The Disadvantages of DSR (Direct Server Return)
I read a very nice blog post yesterday discussing some of the traditional pros and cons of load-balancing configurations. The author comes to the conclusion that if you can use direct server return, you should. I agree with the author's list of pros and cons; DSR is the least intrusive method of deploying a load-balancer in terms of network configuration. But there are quite a few disadvantages missing from the author's list. Author's List of Disadvantages of DSR The disadvantages of Direct Routing are: Backend server must respond to both its own IP (for health checks) and the virtual IP (for load balanced traffic) Port translation or cookie insertion cannot be implemented. The backend server must not reply to ARP requests for the VIP (otherwise it will steal all the traffic from the load balancer) Prior to Windows Server 2008 some odd routing behavior could occur in In some situations either the application or the operating system cannot be modified to utilse Direct Routing. Some additional disadvantages: Protocol sanitization can't be performed. This means vulnerabilities introduced due to manipulation of lax enforcement of RFCs and protocol specifications can't be addressed. Application acceleration can't be applied. Even the simplest of acceleration techniques, e.g. compression, can't be applied because the traffic is bypassing the load-balancer (a.k.a. application delivery controller). Implementing caching solutions become more complex. With a DSR configuration the routing that makes it so easy to implement requires that caching solutions be deployed elsewhere, such as via WCCP on the router. This requires additional configuration and changes to the routing infrastructure, and introduces another point of failure as well as an additional hop, increasing latency. Error/Exception/SOAP fault handling can't be implemented. In order to address failures in applications such as missing files (404) and SOAP Faults (500) it is necessary for the load-balancer to inspect outbound messages. Using a DSR configuration this ability is lost, which means errors are passed directly back to the user without the ability to retry a request, write an entry in the log, or notify an administrator. Data Leak Prevention can't be accomplished. Without the ability to inspect outbound messages, you can't prevent sensitive data (SSN, credit card numbers) from leaving the building. Connection Optimization functionality is lost. TCP multiplexing can't be accomplished in a DSR configuration because it relies on separating client connections from server connections. This reduces the efficiency of your servers and minimizes the value added to your network by a load balancer. There are more disadvantages than you're likely willing to read, so I'll stop there. Suffice to say that the problem with the suggestion to use DSR whenever possible is that if you're an application-aware network administrator you know that most of the time, DSR isn't the right solution because it restricts the ability of the load-balancer (application delivery controller) to perform additional functions that improve the security, performance, and availability of the applications it is delivering. DSR is well-suited, and always has been, to UDP-based streaming applications such as audio and video delivered via RTSP. However, in the increasingly sensitive environment that is application infrastructure, it is necessary to do more than just "load balancing" to improve the performance and reliability of applications. Additional application delivery techniques are an integral component to a well-performing, efficient application infrastructure. DSR may be easier to implement and, in some cases, may be the right solution. But in most cases, it's going to leave you simply serving applications, instead of delivering them. Just because you can, doesn't mean you should.5.7KViews0likes4CommentsThe BIG-IP Application Security Manager Part 6: IP Address Intelligence and Whitelisting
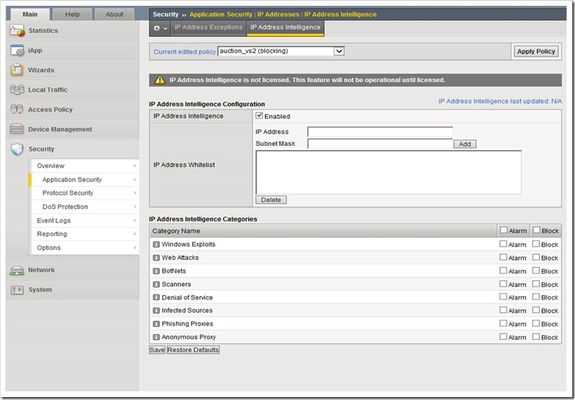
This is the sixth article in a 10-part series on the BIG-IP Application Security Manager (ASM). The first five articles in this series are: What is the BIG-IP ASM? Policy Building The Importance of File Types, Parameters, and URLs Attack Signatures XML Security This article will discuss some really cool ASM features: IP address intelligence and whitelisting. It's hard to defend against all the crazy cyber threats out there today, so wouldn't it be nice to know if the IP address requesting access to your application is trusted or not? And, wouldn't it be convenient to tell certain IP addresses that you explicitly trust them? Well the ASM allows you to do all that! So turn on that ASM and get ready to configure some awesomeness... IP Address Intelligence In·tel·li·gence noun \in-ˈte-lə-jən(t)s\: information concerning an enemy or possible enemy or an area Imagine this...you just launched a fantastic web application, and you want as many visitors as you can possibly get. But, you also want to make sure those visitors are not harmful. These days it's hard to know if the user accessing your application is fraudulent or not. There are so many botnets, proxies, scanners, infected sources, etc running rampant today that it becomes a very