Deploy WAF on any Edge with F5 Distributed Cloud (SaaS Console, Automation)
F5 XC WAAP/WAF presents a clear advantage over classical WAAP/WAFs in that it can be deployed on a variety of environments without loss of functionality. In this first article of a series, we present an overview of the main deployment options for XC WAAP while follow-on articles will dive deeper into the details of the deployment procedures.5.2KViews9likes0Comments
Ready to Go! Deploying F5 Infrastructure Using Terraform
This article describes how using Terraform enables you to rapidly deploy F5 infrastructure. Having something that is "ready to go" is what building infrastructure with Terraform is all about! The article also describes how you can customize your Terraform code to meet your particular needs. Once you have your specific design pattern, you have an automated way of rapidly creating, modifying, or destroying the network/application infrastructure over and over again in minutes, rather than hours or days. My Chosen Environment I will be using: Google Cloud Platform Terraform Github for source control VS Code for Editing Terraform There are also templates in the same repository that will work just as easily in AWS and Azure. What Is Terraform? Terraform is a tool that is produced by Hashicorp. Terraformis a solution for building, changing, and versioning infrastructure safely and efficiently.Terraformcan manage existing and popular service providers as well as custom in-house solutions. Configuration files describe toTerraformthe components needed to run a single application or your entire datacenter. How Can You Deploy F5 Using Terraform? There are many articles about how to install Terraform. This article assumes you have already installed Terraform and are ready to start deploying F5 infrastructure. In this article we will show you how easy it is to: Deploy an Example F5 Terraform Template Modify the Vanilla Terraform Template to Add a Jump-Box Why Would You Want to Modify the Generic Template to Add a Jump-Box? Well, don’t put your management interface on the internet. That is not a good idea. The Terraform example that I will use sets the management interface up with direct access to the internet. There are ACLs that you can configure to only allow connections from specific source IP addresses, which you should definitely employ even if you don’t use a jump-box. An additional layer of security is to add a jump-box so that you have to connect to the jump-box prior to accessing the management interface. From there you could also go ahead and smart card enable your jump-box or provide other two-factor authentication in order to further increase the security of the environment. Using a jump-box is a good best practice, period. For example, CVE-2020-5902 is a critical vulnerability that allowed attackers to actively exploit F5 management interfaces to do things like install coin-miners and malware or to gain administrative access to the hacked device. If your management interface had been internet facing, then it is safe to assume that you would have been breached. Also there were reports from the FBI that state-sponsored organizations were also trying to exploit this flaw. https://www.securityweek.com/iranian-hackers-target-critical-vulnerability-f5s-big-ip By using a jump-box you would not be placing your F5 management interfaces directly on the internet; you would have to access the F5 management interfaces via an RDP connection. Note that you should also harden your jump-box and implement ACLs and two-factor authentication in order to improve the security of the jump-box itself, as it presents a means of access. In this article we build the jump-box, but further hardening (which could also be implemented in Terraform) should be a best practice to make access to your management infrastructure more secure. Deploy a Terraform Example That Deploys F5 Infrastructure 1)Fork template In this example, my starting point is to fork templates published by a fellow F5er Jeff Giroux. This way I can keep my own copy and also make changes as appropriate for my environment. 2) Use git pull to make a local copy of the Terraform code. git clone https://github.com/dudesweet/f5_terraform.git This will pull a local copy of the template using the "git" command that will pull your forked version from github. 3) Explore the code with VS code. I am using VS code as my local editor. You can see that the template has directories for Azure, AWS, and GCP, and has different implementations of high availability; plus there are also auto-scale use cases. Your design pattern of choice will depend upon your requirements. In my case I am going to choose HA via load balancing. 4) Build your network infrastructure, as per the readme. This solution uses a Terraform template to launch a new networking stack. It will create three VPC networks with one subnet each: mgmt, external, internal. Use this terraform template to create your Google VPC infrastructure, and then head back to the [BIG-IP GCP Terraform folder](../) to get started! So navigate to the below directory. ~/f5_terraform/GCP/Infrastructure-only And you are going to want to customize the terraform.tfvars.example file and then re-name that file to terraform.tfvars So fill this out according to you specific environment. These are self explanatory, but: The prefix is used to prefix the infrastructure naming. adminsrcAddr - this is is your friend. This is how you restrict management access from the internet. gcp_project_id - this is your Google project Identifier. Region - your region where you would like the infrastructure to be built. Zone - your zone where you would like the infrastructure to be built. # Google Environment prefix = "mydemo123" adminSrcAddr = "0.0.0.0/0" gcp_project_id = "xxxxx" gcp_region = "us-west1" gcp_zone = "us-west1-b" Also, in the variables.tf you can customize the subnets to your own requirements, but in this case you need three VPCs with subnets (this is GCP so we have one 3 VPCs and a Subnet Per VPC). And then build out the network infrastructure. In the infrastructure directory: ~/f5_terraform/GCP/Infrastructure-only Run the following command: terraform plan "terraform plan" will show you the changes that are going to be made. And then run the command: terraform apply "terraform apply" will build the network infrastructure. "terraform apply" will prompt you with a yes/no to confirm if you want to go ahead and make the changes. Once you have built out your network infrastructure, you should be able to see the infrastructure that you have created inside of Google. Once you have built your networks and firewall rules etc., you can go ahead and build out your F5 infrastructure. 6) Build your F5 infrastructure. As mentioned before, the Terraform template that we are using allows access to the management interfaces from the internet - and you can limit access to the management interface via source IP. In my case, I want to add an additional layer of security by adding a jump-box. So I need to add a separate file with a few lines of Terraform code to instantiate the jump-box in the following directory: ~/f5_terraform/GCP/HA_via_lb After creating a file called jumpbox.tf, in my case I then added the following code to create a jump-box instance and associate it with the management subnet. #creates an ipV4 address to associate with the interface resource "google_compute_address" "static" { name = "ipv4-address" } #Define the type of instance tht you want. I am choosing a windows server. resource "google_compute_instance" "jumphost" { count = 1 name = "myjumphost1" project = var.gcp_project_id machine_type = "n1-standard-8" zone = var.gcp_zone allow_stopping_for_update = true boot_disk { initialize_params { image = "windows-server-2016-dc-v20200714" } } #Define the network interface and then associate the IP with the network interface. network_interface { network = "${var.prefix}-net-mgmt" subnetwork = "${var.prefix}-subnet-mgmt" subnetwork_project = var.gcp_project_id network_ip = var.jumphost_private_ip access_config { nat_ip = google_compute_address.static.address } } #Service account and permissions (how much access the service account has to the Google Meta data service). service_account { scopes = ["cloud-platform", "compute-rw", "storage-ro", "service-management", "service-control", "logging-write", "monitoring"] } } Then I will need to modify the terraform.tfvars.example file to suit my environment, and re-name to terraform.tfvars. # BIG-IP Environment uname= "admin" usecret= "my-secret" gceSshPubKey = "ssh-rsa xxxxx" prefix= "mydemo123" adminSrcAddr = "0.0.0.0/0" mgmtVpc= "xxxxx-net-mgmt" extVpc= "xxxxx-net-ext" intVpc= "xxxxx-net-int" mgmtSubnet= "xxxxx-subnet-mgmt" extSubnet= "xxxxx-subnet-ext" intSubnet= "xxxxx-subnet-int" dns_suffix= "example.com" # BIG-IQ Environment bigIqUsername = "admin" # Google Environment gcp_project_id = "xxxxx" gcp_region= "us-west1" gcp_zone= "us-west1-b" svc_acct= "xxxxx@xxxxx.iam.gserviceaccount.com" privateKeyId= "abcdcba123321" ksecret= "svc-acct-secret" I also added a line into the file called outputs.tf. output "JumpBoxIP" { value = google_compute_instance.jumphost.0.network_interface.0.access_config.0.nat_ip} This line will print out the jump-box IP address that I will use to RDP to the jump-box after a "terraform apply". Note that these templates rely upon the use of Google's secret manager in order to store the admin password. You will need to create a secret that by default is called "my-secret" (but you can call it anything you want), and this is where the Terraform code will pull the admin password from. Using a vault or a secrets manager to store sensitive values for reference in code is a good security best practice as you are only referencing the secrets vault in code and not the literal values themselves. And then build out the f5 infrastructure that will use the network infrastructure that you created earlier. In the HA_via_lb directory: ~/f5_terraform/GCP/HA_via_lb Run the following command: terraform plan "terraform plan" will show you the changes that are going to be made. And then: terraform apply "terraform apply" will add the F5 infrastructure and the jump-boxes. "terraform apply" will prompt you with a yes/no to confirm that you want to go ahead and make the changes. Remove Access to Port 443 on the Management Plane Because this Terraform template uses F5 declarative on boarding (DO) and AS3 to Place the BIG-IPs in an active standby pair and Create an example application on the BIG-IP... ...the example declarations in the Terraform rely on access to the management interface on port 443 as they POST the declarations to the BIG-IP in order to create the configuration. In your case this may present a too much of a risk, but if you use the source IP-based filtering mechanism properly and you use a very strong admin password for the management interface, then you can mitigate this risk for the brief period of time that the management interface would be exposed on the internet for Infrastructure Creation. Again, I deny port 443 after creating the infrastructure. If you can’t do this, you could build a jump-box first and then run the Terraform code from the jump-box. That being said, in my case I go back into the "Infrastructure Only" section and remove port 443 under allowed ports. You can simply edit the networks.tf file in the "Infrastructure Only" directory and re-run the template again. This is the stanza for the firewall rules on the management VPC: resource "google_compute_firewall" "mgmt" { name = "${var.prefix}-allow-mgmt" network = google_compute_network.vpc_mgmt.name source_ranges = [var.adminSrcAddr] allow { protocol = "icmp" } allow { protocol = "tcp" #remove access to port 443 here an re-apply ports = ["22","3389"] } } When you run this "terraform apply" again you will note that changes will only be made to the infrastructure that are modified. Terraform maintains state. It keeps a copy of what has been deployed and therefore will only make a change to the objects that require changes. Ready to Go! When this is all done, you will have a pair of BIG-IPs clustered in (Active/Standby) in Google GCP configured with three NICS. One for management, one for the "external" traffic interface, and one for the "internal" traffic interface. Traffic will ingress from from the Google Load Balancer to the BIG-IP VE, which will the process traffic to the applications that would reside on the "Internal" traffic side. There is now a jump-box that will be used to access the management interfaces to make changes to the BIG-IP configuration. You could also place further DevOps infrastructure on the jump-box in order to automate your application delivery configuration. From here you should be able to: Navigate to your jump-box. In my case, I set a strong password on the jump-box from the Google console. No doubt this could also be automated in the Terraform. Access your Infrastructure via the jump-box. You will be able to access the management IP on the internal IP address on NIC1. You can view a video based overview below. Links and References https://www.youtube.com/watch?v=o5b2OvN9ReM https://github.com/JeffGiroux/f5_terraform https://clouddocs.f5.com/products/extensions/f5-appsvcs-extension/latest/ https://clouddocs.f5.com/products/extensions/f5-declarative-onboarding/latest/ https://clouddocs.f5.com/products/orchestration/terraform/latest/ https://www.terraform.io/2.7KViews1like1CommentAutomate Application Delivery with F5 and HashiCorp Terraform and Consul
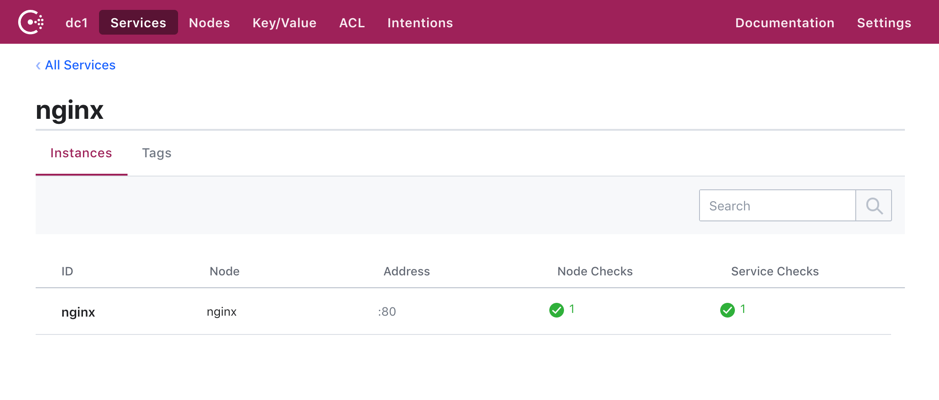
Written by HashiCorp guest author Lance Larsen Today, more companies are adopting DevOps approach and agile methodologies to streamline and automate the application delivery process. HashiCorp enables cloud infrastructure automation, providing a suite of DevOps tools which enable consistent workflows to provision, secure, connect, and run any infrastructure for any application. Below are a few you may have heard of: Terraform Consul Vault Nomad In this article we will focus on HashiCorp Terraform and Consul, and how they accelerate application delivery by enabling network automation when used with F5 BIG-IP (BIG-IP).Modern tooling, hybrid cloud computing, and agile methodologies have our applications iterating at an ever increasing rate. The network, however, has largely lagged in the arena of infrastructure automation, and remains one of the hardest areas to unbottleneck. F5 and HashiCorp bring NetOps to your infrastructure, unleashing your developers to tackle the increasing demands and scale of modern applications with self-service and resilience for your network. Terraform allows us to treat the BIG-IP platform“as code”, so we can provision network infrastructure automatically when deploying new services.Add Consul into the mix, and we can leverage its service registry to catalog our services and enable BIG-IPs service discovery to update services in real time. As services scale up, down, or fail, BIG-IP will automatically update the configuration and route traffic to available and healthy servers. No manual updates, no downtime, good stuff! When you're done with this article you should have a basic understanding of how Consul can provide dynamic updates to BIG-IP, as well as how we can use Terraform for an “as-code” workflow. I’d encourage you to give this integration a try whether it be in your own datacenter or on the cloud - HashiCorp tools go everywhere! Note: This article uses sample IPs from my demo sandbox. Make sure to use IPs from your environment where appropriate. What is Consul? Consul is a service networking solution to connect and secure services across runtime platforms. We will be looking at Consul through the lens of its service discovery capabilities for this integration, but it’s also a fully fledged service mesh, as well as a dynamic configuration