What is HTTP Part X - HTTP/2
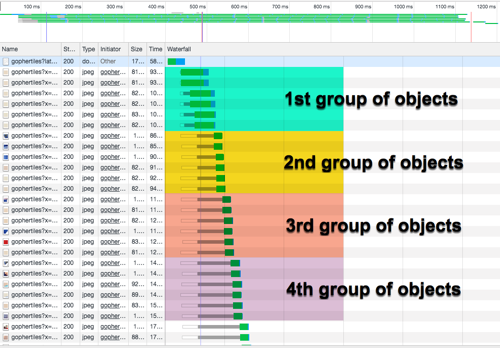
In the penultimate article in this What is HTTP? series we covered iRules and local traffic policies and the power they can unleash on your HTTP traffic. To date in this series, the content primarily focuses on HTTP/1.1, as that is still the predominant industry standard. But make no mistake, HTTP/2 is here and here to stay, garnering 30% of all website traffic and climbing steadily. In this article, we’ll discuss the problems in HTTP/1.1 addressed in HTTP/2 and how BIG-IP supports the major update. What’s So Wrong withHTTP/1.1? It’s obviously a pretty good standard since it’s lasted as long as it has, right? So what’s the problem? Well, let’s set security aside for this article, since the HTTP/2 committee pretty much punted on it anyway, and let’s instead talk about performance. Keep in mind that the foundational constructs of the HTTP protocol come from the internet equivalent of the Jurassic age, where the primary function was to get and post text objects. As the functionality stretched from static sites to dynamic interactive and real-time applications, the underlying protocols didn’t change much to support this departure. That said, the two big issues with HTTP/1.1 as far as performance goes are repetitive meta data and head of line blocking.HTTP was designed to be stateless. As such, all applicable meta data is sent on every request and response, which adds from minimal to a grotesque amount of overhead. Head of Line Blocking For HTTP/1.1, this phenomenon occurs due to each request needs a completed response before a client can make another request. Browser hacks to get around this problem involved increasing the number of TCP connections allowed to each host from one to two and currently at six as you can see in the image below. More connections more objects, right? Well yeah, but you still deal with the overhead of all those connections, and as the number of objects per page continues to grow the scale doesn’t make sense. Other hacks on the server side include things like domain sharding, where you create the illusion of many hosts so the browser creates more connections. This still presents a scale problem eventually. Pipelining was a thing as well, allowing for parallel connections and the utopia of improved performance. But as it turns out, it was not a good thing at all, proving quite difficult to implement properly and brittle at that, resulting in a grand total of ZERO major browsers actually supporting it. Radical Departures - The Big Changes in HTTP/2 HTTP/2 still has the same semantics as HTTP/1. It still has request/response, headers in key/value format, a body, etc. And the great thing for clients is the browser handles the wire protocols, so there are no compatibility issues on that front. There are many improvements and feature enhancements in the HTTP/2 spec, but we’ll focus here on a few of the major changes. John recorded a Lightboard Lesson a while back on HTTP/2 with an overview of more of the features not covered here. From Text to Binary With HTTP/2 comes a new binary framing layer, doing away with the text-based roots of HTTP. As I said, the semantics of HTTP are unchanged, but the way they are encapsulated and transferred between client and server changes significantly. Instead of a text message with headers and body in tow, there are clear delineations for headers and data, transferred in isolated binary-encoded frames (photo courtesy of Google). Client and server need to understand this new wire format in order to exchange messages, but the applications need not change to utilize the core HTTP/2 changes. For backwards compatibility, all client connections begin as HTTP/1 requests with an upgrade header indicating to the server that HTTP/2 is possible. If the server can handle it, a 101 response to switch protocols is issued by the server, and if it can’t the header is simply ignored and the interaction will remain on HTTP/1. You’ll note in the picture above that TLS is optional, and while that’s true to the letter of the RFC law (see my punting on security comment earlier) the major browsers have not implemented that as optional, so if you want to use HTTP/2, you’ll most likely need to do it with encryption. Multiplexed Streams HTTP/2 solves the HTTP/1.1 head of line problem by multiplexing requests over a single TCP connection. This allows clients to make multiple requests of the server without requiring a response to earlier requests. Responses can arrive in any order as the streams all have identifiers (photo courtesy of Google). Compare the image below of an HTTP/2 request to the one from the HTTP/1.1 section above. Notice two things: 1) the reduction of TCP connections from six to one and 2) the concurrency of all the objects being requested. In the brief video below, I toggle back and forth between HTTP/1.1 and HTTP/2 requests at increasing latencies, thanks to a demo tool on golang.org, and show the associated reductions in page load experience as a result. Even at very low latency there is an incredible efficiency in making the switch to HTTP/2. This one change obviates the need for many of the hacks in place for HTTP/1.1 deployments. One thing to note on the head of line blocking: TCP actually becomes a stumbling block for HTTP/2 due to its congestion control algorithms. If there is any packet loss in the TCP connection, the retransmit has to be processed before any of the other streams are managed, effectively halting all traffic on that connection. Protocols like QUIC are being developed to ride the UDP waveand overcome some of the limitations in TCP holding back even better performance in HTTP/2. Header Compression Given that headers and data are now isolated by frame types, the headers can now be compressed independently, and there is a new compression utility specifically for this called HPACK. This occurs at the connection level. The improvements are two-fold. First, the header fields are encoded using Huffman coding thus reducing their transfer size. Second, the client and server maintain a table of previous headers that is indexed. This table has static entries that are pre-defined on common HTTP headers, and dynamic entries added as headers are seen. Once dynamic entries are present in the table, the index for that dynamic entry will be passed instead of the head values themselves (photo courtesy of amphinicy.com). BIG-IP Support F5 introduced the HTTP/2 profile in 11.6 as an early access, but it hit general availability in 12.0. The BIG-IP implementation supports HTTP/2 as a gateway, meaning that all your clients can interact with the BIG-IP over HTTP/2, but server-side traffic remains HTTP/1.1. Applying the profile also requires the HTTP and clientssl profiles. If using the GUI to configure the virtual server, the HTTP/2 Profile field will be grayed out until use select an HTTP profile. It will let you try to save it at that point even without a clientssl profile, but will complain when saving: 01070734:3: Configuration error: In Virtual Server (/Common/h2testvip) http2 specified activation mode requires a client ssl profile As far as the profile itself is concerned, the fields available for configuration are shown in the image below. Most of the fields are pretty self explanatory, but I’ll discuss a few of them briefly. Insert Header - this field allows you to configure a header to inform the HTTP/1.1 server on the back end that the front-end connection is HTTP/2. Activation Modes - The options here are to restrict modes toALPN only, which would then allow HTTP/1.1 or negatiate to HTTP/2 or Always, which tells BIG-IP that all connections will be HTTP/2. Receive Window - We didn’t cover the flow control functionality in HTTP/2, but this setting sets the level (HTTP/2 v3+) where individual streams can be stalled. Write Size - This is the size of the data frames in bytes that HTTP/2 will send in a single write operation. Larger size will improve network utilization at the expense of an increased buffer of the data. Header Table Size - This is the size of the indexed static/dynamic table that HPACK uses for header compression. Larger table size will improve compression, but at the expense of memory. In this article, we covered the basics of the major benefits of HTTP/2. There are more optimizations and features to explore, such as server push, which is not yet supported by BIG-IP. You can read about many of those features here on this very excellent article on Google’s developers portal where some of the images in this article came from.2.5KViews1like2Comments
Tightening the Security of HTTP Traffic part 1