daunting task to figure out which ones are good and which ones are bad. The IP Address Intelligence feature on the BIG-IP ASM identifies IP addresses that are associated with high risk activity. When a client connection is initialized, the ASM monitors information from Layer 3 and determines if a client is already known to have a high risk profile. It's the application-equivalent of the FBI's most wanted list! The system uses an automated algorithm to gather evidence of threats based on observation, context, and statistical modeling. The bad IP addresses are catalogued and tracked indefinitely. If one of these bad IP addresses attempts to access your application...guess what? Sorry, no dice for the bad IP. The ASM also enables the use of the HTTP X-Forwarded-For (XFF) header as the source of the client IP identification instead of the Layer 3 address header. If you allow the XFF to be trusted, then this header's inner-most value is used, but if the XFF is not trusted, the source address from the IP header is used. The Database I'm sure by now you are curious about the size and function of that IP Address Intelligence database. The IP Address Intelligence feature uses the online IP address reputation service that is maintained by Webroot security services. As you can imagine, the list of bad IP addresses grows every day. Currently, the database contains well over 230 million IP addresses...and counting! The IP Address Intelligence feature uses a BIG-IP shared daemon called "iprepd" and a matching database file. The iprepd daemon updates the database file every 5 minutes...that's almost real-time updates! It does this automatically (there's no manual update option), so you can have the peace of mind that comes with knowing your application is protected from the most up-to-date list of known bad IP addresses. When the database is updated, it only downloads the changes from your current database, so the downloads go pretty quick (except the very first one). Because the IP Address Intelligence feature uses an external service for database maintenance and functionality, it requires a separate add-on license. The database file is not included with the ASM bundled software, but once you activate the license, the BIG-IP will contact the provider site and download the database. Here's another really cool thing about this feature...once it's enabled, you can use it with all your BIG-IP modules...not just the ASM! Also, if your license ever expires (we all know you would never let this happen, but just play along for a second), the local database will still be queried and used...it just won't get the every-5-minute updates any more. If you ever want to check on the status of the database (how many IPs were added/deleted/changed during updates), you can use the following command (the last row will show you the total number of IP addresses in the database): tail /var/log/iprepd/iprepd.log One last thing you should know before we dive into the BIG-IP configuration details...IP Address Intelligence is available with BIG-IP version 11.2 and newer. So, get off that 10.x (or 9.x) box and upgrade to these features that are not only really cool but are also extremely important for the protection of your valuable business assets. BIG-IP Configuration You can find all the IP Address Intelligence goodness by navigating to Security >> Application Security >> IP Addresses >> IP Address Intelligence. The following screenshot provides the details of the configuration options for this feature. You may have noticed that in my lab version of the BIG-IP ASM I don't have IP Address Intelligence licensed, but also notice that if it were licensed, the blue text on the right side of the screen toward the top of the page would show the last time/day the database was updated. This is an easy way to check on the database updates from the GUI rather than the command line if you lean that way (don't worry, we don't judge). As you can see, there are several IP Address Intelligence Categories, and each bad IP address will fall into one (or more) of these categories. You have the option of Alarming or Blocking (or both) each category. Here's a quick list of what each category includes: Windows Exploits - includes active IP address offering or distributing malware, shell code, rootkits, worms, and viruses Web Attacks - includes cross site scripting, iFrame injection, SQL injection, cross domain injection, and domain password brute force BotNets - includes Botnet Command and Control channels and an infected zombie machine controlled by a Bot master Scanners - includes all reconnaissance, such as probes, host scan, domain scan, and password brute force Denial of Service - includes DoS, DDoS, anomalous syn flood, and anomalous traffic detection Infected Sources - includes IP addresses currently known to be infected with malware and IP addresses with an average "low" Reputation Index score. Phishing Proxies - includes IP addresses hosting phishing sites and other kind of fraud activities such as Ad Click Fraud and Gaming fraud Anonymous Proxy - includes IP addresses that provide proxy and anonymizing services and IP addresses registered with the Tor anonymity network The last thing I'll mention on the IP Address Intelligence Categories is that you can look up a specific IP address