BIG-IP Advanced Firewall Manager (AFM) DNS NXDOMAIN Query Attack Type Walkthrough - part two
This is part two of theBIG-IPAdvanced Firewall Manager (AFM) DNS NXDOMAIN Query Attack Type Walkthrough article series. Part one is athttps://community.f5.com/t5/technical-articles/big-ip-advanced-firewall-manager-afm-dns-nxdomain-query-attack/ta-p/317656 Reviewing Part One In part one, we looked at: What and How of DNS NXDOMAIN response and flood definitions How threat actors generate random dns queries with the use of Domain Generation Algorithms and concepts such as DNS Blackhole, Fast Flux,DNS water torture attack What information can be used in observing NXDOMAIN response spike ReviewingBIG-IP DNS profile statistics collected using a periodic data collection script - provides visibility/statistics on the type of requests and responses the DNS listener processed which are useful when reviewing a recent DNS traffic spike event and understanding the characteristic of the traffic. Reviewing sample packet capture during a NXDOMAIN response spike and reducing and zooming in to the data of interest using commands such as capinfos, tshark, sort, uniq, wc Configuring Detection and Mitigation Thresholds In this article, we will continue using the information gathered from the NXDOMAIN response flood packet capture and configure BIG-IP Advanced Firewall Manager (AFM) DNS NXDOMAIN Query Attack Type Detection and Mitigation Thresholds. Configuring BIG-IP AFM DNS NXDOMAIN attack type to mitigate NXDOMAIN response spike Now that we have information from the sample packet capture and extracted DNS names we can start working on using these information to configure BIG-IP AFM NXDOMAIN attack type Detection and Mitigation thresholds. The sample packet capture we reviewed ran approx. 13 mins and recorded 60063 packets. If we divide the number of packets to number of seconds the pcap ran - 60063 p/780s, the number of packets per second is 334 packets per second. Since the packet capture contains only DNS traffic, we can expect it to have both dns requests and responses, which further reduces to 167 packets per second for either dns request or response. Since NXDOMAIN is a response and the packet capture was taken in a simulated attack to produce NXDOMAIN response, we can use this 167 packets per second as a baseline of what attack traffic looks like. We should aim for a lower number of packets per second to detect the attack and provide an allowance before we start mitigating the NXDOMAIN response flood. For the purpose of the demonstration, I have configured a lower detection and mitigation threshold to mitigate the NXDOMAIN response flood. This configuration is on a DNS enabled AFM DoS protection profile that will be applied to a Virtual Server. Dns-dos-protect is the name of the profile in this lab test. Configuring BIG-IP AFM DNS NXDOMAIN query attack type in a DNS enabled AFM DoS protection profile Detection Threshold: 20 EPS Mitigation Threshold: 30 EPS I'll be using 2 test clients to send a flood dns queries to a DNS listener for the hostnames generated thru DGA. As expected, the response for these queries will be NXDOMAIN and the AFM DNS NXDOMAIN Query Attack type will detect the attack as soon as 20 NXDOMAIN responses are observed and will start to drop excess of 30 NXDOMAIN responses. Here is a sample script to read a file , line by line, that contains DNS names to query. 10.93.56.197 is the DNS listener where the DNS enabled AFM DoS protection profile "dns-dos-protect" is applied to. root@ubuntu-server1:~# cat nxdig.sh #!/bin/bash while read -r line; do dig @10.93.56.197 "$line" done wait Here is the DNS listener DoS protection profile configuration. It also shows dos-dns-logging-profile is used as a Log profile. Here is the dos-dns-logging-profile Log profile profile configuration which only have DNS DoS protection logs enabled and logging to the local-db-publisher (logdb, a mysql db in the BIG-IP) Using the tmsh show security dos profile <DoS Protection profile name>, we can view the statistics observed by the DoS protection profile per Attack Type. In this test, only NXDOMAIN Query is enabled. Using the same periodic data capture script when we observed the ltm dns profile statistics, we can capture statistics for the DoS protection profile for review and understanding the phases of the attack being observed. while true; do date >> /var/tmp/afm_nx_stats; tmsh show security dos profile dns-dos-protect >> /var/tmp/afm_nx_stats; echo "###################" >> /var/tmp/afm_nx_stats; sleep 2; done Run the dns query flood using the script while true; do ./nxdig.sh < nx.txt 2>&1; done Here is a screenshot when the detection threshold of the NXDOMAIN Query attack type was exceeded, see the Attack Status. Here is when the Attack is being Mitigated Here is when there is no more Attack being detected A look at the periodic data capture for the DoS protection profile shows interesting statistics. Attack Detected - value of 1 means attack is detected which also means the detection threshold was exceeded, value of 0 means no attack currently detected. Stats - number of packets observed by the Attack type - this is a cumulative value since the BIG-IP booted up Stats Rate - current number of packets observed by the Attack type - provides an idea of how much of this type of packets currently observed, you can think of this as the current - Events Per Second - EPS of the attack type Stats 1m - average number of packets per second observed by the Attack type in the last 1m - provides an idea of average number packets of this type every second for the last 1m The Stats Rate and Stats 1m can provide an idea of how much packets can be seen in the current second and the average per second in the last minute. In non-attack scenario, observing these values shows what normal number of packets may look like. During an attack scenario - detection threshold exceeded - it can provide an idea how much the attack type was seeing. These information can then be used as a basis for setting the mitigation threshold. For example, it was observed that the Stats 1m value was 21 and during an attack scenario, the Stats Rate value was 245, this is about 12x of the average and the volume appears to be an attack. Depending on the risk appetite of the business, an allowance of 2x of the average number of packets for the attack type is where they want to drop exceeding packets , thus, 42 EPS can be configured for the mitigation threshold. Do note, setting low detection and mitigation thresholds can cause false positives, triggering detection and mitigation too early. Therefore it is important to understand the traffic characteristic for an attack type. In the gathered data, we can see here Attack Detected is 1, which means the detection threshold was exceeded. Stats Rate is at 245 which do exceed the 20 EPS detection threshold. Note that there were no Drops stats yet. Tue Jun 27 07:47:52 PDT 2023 | Attack Detected 1 | .. | Aggregate Attack Detected 1 | Attack Count 1 .... | Stats 1461 | Stats Rate 245 | Stats 1m 21 | Stats 1h 0 | Drops 0 4 seconds later, we do see the Drops count is 2, which tells us the Mitigation threshold - configured as 30 EPS - was exceeded. Tue Jun 27 07:47:56 PDT 2023 Attack Detected 1 ... | Aggregate Attack Detected 1 | Attack Count 1 | Stats 1h Samples 0 | Stats 1516 | Stats Rate 0 | Stats 1m 20 | Stats 1h 0 | Drops 2 3 seconds later, we do see the Drops count is 4, which tells us the mitigation is ongoing and dropping excess packets. Tue Jun 27 07:47:59 PDT 2023 | Attack Detected 1 ... | Aggregate Attack Detected 1 | Attack Count 1 | Stats 1h Samples 0 | Stats 1578 | Stats Rate 0 | Stats 1m 20 | Stats 1h 0 | Drops 4 From these sample stats, particularly the 'Stats' value, in the 7 seconds - 07:47:52 to 07:47:59 - the difference is 117 (1578 - 1461), which tells us that the packet of this type volume is low - averages at 17 packets per second for the last 7 seconds.If the difference on these 'Stats' values are much bigger, then we potentially have traffic spike. Drops stats increasing means that an attack is still being mitigated and the volume of the packets is not yet lower that the defined mitigation threshold.Drops - number of packets observed by the Attack type - this is a cumulative value since the BIG-IP booted upDrops Rate - current number of packets dropped by the Attack type Reviewing DoS stats information in the Reporting DoS DashboardWe have seen the DoS protection profile stats output, now we switch to the GUI and review the same DoS stats information.In the Reporting DoS Dashboard, there are records of the recorded Attacks. The timeframe can be adjusted to find incident of interest. In the testing done, I filtered DNS only and Attack IDs are displayed along with very useful information and statistics. In this screenshot, Attack ID 2958374472 was selected and relevant statistics are displayed. It was of DNS NXDOMAIN query Attack type/vector it shows how much packets were observed in this attack, which is 235 packets, and dropped packets at 25. Avg PPS - average packets per second for the duration of the attack, similar to the Stats Rate 1m, can also be used as a basis for the Detection and mitigation threshold of the attack type. Domain names observed are also recorded along with the same statistics on the attack. Configuring BIG-IP AFM DNS NXDOMAIN query attack type in AFM Device DoS Protection AFM Device Protection also have the DNS NXDOMAIN query attack type. This is a device wide protection and protects the self Ips and Virtual Servers of the BIG-IP. Detection and Mitigation thresholds can be configured the same way, observed the traffic type using the same type of statistics - but this time its Device DoS protection specific. Here is a sample of tmshshow security dos device-config dos-device-configoutput and piping it to grep to filter specifically lines for DNS NXDOMAIN Query. tmsh show security dos device-config dos-device-config | grep -i nxdomain -A 40 Security::DoS Config: DNS NXDOMAIN Query ------------------------------------------------------ Statistics Type Count Detection Method Static Vector - Inline Status Ready Attack Detected 1 ... Aggregate Attack Detected 1 Attack Count 20 Stats 1h Samples 0 Stats 46580 Stats Rate 187 Stats 1m 73 Stats 1h 8 ... Drops 150 ...snip.. AutoDetection 137 Mitigation Low 4294967295 Similarly, in the GUI, we can observe the states of an attack detected and mitigated by the NXDOMAIN query attack type configured in the AFM Device DoS protection. Here is the Detection and Mitigation threshold configuration Attack Detected Attack being Mitigated We can review the Reporting DoS Dashboard of the Attack events for the Device DoS and review the statistics Configuring Valid FQDNs in the DNS NXDOMAIN Query Attack type TheDNS NXDOMAIN Query Attack type has a configuration calledValid FQDNs and is described as: Allows you to create a whitelist of valid fully qualified domain names. In theAdd new FQDNfield, type a domain name and clickCheckto see if it is already on the list, clickAddto add it to the list, or clickDeleteto remove it from the whitelist. Take the name qehspqnmrn[.]fop789[.]loc as an example. Let's assume that this is a valid DNS hostname/FQDN and we do not wantDNS NXDOMAIN Query Attack type to drop packets for its response even though it would result in a NXDOMAIN response. We can add it in theValid FQDNslist from the GUI or tmsh. Here is the tmsh example, sinceqehspqnmrn[.]fop789[.]loc is already in the Valid FQDNs list, let's add another FQDN site1[.]fop789[.]loc. tmsh modify security dos device-config dos-device-config dos-device-vector { dns-nxdomain-query { valid-domains add { site1[.]fop789[.]loc } } } Here is the tmsh output when listing the DNS NXDOMAIN Query Attack Type including the Valid FQDNs. tmsh list security dos device-config dos-device-config dos-device-vector { dns-nxdomain-query } security dos device-config dos-device-config { dos-device-vector { dns-nxdomain-query { ... valid-domains { qehspqnmrn[.]fop789[.]loc site1[.]fop789[.]loc } } } } To verify that the packets for the FQDN in the Valid FQDNs list are not being dropped, we can look at theReporting DoS Dashboard. We can see ongoing attacks are reported and also lists the Domain Names in the attack. Taking a closer look at the statistics,qehspqnmrn[.]fop789[.]loc in the Domain Name list has NO packet Drops and NO Attack detected. The rest of the DNS names in the list have Drops and Attacks and are being mitigated by the AFM DNS NXDOMAIN query attack type.2.6KViews2likes0CommentsBIG-IP Advanced Firewall Manager (AFM) DNS NXDOMAIN Query Attack Type Walkthrough