Summary HTTP is the de facto protocol used to communicate over the internet. The security challenges that exists today was not considered when designing the HTTP protocol. Web browsers are generally used to interact with web applications. However, this interaction is not secured in most deployments, despite the existence of a number of http headers that can be leveraged by application developers to tighten the security of their applications. In this article, I will give an overview of some important headers that can be added to HTTP responses in order to improve the security web applications. I will also provide sample iRules that can be implemented on F5 BigIP to insert those headers in HTTP responses. Content This article has been made in a series of 3 parts to make it easier to read and digest. The following headers will be reviewed in different parts of this article: Part 1: A brief overview of Cross-Site Scripting (XSS) vulnerability X-XSS-Protection HttpOnly flag for cookies Secure flag for cookies Part 2: The X-Frame Options Header HTTP Strict Transport Security X-Content-Type-Options Content-Security-Policy Public Key Pinning Extension for HTTP (HPKP) Part 3: Server and X-Powered-By Cookie encryption Https (SSL/TLS) A brief overview of XSS Attacks Before going further into the details of the headers we need to implement to improve the security of http traffic, it is important to make a quick review of the Cross-Site Scripting (XSS) attack,which is the most prevalent web application security flaw . This is important because any of the security measure we will review may be completely useless if an XSS flaw exist on the application.The security measures proposed in this article rely on the browsernot infected by any kind of malware (including XSS) and working properly. A Cross-Site Scripting (XSS) attack is a type of injection attack where a malicious script is injected into a trusted but vulnerable web applications. The malicious script is send to victim browser as client side script when the user uses a vulnerable web app. XSS are generally caused by poor input validation or encoding by web application developers. An XSS attack can load a malware (JavaScript) into to browser and make it behave in a completely unpredictable manner, thus making all other protection mechanism useless. Cross-Site scripting was ranked third in the last OWASP 2013 top 10 security vulnerabilities. Detailed information on XSS can be found on OWASP website. 1. TheX-XSS-Protection header The X-XSS-Protection header enables the Cross-Site Scripting filter on the browser. When enabled, the XSS Filter operates as a browser component with visibility into all requests / responses flowing through the browser.When the filter detects a likely XSS in a request or response, it prevents the malicious script from executing. The X-XSS-Protection header is supported by most major browsers. Usage: X-XSS-Protection: 0 XSS protection filter is disabled (facebook) X-XSS-Protection: 1 XSS protection filter is enable. Upon XSS attack detection, the browser will sanitize the page. X-XSS-Protection: 1; mode=block If XSS attack is detected, The browser blocks the page in order to stop the attack. (Google, Twitter) Note: If third party scripts are allowed to run on your web application, enabling XSS-Protection might prevents some scripts from working properly. As such, proper considerations should be made before enabling the header. 1.1 Example of how this header is used: the following command can be used to see which http headers are enabled on a web application. This command sends a single http request to the destination application and follows redirection. Therefore it is completely harmless and is only used for educational purposes in this article. I will use the same commandthroughout the article against somes well known sites, that are build with high security standards, in order to demonstrate how the discussed headers are used in real life. curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -sD - https://www.google.com -o /dev/null HTTP/1.1 200 OK Date: Mon, 07 Aug 2017 11:24:08 GMT Expires: -1 Cache-Control: private, max-age=0 Server: gws X-XSS-Protection: 1; mode=block [...] 1.2 iRule to enableXSS-Protection The following iRule can be used to insertXSS-Protection header to all http responses: when HTTP_RESPONSE { if { !([ HTTP::header exists "X-XSS-Protection“ ])} { HTTP::header insert "X-XSS-Protection" "1; mode=block" } } 2.HttpOnly flag for cookies When added to cookies in HTTP responses, the HttpOnly flag prevents client side scripts from accessing cookies. Existing cross-site scripting flaws on the web applicationwill not be exploited by using this cookie. The HttpOnly flag relies on the browser to prevent XSS attacks, when set by the server.This flag is supported by all major browsers in their latest versions. It was Introduced in 2002 by Microsoft in IE6 SP1. Note: Using older browser exposes you to higher security risk as older browsers may not support some of the security headers discussed in this article. 2.1 Example: curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -sD - https://www.google.com -o /dev/null HTTP/1.1 200 OK Date: Wed, 16 Aug 2017 19:34:36 GMT Expires: -1 [..] Server: gws X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Set-Cookie: NID=110=rKlFElgqL3YuhyKtxcIr0PiSE; expires=Thu, 15-Feb-2018 19:34:36 GMT; path=/; domain=.google.com; HttpOnly Alt-Svc: quic=":443"; ma=2592000; v="39,38,37,35" [...] 2.2 iRule to add HttpOnly flag to all cookies for http responses: If added to Big-IP LTM virtual server, the following iRule will add the HttpOnly flag to all cookies in http responses. when HTTP_RESPONSE { foreach mycookie [HTTP::cookie names] { HTTP::cookie httponly $mycookie enable } } 3.Secure flag for cookies The purpose of the secure flag is to prevent cookies from being observed by unauthorized parties due to the transmission of a the cookie in clear text. When a cookie has the secure flag attribute, Browsers that support the secure flag will only send this cookie within a secure session(HTTPS). This means that, if the web application accidentally points to a hard coded http link, the cookie will not be send. Enabling secure flag for cookies is common and recommended 3.1 Example curl -L -A "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0" -s -D - https://www.f5.com -o /dev/null HTTP/1.1 200 OK Cache-Control: private Content-Type: text/html; charset=utf-8 […] Set-Cookie: BIGipServer=!M+eTuU0mHEu4R8mBiet1HZsOy/41nDC5VnWBAlE5bvU0446qCYN4w/jKbf2+U8d8EVe+BxHFZ5+UJYg=; path=/; Httponly;Secure Strict-Transport-Security: max-age=16070400 […] 3.2 Setting the secure flag with iRule If added to Big-IP LTM virtual server, the following iRule will add the secure flag to all http responses. when HTTP_RESPONSE { foreach mycookie [HTTP::cookie names] { HTTP::cookie secure $mycookie enable } }3.6KViews3likes3Comments
LineRate HTTP to HTTPS redirect
Here's a quick LineRate proxy code snippet to convert an HTTP request to a HTTPS request using the embedded Node.js engine. The relevant parts of the LineRate proxy config are below, as well. By modifying the redirect_domain variable, you can redirect HTTP to HTTPS as well as doing a non-www to a www redirect. For example, you can redirect a request for http://example.com to https://www.example.com . The original URI is simply appended to the redirected request, so a request for http://example.com/page1.html will be redirected to https://www.example.com/page1.html . This example uses the self-signed SSL certificate that is included in the LineRate distribution. This is fine for testing, but make sure to create a new SSL profile with your site certificate and key when going to production. As always, the scripting docs can be found here. redirect.js: Put this script in the default scripts directory - /home/linerate/data/scripting/proxy/ and update the redirect_domain and redirect_type variables for your environment. "use strict"; var vsm = require('lrs/virtualServerModule'); // domain name to which to redirect var redirect_domain = 'www.example.com'; // type of redirect. 301 = temporary, 302 = permanent var redirect_type = 302; vsm.on('exist', 'vs_example.com', function(vs) { console.log('Redirect script installed on Virtual Server: ' + vs.id); vs.on('request', function(servReq, servResp, cliReq) { servResp.writeHead(redirect_type, { 'Location': 'https://' + redirect_domain + servReq.url }); servResp.end(); }); }); LineRate config: real-server rs1 ip address 10.1.2.100 80 admin-status online ! virtual-ip vip_example.com ip address 192.0.2.1 80 admin-status online ! virtual-ip vip_example.com_https ip address 192.0.2.1 443 attach ssl profile self-signed admin-status online ! virtual-server vs_example.com attach virtual-ip vip_example.com default attach real-server rs1 ! virtual-server vs_example.com_https attach virtual-ip vip_example.com_https default attach real-server rs1 ! script redirect source file "proxy/redirect.js" admin-status online Example: user@m1:~/ > curl -L -k -D - http://example.com/test HTTP/1.1 302 Found Location: https://www.example.com/test Date: Wed, 03-Sep-2014 16:39:53 GMT Transfer-Encoding: chunked HTTP/1.1 200 OK Content-Type: text/plain Date: Wed, 03-Sep-2014 16:39:53 GMT Transfer-Encoding: chunked hello world216Views0likes0CommentsWhat is HTTP Part VIII - Compression and Caching