store. Head over to the HashiCorp learn portal for Consul if you want to learn more about these other use cases. The architecture is a distributed, highly available system. Nodes that provide services to Consul run a Consul agent. A node could be a physical server, VM, or container.The agent is responsible for health checking the service it runs as well as the node itself. Agents report this information to the Consul servers, where we have a view of services running in the catalog. Agents are mostly stateless and talk to one or more Consul servers. The consul servers are where data is stored and replicated. A cluster of Consul servers is recommended to balance availability and performance. A cluster of consul servers usually serve a low latency network, but can be joined to other clusters across a WAN for multi-datacenter capability. Let’s look at a simple health check for a Nginx web server. We’d typically run an agent in client mode on the web server node. Below is the check definition in json for that agent. { "service": { "name": "nginx", "port": 80, "checks": [ { "id": "nginx", "name": "nginx TCP Check", "tcp": "localhost:80", "interval": "5s", "timeout": "3s" } ] } } We can see we’ve got a simple TCP check on port 80 for a service we’ve identified as Nginx. If that web server was healthy, the Consul servers would reflect that in the catalog. The above example is from a simple Consul datacenter that looks like this. $ consul members Node Address Status Type Build Protocol DC Segment consul 10.0.0.100:8301 alive server 1.5.3 2 dc1 <all> nginx 10.0.0.109:8301 alive client 1.5.3 2 dc1 <default> BIG-IP has an AS3 extension for Consul that allows it to query Consul’s catalog for healthy services and update it’s member pools. This is powerful because virtual servers can be declared ahead of an application deployment, and we do not need to provide a static set of IPs that may be ephemeral or become unhealthy over time. No more waiting, ticket queues, and downtime. More on this AS3 functionality later. Now, we’ll explore a little more below on how we can take this construct and apply it “as code”. What about Terraform? Terraform is an extremely popular tool for managing infrastructure. We can define it “as code” to manage the full lifecycle. Predictable changes and a consistent repeatable workflow help you avoid mistakes and save time. The Terraform ecosystem has over 25,000 commits, more than 1000 modules, and over 200 providers. F5 has excellent support for Terraform, and BIG-IP is no exception. Remember that AS3 support for Consul we discussed earlier? Let’s take a look at an AS3 declaration for Consul with service discovery enabled. AS3 is declarative just like Terraform, and we can infer quite a bit from its definition. AS3 allows us to tell BIG-IP what we want it to look like, and it will figure out the best way to do it for us. { "class": "ADC", "schemaVersion": "3.7.0", "id": "Consul_SD", "controls": { "class": "Controls", "trace": true, "logLevel": "debug" }, "Consul_SD": { "class": "Tenant", "Nginx": { "class": "Application", "template": "http", "serviceMain": { "class": "Service_HTTP", "virtualPort": 8080, "virtualAddresses": [ "10.0.0.200" ], "pool": "web_pool" }, "web_pool": { "class": "Pool", "monitors": [ "http" ], "members": [ { "servicePort": 80, "addressDiscovery": "consul", "updateInterval": 15, "uri": "http://10.0.0.100:8500/v1/catalog/service/nginx" } ] } } } } We see this declaration creates a partition named “Consul_SD”. In that partition we have a virtual server named “serviceMain”, and its pool members will be queried from Consul’s catalog using the List Nodes for Service API. The IP addresses, the virtual server and Consul endpoint, will be specific to your environment.I’ve chosen to compliment Consul’s health checking with some additional monitoring from F5 in this example that can be seen in the pool monitor. Now that we’ve learned a little bit about Consul and Terraform, let’s use them together for an end-to-end solution with BIG-IP. Putting it all together This section assumes you have an existing BIG-IP instance, and a Consul datacenter with a registered service. I use Nginx in this example. The HashiCorp getting started with Consul track can help you spin up a healthy Consul datacenter with a sample service. Let’s revisit our AS3 declaration from earlier, and apply it with Terraform. You can check out support for the full provider here. Below is our simple Terraform file. The “nginx.json” contains the declaration from above. provider "bigip" { address = "${var.address}" username = "${var.username}" password = "${var.password}" } resource "bigip_as3" "nginx" { as3_json = "${file("nginx.json")}" tenant_name = "consul_sd" } If you are looking for a more secure way to store sensitive material, such as your BIG-IP provider credentials, you can check out Terraform Enterprise. We can run a Terraform plan and validate our AS3 declaration before we apply it. $ terraform plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # bigip_as3.nginx will be created + resource "bigip_as3" "nginx" { + as3_json = jsonencode( { + Consul_SD = { + Nginx = { + class = "Application" + serviceMain = { + class = "Service_HTTP" + pool = "web_pool" + virtualAddresses = [ + "10.0.0.200", ] + virtualPort = 8080 } + template = "http" + web_pool = { + class = "Pool" + members = [ + { + addressDiscovery = "consul" + servicePort = 80 + updateInterval = 5 + uri = "http://10.0.0.100:8500/v1/catalog/service/nginx" }, ] + monitors = [ + "http", ] } } + class = "Tenant" } + class = "ADC" + controls = { + class = "Controls" + logLevel = "debug" + trace = true } + id = "Consul_SD" + schemaVersion = "3.7.0" } ) + id = (known after apply) + tenant_name = "consul_sd" } Plan: 1 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run. That output looks good. Let’s go ahead and apply it to our BIG-IP. bigip_as3.nginx: Creating... bigip_as3.nginx: Still creating... [10s elapsed] bigip_as3.nginx: Still creating... [20s elapsed] bigip_as3.nginx: Still creating... [30s elapsed] bigip_as3.nginx: Creation complete after 35s [id=consul_sd] Apply complete! Resources: 1 added, 0 changed, 0 destroyed Now we can check the Consul server and see if we are getting requests. We can see log entries for the Nginx service coming from BIG-IP below. consul monitor -log-level=debug 2019/09/17 03:42:36 [DEBUG] http: Request GET /v1/catalog/service/nginx (104.222µs) from=10.0.0.200:43664 2019/09/17 03:42:41 [DEBUG] http: Request GET /v1/catalog/service/nginx (115.571µs) from=10.0.0.200:44072 2019/09/17 03:42:46 [DEBUG] http: Request GET /v1/catalog/service/nginx (133.711µs) from=10.0.0.200:44452 2019/09/17 03:42:50 [DEBUG] http: Request GET /v1/catalog/service/nginx (110.125µs) from=10.0.0.200:44780 Any authenticated client could make the catalog request, so for our learning, we can use cURL to produce the same response. Notice the IP of the service we are interested in. We will see this IP reflected in BIG-IP for our pool member. $ curl http://10.0.0.100:8500/v1/catalog/service/nginx | jq [ { "ID": "1789c6d6-3ae6-c93b-9fb9-9e106b927b9c", "Node": "ip-10-0-0-109", "Address": "10.0.0.109", "Datacenter": "dc1", "TaggedAddresses": { "lan": "10.0.0.109", "wan": "10.0.0.109" }, "NodeMeta": { "consul-network-segment": "" }, "ServiceKind": "", "ServiceID": "nginx", "ServiceName": "nginx", "ServiceTags": [], "ServiceAddress": "", "ServiceWeights": { "Passing": 1, "Warning": 1 }, "ServiceMeta": {}, "ServicePort": 80, "ServiceEnableTagOverride": false, "ServiceProxyDestination": "", "ServiceProxy": {}, "ServiceConnect": {}, "CreateIndex": 9, "ModifyIndex": 9 } ] The network map of our BIG-IP instance should now reflect the dynamic pool. Last, we should be able to verify that our virtual service actually works. Let’s try it out with a simple cURL request. $ curl http://10.0.0.200:8080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> That’s it! Hello world from Nginx! You’ve successfully registered your first dynamic BIG-IP pool member with Consul, all codified with Terraform! Summary In this article we explored the power of service discovery with BIG-IP and Consul. We added Terraform to apply the workflow “as code” for an end-to-end solution. Check out the resources below to dive deeper into this integration, and stay tuned for more awesome integrations with F5 and Hashicorp! References F5 HashiCorp Terraform Consul Service Discovery Webinar HashiCorp Consul with F5 BIG-IP Learn Guide F5 BIG-IP Docs for Service Discovery Using Hashicorp Consul F5 provider for Terraform Composing AS3 Declarations2.3KViews3likes0CommentsZero-touch configuration of secure apps across BIG-IP tenants using CTS
