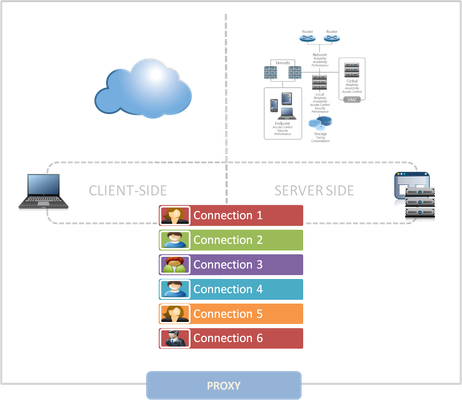
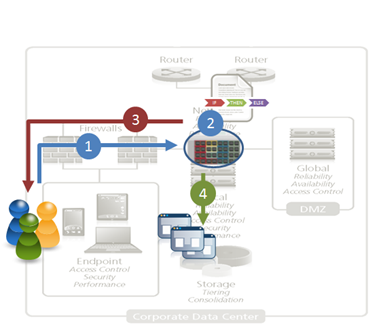
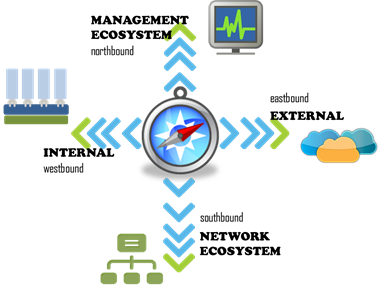
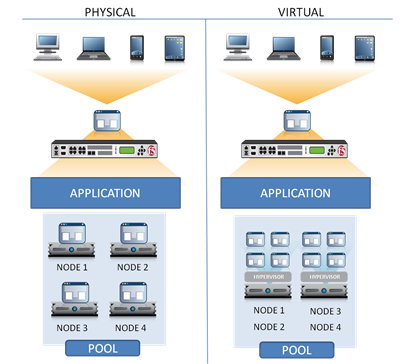
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/architecture\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/architecture\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674584422"}],"cachedText({\"lastModified\":\"1752674584422\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674584422"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1752674579508":{"__typename":"CachedAsset","id":"pages-1752674579508","value":[{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501733000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1752674563867":{"__typename":"CachedAsset","id":"theme:customTheme1-1752674563867","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1752674584422","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1752674584422","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1752674584422","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674577973":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674577973","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1752674584422","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1752674561270":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1752674561270","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1752674590023":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1752674590023","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1752674590023":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1752674590023","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1752674590023":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1752674590023","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1752674590023":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1752674590023","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1752674590023":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1752674590023","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1752674584422","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1752674584422","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674584422","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:279637":{"__typename":"Conversation","id":"conversation:279637","topic":{"__typename":"TkbTopicMessage","uid":279637},"lastPostingActivityTime":"2011-11-22T12:13:42.000-08:00","solved":false},"User:user:171720":{"__typename":"User","uid":171720,"login":"Lori_MacVittie","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-10.svg?time=0"},"id":"user:171720"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQyM2k4M0M2NzcwMDdFOUZERDkw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQyM2k4M0M2NzcwMDdFOUZERDkw?revision=1","title":"0EM1T000001MsbO.png","associationType":"BODY","width":1106,"height":958,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTU2MTlpREI4NkJERjY4RjA4OUQ5Ng?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTU2MTlpREI4NkJERjY4RjA4OUQ5Ng?revision=1","title":"0EM1T000001MsbT.png","associationType":"BODY","width":1106,"height":958,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ5NTJpRTYwNjEwNzgzNzNFRDBFRg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ5NTJpRTYwNjEwNzgzNzNFRDBFRg?revision=1","title":"0EM1T000001MsbY.png","associationType":"BODY","width":1369,"height":999,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNDMwNWlFRjc1NzBGMDc0QThENzIz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNDMwNWlFRjc1NzBGMDc0QThENzIz?revision=1","title":"0151T000003d5LNQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ0NTVpRDBGRDZERkQwNTUyODIyQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ0NTVpRDBGRDZERkQwNTUyODIyQQ?revision=1","title":"0151T000003d5LQQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1","title":"0151T000003d5LCQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTE0NDVpRUNBOTM1N0YzRTMwMjFEQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTE0NDVpRUNBOTM1N0YzRTMwMjFEQQ?revision=1","title":"0151T000003d5LSQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:279637":{"__typename":"TkbTopicMessage","subject":"The Full-Proxy Data Center Architecture","conversation":{"__ref":"Conversation:conversation:279637"},"id":"message:279637","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279637","revisionNum":1,"uid":279637,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":4708},"postTime":"2011-11-21T04:04:00.000-08:00","lastPublishTime":"2011-11-21T04:04:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Why a full-proxy architecture is important to both infrastructure and data centers. \n\n In the early days of load balancing and application delivery there was a lot of confusion about proxy-based architectures and in particular the definition of a full-proxy architecture. Understanding what a full-proxy is will be increasingly important as we continue to re-architect the data center to support a more mobile, virtualized infrastructure in the quest to realize IT as a Service. \n\n THE FULL-PROXY PLATFORM \n\n The reason there is a distinction made between “proxy” and “full-proxy” stems from the handling of connections as they flow through the device. All proxies sit between two entities – in the Internet age almost always “client” and “server” – and mediate connections. While all full-proxies are proxies, the converse is not true. Not all proxies are full-proxies and it is this distinction that needs to be made when making decisions that will impact the data center architecture. \n\n \n\n A full-proxy maintains two separate session tables – one on the client-side, one on the server-side. There is effectively an “air gap” isolation layer between the two internal to the proxy, one that enables focused profiles to be applied specifically to address issues peculiar to each “side” of the proxy. Clients often experience higher latency because of lower bandwidth connections while the servers are generally low latency because they’re connected via a high-speed LAN. The optimizations and acceleration techniques used on the client side are far different than those on the LAN side because the issues that give rise to performance and availability challenges are vastly different. \n\n A full-proxy, with separate connection handling on either side of the “air gap”, can address these challenges. A proxy, which may be a full-proxy but more often than not simply uses a buffer-and-stitch methodology to perform connection management, cannot optimally do so. A typical proxy buffers a connection, often through the TCP handshake process and potentially into the first few packets of application data, but then “stitches” a connection to a given server on the back-end using either layer 4 or layer 7 data, perhaps both. The connection is a single flow from end-to-end and must choose which characteristics of the connection to focus on – client or server – because it cannot simultaneously optimize for both. \n\n The second advantage of a full-proxy is its ability to perform more tasks on the data being exchanged over the connection as it is flowing through the component. Because specific action must be taken to “match up” the connection as its flowing through the full-proxy, the component can inspect, manipulate, and otherwise modify the data before sending it on its way on the server-side. This is what enables termination of SSL, enforcement of security policies, and performance-related services to be applied on a per-client, per-application basis. \n\n This capability translates to broader usage in data center architecture by enabling the implementation of an application delivery tier in which operational risk can be addressed through the enforcement of various policies. In effect, we’re created a full-proxy data center architecture in which the application delivery tier as a whole serves as the “full proxy” that mediates between the clients and the applications. \n\n \n\n THE FULL-PROXY DATA CENTER ARCHITECTURE \n\n A full-proxy data center architecture installs a digital \"air gap” between the client and applications by serving as the aggregation (and conversely disaggregation) point for services. Because all communication is funneled through virtualized applications and services at the application delivery tier, it serves as a strategic point of control at which delivery policies addressing operational risk (performance, availability, security) can be enforced. \n\n A full-proxy data center architecture further has the advantage of isolating end-users from the volatility inherent in highly virtualized and dynamic environments such as cloud computing . It enables solutions such as those used to overcome limitations with virtualization technology, such as those encountered with pod-architectural constraints in VMware View deployments. Traditional access management technologies, for example, are tightly coupled to host names and IP addresses. In a highly virtualized or cloud computing environment, this constraint may spell disaster for either performance or ability to function, or both. By implementing access management in the application delivery tier – on a full-proxy device – volatility is managed through virtualization of the resources, allowing the application delivery controller to worry about details such as IP address and VLAN segments, freeing the access management solution to concern itself with determining whether this user on this device from that location is allowed to access a given resource. \n\n Basically, we’re taking the concept of a full-proxy and expanded it outward to the architecture. Inserting an “application delivery tier” allows for an agile, flexible architecture more supportive of the rapid changes today’s IT organizations must deal with. \n\n Such a tier also provides an effective means to combat modern attacks. Because of its ability to isolate applications, services, and even infrastructure resources, an application delivery tier improves an organizations’ capability to withstand the onslaught of a concerted DDoS attack. The magnitude of difference between the connection capacity of an application delivery controller and most infrastructure (and all servers) gives the entire architecture a higher resiliency in the face of overwhelming connections. This ensures better availability and, when coupled with virtual infrastructure that can scale on-demand when necessary, can also maintain performance levels required by business concerns. \n\n A full-proxy data center architecture is an invaluable asset to IT organizations in meeting the challenges of volatility both inside and outside the data center. \n\n \n\n \n Related blogs & articles: \n\n The Concise Guide to Proxies At the Intersection of Cloud and Control… Cloud Computing and the Truth About SLAs IT Services: Creating Commodities out of Complexity What is a Strategic Point of Control Anyway? The Battle of Economy of Scale versus Control and Flexibility F5 Friday: When Firewalls Fail… F5 Friday: Platform versus Product \n\n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6593","kudosSumWeight":1,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQyM2k4M0M2NzcwMDdFOUZERDkw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTU2MTlpREI4NkJERjY4RjA4OUQ5Ng?