What is BIG-IP Next?
BIG-IP Next LTM and BIG-IP Next WAF hit general availability back in October, and we hit the road for a tour around North America for its arrival party! Those who attended one of our F5 Academy sessions got a deep-dive presentation into BIG-IP Next conceptually, and then a lab session to work through migrating workloads and deploying them. I got to attend four of the events and discuss with so many fantastic community members what's old, what's new, what's borrowed, what's blue...no wait--this is no wedding! But for those of us who've been around the block with BIG-IP for a while, if not married to the tech, we definitely have a relationship with it, for better and worse, right? And that's earned. So any time something new, or in our case "Next" comes around, there's risk and fear involved personally. But don't fret. Seriously. It's going to be different in a lot of ways, but it's going to be great. And there are a crap-ton (thank you Mark Rober!) of improvements that once we all make it through the early stages, we'll embrace and wonder why we were even scared in the first place. So with all that said, will you come on the journey with me? In this first of many articles to come from me this year, I'll cover the high-level basics of what is so next about BIG-IP Next, and in future entries we'll be digging into the tech and learning together. BIG-IP and BIG-IP Next Conceptually - A Comparison BIG-IP has been around since before the turn of the century (which is almost old enough to rent a car here in the United States) and this year marks the 20 year anniversary of TMOS. That the traffic management microkernel (TMM) is still grokking like a boss all these years later is a testament to that early innovation! So whereas TMOS as a system is winding down, it's heart, TMM, will go on (cue sappy Celine Dion ditty in 3, 2, 1...) Let's take a look at what was and what is. With TMOS, the data plane and control plane compete for resources as it's one big system. With BIG-IP, the separation of duties is more explicit and intentionally designed to scale on the control plane. Also, the product modules are no longer either completely integrated in TMM or plugins to TMM, but rather, isolated to their own container structures. The image above might convey the idea that LTM or WAF or any of the other modules are single containers, but that's just shown that way for brevity. Each module is an array of containers. But don't let that scare you. The underlying kubernetes architecture is an abstraction that you may--but certainly are not required to--care about. TMM continues to be its awesome TMM self. The significant change operationally is how you interact with BIG-IP. With TMOS, historically you engage directly with each device, even if you have some other tools like BIG-IQ or third-party administration/automation platforms. With BIG-IP Next, everything is centralized on Central Manager, and the BIG-IP Next instances, whether they are running on rSeries, VELOS, or Virtual Edition, are just destinations for your workloads. In fact, outside of sidecar proxies for troubleshooting, instance logins won't even be supported! Yes, this is a paradigm shift. With BIG-IP Next, you will no longer be configuration-object focused. You will be application-focused. You'll still have the nerd-knobs to tweak and turn, but they'll be done within the context of an application declaration. If you haven't started your automation journey yet, you might not be familiar with AS3. It's been out now for years and works with BIG-IP to deploy applications declaratively. Instead of following a long pre-flight checklist with 87 steps to go from nothing to a working application, you simply define the parameters of your application in a blob of JSON data and click the easy button. For BIG-IP Next, this is the way. Now, in the Central Manager GUI, you might interact with FAST templates that deliver a more traditional view into configuring applications, but the underlying configuration engine is all AS3. For more, I hosted aseries of streams in December to introduce AS3 Foundations, I highly recommend you take the time to digest the basics. Benefits I'm Excited About There are many and you can read about them on the product page on F5.com. But here's my short list: API-first. Period. BIG-IP had APIs with iControl from the era before APIs were even cool, but they were not first-class citizens. The resulting performance at scale requires effort to manage effectively. Not only performance, but feature parity among iControl REST, iControl SOAP, tmsh, and the GUI has been a challenge because of the way development occurred over time. Not so with BIG-IP Next. Everything is API-first, so all tooling is able to consume everything. This is huge! Migration assistance. Central Manager has the JOURNEYS tool on sterroids built-in to the experience. Upload your UCS, evaluate your applications to see what can be migrated without updates, and deploy! It really is that easy. Sure, there's work to be done for applications that aren't fully compatible yet, but it's a great start. You can do this piece (and I recommend that you do) before you even think about deploying a single instance just to learn what work you have ahead of you and what solutions you might need to adapt to be ready. Simplified patch/upgrade process. If you know, you know...patches are upgrades with BIG-IP, and not in place at that. This is drastically improved with BIG-IP Next! Because of the containerized nature of the system, individual containers can be targeted for patching, and depending on the container, may not even require a downtime consideration. Release cycle. A more frequent release cadence might terrify the customers among us that like to space out their upgrades to once every three years or so, but for the rest of us, feature delivery to the tune of weeks instead of twice per year is an exciting development (pun intended!) Features I'm Excited About Versioning for iRules and policies. For those of us who write/manage these things, this