Controlling a Pool Members Ratio and Priority Group with iControl
A Little Background A question came in through the iControl forums about controlling a pool members ratio and priority programmatically. The issue really involves how the API’s use multi-dimensional arrays but I thought it would be a good opportunity to talk about ratio and priority groups for those that don’t understand how they work. In the first part of this article, I’ll talk a little about what pool members are and how their ratio and priorities apply to how traffic is assigned to them in a load balancing setup. The details in this article were based on BIG-IP version 11.1, but the concepts can apply to other previous versions as well. Load Balancing In it’s very basic form, a load balancing setup involves a virtual ip address (referred to as a VIP) that virtualized a set of backend servers. The idea is that if your application gets very popular, you don’t want to have to rely on a single server to handle the traffic. A VIP contains an object called a “pool” which is essentially a collection of servers that it can distribute traffic to. The method of distributing traffic is referred to as a “Load Balancing Method”. You may have heard the term “Round Robin” before. In this method, connections are passed one at a time from server to server. In most cases though, this is not the best method due to characteristics of the application you are serving. Here are a list of the available load balancing methods in BIG-IP version 11.1. Load Balancing Methods in BIG-IP version 11.1 Round Robin: Specifies that the system passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. This method works well in most configurations, especially if the equipment that you are load balancing is roughly equal in processing speed and memory. Ratio (member): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine within the pool. Least Connections (member): Specifies that the system passes a new connection to the node that has the least number of current connections in the pool. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. Observed (member): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (member), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (member): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Ratio (node): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine across all pools of which the server is a member. Least Connections (node): Specifies that the system passes a new connection to the node that has the least number of current connections out of all pools of which a node is a member. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node, or the fastest node response time. Fastest (node): Specifies that the system passes a new connection based on the fastest response of all pools of which a server is a member. This method might be particularly useful in environments where nodes are distributed across different logical networks. Observed (node): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (node), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (node): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Dynamic Ratio (node) : This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. Fastest (application): Passes a new connection based on the fastest response of all currently active nodes in a pool. This method might be particularly useful in environments where nodes are distributed across different logical networks. Least Sessions: Specifies that the system passes a new connection to the node that has the least number of current sessions. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current sessions. Dynamic Ratio (member): This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. L3 Address: This method functions in the same way as the Least Connections methods. We are deprecating it, so you should not use it. Weighted Least Connections (member): Specifies that the system uses the value you specify in Connection Limit to establish a proportional algorithm for each pool member. The system bases the load balancing decision on that proportion and the number of current connections to that pool member. For example,member_a has 20 connections and its connection limit is 100, so it is at 20% of capacity. Similarly, member_b has 20 connections and its connection limit is 200, so it is at 10% of capacity. In this case, the system select selects member_b. This algorithm requires all pool members to have a non-zero connection limit specified. Weighted Least Connections (node): Specifies that the system uses the value you specify in the node's Connection Limitand the number of current connections to a node to establish a proportional algorithm. This algorithm requires all nodes used by pool members to have a non-zero connection limit specified. Ratios The ratio is used by the ratio-related load balancing methods to load balance connections. The ratio specifies the ratio weight to assign to the pool member. Valid values range from 1 through 100. The default is 1, which means that each pool member has an equal ratio proportion. So, if you have server1 a with a ratio value of “10” and server2 with a ratio value of “1”, server1 will get served 10 connections for every one that server2 receives. This can be useful when you have different classes of servers with different performance capabilities. Priority Group The priority group is a number that groups pool members together. The default is 0, meaning that the member has no priority. To specify a priority, you must activate priority group usage when you create a new pool or when adding or removing pool members. When activated, the system load balances traffic according to the priority group number assigned to the pool member. The higher the number, the higher the priority, so a member with a priority of 3 has higher priority than a member with a priority of 1. The easiest way to think of priority groups is as if you are creating mini-pools of servers within a single pool. You put members A, B, and C in to priority group 5 and members D, E, and F in priority group 1. Members A, B, and C will be served traffic according to their ratios (assuming you have ratio loadbalancing configured). If all those servers have reached their thresholds, then traffic will be distributed to servers D, E, and F in priority group 1. he default setting for priority group activation is Disabled. Once you enable this setting, you can specify pool member priority when you create a new pool or on a pool member's properties screen. The system treats same-priority pool members as a group. To enable priority group activation in the admin GUI, select Less than from the list, and in the Available Member(s) box, type a number from 0 to 65535 that represents the minimum number of members that must be available in one priority group before the system directs traffic to members in a lower priority group. When a sufficient number of members become available in the higher priority group, the system again directs traffic to the higher priority group. Implementing in Code The two methods to retrieve the priority and ratio values are very similar. They both take two parameters: a list of pools to query, and a 2-D array of members (a list for each pool member passed in). long [] [] get_member_priority( in String [] pool_names, in Common__AddressPort [] [] members ); long [] [] get_member_ratio( in String [] pool_names, in Common__AddressPort [] [] members ); The following PowerShell function (utilizing the iControl PowerShell Library), takes as input a pool and a single member. It then make a call to query the ratio and priority for the specific member and writes it to the console. function Get-PoolMemberDetails() { param( $Pool = $null, $Member = $null ); $AddrPort = Parse-AddressPort $Member; $RatioAofA = (Get-F5.iControl).LocalLBPool.get_member_ratio( @($Pool), @( @($AddrPort) ) ); $PriorityAofA = (Get-F5.iControl).LocalLBPool.get_member_priority( @($Pool), @( @($AddrPort) ) ); $ratio = $RatioAofA[0][0]; $priority = $PriorityAofA[0][0]; "Pool '$Pool' member '$Member' ratio '$ratio' priority '$priority'"; } Setting the values with the set_member_priority and set_member_ratio methods take the same first two parameters as their associated get_* methods, but add a third parameter for the priorities and ratios for the pool members. set_member_priority( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] priorities ); set_member_ratio( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] ratios ); The following Powershell function takes as input the Pool and Member with optional values for the Ratio and Priority. If either of those are set, the function will call the appropriate iControl methods to set their values. function Set-PoolMemberDetails() { param( $Pool = $null, $Member = $null, $Ratio = $null, $Priority = $null ); $AddrPort = Parse-AddressPort $Member; if ( $null -ne $Ratio ) { (Get-F5.iControl).LocalLBPool.set_member_ratio( @($Pool), @( @($AddrPort) ), @($Ratio) ); } if ( $null -ne $Priority ) { (Get-F5.iControl).LocalLBPool.set_member_priority( @($Pool), @( @($AddrPort) ), @($Priority) ); } } In case you were wondering how to create the Common::AddressPort structure for the $AddrPort variables in the above examples, here’s a helper function I wrote to allocate the object and fill in it’s properties. function Parse-AddressPort() { param($Value); $tokens = $Value.Split(":"); $r = New-Object iControl.CommonAddressPort; $r.address = $tokens[0]; $r.port = $tokens[1]; $r; } Download The Source The full source for this example can be found in the iControl CodeShare under PowerShell PoolMember Ratio and Priority.27KViews0likes3CommentsAccessing TCP Options from iRules
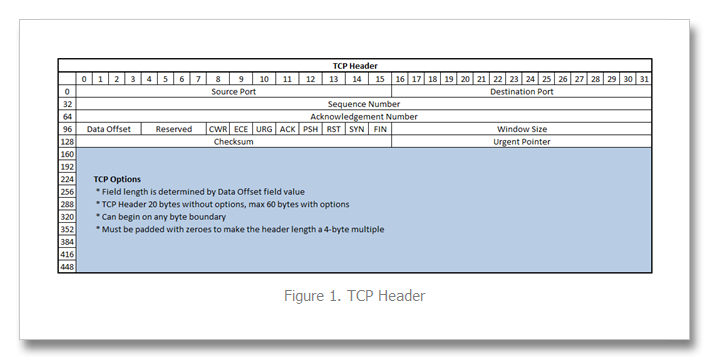
I’ve written several articles on the TCP profile and enjoy digging into TCP. It’s a beast, and I am constantly re-learning the inner workings. Still etched in my visual memory map, however, is the TCP header format, shown in Figure 1 below. Since 9.0 was released, TCP payload data (that which comes after the header) has been consumable in iRules via the TCP::payload and the port information has been available in the contextual commands TCP::local_port/TCP::remote_port and of course TCP::client_port/TCP::server_port. Options, however, have been inaccessible. But beginning with version 10.2.0-HF2, it is now possible to retrieve data from the options fields. Preparing the BIG-IP Prior to version 11.0, it was necessary to set a bigpipe database key with the option (or options) of interest: bigpipe db Rules.Tcpoption.settings [option, first|last], [option, first|last] In version 11.0 and forward, the DB keys are no more and you need to create a tcp profile with the these options defined, like so: ltm profile tcp tcp_opt { app-service none tcp-options "{option first|last} {option first|last}" } The option is an integer between 2 and 255, and the first/last setting indicates whether the system will retain the first or last instance of the specified option. Once that key is set, you’ll need to do a bigstart restart for it to take (warning: service impacting). Note also that the LTM only collects option data starting with the ACK of a connection. The initial SYN is ignored even if you select the first keyword. This is done to prevent a SYN flood attack (in keeping with SYN-cookies). A New iRules Command: TCP::option The TCP::option command has the following syntax: TCP::option get <option> v11 Additions/Changes: TCP::option set <option number> <value> <next|all> TCP::option noset <option number> Pretty simple, no? So now that you can access them, what fun can be had? Real World Scenario: Akamai In Akamai’s IPA and SXL product lines, they support client IP visibility by embedding a version number (one byte) and an IPv4 address (four bytes) as part of their overlay path feature in tcp option number 28. To access this data, we first set the database key: tmsh create ltm profile tcp tcp_opt tcp-options "{28 first}" Now, the iRule utilizing the TCP::option command: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt28 cH8 ver addr if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { scan $addr "%2x%2x%2x%2x" ip1 ip2 ip3 ip4 set optaddr "$ip1.$ip2.$ip3.$ip4" } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } The Akamai version should be one, so we log if not. Otherwise, we take the address (stored in the variable addr in hex) and scan it to get the decimal equivalents to build the address for inserting in the X-Forwarded-For header. Cool, right? Also cool—along with the new TCP::option command , an extension was made to the IP::addr command to parse binary fields into a dotted decimal IP address. This extension is also available beginning in 10.2.0-HF2, but extended in 11.0. Here’s the syntax: IP::addr parse [-ipv4 | -ipv6 [swap]] <binary field> [<offset>] So for example, if you had an IPv6 address in option 28 with a 1 byte offset, you would parse that like: log local0. "IP::addr parse IPv6 output: [IP::addr parse -ipv6 [TCP::option get 28] 1]" ## Log Result ## May 27 21:51:34 ltm13 info tmm[27207]: Rule /Common/tcpopt_test <CLIENT_ACCEPTED>: IP::addr parse IPv6 output: 2601:1930:bd51:a3e0:20cd:a50b:1cc1:ad13 But in the context of our TCP option, we have 5-bytes of data with the first byte not mattering in the context of an address, so we get at the address with this: set optaddr [IP::addr parse -ipv4 [TCP::option get 28] 1] This cleans up the rule a bit: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } No need to store the address in the first binary scan and no need for the scan command at all so I eliminated those. Setting a forwarding header is not the only thing we can do with this data. It could also be shipped off to a logging server, or used as a snat address (assuming the server had either a default route to the BIG-IP, or specific routes for the customer destinations, which is doubtful). Logging is trivial, shown below with the log command. The HSL commands could be used in lieu of log if sending off-box to a log server. when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "Client IP extracted from Akamai TCP option is $optaddr" } } } If setting the provided IP as a snat address, you’ll want to make sure it’s a valid IP address before doing so. You can use the TCL catch command and IP::addr to perform this check as seen in the iRule below: when CLIENT_ACCEPTED { set addrs [list \ "192.168.1.1" \ "256.168.1.1" \ "192.256.1.1" \ "192.168.256.1" \ "192.168.1.256" \ ] foreach x $addrs { if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "IP $x is invalid" } else { log local0. "IP $x is valid" } } } The output of this iRule: <CLIENT_ACCEPTED>: IP 192.168.1.1 is valid <CLIENT_ACCEPTED>: IP 256.168.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.256.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.256.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.1.256 is invalid Adding this logic into a functional rule with snat: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "$optaddr is not a valid address" snat automap } else { log local0. "Akamai inserted Client IP is $optaddr. Setting as snat address." snat $optaddr } } } Alternative TCP Option Use Cases The Akamai solution shows an application implementation taking advantage of normally unused space in TCP headers. There are, however, defined uses for several option “kind” numbers. The list is available here: http://www.iana.org/assignments/tcp-parameters/tcp-parameters.xml. Some options that might be useful in troubleshooting efforts: Opkind 2 – Max Segment Size Opkind 3 – Window Scaling Opkind 5 – Selective Acknowledgements Opkind 8 – Timestamps Of course, with tcpdump you get all this plus the context of other header information and data, but hey, another tool in the toolbox, right? Addendum I've been working with F5 SE Leonardo Simon on on additional examples I wanted to share here that uses option 28 or 253 to extract an IPv6 address if the version is 34 and otherwise extracts an IPv4 address if the version is 1 or 2. Option 28 when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] binary scan $opt28 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt28 1] log local0. "opt28 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "opt28 ipv4 address: $optaddr" } } Option 253 when CLIENT_ACCEPTED { set opt253 [TCP::option get 253] binary scan $opt253 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt253 1] log local0. "opt253 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt253 1] log local0. "opt253 ipv4 address: $optaddr" } }17KViews2likes10Comments
APM Configuration to Support Duo MFA using iRule