Introduction In this article, we will look at configuring BIG-IP Advanced Firewall Manager's (AFM) DNS NXDOMAIN attack type in the Device Protection and DNS enabled protection profile to mitigate DNS NXDOMAIN response floods. We will review data from a packet capture and BIG-IP DNS' DNS profile statistics to set detection and mitigation thresholds. This is part one of two of this article series. Part two is athttps://community.f5.com/t5/technical-articles/big-ip-advanced-firewall-manager-afm-dns-nxdomain-query-attack/ta-p/317681 What is a NXDOMAIN dns response The DNS protocol [RFC1035] defines response code 3 as "Name Error", or "NXDOMAIN" [RFC2308], which means that the queried domain name does not exist in the DNS. Since domain names are represented as a tree of labels ([RFC1034], Section3.1), nonexistence of a node implies nonexistence of the entire subtree rooted at this node. From https://datatracker.ietf.org/doc/html/rfc8020#page-5 How is NXDOMAIN dns response generated RCODE Response code - this 4 bit field is set as part of responses. The values have the following interpretation: 3 Name Error - Meaningful only for responses from an authoritative name server, this code signifies that the domain name referenced in the query does not exist. https://datatracker.ietf.org/doc/html/rfc1035#section-4.1.1 What is a NXDOMAIN (response) flood? From the F5 Glossary in https://www.f5.com/glossary/dns-flood-nxdomain-flood The roadmap to every single computer on the Internet is held in DNS servers. The DNS NXDOMAIN flood attack attempts to make servers disappear from the Internet by making it impossible for clients to access the roadmap. In this attack, the attacker floods the DNS server with requests for invalid or nonexistent records. The DNS server spends its time searching for something that doesn't exist instead of serving legitimate requests. The result is that the cache on the DNS server gets filled with bad requests, and clients can't find the servers they are looking for. How do threat actors generate random dns queries There are many tools to generate a flood of DNS queries . The DNS records in the flood of DNS queries for the most part, should be unique if an attacker wants to poison a DNS servers cache. Otherwise, a DNS administrator can simply blackhole if the same DNS record is queried in DNS flood query. DNS Blackhole https://en.wikipedia.org/wiki/DNS_sinkhole Here is a devcentral article on DNS Blackhole implemented in an iRule https://community.f5.com/t5/codeshare/dns-blackhole/ta-p/283786 Domain Generation Algorithms To generate many random host records for one or many domains, Domain Generation Algorithms are used. https://en.wikipedia.org/wiki/Domain_generation_algorithm Many examples of DGA as collected in https://github.com/baderj/domain_generation_algorithms shows how these random records may look like. In the lab setup we will be using, we have the fop789[.]loc domain, and I borrowed from the github page random host list generated thru the "mydoom (aka Novarg, Mimail.R, Shimgapi)" DGA and appended the host part of the host list to the test lab domain . qehspqnmrn[.]fop789[.]loc mmahaesqar[.]fop789[.]loc pwprhhnqqn[.]fop789[.]loc .... Here is a sample query using the one of the hostnames. As expected, a NXDOMAIN response is received because this record does not exist in the sample lab domain fop789.loc. root@ubuntu-server1:~# dig @10.93.56.197 qehspqnmrn.fop789.loc ; <<>> DiG 9.16.1-Ubuntu <<>> @10.93.56.197 qehspqnmrn.fop789.loc ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 1279 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;qehspqnmrn.fop789.loc. IN A ;; AUTHORITY SECTION: fop789.loc. 300 IN SOA ns1.fop789.loc. hostmaster.ns1.fop789.loc. 2023041101 10800 3600 604800 86400 ;; Query time: 4 msec ;; SERVER: 10.93.56.197#53(10.93.56.197) ;; WHEN: Sun Jun 25 11:10:41 UTC 2023 ;; MSG SIZE rcvd: 101 root@ubuntu-server1:~# The most prevalent reason why threat actors would use DGA is in malware and phishing campaigns to avoid detection and resilient to counter measures. The evasion technique used is Fast flux. Fast flux Fast flux is a domain name system (DNS) based evasion technique used by cyber criminals to hide phishing and malware delivery websites behind an ever-changing network of compromised hosts acting as reverse proxies to the backend botnet master—a bulletproof autonomous system. It can also refer to the combination of peer-to-peer networking, distributed command and control, web-based load balancing and proxy redirection used to make malware networks more resistant to discovery and counter-measures. The fundamental idea behind fast-flux is to have numerous IP addresses associated with a single fully qualified domain name, where the IP addresses are swapped in and out with extremely high frequency, through changing DNS resource records, thus the authoritative name servers of the said fast-fluxing domain name is—in most cases—hosted by the criminal actor Depending on the configuration and complexity of the infrastructure, fast-fluxing is generally classified into single, double, and domain fast-flux networks. Fast-fluxing remains an intricate problem in network security and current countermeasures remain ineffective. https://en.wikipedia.org/wiki/Fast_flux What information can be used in observing NXDOMAIN response spike There are several sources of information that can be used when NXDOMAIN response spike. BIG-IP DNS profile statistics A BIG-IP DNS listener (Virtual Server) will have a DNS profile applied to it. This profile provides access to DNS traffic statistics. In particular, "Question Type" and "Return Code" sections has statistics on DNS record types queried and return code count. Here is a sample output from a script that periodically captured DNS profile statistics - stats were taken 20 seconds apart. These were taken during a lab test where NXDOMAIN response flood is being simulated. Here is the sample script: while true; do date >> /var/tmp/dns_stat.txt; tmsh show ltm profile dns dns-prof-1 >> /var/tmp/dns_stat.txt; echo "###################" >> /var/tmp/dns_stat.txt; sleep 20; done Notice that the "Question Type" has only "A" records queried and in the "Return Code (RCODE)" , only " No Name (NXDOMAIN)" were the responses. Date: Sun Jun 25 11:15:59 PDT 2023 --------------------------------------------------- Ltm::DNS Profile: dns-prof-1 --------------------------------------------------- Virtual Server Name N/A Query Message Recursion Desired (RD) 18847 100.0 DNSSEC Checking Disabled (CD) 0 0.0 EDNS0 18847 100.0 Client Subnet 0 0.0 Client Subnet Inserted 0 0.0 Operation Code (OpCode) Query 18847 100.0 Notify 0 0.0 Update 0 0.0 Other 0 0.0 Question Type A 18847 100.0 AAAA 0 0.0 ANY 0 0.0 CNAME 0 0.0 MX 0 0.0 ... Other 0 0.0 Response Message Authoritative Answer (AA) 18843 99.9 Recursion Available (RA) 0 0.0 Authenticated Data (AD) 0 0.0 Truncated (TC) 0 0.0 Return Code (RCODE) No Error 1 0.0 No Name (NXDOMAIN) 18842 99.9 Server Failed 0 0.0 Refused 1 0.0 Bad EDNS Version 0 0.0 Name Error (NXDOMAIN) Override 0 0.0 EDNS0 client subnet 0 0.0 Date: Sun Jun 25 11:16:19 PDT 2023 Query Message Recursion Desired (RD) 18993 100.0 DNSSEC Checking Disabled (CD) 0 0.0 EDNS0 18993 100.0 Client Subnet 0 0.0 Client Subnet Inserted 0 0.0 Operation Code (OpCode) Query 18993 100.0 Notify 0 0.0 Update 0 0.0 Other 0 0.0 Question Type A 18993 100.0 AAAA 0 0.0 ANY 0 0.0 CNAME 0 0.0 ... Other 0 0.0 Response Message Authoritative Answer (AA) 18989 99.9 Recursion Available (RA) 0 0.0 Authenticated Data (AD) 0 0.0 Truncated (TC) 0 0.0 Return Code (RCODE) No Error 1 0.0 No Name (NXDOMAIN) 18988 99.9 Server Failed 0 0.0 Refused 1 0.0 Bad EDNS Version 0 0.0 Name Error (NXDOMAIN) Override 0 0.0 EDNS0 client subnet 0 0.0 Sample packet capture during a NXDOMAIN response spike Earlier, we reviewed what is Domain Generation Algorithm (DGA) and that its used to generate random DNS names which are used by threat actors in fast flux technique to evade detection and mitigations for their phishing and malware campaigns. The sample packet capture was taken while using the sample random DNS names generated thru a DGA to simulate a NXDOMAIN response flood. Using the capinfos command, we can observe various details about the packet capture. First and last packet time tells us how long this pcap was running, in this case it has been around 13 mins. Also average packet rate per second, 76 packets/sec, can be useful if we are looking to find a baseline on packets per second value. And other packet capture details which may be useful depending on your purpose. Since we are looking at DNS traffic, remember its query and response packets, so 76 packets per second, presumably may contain both type of packets, thus, estimation of 38 packets per second for dns queries. [root@bigip:TimeLimitedModules::Active:Standalone] tmp # capinfos nx-4.pcap File name: nx-4.pcap File type: Wireshark/tcpdump/... - pcap File encapsulation: Ethernet File timestamp precision: microseconds (6) Packet size limit: file hdr: 65535 bytes Number of packets: 60 k File size: 16 MB Data size: 15 MB Capture duration: 786.961838 seconds First packet time: 2023-06-25 11:05:48.352417 Last packet time: 2023-06-25 11:18:55.314255 Data byte rate: 19 kBps Data bit rate: 159 kbps Average packet size: 260.57 bytes Average packet rate: 76 packets/s SHA1: 10d3652ce3b97d68d16f324ee6eaac918b8f34d9 RIPEMD160: 7c766e4e5819fb9f5c90cee133f0e1f61e9b5801 MD5: 51cd10815de35802460ae0b26e156d66 Strict time order: False Number of interfaces in file: 1 Interface #0 info: Encapsulation = Ethernet (1 - ether) Capture length = 65535 Time precision = microseconds (6) Time ticks per second = 1000000 Number of stat entries = 0 Number of packets = 60063 Next up, use tshark to get more information from the packet capture. Specifically, we are interested in the dns related information, such as the DNS records queried and the DNS response. Extract all dns names from the packet capture - queries or response [root@bigip:TimeLimitedModules::Active:Standalone] tmp # tshark -r nx-4.pcap -n -T fields -e dns.qry.name > nx-4-pcap-records.txt Running as user "root" and group "root". This could be dangerous. Reviewing the number of dns names extracted, it matches the output from capinfos - 60063. [root@bigip:TimeLimitedModules::Active:Standalone] tmp # cat nx-4-pcap-records.txt | wc -l 60063 Sort the dns names extracted from the pcap - notice the randomness of these dns names. Could be fast flux technique or an attempt to drown a DNS server of random records that it needs to search and eventually cause service disruption - a classic DNS water torture attack. The sample DNS names taken from the pcap are still not so random and are short. There are longer and more random hostnames that can be generated by DGAs and this can really take a lot of memory and cpu resource from a DNS server. [root@bigip:TimeLimitedModules::Active:Standalone] tmp # cat nx-4-pcap-records.txt | sort | uniq -c | sort -nrk 1 3514 mmahaesqar.fop789.loc 3512 arphansaqh.fop789.loc 3509 hwepmerswa.fop789.loc 3508 qrqnswerqs.fop789.loc 3506 seenwrqrps.fop789.loc 3506 pwprhhnqqn.fop789.loc 3506 hrhspsrenn.fop789.loc 3506 arwrseqssh.fop789.loc 3505 eqqhnpswmh.fop789.loc 3504 fop789.locaehwmnms.fop789.loc 3503 qehspqnmrn.fop789.loc 3503 psrhaaeqqa.fop789.loc 3503 paepnpamea.fop789.loc 3503 ewamspqwha.fop789.loc 3501 aepaaemrmn.fop789.loc 3500 mrspmramrn.fop789.loc 3499 rnqhapapwn.fop789.loc 475 DNS Water Torture Denial-of-Service Attacks Customers reported pseudo-random subdomain or “DNS water torture attacks” hitting their networks with half a million connections per second. Outages were occurring even if a network wasn’t the direct target of the attack. For example, service providers still felt the effects as the DNS water torture traffic passed through their networks and saturated their pipes. To pull off a DNS water torture attack, an attacker leverages a botnet (or thingbot) to make thousands of DNS requests for fake subdomains against an Authoritative Name Server.1 Because the requests are for non-existent subdomains or hosts, the requests consume the memory and processing resources on the main resolver. If there are intermediary DNS resolvers inline, they too get clogged up with these fake requests. For legitimate end users, all this resource consumption means everything runs slow or even stops, resulting in a denial of service. https://www.f5.com/labs/articles/threat-intelligence/the-dns-attacks-we-re-still-seeing#:~:text=To%20pull%20off%20a%20DNS,against%20an%20Authoritative%20Name%20Server.&text=Because%20the%20requests%20are%20for,resources%20on%20the%20main%20resolver. Filtering further, we can extract the DNS response packets only [root@bigip:TimeLimitedModules::Active:Standalone] tmp # tshark -r nx-4.pcap -n -Y "dns.flags.response == 1" -T fields -e dns.qry.name > nx-4-pcap-records-response.txt Running as user "root" and group "root". This could be dangerous. DNS response packets only count shows 29994, approx half of the previous output of 60063 [root@bigip:TimeLimitedModules::Active:Standalone] tmp # cat nx-4-pcap-records-response.txt | wc -l 29994 We can then sort DNS response packets only and find the number of times each DNS name was responded to. We know that the response to these queries are NXDOMAIN because we don’t have these records in the lab DNS server records list. We can also observe which DNS names were responded the most. In the example output, each of the records were responded almost equally. [root@bigip:TimeLimitedModules::Active:Standalone] tmp # cat nx-4-pcap-records-response.txt | sort | uniq -c | sort -nrk 1 1748 qehspqnmrn.fop789.loc 1748 mmahaesqar.fop789.loc 1746 seenwrqrps.fop789.loc .... 1746 aepaaemrmn.fop789.loc 1744 paepnpamea.fop789.loc 1744 arphansaqh.fop789.loc 1742 eqqhnpswmh.fop789.loc 3161.1KViews1like0CommentsPacket Tracing in BIG-IP AFM
