F5 Predicts: Education gets personal
The topic of education is taking centre stage today like never before. I think we can all agree that education has come a long way from the days where students and teachers were confined to a classroom with a chalkboard. Technology now underpins virtually every sector and education is no exception. The Internet is now the principal enabling mechanism by which students assemble, spread ideas and sow economic opportunities. Education data has become a hot topic in a quest to transform the manner in which students learn. According to Steven Ross, a professor at the Centre for Research and Reform in Education at Johns Hopkins University, the use of data to customise education for students will be the key driver for learning in the future[1].This technological revolution has resulted in a surge of online learning courses accessible to anyone with a smart device. A two-year assessment of the massive open online courses (MOOCs) created by HarvardX and MITxrevealed that there were 1.7 million course entries in the 68 MOOC [2].This translates to about 1 million unique participants, who on average engage with 1.7 courses each. This equity of education is undoubtedly providing vast opportunities for students around the globe and improving their access to education. With more than half a million apps to choose from on different platforms such as the iOS and Android, both teachers and students can obtain digital resources on any subject. As education progresses in the digital era, here are some considerations for educational institutions to consider: Scale and security The emergence of a smogasborad of MOOC providers, such as Coursera and edX, have challenged the traditional, geographical and technological boundaries of education today. Digital learning will continue to grow driving the demand for seamless and user friendly learning environments. In addition, technological advancements in education offers new opportunities for government and enterprises. It will be most effective if provided these organisations have the ability to rapidly scale and adapt to an all new digital world – having information services easily available, accessible and secured. Many educational institutions have just as many users as those in large multinational corporations and are faced with the issue of scale when delivering applications. The aim now is no longer about how to get fast connection for students, but how quickly content can be provisioned and served and how seamless the user experience can be. No longer can traditional methods provide our customers with the horizontal scaling needed. They require an intelligent and flexible framework to deploy and manage applications and resources. Hence, having an application-centric infrastructure in place to accelerate the roll-out of curriculum to its user base, is critical in addition to securing user access and traffic in the overall environment. Ensuring connectivity We live in a Gen-Y world that demands a high level of convenience and speed from practically everyone and anything. This demand for convenience has brought about reform and revolutionised the way education is delivered to students. Furthermore, the Internet of things (IoT), has introduced a whole new raft of ways in which teachers can educate their students. Whether teaching and learning is via connected devices such as a Smart Board or iPad, seamless access to data and content have never been more pertinent than now. With the increasing reliance on Internet bandwidth, textbooks are no longer the primary means of educating, given that students are becoming more web oriented. The shift helps educational institutes to better personalise the curriculum based on data garnered from students and their work. Duty of care As the cloud continues to test and transform the realms of education around the world, educational institutions are opting for a centralised services model, where they can easily select the services they want delivered to students to enhance their learning experience. Hence, educational institutions have a duty of care around the type of content accessed and how it is obtained by students. They can enforce acceptable use policies by only delivering content that is useful to the curriculum, with strong user identification and access policies in place. By securing the app, malware and viruses can be mitigated from the institute’s environment. From an outbound perspective, educators can be assured that students are only getting the content they are meant to get access to. F5 has the answer BIG-IP LTM acts as the bedrock for educational organisations to provision, optimise and deliver its services. It provides the ability to publish applications out to the Internet in a quickly and timely manner within a controlled and secured environment. F5 crucially provides both the performance and the horizontal scaling required to meet the highest levels of throughput. At the same time, BIG-IP APM provides schools with the ability to leverage virtual desktop infrastructure (VDI) applications downstream, scale up and down and not have to install costly VDI gateways on site, whilst centralising the security decisions that come with it. As part of this, custom iApps can be developed to rapidly and consistently deliver, as well as reconfigure the applications that are published out to the Internet in a secure, seamless and manageable way. BIG-IP Application Security Manager (ASM) provides an application layer security to protect vital educational assets, as well as the applications and content being continuously published. ASM allows educational institutes to tailor security profiles that fit like a glove to wrap seamlessly around every application. It also gives a level of assurance that all applications are delivered in a secure manner. Education tomorrow It is hard not to feel the profound impact that technology has on education. Technology in the digital era has created a new level of personalised learning. The time is ripe for the digitisation of education, but the integrity of the process demands the presence of technology being at the forefront, so as to ensure the security, scalability and delivery of content and data. The equity of education that technology offers, helps with addressing factors such as access to education, language, affordability, distance, and equality. Furthermore, it eliminates geographical boundaries by enabling the mass delivery of quality education with the right policies in place. [1] http://www.wsj.com/articles/SB10001424052702304756104579451241225610478 [2] http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2586847844Views0likes3Comments
F5 in AWS Part 4 - Orchestrating BIG-IP Application Services with Open-Source tools
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 The following post references code hosted at F5's Github repository f5networks/aws-deployments. This code provides a demonstration of using open-source tools to configure and orchestrate BIG-IP. Full documentation for F5 BIG-IP cloud work can be found at Cloud Docs: F5 Public Cloud Integrations. So far we have talked above AWS networking basics, how to run BIG-IP in a VPC, and highly-available deployment footprints. In this post, we’ll move on to my favorite topic, orchestration. By this point, you probably have several VMs running in AWS. You’ve lost track of which configuration is setup on which VM, and you have found yourself slowly going mad as you toggle between the AWS web portal and several SSH windows. I call this ‘point-and-click’ purgatory. Let's be blunt, why would you move to cloud without realizing the benefits of automation, of which cloud is a large enabler. If you remember our second article, we mentioned CloudFormation templates as a great way to deploy a standardized set of resources (perhaps BIG-IP + the additional virtualized network resources) in EC2. This is a great start, but we need to configure these resources once they have started, and we need a way to define and execute workflows which will run across a set of hosts, perhaps even hosts which are external to the AWS environment. Enter the use of open-source configuration management and workflow tools that have been popularized by the software development community. Open-source configuration management and AWS APIs Lately, I have been playing with Ansible, which is a python-based, agentless workflow engine for IT automation. By agentless, I mean that you don’t need to install an agent on hosts under management. Ansible, like the other tools, provides a number of libraries (or “modules”) which provide the ability to manage a diverse collection of remote systems. These modules are typically implemented through the use of API calls, often over HTTP. Out of the box, Ansible comes with several modules for managing resources in AWS. While the EC2 libraries provided are useful for basic orchestration use cases, we decided it would be easier to atomically manage sets of resources using the CloudFormation module. In doing so, we were able to deploy entire CloudFormation stacks which would include items like VPCs, networking elements, BIG-IP, app servers, etc. Underneath the covers, the CloudFormation: Ansible module and our own project use the python module to interact with AWS service endpoints. Ansible provides some basic modules for managing BIG-IP configuration resources. These along with libraries for similar tools can be found here: Ansible Puppet SaltStack In the rest of this post, I’ll discuss some work colleagues and I have done to automate BIG-IP deployments in AWS using Ansible. While we chose to use Ansible, we readily admit that Puppet, Chef, Salt and whatever else you use are all appropriate choices for implementing deployment and configuration management workflows for your network. Each have their upsides and downsides, and different tools may lend themselves to different use cases for your infrastructure. Browse the web to figure out which tool is right for you. Using Standardized BIG-IP Interfaces Speaking of APIs, for years F5 has provided the ability to programmatically configure BIG-IP using iControlSOAP. As the audiences performing automation work have matured, so have the weapons of choice. The new hot ticket is REST (Representational State Transfer), and guess what, BIG-IP has a REST interface (you can probably figure out what it is called). Together, iControlSOAP and iControlREST give you the power to manage nearly every configuration element and feature of BIG-IP. These interfaces become extremely powerful when you combine them with your favorite open-source configuration management tool and a cloud that allows you to spin up and down compute and networking resources. In the project described below, we have also made use of iApps using iControlRest as a way to create a standard virtual server configuration with the correct policies and profiles. The documentation in Github describes this in detail, but our approach shows how iApps provide a strongly supported approach for managing network policy across engineering teams. For example, imagine that a team of software engineers has written a framework to deploy applications. You can package the network policy into iApps for various types of apps, and pass these to the teams writing the deployment framework. Implementing a Service Catalog To pull the above concepts together, a colleague and I put together the aws-deployments project.The goal was to build a simple service catalog which would enable a user to deploy a containerized application in EC2 with BIG-IP network services sitting in front. This is example code that is not supported by F5 support but is a proof of concept to show how you can fully automate production-like deployments in AWS. Some highlights of the project include: Use of iControlRest and iControlSoap within Ansible playbooks to setup advanced topologies of BIG-IP in AWS. Automated deployment of a basic ASM web application firewall policy to protect a vulnerable web app (Hackazon. Use of iApps to manage virtual server configurations, including the WAF policy mentioned above. Figure 1 - Generic Architecture for automating application deployments in public or private cloud In examination of the code, you will see that we provide the opportunity to provision all the development models outlined in our earlier post (a single standalone VE, standalones BIG-IP VEs striped availability zones, clusters within an availability zone, etc). We used Ansible and the interfaces on BIG-IP to orchestrate the workflows assoiated with these deployment models. To perform the clustering step, we have used the iControlSoap interface on BIG-IP. The final set of technology used is depicted in Figure 3. Figure 2 - Technologies used in the aws-deployments project on Github Read the Code and Test It Yourself All the code I have mentioned is available at f5networks/aws-deployments. We encourage you to download and run the code for yourself. Instructions for setting up a development environment which includes the necessary dependencies is easy. We have packaged all the dependencies for use with either Vagrant or Docker as development tools. The instructions for either of these approaches can be found in the README.md or in the /docs directory. The following video shows an end-to-end usage example. (Keep in mind that the code has been updated since this video was produced). At the end of the day, our goal for this work was to collect customer feedback. Please provide some by leaving a comment below, or by filing ‘pull requests’ or ‘issues’ in Github. In the next few weeks, we will be updating the project to include the Hackazon app mentioned above, show how to cluster BIG-IP across availability zones, and how to deploy an ASM profile with an iApp. Have fun!1.3KViews1like3Comments
