wils
11 Topics
WILS: How can a load balancer keep a single server site available?
Most people don’t start thinking they need a “load balancer” until they need a second server. But even if you’ve only got one server a “load balancer” can help with availability, with performance, and make the transition later on to a multiple server site a whole lot easier. Before we reveal the secret sauce, let me first say that if you have only one server and the application crashes or the network stack flakes out, you’re out of luck. There are a lot of things load balancers/application delivery controllers can do with only one server, but automagically fixing application crashes or network connectivity issues ain’t in the list. If these are concerns, then you really do need a second server. But if you’re just worried about standing up to the load then a Load balancer for even a single server can definitely give you a boost.422Views0likes2CommentsWILS: Moore’s Law + Application (Un)Scalability = Virtualization
#Virtualization was inevitable. One of the interesting side effects of having been a developer before migrating to a more network-focused view of the world* is it’s easier to understand the limitations and constraints posed on networking-based software, such as web servers. During the early days of virtualization adoption, particularly related to efforts around architecting more scalable applications, VMware (and others) did a number of performance and capacity-related tests in 2010 that concluded “lots of little web servers” scale and perform better than a few “big” web servers. Although virtualization overhead varies depending on the workload, the observed 16 percent performance degradation is an expected result when running the highly I/O‐intensive SPECweb2005 workload. But when we added the second processor, the performance difference between the two‐CPU native configuration and the virtual configuration that consisted of two virtual machines running in parallel quickly diminished to 9 percent. As we further increased the number of processors, the configuration using multiple virtual machines did not exhibit the scalability bottlenecks observed on the single native node, and the cumulative performance of the configuration with multiple virtual machines well exceeded the performance of a single native node. -- “Consolidating Web Applications Using VMware Infrastructure” [PDF, VMware] The primary reason for this is session management and the corresponding amount of memory required. Capacity is a simple case of being constrained by the size of the data required to store the session. Performance, however, is a matter of computer science (and lots of math). We could go through the Big O math of hash tables versus linked lists versus binary search trees, et al, but suffice to say that in general, most algorithmic performance degrades the larger N is (where N is the number of entries in the data store, regardless of the actual mechanism) with varying performance for inserts and lookups. Thus, it is no surprise that for most web servers, hard-coded limitations on the maximum number of clients, threads, and connections exist. All these related to session management and have an impact on capacity as well as performance. One assumes the default limitations are those the developers, after extensive experience and testing, have determined provide the optimal amount of capacity without sacrificing performance. It should be noted that these limitations do not scale along with Moore’s law. The speed of the CPU (or number of CPUs) does impact performance, but not necessarily capacity – because capacity is about sessions and longevity of sessions (which today is very long given our tendency toward Web 2.0 interactive, real-time refreshing applications). This constraint does not, however, have any impact whatsoever on the growth of computing power and resources. Memory continues to grow as do the number of CPUs, cores, and speed with which instructions can be executed. What the end result of this is that “scale up” is no longer really an option for increasing capacity of applications. Adding more CPUs or more memory exposes the reality of diminishing returns. The second 4GB of memory does not net you the same capacity in terms of users and/or connections as the first 4GB, because performance degrades in conjunction with increase in memory utilization. Again, we could go into the performance characteristics of the underlying algorithms where resizing and searching of core data structures becomes more and more expensive, but let’s leave that to those so inclined to dig into the math. The result is it shouldn’t have been a surprise when research showed “lots of little web servers”, i.e. scale out, was better than “a few big web servers”, i.e. scale up. Virtualization - or some solution similar that enabled operators to partition out the increasing amount of compute resources in such a way as to create “lots of little web servers” – was inevitable because networked applications simply do not scale along with Moore’s Law. *A Master’s degree in Computer Science doesn’t hurt here, either, at least for understanding the performance of algorithms and their various limitations Lots of Little Virtual Web Applications Scale Out Better than Scaling Up Consolidating Web Applications Using VMware Infrastructure To Take Advantage of Cloud Computing You Must Unlearn, Luke. It’s 2am: Do You Know What Algorithm Your Load Balancer is Using? Virtual Machine Density as the New Measure of IT Efficiency230Views0likes0CommentsWILS: Virtualization, Clustering, and Disaster Recovery
