Oracle RAC Connection String Rewrite
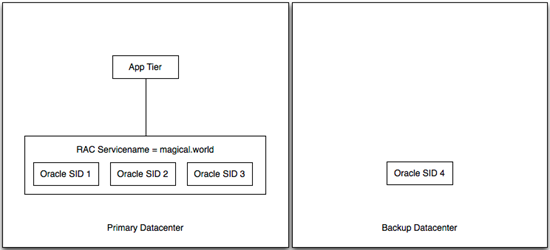
My buddy Brent Imhoff is back with another excellent customer solution to follow up his IPS traffic inspection solution. This solution is a modification of the original iRule for db context switching from the deployment guide for Oracle Database and RAC. Problem Description Customer has two Oracle instances, one in a primary datacenter and one in the secondary datacenter. The primary datacenter is comprised of three Oracle instances, each with a unique Oracle System ID (SID), as part of an Oracle Real Application Cluster (RAC). The secondary datacenter is setup as a single node with it's own SID. The RAC is essentially a load balancer for Oracle nodes, but somewhat limited in that it doesn't work between data centers. As part of the RAC implementation, a Service Name is defined in the RAC configuration and clients use the service name in the connect string. RAC evaluates the service name and makes a determination regarding which SID could handle the request appropriately. Alternatively, clients can use the SID to connect directly to an Oracle node. The customer has some 800 applications that rely on these databases. Because there is RAC only in one location, they are forced to change connect strings each time they need to change the data sources for things like maintenance. Additionally, it removes the possibility of an automated failover if something goes wrong unexpectedly. The customer asked F5 if we could be an Oracle proxy to handle the rewrite of connect strings and essentially make the clients unaware of any changes that might be happening to the Oracle nodes. Old and Busted (aka Oh Crap! My database died. Quick! Change 800 configurations to get things working again!) Solution Inserting the F5 solution, the customer was able to create a single IP/port that was highly available to be used by the app tier. Using priority groups, we were able to balance traffic to each oracle node and dynamically rewrite the connect strings to match the node being used to service the request. We tested two scenarios: minimal traffic and gobs of traffic. When we failed an Oracle node under minimal traffic, the application tier was completely unaware of any change at all. No log messages, no errors, it just went along it's merry way. Running the same test with gobs of traffic (couple of GBs of transactions), the application noticed something wasn't quite right, resent the transactions that didn't make it, and happily continued. No oracle DBA intervention required. New Hotness - (aka The Magic of iRules) Configuration Use the Oracle deployment guide to ensure TCP profiles are created correctly. Also included are good procedures for building node monitors for each Oracle member. Once those are all in place, use an iRule similar to the following. This could be made more generic to accurately calculate the length of the payload replacement. The service_name and replacement SID's could also be defined as variables to make the deployment more straight forward. There's also a hack that limits the SID patching length to 1 time. In the Oracle deployment guide, the iRule is written to accommodate multiple rewrites of connect strings in a given flow. In our testing, it seemed to be adding the same offset to the list twice (which screwed things up pretty nicely). I'm not sure why that was happening, but the hack fixed it (at least in this instance). 1: when CLIENT_DATA { 2: 3: if { [TCP::payload] contains "(CONNECT_DATA=" } { 4: log local0. "Have access to TCP::Payload" 5: set service_match [regexp -all -inline -indices "\(SERVICE_NAME=some_datasource_service.world\)" [TCP::payload]] 6: log "Found a service_match = $service_match" 7: 8: set tmp [lindex $service_match 1] 9: set newservice [list $tmp] 10: 11: foreach instance $newservice { 12: log local0. "Iterating through connect strings in the payload. Raw: $instance" 13: set service_start [lindex $instance 0] 14: 15: set original_tcp_length [TCP::payload length] 16: TCP::payload replace $service_start 34 $sid 17: log local0. "Inserted SID at $service_start offset." 