Overview BIG-IP APM has supported Duo as an MFA provider for a long time with RADIUS-based integration. Recently, Duo has added support for Universal Prompt that uses Open ID Connect (OIDC) protocol to provide two-factor authentication. To integrate APM as an OIDC client and resource server, and Duo as an Identity Provider (IdP), Duo requires the user’s logon name and custom parameters to be sent for Authentication and Token request. This guide describes the configuration required on APM to enable Duo MFA integration using an iRule. iRules addresses the custom parameter challenges by generating the needed custom values and saving them in session variables, which the OAuth Client agent then uses to perform MFA with Duo. This integration procedure is supported on BIG-IP versions 13.1, 14.1x, 15.1x, and 16.x. To integrate Duo MFA with APM, complete the following tasks: 1. Choose deployment type: Per-request or Per-session 2. Configure credentials and policies for MFA on the DUO web portal 3. Create OAuth objects on the BIG-IP system 4. Configure the iRule 5. Create the appropriate access policy/policies on the BIG-IP system 6. Apply policy/policies and iRule to the APM virtual server Choose deployment type APM supports two different types of policies for performing authentication functions. Per-session policies: Per-session policies provide authentication and authorization functions that occur only at the beginning of a user’s session. These policies are compatible with most APM use cases such as VPN, Webtop portal, Remote Desktop, federation IdP, etc. Per-request policies: Per-request policies provide dynamic authentication and authorization functionality that may occur at any time during a user’s session, such as step-up authentication or auditing functions only for certain resources. These policies are only compatible with Identity Aware Proxy and Web Access Management use cases and cannot be used with VPN or webtop portals. This guide contains information about setting up both policy types. Prerequisites Ensure the BIG-IP system has DNS and internet connectivity to contact Duo directly for validating the user's OAuth tokens. Configure credentials and policies for MFA on Duo web portal Before you can protect your F5 BIG-IP APM Web application with Duo, you will first need to sign up for a Duo account. 1. Log in to the Duo Admin Panel and navigate to Applications. 2. Click Protect an application. Figure 1: Duo Admin Panel – Protect an Application 3. Locate the entry for F5 BIG-IP APM Web in the applications list and click Protect to get the Client ID, Client secret, and API hostname. You will need this information to configure objects on APM. Figure 2: Duo Admin Panel – F5 BIG-IP APM Web 4. As DUO is used as a secondary authentication factor, the user’s logon name is sent along with the authentication request. Depending on your security policy, you may want to pre-provision users in Duo, or you may allow them to self-provision to set their preferred authentication type when they first log on. To add users to the Duo system, navigate to the Dashboard page and click the Add New...-> Add User button. A Duo username should match the user's primary authentication username. Refer to the https://duo.com/docs/enrolling-users link for the different methods of user enrollment. Refer to Duo Universal Prompt for additional information on Duo’s two-factor authentication. Create OAuth objects on the BIG-IP system Create a JSON web key When APM is configured to act as an OAuth client or resource server, it uses JSON web keys (JWKs) to validate the JSON web tokens it receives from Duo. To create a JSON web key: 1. On the Main tab, select Access > Federation > JSON Web Token > Key Configuration. The Key Configuration screen opens. 2. To add a new key configuration, click Create. 3. In the ID and Shared Secret fields, enter the Client ID and Client Secret values respectively obtained from Duo when protecting the application. 4. In the Type list, select the cryptographic algorithm used to sign the JSON web key. Figure 3: Key Configuration screen 5. Click Save. Create a JSON web token As an OAuth client or resource server, APM validates the JSON web tokens (JWT) it receives from Duo. To create a JSON web token: 1. On the Main tab, select Access > Federation > JSON Web Token > Token Configuration. The Token Configuration screen opens. 2. To add a new token configuration, click Create. 3. In the Issuer field, enter the API hostname value obtained from Duo when protecting the application. 4. In the Signing Algorithms area, select from the Available list and populate the Allowed and Blocked lists. 5. In the Keys (JWK) area, select the previously configured JSON web key in the allowed list of keys. Figure 4: Token Configuration screen 6. Click Save. Configure Duo as an OAuth provider APM uses the OAuth provider settings to get URIs on the external OAuth authorization server for JWT web tokens. To configure an OAuth provider: 1. On the Main tab, select Access > Federation > OAuth Client / Resource Server > Provider. The Provider screen opens. 2. To add a provider, click Create. 3. In the Name field, type a name for the provider. 4. From the Type list, select Custom. 5. For Token Configuration (JWT), select a configuration from the list. 6. In the Authentication URI field, type the URI on the provider where APM should redirect the user for authentication. The hostname is the same as the API hostname in the Duo application. 7. In the Token URI field, type the URI on the provider where APM can get a token. The hostname is the same as the API hostname in the Duo application. Figure 5: OAuth Provider screen 8. Click Finished. Configure Duo server for APM The OAuth Server settings specify the OAuth provider and role that Access Policy Manager (APM) plays with that provider. It also sets the Client ID, Client Secret, and Client’s SSL certificates that APM uses to communicate with the provider. To configure a Duo server: 1. On the Main tab, select Access > Federation > OAuth Client / Resource Server > OAuth Server. The OAuth Server screen opens. 2. To add a server, click Create. 3. In the Name field, type a name for the Duo server. 4. From the Mode list, select how you want the APM to be configured. 5. From the Type list, select Custom. 6. From the OAuth Provider list, select the Duo provider. 7. From the DNS Resolver list, select a DNS resolver (or click the plus (+) icon, create a DNS resolver, and then select it). 8. In the Token Validation Interval field, type a number. In a per-request policy subroutine configured to validate the token, the subroutine repeats at this interval or the expiry time of the access token, whichever is shorter. 9. In the Client Settings area, paste the Client ID and Client secret you obtained from Duo when protecting the application. 10. From the Client's ServerSSL Profile Name, select a server SSL profile. Figure 6: OAuth Server screen 11. Click Finished. Configure an auth-redirect-request and a token-request Requests specify the HTTP method, parameters, and headers to use for the specific type of request. An auth-redirect-request tells Duo where to redirect the end-user, and a token-request accesses the authorization server for obtaining an access token. To configure an auth-redirect-request: 1. On the Main tab, select Access > Federation > OAuth Client / Resource Server > Request. The Request screen opens. 2. To add a request, click Create. 3. In the Name field, type a name for the request. 4. For the HTTP Method, select GET. 5. For the Type, select auth-redirect-request. 6. As shown in Figure 7, specify the list of GET parameters to be sent: request parameter with value depending on the type of policy For per-request policy: %{subsession.custom.jwt_duo} For per-session policy: %{session.custom.jwt_duo} client_id parameter with type client-id response_type parameter with type response-type Figure 7: Request screen with auth-redirect-request (Use “subsession.custom…” for Per-request or “session.custom…” for Per-session) 7. Click Finished. To configure a token-request: 1. On the Main tab, select Access > Federation > OAuth Client / Resource Server > Request. The Request screen opens. 2. To add a request, click Create. 3. In the Name field, type a name for the request. 4. For the HTTP Method, select POST. 5. For the Type, select token-request. 6. As shown in Figure 8, specify the list of POST parameters to be sent: client_assertion parameter with value depending on the type of policy For per-request policy: %{subsession.custom.jwt_duo_token} For per-session policy: %{session.custom.jwt_duo_token} client_assertion_type parameter with value urn:ietf:params:oauth:client-assertion-type:jwt-bearer grant_type parameter with type grant-type redirect_uri parameter with type redirect-uri Figure 8: Request screen with token-request (Use “subsession.custom…” for Per-request or “session.custom…” for Per-session) 7. Click Finished. Configure the iRule iRules gives you the ability to customize and manage your network traffic. Configure an iRule that creates the required sub-session variables and usernames for Duo integration. Note: This iRule has sections for both per-request and per-session policies and can be used for either type of deployment. To configure an iRule: 1. On the Main tab, click Local Traffic > iRules. 2. To create an iRules, click Create. 3. In the Name field, type a name for the iRule. 4. Copy the sample code given below and paste it in the Definition field. Replace the following variables with values specific to the Duo application: <Duo Client ID> in the getClientId function with Duo Application ID. <Duo API Hostname> in the createJwtToken function with API Hostname. For example, https://api-duohostname.com/oauth/v1/token. <JSON Web Key> in the getJwkName function with the configured JSON web key. Note: The iRule ID here is set as JWT_CREATE. You can rename the ID as desired. You specify this ID in the iRule Event agent in Visual Policy Editor. Note: The variables used in the below example are global, which may affect your performance. Refer to the K95240202: Understanding iRule variable scope article for further information on global variables, and determine if you use a local variable for your implementation. proc randAZazStr {len} { return [subst [string repeat {[format %c [expr {int(rand() * 26) + (rand() > .5 ? 97 : 65)}]]} $len]] } proc getClientId { return <Duo Client ID> } proc getExpiryTime { set exp [clock seconds] set exp [expr $exp + 900] return $exp } proc getJwtHeader { return "{\"alg\":\"HS512\",\"typ\":\"JWT\"}" } proc getJwkName { return <JSON Web Key> #e.g. return "/Common/duo_jwk" } proc createJwt {duo_uname} { set header [call getJwtHeader] set exp [call getExpiryTime] set client_id [call getClientId] set redirect_uri "https://" set redirect [ACCESS::session data get "session.server.network.name"] append redirect_uri $redirect append redirect_uri "/oauth/client/redirect" set payload "{\"response_type\": \"code\",\"scope\":\"openid\",\"exp\":${exp},\"client_id\":\"${client_id}\",\"redirect_uri\":\"${redirect_uri}\",\"duo_uname\":\"${duo_uname}\"}" set jwt_duo [ ACCESS::oauth sign -header $header -payload $payload -alg HS512 -key [call getJwkName] ] return $jwt_duo } proc createJwtToken { set header [call getJwtHeader] set exp [call getExpiryTime] set client_id [call getClientId] set aud "<Duo API Hostname>/oauth/v1/token" #Example: set aud https://api-duohostname.com/oauth/v1/token set jti [call randAZazStr 32] set payload "{\"sub\": \"${client_id}\",\"iss\":\"${client_id}\",\"aud\":\"${aud}\",\"exp\":${exp},\"jti\":\"${jti}\"}" set jwt_duo [ ACCESS::oauth sign -header $header -payload $payload -alg HS512 -key [call getJwkName] ] return $jwt_duo } when ACCESS_POLICY_AGENT_EVENT { set irname [ACCESS::policy agent_id] if { $irname eq "JWT_CREATE" } { set ::duo_uname [ACCESS::session data get "session.logon.last.username"] ACCESS::session data set session.custom.jwt_duo [call createJwt $::duo_uname] ACCESS::session data set session.custom.jwt_duo_token [call createJwtToken] } } when ACCESS_PER_REQUEST_AGENT_EVENT { set irname [ACCESS::perflow get perflow.irule_agent_id] if { $irname eq "JWT_CREATE" } { set ::duo_uname [ACCESS::session data get "session.logon.last.username"] ACCESS::perflow set perflow.custom [call createJwt $::duo_uname] ACCESS::perflow set perflow.scratchpad [call createJwtToken] } } Figure 9: iRule screen 5. Click Finished. Create the appropriate access policy/policies on the BIG-IP system Per-request policy Skip this section for a per-session type deployment The per-request policy is used to perform secondary authentication with Duo. Configure the access policies through the access menu, using the Visual Policy Editor. The per-request access policy must have a subroutine with an iRule Event, Variable Assign, and an OAuth Client agent that requests authorization and tokens from an OAuth server. You may use other per-request policy items such as URL branching or Client Type to call Duo only for certain target URIs. Figure 10 shows a subroutine named duosubroutine in the per-request policy that handles Duo MFA authentication. Figure 10: Per-request policy in Visual Policy Editor Configuring the iRule Event agent The iRule Event agent specifies the iRule ID to be executed for Duo integration. In the ID field, type the iRule ID as configured in the iRule. Figure 11: iRule Event agent in Visual Policy Editor Configuring the Variable Assign agent The Variable Assign agent specifies the variables for token and redirect requests and assigns a value for Duo MFA in a subroutine. This is required only for per-request type deployment. Add sub-session variables as custom variables and assign their custom Tcl expressions as shown in Figure 12. subsession.custom.jwt_duo_token = return [mcget {perflow.scratchpad}] subsession.custom.jwt_duo = return [mcget {perflow.custom}] Figure 12: Variable Assign agent in Visual Policy Editor Configuring the OAuth Client agent An OAuth Client agent requests authorization and tokens from the Duo server. Specify OAuth parameters as shown in Figure 13. In the Server list, select the Duo server to which the OAuth client directs requests. In the Authentication Redirect Request list, select the auth-redirect-request configured earlier. In the Token Request list, select the token-request configured earlier. Some deployments may not need the additional information provided by OpenID Connect. You could, in that case, disable it. Figure 13: OAuth Client agent in Visual Policy Editor Per-session policy Configure the Per Session policy as appropriate for your chosen deployment type. Per-request: The per-session policy must contain at least one logon page to set the username variable in the user’s session. Preferably it should also perform some type of primary authentication. This validated username is used later in the per-request policy. Per-session: The per-session policy is used for all authentication. A per-request policy is not used. Figures 14a and 14b show a per-session policy that runs when a client initiates a session. Depending on the actions you include in the access policy, it can authenticate the user and perform actions that populate session variables with data for use throughout the session. Figure 14a: Per-session policy in Visual Policy Editor performs both primary authentication and Duo authentication (for per-session use case) Figure 14b: Per-session policy in Visual Policy Editor performs primary authentication only (for per-request use case) Apply policy/policies and iRule to the APM virtual server Finally, apply the per-request policy, per-session policy, and iRule to the APM virtual server. You assign iRules as a resource to the virtual server that users connect. Configure the virtual server’s default pool to the protected local web resource. Apply policy/policies to the virtual server Per-request policy To attach policies to the virtual server: 1. On the Main tab, click Local Traffic > Virtual Servers. 2. Select the Virtual Server. 3. In the Access Policy section, select the policy you created. 4. Click Finished. Figure 15: Access Policy section in Virtual Server (per-request policy) Per-session policy Figure 16 shows the Access Policy section in Virtual Server when the per-session policy is deployed. Figure 16: Access Policy section in Virtual Server (per-session policy) Apply iRule to the virtual server To attach the iRule to the virtual server: 1. On the Main tab, click Local Traffic > Virtual Servers. 2. Select the Virtual Server. 3. Select the Resources tab. 4. Click Manage in the iRules section. 5. Select an iRule from the Available list and add it to the Enabled list. 6. Click Finished.15KViews10likes47CommentsAPM-DHCP Access Policy Example and Detailed Instructions
Prepared with Mark Quevedo, F5 Principal Software Engineer May, 2020 Sectional Navigation links Important Version Notes || Installation Guide || What Is Going On Here? || Parameters You Set In Your APM Access Policy || Results of DHCP Request You Use in Access Policy || Compatibility Tips and Troubleshooting Introduction Ordinarily you assign an IP address to the “inside end” of an APM Network Tunnel (full VPN connection) from an address Lease Pool, from a static list, or from an LDAP or RADIUS attribute. However, you may wish to assign an IP address you get from a DHCP server. Perhaps the DHCP server manages all available client addresses. Perhaps it handles dynamic DNS for named client workstations. Or perhaps the DHCP server assigns certain users specific IP addresses (for security filtering). Your DHCP server may even assign client DNS settings as well as IP addresses. APM lacks DHCP address assignment support (though f5's old Firepass VPN had it ). We will use f5 iRules to enable DHCP with APM. We will send data from APM session variables to the DHCP server so it can issue the “right” IP address to each VPN tunnel based on user identity, client info, etc. Important Version Notes Version v4c includes important improvements and bug fixes. If you are using an older version, you should upgrade. Just import the template with “Overwrite existing templates” checked, then “reconfigure” your APM-DHCP Application Service—you can simply click “Finished” without changing any options to update the iRules in place. Installation Guide First install the APM-DHCP iApp template (file DHCP_for_APM.tmpl). Create a new Application Service as shown (choose any name you wish). Use the iApp to manage the APM-DHCP virtual servers you need. (The iApp will also install necessary iRules.) You must define at least one APM-DHCP virtual server to receive and send DHCP packets. Usually an APM-DHCP virtual server needs an IP address on the subnet on which you expect your DHCP server(s) to assign client addresses. You may define additional APM-DHCP virtual servers to request IP addresses on additional subnets from DHCP. However, if your DHCP server(s) support subnet-selection (see session.dhcp.subnet below) then you may only need a single APM-DHCP virtual server and it may use any IP that can talk to your DHCP server(s). It is best to give each APM-DHCP virtual server a unique IP address but you may use an BIG-IP Self IP as per SOL13896 . Ensure your APM and APM-DHCP virtual servers are in the same TMOS Traffic Group (if that is impossible set TMOS db key tmm.sessiondb.match_ha_unit to false). Ensure that your APM-DHCP virtual server(s) and DHCP server(s) or relay(s) are reachable via the same BIG-IP route domain. Specify in your IP addresses any non-zero route-domains you are using (e.g., “192.168.0.20%3”)—this is essential. (It is not mandatory to put your DHCP-related Access Policy Items into a Macro—but doing so makes the below screenshot less wide!) Into your APM Access Policy, following your Logon Page and AD Auth (or XYZ Auth) Items (etc.) but before any (Full/Advanced/simple) Resource Assign Item which assigns the Network Access Resource (VPN), insert both Machine Info and Windows Info Items. (The Windows Info Item will not bother non-Windows clients.) Next insert a Variable Assign Item and name it “DHCP Setup”. In your “DHCP Setup” Item, set any DHCP parameters (explained below) that you need as custom session variables. You must set session.dhcp.servers. You must also set session.dhcp.virtIP to the IP address of an APM-DHCP virtual server (either here or at some point before the “DHCP_Req” iRule Event Item). Finally, insert an iRule Event Item (name it “DHCP Req”) and set its Agent ID to DHCP_req. Give it a Branch Rule “Got IP” using the expression “expr {[mcget {session.dhcp.address}] ne ""}” as illustrated. You must attach iRule ir-apm-policy-dhcp to your APM virtual server (the virtual server to which your clients connect). Neither the Machine Info Item nor the Windows Info Item is mandatory. However, each gathers data which common DHCP servers want to see. By default DHCP_req will send that data, when available, to your DHCP servers. See below for advanced options: DHCP protocol settings, data sent to DHCP server(s), etc. Typically your requests will include a user identifier from session.dhcp.subscriber_ID and client (machine or connection) identifiers from other parameters. The client IP address assigned by DHCP will appear in session.dhcp.address. By default, the DHCP_req iRule Event handler will also copy that IP address into session.requested.clientip where the Network Access Resource will find it. You may override that behavior by setting session.dhcp.copy2var (see below). Any “vendor-specific information” supplied by the DHCP server 1 (keyed by the value of session.dhcp.vendor_class) will appear in variables session.dhcp.vinfo.N where N is a tag number (1-254). You may assign meanings to tag numbers. Any DNS parameters the DHCP server supplies 2 are in session.dhcp.dns_servers and session.dhcp.dns_suffix. If you want clients to use those DNS server(s) and/or DNS default search domain, put the name of every Network Access Resource your Access Policy may assign to the client into the session.dhcp.dns_na_list option. NB: this solution does not renew DHCP address leases automatically, but it does release IP addresses obtained from DHCP after APM access sessions terminate. 