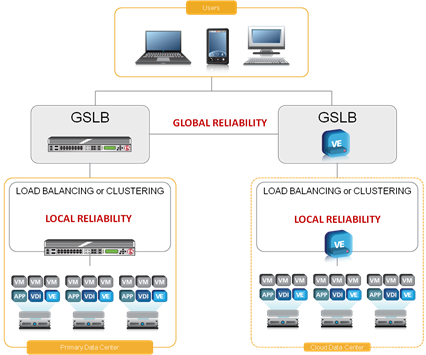
#virtualization Clustering is local. Disaster recovery is global. There are two levels of reliability for an application. There’s local and there’s global. We might want to consider it more simply as “inside” and “outside” reliability. Virtualization enables local reliability – the inside kind of reliability. Whether you’re relying upon clustering or load balancing (each has advantages and disadvantages, but for purposes of reliability and this discussion we’ll assume equal capabilities) to provide the abstraction isn’t as important as recognizing that in terms of reliability you’re acting at the local, i.e. inside, level. A cluster or pool, in load balancing parlance, is able to maintain local reliability by distributing load across multiple instances of the application. We can transparently add or remove instances to achieve the elasticity necessary to meet demand, thus ensuring reliability. In the event of a local disaster, such as the failure of a virtual machine, we can take the failed instance out of the rotation and even provision another to replace it. What clustering (load balancing) can’t do is address global reliability, i.e. outside reliability. Global reliability must be addressed using a different technology, normally referred to as Global Server Load Balancing (GLSB). The terminology grew out of the days when global reliability was achieved by load balancing individual servers across the globe to ensure a failure in the network or at a specific location could not interrupt the service. As demand grew, GSLB performed the same functions, but did so at a site level, essentially load balancing sites instead of individual servers. The name remains, however confusing that may be to the uninitiated. To achieve global reliability you need GSLB. To avoid the detrimental effects of a disaster in the network or at the site level, you must be able to direct users to an active location. This is realized in most implementations through simple DNS load balancing techniques; i.e. when a user makes a request the GSLB service responds with the IP address of an appropriate, active site. GLSB is capable of much more complex decision making, however, and decisions can be based on a variety of business and operational parameters, at the discretion of the organization. The GSLB service monitors each of the local sites, and is able to detect an outage within seconds and begin directing users elsewhere. At the local level, clustering and load balancing also monitor the “health” of individual instances and can react similarly in the event of a failure, but do so only at the local level. If the site fails, as might be the case in the event of a disaster, the local service is unable to do anything about it. It can’t redirect globally, it can’t notify other components. It’s just gone. For disaster recovery purposes, this is important stuff. When cloud first drifted onto the scene is was postulated that the cheaper compute would make implementing secondary data centers specifically for disaster recovery purposes more financially feasible for a wider variety of organizations. While that’s true in the sense that it’s way cheaper than building a secondary data center, many of the technological foundations remain the same: GSLB and a replicated environment. Some folks balk at the replication and point to transparent migration as a solution. After all, why pay even pennies on the hour instances that may never be put into commission? The problem is that transparent migration of virtual machines is only useful while the VMs are live and running. If they aren’t, such as might be the case in the event of a disaster, the site can’t be replicated and global reliability fails. A cluster-to-cluster failover via a bridged network to the cloud might sound like a good idea, but it isn’t practical when applied to a disaster recovery scenario. Too much depends on the availability of the site, of the network, and of the clustering/load balancing mechanism itself. If any one of the components has failed, global reliability is unrealizable. To achieve true global reliability regardless of the involvement of cloud computing , you’re going to need to implement a good old-fashioned GSLB architecture, complete with the network components and replicated application infrastructure. Local reliability (inside) may be achievable with virtual clustering solutions, but global reliability requires a very different architecture and set of technologies. Disaster recovery strategies cannot rely on local reliability, they must be based on global reliability. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Back to Basics: Load balancing Virtualized Applications The Cost of Ignoring ‘Non-Human’ Visitors Cloud Bursting: Gateway Drug for Hybrid Cloud The HTTP 2.0 War has Just Begun Why Layer 7 Load Balancing Doesn’t Suck Network versus Application Layer Prioritization WILS: The Many Faces of TCP WILS: WPO versus FEO221Views0likes0CommentsWILS: The Many Faces of TCP
