fail over
8 TopicsConfigure HA Groups on BIG-IP
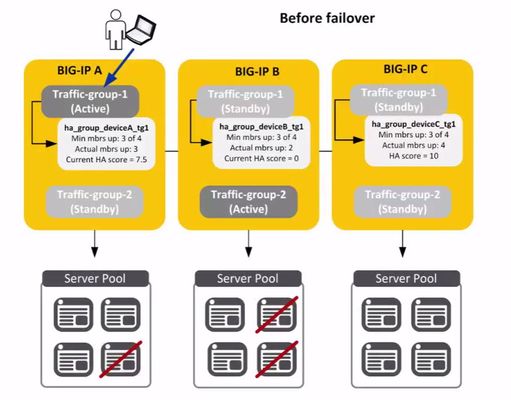
Last week we talked about how HA Groups work on BIG-IP and this week we’ll look at how to configure HA Groupson BIG-IP. To recap, an HA group is a configuration object you create and assign to a traffic group for devices in a device group. An HA group defines health criteria for a resource (such as an application server pool) that the traffic group uses. With an HA group, the BIG-IP system can decide whether to keep a traffic group active on its current device or fail over the traffic group to another device when resources such as pool members fall below a certain level. First, some prerequisites: Basic Setup: Each BIG-IP (v13) is licensed, provisioned and configured to run BIG-IP LTM HA Configuration: All BIG-IP devices are members of a sync-failover device group and synced Each BIG-IP has a unique virtual server with a unique server pool assigned to it All virtual addresses are associated with traffic-group-1 To the BIG-IP GUI! First you go to System>High Availability>HA Group List>and then click the Create button. The first thing is to name the group. Give it a detailed name to indicate the object group type, the device it pertains to and the traffic group it pertains to. In this case, we’ll call it ‘ha_group_deviceA_tg1.’ Next, we’ll click Add in the Pools area under Health Conditions and add the pool for BIG-IP A to the HA Group which we’ve already created. We then move on to the minimum member count. The minimum member count is members that need to be up for traffic-group-1 to remain active on BIG-IP A. In this case, we want 3 out of 4 members to be up. If that number falls below 3, the BIG-IP will automatically fail the traffic group over to another device in the device group. Next is HA Score and this is the sufficient threshold which is the number of up pool members you want to represent a full health score. In this case, we’ll choose 4. So if 4 pool members are up then it is considered to have a full health score. If fewer than 4 members are up, then this health score would be lower. We’ll give it a default weight of 10 since 10 represents the full HA score for BIG-IP A. We’re going to say that all 4 members need to be active in the group in order for BIG-IP to give BIG-IP A an HA score of 10. And we click Add. We’ll then see a summary of the health conditions we just specified including the minimum member count and sufficient member count. Then click Create HA Group. Next, we go to Device Management>Traffic Groups>and click on traffic-group-1. Now, we’ll associate this new HA Group with traffic-group-1. Go to the HA Group setting and select the new HA Group from the drop-down list. And then select the Failover Method to Device with the Best HA Score. Click Save. Now we do the same thing for BIG-IP B. So again, go to System>High Availability>HA Group List>and then click the Create button. Give it a special name, click Add in the Pools area and select the pool you’ve already created for BIG-IP B. Again, for our situation, we’ll specify a minimum of 3 members to be up if traffic-group-1 is active on BIG-IP B. This minimum number does not have to be the same as the other HA Group, but it is for this example. Again, a default weight of 10 in the HA Score for all pool members. Click Add and then Create HA Group for BIG-IP B. And then, Device Management>Traffic Groups> and click traffic-group-1. Choose BIG-IP B’s HA Group and select the same Failover method as BIG-IP A – Based on HA Score. Click Save. Lastly, you would create another HA Group on BIG-IP C as we’ve done on BIG-IP A and BIG-IP B. Once that happens, you’ll have the same set up as this: As you can see, BIG-IP A has lost another pool member causing traffic-group-1 to failover and the BIG-IP software has chosen BIG-IP C as the next active device to host the traffic group because BIG-IP C has the highest HA Score based on the health of its pool. Thanks to our TechPubs group for the basis of this article and check out a video demo here. ps9.1KViews1like0CommentsHigh Availability Groups on BIG-IP
High Availability of applications is critical to an organization’s survival. On BIG-IP, HA Groups is a feature that allows BIG-IP to fail over automatically based not on the health of the BIG-IP system itself but rather on the health of external resources within a traffic group. These external resources include the health and availability of pool members, trunk links, VIPRION cluster members or a combination of all three. This is the only cause of failover that is triggered based on resources outside of the BIG-IP. An HA group is a configuration object you create and assign to a traffic group for devices in a device group. An HA group defines health criteria for a resource (such as an application server pool) that the traffic group uses. With an HA group, the BIG-IP system can decide whether to keep a traffic group active on its current device or fail over the traffic group to another device when resources such as pool members fall below a certain level. In this scenario, there are three BIG-IP Devices – A, B, C and each