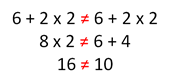2.5 bad ways to implement a server load balancing architecture
I'm in a bit of mood after reading a Javaworld article on server load balancing that presents some fairly poor ideas on architectural implementations. It's not the concepts that are necessarily wrong; they will work. It's the architectures offered as a method of load balancing made me do a double-take and say "What?" I started reading this article because it was part 2 of a series on load balancing and this installment focused on application layer load balancing. You know, layer 7 load balancing. Something we at F5 just might know a thing or two about. But you never know where and from whom you'll learn something new, so I was eager to dive in and learn something. I learned something alright. I learned a couple of bad ways to implement a server load balancing architecture. TWO LOAD BALANCERS? The first indication I wasn't going to be pleased with these suggestions came with the description of a "popular" load-balancing architecture that included two load balancers: one for the transport layer (layer 4) and another for the application layer (layer 7). In contrast to low-level load balancing solutions, application-level server load balancing operates with application knowledge. One popular load-balancing architecture, shown in Figure 1, includes both an application-level load balancer and a transport-level load balancer. Even the most rudimentary, entry level load balancers on the market today - software and hardware, free and commercial - can handle both transport and application layer load balancing. There is absolutely no need to deploy two separate load balancers to handle two different layers in the stack. This is a poor architecture introducing unnecessary management and architectural complexity as well as additional points of failure into the network architecture. It's bad for performance because it introduces additional hops and points of inspection through which application messages must flow. To give the author credit he does recognize this and offers up a second option to counter the negative impact of the "additional network hops." One way to avoid additional network hops is to make use of the HTTP redirect directive. With the help of the redirect directive, the server reroutes a client to another location. Instead of returning the requested object, the server returns a redirect response such as 303. I found it interesting that the author cited an HTTP response code of 303, which is rarely returned in conjunction with redirects. More often a 302 is used. But it is valid, if not a bit odd. That's not the real problem with this one, anyway. The author claims "The HTTP redirect approach has two weaknesses." That's true, it has two weaknesses - and a few more as well. He correctly identifies that this approach does nothing for availability and exposes the infrastructure, which is a security risk. But he fails to mention that using HTTP redirects introduces additional latency because it requires additional requests that must be made by the client (increasing network traffic), and that it is further incapable of providing any other advanced functionality at the load balancing point because it essentially turns the architecture into a variation of a DSR (direct server return) configuration. THAT"S ONLY 2 BAD WAYS, WHERE'S THE .5? The half bad way comes from the fact that the solutions are presented as a Java based solution. They will work in the sense that they do what the author says they'll do, but they won't scale. Consider this: the reason you're implementing load balancing is to scale, because one server can't handle the load. A solution that involves putting a single server - with the same limitations on connections and session tables - in front of two servers with essentially the twice the capacity of the load balancer gains you nothing. The single server may be able to handle 1.5 times (if you're lucky) what the servers serving applications may be capable of due to the fact that the burden of processing application requests has been offloaded to the application servers, but you're still limited in the number of concurrent users and connections you can handle because it's limited by the platform on which you are deploying the solution. An application server acting as a cluster controller or load balancer simply doesn't scale as well as a purpose-built load balancing solution because it isn't optimized to be a load balancer and its resource management is limited to that of a typical application server. That's true whether you're using a software solution like Apache mod_proxy_balancer or hardware solution. So if you're implementing this type of a solution to scale an application, you aren't going to see the benefits you think you are, and in fact you may see a degradation of performance due to the introduction of additional hops, additional processing, and poorly designed network architectures. I'm all for load balancing, obviously, but I'm also all for doing it the right way. And these solutions are just not the right way to implement a load balancing solution unless you're trying to learn the concepts involved or are in a computer science class in college. If you're going to do something, do it right. And doing it right means taking into consideration the goals of the solution you're trying to implement. The goals of a load balancing solution are to provide availability and scale, neither of which the solutions presented in this article will truly achieve.291Views0likes1CommentIT as a Service: A Stateless Infrastructure Architecture Model