18: 19: TCP::payload replace 0 2 [binary format S1 [TCP::payload length]] 20: log local0. "Updated packet with new length: [TCP::payload length] - original $original_tcp_length" 21: 22: ## 23: ##set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION=(ADDRESS=" 0] 24: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 25: log local0. "Looking for connect: $looking_for_connect" 26: ##set connect_data_length [string length [findstr [TCP::payload] "(DESCRIPTION=(ADDRESS=" 0]] 27: set connect_data_length [string length [findstr [TCP::payload] "(DESCRIPTION" 0]] 28: TCP::payload replace 24 2 [binary format S1 $connect_data_length] 29: log local0. "New Oracle data length is $connect_data_length" 30: 31: } 32: } 33: if { [TCP::payload] contains "(CONNECT_DATA=" } { 34: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 35: log local0. "2. Looking for connect: $looking_for_connect" 36: } 37: 38: TCP::release 39: TCP::collect 40: 41: } 42: when LB_SELECTED { 43: 44: log local0. "Entering LB_SELECTED" 45: if { [TCP::payload] contains "(CONNECT_DATA=" } { 46: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 47: log local0. "1. Looking for connect: $looking_for_connect" 48: } 49: 50: 51: switch [LB::server addr] { 52: 10.10.10.152 { ; 53: set sid "SID=ORAPRIME1" 54: } 55: 10.10.10.153 { ; 56: set sid "SID=ORAPRIME2" 57: } 58: 10.10.10.154 { ; 59: set sid "SID=ORAPRIME3" 60: } 61: 10.44.44.44 { ; 62: set sid "SID=ORABACKUP" 63: } 64: } 65: TCP::collect 66: log local0. "Exiting LB_SELECTED" 67: } Related Articles DevCentral Groups - Oracle / F5 Solutions Oracle/F5 RAC Integration and DevArt - DevCentral - DevCentral ... Delivering on Oracle Cloud Oracle OpenWorld 2012: The Video Outtakes Oracle OpenWorld 2012: That's a Wrap HA between third party apps and Oracle RAC databases using f5 ... Oracle Database traffic load-balancing - DevCentral - DevCentral ... Oracle OpenWorld 2012: BIG-IP APM Integration - Oracle Access ... Technorati Tags: Oracle, RAC746Views0likes5CommentsOracle WebLogic Server
F5 and Oracle have long collaborated on delivering market-leading application delivery solutions for WebLogic Server. F5 has designed an integrated, agile, and adaptable network platform for delivering WebLogic applications across the LAN and WAN, and packaged this information in our deployment guides and iApp templates. The result is an intelligent and powerful solution that secures and speeds your WebLogic deployment today, while providing an optimized architecture for the future. The following simple, logical configuration example shows one of the ways you can configure the BIG-IP system for Oracle WebLogic Servers using BIG-IP AAM technology to speed traffic across the WAN. See https://f5.com/solutions/deployment-guidesto find the appropriate deployment guide for quickly and accurately configuring the BIG-IP system for Oracle WebLogic Server. If you have any feedback on these or other F5 guides or iApp templates, leave it in the comment section below or email us at solutionsfeedback@f5.com. We use your feedback to help shape our new iApps and deployment guides.419Views0likes1Comment
20 Lines or Less #69: Port Ranges, Oracle Connections and Pool Member Toggling
What could you do with your code in 20 Lines or Less? That's the question I like to ask for the DevCentral community, and every time I do, I go looking to find cool new examples that show just how flexible and powerful iRules can be without getting in over your head. Thus was born the 20LoL (20 Lines or Less) series. Over the years I’ve poked at, talked about and worked to help hundreds of iRules examples proliferate, all of which were doing downright cool things in less than 21 lines of code. In this installment we get to look at a few more killer examples brought to you by a couple of the hottest iRuling minds the world has to offer, currently. And no, none of them are from me, so I can totally say that and not be “that guy”. Kevin Stewart and the infamous Hoolio have been tearing up the new Q&A section on the fantastic “Hero” version of DevCentral and doling out the coding geekery in healthy doses. Kevin, especially, has been absolutely crushing it, already amassing over 1700 “devpoints”, which are the new currency handed out on DevCentral for answering questions and generally doing things that are hawesome. While it’s odd to see someone other than Aaron on the top of the E-ego list, it’s always good to have new blood challenging the old guard for top billing. Maybe we’ll have a race once Kevin slows down from warp-speed posting, assuming he does. For now, long live the new king, and good on him for kicking major tail for the sake of the community. Are you curious to see just what these F5 programmability hot-shots handed out as sage knowledge this week? Well let’s get to it… Need iRule to Manage VIP & Port Range http://bit.ly/15RFaJA Piecing together the somewhat sparse information in the original