.0.0-0-port Your Turn What standards do you use? Share in the comments section below, or post to the forum thread. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"1674","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:330193":{"__typename":"Conversation","id":"conversation:330193","topic":{"__typename":"TkbTopicMessage","uid":330193},"lastPostingActivityTime":"2024-08-28T10:07:18.146-07:00","solved":false},"User:user:73390":{"__typename":"User","uid":73390,"login":"Doug_Gallarda","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS03MzM5MC16eVAxM0E?image-coordinates=48%2C0%2C1204%2C1156"},"id":"user:73390"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMzAxOTMtWFVKdUlP?revision=4\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMzAxOTMtWFVKdUlP?revision=4","title":"Screenshot 2024-05-30 at 9.13.53 PM.png","associationType":"BODY","width":1220,"height":988,"altText":""},"TkbTopicMessage:message:330193":{"__typename":"TkbTopicMessage","subject":"NGINX Virtual Machine Building with cloud-init","conversation":{"__ref":"Conversation:conversation:330193"},"id":"message:330193","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:330193","revisionNum":4,"uid":330193,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:73390"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":" Traditionally, building new servers was a manual process. A system administrator had a run book with all the steps required and would perform each task one by one. If the admin had multiple servers to build the same steps were repeated over and over. \n All public cloud compute platforms provide an automation tool called cloud-init that makes it easy to automate configuration tasks while a new VM instance is being launched. \n In this article, you will learn how to automate the process of building out a new NGINX Plus server using cloud-init. ","introduction":"Quickly create fresh NGINX VMs on any cloud provider","metrics":{"__typename":"MessageMetrics","views":799},"postTime":"2024-06-07T05:00:00.037-07:00","lastPublishTime":"2024-08-28T10:07:18.146-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" The joy and burden of building new servers \n The initial build of a new application server requires multiple steps. First, the operating system must be installed. Then additional software packages need to be added as required by the application. Lastly, both the operating system and software package configurations need to be customized to the needs of the runtime environment. \n Traditionally, building new servers was a manual process. A system administrator had a run book with all the steps required and would perform each task one by one. If the admin had multiple servers to build, the same steps were repeated over and over. \n Looking at Installing NGINX Plus on Debian or Ubuntu as an example, an administrator needs to complete around 14 tasks. If these tasks must be performed manually every time a new VM is launched, much time can be wasted. \n One way to reduce this burden is to build out one server, snapshot it, and then clone that snapshot for every additional server that needs to be deployed. All hypervisor platforms have this capability. The problem with snapshots, however, is that it captures the state of a server at a specific moment in time. If new versions of the operating system or software packages are released, your golden image becomes obsolete. \n Rather than taking a picture of a server after it's been configured, another approach is to automate the execution of the configuration tasks themselves. Every time a new server is launched, the configuration is built from scratch, including the latest versions of the operating system and software packages. Now every new server arrives fresh instead of a clone of a configuration created months ago. \n Introducing cloud-init \n In this article, you will learn how to automate the process of building out a new NGINX Plus server using cloud-init. \n The beauty of cloud-init is that all public cloud providers already include it as a built-in feature. You can even build local VMs on your own hardware or laptop. Just put your configuration tasks into a simple text file and it can be used to build new VMs anywhere cloud-init is available. \n Automating NGINX Plus Installation \n Let's take a look at how cloud-init can automate the process of installing NGINX Plus on a Ubuntu server. Below is the \"simple text file\" (formatted as YAML) that describes what tasks need to be performed. Notice that we are not just replicating each command-line operation into a shell script. This is much better than that. The contents are more declarative in nature, where we describe our desired final state rather than providing the imperative steps to get there. Now let's walk through each section of this file to see how it works. \n #cloud-config\n\nwrite_files:\n - content: |\n -----BEGIN CERTIFICATE-----\n MIIETDCCAzSgAwIBAgIRAN0W2fO6kAXvYOhjggkZ608wDQYJKoZIhvcNAQELBQAw\n Zj7Kh4dgUD+jOI5rJgn5DGm7inpiJf5eksH+scrOVTP+WuJHs8VzhH0UUqAwM3Tx\n <REDACTED>\n iIyDaR6Z9XvtFWiVyjfWv/R9hutbc7QLpbbcC/JIAmrUnskTlFu1Mz00p7Jis8f4\n 