How to get a F5 BIG-IP VE Developer Lab License
To assist DevOps teams improve their development for the BIG-IP platform, F5 offers a low cost developer lab license.This license can be purchased from your authorized F5 vendor. If you do not have an F5 vendor, you can purchase a lab license online: CDW BIG-IP Virtual Edition Lab License CDW Canada BIG-IP Virtual Edition Lab License Once completed, the order is sent to F5 for fulfillment and your license will be delivered shortly after via e-mail. F5 is investigating ways to improve this process. To download the BIG-IP Virtual Edition, please log into downloads.f5.com (separate login from DevCentral), and navigate to your appropriate virtual edition, example: For VMware Fusion or Workstation or ESX/i:BIGIP-16.1.2-0.0.18.ALL-vmware.ova For Microsoft HyperV:BIGIP-16.1.2-0.0.18.ALL.vhd.zip KVM RHEL/CentoOS: BIGIP-16.1.2-0.0.18.ALL.qcow2.zip Note: There are also 1 Slot versions of the above images where a 2nd boot partition is not needed for in-place upgrades. These images include_1SLOT- to the image name instead of ALL. The below guides will help get you started with F5 BIG-IP Virtual Edition to develop for VMWare Fusion, AWS, Azure, VMware, or Microsoft Hyper-V. These guides follow standard practices for installing in production environments and performance recommendations change based on lower use/non-critical needs fo Dev/Lab environments. Similar to driving a tank, use your best judgement. DeployingF5 BIG-IP Virtual Edition on VMware Fusion Deploying F5 BIG-IP in Microsoft Azure for Developers Deploying F5 BIG-IP in AWS for Developers Deploying F5 BIG-IP in Windows Server Hyper-V for Developers Deploying F5 BIG-IP in VMware vCloud Director and ESX for Developers Note: F5 Support maintains authoritativeAzure, AWS, Hyper-V, and ESX/vCloud installation documentation. VMware Fusion is not an official F5-supported hypervisor so DevCentral publishes the Fusion guide with the help of our Field Systems Engineering teams.73KViews13likes143CommentsGet Started with BIG-IP and BIG-IQ Virtual Edition (VE) Trial
Welcome to the BIG-IP and BIG-IQ trials page! This will be your jumping off point for setting up a trial version of BIG-IP VE or BIG-IQ VE in your environment. As you can see below, everything you’ll need is included and organized by operating environment — namely by public/private cloud or virtualization platform. To get started with your trial, use the following software and documentation which can be found in the links below. Upon requesting a trial, you should have received an email containing your license keys. Please bear in mind that it can take up to 30 minutes to receive your licenses. Don't have a trial license?Get one here. Or if you're ready to buy, contact us. Looking for other Resourceslike tools, compatibility matrix... BIG-IP VE and BIG-IQ VE When you sign up for the BIG-IP and BIG-IQ VE trial, you receive a set of license keys. Each key will correspond to a component listed below: BIG-IQ Centralized Management (CM) — Manages the lifecycle of BIG-IP instances including analytics, licenses, configurations, and auto-scaling policies BIG-IQ Data Collection Device (DCD) — Aggregates logs and analytics of traffic and BIG-IP instances to be used by BIG-IQ BIG-IP Local Traffic Manager (LTM), Access (APM), Advanced WAF (ASM), Network Firewall (AFM), DNS — Keep your apps up and running with BIG-IP application delivery controllers. BIG-IP Local Traffic Manager (LTM) and BIG-IP DNS handle your application traffic and secure your infrastructure. You’ll get built-in security, traffic management, and performance application services, whether your applications live in a private data center or in the cloud. Select the hypervisor or environment where you want to run VE: AWS CFT for single NIC deployment CFT for three NIC deployment BIG-IP VE images in the AWS Marketplace BIG-IQ VE images in the AWS Marketplace BIG-IP AWS documentation BIG-IP video: Single NIC deploy in AWS BIG-IQ AWS documentation Setting up and Configuring a BIG-IQ Centralized Management Solution BIG-IQ Centralized Management Trial Quick Start Azure Azure Resource Manager (ARM) template for single NIC deployment Azure ARM template for threeNIC deployment BIG-IP VE images in the Azure Marketplace BIG-IQ VE images in the Azure Marketplace BIG-IQ Centralized Management Trial Quick Start BIG-IP VE Azure documentation Video: BIG-IP VE Single NIC deploy in Azure BIG-IQ VE Azure documentation Setting up and Configuring a BIG-IQ Centralized Management Solution VMware/KVM/Openstack Download BIG-IP VE image Download BIG-IQ VE image BIG-IP VE Setup BIG-IQ VE Setup Setting up and Configuring a BIG-IQ Centralized Management Solution Google Cloud Google Deployment Manager template for single NIC deployment Google Deployment Manager template for threeNIC deployment BIG-IP VE images in Google Cloud Google Cloud Platform documentation Video:Single NIC deploy inGoogle Other Resources AskF5 Github community(f5devcentral,f5networks) Tools toautomate your deployment BIG-IQ Onboarding Tool F5 Declarative Onboarding F5 Application Services 3 Extension Other Tools: F5 SDK (Python) F5 Application Services Templates (FAST) F5 Cloud Failover F5 Telemetry Streaming Find out which hypervisor versions are supported with each release of VE. BIG-IP Compatibility Matrix BIG-IQ Compatibility Matrix Do you haveany comments orquestions? Ask here62KViews8likes24CommentsWhat Is BIG-IP?