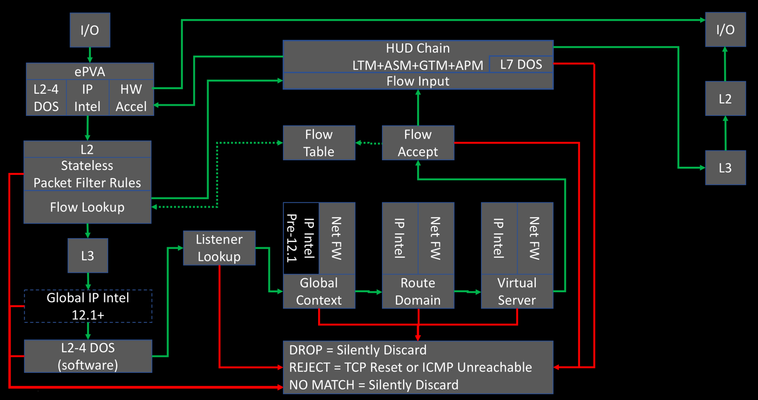
New in the v13 release of the BIG-IP Advanced Firewall Manager is the capability to insert a packet trace into the internal flow so you can analyze what component within the system is allowing or blocking packets based on your configuration of features and rule sets. If you recall from our Lightboard Lesson on the BIG-IP Life of a Packet, the packet flow diagram looks like this: The packet tracing is inserted at L3 immediately prior to the Global IP intelligence. Because it is after the L2 section, this means that a) we cannot capture in tcpdump so we can’t see them in flight and b) no physical layer details will matter as it relates to testing. That said, it’s incredibly useful for what is and is not allowing your packets through. You can insert tcp, udp, sctp, and icmp packets, with a limited set of (appropriate to each protocol) attributes for each. To get to the packet trace utility in the GUI, navigate to Network->Network Security->Packet Tester as show below. Note: In v13.1 this feature has been moved to Security -> Debug -> Packet Tester. This will launch the packet testing tool as shown here: Note with this tcp selection, in addition to setting the flags, you can configure the source and destination ip/port, source vlan, and trace options as it relates to policy and logging. An example packet trace shows the output of the trace after it completes: You’ll notice here that IP Intelligence and DoS have no beef with the packet, but there is no virtual match so the default action at the end of the path is to reject. Note that you can also use the packet trace utility in tmsh. The command is tmsh show net packet-tester security and results in an output like below. tmsh show net packet-tester security protocol tcp syn src-addr 192.168.101.2 src-port 21233 dst-addr 192.168.101.55 dst-port 8080 src-vlan external ************************* Packet Tester Data: ************************* Packet SrcIP/Port:192.168.101.2/21233 Src Vlan external Packet DstIP/Port:192.168.101.55/8080 Packet Protocol: tcp Packet Trace Option: Check Staged:Disable, Trigger Log:Disable Stage:Device-IP Intelligence Result: Default Stage:Device-DoS Result: Default Stage:Device-Access Control Result: Drop Stage:Route Domain-IP Intelligence (unset) Result: Default Stage:Route Domain-Access Control (unset) Result: Drop Stage:Listener-IP Intelligence (No Listener) Result: Default Stage:Listener-DoS (No Listener) Result: Default Stage:Listener-Access Control (No Listener) Result: Drop Stage:Device Default Result: Drop Final Result Packet SrcIP/Port:192.168.101.2/21233 Src Vlan external Packet DstIP/Port:192.168.101.55/8080 Packet Protocol: tcp Packet Trace Option: Check Staged:Disable, Trigger Log:Disable Stage:Device-Access Control Policy Name: unset Rule Name: unset Stage:Route Domain-Access Control Route Domain name: unset Policy Name: unset Rule Name: unset Stage:Listener-Access Control Listener name: unset Policy Name: unset Rule Name: unset Default Rule : No Device Default Rule Final Action : Drop Total records returned: 1 And because of tmsh, you can easily script packet generation with bash or even a tmsh script if you’re feeling the Tcl love. Current Limitations Only one packet can be inserted at a time, so even a scripted experience via tmsh will result in very low packets per second, which isn’t likely to really impact DoS for valid tests. Only valid headers are allowed, so a large part of typical red team attack vectors are not covered. No tcpdump visibility. No hardware paths. Basic visibility tools like the packet tester are great additions to the BIG-IP AFM. Whether it’s for testing new rules, validating existing ones, or simply throwing a bone over the fence to your operational security team to know where in your configuration an isolated action is being trapped, the v13 AFM packet tester has you covered!2.6KViews1like11Comments
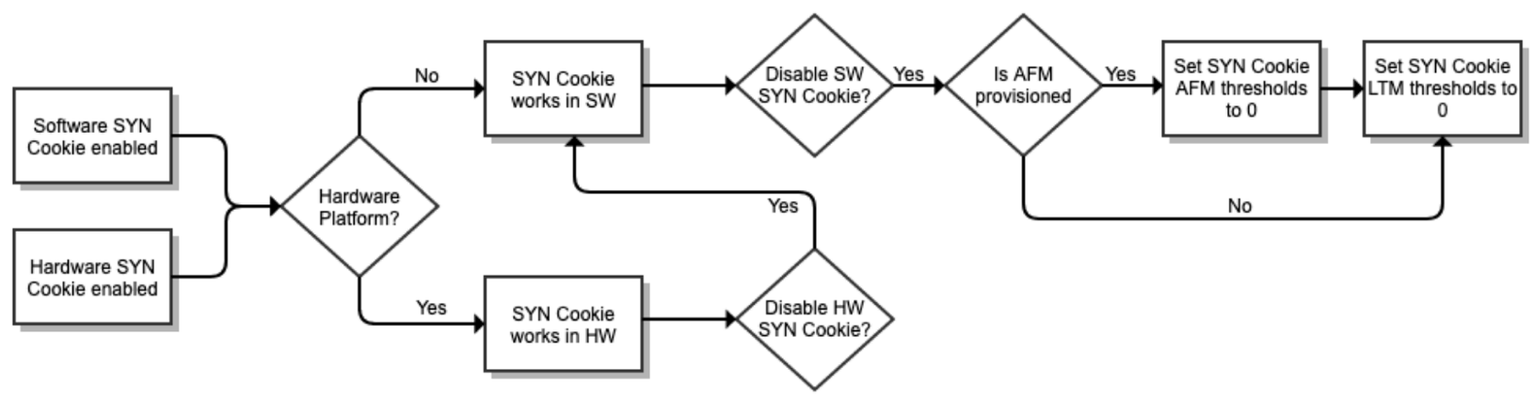
2. SYN Cookie: Operation
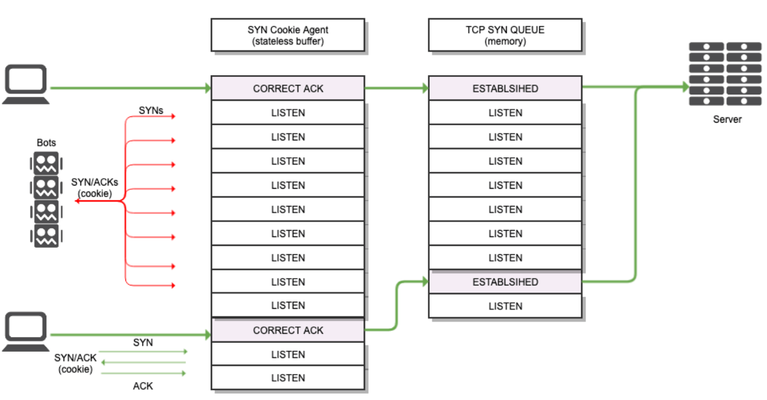
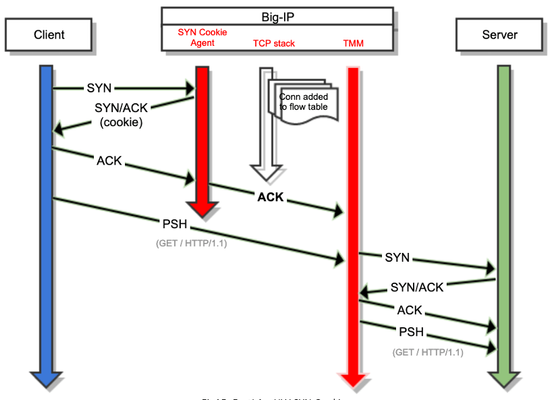
Introduction As concluded in the last article, in order to avoid allocating space for TCB, the attacked device needs to reject TCP SYN packets sent by clients. In this article I will explain how a system can do this without causing service disruption, and more specifically I will explain how this work in BIG-IP. Implementation Since attacked device need to alter default TCP 3WHS behaviour the best option is implementing SYN Cookie countermeasure in an intermediate device, so you offload your servers from this task. In this way if connection is not legitimate then it is just never forwarded to the backend server and therefore it will not waste any kind of extra resourcess. Since BIG-IP is already in charge of handling application traffic directed towards servers it is the best place to implement SYN Cookie. What BIG-IP does is adding an extra layer, which we can call SYN Cookie Agent, that basically implement a stateless buffer between client and BIG-IP TCP stack. This agent is in charge of handling client’s TCP SYN packets by modifying slightly the standard behaviour of TCP 3WHS, this modification comes in two flavours depending on what type of routing role BIG-IP is playing between client and server. Symmetric routing This is the typical situation. In this environment BIG-IP is sited in the middle of the TCP conversation and all the traffic from/to server pass through it. The SYN Cookie operation in this case is briefly described below: Client sends a TCP SYN packet to BIG-IP. BIG-IP uses a stateless buffer for answering each client SYN with a SYN/ACK. BIG-IP generates the 32 bits sequence number which will be included in SYN/ACK packet sent to the client. BIG-IPencodes essential and mandatory information of the connection in 24 bits. BIG-IP hashes the previous encoded information. BIG-IP also encodes other values like MSS in the remaining bits. BIG-IP generates the SYN/ACK response packet and includes the hash and other encoded information as sequence number for the packet. This is the so calledSYN Cookie. BIG-IP sends SYN/ACK to client. BIG-IP discards the SYN from the stateless buffer, in other words, BIG-IP removes all information related to this TCP connection. At this point no memory has been allocated for TCP connection (TCB). Client sends correct ACK to BIG-IP acknowledging BIG-IP’s sequence number. BIG-IP validates ACK. BIG-IP subtracts one to this ACK. BIG-IP runs the hash function using connection information as input (see point 3-b above). Then it compares it with the hash provided in the ACK, if they match then it means client sent a correct SYN Cookie response and that client is legitimate. BIG-IP uses connection information in the ACK TCP/IP headers to create an entry in connflow. At this time is when BIG-IP builds TCB entry, so it's the first time BIG-IP uses memory to save connection information. BIG-IP increase related SYN Cookie stats. BIG-IP starts and complete a TCP 3WHS with backend server on behalf of the client since we are sure that client is legitimate. Now traffic for the connection is proxied by BIG-IP as usual attending to configured L4 profile in the virtual server. *If ACK packet received by BIG-IP is a spurious ACK then BIG-IP will discard it and no entry will be created in connection table. Since attackers will never send a correct response to a SYN/ACK then you can be sure that TCB entries are never created for them. Only legitimate clients will use BIG-IP resources as shown in diagram: Fig4. TCP SYN Flood attack with SYN Cookie countermeasure Asymmetric routing In an asymmetric environment, also called nPath or DSR, you face a different problem because Big-IP cannot establish a direct TCP 3WHS with the server (point 11 in last section). As you can see in below diagram SYN/ACK packet sent from server to client would not traverse Big-IP, so method used for symmetric routing cannot be used in this case. You need another way to trust in clients and discard them as attackers, so clients then can complete TCP 3WHS directly with the server. Fig5. TCP state diagram section for asymmetric routing + FastL4 In order to circumvent this problem BIG-IP takes the advantage of the fact that applications will try to start a second TCP connection if a first TCP 3WHS is RST by the server. What BIG-IP does in asymmetric routing environments is completing the TCP three way handshake with client, issuing SYN Cookie as I described for symmetric routing, and once BIG-IP confirms that client is trustworthy it will add its IP to SYN Cookie Whitelist, it will send a RST to the client and it will close the TCP connection. At this point client will try to start a new connection and this time BIG-IP will let the client talk directly to the server as it would do under normal circumstances (see diagram above). The process is briefly described below: Client sends a TCP SYN packet to BIG-IP. BIG-IP generates the sequence number as explained for symmetric routing. BIG-IP generates the SYN/ACK response packet and includes the calculated sequence number for the packet. BIG-IP sends SYN/ACK to client and then remove all information related to this TCP connection. At this point no memory has been allocated for TCP connection (TCB). Client sends correct ACK to BIG-IP acknowledging sequence number. BIG-IP validates ACK. BIG-IP substract one to this ACK so it can decode needed information and check hash. BIG-IP increase related SYN Cookie stats. BIG-IP sends a RST to client and discards TCP connection. Big-IP adds client’s IP to Whitelist. Clients starts a new TCP connection. BIG-IP lets client to start this new TCP connection directly to the server since it knows that server is legitimate. *If ACK packet received by BIG-IP is a spurious ACK then BIG-IP will discard it and no entry will be created in connection table. Fig6. TCP 3WHS flow in asymmetric routing DSR whitelist has some important characteristics you need to take into account: By default IP is added 30 seconds to the whitelist (DB Key tm.flowstate.timeout). Client’s IP is added to whitelist for 30 seconds but only if there is no traffic from this client, if BIG-IP have already seen ACK from this client then its IP is removed from whitelist since connection has been already established between client and server. Whitelist is common to all virtual servers, so if a client is whitelisted it will be for all applications. Whitelist it is not mirrored. Whitelist it is not shared among blades. SYN Cookie Challenge When a TCP connection is initiated the TCP SYN packet sent by the client specify certain values that define the connection, some of these values are mandatory, like source and destination IP and port, otherwise you would not be able to identify the correct connection when packets arrive. Some other values are optional and they are used to improve performance, like TCP options or WAN optimizations. Under normal circumstances, upon TCP SYN reception the system creates a TCB entry where all this information is saved. BIG-IP will use this information to set up the TCP connection with the backend server. The problem we face is that when SYN Cookie is in play device does not create the TCB entry, only a limited piece of connection information is collected, so the information that BIG-IP has about the TCP connection is limited. Remember that SYN Cookie is not handled by TCP stack but by the stateless SYN Cookie Agent, so we cannot save the connection details. What BIG-IP does instead is encoding key information in 24 bits, this left only some bits for the rest of data. While there is no room for values like Window Scale information, however we have space for other values, for example 3 bits reserved for MSS value. This limits MSS possible values to 8, the most commonly used values, and the one chosen will the nearest to the original MSS value. However, note that MSS limitation has a workaround through configuration in FastL4 profile that it can help in some cases. The option SYN Cookie MSS in this profile specifies a value that overrides the SYN cookie maximum segment size (MSS) value in the SYN-ACK packet that is returned to the client. Valid values are 0, and values from 256 through 9162. The default is 0, which means no override. You might use this option if backend servers use a different MSS value for SYN cookies than the BIG-IP system does. If this is not enough for some customers, BIG-IP overcomes this problem by using TCP timestamp space to save extra information about TCP connection, in other words we create a second extra SYN Cookie. This space is used to record the client and server side Window Scale values, or the SACK info which are then made available to the TCP stack via this cookie if the connection is accepted. Note that TCP connection will only be accepted if both SYN Cookies (standard and Timestamp) are correct. So all this means that if the client starts a connection with TCP TS set then Big-IP will have more space to encode information and hence the performance will be improved when under TCP SYN flood attack. NOTE: SYN Cookie Timestamp extension (software or hardware) only work for standard virtual servers currently. FastL4 virtual servers only supports MMS option in SYN Cookie mode. Conclusion Now you know how SYN Cookie works under the hoods. In next article I will describe when SYN Cookie is activated and I will give specific details of BIG-IP SYN Cookie operation. Note that limitations related to SYN Cookie commented in this article are not caused specifically by BIG-IP SYN Cookie implementation but by SYN Cookie standard itself. In fact, F5 Networks implements some improvements on SYN Cookie to get a better performance and provide some extra features.2.7KViews2likes3Comments7. SYN Cookie: Troubleshooting Stats