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ5NTJpRTYwNjEwNzgzNzNFRDBFRg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNDMwNWlFRjc1NzBGMDc0QThENzIz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTQ0NTVpRDBGRDZERkQwNTUyODIyQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk2MzctMTE0NDVpRUNBOTM1N0YzRTMwMjFEQQ?revision=1\"}"}}],"totalCount":7,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280467":{"__typename":"Conversation","id":"conversation:280467","topic":{"__typename":"TkbTopicMessage","uid":280467},"lastPostingActivityTime":"2011-10-12T04:31:00.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMzM3OGkyMkUyODAwNEI0MjNGODVD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMzM3OGkyMkUyODAwNEI0MjNGODVD?revision=1","title":"0151T000003d8HyQAI.png","associationType":"BODY","width":381,"height":329,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTIwODZpRUEyNTc1Q0VDNUEyMDRFNA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTIwODZpRUEyNTc1Q0VDNUEyMDRFNA?revision=1","title":"0151T000003d5CpQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTM0OTJpQjBDMkE3QjE1NkEyODFCMg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTM0OTJpQjBDMkE3QjE1NkEyODFCMg?revision=1","title":"0151T000003d5CqQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTQ5MDZpNDQ5OURFNkY0ODNDRDJFQg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTQ5MDZpNDQ5OURFNkY0ODNDRDJFQg?revision=1","title":"0151T000003d5CrQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTAxODBpRDJEMUNCREUxNERDQjFFRQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTAxODBpRDJEMUNCREUxNERDQjFFRQ?revision=1","title":"0151T000003d5CsQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTYzOWk0OENBNTE2RTk5NDlGNzE4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTYzOWk0OENBNTE2RTk5NDlGNzE4?revision=1","title":"0151T000003d5CtQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTA2NjlpNENERkQ2NkM1Mzk0QjhFNQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTA2NjlpNENERkQ2NkM1Mzk0QjhFNQ?revision=1","title":"0151T000003d5CyQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:280467":{"__typename":"TkbTopicMessage","subject":"Infrastructure Architecture: Whitelisting with JSON and API Keys","conversation":{"__ref":"Conversation:conversation:280467"},"id":"message:280467","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280467","revisionNum":1,"uid":280467,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3099},"postTime":"2011-10-12T04:31:00.000-07:00","lastPublishTime":"2011-10-12T04:31:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Application delivery infrastructure can be a valuable partner in architecting solutions …. AJAX and JSON have changed the way in which we architect applications, especially with respect to their ascendancy to rule the realm of integration, i.e. the API. Policies are generally focused on the URI, which has effectively become the exposed interface to any given application function. It’s REST-ful, it’s service-oriented, and it works well. Because we’ve taken to leveraging the URI as a basic building block, as the entry-point into an application, it affords the opportunity to optimize architectures and make more efficient the use of compute power available for processing. This is an increasingly important point, as capacity has become a focal point around which cost and efficiency is measured. By offloading functions to other systems when possible, we are able to increase the useful processing capacity of an given application instance and ensure a higher ratio of valuable processing to resources is achieved. The ability of application delivery infrastructure to intercept, inspect, and manipulate the exchange of data between client and server should not be underestimated. A full-proxy based infrastructure component can provide valuable services to the application architect that can enhance the performance and reliability of applications while abstracting functionality in a way that alleviates the need to modify applications to support new initiatives. AN EXAMPLE Consider, for example, a business requirement specifying that only certain authorized partners (in the integration sense) are allowed to retrieve certain dynamic content via an exposed application API. There are myriad ways in which such a requirement could be implemented, including requiring authentication and subsequent tokens to authorize access – likely the most common means of providing such access management in conjunction with an API. Most of these options require several steps, however, and interaction directly with the application to examine credentials and determine authorization to requested resources. This consumes valuable compute that could otherwise be used to serve requests. An alternative approach would be to provide authorized consumers with a more standards-based method of access that includes, in the request, the very means by which authorization can be determined. Taking a lesson from the credit card industry, for example, an algorithm can be used to determine the validity of a particular customer ID or authorization token. An API key, if you will, that is not stored in a database (and thus requires a lookup) but rather is algorithmic and therefore able to be verified as valid without needing a specific lookup at run-time. Assuming such a token or API key were embedded in the URI, the application delivery service can then extract the key, verify its authenticity using an algorithm, and subsequently allow or deny access based on the result. This architecture is based on the premise that the application delivery service is capable of responding with the appropriate JSON in the event that the API key is determined to be invalid. Such a service must therefore be network-side scripting capable. Assuming such a platform exists, one can easily implement this architecture and enjoy the improved capacity and resulting performance boost from the offload of authorization and access management functions to the infrastructure. 1. A request is received by the application delivery service. 2. The application delivery service extracts the API key from the URI and determines validity. 3. If the API key is not legitimate, a JSON-encoded response is returned. 4. If the API key is valid, the request is passed on to the appropriate web/application server for processing. Such an approach can also be used to enable or disable functionality within an application, including live-streams. Assume a site that serves up streaming content, but only to authorized (registered) users. When requests for that content arrive, the application delivery service can dynamically determine, using an embedded key or some portion of the URI, whether to serve up the content or not. If it deems the request invalid, it can return a JSON response that effectively “turns off” the streaming content, thereby eliminating the ability of non-registered (or non-paying) customers to access live content. Such an approach could also be useful in the event of a service failure; if content is not available, the application delivery service can easily turn off and/or respond to the request, providing feedback to the user that is valuable in reducing their frustration with AJAX-enabled sites that too often simply “stop working” without any kind of feedback or message to the end user. The application delivery service could, of course, perform other actions based on the in/validity of the request, such as directing the request be fulfilled by a service generating older or non-dynamic streaming content, using its ability to perform application level routing. The possibilities are quite extensive and implementation depends entirely on goals and requirements to be met. Such features become more appealing when they are, through their capabilities, able to intelligently make use of resources in various locations. Cloud-hosted services may be more or less desirable for use in an application, and thus leveraging application delivery services to either enable or reduce the traffic sent to such services may be financially and operationally beneficial. ARCHITECTURE is KEY The core principle to remember here is that ultimately infrastructure architecture plays (or can and should play) a vital role in designing and deploying applications today. With the increasing interest and use of cloud computing and APIs, it is rapidly becoming necessary to leverage resources and services external to the application as a means to rapidly deploy new functionality and support for new features. The abstraction offered by application delivery services provides an effective, cross-site and cross-application means of enabling what were once application-only services within the infrastructure. This abstraction and service-oriented approach reduces the burden on the application as well as its developers. The application delivery service is almost always the first service in the oft-times lengthy chain of services required to respond to a client’s request. Leveraging its capabilities to inspect and manipulate as well as route and respond to those requests allows architects to formulate new strategies and ways to provide their own services, as well as leveraging existing and integrated resources for maximum efficiency, with minimal effort. Related blogs & articles: HTML5 Going Like Gangbusters But Will Anyone Notice? Web 2.0 Killed the Middleware Star The Inevitable Eventual Consistency of Cloud Computing Let’s Face It: PaaS is Just SOA for Platforms Without the Baggage Cloud-Tiered Architectural Models are Bad Except When They Aren’t The Database Tier is Not Elastic The New Distribution of The 3-Tiered Architecture Changes Everything Sessions, Sessions Everywhere ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7358","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMzM3OGkyMkUyODAwNEI0MjNGODVD?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTIwODZpRUEyNTc1Q0VDNUEyMDRFNA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTM0OTJpQjBDMkE3QjE1NkEyODFCMg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTQ5MDZpNDQ5OURFNkY0ODNDRDJFQg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTAxODBpRDJEMUNCREUxNERDQjFFRQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTYzOWk0OENBNTE2RTk5NDlGNzE4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA0NjctMTA2NjlpNENERkQ2NkM1Mzk0QjhFNQ?revision=1\"}"}}],"totalCount":7,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286177":{"__typename":"Conversation","id":"conversation:286177","topic":{"__typename":"TkbTopicMessage","uid":286177},"lastPostingActivityTime":"2009-07-30T04:07:59.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1","title":"0151T000003d7kjQAA.jpg","associationType":"BODY","width":170,"height":170,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1","title":"0151T000003d7ujQAA.jpg","associationType":"BODY","width":447,"height":108,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1","title":"0151T000003d8I1QAI.jpg","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1","title":"0151T000003d8MMQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:286177":{"__typename":"TkbTopicMessage","subject":"What is server offload and why do I need it?","conversation":{"__ref":"Conversation:conversation:286177"},"id":"message:286177","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286177","revisionNum":1,"uid":286177,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2900},"postTime":"2009-06-17T04:07:37.000-07:00","lastPublishTime":"2009-06-17T04:07:37.