tl;dr - BIG-IP is a collection of hardware platforms and software solutions providing services focused on security, reliability, and performance. F5's BIG-IP is a family of products covering software and hardware designed around application availability, access control, and security solutions. That's right, the BIG-IP name is interchangeable between F5's software and hardware application delivery controller and security products. This is different from BIG-IQ, a suite of management and orchestration tools, and F5 Silverline, F5's SaaS platform. When people refer to BIG-IP this can mean a single software module in BIG-IP's software family or it could mean a hardware chassis sitting in your datacenter. This can sometimes cause a lot of confusion when people say they have question about "BIG-IP" but we'll break it down here to reduce the confusion. BIG-IP Software BIG-IP software products are licensed modules that run on top of F5's Traffic Management Operation System® (TMOS). This custom operating system is an event driven operating system designed specifically to inspect network and application traffic and make real-time decisions based on the configurations you provide. The BIG-IP software can run on hardware or can run in virtualized environments. Virtualized systems provide BIG-IP software functionality where hardware implementations are unavailable, including public clouds and various managed infrastructures where rack space is a critical commodity. BIG-IP Primary Software Modules BIG-IP Local Traffic Manager (LTM) - Central to F5's full traffic proxy functionality, LTM provides the platform for creating virtual servers, performance, service, protocol, authentication, and security profiles to define and shape your application traffic. Most other modules in the BIG-IP family use LTM as a foundation for enhanced services. BIG-IP DNS - Formerly Global Traffic Manager, BIG-IP DNS provides similar security and load balancing features that LTM offers but at a global/multi-site scale. BIG-IP DNS offers services to distribute and secure DNS traffic advertising your application namespaces. BIG-IP Access Policy Manager (APM) - Provides federation, SSO, application access policies, and secure web tunneling. Allow granular access to your various applications, virtualized desktop environments, or just go full VPN tunnel. Secure Web Gateway Services (SWG) - Paired with APM, SWG enables access policy control for internet usage. You can allow, block, verify and log traffic with APM's access policies allowing flexibility around your acceptable internet and public web application use. You know.... contractors and interns shouldn't use Facebook but you're not going to be responsible why the CFO can't access their cat pics. BIG-IP Application Security Manager (ASM) - This is F5's web application firewall (WAF) solution. Traditional firewalls and layer 3 protection don't understand the complexities of many web applications. ASM allows you to tailor acceptable and expected application behavior on a per application basis . Zero day, DoS, and click fraud all rely on traditional security device's inability to protect unique application needs; ASM fills the gap between traditional firewall and tailored granular application protection. BIG-IP Advanced Firewall Manager (AFM) - AFM is designed to reduce the hardware and extra hops required when ADC's are paired with traditional firewalls. Operating at L3/L4, AFM helps protect traffic destined for your data center. Paired with ASM, you can implement protection services at L3 - L7 for a full ADC and Security solution in one box or virtual environment. BIG-IP Hardware BIG-IP hardware offers several types of purpose-built custom solutions, all designed in-house by our fantastic engineers; no white boxes here. BIG-IP hardware is offered via series releases, each offering improvements for performance and features determined by customer requirements. These may include increased port capacity, traffic throughput, CPU performance, FPGA feature functionality for hardware-based scalability, and virtualization capabilities. There are two primary variations of BIG-IP hardware, single chassis design, or VIPRION modular designs. Each offer unique advantages for internal and collocated infrastructures. Updates in processor architecture, FPGA, and interface performance gains are common so we recommend referring to F5's hardware pagefor more information.61KViews2likes3Comments
Configure the F5 BIG-IP as an Explicit Forward Web Proxy Using LTM
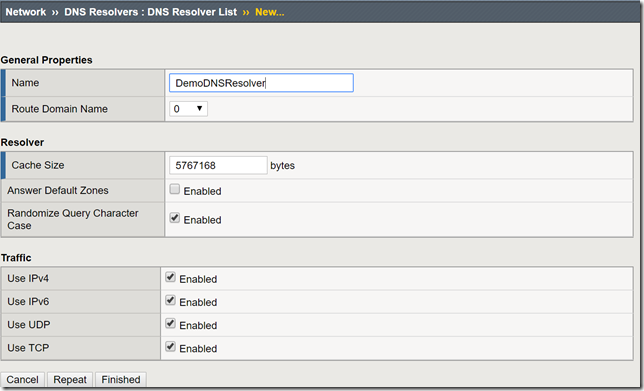
In a previous article, I provided a guide on using F5's Access Policy Manager (APM) and Secure Web Gateway (SWG) to provide forward web proxy services. While that guide was for organizations that are looking to provide secure internet access for their internal users, URL filtering as well as securing against both inbound and outbound malware, this guide will use only F5's Local Traffic Manager to allow internal clients external internet access. This week I was working with F5's very talented professional services team and we were presented with a requirement to allow workstation agents internet access to known secure sites to provide logs and analytics. Of course, this capability can be used to meet a number of other use cases, this was a real-world use case I wanted to share. So with that, let's get to it! Creating a DNS Resolver Navigate to Network > DNS Resolvers > click Create Name: DemoDNSResolver Leave all other settings at their defaults and click Finished Click the newly created DNS resolver object Click Forward Zones Click Add In this use case, we will be forwarding all requests to this DNS resolver. Name: . Address: 8.8.8.8 Note: Please use the correct DNS server for your use case. Service Port: 53 Click Add and Finished Creating a Network Tunnel Navigate to Network > Tunnels > Tunnel List > click Create Name: DemoTunnel Profile: tcp-forward Leave all other settings default and click Finished Create an http Profile Navigate to Local Traffic > Profiles > Services > HTTP > click Create Name: DemoExplicitHTTP Proxy Mode: Explicit Parent Profile: http-explict Scroll until you reach Explicit Proxy settings. DNS Resolver: DemoDNSResolver Tunnel Name: DemoTunnel Leave all other settings default and click Finish Create an Explicit Proxy Virtual Server Navigate to Local Traffic > Virtual Servers > click Create Name: explicit_proxy_vs Type: Standard Destination Address/Mask: 10.1.20.254 Note: This must be an IP address the internal clients can reach. Service Port: 8080 Protocol: TCP Note: This use case was for TCP traffic directed at known hosts on the internet. If you require other protocols or all, select the correct option for your use case from the drop-down menu. Protocol Profile (Client): f5-tcp-progressive Protocol Profile (Server): f5-tcp-wan HTTP Profile: DemoExplicitHTTP VLAN and Tunnel Traffic Enabled on: Internal Source Address Translation: Auto Map Leave all other settings at their defaults and click Finish. Create a Fast L4 Profile Navigate to Local Traffic > Profiles: Protocol: Fast L4 > click Create Name: demo_fastl4 Parent Profile: fastL4 Enable Loose Initiation and Loose Close as shown in the screenshot below. Click Finished Create a