api
70 TopicsGetting started with the F5 Distributed Cloud Web App and API Protection Demo Guide
Overview Sometimes all it takes to get started learning something new is just a little guidance, for those times when we just don't know where to begin. Providing that direction is the purpose of the F5 Distributed Cloud Web App and API Protection (XC WAAP) demo guide. The guide and accompanying demo videos will run you through sample app deployment, as well as App, API, Bot, and DDoS Protection use cases. We provide the app, the testing tool, and the guidance, everything you need to get started and kick the tires. All you need to bring is an F5 Distributed Cloud Account (trial is sufficient for this demo guide) and a bit of time. The guide uses a representative customer app scenario: a Star Ratings application which collects user ratings and reviews/comments on various items. The app runs on Kubernetes, and can be deployed on any cloud, but for the purposes of the demo guide we will deploy it on F5 XC virtual Kubernetes (vK8s) and protect it with F5 XC WAAP. The Scenario The Guide https://github.com/f5devcentral/xcwaapdemoguide Video Series Part 1: Infrastructure Setup Video Series Part 2: WAF Configuration Video Series Part 3: API Protection Video Series Part 4: Bot & DDoS Detection and Protection "Nature is a mutable cloud, which is always and never the same." - Ralph Waldo Emerson We might not wax that philosophically around here, but our heads are in the cloud nonetheless! Join the F5 Distributed Cloud user group today and learn more with your peers and other F5 experts. 4.8KViews7likes0Comments
4.8KViews7likes0CommentsApplication Programming Interface (API) Authentication types simplified
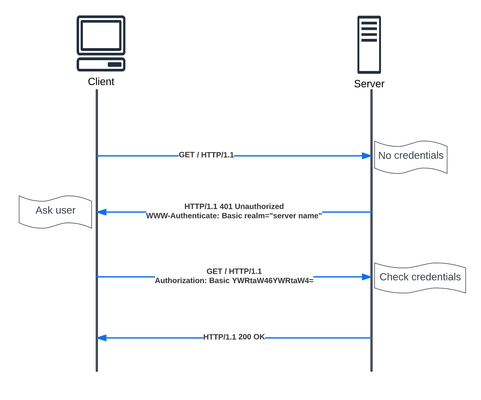
API is a critical part of most of our modern applications. In this article we will walkthrough the different authentication types, to help us in the future articles covering NGINX API Connectivity Manager authentication and NGINX Single Sign-on.4KViews5likes0CommentsAdvanced WAF v16.0 - Declarative API
Since v15.1 (in draft), F5® BIG-IP® Advanced WAF™ can import Declarative WAF policy in JSON format. The F5® BIG-IP® Advanced Web Application Firewall (Advanced WAF) security policies can be deployed using the declarative JSON format, facilitating easy integration into a CI/CD pipeline. The declarative policies are extracted from a source control system, for example Git, and imported into the BIG-IP. Using the provided declarative policy templates, you can modify the necessary parameters, save the JSON file, and import the updated security policy into your BIG-IP devices. The declarative policy copies the content of the template and adds the adjustments and modifications on to it. The templates therefore allow you to concentrate only on the specific settings that need to be adapted for the specific application that the policy protects. This Declarative WAF JSON policy is similar to NGINX App Protect policy. You can find more information on the Declarative Policy here : NAP : https://docs.nginx.com/nginx-app-protect/policy/ Adv. WAF : https://techdocs.f5.com/en-us/bigip-15-1-0/big-ip-declarative-security-policy.html Audience This guide is written for IT professionals who need to automate their WAF policy and are familiar with Advanced WAF configuration. These IT professionals can fill a variety of roles: SecOps deploying and maintaining WAF policy in Advanced WAF DevOps deploying applications in modern environment and willing to integrate Advanced WAF in their CI/CD pipeline F5 partners who sell technology or create implementation documentation This article covers how to PUSH/PULL a declarative WAF policy in Advanced WAF: With Postman With AS3 Table of contents Upload Policy in BIG-IP Check the import Apply the policy OpenAPI Spec File import AS3 declaration CI/CD integration Find the Policy-ID Update an existing policy Video demonstration First of all, you need a JSON WAF policy, as below : { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false } } } 1. Upload Policy in BIG-IP There are 2 options to upload a JSON file into the BIG-IP: 1.1 Either you PUSH the file into the BIG-IP and you IMPORT IT OR 1.2 the BIG-IP PULL the file from a repository (and the IMPORT is included) <- BEST option 1.1 PUSH JSON file into the BIG-IP The call is below. As you can notice, it requires a 'Content-Range' header. And the value is 0-(filesize-1)/filesize. In the example below, the file size is 662 bytes. This is not easy to integrate in a CICD pipeline, so we created the PULL method instead of the PUSH (in v16.0) curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/file-transfer/uploads/policy-api.json' \ --header 'Content-Range: 0-661/662' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --header 'Content-Type: application/json' \ --data-binary '@/C:/Users/user/Desktop/policy-api.json' At this