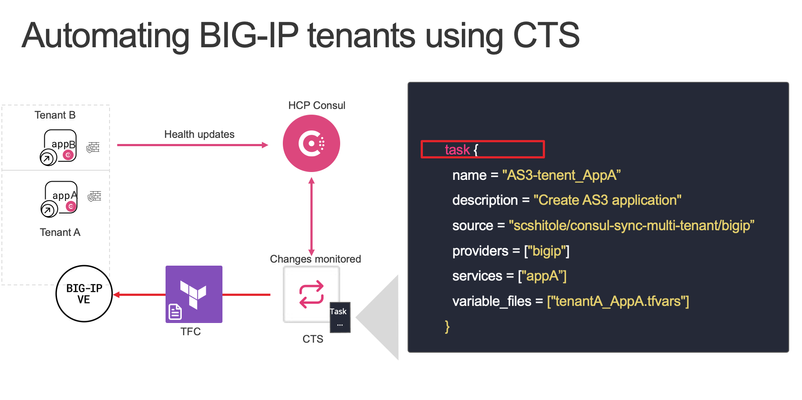
Deploying application workloads by developers or scaling operations traditionally involves submitting tickets, the network team assigning IP addresses, and the security team configuring policies. This siloed approach is time and resource intensive. Today, there are tools and automation to simplify processes and help developers become more independent to deploy and scale applications securely. In today's blog, we will talk about how we can deploy secure applications with an Advanced Web Application Firewall (AWAF) Policy on a F5 BIG-IP using automation. We will also look at a scenario where an existing application can be scaled up or scaled down, without any manual interventions. First, let us look at the tools involved. What are the Tools used? We will be using F5 Application Services Templates (FAST) to deploy application objects and AWAF policy on the BIG-IP. For more details about FAST, refer to https://clouddocs.f5.com/products/extensions/f5-appsvcs-extension/latest/We will also be using HashiCorp Consul Terraform Sync, Consul HCP, and Terraform Cloud to automate our application management workflows. How does the solution work? We will use Consul Terraform Sync (CTS) to define the tasks. The tasks in CTS refer to the BIG-IP-Terraform module that has the FAST terraform resource. This is used to push the necessary configurations object whenever services are added or removed on a BIG-IP. The back end application nodes are running the consul agent and are registered to HCP Consul. CTS continuously monitors the HCP Consul catalog for changes. Let's talk about the CTS file, below is an example CTS file which you can customize and use it. # Consul Block consul { address = "localhost:8500" service_registration { enabled = true service_name = "CTS Event AS3 WAF" default_check { enabled = true address = "http://localhost:8558" } } token = "${consul_acl_token}" } # Driver block driver "terraform-cloud" { hostname = "https://app.terraform.io" organization = "SCStest" token = "<token>" required_providers { bigip = { source = "F5Networks/bigip" } } } terraform_provider "bigip" { address = "5.2.2.29:8443" username = "admin" password = "s8!" } task { name = "AS3-tenent_AppA" description = "BIG-IP example" source = "scshitole/consul-sync-multi-tenant/bigip" providers = ["bigip"] services = ["appA"] variable_files = ["tenantA_AppA.tfvars"] } task { name = "AS3-tenent_AppB" description = "BIG-IP example" source = "scshitole/consul-sync-multi-tenant/bigip" providers = ["bigip"] services = ["appB"] variable_files = ["tenantB_AppB.tfvars"] } Consul Block contains Consul agent address with the port, health check and HCP Consul token information. Driver block consists of terraform cloud details like org name, HCP terraform token and BIG-IP provider. You can also pass the address, username & password for BIG-IP provider using env variables. You can see we have a ‘task’ block in the configuration, this block defines what will be configured on the BIG-IP whenever a service is registered to the HCP Consul Catalog. In the above example, we have service or app ‘AppA’ so whenever CTS sees that service on the HCP Consul catalog it will push the configuration on BIG-IP using the terraform module provided in the source in the task block. The source in the task block uses terraform module registered at https://registry.terraform.io/modules/scshitole/consul-sync-multi-tenant/bigip/latest and the repository is at https://registry.terraform.io/modules/scshitole/consul-sync-multi-tenant/bigip/latest The terraform module uploads the FAST template file into the BIG-IP along with the virtual server and pool configuration. It also attaches the AWAF policy to the virtual server. Enables BIG-IP to do service discovery forService Events on HCP Consul Creates a new example API endpoint like /mgmt/shared/service-discovery/task/~Consul_SD~Nginx~nginx_pool Which can be used to configure the pool member using the terraform resource "bigip_event_service_discovery” to add or remove the pool members Below is the example Fast template YAML title: Consul Service Discovery description: This template will create a virtual server that will use event driven service discovery definitions: tenant: title: Name of tenant description: give a unique name for this tenant app: title: Application description: give a unique name for this application defpool: title: pool defination description: should follow format poolname_pool only virtualAddress: title: Virtual Address description: IP addresses of virtual addresses (will create 80/443) virtualPort: title: Virtual Port description: Port that will be used type: integer parameters: virtualAddress: 10.0.0.200 virtualPort: 8080 tenant: "Consul_SD" app: "Nginx" defpool: "nginx_pool" template: | { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.0.0", "id": "urn:uuid:940bdb69-9bcd-4c5c-9a34-62777210b581", "label": "Consul Webinar", "remark": "Consul Webinar", "{{tenant}}": { "class": "Tenant", "{{app}}": { "class": "Application", "{{app}}_vs": { "class": "Service_HTTP", "virtualPort": {{virtualPort}}, "virtualAddresses": [ "{{virtualAddress}}" ], "pool": "{{defpool}}", "policyWAF": { "use": "Arcadia_WAF_API_policy" }, "persistenceMethods": [], "profileMultiplex": { "bigip": "/Common/oneconnect" } }, "Arcadia_WAF_API_policy": { "class": "WAF_Policy", "url": "https://gist.githubusercontent.com/scshitole/7b7cdcfbd48797d90769ae587324cc9b/raw/6f7a9be072230685956f84652312b3c7e153c6cf/WAFpolicy.json", "ignoreChanges": true }, "{{defpool}}": { "class": "Pool", "monitors": [ "http" ], "members": [{ "servicePort": 80, "addressDiscovery": "event" }] } } } } } and here is the module main.tf file terraform { required_providers { bigip = { source = "f5networks/bigip" version = "~> 1.15.0" } } } locals { tenant_params = jsonencode({ "tenant": var.tenant, "app": var.app, "virtualAddress": var.virtualAddress, "defpool": var.defpool, "virtualPort": var.virtualPort }) } # generate zip file data "archive_file" "template_zip" { type = "zip" source_file = "${path.module}/template/ConsulWebinar.yaml" output_path = "${path.module}/template/ConsulWebinar.zip" } # deploy fast template resource "bigip_fast_template" "consul-webinar" { name = "ConsulWebinar" source = "${path.module}/template/ConsulWebinar.zip" md5_hash = filemd5("${path.module}/template/ConsulWebinar.zip") depends_on = [data.archive_file.template_zip] } resource "bigip_fast_application" "nginx-webserver" { template = "ConsulWebinar/ConsulWebinar" fast_json = local.tenant_params depends_on = [bigip_fast_template.consul-webinar] } locals { # Create a map of service names to instance IDs service_ids = transpose({ for id, s in var.services : id => [s.name] }) # Group service instances by name grouped = { for name, ids in local.service_ids : name => [ for id in ids : var.services[id] ] } } resource "bigip_event_service_discovery" "event_pools" { for_each = local.service_ids taskid = "~${var.tenant}~${var.app}~${each.key}_pool" dynamic "node" { for_each = local.grouped[each.key] content { id = node.value.node_address ip = node.value.node_address port = node.value.port } } depends_on = [bigip_fast_application.nginx-webserver] } Configuring