Implementing ECC+PFS on LineRate (Part 1/3): Choosing ECC Curves and Preparing SSL Certificates
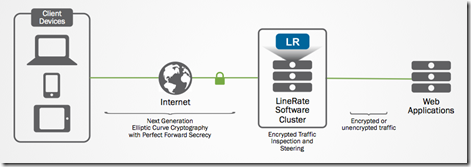
(Editors note: the LineRate product has been discontinued for several years. 09/2023) --- Overview In case you missed it,Why ECC and PFS Matter: SSL offloading with LineRatedetails some of the reasons why ECC-based SSL has advantages over RSA cryptography for both performance and security. This article will generate all the necessary ECC certificates with the secp384r1 curve so that they may be used to configure an LineRate System for SSL Offload. Getting Started with LineRate In order to appreciate the advantages of SSL/TLS Offload available via LineRate as discussed in this article, let's take a closer look at how to configure SSL/TLS Offloading on a LineRate system. This example will implement Elliptical Curve Cryptography and Perfect Forward Secrecy. SSL Offloading will be added to an existing LineRate System that has one public-facing Virtual IP (10.10.11.11) that proxies web requests to a Real Server on an internal network (10.10.10.1). The following diagram demonstrates this configuration: Figure 1: A high-level implementation of SSL Offload Overall, these steps will be completed in order to enable SSL Offloading on the LineRate System: Generate a private key specifying the secp384r1 elliptic curve Obtain a certificate from a CA Configure an SSL profile and attach it to the Virtual IP Note that this implementation will enable only ECDHE cipher suites. ECDH cipher suites are available, but these do not implement the PFS feature. Further, in production deployments, considerations to implement additional types of SSL cryptography might be needed in order to allow backward compatibility for older clients. Generating a private key for Elliptical Curve Cryptography When considering the ECC curve to use for your environment, you may choose one from the currently available curves list in the LineRate documentation. It is important to be cognizant of the curve support for the browsers or applications your application targets using. Generally, the NIST P-256, P-384, and P-521 curves have the widest support. This example will use the secp384r1 (NIST P-384) curve, which provides an RSA equivalent key of 7680-bits. Supported curves with OpenSSL can be found by running the openssl ecparam -list_curves command, which may be important depending on which curve is chosen for your SSL/TLS deployment. Using OpenSSL, a private key is generated for use with ssloffload.lineratesystems.com. The ECC SECP curve over a 384-bit prime field (secp384r1) is specified: openssl ecparam -genkey -name secp384r1 -out ssloffload.lineratesystems.com.key.pem This command results in the following private key: -----BEGIN EC PARAMETERS----- BgUrgQQAIg== -----END EC PARAMETERS----- -----BEGIN EC PRIVATE KEY----- MIGkAgEBBDD1Kx9hghSGCTujAaqlnU2hs/spEOhfpKY9EO3mYTtDmKqkuJLKtv1P 1/QINzAU7JigBwYFK4EEACKhZANiAASLp1bvf/VJBJn4kgUFundwvBv03Q7c3tlX kh6Jfdo3lpP2Mf/K09bpt+4RlDKQynajq6qAJ1tJ6Wz79EepLB2U40fC/3OBDFQx 5gSjRp8Y6aq8c+H8gs0RKAL+I0c8xDo= -----END EC PRIVATE KEY----- Generating a Certificate Request (CSR) to provide the Certificate Authority (CA) After the primary key is obtained, a certificate request (CSR) can be created. Using OpenSSL again, the following command is issued filling out all relevant information in the successive prompts: openssl req -new -key ssloffload.lineratesystems.com.key.pem -out ssloffload.lineratesystems.com.csr.pem This results in the following CSR: -----BEGIN CERTIFICATE REQUEST----- MIIB3jCCAWQCAQAwga8xCzAJBgNVBAYTAlVTMREwDwYDVQQIEwhDb2xvcmFkbzET MBEGA1UEBxMKTG91aXN2aWxsZTEUMBIGA1UEChMLRjUgTmV0d29ya3MxGTAXBgNV BAsTEExpbmVSYXRlIFN5c3RlbXMxJzAlBgNVBAMTHnNzbG9mZmxvYWQubGluZXJh dGVzeXN0ZW1zLmNvbTEeMBwGCSqGSIb3DQEJARYPYS5yYWdvbmVAZjUuY29tMHYw EAYHKoZIzj0CAQYFK4EEACIDYgAEi6dW73/1SQSZ+JIFBbp3cLwb9N0O3N7ZV5Ie iX3aN5aT9jH/ytPW6bfuEZQykMp2o6uqgCdbSels+/RHqSwdlONHwv9zgQxUMeYE o0afGOmqvHPh/ILNESgC/iNHPMQ6oDUwFwYJKoZIhvcNAQkHMQoTCGNpc2NvMTIz MBoGCSqGSIb3DQEJAjENEwtGNSBOZXR3b3JrczAJBgcqhkjOPQQBA2kAMGYCMQCn h1NHGzigooYsohQBzf5P5KO3Z0/H24Z7w8nFZ/iGTEHa0+tmtGK/gNGFaSH1ULcC MQCcFea3plRPm45l2hjsB/CusdNo0DJUPMubLRZ5mgeThS/N6Eb0AHJSjBJlE1fI a4s= -----END CERTIFICATE REQUEST----- Obtaining a Certificate from a Certificate Authority (CA) Rather than using a self-signed certificate, a test certificate is obtained from Entrust. Upon completing the certificate request and receiving it from Entrust, a simple conversion needs to be done to PEM format. This can be done with the following OpenSSL command: openssl x509 -inform der -in ssloffload.lineratesystems.com.cer -out ssloffload.lineratesystems.com.cer.pem This results in the following certificate: -----BEGIN CERTIFICATE----- MIIC5jCCAm2gAwIBAgIETUKHWzAKBggqhkjOPQQDAzBtMQswCQYDVQQGEwJVUzEW MBQGA1UEChMNRW50cnVzdCwgSW5jLjEfMB0GA1UECxMWRm9yIFRlc3QgUHVycG9z ZXMgT25seTElMCMGA1UEAxMcRW50cnVzdCBFQ0MgRGVtb25zdHJhdGlvbiBDQTAe Fw0xNDA4MTExODQ3MTZaFw0xNDEwMTAxOTE3MTZaMGkxHzAdBgNVBAsTFkZvciBU ZXN0IFB1cnBvc2VzIE9ubHkxHTAbBgNVBAsTFFBlcnNvbmEgTm90IFZlcmlmaWVk MScwJQYDVQQDEx5zc2xvZmZsb2FkLmxpbmVyYXRlc3lzdGVtcy5jb20wdjAQBgcq hkjOPQIBBgUrgQQAIgNiAASLp1bvf/VJBJn4kgUFundwvBv03Q7c3tlXkh6Jfdo3 lpP2Mf/K09bpt+4RlDKQynajq6qAJ1tJ6Wz79EepLB2U40fC/3OBDFQx5gSjRp8Y 6aq8c+H8gs0RKAL+I0c8xDqjgeEwgd4wDgYDVR0PAQH/BAQDAgeAMB0GA1UdJQQW MBQGCCsGAQUFBwMBBggrBgEFBQcDAjA3BgNVHR8EMDAuMCygKqAohiZodHRwOi8v Y3JsLmVudHJ1c3QuY29tL0NSTC9lY2NkZW1vLmNybDApBgNVHREEIjAggh5zc2xv ZmZsb2FkLmxpbmVyYXRlc3lzdGVtcy5jb20wHwYDVR0jBBgwFoAUJAVL4WSCGvgJ zPt4eSH6cOaTMuowHQYDVR0OBBYEFESqK6HoSFIYkItcfekqqozX+z++MAkGA1Ud EwQCMAAwCgYIKoZIzj0EAwMDZwAwZAIwXWvK2++3500EVaPbwvJ39zp2IIQ98f66 /7fgroRGZ2WoKLBzKHRljVd1Gyrl2E3BAjBG9yPQqTNuhPKk8mBSUYEi/CS7Z5xt dXY/e7ivGEwi65z6iFCWuliHI55iLnXq7OU= -----END CERTIFICATE----- Note that the certificate generation process is very familiar with Elliptical Curve Cryptography versus traditional cryptographic algorithms like RSA. Only a few differences are found in the generation of the primary key where an ECC curve is specified. Continue the Configuration Now that the certificates needed to configure Elliptical Curve Cryptography have been created, it is now time to configure SSL Offloading on LineRate. Part 2: Configuring SSL Offload on LineRate continues the demonstration of SSL Offloading by importing the certificate information generated in this article and getting the system up and running. In case you missed it,Why ECC and PFS Matter: SSL offloading with LineRatedetails some of the reasons why ECC-based SSL has advantages over RSA cryptography for both performance and security. (Editors note: the LineRate product has been discontinued for several years. 09/2023) Stay Tuned! Next week a demonstration on how to verify a correct implementation of SSL with ECC+PFS on LineRate will make a debut on DevCentral. The article will detail how to check for ECC SSL on the wire via WireShark and in the browser. In the meantime, take some time to download LineRate and test out its SSL Offloading capabilities. In case you missed any content, or would like to reference it again, here are the articles related to implementing SSL Offload with ECC and PFS on LineRate: Why ECC and PFS Matter: SSL offloading with LineRate Implementing ECC+PFS on LineRate (Part 1/3): Choosing ECC Curves and Preparing SSL Certificates Implementing ECC+PFS on LineRate (Part 2/3): Configuring SSL Offload on LineRate Implementing ECC+PFS on LineRate (Part 3/3): Confirming the Operation of SSL Offloading385Views0likes0Comments
F5 Friday: App Proxy or ADC?