and see what category(ies) it falls into. Type this little beauty into the command line and you'll see the categories (if any) for the given IP address: iprep_lookup x.x.x.x (where x.x.x.x is the IP address) Don't Forget The Other Block... After you select the blocking settings for the categories listed above, you need to make one more stop before the ASM will block these bad boys. Head over to Security >> Application Security >> Blocking >> Settings and make sure you check the "Block" setting for the "Access from malicious IP address" setting. The screenshot below gives you all the details... Is My Name On That List? Now that we have figured out all the ways to block these bad IP addresses, let's turn our focus on how to let the good guys in. The BIG-IP ASM includes a feature called "IP Address Exceptions" that gives you the ability to explicitly allow certain IP addresses. You can navigate to Security >> Application Security >> IP Addresses >> IP Address Exceptions and you will see the following screen: As you can see, this one is pretty simple and straightforward. You simply add an IP Address and optional Netmask (255.255.255.255 will be the Netmask if you don't add one), and then you select one or more of the options listed. When the Policy Builder trusted IP option is enabled, the Policy Builder will consider traffic from this specified IP address as being safe. The Policy Builder will automatically add to the security policy any data logged from traffic sent from this IP address. Selecting this option also automatically adds this IP address to the Trusted IP Addresses setting on the Policy Building Configuration screen. If you don't enable this option, the Policy Builder will not consider traffic from this IP address as being any different than traffic from any other IP address. When the Ignore in Anomaly Detection option is enabled, the ASM will consider this IP address as legitimate and will not consider it when performing brute force prevention and web scraping detection. Once you enable this option, the system automatically adds this IP address to the IP Address Whitelist setting for Anomaly Detection. If you don't enable this option, the ASM will not consider traffic from this IP address as being any safer than traffic from any other IP address. When the Ignore in Learning Suggestions option is enabled, the ASM will not generate learning suggestions from traffic sent from this IP address. If you don't enable this option, the ASM will generate learning suggestions from the IP's traffic. When the Never block this IP Address option is enabled, guess what? The ASM will not block requests sent from this IP address...even if your security policy is configured to block all traffic. If you don't enable this option, the ASM will treat this IP address the same as all others. When the Never log traffic from this IP Address option is enabled, the system will not log requests or responses sent from this IP address...even if the traffic is illegal and even if your security policy is configured to log all traffic. If you don't enable this option, the ASM will simply continue to log traffic as specified in the settings of your security policy’s Logging Profile. On a related note, this option can be quite helpful when you have approved scanners testing your application on a regular basis. You may want to keep the scanner traffic out of your logs so that you can more easily focus on the user traffic. When the Ignore IP Address Intelligence option is enabled, the ASM will consider this IP address as legitimate even if it is found in the IP Address Intelligence database (you know...the one we just talked about). Once you enable this option, the system automatically adds this IP address to the IP Address Whitelist setting for IP Addresses Intelligence (you can check out the screenshot in the section above and see where these IP addresses would be listed). If you don't enable this option, the ASM will not consider traffic from this IP address as being any safer than traffic from any other IP address. Well, that's it for this edition of the BIG-IP ASM series...be sure to check back next time when we dive into some more really cool features! Update: Now that the article series is complete, I wanted to share the links to each article. If I add any more in the future, I'll update this list. What is the BIG-IP ASM? Policy Building The Importance of File Types, Parameters, and URLs Attack Signatures XML Security IP Address Intelligence and Whitelisting Geolocation Data Guard Username and Session Awareness Tracking Event Logging3.5KViews0likes2CommentsWILS: Network Load Balancing versus Application Load Balancing