post, it looks like the request was for the ability to have a specific port range (8000-8020) opened on a given virtual, and to have each of those ports directed to a specific pool on the back end. I.E. domain.com:8000 –> pool1, domain.com:8001 –> pool2, and so on. While this could absolutely be done in a static, holy-cow-why-would-you-do-that-much-annoying-configuration-by-hand manner, Aaron was, not shockingly, much more clever than that. He whipped up an exceedingly small, simple iRule that makes this whole process as easy as pi. All the user needs to do is create the pools that things should be directed to with a common naming scheme, in this example “mypool_<port>”, and this iRule will play middle-man and ship the traffic to the appropriate pools without so much as a second thought. Combine this with a virtual that listens on all ports, and you’re good to go. For added security he even added a “drop” to the else clause to be sure that only the desired ports (8000-8020) are accepted and passed to the back end. Simple, elegant, efficient, awesome. We’ve grown to expect nothing less from Aaron, and he doesn’t disappoint whether dealing with extraordinarily complex, near impossible solutions or the simplest, smallest chunks of code, like this one, that still solve real world problems and make life easier. That’s what the 20LoL is all about. 1: when CLIENT_ACCEPTED { 2: if {[TCP::local_port] >= 8000 && [TCP::local_port] <= 8020}{ 3: pool mypool_[TCP::local_port] 4: } else { 5: drop 6: } 7: } Replace SID to SERVICE_NAME in Oracle connection string http://bit.ly/18clno4 For a slightly more complex look at what iRules can churn out in only a few lines of code, Kevin dove in to help a community member looking to do some in-line replacement of an Oracle connection string on the wire. This iRule is admittedly a bit more than the 7 line beauty above, but at a scant 16 lines of effective code, the below is pretty darn impressive when you think about what’s happening. The client attempts to connect to the Oracle DB, the LTM proxies the connection, inspects the data in-line, modifies the stream on the fly, makes all necessary adjustments to the content to connect with the new information, and passes things along to the back-end with no one the wiser, all at wire speed. Yeah, okay, so maybe that’s not so bad for 16 lines of code, eh? I’ll take it. This one hasn’t been fully tested yet, and it looks like there is still some chatter in the thread about how to get it 100% locked down and functional, so don’t go dumping the below into your prod environment without testing, but it’s a great example of just what can be achieved with iRules without much heavy lifting. How can you not love this stuff? 1: when CLIENT_ACCEPTED { 2: TCP::collect 3: } 4: 5: when CLIENT_DATA { 6: set sid_match 0 7: if { [TCP::payload] contains "CONNECT_DATA=" } { 8: set sid_match 1 9: log local0. "original payload = [TCP::payload]" 10: set service_name "SERVICE_NAME=MYSERVICENAME" 11: if { [regsub -all -nocase "SID=MYSID" [TCP::payload] "$service_name" newdata] } { 12: TCP::payload replace 0 [TCP::payload length] "" 13: TCP::payload replace 0 0 $newdata 14: log local0. "replaced payload = $newdata" 15: } 16: } 17: TCP::release 18: TCP::collect 19: } iRule to disable a pool to new connections http://bit.ly/1ei25Rq Scenario: At a specific time of day, you need to selectively, automatically disable two specific members members of a pool, without disabling the entire pool as a whole, for a specific duration, denying any new connections and then re-enabling those members once the window of time during which they should be offline has passed, all without any human intervention. Who wants to place a bet on how much scripting that would take? That’s a pretty complex list of tasks/criteria, no? 50 lines? 30? Try 16. That’s right, 16 lines of effective code executing to net you all of the above, all of which were hatched out of the fierce mind of the point hoarding, post crushing Q&A wizard that is Kevin Stewart. I’m not sure what his deal with snippets that number 16 lines, but I’m not complaining about this week’s particular trend. As to the code: its really pretty simple when you dig into it. Set up the window the things should be offline with a couple of variables. Set up the pool name and member addresses. On each new request check the time and see if we’re in that window, and if so, knock the pool members offline. Simple, effective, and super helpful to anyone trying to set up this kind of downtime window. I know we’ve seen examples similar to this before but nothing quite this style that deals with one or more individual pool members, rather than a pool at large. The difference could be very handy indeed, and we’re all about being useful pots ‘round these parts. The original thread also has some more examples and iterations that may be useful, depending on your specific needs, so take a gander. 