device has two traffic groups on it. As you can see, for BIG-IP A, traffic-group 1 is active. For BIG-IP B, traffic-group 2 is active and for BIG-IP C, both traffic groups are in a standby state. Attached to traffic-group 1 on BIG-IP A is an HA group which specifies that there needs to be a minimum of 3 pool members out of 4 to be up for traffic-group-1 to remain active on BIG-IP A. Similarly, on BIG-IP B the traffic-group needs a minimum of 3 pool members up out of 4 for this traffic group to stay active on BIG-IP B. On BIG-IP A, if fewer than 3 members of traffic-group-1 are up, this traffic-group will fail-over. So let’s say that 2 pool members go down on BIG-IP A. Traffic-group-1 responds by failing-over to the device (BIG-IP) that has the healthiest pool…which in this case is BIG-IP C. Now we see that traffic-group-1 is active on BIG-IP C. Achieving the ultimate ‘Five Nines’ of web site availability (around 5 minutes of downtime a year) has been a goal of many organizations since the beginning of the internet era. There are several ways to accomplish this but essentially a few principles apply. Eliminate single points of failure by adding redundancy so if one component fails, the entire system still works. Have reliable crossover to the duplicate systems so they are ready when needed. And have the ability to detect failures as they occur so proper action can be taken. If the first two are in place, hopefully you never see a failure. But if you do, HA Groups can help. ps Related: Lightboard Lessons: BIG-IP Basic Nomenclature Lightboard Lessons: Device Services Clustering HA Groups Overview2.2KViews0likes2Comments
Why Layer 7 Load Balancing Doesn’t Suck
Alternative title: Didn’t We Resolve This One 10 Years Ago? There’s always been a bit of a disconnect between traditional network-focused ops and more modern, application-focused ops when it comes to infrastructure architecture. The arguments for an against layer 7 (application) load balancing first appeared nearly a decade ago when the concept was introduced. These arguments were being tossed around at the same time we were all arguing for or against various QoS (Quality of Service) technologies, namely the now infamous “rate shaping” versus “queuing” debate. If you missed that one, well, imagine an argument similar to that today of “public” versus “private” clouds. Same goals, different focus on how to get there. Seeing this one crop up again is not really any more surprising than seeing some of the other old debates bubbling to the surface. cloud computing and virtualization have brought network infrastructure and its capabilities, advantages and disadvantages – as well as its role in architecting a dynamic data center – to the fore again. But seriously? You’d think the arguments would have evolved in the past ten years. While load balancing hardware marketing execs get very excited about the fact that their product can magically scale your application by using amazing Layer 7 technology in the Load balancer such as cookie inserts and tracking/re-writing. What they fail to mention is that any application that requires the load balancer to keep track of session related information within the communications stream can never ever be scalable or reliable. -- Why Layer 7 load balancing sucks… I myself have never shied away from mentioning the session management capabilities of a full-proxy application delivery controller (ADC) and, in fact, I have spent much time advocating on behalf of its benefits to architectural flexibility, scalability, and security. Second, argument by selective observation is a poor basis upon which to make any argument, particularly this one. While persistence-based load balancing is indeed one of the scenarios in which an advanced application delivery controller is often used (and in some environments, such as scaling out VDI deployments, is a requirement) this is a fairly rudimentary task assigned to such devices. The use of layer 7 routing, aka page routing in some circles (such as Facebook), is a highly desirable capability to have at your disposable. It enables more flexible, scalable architectures by creating scalability domains based on application-specific functions. There are a plethora of architectural patterns that leverage the use of an intelligent, application-aware intermediary (i.e. layer 7 load balancing capable ADC). Here’s a few I’ve written myself, but rest assured there are many more examples of infrastructure scalability patterns out there on the Internets: Infrastructure Architecture: Avoiding a Technical Ambush Infrastructure Scalability Pattern: Partition by Function or Type Applying Scalability Patterns to Infrastructure Architecture Infrastructure Scalability Pattern: Sharding Streams Interestingly, ten years ago this argument may have held some water. This was before full-proxy application delivery controllers were natively able to extract the necessary HTTP headers (where cookies are exchanged). That means in the past, such devices had to laboriously find and extract the cookie and its value from the textual representation of the headers, which obviously