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" One of the tasks of an enterprise architect is to design a framework atop which developers can implement and deploy applications consistently and easily. The consistency is important for internal business continuity and reuse; common objects, operations, and processes can be reused across applications to make development and integration with other applications and systems easier. Architects also often decide where functionality resides and design the base application infrastructure framework. Application server, identity management, messaging, and integration are all often a part of such architecture designs. Rarely does the architect concern him/herself with the network infrastructure, as that is the purview of “that group”; the “you know who I’m talking about” group. And for the most part there’s no need for architects to concern themselves with network-oriented architecture. Applications should not need to know on which VLAN they will be deployed or what their default gateway might be. But what architects might need to know – and probably should know – is whether the network infrastructure supports “server offload” of some application functions or not, and how that can benefit their enterprise architecture and the applications which will be deployed atop it. WHAT IT IS Server offload is a generic term used by the networking industry to indicate some functionality designed to improve the performance or security of applications. We use the term “offload” because the functionality is “offloaded” from the server and moved to an application network infrastructure device instead. Server offload works because the application network infrastructure is almost always these days deployed in front of the web/application servers and is in fact acting as a broker (proxy) between the client and the server. Server offload is generally offered by load balancers and application delivery controllers. You can think of server offload like a relay race. The application network infrastructure device runs the first leg and then hands off the baton (the request) to the server. When the server is finished, the application network infrastructure device gets to run another leg, and then the race is done as the response is sent back to the client. There are basically two kinds of server offload functionality: Protocol processing offload Protocol processing offload includes functions like SSL termination and TCP optimizations. Rather than enable SSL communication on the web/application server, it can be “offloaded” to an application network infrastructure device and shared across all applications requiring secured communications. Offloading SSL to an application network infrastructure device improves application performance because the device is generally optimized to handle the complex calculations involved in encryption and decryption of secured data and web/application servers are not. TCP optimization is a little different. We say TCP session management is “offloaded” to the server but that’s really not what happens as obviously TCP connections are still opened, closed, and managed on the server as well. Offloading TCP session management means that the application network infrastructure is managing the connections between itself and the server in such a way as to reduce the total number of connections needed without impacting the capacity of the application. This is more commonly referred to as TCP multiplexing and it “offloads” the overhead of TCP connection management from the web/application server to the application network infrastructure device by effectively giving up control over those connections. By allowing an application network infrastructure device to decide how many connections to maintain and which ones to use to communicate with the server, it can manage thousands of client-side connections using merely hundreds of server-side connections. Reducing the overhead associated with opening and closing TCP sockets on the web/application server improves application performance and actually increases the user capacity of servers. TCP offload is beneficial to all TCP-based applications, but is particularly beneficial for Web 2.0 applications making use of AJAX and other near real-time technologies that maintain one or more connections to the server for its functionality. Protocol processing offload does not require any modifications to the applications. Application-oriented offload Application-oriented offload includes the ability to implement shared services on an application network infrastructure device. This is often accomplished via a network-side scripting capability, but some functionality has become so commonplace that it is now built into the core features available on application network infrastructure solutions. Application-oriented offload can include functions like cookie encryption/decryption, compression, caching, URI rewriting, HTTP redirection, DLP (Data Leak Prevention), selective data encryption, application security functionality, and data transformation. When network-side scripting is available, virtually any kind of pre or post-processing can be offloaded to the application network infrastructure and thereafter shared with all applications. Application-oriented offload works because the application network infrastructure solution is mediating between the client and the server and it has the ability to inspect and manipulate the application data. The benefits of application-oriented offload are that the services implemented can be shared across multiple applications and in many cases the functionality removes the need for the web/application server to handle a specific request. For example, HTTP redirection can be fully accomplished on the application network infrastructure device. HTTP redirection is often used as a means to handle application upgrades, commonly mistyped URIs, or as part of the application logic when certain conditions are met. Application security offload usually falls into this category because it is application – or at least application data – specific. Application security offload can include scanning URIs and data for malicious content, validating the existence of specific cookies/data required for the application, etc… This kind of offload improves server efficiency and performance but a bigger benefit is consistent, shared security across all applications for which the service is enabled. Some application-oriented offload can require modification to the application, so it is important to design such features into the application architecture before development and deployment. While it is certainly possible to add such functionality into the architecture after deployment, it is always easier to do so at the beginning. WHY YOU NEED IT Server offload is a way to increase the efficiency of servers and improve application performance and security. Server offload increases efficiency of servers by alleviating the need for the web/application server to consume resources performing tasks that can be performed more efficiently on an application network infrastructure solution. The two best examples of this are SSL encryption/decryption and compression. Both are CPU intense operations that can consume 20-40% of a web/application server’s resources. By offloading these functions to an application network infrastructure solution, servers “reclaim” those resources and can use them instead to execute application logic, serve more users, handle more requests, and do so faster. Server offload improves application performance by allowing the web/application server to concentrate on what it is designed to do: serve applications and putting the onus for performing ancillary functions on a platform that is more optimized to handle those functions. Server offload provides these benefits whether you have a traditional client-server architecture or have moved (or are moving) toward a virtualized infrastructure. Applications deployed on virtual servers still use TCP connections and SSL and run applications and therefore will benefit the same as those deployed on traditional servers. I am wondering why not all websites enabling this great feature GZIP? 3 Really good reasons you should use TCP multiplexing SOA & Web 2.0: The Connection Management Challenge Understanding network-side scripting I am in your HTTP headers, attacking your application Infrastructure 2.0: As a matter of fact that isn't what it means ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"8771","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}"}}],"totalCount":10,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:279167":{"__typename":"Conversation","id":"conversation:279167","topic":{"__typename":"TkbTopicMessage","uid":279167},"lastPostingActivityTime":"2011-12-09T04:41:00.000-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzk0MGkyQUUwOTVCNjRGQzQzNDU4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzk0MGkyQUUwOTVCNjRGQzQzNDU4?revision=1","title":"0151T000003d5MBQAY.png","associationType":"BODY","width":240,"height":86,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctODU0OWk4NkVFMTlBNEJBNjRDQjQ2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctODU0OWk4NkVFMTlBNEJBNjRDQjQ2?revision=1","title":"0151T000003d5MCQAY.png","associationType":"BODY","width":803,"height":425,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1","title":"0151T000003d5LCQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1","title":"0151T000003d8TvQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1","title":"0151T000003d8TdQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:279167":{"__typename":"TkbTopicMessage","subject":"F5 Friday: Load Balancing MySQL with F5 BIG-IP","conversation":{"__ref":"Conversation:conversation:279167"},"id":"message:279167","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279167","revisionNum":1,"uid":279167,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2827},"postTime":"2011-12-09T04:41:00.000-08:00","lastPublishTime":"2011-12-09T04:41:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Scaling MySQL just got a whole lot easier load balancing MySQL – any database, really – is not a trivial task. Generally speaking one does not simply round robin your way through a cluster of MySQL databases as a means to achieve scalability. It is databases, in fact, that have driven a wide variety of scalability patterns such as sharding and partitioning to achieve the ultimate goal of high-performance and scalability simultaneously. Unfortunately, most folks don’t architect their applications with scalability in mind. A single database is all that’s necessary at first, and because of the way in which the application interacts with the database, it doesn’t make sense to code in support for multiple database instances, such as is often implemented with a MySQL master-slave cluster. That’s because the application has to actually open a connection to the database in question. If you’re only starting with one database, you really can’t code in a connection to a separate instance. Eventually that application’s usage grows and the demands upon the database require a more scalable approach. Enter the MySQL master/slave relationship. A typical configuration is to maintain the master as the “write” database, i.e. all updates and/or