#fasterapp Veno. Hybla. CTCP. HSTCP. Fast TCP. Not familiar with these variants? Read on… Anyone who’s involved with web application performance – either measuring or addressing – knows there are literally hundreds of RFCs designed to improve the performance of TCP (which in turn, one hopes, improves the performance of HTTP-delivered applications that ultimately rely on TCP). But what may not be known is that there are a number of variations on the TCP theme; slightly modified versions of the protocol that are designed to improve upon TCP under specific network conditions. A Burton IT research note (G00218070), “Wireless Performance Issues and Solutions for Mobile Users” published in January 2012 goes into much more detail on these variations. As this is a WILS post, I will keep it short and sweet, and encourage you to read through the aforementioned research note for more details or visit the homepages / RFC details for each variation. High Speed TCP (HSTCP) Designed for network conditions exhibiting high error rates or bursty data flows. Especially useful over high-latency links with large TCP receive window sizes. HSTCP RFC 3649 Fast TCP Developed at Caltech, Fast TCP is similar to HSTCP but exhibits better throughput and faster recovery as errors rates increase. It is patented, and embedded in products from FastSoft. Fast TCP Site at Caltech Compound TCP (CTCP) CTCP was developed by Microsoft and included in Windows Vista and Windows Server 2008. It combines principles of HSTCP and Fast TCP and according to the research note provides equivalent performance to HSTCP but without the same impact on normal TCP flows. CTCP Working Draft TCP Hybla Designed for high-latency satellite links with large error rates. TCP Hybla Website TCP Veno Designed for WLAN and WAN links, TCP Veno tries to determine whether packet loss was caused by random signal variations or congestion, avoiding reducing transmission rates when packet loss is due to noise. TCP Veno: Solution to TCP over Wireless [presentation] Interestingly, some of these protocols can actually inhibit performance when used in normal network conditions, which seems to make the case that the ultimate solution to choosing a TCP variation is not to choose only one, but to choose one intelligently on-demand. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND.191Views0likes0CommentsWILS: SSL TPS versus HTTP TPS over SSL
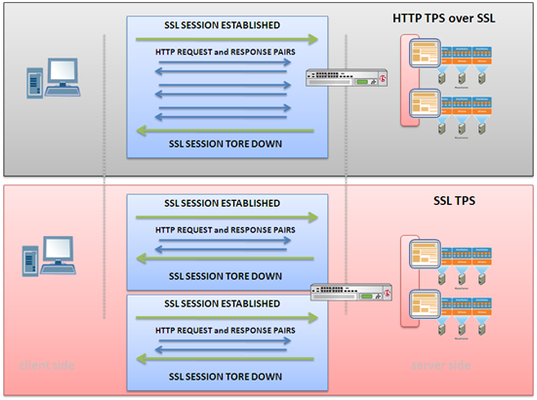
The difference between these two performance metrics is significant so be sure you know which one you’re measuring, and which one you wanted to be measuring. It may be the case that you’ve decided that SSL is, in fact, a good idea for securing data in transit. Excellent. Now you’re trying to figure out how to implement support and you’re testing solutions or perhaps trying to peruse reports someone else generated from testing. Excellent. I’m a huge testing fan and it really is one of the best ways to size a solution specifically for your environment. Some of the terminology used to describe specific performance metrics in application delivery, however, can be misleading. The difference between SSL TPS (Transactions per second) and HTTP TPS over SSL, for example, are significant and therefore should not be used interchangeably when comparing performance and capacity of any solution – that goes for software, hardware, or some yet-to-be-defined combination thereof. The reasons why interpreting claims of SSL TPS are so difficult is due to the ambiguity that comes from SSL itself. SSL “transactions” are, by general industry agreement (unenforceable, of course) a single transaction that is “wrapped” in an SSL session. Generally speaking one SSL transaction is considered: 1. Session establishment (authentication, key exchange) 2. Exchange of data over SSL, often a 1KB file over HTTP 3. Session closure Seems logical, but technically speaking a single SSL transaction could be interpreted as any single transaction conducted over an SSL encrypted session because the very act of transmitting data over the SSL session necessarily requires SSL-related operations. SSL session establishment requires a handshake and an exchange of keys, and the transfer of data within such a session requires the invocation of encryption and decryption operations (often referred to as bulk encryption). Therefore it is technically accurate for SSL capacity/performance metrics to use the term “SSL TPS” and be referring to two completely different things. This means it is important that whomever is interested in such data must do a little research to determine exactly what is meant by SSL TPS