F5 in AWS Part 5 - Cloud-init, Single-NIC, and Auto Scale Out in BIG-IP
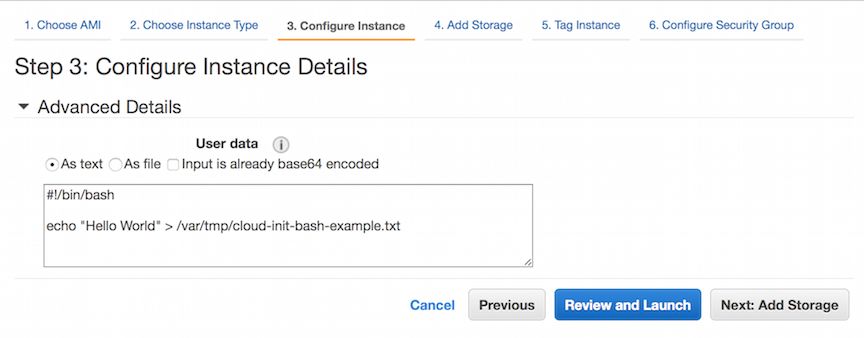
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 The following article covers features and examplesin the 12.1 AWS Marketplace release, discussed in the following documentation: Amazon Web Services: Single NIC BIG-IP VE Amazon Web Services: Auto Scaling BIG-IP VE You can find the BIG-IP Hourly and BYOL releases in the Amazon marketplace here. BIG-IP utility billing images are available, which makes it a great time to talk about some of the functionality. So far in Chris’s series, we have discussed some of the highly-available deployment footprints of BIG-IP in AWS and how these might be orchestrated. Several of these footprints leverage BIG-IP's Device Service Clustering (DSC) technology for configuration management across devices and also lend themselves to multi-app or multi-tenant configurations in a shared-service model. But what if you want to deploy BIG-IP on a per-app or per-tenant basis, in a horizontally scalable footprint that plays well with the concepts of elasticity and immutability in cloud? Today we have just the option for you. Before highlighting these scalable deployment models in AWS, we need to cover cloud-init and single-NIC configurations; two important additions to BIG-IP that enable an Auto Scaling topology. Elasticity Elastiity is obviously one of the biggest promises/benefits of cloud. By leveraging cloud, we are essentially tapping into the "unlimited" (at least relative to our own datacenters) resources large cloud providers have built. In actual practice, this means adopting new methodologies and approaches to truely deliver this. Immutablity In traditional operational model of datacenters, everything was "actively" managed. Physical Infrastructure still tends to lend itself to active management but even virtualized services and applications running on top of the infrastructure were actively managed. For example, servers were patched, code was live upgraded inplace, etc. However, to achieve true elasticity, where things are spinning up or down and more ephemeral in nature, it required a new approach. Instead of trying to patch or upgrade individual instances, the approach was treating them as disposable which meant focusing more on the build process itself. ex. Netflix's famous Building with Legos approach. Yes, the concept of golden images/snapshots existed since virtualization but cloud, with self-service, automation and auto scale functionality, forced this to a new level. Operations focus shifted more towards a consistent and repeatable "build" or "packaging" effort, with final goal of creating instances that didn't need to be touched, logged into, etc. In the specific context of AWS's Auto Scale groups, that means modifying the Auto Scale Group's "launch config". The steps for creating the new instances involve either referencing an entirely new image ID or maybe modification to a cloud-init config. Cloud-init What is it? First, let’s talk about cloud-init as it is used with most Linux distributions. Most of you who are evaluating or operating in the cloud have heard of it. For those who haven’t, cloud-init is an industry standard for bootstrapping machines at startup. It provides a simple domain specific language for common infrastructure provisioning tasks. You can read the official docs here. For the average linux or systems engineer, cloud-init is used to perform tasks such as installing a custom package, updating yum repositories or installing certificates to perform final customizations to a "base" or “golden” image. For example, the Security team might create an approved hardened base image and various Dev teams would use cloud-init to customize the image so it booted up with an ‘identity’ if you will – an application server with an Apache webserver running or a database server with MySQL provisioned. Let’s start with the most basic "Hello World" use of cloud-init, passing in User Data (in this case a simple bash script). If launching an instance via the AWS Console, on the Configure Instance page, navigate down the “Advanced Details”: Figure 1: User Data input field - bash However, User Data is limited to < 16KBs and one of the real powers of cloud-init came from extending functionality past this boundry and providing a standardized way to provision, or ah humm, "initialize" instances.Instead of using unwieldy bash scripts that probed whether it was an Ubuntu or a Redhat instance and used this OS method or that OS method (ex. use apt-get vs. rpm) to install a package, configure users, dns settings, mount a drive, etc. you could pass a yaml file starting with #cloud-config file that did a lot of this heavy lifting for you. Figure 2: User Data input field - cloud-config Similar to one of the benefits of Chef, Puppet, Salt or Ansible, it provided a reliable OS or distribution abstraction but where those approaches require external orchestration to configure instances, this was internally orchestrated from the very first boot which was more condusive to the "immutable" workflow. NOTE: cloud-init also compliments and helps boot strap those tools for more advanced or sophisticated workflows (ex. installing Chef/Puppet to keep long running non-immutable services under operation/management and preventing configuration drift). This brings us to another important distinction. Cloud-init originated as a project from Canonical (Ubuntu) and was designed for general purpose OSs. The BIG-IP's OS (TMOS) however is a highly customized, hardened OS so most of the modules don't strictly apply. Much of the Big-IP's configuration is consumed via its APIs (TMSH, iControl REST, etc.) and stored in it's database MCPD. We can still achieve some of the benefits of having cloud-init but instead, we will mostly leverage the simple bash processor. So when Auto Scaling BIG-IPs, there are a couple of approaches. 1) Creating a custom image as described in the official documentation. 2) Providing a cloud-init configuration This is a little lighter weight approach in that it doesn't require the customization work above. 3) Using a combination of the two, creating a custom image and leveraging cloud-init. For example, you may create a custom image with ASM provisioned, SSL certs/keys installed, and use cloud-init to configure additional environment specific elements. Disclaimer: Packaging is an art, just look at the rise of Docker and new operating systems. Ideally, the more you bake into the image upfront, the more predictable it will be and faster it deploys. However, the less you build-in, the more flexible you can be. Things like installing libraries, compiling, etc. are usually worth building in the image upfront. However, the BIG-IP is already a hardened image and things like installing libraries is not something required or recommended so the task is more about addressing the last/lighter weight configuration steps. However, depending on your priorities and objectives,installing sensitive keying material, setting credentials, pre-provisioning modules, etc. might make good candidates for investing in building custom images. Using Cloud-init with CloudFormation templates Remember when we talked about how you could use CloudFormation templates in a previous post to setup BIG-IP in a standard way? Because the CloudFormation service by itself only gave us the ability to lay down the EC2/VPC infrastructure, we were still left with remaining 80% of the work to do; we needed an external agent or service (in our case Ansible) to configure the BIG-IP and application services. Now, with cloud-init on the BIG-IP (using version 12.0 or later), we can perform that last 80% for you. Using Cloud-init with BIG-IP As you can imagine, there’s quite a lot you can do with just that one simple bash script shown above. However, more interestingly, we also installed AWS’s Cloudformation Helper scripts. http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-helper-scripts-reference.html to help extend cloud-init and unlock a larger more powerful set of AWS functionality. So when used with Cloudformation, our User Data simply changes to executing the following AWS Cloudformation helper script instead. "UserData": { "Fn::Base64": { "Fn::Join": [ "", [ "#!/bin/bash\n", "/opt/aws/apitools/cfn-init-1.4-0.amzn1/bin/cfn-init -v -s ", { "Ref": "AWS::StackId" }, " -r ", "Bigip1Instance", " --region ", { "Ref": "AWS::Region" }, "\n" ] ] } } This allows us to do things like obtaining variables passed in from Cloudformation environment, grabbing various information from the metadata service, creating or downloading files, running particular sequence of commands, etc. so once BIG-IP has finishing running, our entire application delivery service is up and running. For more information, this page discusses how meta-data is attached to an instance using CloudFormation templates: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-init.html#aws-resource-init-commands. Example BYOL and Utility CloudFormation Templates We’ve posted several examples on github to get you started. https://github.com/f5networks/f5-aws-cloudformation In just a few short clicks, you can have an entire BIG-IP deployment up and running. The two examples belowwill launch an entire reference stack complete with VPCs, Subnets, Routing Tables, sample webserver, etc. andshow the use of cloud-init to bootstrap a BIG-IP. Cloud-init is used to configure interfaces, Self-IPs, database variables, a simple virtual server, and in the case of of the BYOL instance, to license BIG-IP. Let’s take a closer look at the BIG-IP resource created in one of these to see what’s going on here: "Bigip1Instance ": { "Metadata ": { "AWS::CloudFormation::Init ": { "config ": { "files ": { "/tmp/firstrun.config ": { "content ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", "HOSTNAME=`curl http://169.254.169.254/latest/meta-data/hostname`\n ", "TZ='UTC'\n ", "BIGIP_ADMIN_USERNAME=' ", { "Ref ": "BigipAdminUsername " }, "'\n ", "BIGIP_ADMIN_PASSWORD=' ", { "Ref ": "BigipAdminPassword " }, "'\n ", "MANAGEMENT_GUI_PORT=' ", { "Ref ": "BigipManagementGuiPort " }, "'\n ", "GATEWAY_MAC=`ifconfig eth0 | egrep HWaddr | awk '{print tolower($5)}'`\n ", "GATEWAY_CIDR_BLOCK=`curl http://169.254.169.254/latest/meta-data/network/interfaces/macs/${GATEWAY_MAC}/subnet-ipv4-cidr-block`\n ", "GATEWAY_NET=${GATEWAY_CIDR_BLOCK%/*}\n ", "GATEWAY_PREFIX=${GATEWAY_CIDR_BLOCK#*/}\n ", "GATEWAY=`echo ${GATEWAY_NET} | awk -F. '{ print $1\ ".\ "$2\ ".\ "$3\ ".\ "$4+1 }'`\n ", "VPC_CIDR_BLOCK=`curl http://169.254.169.254/latest/meta-data/network/interfaces/macs/${GATEWAY_MAC}/vpc-ipv4-cidr-block`\n ", "VPC_NET=${VPC_CIDR_BLOCK%/*}\n ", "VPC_PREFIX=${VPC_CIDR_BLOCK#*/}\n ", "NAME_SERVER=`echo ${VPC_NET} | awk -F. '{ print $1\ ".\ "$2\ ".\ "$3\ ".