(Editors note: the LineRate product has been discontinued for several years. 09/2023) --- Choosing between BIG-IP and LineRate isn't as difficult as it seems.... Our recent announcement of the availability of LineRate Point raised the same question over and over: isn't this just a software-version of BIG-IP? How do I know when to choose LineRate Point instead of BIG-IP VE (Virtual Edition)? Aren't they the same?? No, no they aren't. LineRate Point (and really Line Rate Precision, too) is more akin to an app proxy while BIG-IP VE remains, of course, an ADC (Application Delivery Controller). That's not even pedantry, it's core to what each of the two solutions supports - both in their capabilities, their extensibility, and the applications they're designed to deliver services for. Platforms and Proxies First, let's remember that an ADC is a platform; that is, it's a software system supporting extensibility through modules. That's why we have BIG-IP . Because BIG-IP is really a platform, and its capabilities to deliver software defined application services (SDAS) are enabled through the modules it supports. Whether it's BIG-IP on F5 hardware or BIG-IP VE in the cloud or in virtual machines, it's still an extensible ADC platform. LineRate Point is a layer 7 load balancer; it's an app proxy. It's primary goal is to serve HTTP/S applications with scalability and security (like SSL and TLS). It's not extensible like BIG-IP VE. There are no "modules" you can deploy to expand its capabilities. It is what it is - a lightweight, load balancing layer 7 app proxy. Extensibility in the LineRate world is achieved with LineRate Precision, which includes node.js data path programmability (scripting) as a means to create new services, new functionality, and implement a variety of infrastructure patterns like A/B testing, Canary Deployments, Blue/Green deployments, and more. That's where the confusion with BIG-IP VE usually comes in, because in addition to its platform extensibility, BIG-IP VE also enables data path programmability through iRules. So how do you choose between the options? There's BIG-IP on F5 hardware, BIG-IP VE (virtual) and cloud (AWS, Azure, Rackspace, IBM, etc…), LineRate Point and Precision for cloud (Amazon EC2) and virtual as well as bare-metal. The best way to choose is to base it on (wait for it, wait for it) the application for which you need services delivered. C'mon, you saw that coming - it's an application world, after all, and F5 is always all about that application. Applications, Scale and Service Delivery It really is all about that application. The scale, the nature of the business function the application provides, and the services required to deliver that application are critical components in the choice of what is basically ADC or App Proxy. And you know me, a picture is worth at least 1024 words, so here it is: The first assumption we're making (and I think it's a good assumption) is that if someone deployed an application and is using it within the context of the business (or line of business or department or, well, you get the picture) then it's important enough to need some service. Maybe that's just scale or availability, maybe it needs security or a performance-boosting push, but it probably needs something. What it needs may be dependent on the number of users, the criticality of the application to productivity and profit, and the sensitivity of the data it interacts with. Given that set of criteria, you can start to see that business critical and major line of business applications - ERP, Sharepoint, Exchange, etc... - have few instances but thousands of users. These apps require high availability, massive scale, security and often performance boosts. They need multiple application services. That means BIG-IP*, and probably BIG-IP on F5 hardware or, perhaps, the deployment of a High Performance Services Fabric comprised of many BIG-IP VE using F5 Synthesis. Either way, you're talking high capacity BIG-IP. As we move down the triangular stack, we start running into line of business apps that number in the hundreds, and may have hundreds of users. These apps are of two ilk: 1. Those that require multiple application services, and 2. Those that require data path programmability Now, the app may need one or the other or both. The first question to ask (and this isn't obvious) is what protocols do the applications support? Yes, that actually is very relevant. Line Rate is basically providing app proxy services; that means app protocols like HTTP and HTTPs. Not UDP, not SIP, not RDP or PCoIP. If you need that kind of protocol support, the answer at this layer is BIG-IP VE. If the answer was HTTP or HTTPS, now you're faced with a second (easy) question: do you need multiple services? Do you need availability (load balancing and failover) plus performance boosting services like caching and acceleration options? Do you need availability plus identity management (like SSO or SAML)? If you need availability plus then the answer, again, is you should choose BIG-IP VE. If you just need availability, now you get into a more difficult decision tree. If you want (or need) data path programmability (such as might be used to patch zero-day security vulnerabilities or do some layer 7 app routing) then the question is what language do you want to script in? Do you want node.js? Choose Line Rate Precision. Want iRules? Choose BIG-IP VE. There's really no "right" or "wrong" answer here, it's a matter of preference (and probably skill set availability or standard practices in your organization). Finally, you reach the broad bottom of the triangle, where the number of apps may be in the thousands but the users per app is minimal. This is where apps need basic availability but little more. This layer is where orchestration support (robust APIs) become as important as the service itself, because continuous delivery (CD) is in play as well as other DevOps-related practices like continuous integration and testing. This environment is often very fluid, highly volatile and always in motion, requiring similar characteristics of any availability services required. In this layer of the enterprise application stack, Line Rate Point is your best choice. Coupled with our newly introduced Volume Licensing Subscription (VLS), LineRate Point here offers both the support for the environment (with its robust, proper REST API) and its software or virtual form-factor along with excellent economy of scale. Hopefully this handy-dandy guide to F5 and enterprise application segmentation helps to sort out the question whether you should choose BIG-IP, BIG-IP VE or a flavor of LineRate. Happy Friday! * Oh, I know, you could provide those services with a conga line of point products but platforms are a significant means of enabling standardization and consolidation, which greatly enhance overall value and lower both operating and capital costs.315Views0likes0CommentsF5 Synthesis: Keeping the licensing creep out of expanding software options
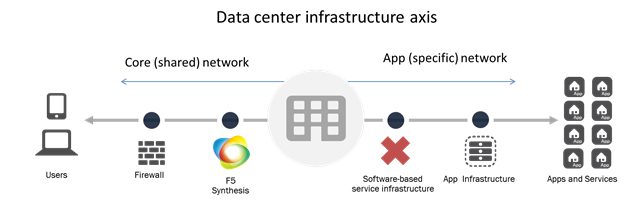
(Editors note: the LineRate product has been discontinued for several years. 