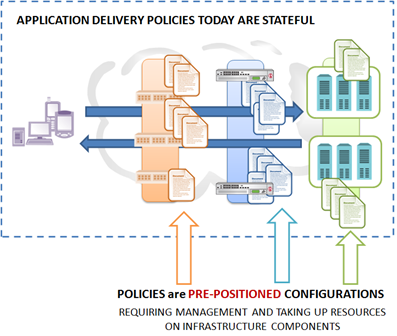
The dynamic data center of the future, enabled by IT as a Service, is stateless. One of the core concepts associated with SOA – and one that failed to really take hold, unfortunately – was the ability to bind, i.e. invoke, a service at run-time. WSDL was designed to loosely couple services to clients, whether they were systems, applications or users, in a way that was dynamic. The information contained in the WSDL provided everything necessary to interface with a service on-demand without requiring hard-coded integration techniques used in the past. The theory was you’d find an appropriate service, hopefully in a registry (UDDI-based), grab the WSDL, set up the call, and then invoke the service. In this way, the service could “migrate” because its location and invocation specific meta-data was in the WSDL, not hard-coded in the client, and the client could “reconfigure”, as it were, on the fly. There are myriad reasons why this failed to really take hold (notably that IT culture inhibited the enforcement of a strong and consistent governance strategy) but the idea was and remains sound. The goal of a “stateless” architecture, as it were, remains a key characteristic of what is increasingly being called IT as a Service – or “private” cloud computing . TODAY: STATEFUL INFRASTRUCTURE ARCHITECTURE The reason the concept of a “stateless” infrastructure architecture is so vital to a successful IT as a Service initiative is the volatility inherent in both the application and network infrastructure needed to support such an agile ecosystem. IP addresses, often used to bypass the latency induced by resolution of host names at run-time from DNS calls, tightly couple systems together – including network services. Routing and layer 3 switching use IP addresses to create a virtual topology of the architecture and ensure the flow of data from one component to the next, based on policy or pre-determine routes as meets the needs of the IT organization. It is those policies that in many cases can be eliminated; replaced with a more service-oriented approach that provisions resources on-demand, in real-time. This eliminates the “state” of an application architecture by removing delivery dependencies on myriad policies hard-coded throughout the network. Policies are inexorably tied to configurations, which are the infrastructure equivalent of state in the infrastructure architecture. Because of the reliance on IP addresses imposed by the very nature of network and Internet architectural design, we’ll likely never reach full independence from IP addresses. But we can move closer to a “stateless” run-time infrastructure architecture inside the data center by considering those policies that can be eliminated and instead invoked at run-time. Not only would such an architecture remove the tight coupling between policies and infrastructure, but also between applications and the infrastructure tasked with delivering them. In this way, applications could more easily be migrated across environments, because they are not tightly bound to the networking and security policies deployed on infrastructure components across the data center. The pre-positioning of policies across the infrastructure requires codifying topological and architectural meta-data in a configuration. That configuration requires management; it requires resources on the infrastructure – storage and memory – while the device is active. It is an extra step in the operational process of deploying, migrating and generally managing an application. It is “state” and it can be reduced – though not eliminated – in such a way as to make the run-time environment, at least, stateless and thus more motile. TOMORROW: STATELESS INFRASTRUCTURE ARCHITECTURE What’s needed to move from a state-dependent infrastructure architecture to one that is more stateless is to start viewing infrastructure functions as services. Services can be invoked, they are loosely coupled, they are independent of solution and product. Much in the same way that stateless application architectures address the problems associated with persistence and impede real-time migration of applications across disparate environments, so too does stateless infrastructure architectures address the same issues inherent in policy-based networking – policy persistence. While standardized APIs and common meta-data models can alleviate much of the pain associated with migration of architectures between environments, they still assume the existence of specific types of components (unless, of course, a truly service-oriented model in which services, not product functions, are encapsulated). Such a model extends the coupling between components and in fact can “break” if said service does not