Introduction In this article I will explain what SYN Cookie stats you can consult and their meaning. There are more complex stats than the explained in this article but they are intended for helping F5 engineers when cases become complex. SYN Cookie stats First at all, in order to troubleshoot SYN Cookie you need to know how you can check SYN Cookie stats easily and understand what you are reading. The easiest way to see these stats in a device running LTM module based SYN Cookie is by running below command and focusing in SYN Cookies section of the output: # tmsh show ltm virtual <virtual> SYN Cookies Statusfull-hardware Hardware SYN Cookie Instances6 Software SYN Cookie Instances0 Current SYN Cache2.0K SYN Cache Overflow24 Total Software4.3M Total Software Accepted0 Total Software Rejected0 Total Hardware21.7M Total Hardware Accepted3 Let’s go through each field to know what they means: Status: [full-software/full-hardware|not-activated]. This value describes what type of SYN Cookie mode has been activated, software or hardware. Once an attack has finished it is normal that LTM takes some time to deactivate SYN Cookie mode after attack traffic stops. Calculation is complex and related to specific platform and several factors, also we do not want SYN Cookie entering in an activating/deactivating loop in case TCP SYN packets per second reaching device are near to the configured SYN cache threshold. So delay of 30-60 seconds before SYN Cookie being deactivated is in normal range. Hardware SYN Cookie Instances: How many TMMs are under Hardware SYN Cookie mode. Software SYN Cookie Instances: How many TMMs are under Software SYN Cookie mode. It indicates if software is currently generating SYN cookies. Current SYN Cache: Indicates how many embryonic connections are handled by BIG-IP (refreshed every 2 seconds). SYN cache is always counting embryonic connections, regardless if SYN Cookie is activated or not. So even if SYN Cookies is completely turned off, we still have embryonic flows that have not been promoted to full flows yet (SYNs which has not completed 3WHS), this means that cache counter will still be used regularly, so is normal having a value different than 0. Disabling SYN Cookie will not avoid this counter increase but thresholds will not be taken into account. Since SYN cache is no longer a cache, as explained in prior articles, and the stat is merely a counter of embryonic flows, it does not consume memory resources. As the embryonic flows are promoted or time out, this value will decrease. SYN Cache Overflow (per TMM): It is incremented whenever the SYN cache threshold is exceeded and SYN cookies need to be generated. It increments in one per each TMM instance and this value is a counter that only increases, so we can consult the value to know how many times SYN Cookie has been activated since last stats reset, remember, per TMM. Total Software:Number of challenges generated by Software. This is increased regardless if client sends a response, does not send any response or the response is not correct. Total Software Accepted:Number of TCP handshakes that were correctly handled with clients. Total Software Rejected:Number of wrong responses to challenges. Remember that ALL rejected SYN cookies are in software, there is no hardware rejected. Total Hardware: Number of challenges generated by Hardware. Total Hardware Accepted:Number of TCP handshakes that were correctly handled with clients. In case you have configured AFM based SYN Cookie then you can use two easy sources of information, the already explained LTM command above, but also you can check stats for TCP half open DoS vector, at device or virtual server context, as you would do with any other DoS vector. Let’s check the most important fields at device context. # tmsh show security dos device-config | grep -A 40 half Statistics TypeCount StatusReady Attack Detected1 *Attacked Dst Detected0 *Bad Actor Attack Detected0 Aggregate Attack Detected1 Attack Count2 *Stats 1h Samples0 Stats408 *Stats Rate408 Stats 1m104 Stats 1h0 Drops1063 *Drops Rate1063 Drops 1m187 Drops 1h4 *Int Drops0 *Int Drops Rate0 *Int Drops 1m0 *Int Drops 1h0 Status: This field confirm if this specific DoS vector is ready to detect TCP SYN flood attacks. You have to take into account that you could decide to configure this DoS vector with Auto-threshold, in which case AFM would be in charge of deciding the best threshold. Note that by enabling auto-threshold AFM would need some time to learn the traffic pattern of your environment, until it has enough information to create a correct threshold you will not see this field as Ready but as Learning. If vector is configured manually you always see it as Ready. Attack detected: It informs you if currently there is an ongoing attack and detected by AFM. Aggregate attack detected: Since DoS stats shown above are for device context the detected attack is aggregate. Attack Count: Gives information about how many attacks have been detected since stats were reset last time. It does not decrease. Stats: Number of embryonic connections at this current second. Remember that since this is a snapshot, the counter could go increase or decrease. This is different to other DoS vectors where it only increases. Stats 1m: Average of the Stats in the last minute. This is the average number ofembryonic connections that AFM has seen when taking sampling every 1s. Stats 1h: Average of the Stats 1m in the last hour. Drops: It counts the number of wrong ACKs received. In other words this is the current snapshot of: Number of SYN Cookies – Number of validated ACKs received Drops 1m: Average of the Drops in the last minute Drops 1h: Average of the Drops 1m in the last hour I have added an asterisk to some fields to point to values that has not real meaning for SYN Cookie DoS vector, or information is not really useful from my perspective, but they are included to have coherence with other DoS attack stats information. Note: Detection logic for this vector is not based on the Stats 1m, as other DoS vectors, instead it is based on the current number of embryonic connections, that is, value seen in Stats counter. Interpreting stats Once you know what each important stat mean I will give some advises when you interpret SYN Cookie stats. You should know some of them already if you have read all articles in this series: Hardware can offload TMM for validation, so you can see a number of software generated SYN Cookies much bigger than software validated SYN Cookie since software generates cookies that are validated by hardware as well. Since it is possible that a software generated SYN Cookie be accepted by hardware and vice versa, hardware generated SYN Cookies be accepted by software, you could think that value for Total Software is the same than the result of adding the Total Software Accepted plus Total Software rejected. But that is NOT true since it can be possible that a SYN Cookie sent by BIG-IP does not have a response (ACK), quite typical during a SYN flood attack indeed. In this case nothing adds up because generated SYN Cookie was not accepted nor rejected. Remember that SYN cookie’s responses discarded by hardware will be rejected by software, so all rejects are in software. This is why there is not counter for Total Hardware rejected. This means that Total Software Rejected can be increase by Total Hardware. When there is an attack vectors definition that match this attack will be increased. So, for example, during a TCP SYN flood attack you will see that Stats increases for TCP half open and TCP SYN flood (maybe others like low TTL,... as well). Also Stats will increase in all contexts (device and virtual server). The first vector in an specific context whose limit is exceeded it will start to mitigate. This is important because in cases where TCP SYN flood DoS vector has a lower threshold than TCP half open DoS vector, you will notice that traffic is dropped but you did not expect this behavior. Check article 5 for more information. Example In this part you will learn what stats changes you should expect to see when a TCP SYN flood attack is detected and SYN Cookie is activated, so it starts to mitigate the attack.Let’s interpret below stats: During attack Statusfull-hardware Hardware SYN Cookie Instances6 Software SYN Cookie Instances0 Current SYN Cache1 SYN Cache Overflow24 Total Software10.1K Total Software Accepted0 Total Software Rejected0 Total Hardware165.1M Total Hardware Accepted3 After attack Statusnot-activated Hardware SYN Cookie Instances0 Software SYN Cookie Instances0 Current SYN Cache15 SYN Cache Overflow24 Total Software10.1K Total Software Accepted0 Total Software Rejected0 Total Hardware171.0M Total Hardware Accepted3 Before the attack, before SYN Cookie is activated, you will see Current SYN Cache stats starts to increase quickly since TCP SYN packets are causing an increment of embryonic connections. Once SYN Cache threshold has been reached in a TMM then SYN Cache Overflow will increase attending to the number of TMMs that detected the attack. In above example you see 24 because this is a 6 CPUs device and 4 TCP SYN Flood attacks were detected by SYN Cookie. Remember this counter will never decrease unless we reset stats. During attack SYN cookie is activated so Current SYN Cache will start to decrease until reaching 0 because SYN Cookie Agent starts to handle TCP 3WHS, in other words, TCP stack stops to receive TCP SYN packets. We can check how many TMMs have SYN cookie activated currently looking at Hardware/Software SYN Cookie Instances counter. Note this match with what I explained for SYN Cache Overflow value. Legitimate connections are counted under Total Hardware/Software Accepted. In this case, we can see that although several millions of TCP SYN packets reached the device only 3 TCP 3WHS were correctly carried out. As you can see this device has Hardware SYN Cookie configured and working, but you can read that software also generates SYN Cookie challenges (Total Software). As commented in article number six of these series, this is expected and can be due to collisions or due to validations of first challenges when SYN Cookie is activated and TMMs handles TCP SYN packets until it enables hardware to do it. This does not affect device performance. In order to change from ‘Status full-hardware’ to ‘Status not-activated’ both HSBs must exit from SYN Cookie mode. Conclusion Now you know how to interpret stats, so you know can deduce information about the past and the present status of your device related to SYN Cookie. In next two article I will end up this series and this troubleshooting part talking about traffic captures and meaning of logs.2.1KViews1like3Comments
Explanation of F5 DDoS threshold modes