stage, the policy is still a file in the BIG-IP file system. We need to import it into Adv. WAF. To do so, the next call is required. This call import the file "policy-api.json" uploaded previously. An CREATE the policy /Common/policy-api-arcadia curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Content-Type: application/javascript' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --data-raw '{ "filename":"policy-api.json", "policy": { "fullPath":"/Common/policy-api-arcadia" } }' 1.2 PULL JSON file from a repository Here, the JSON file is hosted somewhere (in Gitlab or Github ...). And the BIG-IP will pull it. The call is below. As you can notice, the call refers to the remote repo and the body is a JSON payload. Just change the link value with your JSON policy URL. With one call, the policy is PULLED and IMPORTED. curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Content-Type: application/json' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --data-raw '{ "fileReference": { "link": "http://10.1.20.4/root/as3-waf/-/raw/master/policy-api.json" } }' A second version of this call exists, and refer to the fullPath of the policy. This will allow you to update the policy, from a second version of the JSON file, easily. One call for the creation and the update. As you can notice below, we add the "policy":"fullPath" directive. The value of the "fullPath" is the partition and the name of the policy set in the JSON policy file. This method is VERY USEFUL for CI/CD integrations. curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Content-Type: application/json' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --data-raw '{ "fileReference": { "link": "http://10.1.20.4/root/as3-waf/-/raw/master/policy-api.json" }, "policy": { "fullPath":"/Common/policy-api-arcadia" } }' 2. Check the IMPORT Check if the IMPORT worked. To do so, run the next call. curl --location --request GET 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ You should see a 200 OK, with the content below (truncated in this example). Please notice the "status":"COMPLETED". { "kind": "tm:asm:tasks:import-policy:import-policy-taskcollectionstate", "selfLink": "https://localhost/mgmt/tm/asm/tasks/import-policy?ver=16.0.0", "totalItems": 11, "items": [ { "isBase64": false, "executionStartTime": "2020-07-21T15:50:22Z", "status": "COMPLETED", "lastUpdateMicros": 1.595346627e+15, "getPolicyAttributesOnly": false, ... From now, your policy is imported and created in the BIG-IP. You can assign it to a VS as usual (Imperative Call or AS3 Call). But in the next session, I will show you how to create a Service with AS3 including the WAF policy. 3. APPLY the policy As you may know, a WAF policy needs to be applied after each change. This is the call. curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/tasks/apply-policy/' \ --header 'Content-Type: application/json' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --data-raw '{"policy":{"fullPath":"/Common/policy-api-arcadia"}}' 4. OpenAPI spec file IMPORT As you know, Adv. WAF supports OpenAPI spec (2.0 and 3.0). Now, with the declarative WAF, we can import the OAS file as well. The BEST solution, is to PULL the OAS file from a repo. And in most of the customer' projects, it will be the case. In the example below, the OAS file is hosted in SwaggerHub (Github for Swagger files). But the file could reside in a private Gitlab repo for instance. The URL of the project is : https://app.swaggerhub.com/apis/F5EMEASSA/Arcadia-OAS3/1.0.0-oas3 The URL of the OAS file is : https://api.swaggerhub.com/apis/F5EMEASSA/Arcadia-OAS3/1.0.0-oas3 This swagger file (OpenAPI 3.0 Spec file) includes all the application URL and parameters. What's more, it includes the documentation (for NGINX APIm Dev Portal). Now, it is pretty easy to create a WAF JSON Policy with API Security template, referring to the OAS file. Below, you can notice the new section "open-api-files" with the link reference to SwaggerHub. And the new template POLICY_TEMPLATE_API_SECURITY. Now, when I upload / import and apply the policy, Adv. WAF will download the OAS file from SwaggerHub and create the policy based on API_Security template. { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "https://api.swaggerhub.com/apis/F5EMEASSA/Arcadia-OAS3/1.0.0-oas3" } ] } } 5. AS3 declaration Now, it is time to learn how we can do all of these steps in one call with AS3 (3.18 minimum). The documentation is here : https://clouddocs.f5.com/products/extensions/f5-appsvcs-extension/latest/declarations/application-security.html?highlight=waf_policy#virtual-service-referencing-an-external-security-policy With this AS3 declaration, we: Import the WAF policy from a external repo Import the Swagger file (if the WAF policy refers to an OAS file) from an external repo Create the service { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.2.0", "id": "Prod_API_AS3", "API-Prod": { "class": "Tenant", "defaultRouteDomain": 