Are you load balancing servers or applications? Network traffic or application requests? If your strategy to application availability is network-based you might need a change in direction (up the stack). Can you see the application now? Network load balancing is the distribution of traffic based on network variables, such as IP address and destination ports. It is layer 4 (TCP) and below and is not designed to take into consideration anything at the application layer such as content type, cookie data, custom headers, user location, or the application behavior. It is context-less, caring only about the network-layer information contained within the packets it is directing this way and that. Application load balancing is the distribution of requests based on multiple variables, from the network layer to the application layer. It is context-aware and can direct requests based on any single variable as easily as it can a combination of variables. Applications are load balanced based on their peculiar behavior and not solely on server (operating system or virtualization layer) information. The difference between the two is important because network load balancing cannot assure availability of the application. This is because it bases its decisions solely on network and TCP-layer variables and has no awareness of the application at all. Generally a network load balancer will determine “availability” based on the ability of a server to respond to ICMP ping, or to correctly complete the three-way TCP handshake. An application load balancer goes much deeper, and is capable of determining availability based on not only a successful HTTP GET of a particular page but also the verification that the content is as was expected based on the input parameters. This is also important to note when considering the deployment of multiple applications on the same host sharing IP addresses (virtual hosts in old skool speak). A network load balancer will not differentiate between Application A and Application B when checking availability (indeed it cannot unless ports are different) but an application load balancer will differentiate between the two applications by examining the application layer data available to it. This difference means that a network load balancer may end up sending requests to an application that has crashed or is offline, but an application load balancer will never make that same mistake. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. WILS: InfoSec Needs to Focus on Access not Protection WILS: Applications Should Be Like Sith Lords WILS: Cloud Changes How But Not What WILS: Application Acceleration versus Optimization WILS: Automation versus Orchestration Layer 7 Switching + Load Balancing = Layer 7 Load Balancing Business-Layer Load Balancing Not all application requests are created equal Cloud Balancing, Cloud Bursting, and Intercloud The Infrastructure 2.0 Trifecta713Views0likes0CommentsWILS: Client IP or Not Client IP, SNAT is the Question
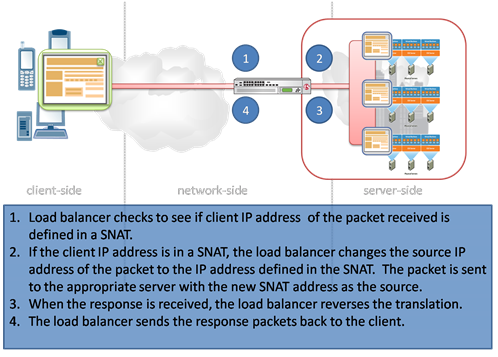
Ever wonder why requests coming through proxy-based solutions, particularly load balancers, end up with an IP address other than the real client? It’s not just a network administrator having fun at your expense. SNAT is the question – and the answer. SNAT is the common abbreviation for Secure NAT, so-called because the configured address will not accept inbound connections and is, therefore, supposed to be secure. It is also sometimes (more accurately in the opinion of many) referred to as Source NAT, however, because it acts on source IP address instead of the destination IP address as is the case for NAT usage. In load balancing scenarios SNAT is used to change the source IP of incoming requests to that of the Load balancer. Now you’re probably thinking this is the reason we end up having to jump through hoops like X-FORWARDED-FOR to get the real client IP address and you’d be right. But the use of SNAT for this purpose isn’t intentionally malevolent. Really. In most cases it’s used to force the return path for responses through the load balancer, which is important when network routing from the server (virtual or physical) to the client would bypass the load balancer. This is often true because servers need a way to access the Internet for various reasons including automated updates and when the application hosted on the server needs to call out to a third-party application, such as integrating with a Web 2.0 site via an API call. In these situations it is desirable for the server to bypass the load balancer because the traffic is initiated by the server, and is not usually being managed by the load balancer. In the case of a request coming from a client the response needs to return through the load balancer because incoming requests are usually destination NAT’d in most load balancing configurations, so the traffic has to traverse the same path, in reverse, in order to undo that translation and ensure the response is delivered to the client. Most land balancing solutions offer the ability to specify, on a per-IP address basis, the SNAT mappings as well as providing an “auto map” feature which uses the IP addresses assigned to load balancer (often called “self-ip” addresses) to perform the SNAT mappings. Advanced load balancers have additional methods of assigning SNAT mappings including assigning a “pool” of addresses to a virtual (network) server to be used automatically as well as intelligent SNAT capabilities that allow the use of network-side scripting to manipulate on a case-by-case basis the SNAT mappings. Most configurations can comfortably use the auto map feature to manage SNAT, by far the least complex of the available configurations. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Using "X-Forwarded-For" in Apache or PHP SNAT Translation Overflow Working around client-side limitations on custom HTTP headers WILS: Why Does Load Balancing Improve Application Performance? WILS: The Concise Guide to *-Load Balancing WILS: Network Load Balancing versus Application Load Balancing All WILS Topics on DevCentral If Load Balancers Are Dead Why Do We Keep Talking About Them?453Views0likes2CommentsWhat really breaks the "end-to-end nature of the Internet"