Der Reader, In my article “Concept of Device DOS and DOS profile”, I recommended to use the “Fully Automatic” or “Multiplier” based configuration option for some DOS vectors. In this article I would like to explain how these threshold modes work and what is happening behind the scene. When you configure a DOS vector you have the option to choose between different threshold modes: “Fully Automatic”, “Auto Detection / Multiplier Based”, “Manual Detection / Auto Mitigation” and “Fully Manual”. Figure 1: Threshold Modes The two options I normally use on many vectors are “Fully Automatic” and “Auto Detection / Multiplier Based”. But what are these two options do for me? To manually set thresholds is for some vectors not an easy task. I mean who really knows how many PUSH/ACK packets/sec for example are usually hitting the device or a specific service? And when I have an idea about a value, should this be a static value? Or should I better take the maximum value I have seen so far? And how many packets per second should I put on top to make sure the system is not kicking in too early? When should I adjust it? Do I have increasing traffic? Fully Automatic In reality, the rate changes constantly and most likely during the day I will have more PUSH/ACK packets/sec then during the night. What happens when there is a campaign or an event like “Black Friday” and way more users are visiting the webpage then usually? During these high traffic events, my suggested thresholds might be no longer correct which could lead to “good” traffic getting dropped. All this should be taken into consideration when setting a threshold and it ends up being very difficult to do manually. It´s better to make the machine doing it for you and this is what “Fully Automatic” is about. Figure 2: Expected EPS As soon as you use this option, it leverages from the learning it has done since traffic is passing through the BIG-IP, or since you have enforced the relearning, which resets everything learned so far and starts from new. The system continuously calculates the expected rates for all the vectors based on the historic rates of traffic. It takes the information up to one year and calculates them with different weights in order to know which packets rate should be expected at that time and day for that specific vector in the specific context (Device, Virtual Server/Protected Object). The system then calculates a padding on top of this expected rate. This rate is called Detection Rate and is dependent on the “threshold sensitivity” you have configured: Low Sensitivity means 66% padding Medium Sensitivity means 40% padding High Sensitivity means 0% padding Figure 3: Detection EPS As soon as the current rate is above the detection value, the BIG-IP will show the message “Attack detected”, which actually means anomaly detected, because it sees more packets of that specific vector then expected + the padding (detection_rate). But DoS mitigation will not start at that point! Figure 4: Current EPS Keep in mind, when you run the BIG-IP in stateful mode it will drop 'out of state' packets anyway. This has nothing to do with DoS functionalities. But what happens when there is a serious flood and the BIG-IP CPU gets high because of the massive number of packets it has to deal with? This is when the second part of the “Fully Automatic” approach comes into the game. Again, depending on your threshold sensitivity the DOS mitigation starts as soon as a certain level of stress is detected on the CPU of the BIG-IP. Figure 5: Mitigation Threshold Low Sensitivity means 78,3% TMM load Medium Sensitivity means 68,3% TMM load High Sensitivity means 51,6% TMM load Note, that the mitigation is per TMM and therefore the stress and rate per TMM is relevant. When the traffic rate for that vector is above the detection rate and the CPU of the BIG-IP (Device DOS) is “too” busy, the mitigation kicks in and will rate limit on that specific vector. When a DOS vector is hardware supported, FPGAs drop the packets at the switch level of the BIG-IP. If that DOS vector is not hardware supported, then the packet is dropped at a very early stage of the life cycle of a packet inside a BIG-IP. The rate at which are packets dropped is dynamic (mitigation rate), depending on the incoming number of packets for that vector and the CPU (TMM) stress of the BIG-IP. This allows the stress of the CPU to go down as it has to deal with less packets. Once the incoming rate is again below the detection rate, the system declares the attack as ended. Note: When an attack is detected, the packet rate during that time will not go into the calculation of expected rates for the future. This ensures that the BIG-IP will not learn from attack traffic skewing the automatic thresholds. All traffic rates below the detection (or below the floor value, when configured) rate modify the expected rate for the future and the BIG-IP will adjust the detection rate automatically. For most of the vectors you can configure a floor and ceiling value. Floor means that as long as the traffic value is below that threshold, the mitigation for that vector will never kick in. Even when the CPU is at 100%. Ceiling means that mitigation always kicks in at that rate, even when the CPU is idle. With these two values the dynamic and automatic process is done between floor and ceiling. Mitigation only gets executed when the rate is above the rate of the Floor EPS and Detection EPS AND stress on the particular context is measured. Figure 6: Floor and Ceiling EPS What is the difference when you use “Fully Automatic” on Device level compared to VS/PO (DOS profile) level? Everything is the same, except that on VS or Protected Object (PO) level the relevant stress is NOT the BIG-IP device stress, it is the stress of the service you are protecting (web-, DNS, IMAP-server, network, ...). BIG-IP can measure the stress of the service by measuring TCP attributes like retransmission, window size, congestion, etc. This gives a good indication on how busy a service is. This works very well for request/response protocols like TCP, HTTP, DNS. I recommend using this, when the Protected Object is a single service and not a “wildcard” Protected Object covering for example a network or service range. When the Protected Object is a “wildcard” service and/or a UDP service (except DNS), I recommend using “Auto Detection / Multiplier Option”. It works in the same way as the “Fully Automatic” from the learning perspective, but the mitigation condition is not stress, it is the multiplication of the detection rate. For example, the detection rate for a specific vector is calculated to be 100k packets/sec. By default, the multiplication rate is “500”, which means 5x. Therefore, the mitigation rate is calculated to 500k packets/sec. If that particular vector has more than 500k packets/sec those packets would be dropped. The multiplication rate can also be individually configured. Like in the screenshot, where it is set to 8x (800). Figure 7: Auto Detection / Multiplier Based Mitigation The benefit of this mode is that the BIG-IP will automatically learn the baseline for that vector and will only start to mitigate based on a large spike. The mitigation rate is always a multiplication of the detection rate, which is 5x by default but is configurable. When should I use “Fully Manual”? When you want to rate-limit a specific vector to a certain number of packets/sec, then “Fully Manual” is the right choice. Very good examples for that type of vector are the “Bad Header” vector types. These type of packets will never get forwarded by the BIG-IP so dropping them by a DoS vector saves the CPU, which is beneficial under DoS conditions. In the screenshot below is a vector configured as “Fully Manual”. Next I’ll describe what each of the options means. Figure 8: Fully Manual Detection Threshold EPS configures the packet rate/sec (pps) when you will get a log messages (NO mitigation!). Detection Threshold % compares the current pps rate for that vector with the multiplication of the configured percentage (in this example 5 for 500%) with the 1-minute average rate. If the current rate is higher, then you will get a log message. Mitigation Threshold EPS rate limits to that configured value (mitigation). I recommend setting the threshold (Mitigation Threshold EPS) to something relatively low like ‘10’ or ‘100’ on ‘Bad Header’ type of vectors. You can also set it also to ‘0’, which means all packets hitting this vector will get dropped by the DoS function which usually is done in hardware (FPGA). With the ‘Detection Threshold EPS’ you set the rate at which you want to get a log messages for that vector. If you do it this way, then you get a warning message like this one to inform you about the logging behavior: Warning generated: DOS attack data (bad-tcp-flags-all-set): Since drop limit is less than detection limit, packets dropped below the detection limit rate will not be logged. Another use-case for “Fully Manual” is when you know the maximum number of these packets the service can handle. But here my recommendation is to still use “Fully Automatic” and set the maximum rate with the Ceiling threshold, because then the protected service will benefit from both threshold options. Important: Please keep in mind, when you set manual thresholds for Device DoS the thresholds are to protect each TMM. Therefore the value you set is per TMM! An exception to this is the Sweep and Flood vector where the threshold is per BIG-IP/service and not per TMM like on DoS profiles. When using manual thresholds for aDOS profileof a Protected Object thethreshold configuration is per service (all packets targeted to the protected service) NOT per TMM like on the Device level. Here the goal is to set how many packets are allowed to pass the BIG-IP and reach the service. The distribution of these thresholds to the TMMs is done in a dynamic way: Every TMM gets a percentage of the configured threshold, based on the EPS (Events Per Second, which is in this context Packets Per Second) for the specific vector the system has seen in the second before on this TMM. This mechanism protects against hash type of attacks. Ok, I hope this article gives you a better understanding on how ‘Fully Manual’, ‘Fully Automatic’ and ‘Auto Detection / Multiplier Based Mitigation’ works. They are important concepts to understand, especially when they work in conjunction with stress measurement. This means the BIG-IP will only kick in with the DoS mitigation when the protected object (BIG-IP or the service behind the BIG-IP) is under stress. -Why risk false positives, when not necessary? With my next article I will demonstrate you how Device DoS and the DoS profiles work together andhow the stateful concept cooperates with the DoS mitigation. I will show you some DoS commands to test it and also commands to get details from the BIG-IP via CLI. Thank you, sVen Mueller9KViews20likes10CommentsDemonstration of Device DoS and Per-Service DoS protection
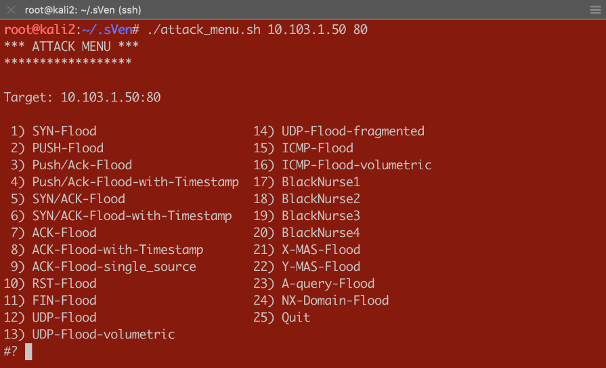
Dear Reader, This article is intended to show what effect the different threshold modes have on the Device and Per-Service (VS/PO) context. I will be using practical examples to demonstrate those effects. You will get to review a couple of scripts which will help you to do DoS flood tests and “visualizing” results on the CLI. In my first article (https://devcentral.f5.com/s/articles/Concept-of-F5-Device-DoS-and-DoS-profiles), I talked about the concept of F5 Device DoS and Per-Service DoS protection (DoS profiles). I also covered the physical and logical data path, which explains the order of Device DoS and Per-Service DoS using the DoS profiles. In the second article (https://devcentral.f5.com/s/articles/Explanation-of-F5-DDoS-threshold-modes), I explained how the different threshold modes are working. In this third article, I would like to show you what it means when the different modes work together. But, before I start doing some tests to show the behavior, I would like to give you a quick introduction into the toolset I´m using for these tests. Toolset First of all, how to do some floods? Different tools that can be found on the Internet are available for use. Whatever tools you might prefer, just download the tool and run it against your Device Under Test (DUT). If you would like to use my script you can get it from GitHub: https://github.com/sv3n-mu3ll3r/DDoS-Scripts With this script - it uses hping - you can run different type of attacks. Simply start it with: $ ./attack_menu.sh <IP> <PORT> A menu of different attacks will be presented which you can launch against the used IP and port as a parameter. Figure 1:Attack Menu To see what L3/4 DoS events are currently ongoing on your BIG-IP, simply go to the DoS Overview page. Figure 2:DoS Overview page I personally prefer to use the CLI to get the details I´m interested in. This way I don´t need to switch between CLI to launch my attacks and GUI to see the results. For that reason, I created a script which shows me what I am most interested in. Figure 3:DoS stats via CLI You can download that script here: https://github.com/sv3n-mu3ll3r/F5_show_DoS_stats_scripts Simply run it with the “watch” command and the parameter “-c” to get a colored output (-c is only available starting with TMOS version 14.0): What is this script showing you? context_name: This is the context, either PO/VS or the Device in which the vector is running vector_name: This is the name of the DoS vector attack_detected:When it shows “1”, then an attack has been detected, which means the ‘stats_rate’ is above the ‘detection-rate'. stats_rate: Shows you the current incoming pps rate for that vector in this context drops_rate: Shows you the number dropped pps rate in software (not FPGA) for that vector in this context int_drops_rate: Shows you the number dropped pps rate in hardware (FPGA) for that vector in this context ba_stats_rate: Shows you the pps rate for bad actors ba_drops_rate: Shows you the pps rate of dropped ‘bad actors’ in HW and SW bd_stats_rate:Shows you the pps rate for attacked destination bd_drop_rate: Shows you the pps rate for dropped ‘attacked destination’ mitigation_curr: Shows the current mitigation rate (per tmm) for that vector in that context detection: Shows you the current detection rate (per tmm) for that vector in that context wl_count: Shows you the number of whitelist hits for that vector in that context hw_offload: When it shows ‘1’ it means that FPGAs are involved in the mitigation int_dropped_bytes_rate: Gives you the rate of in HW dropped bytes for that vector in that context dropped_bytes_rate: Gives you the rate of in SW dropped bytes for that vector in that context When a line is displayed in green, it means packets hitting that vector. However, no anomaly is detected or anything is mitigated (dropped) via DoS. If a line turns yellow, then an attack - anomaly – has been detected but no packets are dropped via DoS functionalities. When the color turns red, then the system is actually mitigating and dropping packets via DoS functionalities on that vector in that context. Start Testing Before we start doing some tests, let me provide you with a quick overview of my own lab setup. I´m using a DHD (DDoS Hybrid Defender) running on a i5800 box with TMOS version 15.1 My traffic generator sends around 5-6 Gbps legitimate (HTTP and DNS) traffic through the box which is connected in L2 mode (v-wire) to my network. On the “client” side, where my clean traffic generator is located, my attacking clients are located as well by use of my DoS script. On the “server” side, I run a web service and DNS service, which I´m going to attack. Ok, now let’s do some test so see the behavior of the box and double check that we really understand the DDoS mitigation concept of BIG-IP. Y-MAS flood against a protected server Let’s start with a simple Y-MAS (all TCP flags cleared) flood. You can only configure this vector on the device context and only in manual mode. Which is ok, because this TCP packet is not valid and would get drop by the operating system (TMOS) anyway. But, because I want this type of packet get dropped in hardware (FPGA) very early, when they hit the box, mostly without touching the CPU, I set the thresholds to ‘10’ on the Mitigation Threshold EPS and to ‘10’ on Detection Threshold EPS. That means as soon as a TMM sees more then 10 pps for that vector it will give me a log message and also rate-limit this type of packets per TMM to 10 packets per second. That means that everything below that threshold will get to the operating system (TMOS) and get dropped there. Figure 4:Bad TCP Flags vector As soon as I start the attack, which targets the web service (10.103.1.50, port 80) behind the DHD with randomized source IPs. $ /usr/sbin/hping3 --ymas -p 80 10.103.1.50 --flood --rand-source I do get a log messages in /var/log/ltm: Feb5 10:57:52 lon-i5800-1 err tmm3[15367]: 01010252:3: A Enforced Device DOS attack start was detected for vector Bad TCP flags (all cleared), Attack ID 546994598. And, my script shows me the details on that attack in real time (the line is in ‘red’, indicating we are mitigating): Currently 437569 pps are hitting the device. 