is huge! Typically I'd version by including it in the title, and I know some who set release tags in repos. With Central Manager, it's built-in and you can deploy iRules and polices by version and do diffs in place. I'm super excited about this! Did I mention the API? On the API front...it's one API, for all functionality. No digging and scraping through the GUI, tmsh, iControl REST, iControl SOAP, building out a node.js app to deploy a custom API endpoint with iControl LX, if even possible with some of the modules like APM or ASM. Nope, it's all there in one API. Glorious. Centralized dashboards. This one is for the Ops teams! Who among us has spent many a day building custom dashboards to consume stats from BIG-IPs across your org to have a single pane of glass to manage? I for one, and I'm thrilled to see system, application, and security data centralized for analysis and alerting. Log/metric streaming. And finally, logs and metrics! Telemetry Streaming from the F5 Automation Toolchain doesn't come forward in BIG-IP Next, but the ideas behind it do. If you need your data elsewhere from Central Manager, you can set up remote logging with OpenTelemetry (see the link in the resources listed below for a first published example of this.) There are some great features coming with DNS, Access, and all the other modules when they are released as well. I'll cover those when they hit general availability. Let's Go! In the coming weeks, I'll be releasing articles on installation and licensing walk-throughs for Central Manager and the instances, andcontent from our awesome group of authors is already starting to flow as well. Here are a few entries you can feast your eyes on, including an instance Proxmox installation: For the kubernetes crowd, BIG-IP Next CNF Solutions for RedHat Openshift Installing BIG-IP Next Instance on Proxmox Remote Logging with BIG-IP Next and OpenTelemetry Are you ready? Grab a trial licensefrom your MyF5 dashboard and get going! And make sure to join us in the BIG-IP Next Academy group here on DevCentral. The launch team is actively engaged there for next-related questions/issues, so that's the place to be in your early journey! Also...if you want the ultimate jump-start for all things BIG-IP Next, join usatAppWorld 2024 in SanJose next month!3.2KViews17likes4CommentsF5 Distributed Cloud - Customer Edge Site - Deployment & Routing Options
F5 Distributed Cloud Customer Edge (CE) software deployment models for scale and routing for enterprises deploying multi-cloud infrastructure. Today's service delivery environments are comprised of multiple clouds in a hybrid cloud environment. How your multi-cloud solution attaches to your existing on-prem and cloud networks can be the difference between a successful overlay fabric, and one that leave you wanting more out of your solution. Learn your options with F5 Distributed Cloud Customer Edge software.8.5KViews16likes2CommentsF5 Distributed Cloud - Regional Decryption with Virtual Sites
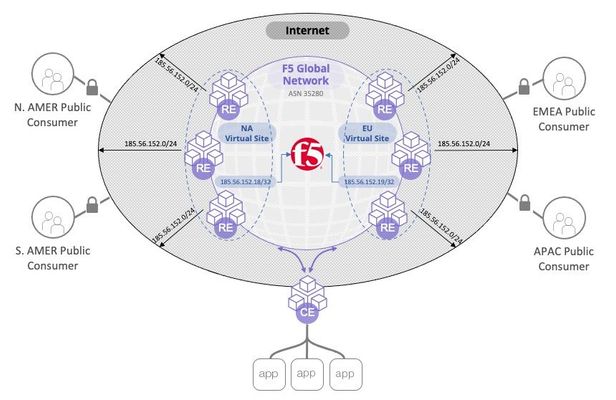
In this article we discuss how the F5 Distributed Cloud can be configured to support regulatory demands for TLS termination of traffic to specific regions around the world. The article provides insight into the F5 Distributed Cloud global backbone and application delivery network (ADN). The article goes on to inspect how the F5 Distriubted Cloud is able to achieve these custom topologies in a multi-tenant architecture while adhearing to the "rules of the internet" for route summarization. Read on to learn about the flexibility of F5's SaaS platform providing application delivery and security solutions for your applications.4.6KViews15likes2CommentsF5 Distributed Cloud - Listener Logic
In a proxy, there is a client-side and server-side connection. In this article, we'll focus on how the proxy "picks-up" or "listens" for traffic on the client-side. There are many options and creative ideas that adapt to enterprises business needs. First, we need to know the mechanics and what is possible, and this article covers those basics.1.4KViews13likes1CommentHow to get a F5 BIG-IP VE Developer Lab License
To assist DevOps teams improve their development for the BIG-IP platform, F5 offers a low cost developer lab license.This license can be purchased from your authorized F5 vendor. If you do not have an F5 vendor, you can purchase a lab license online: CDW BIG-IP Virtual Edition Lab License CDW Canada BIG-IP Virtual Edition Lab License Once completed, the order is sent to F5 for fulfillment and your license will be delivered shortly after via e-mail. F5 is investigating ways to improve this process. To download the BIG-IP Virtual Edition, please log into downloads.f5.com (separate login from DevCentral), and navigate to your appropriate virtual edition, example: For VMware Fusion or Workstation or ESX/i:BIGIP-16.1.2-0.0.18.ALL-vmware.ova For Microsoft HyperV:BIGIP-16.1.2-0.0.18.ALL.vhd.zip KVM RHEL/CentoOS: BIGIP-16.1.2-0.0.18.ALL.qcow2.zip Note: There are also 1 Slot versions of the above images where a 2nd boot partition is not needed for in-place upgrades. These images include_1SLOT- to the image name instead of ALL. The below guides will help get you started with F5 BIG-IP Virtual Edition to develop for VMWare Fusion, AWS, Azure, VMware, or Microsoft Hyper-V. These guides follow standard practices for installing in production environments and performance recommendations change based on lower use/non-critical needs fo Dev/Lab environments. Similar to driving a tank, use your best judgement. DeployingF5 BIG-IP Virtual Edition on VMware Fusion Deploying F5 BIG-IP in Microsoft Azure for Developers Deploying F5 BIG-IP in AWS for Developers Deploying F5 BIG-IP in Windows Server Hyper-V for Developers Deploying F5 BIG-IP in VMware vCloud Director and ESX for Developers Note: F5 Support maintains authoritativeAzure, AWS, Hyper-V, and ESX/vCloud installation documentation. VMware Fusion is not an official F5-supported hypervisor so DevCentral publishes the Fusion guide with the help of our Field Systems Engineering teams.73KViews13likes143CommentsF5 Distributed Cloud - Service Policy - Header Matching Logic & Processing