IPv6 was supposed to eliminate NAT (Network Address Translation). But in order to make the transition from IPv4 reasonable and less painful, it's being added to IPv6. It's intended use in being included in IPv6 is to create gateways that bridge between IPv6 and IPv4 while the transition occurs. The IETF is not thrilled however. It's description of how it feels about NAT and the necessity to include it make it sound like school-children forced to allow that kid to play in their game of kickball. And then they put him in far right field. And I mean far right field so it's obvious what they think of him. This Network World article describes NAT as "much maligned" and reminds us that purists hate it for breaking the end-to-end communication model on which the Internet was designed. From the article: NAT is deployed in routers, servers and firewalls, and it adds complexity and cost to enterprise networks. Internet purists hate NATs because they break the end-to-end nature of the Internet; this is the idea that any end user can communicate directly to another end user over the Internet without middle boxes altering their packets. I'm guessing purists hate a whole lot of technologies because there are a ton of other technologies and products that are essentially "middle boxes altering packets." The problem is I don't want any end user communicating directly with me. I want their packets inspected, sanitized, and thoroughly cleansed before they get anywhere near me. I want them altered or nuked into the ether, particularly if they're full of nastiness or hell-bent on destroying the delicate balance that is my desktop. Alteration of packets is a necessity to address protocol errors and perform all sorts of interesting application delivery functions. Alteration of packets is necessary to add caching control to web applications that are not written with caching in mind; it's necessary to rewrite URIs, and to protect sensitive data from escaping the confines of the data center. Alteration of packets by "middle boxes" (i.e. intermediaries or proxies) is a requirement for optimizing and securing application data. And more than just solving the lack of IPv4 problems, NAT has become a primary security mechanism for ensuring end users aren't directly reachable by external applications. Even if I had enough IPv4 addresses to put all the machines in my home on the public Internet, I wouldn't. That's just asking for trouble, especially when some of those machines are being used by teenagers whose idea of security is using "hotbutterfly99" as their username on HotMail or Yahoo. And there's not that much difference between those teenagers and many corporate employees. Geoff Huston, chief scientist at APNIC and an expert on IPv4 address depletion Huston says NATs are useful for addressing, packet filtering and other functions. He says the real problem with NATs is that they lack standards, and that is an area where the IETF can make improvements in NATs for IPv6. "The IETF's position of ignoring NATs some years back forced NAT software builders to exercise their own creativity when designing their version of NATs," Huston says. "This variation of NAT behavior is a far, far worse problem than NATs themselves." But it goes deeper than just a lack of standards and being "impure". When it comes down to it the root of the problem - what really breaks the end-to-end model of the Internet - is people. It's the nature of people to do things they shouldn't, to code applications without concern or regard for the bigger picture, to just outright make mistakes, and in some cases to be malicious and hell bent on destruction. So long as it's people writing applications and using the Internet, alteration of packets by "middle boxes" is going to be a requirement if we want to keep applications secure, fast, and available. Especially secure. Packets are going to continue to be altered when IPv6 is fully adopted whether NAT remains used or not, because people can't be upgraded to a new version that addresses our behavior, and we don't have a way to enforce a behavioral RFC on every Internet user in the world. Besides, given all the good that comes out of "middle boxes altering packets": optimization, scalability, application layer networking, acceleration, and of course, security, I'm just not convinced that NAT and other technologies breaking the end-to-end nature of the Internet is a bad thing after all.316Views0likes1CommentThe days of IP-based management are numbered