\ "$4+2 }'`\n ", "POOLMEM=' ", { "Fn::GetAtt ": [ "Webserver ", "PrivateIp " ] }, "'\n ", "POOLMEMPORT=80\n ", "APPNAME='demo-app-1'\n ", "VIRTUALSERVERPORT=80\n ", "CRT='default.crt'\n ", "KEY='default.key'\n " ] ] }, "group ": "root ", "mode ": "000755 ", "owner ": "root " }, "/tmp/firstrun.utils ": { "group ": "root ", "mode ": "000755 ", "owner ": "root ", "source ": "http://cdn.f5.com/product/templates/utils/firstrun.utils " } "/tmp/firstrun.sh ": { "content ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", ". /tmp/firstrun.config\n ", ". /tmp/firstrun.utils\n ", "FILE=/tmp/firstrun.log\n ", "if [ ! -e $FILE ]\n ", " then\n ", " touch $FILE\n ", " nohup $0 0<&- &>/dev/null &\n ", " exit\n ", "fi\n ", "exec 1<&-\n ", "exec 2<&-\n ", "exec 1<>$FILE\n ", "exec 2>&1\n ", "date\n ", "checkF5Ready\n ", "echo 'starting tmsh config'\n ", "tmsh modify sys ntp timezone ${TZ}\n ", "tmsh modify sys ntp servers add { 0.pool.ntp.org 1.pool.ntp.org }\n ", "tmsh modify sys dns name-servers add { ${NAME_SERVER} }\n ", "tmsh modify sys global-settings gui-setup disabled\n ", "tmsh modify sys global-settings hostname ${HOSTNAME}\n ", "tmsh modify auth user admin password \ "'${BIGIP_ADMIN_PASSWORD}'\ "\n ", "tmsh save /sys config\n ", "tmsh modify sys httpd ssl-port ${MANAGEMENT_GUI_PORT}\n ", "tmsh modify net self-allow defaults add { tcp:${MANAGEMENT_GUI_PORT} }\n ", "if [[ \ "${MANAGEMENT_GUI_PORT}\ " != \ "443\ " ]]; then tmsh modify net self-allow defaults delete { tcp:443 }; fi \n ", "tmsh mv cm device bigip1 ${HOSTNAME}\n ", "tmsh save /sys config\n ", "checkStatusnoret\n ", "sleep 20 \n ", "tmsh save /sys config\n ", "tmsh create ltm pool ${APPNAME}-pool members add { ${POOLMEM}:${POOLMEMPORT} } monitor http\n ", "tmsh create ltm policy uri-routing-policy controls add { forwarding } requires add { http } strategy first-match legacy\n ", "tmsh modify ltm policy uri-routing-policy rules add { service1.example.com { conditions add { 0 { http-uri host values { service1.example.com } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 1 } }\n ", "tmsh modify ltm policy uri-routing-policy rules add { service2.example.com { conditions add { 0 { http-uri host values { service2.example.com } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 2 } }\n ", "tmsh modify ltm policy uri-routing-policy rules add { apiv2 { conditions add { 0 { http-uri path starts-with values { /apiv2 } } } actions add { 0 { forward select pool ${APPNAME}-pool } } ordinal 3 } }\n ", "tmsh create ltm virtual /Common/${APPNAME}-${VIRTUALSERVERPORT} { destination 0.0.0.0:${VIRTUALSERVERPORT} mask any ip-protocol tcp pool /Common/${APPNAME}-pool policies replace-all-with { uri-routing-policy { } } profiles replace-all-with { tcp { } http { } } source 0.0.0.0/0 source-address-translation { type automap } translate-address enabled translate-port enabled }\n ", "tmsh save /sys config\n ", "date\n ", "# typically want to remove firstrun.config after first boot\n ", "# rm /tmp/firstrun.config\n " ] ] }, "group ": "root ", "mode ": "000755 ", "owner ": "root " } }, "commands ": { "b-configure-Bigip ": { "command ": "/tmp/firstrun.sh\n " } } } } }, "Properties ": { "ImageId ": { "Fn::FindInMap ": [ "BigipRegionMap ", { "Ref ": "AWS::Region " }, { "Ref ": "BigipPerformanceType " } ] }, "InstanceType ": { "Ref ": "BigipInstanceType " }, "KeyName ": { "Ref ": "KeyName " }, "NetworkInterfaces ": [ { "Description ": "Public or External Interface ", "DeviceIndex ": "0 ", "NetworkInterfaceId ": { "Ref ": "Bigip1ExternalInterface " } } ], "Tags ": [ { "Key ": "Application ", "Value ": { "Ref ": "AWS::StackName " } }, { "Key ": "Name ", "Value ": { "Fn::Join ": [ " ", [ "BIG-IP: ", { "Ref ": "AWS::StackName " } ] ] } } ], "UserData ": { "Fn::Base64 ": { "Fn::Join ": [ " ", [ "#!/bin/bash\n ", "/opt/aws/apitools/cfn-init-1.4-0.amzn1/bin/cfn-init -v -s ", { "Ref ": "AWS::StackId " }, " -r ", "Bigip1Instance ", " --region ", { "Ref ": "AWS::Region " }, "\n " ] ] } } }, "Type ": "AWS::EC2::Instance " } Above may look like a lot at first but high level, we start by creating some files "inline" as well as “sourcing” some files from a remote location. /tmp/firstrun.config - Here we create a file inline, laying down variables from the Cloudformation Stack deployment itself and even the metadata service (http://169.254.169.254/latest/meta-data/). Take a look at the “Ref” stanzas. When this file is laid down on the BIG-IP disk itself, those variables will be interpolated and contain the actual contents. The idea here is to try to keep config and execution separate. /tmp/firstrun.utils – These are just some helper functions to help with initial provisioning. We use those to determine when the BIG-IP is ready for this particular configuration (ex. after a licensing or provisioning step). Note that instead of creating the file inline like the config file above, we simply “source” or download the file from a remote location. /tmp/firstrun.sh – This file is created inline as well and where it really all comes together. The first thing we do is load config variables from the firstrun.conf file and load the helper functions from firstrun.utils. We then create separate log file (/tmp/firstrun.log) to capture the output of this particular script. Capturing the output of these various commands just helps with debugging runs. Then we run a function called checkF5Ready (that we loaded from that helper function file) to make sure BIG-IP’s database is up and ready to accept a configuration. The rest may look more familiar and where most of the user customization takes place. We use variables from the config file to configure the BIG-IP using familiar methods like TMSH and iControl REST. Technically, you could lay down an entire config file (like SCF) and load it instead. We use tmsh here for simplicity. The possibilities are endless though. Disclaimer: the specific implementation above will certainly be optimized and evolve but the most important take away is we can now leverage cloud-init and AWS's helper libraries to help bootstrap the BIG-IP into a working configuration from the very first boot! Debugging Cloud-init What if something goes wrong? Where do you look for more information? The first place you might look is in various cloud-init logs in /var/log (cloud-init.log, cfn-init.log, cfn-wire.log): Below is an example for the CFTs below: [admin@ip-10-0-0-205:NO LICENSE:Standalone] log # tail -150 cfn-init.log 2016-01-11 10:47:59,353 [DEBUG] CloudFormation client initialized with endpoint https://cloudformation.us-east-1.amazonaws.com 2016-01-11 10:47:59,353 [DEBUG] Describing resource BigipEc2Instance in stack arn:aws:cloudformation:us-east-1:452013943082:stack/as-testing-byol-bigip/07c962d0-b893-11e5-9174-500c217b4a62 2016-01-11 10:47:59,782 [DEBUG] Not setting a reboot trigger as scheduling support is not available 2016-01-11 10:47:59,790 [INFO] Running configSets: default 2016-01-11 10:47:59,791 [INFO] Running configSet default 2016-01-11 10:47:59,791 [INFO] Running config config 2016-01-11 10:47:59,792 [DEBUG] No packages specified 2016-01-11 10:47:59,792 [DEBUG] No groups specified 2016-01-11 10:47:59,792 [DEBUG] No users specified 2016-01-11 10:47:59,792 [DEBUG] Writing content to /tmp/firstrun.config 2016-01-11 10:47:59,792 [DEBUG] No mode specified for /tmp/firstrun.config 2016-01-11 10:47:59,793 [DEBUG] Writing content to /tmp/firstrun.sh 2016-01-11 10:47:59,793 [DEBUG] Setting mode for /tmp/firstrun.sh to 000755 2016-01-11 10:47:59,793 [DEBUG] Setting owner 0 and group 0 for /tmp/firstrun.sh 2016-01-11 10:47:59,793 [DEBUG] Running command b-configure-BigIP 2016-01-11 10:47:59,793 [DEBUG] No test for command b-configure-BigIP 2016-01-11 10:47:59,840 [INFO] Command b-configure-BigIP succeeded 2016-01-11 10:47:59,841 [DEBUG] Command b-configure-BigIP output: % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 40 0 40 0 0 74211 0 --:--:-- --:--:-- --:--:-- 40000 2016-01-11 10:47:59,841 [DEBUG] No services specified 2016-01-11 10:47:59,844 [INFO] ConfigSets completed 2016-01-11 10:47:59,851 [DEBUG] Not clearing reboot trigger as scheduling support is not available [admin@ip-10-0-0-205:NO LICENSE:Standalone] log # If trying out the example templates above, you can inspect the various files mentioned. Ex. In addition to checking for their general presence: /tmp/firstrun.config= make sure variables were passed as you expected. /tmp/firstrun.utils= Make sure exists and was downloaded /tmp/firstrun.log = See if any obvious errors were outputted. It may also be worth checking AWS Cloudformation Console to make sure you passed the parameters you were expecting. Single-NIC Another one of the important building blocks introduced with 12.0 on AWS and Azure Virtual Editions is the ability to run BIG-IP with just a single network interface. Typically, BIG-IPs were deployed in a multi-interface model, where interfaces were attached to an out-of-band management network and one or more traffic (or "data-plane") networks. But, as we know, cloud architectures scale by requiring simplicity, especially at the network level. To this day, some clouds can only support instances with a single IP on a single NIC. In AWS’s case, although they do support multiple NIC/multiple IP, some of their services like ELB only point to first IP address of the first NIC. So this Single-NIC configuration makes it not only possible but also dramatically easier to deploy in these various architectures. How this works: We can now attach just one interface to the instance and BIG-IP will start up, recognize this, use DHCP to configure the necessary settings on that interface. Underneath the hood, the following DB keys will be set: admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list sys db provision.1nic one-line sys db provision.1nic { value "enable" } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list sys db provision.1nicautoconfig one-line sys db provision.1nicautoconfig { value "enable" } provision.1nic = allows both management and data-plane to use the same interface provision.1nicautoconfig = uses address from DHCP to configure a vlan, Self-IP and default gateway. Ex. network objects automatically configured admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net vlan net vlan internal if-index 112 interfaces { 1.0 { } } tag 4094 } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net self net self self_1nic { address 10.0.1.65/24 allow-service { default } traffic-group traffic-group-local-only vlan internal } admin@(ip-10-0-1-65)(cfg-sync Standalone)(Active)(/Common)(tmos)# list net route net route default { gw 10.0.1.1 network default } Note: Traffic Management Shell and the Configuration Utility (GUI) are still available on ports 22 and 443 respectively. If you want to run the management GUI on a higher port (for instance if you don’t have the BIG-IPs behind a Port Address Translation service (like ELB) and want to run an HTTPS virtual on 443), use the following commands: tmsh modify sys httpd ssl-port 8443 tmsh modify net self-allow defaults add { tcp:8443 } tmsh modify net self-allow defaults delete { tcp:443 } WARNING: Now that management and dataplane run on the same interface, make sure to modify your Security Groups to restrict access to SSH and whatever port you use for the Mgmt GUI port to trusted networks. UPDATE: On Single-Nic, Device Service Clustering currently only supports Configuration Syncing (Network Failover is restricted for now due to BZ-606032). In general, the single-NIC model lends itself better to single-tenant or per-app deployments, where you need the advanced services from BIG-IP like content routing policies, iRules scripting, WAF, etc. but don’t necessarily care for maintaining a management subnet in the deployment and are just optimizing or securing a single application. By single tenant we also mean single management domain as you're typically running everything through a single wildcard virtual (ex. 0.0.0.0/0, 0.0.0.0/80, 0.0.0.0/443, etc.) vs. giving each tenant its own Virtual Server (usually with its own IP and configuration) to manage. However, you can still technically run multiple applications behind this virtual with a policy or iRule, where you make traffic steering decisions based on L4-L7 content (SNI, hostname headers, URIs, etc.). In addition, if the BIG-IPs are sitting behind a Port Address Translation service, it also possible to stack virtual services on ports instead. Ex. 0.0.0.0:444 = Virtual Service 1 0.0.0.0:445 = Virtual Service 2 0.0.0.0:446 = Virtual Service 3 We’ll let you get creative here…. BIG-IP Auto Scale Finally, the last component of Auto Scaling BIG-IPs involves building scaling policies via Cloudwatch Alarms. In addition to the built-in EC2 metrics in CloudWatch, BIG-IP can report its own set of metrics, shown below: Figure 3: Cloudwatch metrics to scale BIG-IPs based on traffic load. This can be configured with the following TMSH commands on any version 12.0 or later build: tmsh modify sys autoscale-group autoscale-group-id ${BIGIP_ASG_NAME} tmsh load sys config merge file /usr/share/aws/metrics/aws-cloudwatch-icall-metrics-config These commands tell BIG-IP to push the above metrics to a custom “Namespace” on which we can roll up data via standard aggregation functions (min, max, average, sum). This namespace (based on Auto Scale group name) will appear as a row under in the “Custom metrics” dropdown on the left side-bar in CloudWatch (left side of Figure 1). Once these BIG-IP or EC2 metrics have been populated, CloudWatch alarms can be built, and these alarms are available for use in Auto Scaling policies for the BIG-IP Auto Scale group. (Amazon provides some nice instructions here). Auto Scaling Pool Members and Service Discovery If you are scaling your ADC tier, you are likely also going to be scaling your application as well. There are two options for discovering pool members in your application's auto scale group. 