Learn about the F5 Distributed Cloud service policy feature and how to apply logic to your match criteria (and/or). This understanding of the logic structures within service policies unlocks endless combinations of application security services.1.5KViews12likes1Comment
BIG-IP Scale-out/Multi-tier構成のポイント解説
はじめに BIG-IPは、1台で負荷分散、SSLアクセラレータ、フォワードプロキシ、ネットワーク保護、ウェブアプリケーション保護、リモートアクセス等の複数機能の提供が可能で、システムを集約させることが可能ですが、以下のようなケースで複数のBIG-IPに処理を分散させることも可能です。 - 高スペックな1台のBIG-IPで処理しきれない非常に多量のトラフィックを複数のBIG-IPに分散 - スモールスタートし、トラフィックや利用ユーザー数の増加に合わせて、BIG-IPを追加 しかしながら、複数BIG-IPで処理を行う場合は、以下のことも考慮の必要があります。 - 複数BIG-IPの負荷分散の考慮 - BIG-IPでSNATの構成を利用しない場合、構成の検討が必要 これらの検討事項は、BIG-IPをMulti-tier構成にすることで、実現が可能です。 本ブログでは、Scale-out/Multi-tier構成にする場合のネットワーク構成、HA構成、ライセンスによる注意事項を解説します。 1. ネットワーク構成につきまして Tier1 - Tier2とTier2 - Tier3間のVLANは別にすることをお勧めします。 また、戻りのTrafficのためにTier2とTier3のBIG-IPでは、Auto Last Hopは有効にします。 2. HA構成 Tier1/Tier3に相当する機器は、耐障害性を高めるためにActive-Standbyをお勧めします。 Tier2に相当する機器は、Standaloneを並べることも可能ですが、Active-Activeの構成でもメリットがあると考えられます。 Active-Activeにするメリットとしては以下が考えられます。 - ConfigをSyncさせることによって複数台の設定が容易になること - Active-Activeにすることにより、障害時は、すぐに別のリソースに切り替わること (Tier1でHealth Monitorと併用すれば障害時の切り替えの時に、よりメリットがあると考えられます) Active-Activeにした場合には、Traffic GroupのFailover Methodに以下の設定も追加して、特定のBIG-IPにActiveのリソースが偏らないようにします。 - Failover using Preferred Device Order and then Load Aware - Always Failback to First Device if it is Available 3. ライセンスによる注意事項 APMの場合、Active-Activeはサポートしておりませんので、Tier2をAPMにする場合は、Standaloneの機器を並べることになります。 4.まとめ 本ブログでは、Scale-out/Multi-tier構成を実施する場合の、考慮点等を解説しました。 Multi-tier構成については、Scale-out構成との組み合わせだけではなく、それぞれのtierで別のモジュールを動作させること等柔軟な構成が考えられます。 負荷分散、SSLアクセラレータ、フォワードプロキシ、ネットワーク保護、ウェブアプリケーション保護、リモートアクセス等様々なシーンで適用できますのでBIG-IPをぜひご活用ください。1.1KViews12likes0CommentsAS3 Best Practice
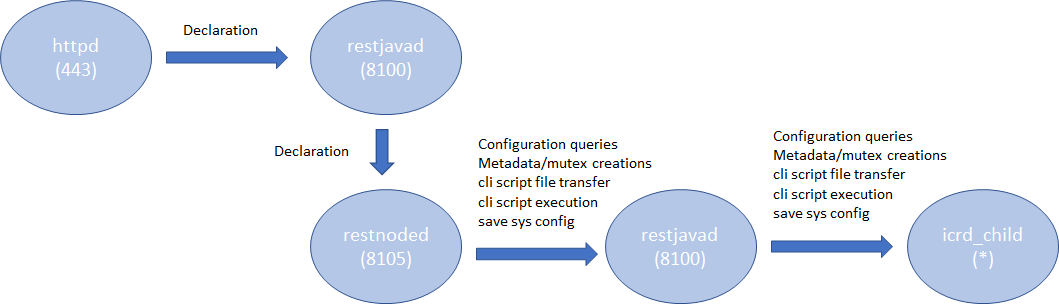
Introduction AS3 is a declarative API that uses JSON key-value pairs to describe a BIG-IP configuration. From virtual IP to virtual server, to the members, pools, and nodes required, AS3 provides a simple, readable format in which to describe a configuration. Once you've got the configuration, all that's needed is to POST it to the BIG-IP, where the AS3 extension will happily accept it and execute the commands necessary to turn it into a fully functional, deployed BIG-IP configuration. If you are new to AS3, start reading the following references: Products - Automation and orchestration toolchain(f5.com; Product information) Application Services 3 Extension Documentation(clouddocs; API documentation and guides) F5 Application Services 3 Extension(AS3) (GitHub; Source repository) This article describes some considerations in order to efficiently deploy the AS3 configurations. Architecture In the TMOS space, the services that AS3 provides are processed by a daemon named 'restnoded'. It relies on the existing BIG-IP framework for deploying declarations. The framework consists of httpd, restjavad and icrd_child as depicted below (the numbers in parenthesis are listening TCP port numbers). These processes are also used by other services. For example, restjavad is a gateway for all the iControl REST requests, and is used by a number of services on BIG-IP and BIG-IQ. When an interaction between any of the processes fails, AS3 operation fails. The failures stem from lack of resources, timeouts, data exceeding predefined thresholds, resource contention among the services, and more. In order to complete AS3 operations successfully, it is advised to follow the Best Practice outlined below. Best Practice Your single source of truth is your declaration Refrain from overwriting the AS3-deployed BIG-IP configurations by the other means such as TMSH, GUI or iControl REST calls. Since you started to use the AS3 declarative model, the source of truth for your device's configurations is in your declaration, not the BIG-IP configuration files. Although AS3 tries to weigh BIG-IP locally stored configurations as much as it can do, discrepancy between the declaration and the current configuration on BIG-IP may cause the AS3 to perform less efficiently or error unexpectedly. When you wish to change a section of a tenant (e.g., pool name change), modify the declaration and submit it. Keep the number of applications in one tenant to a minimum AS3 processes each tenant separately.Having too many applications (virtual servers) in a single tenant (partition) results in a lengthy poll when determining the current configuration. In extreme cases (thousands of virtuals), the action may time out. When you want to deploy a thousand or more applications on a single device, consider chunking the work for AS3 by spreading the applications across multiple tenants (say, 100 applications per tenant). AS3 tenant access behavior behaves as BIG-IP partition behavior.A non-Common partition virtual cannot gain access to another partition's pool, and in the same way, an AS3 application does not have access to a pool or profile in another tenant.In order to share configuration across tenants, AS3 allows configuration of the "Shared" application within the "Common" tenant.AS3 avoids race conditions while configuring /Common/Shared by processing additions first and deletions last, as shown below.This dual process may cause some additional delay in declaration handling. Overwrite rather than patching (POSTing is a more efficient practice than PATCHing) AS3 is a stateless machine and is idempotent. It polls BIG-IP for its full configuration, performs a current-vs-desired state comparison, and generates an optimal set of REST calls to fill the differences.When the initial state of BIG-IP is blank, the poll time is negligible.This is why initial configuration with AS3 is often quicker than subsequent changes, especially when the tenant contains a large number of applications. AS3 provides the means to partially modify using PATCH (seeAS3 API Methods Details), but do not expect PATCH changes to be performant.AS3 processes