3 Please configure your DHCP server(s) for an address lease time longer than your APM Maximum Session Timeout. Do not configure APM-DHCP virtual servers in different BIG-IP route domains so they share any part of a DHCP client IP range (address lease pool). For example, do not use two different APM-DHCP virtual servers 10.1.5.2%6 and 10.1.5.2%8 with one DHCP client IP range 10.1.5.10—10.1.5.250. APM-DHCP won’t recognize when two VPN sessions in different route domains get the same client IP from a non-route-domain-aware DHCP server, so it may not release their IP’s in proper sequence. This solution releases DHCP address leases for terminated APM sessions every once in a while, when a new connection comes in to the APM virtual server (because the BIG IP only executes the relevant iRules on the “event” of each new connection). When traffic is sparse (say, in the middle of the night) there may be some delay in releasing addresses for dead sessions. If ever you think this solution isn’t working properly, be sure to check the BIG IP’s LTM log for warning and error messages. DHCP Setup (a Variable Assign Item) will look like: Put the IP of (one of) your APM-DHCP virtual server(s) in session.dhcp.virtIP. Your DHCP server list may contain addresses of DHCP servers or relays. You may list a directed broadcast address (e.g., “172.16.11.255”) instead of server addresses but that will generate extra network chatter. To log information about DHCP processing for the current APM session you may set variable session.dhcp.debug to true (don’t leave it enabled when not debugging). DHCP Req (an iRule Event Item) will look like: Note DHCP Req branch rules: If DHCP fails, you may wish to warn the user: (It is not mandatory to Deny access after DHCP failure—you may substitute another address into session.requested.clientip or let the Network Access Resource use a Lease Pool.) What is going on here? We may send out DHCP request packets easily enough using iRules’ SIDEBAND functions, but it is difficult to collect DHCP replies using SIDEBAND. 4 Instead, we must set up a distinct LTM virtual server to receive DHCP replies on UDP port 67 at a fixed address. We tell the DHCP server(s) we are a DHCP relay device so replies will come back to us directly (no broadcasting). 5 For a nice explanation of the DHCP request process see http://technet.microsoft.com/en-us/library/cc940466.aspx. At this time, we support only IPv4, though adding IPv6 would require only toil, not genius. By default, a DHCP server will assign a client IP on the subnet where the DHCP relay device (that is, your APM-DHCP virtual server) is homed. For example, if your APM-DHCP virtual server’s address were 172.30.4.2/22 the DHCP server would typically lease out a client IP on subnet 172.30.4.0. Moreover, the DHCP server will communicate directly with the relay-device IP so appropriate routes must exist and firewall rules must permit. If you expect to assign client IP’s to APM tunnel endpoints on multiple subnets you may need multiple APM-DHCP virtual servers (one per subnet). Alternatively, some but not all DHCP servers 6 support the rfc3011 “subnet selection” or rfc3527 “subnet/link-selection sub-option” so you can request a client IP on a specified subnet using a single APM-DHCP virtual server (relay device) IP which is not homed on the target subnet but which can communicate easily with the DHCP server(s): see parameter session.dhcp.subnet below. NOTE: The subnet(s) on which APM Network Access (VPN) tunnels are homed need not exist on any actual VLAN so long as routes to any such subnet(s) lead to your APM (BIG-IP) device. Suppose you wish to support 1000 simultaneous VPN connections and most of your corporate subnets are /24’s—but you don’t want to set up four subnets for VPN users. You could define a virtual subnet—say, 172.30.4.0/22—tell your DHCP server(s) to assign addresses from 172.30.4.3 thru 172.30.7.254 to clients, put an APM-DHCP virtual server on 172.30.4.2, and so long as your Layer-3 network knows that your APM BIG-IP is the gateway to 172.30.4.0/22, you’re golden. When an APM Access Policy wants an IP address from DHCP, it will first set some parameters into APM session variables (especially the IP address(es) of one or more DHCP server(s)) using a Variable Assign Item, then use an iRule Event Item to invoke iRule Agent DHCP_req in ir apm policy dhcp. DHCP_req will send DHCPDISCOVERY packets to the specified DHCP server(s). The DHCP server(s) will reply to those packets via the APM-DHCP virtual-server, to which iRule ir apm dhcp must be attached. That iRule will finish the 4-packet DHCP handshake to lease an IP address. DHCP_req handles timeouts/retransmissions and copies the client IP address assigned by the DHCP server into APM session variables for the Access Policy to use. We use the APM Session-ID as the DHCP transaction-ID XID and also (by default) in the value of chaddr to avert collisions and facilitate log tracing. Parameters You Set In Your APM Access Policy Required Parameters session.dhcp.virtIP IP address of an APM-DHCP virtual-server (on UDP port 67) with iRule ir-apm-dhcp. This IP must be reachable from your DHCP server(s). A DHCP server will usually assign a client IP on the same subnet as this IP, though you may be able to override that by setting session.dhcp.subnet. You may create APM-DHCP virtual servers on different subnets, then set session.dhcp.virtIP in your Access Policy (or branch) to any one of them as a way to request a client IP on a particular subnet. No default. Examples (“Custom Expression” format): expr {"172.16.10.245"} or expr {"192.0.2.7%15"} session.dhcp.servers A TCL list of one or more IP addresses for DHCP servers (or DHCP relays, such as a nearby IP router). When requesting a client IP address, DHCP packets will be sent to every server on this list. NB: IP broadcast addresses like 10.0.7.255 may be specified but it is better to list specific servers (or relays). Default: none. Examples (“Custom Expression” format): expr {[list "10.0.5.20" "10.0.7.20"]} or expr {[list "172.30.1.20%5"]} Optional Parameters (including some DHCP Options) NOTE: when you leave a parameter undefined or empty, a suitable value from the APM session environment may be substituted (see details below). The defaults produce good results in most cases. Unless otherwise noted, set parameters as Text values. To exclude a parameter entirely set its Text value to '' [two ASCII single-quotes] (equivalent to Custom Expression return {''} ). White-space and single-quotes are trimmed from the ends of parameter values, so '' indicates a nil value. It is best to put “Machine Info” and “Windows Info” Items into your Access Policy ahead of your iRule Event “DHCP_req” Item (Windows Info is not available for Mac clients beginning at version 15.1.5 as they are no longer considered safe). session.dhcp.debug Set to 1 or “true” to log DHCP-processing details for the current APM session. Default: false. session.dhcp.firepass Leave this undefined or empty (or set to “false”) to use APM defaults (better in nearly all cases). Set to “true” to activate “Firepass mode” which alters the default values of several other options to make DHCP messages from this Access Policy resemble messages from the old F5 Firepass product. session.dhcp.copy2var Leave this undefined or empty (the default) and the client IP address from DHCP will be copied into the Access Policy session variable session.requested.clientip, thereby setting the Network Access (VPN) tunnel’s inside IP address. To override the default, name another session variable here or set this to (Text) '' to avert copying the IP address to any variable. session.dhcp.dns_na_list To set the client's DNS server(s) and/or DNS default search domain from DHCP, put here a Custom Expression TCL list of the name(s) of the Network Access Resource(s) you may assign to the client session. Default: none. Example: expr {[list "/Common/NA" "/Common/alt-NA"]} session.dhcp.broadcast Set to “true” to set the DHCP broadcast flag (you almost certainly should not use this). session.dhcp.vendor_class Option 60 A short string (32 characters max) identifying your VPN server. Default: “f5 APM”. Based on this value the DHCP server may send data to session.dhcp.vinfo.N (see below). session.dhcp.user_class Option 77 A Custom Expression TCL list of strings by which the DHCP server may recognize the class of the client device (e.g., “kiosk”). Default: none (do not put '' here). Example: expr {[list "mobile" "tablet"]} session.dhcp.client_ID Option 61 A unique identifier for the remote client device. Microsoft Windows DHCP servers expect a representation of the MAC address of the client's primary NIC. If left undefined or empty the primary MAC address discovered by the Access Policy Machine Info Item (if any) will be used. If no value is set and no Machine Info is available then no client_ID will be sent and the DHCP server will distinguish clients by APM-assigned ephemeral addresses (in session.dhcp.hwcode). If you supply a client_ID value you may specify a special code, a MAC address, a binary string, or a text string. Set the special code “NONE” (or '') to avoid sending any client_ID, whether Machine Info is available or not. Set the special code “XIDMAC” to send a unique MAC address for each APM VPN session—that will satisfy DHCP servers desiring client_ID‘s while averting IP collisions due to conflicting Machine Info MAC’s like Apple Mac Pro’s sometimes provide. A value containing twelve hexadecimal digits, possibly separated by hyphens or colons into six groups of two or by periods into three groups of four, will be encoded as a MAC address. Values consisting only of hexadecimal digits, of any length other than twelve hexits, will be encoded as a binary string. A value which contains chars other than [0-9A-Fa-f] and doesn't seem to be a MAC address will be encoded as a text string. You may enclose a text string in ASCII single-quotes (') to avert interpretation as hex/binary (the quotes are not part of the text value). On the wire, MAC-addresses and text-strings will be prefixed by type codes 0x01 and 0x00 respectively; if you specify a binary string (in hex format) you must include any needed codes. Default: client MAC from Machine Info, otherwise none. Example (Text value): “08-00-2b-2e-d8-5e”. session.dhcp.hostname Option 12 A hostname for the client. If left undefined or empty, the short computer name discovered by the APM Access Policy Windows Info Item (if any) will be used. session.dhcp.subscriber_ID Sub-option 6 of Option 82 An identifier for the VPN user. If undefined or empty, the value of APM session variable session.logon.last.username will be used (generally the user's UID or SAMAccountName). session.dhcp.circuit_ID Sub-option 1 of Option 82 An identifier for the “circuit” or network endpoint to which client connected. If left undefined or empty, the IP address of the (current) APM virtual server will be used. session.dhcp.remote_ID Sub-option 2 of Option 82 An identifier for the client's end of the connection. If left undefined or empty, the client’s IP address + port will be used. session.dhcp.subnet Option 118 Sub-option 5 of Option 82 The address (e.g., 172.16.99.0) of the IP subnet on which you desire a client address. With this option you may home session.dhcp.virtIP on another (more convenient) subnet. MS Windows Server 2016 added support for this but some other DHCP servers still lack support. Default: none. session.dhcp.hwcode Controls content of BOOTP htype, hlen, and chaddr fields. If left undefined or empty, a per-session value optimal in most situations will be used (asserting that chaddr, a copy of XID, identifies a “serial line”). If your DHCP server will not accept the default, you may set this to “MAC” and chaddr will be a locally-administered Ethernet MAC (embedding XID). When neither of those work you may force any value you wish by concatenating hexadecimal digits setting the value of htype (2 hexits) and chaddr (a string of 0–32 hexits). E.g., a 6-octet Ethernet address resembles “01400c2925ea88”. Most useful in the last case is the MAC address of session.dhcp.virtIP (i.e., a specific BIG-IP MAC) since broken DHCP servers may send Layer 2 packets directly to that address. Results of DHCP Request For Use In Access Policy session.dhcp.address <-- client IP address assigned by DHCP! session.dhcp.message session.dhcp.server, session.dhcp.relay session.dhcp.expires, session.dhcp.issued session.dhcp.lease, session.dhcp.rebind, session.dhcp.renew session.dhcp.vinfo.N session.dhcp.dns_servers, session.dhcp.dns_suffix session.dhcp.xid, session.dhcp.hex_client_id, session.dhcp.hwx If a DHCP request succeeds the client IP address appears in session.dhcp.address. If that is empty look in session.dhcp.message for an error message. The IP address of the DHCP server which issued (or refused) the client IP is in session.dhcp.server (if session.dhcp.relay differs then DHCP messages were relayed). Lease expiration time is in session.dhcp.expires. Variables session.dhcp.{lease, rebind, renew} indicate the duration of the address lease, plus the rebind and renew times, in seconds relative to the clock value in session.dhcp.issued (issued time). See session.dhcp.vinfo.N where N is tag number for Option 43 vendor-specific information. If the DHCP server sends client DNS server(s) and/or default search domain, those appear in session.dhcp.dns_servers and/or session.dhcp.dns_suffix. To assist in log analysis and debugging, session.dhcp.xid contains the XID code used in the DHCP request. The client_ID value (if any) sent to the DHCP server(s) is in session.dhcp.hex_client_id. The DHCP request’s htype and chaddr values (in hex) are concatenated in session.dhcp.hwx. Compatibility Tips and Troubleshooting Concern Response My custom parameter seems to be ignored. You should set most custom parameters as Text values (they may morph to Custom Expressions). My users with Apple Mac Pro’s sometimes get no DHCP IP or a conflicting one. A few Apple laptops sometimes give the Machine Info Item bogus MAC addresses. Set session.dhcp.client_ID to “XIDMAC“ to use unique per-session identifiers for clients. After a VPN session ends, I expect the very next session to reuse the same DHCP IP but that doesn’t happen. Many DHCP servers cycle through all the client IP’s available for one subnet before reusing any. Also, after a session ends APM-DHCP takes a few minutes to release its DHCP IP. When I test APM-DHCP with APM VE running on VMware Workstation, none of my sessions gets an IP from DHCP. VMware Workstation’s built-in DHCP server sends bogus DHCP packets. Use another DHCP server for testing (Linux dhcpd(8) is cheap and reliable). I use BIG-IP route domains and I notice that some of my VPN clients are getting duplicate DHCP IP addresses. Decorate the IP addresses of your APM-DHCP virtual servers, both in the iApp and in session.dhcp.virtIP, with their route-domain ID’s in “percent notation” like “192.0.2.5%3”. APM-DHCP is not working. Double-check your configuration. Look for errors in the LTM log. Set session.dhcp.debug to “true” before trying to start a VPN session, then examine DHCP debugging messages in the LTM log to see if you can figure out the problem. Even after looking at debugging messages in the log I still don’t know why APM-DHCP is not working. Run “tcpdump –ne -i 0.0 -s0 port 67” to see where the DHCP handshake fails. Are DISCOVER packets sent? Do any DHCP servers reply with OFFER packets? Is a REQUEST sent to accept an OFFER? Does the DHCP server ACK that REQUEST? If you see an OFFER but no REQUEST, check for bogus multicast MAC addresses in the OFFER packet. If no OFFER follows DISCOVER, what does the DHCP server’s log show? Is there a valid zone/lease-pool for you? Check the network path for routing errors, hostile firewall rules, or DHCP relay issues. Endnotes In DHCP Option 43 (rfc2132). In DHCP Options 6 and 15 (rfc2132). Prior to version v3h, under certain circumstances with some DHCP servers, address-release delays could cause two active sessions to get the same IP address. And even more difficult using [listen], for those of you in the back of the room. A bug in some versions of VMware Workstation’s DHCP server makes this solution appear to fail. The broken DHCP server sends messages to DHCP relays in unicast IP packets encapsulated in broadcast MAC frames. Anormal BIG-IP virtual server will not receive such packets. As of Winter 2017 the ISC, Cisco, and MS Windows Server 2016 DHCP servers support the subnet/link selection options but older Windows Server and Infoblox DHCP servers do not. Supporting Files - Download attached ZIP File Here.14KViews7likes52CommentsGetting Started with iRules: Variables