The focus of cloud and virtualization discussions today revolve primarily around hypervisors, virtual machines, automation, network and application network infrastructure; on the dynamic infrastructure necessary to enable a truly dynamic data center. In all the hype we’ve lost sight of the impact these changes will have on other critical IT systems such as network systems management (NSM) and application performance management (APM). You know their names: IBM, CA, Compuware, BMC, HP. There are likely one or more of their systems monitoring and managing applications and systems in your data center right now. They provide alerts, notifications, and the reports IT managers demand on a monthly or weekly basis to prove IT is meeting the service-level agreements around performance and availability made with business stakeholders. In a truly dynamic data center, one in which resources are shared in order to provide the scalability and capacity needed to meet those service-level agreements, IP addresses are likely to become as mobile as the applications and infrastructure that need them. An application may or may not use the same IP address when it moves from one location to another; an application will use multiple IP addresses when it scales automatically and those IP addresses may or may not be static. It is already apparent that DHCP will play a larger role in the dynamic data center than it does in a classic data center architecture. DHCP is not often used within the core data center precisely because it is not guaranteed. Oh, you can designate that *this* MAC address is always assigned *that* dynamic IP address, but essentially what you’re doing is creating a static map that is in execution no different than a static bound IP address. And in a dynamic data center, the MAC address is not guaranteed precisely because virtual instances of applications may move from hardware to hardware based on current performance, availability, and capacity needs. The problem then is that NMS and APM is often tied to IP addresses. Using aging standards like SNMP to monitor infrastructure and utilizing agents installed at the OS or application server layer to collect performance data that is ultimately used to generate those eye-candy charts and reports for management. These systems can also generate dependency maps, tying applications to servers to network segments and their support infrastructure such that if any one dependent component fails, an administrator is notified. And it’s almost all monitored based on IP address. When those IP addresses change, as more and more infrastructure is virtualized and applications become more mobile within the data center, the APM and NMS systems will either fail to recognize the change or, more likely, “cry wolf” with alerts and notifications stating an application is down when in truth it is running just fine. The potential to collect erroneous data is detrimental to the ability of IT to show its value to the business, prove its adherence to agreed upon service-level agreements, and to the ability to accurately forecast growth. NMS and APM will be affected by the dynamic data center; they will need to alter the basic premise upon which they have always acted: every application and network device and application network infrastructure solution is tied to an IP address. The bonds between IP address and … everything are slowly being dissolved as we move into an architectural model that abstracts the very network foundations upon which data centers have always been built and then ignores it. While in many cases the bond between a device or application and an IP address will remain, it cannot be assumed to be true. The days of IP-based management are numbered, necessarily, and while that sounds ominous it is really a blessing in disguise. Perhaps the “silver lining in the cloud”, even. All the monitoring and management that goes on in IT is centered around one thing: the application. How well is it performing, how much bandwidth does it need/is it using, is it available, is it secure, is it running. By forcing the issue of IP address management into the forefront by effectively dismissing IP address as a primary method of identification, the cloud and virtualization have done the IT industry in general a huge favor. The dismissal of IP address as an integral means by which an application is identified, managed, and monitored means there must be another way to do it. One that provides more information, better information, and increased visibility into the behavior and needs of that application. NMS and APM, like so many other IT systems management and monitoring solutions, will need to adjust the way in which they monitor, correlate, and manage the infrastructure and applications in the new, dynamic data center. They will need to integrate with whatever means is used to orchestrate and manage the ebb and flow of infrastructure and applications within the data center. The coming network and data center revolution - the move to a dynamic infrastructure and a dynamic data center - will have long-term effects on the systems and applications traditionally used to manage and monitor them. We need to start considering the ramifications now in order to be ready before it becomes an urgent need.305Views0likes4CommentsThe Rise of the Out-of-Band Management Network