took time and processing cycles (i.e. added latency). But that’s not been the case since oh, 2004-2005 when such capabilities were recognized as being a requirement for most organizations and were moved into native processing, which reduced the impact of such extraction and evaluation to a negligible, i.e. trivial, amount of delay and effectively removed as an objection this argument. THE SECURITY FACTOR Both this technique and trivial tasks like tracking and re-writing do, as pointed out, require session tracking – TCP session tracking, to be exact. Interestingly, it turns out that this is a Very Good Idea TM from a security perspective as it provides a layer of protection against DDoS attacks at lower levels of the stack and enables an application-aware ADC to more effectively thwart application-layer DDoS attacks, such as SlowLoris and HTTP GET floods. A simple, layer 4 load balancing solution (one that ignores session tracking, as is implied by the author) can neither recognize nor defend against such attacks because they maintain no sense of state. Ultimately this means the application and/or web server is at high risk of being overwhelmed by even modest attacks, because these servers are incapable of scaling sessions at the magnitude required to sustain availability under such conditions. This is true in general of high volumes of traffic or under overwhelming loads due to processor-intense workloads. A full-proxy device mitigates many of the issues associated with concurrency and throughput simply by virtue of its dual-stacked nature. SCALABILITY As far as scalability goes, really? This is such an old and inaccurate argument (and put forth with no data, to boot) that I’m not sure it’s worth presenting a counter argument. Many thousands of customers use application delivery controllers to perform layer 7 load balancing specifically for availability assurance. Terminating sessions does require session management (see above), but to claim that this fact is a detriment to availability and business continuity shows a decided lack of understanding of failover mechanisms that provide near stateful-failover (true stateful-failover is impossible at any layer). The claim that such mechanisms require network bandwidth indicates either a purposeful ignorance with respect to modern failover mechanisms or simply failure to investigate. We’ve come a long way, baby, since then. In fact, it is nigh unto impossible for a simple layer 4 load balancing mechanism to provide the level of availability and consistency claimed, because such an architecture is incapable of monitoring the entire application (which consists of all instances of the application residing on app/web servers, regardless of form-factor). See axiom #3 (Context-Aware) in “The Three Axioms of Application Delivery”. The Case (For & Against) Network-Driven Scalability in Cloud Computing Environments The Case (For & Against) Management-Driven Scalability in Cloud Computing Environments The Case (For & Against) Application-Driven Scalability in Cloud Computing Environments Resolution to the Case (For & Against) X-Driven Scalability in Cloud Computing Environments The author’s claim seems to rest almost entirely on the argument “Google does layer 4 not layer 7” to which I say, “So?” If you’re going to tell part of the story, tell the entire story. Google also does not use a traditional three-tiered approach to application architecture, nor do its most demanding services (search) require state, nor does it lack the capacity necessary to thwart attacks (which cannot be said for most organizations on the planet). There is a big difference between modern, stateless applications (and many benefits) and traditional three-tiered application architectures. Now it may in fact be the case that regardless of architecture an application and its supporting infrastructure do not require layer 7 load balancing services. In that case, absolutely – go with layer 4. But to claim layer 7 load balancing is not scalable, or resilient, or high-performance enough when there is plenty of industry-wide evidence to prove otherwise is simply a case of not wanting to recognize it.660Views0likes0CommentsLoad Balancing 101: Scale versus Fail
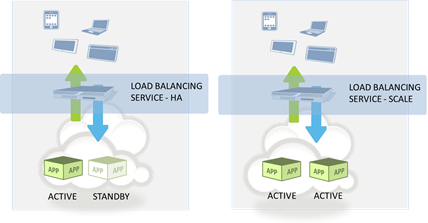
#cloud Elasticity is a design pattern for scalability, not necessarily failability. One of the phrases you hear associated with cloud computing is "architecting for failure." Rather than build in a lot of hardware-level redundancy – power, disk, network, etc… – the idea is that you expect it to fail and can simply replace the application (which is what you care about anyway, right?) with a clone running on the same cheap hardware somewhere else in the data center. Awesome idea, right? But when it comes down to it, cloud computing environments are architected for scale, not fail. SCALE versus FAIL Most enterprise-class data centers have been architected with failure in mind; we call these high-availability (HA) architectures. The goal is to ensure that if any element in the data path fails that another can almost immediately take its place. Within a hardware