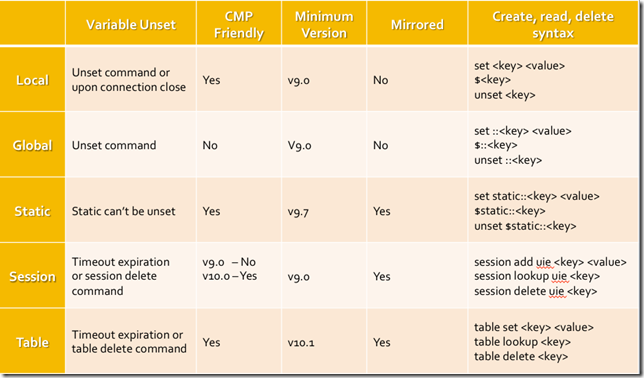
If you've been following along in this series, it's time to add another building block to the framework of what iRules are and can do. If you're new, it would behoove you to start at the beginning and catch up. So far we've covered introductions across the board for programming basics and concepts, F5 terminology and basic technology concepts, the core of what iRules are and why you'd use them, as well as a couple of cornerstone iRules concepts like events and priorities. All of these concepts are required to get a proper understanding of the base iRules infrastructure and functionality. Using those concepts as foundations we're going to add to the mix something that's integral to any programming language: variables. We'll cover a bit about what variables are, but also some iRules specific variables functionality and commentary. Things to look for in this article: What is a variable? How do I work with variables in my iRule? What types of variables are available to me in iRules? Is there a performance impact when using variables? When should I use variables? What is a variable? A variable, in simple terms, is a piece of data stored in memory. This is done usually with the notion of using that data again at some point, recalling it to make use of it later in your script. For instance if you want to store the hostname of an incoming connection so that you can reference that hostname on the response, or if you want to store the result of a given command, etc. those things would be stored in a variable. Every scripting language has variables of some form or another, and they're quite important in the grand scheme of things. Without them you'd be building static scripts to perform one off, iterative tasks. Variables are a large part of what allows dynamic programming to account for multiple conditions and use cases. Whether it's storing the data from a math operation to be compared against a desired result, or checking to see if a given condition has been met yet, variables are at the very core of just about everything in programming, and aren't something that we could live without in modern coding. The idea is simple, take a piece of data, whether it's a number or a string or...anything, and store it in memory with a unique name. Then, later, you can recall the value of that data by simply referencing the name you created to represent it. You can, of course, modify, or delete variables at will also. How do I work with variables in my iRule? There are two main functions when it comes to any variable: setting and retrieving. To set a variable in Tcl you simply use the set command and specify the desired value. This can be a static or dynamic value, such as an integer or the result of a command. The desired value is then stored in memory and associated with the variable name supplied. This looks like: #Basic variable creation in Tcl set integer 5 set hostname [HTTP::host] To retrieve the value associated with a given variable you simply reference that variable directly and you will get the resulting value. For instance "$integer" and "$hostname" would reference the values from the above example. Of course calling them by themselves won't do much good. Simple referring to a variable within your code will do pretty much nothing. You'll almost certainly be referencing the variables in relation to something or from another command. I.E.: #Basic variable reference to retrieve and use the value stored in memory if {$integer > 0) { log local0. "Host: $hostname" } What types of variables are available to me in iRules? This topic can creep in scope pretty darn quickly, given that variables are just a simple memory structure, and there are many different types of memory structures available to you via Tcl and iRules. From simple variables to arrays to tables and data groups, there are many ways to manage data in memory. For the purposes of this article, however, we're going to focus on the two main types of actual variables and leave the discussion of other data structures for later. There are two main types of variables in iRules, local and global. Local Variables All variables, unless otherwise specified, are created as local variables within an iRule. What does that mean? Well, a local variable means that it is assigned the same scope as the iRule that created it. All iRules are inherently connection based, and as such all local variables are connection based as well. This means that the connection dictates the memory space for a given iRule's local variables and data. For instance, if connection1 comes in and an iRule executes, creating 5 variables, those variables will only exist until connection1 closes and the connection is terminated on the BIG-IP. At that time the memory allocated to that flow will be freed up, and the variables created while processing that particular connection's iRule(s) will no longer be accessible. This is the case with all iRules and all variables created from within an iRule using the basic set command structure pictured above. Local variables are low cost, easy to use, you never have to worry about memory management with them, as they are automatically cleaned up when the connection terminates. It's important to remember that iRules as a whole, and the variables therein are connection bound. This can cause some confusion when people are expecting a more static state. Local variables will account for the vast majority of your variable usage within iRules. They're efficient, easy to use, and highly useful depending on the situation. These can be set directly as shown above but are also often the result of a command that provides output. There are also multiple ways to reference a variable within iRules. When using a command that directly affects the variable it is usually appropriate to leave the "$" off and reference the name directly, other times braces allow you to more clearly define the beginning and end of a variable name. Some examples would look like: #Standard variable reference log local0. "My host is $host" #Set variable to the output of a particular command using brackets [] set int [expr {5 + 8}] #Directly manipulating a variable's value means no "$", most times incr int #Bracing can allow you to deliniate between variable name and adjacent characters log local0. "Today's date is the ${int}th" Global Variables "Global variables" is a bit of a misnomer, actually. This is the general terminology used within most programming languages, including Tcl, for variables that exist outside of the local memory space. I.E., in the case of iRules, variables that exist beyond the constraints of a single connection. For instance, what if I want to store the IP address of my logging server, and have that always available, to every connection that comes through the BIG-IP, without having to re-set that variable every single time my iRule fires? That would be a global variable. Tcl has a mechanism for handling this, and it's relatively easy to use. Interestingly, though...we aren't using it. The global variable handling within Tcl requires a shared memory space, which in our world does something referred to as "demoting" from CMP. As you'll recall from the "Introduction to F5 Technology & Terms" article, CMP is Clustered Multi-Processing, and is the technology that allows us to distribute tasks within the BIG-IP to multiple cores in an efficient, scalable manner. Because of the requirements of the default Tcl global variable handling, making use of a global variable within Tcl forces any connection going through the Virtual to which the offending iRule is applied to be demoted from CMP, I.E. use only a single processing core, rather than all of them to process the traffic for that Virtual. This is a bad thing, and will severely limit performance. As such, we strongly recommend avoiding global variables in their traditional sense all together. But what about that log server address? There's still a definite need for long lived data to be stored in memory and available at will. It's for this purpose that we've included a new namespace within iRules called the "static" namespace. You can effectively set static global variable data in the static namespace without breaking CMP, and thereby not decreasing performance. To do so simply set up your static::varname variables, likely in RULE_INIT, since that special event only runs once at load time and static variables are global in scope, meaning they stay set until the configuration is reloaded. Once these variables are set you can call them like you would any other variable from within any iRule, and they will always be available. It looks something like this: #Set a static variable value, which will exist until config reload, living outside of the scope of any one particular iRule set static::logserver "10.10.1.145" #Reference that static variable just as you would any other variable from within any iRule log $static::logserver "This is a remote log message" For a more complete look at the different types of memory structures that you can access in iRules, I've included a handy dandy table to show memory structures by type along with some information about each, and an example of using that structure. We'll cover some of these in more detail in later installments of this series, but I want to make you aware of the different types of memory structures available. Note: There is a slight error in the table. It IS possible to unset static variables. Is there a performance impact when using variables? Running any command that isn't cached in any script has some cost associated with it, there's just no way around it. Variables in iRules happen to have a miniscule cost, generally speaking, so long as you're using them appropriately. The cost associated with a variable is in the creation process. It takes resources, albeit a very small amount, to store the desired data in memory and create a reference to that data to be used in the future. Accessing a variable is simply making a call to that reference, and as such doesn't have an additional cost. A common misunderstanding, however, is just what constitutes a variable within iRules, vs. a command or function that will perform a query. Many people see things like "HTTP::host" or "IP::client_addr" and, due to the format, assume it is a command or function and as such will cost CPU cycles to query the value and return it. This is not the case at all. These type of references are cached within TMM, so whether you call "HTTP::host" once or 100 times, you're not going to require more resources, as you're not performing a query to determine the hostname each time, rather just referencing a value that's already stored in memory. Think of these and many other similar commands as pre-populated variable data that you can use at will. When should I use variables? While the cost of creating variables is low, there still is some overhead associated with it. In iRules, due to the exorbitantly high rate of execution in some deployments, we tend to lean towards extreme efficiency mindedness. In this vein we recommend only using variables where they are actually necessary, rather than many programming practices which dictate to use them often as a means of keeping code tidy, even when not truly warranted. For instance, a common practice with many new iRule programmers is to do things like set host [HTTP::host] As I just explained above, however, this is completely unnecessary. Rather, it would be more efficient to simply re-use the HTTP::host command any time you need to reference this information. When it does make sense to use a variable, however, is when you are going to modify the data in some way. For instance log local0. "My lower case URI: [string tolower [HTTP::uri]]" The above will give you an all lowercase representation of the HTTP URI. This is a very common use case, and it is not abnormal to have the need to reference the lowercase version of the URI multiple times in a given iRule. While the HTTP::uri command is cached and will not incur additional overhead regardless of how many times you reference it, the string tolower command is not. As such, it would make sense in this case, assuming you're going to reference the lowercase URI at least 2 or more times, to create a variable and reference that: set loweruri [string tolower [HTTP::uri]] log local0. "My lower case URI: $loweruri" Effectively you want to use variables any time you are going to have to repeat any operation against a value that has a cost associated with it. Rather than repeat that operation multiple times and accumulate extra overhead it's better to perform the operation once, store the result, and reference the variable from there. That covers the basics of variables: What they are, how they work, when to use them and when not, which types you can make use of and how they'll affect your performance, if at all. Hopefully that allows you to approach your iRules with that much more confidence, understanding such a core piece of their makeup. In the next article we'll dig into control structures and operators.14KViews3likes3Comments
iRule to set SameSite for compatible clients and remove it for incompatible clients (LTM|ASM|APM)
A bunch of us have been refining approaches to help customers handle the new browser enforcement of the HTTP cookie SameSite attribute. I think we have a pretty solid approach now to handle compatible and incompatible user-agents. The iRule: Allows the admin to set the SameSite attribute on BIG-IP and web application cookies (all cookies, explicitly named cookies or cookies that start with a string) for user-agents that handle the SameSite attribute Allows the admin to remove the SameSite attribute for user-agents which do not support SameSite=None. The behavior for an incompatible client receiving a cookie with SameSite not set should be the same as a compatible client handling SameSite=None (the incompatible client should send the cookie on third party requests) The iRule uses Simon Kowallik's updated string matching logic to handle the incompatible user-agent from Chomium's blog: https://www.chromium.org/updates/same-site/incompatible-clients Note this iRule only modifies BIG-IP and web application cookies found in Set-Cookie headers. It does not attempt to modify cookies that the BIG-IP or web application sets via Javascript or other methods. BIG-IP ASM is known to set some cookies via Javascript. If you require support for this, please open a case with F5 support (https://support.f5.com) and request your case be added to: BZ875909: Allow admin configuration of SameSite attribute on ASM system cookies set via Set-Cookie and Javascript Updates to the iRule can be found in the irules-toolbox repo on GitHub. This specific version is for v12+, but there is a pre-v12 version in the repo as well. Configuration options in the iRule: samesite_security: Set this to Strict, Lax or None. The description for these values is in the iRule quoted below: # Set BIG-IP and app cookies found in Set-Cookie headers using this iRule to: # # none: Cookies will be sent in both first-party context and cross-origin requests; #however, the value must be explicitly set to None and all browser requests must #follow the HTTPS protocol and include the Secure attribute which requires an encrypted #connection. Cookies that don't adhere to that requirement will be rejected. #Both attributes are required together. If just None is specified without Secure or #if the HTTPS protocol is not used, the third-party cookie will be rejected. # # lax: Cookies will be sent automatically only in a first-party context and with HTTP GET requests. #SameSite cookies will be withheld on cross-site sub-requests, such as calls to load images or iframes, #but will be sent when a user navigates to the URL from an external site, e.g., by following a link. # # strict: browser never sends cookies in requests to third party domains # #Above definitions from: https://docs.microsoft.com/en-us/microsoftteams/platform/resources/samesite-cookie-update # # Note: this iRule does not modify cookies set on the client using Javascript or other methods outside of Set-Cookie headers! set samesite_security "none" Uncomment the next command if you're using this iRule on an APM virtual server with an access profile: # Uncomment when using this iRule on an APM-enabled virtual server so the MRHSession cookies will be rewritten # The iRule cannot be saved on a virtual server with this option uncommented if there is no Access profile also enabled #ACCESS::restrict_irule_events disable Now define whether you want to rewrite all web application and BIG-IP cookies found in the Set-Cookie header(s). Set this to 1 to rewrite SameSite on all cookies in Set-Cookie headers. Else, if you want to define specifically named or prefixed cookies, set this option to 0, and proceed to the next two config options, #2 and #3 # 1. If you want to set SameSite on all BIG-IP and web application cookies for compliant user-agents, set this option to 1 # Else, if you want to use the next two options for rewriting explicit named cookies or cookie prefixes, set this option to 0 set set_samesite_on_all 0 If you don't want to rewrite all cookies using option #1 above, you can choose to rewrite explicitly named cookies in option #2. Set the exact cookie names in the named_cookie list. Replace MRHSession and LastMRH_Session, which are examples of the cookies APM uses. If you do not want to rewrite exact cookie names, comment out the first example and uncomment the second example "set named_cookies {}" # 2. Rewrite SameSite on specific named cookies # # To enable this, list the specific named cookies in the list command and comment out the second set command below # To disable this, set this variable to {} and comment out the first set command below set named_cookies [list {MRHSession} {LastMRH_Session}] #set named_cookies {} If you don't want to rewrite all cookies using option #1 above, you can choose to rewrite cookies using a prefix in option #3. Set the cookie name prefixes in the named_cookie list. Replace BIGipServer and TS, which are examples of the cookie prefixes LTM uses for persistence and ASM uses for session tracking, with the prefixes of the cookie names you want to rewrite. If you do not want to rewrite using cookie name prefixes, comment out the first example and uncomment the second example "set named_cookies {}" # 3. Rewrite cookies with a prefix like BIG-IP persistence cookies # To enable this, list the cookie name prefixes in the list command and comment out the second set command below # To disable this, set this variable to {} and comment out the first set command below set cookie_prefixes [list {BIGipServer} {TS}] #set cookie_prefixes {} If your application or BIG-IP configuration sets cookies in the Set-Cookie headers with SameSite=None, incompatible user-agents will either reject the cookie or treat the cookie as if it was set for SameSite=Strict (https://www.chromium.org/updates/same-site/incompatible-clients). You can set remove_samesite_for_incompatible_user_agents to 1 to have this iRule remove SameSite attributes from all cookies sent to incompatible browsers. # For incompatible user-agents, this iRule can remove the SameSite attribute from all cookies sent to the client via Set-Cookie headers # This is only necessary if BIG-IP or the web application being load balanced sets SameSite=None for all clients # set to 1 to enable, 0 to disable set remove_samesite_for_incompatible_user_agents 1 While testing, you can set samesite_debug to 1 to test and get debug written to /var/log/ltm. Make sure to disable this option when you're done testing, before putting the iRule into production! # Log debug to /var/log/ltm? 1=yes, 0=no # set to 0 after testing set samesite_debug 1 The full iRule: (Updates can be found in the irules-toolbox repo on GitHub. This specific version is for v12+, but there is a pre-v12 version in the repo as well.) # iRule: samesite_cookie_handling # author: Simon Kowallik # version: 1.3 # # History: version - author - description # 1.0 - Simon Kowallik - initial version # 1.1 - Aaron Hooley - updated to add support for setting SameSite to Strict|Lax|None for BIG-IP and app cookies in Set-Cookie headers # - Add option to remove SameSite=None cookies for incompatible browsers # 1.2 - Aaron Hooley - Added option to rewrite all cookies without naming them explicitly or with prefixes # 1.3 - Aaron Hooley - set samesite_compatible to 0 by default instead of a null string # # What the iRule does: # Sets SameSite to Strict, Lax or None (and sets Secure when SameSite=None) for compatible user-agents # Optionally removes SameSite attribute from all cookies for incompatible user-agents so they'll handle cookies as if they were SameSite=None # # The iRule should work for: # - LTM for web app cookies and persistence cookies, except those that the web app sets via Javascript # - ASM for web app cookies and all ASM cookies except those that ASM or the web app sets via Javascript # - APM for web app cookies and all APM cookies you configure in the config variable $named_cookies, except those that the web app sets via Javascript # # The iRule requires BIG-IP v12 or greater to use the HTTP::cookie attribute command # # RFC "standards" # https://tools.ietf.org/html/draft-west-cookie-incrementalism-00 # https://tools.ietf.org/html/draft-ietf-httpbis-rfc6265bis-05 # further reading: # https://web.dev/samesite-cookies-explained/ # https://web.dev/samesite-cookie-recipes/ # https://blog.chromium.org/2019/10/developers-get-ready-for-new.html # https://www.chromium.org/updates/same-site # https://www.chromium.org/updates/same-site/incompatible-clients proc checkSameSiteCompatible {user_agent} { # Procedure to check if a user-agent supports SameSite=None on cookies # # usage: # set isSameSiteCompatible [call checkSameSiteCompatible {User-Agent-String}] # # check for incompatible user-agents: https://www.chromium.org/updates/same-site/incompatible-clients # based on https://devcentral.f5.com/s/articles/HTTP-cookie-SameSite-test-detection-of-browsers-with-incompatible-SameSite-None-handling switch -glob -- [set user_agent [string tolower $user_agent]] { {*chrome/5[1-9].[0-9]*} - {*chrome/6[0-6].[0-9]*} - {*chromium/5[1-9].[0-9]*} - {*chromium/6[0-6].[0-9]*} - {*ip?*; cpu *os 12*applewebkit*} - {*macintosh;*mac os x 10_14*version*safari*} - {mozilla*macintosh;*mac os x 10_14*applewebkit*khtml, like gecko*} { # no samesite support return 0 } {*ucbrowser/*} { switch -glob -- $user_agent { {*ucbrowser/[1-9].*} - {*ucbrowser/1[0-1].*} - {*ucbrowser/12.[0-9].*} - {*ucbrowser/12.1[0-1].*} - {*ucbrowser/12.12.*} - {*ucbrowser/12.13.[0-2]*} { # no samesite support return 0 } } } } # If the current user-agent didn't match any known incompatible browser list, assume it can handle SameSite=None return 1 # CPU Cycles on Executing (>100k test runs) # Average 22000-42000 (fastest to slowest path) # Maximum 214263 # Minimum 13763 } # the iRule code when CLIENT_ACCEPTED priority 100 { # Set BIG-IP and app cookies found in Set-Cookie headers using this iRule to: # # none: Cookies will be sent in both first-party context and cross-origin requests; # however, the value must be explicitly set to None and all browser requests must # follow the HTTPS protocol and include the Secure attribute which requires an encrypted # connection. Cookies that don't adhere to that requirement will be rejected. # Both attributes are required together. If just None is specified without Secure or # if the HTTPS protocol is not used, the third-party cookie will be rejected. # # lax: Cookies will be sent automatically only in a first-party context and with HTTP GET requests. # SameSite cookies will be withheld on cross-site sub-requests, such as calls to load images or iframes, # but will be sent when a user navigates to the URL from an external site, e.g., by following a link. # # strict: browser never sends cookies in requests to third party domains # # Above definitions from: https://docs.microsoft.com/en-us/microsoftteams/platform/resources/samesite-cookie-update # # Note: this iRule does not modify cookies set on the client using Javascript or other methods outside of Set-Cookie headers! set samesite_security "none" # Uncomment when using this iRule on an APM-enabled virtual server so the MRHSession cookies will be rewritten # The iRule cannot be saved on a virtual server with this option uncommented if there is no Access profile also enabled #ACCESS::restrict_irule_events disable # 1. If you want to set SameSite on all BIG-IP and web application cookies for compliant user-agents, set this option to 1 # Else, if you want to use the next two options for rewriting explicit named cookies or cookie prefixes, set this option to 0 set set_samesite_on_all 0 # 2. Rewrite SameSite on specific named cookies # # To enable this, list the specific named cookies in the list command and comment out the second set command below # To disable this, set this variable to {} and comment out the first set command below set named_cookies [list {MRHSession} {LastMRH_Session}] #set named_cookies {} # 3. Rewrite cookies with a prefix like BIG-IP persistence cookies # To enable this, list the cookie name prefixes in the list command and comment out the second set command below # To disable this, set this variable to {} and comment out the first set command below set cookie_prefixes [list {BIGipServer} {TS}] #set cookie_prefixes {} # For incompatible user-agents, this iRule can remove the SameSite attribute from all cookies sent to the client via Set-Cookie headers # This is only necessary if BIG-IP or the web application being load balanced sets SameSite=None for all clients # set to 1 to enable, 0 to disable set remove_samesite_for_incompatible_user_agents 1 # Log debug to /var/log/ltm? 1=yes, 0=no # set to 0 after testing set samesite_debug 1 # You shouldn't have to make changes to configuration below here # Track the user-agent and whether it supports the SameSite cookie attribute set samesite_compatible 0 set user_agent {} if { $samesite_debug }{ set prefix "[IP::client_addr]:[TCP::client_port]:" log local0. "$prefix [string repeat "=" 40]" log local0. "$prefix \$samesite_security=$samesite_security; \$set_samesite_on_all=$set_samesite_on_all; \$named_cookies=$named_cookies; \$cookie_prefixes=$cookie_prefixes, \ \$remove_samesite_for_incompatible_user_agents=$remove_samesite_for_incompatible_user_agents" } } # Run this test event before any other iRule HTTP_REQUEST events to set the User-Agent header value # Comment out this event when done testing user-agents #when HTTP_REQUEST priority 2 { # known compatible # HTTP::header replace user-agent {my compatible user agent string} # known INcompatible # HTTP::header replace user-agent {chrome/51.10} #} # Run this iRule before any other iRule HTTP_REQUEST events when HTTP_REQUEST priority 100 { # If we're setting samesite=none, we need to check the user-agent to see if it's compatible if { not [string equal -nocase $samesite_security "none"] }{ # Not setting SameSite=None, so exit this event return } # Inspect user-agent once per TCP session for higher performance if the user-agent hasn't changed if { $samesite_compatible == 0 or $user_agent ne [HTTP::header value {User-Agent}]} { set user_agent [HTTP::header value {User-Agent}] set samesite_compatible [call checkSameSiteCompatible $user_agent] if { $samesite_debug }{ log local0. "$prefix Got \$samesite_compatible=$samesite_compatible and saved current \$user_agent: $user_agent" } } } # Run this response event with priority 900 after all other iRules to parse the final cookies from the application and BIG-IP when HTTP_RESPONSE_RELEASE priority 900 { # Log the pre-existing Set-Cookie header values if { $samesite_debug }{ log local0. "$prefix Set-Cookie value(s): [HTTP::header values {Set-Cookie}]" } if { $samesite_compatible } { # user-agent is compatible with SameSite=None, set SameSite on matching cookies if { $set_samesite_on_all }{ if { $samesite_debug }{ log local0. "$prefix Setting SameSite=$samesite_security on all cookies and exiting" } foreach cookie [HTTP::cookie names] { if { $samesite_debug }{ log local0. "$prefix Set SameSite=$samesite_security on $cookie" } # Remove any prior instances of SameSite attributes HTTP::cookie attribute $cookie remove {samesite} # Insert a new SameSite attribute HTTP::cookie attribute $cookie insert {samesite} $samesite_security # If samesite attribute is set to None, then the Secure flag must be set for browsers to accept the cookie if {[string equal -nocase $samesite_security "none"]} { HTTP::cookie secure $cookie enable } } # Exit this event in this iRule as we've already rewritten all cookies with SameSite return } # Match named cookies exactly if { $named_cookies ne {} }{ foreach cookie $named_cookies { if { [HTTP::cookie exists $cookie] } { # Remove any pre-existing SameSite attributes from this cookie as most clients use the most strict value if multiple instances are set HTTP::cookie attribute $cookie remove {SameSite} # Insert the SameSite attribute HTTP::cookie attribute $cookie insert {SameSite} $samesite_security # If samesite attribute is set to None, then the Secure flag must be set for browsers to accept the cookie if {[string equal -nocase $samesite_security "none"]} { HTTP::cookie secure $cookie enable } if { $samesite_debug }{ log local0. "$prefix Matched explicitly named cookie $cookie, set SameSite=$samesite_security" } if { $samesite_debug }{ log local0. "$prefix " } } } } # Match a cookie prefix (cookie name starts with a prefix from the $cookie_prefixes list) if { $cookie_prefixes ne {} }{ foreach cookie [HTTP::cookie names] { foreach cookie_prefix $cookie_prefixes { if { $cookie starts_with $cookie_prefix } { # Remove any pre-existing SameSite attributes from this cookie as most clients use the most strict value if multiple instances are set HTTP::cookie attribute $cookie remove {SameSite} # Insert the SameSite attribute HTTP::cookie attribute $cookie insert {SameSite} $samesite_security # If samesite attribute is set to None, then the Secure flag must be set for browsers to accept the cookie if { [string equal -nocase $samesite_security "none"] } { HTTP::cookie secure $cookie enable } if { $samesite_debug }{ log local0. "$prefix Matched prefixed cookie $cookie, with prefix $cookie_prefix, set SameSite=$samesite_security, breaking from loop" } break } } } } } else { # User-agent can't handle SameSite=None if { $remove_samesite_for_incompatible_user_agents }{ # User-agent can't handle SameSite=None, so remove SameSite attribute from all cookies if SameSite=None # This will use CPU cycles on BIG-IP so only enable it if you know BIG-IP or the web application is setting # SameSite=None for all clients including incompatible ones foreach cookie [HTTP::cookie names] { if { [string tolower [HTTP::cookie attribute $cookie value SameSite]] eq "none" }{ HTTP::cookie attribute $cookie remove SameSite if { $samesite_debug }{ log local0. "$prefix Removing SameSite for incompatible client from cookie=$cookie" } } } } } # Log the modified Set-Cookie header values if { $samesite_debug }{ log local0. "$prefix Final Set-Cookies: [HTTP::header values {Set-Cookie}]" } }13KViews9likes21CommentsGetting Started with iRules: Basic Concepts
Welcome to the third installment of this series, wherein we will, for the first time, actually discuss iRules at length. That may sound odd, but there has been some important foundational work to do before diving too deep into the technology behind iRules themselves. If you’re new to F5, new to programming, new to both, or just looking for a refresher on some very rudimentary concepts and terminology, I recommend checking out the first two articles in this series so that we’re all on the same page as we wade into iRules proper. Don't worry, we'll wait! Back for more? Great! Now that everyone is equally equipped, let’s dig in a bit to the meat of the topic at hand: iRules. Following a similar style as the first two introduction articles in this series, we’ll outline a few topics to cover, and then delve into them. To give a general introduction to iRules as a technology we’ll try to answer the following questions: What is an iRule? How does an iRule work? When would I use an iRule? When would I not use an iRule? What is an iRule? An iRule, in its most simple terminology, is a script that executes against network traffic passing through an F5 device. That’s pretty vague, though, so let’s try and define a bit more about what actually occurs within an iRule. The idea is pretty straightforward; iRules gives you the capability to write simple, network aware pieces of code that will influence your network traffic in a variety of ways. Whether you’re looking to do some form of custom persistence or rate limiting that isn’t currently available within the product’s built-in options, or looking to completely customize the user experience by granularly controlling the flow or even the contents of a given session/packet(s), that’s what iRules was built for. iRules can route, re-route, redirect, inspect, modify, delay, discard or reject, log or … do just about anything else with network traffic passing through a BIG-IP. The idea behind iRules is to make the BIG-IP nearly infinitely flexible. We recognized early on the need for users to be able to configure their systems to interact with network traffic in many ways that either we haven’t thought of, or are simply corner cases and/or in the minority of traffic being dealt with by our users. As such, rather than forcing them to submit requests for us to modify our core architecture every time they wanted to be able to use their F5 devices in a manner that slightly diverged from the collection of check boxes and drop downs available in the standard UI, we offered them iRules, and thereby a way to do what they need, when they need it. At the end of the day iRules is a network aware, customized language with which a user can add business and application logic to their deployment at the network layer. You can see a basic example iRule below, this is what iRules look like, and we will explore the different parts of an iRule in far more depth in coming parts of this series. If you're not fully comfortable with the code yet, don't let that scare you, we'll dig into each part of what you'll need to build iRules as the series continues. For now the idea is to start making iRules look and feel more familiar. # Rename a cookie by inserting a new cookie name with the same value as the original. Then remove the old cookie. when HTTP_REQUEST { # Check if old cookie exists in request if { [HTTP::cookie exists "old-cookie-name"] } { # Insert a new cookie with the new name and old cookie's value HTTP::cookie insert name "new-cookie-name" value [HTTP::cookie value "old-cookie-name"] # Remove the old cookie HTTP::cookie remove "old-cookie-name" } } How does an iRule work? To start at the beginning, as it were, an iRule is first and foremost a configuration object, in F5 terms. This means that it is a part of your general bigip.conf along with your pools, virtual servers, monitors, etc. It is entered into the system either via the GUI or CLI, generally speaking. There is also an iRules Editor available for download on DevCentral that is a windows tool for editing and deploying/testing iRules which can be extremely useful. Unlike most configuration objects, though, an iRule is completely user generated and customizable. An iRule is a script, at