Cloud and virtualization share a common attribute: dynamism. That dynamism comes at a price… Let’s talk about management. Specifically, let’s talk about how management of infrastructure impacts the network and vice-versa, because there is a tendency to ignore that the more devices and solutions you have in an infrastructure the more chatty they necessarily become. In most organizations management of the infrastructure is accomplished via a management network. This is usually separate from the core network in that it is segmented out by VLANs, but it is still using the core physical network to transport data between devices and management solutions. In some organizations an “overlay management network” or “out-of-band” network is used. This network is isolated – physically – from the core network and essentially requires a second network implementation over which devices and management solutions communicate. This is obviously an expensive proposition, and not one that is implemented unless it’s absolutely necessary. Andrew Bach, senior vice president of network services for NYSE Euronext (New York Stock Exchange) had this to say about an “overlay management network” in “Out-of-band network management ensures data center network uptime” Bach said out-of-band network management requires not only a separate network infrastructure but a second networking vendor. NYSE Euronext couldn't simply use its production network vendor, Juniper, to build the overlay network. He described this approach as providing his data center network with genetic diversity. "This is a generalized comment on network design philosophy and not reflective on any one vendor. Once you buy into a vendor, there is always a possibility that their fundamental operating system could have a very bad day," Bach said. "If you have systemic failure in that code, and if your management platform is of the same breed and generation, then there is a very good chance that you will not only lose the core network but you will also lose your management network. You will wind up with absolutely no way to see what's going on in that network, with no way to effect repairs because everything is dead and everything is suffering from the same failure." "Traditionally, in more conventional data centers, what you do is you buy a vendor's network management tool, you attach it to the network and you manage the network in-band – that is, the management traffic flows over the same pipes as the production traffic," Bach said. Most enterprises will manage their data center network in-band by setting up a VLAN for management traffic across the infrastructure and dedicating a certain level of quality of service (QoS) to that management traffic so that it can get through when the production traffic is having a problem, said Joe Skorupa, research vice president at Gartner. Right now most enterprises manage their infrastructure via a management network that’s logically separate but not physically isolated from the core network. A kind of hybrid solution. But with the growing interest in implementing private cloud computing that will certainly increase the collaboration amongst infrastructure components and a true out-of-band management implementation may become a necessity for more organizations – both horizontally across industries and vertically down the “size” stack.280Views0likes1CommentThe IP Address – Identity Disconnect
The advent of virtualization brought about awareness of the need to decouple applications from IP addresses. The same holds true on the client side – perhaps even more so than in the data center. I could quote The Prisoner, but that would be so cliché, wouldn’t it? Instead, let me ask a question: just which IP address am I? Am I the one associated with the gateway that proxies for my mobile phone web access? Or am I the one that’s currently assigned to my laptop – the one that will change tomorrow because today I am in California and tomorrow I’ll be home? Or am I the one assigned to me when I’m connected via an SSL VPN to corporate headquarters? If you’re tying identity to IP addresses then you’d better be a psychiatrist in addition to your day job because most users have multiple IP address disorder. IP addresses are often utilized as part of an identification process. After all, a web application needs some way to identify a user that’s not supplied by the user. There’s a level of trust inherent in the IP address that doesn’t exist with my name or any other user-supplied piece of data because, well, it’s user supplied. An IP address is assigned or handed-out dynamically by what is an unemotional, uninvolved technical process that does not generally attempt to deceive, dissemble, or trick anyone with the data. An IP address is simply a number. But given the increasingly dynamic nature of data centers, of cloud computing, and of users accessing web-based services via multiple devices – sometimes at the same time – it seems a bad idea to base any part of identification on an IP address that could, after all, change in five minutes. IP addresses are no longer guaranteed in the data center, that’s the premise of much of the work around IF-MAP and dynamic connectivity and Infrastructure 2.0, so why do we assume it would be so on the client side? Ridonculous! The decoupling of IP address from identity seems a foregone conclusion. It’s simply not useful anymore. Add to this the fact that IP address depletion truly is a serious problem – the NRO announced recently that less than 10% of all public IPv4 addresses are still available – and it seems an appropriate time to decouple application and infrastructure from relying on client IP addresses as a form of identification.248Views0likes3CommentsIs the URL headed for the endangered technology list?