1: when RULE_INIT { 2: set static::START_OFF_TIME "09:30 AM" 3: set static::END_OFF_TIME "10:00 AM" 4: set static::DOWN_POOL "local-pool" 5: set static::DOWN_MEMBERS [list "10.70.0.1 80" "10.70.0.2 80"] 6: } 7: when CLIENT_ACCEPTED { 8: set start_off_time [clock scan $static::START_OFF_TIME] 9: set end_off_time [clock scan $static::END_OFF_TIME] 10: set now [clock seconds] 11: 12: if { ( [expr $now > $start_off_time] ) and ( [expr $now < $end_off_time] ) } { 13: foreach x $static::DOWN_MEMBERS { 14: LB::down pool $static::DOWN_POOL member [lindex $x 0] [lindex $x 1] 15: } 16: } 17: }419Views0likes0Comments
Oracle Endeca with F5 BIG-IP LTM
Am in the middle of working on a cool project with the Oracle E-Business Suite dev team at Oracle, to add Endeca to an existing EBS 12 environment. The EBS and Endeca teams are working with F5 to provide High Availability, Application Monitoring, and Load Balancing to the Endeca platform servers. For more information on Endeca, check it out here: http://www.oracle.com/us/products/applications/commerce/endeca/overview/index.html There are 2 "tiers" of servers in an Endeca deployment, the Studio Servers, and the Endeca Servers themselves. As both of these tiers communicate to users and each other with HTTP, this is perfect for F5 LTM. We can monitor, load balancing, and do things like SSL offload for these servers. We will also trying using compression and caching between the Studio servers and the user's browser, to see if we can optimize the delivery of HTTP content. You can see an example ofa typical HA Endeca environmentin theEndeca Administrative Guide. http://docs.oracle.com/cd/E35976_01/server.740/es_admin/toc.htm#Cluster%20overview After we finish some more testing over the next few months, we will be releasing a deployment guide will all the Best Practices that we have uncovered, and share them with everyone. In the meanitme, if you need F5 with Endeca, you can contact us here. -Chris. Update for September, 2013. We have finished the testing, and have an F5 Deployment Guide for Oracle Endeca using LTM. You can find it here: http://www.f5.com/pdf/deployment-guides/oracle-endeca-dg.pdf -Chris.377Views0likes1Comment
Databases in the Cloud Revisited
A few of us were talking on Facebook about high speed rail (HSR) and where/when it makes sense the other day, and I finally said that it almost never does. Trains lost out to automobiles precisely because they are rigid and inflexible, while population densities and travel requirements are highly flexible. That hasn’t changed since the early 1900s, and isn’t likely to in the future, so we should be looking at different technologies to answer the problems that HSR tries to address. And since everything in my universe is inspiration for either blogging or gaming, this lead me to reconsider the state of cloud and the state of cloud databases in light of synergistic technologies (did I just use “synergistic technologies in a blog? Arrrggghhh…). There are several reasons why your organization might be looking to move out of a physical datacenter, or to have a backup datacenter that is completely virtual. Think of the disaster in Japan or hurricane Katrina. In both cases, having even the mission critical portions of your datacenter replicated to the cloud would keep your organization online while you recovered from all of the other very real issues such a disaster creates. In other cases, if you are a global organization, the cost of maintaining your own global infrastructure might well be more than utilizing a global cloud provider for many services… Though I’ve not checked, if I were CIO of a global organization today, I would be looking into it pretty closely, particularly since this option should continue to get more appealing as technology continues to catch up with hype. Today though, I’m going to revisit databases, because like trains, they are in one place, and are rigid. If you’ve ever played with database Continuous Data Protection or near-real-time replication, you know this particular technology area has issues that are only now starting to see technological resolution. Over