its core after all. Regardless of how an iRule gets there, be it UI, CLI or Editor, once an iRule is part of your config, it is then compiled as soon as that configuration is saved. One of the gross misconceptions about iRules is that, as with most interpreted scripting languages such as TCL, and interpreter must be instantiated every time an iRule is executed to parse the code and process it. This is not true at all, because every time you save your configuration all of your iRules are pre-compiled into what is referred to as “byte code”. Byte code is mostly compiled and has the vast majority of the interpreter tasks already performed, so that TMM can directly interpret the remaining object. This makes for far higher performance and as such, increase scalability. Now that the iRule is saved and pre-compiled, it must then be applied to a virtual server before it can affect any traffic. An iRule that is not applied to a virtual is effectively disabled, for all intents and purposes. Once you’ve applied an iRule to a given virtual server, however, it will now technically be applied against all traffic passing through that virtual. Keep in mind though, that this does not necessarily mean that all traffic passing through the virtual in question will be affected. IRules are most often very selective in which traffic they affect, be it to modify, re-route or otherwise. This is done through both logical constructs within the iRules, but also through the use of events within the iRule itself. Events are one of the ways in which iRules have been made to be network aware, as a language. An event, which we’ll dig into in much more detail in the next installment of this series, is a way of executing iRules code at a given point in time within the flow of a networking session. If I only want to execute a section of code once for each new connection to the virtual server to which my iRule is applied, I could easily do so by writing some simple code in the appropriate event. Events are also important because they indicate at which point in the proxy chain (sometimes referred to as a hud chain) an iRule executes. Given that BIG-IP is a bi-directional proxy, it is important for iRules to execute on not only the right side of the proxy, but at the right moment in the network flow. So now you have an iRule added to your configuration, it has been automatically pre-compiled to byte code when the configuration was saved, you have it applied to the appropriate virtual server, and the code within the iRule calls out the desired event in which you want your code to execute; now is when the magic happens, as it were. This is where the massive collection of iRules commands comes into play. From header modification to full on payload replacement to creating a socket connection to an outside system and making a request before processing traffic for your virtual, there are very few limitations to what can be achieved when combining the appropriate series of iRules commands. Those commands are then processed by TMM, which will affect whatever change(s) it needs to the traffic it is processing for the given session, depending on what you’ve designed your iRule to do. The true power of iRules largely comes into play thanks to the massive array of custom commands that we’ve built into the language, allowing you to leverage your BIG-IP to the fullest. When would I use an iRule? The ideal time to use an iRule is when you’re looking to add some form of functionality to your application or app deployment, at the network layer, and that functionality is not already readily available via the built in configuration options in your BIG-IP. Whether it’s looking to perform some kind of custom redirect or logging specific information about users’ sessions or a vast array of other possibilities, iRules can add valuable business logic or even application functionality to your deployment. iRules have a single point of management, your BIG-IP, as opposed to being distributed to every server hosting whichever application you’re trying to modify or affect. This can save valuable management time, and can also be a large benefit in time to deployment. It is often far easier to deploy an iRule or an iRule change than it is to modify your application for a quick fix. As an example, one of the most common uses of iRules when it was first introduced was to redirect all traffic from HTTP (port 80) to HTTPS (port 443) without affecting either the host or the requested URI for the connection. This was (and still is, pictured below) a very simple iRule, but it wasn’t at the time a feature available in the standard configuration options for BIG-IP. when HTTP_REQUEST { HTTP::redirect "https://[HTTP::host][HTTP::uri]" } When would I not use an iRule? The above example of an HTTP to HTTPS redirect iRule actually depicts perfectly when to not use an iRule, because that functionality was so popular that it has since been added as a profile option directly in the BIG-IP configuration. As such, it is more appropriate, and technically higher performance, to use that feature in the profile as opposed to writing an iRule to perform the same task. A general rule of thumb is: Any time you can do something from within the standard config options, profiles, GUI or CLI – do it there first. If you’re looking to perform a task that can’t be accomplished via the “built-in” means of configuration, then it is a perfect time to turn to iRules to expand the possibilities. For examples of using local traffic policies in lieu of iRules, check out Chase’s To iRule or Not to iRule article. This is for a few reasons, not the least of which is performance. iRules are extremely high performance, as a rule, and if written properly, but there is always a slight benefit in performance when you can run functionality directly from built in, core features as opposed to a custom created script, even an iRule. Also, though, it is easier to maintain a feature built into the product through upgrades, rather than re-testing and managing an iRule that could be easily replaced with a few configuration options. This concludes the introductions of core concepts in the series. Hopefully this gives everyone a solid place to start to allow us to begin digging into an array of iRules topics with more confidence and a unified starting place. Starting with the next installment of the series we will begin to delve deeper into individual iRules concepts and functionality, beginning with events and priorities.11KViews4likes0Comments
LTM Policy
Introduction F5 Local Traffic Manager (LTM) has always provided customers with the ability to optimize their network deployment by providing tools that can observe network traffic which also allow the administrator to configure various actions to take based on those observations. This is embodied in the fundamental concept of a virtual server, which groups traffic into pools based on observed IP addresses, ports, and DNS names, and furthered by extensions like iRules, which provide a tremendous amount of flexibility and customizability. For HTTP traffic up until BIG-IP 11.4.0, the HTTP Class module provided the ability for an administrator to match various parts of an HTTP transaction using regular expressions, and specify an associated action to take. These include actions such as inserting or removing a header, sending a redirect, or deciding to which vlan or pool a request should be forwarded. This was a flexible approach, but regular expression processing can be performance intensive, serial evaluation can get bogged down when the number of conditions increases, and sometimes proper coverage would require the administrator to configure specific ordering of evaluation. With the growth of traffic on the internet, and the explosion of HTTP traffic in particular, organizations are increasingly in need of more sophisticated tools which can observe traffic more in-depth and execute actions with good performance. LTM Policy LTM Policy first appeared in BIG-IP 11.4.0 as a flexible and high-performance replacement for HTTP Class. Additional capabilities and features have been continuously added since that time. At its core, LTM Policy is a data-driven rules engine which is tightly integrated with the Traffic Management Microkernel (tmm). One of the big improvements brought by LTM Policy is the accelerated and unique way that it can evaluate all conditions in parallel. When one or more policies are applied to a virtual server, they go through a compilation step that builds a combined, high-performance internal decision tree for all of the rules, conditions, and actions. This optimized representation of a virtual server's policies guarantees that every condition is only evaluated once and allows for parallel evaluation of all conditions, as well as other performance boosts, such as short-circuit evaluation. Another improvement is that conditions can observe attributes from both the request and the response, not just the request. Unlike HTTP Class, where its first-match-win could lead to ordering issues, LTM Policy can trigger on the first matching condition, all matches, the most specific match, or execute a default action when there are no condition matches. Policies What is a policy? A policy is a collection of rules, and is associated with a matching strategy, aspects the policy requires, and other aspects the policy controls. Every rule in a policy has a set of conditions and a set of actions, where either set may be empty. Conditions Conditions describe the comparisons that occur when traffic flows through a virtual server. The properties available to a condition depend on what aspect the policy requires. (See Conditions chart below.) For example, if a policy requires the http aspect, then HTTP-specific entities like headers, cookies, URI can be used in comparisons. If the policy requires this aspect: Then these Operands are available: Some of the properties that are available for comparison in conditions: none cpu-usage 1, 5, 15 minute load average tcp tcp (+ all above) IP address, port, mss http geoip geographic region associated with IP address http-uri domain, path, query string http-method HTTP method, e.g. GET, POST, etc. http-version versions of HTTP protocol http-status numeric and text response status codes http-host host and port value from Host: header http-header header name http-referer all components of Referer: URI http-cookie cookie name http-set-cookie all components of Set-Cookie http-basic-auth username, password http-user-agent (+ all above) browser type, version; device make, model client-ssl client-ssl protocol, cipher, cipher strength ssl-persistence ssl-extension server name, alpn, npn ssl-cert common-name from cert Actions Actions are commands which are executed when the associated conditions match. As with conditions, the actions available to a policy depend on which aspects the policy controls. (See Action chart below.) For example, if a policy controls the forwarding aspect, then forwarding-specific actions, such as selecting a pool, virtual server, or vlan are available. A default rule is a rule which has no conditions - and is therefore considered to always be a match - plus one or more actions. A default rule is typically ordered such that it would be the last rule evaluated. In policies with a first-match or best-match strategy (see below), the default rule is only run when no other rules match; policies with an all-match strategy will always execute default rule actions. If the policy Controls this aspect: Then these Targets are available: Which enables you to specify some of these Actions: (none specified) ltm-policy disable LTM Policy http enable/disable HTTP filter http-uri replace path, query string, or full URI http-host replace Host: header http-header insert/remove/replace HTTP header http-referer insert/remove/replace Referer: http-cookie insert/remove Cookie in request http-set-cookie insert/remove Set-Cookie in response log write to system logs tcl evaluate Tcl expression tcp-nagle enable/disable Nagle's algorithm forwarding forward pick pool, vlan, nexthop, rateclass http-reply send redirect to client caching cache enable/disable caching compression compress enable/disable compression decompress enable/disable decompression classification pem classify traffic category/application request-adaptation request-adapt enable/disable content adaptation through internal virtual server response-adaptation response-adapt enable/disable content adaptation through internal virtual server server-ssl server-ssl enable/disable server ssl persistence persist Select persistence (e.g. cookie, source address, hash, etc) Strategy All policies are associated with a strategy, which determines the behavior when multiple rules have matching conditions. As their titles suggest, the First Match strategy will execute the actions for the first rule that matches, All Match strategy will execute the actions for all rules which match, and Best Match will select the rule which has the most specific match. The most specific match is determined by comparing the rules for the number of conditions that matched, the longest matches, or the matches which are deemed to be more significant. Multiple policies can be applied to a virtual server. The only restriction is that each aspect of the system (e.g. forwarding, caching, see Actions table) may only be controlled by one policy. This is a reasonable restriction to avoid ambiguous situations where multiple policies controlling the same aspect match but specify conflicting actions. LTM Policy and iRules iRules are an important and long-standing part of the BIG-IP architecture, and pervasive throughout the product. There is some overlap between what can be controlled by LTM Policy and iRules, not surprisingly that most of the overlap is in the realm of HTTP traffic handling. And just about anything that is possible in LTM Policy can also be written as an iRule. LTM Policy is a structured, data-driven collection of rules. iRules and Tcl are more of a general purpose programming language which provide lots of power and flexibility, but also require some programming skills. Because policies are structured and can be created by populating tables in a web UI, it is more approachable for those with limited programming skills. So, when to use LTM Policy and when to use iRules? As a general rule, where there is identical functionality, LTM Policy should be able to offer better performance. There are situations where LTM Policy may be a better choice. when rules need to span different events, (e.g. a rule that considers both request and response) dealing with HTTP headers and cookies (e.g. LTM Policy has more direct access to internal HTTP state) when there are large number of conditions (pre-compiled internal decision trees can evaluate conditions in parallel) when conditions have a lot of commonality For supported events (such as HTTP_REQUEST or HTTP_RESPONSE) , LTM Policy evaluation occurs before iRule evaluation. This means that it is possible to write an iRule to override an LTM Policy decision. LTM Policy leverages standard iRule functions Beginning with releases in 2015, selected LTM Policy actions support Tcl command substitutions and the ability to call standard iRule commands . The intention is to empower the administrator with quick, read-only access to the runtime environment. For example, it is possible to specify an expression which includes data about the current connection, such as [HTTP::uri ] which gets substituted at runtime to the URI value of the current request. Tcl support in LTM Policy is not intended as a hook for general purpose programming, and can result in an error when making calls which might have side effects, or calls which might cause a processing delay. There is also a performance trade-off to consider as well, as Tcl’s flexibility comes with a runtime cost. Below is a summary of actions which support Tcl expressions: Target Action(s) Parameter Note http-uri replace value Full URI path URI path component query string URI query string component http-header insert value Arbitrary HTTP header replace value http-cookie insert value Cookie: header http-host replace value Host: header http-referer replace value Referer: header http-set-cookie insert value Set-Cookie: header domain path log message Write to syslog tcl * setvar expression set variable in Tcl runtime environment http-reply * redirect location redirect client to location * This action has supported Tcl expressions since BigIP 11.4. While a comprehensive list of valid Tcl commands is beyond the scope of this document, it should be noted that not every Tcl command will be valid at any given time. Most standard iRule commands are associated with a tmm event , as are LTM Policy actions. For example, in the LTM Policy event request, iRule commands which are valid in the context of HTTP_REQUEST event will validate without error. A validation error will be raised if one attempts to use iRule commands that are not valid in the current event scope. For example, in an LTM Policy action associated with the request (i.e. HTTP_REQUEST) event context, specifying an expression like [HTTP::status] , which is only valid in a response event context, will not pass the validation check. iRules support LTM Policy There are several iRule commands defined which can be used to access information about policies attached to the virtual server. POLICY::controls - iRule command which returns details about the policy controls for the virtual server the iRule is enabled on POLICY::names - iRule command which returns details about the policy names for the virtual server the iRule is enabled on. POLICY::rules - iRule command which returns the policy rules of the supplied policy that had actions executed. POLICY::targets - iRule command which returns or sets properties of the policy rule targets for the policies associated with the virtual server that the iRule is enabled on What can I do with it? Sky's the limit. Here are some sample tasks and LTM Policies that could be used to implement them. Keep in mind that the policy definitions shown below, which at first glance appear to be more complicated than an equivalent iRule, are