when presented with such data. Based on the definition the actual results mean different things. When used to refer to HTTP TPS over SSL the constraint is actually on the bulk encryption rate (related more to response time, latency, and throughput measurements), while SSL TPS measures the number of SSL sessions that can be created per second and is more related to capacity than response time metrics. It can be difficult to determine which method was utilized, but if you see the term “SSL ID re-use” anywhere, you can be relatively certain the test results refer to HTTP TPS over SSL rather than SSL TPS. When SSL session IDs are reused, the handshaking and key exchange steps are skipped, which reduces the number of computationally expensive RSA operations that must be performed and artificially increases the results. As always, if you aren’t sure what a performance metric really means, ask. If you don’t get a straight answer, ask again, or take advantage of all that great social networking you’re doing and find someone you trust to help you determine what was really tested. Basing architectural decisions on misleading or misunderstood data can cause grief and be expensive later when you have to purchase additional licenses or solutions to bring your capacity up to what was originally expected. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. The Anatomy of an SSL Handshake When Did Specialized Hardware Become a Dirty Word? WILS: Virtual Server versus Virtual IP Address Following Google’s Lead on Security? Don’t Forget to Encrypt Cookies WILS: What Does It Mean to Align IT with the Business WILS: Three Ways To Better Utilize Resources In Any Data Center WILS: Why Does Load Balancing Improve Application Performance? WILS: Application Acceleration versus Optimization All WILS Topics on DevCentral What is server offload and why do I need it?1.3KViews0likes3CommentsWILS: Content (Application) Switching is like VLANs for HTTP
We focus a lot on encouraging developers to get more “ops” oriented, but seem to have forgotten networking pros also need to get more “apps” oriented. Most networking professionals know their relevant protocols, the ones they work with day in and day out, that many of them are able to read a live packet capture without requiring a protocol translation to “plain English”. These folks can narrow down a packet as having come from a specific component from its ARP address because they’ve spent a lot of time analyzing and troubleshooting network issues. And while these same pros understanding load balancing from a traffic routing decision making point of view because in many ways it is similar to trunking and link aggregation (LAG) – teaming and bonding – things get a bit less clear as we move up the stack. Sure, TCP (layer 4) load balancing makes sense, it’s port and IP based and there’s plenty of ways in which networking protocols can be manipulated and routed based on a combination of the two. But let’s move up to HTTP and Layer 7 load balancing, beyond the simple traffic in –> traffic out decision making that’s associated with simple load balancing algorithms like round robin or its cousins least connections and fastest response time. Content – or application - switching is the use of application protocols or data in making a load balancing (application routing) decision. Instead of letting an algorithm decide which pool of servers will service a request, the decision is made by inspecting the HTTP headers and data in the exchange. The simplest, and most common case, involves using the URI as the basis for a sharding-style scalability domain in which content is sorted out at the load balancing device and directed to appropriate pools of compute resources. CONTENT SWITCHING = VLANs for HTTP Examining a simple diagram, it’s a fairly trivial configuration and architecture that requires only that the URIs upon which decisions will be made are known and simplified to a common factor. You wouldn’t want to specify every single possible URI in the configuration, that would be like configuring static routing tables for every IP address in your network. Ugly – and not of the Shrek ugly kind, but the “made for SyFy" horror-flick kind, ugly and painful. Networking pros would likely never architect a solution that requires that level of routing granularity as it would negatively impact performance as well as make any changes behind the switch horribly disruptive. Instead, they’d likely leverage VLAN and VLAN routing, instead, to provide the kind of separation of traffic necessary to implement the desired network architecture. When packets arrive at the switch in question, it has (may have) a VLAN tag. The switch intercepts the packet, inspects it, and upon finding the VLAN tag routes the packet out the appropriate egress port to the next hop. In this way, traffic and users and applications can be segregated, bandwidth utilization more evenly distributed across a network, and routing tables simplified because they can be based on VLAN ID rather than individual IP addresses, making adds and removals non-disruptive