each PATCH by (1) performing a GET to obtain the last declaration, (2) patching that declaration, and (3) POSTing the entire declaration to itself.A PATCH of one pool member is therefore slower than a POST of your entire tenant configuration.If you decide to use PATCH,make sure that the tenant configuration is a manageable size. Note: Using PATCH to make a surgical change is convenient, but using PATCH over POST breaks the declarative model. Your declaration should be your single source of truth.If you include PATCH, the source of truth becomes "POST this file, then apply one or more PATCH declarations." Get the latest version AS3 is evolving rapidly with new features that customers have been wishing for along with fixes for known issues. Visitthe AS3 section of the F5 Networks Github.Issuessection shows what features and fixes have been incorporated. For BIG-IQ, check K54909607: BIG-IQ Centralized Management compatibility with F5 Application Services 3 Extension and F5 Declarative Onboarding for compatibilities with BIG-IQ versions before installation. Use administrator Use a user with the administrator role when you submit your declaration to a target BIG-IP device. Your may find your role insufficient to manipulate BIG-IP objects that are included in your declaration. Even one authorized item will cause the entire operation to fail and role back. See the following articles for more on BIG-IP user and role. Manual Chapter : User Roles (12.x) Manual Chapter : User Roles (13.x) Manual Chapter : User Roles (14.x) Prerequisites and Requirements(clouddocs AS3 document) Use Basic Authentication for a large declaration You can choose either Basic Authentication (HTTP Authorization header) or Token-Based Authentication (F5 proprietary X-F5-Auth-Token) for accessing BIG-IP. While the Basic Authentication can be used any time, a token obtained for the Token-Based Authentication expires after 1,200 seconds (20 minutes). While AS3 does re-request a new token upon expiry, it requires time to perform the operation, which may cause AS3 to slow down. Also, the number of tokens for a user is limited to 100 (since 13.1), hence if you happen to have other iControl REST players (such as BIG-IQ or your custom iControl REST scripts) using the Token-Based Authentication for the same user, AS3 may not be able to obtain the next token, and your request will fail. See the following articles for more on the Token-Based Authentication. Demystifying iControl REST Part 6: Token-Based Authentication(DevCentral article). iControl REST Authentication Token Management(DevCentral article) Authentication and Authorization(clouddocs AS3 document) Choose the best window for deployment AS3 (restnoded daemon) is a Control Plane process. It competes against other Control Plane processes such as monpd and iRules LX (node.js) for CPU/memory resources. AS3 uses the iControl REST framework for manipulating the BIG-IP resources. This implies that its operation is impacted by any processes that use httpd (e.g., GUI), restjavad, icrd_child and mcpd. If you have resource-hungry processes that run periodically (e.g., avrd), you may want to run your AS3 declaration during some other time window. See the following K articles for alist of processes K89999342 BIG-IP Daemons (12.x) K05645522BIG-IP Daemons (v13.x) K67197865BIG-IP Daemons (v14.x) K14020: BIG-IP ASM daemons (11.x - 15.x) K14462: Overview of BIG-IP AAM daemons (11.x - 15.x) Workarounds If you experience issues such as timeout on restjavad, it is possible that your AS3 operation had resource issues. After reviewing the Best Practice above but still unable to alleviate the problem, you may be able to temporarily fix it by applying the following tactics. Increase the restjavad memory allocation The memory size of restjavad can be increased by the following tmsh sys db commands tmsh modify sys db provision.extramb value <value> tmsh modify sys db restjavad.useextramb value true The provision.extramb db key changes the maximum Java heap memory to (192 + <value> * 8 / 10) MB. The default value is 0. After changing the memory size, you need to restart restjavad. tmsh restart sys service restjavad See the following article for more on the memory allocation: K26427018: Overview of Management provisioning Increase a number of icrd_child processes restjavad spawns a number of icrd_child processes depending on the load. The maximum number of icrd_child processes can be configured from /etc/icrd.conf. Please consult F5 Support for details. See the following article for more on the icrd_child process verbosity: K96840770: Configuring the log verbosity for iControl REST API related to icrd_child Decrease the verbosity levels of restjavad and icrd_child Writing log messages to the file system is not exactly free of charge. Writing unnecessarily large amount of messages to files would increase the I/O wait, hence results in slowness of processes. If you have changed the verbosity levels of restjavad and/or icrd_child, consider rolling back the default levels. See the following article for methods to change verbosity level: K15436: Configuring the verbosity for restjavad logs on the BIG-IP system13KViews12likes2CommentsHow to Split DNS with Managed Namespace on F5 Distributed Cloud (XC) Part 1 – DNS over HTTPS