09/2023) --- One of the funny things about infrastructure moving toward a mix of hardware and software (virtual or traditional) is that the issues that plague software come with it. Oh, maybe not right away, but eventually they crawl out of the deep recesses of the data center like a Creeper in Minecraft and explode on the unsuspecting adventurer, er, professional. While licensing network infrastructure has never been painless, it's never been as complicated or difficult as its software counterparts simply due to the sheer magnitude of difference between the number of network boxes under management and the number of software applications and infrastructure under management. That is changing. Rapidly. Whether it's because of expanding cloud footprints or a need to support microservices and highly virtualized environments, the reality is that the volume of software-based infrastructure is increasing. Like its application counterparts, that means licensing challenges are increasing too. That means We (that's the corporate F5 "we") have to change, too. As we continue to expand the software offerings available for F5 Synthesis beyond cloud and virtualization, we need to also adjust licensing options. That means staying true to the Synthesis tenet of Simplified Business Models. That's why we're making not one but two announcements at the same time. The first is the expansion of existing software options for F5 Synthesis. In addition to cloud-native and virtual editions of BIG-IP, we're making available a lightweight, load balancing service - LineRate Point. LineRate Point complements existing Synthesis services by supporting more directly the needs of application and operations teams for agile, programmable application-affine services in the data center or in the cloud, on- and off-premise. This is a missing component as the data center architecture bifurcates into a shared, core network and an app specific (business) network. Whether it's a focus on moving toward Network Service Virtualization or a need to deploy on a per-app / per-service basis thanks to microservices or increasing mobile application development, LineRate Point offers the scale and security necessary without compromising on the agility or programmability required to fit into the more volatile environment of the growing application network. But a sudden explosion of LineRate Point (or any service, really) anyway across the potential deployment spectrum would create the same kind of tracking and management headaches experienced by software infrastructure and applications. Licensing becomes a nightmare, particularly when instances might be provisioned and terminated on a more frequent basis than is typical for most network-deployed services. So along with the introduction of LineRate Point we're also bringing to F5 Synthesis Volume License Subscriptions (VLS). VLS holds true to the tenet of simplified business models both by offering F5 Synthesis software options (VE, cloud and LineRate Point) with a licensing model that fits the more expansive use of these services to support microservices, cloud and virtualization. VLS brings to F5 Synthesis the ability to support the migration of service infrastructure closer to the applications it is supporting without sacrificing the need for management and licensing. VLS also simplifies a virtual-based Synthesis High Performance Service Fabric by centralizing licensing of large numbers of virtual BIG-IP instances (VE) and simplifying the process. According to a 2014 InformationWeek survey on software licensing, nearly 40% of organizations have a dedicated resource who spends more than 50% of their time managing licenses and subscriptions. Moving to a more software-focused approach for infrastructure services will eventually do the same if it's not carefully managed from the start. By taking advantage of F5 Synthesis Simplified Business Models and its VLS offering, organizations can avoid the inevitable by bringing a simplified licensing strategy along with their software-based service infrastructure. You can learn more about F5 Synthesis Simplified Business Models by following Alex Rublowsky, Senior Director of Licensing Business Models, here on DevCentral as he shares more insight into the growing licensing options available for F5's expanding software portfolio.462Views0likes0CommentsDevCentral Top 5: Sep 8, 2014
But soft! What light through yonder window breaks? It is the east, and this week's edition of the DevCentral Top 5 is the sun. Yep, you guessed it. The top 5 is back...but unlike Shakespeare's Romeo and Juliet, this is no tragedy. Rather, it's a celebration of the most awesome articles you'll read anywhere on the Internet. Our DevCentral authors have been writing with freakish speed and determination, and they have turned out quality articles that are simply second to none. Choosing only five articles was a tough task given all the great content out there, but here's my take on the top articles since our last posting. F5 SOC Malware Summary Report: Neverquest I literally could have chosen five Lori MacVittie articles for this "top 5" but I resisted the urge and only chose one. In this article, Lori explains the details of a Trojan known as "Neverquest" that has been active since July 2013. Most of us get that warm, fuzzy, secure feeling when using 2-factor authentication because, you know, it's got 2 factors! Maybe automated malware has a shot at cracking one factor, but two? No way. Well, apparently Neverquest has found a way to automate the demise of our beloved 2FA. Lori does a magnificent job of explaining how Neverquest works, and then she discusses the amazing work that was completed by our F5 Security Operations Center in their analysis of this malware (in case you didn't know, F5 has a Security Operations Center that analyzes malware like this and provides amazing reports that are free for anyone to read). Lori provides links to the downloads of the executive summary as well as the full technical analysis of Neverquest. This one is not optional...if you care about anything at all, you gotta read this one. Leveraging BIG-IP APM for seamless client NTLM Authentication Michael Koyfman reminds us why we love the BIG-IP APM...transparent seamless authentication for users. In this article, Michael specifically discusses how to configure the APM to perform client NTLM authentication and use it in the context of sending a SAML assertion to the Office 365 service. This is a step-by-step masterpiece that shows you exactly what to do at every turn. In the end, you point your browser to the FQDN of the APM virtual server and you will be silently authenticated (let's be honest...silent authentication is a bucket-list item for each and every one of us). Michael also reminds us of the SSO options at the end of his article. Webshells Nir Zigler introduces us to Webshells (web scripts that act as a control panel for the server running them), and talks about some of the common uses for these scripts. But you know the story...scripts that were created for good can also be used for evil. After Nir explains all the valid uses for legitimate webshells, he takes us to a place where mere mortals dare not tread...through a webshell attack. He gives us an overview of how a webshell attack works, and then he explains some of the specific tools that are used for these nefarious actions. After walking through the power and functionality of an open source webshell called b374k, Nir shows how this tool can be used to attack an unsuspecting user. But have no fear! Nir finishes up the article by discussing the power of the BIG-IP ASM and how it will detect and prevent webshell attacks. Continuing the DDoS Arms Race How long have DDoS attacks been around, and why are they still news today? Because they are consistently one of the top attack vectors that companies face today. Shauntine'z discusses the DDoS arms race and provides some poignant statistics that remind us of the very real and credible DDoS threat. But the article doesn't stop there...it goes on to provide some excellent tips on what to do to strengthen your DDoS defense posture (it even has a well-placed picture of Professor John Frink...you gotta check this one out). Last, Shauntine'z reveals new features that are loaded in the latest release of the BIG-IP...version 11.6. The AFM and ASM have some new and exciting capabilities that are "must haves" for any company that is serious about securing their applications and critical business functions. (Editors note: the LineRate product has been discontinued for several years. 09/2023) Why ECC and PFS Matter: SSL offloading with LineRate We all know that sensitive data traverses our networks every day. We also know it's critically important to secure this information. We also know that SSL/TLS is the primary method used to secure said information. Andrew Ragone discusses SSL offloading and tells us why Elliptical Curve Cryptography (ECC) and Perfect Forward Secrecy (PFS) are great candidates for securing your information. He highlights the advantages of the software based LineRate solution, and gives great examples of why LineRate is the clear-cut winner over any existing software-based or hardware-based SSL/TLS offload solutions. Andrew also published another series of articles related to this very topic, and in these articles he walks you through the exact steps needed to configure SSL certificates and offload SSL on LineRate. On that subject...if you haven't had a chance to check out LineRate and learn all about the awesomeness that it is, do yourself a favor and visit190Views0likes0Comments