exist. Conversely, a stateless architecture assumes nothing; it does not assume the existence of any specific component but merely indicates the need for a particular service as part of the application session flow that can be fulfilled by any appropriate infrastructure providing such a service. This allows the provider more flexibility as they can implement the service without exposing the underlying implementation – exactly as a service-oriented architecture intended. It further allows providers – and customers – to move fluidly between implementations without concern as only the service need exist. The difficulty is determining what services can be de-coupled from infrastructure components and invoked on-demand, at run-time. This is not just an application concern, it becomes an infrastructure component concern, as well, as each component in the flow might invoke an upstream – or downstream – service depending on the context of the request or response being processed. Assuming that such services exist and can be invoked dynamically through a component and implementation-agnostic mechanism, it is then possible to eliminate many of the pre-positioned, hard-coded policies across the infrastructure and instead invoke them dynamically. Doing so reduces the configuration management required to maintain such policies, as well as eliminating complexity in the provisioning process which must, necessarily, include policy configuration across the infrastructure in a well-established and integrated enterprise-class architecture. Assuming as well that providers have implemented support for similar services, one can begin to see the migratory issues are more easily redressed and the complications caused by needed to pre-provision services and address policy persistence during migration mostly eliminated. SERVICE-ORIENTED THINKING One way of accomplishing such a major transformation in the data center – from policy to service-oriented architecture – is to shift our thinking from functions to services. It is not necessarily efficient to simply transplant a software service-oriented approach to infrastructure because the demands on performance and aversion to latency makes a dynamic, run-time binding to services unappealing. It also requires a radical change in infrastructure architecture by adding the components and services necessary to support such a model – registries and the ability of infrastructure components to take advantage of them. An in-line, transparent invocation method for infrastructure services offers the same flexibility and motility for applications and infrastructure without imposing performance or additional dependency constraints on implementers. But to achieve a stateless infrastructure architectural model, one must first shift their thinking from functions to services and begin to visualize a data center in which application requests and responses communicate the need for particular downstream and upstream services with them, rather than completely in hard-coded policies stored in component configurations. It is unlikely that in the near-term we can completely eliminate the need for hard-coded configuration, we’re just no where near that level of dynamism and may never be. But for many services – particularly those associated with run-time delivery of applications, we can achieve the stateless architecture necessary to realize a more mobile and dynamic data center. Now Witness the Power of this Fully Operational Feedback Loop Cloud is the How not the What Challenging the Firewall Data Center Dogma Cloud-Tiered Architectural Models are Bad Except When They Aren’t Cloud Chemistry 101 You Can’t Have IT as a Service Until IT Has Infrastructure as a Service Let’s Face It: PaaS is Just SOA for Platforms Without the Baggage The New Distribution of The 3-Tiered Architecture Changes Everything486Views0likes1CommentThe Order of (Network) Operations
Thought those math rules you learned in 6 th grade were useless? Think again…some are more applicable to the architecture of your data center than you might think. Remember back when you were in the 6 th grade, learning about the order of operations in math class? You might recall that you learned that the order in which mathematical operators were applied can have a significant impact on the result. That’s why we learned there’s an order of operations – a set of rules – that we need to follow in order to ensure that we always get the correct answer when performing mathematical equations. Rule 1: First perform any calculations inside parentheses. Rule 2: Next perform all multiplications and divisions, working from left to right. Rule 3: Lastly, perform all additions and subtractions, working from left to right. Similarly, the order in which network and application delivery operations are applied can dramatically impact the performance and efficiency of the delivery of applications – no matter where those applications reside.349Views0likes1CommentHTML5 Web Sockets Changes the Scalability Game