from a network configuration viewpoint. The use of VLAN tagging enables network virtualization in much the same way server virtualization is used: to divvy up physical resources into discrete, virtual packages that can be constrained and more easily managed. Content switching moves into the realm of application virtualization, in which an application is divvied up and distributed across resources as a means to achieve higher efficiency and better performance. Content (application or layer 7) switching utilizes the same concepts: an HTTP request arrives, the load balancing service intercepts it, inspects the HTTP header (instead of the IP headers) for the URI “tag”, and then routes the request to the appropriate pool (next hop) of resources. Basically, if you treat content switching as though it were VLANs for HTTP, with the “tag” being the HTTP header URI, you’d be right on the money. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. WILS: Layer 7 (Protocol) versus Layer 7 (Application) What is Network-based Application Virtualization and Why Do You Need It? WILS: Three Ways To Better Utilize Resources In Any Data Center WILS: The Concise Guide to *-Load Balancing WILS: Network Load Balancing versus Application Load Balancing Infrastructure Scalability Pattern: Sharding Sessions Applying Scalability Patterns to Infrastructure Architecture Infrastructure Scalability Pattern: Partition by Function or Type200Views0likes0CommentsWILS: The Importance of DTLS to Successful VDI
One of the universal truths about user adoption is that if performance degrades, they will kick and scream and ultimately destroy your project. Most VDI (Virtual Desktop Infrastructure) solutions today still make use of traditional thin-client protocols like RDP (Remote Desktop Protocol) as a means to enable communication between the client and their virtual desktop. Starting with VMware View 4.5, VMware introduced the high-performance PCoIP (PC over IP) communications protocol. While PCoIP is usually associated with rich media delivery, it is also useful in improving performance over distances. Such as the distances often associated with remote access. You know, the remote access by employees whose communications you particularly want to secure because it’s traversing the wild, open Internet. Probably with the use of an SSL VPN. Unfortunately, most traditional SSL VPN devices are unable to properly handle this unique protocol and therefore run slow, which degrades the user experience. The result? A significant hindrance to adoption of VDI has just been introduced and your mission, whether you choose to accept it or not, is to find a way to improve performance such that both IT and your user community can benefit from using VDI. The solution is actually fairly simple, at least in theory. PCoIP is a datagram (UDP) based protocol. Wrapping it up in what is a TCP-based security protocol, SSL, slows it down. That’s because TCP is (designed to be) reliable, checking and ensuring packets are received before continuing on. On the other hand UDP is a fire-and-assume-the-best-unless-otherwise-notified protocol, streaming out packets and assuming clients have received them. It’s not as reliable, but it’s much faster and it’s not at all uncommon. Video, audio, and even DNS often leverages UDP for speedy transmission with less overhead. So what you need, then, is a datagram-focused transport layer security protocol. Enter DTLS: In information technology, the Datagram Transport Layer Security (DTLS) protocol provides communications privacy for datagram protocols. DTLS allows datagram-based applications to communicate in a way that is designed to prevent eavesdropping, tampering, or message forgery. The DTLS protocol is based on the stream-oriented TLS protocol and is intended to provide similar security guarantees. The datagram semantics of the underlying transport are preserved by the DTLS protocol — the application will not suffer from the delays associated with stream protocols, but will have to deal with packet reordering, loss of datagram and data larger than a datagram packet size. -- Wikipedia If your increasingly misnamed SSL VPN (which is why much of the industry has moved to calling them “secure remote access” devices) is capable of leveraging DTLS to secure PCoIP, you’ve got it made. If it can’t, well, attempts to deliver VDI to remote or roaming employees over long distances may suffer setbacks or outright defeat due to a refusal to adopt based on performance and availability challenges experienced by the end users. DTLS is the best alternative to ensuring secure remote access to virtual desktops remains secured over long distances without suffering unacceptable performance degradation. If you’re looking to upgrade, migrate, or just now getting into secure remote access and you’re also considering VDI via VMware, ask about DTLS support before you sign on the dotted line. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Related blogs & articles: WILS: Load Balancing and Ephemeral Port Exhaustion All WILS Topics on DevCentral WILS: SSL TPS versus HTTP TPS over SSL WILS: Three Ways To Better Utilize Resources In Any Data Center WILS: Why Does Load Balancing Improve Application Performance? WILS: A Good Hall Monitor Actually Checks the Hall Pass WILS: Applications Should Be Like Sith Lords F5 Friday: Beyond the VPN to VAN F5 Friday: Secure, Scalable and Fast VMware View Deployment Desktop Virtualization Solutions from F5384Views0likes2CommentsWILS: Client IP or Not Client IP, SNAT is the Question