Introduction DNS, everyone’s least favorite infrastructure service. So simple, yet so hard. Simple because it’s really just some text files served up, so hard because get it wrong and everything breaks. And it really doesn’t require a ton of resources, so why use a lot? Containers, rulers of our age, everything must be a container! Not really, but we are in a major shift from waterfall to modern architecture, and its handy to have something small that can be spun up in a lot of locations for redundancy and automated for our needs. "Nature is a mutable cloud, which is always and never the same." - Ralph Waldo Emerson We might not wax that philosophically around here, but our heads are in the cloud nonetheless! Join the F5 Distributed Cloud user group today and learn more with your peers and other F5 experts. But also, if I don’t want to spin up servers or hardware, I probably don’t want to spin up a container infrastructure either. So, use F5 XC Managed K8s solutions… F5 XC is a platform that can not only be used to provide native security solutions in any cloud or datacenter but is also a compute platform like any other cloud service provider. Bring us all your containers to host and secure. For this use-case we are going to use our Managed Namespace solution. It’s very similar to our Managed K8s solution, but more of a sandbox with hardened security policies. Part 1 will focus on DNS over HTTPS, Part 2 will cover TCP/UDP, however, the initial deployment will set up all the ports and services needed for Part 2 now. Managed Namespace - Sandbox Policies Architecture For this solution I went with Bind 9.19-dev, which seemed to have some issues with grpc and HTTP/2 conversion, which I was able to resolve by slapping NGINX in front of the DNS over HTTPS listener to proxy grpc to http/2, all other TCP/UDP traffic goes directly to Bind. Hopefully this is patched in future Bind releases. Otherwise, it’s just a standard tcp/udp DNS deployment. An important note about the architecture is that the workloads can be deployed on Customer Edge Nodes or on F5 owned Regions, so if there is no desire to manage a node on-premises, or manage / host k8s whether on-prem or in a 3 rd party Cloud Service Provider, running on our regions works perfectly fine and give a tremendous amount of redundancy. Managed Namespace Deployment From within the XC Console, we need to ensure that there is a Managed Namespace deployed, so click on the Distributed Apps Tile. Under Applications, select Virtual K8s. From here, if there is not already a vk8s deployed in the namespace, deploy one now. We won’t be covering deploying virtual k8s here, but it’s not too complex, click add new, give it a name, select some virtual sites, leave service isolation disabled and choose a default workload flavor. Once the Managed Namespace (virtual k8s) is online, you can download the kubeconfig by clicking the ellipses on the far right and selecting Kubeconfig. For a more detailed walkthrough of Creating a Managed Namespace you can go to the F5 Tech Docs located here: https://docs.cloud.f5.com/docs/how-to/app-management/create-vk8s-obj Click-Ops Deployment Since it would take up a ton of space I will not cover Click-Ops deployment of workloads, while it may be in a future article a detailed walkthrough can be found here today:https://docs.cloud.f5.com/docs/how-to/app-management/vk8s-workload Kubectl Deployment We WILL be covering deployment via kubectl with a manifest in this guide, so now we can actually start getting into it. As detailed in the architecture we are going to proxy requests to bind via NGINX, and to get NGINX set up as a proxy to Bind we need to get it configured. Posting the YAML in the article was a bit long, so all sources are posted in github and the yaml images link to the specific sections, while a full manifest is located near the end of the article. NGINX Config-Map There are a couple of critical or key differences to pay attention to when deploying to Managed Namespaces versus another k8s provider. The main one that we care about now is annotations. In the context we will be using them, they determine where the configurations and workloads will be deployed, and in other scenarios also include things like workload flavors and other internal details. ves.io/sites: determines the sites we are going to want the objects deployed to. This can be a Customer Site, a Virtual Site, or to all F5 XC Owned Regions. In our nginx.conf, All of these configs are standard as well with a location added for a health check and some self signed certs to force a secure channel. If you need a quick command to generate Cert & Key without searching: openssl req -x509 -nodes -subj '/CN=bind9.local' -newkey rsa:4096 -keyout /etc/ssl/private/dns.key -out /etc/ssl/certs/dns.pem -sha256 -days 3650 Server Block & Upstream upstream http2-doh { server 127.0.0.1:80; } server { listen 8080 default_server; listen 4443 ssl http2; server_name _; # TLS certificate chain and corresponding private key ssl_certificate /etc/ssl/certs/dns.pem; ssl_certificate_key /etc/ssl/private/dns.key; location / { grpc_pass grpc://http2-doh; } location /health-check { add_header Content-Type text/plain; return 200 'what is up buttercup?!'; } } Source: config-map.yml Deployment The deployment models in XC are pretty great, deploy to a cloud site, deploy to on-prem datacenters, deploy to our compute, or any combination. The services can then be published to the internet, to a cloud site, or to an on-prem site with all of the same security models for every facility. The deployment is pretty standard as well, the important pieces are ves.io/sites: this is important for the same reasons mentioned previously, but determines where the workloads will reside, with the same options as before. Environment Variables are where we need to tweek the settings a bit. A full listing of the values can be seen here:https://github.com/Mikej81/docker-bind Some of the values should be self-explanatory, but an important setting for a zone / a mapping is DNS_A. If there is a desire to bring in full zone files, it is possible to create that via a FILE value or a config map for Bind and storing the zone file in the proper named path and mapping the volume.