#HTML5 Web Sockets are poised to completely change scalability models … again. Using Web Sockets instead of XMLHTTPRequest and AJAX polling methods will dramatically reduce the number of connections required by servers and thus has a positive impact on performance. But that reliance on a single connection also changes the scalability game, at least in terms of architecture. Here comes the (computer) science… If you aren’t familiar with what is sure to be a disruptive web technology you should be. Web Sockets, while not broadly in use (it is only a specification, and a non-stable one at that) today is getting a lot of attention based on its core precepts and model. Web Sockets Defined in the Communications section of the HTML5 specification, HTML5 Web Sockets represents the next evolution of web communications—a full-duplex, bidirectional communications channel that operates through a single socket over the Web. HTML5 Web Sockets provides a true standard that you can use to build scalable, real-time web applications. In addition, since it provides a socket that is native to the browser, it eliminates many of the problems Comet solutions are prone to. Web Sockets removes the overhead and dramatically reduces complexity. - HTML5 Web Sockets: A Quantum Leap in Scalability for the Web So far, so good. The premise upon which the improvements in scalability coming from Web Sockets are based is the elimination of HTTP headers (reduces bandwidth dramatically) and session management overhead that can be incurred by the closing and opening of TCP connections. There’s only one connection required between the client and server over which much smaller data segments can be sent without necessarily requiring a request and a response pair. That communication pattern is definitely more scalable from a performance perspective, and also has a positive impact of reducing the number of connections per client required on the server. Similar techniques have long been used in application delivery (TCP multiplexing) to achieve the same results – a more scalable application. So far, so good. Where the scalability model ends up having a significant impact on infrastructure and architectures is the longevity of that single connection: Unlike regular HTTP traffic, which uses a request/response protocol, WebSocket connections can remain open for a long time. - How HTML5 Web Sockets Interact With Proxy Servers This single, persistent connection combined with a lot of, shall we say, interesting commentary on the interaction with intermediate proxies such as load balancers. But ignoring that for the nonce, let’s focus on the “remain open for a long time.” A given application instance has a limit on the number of concurrent connections it can theoretically and operationally manage before it reaches the threshold at which performance begins to dramatically degrade. That’s the price paid for TCP session management in general by every device and server that manages TCP-based connections. But Lori, you’re thinking, HTTP 1.1 connections are persistent, too. In fact, you don’t even have to tell an HTTP 1.1 server to keep-alive the connection! This really isn’t a big change. Whoa there hoss, yes it is. While you’d be right in that HTTP connections are also persistent, they generally have very short connection timeout settings. For example, the default connection timeout for Apache 2.0 is 15 seconds and for Apache 2.2 a mere 5 seconds. A well-tuned web server, in fact, will have thresholds that closely match the interaction patterns of the application it is hosting. This is because it’s a recognized truism that long and often idle connections tie up server processes or threads that negatively impact overall capacity and performance. Thus the introduction of connections that remain open for a long time changes the capacity of the server and introduces potential performance issues when that same server is also tasked with managing other short-lived, connection-oriented requests. Why this Changes the Game… One of the most common inhibitors of scale and high-performance for web applications today is the deployment of both near-real-time communication functions (AJAX) and traditional web content functions on the same server. That’s because web servers do not support a per-application HTTP profile. That is to say, the configuration for a web server is global; every communication exchange uses the same configuration values such as connection timeouts. That means configuring the web server for exchanges that would benefit from a longer time out end up with a lot of hanging connections doing absolutely nothing because they were used to grab standard dynamic or static content and then ignored. Conversely, configuring for quick bursts of requests necessarily sets timeout values too low for near or real-time exchanges and can cause performance issues as a client continually opens and re-opens connections. Remember, an idle connection is a drain on resources that directly impacts the performance and capacity of applications. So it’s a Very Bad Thing™. One of the solutions to this somewhat frustrating conundrum, made more feasible by the advent of cloud computing and virtualization, is to deploy specialized servers in a scalability domain-based architecture using infrastructure scalability patterns. Another approach to ensuring scalability is to offload responsibility for performance and connection