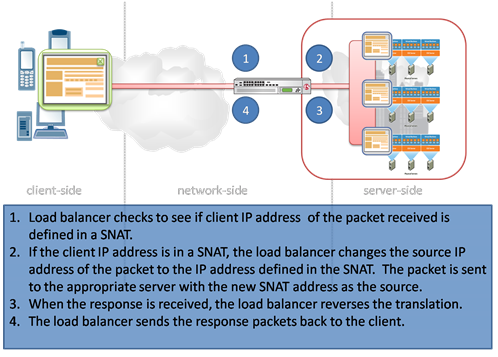
Ever wonder why requests coming through proxy-based solutions, particularly load balancers, end up with an IP address other than the real client? It’s not just a network administrator having fun at your expense. SNAT is the question – and the answer. SNAT is the common abbreviation for Secure NAT, so-called because the configured address will not accept inbound connections and is, therefore, supposed to be secure. It is also sometimes (more accurately in the opinion of many) referred to as Source NAT, however, because it acts on source IP address instead of the destination IP address as is the case for NAT usage. In load balancing scenarios SNAT is used to change the source IP of incoming requests to that of the Load balancer. Now you’re probably thinking this is the reason we end up having to jump through hoops like X-FORWARDED-FOR to get the real client IP address and you’d be right. But the use of SNAT for this purpose isn’t intentionally malevolent. Really. In most cases it’s used to force the return path for responses through the load balancer, which is important when network routing from the server (virtual or physical) to the client would bypass the load balancer. This is often true because servers need a way to access the Internet for various reasons including automated updates and when the application hosted on the server needs to call out to a third-party application, such as integrating with a Web 2.0 site via an API call. In these situations it is desirable for the server to bypass the load balancer because the traffic is initiated by the server, and is not usually being managed by the load balancer. In the case of a request coming from a client the response needs to return through the load balancer because incoming requests are usually destination NAT’d in most load balancing configurations, so the traffic has to traverse the same path, in reverse, in order to undo that translation and ensure the response is delivered to the client. Most land balancing solutions offer the ability to specify, on a per-IP address basis, the SNAT mappings as well as providing an “auto map” feature which uses the IP addresses assigned to load balancer (often called “self-ip” addresses) to perform the SNAT mappings. Advanced load balancers have additional methods of assigning SNAT mappings including assigning a “pool” of addresses to a virtual (network) server to be used automatically as well as intelligent SNAT capabilities that allow the use of network-side scripting to manipulate on a case-by-case basis the SNAT mappings. Most configurations can comfortably use the auto map feature to manage SNAT, by far the least complex of the available configurations. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Using "X-Forwarded-For" in Apache or PHP SNAT Translation Overflow Working around client-side limitations on custom HTTP headers WILS: Why Does Load Balancing Improve Application Performance? WILS: The Concise Guide to *-Load Balancing WILS: Network Load Balancing versus Application Load Balancing All WILS Topics on DevCentral If Load Balancers Are Dead Why Do We Keep Talking About Them?468Views0likes2CommentsWILS: Load Balancing and Ephemeral Port Exhaustion
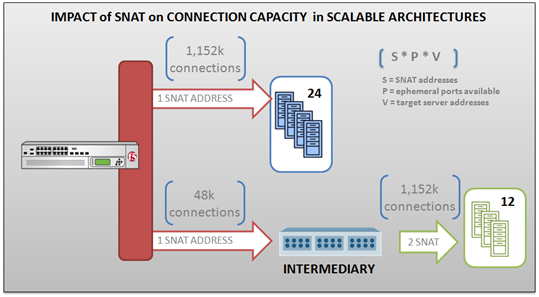
Understanding the relationship between SNAT and connection limitations in full proxy intermediaries. If you’ve previously delved into the world of SNAT (which is becoming increasingly important in large-scale implementations, such as those in the service provider world) you remember that SNAT essentially provides an IP address from which a full-proxy intermediary can communicate with server-side resources and maintain control over the return routing path. There is an interesting relationship between intermediaries that leverage two separate TCP stacks (such as full-proxies) and SNAT in terms of concurrent (open) connections that can be supported by any given “virtual” server (or virtual IP address, as they are often referred to in the industry). The number of ephemeral ports that can be used by any client IP address is 65535. Programmer types will recognize that as a natural limitation imposed by the use of an unsigned short integer (16 bits) in many programming languages. Now, what that means is that for each SNAT address assigned to a virtual IP address, a theoretical total of 65535 connections can be open at any other single address at any given time. This is because in a full-proxy architecture the intermediary is acting as a client and while servers use well-known ports for communication, clients do not. They use ephemeral (temporary) ports, the value of which is communicated to the server in the source port field in the request. Each additional SNAT address available increases the total number of connections by some portion of that space. As you should never use ephemeral ports in the privileged range (port numbers under 1024 are traditionally reserved for firewall and other sanity checkers - see /etc/services on any Unix box) that number can be as many as 64512 available ports between the SNAT address and any other IP address. For example, if a server pool (virtual or iron) has 24 members and assuming the SNAT address is configured to use ephemeral ports in the range of 1024-65535, then a single SNAT address results in a total of 24 x 48k = 1,152k concurrent connections to the pool. If the SNAT is assigned to a virtual server that is targeting a single address (like another virtual server or another intermediate device) then the total connections is 1 x 48k = 48k connections. Obviously this has a rather profound impact on scalability and capacity planning. If you only have one SNAT address available and you need the capabilities of a full-proxy (such as payload inspection inbound and out) you can only support a limited number of connections (and by extension, users). Some solutions provide the means by which these limitations can be mitigated, such as the ability to configure a SNAT pool (a set of dedicated IP addresses) from which SNAT addresses can be automatically pulled and used to automatically increase the number of available ephemeral ports. Running out of ephemeral ports is known as “ephemeral port exhaustion” as you have exhausted the ports available from which a connection to the server resource can be made. In practice the number of ephemeral ports available for any given IP address can be limited by operating system implementations and is always much lower than the 65535 available per IP address. For example, the IANA official suggestion is that ephemeral ports use 49152 through 65535, which means a limitation of 16383 open connections per address. Any full-proxy intermediary that has adopted this suggestion would necessarily require more SNAT addresses to scale an application to more concurrent connections. One of the advantages of a solution implementing a custom TCP/IP stack, then, is that they can ignore the suggestion on ephemeral port assignment typically imposed at the operating system or underlying software layer and increase the range to the full 65535 if desired. Another major advantage is making aggressive use of TIME-WAIT recycling. Normal TCP stacks hold on to the ephemeral port for seconds to minutes after a connection closes. This leads to odd bursting behavior. With proper use of TCP timestamps you can recycle that ephemeral port almost immediately. Regardless, it is an important relationship to remember, especially if it appears that the Load balancer (intermediary) is suddenly the bottleneck when demand increases. It may be that you don’t have enough IP addresses and thus ports available to handle the load. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Related Posts All WILS Topics on DevCentral Server Virtualization versus Server Virtualization885Views0likes0CommentsWILS: Automation versus Orchestration
Infrastructure 2.0 is not just about automation, but rather is about the orchestration of processes, which are actually two different things: the former is little more than advanced scripting, the latter requires participation and decision making on the part of the infrastructure involved. Automation is the process of codifying – usually through a scripting language but not always – a specific task. This task usually has one goal, though it may have several steps that have to be performed to accomplish it. An example would be “bring this server down for maintenance.” This may require quiescing connections if it is an application server, and stopping specific processes and then taking it offline. But the automation is of a specific task. Orchestration, on the other hand, is the codification of a complete process. In the case of cloud computing and IT this can also accomplished using scripts but more often involves the use of APIs – both RESTful and SOAPy. Orchestration ties together a set of automated tasks into a single process (operational in the case of IT, business in the case of many other solutions) and may span multiple devices, applications, solutions, and even data centers. “Bring this server down for maintenance” may actually be a single task in a larger process that is “Deploying a new version of an application.” The subtle difference between automation and orchestration is important primarily because the former is focused on codifying a concrete set of steps normally handled manually but that are done to a device or component. The latter often requires participation and decision making on the part of the infrastructure being orchestrated - the infrastructure is an active participant, a collaborator, in orchestration but is likely not in automation. The Context-Aware Cloud209Views0likes1Comment