0, "API": { "class": "Application", "template": "generic", "VS_API": { "class": "Service_HTTPS", "remark": "Accepts HTTPS/TLS connections on port 443", "virtualAddresses": ["10.1.10.27"], "redirect80": false, "pool": "pool_NGINX_API_AS3", "policyWAF": { "use": "Arcadia_WAF_API_policy" }, "securityLogProfiles": [{ "bigip": "/Common/Log all requests" }], "profileTCP": { "egress": "wan", "ingress": { "use": "TCP_Profile" } }, "profileHTTP": { "use": "custom_http_profile" }, "serverTLS": { "bigip": "/Common/arcadia_client_ssl" } }, "Arcadia_WAF_API_policy": { "class": "WAF_Policy", "url": "http://10.1.20.4/root/as3-waf-api/-/raw/master/policy-api.json", "ignoreChanges": true }, "pool_NGINX_API_AS3": { "class": "Pool", "monitors": ["http"], "members": [{ "servicePort": 8080, "serverAddresses": ["10.1.20.9"] }] }, "custom_http_profile": { "class": "HTTP_Profile", "xForwardedFor": true }, "TCP_Profile": { "class": "TCP_Profile", "idleTimeout": 60 } } } } } 6. CI/CID integration As you can notice, it is very easy to create a service with a WAF policy pulled from an external repo. So, it is easy to integrate these calls (or the AS3 call) into a CI/CD pipeline. Below, an Ansible playbook example. This playbook run the AS3 call above. That's it :) --- - hosts: bigip connection: local gather_facts: false vars: my_admin: "admin" my_password: "admin" bigip: "10.1.1.12" tasks: - name: Deploy AS3 WebApp uri: url: "https://{{ bigip }}/mgmt/shared/appsvcs/declare" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic YWRtaW46YWRtaW4=" body: "{{ lookup('file','as3.json') }}" body_format: json validate_certs: no status_code: 200 7. FIND the Policy-ID When the policy is created, a Policy-ID is assigned. By default, this ID doesn't appear anywhere. Neither in the GUI, nor in the response after the creation. You have to calculate it or ask for it. This ID is required for several actions in a CI/CD pipeline. 7.1 Calculate the Policy-ID We created this python script to calculate the Policy-ID. It is an hash from the Policy name (including the partition). For the previous created policy named "/Common/policy-api-arcadia", the policy ID is "Ar5wrwmFRroUYsMA6DuxlQ" Paste this python code in a new waf-policy-id.py file, and run the command python waf-policy-id.py "/Common/policy-api-arcadia" Outcome will be The Policy-ID for /Common/policy-api-arcadia is: Ar5wrwmFRroUYsMA6DuxlQ #!/usr/bin/python from hashlib import md5 import base64 import sys pname = sys.argv[1] print 'The Policy-ID for', sys.argv[1], 'is:', base64.b64encode(md5(pname.encode()).digest()).replace("=", "") 7.2 Retrieve the Policy-ID and fullPath with a REST API call Make this call below, and you will see in the response, all the policy creations. Find yours and collect the PolicyReference directive. The Policy-ID is in the link value "link": "https://localhost/mgmt/tm/asm/policies/Ar5wrwmFRroUYsMA6DuxlQ?ver=16.0.0" You can see as well, at the end of the definition, the "fileReference" referring to the JSON file pulled by the BIG-IP. And please notice the "fullPath", required if you want to update your policy curl --location --request GET 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Content-Range: 0-601/601' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ { "isBase64": false, "executionStartTime": "2020-07-22T11:23:42Z", "status": "COMPLETED", "lastUpdateMicros": 1.595417027e+15, "getPolicyAttributesOnly": false, "kind": "tm:asm:tasks:import-policy:import-policy-taskstate", "selfLink": "https://localhost/mgmt/tm/asm/tasks/import-policy/B45J0ySjSJ9y9fsPZ2JNvA?ver=16.0.0", "filename": "", "policyReference": { "link": "https://localhost/mgmt/tm/asm/policies/Ar5wrwmFRroUYsMA6DuxlQ?ver=16.0.0", "fullPath": "/Common/policy-api-arcadia" }, "endTime": "2020-07-22T11:23:47Z", "startTime": "2020-07-22T11:23:42Z", "id": "B45J0ySjSJ9y9fsPZ2JNvA", "retainInheritanceSettings": false, "result": { "policyReference": { "link": "https://localhost/mgmt/tm/asm/policies/Ar5wrwmFRroUYsMA6DuxlQ?ver=16.0.0", "fullPath": "/Common/policy-api-arcadia" }, "message": "The operation was completed successfully. The security policy name is '/Common/policy-api-arcadia'. " }, "fileReference": { "link": "http://10.1.20.4/root/as3-waf/-/raw/master/policy-api.json" } }, 8 UPDATE an existing policy It is pretty easy to update the WAF policy from a new JSON file version. To do so, collect from the previous call 7.2 Retrieve the Policy-ID and fullPath with a REST API call the "Policy" and "fullPath" directive. This is the path of the Policy in the BIG-IP. Then run the call below, same as 1.2 PULL JSON file from a repository, but add the Policy and fullPath directives Don't forget to APPLY this new version of the policy 3. APPLY the policy curl --location --request POST 'https://10.1.1.12/mgmt/tm/asm/tasks/import-policy/' \ --header 'Content-Type: application/json' \ --header 'Authorization: Basic YWRtaW46YWRtaW4=' \ --data-raw '{ "fileReference": { "link": "http://10.1.20.4/root/as3-waf/-/raw/master/policy-api.json" }, "policy": { "fullPath":"/Common/policy-api-arcadia" } }' TIP : this call, above, can be used in place of the FIRST call when we created the policy "1.2 PULL JSON file from a repository". But be careful, the fullPath is the name set in the JSON policy file. The 2 values need to match: "name": "policy-api-arcadia" in the JSON Policy file pulled by the BIG-IP "policy":"fullPath" in the POST call 9 Video demonstration In order to help you to understand how it looks with the BIG-IP, I created this video covering 4 topics explained in this article : The JSON WAF policy Pull the policy from a remote repository Update the WAF policy with a new version of the declarative JSON file Deploy a full service with AS3 and Declarative WAF policy At the end of this video, you will be able to adapt the REST Declarative API calls to your infrastructure, in order to deploy protected services with your CI/CD pipelines. Direct link to the video on DevCentral YouTube channel : https://youtu.be/EDvVwlwEFRw3.9KViews5likes2Comments
Securing APIs with BigIP
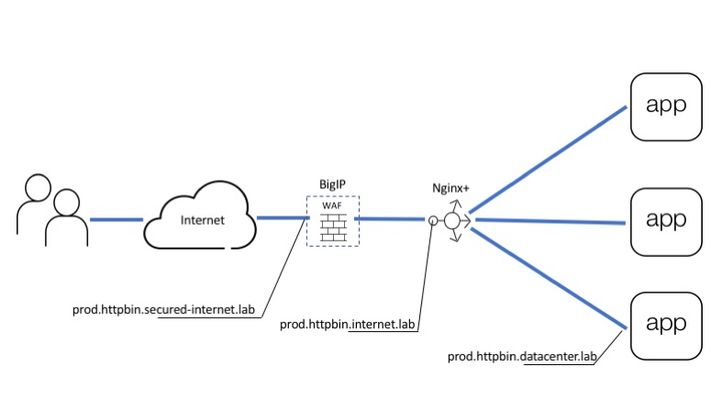
Introduction API servers respond to requests using the HTTP protocol, much like Web Servers. Therefore, API servers are susceptible to HTTP attacks in ways similar to Web Servers. Previous articles covered how to publish an API using the NGINX platform as an API management gateway. These APIs are still exposed to web attacks and defensive mechanisms are needed to defend the API against web attacks, denial of service, and Bots. The diagram below shows all the layers needed to deliver and defend APIs. BIGIP provides the protection and NGINX Plus provides API management. Picture 1. This article covers Advanced Web Application Firewall (AWAF) to protect against HTTP vulnerabilities Unified Bot Defense to protect against bots Behavioral Anomaly DoS Defense to prevent DoS attacks As shown in Picture 1, above BIG-IP goes in front of the API management gateway as an additional security gateway. The beauty of this approach is that BIG-IP can be initially deployed on the side while the API is being delivered to users through the NGINX Plus gateway directly. Once BIG-IP is configured to forward good requests to NGINX Plus and security policies are in place, BIG-IP can be brought into the traffic flow by simply changing the DNS records for "prod.httpbin.internet.lab" to point to BIG-IP instead of NGINX Plus. From this point on all calls will automatically arrive at BIG-IP for inspection and only those that pass all verifications will be forwarded to the next layer. Configuring Data Path Data path configuration for this use case is pretty common for BIG-IP which is historically a load balancer. It includes: Virtual Server (listens for API calls) SSL profile (defines SSL settings) SSL certificate and key (cryptographically identifies virtual server) Pool (destination for passed calls) Picture below shows how all of the configuration pieces work together. Picture 3. At first upload server certificate and key Setup SSL profile to use a certificate from the previous step Finally, create a virtual server and a pool to accept API calls and forward them to the backend From this point IG-IP accepts all requests which go to "prod.httpbin.secured-internet.lab" hostname and forwards them to API management gateway powered by NGINX Plus. Setting up WAF policy As you may already know every API starts from the OpenAPI file which describes all available endpoints, parameters, authentication methods, etc. This file contains all details related to API definition and it is widely used by most tools including F5's WAF for self-configuration. Imported OpenAPI file automatically configures policy with all API specific parameters as a list of allowed URLs, parameters, methods, and so on. Therefore WAF configuration narrows down to importing OpenAPI file and using policy template for API security. Create a policy Specify policy name, template, swagger file, virtual server and logging profile. API security template pre-configures WAF policy with all necessary violations and signatures to protect API backend. OpenAPI file introduces application-specific configuration to a policy as a list of allowed URLs, parameters, and methods. That is it. WAF policy is configured and assigned to the virtual server. Now we can test that only legitimate requests to allowed resources go through. For example request to URL which does not exist in the policy will be blocked: ubuntu@ip-10-1-1-7:~$ http -v https://prod.httpbin.secured-internet.lab/urldoesntexist GET /urldoesntexist HTTP/1.1 Accept: */* Accept-Encoding: gzip, deflate Connection: keep-alive Host: prod.httpbin.secured-internet.lab User-Agent: HTTPie/0.9.2 HTTP/1.1 403 