Multi-tenancy You can configure multiple tenants with the AWAF policy on the virtual server for each tenant by just updating the f5nia.hcl file with additional tasks and defining new app.tfvars file for each of the tasks. The app.tfvars file will define parameters like the name for the tenant on BIG-IP, application name, Virtual Server IP, Pool name, and BIG-IP credentials. You can configure multiple tenants with AWAF policy attached to the Virtual server by defining a new task in the Consul terraform Sync file. tenant="tenant_AppB" app="AppB" virtualAddress="10.0.0.202" virtualPort=8080 defpool="appB_pool" address="5.7.14.4" username="admin" password="PxxxxayJ" port=8443 “tenant” is the name of the partition on BIG-IP where the application objects are residing “app” name of the application which is running “virtualAddress” is the virtual server address “defpool” is the name of the Pool, it must follow app name and “_pool” address, username, password, and port to access BIG-IP You can also customize the AWAF policy as per your needs and package it into the FAST Yamal template, the example AWAF policy is shown below { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false } } } How to use the repository? Git clone https://github.com/f5businessdevelopment/f5_hcp_consul.git Change dir to cd f5_hcp_consul Copy terraform.tfvars.example to terraform.tfvars and customize as per your setup Issue terraform plan & apply F5 BIG-IP, backend applications AppA, AppB as well as jump instance is created on AWS You can see the services on HCP Consul Update BIG-IP with latest AS3 app services rpm, Fast template and enable ASM ssh to the jump box and change dir to “cts” also issue sudo su Update the *.tfvars file and f5nia.hcl as per your setup Start the CTS service by issuing “consul-terraform-sync config-file=f5nia.hcl” The above step will upload the FAST template and configure BIG-IP for Service discovery events and monitor HCP Consul for the Apps. The assumption is you are using HCP Consul, Terraform Cloud, and Enterprise Consul Terraform Sync Detail video is available athttps://youtu.be/11ssWNyVjF0. You can find additonal integrations of F5 BIG-IP and HashiCorp Tools at this link Conclusion: In dynamic, multi-tenant application environments, change management can become cumbersome and error prone. FAST templates on the BIG-IP provide a fantastic way to abstract configuration objects and enable simpler automation – which can help ops teams and developers to cut down application deployment times. Using FAST with service discovery and automation, can facilitate zero-touch configuration management for your applications workloads.2.1KViews0likes0Comments
Using F5's Terraform modules in an air-gapped environment
Introduction IT Industry research, such as Accelerate, shows improving a company's ability to deliver software is critical to their overall success. The following key practices and design principles are cornerstones to that improvement. Version control of code and configuration Automation of Deployment Automation of Testing and Test Data Management "Shifting Left" on Security Loosely Coupled Architectures Pro-active Notification F5 has published Terraform modules on GitHub.com to help customers adopt deployment automation practices, focused on streamlining instantiation of BIG-IPs on AWS, Azure, and Google. Using these modules allows F5 customers to leverage their embedded knowledge and expertise. But we have limited access to public resources Not all customer Terraform automation hosts running the CLI or enterprise products are able to access public internet resources like GitHub.com and the Terraform Registry. The following steps describe how to create and maintain a private air-gapped copy of F5's modules for these secured customer environments. Creating your air-gapped copy of the modules you need This example uses a personal GitHub account as an analog for air-gapped targets. So, we can't use the fork feature of github.com to create the copy. For this approach, we're assuming a workstation that has access to both the source repository host and the target repository host. So, not truly fully air-gapped. We'll show a workflow using git bundle in the future. Retrieve remote URL for one of the modules at F5's devcentral GitHub account Export the remote URL for the source repository export MODULEGITHUBURL="git@github.com:f5devcentral/terraform-aws-bigip-module.git" Create a repository on target air-gapped host Follow the appropriate directions for the air-gapped hosted Git (BitBucket, GitLab, GitHub Enterprise, etc.). And, retrieve the remote url for this repository. Export the remote URL for the air-gapped repository Note: The air-gapped repository is still empty at this point. Note: The example is using github.com, your real-world use will be using your internal git host export MODULEAIRGAPURL="git@github.com:myteamsaccount/localmodulerepo.git" Clone the module source repository This example uses F5's module for Azure git clone $MODULEGITHUBURL Add the target repository as an additional remote Again, we're using F5's AWS module as an example. We're using the remote url exported as MODULEAIRGAPURL to create the additional git repository remote. cd terraform-aws-bigip-module git remote add airgap $MODULEAIRGAPURL Pass the latest to the air-gapped repository Note: In the example below we're pushing the main branch. In some older repositories, the primary repository branch may still be named master . Note: Pushing the tags into the airgap repository is critical to version management of the modules. # get the latest from the origin repository git fetch origin # push any changes to the airgap repository git push airgap main # push all repository tags to the airgap repository git push --tags airgap Using your air-gapped copy of the modules Identify the module version to use This lists all of the tags available in the repository. git tag e.g. 0.9.2 v0.9 v0.9.1 v0.9.3 v0.9.4 v0.9.5 Review new versions for environment acceptance At this point, your organization should perform any acceptance testing of the new tags prior to using them in production environments. Source reference in Terraform module using git Unlike using the Terraform Registry, when using git as your module resource the version reference is included in the source URL. The source reference is the prefix git:: followed by the remote URL of the airgap repository, followed by ?ref= , finally followed by the tag identified in the previous step. Note: We are referencing the airgap repository, NOT the origin repository. Note: It is highly recommended to include the version reference in the URL. If the reference is not included in the URL, the latest commit to the default branch will be used at apply time. This means that the results of an apply will be non-deterministic, causing unexpected results, possibly service disruptions. module "bigip" { source = "git::https://github.com/myteamsaccount/localmodulerepo.git?ref=v0.9.3" ... } Check out Terraform for more detailed configuration requirements Source reference in Terraform module using a private Terraform registry If you have an instance of Terraform Enterprise it's possible to connect the private git repository created above to the [private module registry(https://www.terraform.io/docs/enterprise/admin/module-sharing.html)] available in Terraform Enterprise. module "bigip" { source = "privateregistry/modulereference" version = "v0.9.3" ... } Maintaining your air-gapped copy of the modules On-going maintenance of private repository Once the repository is established, perform the following actions whenever you want to retrieve the latest versions of the F5 modules. If you have a registry enabled on Terraform Enterprise, it should update automatically when the private repository is updated. # get the latest from the origin repository git fetch origin # push any changes to the airgap repository git push airgap main # push all repository tags to the airgap repository git push --tags airgap Review new versions for environment acceptance When your private repository is updated, do not forget to perform any acceptance testing you need to validate compliance and compatibility with your environment's expectations. Other references Installing and running iControl extensions in isolated GCP VPCs Deploy BIG-IP on GCP with GDM without Internet access1.6KViews1like0CommentsPushing Updates to BIG-IP w/ HashiCorp Consul Terraform Sync