management to an appropriately capable intermediary. Now, one would hope that a web server implementing support for both HTTP and Web Sockets would support separately configurable values for communication settings on at least the protocol level. Today there are very few web servers that support both HTTP and Web Sockets. It’s a nascent and still evolving standard so many of the servers are “pure” Web Sockets servers, many implemented in familiar scripting languages like PHP and Python. Which means two separate sets of servers that must be managed and scaled. Which should sound a lot like … specialized servers in a scalability domain-based architecture. The more things change, the more they stay the same. The second impact on scalability architectures centers on the premise that Web Sockets keep one connection open over which message bits can be exchanged. This ties up resources, but it also requires that clients maintain a connection to a specific server instance. This means infrastructure (like load balancers and web/application servers) will need to support persistence (not the same as persistent, you can read about the difference here if you’re so inclined). That’s because once connected to a Web Socket service the performance benefits are only realized if you stay connected to that same service. If you don’t and end up opening a second (or Heaven-forbid a third or more) connection, the first connection may remain open until it times out. Given that the premise of the Web Socket is to stay open – even through potentially longer idle intervals – it may remain open, with no client, until the configured time out. That means completely useless resources tied up by … nothing. Persistence-based load balancing is a common feature of next-generation load balancers (application delivery controllers) and even most cloud-based load balancing services. It is also commonly implemented in application server clustering offerings, where you’ll find it called server-affinity. It is worth noting that persistence-based load balancing is not without its own set of gotchas when it comes to performance and capacity. THE ANSWER: ARCHITECTURE The reason that these two ramifications of Web Sockets impacts the scalability game is it requires an broader architectural approach to scalability. It can’t necessarily be achieved simply by duplicating services and distributing the load across them. Persistence requires collaboration with the load distribution mechanism and there are protocol-based security constraints with respect to incorporating even intra-domain content in a single page/application. While these security constraints are addressable through configuration, the same caveats with regards to the lack of granularity in configuration at the infrastructure (web/application server) layer must be made. Careful consideration of what may be accidentally allowed and/or disallowed is necessary to prevent unintended consequences. And that’s not even starting to consider the potential use of Web Sockets as an attack vector, particularly in the realm of DDoS. The long-lived nature of a Web Socket connection is bound to be exploited at some point in the future, which will engender another round of evaluating how to best address application-layer DDoS attacks. A service-focused, distributed (and collaborative) approach to scalability is likely to garner the highest levels of success when employing Web Socket-based functionality within a broader web application, as opposed to the popular cookie-cutter cloning approach made exceedingly easy by virtualization. Infrastructure Scalability Pattern: Partition by Function or Type Infrastructure Scalability Pattern: Sharding Sessions Amazon Makes the Cloud Sticky Load Balancing Fu: Beware the Algorithm and Sticky Sessions Et Tu, Browser? Forget Hyper-Scale. Think Hyper-Local Scale. Infrastructure Scalability Pattern: Sharding Streams Infrastructure Architecture: Whitelisting with JSON and API Keys Does This Application Make My Browser Look Fat? HTTP Now Serving … Everything620Views0likes5CommentsLoad Balancing Fu: Beware the Algorithm and Sticky Sessions
The choice of load balancing algorithms can directly impact – for good or ill – the performance, behavior and capacity of applications. Beware making incompatible choices in architecture and algorithms. One of the most persistent issues encountered when deploying applications in scalable architectures involves sessions and the need for persistence-based (a.k.a. sticky) load balancing services to maintain state for the duration of an end-user’s session. It is common enough that even the rudimentary load balancing services offered by cloud computing providers such as Amazon include the option to enable persistence-based load balancing. While the use of persistence addresses the problem of maintaining session state, it introduces other operational issues that must also be addressed to ensure consistent operational behavior of load balancing services. In particular, the use of the Round Robin load balancing algorithm in conjunction with persistence-based load balancing should be discouraged if not outright disallowed. ROUND ROBIN + PERSISTENCE –> POTENTIALLY UNEQUAL