platform, this implies dual power supplies, a high RAID level, and lights-out management. At the network and higher level, this requires redundant network elements – from load balancers to switches to routers to firewalls to servers, all elements must be duplicated to ensure a (near) immediate failover in the event of a failure. This generally requires configurations and support for floating (shared) IP addresses across redundant elements, allowing for immediate redirection upon detection of a failure upstream. At the application/server tier, the shared address concept is still applied but it is done so at the load balancing layer, where VIP (virtual IP addresses) act as a virtual instance of the application. A primary node (server) is designated that is active with a secondary being designated as the "backup" instance which remains idle in "standby" mode*. If the primary instance fails – whether due to hardware or software or network failure – the secondary immediately becomes active, and continuity of service is assured by virtue of the fact that existing sessions are managed by the load balancing service, not the server. In the event a network element fails, continuity (high-availability) is achieved due to the mirroring (replication) of those same sessions between the active (primary) and standby (secondary) elements. Is it perfect? No, but it does provide sub-second response to failure, which means very high levels of availability (or as I like to call it, failability). That's architected for "FAIL". Now, most cloud computing environments are architected not with failure in mind but with scale in mind – that is, they are designed to enable elasticity (scale out, scale in) that is, in part, based on the ability to rapidly provision the resources required. A load balancing instance is required and it works in much the same way as a high-availability architecture (minus the redundancy). The load balancing service acts as the virtual application, with at least one instance behind it. As demand increases, new instances are provisioned and added to the service to ensure that performance and availability are not adversely impacted. When this process is also capable of scaling back in by automatically eliminating instances when demand contracts it's called "elasticity". If the only instance available fails, this architecture is not going to provide high availability of the application because it takes time to launch an instance to replace it. Even if there are ten active instances and one fails, performance and/or availability for some clients may be impacted because, as noted already, it takes time to launch an instance to replace it. Similarly, if an upstream element fails, such as the load balancing service, availability may be adversely impacted – because it takes time to replace it. But when considering how well the system responds to changes in demand for resources, it works well. That's scalability. That's architected for "SCALE". SCALE and FAIL are NOT INTERCHANGEABLE These two are not interchangeable, they cannot be conflated with the expectation that either architecture is able to meet both goals equally well. They are designed to resolve two different problems. The two can be combined to achieve a scalable, high-availability architecture where redundancy is used to assure availability while elasticity is leveraged to realize scale while reducing the time to provision and investment costs by implementing a virtual, flexible resource model. It's important to understand the difference in these architectures especially when looking to public cloud as an option because they are primarily designed to enable scalability, not failability. If you absolutely need failability, you'll need to do some legwork of your own (scripts or manual intervention – perhaps both) to ensure a more seamless failover in the event of failure or specifically seek out cloud providers that recognize the inherent differences between the two architectures and support either the one you need, or both. Relying on an elastic architecture to provide high-availability – or vice-versa – is likely to end poorly. Downtime cost source: IT Downtime Costs $26.5 Billion In Lost Revenue The Colonial Data Center and Virtualization Back to Basics: Load balancing Virtualized Applications Cloud Bursting: Gateway Drug for Hybrid Cloud The HTTP 2.0 War has Just Begun Why Layer 7 Load Balancing Doesn’t Suck Network versus Application Layer Prioritization224Views0likes0CommentsMission Impossible: Stateful Cloud Failover