inserts must use the master, while the slave instance is used as a “read only” instance. Obviously this means the application code must be changed to support this kind of functional sharding. Unless you leverage network server virtualization from a load balancing service capable of acting as a full-proxy at layer 7 (application) like BIG-IP. This solution leverages iRules to implement database load balancing. While this specific example is designed to perform the common functional sharding pattern of read-write separation for a master-slave MySQL cluster, the flexibility of iRules is such that other architectural solutions can easily be designed using the same basic functions. Location based sharding is another popular means of scaling databases, and using the GeoLocation capabilities of BIG-IP along with iRules to inspect and route database requests, it should be a fairly trivial architectural task to implement. The ability to further extend sharding or other distribution methodologies for scaling databases without modifying the application itself is a huge bonus for both developers and operations. By decoupling the application from the database, it provides a more flexibility set of scalability domains in which technology targeted scalability strategies can be leveraged independent of the other layers. This is an important facet of agile infrastructure architecture and should not be underestimated as a benefit of network server virtualization. MySQL Load Balancing Resources: MySQL Proxy iRule MySQL Proxy iApp (deployment package for BIG-IP v11) The Full-Proxy Data Center Architecture Infrastructure Scalability Pattern: Sharding Streams Infrastructure Scalability Pattern: Sharding Sessions Infrastructure Scalability Pattern: Partition by Function or Type IT as a Service: A Stateless Infrastructure Architecture Model F5 Friday: Platform versus Product At the Intersection of Cloud and Control… What is a Strategic Point of Control Anyway? All F5 Friday Posts on DevCentral Why Single-Stack Infrastructure Sucks ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3494","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzk0MGkyQUUwOTVCNjRGQzQzNDU4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctODU0OWk4NkVFMTlBNEJBNjRDQjQ2?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNTk0MGk0QzZFRTUyN0U2RjVENDlG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzkxNjctNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1\"}"}}],"totalCount":5,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280535":{"__typename":"Conversation","id":"conversation:280535","topic":{"__typename":"TkbTopicMessage","uid":280535},"lastPostingActivityTime":"2017-08-10T10:00:26.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1","title":"0151T000003d9HYQAY.jpg","associationType":"BODY","width":171,"height":171,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1","title":"0151T000003d9HZQAY.png","associationType":"BODY","width":490,"height":326,"altText":null},"TkbTopicMessage:message:280535":{"__typename":"TkbTopicMessage","subject":"The Challenges of SQL Load Balancing","conversation":{"__ref":"Conversation:conversation:280535"},"id":"message:280535","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280535","revisionNum":1,"uid":280535,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2500},"postTime":"2012-04-02T04:31:00.000-07:00","lastPublishTime":"2012-04-02T04:31:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"11020","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:278988":{"__typename":"Conversation","id":"conversation:278988","topic":{"__typename":"TkbTopicMessage","uid":278988},"lastPostingActivityTime":"2018-05-31T13:31:15.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTUzMjdpRkEwOEEwMjUyMjdDQkM4NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTUzMjdpRkEwOEEwMjUyMjdDQkM4NA?revision=1","title":"0151T000003d8UHQAY.png","associationType":"BODY","width":240,"height":187,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzY1MWlBQTY0MDhBQTdERjAzREUz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzY1MWlBQTY0MDhBQTdERjAzREUz?revision=1","title":"0151T000003d4ItQAI.gif","associationType":"QUOTE","width":24,"height":13,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtOTMzMGkyNDBEM0UwMzkzQzBBMjc2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtOTMzMGkyNDBEM0UwMzkzQzBBMjc2?revision=1","title":"0151T000003d4IuQAI.gif","associationType":"QUOTE","width":24,"height":13,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTM4ODNpN0Y3QjlFMjc4NDU2MzBFQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTM4ODNpN0Y3QjlFMjc4NDU2MzBFQQ?revision=1","title":"0151T000003d8UGQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMjgwNWk3Q0ZGNjZGNEQxNDM4QkEx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMjgwNWk3Q0ZGNjZGNEQxNDM4QkEx?revision=1","title":"0151T000003d8U6QAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1","title":"0151T000003d8TvQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1","title":"0151T000003d8TdQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNjE3aUE5OEQxODQ3NDVFMjdGRDA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNjE3aUE5OEQxODQ3NDVFMjdGRDA?revision=1","title":"0151T000003d8UAQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTA2MmkwMEMzNzdGOEJFMjQxNjBC?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTA2MmkwMEMzNzdGOEJFMjQxNjBC?revision=1","title":"0151T000003d8ToQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTY0OWk3NjBGNDIzQzc5RTVENjVF?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTY0OWk3NjBGNDIzQzc5RTVENjVF?revision=1","title":"0151T000003d8UDQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTQ2N2kwMTQ1ODM3MjY0NDQxODcw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTQ2N2kwMTQ1ODM3MjY0NDQxODcw?revision=1","title":"0151T000003d8U7QAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDc4MWlGOTAwOEMzOEYxNDVCOEQx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDc4MWlGOTAwOEMzOEYxNDVCOEQx?revision=1","title":"0151T000003d8U9QAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDQ3NGk4RjFCRjFGQTlFNjVEMkRE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDQ3NGk4RjFCRjFGQTlFNjVEMkRE?revision=1","title":"0151T000003d8UFQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMzc2OGlGRDBCNDIyQzE5NDZFQkZG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMzc2OGlGRDBCNDIyQzE5NDZFQkZG?revision=1","title":"0151T000003d8UCQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:278988":{"__typename":"TkbTopicMessage","subject":"Load Balancing Fu: Beware the Algorithm and Sticky Sessions","conversation":{"__ref":"Conversation:conversation:278988"},"id":"message:278988","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:278988","revisionNum":1,"uid":278988,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2399},"postTime":"2011-06-06T03:24:14.000-07:00","lastPublishTime":"2011-06-06T03:24:14.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" The choice of load balancing algorithms can directly impact – for good or ill – the performance, behavior and capacity of applications. Beware making incompatible choices in architecture and algorithms. One of the most persistent issues encountered when deploying applications in scalable architectures involves sessions and the need for persistence-based (a.k.a. sticky) load balancing services to maintain state for the duration of an end-user’s session. It is common enough that even the rudimentary load balancing services offered by cloud computing providers such as Amazon include the option to enable persistence-based load balancing. While the use of persistence addresses the problem of maintaining session state, it introduces other operational issues that must also be addressed to ensure consistent operational behavior of load balancing services. In particular, the use of the Round Robin load balancing algorithm in conjunction with persistence-based load balancing should be discouraged if not outright disallowed. ROUND ROBIN + PERSISTENCE –> POTENTIALLY UNEQUAL DISTRIBUTION of LOAD When scaling applications there are two primary concerns: concurrent user capacity and performance. These two concerns are interrelated in that as capacity is consumed, performance degrades. This is particularly true of applications storing state as each request requires that the application server perform a lookup to retrieve the user session. The more sessions stored, the longer it takes to find and retrieve the session. The exactly efficiency of such lookups is determined by the underlying storage data structure and algorithm used to search the structure for the appropriate session. If you remember your undergraduate classes in data structures and computing Big (O) you’ll remember that some structures scale more efficiently in terms of performance than do others. The general rule of thumb, however, is that the more data stored, the longer the lookup. Only the amount of degradation is variable based on the efficiency of the algorithms used. Therefore, the more sessions in use on an application server instance, the poorer the performance. This is one of the reasons you want to choose a load balancing algorithm that evenly distributes load across all instances and ultimately why lots of little web servers scaled out offer better performance than a few, scaled up web servers. Now, when you apply persistence to the load balancing equation it essentially interrupts the normal operation of the algorithm, ignoring it. That’s the way it’s supposed to work: the algorithm essentially applies only to requests until a server-side session (state) is established and thereafter (when the session has been created) you want the end-user to interact with the same server to ensure consistent and expected application behavior. For example, consider this solution note for BIG-IP. Note that this is true of all load balancing services: A persistence profile allows a returning client to connect directly to the server to which it last connected. In some cases, assigning a persistence profile to a virtual server can create the appearance that the BIG-IP system is incorrectly distributing more requests to a particular server. However, when you enable a persistence profile for a virtual server, a returning client is allowed to bypass the load balancing method and connect directly to the pool member. As a result, the traffic load across pool members may be uneven, especially if the persistence profile is configured with a high timeout value. -- Causes of Uneven Traffic Distribution Across BIG-IP Pool Members So far so good. The problem with round robin- – and reason I’m picking on Round Robin specifically - is that round robin is pretty, well, dumb in its decision making. It doesn’t factor anything into its decision regarding which instance gets the next request. It’s as simple as “next in line\", period. Depending on the number of users and at what point a session is created, this can lead to scenarios in which the majority of sessions are created on just a few instances. The result is a couple of overwhelmed instances (with performance degradations commensurate with the reduction in available resources) and a bunch of barely touched instances. The smaller the pool of instances, the more likely it is that a small number of servers will be disproportionately burdened. Again, lots of little (virtual) web servers scales out more evenly