the last year, I have talked about cloud and remote databases a few times, talking about early options for cloud databases, and mentioning Oracle Goldengate – or praising Goldengate is probably more accurate. Going to the west in the US? HSR is not an option. The thing is that the options get a lot more interesting if you have Goldengate available. There are a ton of tools, both integral to database systems and third-party that allow you to encrypt data at rest these days, and while it is not the most efficient access method, it does make your data more protected. Add to this capability the functionality of Oracle Goldengate – or if you don’t need heterogeneous support, any of the various database replication technologies available from Oracle, Microsoft, and IBM, you can seamlessly move data to the cloud behind the scenes, without interfering with your existing database. Yes, initial configuration of database replication will generally require work on the database server, but once configured, most of them run without interfering with the functionality of the primary database in any way – though if it is one that runs inside the RDBMS, remember that it will use up CPU cycles at the least, and most will work inside of a transaction so that they can insure transaction integrity on the target database, so know your solution. Running inside the primary transaction is not necessary, and for many uses may not even be desirable, so if you want your commits to happen rapidly, something like Goldengate that spawns a separate transaction for the replica are a good option… Just remember that you then need to pay attention to alerts from the replication tool so that you don’t end up with successful transactions on the primary not getting replicated because something goes wrong with the transaction on the secondary. But for DBAs, this is just an extension of their daily work, as long as someone is watching the logs. With the advent of Goldengate, advanced database encryption technology, and products like our own BIG-IPWOM, you now have the ability to drive a replica of your database into the cloud. This is certainly a boon for backup purposes, but it also adds an interesting perspective to application mobility. You can turn on replication from your data center to the cloud or from cloud provider A to cloud provider B, then use VMotion to move your application VMS… And you’re off to a new location. If you think you’ll be moving frequently, this can all be configured ahead of time, so you can flick a switch and move applications at will. You will, of course, have to weigh the impact of complete or near-complete database encryption against the benefits of cloud usage. Even if you use the adaptability of the cloud to speed encryption and decryption operations by distributing them over several instances, you’ll still have to pay for that CPU time, so there is a balancing act that needs some exploration before you’ll be certain this solution is a fit for you. And at this juncture, I don’t believe putting unencrypted corporate data of any kind into the cloud is a good idea. Every time I say that, it angers some cloud providers, but frankly, cloud being new and by definition shared resources, it is up to the provider to prove it is safe, not up to us to take their word for it. Until then, encryption is your friend, both going to/from the cloud and at rest in the cloud. I say the same thing about Cloud Storage Gateways, it is just a function of the current state of cloud technology, not some kind of unreasoning bias. So the key then is to make sure your applications are ready to be moved. This is actually pretty easy in the world of portable VMs, since the entire VM will pick up and move. The only catch is that you need to make sure users can get to the application at the new location. There are a ton of Global DNS solutions like F5’s BIG-IP Global Traffic Manager that can get your users where they need to be, since your public-facing IPs will be changing when moving from organization to organization. Everything else should be set, since you can use internal IP addresses to communicate between your application VMs and database VMs. Utilizing a some form of in-flight encryption and some form of acceleration for your database replication will round out the solution architecture, and leave you with a road map that looks more like a highway map than an HSR map. More flexible, more pervasive.365Views0likes0Comments
F5 Friday: Applications aren't protocols. They're Opportunities.