382 pps are blocked by DDoS in SW (CPU) and 437187 are blocked in HW (FPGA). Figure 5:Mitigating Y-Flood Great, that was easy. :-) Now, let’s do another TCP flood against my web server. RST-flood against a protected server with Fully manual Threshold mode: For this test I´m using the “Fully Manual” mode, which configures the thresholds for the whole service we are protecting with the DoS profile, which is attached to my VS/PO. Figure 6:RST flood with manual configuration My Detection Threshold and my Mitigation Threshold EPS is set to ‘100’. That means as soon as we see more then 100 RST packets hitting the configured VS/PO on my BIG-IP for this web server, the system will start to rate-limit and send a log message. Figure 7:Mitigating RST flood on PO level Perfect. We see the vector in the context of my web server (/Common/PO_10.103.1.50_HTTP) is blocking (rate-limiting) as expected from the configuration. Please ignore the 'IP bad src' which is in detected mode. This is because 'hping' creates randomized IPs and not all of them are valid. RST-flood against a protected server with Fully Automatic Threshold mode: In this test I set the Threshold Mode for the RST vector on the DoS profile which is attached to my web server to ‘Fully Automatic’ and this is what you would most likely do in the real world as well. Figure 8:RST vector configuration with Fully Automatic But, what does this mean for the test now? I run the same flood against the same destination and my script shows me the anomaly on the VS/PO (and on the device context), but it does not mitigate! Why would this happen? Figure 9:RST flood with Fully Automatic configuration When we take a closer look at the screenshot we see that the ‘stats_rate’ shows 730969 pps. The detection rate shows 25. From where is this 25 coming? As we know, when ‘Fully Automatic’ is enabled then the system learns from history. In this case, the history was even lower than 25, but because I set the floor value to 100, the detection rate per TMM is 25 (floor_value / number of TMMs), which in my case is 100/4 = 25 So, we need to recognize, that the ‘stats_rate’ value represents all packets for that vector in that context and the detection value is showing the per TMM value. This value explains us why the system has detected an attack, but why is it not dropping via DoS functionalities? To understand this, we need to remember that the mitigation in ‘Fully Automatic’ mode will ONLY kick in if the incoming rate for that vector is above the detection rate (condition is here now true) AND the stress on the service is too high. But, because BIG-IP is configures as a stateful device, this randomized RST packets will never reach the web service, because they get all dropped latest by the state engine of the BIG-IP. Therefor the service will never have stress caused by this flood.This is one of the nice benefits of having a stateful DoS device. So, the vector on the web server context will not mitigate here, because the web server will not be stressed by this type of TCP attack. This does also explains the Server Stress visualization in the GUI, which didn´t change before and during the attack. Figure 10:DoS Overview in the GUI But, what happens if the attack gets stronger and stronger or the BIG-IP is too busy dealing with all this RST packets? This is when the Device DOS kicks in but only if you have configured it in ‘Fully Automatic’ mode as well. As soon as the BIG-IP receives more RST packets then usually (detection rate) AND the stress (CPU load) on the BIG-IP gets too high, it starts to mitigate on the device context. This is what you can see here: Figure 11:'massive' RST flood with Fully Automatic configuration The flood still goes against the same web server, but the mitigation is done on the device context, because the CPU utilization on the BIG-IP is too high. In the screenshot below you can see that the value for the mitigation (mitigation_curr) is set to 5000 on the device context, which is the same as the detection value. This value resultsfrom the 'floor' value as well. It is the smallest possible value, because the detection and mitigation rate will never be below the 'floor' value. The mitigation rate is calculated dynamically based on the stress of the BIG-IP. In this test I artificially increased the stress on the BIG-IP and therefor the mitigation rate was calculated to the lowest possible number, which is the same as the detection rate. I will provide an explanation of how I did that later. Figure 13:Device context configuration for RST Flood Because this is the device config, the value you enter in the GUI is per TMM and this is reflected on the script output as well. What does this mean for the false-positive rate? First of all, all RST packets not belonging to an existing flow will kicked out by the state engine. At this point we don´t have any false positives. If the attack increases and the CPU can´t handle the number of packets anymore, then the DOS protection on the device context kicks in. With the configuration we have done so far, it will do the rate-limiting on all RST packets hitting the BIG-IP. There is no differentiation anymore between good and bad RST, or if the RST has the destination of server 1 or server 2, and so on. This means that at this point we can face false positives with this configuration. Is this bad? Well, false-positives are always bad, but at this point you can say it´s better to have few false-positives then a service going down or, even more critical, when your DoS device goes down. What can you do to only have false positives on the destination which is under attack? You probably have recognized that you can also enable “Attacked Destination Detection” on the DoS vector, which makes sense on the device context and on a DoS profile which is used on protected object (VS), that covers a whole network. Figure 14:Device context configuration for RST Flood with 'Attacked Destination Detection' enabled If the attack now hits one or multiple IPs in that network, BIG-IP will identify them and will do the rate-limiting only on the destination(s) under attack. Which still means that you could face false positives, but they will be at least only on the IPs under attack. This is what we see here: Figure 15:Device context mitigation on attacked destination(s) The majority of the RST packet drops are done on the “bad destination” (bd_drops_rate), which is the IP under attack. The other option you can also set is “Bad Actor Detection”. When this is enabled the system identifies the source(s) which causes the load and will do the rate limiting for that IP address(es). This usually works very well for amplification attacks, where the attack packets coming from ‘specific’ hosts and are not randomized sources. Figure 16:Device context mitigation on attacked destination(s) and bad actor(s) Here you can see the majority of the mitigation is done on ‘bad actors’. This reduces the chance of false positives massively. Figure 17:Device context configuration for RST Flood with 'Attacked Destination Detection' and 'Bad Actor Detection' enabled You also have multiple additional options to deal with ‘attacked destination’ and ‘bad actors’, but this is something I will cover in another article. Artificial increase BIG-IPs CPU load Before I finish this article, I would like to give you an idea on how you could increase the CPU load of the BIG-IP for your own testing. Because, as we know, with “Fully Automatic” on the device context, the mitigation kicks only in if the packet rate is above the detection rate AND the CPU utilization on the BIG-IP is “too” high. This is sometimes difficult to archive in a lab because you may not be able to send enough packets to stress the CPUs of a HW BIG-IP. In this use-case I use a simple iRule, which I attach to the VS/PO that is under attack. Figure 18:Stress iRule When I start my attack, I send the traffic with a specific TTL for identification. This TTL is configured in my iRule in order to get a CPU intensive string compare function to work on every attack packet. Here is an example for 'hping': $ /usr/sbin/hping3 --rst -p 80 10.103.1.50 --ttl 5 --flood --rand-source This can easily drive the CPU very high and the DDoS rate-limiting kicks in very aggressive. Summary I hope that this article provides you with an even better understanding on what effect the different threshold modes have on the attack mitigation. Of course, keep in mind this are just the ‘static DoS’ vectors. In later articles I will explain also the 'Behavioral DoS' and the Cookie based mitigation, which helps to massively reduce the chance of a false positives. But, also keep in mind, the DoS vectors start to act in microseconds and are very effective for protecting. Thank you, sVen Mueller3.4KViews11likes3Comments9. SYN Cookie Troubleshooting: Logs
Introduction In this last article I will add the last piece of information you can check when troubleshooting TCP SYN Cookie attacks, logs. With this information together with all that you have learned until now you should be able to understand how SYN Cookie is behaving and decide if there is any change you should do in your configuration to improve it. Use cases LTM SYN Cookie at Global context Logs when Global SYN Check Threshold or Default Per Virtual Server SYN Check Threshold has been exceeded are similar, so in order to know in which context was SYN Cookie activated you need to focus on specific text in logs. For example, by having below config: turboflex profile feature => adc tmsh list sys db pvasyncookies.enabled => true tmsh list ltm global-settings connection default-vs-syn-challenge-threshold => 1500 <= tmsh list ltm global-settings connection global-syn-challenge-threshold => 2050 <= tmsh list ltm profile fastl4 syn-cookie-enable => enabled You will get logs similar to the ones below if Global SYN cache has been reached: Dec 7 03:03:02 B12050-R67-S8 warning tmm9[5507]: 01010055:4: Syncookie embryonic connection counter 2051 exceeded sys threshold 2050 Dec 7 03:03:02 B12050-R67-S8 warning tmm5[5507]: 01010055:4: Syncookie embryonic connection counter 2051 exceeded sys threshold 2050 Dec 7 03:03:02 B12050-R67-S8 notice tmm5[5507]: 01010240:5: Syncookie HW mode activated, server name = /Common/syncookie_test server IP = 10.10.20.212:80, HSB modId = 1 Dec 7 03:03:02 B12050-R67-S8 notice tmm9[5507]: 01010240:5: Syncookie HW mode activated, server name = /Common/syncookie_test server IP = 10.10.20.212:80, HSB modId = 2 As you can notice there are two different messages, the first one informs about Software SYN Cookie being activated at Global context, and the second one tells us that Hardware is offloading SYN Cookie from Software. Since there is a minimum delay before Hardware to start to offload SYN Cookie is expected to see a non zero value for the counter Current SYN Cache stats. See article in this SYN Cookie series for more information about stats. Global SYN cache value is configured per TMM, so you see in the log that 2050 threshold has been exceeded in the TMM, and therefore SYN Cookie is activated globally in the device. In this specific example the device has two HSBs and BIG-IP decided that tmm9 and tmm5 would activate each one of them this is why we see the logs repeated. LTM SYN Cookie at Virtual context