and efficiently than a few big (virtual) web servers. Assuming a pool of similarly-capable instances (RAM and CPU about equal on all) there are other load balancing algorithms that should be considered more appropriate for use in conjunction with persistence-based load balancing configurations. Least connections should provide better distribution, although the assumption that an active connection is equivalent to the number of sessions currently in memory on the application server could prove to be incorrect at some point, leading to the same situation as would be the case with the choice of round robin. It is still a better option, but not an infallible one. Fastest response time is likely a better indicator of capacity as we know that responses times increase along with resource consumption, thus a faster responding instance is likely (but not guaranteed) to have more capacity available. Again, this algorithm in conjunction with persistence is not a panacea. Better options for a load balancing algorithm include those that are application aware; that is, algorithms that can factor into the decision making process the current load on the application instance and thus direct requests toward less burdened instances, resulting in a more even distribution of load across available instances. NON-ALGORITHMIC SOLUTIONS There are also non-algorithmic, i.e. architectural, solutions that can address this issue. DIVIDE and CONQUER In cloud computing environments, where it is less likely to find available algorithms other than industry standard (none of which are application-aware), it may be necessary to approach the problem with a divide and conquer strategy, i.e. lots of little servers. Rather than choosing one or two “large” instances, choose to scale out with four or five “small” instances, thus providing a better (but not guaranteed) statistical chance of load being distributed more evenly across instances. FLANKING STRATEGY If the option is available, an architectural “flanking” strategy that leverages layer 7 load balancing, a.k.a. content/application switching, will also provide better consumptive rates as well as more consistent performance. An architectural strategy of this sort is in line with sharding practices at the data layer in that it separates out by some attribute different kinds of content and serves that content from separate pools. Thus, image or other static content may come from one pool of resources while session-oriented, process intensive dynamic content may come from another pool. This allows different strategies – and algorithms – to be used simultaneously without sacrificing the notion of a single point of entry through which all users interact on the client-side. Regardless of how you choose to address the potential impact on capacity, it is important to recognize the intimate relationship between infrastructure services and applications. A more integrated architectural approach to application delivery can result in a much more efficient and better performing application. Understanding the relationship between delivery services and application performance and capacity can also help improve on operational costs, especially in cloud computing environments that constrain the choices of load balancing algorithms. As always, test early and test often and test under high load if you want to be assured that the load balancing algorithm is suitable to meet your operational and business requirements. WILS: Why Does Load Balancing Improve Application Performance? Load Balancing in a Cloud Infrastructure Scalability Pattern: Sharding Sessions Infrastructure Scalability Pattern: Partition by Function or Type It’s 2am: Do You Know What Algorithm Your Load Balancer is Using? Lots of Little Virtual Web Applications Scale Out Better than Scaling Up Sessions, Sessions Everywhere Choosing a Load Balancing Algorithm Requires DevOps Fu Amazon Makes the Cloud Sticky To Boldly Go Where No Production Application Has Gone Before Cloud Testing: The Next Generation ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"8834","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTUzMjdpRkEwOEEwMjUyMjdDQkM4NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzY1MWlBQTY0MDhBQTdERjAzREUz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtOTMzMGkyNDBEM0UwMzkzQzBBMjc2?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMTM4ODNpN0Y3QjlFMjc4NDU2MzBFQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMjgwNWk3Q0ZGNjZGNEQxNDM4QkEx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNzQ1NGkxODJDOUMxREQxRTZCMkUx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDE3MGlEOTMyRDQ3NEFEMDhCMjk5?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNjE3aUE5OEQxODQ3NDVFMjdGRDA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTA2MmkwMEMzNzdGOEJFMjQxNjBC?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTY0OWk3NjBGNDIzQzc5RTVENjVF?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNTQ2N2kwMTQ1ODM3MjY0NDQxODcw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEy","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDc4MWlGOTAwOEMzOEYxNDVCOEQx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEz","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtNDQ3NGk4RjFCRjFGQTlFNjVEMkRE?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE0","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzg5ODgtMzc2OGlGRDBCNDIyQzE5NDZFQkZG?revision=1\"}"}}],"totalCount":14,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280057":{"__typename":"Conversation","id":"conversation:280057","topic":{"__typename":"TkbTopicMessage","uid":280057},"lastPostingActivityTime":"2019-04-28T07:37:47.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctOTY0MWk4Rjk3MDk2QzQ5N0YyNjc4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctOTY0MWk4Rjk3MDk2QzQ5N0YyNjc4?revision=1","title":"0151T000003d5KiQAI.jpg","associationType":"BODY","width":189,"height":223,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMTUxMTJpQTMzQ0VCMzAyNENGQzM3Ng?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMTUxMTJpQTMzQ0VCMzAyNENGQzM3Ng?revision=1","title":"0151T000003d5KjQAI.png","associationType":"BODY","width":436,"height":193,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctODk3NmlEODRBRDMwRjExMDUxNUU3?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctODk3NmlEODRBRDMwRjExMDUxNUU3?revision=1","title":"0151T000003d5E7QAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMjkzaThENDc2NkYxQ0Q0MzEwRkE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMjkzaThENDc2NkYxQ0Q0MzEwRkE?revision=1","title":"0151T000003d5E8QAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:280057":{"__typename":"TkbTopicMessage","subject":"HTML5 Web Sockets Changes the Scalability Game","conversation":{"__ref":"Conversation:conversation:280057"},"id":"message:280057","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280057","revisionNum":1,"uid":280057,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":998},"postTime":"2011-11-07T03:36:00.000-08:00","lastPublishTime":"2011-11-07T03:36:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #HTML5 Web Sockets are poised to completely change scalability models … again. Using Web Sockets instead of XMLHTTPRequest and AJAX polling methods will dramatically reduce the number of connections required by servers and thus has a positive impact on performance. But that reliance on a single connection also changes the scalability game, at least in terms of architecture. Here comes the (computer) science… If you aren’t familiar with what is sure to be a disruptive web technology you should be. Web Sockets, while not broadly in use (it is only a specification, and a non-stable one at that) today is getting a lot of attention based on its core precepts and model. Web Sockets Defined in the Communications section of the HTML5 specification, HTML5 Web Sockets represents the next evolution of web communications—a full-duplex, bidirectional communications channel that operates through a single socket over the Web. HTML5 Web Sockets provides a true standard that you can use to build scalable, real-time web applications. In addition, since it provides a socket that is native to the browser, it eliminates many of the problems Comet solutions are prone to. Web Sockets removes the overhead and dramatically reduces complexity. - HTML5 Web Sockets: A Quantum Leap in Scalability for the Web So far, so good. The premise upon which the improvements in scalability coming from Web Sockets are based is the elimination of HTTP headers (reduces bandwidth dramatically) and session management overhead that can be incurred by the closing and opening of TCP connections. There’s only one connection required between the client and server over which much smaller data segments can be sent without necessarily requiring a request and a response pair. That communication pattern is definitely more scalable from a performance perspective, and also has a positive impact of reducing the number of connections per client required on the server. Similar techniques have long been used in application delivery (TCP multiplexing) to achieve the same results – a more scalable application. So far, so good. Where the scalability model ends up having a significant impact on infrastructure and architectures is the longevity of that single connection: Unlike regular HTTP traffic, which uses a request/response protocol, WebSocket connections can remain open for a long time. - How HTML5 Web Sockets Interact With Proxy Servers This single, persistent connection combined with a lot of, shall we say, interesting commentary on the interaction with intermediate proxies such as load balancers. But ignoring that for the nonce, let’s focus on the “remain open for a long time.” A given application instance has a limit on the number of concurrent connections it can theoretically and operationally manage before it reaches the threshold at which performance begins to dramatically degrade. That’s the price paid for TCP session management in general by every device and server that manages TCP-based connections. But Lori, you’re thinking, HTTP 1.1 connections are persistent, too. In fact, you don’t even have to tell an HTTP 1.1 server to keep-alive the connection! This really isn’t a big change. Whoa there hoss, yes it is. While you’d be right in that HTTP connections are also persistent, they generally have very short connection timeout settings. For example, the default connection timeout for Apache 2.0 is 15 seconds and for Apache 2.2 a mere 5 seconds. A well-tuned web server, in fact, will have thresholds that closely match the interaction patterns of the application it is hosting. This is because it’s a recognized truism that long and often idle connections tie up server processes or threads that negatively impact overall capacity and performance. Thus the introduction of connections that remain open for a long time changes the capacity of the server and introduces potential performance issues when that same server is also tasked with managing other short-lived, connection-oriented requests. Why this Changes the Game… One of the most common inhibitors of scale and high-performance for web applications today is the deployment of both near-real-time communication functions (AJAX) and traditional web content functions on the same server. That’s because web servers do not support a per-application HTTP