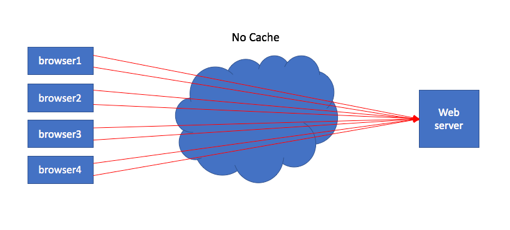
In the last article of this What is HTTP? series we covered the nuances of OneConnect on HTTP traffic through the BIG-IP. In this article, we’ll cover caching and compression. We’ll deal with compression first, and then move on to caching. Compression In the very early days of the internet, much of the content was text based. This meant that the majority of resources were very small in nature. As popularity grew, the desire for more rich content filled with images grew as well, and resource sized began to explode. What had not yet exploded yet, however, was the bandwidth available to handle all that rich content (and you could argue that’s still the case in mobile and remote terrestrial networks as well.) This intersection of more resources without more bandwidth led to HTTP development in a few different areas: Methods for getting or sending partial resources Methods for identifying if resources needed to be retrieved at all Methods for reducing resources during transit that could be successfully reproduced after receipt The various rangeheaders were developed to handle the first case, caching, which we will discuss later in this article, was developed to handle the second case, and compression was developed to handle the third case. The basic definition of data compression is simply reducing the bits necessary to accurately represent the resource. This is done not only to save network bandwidth, but also on storage devices to save space. And of course money in both areas as well. In HTTP/1.0, end-to-end compression was possible, but not hop-by-hop as it does not have a distinguishing mechanism between the two. That is addressed in HTTP/1.1, so intermediaries can use complex algorithms unknown to the server or client to compress data between them and translate accordingly when speaking to the clients and servers respectively. In 11.x forward, compression is managed in its own profile. Prior to 11.x, it was included in the http profile. The httpcompression profile overview on AskF5 is very thorough, so I won’t repeat that information here, but you will want to pay attention to the compression level if you are using gzip (default.) The default of level 1 is fast from the perspective of the act of compressing on BIG-IP, but having done minimal compressing, reaps the least amount of benefit on the wire. If a particular application has great need for less bandwidth utilization toward the clientside of the network footprint, bumping up to level 6 will increase the reduction in bandwidth without overly taxing the BIG-IP to perform the operation. Also, it’s best to avoid compressing data that has already been compressed, like images and pdfs. Compressing them actually makes the resource larger, and wastes BIG-IP resources doing it! SVG format would be an exception to that rule. Also, don’t compress small files. The profile default is 1M for minimum content length. For BIG-IP hardware platforms, compression can be performed in hardware to offload that function. There is a database variable that you can configure to select the data compression strategy via sys modify db compression.strategy . The default value is latency, but there are four other strategies you can employ as covered in the manual. Caching Web caching could (and probably should) be its own multi-part series. The complexities are numerous, and the details plentiful. We did a series called Project Acceleration that covered some of the TCP optimization and compression topics, as well as the larger product we used to call Web Accelerator but is now the Application Acceleration Manager or AAM. AAM is caching and application optimization on steroids and we are not going to dive that deep here. We are going to focus specifically on HTTP caching and how the default functionality of the ramcache works on the BIG-IP. Consider the situation where there is no caching: In this scenario, every request from the browser communicates with the web server, no matter how infrequently the content changes. This is a wasteful use of resources on the server, the network, and even the client itself. The most important resource to our short attention span end users is time! The more objects and distance from the server, the longer the end user waits for that page to render. One way to help is to allow local caching in the browser: This way, the first request will hit the web server, and repeat requests for that same resource will be pulled from the cache (assuming the resource is still valid, more on that below.) Finally, there is the intermediary cache. This can live immediately in front of the end users like in an enterprise LAN, in a content distribution network, immediately in front of the servers in a datacenter, or all of the above! In this case, the browser1 client requests an object not yet in the cache serving all the browser clients shown. Once the cache has the object from the server, it will serve it to all the browser clients, which offloads the requests to server, saves the time in doing so, and brings the response closer to the browser clients as well. Given the benefits of a caching solution, let’s talk briefly of the risks. If you take the control of what’s served away from the server and put it in the hands of an intermediary, especially an intermediary the administrators of the origin server might not have authority over, how do you control then what content the browsers ultimately are loading? That’s where the HTTP standards on caching control come into play. HTTP/1.0 introduced the Pragma, If-Modified-Since, Last-Modified, and Expires headers for cache control. The Cache-Control and ETag headers along with a slew of “If-“ conditional headers were introduced in HTTP/1.1, but you will see many of the HTTP/1.0 cache headers in responses alongside the HTTP/1.1 headers for backwards compatibility. Rather than try to cover the breadth of caching here, I’ll leave it to the reader to dig into the quite good resources linked at the bottom (start with "Things Caches Do") for detailed understanding. However, there's a lot to glean from your browser developer tools and tools like Fiddler and HttpWatch. Consider this request from my browser for the globe-sm.svg file on f5.com. Near the bottom of the image, I’ve highlighted the request Cache-Control header, which has a value of no-cache. This isn’t a very intuitive name, but what the client is directing the cache is that it must submit the request to the origin server every time, even if the content is fresh. This assures authentication is respected while still allowing for the cache to be utilized for content delivery. In the response, the Cache-Control header has two values: public and max-age. The max-age here is quite large, so this is obviously an asset that is not expected to change much. The public directive means the resource can be stored in a shared cache. Now that we have a basic idea what caching is, how does the BIG-IP handle it? The basic caching available in LTM is handled in the same profile that AAM uses, but there are some features missing when AAM is not provisioned. It used to be called ramcache, but now is the webacceleration profile. Solution K14903 provides the overview of the webacceleration profile but we’ll discuss the cache size briefly. Unlike the Web Accelerator, there is no disk associated with the ramcache. As the name implies, this is “hot” cache in memory. So if you are memory limited on your BIG-IP, 100MB might be a little too large to keep locally. Managing the items in cache can be done via the tmsh command line with the ltm profile ramcache command. tmsh show/delete operations can be used against this method. An example show on my local test box: root@(ltm3)(cfg-sync Standalone)(Active)(/Common)(tmos)# show ltm profile ramcache webacceleration Ltm::Ramcaches /Common/webacceleration Host: 192.168.102.62 URI : / -------------------------------------- Source Slot/TMM 1/1 Owner Slot/TMM 1/1 Rank 1 Size (bytes) 3545 Hits 5 Received 2017-11-30 22:16:47 Last Sent 2017-11-30 22:56:33 Expires 2017-11-30 23:16:47 Vary Type encoding Vary Count 1 Vary User Agent none Vary Encoding gzip,deflate Again, if you have AAM licensed, you can provision it and then additional fields will be shown in the webacceleration profile above to allow for an acceleration policy to be applied against your virtual server. Resources RFC 2616 - The standard fine print. Things Caches Do- Excellent napkin diagrams that provide simple explanations of caching operations. Caching Tutorial - Comprehensive walk through of caching. HTTP Caching - Brief but informative look at caching from a webdev perspective. HTTP Caching - Google develops page with examples, flowcharts, and advice on caching strategies. Project Acceleration - Our 10 part series on web acceleration technology available on the BIG-IP platform in LTM and/or AAM modules. Solution K5157 - BIG-IP caching and the Vary header Make Your Cache Work For You - Article by Dawn Parzych here on DevCentral on tuning techniques2.6KViews1like0CommentsWhat is HTTP Part IX - Policies and iRules