HashiCorp Consul Terraform Sync (CTS) is a tool/daemon that allows you to push updates to your BIG-IP devices in near real-time (this is also referred to as Network Infrastructure Automation).This helps in scenarios where you want to preserve an existing set of network/security policies and deliver updates to application services faster. Consul Terraform Sync Consul is a service registry that keeps track of where a service is (10.1.20.10:80 and 10.1.20.11:80) and the health of the service (responding to HTTP requests).Terraform allows you to push updates to your infrastructure, but usually in a one and done fashion (fire and forget).NIA is a symbiotic relationship of Terraform and Consul.It allows you to track changes via Consul (new node added/removed from a service) and push the change to your infrastructure via Terraform. Putting CTS in Action We can use CTS to help solve a common problem of how to enable a network/security team to allow an application team to dynamically update the pool members for their application.This will be accomplished by defining a virtual server on the BIG-IP and then enabling the application team to update the state of the pool members (but not allow them to modify the virtual server itself). Defining the Virtual Server The first step is that we want to define what services we want.In this example we use a FAST template to generate an AS3 declaration that will generate a set of Event-Driven Service Discovery pools.The Event-Driven pools will be updated by NIA and we will apply an iControl REST RBAC policy to restrict updates. The FAST template takes the inputs of “tenant”, “virtual server IP”, and “services”. This generates a Virtual Server with 3 pools. Event-Driven Service Discovery Each of the pools is created using Event-Driven Service Discovery that creates a new API endpoint with a path of: /mgmt/shared/service-discovery/task/ ~[tenant]~EventDrivenApps~[service]_pool/nodes You can send a POST API call these to add/remove pool members (it handles creation/deletion of nodes).The format of the API call is an array of node objects: [{“id”:”[identifier]”,”ip”:”[ip address]”,”port”:[port (optional)]}] We can use iControl REST RBAC to limit access to a user to only allow updates via the Event-Driven API. Creating a CTS Task NIA can make use of existing Terraform providers including the F5 BIG-IP Provider.We create our own module that makes use of the Event-Driven API ... resource "bigip_event_service_discovery" "pools" { for_each = local.service_ids taskid = "~EventDriven~EventDrivenApps~${each.key}_pool" dynamic "node" { for_each = local.groups[each.key] content { id = node.value.node ip = node.value.node_address port = node.value.port } } } ... Once NIA is run we can see it updating the BIG-IP - Finding f5networks/bigip versions matching "~> 1.5.0"... ... module.AS3.bigip_event_service_discovery.pools["app003"]: Creating... … module.AS3.bigip_event_service_discovery.pools["app002"]: Creation complete after 0s [id=~EventDriven~EventDrivenApps~app002_pool] Apply complete! Resources: 3 added, 0 changed, 0 destroyed. Scaling up the environment to go from 3 pool members to 10 you can see NIA pick-up the changes and apply them to the BIG-IP in near real-time. module.AS3.bigip_event_service_discovery.pools["app001"]: Refreshing state... [id=~EventDriven~EventDrivenApps~app001_pool] … module.AS3.bigip_event_service_discovery.pools["app002"]: Modifying... [id=~EventDriven~EventDrivenApps~app002_pool] … module.AS3.bigip_event_service_discovery.pools["app002"]: Modifications complete after 0s [id=~EventDriven~EventDrivenApps~app002_pool] Apply complete! Resources: 0 added, 3 changed, 0 destroyed. NIA can be run interactively at the command-line, but you can also run it as a system service (i.e. under systemd). Alternate Method In the previous example you saw an example of using AS3 to define the Virtual Server resource.You can also opt to use Event-Driven API directly on an existing BIG-IP pool (just be warned that it will obliterate any existing pool members once you send an update via the Event-Driven nodes API).To create a new Event-Driven pool you would send a POST call with the following payload to /mgmt/shared/service-discovery/task { "id": "test_pool", "schemaVersion": "1.0.0", "provider": "event", "resources": [ { "type": "pool", "path": "/Common/test_pool", "options": { "servicePort": 8080 } } ], "nodePrefix": "/Common/" } You would then be able to access it with the id of “test_pool”.To remove it from Event-Driven Service Discovery you would send a DELETE call to /mgmt/shared/service-discovery/task/test_pool Separation of Concerns In this example you saw how CTS could be used to separate network, security, and application tasks, but these could be easily combined using NIA just as easily.Consul Terraform Sync is now generally available, and I look forward to seeing how you can leverage it.For an example that is similar to this article you can take a look at the following GitHub repo that has an example of using NIA.You can also view another example on the Terraform registry as well.1.6KViews1like8CommentsLightboard Lessons: Zero Touch Application Deployments with Terraform, Consul, and AS3
In this lightboard lesson, I show how you can move from the manual work of traditional app deployments to the automated goodness of zero touch app deployments! This demo solution was shown in a Hashicorp webinar featuring our own Eric Chen, and utilizes Hashicorp's Terraform and Consul applications, as well as the AS3 component of the F5 Automation Toolchain. Resources This demo in detail F5 Terraform automation lab (hosted by WWT, registration required) F5 Resources for Terraform Hands-on Intro to Infrastructure as Code Using Terraform Ready to go! Deploying F5 Infrastructure Using Terraform F5 and Hashicorp Essentials (article series on Terraform, Consul, and Vault)1.2KViews0likes2CommentsHands-on Intro to Infrastructure as Code using Terraform
Related Articles Automate Application Delivery with F5 and HashiCorp Terraform and Consul Quick Intro Terraform is a way of uniquely declaring how to build your infrastructure in a centralised manner using a single declarative language in order to avoid the pain of having to manually configure them in different places. Funnily enough, Terraform not only configures your infrastructure but also boots up your environment. You can literally keep your whole infrastructure declared in a couple of files. Other configuration management tools like Ansible are imperative in nature, i.e. they focus on how the tool should configure something. Terraform is declarative, i.e. it focus on what you want to do and Terraform is supposed to work out how to do it. In terms of commands, the bulk of what you will be doing with Terraform is executing mainly 3 commands:terraform init,terraform planandterraform apply. BIG-IP can be configured using Terraform and there are examples onclouddocs. For all configuration options you can go throughF5 BIG-IP Provider's page. In this article, I will walk you through how to spin up a Kubernetes Cluster on Google Cloud using Terraform just to get you started. We also have an article with an example on how to configure basic BIG-IP settings using Terraform: Automate Application Delivery with F5 and HashiCorp Terraform and Consul How to Install it? Download terraform fromhttps://www.terraform.io/downloads.html After that, you should unpack the executable and on Linux and