generated by a more friendly, web-based UI. The web UI allows the policy author to select valid options from menus, and build up a policy with little worry about programming and proper syntax. Task Configuration If system load average over the last minute is above 5, then disable compression. (This example assumes compression is competing for CPU cycles, and would not apply to scenarios where hardware compression is available.) Demonstrates cpu load conditions and ability to control compression. ltm policy /Common/load-avg { controls { compression } requires { http } rules { rule-1 { actions { 0 { compress disable } } conditions { 0 { cpu-usage last-1min greater values { 5 } } } ordinal 1 } } strategy /Common/first-match } If request is coming from California, forward it to pool pool_ca, and if the request comes from Washington, direct it to pool_wa. Otherwise forward to my-default-pool. Demonstrates geo-IP conditions, actions to forward to specific pool, and a default rule. ltm policy /Common/policy-sa { controls { forwarding } requires { http } rules { defaultrule { actions { 0 { forward select pool /Common/my-default-pool } } ordinal 3 } rule-1 { actions { 0 { forward select pool /Common/pool_ca } } conditions { 0 { geoip region-name values { California } } } ordinal 1 } rule-2 { actions { 0 { forward select pool /Common/pool_wa } } conditions { 0 { geoip region-name values { Washington } } } ordinal 2 } } strategy /Common/first-match } If the request was referred by my-affiliate.com and the response contains an image, set a cookie containing the current time. Example of a policy which spans both request and response, and uses Tcl command substitution for a value. ltm policy /Common/affiliate { requires { http } rules { rule-1 { actions { 0 { http-set-cookie response insert name MyAffiliateCookie value "tcl:[clock format [clock seconds] -format %H:%M:%S]" } } conditions { 0 { http-referer contains values { my-affiliate.com } } 1 { http-header response name Content-type starts-with values { image/ } } } ordinal 1 } } strategy /Common/first-match } Some rules of thumb While there are certainly exceptions to any rule, the following are some general usage guidelines. The maximum number of rules across active policies is limited by memory and cpu capability, but more than a thousand is starting to be a lot . Using Tcl command substitutions in actions can have performance implications; the more Tcl, the more performance impact. Only use Tcl commands that read and quickly return data; avoid those that change internal state or cause any delays. Conclusion LTM Policy is a powerful, flexible, and high-performance tool that administrators can leverage for application deployment. Its table-driven user interface requires very little in the way of programming experience, and new capabilities have been added continuously with each release.11KViews1like15Comments
Decrypting TLS traffic on BIG-IP
1 Introduction As soon as I joined F5 Support, over 5 years ago, one of the first things I had to learn quickly was to decrypt TLS traffic becausemost of our customers useL7 applications protectedby TLS layer. In this article, I will show 4 ways to decrypt traffic on BIG-IP, including thenew one just release in v15.xthat is ideal for TLS1.3 where TLS handshake is also encrypted. If that's what you want to know just skip totcpdump --f5 ssl optionsection as this new approach is just a parameter added to tcpdump. As this article is very hands-on, I will show my lab topology for the tests I performed and then every possible way I used to decrypt customer's traffic working for Engineering Services at F5. 2 Lab Topology This is the lab topology I used for the lab test where all tests were performed: Also, for every capture I issued the followingcurlcommand: Update: the virtual server's IP address is actually 10.199.3.145/32 2 The 4 ways to decrypt BIG-IP's traffic RSA private key decryption There are 3 constraints here: Full TLS handshake has to be captured CheckAppendix 2to learn how to to disable BIG-IP's cache RSA key exchange has to be used, i.e. no (EC)DHE CheckAppendix1to understand how to check what's key exchange method used in your TLS connection CheckAppendix 2to understandhow to prioritise RSA as key exchange method Private key has to be copied to Wireshark machine (ssldump command solves this problem) Roughly, to accomplish that we can setCache Sizeto 0 on SSL profile and remove (EC)DHE fromCipher Suites(seeAppendix 1for details) I first took a packet capture using :pmodifier to capture only the client and server flows specific to my Client's IP address (10.199.3.1): Note: The0.0interface will capture any forwarding plane traffic (tmm) andnnnis the highest noise to capture as much flow information as possible to be displayed on the F5 dissector header.For more details about tcpdump syntax, please have a look atK13637: Capturing internal TMM information with tcpdumpandK411: Overview of packet tracing with the tcpdump utility. Also,we need to make sure we capture the full TLS handshake. It's perfectly fine to captureresumed TLS sessionsas long as full TLS handshake has been previously captured. Initially, our capture is unencrypted as seen below: On Mac, I clicked onWireshark→Preferences: ThenProtocols→TLS→RSA keys listwhere we see a window where we can reference BIG-IP's (or server if we want to decrypt server SSL side) private key: Once we get there, we need to add any IP address of the flow we want Wireshark to decrypt, the corresponding port and the private key file (default.crtfor Client SSL profile in this particular lab test): Note:For Client SSL profile, this would be the private key onCertificate Chainfield corresponding to the end entity Certificate being served to client machines through the Virtual Server. For Server SSL profile, the private key is located on the back-end server and the key would be the one corresponding to the end entity Certificate sent in the TLSCertificatemessage sent from back-end server to BIG-IP during TLS handshake. Once we clickOK, we can see the HTTP decrypted traffic (in green): In production environment, we would normally avoid copying private keys to different machines soanother option is usessldumpcommand directly on the server we're trying to capture. Again, if we're capturing Client SSL traffic,ssldumpis already installed on BIG-IP. We would follow the same steps as before but instead of copying private key to Wireshark machine, we would simply issue this command on the BIG-IP (or back-end server if it's Server SSL traffic): Syntax:ssldump-r<capture.pcap>-k<private key.key>-M<type a name for your ssldump file here.pms>. For more details, please have a look atK10209: Overview of packet tracing with the ssldump utility. Inssldump-generated.pms, we should find enough information for Wireshark to decrypt the capture: Syntax:ssldump-r<capture.pcap>-k<private key.key>-M<type a name for your ssldump file here.pms>. For more details, please have a look atK10209: Overview of packet tracing with the ssldump utility. Inssldump-generated.pms, we should find enough information for Wireshark to decrypt the capture: After I clickedOK, we indeed see the decrypted http traffic back again: We didn't have to copy BIG-IP's private key to Wireshark machine here. iRules The only constraint here is that we should apply the iRule to the virtual server in question. Sometimes that's not desirable, especially when we're troubleshooting an issue where we want the configuration to be unchanged. Note: there is abugthat affects versions 11.6.x and 12.x that was fixed on 13.x. It records the wrong TLS Session ID to LTM logs. The workaround would be to manually copy the Session ID from tcpdump capture or to use RSA decryption as in previous example. You can also combine bothSSL::clientrandomandSSL::sessionidwhich isthe ideal: Reference: K12783074: Decrypting SSL traffic using the SSL::sessionsecret iRules command (12.x and later) Again, I took a capture usingtcpdumpcommand: After applying above iRule to our HTTPS virtual server and taking tcpdump capture, I see this on /var/log/ltm: To copy this to a *.pms file wecanuseon Wireshark we can use sed command (reference:K12783074): Note:If you don't want to overwrite completely the PMS file make sure youuse >> instead of >. The endresult would be something like this: As both resumed and full TLS sessions have client random value, I only had to copy CLIENT_RANDOM + Master secret to our PMS file because all Wireshark needs is a session reference to apply master secret. To decrypt file on Wireshark just go toWireshark→Preferences→Protocols→TLS→Pre-Master Key logfile namelike we did inssldumpsection and add file we just created: As seen on LTM logs,CLIENTSSL_HANDSHAKEevent captured master secret from our client-side connection andSERVERSSL_HANDSHAKEfrom server side. In this case, we should have both client and server sides decrypted, even though we never had access to back-end server: Notice added anhttpfilter to show you both client and and server traffic were decrypted this time. tcpdump --f5 ssl option This was introduced in 15.x and we don't need to change virtual server configuration by adding iRules. The only thing we need to do is to enabletcpdump.sslproviderdb variable which is disabled by default: After that, when we take tcpdump capture, we just need to add --f5 ssl to the command like this: Notice that we've got a warning message because Master Secret will be copied to tcpdump capture itself, so we need to be careful with who we share such capture with. I had to update my Wireshark to v3.2.+ and clicked onAnalyze→Enabled Protocols: And enable F5 TLS dissector: Once we open the capture, we can find all the information you need to create our PMS file embedded in the capture: Very cool, isn't it? We can then copy the Master Secretand Client Random values by right clicking like this: And then paste it to a blank PMS file. I first pasted the Client Random value followed by Master Secret value like this: Note: I manually typedCLIENT_RANDOMand then pasted both values for both client and server sides directly from tcpdump capture. The last step was to go toWireshark→Preferences→Protocols→TLSand add it toPre-master-Secret log filenameand clickOK: Fair enough! Capture decrypted on both client and server sides: I usedhttpfilter to display only decrypted HTTP packets just like in iRule section. Appendix 1 How do we know which Key Exchange method is being used? RSA private key can only decrypt traffic on Wireshark if RSA is the key exchange method negotiated during TLS handshake. Client side will tell the Server side which ciphers it support and server side will reply with the chosen cipher onServer Hellomessage. With that in mind, on Wireshark, we'd click onServer Helloheader underCipher Suite: Key Exchange and Authentication both come before theWITHkeyword. In above example, because there's only RSA we can say that RSA is used for both Key Exchange and Authentication. In the following example, ECDHE is used for key exchange and RSAfor authentication: Appendix 2 Disabling Session Resumption and Prioritising RSA key exchange We can set Cache Size to 0 to disableTLS session resumptionand change the Cipher Suites to anything that makes BIG-IP pick RSA for Key Exchange:11KViews12likes10CommentsTLS Fingerprinting - a method for identifying a TLS client without decrypting
Hello, Kevin Stewart here. A while back someone asked an interesting question in the DevCentral forum about selecting a client SSL profile based on the device (ex. iOS, Android, Windows Phone). Normally you'd use a browser User-Agent HTTP header to identify the client user agent, but in this case, and based on the OSI model, you wouldn't be able to select an SSL profile (OSI layer 6) based on a User-Agent HTTP header (OSI layer 7), because at this point in time you don't yet have the layer 7 data - it's still encrypted. You could, however, use layer 3 or 4 data (IPs and ports), but that's generally not useful for identifying the client user agent. But there might still be a way... Lee Brotherston has discovered that during an SSL handshake, most client user agents (different browsers, Dropbox, Skype, etc.) will initiate an SSL handshake request in an ever-so-unique way. The ordered combination of TLS version, record TLS version, ciphersuites, compression options, list of extensions, elliptic curves and signature algorithms are all specific enough that you can actually build a signature based on that data, and the collection of signatures into a database. From that discovery Lee created a project called "tls-fingerprinting". Please check it out. Now certainly, a client's ClientHello could be modified to support different ciphersuites and other features, the same way you could spoof a User-Agent HTTP header. However this modification will often lower security by re-introducing previously unsupported options, or in many cases modification to the user agent's SSL parameters isn't easy or isn't possible. So given that we now have a new way to identify a user agent based on the client's ClientHello (the first message in the SSL handshake), I decided to re-visit the original DC forum request by integrating Lee's database into an iRules-based solution. The code example in the aforementioned thread just used the client's ciphersuite list, however, so today I'm going to expand on that and use all of the paramaters from the tls-fingerprinting database. Before we get started, I should mention two things: This article is going to be long (sorry about that), and We're going to break it down into a few phases, specifically Defining the values in the tls-fingerprinting signature Exporting and converting the tls-fingerprinting database to a BIG-IP external data group Creating a fingerprintTLS PROC iRule (name this "Library-Rule") Creating the caller iRule So let's get started. Defining the values in the tls-fingerprinting signature Here's an example signature entry in Lee's tls-fingerprinting database (JSON version): {"id": 0, "desc": "ThunderBird (v38.0.1 OS X)", "record_tls_version": "0x0301", "tls_version": "0x0303", "ciphersuite_length": "0x0016", "ciphersuite": "0xC02B 0xC02F 0xC00A 0xC009 0xC013 0xC014 0x0033 0x0039 0x002F 0x0035 0x000A", "compression_length": "1", "compression": "0x00", "extensions": "0x0000 0xFF01 0x000A 0x000B 0x0023 0x0005 0x000D 0x0015" , "e_curves": "0x0017 0x0018 0x0019" , "sig_alg": "0x0401 0x0501 0x0201 0x0403 0x0503 0x0203 0x0402 0x0202" , "ec_point_fmt": "0x00" } Broken down it looks like this: { "id": 0, "desc": "ThunderBird (v38.0.1 OS X)", "record_tls_version": "0x0301", "tls_version": "0x0303", "ciphersuite_length": "0x0016", "ciphersuite": "0xC02B 0xC02F 0xC00A 0xC009 0xC013 0xC014 0x0033 0x0039 0x002F 0x0035 0x000A", "compression_length": "1", "compression": "0x00", "extensions": "0x0000 0xFF01 0x000A 0x000B 0x0023 0x0005 0x000D 0x0015" , "e_curves": "0x0017 0x0018 0x0019" , "sig_alg": "0x0401 0x0501 0x0201 0x0403 0x0503 0x0203 0x0402 0x0202" , "ec_point_fmt": "0x00" } This is a pretty straight forward set of JSON key-value pairs. And if you're curious about what any of these values mean, I urge you to fire up Wireshark, open a browser to some HTTPS site, and then find a ClientHello message in the capture. You'll see all of these values and more, except for the first two, in that message. Our job then is to a) export the set of signatures to a BIG-IP external data group, and b) create an iRule that extracts all of these values from the client's ClientHello and compares those to the set of signatures in the data group. Of course iRules don't natively support JSON parsing, and while yes I could use iRulesLX for this, I decided to simply reformat the signatures in the data group to something more condusive to TCL iRules. Exporting and converting the tls-fingerprinting database to a BIG-IP external data group I don't really care about the "id" value, so I'll leave that out. And the "desc" field will be the value in the data group. The key will be the concatenation of all of the remaining fields. "signature_data" := "ThunderBird (v38.0.1 OS X)", I'm also going to remove the "0x" from the hex values, remove whitespace, and delimit each field with the plus (+) sign, so the resulting key for the above signature will look like this: 0301+0303+0016+C02BC02FC00AC009C013C01400330039002F0035000A+1+00+0000FF01000A000B00230005000D0015+001700180019+04010501020104030503020304020202+00 If any of the values don't exist (ex. the signature doesn't have a sig_alg value), that value is replaced with "@@@@" in the resulting key. Okay, so to convert the tls-fingerprinting database to a BIG-IP external data group, you have to: 1. Download it - the current JSON-based database is here: https://github.com/LeeBrotherston/tls-fingerprinting/blob/master/fingerprints/fingerprints.json. Copy that JSON data in whole to a local text file. The conversion script uses BASH, so you need a Linux or Mac box. I named the file 'fingerprint.db'. 2. Convert it - use the following BASH script to extract each of the fields from each of the signatures. I should warn you now that my sed/awk/grep foo isn't strong, so I borrowed a BASH JSON parser from here: https://gist.github.com/cjus/1047794 #!