LineRate: Excessive HTTP 404 Throttling
Fusker thwarting using the LineRate Node.js datapath scripting engine Fuskering is so fun to say, I couldn't resisting writing article about it. But, aside from just raising eyebrows when you use the term, fuskering is a real problem for some site maintainers. And having been in this position myself, I can verify that it's a difficult problem to solve. A flexible, programmable data-path, like the LineRate load balancer, makes light work of solving these kinds of problems. Background So, what exactly is fuskering? Simply stated, fuskering is requesting successive URL paths using a known pattern. For example, if you knew example.com had images stored at http://example.com/img01.jpg and http://example.com/img02.jpg . You might venture to guess that there is also an image at http://example.com/img03.jpg . And if I find that img03.jpg was there, I might as well try img04.jpg . Utilities, like curl, make automating this process extremely easy. Photo sites are a typical target for fuskering because image filenames are usually pretty predictable. Think about a URL like http://example.com/shard1/user/jane/springbreak14/DSCN5029.jpg and you start to see where this could be a problem. Not only is this a potential privacy concern, but it's also a huge burden on the datacenter assets serving those files. In some multi-tier architectures, serving a 404 is actually more burdensome than serving an asset that exists. When you request something that doesn't exist, it's possible that all of the following could happen: Cache miss on CDN, CDN requests from origin Front end load balancer receives requests, makes balancing decision, forwards request Web tier receives request, processes and sends to caching tier Caching tier receives request and consults memory cache and then disk cache. Another cache miss Services API tier receives request for URL to file system mapping At this point, either your well written object storage API will signal to you that the file really doesn't exist or you're not using object storage and you have to actually make a request to the local disk or NAS. In either case, that's a lot of work just to find out that something doesn't exist. Assets that do exist, end up in one of the caching tiers and are found and served much earlier in this process, typically right from CDN and the request never even touches your infrastructure. If your site is handling a lot of requests and they are spread across many servers - and possibly many data centers - correlating all the data to try and mitigate this problem can be tedious and time consuming. You have to log each request, aggregate it somewhere, perform analytics and then take action. All the while, your infrastructure is suffering. Options and limitations Requiring authentication and filename scrambling are two ways to reduce the likelihood that your site will attract fuskers in the first place. Of course, these methods do not actually make fuskering impossible, but by requiring the user to enter identifying information or by making the filenames extremely difficult to guess, the potential consequences and level of effort become too great, and the user will likely move on. The technique detailed in this article is just one of many ways to combat fuskers. Some other possible solutions are user-agent string checking, using CAPTCHA, using services like CloudFlare, traffic scrubbing facilities, etc. None of these is a silver bullet (or cheap, in some cases), but you could evaluate them all and figure out what works best for your environment and your wallet. There are also ways for a determined user to subvert a lot of these protective measures: Tor, X-Forwarded-For spoofing, using multiple source IPs, and adaptive scripts to minimize the effect of the block time window (i.e. Send max_404 requests, wait time_window , repeat), etc. [One] Solution Having a programmable data path makes solving (or at least mitigating) this issue easy. We can track each HTTP session, analyze the request and response, and have all the details we need to detect excessive 404's and throttle them. I provide a complete script to do this at the end; I'll describe the solution and how the script works next. This article uses fuskering as motivation for this solution, but realize that the source of excessive 404's could come from a variety of sources, such as: people that automate data collection from your site (and forget to update request paths when they change), a misbehaving application, resources that moved without a proper 301/302 redirect, or a true 404 DoS attack (which is meant to exploit all the things I mention in the Background section), just to name a few. Script overview We're going to use the local LineRate Redis instance for tracking the 404 info. We're storing a key-value pair, where the key is the client's IP address and the value is the number of 404 responses that client has received in a configurable time window. This "time window" is handled by setting an expiration on the key-value pair and then extending it if necessary. If no 404's are detected during the grace period, the entry expires and the client is not subject to any request throttling. When a new request is received, the client's IP is determined (see next section on Source IP) and checked against the Redis database. If a db entry is found and the corresponding value exceeds the allowed number of 404's, we intercept the request and respond directly from the load balancer with an HTTP 403. On the response side, when we detect a 404 is being returned to a client, we increment the counter for the client IP in the Redis db. If the client's IP doesn't exist, we add it and init the value to '1'. In either case, the time window is also set. The time window and the maximum number of 404's are configurable via the config object. Source IP To accurately analyze the 404's, you need to know the client's true source IP. Remember that any connection coming through a proxy is not going to have the actual client's source IP. Enter the X-Forwarded-For (XFF) header. If present, the XFF header will contain an ordered, comma-separated list of IP addresses. Each IP identifies another proxy, load balancer or forwarding device that the request passed through before it got to you. IPs are appended to this list, so the first IP is that of the actual client. In our script logic, we can check for the XFF header and if it's present, use the first IP in this list as the client IP. In the absence of a XFF header, we'll simply use the 'remoteAddress' of the connection object. redis There's a couple important things to point out in regards to using the included Redis server. First, the LineRate load balancer runs multiple instances of the Node.js engine and variables are unique to that instance. If you were to store 404 tracking info in local variables, you might get results that you don't expect. See here for more info. Second, using redis lends itself especially well to this example because you can run this script on all the virtual-servers for your site and get instant aggregated analysis and action. The Script If you're not already familiar with Node.js and the LineRate scripting engine, be sure to check out the LineRate Scripting Developer's Guide. requires and config Load the required modules and initialize the config object. You might want to tune config.time_window and config.max_404 to your environment. Continue reading to gain a better understanding of the implications of changing these values. var vsm = require('lrs/virtualServerModule'); var async = require('async'); var redis = require('redis').createClient(); // Change config as needed. var config = { vs: 'vs_http', // name of virtual-server time_window: 10, // window in seconds max_404: 10 // max 404's per time window }; redis Pretty basic stuff here, but note that we're loading the module and creating a client object all in one line. var redis = require('redis').createClient(); redis.on('error', function (err) { console.log('Error' + err); }); redis.on('ready', function () { console.log('Connected to redis'); }); onRequest() - async waterfall The async module is used to provide