Wild Card Virtual Server In order to catch and forward all traffic to the BIG-IP's default gateway, we will create a virtual server to accept traffic from our explicit proxy virtual server created in the previous steps. Navigate to Local Traffic > Virtual Servers > Virtual Server List > click Create Name: wildcard_VS Type: Forwarding (IP) Source Address: 0.0.0.0/0 Destination Address: 0.0.0.0/0 Protocol: *All Protocols Service Port: 0 *All Ports Protocol Profile: demo_fastl4 VLAN and Tunnel Traffic: Enabled on...DemoTunnel Source Address Translation: Auto Map Leave all other settings at their defaults and click Finished. Testing and Validation Navigate to a workstation on your internal network. Launch Internet Explorer or the browser of your preference. Modify the proxy settings to reflect the explicit_proxy_VS created in previous steps. Attempt to access several sites and validate you are able to reach them. Whether successful or unsuccessful, navigate to Local Traffic > Virtual Servers > Virtual Server List > click the Statistics tab. Validate traffic is hitting both of the virtual servers created above. If it is not, for troubleshooting purposes only configure to the virtual servers to accept traffic on All VLANs and Tunnels as well as useful tools such as curl and tcpdump. You have now successfully configured your F5 BIG-IP to act as an explicit forward web proxy using LTM only. As stated above, this use case is not meant to fulfill all forward proxy use cases. If URL filtering and malware protection are required, APM and SWG integration should be considered. Until next time!33KViews6likes34Comments
ADFS Proxy Replacement on F5 BIG-IP
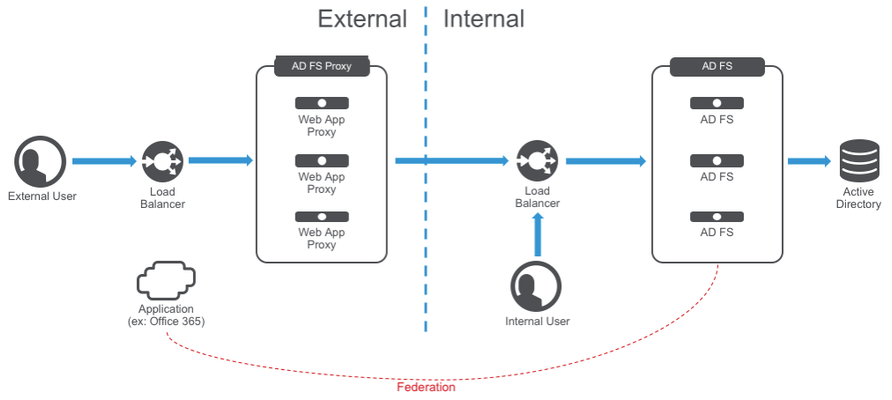
BIG-IP Access Policy Manager can now replace the need for Web Application Proxy servers providing security for your modern AD FS deployment with MS-ADFSPIP support released in BIG-IP v13.1. This article will provide a one stop shop for you to gather information on the solution and leverage it in your environment. What is an AD FS Proxy? AD FS proxies are Windows servers that provide access to external users to the AD FS farm in the internal network. This is done on a server called a Web Application Proxy (WAP). More recent versions of Active Directory Federation Services require the proxy to support MS-ADFSPIP (ADFS Proxy Integration Protocol) which involves client certificate auth between proxy and AD FS, trust establishment, header injection, and more. As noted above, BIG-IP APM v13.1 has support for MS-ADFSPIP. You can see Microsoft’s notes on this and supported third party proxies here, noting that F5 is on the list. Here’s a typical ADFS deployment: So what does BIG-IP do for me? Glad you asked! Here’s an example of the single tier deployment architecture. You can also split these roles into a two tier architecture. As you can see, BIG-IP is taking the roles of both load balancer and the web application proxies protecting AD FS. In this diagram we’re adding additional security with Advanced WAF, DDoS, and Network Firewall services. You can see the F5/Microsoft announcement at Ignite hereabout this new feature. If you want to understand more about the architecture, check out John Wagnon’s awesome lightboard lesson here. How do I deploy it? There are a few ways to do it. The simplest is with the latest iApp template to help you deploy everything, available from https://downloads.f5.com. Make sure you’re using at least v1.2.0rc6. You can also get the related deployment guide here. If you want to deploy manually, there are instructions in the deployment guide. The support article here also covers basic deployment and how the pieces work. Who doesn’t love reading support articles? For the admin the new feature comes down to this amazing simple checkbox: Checking a box and entering credentials is WAY easier than deploying multiple Windows servers, configuring them as WAPs, establishing trust, then maintaining and securing them going forward. Access Policy Manager will maintain that trust, exchanging certificates automatically before they expire with AD FS. Note that no access profile is assigned above. If you want one to add more security flexibility then the access profile is supported as well. Check the deployment guide for requirements. If you don’t use one, no access sessions are used. Here’s a quick video explaining the solution and demoing deployment using the iApp. What else can I do? You can add more security using access profiles to add preauthentication, multifactor, etc. A basic access policy (with Azure MFA optional) is included in the iApp. Also included in the iApp is network firewall policy deployment. You can add Advanced WAF features like brute force, credential stuffing, bot protection, and more if desired too.27KViews0likes49CommentsControlling a Pool Members Ratio and Priority Group with iControl
A Little Background A question came in through the iControl forums about controlling a pool members ratio and priority programmatically. The issue really involves how the API’s use multi-dimensional arrays but I thought it would be a good opportunity to talk about ratio and priority groups for those that don’t understand how they work. In the first part of this article, I’ll talk a little about what pool members are and how their ratio and priorities apply to how traffic is assigned to them in a load balancing setup. The details in this article were based on BIG-IP version 11.1, but the concepts can apply to other previous versions as well. Load Balancing In it’s very basic form, a load balancing setup involves a virtual ip address (referred to as a VIP) that virtualized a set of backend servers. The idea is that if your application gets very popular, you don’t want to have to rely on a single server to handle the traffic. A VIP contains an object called a “pool” which is essentially a collection of servers that it can distribute traffic to. The method of distributing traffic is referred to as a “Load Balancing Method”. You may have heard the term “Round Robin” before. In this method, connections are passed one at a time from server to server. In most cases though, this is not the best method due to characteristics of the application you are serving. Here are a list of the available load balancing methods in BIG-IP version 11.1. Load Balancing Methods in BIG-IP version 11.1 Round Robin: Specifies that the system passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. This method works well in most configurations, especially if the equipment that you are load balancing is roughly equal in processing speed and memory. Ratio (member): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine within the pool. Least Connections (member): Specifies that the system passes a new connection to the node that has the least number of current connections in the pool. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. Observed (member): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (member), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (member): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Ratio (node): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine across all pools of which the server is a member. Least Connections (node): Specifies that the system passes a new connection to the node that has the least number of current connections out of all pools of which a node is a member. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node, or the fastest node response time. Fastest (node): Specifies that the system passes a new connection based on the fastest response of all pools of which a server is a member. This method might be particularly useful in environments where nodes are distributed across different logical networks. Observed (node): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (node), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (node): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Dynamic Ratio (node) : This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. Fastest (application): Passes a new connection based on the fastest response of all currently active nodes in a pool. This method might be particularly useful in environments where nodes are distributed across different logical networks. Least Sessions: Specifies that the system passes a new connection to the node that has the least number of current sessions. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current sessions. Dynamic Ratio (member): This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. L3 Address: This method functions in the same way as the Least Connections methods. We are deprecating it, so you should not use it. Weighted Least Connections (member): Specifies that the system uses the value you specify in Connection Limit to establish a proportional algorithm for each pool member. The system bases the load balancing decision on that proportion and the number of current connections to that pool member. For example,member_a has 20 connections and its connection limit is 100, so it is at 20% of capacity. Similarly, member_b has 20 connections and its connection limit is 200, so it is at 10% of capacity. In this case, the system select selects member_b. This algorithm requires all pool members to have a non-zero connection limit specified. Weighted Least Connections (node): Specifies that the system uses the value you specify in the node's Connection Limitand the number of current connections to a node to establish a proportional algorithm. This algorithm requires all nodes used by pool members to have a non-zero connection limit specified. Ratios The ratio is used by the ratio-related load balancing methods to load balance connections. The ratio specifies the ratio weight to assign to the pool member. Valid values range from 1 through 100. The default is 1, which means that each pool member has an equal ratio proportion. So, if you have server1 a with a ratio value of “10” and server2 with a ratio value of “1”, server1 will get served 10 connections for every one that server2 receives. This can be useful when you have different classes of servers with different performance capabilities. Priority Group The priority group is a number that groups pool members together. The default is 0, meaning that the member has no priority. To specify a priority, you must activate priority group usage when you create a new pool or when adding or removing pool members. When activated, the system load balances traffic according to the priority group number assigned to the pool member. The higher the number, the higher the priority, so a member with a priority of 3 has higher priority than a member with a priority of 1. The easiest way to think of priority groups is as if you are creating mini-pools of servers within a single pool. You put members A, B, and C in to priority group 5 and members D, E, and F in priority group 1. Members A, B, and C will be served traffic according to their ratios (assuming you have ratio loadbalancing configured). If all those servers have reached their thresholds, then traffic will be distributed to servers D, E, and F in priority group 1. he default setting for priority group activation is Disabled. Once you enable this setting, you can specify pool member priority when you create a new pool or on a pool member's properties screen. The system treats same-priority pool members as a group. To enable priority group activation in the admin GUI, select Less than from the list, and in the Available Member(s) box, type a number from 0 to 65535 that represents the minimum number of members that must be available in one priority group before the system directs traffic to members in a lower priority group. When a sufficient number of members become available in the higher priority group, the system again directs traffic to the higher priority group. Implementing in Code The two methods to retrieve the priority and ratio values are very similar. They both take two parameters: a list of pools to query, and a 2-D array of members (a list for each pool member passed in). long [] [] get_member_priority( in String [] pool_names, in Common__AddressPort [] [] members ); long [] [] get_member_ratio( in String [] pool_names, in Common__AddressPort [] [] members ); The following PowerShell function (utilizing the iControl PowerShell Library), takes as input a pool and a single member. It then make a call to query the ratio and priority for the specific member and writes it to the console. function Get-PoolMemberDetails() { param( $Pool = $null, $Member = $null ); $AddrPort = Parse-AddressPort $Member; $RatioAofA = (Get-F5.iControl).LocalLBPool.get_member_ratio( @($Pool), @( @($AddrPort) ) ); $PriorityAofA = (Get-F5.iControl).LocalLBPool.get_member_priority( @($Pool), @( @($AddrPort) ) ); $ratio = $RatioAofA[0][0]; $priority = $PriorityAofA[0][0]; "Pool '$Pool' member '$Member' ratio '$ratio' priority '$priority'"; } Setting the values with the set_member_priority and set_member_ratio methods take the same first two parameters as their associated get_* methods, but add a third parameter for the priorities and ratios for the pool members. set_member_priority( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] priorities ); set_member_ratio( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] ratios ); The following Powershell function takes as input the Pool and Member with optional values for the Ratio and Priority. If either of those are set, the function will call the appropriate iControl methods to set their values. function Set-PoolMemberDetails() { param( $Pool = $null, $Member = $null, $Ratio = $null, $Priority = $null ); $AddrPort = Parse-AddressPort $Member; if ( $null -ne $Ratio ) { (Get-F5.iControl).LocalLBPool.set_member_ratio( @($Pool), @( @($AddrPort) ), @($Ratio) ); } if ( $null -ne $Priority ) { (Get-F5.iControl).LocalLBPool.set_member_priority( @($Pool), @( @($AddrPort) ), @($Priority) ); } } In case you were wondering how to create the Common::AddressPort structure for the $AddrPort variables in the above examples, here’s a helper function I wrote to allocate the object and fill in it’s properties. function Parse-AddressPort() { param($Value); $tokens = $Value.Split(":"); $r = New-Object iControl.CommonAddressPort; $r.address = $tokens[0]; $r.port = $tokens[1]; $r; } Download The Source The full source for this example can be found in the iControl CodeShare under PowerShell PoolMember Ratio and Priority.27KViews0likes3CommentsWhat is Load Balancing?