DISTRIBUTION of LOAD When scaling applications there are two primary concerns: concurrent user capacity and performance. These two concerns are interrelated in that as capacity is consumed, performance degrades. This is particularly true of applications storing state as each request requires that the application server perform a lookup to retrieve the user session. The more sessions stored, the longer it takes to find and retrieve the session. The exactly efficiency of such lookups is determined by the underlying storage data structure and algorithm used to search the structure for the appropriate session. If you remember your undergraduate classes in data structures and computing Big (O) you’ll remember that some structures scale more efficiently in terms of performance than do others. The general rule of thumb, however, is that the more data stored, the longer the lookup. Only the amount of degradation is variable based on the efficiency of the algorithms used. Therefore, the more sessions in use on an application server instance, the poorer the performance. This is one of the reasons you want to choose a load balancing algorithm that evenly distributes load across all instances and ultimately why lots of little web servers scaled out offer better performance than a few, scaled up web servers. Now, when you apply persistence to the load balancing equation it essentially interrupts the normal operation of the algorithm, ignoring it. That’s the way it’s supposed to work: the algorithm essentially applies only to requests until a server-side session (state) is established and thereafter (when the session has been created) you want the end-user to interact with the same server to ensure consistent and expected application behavior. For example, consider this solution note for BIG-IP. Note that this is true of all load balancing services: A persistence profile allows a returning client to connect directly to the server to which it last connected. In some cases, assigning a persistence profile to a virtual server can create the appearance that the BIG-IP system is incorrectly distributing more requests to a particular server. However, when you enable a persistence profile for a virtual server, a returning client is allowed to bypass the load balancing method and connect directly to the pool member. As a result, the traffic load across pool members may be uneven, especially if the persistence profile is configured with a high timeout value. -- Causes of Uneven Traffic Distribution Across BIG-IP Pool Members So far so good. The problem with round robin- – and reason I’m picking on Round Robin specifically - is that round robin is pretty, well, dumb in its decision making. It doesn’t factor anything into its decision regarding which instance gets the next request. It’s as simple as “next in line", period. Depending on the number of users and at what point a session is created, this can lead to scenarios in which the majority of sessions are created on just a few instances. The result is a couple of overwhelmed instances (with performance degradations commensurate with the reduction in available resources) and a bunch of barely touched instances. The smaller the pool of instances, the more likely it is that a small number of servers will be disproportionately burdened. Again, lots of little (virtual) web servers scales out more evenly and efficiently than a few big (virtual) web servers. Assuming a pool of similarly-capable instances (RAM and CPU about equal on all) there are other load balancing algorithms that should be considered more appropriate for use in conjunction with persistence-based load balancing configurations. Least connections should provide better distribution, although the assumption that an active connection is equivalent to the number of sessions currently in memory on the application server could prove to be incorrect at some point, leading to the same situation as would be the case with the choice of round robin. It is still a better option, but not an infallible one. Fastest response time is likely a better indicator of capacity as we know that responses times increase along with resource consumption, thus a faster responding instance is likely (but not guaranteed) to have more capacity available. Again, this algorithm in conjunction with persistence is not a panacea. Better options for a load balancing algorithm include those that are application aware; that is, algorithms that can factor into the decision making process the current load on the application instance and thus direct requests toward less burdened instances, resulting in a more even distribution of load across available instances. NON-ALGORITHMIC SOLUTIONS There are also non-algorithmic, i.e. architectural, solutions that can address this issue. DIVIDE and CONQUER In cloud computing environments, where it is less likely to find available algorithms other than industry standard (none of which are application-aware), it may be necessary to approach the problem with a divide and conquer strategy, i.e. lots of little servers. Rather than choosing one or two “large” instances, choose to scale out with four or five “small” instances, thus providing a better (but