some structure to the code and to ensure that things happen in the proper order. When we receive a new request from a client, we get the client's IP, check it against the database and then handle the the rest of the request/response processes. Each of the functions are detailed next. function onRequest(servReq, servResp, cliReq) { async.waterfall([ function(callback) { get_client_ip(servReq, callback); }, function(client_ip, callback) { check_client(client_ip, callback); }, function(throttle, client_ip, callback) { doRequest(servResp, cliReq, throttle, client_ip, callback); }, ], function (err, result) { if (err) { throw new Error(err); // blow up } }); } get_client_ip() Check for the presence of the XFF header. If present, get the client IP from the header value. If not, use remoteAddress from the servReq connection object. function get_client_ip(servReq, callback) { var client_ip; // check xff header for client ip first if ('x-forwarded-for' in servReq.headers) { client_ip = servReq.headers['x-forwarded-for'].split(',').shift(); } else { client_ip = servReq.connection.remoteAddress; } return callback(null, client_ip); } check_client() check_client() is where we determine whether to block the request. If the client's IP is in redis and the corresponding value exceeds that of config.max_404 , we set throttle to true . Else, throttle remains false . throttle is used in the next function to either allow or block the request. function check_client(client_ip, callback) { var throttle = false; redis.get(client_ip, function (err, reply) { if (err) { return callback(err); } if (reply >= config.max_404) { throttle = true; } return callback(null, throttle, client_ip); }); } doRequest() In doRequest() , the first thing we do is check to see if throttle is true . If it is, we simply return a 403 and close the connection. If you wanted more aggressive throttling, you could also update the expiration time of the redis key associated with this client's IP here. If there is no throttle, we register a listener for the 'response' to the cliReq() and send the request on to the client. When we receive the response, we check the status code. If it's a 404, we increment the redis 404 counter. For any client that requests more than config.max_404 in a rolling window of config.time_window will start to get blocked. Once the time window passes, the requests will be allowed again. function doRequest(servResp, cliReq, throttle, client_ip, callback) { if (throttle) { servResp.writeHead(403); servResp.end('404 throttle. Your IP has been recorded.\n'); // note you could choose to bump the redis key timeout here // and effectively lock out the user completely (even for good requests) // until they stop ALL requests for 'time_window' return callback(null, 'done'); } else { cliReq.on('response', function(cliResp) { var status_code = cliResp.statusCode; if (status_code === 404) { redis.multi() .incr(client_ip) .expire(client_ip, config.time_window) .exec(function (err, replies) { if (err) { return callback(err); } }) } // Fastpipe response cliResp.bindHeaders(servResp); cliResp.fastPipe(servResp); }); cliReq(); return callback(null, 'done'); } } Testing This bash one-liner will use curl to send 15 consecutive requests for an image that doesn't exist and results in a 404 response. Note the change from '404' to '403' from request #10 to request #11. This is the throttling in action. > for i in $(seq -w 1 15);do echo -n "${i}: `date` :: "; curl -w "%{http_code}\n" -o /dev/null -s http://example.com/noexist.jpg;done 01: Fri Feb 13 09:59:44 MST 2015 :: 404 02: Fri Feb 13 09:59:44 MST 2015 :: 404 03: Fri Feb 13 09:59:44 MST 2015 :: 404 04: Fri Feb 13 09:59:44 MST 2015 :: 404 05: Fri Feb 13 09:59:44 MST 2015 :: 404 06: Fri Feb 13 09:59:44 MST 2015 :: 404 07: Fri Feb 13 09:59:44 MST 2015 :: 404 08: Fri Feb 13 09:59:44 MST 2015 :: 404 09: Fri Feb 13 09:59:44 MST 2015 :: 404 10: Fri Feb 13 09:59:44 MST 2015 :: 404 11: Fri Feb 13 09:59:44 MST 2015 :: 403 12: Fri Feb 13 09:59:44 MST 2015 :: 403 13: Fri Feb 13 09:59:44 MST 2015 :: 403 14: Fri Feb 13 09:59:44 MST 2015 :: 403 15: Fri Feb 13 09:59:44 MST 2015 :: 403 Pulling it all together, here's the full script. Happy cloning! Please leave a comment or reach out to us with any questions or suggestions and if you're not a LineRate user yet, remember you can try it out for free.405Views0likes0Comments
Robot regulation with LineRate
This article discusses a method for regulating HTTP accessesfrom robots (aka. crawlers, spiders, or bots) by the use of F5 LineRate Precision Load Balancer. A growing number of accessesfrom robots can potentially affect the performance of your web services. Studies show that robots accounted for 35% of accesses in 2005 [1], and increased to 61.5% in 2013 [2]. Many sites employ the de facto Robots Exclusion Protocol standard [3] to regulate the access, however, not all the robots follow this advisory mechanism [4]. You can filter the disobedient robots somehow, but that will be an extra burden for already heavily loaded web servers. In this use-case scenario, we utilize LineRate scripting to exclude the known robots before they reach the backend servers. The story is simple. When a request hits LineRate, it checks the HTTP User-Agent request header. If it belongs to one of the known robots, LineRate sends the 403 Forbidden message back to the client without conveying the request to the backend servers. A list of known robots can be obtained from a number of web sites. In this article, user-agent.org was chosen as the source because it provides a XML formatted list. The list contains legitimate user agents, so only the entries marked as 'Robots' or 'Spam' must be extracted. Here is the code. 'use strict'; var vsm = require('lrs/virtualServerModule'); var http = require('http'); var event = require('events'); var xml = require('xml2js'); First, include necessary modules. lrs/virtualServerModule is a LineRate specific module that handles traffic. http and events are standard Node.js modules: The former is used to access the user-agent.org server as a HTTP client, and the latter is for custom event handling. xml2js is an NPM module that translates a XML formatted string to the JSON object. function GetRobots () { this.vsname = 'vs40'; this.ops = { host: '80.67.17.172', path: '/allagents.xml', headers: {'Host': 'www.user-agents.org', 'Accept': '*/*'} }; this.stat404 = 403; this.body403 = Forbidden; this.head403 = {'Content-Type': 'text/plain', 'Content-length': this.body403.length}; this.xml = ''; // populated by getter() this.list = {}; // populated by parser() }; GetRobots.prototype = new event.EventEmitter; The GetRobot class stores information such as HTTP access information and 403 response message. In order to handle custom events, the class is extended by the Events.EventEmitter. The class contains two methods (functions): GetRobot.parser() is for parsing XML strings into JSON objects, and GetRobot.getter() is for getting the XML data. // Parse XML string into an object GetRobots.prototype.parser = function() { var reg = /[RS]/i; var self = this; try { xml.parseString(self.xml, function(e, res) { if (e || ! res) console.error('robot: parser eror: ' + e); else if (! res['user-agents'] || ! res['user-agents']['user-agent']) console.error('robot: parser got malformed data.'); else { var array = res['user-agents']['user-agent']; for ( var i=0; i<array.length; i++) { if (reg.test(array[i].Type)) self.list[(array[i].String)[0]] = 1; } self.emit('parser'); } }); } catch(e) { console.error('robot: parser got unknown error ' + e); } }; This is the parser method. The XML data retrieved is structured in the <user-agents><user-agent>....</user-agent></user-agents> format. Each <user-agent>....