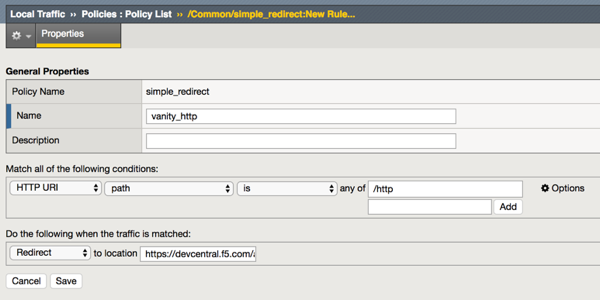
In the previous article of this What is HTTP? series we covered optimization techniques in HTTP with compression and caching. In this article we pivot slightly from describing the protocol itself to showing ways to interact with the HTTP protocol on BIG-IP: policies and iRules. There is a plethora of content on DevCentral for how and what policies are, so rather than regurgitate that here, we’ll focus on what you can do with each approach and show a couple common examples. Before we do, however, run (don’t walk!) over to Chase Abbott’s To iRule, or not to iRule: Introduction to Local Traffic Policies article and Steve McCarthy’s LTM Policy article and read those first. Seriously, stop here and read those articles! Example 1: Simple HTTP Redirect I haven’t performed any advanced analysis on our Q&A section in quite a while, but at one time, redirection held the lion’s share of questions, and I still see them trickle in. Sometimes an application owner will move resources from one location to another within the app, either because the underlying platform has changed or navigation or site map redesign has occurred. Alternatively, the app owner may just want some vanity or random URLs to surface in advertisements so it’s easier to market and track demographically. To reorient application clients to the new resource locations, you can simply rewrite the URL before sending to the server, which will be unnoticed by the client, or you can redirect them to the new resource, which results in an HTTP response to the client and a second request for BIG-IP to handle the request for the “right” resource. The 300 level status codes are used by the “server" to instruct the client on necessary additional actions. The two primary redirection codes are 301, which instructs the client that the resource has been moved permanently, and the 302, which instructs the client that the move is temporary. For this example, we’re going to create a vanity URL to temporarily redirect clients from /http to this series landing page at/articles/sid/8311. Policy Solution Each policy has one or more rules. In this policy, we just need the one rule that has the condition of /http as the path and the action of redirecting a matching condition to the specified URL. ltm policy simple_redirect { controls { forwarding } last-modified 2017-12-14:23:22:51 requires { http } rules { vanity_http { actions { 0 { http-reply redirect location https://devcentral.f5.com/s/articles/sid/8311 } } conditions { 0 { http-uri path values { /http } } } } } status published strategy first-match } Writing policies textually can be a little overwhelming, but you can also configure them in the GUI as shown below. Note that in version 12.1 and later, you need to publish a policy before it can be used, and altering policies requires making a draft copy before activating any changes. iRules Solution The iRule solution is actually quite short. when HTTP_REQUEST { if { [HTTP::path] eq "/http" } { HTTP::redirect "https://devcentral.f5.com/s/articles/sid/8311" } } While short and simple, it is not likely to be as performant as the policy. However, since it is a very simple iRule with little overhead, the performance savings might not justify the complexity of using policies, especially if the work is being done on the command line. Also of note, if the requirement is a permanent redirect, then you must use an iRule because you cannot force a 301 from a policy alone. With a permanent redirect, you have to change the the HTTP::redirect command to an HTTP::respond and specify the 301 with a location header. when HTTP_REQUEST { if { [HTTP::path] eq "/http" } { HTTP::respond 301 Location "https://devcentral.f5.com/s/articles/sid/8311" } } There is a way to use a policy/iRule hybrid for 301 redirection, but if you need the iRule from the policy, I'd recommend just using the iRule approach. Example 2: Replace X-Forwarded-For with Client IP Address Malicious users might try to forge client IPs in the X-Forwarded-For (XFF) header, which can potentially lead to bad things. In this example, we’ll strip any XFF header in the client request and insert a new one. Policy Solution In this policy, we don't care what the conditions are, we want a sweeping decision to replace the XFF header, so no condition is necessary, just an action. You'll notice the tcl: immediately before using the iRules [IP::client_addr] . These tcl expressions are supported in policies, and are a compromise of performance for additional flexibility. ltm policy xff { last-modified 2017-12-15:00:39:26 requires { http } rules { remove_replace { actions { 0 { http-header replace name X-Forwarded-For value tcl:[IP::client_addr] } } } } status published strategy first-match } This works great if you have a single XFF header, but what if you have multiples? Let's check wireshark on my curl command to insert two headers with IP addresses 172.16.31.2 and 172.16.31.3. You can see that one of the two XFF headers was replaced, but not both, which does not accomplish our goal. So instead, we need to do a remove and insert in the policy like below. ltm policy xff { last-modified 2017-12-15:00:35:35 requires { http } rules { remove_replace { actions { 0 { http-header remove name X-Forwarded-For } 1 { http-header insert name X-Forwarded-For value tcl:[IP::client_addr] } } } } status published strategy first-match } Removing and re-inserting, we were able to achieve our goal as shown in the wireshark output from the same two IP address inserted in XFF headers from a curl request. iRules Solution The iRule is much like the policy in that we’ll remove and insert. when HTTP_REQUEST { HTTP::header remove "X-Forwarded-For" HTTP::header insert "X-Forwarded-For" [IP::client_addr] # You could also use replace since it will insert if missing # HTTP::header replace "X-Forwarded-For" [IP::client_addr] } Again, short and sweet! Like the policy example above, using HTTP::header remove in the header command removes all occurrences of the XFF header, not just the last match, which is what HTTP::header replace does. Profile Solution This is where we step back a little and evaluate whether we need an iRule or policy at all.You might recall frompart five of this seriesthe settings in the HTTP profile for the X-Forwarded-For header. But with that, I noted that enabling this just adds another X-Forwarded-For header, it doesn’t replace the existing ones. But a slick little workaround (much like our policy solution above, but completely contained in the http profile!) is to add the header to the remove and insert fields, with the values set as shown below. Keep in mind you can only erase/insert a single header, so it works for this single solution, but as soon as you have more parameters the policy or iRule is the better option. Profiles, Policies, and iRules…Where’s My Point of Control? This isn’t an HTTP problem, but since we’re talking about solutions, I’d be remiss if I didn’t address it. Performance is a big concern with deployments, but not the only concern. One other big area that needs to be carefully planned is where your operational team is comfortable with points of control. If application logic is distributed among profiles, policies, and iRules, and that changes not just within a single app but across all applications, there is significant risk for resolving issues when they do arise if documentation of the solutions is lacking. It’s perfectly ok to spread the logic around, but everyone should be aware that XYZ is in iRules, ABC is in policies, and DEF is in profiles. Otherwise, your operations teams will spend a significant amount of time just mapping out what belongs where so they can understand the application flow within the BIG-IP! I say all that to drive home the point that all iRules is an ok solution if the needs policies address is a small percentage of the overall application services configured on BIG-IP. It’s also ok to standardize on policies and push back on application teams to move the issues policies can’t address back into the application itself. The great thing is you have options. Additional Resources Getting Started with iRules iRule Recipe 1: Single URL Explicit Redirect Codeshare: iRules & HTTP Getting Started with Policies (AskF5 Manual) LTM Policy Recipes I LTM Policy Recipes II Automatically Redirect http to https on a Virtual Server(Ask F5 Solution) Forwarded HTTP Extension Insertion - RFC 7239 (Codeshare iRule)712Views0likes0CommentsWhat is HTTP?