The quest for truly stateful failover continues… Lightning was the latest cause of an outage at Amazon, this time in its European zones. Lightning, like tornadoes, volcanoes, and hurricanes are often categorized as “Acts of God” and therefore beyond the sphere of control of, well, anyone other than God. Outages or damages caused by such are rarely reimbursable and it’s very hard to blame an organization for not having a “plan” to react to the loss of both primary and secondary power supplies due to intense lightning strikes. The odds of a lightning strike are pretty high in the first place – 576000 to 1 – and though the results can be disastrous, such risk is often categorized as low enough to not warrant a specific “plan” to redress. What’s interesting about the analysis of the outage is the focus on what is, essentially, stateful failover capabilities. The Holy Grail of disaster recovery is to design a set of physically disparate systems in which the secondary system, in the event the primary fails, immediately takes over with no interruption in service or loss of data. Yes, you read that right: it’s a zero-tolerance policy with respect to service and data loss. And we’ve never, ever achieved it. Not that we haven’t tried, mind you, as Charles Babcock points out in his analysis of the outage: Some companies now employ a form of disaster recovery that stores a duplicate set of virtual machines at a separate site; they're started up in the event of failure at the primary site. But Kodukula said such a process takes several minutes to get systems started at an alternative site. It also results in loss of several minutes worth of data. Another alternative is to set up a data replication system to feed real-time data into the second site. If systems are kept running continuously, they can pick up the work of the failed systems with a minimum of data loss, he said. But companies need to employ their coordination expertise to make such a system work, and some data may still be lost. -- Amazon Cloud Outage: What Can Be Learned? (Charles Babcock, InformationWeek, August 2011) Disaster recovery plans are designed and implemented with the intention of minimizing loss. Practitioners are well aware that a zero-tolerance policy toward data loss for disaster recovery architectures is unrealistic. That is in part due to the “weakest link” theory that says a system’s is only as good as its weakest component’s . No application or network component can perform absolutely zero-tolerance failover, a.k.a. stateful failover, on its own. There is always the possibility that some few connections, transactions or sessions will be lost when a system fails over to a secondary system. Consider it an immutable axiom of computer science that distributed systems can never be data-level consistent. Period. If you think about it, you’ll see why we can deduce, then, that we’ll likely never see stateful failover of network devices. Hint: it’s because ultimately all state, even in network components, is stored in some form of “database” whether structured, unstructured, or table-based and distributed systems can never be data-level consistent. And if even a single connection|transaction|session is lost from a component’s table, it’s not stateful, because stateful implies zero-tolerance for loss. WHY ZERO-TOLERANCE LOSS is IMPOSSIBLE Now consider what we’re trying to do in a failover situation. Generally speaking we’re talking about component-level failure which, in theory and practice, is much easier than a full-scale architectural failover scenario. One device fails, the secondary takes over. As long as data has been synchronized between the two, we should theoretically be able to achieve stateful failover, right? Except we can’t. One of the realities with respect to high availability architectures is that synchronization is not continuous and neither is heartbeat monitoring (the mechanism by which redundant pairs periodically check to ensure the primary is still active). These processes occur on a period interval as defined by operational requirements, but are generally in the 3-5 second range. Assuming a connection from a client is made at point A, and the primary component fails at point A+1 second, it is unlikely that its session data will be replicated to the secondary before point A+3 seconds, at which time the secondary determines the primary has failed and takes over operation. This “miss” results in data loss. A minute amount, most likely, but it’s still data loss. Basically the axiom that zero-tolerance loss is impossible is a manifestation in the network infrastructure of Brewer’s CAP theorem at work which says you cannot simultaneously have Consistency, Availability and Partition Tolerance. This is evident before we even consider the slight delay that occurs on the network despite the use of gratuitous ARP to ensure a smooth(er) transition between units in the event of a failover, during which time the service may be (rightfully) perceived as unavailable. But we don’t need to complicate things any more than they already are, methinks. What is additionally frustrating, perhaps, is that the data loss could potentially be caused by a component other than the one that fails. That is, because of the interconnected and therefore interdependent nature of the network, a sort of cascading effect can occur in the event of a failover based on the topological design of the systems. It’s the architecture, silly, that determines whether data loss will be localized to the failing components or cascade throughout the entire architecture. High availability architectures based on a parallel data path design are subject to higher data loss throughout the network than are those based on