</user-agent> contains information of an user agent. The tags we are after are <String> and <Type>. The <String> tag contains the value of the HTTP's User-Agent. The <Type> tag contains the type of agents: We are after the Type R(obot) or S(pam) as shown in the regular expression in the code. After it completes parsing, it emits the custom 'parser' event. // Retrieve the XML formatted user agent list GetRobots.prototype.getter = function() { var self = this; try { var client = http.request(self.ops, function(res) { var data = []; res.on('data', function(str) { data.push(str); }); res.on('end', function() { self.xml = data.join(''); self.emit('getter'); }); }).end(); } catch(e) { console.error('robot: getter error: ' + e.message); } }; This snippet is the getter. It sends a HTTP GET request to the server, and receives the XML string. After it receives all the XML data, it emits the custom 'getter' event. // main part var robo = new GetRobots(); vsm.on('exist', robo.vsname, function(vso) { robo.on('getter', function() { console.log('robot: got XML file. ' + robo.xml.length + ' bytes.'); robo.on('parser', function() { var num = (Object.keys(robo.list)).length; console.log('robot: got ' + num + ' robots.'); vso.on('request', function(servReq, servResp, cliReq) { var agent = servReq.headers['User-Agent']; if (robo.list[agent]) { servResp.writeHead(robo.stat403, robo.head403); servResp.end(robo.body403); } else { cliReq(); } }); }); robo.parser(); }); robo.getter(); }); console.log('robot: retrieving info from ' + robo.ops.headers['Host']); Now, combine them together. The code follows the following steps sequentially. Instantiate the class (the object is robo here). Then, log the message (shown at the end of the code). Check if the LineRate virtual server exists (vsm.on('exist', ...)). The name of the virtual server is hard-coded in the class definition. Register the 'getter' event to the robo object using the on function (robo.on('getter', ...)). Then, run the getter() to retrieve the XML formatted agent list from the user-agent.org. You need to run the getter() AFTER the event is registered. Otherwise, the object may miss the event because it is not prepared to catch it. After the getter() completes (received the 'getter' event), register the 'parser' event to the robo object (robo.on('parser', ...)). Then, run the parser() to parse the retrieved XML data. Note that you want to run the parser() only after the completion of the getter(). Otherwise, the parser() tries to parse null string as the data is not prepared there yet. Once the list of robots becomes ready, register the LineRate's 'request' event (vso.on('request', ...)) so the script can start processing the traffic. The rest of the story is simple. If the User-Agent header contains any of the agent names listed, send the 403 message back to the client (robot). Otherwise, pass the request through to the backend servers. Let's test the script. Try accessing to the LineRate with your browser. It should return the backend server's data as if there is no intermediate processor exists. Try mimicking a robot (any of them with the R or S mark) using curl as below. $ curl -D - -H "User-Agent: DoCoMo/1.0/Nxxxi/c10" 192.168.184.40 HTTP/1.1 403 Forbidden Content-Type: text/plain Content-length: 9 Date: Tue, 03-Mar-2015 04:03:56 GMT Forbidden The User-Agent string must be the exact match to the string appeared in the user-agent.org list. The script leaves the following log messages upon statup. robot: retrieving info from www.user-agents.org robot: got XML file. 693519 bytes. robot: got 1527 robots. While the script runs fine, there are a few possible alterations that can make it nicer. Waterfall the process - The script must run virtual server check, getter, parser, and traffic processing in sequence. The NPM async module is handy for such a deeply nested structure. See our "LineRate: HTTP session ID persistence in scripting using memcache" DevCentral article for more details. Handle the lengthy initialization process nicely - It takes noticeable time for the getter and parser to prepare the list of robots (it took about 8s in the authors environment). While the script is preparing for the essential data, any incoming request is passed through as if no process is performed by the proxy - so robots can access the servers for the first several seconds. If you want to change this behavior, check our "A LineRate script with lengthy initialization process" DevCentral article. Cater for multiple instances - LineRate may spawn multiple HTTP processing engines (called lb_http) depending on a number of vCPUs (cores/hyper-threads). With the script above, each engine runs getter and parser, keeping the same data individually. You can run the getter and parser just once on a designated instance, and make the data available to all others. Learn the data sharing methods from "A Variable Is Unset That I Know Set" in our Product Documentation or "LineRate and Redis pub/sub" DevCentral article. Please leave a comment or reach out to us with any questions or suggestions and if you're not a LineRate user yet, remember you can try it out for free. References: [1] Yang Sun, Ziming Zhuang, and C. Lee Giles: "A large-scale study of robots.txt", Proc. 16th Int. Conf World Wide Web (WWW 2007), 1123-1124 (May 2007). [2] Igal Zeifman: "Report: Bot traffic is up to 61.5% of all website traffic", Incapsula's Blog (09 Dec 2013). [3] The Web Robots Pages. The protocol was proposed to IETF by M. Koster in 1996. [4] C. Lee Giles, Yang Sun, and Isaac G. Councill: "Measuring the web crawler ethics", Proc. 19th Int. Conf. World Wide Web (WWW 2010), 1101-1102 (Apr 2010).273Views0likes0CommentsUsing LineRate to support multiple domains or applications
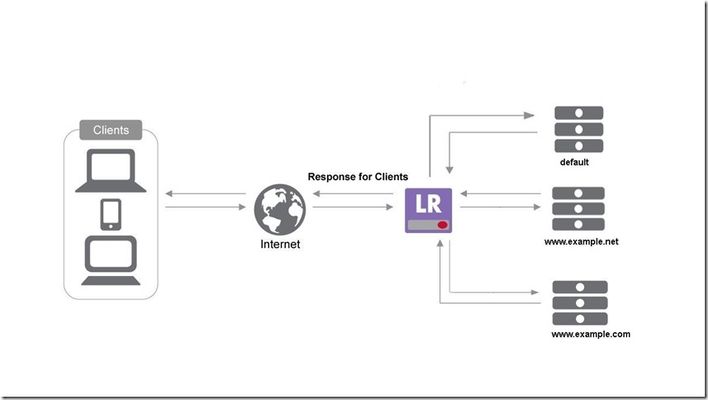
Here at F5's LineRate division we often write about our Node.js scripting engine and its use cases by way of script examples. But today I am going to describe to you a less talked about feature in our product. In the world of applications it is not uncommon to have multiple domains mapped to the same IP address. LineRate provides the ability to attach the same virtual IP to more than one virtual server. This can be useful where an organisation has several applications for its customers, or the case were organisations have merged and IT systems are being rationalized. In such cases (as shown in the figure below) applications and their domains can have dedicated virtual servers on a LineRate load balancer. When a client makes an HTTP request, the LineRate load balancer inspects the 'Host' field in the HTTP header and directs it to the appropriate virtual server. This is accomplished with the hostname configuration on the virtual server. Step-by-step guide Configure a virtual IP (eg. vipweb1 in the below configuration example) for the services or applications Configure a virtual server (eg. example-com) that is dedicated for a service or application using the hostname configuration - hostname www.example.com Configure another virtual server (eg. example-net) that is dedicated for another service or application using the hostname configuration - hostname www.example.net Attach the same virtual IP (vipweb1) common to these services that their virtual servers will listen on Configure a virtual server that is the default (eg. default-server) for a same virtual IP - ' attach virtual-ip default' - this will be the 'catch-all virtual server' for all HTTP requests that don't have a dedicated virtual server hostname configuration example ! virtual-ip vipweb1 ip address 192.0.2.1 80 base vipbase_vip1 admin-status online ! virtual-server example-com lb-algorithm round-robin service http hostname www.example.com attach virtual-ip vipweb1 attach real-server rsweb1 attach real-server rsweb2 ! virtual-server example-net lb-algorithm round-robin service http hostname www.example.net attach virtual-ip vipweb1 attach real-server rsweb3 ! virtual-server default-server lb-algorithm round-robin service http attach virtual-ip vipweb1 default attach real-server rsweb4 attach real-server rsweb5 ! If you happen to experience a '404 not found' response to an HTTP request for a host that does not have a default virtual server i.e. a virtual server without an explicit hostname attached, please check that you have followed step 5 correctly. The 404 response in this case indicates that the host lookup resulted in no default virtual server to service the request. If you haven't tried out LineRate, have a go, it's free. If you have further questions on this or any of the related articles on LineRate at DevCentral, reach out to us. We are here to help. Related articles LineRate on DevCentral236Views0likes0CommentsMitigating the favicon bug through LineRate scripting
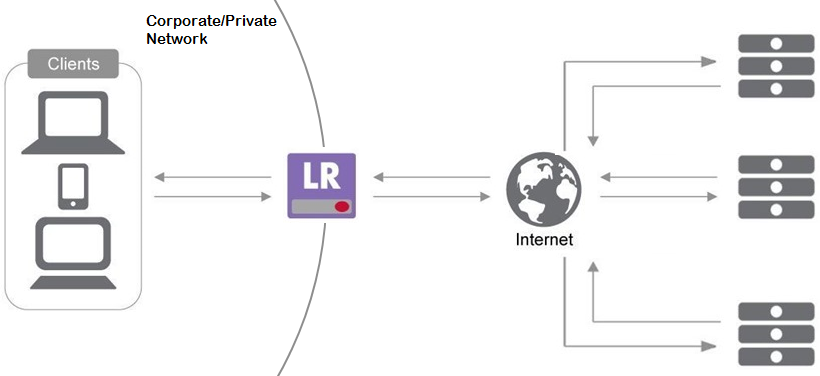