Forbidden Cache-Control: no-cache Connection: close Content-Length: 38 Content-Type: application/json; charset=utf-8 Pragma: no-cache { "supportID": "1656927099224588298" } Request with SQL injection also blocked: Configuring Bot Defense Starting from BIG-IP release 14.1 proactive bot defense, web scraping, and bot detection features are combined under Bot Defense profile. Therefore current bot defense forms a unified tool to prevent all types of bots from accessing your web asset. Bot detection and mitigation mechanisms heavily rely on signatures and javascript (JS) based challenges. JS challenges run in a client browser and help to identify client type/malicious activities or apply mitigation by injecting a CAPTCHA or slowing down a client by making a browser perform a heavy calculation. Since this article is focused on protecting APIs it is important to note that JS challenges need to be used with caution in this case. Keep in mind that robots might be legitimate users for an API. However, robots similar to bots can not execute javascript. So when a robot receives JS it considers JS as API response. Such response does not align with what a robot expects and the application may break. If you know an API is serving automated processes avoid the use of JS-based challenges or test every JS-based feature in the staging environment first. Configuration to detect and handle many different types of Bots can be simplified by using any of the three pre-configured security modes: Relaxed (Challenge free, mitigates only 100% bad bots based on signatures ) Balanced (Let suspicious clients prove good behavior by executing JS challenges or solving CAPTCHA) Strict (Blocks all kinds of bots, verifies browsers, and collects device id from all clients) It is best to start with the relaxed template and tighten up the configuration as familiarity grows with the traffic that the API endpoints see. Once the profile is created assign it to the same virtual server at "Local Traffic ›› Virtual Servers : Virtual Server List ›› prod.httpbin.secured-internet.lab ›› Security" page. Such configuration performs bot detection based on data that is available in requests such as URL, user-agent, or header order. This mode is safe for all kinds of API users (browser-based or code-based robots) and you can see transaction outcome on "Security ›› Event Logs : Bot Defense : Bot Requests" page. If there are false positives you can adjust bot status or create a new trusted one for your robots through "Security ›› Bot Defense : Bot Signatures : Bot Signatures List". Setting Up DDoS Defense WAF and BOT defenses can detect requests with attack signatures or requests that are generated by malicious clients. However, attackers can send attacks composed of legitimate requests at a high scale, that can bring down an API endpoint. The following features present in the BIG-IP can be used to defeat Denial of Service attacks against API endpoints. Transaction per second (TPS) Based DoS Defense Stress Based DoS Defense Behavioral Anomaly Based DoS Defense Eviction Policies TPS-based DoS defense is the most straightforward protection mechanism. In this mode, BigIP measures requests rate for parameters such as Source IP, URL, Site, etc. In case the per minute rate becomes higher than the configured threshold then the attack gets triggered, and selected mitigation modes are applied to ‘all’ requests identified by the parameter. The stress-based mode works similarly to TPS, but instead of applying mitigation right after the threshold is crossed it only mitigates when the protected asset is under stress. This approach significantly reduces false positives. Behavioral anomaly detection (BADoS) mode offers the most advanced security and accuracy. This mode does not require the administrator to perform any configuration, other than turning the feature on. A machine learning algorithm is used to detect whether the protected asset is under attack or not. Another machine learning algorithm is used to baseline the traffic in peacetime. When the ‘attack detector algorithm’ identifies that the protected asset is under stress and non-responsive, then the second algorithm stops learning and looks for anomalies. Signatures matching these anomalies are automatically created. Anomalies discovered during attack time are likely nefarious and are eliminated from the traffic by application of dynamically discovered signatures. BADoS will automatically build a good traffic baseline, detect anomalies and stop them if the API endpoint is under stress. Conclusion F5 offers a multi-layered solution for protecting APIs, which is easy to configure. Please connect with me via comments and keep an eye on more articles in this series. Good luck!3.8KViews2likes2CommentsiControl Library For Java With Source