cross-connected data path designs. Certainly the latter is more complicated and harder to manage, but it’s less prone to data loss cascade throughout the infrastructure. Now, add in the possibility that cloud-based disaster recovery systems necessarily leverage a network connection instead of a point-to-point serial connection. Network latency can lengthen the process and, if the failure is in the network connection itself, is obviously going to negatively impact the amount of data lost because synchronization cannot occur at all for that period of time when the failed primary is still “active” and the secondary realizes there’s a problem, Houston, and takes over responsibility. Now take these potential hiccups and multiply them by every redundant component in the system you are trying to assure availability for, and remember to take into consideration that to fail over to a second “site” requires not only data (as in database) replication but also state data replication across the entire infrastructure. Clearly, this is an unpossible task. A truly stateful cloud-based failover might be able to occur if the stars were aligned just right and the chickens sacrificed and the no-fail dance performed to do so. And even then, I’d bet against it happening. The replication of state residing in infrastructure components, regardless of how necessary they may be, is almost never, ever attempted. The reality is that we have to count on some data loss and the best strategy we can have is to minimize the loss in part by minimizing the data that must be replicated and components that must be failed over. Or is it? F5 Friday: Elastic Applications are Enabled by Dynamic Infrastructure The Database Tier is Not Elastic Greedy (IT) Algorithms The Impossibility of CAP and Cloud Brewer’s CAP Theorem Joe Weinman – Cloud Computing is NP-Complete Proof Cloud Computing Goes Back to College221Views0likes0Comments
Once Again, I Can Haz Storage As A Service?
While plenty of people have had a mouthful (or page full, or pipe full) of things to say about the Amazon outage, the one thing that it brings to the fore is not a problem with cloud, but a problem with storage. Long ago, the default mechanism for “High Availability” was to have two complete copies of something (say a network switch) and when one went down, the other was brought up with the same IP. It is sad to say that even this is far-and-away better than the level of redundancy that most of us place in our storage. The reasons are pretty straight-forward, you can put in a redundant pair of NAS heads, or a redundant pair of file/directory virtualization appliances like our own ARX, but a redundant pair of all of your storage? The cost alone would be prohibitive. Amazon’s problems seem to stem from a controller problem, not a data redundancy problem, but I’m not an insider, so that is just appearances. But most of us suffer from the opposite. High availability entry points protect data that is all too often a single point of failure. I know I lived through the sudden and irrevocable crashing of an AIX NAS once, and it wasn’t pretty. When the third disk turned up bad, we were out of luck, had to wait for priority shipment of new disks and then do a full restore… The entire time being down in a business where time is money. The critical importance of the data that is the engine of our enterprises these days makes building that cost-prohibitive truly redundant architecture a necessity. If you don’t already have a complete replica of your data somewhere, it is worth looking into file and database replication technologies. Honestly, if you choose to keep your replicas on cheaper, slower disk, you can save a bundle and still have the security that even if your entire storage system goes down, you’ll have the ability to keep the business running. But what I’d like to see is full blown storage as a service. We couldn’t call it SaaS, so I’ll propose we name it Storage Tiers As A Service Host, just so we can use the acronym Staash. The worthy goal of this technology would be the ability to automatically, with no administrator interaction, redirect all traffic to device A over to device B, heterogeneously. So your core datacenter NAS goes down hard, lets call it a power failure to one or more racks, Staash would detect that the primary is off-line and substitute your secondary for it in the storage hierarchy. People might notice that files are served up more slowly, depending upon your configuration, but they’ll also still be working. Given sufficient maturity, this model could even go so far as to allow them to save changes made to documents that were open at the time that the primary NAS went down, though this would be a future iteration of the concept. Today we have automated redundancy all the way to the final step, it is high time we implemented redundancy on that last little bit, and made our storage more agile. While I could reasonably argue that a File/Directory Virtualization device like F5’s ARX is the perfect place to implement this functionality – it is already heterogeneous, it sits between users and data, and it is capable of being deployed