tl;dr - The Hypertext Transfer Protocol, or HTTP, is the predominant tool in the transferring of resources on the web, and a "must-know" for many application delivery concepts utilized on BIG-IP HTTP defines the structure of messages between web components such as browser or command line clients, servers like Apache or Nginx, and proxies like the BIG-IP. As most of our customers manage, optimize, and secure at least some HTTP traffic on their BIG-IP devices, it’s important to understand the protocol. This introductory article is the first of eleven parts on the HTTP protocol and how BIG-IP supports it. The series will take the following shape: What is HTTP? (this article) HTTP Series Part II - Underlying Protocols HTTP Series Part III - Terminology HTTP Series Part IV - Clients, Proxies, & Servers — Oh My! HTTP Series Part V - Profile Basic Settings HTTP Series Part VI - Profile Enforcement HTTP Series Part VII - Oneconnect HTTP Series Part VIII - Compression & Caching HTTP Series Part IX - Policies & iRules HTTP Series Part X- HTTP/2 A Little History Before the World Wide Web of Hypertext Markup Language (HTML) was pioneered, the internet was alive and well with bulletin boards, ftp, and gopher, among other applications. In fact, by the early 1990’s, ftp accounted for more than 50% of the internet traffic! But with the advent of HTML and HTTP, it only took a few years for the World Wide Web to completely rework the makeup of the internet. By the late 1990’s, more than 75% of the internet traffic belonged to the web. What makes up the web? Well get ready for a little acronym salad. There are three semantic components of the web: URIs, HTML, and HTTP. The URI is the Uniform Resource Identifier. Think of the URI as a pointer. The URI is a simple string and consists of three parts: the protocol, the server, and the resource. Consider https://devcentral.f5.com/s/articles/ . The protocol is https, the server is devcentral.f5.com, and the resources is /articles/. URL, which stands for Uniform Resource Locator, is actually a form of a URI, but for the most part they can be used interchangeably. I will clarify the difference in the terminology article. HTML is short for the HyperText Markup Language. It’s based on the more generic SGML, or Standard Generic Markup Language. HTML allows content creators to provide structure, text, pictures, and links to documents. In our context, this is the HTTP payload that BIG-IP might inspect, block, update, etc. HTTP as declared earlier, is the most common way of transferring resources on the web. It’s core functionality is a request/response relationship where messages are exchanged. An example of a GET message in the HTTP/1.1 version is shown in the image below. This is eye candy for now as we’ll dig in to the underlying protocols and HTTP terminology shown here in the following two articles. But take notice of the components we talked about earlier defined there. The protocol is identified as HTTP. Following the method is our resource /home, and the server is identified in the Host header. Also take note of all those silly carriage returns and new lines. Oh, the CRLF!! If you’ve dealt with monitors, you can feel our collective pain! HTTP Version History Whereas HTTP/2 has been done for more than two years now, current usage is growing but less than 20%, with HTTP/1.1 laboring along as the dominant player. We’ll cover version-specific nuances later in this series, but the major releases throughout the history of the web are: HTTP/0.9 - 1990 HTTP/1.0 - 1996 HTTP/1.1 - 1999 HTTP/2 - 2015 Given the advancements in technology in the last 18 years, the longevity of HTTP/1.1 is a testament to that committee (or an indictment on the HTTP/2 committee, you decide!) Needless-to-say, due to the longevity of HTTP/1.1, most of the industry expertise exists here. We’ll wrap this series with HTTP/2, but up front, know that it’s a pretty major departure from HTTP/1.1, most notably is that it is a binary protocol, whereas earlier versions of HTTP were all textual.1.5KViews4likes7CommentsWhat is HTTP Part V - HTTP Profile Basic Settings
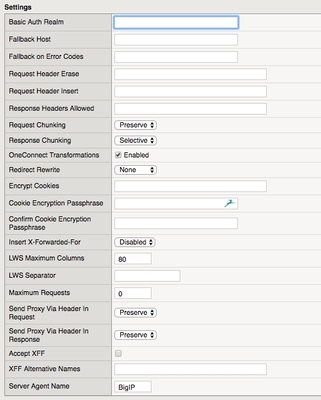
In the first four parts of this series on HTTP, we laid the foundation for understanding what’s to come. In this article, we’ll focus on the basic settings in the BIG-IP HTTP profile. Before we dive into the HTTP-specific settings, however, let’s briefly discuss the nature of a profile. In the BIG-IP, every application is serviced by one or more virtual servers. There are literally hundreds of individual settings one can make to tune the various protocols used to service applications. Tweaking every individual setting for every individual application is not only time consuming, but at risk for human error. A profile allows an administrator to configure a sub-set of (usually) protocol specific settings that can then be applied to one or more virtual servers. Profiles can also be tiered in that you can have a baseline parent profile, and then use that to create child profiles based on that parent profile to tweak individual settings as necessary. The built-in profiles can be changed but it is not recommended you do so. The recommendation is to create a child based on a built-in profile, and customize from there. The settings we’ll focus on today are shown in the screen capture below. Note that this is TMOS version 12.1 HF1. The HTTP profile has oscillated over the versions to include or disclude various feature sets, so don’t be alarmed if your view is different. There are a few proxy modes available in the HTTP profile, but we’ll focus on reverse proxy mode. Basic Auth Realm The realm is a scope of protection for resources on an origin server. Think of realms as partitions where each can have their own authentication schemes. When authentication is required, the server should respond with a status of 401 and the WWW-Authenticate header. If you set this field to testrealm, the header value returned to the client will be Basic realm=“testrealm”. On the client end, when this response is received, a browser pop-up will trigger and provide a message like Please enter your username and password for : though some browsers do not provide the realm in this message. Fallback The two fallback fields in the profile are useful for handling adverse conditions in availability of your server pool of resources. The Fallback on Error Codes field allows you to set status codes in a space-separated list that will redirect to your Fallback Host when the server responds with any of those codes. This is useful hiding back end issues for a better user experience as well as securing any underlying server information leakage. The Fallback Host by itself is utilized when there are no available nodes to send requests to. When this happens, a status of 302 (a temporary redirect)with the specified host is returned to the client. Header Insertions, Erasures, & Allowances The profile supports limited insert/remove/sanitize functionality. On requests, you can select a single header to insert and a single header to remove. There is a precedence for insertions and removals you'll want to keep in mind if you are inserting and removing the same header. Not sure why you'd do that but I tested and it appears that the HSTS and X-Forwarded-For features will be inserted first, if either are specified in the Request Header Erase they will be removed, and if also specified in the Request Header Insert, will be re-inserted on the way to the server. On responses, you can specify a space-separated list of allowed headers and headers not in that list will be removed before the response is returned to the client. If any of that doesn’t meet your needs, you can further customize the experience with local traffic policies or iRules, which we’ll dig into in part nine of this series. Chunking The request/response chunking fields help deal with compression. We’ll talk about compression in part eight of this series. These fields control how BIG-IP handles chunked content from clients and servers as indicated in the Transfer-Encoding header. The table below shows how the settings in the profile handle chunked and unchecked data for requests and responses. OneConnect Transformations We’ll address OneConnect in part seven of this series, but basically, by enabling transformations AND having a OneConnect profile, it allows the system to change non-keepalive connection requests on the client side to keep alive connections on the server side. If this feature is enabled WITHOUT a OneConnect profile, which is default, there is no action taken. Redirect Rewrites SSL offload is a very popular component for BIG-IP deployments. Traffic from client->BIG-IP is typically secured with SSL, and often, not protected from BIG-IP->server. Some servers are either not configured or just not able to handle returning secured URLs if the server is serving unsecured content. There are many ways to handle this, but this particular setting can be configured to assure that all or request-matching URLs are rewritten from http:// to https:// links. For redirects to node IP addresses, you can also configure the redirect to be rewritten to the virtual server address instead. The default for this setting is to not rewrite redirects. The actions taken for each option in the rewrites is as follows: None: Specifies that the system does not rewrite the URI in any HTTP redirect responses. All: Specifies that the system rewrites the URI in all HTTP redirect responses. Matching: Specifies that the system rewrites the URI in any HTTP redirect responses that match the request URI. Nodes: Specifies that if the URI contains a node IP address instead of a host name, the system changes it to the virtual server address. Note that it is not content that is being rewritten here. Only the Location header in the redirect is updated. Cookie Encryption This is a security feature, enabling you to take an unencrypted cookie in a server response, encrypt it with 192-bit AES cipher, and b64 encode it before sending the response to the client. Multiple cookies can be specified in a space-separated list. This can also be done in iRules against all cookies without calling out specific cookie names. X-Forwarded-For The X-Forwarded-For header is a de-facto standard for passing client IP addresses to servers when the true nature of the force (ahem, the IP path) is not visible to servers. This is common with network address translation being prevalent between clients and server. By default the Insert field is disabled, but if enabled, the client-side IP address of the packets being received by BIG-IP will