profile. That is to say, the configuration for a web server is global; every communication exchange uses the same configuration values such as connection timeouts. That means configuring the web server for exchanges that would benefit from a longer time out end up with a lot of hanging connections doing absolutely nothing because they were used to grab standard dynamic or static content and then ignored. Conversely, configuring for quick bursts of requests necessarily sets timeout values too low for near or real-time exchanges and can cause performance issues as a client continually opens and re-opens connections. Remember, an idle connection is a drain on resources that directly impacts the performance and capacity of applications. So it’s a Very Bad Thing™. One of the solutions to this somewhat frustrating conundrum, made more feasible by the advent of cloud computing and virtualization, is to deploy specialized servers in a scalability domain-based architecture using infrastructure scalability patterns. Another approach to ensuring scalability is to offload responsibility for performance and connection management to an appropriately capable intermediary. Now, one would hope that a web server implementing support for both HTTP and Web Sockets would support separately configurable values for communication settings on at least the protocol level. Today there are very few web servers that support both HTTP and Web Sockets. It’s a nascent and still evolving standard so many of the servers are “pure” Web Sockets servers, many implemented in familiar scripting languages like PHP and Python. Which means two separate sets of servers that must be managed and scaled. Which should sound a lot like … specialized servers in a scalability domain-based architecture. The more things change, the more they stay the same. The second impact on scalability architectures centers on the premise that Web Sockets keep one connection open over which message bits can be exchanged. This ties up resources, but it also requires that clients maintain a connection to a specific server instance. This means infrastructure (like load balancers and web/application servers) will need to support persistence (not the same as persistent, you can read about the difference here if you’re so inclined). That’s because once connected to a Web Socket service the performance benefits are only realized if you stay connected to that same service. If you don’t and end up opening a second (or Heaven-forbid a third or more) connection, the first connection may remain open until it times out. Given that the premise of the Web Socket is to stay open – even through potentially longer idle intervals – it may remain open, with no client, until the configured time out. That means completely useless resources tied up by … nothing. Persistence-based load balancing is a common feature of next-generation load balancers (application delivery controllers) and even most cloud-based load balancing services. It is also commonly implemented in application server clustering offerings, where you’ll find it called server-affinity. It is worth noting that persistence-based load balancing is not without its own set of gotchas when it comes to performance and capacity. THE ANSWER: ARCHITECTURE The reason that these two ramifications of Web Sockets impacts the scalability game is it requires an broader architectural approach to scalability. It can’t necessarily be achieved simply by duplicating services and distributing the load across them. Persistence requires collaboration with the load distribution mechanism and there are protocol-based security constraints with respect to incorporating even intra-domain content in a single page/application. While these security constraints are addressable through configuration, the same caveats with regards to the lack of granularity in configuration at the infrastructure (web/application server) layer must be made. Careful consideration of what may be accidentally allowed and/or disallowed is necessary to prevent unintended consequences. And that’s not even starting to consider the potential use of Web Sockets as an attack vector, particularly in the realm of DDoS. The long-lived nature of a Web Socket connection is bound to be exploited at some point in the future, which will engender another round of evaluating how to best address application-layer DDoS attacks. A service-focused, distributed (and collaborative) approach to scalability is likely to garner the highest levels of success when employing Web Socket-based functionality within a broader web application, as opposed to the popular cookie-cutter cloning approach made exceedingly easy by virtualization. Infrastructure Scalability Pattern: Partition by Function or Type Infrastructure Scalability Pattern: Sharding Sessions Amazon Makes the Cloud Sticky Load Balancing Fu: Beware the Algorithm and Sticky Sessions Et Tu, Browser? Forget Hyper-Scale. Think Hyper-Local Scale. Infrastructure Scalability Pattern: Sharding Streams Infrastructure Architecture: Whitelisting with JSON and API Keys Does This Application Make My Browser Look Fat? HTTP Now Serving … Everything ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"9845","kudosSumWeight":0,"repliesCount":5,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctOTY0MWk4Rjk3MDk2QzQ5N0YyNjc4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMTUxMTJpQTMzQ0VCMzAyNENGQzM3Ng?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctODk3NmlEODRBRDMwRjExMDUxNUU3?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAwNTctMjkzaThENDc2NkYxQ0Q0MzEwRkE?revision=1\"}"}}],"totalCount":4,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:283999":{"__typename":"Conversation","id":"conversation:283999","topic":{"__typename":"TkbTopicMessage","uid":283999},"lastPostingActivityTime":"2012-09-19T06:31:00.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODM5OTktMTE2NTlpQTZGNUYzQkNDNkE1MDQ4MA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODM5OTktMTE2NTlpQTZGNUYzQkNDNkE1MDQ4MA?revision=1","title":"0151T000003d7liQAA.png","associationType":"BODY","width":392,"height":289,"altText":null},"TkbTopicMessage:message:283999":{"__typename":"TkbTopicMessage","subject":"WILS: The Data Center API Compass Rose","conversation":{"__ref":"Conversation:conversation:283999"},"id":"message:283999","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:283999","revisionNum":1,"uid":283999,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":900},"postTime":"2012-09-19T06:31:00.000-07:00","lastPublishTime":"2012-09-19T06:31:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #SDN #cloud North, South, East, West. Defining directional APIs. \n There's an unwritten rule that says when describing a network architecture the perimeter of the data center is at the top. Similarly application data flow begins at the UI (presentation) layer and extends downward, toward the data tier. This directional flow has led to the use of the terms \"northbound\" and \"southbound\" to describe API responsibility within SDN (Software Defined Network) architectures and is likely to continue to expand to encompass in general the increasingly-API driven data center models. \n But while network aficionados may use these terms with alacrity, they are not always well described or described in a way that a broad spectrum of IT professionals will immediately understand. \n Too, these terms are increasingly used by systems other than those directly related to SDN to describe APIs and how they integrate with other systems within the data center. \n So let's set about rectifying that, shall we? \n NORTHBOUND The northbound API in an SDN architecture describes the APIs used to communicate with the controller. In a general sense, the northbound API is the interconnect with the management ecosystem. That is, with systems external to the device responsible for instructing, monitoring, or otherwise managing the device in some way. \n Examples in the enterprise data center would be integration with HP, VMware, and Microsoft management solutions for purposes of automation and orchestration and the sharing of actionable data between systems. \n SOUTHBOUND \n The southbound API interconnects with the network ecosystem. In an SDN this would be the switching fabric. In other systems this would be those network devices with which the device integrates for the purposes of routing, switching and otherwise directing traffic. \n Examples in the enterprise data center would be the use of OpenFlow to communicate with the switch fabric, network virtualization protocols, or the integration of a distributed delivery network. \n EASTBOUND \n Eastbound describes APIs used to integrate the device with external systems, such as cloud providers and cloud-hosted services. \n Examples in the enterprise data center would be a cloud gateway taking advantage of a cloud provider's API to enable a normalized network bridge that extends the data center eastward, into the cloud. \n WESTBOUND \n Westbound APIs are used to enable integration with the device, a la plug-ins to a platform. These APIs are internal-focused and enable a platform upon which third-party functionality can be developed and deployed. \n Examples in the enterprise data center would be proprietary APIs for network operating systems that enable a plug-in architecture for extending device capabilities beyond what is available \"out of the box.\" \n \n Certainly others will have a slightly different take on directional API definitions, though north and south-bound API descriptions are generally similar throughout the industry at this time. However, you can assume these definitions are applicable if and when I use them in future blogs. \n \n \n Architecting Scalable Infrastructures: CPS versus DPS SDN is Network Control. ADN is Application Control. The Cloud Integration Stack Hybrid Architectures Do Not Require Private Cloud Identity Gone Wild! Cloud Edition Cloud Bursting: Gateway Drug for Hybrid Cloud The Conspecific Hybrid Cloud \n \n\n \n \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3475","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODM5OTktMTE2NTlpQTZGNUYzQkNDNkE1MDQ4MA?revision=1\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280124":{"__typename":"Conversation","id":"conversation:280124","topic":{"__typename":"TkbTopicMessage","uid":280124},"lastPostingActivityTime":"2013-07-26T10:05:39.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtODI5aTIwMTlBOEE3Njc0M0IyQTY?