Applications are as integral to F5 technologies as they are to your business. An old adage holds that an individual can be judged by the company he keeps. If that holds true for organizations, then F5 would do well to be judged by the vast array of individual contributors, partners, and customers in its ecosystem. From its long history of partnering with companies like Microsoft, IBM, HP, Dell, VMware, Oracle, and SAP to its astounding community of over 160,000 engineers, administrators and developers speaks volumes about its commitment to and ability to develop joint and custom solutions. F5 is committed to delivering applications no matter where they might reside or what architecture they might be using. Because of its full proxy architecture, F5’s ADC platform is able to intercept, inspect and interact with applications at every layer of the network. That means tuning TCP stacks for mobile apps, protecting web applications from malicious code whether they’re talking JSON or XML, and optimizing delivery via HTTP (or HTTP 2.0 or SPDY) by understanding the myriad types of content that make up a web application: CSS, images, JavaScript and HTML. But being application-driven goes beyond delivery optimization and must cover the broad spectrum of technologies needed not only to deliver an app to a consumer or employee, but manage its availability, scale and security. Every application requires a supporting cast of services to meet a specific set of business and user expectations, such as logging, monitoring and failover. Over the 18 years in which F5 has been delivering applications it has developed technologies specifically geared to making sure these supporting services are driven by applications, imbuing each of them with the application awareness and intelligence necessary to efficiently scale, secure and keep them available. With the increasing adoption of hybrid cloud architectures and the need to operationally scale the data center, it is important to consider the depth and breadth to which ADC automation and orchestration support an application focus. Whether looking at APIs or management capabilities, an ADC should provide the means by which the services applications need can be holistically provisioned and managed from the perspective of the application, not the individual services. Technology that is application-driven, enabling app owners and administrators the ability to programmatically define provisioning and management of all the application services needed to deliver the application is critical moving forward to ensure success. F5 iApps and F5 BIG-IQ Cloud do just that, enabling app owners and operations to rapidly provision services that improve the security, availability and performance of the applications that are the future of the business. That programmability is important, especially as it relates to applications according to our recent survey (results forthcoming)in which a plurality of respondents indicated application templates are "somewhat or very important" to the provisioning of their applications along with other forms of programmability associated with software-defined architectures including cloud computing. Applications increasingly represent opportunity, whether it's to improve productivity or increase profit. Capabilities that improve the success rate of those applications are imperative and require a deeper understanding of an application and its unique delivery needs than a protocol and a port. F5 not only partners with application providers, it encapsulates the expertise and knowledge of how best to deliver those applications in its technologies and offers that same capability to each and every organization to tailor the delivery of their applications to meet and exceed security, reliability and performance goals. Because applications aren't just a set of protocols and ports, they're opportunities. And how you respond to opportunity is as important as opening the door in the first place.324Views0likes0CommentsOracle Periodically Security Update – Mitigating with ASM
Recently Oracle published its periodically security advisory. The advisory contains fixes for 334 CVEs, 231 of them are exploitable over the HTTP protocol. Oracle tends not to publicly disclose details related to the attack vectors of the vulnerabilities they publish; however, we could tell based on public information that already exist for some of the vulnerabilities whether we are able to mitigate the attack vector with existing ASM signatures. BIG-IP ASM customers are already protected against the following vulnerabilities published in the advisory: CVE Identifier Product Signature IDs / Attack Type CVE-2018-2943 Oracle Fusion Middleware MapViewer Path Traversal Signatures CVE-2018-3101 Oracle WebCenter Portal 200018018,200018030,200018036,200018037 CVE-2018-2894 Oracle WebLogic Server 200004048, Java Server Side Code Injection Signatures CVE-2018-2945 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-2946 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-2947 JD Edwards EnterpriseOne Tools Path Traversal Signatures CVE-2018-2948 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-2949 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-2950 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-3100 Oracle Business Process Management Suite SQL-Injection Signatures CVE-2018-3105 Oracle SOA Suite Path Traversal Signatures CVE-2018-2999 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-3006 JD Edwards EnterpriseOne Tools Cross Site Scripting (XSS) Signatures CVE-2018-3016 PeopleSoft Enterprise PeopleTools Cross Site Scripting (XSS) Signatures CVE-2018-7489 Oracle WebLogic Server Java Server Side Code Injection Signatures We are constantly monitoring newly disclosed information and PoCs containing the attack vectors for the other vulnerabilities not mentioned in the table above and will release ASM signature updates if required.301Views0likes1CommentCloud Computing: Will data integration be its Achilles Heel?