be inserted into the X-Forwarded-For header and sent to the server. As X-Forwarded-For is a de-facto standard, that means that it is no standard at all, and some proxies with insert an additional header and some will just append to a header. The Accept XFF and XFF Alternate Names fields are used for system level statistics and whether they can be trusted. More details on that (specific to ASM) can be found in solution K12264. Enabling X-Forwarded-For in the HTTP profile does not sanitize existing X-Forwarded-For headers already present in the client request. If there are two present in the request, then BIG-IP if configured to insert one will add a third. You can test this easily with curl: curl -H "X-Forwarded-For: 172.16.31.2" -H "X-Forwarded-For: 172.16.31.3" http://www.test.local/ Here are my wireshark captures on my Ubuntu test server before and after enabling the XFF header insertion in the profile: If you want to pass oneX-Forwarded-For and one only to the server, an iRule is a good idea to achieve this behavior. Linear White Space There are two fields for handling linear white space: max columns (default: 80) and the separator (default: \r\n). Linear white space is any number of spaces, tabs, newlines IF followed by at least one space or tab. From RFC2616: A CRLF is allowed in the definition of TEXT only as part of a header field continuation. It is expected that the folding LWS will be replaced with a single SP before interpretation of the TEXT value. I've not had a reason to ever change these settings. you can test for the presence of linear white space in a header with the HTTP::header lws command. This stack thread has a good answer on what linear white space is. Max Requests This is pretty straightforward. The default of zero does not limit the number of HTTP requests per connection, but changing this number will limit client requests on a per-connection basis to the value specified. Via Headers Regardless of request or response, this setting controls how BIG-IP handles the Via header. Like trace route for IP packets, the Via header will be appended with each intermediary along the way, so when the message reaches its destination, the HTTP path (not the IP path) should be known (whereas all HTTP/1.1 proxies are required to participate, HTTP/1.0 proxies that may or may not append the Via header.) When updating the header, the proxy is required to identify their hostname (or a pseudonym) and the HTTP version of the previous server in the path. Each proxy appends the information in sequential order to the header. Here’s an example Via header from Mozilla’s developer portal. Via: 1.1 vegur Via: HTTP/1.1 GWA Via: 1.0 fred, 1.1 p.example.net The available selections for this setting, request or response, is to preserve, remove, or append the Via header. Server Agent Name This is the value that BIG-IP populates in the Server header for response traffic. The default of BigIP gives away infrastructure clues, so many implementations will change this default. The Server header is analogous in response traffic to the User Agent header in client traffic. What questions do you have? Drop a comment below if there is anything I can clarify. Join me next week when we move on to the HTTP profile enforcement settings.3.1KViews0likes13Comments2.5 bad ways to implement a server load balancing architecture
I'm in a bit of mood after reading a Javaworld article on server load balancing that presents some fairly poor ideas on architectural implementations. It's not the concepts that are necessarily wrong; they will work. It's the architectures offered as a method of load balancing made me do a double-take and say "What?" I started reading this article because it was part 2 of a series on load balancing and this installment focused on application layer load balancing. You know, layer 7 load balancing. Something we at F5 just might know a thing or two about. But you never know where and from whom you'll learn something new, so I was eager to dive in and learn something. I learned something alright. I learned a couple of bad ways to implement a server load balancing architecture. TWO LOAD BALANCERS? The first indication I wasn't going to be pleased with these suggestions came with the description of a "popular" load-balancing architecture that included two load balancers: one for the transport layer (layer 4) and another for the application layer (layer 7). In contrast to low-level load balancing solutions, application-level server load balancing operates with application knowledge. One popular load-balancing architecture, shown in Figure 1, includes both an application-level load balancer and a transport-level load balancer. Even the most rudimentary, entry level load balancers on the market today - software and hardware, free and commercial - can handle both transport and application layer load balancing. There is absolutely no need to deploy two separate load balancers to handle two different layers in the stack. This is a poor architecture introducing unnecessary management and architectural complexity as well as additional points of failure into the network architecture. It's bad for performance because it introduces additional hops and points of inspection through which application messages must flow. To give the author credit he does recognize this and offers up a second option to counter the negative impact of the "additional network hops." One way to avoid additional network hops is to make use of the HTTP redirect directive. With the help of the redirect directive, the server reroutes a client to another location. Instead of returning the requested object, the server returns a redirect response such as 303. I found it interesting that the author cited an HTTP response code of 303, which is rarely returned in conjunction with redirects. More often a 302 is used. But it is valid, if not a bit odd. That's not the real problem with this one, anyway. The author claims "The HTTP redirect approach has two weaknesses." That's true, it has two weaknesses - and a few more as well. He correctly identifies that this approach does nothing for availability and exposes the infrastructure, which is a security risk. But he fails to mention that using HTTP redirects introduces additional latency because it requires additional requests that must be made by the client (increasing network traffic), and that it is further incapable of providing any other advanced functionality at the load balancing point because it essentially turns the architecture into a variation of a DSR (direct server return) configuration. THAT"S ONLY 2 BAD WAYS, WHERE'S THE .5? The half bad way comes from the fact that the solutions are presented as a Java based solution. They will work in the sense that they do what the author says they'll do, but they won't scale. Consider this: the reason you're implementing load balancing is to scale, because one server can't handle the load. A solution that involves putting a single server - with the same limitations on connections and session tables - in front of two servers with essentially the twice the capacity of the load balancer gains you nothing. The single server may be able to handle 1.5 times (if you're lucky) what the servers serving applications may be capable of due to the fact that the burden of processing application requests has been offloaded to the application servers, but you're still limited in the number of concurrent users and connections you can handle because it's limited by the platform on which you are deploying the solution. An application server acting as a cluster controller or load balancer simply doesn't scale as well as a purpose-built load balancing solution because it isn't optimized to be a load balancer and its resource management is limited to that of a typical application server. That's true whether you're using a software solution like Apache mod_proxy_balancer or hardware solution. So if you're implementing this type of a solution to scale an application, you aren't going to see the benefits you think you are, and in fact you may see a degradation of performance due to the introduction of additional hops, additional processing, and poorly designed network architectures. I'm all for load balancing, obviously, but I'm also all for doing it the right way. And these solutions are just not the right way to implement a load balancing solution unless you're trying to learn the concepts involved or are in a computer science class in college. If you're going to do something, do it right. And doing it right means taking into consideration the goals of the solution you're trying to implement. The goals of a load balancing solution are to provide availability and scale, neither of which the solutions presented in this article will truly achieve.291Views0likes1Comment
Tools and facilities to troubleshoot HTTP/3 over QUIC with the BIG-IP system
Introduction This article is for engineers who are troubleshooting issues related to HTTP/3 over QUIC as you deploy this new technology on your BIG-IP system. As you perform your troubleshooting tasks, the BIG-IP system provides you a set of useful tools along with other third party software to identify the root cause of issues and even tune HTTP/3 performance to maximize your system's potential. Overview of HTTP/3 and QUIC HTTP/3 is the next version of the HTTP protocol after HTTP/2. The most significant change in HTTP/3 from its predecessors is that it uses the UDP protocol instead of TCP. HTTP/3 uses a new Internet transport protocol, QUIC uses streams at the transport layer and provides TCP-like congestion control and loss recovery. One major improvement QUIC provides is it combines the typical 3-way TCP handshake with TLS 1.3's handshake. This improves the time required to establish a connection. Hence, you may see QUIC as providing the functions previously provided by TCP, TLS, and HTTP/2 as shown in the following diagram: For an overview of HTTP/3 over QUIC with the BIG-IP system, refer to K60235402: Overview of the BIG-IP HTTP/3 and QUIC profiles. Available tools and facilties Beginning in BIG-IP 15.1.0.1, HTTP/3 over QUIC (client-side only) is available as an experimental feature on the BIG-IP system. Beginning in BIG-IP 16.1.0, BIG-IP supports QUIC and HTTP/3. In addition to that feature, there are tools and facilities that are available to help you troubleshoot issues you might encounter. Install an HTTP/3 command line client Use a browser that supports QUIC Review statistics on your BIG-IP system Enable QUIC debug logging on the BIG-IP system Perform advanced troubleshooting with Packet Tracing Use the NetLog feature from the Chromium Project to capture a NetLog dump. Use the tcpdump command and Wireshark to capture and analyze traffic. Use the qlog trace system database key on the BIG-IP system. Important: For BIG-IP versions prior to 16.1.0 that are in the experimental stages, it is important that you note in your troubleshooting, the version of the ietf draft that your client and server implements. For example, in the Hello packets between the client and server, version negotiation is performed to ensure that client and server agree to a QUIC version that is mutually supported. In BIG-IP 15.1.0.1, the HTTP/3 and QUIC profiles in the BIG-IP system are experimental implementations of draft-ietf-quic-http-24 and draft-ietf-quic-transport-24 respectively. You need to consider this when configuring the Alt-Svc header in HTTP/3 discovery. For some browsers such as those from the Chromium project, Chrome canary, Microsoft Edge canary and Opera, when starting these browsers from the command line, you need to provide the QUIC version it implements. For example, for Chrome canary, you run the following command: chrome.exe --enable-quic --quic-version=h3-25. Only implementations of the final, published RFC can identify themselves ash3. Until such an RFC exists, implementations must not identify themselves using theh3string. 