1) FQDN Nodes For example, in a typicalsandwichdeployment, your application members might also be sitting behind an internal ELB so you would simply point your FQDN node at the ELB's DNS. For more information, please see: https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/ltm-implementations-12-1-0/25.html?sr=56133323 2) BIG-IP's AWS Auto Scale Pool Member Discovery feature (introduced v12.0) This feature polls the Auto Scale Group via API calls and populates the pool based on its membership. For more information, please see: https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/bigip-ve-autoscaling-amazon-ec2-12-1-0/2.html Putting it all together The high-level steps for Auto Scaling BIG-IP include the following: Optionally* creating an ElasticLoadBalancer group which will direct traffic to BIG-IPs in your Auto Scale group once they become operational. Otherwise, will need Global Server Load Balancing (GSLB). Creating a launch configuration in EC2 (referencing either custom image id and/or using Cloud-init scripts as described above) Creating an Auto Scale group using this launch configuration Creating CloudWatch alarms using the EC2 or custom metrics reported by BIG-IP. Creating scaling policies for your BIG-IP Auto Scale group using the alarms above. You will want to create both scale up and scale down policies. Here are some things to keep in mind when Auto Scaling BIG-IP ● BIG-IP must run in a single-interface configuration with a wildcard listener (as we talked about earlier). This is required because we don't know what IP address the BIG-IP will get. ● Auto Scale Groups themselves consist of utility instances of BIG-IP ● The scale up time for BIG-IP is about 12-20 minutes depending on what is configured or provisioned. While this may seem like a long-time, creating the right scaling policies (polling intervals, thresholds, unit of scale) make this a non-issue. ● This deployment model lends itself toward the themes of stateless, horizontal scalability and immutability embraced by the cloud. Currently, the config on each device is updated once and only once at device startup. The only way to change the config will be through the creation of a new image or modification to the launch configuration. Stay tuned for a clustered deployment which is managed in a more traditional operational approach. If interesting in exploring Auto Scale further, we have put together some examples of scaling the BIG-IP tier here: https://github.com/f5devcentral/f5-aws-autoscale * Above github repository also provides some examples of incorporating BYOL instances in the deployment to help leverage BYOL instances for your static load and using Auto Scale instances for your dynamic load. See the READMEs for more information. CloudFormation templates with Auto Scaled BIG-IP and Application Need some ideas on how you might leverage these solutions? Now that you can completely deploy a solution with a single template, how about building service catalog items for your business units that deploy different BIG-IP services (LB, WAF) or a managed service build on top of AWS that can be easily deployed each time you on-board a new customer?2.6KViews0likes7Comments
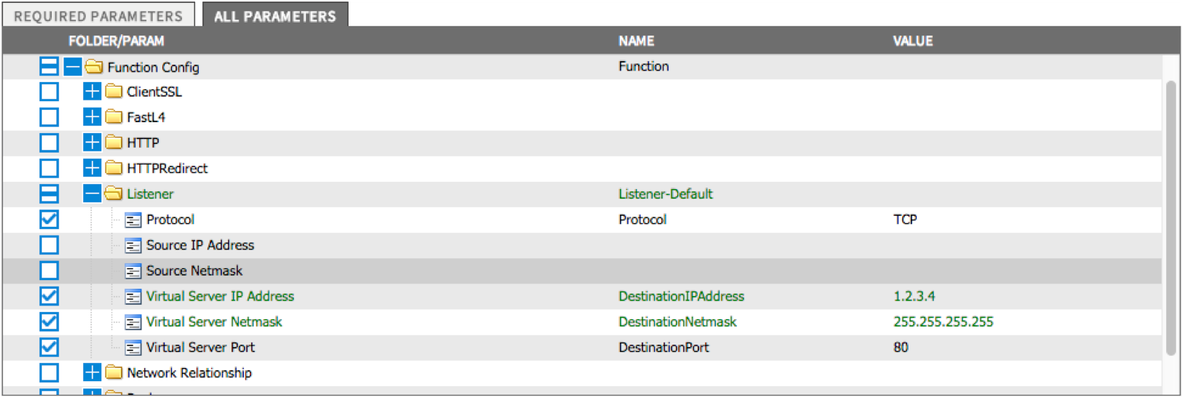
Building Application Delivery Services from Templates using the REST API (for People Like Me).
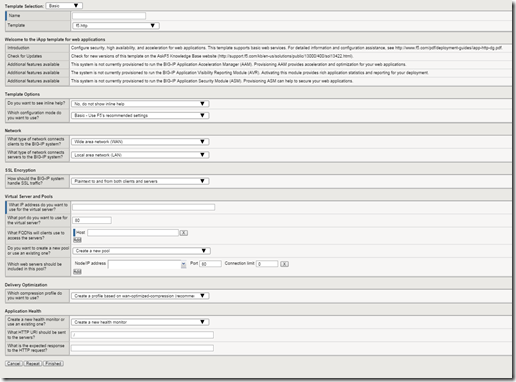
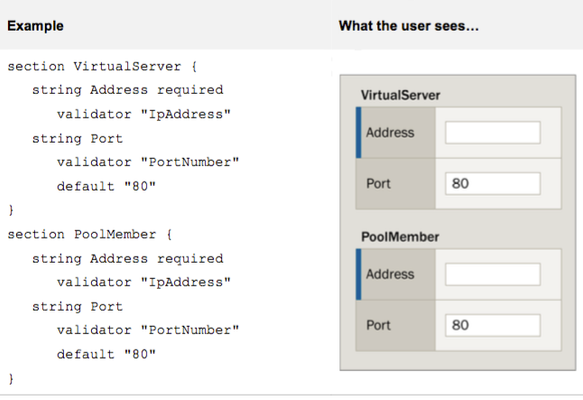
I’ve talked before about the value of Application Policies (AKA Service Templates, AKA iApp Templates). So has my esteemed colleague Nathan Pearce. We think they are pretty important, especially if you’re looking to deploy complex application delivery services using automation tools. There are quite a lot of resources availabe to help you do this, including a great guide from Chris Mutzel, and some cool Python scripts and tools from the shy and retiring Hitesh Patel on Github. These are great, and if you are up to speed on iControl and REST then stop reading this and head to one of those places. They are clever over there. However, to steal a line: “I’m not a smart man” (that’s probably why I’ve ended up as an explainer, rather than a true creator.) I needed some more basic information and examples before I moved on to these. I thought it might be worth documenting my journey, if nothing else for the amusement of others. First REST – I read up on the BIG-IP REST API here. There is a lot of useful information there. Now our service template implementation – iApp Templates and their resultant Application Services. For the purposes of this first blog we are going to be using about the most basic template – HTTP. This template simply creates a standard L7 VIP with a pool of servers at the backend. Jump on a BIG-IP and take a look – it’s pretty simple: We are going to stick with straight HTTP, port 80 for now. This is just to understand the template and how to create a service using it via the REST API. To keep this as simple as possible we’ll be using the Chrome Advanced REST Client. You can use other tools like curl or the REST client of your choice, of course. The first thing we are going to do is to create a new application service on the BIG-IP using the GUI. What? Yes, I know that seems backwards – but first we need to see what a deployed service looks like when we qurey it using REST. If anyone blagged their way through Visual Basic for Applications by mainly recording macro steps and then editing the resulting code, you know what I’m talking about. So here we have the resulting service – note that the pool members are dummies - they don’t exist so the monitor will mark them as down. OK, so what does this look like if you query for it using REST? Lets find out by executing a GET in the REST client with this URL: https://<my-bigip>/mgmt/tm/sys/application/service/~Common~test1.app~test1?expandSubcollections=true So what does all that mean? Well the first bit is obvious, even to me. “ https://<my-bigip> ” is the address of the BIG-IP, not much to ponder there. Now we have the path to the API section that gets us to application services “ /mgmt/tm/sys/application/service/ ” – there is a good post explaining how this works here. Full documentation for the URLs/modules are in the REST user guide. Now we get down to our deployed service “ /~Common~test1.app~test1 ”. This one is maybe a little harder to get. First you need to know that some of our resource names have a “/” in their name - to get around that we simply replace “/” with “~” in the URL. If you were to query all the application services on the BIG-IP using https://<my-bigip>/mgmt/tm/sys/application/service/ If you are using the advanced REST client display this using the JSON tab to get a nice color coded output. You would be able to see the key value pair "fullPath": "/Common/test1.app/test1" – that’s what we are representing with our “~Common~test1.app~test1 ” . I’m sure there is an excellent architectural reason for why this is the full path, and one day I’ll find the motivation to go and discover it. But today is not that day, today I want to make something work. Finally there is the query string “?expandSubcollections=true” This simply expands any objects that are part of the application service but also an object in their own right – known as subcollections. A great example is a pool member of a pool. The pool is an object with its own properties (such as load balancing algorithm) that also contains a collection of pool members that each have their own properties (e.g. address, port, connection limit). In this instance it actually makes no difference in this example, but it may well do so later so we will leave it in. Subcollections are nicely explained here. Still with me? Great. Let’s take a look at the output of the GET: {"kind":"tm:sys:application:service:servicestate", "name":"test1","partition":"Common", "subPath":"test1.app", "fullPath":"/Common/test1.app/test1", "generation":188, "selfLink":"https://localhost/mgmt/tm/sys/application/service/~Common~test1.app~test1?expandSubcollections=true&ver=12.0.0", "deviceGroup":"none", "inheritedDevicegroup":"true", "inheritedTrafficGroup":"true","strictUpdates":"enabled", "template":"/Common/f5.http", "templateReference":{"link":"https://localhost/mgmt/tm/sys/application/template/~Common~f5.http?ver=12.0.0"}, "templateModified":"no", "trafficGroup":"/Common/traffic-group-1", "trafficGroupReference":{"link":"https://localhost/mgmt/tm/cm/traffic-group/~Common~traffic-group-1?ver=12.0.0"}, "tables":[{"name":"basic__snatpool_members"}, {"name":"net__snatpool_members"}, {"name":"optimizations__hosts"}, {"name":"pool__hosts","columnNames":["name"], "rows":[{"row":["test.test.com"]}]}, {"name":"pool__members", "columnNames":["addr","port","connection_limit"], "rows":[{"row":["10.0.0.10","80","0"]}]}, {"name":"server_pools__servers"}], "variables":[{"name":"client__http_compression", "encrypted":"no","value":"/#create_new#"}, {"name":"monitor__monitor","encrypted":"no","value":"/#create_new#"}, {"name":"monitor__response","encrypted":"no","value":"none"}, {"name":"monitor__uri","encrypted":"no","value":"/"}, {"name":"net__client_mode","encrypted":"no","value":"wan"}, {"name":"net__server_mode","encrypted":"no","value":"lan"}, {"name":"pool__addr","encrypted":"no","value":"10.0.1.28"}, {"name":"pool__pool_to_use","encrypted":"no","value":"/#create_new#"}, {"name":"pool__port","encrypted":"no","value":"80"}, {"name":"ssl__mode","encrypted":"no","value":"no_ssl"}, {"name":"ssl_encryption_questions__advanced","encrypted":"no","value":"no"}, {"name":"ssl_encryption_questions__help","encrypted":"no","value":"hide"} ] } OK, so now we just need to do a quick match up with the properties we created via the GUI to see what everything means. {"kind":"tm:sys:application:service:servicestate", "name":"test1","partition":"Common", "subPath":"test1.app", "fullPath":"/Common/test1.app/test1", "generation":188, "selfLink":"https://localhost/mgmt/tm/sys/application/service/~Common~test1.app~test1? "Test1" - That’s the the name of our application service. Easy. Now let’s ignore some other bits until we get to another section we recognize. {"name":"pool__members", "columnNames":["addr","port","connection_limit"], "rows":[{"row":["10.0.0.10","80","0"]} This is the line that defines the pool members – because there can be more than one we define a list of columns and then the rows afterwards. After that there are lines that instruct the iApp to create new monitors, set the TCP profiles, turn on or off compression etc. Now we get to another important line: {"name":"pool__addr","encrypted":"no","value":"10.0.1.28"} That’s the virtual server address, then the port is next. {"name":"pool__port","encrypted":"no","value":"80"} Why, you are asking, is this the ‘ pool_address ’ and not ‘ VS_address ’? Honestly – I have no idea. I could find out, but that won’t get either of us anywhere and I have a stack of books to read and records to listen to. So actually, there we have it, just a few key lines that define a simple iApp service. That’s probably enough to create a new one right? So let’s try doing a POST with this body: {"kind":"tm:sys:application:service:servicestate", "name":"test2","partition":"Common", "subPath":"test2.app", "fullPath":"/Common/test2.app/test2", "generation":485, "selfLink":"https://localhost/mgmt/tm/sys/application/service/~Common~test2.app~test2?ver=12.0.0", "deviceGroup":"none", "inheritedDevicegroup":"true", "inheritedTrafficGroup":"false", "strictUpdates":"enabled", "template":"/Common/f5.http", "templateReference":{"link":"https://localhost/mgmt/tm/sys/application/template/~Common~f5.http?ver=12.0.0"}, "templateModified":"no","trafficGroup":"/Common/traffic-group-1", "trafficGroupReference":{"link":"https://localhost/mgmt/tm/cm/traffic-group/~Common~traffic-group-1?ver=12.0.0"}, "tables":[{"name":"basic__snatpool_members"}, {"name":"net__snatpool_members"}, {"name":"optimizations__hosts"}, {"name":"pool__hosts", "columnNames":["name"], "rows":[{"row":["test2.test.com"]}]}, {"name":"pool__members", "columnNames":["addr","port","connection_limit"], "rows":[{"row":["10.0.0.20","80","0"]}]}, {"name":"server_pools__servers"}], "variables":[{"name":"client__http_compression", "encrypted":"no","value":"/#create_new#"}, {"name":"monitor__monitor", "encrypted":"no","value":"/#create_new#"}, {"name":"monitor__response","encrypted":"no","value":"none"}, {"name":"monitor__uri","encrypted":"no","value":"/"}, {"name":"net__client_mode","encrypted":"no","value":"wan"}, {"name":"net__server_mode","encrypted":"no","value":"lan"}, {"name":"pool__addr","encrypted":"no","value":"10.0.0.30"}, {"name":"pool__pool_to_use","encrypted":"no","value":"/#create_new#"}, {"name":"pool__port","encrypted":"no","value":"80"}, {"name":"ssl__mode","encrypted":"no","value":"no_ssl"}, {"name":"ssl_encryption_questions__advanced","encrypted":"no","value":"no"}, {"name":"ssl_encryption_questions__help","encrypted":"no","value":"hide"} ]} POST this, and your return should be similar to the GET we did before, but with your new variables. Check the GUI and see what we have: Looks like we’ve just created a new service. Go us. Let’s expand out the test2 application service: There you go – we have created a new configuration from a template in a fairly easy manner. Now I know that the Advanced REST API client is not a scalable enterprise automation tool, but it exposes the heart of how this works and now you might be in a better position to automate with the tool of your choice. Next I’m going to work out how to do an update to the config and redeploy it. Stay tuned. (Note - I'm sorry about the typo riddled earlier version of this article. There were a combination of technological and meat-bag failures. As I say below - "I'm not a smart man". Thanks to those that pointed out my many errors, and no thanks to my blog writing app.)827Views0likes4CommentsGetting Started with iApps: Modifying an Existing iApp
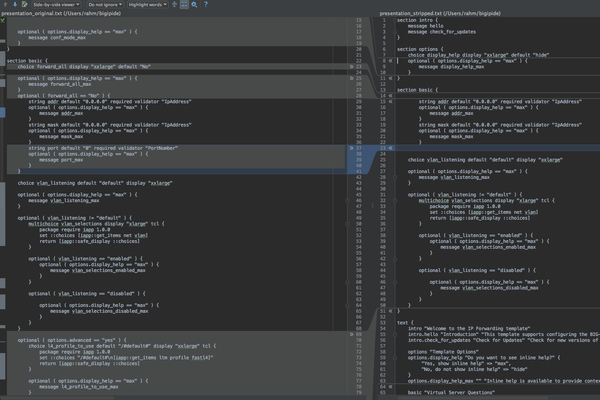
Now that the esteemed Chase Abbott has blazed the trail with all the iApps foundational goodness surrounding concepts and componentsin the first two articles in this Getting Started with iApps series, we can move into the practical! In this article, we'll start small, copying an existing iApp template and modifying it slightly. The IP Forwarding iApp Before we rip open the hood and dismount the engine, let's first take a walk through to evaluate the existing options. As indicated in the video above, we're going to make a couple modifications to this iApp. I don't want the end user of the iApp to have ability to forward all traffic as a default option, regardless of IP version. I want to make sure the port is all ports; no port specification supported. I want to disable the advanced features altogether, removing the ability to specify the fastL4 profile and iRules. Now that we've established what we're going to do, let's get it done! Existing Template The existing template is shown by section below: Implementation Presentation package require iapp 1.0.0 iapp::template start set app $tmsh::app_name set advanced [iapp::is ::options__advanced yes] # destination & mask array # array keys: $::basic__forward_all array set destination { IPv4 { destination any:any mask 0.0.0.0 } IPv6 { destination 0::0.any mask 0::0 } * { destination [iapp::destination $::basic__addr $::basic__port] \ mask $::basic__mask \ [expr { [string match "*:*:*" $::basic__addr] ? "source ::/0" : "" }]} } # PROFILES set use_default_profile [iapp::is ::basic__l4_profile_to_use "/#default#"] # array keys: $advanced,$use_default_profile array set profiles { 1,0 { profiles replace-all-with \{ $::basic__l4_profile_to_use \} } * { profiles replace-all-with \{ \ [iapp::conf create \ ltm profile fastl4 ${app}_fastL4 \ defaults-from fastL4 \ reset-on-timeout disabled \ loose-close enabled \ loose-initialization enabled] \} } } # VLANS # array keys: $::basic__vlan_listening array set vlans { enabled { vlans-enabled vlans replace-all-with \{ $::basic__vlan_selections \} } disabled { vlans-disabled vlans replace-all-with \{ $::basic__vlan_selections \} } default { vlans-disabled vlans none } } # RULES set have_irules [expr { ![iapp::is ::irules__irules ""] }] # array keys $advanced,$have_irules array set rules { 1,1 { rules \{ $::irules__irules \} } * { rules none } } # VIRTUALS set virtual { [iapp::conf create ltm virtual ${app}_VER_Forwarding \ ip-forward \ [iapp::substa destination(VER)] \ [iapp::substa profiles($advanced,$use_default_profile)] \ [iapp::substa vlans($::basic__vlan_listening)] \ [iapp::substa rules($advanced,$have_irules)]] } switch $::basic__forward_all { Yes { subst [string map "VER IPv4" $virtual] subst [string map "VER IPv6" $virtual] } No { subst [string map "VER IP" $virtual] } default { subst [string map "VER $::basic__forward_all" $virtual] } } iapp::template stop section intro { message hello message check_for_updates } section options { choice display_help display "xxlarge" default "hide" optional ( options.display_help == "max" ) { message display_help_max } choice advanced display "xxlarge" default "no" optional ( options.display_help == "max" ) { message conf_mode_max } } section basic { choice forward_all display "xxlarge" default "No" optional ( options.display_help == "max" ) { message forward_all_max } optional ( forward_all == "No" ) { string addr default "0.0.0.0" required validator "IpAddress" optional ( options.display_help == "max" ) { message addr_max } string mask default "0.0.0.0" required validator "IpAddress" optional ( options.display_help == "max" ) { message mask_max } string port default "0" required validator "PortNumber" optional ( options.display_help == "max" ) { message port_max } } choice vlan_listening default "default" display "xxlarge" optional ( options.display_help == "max" ) { message vlan_listening_max } optional ( vlan_listening != "default" ) { multichoice vlan_selections display "xlarge" tcl { package require iapp 1.0.0 set ::choices [iapp::get_items net vlan] return [iapp::safe_display ::choices] } optional ( vlan_listening == "enabled" ) { optional ( options.display_help == "max" ) { message vlan_selections_enabled_max } } optional ( vlan_listening == "disabled" ) { optional ( options.display_help == "max" ) { message vlan_selections_disabled_max } } } optional ( options.advanced == "yes" ) { choice l4_profile_to_use default "/#default#" display "xxlarge" tcl { package require iapp 1.0.0 set ::choices "/#default#\n[iapp::get_items ltm profile fastl4]" return [iapp::safe_display ::choices] } optional ( options.display_help == "max" ) { message l4_profile_to_use_max } } } optional ( options.advanced == "yes" ) { section irules { message irule_1_max optional ( options.display_help == "max" ) { message irule_2_max message irule_3_max } multichoice irules display "xlarge" tcl { package require iapp 1.0.0 set ::choices [iapp::get_items -filter NAME !~ "^_sys_" ltm rule] return [iapp::safe_display ::choices] } } } text { intro "Welcome to the IP Forwarding template" intro.hello "Introduction" "This template supports configuring the BIG-IP to perform IP traffic forwarding." intro.check_for_updates "Check for Updates" "Check for new versions of this template on the AskF5 Knowledge Base website (http://support.f5.com/kb/en-us/solutions/public/13000/400/sol13422.html)." options "Template Options" options.display_help "Do you want to see inline help?" { "Yes, show inline help" => "max", "No, do not show inline help" => "hide" } options.display_help_max "" "Inline help is available to provide contextual descriptions to aid in the completion of this configuration. Select to show or hide the inline help in this template. Important notes and warnings are always visible, no matter which selection you make here." options.advanced "Which configuration mode do you want to use?" { "Basic - Use F5's recommended settings" => "no", "Advanced - Expose advanced options" => "yes" } options.conf_mode_max "" "This template supports twp configurations modes. Basic mode exposes the most commonly used settings, and automatically configures the rest of the options. Advanced mode allows you to review and change all settings." basic "Virtual Server Questions" basic.forward_all "Should this forward all traffic not destined for virtual servers?" { "Forward all IPv4 traffic" => "IPv4", "Forward all IPv6 traffic" => "IPv6", "Forward all IPv4 and IPv6 traffic" => "Yes", "Forward specific traffic" => "No" } basic.forward_all_max "" "Choose whether to have the BIG-IP system forward all traffic that is not destined for a virtual server, or only forward traffic on a specific network, port and/or VLAN that you define. If you select Yes, the system forwards all traffic. If you select No, you must enter the address, mask, and port that define the traffic you want to forward." basic.addr "What network address do you want to use for this virtual server?" basic.addr_max "" "Specifies the address of the destination network, for example, 10.0.0.0. The default 0.0.0.0 is a wildcard for all addresses, however you can still limit what is forwarded by netmask, port, or VLAN." basic.mask "What is the netmask for that address?" basic.mask_max "" "Specifies the netmask, for example 255.255.255.0. The default 0.0.0.0 is a wildcard for any netmask." basic.port "What port do you want this virtual server to use?" basic.port_max "" "Specifies a specific port for forwarding traffic, for example 22. The default 0 is a wildcard for any port." basic.vlan_listening "What VLANs should this IP Forwarding virtual server listen on?" { "All VLANs" => "default", "Enabled on ..." => "enabled", "Disabled on ..." => "disabled" } basic.vlan_listening_max "" "You can choose to forward traffic from all VLANs or just from some of them. If you don't want to enable all VLANs, you can choose to include or exclude named VLANs and forward traffic from all of the rest." basic.vlan_selections "On which VLAN(s) should this IP Forwarding virtual server listen?" basic.vlan_selections_enabled_max "" "Select the VLANs from which traffic will be forwarded." basic.vlan_selections_disabled_max "" "Select the VLANs from which traffic NOT will be forwarded." basic.l4_profile_to_use "What Fast L4 profile do you want to use?" {"Use F5's recommended Fast L4 profile" => "/#default#"} basic.l4_profile_to_use_max "" "If you created a custom Fast L4 profile, you can select it from the list. This is not required for most purposes, and only necessary if you need to replace the default Fast L4 profile functionality." irules "iRules" irules.irules "Do you want to add any custom iRules to this configuration?" irules.irule_1_max "WARNING" "Improper use or misconfigurations of an iRule can result in unwanted application behavior and poor performance of your BIG-IP system. For this reason we recommended you verify the impact of an iRule prior to deployment in a production environment." irules.irule_2_max "" "The BIG-IP system supports a scripting language to allow an administrator to instruct the system to intercept, inspect, transform, direct and track inbound or outbound application traffic. An iRule contains the set of instructions the system uses to process data flowing through it, either in the header or payload of a packet." irules.irule_3_max "" "Correct event priority is critical when assigning multiple iRules. For more information about iRule event priority, see https://devcentral.f5.com/s/wiki/iRules.priority.ashx" } To get started with modifying this template, we want to create a copy. In the GUI, click iApps->Templates->f5.ip_forwarding, and then at the very bottom, click copy. At the iApps >> Clone Template screen, change the Template Name(s) field to the name you want your template to have. I called mine f5_stripped.ip_forwarding. You can edit from here, but at this step I just clicked Finish before re-entering to do the editing work. Back at the iApps template listing, you should see your new iApp, which other than title, should be the same as the original, with the exception of validation (which should now read None.) Click into your new template and now we'll get to work editing. Presentation In the presentation section, we can weed out the basic/advanced section since we aren't allowing