Wesley: Now, there may be problems once our app is in the cloud. Inigo: I'll say. How do I find the data? Once I do, how do I integrate it with the other apps? Once I integrate it, how do I replicate it? If you remember this somewhat altered scene from the Princess Bride, you also remember that no one had any answers for Inigo. That's apropos of this discussion, because no one has any good answers for this version of Inigo either. And no, a holocaust cloak is not going to save the day this time. If you've been considering deploying applications in a public cloud, you've certainly considered what must be the Big Hairy Question regarding cloud computing: how do I get at my data? There's very little discussion about this topic, primarily because at this point there's no easy answer. Data stored in the cloud is not easily accessible for integration with applications not residing in the cloud, which can definitely be a roadblock to adopting public cloud computing. Stacey Higginbotham at GigaOM had a great post on the topic of getting data into the cloud, and while the conclusion that bandwidth is necessary is also applicable to getting your data out of the cloud, the details are left in your capable hands. We had this discussion when SaaS (Software as a Service) first started to pick up steam. If you're using a service like salesforce.com to store business critical data, how do you integrate that back into other applications that may need it? Web services were the first answer, followed by integration appliances and solutions that included custom-built adapters for salesforce.com to more easily enable access and integration to data stored "out there", in the cloud. Amazon offers URL-based and web services access to data stored in its SimpleDB offering, but that doesn't help folks who are using Oracle, SQL Server, or MySQL offerings in the cloud. And SimpleDB is appropriately named; it isn't designed to be an enterprise class service - caveat emptor is in full force if you rely upon it for critical business data. RDBMS' have their own methods of replication and synchronization, but mirroring and real-time replication methods require a lot of bandwidth and very low latency connections - something not every organization can count on having. Of course you can always deploy custom triggers and services that automatically replicate back into the local data center, but that, too, is problematic depending on bandwidth availability and accessibility of applications and databases inside the data center. The reverse scenario is much more likely, with a daemon constantly polling the cloud computing data and pulling updates back into the data center. You can also just leave that data out there in the cloud, implement, or take advantage of if they exist, service-based access to the data and integrate it with business processes and applications inside the data center. You're relying on the availability of the cloud, the Internet, and all the infrastructure in between, but like the solution for integrating with salesforce.com and other SaaS offerings, this is likely the best of a set of "will have to do" options. The issue of data and its integration has not yet raised its ugly head, mostly because very few folks are moving critical business applications into the cloud and admittedly, cloud computing is still in its infancy. But even non-critical applications are going to use or create data, and that data will, invariably, become important or need to be accessed by folks in the organization, which means access to that data will - probably sooner rather than later - become a monkey on the backs of IT. The availability of and ease of access to data stored in the public cloud for integration, data mining, business intelligence, and reporting - all common enterprise application use of data - will certainly affect adoption of cloud computing in general. The benefits of saving dollars on infrastructure (management, acquisition, maintenance) aren't nearly as compelling a reason to use the cloud when those savings would quickly be eaten up by the extra effort necessary to access and integrate data stored in the cloud. Related articles by Zemanta SQL-as-a-Service with CloudSQL bridges cloud and premises Amazon SimpleDB ready for public use Blurring the functional line - Zoho CloudSQL merges on-site and on-cloud As a Service: The many faces of the cloud A comparison of major cloud-computing providers (Amazon, Mosso, GoGrid) Public Data Goes on Amazon's Cloud300Views0likes2CommentsSurviving Disasters with F5 GTM and Oracle Enterprise Manager
Let's say you have 2 or more Data Centers, or locations where you run your applications. MANs, WANs, Cloud whatever - You've architected diverse fiber routes, multipath IP routing, perhaps some Spanning Tree gobblygookness... and you feel confident that your network can handle an outage, right ? So what about the mission critical Applications, Middleware, and Databases running ON TOP of all that fancy, expensive Disaster Recovery bundle of ca$$$h you and the CIO spent ? Did you even test the failover ? Failback ?? How many man-hours and dozens of scripts did it really take ? And more importantly, how much money could your company lose while everyone waits ?? Allow me to try and put your mind at ease, with some great Oracle Enterprise Manager 12c and F5 Networks solutions, and the soothing words of Maximum Availability Architecture Best Practices guidance. We recently finished a hot-off-the-press MAA whitepaper that details how to use F5's Global Traffic Manager with EM12c to provide quick failover of your Data Center's Oracle Management Framework, the EM12c platform itself. You see, it stands to reason, that if you are going to try and move Apps or Databases from one Data Center to another, you have to have a management platform that in and of itself is Highly Available - right ? I mean, how do you even expect to handle the movement of apps and DBs, if your "management framework" is single