1. Install an HTTP/3 command line client Keep in mind that HTTP/3 over QUIC runs on UDP instead of TCP. By default, browsers always initiate a connection to the server using the traditional TCP handshake which will not work with a QUIC server listening for UDP packets. You therefore need to configure HTTP/3 discovery on your BIG-IP system. This can be done by using the HTTP Alternative Services concept which can be implemented either by inserting the Alt-Svc header or via DNS as a HTTPSVC DNS resource record. To insert the Alt-Svc header, refer to K16240003: Configuring HTTP/3 discovery for BIG-IP virtual server. As you troubleshoot your HTTP/3 discovery implementation, you can use a command line tool that does not come with the overhead of HTTP/3 discovery. Following are two popular tools that you can install on your client system: The picoquic client The curl client where you have the option to use either the ntcp2 or quiche software libraries. 2. Use a browser that supports QUIC At this time, browsers by default, still do not support QUIC and do not send the server UDP packets to establish a QUIC connection. The following browsers which are in development support it: Firefox Nightly Chrome Canary (Chromium Project) Microsoft Edge Canary (Chromium Project) Opera (Chromium Project) Note that for browsers from the Chromium project, you need to specify the QUIC ietf version that the browser supports when you launch it. For example, for Chrome, run the following command: chrome.exe --enable-quic --quic-version=h3-25. In most browsers today, you can quickly view the HTTP information exchanged by using the built-in developer tool. To open the tool, select F12 after your browser opens and access any site that supports QUIC. Select the Network tab and under the Protocol column, look at h3-<draft_version> . If the Protocol column is not there, you may have to right click the toolbar to add it. Note: Only implementations of the final, published RFC can identify themselves as h3. Until such an RFC exists, implementations must not identify themselves using the h3 string. Click the name of the HTTP request and you can see that the site returns the Alt-Svc header indicating that it supports HTTP/3 with its ietf draft version. 3. Review statistics on your BIG-IP system The statistics facility on the BIG-IP system displays the system's QUIC traffic processing. On the Configuration utility, go to Local Traffic > Virtual Servers. Select the name of your virtual server and select the Statistics tab. In the Profiles section, select the HTTP/3 and QUIC profiles associated with the virtual server. Alternatively, you can view the statistics from the TMOS shell (tmsh) utility using the following command syntax: tmsh show ltm profile http3 <http3_profile_name> tmsh show ltm profile quic <quic_profile_name> 4. Enable QUIC debug logging on the BIG-IP system You can use the sys db variable tmm.quic.log.level to adjust the verbosity of the QUIC log level to the /var/log/ltm file. Type the following command to see the list of values. tmsh list sys db tmm.quic.log.level value-range sys db tmm.quic.log.level { default-value "Critical" value-range "Critical Error Warning Notice Info Debug" } For example: tmsh modify sys db tmm.quic.log.level value debug 5. Perform advanced troubleshooting with Packet Tracing a. Use the NetLog feature from the Chromium Project to capture a NetLog dump. NetLog is an event logging mechanism for Chrome’s network stack to help debug problems and analyze performance not just for HTTP/3 over QUIC traffic but also HTTP/1.1 and HTTP/2. This feature is available only in browsers from the Chromium project, such as Google Chrome, Opera and Microsoft Edge. The feature provides detailed client side logging including SSL handshake and HTTP content without having to perform decryption or run any commands on your BIG-IP system. To start capturing, open a new tab on your browser and go to, for example, chrome://net-export (Chromium only). For a step by step guide, refer to How to capture a NetLog dump. Once you have your NetLog dump, you can view and analyze it by navigating to netlog-viewer (Chromium only). To analyze QUIC traffic, on the left panel, select Events. In the Description column, identify the URL you requested. For QUIC SSL handshake events, select QUIC_SESSION. For HTTP content, select URL_REQUEST. For example, in the following NetLog dump, the connection failed at the beginning because the client and server could not negotiate a common QUIC version. b. Use the tcpdump command and Wireshark to capture and analyze traffic. The tcpdump command and Wireshark are both essential tools when you need to examine any communication at the packet level. To generate captures and the SSL secrets required to decrypt them, follow the procedure in K05822509: Decrypting HTTP/3 over QUIC with Wireshark. Keep your Wireshark version updated at all times as Wireshark's ability to decode QUIC packets continue to evolve as we speak. c. Use the qlog traces on the BIG-IP system. The BIG-IP qlog trace facility provides you another tool to troubleshoot QUIC communications. By enabling a database variable, the system logs packets and other events to /var/log/trace<TMM_number>.qlog files. qlog is a standardized structured logging format for QUIC and is basically a well-defined JSON file with specified event names and associated data that allows you to use tools like qvis for visualization. Note that the payload is not logged. The qlog trace files are compliant to the IETF schema specified in draft-marx-qlog-main-schema-01. To capture and analyze qlog trace files on your BIG-IP system, perform the following procedure: Capturing qlog trace files on the BIG-IP system Login to the BIG-IP command line. Enable qlogging by typing the following command: tmsh modify sys db quic.qlogging value enable Reproduce the issue you are troubleshooting by initiating QUIC traffic to your virtual server. Disable qlogging by typing the following command: tmsh modify sys db quic.qlogging value disable Note: This step will log required closing json content to the trace files, terminate the trace logging gracefully and is required before you view the files. Sanitizing the qlog trace files Before loading the trace files onto a graphical visualization tool, you first need to sanitize the json content. The tools attempt to fix some common json errors but there may be cases where you need to manually correct some json syntax errors by adding closing braces or commas. Note: Knowledge of different json constructs such as objects, arrays and members may be required when you fix the json files. You can use any of the available online tools such as the following: Json Formatter Fixjson freeformatter Important: Even as the payload information such as IP addresses, or HTTP content are not included in the trace files, you should exercise caution when uploading content to online tools. F5 is not responsible for the privacy and security of your data when you use the third party software listed in this procedure. Alternatively, you can download and install any of the following command line tools on your client device: jsonlint-php jsonlint-py jsonlint-cli Loading and analyzing the qlog trace files with a visualization tool When you have sanitized your json trace files, upload them to a visualization tool for analysis. For example, you can use the following tool available for free. qvis QUIC and HTTP/3 visualization toolsuite The visualization tool can provide you graphical representations of the sequence of messages, congestion information and qlog stats for troubleshooting. For example, the following screenshot, illustrates a sequence diagram of the SSL handshake. Important: Even as payload information such as IP addresses, or HTTP content are not included in the trace files, you should exercise caution when uploading content to online tools. F5 is not responsible for the privacy and security of your data when you use the third party software listed in this procedure. Summary As you use the tools described in this article, you notice that each one helps you troubleshoot issues at the different OSI layers. The built-in developer tools in each browser provide a quick and easy way to view HTTP content but do not let you see the details of the protocol, as do the NetLog tool and Wireshark. However, viewing qlog traces on the qvis graphical tool provides you high level trends and statistics that packet captures do not show. Using the appropriate tool with the right troubleshooting methodology maximizes the potential of HTTP/3 and QUIC for your organization.4.2KViews3likes0CommentsWhat is HTTP Part III - Terminology