Mac place its full path into $PATH environment variable to make it searchable. Here's what I did after I downloaded it to my Mac: It should be similar on Linux. How to get started? The best thing to do to get started with Terraform is to boot up a simple instance of an object from one of providers you're already comfortable with. For example, if you know how to set up a Kubernetes cluster on GCP then try to spin it up using Terraform. I'll show you how to create a Kubernetes Cluster on GCP with Terraform here. Creating a Kubernetes Cluster on GCP with Terraform Adding Provider Information First thing to do is to tell Terraform what kind of provider it is going to configure, i.e. GCP? AWS? BIG-IP? Terraform reads *.tf files from your terraform directory. Let's create a file named providers.tf with Google Cloud provider information: Note that we usedthe keyword "provider" to add our provider's authentication information (GCP in this case). To access your GCP account via a third-party source, different app or Terraform as is the case here, you'd normally create aService Account. I created one specifically for Terraform and that's what most people do. The rest is self-explanatory butcredentialsis where you add the full path to your auth file that you download once you create your service account. Essentially, this will make Terraform authenticate to your GCP cloud account. If you ever logged in to a Google Cloud account, you should know whatprojectsandregions/zonesare. I added the following permissions to my sample Terraform Service Account: Adding Resource Configuration Likewise, if we want to create resources we simply add"resource"keyword. In this case, google_container_cluster means we're spinning up a Kubernetes cluster on GCP. I'm going to create a separate file to keep our resources separate from provider's information just to keep it more tidy. There is no problem doing that at all as Terraform reads through all *.tf files. Here's our file for our Kubernetes cluster: For Kubernetes clusters we usegoogle_container_clusterfollowed by the name of the cluster (I named it rod-clusterin this case). Follow the breakdown of the information I added to above file: name: this is the name of the cluster location: this should be the GCP location where your Kubernetes project resides initial_node_count: this is the number of worker nodes in your cluster nodeconfig/oauth_scopes: these are the required components we need permission to run a Kubernetes cluster on GCP. Now we're ready to initialise Terraform to spin up our GCP Kubernetes cluster. However, before we jump into it, let's quickly answer one simple question. How do we know what keyword exactly to declare in a Terraform file? You can find the command's syntax in Terraform's documentation. Just pick the provider:https://www.terraform.io/docs/providers/index.html Initialising Terraform Now, back to business. The way we initialise Terraform is by executingterraform initcommand in the same directory where your *.tf files reside: In the background, Terraform downloaded GCP's plugin and placed it into .terraform folder: Spinning up Execution Plan The next step is to executeterraform plancommand so that Terraform can automatically check for errors in your *.tf file, connect to your provider using your credentials, and lastly confirm what you've requested is something doable: Our plan seems to be ok so let's move to our last step. Applying Terraform changes This is usually reliable but we never know until we apply it, right? The way we do it is by usingterraform applycommand: You will see the above prompt asking for your confirmation. Just answer yes and Terraform will connect to your provider and apply the changes automatically. Here's what follows the 'yes' answer: If we check my GCP account, we can confirm Terraform created the cluster for us: How to apply changes or destroy? You can useterraform applyagain if you've modified something. To destroy everything you've done you can useterraform destroycommand: Next steps There's much more to Terraform than what we've been through here. We can use variables and there are plenty of other commands. For example, we can create workspaces, ask Terraform to format your code for you and plenty of other things like listing resources Terraform is currently managing, graphs, etc. This is just to give that initial taste of how powerful Terraform is.1.1KViews1like0Comments
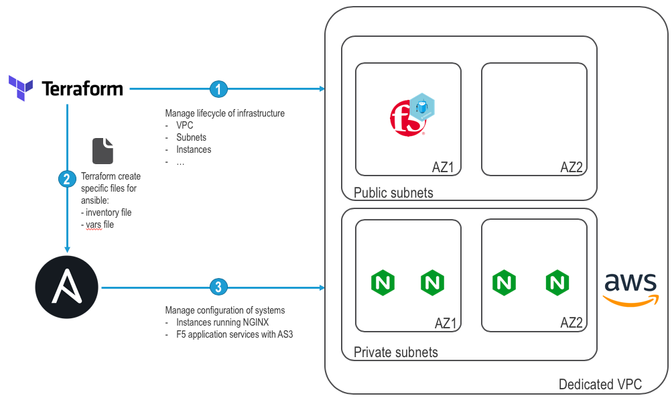
Manage Infrastructure and Services Lifecycle with Terraform and Ansible + Demo
Working as a Solution Architect for F5, Ioften need to have access to a lab environment. 'Traditionally', the method to implement a lab was to leverage tools like Vagrant,VMWare,or others. A lab environment on a laptop is limited by its computing capacities (CPU/Memory/disk/...).Today we are often asked to show how we can integrate our solutions with many different tools(Orchestration solutions, Version Control systems, CI Servers, containerized environments, ...). Except if your laptop is a powerful one, it's difficult to build such an environment and have itrun smoothly. If the lab requirements are too demanding for my laptop, Iwould access one of our lab facility to do my work. Thisapproach itself is fine but bring some challenges: If you travel like Ido, latency can become a hindrance and be frustrating. Lab facilities leverage "shared resources". Which means you may face issues due toconflicting IP addresses, switch misconfiguration, maintenance operations, ... Some resources may already be reserved/used by another fellow colleague and not be available. You may also face other constraints making both deployment models difficult: Need to share access to the lab. Not easy when it runs on your laptop or in a private cloud that is not always opened to the outside world. People may need to be able to replicate your lab in their own environment. Stability/time needed for maintenance: Using a lab over and over will make it messy. You usually At some point, you'll reach a stage where you want to create a "new" environment that is clean and "trustworthy" (until you played too much with it again) I'm sure i've missed other constraints but you get the idea: maintaining a lab and using it in a collaborativemanner is challenging. Luckily, it's easier today to achieve those objectices: Leverage Public Cloud! Public Cloud gives you access to "unlimited" computing services over Internet that can be automated/orchestrated. With Public Cloud, you have access to an API allowing you to spin up a new environment with all therelevant tools deployed. This way, you may go straight into work (after enjoying a nice cup of coffee/tea while yourinfrastructure is being deployed! ).Once your work is done, you can destroy this environment and save money. When you'll need a lab again, you'll be able to spin a new/clean environment in a matter of minutes and be confident that it's a "healthy lab" When working on Automation/Orchestration of Public cloud environments, I see two dominant tools: Terraform andAnsible. https://www.terraform.io Terraform is an open source command line tool that can be used to provision an infrastructure on dozensof different platforms and services (AWS, Azure, ...).One of the strength of Terraform is that it is declarative: You specify the expected "state" of yourinfrastructure and Terraform will take care of all the underlying complexities (Does it need to be provisioned? Should I update the settings of a component? Which components should be created first? Do we need to deleteresources that are not required anymore, ... ).Terraform will store the "state" of your infrastructure and configuration to be more efficient in its work. https://www.ansible.com Ansible is a provisioning and configuration management tool. It is designed to automate application deployments.One of the strength of Ansible is that it doesn't require any "agents" to run on the targetted