Included are the binary distribution of the iControl library for Java and Apache Axis. These releases coincides through version BIG-IP, version 13.0.0. iControl Assembly for Java 11.3.0 iControl Assembly for Java 11.4.0 iControl Assembly for Java 11.4.1 iControl Assembly for Java 11.5.0 iControl Assembly for Java 11.6.0 iControl Assembly for Java 12.0.0 iControl Assembly for Java 12.1.0 iControl Assembly for Java 13.0.0 iControl Assembly for Java 13.1.0 The source distribution of the iControl library for Java with Apache Axis. These releases coincide through version BIG-IP, version 12.1.0. The source code for this project is no longer maintained but available at our at f5-icontrol-library-java repository on GitHub. iControl Assembly Java Source 11.4.0 (older release not available on Github) iControl Assembly Java Source 11.4.1 iControl Assembly Java Source 11.5.0 iControl Assembly Java Source 11.6.0 iControl Assembly Java Source 12.1.03.4KViews0likes0CommentsBehavioral DDOS Grafana Dashboard using BIG-IP APIs
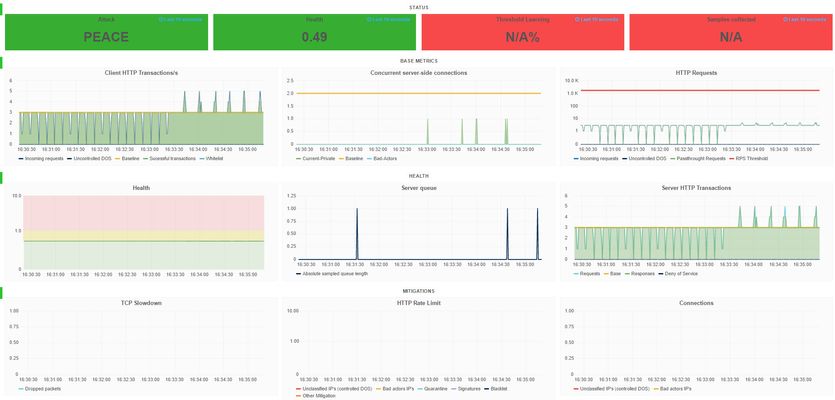
From the desk of Pavel Borovsky (March 15, 2017) F5 L7 Behavioral DDOS feature provides with API's to monitor and debug the detection and mitigation process in real time. To provide an example on how to use the API we developed Grafana plugin that utilizes the API and shows real time data on the Dos attacks. How to install the Dashboard on Grafana: Install Grafana 4.1 Install the following panels: grafana-piechart-panel https://grafana.net/plugins/grafana-piechart-panel grafana-worldmap-panel https://grafana.net/plugins/grafana-worldmap-panel mtanda-histogram-panel https://grafana.net/plugins/mtanda-histogram-panel Install admdb plugin copy data\plugins\grafana-admdb-datasource copy public\dashboards*.json enable dashboards Configure the dashboard(see example defaults.ini attached) edit conf/defaults.ini modify these lines: [dashboards.json] enabled = true path = public/dashboards Enable admdb on big IP: tmsh modify sys db adm.cloud.host value local Add data source to Grafana using web interface as in the following screenshot: Download the Grafana bados dahsboard here.2.7KViews1like2CommentsSecuring SSL Keys on your BIG-IP
Losing your keys is a real problem While losing your car keys is indeed a pain, I mean losing your Web Server Keys. Lost keys can expose your website to a Man in The Middle (MiTM) Attack. While in the middle, an attacker can use those keys to decrypt the traffic between your clients and your servers. All of the data is open to be read by the hacker. How can we help make sure you're not the poor soul in the picture? Let's start with a little Crypto background. What is a Cryptographic key? A cryptographic key is pretty much like any other key. It unlocks a door; in this case, the door is a ciphered piece of text. I'll save the mechanics for what enciphering and deciphering are for another time, but suffice to say when traffic is encrypted, we need to encrypt it in such a way that it cannot be easily decrypted. In asymmetric encryption, there are two files – one is a certificate (the lock on the door—also known as the “public key”), and the other one is the key (the, uh, key?--also known as the “private key”). The certificate is the public part anybody can have. We share that readily, possibly through infrastructure that automatically transfers the info or delivers the certificate over a handshake or an email. An example of an RSA certificate file … slightly obfuscated because I am somewhat paranoid. The key itself is what stores the secret component, and it is the file we need to protect. An example of an RSA key file. Storing Cryptographic Files We can protect our key by storing it somewhere securely and ensuring that access is extremely limited. There are tools, like hardware security modules (HSM) that do this for us, and there are standards like Federal Information Processing Standard (FIPS) 140 (https://csrc.nist.gov/publications/detail/fips/140/3/final) which define many of the specifications around storing keys, including access and retention. When there are 1000s of keys to manage, it makes sense to invest in these tools. For others, we might just want to store them in a secure location, and there are several ways to do that. File Storage Indeed, the first is file access controls. We can limit access to these files using ACLs and read/write protection, and we definitely should do that. By default, on Linux distributions, you haveto correctly set the file permissions for some applications to even use your keys. Properly setting the file permissions is necessary, but with this mechanism alone, anyone who is able to get the necessary access to any of the systems storing the key can copy the key—it is just a small string of text--and do whatever they want with it. While gaining access to a BIGIP is not simple, there are many ways this can be done such as a disgruntled administrator, a vulnerability, a weak access password, and so on. Further, OpenSSL (www.openssl.org) provides a means to add a passphrase to this file so that instead of storing the file data as plain text, the file itself is enciphered with a passphrase even to read it. Shown here is a file – the same "key" even – without and then with a passphrase: Plaintext key file. You will notice that in the image above, we can read the key's text is displayed right after the header – that is THE KEY itself. Key file protected with an OpenSSL Passphrase enciphered with AES256. However, in the next image, there's a "Proc-Type:" and "DEK-Info:" header. The text of the file is NOT the actual key but an enciphered version of the key. Doing this means that, even with file access, an attacker would still need to get the Passphrase to use the key. It adds an extra factor of authentication to use the file. It is not as secure as a Hardware Security Module, but it is at least another layer of protection from unwanted access to your keys. Now, note that the key itself has not changed. The file is the only change. Once you read the file with the proper access, the resulting key string remains the same. Passphrases and TMOS Within the BIG-IP configuration, these files are stored in an unencrypted version or an encrypted version depending on whether or not a Passphrase was supplied when they were loaded. To protect the Passphrase-protected files, TMOS includes Secure Vault (https://support.f5.com/csp/article/K73034260), which uses a "Master Key" which encrypts the file passphrases into the BIG-IP configuration. TMOS stores the OpenSSL Passphrase, but the Passphrase itself is stored in an encrypted format in the configuration files. To access the keys, you now need both the required TMOS access permissions and the Passphrase to read the contents. So, merely gaining access to the system is not enough to steal the key and use it to decrypt confidential data! Neat, huh? But Security is HARD!!! Yup, security is hard, and I would say moderately annoying, and a lot of people skip this step of adding the Passphrase to their keys. It is easier to store them as plain text, which allows loading them into TMOS without a Passphrase. When the keys are used in a Client or Server SSL profile, that pesky Passphrase isn't required. More comfortable, sure, but this isn't a smart or secure way to work. Plaintext keys came up recently with a customer. The customer had conducted a thorough security audit and determined that having keys available in plaintext on the file system was a possible threat to customer data integrity. This finding led to a requirement that all keys across the organization need to use a Passphrase. Great idea, but how could they retrofit the 100s of keys already loaded without a Passphrase? Luckily, OpenSSL provides a mechanism for managing the Passphrase associated with a key. You can change, add, or remove the Passphrase with a simple command. Here's the command if you want to copy it: openssl rsa -aes256 -in devcentral-example-key-open -out devcentral-key-protected Using this command, OpenSSL takes the "in" file and adds a Passphrase to the "out" file, enciphering it in the desired format specified (AES256). Fortunately, this is possible using the BIG-IP RESTful API and a few shell calls to manage the underlying files. The steps are: Copy the keys. Run the OpenSSL command to add a passphrase and encipher a copy of the file. Load the new, enciphered version of the key onto the BIG-IP. Get a list of the SSL Client and Server profiles using the plaintext key. Update these profiles with the new name of the encrypted key and Passphrase. Optionally remove the plaintext version of the key. I have built a sample script that does all this for you! I've posted it on my Github here https://github.com/pmscheffler/securekey, and you're welcome to take a copy and give it a try. Since it uses your keys, I would suggest thorough testing and making sure you're not using it in Production the first time out! Protecting the Keys to Your Door If you haven't adopted Passphrases on your keys because you thought it was too much effort to maintain, I hope you take a moment to check out the script and see that it isn't a lot to manage them in this manner. If you find the script useful or have another method you use – please let me know in the comments below. Hopefully, you never have a case where your customer data is exposed in a Man in the Middle breach because you lost your keys.2.5KViews0likes5Comments
Load Balancing versus Application Routing
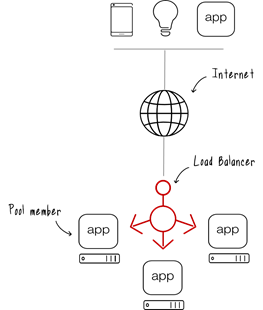