**Not covered here** We will also be mapping some example self-signed certificates, which are only required if encryption is desired all the way to the container / pod. apiVersion: apps/v1 kind: Deployment metadata: name: bind-doh-dep labels: app: bind annotations: ves.io/sites: system/coleman-azure,system/coleman-cluster-100,system/colemantest spec: replicas: 1 selector: matchLabels: app: bind template: metadata: labels: app: bind spec: containers: - name: bind image: mcoleman81/bind-doh env: - name: DOCKER_LOGS value: "1" - name: ALLOW_QUERY value: "any" - name: ALLOW_RECURSION value: "any" - name: DNS_FORWARDER value: "8.8.8.8, 8.8.4.4" - name: DNS_A value: domain1.com=68.183.126.197,domain2.com=68.183.126.197 Source: deployment.yml Services We are almost done building out the manifest. We created the config map, we created the deployment, now we just need to expose some services. The targetPorts need to be above 1024 in the managed namespace so if those are changed, just follow that guideline. apiVersion: v1 kind: Service metadata: name: bind-services annotations: ves.io/sites: system/coleman-azure spec: type: ClusterIP selector: app: bind ports: - name: dns-udp port: 53 targetPort: 5553 protocol: UDP - name: dns-tcp port: 53 targetPort: 5353 protocol: TCP - name: dns-http port: 80 targetPort: 8888 protocol: TCP - name: nginx-http-listener port: 8080 targetPort: 8080 protocol: TCP - name: nginx-https-listener port: 4443 targetPort: 4443 protocol: TCP Source: service.yml Based on everything we have done, we know that the service name will be our [servicename].[namespace created previously], in my case it will be bind-services.m-coleman. We will need that value in a few steps when creating our Origin Pool. bind-manifest.yml Putting it all together! Full manifest can be found here:bind-manifest.yml Apply! kubectl apply -f bind-manifest.yml Application Deliver & Load Balancers HTTPS Origin Now we can create an origin pool. Over on the left menu, under Manage, Load Balancers, click Origin Pools. Let’s give our origin pool a name, and add some Origin Servers, so under Origin Servers, click Add Item. In the Origin Server settings, we want to select K8s Service Name of Origin Server on given Sites as our type, and enter our service name, which will be the service name we remembered from earlier and our namespace, so “servicename.namespace”. For the Site, we select one of the sites we deployed the workload to, and under Select Network on the Site, we want to select vK8s Networks on the Site, then click Apply. Do this for each site we deployed to so we have several servers in our Origin Pool. We also need to tweak the TLS settings since it will be encrypted over 4443 to the origin, but we don’t want to validate the certs since they are self-signed certs with low security settings, in my case, so update this as needed. Once everything is set right, click Save and Exit. HTTPS Load Balancer Now we need a load balancer, on the left menu bar, under Manage, select Load Balanacers and click HTTP Load Balancers. Click Add HTTP Load Balancer and lets assign a name. This is another location where configurations will diverge, for ease of deployment I am going to use an HTTPS Load Balancer with Auto Generated Certificates, but you can use HTTPS with Custom certificates as well. Note: For HTTPS with Auto-Certificate, Advertisement is Internet only, Custom Certificate allows Internet and Internal based advertising. HSTS is optional, as are most of the options shown below aside from Load Balancer Type and HTTPS Port. Under Origin, we Add Item and add the origin pool we created previously. Under Other Settings is where we can configure how & where the service is advertised. If we are going to advertise this service to an internal network only, we would select Custom here, then click configure. An example of what that would look like would be to click add item under the Custom Advertise VIP Configuration menu, Select the type of Site to advertise to, the type of interface to advertise on, and the specific site location. Click Apply as needed, then Save and Exit. Moment of Truth There are several ways to test to make sure we have everything up and running, first lets make sure our services are up. kubectl get services -n m-coleman NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE bind-services ClusterIP 192.168.175.193 <none> 53/UDP,53/TCP,80/TCP,8080/TCP,4443/TCP 3h57m Curl has built in DNS over HTTPS support so we can test via curl to see if our sites are resolving so first ill test one of our custom zones / A records. We are in business! We can also test with firefox or chrome or any number of other tools. Dig Dog Kdig Etc In Part 2 we will cover publishing TCP and UDP.2.6KViews11likes0CommentsUse F5 Distributed Cloud to service chain WAAP and CDN
The Content Delivery Network (CDN) market has become increasingly commoditized. Many providers have augmented their CDN capabilities with WAFs/WAAPs, DNS, load balancing, edge compute, and networking. Managing all these solutions together creates a web of operational complexity, which can be confusing. F5’s synergistic bundling of CDN with Web Application and API Protection (WAAP) benefits those looking for simplicity and ease of use. It provides a way around the complications and silos that many resource-strapped organizations face with their IT systems. This bundling also signifies how CDN has become a commodity product often not purchased independently anymore. This trend is encouraging many competitors to evolve their capabilities to include edge computing – a space where F5 has gained considerable experience in recent years. F5 is rapidly catching up to other providers’ CDNs. F5’s experience and leadership building the world’s best-of-breed Application Delivery Controller (ADC), the BIG-IP load balancer, put it in a unique position to offer the best application delivery and security services directly at the edge with many of its CDN points of presence. With robust regional edge capabilities and a global network, F5 has entered the CDN space with a complementary offering to an already compelling suite of features. This includes the ability to run microservices and Kubernetes workloads anywhere, with a complete range of services to support app infrastructure deployment, scale, and lifecycle management all within a single management console. With advancements made in the application security space at F5, WAAP capabilities are directly integrated into the Distributed Cloud Platform to protect both web apps and APIs. Features include (yet not limited to): Web Application Firewall: Signature + Behavioral WAF functionality