in HA pairs… All the pre-requisites for Staash to be implemented – I don’t think your average storage or server administrator much cares where it is implemented, as long as it is implemented. We’re about 90% there. You can replicate your data – and you can replicate it heterogeneously. You can set up an HA pair of NAS heads (if you are a single-vendor shop) or File/Directory virtualization devices whether you are single-vendor or heterogeneous, and with a file/directory virtualization tool you have already abstracted the user from the physical storage location in a very IT-friendly way (files are still saved together, storage is managed in a reasonable manner, only files with naming conflicts are renamed, etc), all that is left is to auto-switch from your high-end primary to a replica created however your organization does these things… And then you are truly redundantly designed. It’s been what, forty years? That’s almost as long as I’ve been alive. Of course, I think this would fit in well with my long-term vision of protocol independence too, but sometimes I want to pack too much into one idea or one blog, so I’ll leave it with “let’s start implementing our storage architecture like we do our server architecture… No single point of failure. No doubt someone out there is working on this configuration… Here’s hoping they call it Staash when it comes out. The cat in the picture above is Jennifer Leggio’s kitty Clarabelle. Thanks to Jen for letting me use the pic!197Views0likes0CommentsReliability does not come from SOA Governance
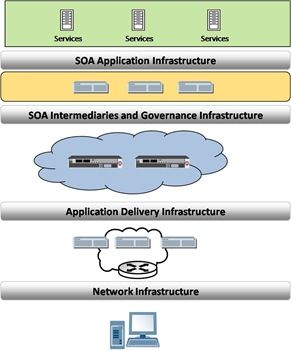
An interesting InformationWeek article asks whether SOA intermediaries such as "enterprise service bus, design-time governance, runtime management, and XML security gateways" are required for an effective SOA. It further posits that SOA governance is a must for any successful SOA initiative. As usual, the report (offered free courtesy of IBM), focuses on SOA infrastructure that while certainly fitting into the categories of SOA intermediary and governance does very little to assure stability and reliability of those rich Internet applications and composite mashups being built atop the corporate SOA. Effective SOA Requires Intermediaries via InformationWeek In addition to attracting new customers with innovative capabilities, it's equally important for businesses to offer stable, trusted services that are capable of delivering the high quality of service that users now demand. Without IT governance, the Web-oriented world of rich Internet applications and composite mashups can easily become unstable and unreliable. To improve your chances for success, establish discipline through a strong IT governance program where quality of service, security, and management issues are of equal importance. As is often the case, application delivery infrastructure is relegated to "cloud" status; it's depicted as a cloud within the SOA or network and obscured, as though it has very little to do with the successful delivery of services and applications. Application delivery infrastructure is treated on par with layer 2-3 network infrastructure: dumb boxes whose functionality and features have little to do with application development, deployment, or delivery and is therefore beneath the notice of architects and developers alike. SOA intermediaries, while certainly a foundational aspect of a strong, reliable SOA infrastructure, are only part of the story. Reliability of services can't be truly offered by SOA intermediaries nor can they be provided by traditional layer 2-3 (switches, routers, hubs) network infrastructure. A dumb load-balancer cannot optimize inter-service communication to ensure higher capacity (availability and reliability) and better performance. A traditional layer 2/3 switch cannot inspect XML/SOAP/JSON messages and intelligently direct those messages to the appropriate ESB or service pool. But neither can SOA intermediaries provide reliability and stability of services. Like ESB load-balancing and availability services, SOA intermediaries are largely incapable of ensuring the reliable delivery of SOA applications and services because their tasks are focused on runtime governance (authentication, authorization, monitoring, content based routing) and their load-balancing and network-focused delivery capabilities are largely on par with that of traditional l2-3 network infrastructure. High-availability and failover functionality is rudimentary at best in SOA intermediaries. The author mentions convergence and consolidation of the SOA intermediary market, but that same market has yet to see the issue of performance and reliability truly addressed by any SOA intermediary. Optimization and acceleration services, available to web applications for many years, have yet to be offered to SOA by these intermediaries. That's perfectly acceptable, because it's not their responsibility. When it comes to increasing capacity of services, ensuring quality of service, and intelligently managing the distribution of requests the answer is not a SOA intermediary or a traditional load-balancer; that requires an