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtODI5aTIwMTlBOEE3Njc0M0IyQTY?revision=1","title":"0151T000003d5RNQAY.png","associationType":"BODY","width":404,"height":364,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTE2NTZpQ0Q3MEQ3NkREQkIzNTE1Nw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTE2NTZpQ0Q3MEQ3NkREQkIzNTE1Nw?revision=1","title":"0151T000003d5ROQAY.png","associationType":"BODY","width":353,"height":175,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTI2NmlCQTA4RjExQjk1NTAxQzA2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTI2NmlCQTA4RjExQjk1NTAxQzA2?revision=1","title":"0151T000003d5RPQAY.png","associationType":"BODY","width":430,"height":208,"altText":null},"TkbTopicMessage:message:280124":{"__typename":"TkbTopicMessage","subject":"Back to Basics: Load balancing Virtualized Applications","conversation":{"__ref":"Conversation:conversation:280124"},"id":"message:280124","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280124","revisionNum":1,"uid":280124,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":859},"postTime":"2012-04-30T04:34:00.000-07:00","lastPublishTime":"2012-04-30T04:34:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #virtualization load balancing in a virtualized world is the same as it ever was, but different. The introduction of virtualization and cloud computing to data centers has been heralded as “transformational” and “disruptive” and “game changing.” From an operational IT perspective, that’s absolutely true. But like transformational innovation in other industries, such disruption is often not in how the core solution is leveraged or used, but how it impacts operations and the broader ecosystem, rather than the individual tasked with using the solution. The transformation of the auto-industry, for example, toward alternative fuel-sourced vehicles is disruptive and changes much about the industry. But it doesn’t change the way you drive a car; it still works on the same principles and the skills you’ve learned driving gas powered cars are still applicable to alternative fuel-source cars. What changes for the operator – just as within IT - is there may be new concerns with which you must contend. Load balancing virtualized applications is in this category. While the core principles you’ve always applied to load balancing applications still applies, there are a few additional concerns that arise from the use of virtualization that you’re going to have to take into consideration. LOAD BALANCING 101 REFRESH Let’s remember quickly how load balancing traditional applications works, shall we? The load balancing service presents to the end-user a single endpoint, i.e. “the application”. Users communicate exclusively with that endpoint. The load balancing service communicates with a pool of resources comprised of one or more application instances. It is by adding instances to the pool that an application is able to scale horizontally to meet demand. In the most common traditional load balancing environment, each application instance is hosted on a single, physical server. The availability of the “application” is maintained by insuring there are always enough instances (nodes) available to compensate for any failures that might occur at the physical server, operating system, platform, or application layers. Load balancing services also allow for the designation of “back up” nodes. Each node in a pool may have a back up node that is only activated in the event of a failure. This is used primarily for high-availability purposes to ensure continuous application availability rather than for scaling purposes. Now, when we replace the physical servers with virtual servers, we have pretty much the same system. There still exists a pool of resources that comprise “the application”, the load balancing service still mediates for the end-user, and there are still enough application instances in the pool to compensate for failure, thus ensuring availability of “the application.” However, there are some new potential sources of failure that must be addressed that impact the topology – the physical placement – of the application instances in the pool. TWO RULES for LOAD BALANCING VIRTUALIZED APPLICATIONS One of the most important changes coming from virtualization that must be addressed is fault isolation. Assume for a moment that we took all four physical nodes and consolidated them on a single, physical virtualized platform. In theory, nothing changes. The load balancing service views a “node” as a unique combination of IP address and TCP port, and whether that’s hosted on a virtual platform or a physical server is irrelevant to the load balancing service. The load balancing algorithms still work the same way, nodes are selected as directed by configured policies, backup nodes are still used to ensure continuous availability, and nothing about the way in which load balancing works changes. But it’s very relevant to operations because this type of server-consolidated deployment model introduces higher unrecoverable failure scenarios and it will directly impact the performance (in a bad way) of “the application.” There are a couple operational axioms at work here: 1. Shared infrastructure (network, compute, storage) means shared risk. 2. As load increases, performance decreases. Let’s say “Node 1” fails. In both the physical and virtual deployments, the load is simply shifted to the remaining active nodes. No problem. But what if the network connectivity between the load balancing service and “Node 1” fails? In a physical deployment, no problem – each node has its own physical connection and is unlikely to impact the other nodes. But what about the virtual deployment? Each node has its own virtual network connection, certainly, but does it have its own physical network connection or is it shared? If it’s a shared physical connection and it fails, then all nodes will fail – leaving “the application” unavailable. Load Balancing Virtualized Applications Rule #1: Team and Trunk. Physical network redundancy is a must. Modern server platforms are generally enabled with at least 2 if not 4 GBE connections, use them. So now you’ve got your network topology designed to ensure that a physical failure will not take out every application instance on the server. Next you need to consider how the application instances are isolated and deployed to ensure that a failure at the hypervisor layer does not disrupt all application instances. Consider that there are two possible reasons you are implementing load balancing: scalability and availability. In the former, you’re trying to ensure supply meets demand. In the latter, you’re trying to mitigate potential failure in a way to ensure “the application” is always available, regardless of failure. If there is a failure at the hypervisor layer, all instances relying on that hypervisor will be impacted (and not in a good way). Regardless of why you’re implementing load balancing, the result of such a failure is the same, instances are unavailable. Similarly, if the physical device on which virtualized applications are deployed fails, every instance on that device will be down. In both cases, if all your virtual eggs are in one basket and there’s a failure at the hypervisor layer, you’re in trouble. Load Balancing Virtualized Applications Rule #2: Divide and Conquer. Application instance redundancy is a must. Never put all your application instances on a single virtualized or physical platform. Spread them across at least two, to isolate potential failures in the virtualization layer or at the physical server layer. Node backups should always be located on physically separate devices. Load balancing services are adept at discerning failure but they are not necessarily able to determine the source. A failure to communicate with an application instance could be caused by a bad cable, a failed port, an unresponsive network stack, or an application error. The load balancing service knows the application instance is down, but not necessarily why it’s down. If it’s a crashed instance, then failing over to a back up instance on the same server is probably going to work out fine. But if the root cause is a failed port or bad cable, failing over to a backup instance on the same server isn’t going to help – because it is down too. It is imperative to ensure availability that there are always at least two of everything – and that means physical devices, as well. Never put all your eggs in one basket – at any layer. THE PERFORMANCE IMPACT Aside from general availability issues, there is also the very real possibility that where you deploy virtualized application instances will impact performance of “the application.” Remember that even though you can designate CPU and memory on a per application instance, they still ultimately shared I/O – both storage and network. That means even if you use rate limiting technologies to try to manage bandwidth consumption as a means to reduce congestion or latency, ultimately you’re impacting performance. If you don’t use rate limiting or other bandwidth-focused solutions to manage the shared network resource, you run the risk of congestion and increasing latency on the wire. Similarly, shared storage is even more problematic because when you trace I/O down through the system, you end up at a single, shared I/O controller that is going to have some serious limitations on it. I/O intense application instances deployed on the same physical device are going to cause contention in the underlying system, which is going to negatively impact performance. Again, divide and conquer. Disperse such instances across two (or more) physical servers. The number of servers will depend on the overall scale of the application and the resource consumption rate. Load balancing will be able to assist in maintaining performance across instances if you take advantage of a response-time aware algorithm such as fastest response time (the assumption is that response time correlates directly to load and in most cases, this is true). This keeps any given instance from becoming overwhelmed. Ultimately, what this means is that you have to be a little more aware of physical deployment location for application instances than you did with pure physical deployments. Consolidation is a great way to reduce operational and capital expenditures, but it also means consolidating risk. LOCATION MATTERS This is a particularly tough nut to crack especially when combined with the desire to implement auto-scaling operations in a more cloud-like environment. The idea that you can leverage “whatever idle resources” you can find to scale out applications on-demand is powerful, but it’s also potentially fraught with risk if you’re unable to control placement at all. While the possibility that every instance would end up deployed on a single server or even a select handful of servers is minimal, there is the possibility that multiple instances could be deployed in a way that means a single server failure could eliminate a sizeable number of application instances, resulting in an unacceptable degradation of performance or even downtime for some percentage of users. In the end, location really does matter when it comes to load balancing virtualized applications. Where they are deployed and in what groupings becomes a critical factor for maintaining performance and availability. The tendency to increase VM density is high, but that tendency can lead to highly disruptive situations in the event of a failed component. Be aware that cost savings from mass-consolidation and “high efficiency” through increasing VM density metrics may look good now, but may not look so good through the lens of hindsight. Digital is Different The Cost of Ignoring ‘Non-Human’ Visitors Cloud Bursting: Gateway Drug for Hybrid Cloud The HTTP 2.0 War has Just Begun Why Layer 7 Load Balancing Doesn’t Suck Network versus Application Layer Prioritization Complexity Drives Consolidation Performance in the Cloud: Business Jitter is Bad ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"11154","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtODI5aTIwMTlBOEE3Njc0M0IyQTY?