site only, and thatsite now looks like something from the movie Twister ? Of course, it could be any natural or man-made disaster, but the fiber-eating backhoe is my fave. You need a fully HA EM12c environment to start with first, like the cornerstone of any solid DR/BC solution, the foundation has to be there first. For more details on the different Level 1-4 architectures and descriptions, see the EM12c Framework docs, Part Number E24473-18. But at Last, for Level 4, the best of the best: after you set up Level 3 in each of your sites, you add GTM to your DNS system to quickly detect failures and route both EM agent and administrative access from one Data Center to the other. Where to find all this goodness? The F5 Oracle Enterprise Manager, and Oracle MAA pages. EM Level 3 HA Guide: http://www.oracle.com/technetwork/oem/framework-infra/wp-em12c-config-oms-ha-bigip-1552459.pdf EM Level 4 HA Guide: http://www.oracle.com/technetwork/database/availability/oms-dr-f5-big-ip-gtm-1880830.pdf So if on some dark day you do end up with DataCenter-Twisted for your Primary site, GTM will route you to the Standby site, where EM12c is up and running and waiting to help you control the Apps, Middleware and Databases that are critical to your business. And just in case you are wondering, it is rumored that F5 Networks gets its name from the F5 class tornado ...275Views0likes0CommentsDefense in Depth in Context
In the days of yore, a military technique called Defense-in-Depth was used to protect kingdoms, castles, and other locations where you might be vulnerable to attack. It's a layered defense strategy where the attacker would have to breach several layers of protection to finally reach the intended target. It allows the defender to spread their resources and not put all of the protection in one location. It's also a multifaceted approach to protection in that there are other mechanisms in place to help; and it's redundant so if a component failed or is compromised, there are others that are ready to step in to keep the protection in tack. Information technology also recognizes this technique as one of the 'best practices' when protecting systems. The infrastructure and systems they support are fortified with a layered security approach. There are firewalls at the edge and often, security mechanisms at every segment of the network. Circumvent one, the next layer should net them. There is one little flaw with the Defense-in-Depth strategy - it is designed to slow down attacks, not necessarily stop them. It gives you time to mobilize a counter-offensive and it's an expensive and complex proposition if you are an attacker. It's more of a deterrent than anything and ultimately, the attacker could decide that the benefits of continuing the attack outweigh the additional costs. In the digital world, it is also interpreted as redundancy. Place multiple iterations of a defensive mechanism within the path of the attacker. The problem is that the only way to increase the cost and complexity for the attacker is to raise the cost and complexity of your own defenses. Complexity is the kryptonite of good security and what you really need is security based on context. Context takes into account the environment or conditions surrounding an event to make an informed decision about how to apply security. This is especially true when protecting a database. Database firewalls are critical components to protecting your valuable data and can stop a SQL Injection attack, for instance, in an instant. What they lack is the ability to decipher contextual data like userid, session, cookie, browser type, IP address, location and other meta-data of who or what actually performed the attack. While it can see that a particular SQL query is invalid, it cannot decipher who made the request. Web Application Firewalls on the other hand can gather user side information since many of its policy decisions are based on the user's context. A WAF monitors every request and response from the browser to the web application and consults a policy to determine if the action and data are allowed. It uses such information as user, session, cookie and other contextual data to decide if it is a valid request. Independent technologies that protect against web attacks or database attacks are available, but they have not been linked to provide unified notification and reporting. Now imagine if your database was protected by a layered, defense-in-depth architecture along with the contextual information to make informed, intelligent decisions about database security incidents. The integration of BIG-IP ASM with Oracle's Database Firewall offers the database protection that Oracle is known for and the contextual intelligence that is baked into every F5 solution. Unified reporting for both the application firewall and database firewall provides more convenient and comprehensive security monitoring. Integration between the two security solutions offers a holistic approach to protecting web and database tiers from SQL injection type of attacks. The integration gives you the layered protection many security professionals recognize as a best practice, plus the contextual information needed to make intelligent decisions about what action to take. This solution provides improved SQL injection protection to F5 customers and correlated reporting for richer forensic information on SQL injection attacks to Oracle database customers. It’s an end-to-end web application and database security solution to protect data, customers, and their businesses. ps Resources: F5 Joins with Oracle to Offer Enhanced Security for Web-Based Database Applications Security for Web-Based Database Applications Enhanced With F5 and Oracle Product Integration Using Oracle Database Firewall with BIG-IP ASM F5 Networks Adds To Oracle Database Oracle Database Firewall BIG-IP Application Security Manager The “True Security Company” Red Herring F5 Friday: Two Heads are Better Than One260Views0likes0Comments