For the same configuration example I showed above you will see log similar to one below if Virtual SYN cache has been reached: Oct 18 02:26:32 I7800-R68-S7 warning tmm[15666]: 01010038:4: Syncookie counter 251 exceeded vip threshold 250 for virtual = 10.10.20.212:80 Oct 18 02:26:32 I7800-R68-S7 notice tmm[15666]: 01010240:5: Syncookie HW mode activated, server name = /Common/wildcardCookie server IP = 10.10.20.212:80, HSB modId = 1 Oct 18 02:26:32 I7800-R68-S7 notice tmm[15666]: 01010240:5: Syncookie HW mode activated, server name = /Common/wildcardCookie server IP = 10.10.20.212:80, HSB modId = 2 Virtual SYN cache value is configured globally meaning that the configured value must be divided among TMMs to know when SYN cookie will be enabled on each TMM. Run below command to see physical number of cores: tmsh sho sys hard | grep core In this example device has 6 TMMs, so 1500/6 is 250. Note that you will see a warning message entry per TMM (I removed 3 log entries in above example order to summarize) and per HSB ID. Log does not always show the VIP’s IP, it depends on type of VIP. For example in below case: Oct 17 04:04:54 I7800-R68-S7 warning tmm2[22805]: 01010038:4: Syncookie counter 251 exceeded vip threshold 250 for virtual = 10.10.20.212:80 Oct 17 04:04:54 I7800-R68-S7 warning tmm3[22805]: 01010038:4: Syncookie counter 251 exceeded vip threshold 250 for virtual = 10.10.20.212:80 Oct 17 04:04:55 I7800-R68-S7 notice tmm2[22805]: 01010240:5: Syncookie HW mode activated, server name = /Common/wildcardCookie server IP = 10.10.20.212:80, HSB modId = 1 Oct 17 04:05:51 I7800-R68-S7 notice tmm2[22805]: 01010241:5: Syncookie HW mode exited,server name = /Common/wildcardCookie server IP = 10.10.20.212:80, HSB modId = 1 from HSB There is not any virtual configured with destination IP 10.10.20.212. In fact traffic is handled by a wildcard VIP listening on 0.0.0.0/0, this logged IP is the destination IP:Port in the request that triggered SYN Cookie. You can consider this IP as the most probable attacked IP since it was the one that exceeded the threshold, so you can assume there are more attacks to this IP, however attack could have a random destination IPs target. Important: Per-Virtual SYN Cookie threshold MUST be lower than Global threshold, if you configure Virtual Server threshold higher than Global, or 0, then internally BIG-IP will set SYN Cookie Global threshold equals to Per-Virtual SYN Cookie threshold. LTM SYN Cookie at VLAN context Configuration example for triggering LTM SYN Cookie at VLAN context: turboflex profile feature => adc tmsh list sys db pvasyncookies.enabled => true tmsh list ltm global-settings connection vlan-syn-cookie => enabled tmsh list net vlan hardware-syncookie => [vlan external: 2888] tmsh list ltm global-settings connection default-vs-syn-challenge-threshold => 0 tmsh list ltm global-settings connection global-syn-challenge-threshold => 2500 When SYN cookie is triggered you get log: Oct 17 10:27:23 I7800-R68-S7 notice tmm[15666]: 01010292:5: Hardware syncookie protection activated on VLAN 1160 (syncache:2916 syn flood pkt rate:0) In this case you will see that information related to virtual servers on this VLAN will show SYN cookie as ‘not activated’ because protection is at VLAN context: #tmsh show ltm virtual | grep ' status ' -i Statusnot-activated Statusnot-activated If you configure SYN Cookie per VLAN but Turboflex adc/security is not provisioned then you will get: Oct 17 04:39:52 I7800-R68-S7.sin.pslab.local warning mcpd[7643]: 01071859:4: Warning generated : This platform supports Neuron-based Syncookie protection on per VS basis (including wildcard virtual). Please use that feature instead AFM SYN Cookie at Global context Main different in AFM default log is that you will not get a message telling you the threshold it has been exceeded, instead log will inform you directly about the context that detected the attack. Configuration example for triggering AFM SYN Cookie at global context: turboflex profile feature=> security tmsh list ltm global-settings connection vlan-syn-cookie=> enabled tmsh list net vlan hardware-syncookie[not compatible with DoS device] tmsh list sys db pvasyncookies.enabled=> true tmsh list ltm global-settings connection default-vs-syn-challenge-threshold.=> 0 tmsh list ltm global-settings connection global-syn-challenge-threshold=> 2500 tmsh list security dos device-config default-internal-rate-limit (tcp-half-open)=> >2500 tmsh list security dos device-config detection-threshold-pps (tcp-half-open)=> 2500 tmsh list ltm profile fastl4 syn-cookie-enable=> enabled AFM Device DoS has preference over LTM Global SYN Cookie, so in above configuration AFM tcp half open vector will be triggered: Oct 19 02:23:41 I7800-R68-S7 err tmm[23288]: 01010252:3: A Enforced Device DOS attack start was detected for vector TCP half open, Attack ID 1213152658. Oct 19 02:29:23 I7800-R68-S7 notice tmm[23288]: 01010253:5: A Enforced Device DOS attack has stopped for vector TCP half open, Attack ID 1213152658. In the example above you can see that there are logs warning you about an attack that started and stopped, but there is not any log showing if attack is mitigated. This is because you have not configured AFM to log to local-syslog (/var/log/ltm). In this situation DoS logs are basic. If you want to see packets dropped or allowed you need to configure specific security log profile. Be aware that when SYN Cookie is active because Device TCP half open DoS vector’s threshold has been reached then you will not see any Virtual Server showing that SYN Cookie has been activated, as it happens when SYN Cookie VLAN is activated: SYN Cookies Statusnot-activated This is slightly different to LTM Global SYN Cookie, when LTM Global SYN Cookie is enabled BIG-IP will show which specific VIP has SYN Cookie activated (Status Full Hardware/Software). In case you have configured logging for DoS then you would get logs like these: Oct 23 03:56:15 I7800-R68-S7 err tmm[21638]: 01010252:3: A Enforced Device DOS attack start was detected for vector TCP half open, Attack ID 69679369. Oct 23 03:56:15 I7800-R68-S7 info tmm[21638]: 23003138 "Oct 23 2020 03:56:15","10.200.68.7","I7800-R68-S7.sin.pslab.local","Device","","","","","","","TCP half open","69679369","Attack Started","None","0","0","0000000000000000", "Enforced", "Volumetric, Aggregated across all SrcIP's, Device-Wide attack, metric:PPS" Oct 23 03:56:16 I7800-R68-S7 info tmm[21638]: 23003138 "Oct 23 2020 03:56:16","10.200.68.7","I7800-R68-S7.sin.pslab.local","Device","","","","","","","TCP half open","69679369","Attack Sampled","Drop","3023","43331","0000000000000000", "Enforced", "Volumetric, Aggregated across all SrcIP's, Device-Wide attack, metric:PPS" Oct 23 03:56:16 I7800-R68-S7 info tmm[21638]: 23003138 "Oct 23 2020 03:56:16","10.200.68.7","I7800-R68-S7.sin.pslab.local","Device","","","","","","","TCP half open","69679369","Attack Sampled","Drop","3017","69710","0000000000000000", "Enforced", "Volumetric, Aggregated across all SrcIP's, Device-Wide attack, metric:PPS” The meaning of below fields shown in above logs: "Drop","3023","43331","0000000000000000" "Drop","3017","69710","0000000000000000" Are as below: {action} {dos_packets_received} {dos_packets_dropped} {flow_id} Where: {dos_packets_received} - It counts the number of TCP SYNs received for which you have not received the ACK. Also called embryonic SYNs. {dos_packets_dropped} - It counts the number of TCP syncookies that you have sent for which you have not received valid ACK. If you see that {dos_packets_received}are high, but {dos_packets_dropped} are 0 or low, then it just means that AFM is responding to SYN packets with SYN cookies and it is receiving correct ACKs from client. Therefore, AFM is not dropping anything. So this could mean that this is not an attack but a traffic peak. It can happen that you configure a mitigation threshold lower than detection threshold, although you will get a message warning you, you could not realise about it. If this is the case you will not see any log informing you about that there is an attack. This will happen for example with below configuration: tmsh list ltm global-settings connection global-syn-challenge-threshold=> 3400 tmsh list security dos device-config default-internal-rate-limit (tcp-half-open)=> 3000 tmsh list security dos device-config detection-threshold-pps (tcp-half-open)=> 3900 tmsh list ltm profile fastl4 syn-cookie-enable=> disabled Due to this you will see in /var/log/ltm something like: Oct 23 03:38:12 I7800-R68-S7.sin.pslab.local warning mcpd[10516]: 01071859:4: Warning generated : DOS attack data (tcp-half-open): Since drop limit is less than detection limit, packets dropped below the detection limit rate will not be logged. AFM SYN Cookie at Virtual context All information provided in previous use case applies in here, so for below configuration example: tmsh list ltm global-settings connection global-syn-challenge-threshold=> 3400 tmsh list security dos device-config default-internal-rate-limit (tcp-half-open)=> 3000 tmsh list security dos device-config detection (tcp-half-open)=> 3900 list security dos profile SYNCookie dos-network default-internal-rate-limit (tcp-half-open)=> 2000 list security dos profile SYNCookie dos-network detection-threshold-pps (tcp-half-open)=> 1900 tmsh list ltm profile fastl4 <name>=> enabled AFM device SYN Cookie is activated for specific virtual server with security profile applied: Oct 23 04:10:26 I7800-R68-S7 notice tmm[21638]: 01010240:5: Syncookie HW mode activated, server = 0.0.0.0:0, HSB modId = 1 Oct 23 04:10:26 I7800-R68-S7 notice tmm5[21638]: 01010240:5: Syncookie HW mode activated, server = 0.0.0.0:0, HSB modId = 2 Oct 23 04:10:26 I7800-R68-S7 err tmm3[21638]: 01010252:3: A NETWORK /Common/SYNCookie_Test DOS attack start was detected for vector TCP half open, Attack ID 2147786126. Oct 23 04:10:28 I7800-R68-S7 info tmm[16005]: 23003156 "10.200.68.7","I7800-R68-S7.sin.pslab.local","Virtual Server","/Common/SYNCookie_Test","Cryptographic SYN Cookie","16973","0","0","0", Oct 23 04:10:57 I7800-R68-S7 notice tmm5[21638]: 01010253:5: A NETWORK /Common/SYNCookie_Test DOS attack has stopped for vector TCP half open, Attack ID 2147786126. Oct 23 04:12:46 I7800-R68-S7 notice tmm[21638]: 01010241:5: Syncookie HW mode exited,server = 0.0.0.0:0, HSB modId = 1 from HSB Oct 23 04:12:47 I7800-R68-S7 notice tmm5[21638]: 01010241:5: Syncookie HW mode exited,server = 0.0.0.0:0, HSB modId = 2 from HSB Troubleshooting steps When you need to troubleshoot how device is working against a SYN flood attack there are some steps you can follow. Check configuration to make a global idea of what should happen when SYN flood occurs: tmsh show sys turboflex profile feature tmsh list ltm global-settings connection vlan-syn-cookie tmsh list net vlan hardware-syncookie tmsh list sys db pvasyncookies.enabled tmsh list ltm global-settings connection default-vs-syn-challenge-threshold tmsh list ltm global-settings connection global-syn-challenge-threshold tmsh list ltm profile fastl4 syn-cookie-enable tmsh list ltm profile tcp all-properties | grep -E 'profile|syn-cookie' tmsh list ltm profile fastl4 all-properties| grep -E 'profile|syn-cookie' list security dos device-config syn-cookie-whitelist syn-cookie-dsr-flow-reset-by tscookie-vlans tmsh list security dos device-config dos-device-config | grep -A23 half tmsh list security dos profile dos-network {<profile> { network-attack-vector { tcp-half-open } } } *I can miss some commands since I cannot know specific configuration you are using, but above list can give you a good idea about what you have actually configured in your system. Are you using Hardware or Software SYN cookie? Are you using CMP or vCMP? Is device a Neuron platform? Is SYN cookie configured/working in AFM, in LTM or in both? Is SYN cookie enabled at Device, VLAN or Virtual Server context? If issue is at virtual server context, which virtual servers are affected? is the problem happening in a Standard or FastL4 VIP, …? Check logs (date/times) and stats to confirm what it has really happened and since when. Take captures to confirm your findings. Is this an attack? Were there other attacks at the same time (TCP BAD ACK, TCP RST maybe)? Are thresholds correctly configured attending to expected amount of traffic? If clients are hidden by a proxy maybe you could save resources by configuring Challenge and remember. If this is a Neuron platform, is there any error in /var/log/neurond? Check published IDs related to SYN Cookie for specific TMOS versions or/and platforms. Conclusion Now you have enough information to start troubleshooting your own BIG-IP devices if any issue happens, and also and maybe more important you have tools to create the most appropriate configuration attending to your specific platform and traffic patterns. So you can start to take the advantage of your knowledge to improve performance of your device when under TCP SYN flood attack.2.2KViews1like0Comments8. SYN Cookie: Troubleshooting tcpdump