As the lines between DevOps and NetOps continue to blur thanks to the highly distributed models of modern application architectures, there rises a need to understand the difference between load balancing and application routing. These are not the same thing, even though they might be provided by the same service. Load balancing is designed to provide availability through horizontal scale. To scale an application, a load balancer distributes requests across a pool (farm, cluster, whatevs) of duplicated applications (or services). The decision on which pool member gets to respond to a request is based on an algorithm. That algorithm can be quite apathetic as to whether or the chosen pool member is capable of responding or it can be “smart” about its decision, factoring in response times, current load, and even weighting decisions based on all of the above. This is the most basic load balancing pattern in existence. It’s been the foundation for availability (scale and failover) since 1996. Load balancing of this kind is what we often (fondly) refer to as “dumb”. That’s because it’s almost always based on TCP (layer 4 of the OSI stack). Like honey badger, it don’t care about the application (or its protocols) at all. All it worries about is receiving a TCP connection request and matching it up with one of the members in the appropriate pool. It’s not necessarily efficient, but gosh darn it, it works and it works well. Systems have progressed to the point that purpose-built software designed to do nothing but load balancing can manage millions of connections simultaneously. It’s really quite amazing if you’re at all aware that back in the early 2000s most systems could only handle on the order of thousands of simultaneous requests. Now, application routing is something altogether different. First, it requires the system to care about the application and its protocols. That’s because in order to route an application request, the target must first be identified. This identification can be as simple as “what’s the host name” to something as complicated as “what’s the value of an element hidden somewhere in the payload in the form of a JSON key:value pair or XML element.” In between lies the most common application identifier – the URI. Application “routes” can be deduced from the URI by examining its path and extracting certain pieces. This is akin to routing in Express (one of the more popular node.js API frameworks). A URI path in the form of: /user/profile/xxxxx – where xxxxx is an actual user name or account number – can be split apart and used to “route” the request to a specific pool for load balancing or to a designated member (application/service instance). This happens at the “virtual server” construct of the load balancer using some sort of policy or code. Application routing occurs before the load balancing decision. In effect, application routing enables a single load balancer to distribute requests intelligently across multiple applications or services. If you consider modern microservices-based applications combined with APIs (URIs representing specific requests) you can see how this type of functionality becomes useful. An API can be represented as a single domain (api.example.com) to the client, but behind the scenes it is actually comprised of multiple applications or services that are scaled individually using a combination of application routing and load balancing. One of the reasons (aside from my pedantic nature) to understand the difference between application routing and load balancing is that the two are not interchangeable. Routing makes a decision on where to forward something – a packet, an application request, an approval in your business workflow. Load balancing distributes something (packets, requests, approval) across a set of resources designed to process that something. You really can’t (shouldn’t) substitute one for the other. But what it also means is that you have freedom to mix and match how these two interact with one another. You can, for example, use plain old load balancing (POLB) for ingress load balancing and then use application routing (layer 7) to distribute requests (inside a container cluster, perhaps). You can also switch that around and use application routing for ingress traffic, distributing it via POLB inside the application architecture. Load balancing and application routing can be layered, as well, to achieve specific goals with respect to availability and scale. I prefer to use application routing at the ingress because it enables greater variety and granularity in implementing both operational and application architectures more supportive of modern deployment patterns. The decision on where to use POLB vs application routing is largely based on application architecture and requirements. Scale can be achieved with both, though with differing levels of efficacy. That discussion is beyond the scope of today’s post, but there are trade-offs. It cannot be said often enough that the key to scaling applications today is about architectures, not algorithms. Understanding the differences of application routing and load balancing should provide a solid basis for designing highly scalable architectures.2KViews0likes5Comments