tl;dr - Load Balancing is the process of distributing data across disparate services to provide redundancy, reliability, and improve performance. The entire intent of load balancing is to create a system that virtualizes the "service" from the physical servers that actually run that service. A more basic definition is to balance the load across a bunch of physical servers and make those servers look like one great big server to the outside world. There are many reasons to do this, but the primary drivers can be summarized as "scalability," "high availability," and "predictability." Scalability is the capability of dynamically, or easily, adapting to increased load without impacting existing performance. Service virtualization presented an interesting opportunity for scalability; if the service, or the point of user contact, was separated from the actual servers, scaling of the application would simply mean adding more servers or cloud resources which would not be visible to the end user. High Availability (HA) is the capability of a site to remain available and accessible even during the failure of one or more systems. Service virtualization also presented an opportunity for HA; if the point of user contact was separated from the actual servers, the failure of an individual server would not render the entire application unavailable. Predictability is a little less clear as it represents pieces of HA as well as some lessons learned along the way. However, predictability can best be described as the capability of having confidence and control in how the services are being delivered and when they are being delivered in regards to availability, performance, and so on. A Little Background Back in the early days of the commercial Internet, many would-be dot-com millionaires discovered a serious problem in their plans. Mainframes didn't have web server software (not until the AS/400e, anyway) and even if they did, they couldn't afford them on their start-up budgets. What they could afford was standard, off-the-shelf server hardware from one of the ubiquitous PC manufacturers. The problem for most of them? There was no way that a single PC-based server was ever going to handle the amount of traffic their idea would generate and if it went down, they were offline and out of business. Fortunately, some of those folks actually had plans to make their millions by solving that particular problem; thus was born the load balancing market. In the Beginning, There Was DNS Before there were any commercially available, purpose-built load balancing devices, there were many attempts to utilize existing technology to achieve the goals of scalability and HA. The most prevalent, and still used, technology was DNS round-robin. Domain name system (DNS) is the service that translates human-readable names (www.example.com) into machine recognized IP addresses. DNS also provided a way in which each request for name resolution could be answered with multiple IP addresses in different order. Figure 1: Basic DNS response for redundancy The first time a user requested resolution for www.example.com, the DNS server would hand back multiple addresses (one for each server that hosted the application) in order, say 1, 2, and 3. The next time, the DNS server would give back the same addresses, but this time as 2, 3, and 1. This solution was simple and provided the basic characteristics of what customer were looking for by distributing users sequentially across multiple physical machines using the name as the virtualization point. From a scalability standpoint, this solution worked remarkable well; probably the reason why derivatives of this method are still in use today particularly in regards to global load balancing or the distribution of load to different service points around the world. As the service needed to grow, all the business owner needed to do was add a new server, include its IP address in the DNS records, and voila, increased capacity. One note, however, is that DNS responses do have a maximum length that is typically allowed, so there is a potential to outgrow or scale beyond this solution. This solution did little to improve HA. First off, DNS has no capability of knowing if the servers listed are actually working or not, so if a server became unavailable and a user tried to access it before the DNS administrators knew of the failure and removed it from the DNS list, they might get an IP address for a server that didn't work. Proprietary Load Balancing in Software One of the first purpose-built solutions to the load balancing problem was the development of load balancing capabilities built directly into the application software or the operating system (OS) of the application server. While there were as many different implementations as there were companies who developed them, most of the solutions revolved around basic network trickery. For example, one such solution had all of the servers in a cluster listen to a "cluster IP" in addition to their own physical IP address. Figure 2: Proprietary cluster IP load balancing When the user attempted to connect to the service, they connected to the cluster IP instead of to the physical IP of the server. Whichever server in the cluster responded to the connection request first would redirect them to a physical IP address (either their own or another system in the cluster) and the service session would start. One of the key benefits of this solution is that the application developers could use a variety of information to determine which physical IP address the client should connect to. For instance, they could have each server in the cluster maintain a count of how many sessions each clustered member was already servicing and have any new requests directed to the least utilized server. Initially, the scalability of this solution was readily apparent. All you had to do was build a new server, add it to the cluster, and you grew the capacity of your application. Over time, however, the scalability of application-based load balancing came into question. Because the clustered members needed to stay in constant contact with each other concerning who the next connection should go to, the network traffic between the clustered members increased exponentially with each new server added to the cluster. The scalability was great as long as you didn't need to exceed a small number of servers. HA was dramatically increased with these solutions. However, since each iteration of intelligence-enabling HA characteristics had a corresponding server and network utilization impact, this