profile or iRule manipulation (lines 13-19.) Next we'll eliminate the forward_all option since we're not giving them the choice of of IPv4/IPv6 defaults or all networks (lines 23-28; 41.) Moving on, we'll trim the port section (lines 37-40.) Finally, we'll pull the advanced section altogether, which deals with the profiles and iRules (lines 69-96.) In the text area of the presentation, we pull out all the unnecessary text now that those GUI objects will not be present (lines 110-14; 117-123; 130-131; 137; 142-153.) This is best shown in the following images. Implementation The changes in the implementation section follow suit. We remove the arrays for destination (lines 7-15) and profiles (lines 17-29,) as well as the army for rules (lines 38-46,) and the switch for the type of forwarding virtual this will be since we're forcing end users to specify the networks (lines 56-61.) The only thing we need to slightly modify is the virtuals section (lines 48-54.) Here, we are removing the need for the variable and just creating the virtual server with the iapp::conf command. We are not passing a port from the iApp, so we use :any here (line 15) and then use the array as is for vlans to configure those. Screenshot to show these updates is below. Easy enough! Updated iApp code is below. Implementation Presentation package require iapp 1.0.0 iapp::template start set app $tmsh::app_name # VLANS # array keys: $::basic__vlan_listening array set vlans { enabled { vlans-enabled vlans replace-all-with \{ $::basic__vlan_selections \} } disabled { vlans-disabled vlans replace-all-with \{ $::basic__vlan_selections \} } default { vlans-disabled vlans none } } iapp::conf create ltm virtual ${app}_IPv4_Forwarding \ ip-forward \ destination $::basic__addr:any mask $::basic__mask \ [iapp::substa vlans($::basic__vlan_listening)] iapp::template stop section intro { message hello message check_for_updates } section options { choice display_help display "xxlarge" default "hide" optional ( options.display_help == "max" ) { message display_help_max } } section basic { string addr default "0.0.0.0" required validator "IpAddress" optional ( options.display_help == "max" ) { message addr_max } string mask default "0.0.0.0" required validator "IpAddress" optional ( options.display_help == "max" ) { message mask_max } choice vlan_listening default "default" display "xxlarge" optional ( options.display_help == "max" ) { message vlan_listening_max } optional ( vlan_listening != "default" ) { multichoice vlan_selections display "xlarge" tcl { package require iapp 1.0.0 set ::choices [iapp::get_items net vlan] return [iapp::safe_display ::choices] } optional ( vlan_listening == "enabled" ) { optional ( options.display_help == "max" ) { message vlan_selections_enabled_max } } optional ( vlan_listening == "disabled" ) { optional ( options.display_help == "max" ) { message vlan_selections_disabled_max } } } } text { intro "Welcome to the IP Forwarding template" intro.hello "Introduction" "This template supports configuring the BIG-IP to perform IP traffic forwarding." intro.check_for_updates "Check for Updates" "Check for new versions of this template on the AskF5 Knowledge Base website (http://support.f5.com/kb/en-us/solutions/public/13000/400/sol13422.html)." options "Template Options" options.display_help "Do you want to see inline help?" { "Yes, show inline help" => "max", "No, do not show inline help" => "hide" } options.display_help_max "" "Inline help is available to provide contextual descriptions to aid in the completion of this configuration. Select to show or hide the inline help in this template. Important notes and warnings are always visible, no matter which selection you make here." basic "Virtual Server Questions" basic.addr "What network address do you want to use for this virtual server?" basic.addr_max "" "Specifies the address of the destination network, for example, 10.0.0.0. The default 0.0.0.0 is a wildcard for all addresses, however you can still limit what is forwarded by netmask, port, or VLAN." basic.mask "What is the netmask for that address?" basic.mask_max "" "Specifies the netmask, for example 255.255.255.0. The default 0.0.0.0 is a wildcard for any netmask." basic.vlan_listening "What VLANs should this IP Forwarding virtual server listen on?" { "All VLANs" => "default", "Enabled on ..." => "enabled", "Disabled on ..." => "disabled" } basic.vlan_listening_max "" "You can choose to forward traffic from all VLANs or just from some of them. If you don't want to enable all VLANs, you can choose to include or exclude named VLANs and forward traffic from all of the rest." basic.vlan_selections "On which VLAN(s) should this IP Forwarding virtual server listen?" basic.vlan_selections_enabled_max "" "Select the VLANs from which traffic will be forwarded." basic.vlan_selections_disabled_max "" "Select the VLANs from which traffic NOT will be forwarded." } With the finished stripped version of the ip forwarding iApp, we can now deploy the template in a new application service. Join us for the next article in this series, where we'll tackle writing an iApp from scratch!1.7KViews0likes0CommentsGetting Started with iApps: Best Practices
In this final article in the Getting Started with iApps series, we’ll ship gears from concepts and code to best practices and lessons learned. Start Small As stated earlier--iApps are complex. If you don’t know tmsh, or better, tmsh scripting, I’d recommend spending some time getting comfortable at the command line writing scripts before moving to an iApp. Once you have the foundational tmsh skills, start with a simple task like what we covered in the modifying and creating articles in this series. After the pieces start to fit together more clearly, expand from there. Start Basic I mentioned the iApp utility package in the previous article. It’s available and it’s awesome. But it also abstracts some of the work that might confuse what’s actually happening in the iApp. I’d recommend you avoid the utility package while you are learning, then once you’re comfortable, convert your test work to the utility package. Afterwards, starting with the utility package unlocks a lot of functionality that will save you time and headaches. Attributes This is a small but important section of the iApp. When developing an iApp, there may be features that exist on your version that either didn’t exist or changed significantly from previous or later versions. Setting the minimum and maximum versions where applicable might save you or others in the event of upgrades or imports. Also, establishing the required modules up front is important, so don’t forget this step. Presentation This is the user interface for those deploying your template, so it’s important to consider not only the required information, but also the layout. Some best practices for the template design: Use a question and answer format Be simple Be clear Be complete Follow your organization’s nomenclature Gotcha: You may be tempted to expose only a few settings on any particular configuration object, leaving the remaining settings default. But a default when creating objects via the GUI is not necessarily the same default when creating them via tmsh. Example: a virtual server created via the GUI defaults to the tcp profile, but creating a virtual server via tmsh defaults to the fastL4 profile. Make sure to use the layout elements to your advantage. Use the section element to group like features/functionality in your iApp. Hide stuff that isn't required for particular deployments by using the optional element. This makes readability much better Underscores in section variable names are possible, but discouraged. Yes, I broke this rule in the creating an iApp article yesterday! The reason is because the section.variable on the implementation ends up section__variable (double underscore) and if your section also has an underscore, it makes it easy to overlook the differences. Use validators for input fields where they are supported. These are some common validators: Number: Any integer NonNegativeNumber: Any integer >= 0 IpAddress: * for all addresses, or an IPv4 or IPv6 address PortNumber: * for all ports, or an integer value between 0 and 65535 inclusive FQDN:RFC 1034 compliant domain name IpOrFQDN:IPv4, IPv6, or an RFC 1034 complaint domain name. * not allowed Gotcha: validators are not available with the edit choice element, so make sure to add validation on the implementation section for the values returned from these elements. Also very helpful: you can display user-friendly wording while setting a different value that is passed on to the implementation. This is nice for things like the load balancing method, where least-connections-member isn’t awesome to look at, but is the required text string for the tmsh::pool create/modify command. Finally, you can test all your variable setting and such by using the puts command in the implementation section that will log all your values from the presentation section. This information is useful for debugging and is dumped in the /var/tmp/scriptd.out file for review. Examples: puts $::basic_info__validation puts $::basic_info__key puts $::basic_info__rules [root@ltm3:Active:Standalone] config # tail -f /var/tmp/scriptd.out Signature default.key test1 test2 Implementation The implementation section is pretty much a tmsh script, without the required skeleton. the hierarchy of tmsh, for those not well versed, looks like this: The general syntax of tmsh commands is: tmsh <command> <module> [<submodule>] <component> <parameters> The syntax varies slightly depending on where the commands are issued. For example: Location where command is run Syntax tmsh root (tmos) # create /ltm virtual virtual_name... virtual server component of tmsh (tmos.ltm.virtual) # create virtual_name... linux bash prompt config # tmsh create /ltm virtual virtual_name... iApp implementation section tmsh::create "/ltm virtual virtual_name..." iapp::conf create ltm virtual virtual_name... In addition to the declared variables from the presentation section, you can set variables in the implementation section as well. This foreach loop shows the use of a local variable (obj) and the presentation declared variable ($::basic_info__rules) foreach obj $::basic_info__rules { exec "tmsh" "generate" "ltm" "rule" $obj "checksum" } There’s also tmsh::app_name which stores the name of your application service. When creating objects, it’s helpful to name them with your application name as a header. This can be done like so: set app $tmsh::app_name tmsh::create “/ltm pool ${app}_MyPool ... The { } brackets are there so the interpreter to only interprets app when doing the variable lookup. There are a lot more general tcl best practices, but those are out of scope for this article. Reentrancy iApps were created with serving an application over time, not just a Ron Popeil “set it and forget it” experience. That’s more the point of a wizard. This presents a challenge, as you need to create objects initially, but when you reconfigure your iApp, you’re modifying existing objects. In tmsh, this is problematic: if you try to create an existing object, it’ll complain. Why does this work in an iApp then? The answer is, through a process called mark-and-sweep. When the iApp user selects an existing application service and clicks the Reconfigure tab, they are reentering your template and its code. They can keep and/or change their responses to the presentation section prompts. If they make changes that result in a new configuration, the mark-and-sweep process is designed to help transform the old configuration to the new configuration. On reentrancy, the code in the template’s implementation section is re-executed. Conditional code is executed based on the variable values set by you or by the user’s responses. Any tmsh::create commands that are “touched” are marked and converted to tmsh::modify commands. Any objects that are “untouched” are deleted in the sweep. Strict Updates Strike updates protect all the objects generated by an iApp. So if you created an iApp that owns the pool app_myPool, that pool cannot be modified outside of the iApp. This is good when a lot of cooks are in the kitchen and someone inadvertently tries to delete your pool. Because the iApp owns it, that attempt will fail. There are situations where you might be tempted to disable the strict updates, but the better option is to modify the template. If you do disable the strict updates, redeploying the iApp will sometimes overwrite the out-of-band changes. Sometimes. The