Bot Defense: Detect client signals, determining if clients are human or automated DDoS Mitigation: Fully managed by F5 API Security: Continuous inspection and detection of shadow APIs Solution Combining the Distributed Cloud WAAP with CDN as a form of service chaining is a straightforward process. This not only gives you the best security protection for web apps and APIs, but also positions apps regionally to deliver them with low latency and minimal compute per request. In the following solution, we’ve combined Distributed Cloud WAAP and CDN to globally deliver an app protected by a WAF policy from the closest regional point of presence to the user. Follow along as I demonstrate how to configure the basic elements. Configuration Log in to the Distributed Cloud Console and navigate to the DNS Management service. Decide if you want Distributed Cloud to manage the DNS zone as a Primary DNS server or if you’d rather delegate the fully qualified domain name (FQDN) for your app to Distributed Cloud with a CNAME. While using Delegation or Managed DNS is optional, doing so makes it possible for Distributed Cloud to automatically create and manage the SSL certificates needed to securely publish your app. Next, in Distributed Cloud Console, navigate to the Web App and API Protection service, then go to App Firewall, then Add App Firewall. This is where you’ll create the security policy that we’ll later connect our HTTP LB. Let’s use the following basic WAF policy in YAML format, you can paste it directly in to the Console by changing the configuration view to JSON and then changing the format to YAML. Note: This uses the namespace “waap-cdn”, change this to match your individual tenant’s configuration. metadata: name: buytime-waf namespace: waap-cdn labels: {} annotations: {} disable: false spec: blocking: {} detection_settings: signature_selection_setting: default_attack_type_settings: {} high_medium_low_accuracy_signatures: {} enable_suppression: {} enable_threat_campaigns: {} default_violation_settings: {} bot_protection_setting: malicious_bot_action: BLOCK suspicious_bot_action: REPORT good_bot_action: REPORT allow_all_response_codes: {} default_anonymization: {} use_default_blocking_page: {} With the WAF policy saved, it’s time to configure the origin server. Navigate to Load Balancers > Origin Pools, then Add Origin Pool. The following YAML uses a FQDN DNS name reach the app server. Using an IP address for the server is possible as well. metadata: name: buytime-pool namespace: waap-cdn labels: {} annotations: {} disable: false spec: origin_servers: - public_name: dns_name: webserver.f5-cloud-demo.com labels: {} no_tls: {} port: 80 same_as_endpoint_port: {} healthcheck: [] loadbalancer_algorithm: LB_OVERRIDE endpoint_selection: LOCAL_PREFERRED With the supporting WAF and Origin Pool resources configured, it’s time to create the HTTP Load Balancer. Navigate to Load Balancers > HTTP Load Balancers, then create a new one. Use the following YAML to create the LB and use both resources created above. metadata: name: buytime-online namespace: waap-cdn labels: {} annotations: {} disable: false spec: domains: - buytime.waap.f5-cloud-demo.com https_auto_cert: http_redirect: true add_hsts: true port: 443 tls_config: default_security: {} no_mtls: {} default_header: {} enable_path_normalize: {} non_default_loadbalancer: {} header_transformation_type: default_header_transformation: {} advertise_on_public_default_vip: {} default_route_pools: - pool: tenant: your-tenant-uid namespace: waap-cdn name: buytime-pool kind: origin_pool weight: 1 priority: 1 endpoint_subsets: {} routes: [] app_firewall: tenant: your-tenant-uid namespace: waap-cdn name: buytime-waf kind: app_firewall add_location: true no_challenge: {} user_id_client_ip: {} disable_rate_limit: {} waf_exclusion_rules: [] data_guard_rules: [] blocked_clients: [] trusted_clients: [] ddos_mitigation_rules: [] service_policies_from_namespace: {} round_robin: {} disable_trust_client_ip_headers: {} disable_ddos_detection: {} disable_malicious_user_detection: {} disable_api_discovery: {} disable_bot_defense: {} disable_api_definition: {} disable_ip_reputation: {} disable_client_side_defense: {} resource_version: "517528014" With the HTTP LB successfully deployed, check that its status is ready on the status page. You can verify the LB is working by sending a basic request using the command line tool, curl. Confirm that the value of the HTTP header “Server” is “volt-adc”. da.potter@lab ~ % curl -I https://buytime.waap.f5-cloud-demo.com HTTP/2 200 date: Mon, 17 Oct 2022 23:23:55 GMT content-type: text/html; charset=UTF-8 content-length: 2200 vary: Origin access-control-allow-credentials: true accept-ranges: bytes cache-control: public, max-age=0 last-modified: Wed, 24 Feb 2021 11:06:36 GMT etag: W/"898-177d3b82260" x-envoy-upstream-service-time: 136 strict-transport-security: max-age=31536000 set-cookie: 1f945=1666049035840-557942247; Path=/; Domain=f5-cloud-demo.com; Expires=Sun, 17 Oct 2032 23:23:55 GMT set-cookie: 1f9403=viJrSNaAp766P6p6EKZK7nyhofjXCVawnskkzsrMBUZIoNQOEUqXFkyymBAGlYPNQXOUBOOYKFfs0ne+fKAT/ozN5PM4S5hmAIiHQ7JAh48P4AP47wwPqdvC22MSsSejQ0upD9oEhkQEeTG1Iro1N9sLh+w+CtFS7WiXmmJFV9FAl3E2; path=/ x-volterra-location: wes-sea server: volt-adc Now it’s time to configure the CDN Distribution and service chain it to the WAAP HTTP LB. Navigate to Content Delivery Network > Distributions, then Add Distribution. The following YAML creates a basic CDN configuration that uses the WAAP HTTP LB above. metadata: name: buytime-cdn namespace: waap-cdn labels: {} annotations: {} disable: false spec: domains: - buytime.f5-cloud-demo.com https_auto_cert: http_redirect: true add_hsts: true tls_config: tls_12_plus: {} add_location: false more_option: cache_ttl_options: cache_ttl_override: 1m origin_pool: public_name: dns_name: buytime.waap.f5-cloud-demo.com use_tls: use_host_header_as_sni: {} tls_config: default_security: {} volterra_trusted_ca: {} no_mtls: {} origin_servers: - public_name: dns_name: buytime.waap.f5-cloud-demo.com