also limited scalability. The other negative HA impact was in the realm of reliability. Network-Based Load balancing Hardware The second iteration of purpose-built load balancing came about as network-based appliances. These are the true founding fathers of today's Application Delivery Controllers. Because these boxes were application-neutral and resided outside of the application servers themselves, they could achieve their load balancing using much more straight-forward network techniques. In essence, these devices would present a virtual server address to the outside world and when users attempted to connect, it would forward the connection on the most appropriate real server doing bi-directional network address translation (NAT). Figure 3: Load balancing with network-based hardware The load balancer could control exactly which server received which connection and employed "health monitors" of increasing complexity to ensure that the application server (a real, physical server) was responding as needed; if not, it would automatically stop sending traffic to that server until it produced the desired response (indicating that the server was functioning properly). Although the health monitors were rarely as comprehensive as the ones built by the application developers themselves, the network-based hardware approach could provide at least basic load balancing services to nearly every application in a uniform, consistent manner—finally creating a truly virtualized service entry point unique to the application servers serving it. Scalability with this solution was only limited by the throughput of the load balancing equipment and the networks attached to it. It was not uncommon for organization replacing software-based load balancing with a hardware-based solution to see a dramatic drop in the utilization of their servers. HA was also dramatically reinforced with a hardware-based solution. Predictability was a core component added by the network-based load balancing hardware since it was much easier to predict where a new connection would be directed and much easier to manipulate. The advent of the network-based load balancer ushered in a whole new era in the architecture of applications. HA discussions that once revolved around "uptime" quickly became arguments about the meaning of "available" (if a user has to wait 30 seconds for a response, is it available? What about one minute?). This is the basis from which Application Delivery Controllers (ADCs) originated. The ADC Simply put, ADCs are what all good load balancers grew up to be. While most ADC conversations rarely mention load balancing, without the capabilities of the network-based hardware load balancer, they would be unable to affect application delivery at all. Today, we talk about security, availability, and performance, but the underlying load balancing technology is critical to the execution of all. Next Steps Ready to plunge into the next level of Load Balancing? Take a peek at these resources: Go Beyond POLB (Plain Old Load Balancing) The Cloud-Ready ADC BIG-IP Virtual Edition Products, The Virtual ADCs Your Application Delivery Network Has Been Missing Cloud Balancing: The Evolution of Global Server Load Balancing22KViews0likes1Comment
Understanding IPSec IKEv1 negotiation on Wireshark
Related Articles: Understanding IPSec IKEv2 negotiation on Wireshark 1. The Big Picture First 6 Identity Protection (Main Mode) messages negotiate security parameters to protect the next 3 messages (Quick Mode) and whatever is negotiated in Phase 2 is used to protect production traffic (ESP or AH, normally ESP for site-site VPN). We call first 6 messages Phase 1 and last 3 messages as Phase 2. Sample pcap:IPSEC-tunnel-capture-1.pcap(for instructions on how to decrypt it just go to website where I got this sample capture:http://ruwanindikaprasanna.blogspot.com/2017/04/ipsec-capture-with-decryption.html) 2. Phase 1 2.1 Policy Negotiation Both peers add a unique SPI just to uniquely identify each side's Security Association (SA): Inframe #1, the Initiator (.70) sends a set of Proposals containing a set of security parameters (Transforms) that Responder (.71) can pick if it matches its local policies: Fair enough, in frame #2 the Responder (.71) picks one of theTransforms: 2.2 DH Key Exchange Then, next 2 Identity Protection packets both peers exchange Diffie-Hellman public key values and nonces (random numbers) which will then allow both peers to agree on a shared secret key: With DH public key value and the nonce both peers will generate a seed key called SKEYID. A further 3 session keys will be generated using this seed key for different purposes: SKEYID_d(d for derivative): not used by Phase 1. It is used as seed key for Phase2 keys, i.e. seed key for production traffic keys in Plain English. SKEYID_a(a for authentication): this key is used to protect message integrity in every subsequent packets as soon as both peers are authenticated (peers will authenticate each other in next 2 packets). Yes, I know, we verify the integrity by using a hash but throwing a key into a hash adds stronger security to hash and it's called HMAC. SKEYID_e(e for encryption): you'll see that the next 2 packets are also encrypted. As selected encryption algorithm for this phase was AES-CBC (128-bits) then we use AES with this key to symmetrically encrypt further data. Nonceis just to protect against replay attacks by adding some randomness to key generation 2.3 Authentication The purpose of this exchange is to confirm each other's identity. If we said we're going to do this using pre-shared keys then verification consists of checking whether both sides has the same pre-shared key. If it is RSA certificate then peers exchange RSA certificates and assuming the CA that signed each side is trusted then verification complete successfully. In our case, this is done via pre-shared keys: In packet #5 the Initiator sends a hash generated using pre-shared key set as key material so that only those who possess pre-master key can do it: The responder performs the same calculation and confirms the hash is correct. Responder also sends a similar packet back to Initiator in frame #6 but I skipped for brevity. Now we're ready for Phase 2. 3. Phase 2 The purpose of this phase is to establish the security parameters that will be used for production traffic (IPSec SA): Now, Initiator sends its proposals to negotiate the security parameters for production traffic as mentioned (the highlighted yellow proposal is just a sample as the rest is collapsed -this is frame #7): Note:Identification payload carries source and destination tunnel IP addresses and if this doesn't match what is configured on both peers then IPSec negotiation will not proceed. Then, in frame #8 we see that Responder picked one of the Proposals: Frame #9 is just an ACK to the picked proposal confirming that Initiator accepted it: I just highlighted the Hash here to reinforce the fact that since both peers were authenticated in Phase 1, all subsequent messages are authenticated and a new hash (HMAC) is generated for each packet.21KViews1like0Comments