application delivery network with an application fluent application delivery controller at its core. The marriage of Web 2.0 and SOA has crossed the threshold. It's reality. SOA intermediaries are not designed with the capacity and reliability needs of a large-scale Web 2.0 (or any other web-based) application. That chore is left to the "network cloud" in which application delivery currently resides. But it should be its own "cloud", it's own distinct part of the overall architecture. And it ought to be considered as part of the process rather than an afterthought. SOA governance solutions can do very little to improve the capacity, reliability, and performance of SOA and applications built atop that SOA. A successful SOA depends on more than governance and SOA intermediaries; it depends on a well-designed architecture that necessarily includes consideration for the reliability, scalability, and security of both services and the applications - Web 2.0 or otherwise - that will take advantage of those services. That means incorporating an intelligent, dynamic application delivery infrastructure into your SOA before reliability becomes a problem.180Views0likes0CommentsLoad Aware Fabrics
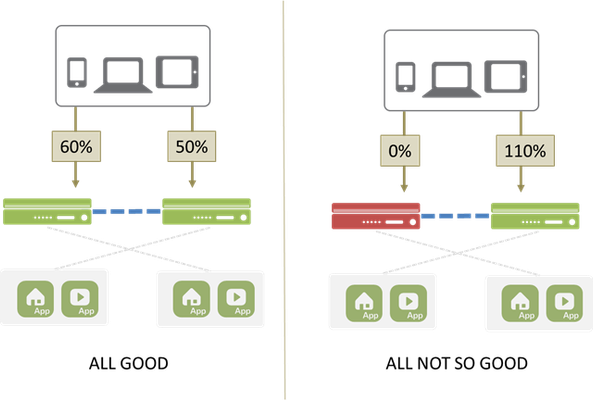
#cloud Heterogeneous infrastructure fabrics are appealing but watch out for the gotchas One of the "rules" of application delivery (and infrastructure in general) has been that when scaling out such technologies, all components must be equal. That started with basic redundancy (deploying two of everything to avoid a single point of failure in the data path) and has remained true until recently. Today, fabrics can be comprised of heterogeneous components. Beefy, physical hardware can be easily paired with virtualized or cloud-hosted components. This is good news for organizations seeking the means to periodically scale out infrastructure without oversubscribing the rest of the year, leaving resources idle. Except when it's not so good, when something goes wrong and there's suddenly not enough capacity to handle the load because of the disparity in component capacity. We (as in the industry) used to never, ever, ever suggest running active-active infrastructure components when load on each component was greater than 50%. The math easily shows why: It's important to note that this scenario isn't just a disaster (failure) based scenario. This is true for maintenance, upgrades, etc... as well. This is why emerging fabric-based models should be active-active-N. That "N" is critically important as a source of resources designed to ensure that the "all not so good" scenario is covered. This fundamental axiom of architecting reliable anything - always match capacity with demand - is the basis for understanding the importance of load-aware failover and distribution in fabric-based architectures. In most HA (high availability) scenarios the network architect carefully determines the order of precedence and failover. These are pre-determined, there's a primary and a secondary (and a tertiary, and so on). That's it. It doesn't matter if the secondary is already near or at capacity, or that it's a virtualized element with limited capacity instead of a more capable piece of hardware. It is what it is. And that "is" could be disastrous to availability. If that "secondary" isn't able to handle the load, users are going to be very angry because either responsiveness will plummet to the point the app might as well be unavailable or it will be completely unavailable. In either case, it's not meeting whatever SLA has been brokered between IT and the business owner of that application. That's why it's vitally important as we move toward fabric-based architectures that failover and redundancy get more intelligent. That the algorithms used to distribute traffic across the fabric get very, very intelligent. Both must become load aware and able to dynamically determine what to do in the event of a failure. The fabric itself ought to be aware of not just how much capacity each individual component can handle but how much it currently is handling, so that if a failure occurs or performance is degrading it can determine dynamically which component (or components, if need be) can take over more load. In the future, that intelligence might also enable the fabric to spin up more resources if it recognizes there's just not enough. As we continue to architect "smarter" networks, we need to re-evaluate existing technology and figure out how it needs to evolve, too, to fit into the new, more dynamic and efficiency-driven world. It's probably true that failover technologies and load balancing algorithms aren't particularly exciting to most people, but they're a necessary and critical function of networks and infrastructure designed to ensure high-availability in the event of (what many would call inevitable) failure. So as network and application service technologies evolve and transform, we've got to be considering how to adapt foundational technologies like failover models to ensure we don't lose the stability necessary to continue evolving the network.146Views0likes0Comments