/bin/bash function jsonval () { ## description desc=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "desc" |awk -F": " '{print $2}'` ## record_tls_version rect=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "record_tls_version" |awk -F": " '{print $2}' |sed 's/0x//g'` if [ -z "$rect" ]; then rect="@@@@"; fi ## tls_version tlsv=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "tls_version" |awk -F": " '{print $2}' |sed 's/0x//g'` if [ -z "$tlsv" ]; then tlsv="@@@@"; fi ## ciphersuite_length cipl=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ciphersuite_length" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$cipl" ]; then cipl="@@@@"; fi ## ciphersuite ciph=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ciphersuite" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ciph" ]; then tlsv="ciph"; fi ## compression_length coml=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "compression_length" |awk -F": " '{print $2}'` if [ -z "$coml" ]; then coml="@@@@"; fi ## compression comp=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "compression" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$comp" ]; then comp="@@@@"; fi ## extensions exte=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "extensions" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$exte" ]; then exte="@@@@"; fi ## e_curves ecur=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "e_curves" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ecur" ]; then ecur="@@@@"; fi ## sig_alg siga=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "sig_alg" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$siga" ]; then siga="@@@@"; fi ## ec_point_fmt ecfp=`echo $1 | sed 's/\\\\\//\//g' | sed 's/[{}]//g' | awk -v k="text" '{n=split($0,a,","); for (i=1; i<=n; i++) print a[i]}' | sed 's/\"\:\"/\|/g' | sed 's/[\,]/ /g' | sed 's/\"//g' | grep -w "ec_point_fmt" |awk -F": " '{print $2}' |sed 's/0x//g' |sed 's/ //g'` if [ -z "$ecfp" ]; then ecfp="@@@@"; fi echo "\"$rect+$tlsv+$cipl+$ciph+$coml+$comp+$exte+$ecur+$siga+$ecfp\" := \"$desc\"," } IFS=} for i in `cat fingerprint.db`; do jsonval $i done Create this BASH script however you like (VI, VIM, Joe, Nano, whatever), save it, chmod it so that it'll execute ('chmod 755 parser.sh'), and then run it ('./parser.sh'). It'll just echo the reformatted signatures to the screen, so you'll want to capture that as a file ('./parser.sh > fingerprint.dg'). It's also be a little slow, again due to my aggregious lack of sed/awk/grep (and regex) foo, but it should still finish in less than a minute. 3. Import it - now go to the BIG-IP management UI, and under System - File Management - Data Group File List, click Import. Choose your reformatted text file, give it a meaningful name (ex. fingerprint_db), select "String" as the File Contents type, and use the same name (ex. fingerprint_db) in the Data Group Name field. On a v12 BIG-IP this will auto-create the local data group. On earlier systems you'll need to go manually create the local data group object that points to this external data group. Creating a fingerprintTLS PROC iRule So now that we've reformatted and imported the fingerprintTLS database, let's build the iRule to parse out the data from the client's ClientHello. I should also warn you that this process requires a lot of binary manipulation, so please don't try to ingest it all at once if you're new to iRules. I'm building this iRule as a separate PROC that other data plane iRules can call. It won't be directly attached to a virtual server. ## Library-Rule ## TLS Fingerprint Procedure ################# ## ## Author: Kevin Stewart, 12/2016 ## Derived from Lee Brotherston's "tls-fingerprinting" project @ https://github.com/LeeBrotherston/tls-fingerprinting ## Purpose: to identify the user agent based on unique characteristics of the TLS ClientHello message ## Input: ## Full TCP payload collected in CLIENT_DATA event of a TLS handshake ClientHello message ## Record length (rlen) ## TLS outer version (outer) ## TLS inner version (inner) ## Client IP ## Server IP ############################################## proc fingerprintTLS { payload rlen outer inner clientip serverip } { ## The first 43 bytes of a ClientHello message are the record type, TLS versions, some length values and the ## handshake type. We should already know this stuff from the calling iRule. We're also going to be walking the ## packet, so the field_offset variable will be used to track where we are. set field_offset 43 ## The first value in the payload after the offset is the session ID, which may be empty. Grab the session ID length ## value and move the field_offset variable that many bytes forward to skip it. binary scan ${payload} @${field_offset}c sessID_len set field_offset [expr {${field_offset} + 1 + ${sessID_len}}] ## The next value in the payload is the ciphersuite list length (how big the ciphersuite list is. We need the binary ## and hex values of this data. binary scan ${payload} @${field_offset}S cipherList_len binary scan ${payload} @${field_offset}H4 cipherList_len_hex set cipherList_len_hex_text ${cipherList_len_hex} ## Now that we have the ciphersuite list length, let's offset the field_offset variable to skip over the length (2) bytes ## and go get the ciphersuite list. Multiple by 2 to get the number of appropriate hex characters. set field_offset [expr {${field_offset} + 2}] set cipherList_len_hex [expr {${cipherList_len} * 2}] binary scan ${payload} @${field_offset}H${cipherList_len_hex} cipherlist ## Next is the compression method length and compression method. First move field_offset to skip past the ciphersuite ## list, then grab the compression method length. Then move field_offset past the length (2) bytes and grab the ## compression method value. Finally, move field_offset past the compression method bytes. set field_offset [expr {${field_offset} + ${cipherList_len}}] binary scan ${payload} @${field_offset}c compression_len #set field_offset [expr {${field_offset} + ${compression_len}}] set field_offset [expr {${field_offset} + 1}] binary scan ${payload} @${field_offset}H[expr {${compression_len} * 2}] compression_type set field_offset [expr {${field_offset} + ${compression_len}}] ## We should be in the extensions section now, so we're going to just run through the remaining data and ## pick out the extensions as we go. But first let's make sure there's more record data left, based on ## the current field_offset vs. rlen. if { [expr {${field_offset} < ${rlen}}] } { ## There's extension data, so let's go get it. Skip the first 2 bytes that are the extensions length set field_offset [expr {${field_offset} + 2}] ## Make a variable to store the extension types we find set extensions_list "" ## Pad rlen by 1 byte set rlen [expr ${rlen} + 1] while { [expr {${field_offset} <= ${rlen}}] } { ## Grab the first 2 bytes to determine the extension type binary scan ${payload} @${field_offset}H4 ext ## Store the extension in the extensions_list variable append extensions_list ${ext} ## Increment field_offset past the 2 bytes of the extension type set field_offset [expr {${field_offset} + 2}] ## Grab the 2 bytes of extension lenth binary scan ${payload} @${field_offset}S ext_len ## Increment field_offset past the 2 bytes of the extension length set field_offset [expr {${field_offset} + 2}] ## Look for specific extension types in case these need to increment the field_offset (and because we need their values) switch $ext { "000b" { ## ec_point_format - there's another 1 byte after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 1}]H[expr {(${ext_len} - 1) * 2}] ext_data set ec_point_format ${ext_data} } "000a" { ## elliptic_curves - there's another 2 bytes after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 2}]H[expr {(${ext_len} - 2) * 2}] ext_data set elliptic_curves ${ext_data} } "000d" { ## sig_alg - there's another 2 bytes after length ## Grab the extension data binary scan ${payload} @[expr {${field_offset} + 2}]H[expr {(${ext_len} - 2) * 2}] ext_data set sig_alg ${ext_data} } default { ## Grab the otherwise unknown extension data binary scan ${payload} @${field_offset}H[expr {${ext_len} * 2}] ext_data } } ## Increment the field_offset past the extension data length. Repeat this loop until we reach rlen (the end of the payload) set field_offset [expr {${field_offset} + ${ext_len}}] } } ## Now let's compile all of that data. set cipl [string toupper ${cipherList_len_hex_text}] set ciph [string toupper ${cipherlist}] set coml ${compression_len} set comp [string toupper ${compression_type}] if { ( [info exists extensions_list] ) and ( ${extensions_list} ne "" ) } { set exte [string toupper ${extensions_list}] } else { set exte "@@@@" } if { ( [info exists elliptic_curves] ) and ( ${elliptic_curves} ne "" ) } { set ecur [string toupper ${elliptic_curves}] } else { set ecur "@@@@" } if { ( [info exists sig_alg] ) and ( ${sig_alg} ne "" ) } { set siga [string toupper ${sig_alg}] } else { set siga "@@@@" } if { ( [info exists ec_point_format] ) and ( ${ec_point_format} ne "" ) } { set ecfp [string toupper ${ec_point_format}] } else { set ecfp "@@@@" } ## Initialize the match variable set match "" ## Now let's build the fingerprint string and search the database set fingerprint_str "${outer}+${inner}+${cipl}+${ciph}+${coml}+${comp}+${exte}+${ecur}+${siga}+${ecfp}" ## Un-comment this line to display the fingerprint string in the LTM log for troubleshooting ## log local0. "${clientip}-${serverip}: fingerprint_str = ${fingerprint_str}" if { [class match ${fingerprint_str} equals fingerprint_db] } { ## Direct match set match [class match -value ${fingerprint_str} equals fingerprint_db] } elseif { not ( ${ciph} starts_with "C0" ) and not ( ${ciph} starts_with "00" ) } { ## Hmm.. there's no direct match, which could either mean a database entry doesn't exist, or Chrome (and Opera) are adding ## special values to the cipherlist, extensions list and elliptic curves list. ## ex. 9A9A, 5A5A, EAEA, BABA, etc. at the beginning of the cipherlist ## Let's strip out these anomalous values and try the match again. ## Substract 2 bytes from cipherlist length set cipl [format %04x [expr [expr 0x${cipl}] - 2]] ## Subtract 2 bytes from the front of the cipher list set ciph [string range ${ciph} 4 end] ## Subtract 2 bytes from the front of the extensions list set exte [string range ${exte} 4 end] ## There might be an additional random set in the string that needs to be removed (pattern is "(.)A\1A") regsub {(.)A\1A} ${exte} "" exte ## If the above regsub doesn't work, try the following: #regsub {(\wA)\1} ${exte} "" exte ## Subtract 2 bytes from the front of the elliptic curves list set ecur [string range ${ecur} 4 end] ## Rebuild the fingerprint string set fingerprint_str "${outer}+${inner}+${cipl}+${ciph}+${coml}+${comp}+${exte}+${ecur}+${siga}+${ecfp}" if { [class match ${fingerprint_str} equals fingerprint_db] } { ## Guess match set match [class match -value ${fingerprint_str} equals fingerprint_db] } else { ## No match set match "" } } ## Return the matching user agent string return ${match} } The PROC requires as input the full TCP payload (of the ClientHello message), the record length (extracted from the ClientHello message), the "outer" record TLS version and "inner" TLS version (also extracted form the ClientHello message). Using these values the PROC basically walks the payload looking for each of the required values (ciphersuite length, ciphersuite list, compression length, compression list, extensions list, elliptic curves, signature algorithms, and ec point formats). If any value doesn't exist in the payload (ex. the ClientHello doesn't contain a Sig_Alg field), that value is replaced with "@@@@". Once all of the values are found, the fingerprint string is created and used to search the data group. If there's a match, the user agent string (ex. ThunderBird (v38.0.1 OS X)) is returned to the caller. While testing this I noticed that newer versions of Chrome and Opera added what looked like "markers" to the ciphersuite list, extensions list, and elliptic curves list (ex. 9A9A, 5A5A, EAEA, BABA - always some alphanumeric value, followed by 'A', and repeated.). A cursory search didn't explain what these are, so maybe someone will know and report back. In the meantime, I added a "guess" function that removed these markers and tried the data group search again. All of the desktop browser testing (including Chrome and Opera) did get an accurate match with either the direct or guessed fingerprint, so I'll leave that in there until I find a better way to handle the markers. Creating the caller iRule The only thing left to do is to create the caller iRule. This iRule only needs to detect an SSL/TLS ClientHello, and then pass that to the fingerprint PROC. This is just a stub iRule to show the proper implementation. Once you've determined a TCP packet is an SSL/TLS handshake ClientHello, call the PROC and then do something useful with the resulting user agent string, like switch the client SSL profile. when CLIENT_ACCEPTED { ## Collect the TCP payload TCP::collect } when CLIENT_DATA { ## Get the TLS packet type and versions if { ! [info exists rlen] } { binary scan [TCP::payload] cH4ScH6H4 rtype outer_sslver rlen hs_type rilen inner_sslver if { ( ${rtype} == 22 ) and ( ${hs_type} == 1 ) } { ## This is a TLS ClientHello message (22 = TLS handshake, 1 = ClientHello) ## Call the fingerprintTLS proc set fingerprint [call Library-Rule::fingerprintTLS [TCP::payload] ${rlen} ${outer_sslver} ${inner_sslver} [IP::client_addr] [IP::local_addr]] ### Do Something here ### log local0. "match = ${fingerprint}" ### Do Something here ### } } # Collect the rest of the record if necessary if { [TCP::payload length] < $rlen } { TCP::collect $rlen } ## Release the paylaod TCP::release } What happens if there's no match? Yes, there are some caveats... It's safe to say that the tls-fingerprinting database isn't all inclusive. In fact it's FAR FROM COMPLETE and not always exact.I found, for example, that my version of Dropbox on a Win7 box (v16.4.30) doesn't make a match. It's nearly impossible to have the signature for every unique user agent every created, and all of the variations and versions of that agent. But what the database does have is the signatures for most browsers, so at the very least it makes for a nice way to whitelist browsers (vs. other agents). It also doesn't technically resolve the question in the original DC forum thread. The question was how to identify the device (ie. iOS, Android, Windows Phone), and for that you'd need some specific agent loaded on the device (not a browser) that could report that information. Mobile device management (MDM) solutions are particularly good at that sort of thing. The browser, Dropbox or other user agent on the mobile device may not specifically report the device (ex. "for iOS"). Some do, but I've found that most don't. At the end of this aticle I've included a few signatures that I found in my testing that aren't in the database. If your curious, uncomment thelog local0. "${clientip}-${serverip}: fingerprint_str = ${fingerprint_str}"line in the fingerprintTLS PROC and then tail the LTM log. The caller iRule is already logging the returned user agent string, so if that is empty, you'll see the empty match in the log (match =), preceded by the unmatched signature. Where this project may be most useful is in outbound traffic management, where you want to decrypt and inspect the Internet-bound traffic, but cannot decrypt some user agents becuase of things like cerificate pinning. Since the pinning decision happens at the client, the only other recourse is to bypass decryption and inspection based on the destination host name or IP address, which can be a tedious thing to manage. TLS fingerprinting might allow you to simply decrypt and inspect for the user agents that you know aren't affected by pinning, specifically browsers. You'll potentially miss some things that you could have decrypted, but you'll save yourself the burden of managing an ever-growing list of pinner exclusions. And on a final note, binary iRule manipulation is a very CPU-intensive thing to do. I could have very simply converted the raw payload to one long hex string (once) and walked that with string tools. I'll update the code when I have some time. Thanks. - Kevin Additional Signatures "0301+0303+0028+C02BC02F009ECC14CC13C00AC009C013C014C007C011003300320039009C002F0035000A00050004+1+00+0000FF01000A000B0023755000050012000D+001700180019+04010501020104030503020304020202+00" := "Dropbox", "0301+0303+0028+C02BC02F009ECC14CC13C00AC009C013C014C007C011003300320039009C002F0035000A00050004+1+00+0000FF01000A000B002300050012000D+001700180019+04010501020104030503020304020202+00" := "Dropbox", "0301+0303+001A+C030C028C014C02FC027C013009F006B0039009E0067003300FF+1+00+0000000B000A0023000D+00170019001C001B0018001A0016000E000D000B000C0009000A+060106020603050105020503040104020403030103020303020102020203+000102" := "Dropbox", "0301+0303+0094+C030C02CC032C02EC02FC02BC031C02D00A500A300A1009F00A400A200A0009EC028C024C014C00AC02AC026C00FC005006B006A006900680039003800370036C027C023C013C009C029C025C00EC00400670040003F003E0033003200310030C012C008C00DC00300880087008600850045004400430042001600130010000D009D009C003D0035003C002F00840041000A00FF+1+00+000B000A0023000D0015+00170019001C001B0018001A0016000E000D000B000C0009000A+060106020603050105020503040104020403030103020303020102020203+000102" := "Dropbox", "0301+0303+0028+C02BC02CC02FC030009E009FC009C00AC013C01400330039C007C011009C009D002F0035000500FF+1+00+0000000B000A0023000D+000E000D0019000B000C00180009000A00160017000800060007001400150004000500120013000100020003000F00100011+060106020603050105020503040104020403030103020303020102020203+000102" := "Android Google API Access", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D0005337400120010000B000A+00170018+0601060305010503040104030301030302010203+00" := "Chrome 47.0.2526.83", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D0005337400120010000B000A+00170018+0601060305010503040104030301030302010203+00" := "Chrome 48.0.2564.97", "0301+0303+001E+CC14CC13C02BC02F009EC00AC0140039C009C0130033009C0035002F000A+1+00+FF01000000170023000D00053374001200107550000B000A0015+00170018+0601060305010503040104030301030302010203+00" := "Chrome 48.0.2564.97", "0301+0303+0022+CCA9CCA8CC14CC13C02BC02FC02CC030C009C013C00AC014009C009D002F0035000A+1+00+FF01000000170023000D0005001200107550000B000A0018+001D00170018+06010603050105030401040302010203+00" := "Android Silk Browser", "0301+0303+0022+CCA9CCA8CC14CC13C02BC02FC02CC030C009C013C00AC014009C009D002F0035000A+1+00+FF01000000170023000D0005001200107550000B000A00180015+001D00170018+06010603050105030401040302010203+00" := "Android Silk Browser" "0303+0303+0038+C02CC02BC030C02F009F009EC024C023C028C027C00AC009C014C01300390033009D009C003D003C0035002F000A006A0040003800320013+1+00+0005000A000B000D0023001000175500FF01+001D00170018+040105010201040305030203020206010603+00" := "Internet Explorer 11.447.14393.0(Win 10)", "0301+0303+0022+C02BC02FC02CC030CCA9CCA8CC14CC13C009C013C00AC014009C009D002F0035000A+1+00+FF0100170023000D0005001200107550000B000A+001D00170018+06010603050105030401040302010203+00" := "Chrome 55.0.2883.87",9.9KViews3likes8Comments