7X4xxTENEFzwPfrXIF/bxpg+X75IRb1aYOXpadxuUrckd7Rb46P4FPPxVzEH7TA7\n -----END CERTIFICATE-----\n path: /etc/ssl/nginx/nginx-repo.crt\n - content: |\n -----BEGIN PRIVATE KEY-----\n MIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQCtKV0irhiXnx4U\n uz1v2neP9ew857iFpZ9FyrsvYqrwaRLdxsBkrU8CgYBRYEknMdfl8OhTcvyYFSMV\n <REDACTED>\n PjQ5U2Kaf3gMia5v4nGkhyKPuvasyvEeupwkIGDvRDmc+/AVtQQbJSJa7O0X1fwE\n aIDBc9S5hiWeqIOK8489IA==\n -----END PRIVATE KEY-----\n path: /etc/ssl/nginx/nginx-repo.key\n\napt:\n conf: |\n Acquire::https::pkgs.nginx.com::Verify-Peer \"true\";\n Acquire::https::pkgs.nginx.com::Verify-Host \"true\";\n Acquire::https::pkgs.nginx.com::SslCert \"/etc/ssl/nginx/nginx-repo.crt\";\n Acquire::https::pkgs.nginx.com::SslKey \"/etc/ssl/nginx/nginx-repo.key\";\n \n sources:\n nginx:\n source: \"deb http://nginx.org/packages/mainline/ubuntu $RELEASE nginx\"\n keyid: 2FD21310B49F6B46\n nginx-plus:\n source: \"deb https://pkgs.nginx.com/plus/ubuntu $RELEASE nginx-plus\"\n keyid: 2FD21310B49F6B46\n app-protect:\n source: \"deb https://pkgs.nginx.com/app-protect/ubuntu $RELEASE nginx-plus\"\n keyid: 2FD21310B49F6B46\n app-protect-dos:\n source: \"deb https://pkgs.nginx.com/app-protect-dos/ubuntu $RELEASE nginx-plus\"\n keyid: 2FD21310B49F6B46\n security-updates:\n source: \"deb https://pkgs.nginx.com/app-protect-security-updates/ubuntu $RELEASE nginx-plus\"\n keyid: A5F6473795E778F4\n keyserver: https://cs.nginx.com/static/keys/app-protect-security-updates.key\n\npackages:\n# - nginx\n - nginx-plus\n# - nginx-plus-module-njs\n# - nginx-ha-keepalived\n# - app-protect\n\nruncmd:\n - systemctl enable --now nginx\n\nfinal_message: \"The system is finally up, after $UPTIME seconds\"\n \n The write_files section (Lines 3-21) \n The NGINX software repository requires mTLS client authentication. Two files are provided to customers to authenticate: nginx-repo.crt and nginx-repo.key. These two files need to be copied to the new server for software installation. The write_files section creates these files with the content included inline in the YAML file. Notice that each line of content needs to be indented to produce valid YAML. I use awk to indent each line like so: \n awk '{$1=\" \"$1}1' nginx-repo.crt \n Being able to create these files using cloud-init is nice because everything is in one YAML file. Of course, you will need to replace the content subsections with the content of your own nginx-repo.crt and nginx-repo.key files. \n The apt section (Lines 23-46) \n With Ubuntu Linux, the apt command is used to install software. To install NGINX Plus we configure apt with two things: \n \n The conf subsection -- Tells apt where the mTLS digital certificate files are that we created in the previous section. \n The sources subsection -- Adds the NGINX software repositories to apt. Each repository has a keyid that refers to a verification key in Ubuntu's keyserver. Notice that the \"security-updates\" keyid is not in Ubuntu's keyserver so a custom keyserver is provided. \n \n The packages section (Lines 48-53) \n Here is where we specify which software packages should be installed. In this case I only need NGINX Plus so I've commented out the others. In this section you can install any package available to Ubuntu that you need. \n The runcmd section (Lines 55-56) \n After install, we just need to run one command to start up NGINX and make sure it automatically starts when the server boots in the future. \n The final_message section (Line 58) \n The final_message is a string that is written to the /var/log/cloud-init-output.log file after the automated install. In this case, I use the $UPTIME variable to record how long it took for the installation process to complete. \n Using a cloud-init file when creating a new VM \n Now that we have a cloud-init file ready to go, let's go ahead and use it to configure a brand new VM. Here are some examples of providing your YAML file when launching a new VM instance: \n On AWS EC2 using the Web UI \n When using the Web UI to launch a new instance, click on Advanced Details at the bottom of the page. Scroll down until you see a section labeled, \"User data - optional.\" You can either paste your YAML into the box provided or click the \"Choose file\" to upload the file from your computer. \n \n On Google Cloud Platform (GCP) using the gcloud CLI \n In addition to a Web UI, cloud platforms also provide a command line interface for launching new VM instances. Here is an example using GCP's CLI: \n gcloud compute instances create mynginx --zone=us-central1-a --image-project=ubuntu-os-cloud --image-family=ubuntu-2204-lts --metadata-from-file user-data=plus.yaml \n Here the metadata-from-file parameter is used to pass our YAML file named \"plus.yaml\" \n On your laptop using multipass \n Canonical, the makers of Ubuntu, provide a tool named Canonical Multipass for running VMs on your Windows, Mac, or Linux laptop or desktop system. When launching a new instance with multipass, you can pass our YAML file like so: \n multipass launch -n mynginx --cloud-init plus.yaml \n Viewing the cloud-init-output log file \n While the cloud-init automated installation is in progress, output for each task is written to /var/log/cloud-init-output.log \n You can view this file after the new instance is booted to verify that each step has completed successfully. Here is a snippet of the end of this log file: \n Cloud-init v. 24.1.3-0ubuntu3 running 'modules:final' at Fri, 31 May 2024 02:24:41 +0000. Up 35.57 seconds.