systems. Ansibleworks by leveraging "Modules". Those modules are consumed to define the "state" of the targetted systems. They areusually executed over SSH (by default). So how to leverage those tools to have a lab available on-demand? In the following demo, we will: Leverage Terraform to manage the lifecycle of a new AWS environment: manage a dedicated VPC with external/internal subnets, Ubuntu instances, F5 solution) In addition to deploying our infrastructure, it will generate the relevant files for Ansible (inventory file to know theIPs of our systems, ansible variable files to know how to configure the F5 solution with AS3) Use Ansible to manage the configuration of our systems: update our ubuntu instances, install NGINX Web serviceon our Ubuntu instances, deploy a standard F5 configuration to load balance our web application with AS3 Here is a summary for the demo: Demo time! By leveraging tools like Terraform or Ansible (you can achieve the same results with other tools), it is easy to handle thelifecycle of an infrastructure and the services running on top of it. This is what people IaC (Infrastructure as Code) Useful links:- If you want to learn more about the setup of this demo, it is posted on Github: here- F5 provides a list of templates to automate deployment in public cloud. It's available here: AWS Templates, Azure Templates, GCP Templates- F5 Application Services 3 (AS3) documentation/examples: here- If you want to learn more about our API and how to automate/orchestrate F5 solutions (free training): F5 A&O Training1KViews2likes1CommentManage BIG-IPs in Azure using Terraform Cloud
Introduction In this article I’ll outline a suite of demonstration resources designed to help you and your IT team explore the possibilities of applying DevOps practices in your own environments. The demonstration resources described below show how tools likeGit, HashiCorpTerraform, HashiCorpSentinel, ChefInspecand F5'sAutomation Toolchaincan be used to introduce some of the practices listed above to F5 BIG-IPs and the IT services they help deliver. By following along with theREADMEin thedemonstration repositoryand the video walk-throughs listed below, you should be able to run this demonstration on your own. Software Delivery Key Practices IT Industry research, such asAccelerate, shows improving a company's ability to deliver software has a significant positive benefit to their overall success. The following practices and design principles are cornerstones to that improvement. Version control of code and configuration Automation of Deployment Automation of Testing and Test Data Management "Shifting Left" on Security Loosely Coupled Architectures Pro-active Notification Caveats These repositories use simplifying demonstration shortcuts for password, key, and network security. Production-ready enterprise designs and workflows should be used in place of these shortcuts. DO NOT ASSUME THAT THE CODE AND CONFIGURATION IN THESE REPOSITORIES IS PRODUCTION-READY The particular source control approach shown in this demonstration is one of many. Before using this approach to support your Infrastructure as Code and Configuration Management assets and workflows, you should learn aboutdifferent patterns of source code managementand determine what best fits your team's needs. A variety of tools are used in this demonstration. In most cases they are not exclusively required and can be replaced with other similar tools. The demonstration uses a licensed version of Terraform Cloud in order to demonstrate the capabilities of HashiCorp Sentinel. If you are using the free version of Terraform Cloud you won't be able to try the policy compliance use-cases, and the rest of the demonstration code should work as expected. Setting up your demonstration automation host Before running the demonstration code, you'll need to set up the IDE host and the Azure account. Instructions for those steps arehere Video walk-throughs Fork the repository and open it in Visual Studio Code (1m36s) Once the tools are installed, you can create your own copy of the repository and open it in your IDE. In the videos, Visual Studio Code is used as the IDE. In order to follow along, you'll need to create your own repository in order to set up the Terraform Cloud configuration and make your own adjustments to build configuration (e.g. the number of application servers deployed) Set up a Terraform Cloud workspace (1m38s) Before running the Terraform Cloud workflow, a Terraform Cloud workspace is required. This video steps you through manually configuring the workspace and linking it to your cloned repository. Programmatically set up Terraform Cloud workspaces for production, test, and development (10m40s) Setting up the workspaces programmatically has the benefits of rapid consistent results and executable knowledge in the form of scripts and configuration files. In this video we step you through programmatically building workspaces for production, test, and development environments usingthis repository. We also programmatically configure simple source-controlled compliance Sentinal policies. Initial build of production, test, and development (7m59s) Everything should be ready for the first build of your production, test, and development environments. In this video, we step you through manually triggering Terraform Cloud builds. In addition, we'll see the impact of Sentinel policies in use, how to override policies that have been triggered, and the audit trail that results. Automated testing of production (4m18s) Once your environment builds have completed, it's critical to validate that they are fit for use. In this video, we step you through a simple set of tests that validate the readiness of the F5 BIG-IPs built by the Terraform Cloud workflow. These tests are not comprehensive, but demonstrate the benefits of an executable "definition of done." The source of an updated version of the Inspec tests used in the demonstration ishere. Manual inspection of production (2m45s) In this video, we walk through the BIG-IPs that were built in the production environment. We inspect the virtual servers and their associated pools, noting the number of application servers that were built and joined to the pool. Programmatically add application servers and include them in the BIG-IP virtual server (8m6s) In this video, we explore the use-case of expanding the pool in the previously built production environment, using a simple change in source control. We'll see the Terraform Cloud workflow automatically trigger a new build based on a merge commit to your cloned repository. New application servers will be built and automatically added to the pool by F5'sService Discovery iApp. Update WAF from a source control repository(no video walk-through) We leave it as an exercise for the reader (or possibly an updated video) to look for the WAF deployed with the virtual server. The WAF is retrieved from source controlhere. In addition, you can experiment with changing the version of the WAF in theAS3 templatein the stanza shown below. Usable values for versions are 0.1.0, 0.1.1, 0.2.0, and 0.2.1. If you choose to do this, follow the same workflow shown in the previous video about scaling the number of application servers. "ASM_Policy": { "class": "WAF_Policy", "url": "https://github.com/mjmenger/waf-policy/raw/0.1.1/asm_policy.xml", "ignoreChanges": false } What's next? If you've followed along through the all of the use-cases in the demonstration repository, you have seen the following: Source-controlled build of an application environment, including BIG-IPs, virtual servers, pools, and WAF policies. Managed changes with logging of authoring and approvals. Automated scaling of application resources and BIG-IP configuration. Automated updates to BIG-IP WAF policies. If you want to realize the benefits of these practices for your IT service delivery, please reach out to your F5 account team.1KViews2likes0Comments