not guaranteed) statistical chance of load being distributed more evenly across instances. FLANKING STRATEGY If the option is available, an architectural “flanking” strategy that leverages layer 7 load balancing, a.k.a. content/application switching, will also provide better consumptive rates as well as more consistent performance. An architectural strategy of this sort is in line with sharding practices at the data layer in that it separates out by some attribute different kinds of content and serves that content from separate pools. Thus, image or other static content may come from one pool of resources while session-oriented, process intensive dynamic content may come from another pool. This allows different strategies – and algorithms – to be used simultaneously without sacrificing the notion of a single point of entry through which all users interact on the client-side. Regardless of how you choose to address the potential impact on capacity, it is important to recognize the intimate relationship between infrastructure services and applications. A more integrated architectural approach to application delivery can result in a much more efficient and better performing application. Understanding the relationship between delivery services and application performance and capacity can also help improve on operational costs, especially in cloud computing environments that constrain the choices of load balancing algorithms. As always, test early and test often and test under high load if you want to be assured that the load balancing algorithm is suitable to meet your operational and business requirements. WILS: Why Does Load Balancing Improve Application Performance? Load Balancing in a Cloud Infrastructure Scalability Pattern: Sharding Sessions Infrastructure Scalability Pattern: Partition by Function or Type It’s 2am: Do You Know What Algorithm Your Load Balancer is Using? Lots of Little Virtual Web Applications Scale Out Better than Scaling Up Sessions, Sessions Everywhere Choosing a Load Balancing Algorithm Requires DevOps Fu Amazon Makes the Cloud Sticky To Boldly Go Where No Production Application Has Gone Before Cloud Testing: The Next Generation2.2KViews0likes1CommentThe Challenges of SQL Load Balancing
#infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s.2.1KViews0likes1CommentDoes Your Cloud Quiesce? It Should.
#cloud #sdn Without the ability to gracefully shutdown the "contraction" side of elasticity may be problematic Quiescence, in a nutshell, is your mom telling you to "finish what you're doing but don't start anything new, we're getting ready to go". It's an integral capability of load balancers (of enterprise-class load balancers, at least) that enables the graceful shutdown of application instances for a variety of purposes (patches, scheduled maintenance, etc... ). In more modern architectures this capability forms the foundation for non-disruptive (and thus live) migration of virtual machines.During the process the VM is moved and launched in location Y, the load balancer continues to send requests to the same VM in location X. Once the VM is available in location Y, the load balancer will no longer send new requests to location X but will continue to manage existing connections until they are complete. Cloud bursting, too, is enabled by the ability of a load balancer to quiesce connections at a global layer (virtual pattern) and at the local layer (bridged pattern). Load balancers must be able to support a "finish what's been started but don't start anything new" mode of operation on any given application The inability of a load balancing service to quiesce connections impacts not only the ability to implement specific architectural patterns, but it can seriously impact elasticity. The IMPACT on ELASTICITY Scaling out is easy, especially in the cloud. Add another instance of the application to the load balancing service and voila! Instant capacity. But scaling back, that's another story. You can't just stop the instance when load contracts, because, well, any existing connections relying on that instance will simply vanish. It's disruptive, in a very negative way, and can have a real impact on revenue (what happened to my order?) as well as productivity (that was three hours of work lost, OMERGERD). Scaling back requires careful collaboration between the load balancing service and the management framework to ensure that the process is graceful, that is, non-disruptive. It is unacceptable to business and operational stakeholders to simply "cut off" connections that may in the middle of executing a transaction or performing critical business functions. The problem is that the load balancing service must be imbued with enough intelligence to discern that there is a state between "up" and "down" for an instance. It must recognize that this state indicates "maintain, but do not add" connections. It is this capability, this stateful capability, that makes it difficult for many cloud and SDN-related architectures to really support the notion of elasticity at the application services layer. They might be able to scale out, but scaling back in requires more intelligence (and stateful awareness) than is currently available with most of these solutions.291Views0likes1CommentThe Three Reasons Hybrid Clouds Will Dominate