\nReading package lists...\nBuilding dependency tree...\nReading state information...\nThe following NEW packages will be installed:\n nginx-plus\n0 upgraded, 1 newly installed, 0 to remove and 51 not upgraded.\nNeed to get 3700 kB of archives.\nAfter this operation, 7378 kB of additional disk space will be used.\nGet:1 https://pkgs.nginx.com/plus/ubuntu noble/nginx-plus amd64 nginx-plus amd64 32-1~noble [3700 kB]\nFetched 3700 kB in 1s (2513 kB/s)\nSelecting previously unselected package nginx-plus.\n(Reading database ... 71839 files and directories currently installed.)\nPreparing to unpack .../nginx-plus_32-1~noble_amd64.deb ...\n----------------------------------------------------------------------\n\nThank you for using NGINX!\n\nPlease find the documentation for NGINX Plus here:\n/usr/share/nginx/html/nginx-modules-reference.pdf\n\nNGINX Plus is proprietary software. EULA and License information:\n/usr/share/doc/nginx-plus/\n\nFor support information, please see:\nhttps://www.nginx.com/support/\n\n----------------------------------------------------------------------\nUnpacking nginx-plus (32-1~noble) ...\nSetting up nginx-plus (32-1~noble) ...\nCreated symlink /etc/systemd/system/multi-user.target.wants/nginx.service → /usr/lib/systemd/system/nginx.service.\nProcessing triggers for man-db (2.12.0-4build2) ...\n\nRunning kernel seems to be up-to-date.\n\nNo services need to be restarted.\n\nNo containers need to be restarted.\n\nNo user sessions are running outdated binaries.\n\nNo VM guests are running outdated hypervisor (qemu) binaries on this host.\nSynchronizing state of nginx.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.\nExecuting: /usr/lib/systemd/systemd-sysv-install enable nginx\nThe system is finally up, after 44.67 seconds \n By the final_message the automated install competed in 44.67 seconds. Much faster than if the administrator had to perform the same tasks manually! \n Conclusion \n There are other automation tools out there, like Ansible from Red Hat and Terraform from Hashicorp. These platforms come with a learning curve and require setup and configuration before they can be used. \n Using cloud-init to automate the build-out of new NGINX Plus servers offers the following advantages: \n \n Included with all public cloud compute offerings. Launching new VMs with cloud-init support comes by default. \n A declarative interface simplifies describing the configuration tasks that need to be automated. \n All instructions go into a single YAML text file that is easy to share across all your compute platforms. \n Instead of using a stale VM golden image, cloud-init does a fresh install and config every time you spin up a new VM. \n \n Hopefully this introduction to using cloud-init to build new NGINX Plus VM instances has been useful. Please feel free to leave any questions or feedback you may have in the comments below. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"11609","kudosSumWeight":3,"repliesCount":4,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMzAxOTMtWFVKdUlP?revision=4\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1752674562364","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1752674562364","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1752674562364","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1752674562364","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1752674562364","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1752674562364","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1752674562364","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1752674562364","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1752674562364","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1752674562364","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1752674562364","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1752674562364","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1752674562364","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1752674562364","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1752674562364","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1752674562364","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1752674562364","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1752674562364","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1752674562364","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1752674562364","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1752674562364","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1752674562364","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1752674562364","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostViewed","tagName":"configuration"},"buildId":"3XH0qYWYCnEYycuN5W4S8","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}