follow_origin_redirect: false resource_version: "518473853" After saving the configuration, verify that the status is “Active”. You can confirm the CDN deployment status for each individual region by going to the distribution’s action button “Show Global Status”, and scrolling down to each region to see that each region’s “site_status.status” value is “DEPLOYMENT_STATUS_DEPLOYED”. Verification With the CDN Distribution successfully deployed, it’s possible to confirm with the following basic request using curl. Take note of the two HTTP headers “Server” and “x-cache-status”. The Server value will now be “volt-cdn”, and the x-cache-status will be “MISS” for the first request. da.potter@lab ~ % curl -I https://buytime.f5-cloud-demo.com HTTP/2 200 date: Mon, 17 Oct 2022 23:24:04 GMT content-type: text/html; charset=UTF-8 content-length: 2200 vary: Origin access-control-allow-credentials: true accept-ranges: bytes cache-control: public, max-age=0 last-modified: Wed, 24 Feb 2021 11:06:36 GMT etag: W/"898-177d3b82260" x-envoy-upstream-service-time: 63 strict-transport-security: max-age=31536000 set-cookie: 1f945=1666049044863-471593352; Path=/; Domain=f5-cloud-demo.com; Expires=Sun, 17 Oct 2032 23:24:04 GMT set-cookie: 1f9403=aCNN1JINHqvWPwkVT5OH3c+OIl6+Ve9Xkjx/zfWxz5AaG24IkeYqZ+y6tQqE9CiFkNk+cnU7NP0EYtgGnxV0dLzuo3yHRi3dzVLT7PEUHpYA2YSXbHY6yTijHbj/rSafchaEEnzegqngS4dBwfe56pBZt52MMWsUU9x3P4yMzeeonxcr; path=/ x-volterra-location: dal3-dal server: volt-cdn x-cache-status: MISS strict-transport-security: max-age=31536000 To see a security violation detected by the WAF in real-time, you can simulate a simple XSS exploit with the following curl: da.potter@lab ~ % curl -Gv "https://buytime.f5-cloud-demo.com?<script>('alert:XSS')</script>" * Trying x.x.x.x:443... * Connected to buytime.f5-cloud-demo.com (x.x.x.x) port 443 (#0) * ALPN, offering h2 * ALPN, offering http/1.1 * successfully set certificate verify locations: * CAfile: /etc/ssl/cert.pem * CApath: none * (304) (OUT), TLS handshake, Client hello (1): * (304) (IN), TLS handshake, Server hello (2): * TLSv1.2 (IN), TLS handshake, Certificate (11): * TLSv1.2 (IN), TLS handshake, Server key exchange (12): * TLSv1.2 (IN), TLS handshake, Server finished (14): * TLSv1.2 (OUT), TLS handshake, Client key exchange (16): * TLSv1.2 (OUT), TLS change cipher, Change cipher spec (1): * TLSv1.2 (OUT), TLS handshake, Finished (20): * TLSv1.2 (IN), TLS change cipher, Change cipher spec (1): * TLSv1.2 (IN), TLS handshake, Finished (20): * SSL connection using TLSv1.2 / ECDHE-ECDSA-AES256-GCM-SHA384 * ALPN, server accepted to use h2 * Server certificate: * subject: CN=buytime.f5-cloud-demo.com * start date: Oct 14 23:51:02 2022 GMT * expire date: Jan 12 23:51:01 2023 GMT * subjectAltName: host "buytime.f5-cloud-demo.com" matched cert's "buytime.f5-cloud-demo.com" * issuer: C=US; O=Let's Encrypt; CN=R3 * SSL certificate verify ok. * Using HTTP2, server supports multiplexing * Connection state changed (HTTP/2 confirmed) * Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0 * Using Stream ID: 1 (easy handle 0x14f010000) > GET /?<script>('alert:XSS')</script> HTTP/2 > Host: buytime.f5-cloud-demo.com > user-agent: curl/7.79.1 > accept: */* > * Connection state changed (MAX_CONCURRENT_STREAMS == 128)! < HTTP/2 200 < date: Sat, 22 Oct 2022 01:04:39 GMT < content-type: text/html; charset=UTF-8 < content-length: 269 < cache-control: no-cache < pragma: no-cache < set-cookie: 1f945=1666400679155-452898837; Path=/; Domain=f5-cloud-demo.com; Expires=Fri, 22 Oct 2032 01:04:39 GMT < set-cookie: 1f9403=/1b+W13c7xNShbbe6zE3KKUDNPCGbxRMVhI64uZny+HFXxpkJMsCKmDWaihBD4KWm82reTlVsS8MumTYQW6ktFQqXeFvrMDFMSKdNSAbVT+IqQfSuVfVRfrtgRkvgzbDEX9TUIhp3xJV3R1jdbUuAAaj9Dhgdsven8FlCaADENYuIlBE; path=/ < x-volterra-location: dal3-dal < server: volt-cdn < x-cache-status: MISS < strict-transport-security: max-age=31536000 < <html><head><title>Request Rejected</title></head> <body>The requested URL was rejected. Please consult with your administrator.<br/><br/> Your support ID is 85281693-eb72-4891-9099-928ffe00869c<br/><br/><a href='javascript:history.back();'>[Go Back]</a></body></html> * Connection #0 to host buytime.f5-cloud-demo.com left intact Notice that the above request intentionally by-passes the CDN cache and is sent to the HTTP LB for the WAF policy to inspect. With this request rejected, you can confirm the attack by navigating to the WAAP HTTP LB Security page under the WAAP Security section within Apps & APIs. After refreshing the page, you’ll see the security violation under the “Top Attacked” panel. Demo To see all of this in action, watch my video below. This uses all of the configuration details above to make a WAAP + CDN service chain in Distributed Cloud. Additional Guides Virtually deploy this solution in our product simulator, or hands-on with step-by-step comprehensive demo guide. The demo guide includes all the steps, including those that are needed prior to deployment, so that once deployed, the solution works end-to-end without any tweaks to local DNS. The demo guide steps can also be automated with Ansible, in case you'd either like to replicate it or simply want to jump to the end and work your way back. Conclusion This shows just how simple it can be to use the Distributed Cloud CDN to frontend your web app protected by a WAF, all natively within the F5 Distributed Cloud’s regional edge POPs. The advantage of this solution should now be clear – the Distributed Cloud CDN is cloud-agnostic, flexible, agile, and you can enforce security policies anywhere, regardless of whether your web app lives on-prem, in and across clouds, or even at the edge. For more information about Distributed Cloud WAAP and Distributed Cloud CDN, visit the following resources: Product website: https://www.f5.com/cloud/products/cdn Distributed Cloud CDN & WAAP Demo Guide: https://github.com/f5devcentral/xcwaapcdnguide Video: https://youtu.be/OUD8R6j5Q8o Simulator: https://simulator.f5.com/s/waap-cdn Demo Guide: https://github.com/f5devcentral/xcwaapcdnguide7KViews10likes0Comments