SNI Routing with BIG-IP
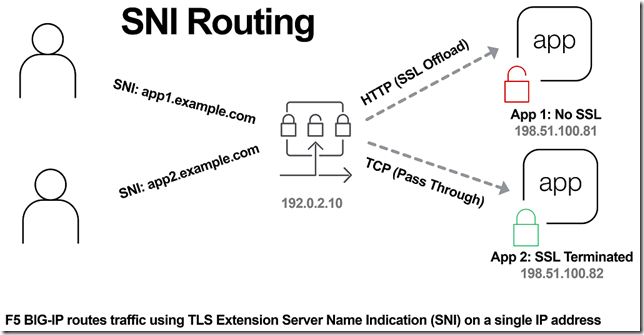
In the previous article, The Three HTTP Routing Patterns, Lori MacVittie covers 3 methods of routing. Today we will look at Server Name Indication (SNI) routing as an additional method of routing HTTPS or any protocol that uses TLS and SNI. Using SNI we can route traffic to a destination without having to terminate the SSL connection. This enables several benefits including: Reduced number of Public IPs Simplified configuration More intelligent routing of TLS traffic Terminating SSL Connections When you havea SSL certificate and key you can perform the cryptographic actions required to encrypt traffic using TLS. This is what I refer to as “terminating the SSL connection” throughout this article. When you want to route traffic this is a chickenand an egg problem, becausefor TLS traffic you want to be able to route the traffic by being able to inspect the contents, but this normally requires being able to “terminate the SSL connection”. The goal of this article is to layer in traffic routing for TLS traffic without having to require having/knowing the original SSL certificate and key. Server Name Indication (SNI) SNI is a TLS extension that makes it possible to "share" certificates on a single IP address. This is possible due to a client using a TLS extension that requests a specific name before the server responds with a SSL certificate. Prior to SNI, the other options would be a wildcard certificate or Subject Alternative Name (SAN) that allows you to specify multiple names with a single certificate. SNI with Virtual Servers It has been possible to use SNI on F5 BIG-IP since TMOS 11.3.0. The following KB13452 outlines how it can be configured. In this scenario (from the KB article) the BIG-IP is terminating the SSL connection. Not all clients support SNI and you will always need to specify a “fallback” profile that will be used if a SNI name is not used or matched. The next example will look at how to use SNI without terminating the SSL connection. SNI Routing Occasionally you may have the need to have a hybrid configuration of terminating SSL connections on the BIG-IP and sending connections without terminating SSL. One method is to create two separate virtual servers, one for SSL connections that the BIG-IP will handle (using clientssl profile) and one that it will not handle SSL (just TCP). This works OK for a small number of backends, but does not scale well if you have many backends (run out of Public IP addresses). Using SNI Routing we can handle everything on a single virtual server / Public IP address. There are 3 methods for performing SNI Routing with BIG-IP iRule with binary scan a. Article by Colin Walker code attribute to Joel Moses b. Code Share by Stanislas Piron iRule with SSL::extensions Local Traffic Policy Option #1 is for folks that prefer complete control of the TLS protocol. It only requires the use of a TCP profile. Options #2 and #3 only require the use of a SSL persistence profile and TCP profile. SNI Routing with Local Traffic Policy We will skip option #1 and #2 in this article and look at using a Local Traffic Policy for SNI Routing. For a review of Local Traffic Policies check out the following DevCentral articles: LTM Policy Jan 2015 Simplifying Local Traffic Policies in BIG-IP 12.1 June 2016 In previous articles about Local Traffic Policiesthe focus was on routing HTTP traffic, but today we will use it to route SSL connections using SNI. In the following example, using a Local Traffic Policy named “sni_routing”, we are setting a condition on the SSL Extension “servername” and sending the traffic to a pool without terminating the SSL connection. The pool member could be another server or another BIG-IP device. The next example will forward the traffic to another virtual server that is configured with a clientssl profile. This uses VIP targeting to send traffic to another virtual server on the same device. In both examples it is important to note that the “condition”/“action” has been changed from occurring on “request” (that maps to a HTTP L7 request) to “ssl client hello”. By performing the action prior to any L7 functions occurring, we can forward the traffic without terminating the SSL connection. The previous example policy, “sni_routing”, can be attached to a Virtual Server that only has a TCP profile and SSL persistence profile. No HTTP or clientssl profile is required! This method can also be used to solve the issue of how to consolidate multiple SSL virtual servers behind a single virtual server that have different APM and/or ASM policies. This is similar to the architecture that is used by the Container Connector for Cloud Foundry; in creating a two-tier load balancing solution on a single device. Routed Correctly? TLS 1.3 has interesting proposals on how to obscure the servername (TLS in TLS?), but for now this is a useful and practical method of handling multiple SSL certs on a single IP. In the future this may still be possible as well with TLS 1.3. For example the use of a HTTP Fronting service could be a tier 1 virtual server (this is just my personal speculation, I have not tried, at the time of publishing this was still a draft proposal). In other news it has been demonstrated that a combination of using SNI and a different host header can be used for “domain fronting”. A method to enforce consistent policy (prevent domain fronting) would be to layer in additional conditions that match requested SNI servername (TLS extension) with requested HOST header (L7 HTTP header). This would help enforce that a tenant is using a certificate that is associated with their application and not “borrowing” the name and certificate that is being used by an adjacent service. We don’t think of a TLS extension as an attribute that can be used to route application traffic, but it is useful and possible on BIG-IP.21KViews0likes16CommentsAutomate Let's Encrypt Certificates on BIG-IP