In the short term, hybrid cloud is going to be the cloud computing model of choice. Amidst all the disconnect at CloudConnect regarding standards and where “cloud” is going was an undercurrent of adoption of what most have come to refer to as a “hybrid cloud computing” model. This model essentially “extends” the data center into “the cloud” and takes advantage of less expensive compute resources on-demand. What’s interesting is that the use of this cheaper compute is the granularity of on-demand. The time interval for which resources are utilized is measured more in project timelines than in minutes or even hours. Organizations need additional compute for lab and quality assurance efforts, for certification testing, for production applications for which budget is limited. These are not snap decisions but rather methodically planned steps along the project management lifecycle. It is on-demand in the sense that it’s “when the organization needs it”, and in the sense that it’s certainly faster than the traditional compute resource acquisition process, which can take weeks or even months. Also mentioned more than once by multiple panelists and speakers was the notion of separating workload such that corporate data remains in the local data center while presentation layers and GUIs move into the cloud computing environment for optimal use of available compute resources. This model works well and addresses issues with data security and privacy, a constant top concern in surveys and polls regarding inhibitors of cloud computing. It’s not just the talk at the conference that makes such a conclusion probabilistic. An Evans Data developer survey last year indicated that more than 60 percent of developers would be focusing on hybrid cloud computing in 2010. Results of the Evans Data Cloud Development Survey, released Jan. 12, show that 61 percent of the more than 400 developers polled said some portion of their organizations' IT resources "will move to the public cloud within the next year," Evans Data said. "However, over 87 percent [of the developers] say half or less then half of their resources will move ... As a result, the hybrid cloud is set to dominate the coming IT landscape." There are three reasons why this model will become the de facto standard strategy for leveraging cloud computing, at least in the short term and probably for longer than some pundits (and providers) hope.334Views0likes2CommentsData Center Feng Shui: Fault Tolerance and Fault Isolation
Like most architectural decisions the two goals do not require mutually exclusive decisions. The difference between fault isolation and fault tolerance is not necessarily intuitive. The differences, though subtle, are profound and have a substantial impact on data center architecture. Fault tolerance is an attribute of systems and architecture that allow it to continue performing its tasks in the event of a component failure. Fault tolerance of servers, for example, is achieved through the use of redundancy in power-supplies, in hard-drives, and in network cards. In an architecture, fault tolerance is also achieved through redundancy by deploying two of everything: two servers, two load balancers, two switches, two firewalls, two Internet connections. The fault tolerant architecture includes no single point of failure; no component that can fail and cause a disruption in service. load balancing, for example, is a fault tolerant-based strategy that leverages multiple application instances to ensure that failure of one instance does not impact the availability of the application. Fault isolation on the other hand is an attribute of systems and architectures that isolates the impact of a failure such that only a single system, application, or component is impacted. Fault isolation allows that a component may fail as long as it does not impact the overall system. That sounds like a paradox, but it’s not. Many intermediary devices employ a “fail open” strategy as a method of fault isolation. When a network device is required to intercept data in order to perform its task – a common web application firewall configuration – it becomes a single point of failure in the data path. To mitigate the potential failure of the device, if something should fail and cause the system to crash it “fails open” and acts like a simple network bridge by simply forwarding packets on to the next device in the chain without performing any processing. If the same component were deployed in a fault-tolerant architecture, there would be deployed two devices and hopefully leveraging non-network based failover mechanisms. Similarly, application infrastructure components are often isolated through a contained deployment model (like sandboxes) that prevent a failure – whether an outright crash or sudden massive consumption of resources – from impacting other applications. Fault isolation is of increasing interest as it relates to cloud computing environments as part of a strategy to minimize the perceived negative impact of shared network, application delivery network, and server infrastructure.384Views0likes2Comments