Have you watched the construction of a big building over time? For the first few weeks, the footers and foundation are being prepared to support the building. it seems like not much is happening, but that ground work is vital to the overall success of the project. So it is with this series, so stay with me—the foundation is important. This week, we begin to dig into the HTTP specifications and we’ll start with defining the related terminology. World Wide Web, or WWW, or simply “the web" - The collection of resources accessible amongst the global interconnected system of computers. Resource - An object or service identified by a URI. A Web page is a resource, but images, scripts, and stylesheets for a webpage would also be resources. Web Page - A document accessible on the web by way of a URI. Example - this article. Web Site - A collection of web pages. An example would be this site, accessed by the DNS hostname devcentral.f5.com. Web Client - The software application that requests the resources on a web site by generating, receiving, and processing HTTP messages. A web client is always the initiator. Web Server - The software application that serves the resources a web site by receiving, processing, and generating HTTP messages. A web server does not initiate traffic to a client. Examples would be Apache, NGINX, IIS, or even an F5 BIG-IP iRule! Uniform Resource Identifier, or URI - As made clear in the name, the URI is an identifier, which can mean the resource name, or location, or both. All URLs (locators) and URNs (names) are URIs, but all URLs/URNs are not URIs. Think Venn diagrams here. Consider https://clouddocs.f5.com/api/irules/. The key difference between a URI (which would be /wiki/iRules.HomePage.ashx in this case) and a URL is the URL combines the name of the resource, the location of that resource (devcentral.f5.com,) and the method to access that resource (https://.) In the URL, the port is assumed to be 80 if the request method is http, and assumed to be 443 if the request method is https. If the default ports are not appropriate for a particular location, they will need to be provided by adding immediately after the hostname like https://devcentral.f5.com/s:50443/wiki/iRules.HomePage.ashx. Message - This is the basic HTTP unit of communication Header - This is the control section within an HTTP message Entity - This is the body of an HTTP message User Agent - This is a string of tokens that should beinserted by a web client as a header called User-Agent. The tokens are listed in order of significance. Most web clients perform this on your behalf, but there are browser tools that allow you to manipulate this, which can be good for testing, client statistics, or even client remediation. Keep in mind that bad actors might also manipulate this for nefarious purposes, so any kind of access control based solely on user agents is ill advised. Proxy - Like in the business world, a proxy acts as an intermediary. A server to clients, and a client to servers, proxies must understand HTTP messages. We’ll dig deeper into proxies in the next article. Cache - This is web resource storage that can exist at the server, any number of intermediary proxies, the browser. Or all of the above. The goals of caching are to reduce bandwidth consumption on the networks, reduce compute resource utilization on the servers, and reduce page load latency on the clients. Cookie - Originally added for managing state (since HTTP itself is a stateless protocol,) a cookie is a small piece of data to be stored by the web client as instructed by the web server. Standards Group Language - I won’t dive deep into this, but as you learn a protocol, knowing how to read RFCs would serve you well. As new protocols, or new versions of existing protocols, are released, there are interpretation challenges that companies work through to make sure everyone is adhering to the “standard.” Sometimes this is an agreeable process, other times not so much. Basic understanding of what must, should, or may be done in a request/response can make your troubleshooting efforts go much more smoothly. Basic Message Format Requests The syntax of an HTTP request message has the following format request-line headers CRLF (carriage return / line feed) message body (optional) An example of this is shown below: -----Request Line---- |GET / HTTP/1.1 --------------------- -------Headers------- |Host: roboraiders.net |Connection: keep-alive |User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36 |Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 |Accept-Encoding: gzip, deflate |Accept-Language: en-US,en;q=0.8 ---------------------- The CRLF (present in the tcpdump capture but not seen here) denotes the end of the headers, and there is no body. Notice in the request line, you see the request method, the URI, and the http protocol version of the client. Responses The syntax of an HTTP response message has a very similar format: status-line headers CRLF (carriage return / line feed) message body (optional) An example of this is shown below: -----Request Line---- |HTTP/1.1 200 OK --------------------- -------Headers------- |Server: openresty/1.9.15.1 |Date: Thu, 21 Sep 2017 17:19:01 GMT |Content-Type: text/html; charset=utf-8 |Transfer-Encoding: chunked |Connection: keep-alive |Vary: Accept-Encoding |Content-Encoding: gzip --------------------- ---Zipped Content---- |866 |...........Y.v.....S...;..$7IsH...7.I..I9:..Y.C`....].b....'.7....eEQoZ..~vf.....x..o?^....|[Q.R/..|.ZV.".*..$......$/EZH../..n.._E..W^.. --------------------- Like the request line of an HTTP request, the protocol of the server is stated in the HTTP response status-line. Also stated is the response code, in this case a 200 ok. You’ll notice that the only header in this case that is similar between the request and response is the Connection header. HTTP Request Methods The URI is a resource with which the client is wanting to interact. The request method provides the “how” the client would like to interact with the resource. There are many request methods, but we’ll focus on the few most popular methods for this article. GET - This method is used by a client to retrieve resources from a server. HEAD - Like the GET method, but only retrieves the metadata that would be returned with the payload of a GET, but no payload is returned. This is useful in monitoring and troubleshooting. POST - Used primarily to upload data from a client to a server, by means of creating or updating an object through a process handler on the server. Due to security concerns, there are usually limitations on who can do this, how it’s done, and how big an update will be allowed. PUT - Typically used to replace the contents of a resource. DELETE - This method removes a resource. PATCH - Used to modify but not replace the contents of a resource. If you are at all interested in using iControl REST to perform automation on your BIG-IP infrastructure, all the methods above except HEAD are instrumental in working with the REST interface. HTTP Headers There are general headers that can apply to both requests and responses, and then there are specific headers based on whether it is a request OR a response message. Note that there are differences between supported HTTP/1.0 and HTTP/1.1 headers, but I’ll leave the nuances to the reader to study. We’ll cover HTTP/2 at the end of this series. Examples in parentheses are not complete, and do not denote the actual header names. RFC 2616 has all the HTTP/1.1 define headers documented. General Headers These headers can be present in either requests or responses. Conceptually, they deal with the broader issues of client/server sessions like timing, caching, and connection management. The Connection header in the request and response messages above is an example of a general connection-management header in action. Request Headers These headers are for requests only, and are utilized to inform the server (and intermediaries) on preferred response behavior (acceptable encodings,) constraints for the server (range of content or host definition,) conditional requests (resource modification timestamps,) and client profile (user agent, authorization.)TheHostheader in the request message above is an example of a request header constraining the server to that identity. Response Headers Like with requests, response headers are for responses only, and are utilized for security(authentication challenges,) caching (timing and validation,) information sharing (identification,) and redirection.TheServerheader in the response message above is an example of a response header identifying the server. Entity Headers Entity headers exist not to provide request or response messaging context, but to provide specific insight about the body or payload of the message. The Content-Type header in the response message above for example is instructing the client that the payload of the response is just text and should be rendered as such. A Note on MIME types - web clients/servers are for the most part "dumb" in that they are do not guess at content types based on analysis, they follow the instructions in the message via the Content-Type header. I've experienced this in both directions. For iControl REST development, BIG-IP returns an error if you send json payload but do not specify application/json in the Content-Type header. I also had a bug in an ASM deployment once where the ASM violation response page was set to text/html but should have been application/json, so the browser client never displayed the error, you had to find it buried in browser tools until we corrected that issue. HTTP Response Status Codes We will conclude with a brief discussion on status codes. Before getting into the specifics, there are a couple general things that should make awareness and analysis a regular part of your system management: security and SEO. On security, there are many things one can learn through status codes (and headers for that matter) on server patterns and behavior, as well as information leakage by not slurping application errors before being returned to clients. With SEO, how redirects and missing files are handled can hurt or help your overall impressions and ranking power. Moz has a good best practices article on managing status codes for search engines. But back to the point and hand: status codes. There are five categories and 41 status codes recognized in HTTP/1.1. Informational - 1xx - This category added for HTTP/1.1. Used to inform clients that a request has been received and the initial request (likely a POST of data) can continue Success - 2xx - Used to inform the client that the request was processed successfully. Redirection - 3xx - The request was received but resource needs to be dealt with in a different way. Client Error - 4xx - Something went wrong on the client side (bad resource, bad authentication, etc.) Server Error -5xx - Something went wrong on the server side. Application monitors pay particularly close attention to the 5xx errors. Security practitioners focus in on 4xx/5xx errors, but even 2xx/3xx messages if baseline volume and accessed resources start to skew from normal. Join us next week when we start to talk about clients, proxies, and servers, oh my!1KViews1like3Comments