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTE2NTZpQ0Q3MEQ3NkREQkIzNTE1Nw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAxMjQtMTI2NmlCQTA4RjExQjk1NTAxQzA2?revision=1\"}"}}],"totalCount":3,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286308":{"__typename":"Conversation","id":"conversation:286308","topic":{"__typename":"TkbTopicMessage","uid":286308},"lastPostingActivityTime":"2009-08-14T10:26:38.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjE1N2lENjZENzFGQzc4Mjg1N0VD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjE1N2lENjZENzFGQzc4Mjg1N0VD?revision=1","title":"0151T000003d85lQAA.png","associationType":"QUOTE","width":18,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTEwNTRpNEJGOThCMTZCRUUxRDM2Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTEwNTRpNEJGOThCMTZCRUUxRDM2Mw?revision=1","title":"0151T000003d85kQAA.jpg","associationType":"BODY","width":240,"height":157,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjEyMWk0MDNENThDMTU2OTY3MUJE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjEyMWk0MDNENThDMTU2OTY3MUJE?revision=1","title":"0151T000003d85jQAA.jpg","associationType":"BODY","width":240,"height":239,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1","title":"0151T000003d8I1QAI.jpg","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1","title":"0151T000003d8MMQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:286308":{"__typename":"TkbTopicMessage","subject":"Beware Using Internal Encryption as an IT Security Blanket","conversation":{"__ref":"Conversation:conversation:286308"},"id":"message:286308","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286308","revisionNum":1,"uid":286308,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":840},"postTime":"2009-05-28T04:02:06.000-07:00","lastPublishTime":"2009-05-28T04:02:06.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" It certainly sounds reasonable: networks are moving toward a perimeter-less model so the line between internal and external network is blurring. The introduction of cloud computing as overdraft protection (cloud-bursting) further blurs that perimeter such that it’s more a suggestion than a rule. That makes the idea of encrypting everything whether it’s on the internal or external network seem to be a reasonable one. Or does it? THE IMPACT ON OPERATIONS A recent post posits that PCI Standard or Not, Encrypting Internal Network Traffic is a Good Thing. The arguments are valid, but there is a catch (there’s always a catch). Consider this nugget from the article: Bottom line is everyone with confidential data to protect should enable encryption on all internal networks with access to that data. In addition, layer 2 security features should be enabled on the access switches carrying said data. Be sure to unencrypt your data streams before sending them to IPS, DLP, and other deep packet inspection devices. This is easy to say but in many cases harder to implement in practice. If you run into any issues feel free to post them here. I realize this is a controversial topic for security geeks (like myself) but given recent PCI breaches that took advantage of the above weaknesses, I have to error on the side of security. Sure more security doesn’t always mean better security, but smarter security always equals better security, which I believe is the case here. [emphasis added] It is the reminder to decrypt data streams before sending them to IPS, DLP, and other “deep packet inspection devices” that brings to light one of the issues with such a decision: complexity of operations and management. It isn’t just the additional latency inherent in the decryption of secured data streams required for a large number of the devices in an architecture to perform their tasks that’s the problem, though that is certainly a concern. The larger problem is the operational inefficiency that comes from the decryption of secured data at multiple points in the architecture. See there’s this little thing called “keys” that have to be shared with every device in the data center that will decrypt data, and that means managing each of those key stores in their own right. Keys are the, well, key to the kingdom of data encryption and if they are lost or stolen it can be disastrous to the security of all affected systems and applications. By better securing data in flight through encryption of all data on the internal network an additional layer of insecurity is introduced that must be managed. But let’s pretend this additional security issue doesn’t exist, that all systems on which these keys are stored are secure (ha!). Operations must still (a) configure every inline device to decrypt and re-encrypt the data stream and (b) manage the keys/certificates on every inline device. That’s in addition to managing the keys/certificates on every endpoint for which data is destined. There’s also the possibility that intermediate devices for which data will be decrypted before receiving – often implemented using spanned/mirrored ports on a switch/router – will require a re-architecting of the network in order to implement such an architecture. Not only must each device be configured to decrypt and re-encrypt data streams, it must be configured to do so for every application that utilizes encryption on the internal network. For an organization with only one or two applications this might not be so onerous a task, but for organizations that may be using multiple applications, domains, and thus keys/certificates, the task of deploying all those keys/certificates and configuring each device and then managing them through the application lifecycle can certainly be a time-consuming process. This isn’t a linear mathematics problem, it’s exponential. For every key or certificate added the cost of managing that information increases by the number of devices that must be in possession of that key/certificate. INTERNAL ENCRYPTION CAN HIDE REAL SECURITY ISSUES The real problem, as evinced by recent breaches of payment card processing vendors like Heartland Systems is not that data was or was not encrypted on the internal network, but that the systems through which that data was flowing were not secured. Attackers gained access through the systems, the ones we are pretending are secure for the sake of argument. Obviously, pretending they are secure is not a wise course of action. One cannot capture and sniff out unsecured data on an internal network without first being on the internal network. This is a very important point so let me say it again: One cannot capture and sniff out unsecured data on an internal network without first being on the internal network. It would seem, then, that the larger issue here is the security of the systems and devices through which sensitive data must travel and that encryption is really just a means of last resort for data traversing the internal network. Internal encryption is often a band-aid which often merely covers up the real problem of insecure systems and poorly implemented security policies. Granted, in many industries internal encryption is a requirement and must be utilized, but those industries also accept and grant IT the understanding that costs will be higher in order to implement such an architecture. The additional costs are built into the business model already. That’s not necessarily true for most organizations where operational efficiency is now just as high a priority as any other IT initiative. The implementation of encryption on internal networks can also lead to a false sense of security. It is important to remember that encrypted tainted data is still tainted data; it is merely hidden from security systems which are passive in nature unless the network is architected (or re-architected) such that the data is decrypted before being channeled through the solutions. Encryption hides data from prying eyes, it does nothing to ensure the legitimacy of the data. Simply initiating a policy of “all data on all networks must be secured via encryption” does not make an organization more secure and in fact it may lead to a less secure organization as it becomes more difficult and costly to implement security solutions designed to dig deeper into the data and ensure it is legitimate traffic free of taint or malicious intent. Bottom line is everyone with confidential data to protect should enable encryption on all internal networks with access to that data. The “bottom line” is everyone with confidential data to protect – which is just about every IT organization out there – needs to understand the ramifications of enabling encryption across the internal network both technically and from a cost/management perspective. Encryption of data on internal networks is not a bad thing to do at all but it is also not a panacea. The benefits of implementing internal encryption need to be weighed against the costs and balanced with risk and not simply tossed blithely over the network like a security blanket. PCI Standard or Not, Encrypting Internal Network Traffic is a Good Thing The Real Meaning of Cloud Security Revealed The Unpossible Task of Eliminating Risk Damned if you do, damned if you don't The IT Security Flowchart ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7538","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjE1N2lENjZENzFGQzc4Mjg1N0VD?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTEwNTRpNEJGOThCMTZCRUUxRDM2Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMjEyMWk0MDNENThDMTU2OTY3MUJE?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYzMDgtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}"}}],"totalCount":11,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1752674584422","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1752674584422","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1752674584422","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1752674584422","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1752674584422","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1752674584422","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1752674584422","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1752674584422","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1752674584422","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1752674584422","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1752674584422","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674584422","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1752674584422","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1752674584422","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1752674584422","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1752674584422","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1752674584422","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1752674584422","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1752674584422","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1752674584422","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1752674584422","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1752674584422","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1752674584422","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674584422":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1752674584422","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostViewed","tagName":"architecture"},"buildId":"8CqYPsxb5UG4aoIp8lqTz","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}