Jeremiah Owyang, Senior Analyst, Social Computing, Forrester Research, tweeted recently on the subject of Chrome, Google's new open source browser. Jeremiah postulates: Chrome is a nod to the future, the address bar is really a search bar. URLs will be an anachronism. That's an interesting prediction, predicated on the ability of a browser translate search terms into destinations on the Internet. Farfetched? Not at all. After all, there already exists a layer of obfuscation between a URL and an Internet destination; one that translates host names into IP addresses, hiding the complexity and difficult in remembering IP addresses from the end-user. And apparently Chrome is already well on its way to sending URLs the way of the dodo bird, otherwise we wouldn't be having this conversation. But IP addresses, though obfuscated and hidden from view for most folks, aren't an anachronism any more than the engine of car. Its complexity, too, is hidden from view and concern for most folks. We don't need to know how the engine gets started, just that turning the key will get it started. In similar fashion, most folks don't need to know how clicking on a particular URL gets them to the right place, they just need to know to click on it. Operating technology doesn't necessarily require understanding of how it works, and the layer of abstraction we place atop technology to make it usable by the majority doesn't necessarily make the underlying technology an anachronism, although in this case Jeremiah may be right - at least from the view point that using URLs as a navigation mechanism may become an anachronism. URLs will still be necessary, they are a part of the foundation of how the web works. But IP addresses are also necessary, and so is the technology that bridges the gap between IP addresses and host names, namely DNS. More interesting, I think, is that Jeremiah is looking into his crystal ball and seeing the first stages of Web 3.0, where context and content is the primary vehicle that drives your journey through the web rather than a list of hyperlinks. Where SEO is king, and owning a keyword will be as important, if not more so, than brand. The move to a semantic web necessarily eliminates the importance of URLs as a visible manifestation, but not as the foundational building blocks of how that web is tied together. To be fair to other browsers, the address bar in FireFox 3 also acts like a search bar. If I type in my name, it automatically suggests several sites tied to my identity, and takes me by default to this blog. Similarly a simple search for "big-ip" automatically takes me to F5's product page on BIG-IP. That's because my default search engine is Google, and it's taking me to the first ranked page for the search results. This isn't Web 3.0, not yet, but it's one of the first visible manifestations we have of what the web will eventually become. That's what I mean about keywords becoming the new brand. Just as "bandaid", which is really a brand name, became a term used to describe all bandages, the opposite will happen - and quickly - in a semantic web where keywords and phrases are automatically translated into URLs. SEO today understands the importance of search terms and keywords, but it's largely a supporting cog in a much larger wheel of marketing efforts. That won't be true when search really is king, rather than just the crown prince. But URLs will still be necessary. After all, the technology that ties keywords and search terms to URLs requires that URLs exist in the first place, and once you get to a site you still have to navigate it. So while I'm not convinced that URLs will become a complete anachronism, they may very well become virtualized. Just like everything else today.203Views0likes0Comments