outcome is not so easily predicted. To illustrate the difficulties, consider two scenarios. Changing an HTTP Profile In this scenario, a simple iApp accepts 2 inputs and constructs a virtual server with a custom HTTP profile: presentation { section virtual { string ip required choice xff { “enabled”, “disabled” } } } implementation { tmsh::create ltm profile http ${tmsh::app_name}_http \ insert-xforwarded-for $::virtual__xff tmsh::create ltm virtual ${tmsh::app_name}_vs \ destination $::virtual__ip:80 \ profiles add \{ ${tmsh::app_name}_http \} } Suppose you deploy this iApp with X-Forwarded-For enabled, then disable strict-updates and edit the HTTP profile directly as shown: Now, re-enter and re-deploy the iApp without changing any inputs. What is the result? You might expect your manual customization of response chunking to remain in place, because there is no mention of response chunking in the iApp code. In this case, however, iApp re-deployment causes chunking to be set back to its default value. Disabling Virtual Server Address Translation In this scenario, you need to disable address translation on a virtual server, which was not possible in the iApp. Disable address translation, then re-enter and re-deploy the iApp again. What is the result this time? You might expect your customization to be overwritten as it was in the previous example. In this case, however, address translation remains disabled. The TMSH “modify” command does not handle defaults consistently across all key-value pairs. This makes tampering with a strictly-enforced configuration especially hazardous. Conclusion iApps are amazingly powerful tools for taking a lot of the guesswork and potential errors out of application deployments. There is so much more to iApps than we could possibly cover in this five article series, but the intention this week was not to make you experts; merely to expose you to the concepts and get your feet wet with some examples. The great thing about iApps is the are not compiled code: all of them, whether F5 supported, F5 contributed, or community contributed, can be analyzed and repurposed for your use.946Views0likes0CommentsF5 Automated Backups - The Right Way
Hi all, Often I've been scouring the devcentral fora and codeshares to find that one piece of handywork that will drastically simplify my automated backup needs on F5 devices. Based on the works of Jason Rahm in his post "Third Time's the Charm: BIG-IP Backups Simplified with iCall" on the 26th of June 2013, I went ahead and created my own iApp that pretty much provides the answers for all my backup-needs. Here's a feature list of this iApp: It allows you to choose between both UCS or SCF as backup-types. (whilst providing ample warnings about SCF not being a very good restore-option due to the incompleteness in some cases) It allows you to provide a passphrase for the UCS archives (the standard GUI also does this, so the iApp should too) It allows you to not include the private keys (same thing: standard GUI does it, so the iApp does it too) It allows you to set a Backup Schedule for every X minutes/hours/days/weeks/months or a custom selection of days in the week It allows you to set the exact time, minute of the hour, day of the week or day of the month when the backup should be performed (depending on the usefulness with regards to the schedule type) It allows you to transfer the backup files to external devices using 4 different protocols, next to providing local storage on the device itself SCP (username/private key without password) SFTP (username/private key without password) FTP (username/password) SMB (using smbclient, with username/password) Local Storage (/var/local/ucs or /var/local/scf) It stores all passwords and private keys in a secure fashion: encrypted by the master key of the unit (f5mku), rendering it safe to store the backups, including the credentials off-box It has a configurable automatic pruning function for the Local Storage option, so the disk doesn't fill up (i.e. keep last X backup files) It allows you to configure the filename using the date/time wildcards from the tcl [clock] command, as well as providing a variable to include the hostname It requires only the WebGUI to establish the configuration you desire It allows you to disable the processes for automated backup, without you having to remove the Application Service or losing any previously entered settings For the external shellscripts it automatically generates, the credentials are stored in encrypted form (using the master key) It allows you to no longer be required to make modifications on the linux command line to get your automated backups running after an RMA or restore operation It cleans up after itself, which means there are no extraneous shellscripts or status files lingering around after the scripts execute I wasn't able to upload the iApp template to this article, so I threw it on pastebin: http://pastebin.com/YbDj3eMN Enjoy! Thomas Schockaert8.4KViews0likes79Comments
DNS over HTTPS Resolution
Introduction I work in the EMEA Professional Services team and in this article I will walk you through a recent solution which I provided to support the F5 Sales team for a Service Provider. You can see the finished iApp here which took a few days of work spread over a few months. This solution is to provide DNS over HTTP resolution - F5 hasthis as a feature soon to be released but in the meantime we needed a working solution. Development I started by looking at the RFC ( https://tools.ietf.org/html/rfc8484 ) to work out what was required and realised that this has two methods - GET and POST, it gives examples of the payload and response so I put together a simple lab and proof of concept. This used curl to send the data - both methods send a DNS wire-format packet, GET base64url-encodes it and sends it as a parameter while POST sends it in the payload directly. I decided it would be simplest to use an iRule with sideband to a local virtual server which would in turn send the traffic to the backend server. Below is the simple pseudocode I created to guide me: when HTTP_REQUEST if URI if method == POST collect payload if method == GET decode payload send payload via sideband return response endwhen when HTTP_DATA send payload via sideband return response endwhen From this you can see that I have 'send payload via sideband' in two places. I like to follow the DRY principle so i immediately thought about procedures in later versions. I have used sideband a number of times before but i reviewed how it works in terms of destination and source address at https://clouddocs.f5.com/api/irules/SIDEBAND.html . For base64url, I decided to start with the built-in base64 decoding function ( https://clouddocs.f5.com/api/irules/b64decode.html ) and use string map to change the erroneous characters. See my lab configuration below with my first version of the iRule: [root@DoH-bigip1:Active:Standalone] config # tmsh list ltm pool ltm pool dns { members { server-1:domain { address 10.20.20.6 } } } [root@DoH-bigip1:Active:Standalone] config # tmsh list ltm virtual ltm virtual DoH { creation-time 2020-05-04:03:17:08 destination 10.10.10.10:https ip-protocol tcp last-modified-time 2020-05-04:03:33:22 mask 255.255.255.255 profiles { clientssl-insecure-compatible { context clientside } http { } tcp { } } rules { DoH } serverssl-use-sni disabled source 0.0.0.0/0 translate-address enabled translate-port enabled vlans { External } vlans-enabled vs-index 4 } ltm virtual dns-tcp { creation-time 2020-05-04:03:15:46 destination 10.10.10.10:domain ip-protocol tcp last-modified-time 2020-05-04:03:15:46 mask 255.255.255.255 pool dns profiles { dns { } tcp { } } serverssl-use-sni disabled source 0.0.0.0/0 source-address-translation { type automap } translate-address enabled translate-port enabled vlans { External } vlans-enabled vs-index 3 } ltm virtual dns-udp { creation-time 2020-05-04:03:14:25 destination 10.10.10.10:domain ip-protocol udp last-modified-time 2020-05-04:03:14:25 mask 255.255.255.255 pool dns profiles { dns { } udp { } } rules { dns-log } serverssl-use-sni disabled source 0.0.0.0/0 source-address-translation { type automap } translate-address enabled translate-port enabled vlans { External } vlans-enabled vs-index 2 } ltm rule DoH { when RULE_INIT { set static::sideband_virtual_server "/Common/dns-udp" } when HTTP_REQUEST { # https://tools.ietf.org/html/rfc8484 if { [HTTP::uri] == "/dns-query" } { if { (([HTTP::method] equals "POST") and (([HTTP::header "accept"] equals "application/dns-message") or ([HTTP::header "content-type"] equals "application/dns-message"))) } { if {[HTTP::header exists "Content-Length"] && [HTTP::header "Content-Length"] <= 65535 && [HTTP::header "Content-Length"] > 0} { log local0.debug "Content-Length [HTTP::header value "Content-Length"]" HTTP::collect [HTTP::header value "Content-Length"] } else { HTTP::collect 100 } } else { HTTP::respond 415 content "Unsupported Media Type" } } else { HTTP::respond 404 } } when HTTP_REQUEST_DATA { # Use sideband set conn_id [connect -protocol UDP -timeout 100 -idle 30 -status conn_status /Common/dns-udp] log local0.debug "Connection status: $conn_status" log local0.debug "Payload B64: [b64encode [HTTP::payload]]" set send_bytes [send -timeout 100 -status send_status $conn_id [HTTP::payload]] log local0.debug "send_status: $send_status" recv -timeout 100 -peek -status recv_status $conn_id result log local0.debug "status: $recv_status Result B64: [b64encode $result]" HTTP::respond 200 content $result noserver content-type application/dns-message vary Accept-Encoding content-length [string length $result] } } ltm rule dns-log { when DNS_REQUEST { log local0.debug "[DNS::question name] [DNS::question class] [DNS::question type]" } when DNS_RESPONSE { set rrs [DNS::answer] foreach rr $rrs { log local0. "[DNS::rdata $rr]" } } } I tested this setup using the following procedure: Create DNS wire request in binary file echo "00 00 01 00 00 01 00 00 00 00 00 00 03 77 77 77 07 65 78 61 6d 70 6c 6503 63 6f 6d 00 00 01 00 01"|xxd -r -p >example_req Perform curl request curl -k -H 'content-type: application/dns-message' --data-binary @example_req -o output_file https://10.10.10.10/dns-query Inspect output file root@DoH-xubuntu-desktop1:~# xxd output_file 00000000: 0000 8580 0001 0001 0001 0002 0377 7777.............www 00000010: 0765 7861 6d70 6c65 0363 6f6d 0000 0100.example.com.... 00000020: 01c0 0c00 0100 0100 093a 8000 0401 0203.........:...... 00000030: 04c0 1000 0200 0100 093a 8000 0b09 6c6f.........:....lo 00000040: 6361 6c68 6f73 7400 c03d 0001 0001 0009calhost..=...... 00000050: 3a80 0004 7f00 0001 c03d 001c 0001 0009:........=...... 00000060: 3a80 0010 0000 0000 0000 0000 0000 0000:............... 