To quote the evil emperor Zurg: "We meet again, for the last time!" It's hard to believe it's been six years since my first rodeo with Let's Encrypt and BIG-IP, but (uncompromised) timestamps don't lie. And maybe this won't be my last look at Let's Encrypt, but it will likely be the last time I do so as a standalone effort, which I'll come back to at the end of this article. The first project was a compilation of shell scripts and python scripts and config files and well, this is no different. But it's all updated to meet the acme protocol version requirements for Let's Encrypt. Here's a quick table to connect all the dots: Description What's Out What's In acme client letsencrypt.sh dehydrated python library f5-common-python bigrest BIG-IP functionality creating the SSL profile utilizing an iRule for the HTTP challenge The f5-common-python library has not been maintained or enhanced for at least a year now, and I have an affinity for the good work Leo did with bigrest and I enjoy using it. I opted not to carry the SSL profile configuration forward because that functionality is more app-specific than the certificates themselves. And finally, whereas my initial project used the DNS challenge with the name.com API, in this proof of concept I chose to use an iRule on the BIG-IP to serve the challenge for Let's Encrypt to perform validation against. Whereas my solution is new, the way Let's Encrypt works has not changed, so I've carried forward the process from my previous article that I've now archived. I'll defer to their how it works page for details, but basically the steps are: Define a list of domains you want to secure Your client reaches out to the Let’s Encrypt servers to initiate a challenge for those domains. The servers will issue an http or dns challenge based on your request You need to place a file on your web server or a txt record in the dns zone file with that challenge information The servers will validate your challenge information and notify you You will clean up your challenge files or txt records The servers will issue the certificate and certificate chain to you You now have the key, cert, and chain, and can deploy to your web servers or in our case, to the BIG-IP Before kicking off a validation and generation event, the client registers your account based on your settings in the config file. The files in this project are as follows: /etc/dehydrated/config # Dehydrated configuration file /etc/dehydrated/domains.txt # Domains to sign and generate certs for /etc/dehydrated/dehydrated # acme client /etc/dehydrated/challenge.irule # iRule configured and deployed to BIG-IP by the hook script /etc/dehydrated/hook_script.py # Python script called by dehydrated for special steps in the cert generation process # Environment Variables export F5_HOST=x.x.x.x export F5_USER=admin export F5_PASS=admin You add your domains to the domains.txt file (more work likely if signing a lot of domains, I tested the one I have access to). The dehydrated client, of course is required, and then the hook script that dehydrated interacts with to deploy challenges and certificates. I aptly named that hook_script.py. For my hook, I'm deploying a challenge iRule to be applied only during the challenge; it is modified each time specific to the challenge supplied from the Let's Encrypt service and is cleaned up after the challenge is tested. And finally, there are a few environment variables I set so the information is not in text files. You could also move these into a credential vault. So to recap, you first register your client, then you can kick off a challenge to generate and deploy certificates. On the client side, it looks like this: ./dehydrated --register --accept-terms ./dehydrated -c Now, for testing, make sure you use the Let's Encrypt staging service instead of production. And since I want to force action every request while testing, I run the second command a little differently: ./dehydrated -c --force --force-validation Depicted graphically, here are the moving parts for the http challenge issued by Let's Encrypt at the request of the dehydrated client, deployed to the F5 BIG-IP, and validated by the Let's Encrypt servers. The Let's Encrypt servers then generate and return certs to the dehydrated client, which then, via the hook script, deploys the certs and keys to the F5 BIG-IP to complete the process. And here's the output of the dehydrated client and hook script in action from the CLI: # ./dehydrated -c --force --force-validation # INFO: Using main config file /etc/dehydrated/config Processing example.com + Checking expire date of existing cert... + Valid till Jun 20 02:03:26 2022 GMT (Longer than 30 days). Ignoring because renew was forced! + Signing domains... + Generating private key... + Generating signing request... + Requesting new certificate order from CA... + Received 1 authorizations URLs from the CA + Handling authorization for example.com + A valid authorization has been found but will be ignored + 1 pending challenge(s) + Deploying challenge tokens... + (hook) Deploying Challenge + (hook) Challenge rule added to virtual. + Responding to challenge for example.com authorization... + Challenge is valid! + Cleaning challenge tokens... + (hook) Cleaning Challenge + (hook) Challenge rule removed from virtual. + Requesting certificate... + Checking certificate... + Done! + Creating fullchain.pem... + (hook) Deploying Certs + (hook) Existing Cert/Key updated in transaction. + Done! This results in a deployed certificate/key pair on the F5 BIG-IP, and is modified in a transaction for future updates. This proof of concept is on github in the f5devcentral org if you'd like to take a look. Before closing, however, I'd like to mention a couple things: This is an update to an existing solution from years ago. It works, but probably isn't the best way to automate today if you're just getting started and have already started pursuing a more modern approach to automation. A better path would be something like Ansible. On that note, there are several solutions you can take a look at, posted below in resources. Resources https://github.com/EquateTechnologies/dehydrated-bigip-ansible https://github.com/f5devcentral/ansible-bigip-letsencrypt-http01 https://github.com/s-archer/acme-ansible-f5 https://github.com/s-archer/terraform-modular/tree/master/lets_encrypt_module(Terraform instead of Ansible) https://community.f5.com/t5/technical-forum/let-s-encrypt-with-cloudflare-dns-and-f5-rest-api/m-p/292943(Similar solution to mine, only slightly more robust with OCSP stapling, the DNS instead of HTTP challenge, and with bash instead of python)20KViews6likes18Comments