A recent report (June 2015) revealed a web browser's problem with a large favicon[1]:The browser crashes when the size of a favicon is larger than what it expects.A favicon is a small image, say 16 x 16 pixels,that is displayed next to a browser's address bar or in the bookmark[2]. Because it is downloaded automatically by the browser, users can't have any clue to the browser's abrupt crash. LineRate can protect the web clients in your private/corporate network by rejecting the large favicons. In this solution, a LineRate instance is configured as a forward-proxy as shown in the figure below. The LineRate proxies HTTP requests from clients in the corporate/private network to servers on the public Intenet, and relays the responses from the servers to the clients. Please refer to our Product Documentation for the configuration guide[3]. Here is the script.When a client in the corporate/private network sends a request, the LineRate checks if the requested resource is a favicon(line 3 and 10).When the response comes back from the server on the Internet, it checks the Content-Length response header value [4]. The LineRate passes the favicon smaller than a predefined threshold (line 4 and 13): Otherwise, it discards the data and sends back 403 error message to the client. 'use strict'; var fpm = require('lrs/forwardProxyModule'); var favicon = /favicon\.ico|gif|png/i; var maxSize = 1000; // # of bytes var vsname = 'fp50'; var errorMessage = 'Sorry, the favicon you requested is too large for you.' fpm.on('exist', vsname, function(fpo) { fpo.on('request', function(servReq, servResp, cliReq) { if (favicon.test(servReq.url)) { cliReq.on('response', function(cliResp) { var len = cliResp.headers['content-length']; if (len > maxSize) { console.log('favicon ' + servReq.url + ' rejected. ' + len + ' bytes.'); servResp.writeHead(403, { 'Content-type': 'text/plain', 'Content-Length': errorMessage.length}); servResp.end(errorMessage); } else { cliResp.bindHeaders(servResp); cliResp.fastPipe(servResp); } }); } cliReq(); }); }); console.log('favicon filter started (fw version).'); The Content-Length header may not be present in the response header (e.g., Transfer-Encoding). In that case, you need to determine its size by checking the amount of data read. The code below is essentially the same as the Content-Length version. Because the favicon data is binary, the Buffer object should be used to read the incoming data chunks (line 14). If you use var ico += ico_chunk, the data chunk is interpreted as UTF-8 characters, hence the image will be corrupted. 'use strict'; var fpm = require('lrs/forwardProxyModule'); var favicon = /favicon\.ico|gif|png/i; var maxSize = 1000; // # of bytes var vsname = 'fp50'; var errorMessage = 'Sorry, the favicon you requested is too large for you.' fpm.on('exist', vsname, function(fpo) { fpo.on('request', function(servReq, servResp, cliReq) { if (favicon.test(servReq.url)) { cliReq.on('response', function(cliResp) { var ico_chunk = []; cliResp.on('data', function(chunk) { ico_chunk.push(chunk); }); cliResp.on('end', function() { var ico = Buffer.concat(ico_chunk); if (ico.length > maxSize) { console.log('favicon ' + servReq.url + ' rejected. ' + ico.length + ' bytes.'); servResp.writeHead(403, { 'Content-type': 'text/plain', 'Content-Length': errorMessage.length}); servResp.end(errorMessage); } else { cliResp.bindHeaders(servResp); servResp.end(ico); } }); }); } cliReq(); }); }); console.log('favicon filter started.'); You may think storing the entire data and flushing at the end is performance-wise not optimal. In that case, you can change the above code (line 11-30) to stream back the chunks as they come in until the size exceeds the threshold. When it reaches the maximum size, the script aborts the session ( cliReq.abort() ). This script won't explicitly send the 403 error to the client. cliReq.on('response', function(cliResp) { var ico_length = 0; var aborted = false; cliResp.on('data', function(chunk) { if(aborted) { return; } // Handles outstanding chunks coming at us before the server cancels the request; this should never happen, but it's here just in case iso_length += chunk.length; // Track length only, not the entire buffer in memory if(iso_length < maxSize) { servResp.write(chunk); // Performance: writes chunks out immediately } else { // Cancel request aborted = true; cliReq.abort(); servResp.end(); } }); cliResp.on('end', function() { if (!aborted && ico_length < maxSize) { servResp.end(); } }); }); You do not need to implement this solution once the browser bug is fixed. Yet, something similar may happen in future, and the fix may not come in timely manner. LineRate can provide solutions for timely security vulnerability mitigation as discussed in this article and others [5,6]. if you wish to respond to incidents by manipulating HTTP transactions, it is time to introduce LineRate. Please leave a comment orreach out to uswith any questions or suggestions and if you're not a LineRate user yet, remember you cantry it out for free. References: [1] benjamingr:Favicon Download Bug, GitHub. [2] Wikipedia:Favicon. [3]LineRate Product Documentation. See the "Configuring a Forward Proxy" section. [4] Fielding & Reschke, Eds.:Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing, RFC 7230 (June 2014). See Section 3.3.2 for theContent-Lengthdefinition. [5] Talley:LineRate: Range header attack mitigation, DevCentral (April 2015). [6] Rajagopal:CVE-2014-3566: Removing SSLv3 from LineRate, DevCentral (October 2014).253Views0likes0CommentsLineRate and Redis pub/sub
Using the pre-installed Redis server on LineRate proxy, we can use pub/sub to push new configuration options and modify the layer 7 data path in real time. Background Each LineRate proxy has multiple data forwarding path processors; each of these processors runs an instance of the Node.js scripting engine. When a new HTTP request has to be processed, one of these script engines will process the request. Which actual script engine handles the request is not deterministic. A traditional approach to updating a script's configuration might be to embed an onRequest function in your script to handle an HTTP POST with new configuration options. However, given that only a single script engine will process this request, only the script running on that engine will 'see' the new options. Scripts running on any other engines will continue to use old options. Here we show you and easy way to push new options to all running processes. How to If you're not already familiar with Node.js and the LineRate scripting engine, you should check out the LineRate Scripting Developer's Guide. Let's jump into the Redis details. Redis is already installed and running on your LineRate proxy, so you can begin to use it immediately. If you're not familiar with the pub/sub concept, it's pretty straight-forward. The idea is that a publisher publishes a message on a particular channel and any subscribers that are subscribed to that same channel will receive the message. In this example, the message will be in JSON format. Be sure to take note of the fact that if your subscriber is not listening on the channel when a message is published, this message will never be seen by that subscriber. I've added some additional code that will store the published options in redis. Any time a subscriber connects, it will check for these values in redis and use them if they exist. This way, any subscriber will always use the most recently published options. Here is the code that will be added to the main script to handle the Redis subscribe function: // load the redis module var redis = require("redis"); // create the subscriber redis client var sub = redis.createClient(); // listen to and process 'message' events sub.on('message', function(channel, message) { // ... // get 'message' and store in 'opts' var opts = JSON.parse(message); // ... }); // subscribe to the 'options' channel sub.subscribe('options'); We can now insert these code pieces into a larger script that uses the options published in the options message. For example, you might want to use LineRate for it's ability to do HTTP traffic replication. You could publish an option called "load" that controls what percentage of requests get replicated. All script engines will 'consume' this message, update the load variable and immediately start replicating only the percentage of requests that you specified. It