00000070: 0000 0001.... My BIG-IP logs: May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST>: Content-Length 33 May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST_DATA>: Doing sideband May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST_DATA>: Connection status: connected May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST_DATA>: Payload B64: AAABAAABAAAAAAAAA3d3dwdleGFtcGxlA2NvbQAAAQAB May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST_DATA>: send_status: sent May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/dns-log <DNS_REQUEST>: www.example.com IN A May4 05:49:12 DoH-bigip1 info tmm[22188]: Rule /Common/dns-log <DNS_RESPONSE>: 1.2.3.4 May4 05:49:12 DoH-bigip1 debug tmm[22188]: Rule /Common/DoH <HTTP_REQUEST_DATA>: status: received Result B64: AACFgAABAAEAAQACA3d3dwdleGFtcGxlA2NvbQAAAQABwAwAAQABAAk6gAAEAQIDBMAQAAIAAQAJOoAACwlsb2NhbGhvc3QAwD0AAQABAAk6gAAEfwAAAcA9ABwAAQAJOoAAEAAAAAAAAAAAAAAAAAAAAAE= I then added GET resolution: when RULE_INIT { set static::sideband_virtual_server "/Common/dns-udp" } when HTTP_REQUEST { # https://tools.ietf.org/html/rfc8484 if { [HTTP::path] == "/dns-query" } { if { (([HTTP::method] equals "POST") and (([HTTP::header "accept"] equals "application/dns-message") or ([HTTP::header "content-type"] equals "application/dns-message"))) } { if {[HTTP::header exists "Content-Length"] && [HTTP::header "Content-Length"] <= 65535 && [HTTP::header "Content-Length"] > 0} { log local0.debug "Content-Length [HTTP::header value "Content-Length"]" HTTP::collect [HTTP::header value "Content-Length"] } else { HTTP::collect 100 } } elseif { [HTTP::method] equals "GET" && [URI::query [HTTP::uri] dns] != "" } { set queryname [b64decode [URI::query [HTTP::uri] dns] ] log local0.debug "QNAME: $queryname" set header [ binary format c12 "0 0 1 0 0 1 0 0 0 0 0 0" ] # FORMAT QNAME set name "" foreach { field } [split $queryname .] { set strlen [ string length $field ] append name [ binary format c $strlen ] append name [ binary format a* $field ] } # QNAME ends with NULL append name [ binary format c "0" ] # QTYPE: A append name [ binary format S 1 ] # QCLASS IN append name [ binary format S 1 ] binary scan "$header$name" H* p log local0.debug "Payload: $p" set conn_id [connect -protocol UDP -timeout 100 -idle 30 -status conn_status /Common/dns-udp] log local0.debug "Connection status: $conn_status" log local0.debug "Payload B64: [b64encode [HTTP::payload]]" set send_bytes [send -timeout 100 -status send_status $conn_id [binary format H* $p] ] log local0.debug "send_status: $send_status" recv -timeout 100 -peek -status recv_status $conn_id result log local0.debug "status: $recv_status Result B64: [b64encode $result]" HTTP::respond 200 content $result noserver content-type application/dns-message vary Accept-Encoding content-length [string length $result] } else { HTTP::respond 415 content "Unsupported Media Type" } } else { HTTP::respond 404 } } when HTTP_REQUEST_DATA { # Use sideband set conn_id [connect -protocol UDP -timeout 100 -idle 30 -status conn_status /Common/dns-udp] log local0.debug "Connection status: $conn_status" log local0.debug "Payload B64: [b64encode [HTTP::payload]]" set send_bytes [send -timeout 100 -status send_status $conn_id [HTTP::payload]] log local0.debug "send_status: $send_status" recv -timeout 100 -peek -status recv_status $conn_id result log local0.debug "status: $recv_status Result B64: [b64encode $result]" HTTP::respond 200 content $result noserver content-type application/dns-message vary Accept-Encoding content-length [string length $result] } Tested below: root@DoH-xubuntu-desktop1:~# curl -k -H 'content-type: application/dns-message' -o output_file_get https://10.10.10.10/dns-query?dns=d3d3LmV4YW1wbGUuY29t % Total% Received % XferdAverage SpeedTimeTimeTimeCurrent DloadUploadTotalSpentLeftSpeed 100116100116009740 --:--:-- --:--:-- --:--:--974 If you are sharp-eyed you will notice that i made a mistake on this - I only sent the encoded name, not an encoded DNS wireformat packet. For reference, see below my notes on how to create the DNS wireformat packet for www.example.com ( which the RFC uses ): 00 00 01 00 00 01 00 00 00 00 00 00 03 77 77 77 07 65 78 61 6d 70 6c 65 03 63 6f 6d 00 00 01 00 01 DNS Header ID = 00 00 Recursion Available = 01 00 QCOUNT = 00 01 ANSCOUT = 00 00 NSCOUNT = 00 00 ARCOUNT = 00 00 DNS Query www LENGTH = 03 FIELD = 77 77 77 ( www ) example LENGTH = 07 ( 7 octets ) FIELD = 65 78 61 6d 70 6c 65 ( example ) com LENGTH = 03 FIELD = 63 6f 6d ( com ) NULL LABEL = 00 ( end of question name ) QTYPE = 00 01 = A QCLASS = 00 01 = IN I modified this to create a v1.0 which worked adequately as a proof of concept. In testing, I saw the following statistics for 1000 consecutive POST requests: [root@DoH-bigip1:Active:Standalone] config # tmsh show ltm rule DoH --------------------------------- Ltm::Rule Event: DoH:HTTP_REQUEST --------------------------------- Priority500 Executions Total1.0K Failures0 Aborts0 CPU Cycles on Executing Average278.8K Maximum6.1M Minimum147.8K -------------------------------------- Ltm::Rule Event: DoH:HTTP_REQUEST_DATA -------------------------------------- Priority500 Executions Total1.0K Failures0 Aborts0 CPU Cycles on Executing Average644.3K Maximum6.3M Minimum391.1K ------------------------------ Ltm::Rule Event: DoH:RULE_INIT ------------------------------ Priority500 Executions Total0 Failures0 Aborts0 CPU Cycles on Executing Average0 Maximum0 Minimum0 Over the subsequent weeks and months, my colleagues gave me feedback on issues or suggestions, and i created a GUI for the iRule with an iApp. The first issue was that it kept generating errors in the base64 decoding command. This is because base64 and base64url are subtly different. To cure this problem, I spent a few hours looking in detail at when it fails and what the difference between base64 and base64url would be, along with some detailed reading. The upshot is that I added a b64urldecode procedure to handle this: procb64urldecode{str}{ #Proceduretoperformbase64urldecoding setstr[stringmap{-+_\/}$str] setpad[expr{[stringlength$str]%4}] if{$pad!=0}{ appendstr[stringrepeat=[expr{4-$pad}]] } if{[catch{b64decode$str}decodedstr]==0and$decodedstr!=""}{ return$decodedstr }else{ loglocal0.err"Base64decodingerrorforstring$str" return"" } } One of my colleagues Brian also did some capacity testing to look at different options and what the highest performance is - through this we realised that going directly to the servers is more performant than sending to a local virtual server, and I also changed the code so that rather than sending, waiting a fixed period and checking the result, the iRule would check in a shorter loop. From this: set send_bytes [send -timeout 100 -status send_status $conn_id [HTTP::payload]] log local0.debug "send_status: $send_status" recv -timeout 100 -peek -status recv_status $conn_id result to this: setsend_bytes[send-timeout100-statussend_status$conn_id$payload] loglocal0.debug"Sent$send_bytesBytesto$member" for{seti0}{$i<$totalLoops}{incri}{ recv-timeout$recvTimeout-statusrecv_status$conn_idresult if{$recv_status=="received"}{ break } } which gave the best performance. You can see the configuration options around this in the iApp so you can set the total timeout and the checking period. iApp You can see that this iApp creates a simple GUI to allow the modification of the iRule - to add logs, change the destination, timers etc. This is common for us to create to allow simple operation of the iRule as part of the system. Closing Thoughts If I wanted to make this truly scalable, I would consider using Message Routing Framework (MRF) which decouples the message ( ie the DNS request ) from the underlying transport, meaning that we can send wherever and however required, duplicate messages, respond locally or anything else which takes your fancy. As i'm sure you know, the beauty of the BIG-IP platform is the ability to use these features to build any solution required in a short timescale. Hopefully this has given you an insight into what we in F5 Professional Services regularly do, and if you have any questions or suggestions about the DNS over HTTPS iApp or more general Professional Services questions then feel free to message me.1.1KViews0likes0Comments
Application Centric Configuration of F5 BIG-IP in Cisco ACI Using BIG-IQ [End of Life]
The F5 and Cisco APIC integration based on the device package and iWorkflow is End Of Life. The latest integration is based on the Cisco AppCenter named ‘F5 ACI ServiceCenter’. Visit https://f5.com/cisco for updated information on the integration. As part of the BIG-IQ 4.5.0 release, we are releasing an "Early Access" integration for Cisco APIC that allows users to build custom device packages to expose any functionality that can be expressed via an iApp using BIG-IQ. If you want to try it yourself, we recommend you join the BIG-IQ Early Access program for full details and support. Background Last fall, we released our 1.0 integration with the Cisco Application Policy Infrastructure (APIC), the cornerstone of the Cisco Application Centric Infrastructure (ACI). Our integration is provided through software called a "device package"--a plugin that runs on the APIC. It exposes a model that describes all the functionality we make available within APIC as well as code that talks to BIG-IPs to configure them appropriately. APIC "owns" the device, so the device package is capable of fully setting up BIG-IPs (it only assumes they have a license and management IP address), device clusters (currently limited to two BIG-IPs) and the application configuration provided by users. It provides two types of "applications" that can be configured: Virtual-Server and SharePoint. The Virtual-Server exposes a reasonable set of parameters you'd expect for a basic virtual server while the SharePoint configuration is built on top of our SharePoint iApp from DevCentral. In December 2014, we released version 1.1.0 of the device package. It adds the ability to use vCMP and implements "dynamic endpoints", which will update the set of pool members as computers are added or removed from endpoint groups. Here is an example of the set of parameters you can configure for the Virtual-Server. It's hard to show all the parameters at once due to the size of the APIC user interface. Each of the folders contains a set of parameters for the virtual server, and I've opened just one folder (Listener) to show you the address and port settings. Providing More Functionality Although our existing functionality is solid and useful, people want more. Users expect they can utilize their BIG-IPs to the fullest extent. They want use AFM, ASM, Web Acceleration, and any other feature that might be on a BIG-IP. There are two ways we can provide more functionality. The first option is to directly expose more parameters to users. This could work and it provides perfect flexibility for all the functionality we provide on BIG-IP. It's also likely to be tremendously complex for users: we're essentially exposing everything in the BIG-IP UI through a new UI. We would also be fighting a perpetual game of catch-up, adding more features to the device package as they are added to BIG-IP. Another option is to expose application-centric configuration using an F5 technology called iApps. iApps are a user-customizable templates for deploying application configurations. In this case, we are leveraging BIG-IQ to create a catalog of customized iApps, where the administrator can control which iApps are accessible to users. BIG-IQ allows the administrator to control which questions are exposed to users as well default answers for the questions. When the catalog of iApps has been created, the administrator can download a custom device package for APIC which exposes exactly those custom iApps to users within APIC. The use of customized iApps ensures both that users can correctly configure their applications and meet any internal requirements (e.g. the use of SSL). Here is an example of an iApp with just three parameters (VIP, pool members, and FQDN) for deploying an HTTP application. Today, the use of BIG-IQ with Cisco APIC means that users have access to approximately 30 iApps that ship with BIG-IP as well as many more availble here on DevCentral. Users can also take advantage of any custom iApps they may have built. We are releasing the ability to use iApps in Cisco APIC via BIG-IQ as "early access" as part of the upcoming BIG-IQ 4.5.0 release and we expect to release it for general availability by summer 2015.You can apply to the EA program for BIG-IQ here. Video Demo This video shows you a walk-through of the BIG-IQ integration with APIC. You will see the creation of the catalog of customized iApps, the installation of the custom device package, and the use of iApps from within BIG-IQ.771Views0likes1Comment
F5 iWorkflow and Cisco ACI : True application centric approach in application deployment (End Of Life)
The F5 and Cisco APIC integration based on the device package and iWorkflow is End Of Life. The latest integration is based on the Cisco AppCenter named ‘F5 ACI ServiceCenter’. Visit https://f5.com/cisco for updated information on the integration. On June 15 th , 2016, F5 released iWorkflow version 2.0, a virtual appliance platform designed to deploy application with greater agility and consistency. F5 iWorkflow Cisco APIC cloud connector provides a conduit allowing APIC to deploy F5 iApps on BIG-IP. By leveraging iWorkflow, administrator has the capability to customize application template and expose it to Cisco APIC thru iWorkflow dynamic device package. F5 iWorkflow also support Cisco APIC Chassis and Device Manager features. Administrator can now build Cisco ACI L4-L7 devices using a pair of F5 BIG-IP vCMP HA guest with a iWorkflow HA cluster. The following 2-part video demo shows: (1) How to deploy iApps virtual server in BIG-IP thru APIC and iWorkflow (2) How to build Cisco ACI L4-L7 devices using F5 vCMP guests HA and iWorkflow HA cluster F5 iWorkflow, BIG-IP and Cisco APIC software compatibility matrix can be found under: https://support.f5.com/kb/en-us/solutions/public/k/11/sol11198324.html Check out iWorkflow DevCentral page for more iWorkflow info: https://devcentral.f5.com/s/wiki/iworkflow.homepage.ashx You can download iWorkflow from https://downloads.f5.com459Views1like1Comment