just so happens we have some code for this. See below in the section sampled_traffic_replication.js for a fully commented script that does sampled traffic replication using parameters received from Redis. It should also be mentioned that if you have multiple LineRate's all performing the same function, they can all subscribe to the same Redis server/channel and all take the appropriate action - all at the same time, all in real-time. Of course we need a way to actually publish new options to the 'options' channel. This could be done in myriad ways. I've included a fully commented Node.js script below called publish_config.js that prompts the user for the appropriate options on the command line and then publishes those options to the 'options' channel. Lastly, here's a sample proxy config snippet for LineRate that you would need: [...] virtual-server vsPrimary attach vipPrimary default attach real-server group ... virtual-server vsReplicate attach vipReplicate default attach real-server group ... virtual-ip vipPrimary admin-status online ip address 192.0.2.10 80 virtual-ip vipReplicate admin-status online ip address 127.0.0.1 8080 [...] sampled_traffic_replication.js "use strict"; var vsm = require('lrs/virtualServerModule'); var http = require('http'); var redis = require("redis"), sub = redis.createClient(); // define initial config options var replicateOptions = { ip: '127.0.0.1', port: 8080, // Replicate every pickInterval requests // by default, don't replicate any traffic pickInterval: 0 }; // pubsub error handling sub.on("error", function(err) { console.log("Redis subscribe Error: " + err); }); // if options already exist in redis, use them sub.on("ready", function() { sub.get('config_options', function (err, reply) { if (reply !== null) { process_options(reply); } }); // switch to subscriber mode to // listen for any published options sub.subscribe('options'); }); function process_options(opts) { opts = JSON.parse(opts); // only update config params if not null if (opts.virtual_server_ip) { replicateOptions.ip = opts.virtual_server_ip; } if (opts.virtual_server_port) { replicateOptions.port = opts.virtual_server_port; } // convert 'load' to 'pickInterval' for internal use if (opts.load) { // convert opts.load string to int opts.load = parseInt(opts.load, 10); if (opts.load === 0) { replicateOptions.pickInterval = opts.load; } else { replicateOptions.pickInterval = Math.round(1 / (opts.load / 100)); } } console.log("Updated options: " + JSON.stringify(replicateOptions)); } var tapServerRequest = function(servReq, servResp, options, onResponse) { // There is no built-in method to clone a request, so we must generate a new // request based on the existing request and send it to the replicate VIP var newReq = http.request({ host: options.ip, port: options.port, method: servReq.method, path: servReq.url}, onResponse); servReq.bindHeaders(newReq); servReq.pipe(newReq); return newReq; } // Listen for config updates on 'options' channel sub.on('message', function(channel, message) { console.log(process.pid + ' Updating config(' + channel + ': ' + message); process_options(message); }); vsm.on('exist', 'vsPrimary', function(vs) { console.log('Replicate traffic script installed on Virtual Server: ' + vs.id); var reqCount = 0; vs.on('request', function(servReq, servResp, cliReq) { var tapStart = Date.now(); var to; var aborted = false; reqCount++; // // decide if request should be replicated; replicate if so // // be sure to handle "0" load scenario gracefully // if (replicateOptions.pickInterval && reqCount % replicateOptions.pickInterval == 0) { var newReq = tapServerRequest(servReq, servResp, replicateOptions, function(resp) { // a close event indicates an improper connection termination resp.on('close', function(err) { console.log('Replicated response error: ' + err); }); resp.on('end', function(err) { console.log('Replicated response error:' + aborted); clearTimeout(to); }); }); // // if replicated request timer exceeds 500ms, abort the request // to = setTimeout(function() { aborted = true; newReq.abort(); }, 500); } // // also send original request along the normal data path // servReq.bindHeaders(cliReq); servReq.pipe(cliReq); cliReq.on('response', function(cliResp) { cliResp.bindHeaders(servResp); cliResp.fastPipe(servResp); }); }); }); publish_config.js "use strict"; var prompt = require('prompt'); var redis = require('redis'); // note you might need Redis server connection // parameters defined here for use in createClient() // method. var redis_client = redis.createClient(); var config_channel = 'options'; var schema = { properties: { virtual_server_ip: { description: 'Virtual Server IP', pattern: /^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$/, message: 'Must be an IP address', required: false }, virtual_server_port: { description: 'Virtual Server port number', pattern: /^[0-9]{1,5}$/, message: 'Must be an integer between 1 and 65535', require: false }, load: { description: 'Percentage of load to replicate', pattern: /^[0-9]{1,3}$/, message: 'Must be an integer between 0 and 100', require: false } } }; prompt.start(); function get_info() { console.log('Enter values; leave blank to not update'); prompt.get(schema, function (err, result) { if (err) { return prompt_error(err); } // // TODO: do some input validation here // var config = JSON.stringify(result) console.log('Sending: ' + config) // publish options via pub/sub redis_publish_message(config_channel, config); redis_client.end(); }); } function redis_publish_message(channel, message) { // publish redis_client.publish(channel,message); // also store JSON message in redis redis_client.set("config_options", message) } function prompt_error(err) { console.log(err); return 1; } //main get_info(); Additional Resources Download LineRate LineRate Scripting Developer's Guide LineRate solution articles LineRate DevCentral266Views0likes0CommentsLineRate HTTP to HTTPS redirect
Here's a quick LineRate proxy code snippet to convert an HTTP request to a HTTPS request using the embedded Node.js engine. The relevant parts of the LineRate proxy config are below, as well. By modifying the redirect_domain variable, you can redirect HTTP to HTTPS as well as doing a non-www to a www redirect. For example, you can redirect a request for http://example.com to https://www.example.com . The original URI is simply appended to the redirected request, so a request for http://example.com/page1.html will be redirected to https://www.example.com/page1.html . This example uses the self-signed SSL certificate that is included in the LineRate distribution. This is fine for testing, but make sure to create a new SSL profile with your site certificate and key when going to production. As always, the scripting docs can be found here. redirect.js: Put this script in the default scripts directory - /home/linerate/data/scripting/proxy/ and update the redirect_domain and redirect_type variables for your environment. "use strict"; var vsm = require('lrs/virtualServerModule'); // domain name to which to redirect var redirect_domain = 'www.example.com'; // type of redirect. 301 = temporary, 302 = permanent var redirect_type = 302; vsm.on('exist', 'vs_example.com', function(vs) { console.log('Redirect script installed on Virtual Server: ' + vs.id); vs.on('request', function(servReq, servResp, cliReq) { servResp.writeHead(redirect_type, { 'Location': 'https://' + redirect_domain + servReq.url }); servResp.end(); }); }); LineRate config: real-server rs1 ip address 10.1.2.100 80 admin-status online ! virtual-ip vip_example.com ip address 192.0.2.1 80 admin-status online ! virtual-ip vip_example.com_https ip address 192.0.2.1 443 attach ssl profile self-signed admin-status online ! virtual-server vs_example.com attach virtual-ip vip_example.com default attach real-server rs1 ! virtual-server vs_example.com_https attach virtual-ip vip_example.com_https default attach real-server rs1 ! script redirect source file "proxy/redirect.js" admin-status online Example: user@m1:~/ > curl -L -k -D - http://example.com/test HTTP/1.1 302 Found Location: https://www.example.com/test Date: Wed, 03-Sep-2014 16:39:53 GMT Transfer-Encoding: chunked HTTP/1.1 200 OK Content-Type: text/plain Date: Wed, 03-Sep-2014 16:39:53 GMT Transfer-Encoding: chunked hello world216Views0likes0Comments