Introduction In this troubleshooting article, I will explain what traffic is expected to collect in a tcpdump capture during an ongoing attack. In this way you can compare with your own environment and understand why you see what you see. Use cases In this section I will show you the most common SYN Cookie configurations and how they affect to the traffic that reach BIG-IP. For each use case I add a diagram explaining the role of each party, so you can use it as a rerefence when reviewing captures. Note that, as a rule of thumb, in tcpdump captures you will see only traffic reaching red TMM arrow in diagrams. FastL4 + Hardware SYN Cookie Fig15. FastL4 + HW SYN Cookie When enabling SYN Cookie hardware offloading in FastL4 you must have into account that, regardless if FastL4 profile is configured as EST or SYN for ‘PVA TCP Offload State’ the capture will be similar to the one I paste below. Also note that colours in captures match with the diagram above, that is, blue (on the left) for client, red (next to blue and green) for BIG-IP and green (on the right) for server. BLUE: 10:55:30.650614 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [S], seq 1486117989, win 5840, options [mss 1460,sackOK,TS val 257012221 ecr 0,nop,wscale 6], length 0 10:55:30.651084 IP 10.10.20.212.80 > 10.10.10.10.33669: Flags [S.], seq 2770916048, ack 1486117990, win 4380, options [mss 1460], length 0 10:55:30.651115 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 10:55:30.651271 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167 RED: 10:48:27.666478 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [.], ack 2770916049, win 5840, length 0 in slot1/tmm3 lis= 10:48:27.666793 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [P.], seq 0:167, ack 1, win 5840, length 167: HTTP: GET /zarapito HTTP/1.1 in slot1/tmm3 lis=/Common/fwd 10:48:27.667073 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [S], seq 1486117989, win 5840, options [mss 1460], length 0 out slot1/tmm3 lis=/Common/fwd 10:48:27.667245 IP 10.10.20.212.80 > 10.10.10.10.33669: Flags [S.], seq 3169243726, ack 1486117990, win 64240, options [mss 1460], length 0 in slot1/tmm3 lis=/Common/fwd 10:48:27.667586 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 out slot1/tmm3 lis=/Common/fwd 10:48:27.667588 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167: HTTP: GET /zarapito HTTP/1.1 out slot1/tmm3 lis=/Common/fwd GREEN: 09:54:39.236239 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [S], seq 1486117989, win 5840, options [mss 1460], length 0 09:54:39.236264 IP 10.10.20.212.80 > 10.10.10.10.33669: Flags [S.], seq 3169243726, ack 1486117990, win 64240, options [mss 1460], length 0 09:54:39.236692 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 09:54:39.236707 IP 10.10.10.10.33669 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167: HTTP: GET /zarapito HTTP/1.1 09:54:39.236728 IP 10.10.20.212.80 > 10.10.10.10.33669: Flags [.], ack 168, win 64073, length 0 There are three important things you can observe in above captures: TCP options are lost in this example. This is because SYN Cookie is offloaded in hardware and for this mode currently only MSS value is trasfered from client side to server side, with some limitations. Check article dedicated to 'Hardware Vs Software' in this article series. In BIG-IP you cannot see the first two packets of TCP 3WHS (SYN and SYN/ACK). This is because hardware is in charge of validating SYN Cookie, since tcpdump is capturing traffic in TMM you only see last ACK packet. Also note that SYN sequence number sent by client to BIG-IP is the same than the one BIG-IP sends to Server. FastL4 + Software SYN Cookie Fig16. FastL4 + SW SYN Cookie In this case, although you are using an accelerated profile (FastL4), since software is handling the TCP 3WHS this allows you to see all packets when you run a traffic capture. Blue is on the left, red in the middle, green on the right. BLUE: 17:32:15.588706 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [S], seq 2986408498, win 5840, options [mss 1460,sackOK,TS val 262963455 ecr 0,nop,wscale 6], length 0 17:32:15.588973 IP 10.10.20.212.80 > 10.10.10.10.34527: Flags [S.], seq 2739000888, ack 2986408499, win 4380, options [mss 1460], length 0 17:32:15.588996 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 17:32:15.589119 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167 RED: 17:25:11.566071 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [S], seq 2986408498, win 5840, options [mss 1460,sackOK,TS val 262963455 ecr 0,nop,wscale 6], length 0 in slot1/tmm3 lis= 17:25:11.566095 IP 10.10.20.212.80 > 10.10.10.10.34527: Flags [S.], seq 2739000888, ack 2986408499, win 4380, options [mss 1460], length 0 out slot1/tmm3 lis=/Common/fwd 17:25:11.566321 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 in slot1/tmm3 lis= 17:25:11.566451 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167: HTTP: GET / HTTP/1.1 in slot1/tmm3 lis=/Common/fwd 17:25:11.566834 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [S], seq 2986408498, win 5840, options [mss 1460], length 0 out slot1/tmm3 lis=/Common/fwd 17:25:11.567058 IP 10.10.20.212.80 > 10.10.10.10.34527: Flags [S.], seq 4131626625, ack 2986408499, win 64240, options [mss 1460], length 0 in slot1/tmm3 lis=/Common/fwd 17:25:11.567344 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 out slot1/tmm3 lis=/Common/fwd 17:25:11.567346 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167: HTTP: GET / HTTP/1.1 out slot1/tmm3 lis=/Common/fwd GREEN: 16:31:24.339490 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [S], seq 2986408498, win 5840, options [mss 1460], length 0 16:31:24.339551 IP 10.10.20.212.80 > 10.10.10.10.34527: Flags [S.], seq 4131626625, ack 2986408499, win 64240, options [mss 1460], length 0 16:31:24.339987 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [.], ack 1, win 5840, length 0 16:31:24.340003 IP 10.10.10.10.34527 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, length 167: HTTP: GET / HTTP/1.1 As it happened in the previous example, BIG-IP does not ACK the HTTP request (PSH) sent by client because a FastL4 profile is being used, what it means that BIG-IP will act as a TCP transparent proxy between server and client. In other words, once correct TCP handshake has done BIG-IP will forward rest of this connection traffic to server directly. Standard + Hardware SYN Cookie Fig17. Standard + Hardware SYN Cookie The main difference in this case is that for Standard virtual server BIG-IP must act as a TCP proxy between client and server during all connection time. This means that BIG-IP sends ACK as response to PSH packet sent by client before this PSH is in fact received by the server. This image has the same color scheme as the first image. BLUE: 14:02:03.606740 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [S], seq 2828374030, win 5840, options [mss 1460,sackOK,TS val 259810460 ecr 0,nop,wscale 6], length 0 14:02:03.606861 IP 10.10.20.212.80 > 10.10.10.10.34522: Flags [S.], seq 2971392569, ack 2828374031, win 4380, options [mss 1460,sackOK,TS val 870079512 ecr 259810460], length 0 14:02:03.606885 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [.], ack 1, win 5840, options [nop,nop,TS val 259810460 ecr 870079512], length 0 14:02:03.607176 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 5840, options [nop,nop,TS val 259810460 ecr 870079512], length 167 RED: 13:55:00.128183 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [.], ack 2971392570, win 5840, options [nop,nop,TS val 259810460 ecr 870079512], length 0 in slot1/tmm4 lis= 13:55:00.128272 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [S], seq 2348737573, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 1607698719 ecr 0], length 0 out slot1/tmm4 lis=/Common/std 13:55:00.128496 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [P.], seq 0:167, ack 1, win 5840, options [nop,nop,TS val 259810460 ecr 870079512], length 167: HTTP: GET / HTTP/1.1 in slot1/tmm4 lis=/Common/std 13:55:00.128501 IP 10.10.20.212.80 > 10.10.10.10.34522: Flags [.], ack 167, win 14767, options [nop,nop,TS val 870079512 ecr 259810460], length 0 out slot1/tmm4 lis=/Common/std 13:55:00.128559 IP 10.10.20.212.80 > 10.10.10.10.34522: Flags [S.], seq 1953609172, ack 2348737574, win 65160, options [mss 1460,sackOK,TS val 1991641654 ecr 1607698719,nop,wscale 7], length 0 in slot1/tmm4 lis=/Common/std 13:55:00.128564 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [.], ack 1, win 14600, options [nop,nop,TS val 1607698719 ecr 1991641654], length 0 out slot1/tmm4 lis=/Common/std 13:55:00.128567 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 14600, options [nop,nop,TS val 1607698719 ecr 1991641654], length 167: HTTP: GET / HTTP/1.1 out slot1/tmm4 lis=/Common/std GREEN: 13:01:12.268012 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [S], seq 2348737573, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 1607698719 ecr 0], length 0 13:01:12.268103 IP 10.10.20.212.80 > 10.10.10.10.34522: Flags [S.], seq 1953609172, ack 2348737574, win 65160, options [mss 1460,sackOK,TS val 1991641654 ecr 1607698719,nop,wscale 7], length 0 13:01:12.268347 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [.], ack 1, win 14600, options [nop,nop,TS val 1607698719 ecr 1991641654], length 0 13:01:12.268355 IP 10.10.10.10.34522 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 14600, options [nop,nop,TS val 1607698719 ecr 1991641654], length 167: HTTP: GET / HTTP/1.1 Note that SYN sequence number sent by client to BIG-IP is different than the one BIG-IP sends to Server (2828374030 Vs 2348737573). This is because we are using Standard virtual server, so there are two independent TCP connections, one between client and BIG-IP and the second between BigIP and server. Again, as commented since in this example Hardware SYN Cookie is used we cannot see first two TCP handshake packets in the capture. Standard + Software SYN Cookie Fig18. Standard + Software SYN Cookie Apparently there are not any difference when capturing traffic of a client request when SYN Cookie is activated or disabled in this case. Only difference is that BIG-IP creates a SYN Cookie challenge and it adds it as a sequence number in SYN/ACK, but looking to capture this change is not clearly visible. We need to compare with log and stats to confirm that in fact SYN Cookie is enabled, also depending in config we can check as well TCP options passed to server side. Color scheme here is the same as the second image. BLUE: 14:32:58.966168 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [S], seq 3344434108, win 5840, options [mss 1460,sackOK,TS val 260274299 ecr 0,nop,wscale 6], length 0 14:32:58.966358 IP 10.10.20.212.80 > 10.10.10.10.34525: Flags [S.], seq 2686010241, ack 3344434109, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 3273182234 ecr 260274299], length 0 14:32:58.966398 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [.], ack 1, win 92, options [nop,nop,TS val 260274299 ecr 3273182234], length 0 14:32:58.966649 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 92, options [nop,nop,TS val 260274300 ecr 3273182234], length 167 RED: 14:25:55.405917 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [S], seq 3344434108, win 5840, options [mss 1460,sackOK,TS val 260274299 ecr 0,nop,wscale 6], length 0 in slot1/tmm1 lis= 14:25:55.405931 IP 10.10.20.212.80 > 10.10.10.10.34525: Flags [S.], seq 2686010241, ack 3344434109, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 3273182234 ecr 260274299], length 0 out slot1/tmm1 lis=/Common/std 14:25:55.406048 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [.], ack 1, win 92, options [nop,nop,TS val 260274299 ecr 3273182234], length 0 in slot1/tmm1 lis= 14:25:55.406355 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 92, options [nop,nop,TS val 260274300 ecr 3273182234], length 167: HTTP: GET / HTTP/1.1 in slot1/tmm1 lis=/Common/std 14:25:55.406359 IP 10.10.20.212.80 > 10.10.10.10.34525: Flags [.], ack 168, win 14767, options [nop,nop,TS val 3273182234 ecr 260274300], length 0 out slot1/tmm1 lis=/Common/std 14:25:55.406131 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [S], seq 2235159701, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 1609553998 ecr 0], length 0 out slot1/tmm1 lis=/Common/std 14:25:55.406524 IP 10.10.20.212.80 > 10.10.10.10.34525: Flags [S.], seq 3205875957, ack 2235159702, win 65160, options [mss 1460,sackOK,TS val 1993497007 ecr 1609553998,nop,wscale 7], length 0 in slot1/tmm1 lis=/Common/std 14:25:55.406527 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [.], ack 1, win 14600, options [nop,nop,TS val 1609553998 ecr 1993497007], length 0 out slot1/tmm1 lis=/Common/std 14:25:55.406531 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 14600, options [nop,nop,TS val 1609553998 ecr 1993497007], length 167: HTTP: GET / HTTP/1.1 out slot1/tmm1 lis=/Common/std GREEN: 13:32:07.645733 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [S], seq 2235159701, win 14600, options [mss 1460,nop,wscale 0,sackOK,TS val 1609553998 ecr 0], length 0 13:32:07.645820 IP 10.10.20.212.80 > 10.10.10.10.34525: Flags [S.], seq 3205875957, ack 2235159702, win 65160, options [mss 1460,sackOK,TS val 1993497007 ecr 1609553998,nop,wscale 7], length 0 13:32:07.646011 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [.], ack 1, win 14600, options [nop,nop,TS val 1609553998 ecr 1993497007], length 0 13:32:07.646022 IP 10.10.10.10.34525 > 10.10.20.212.80: Flags [P.], seq 1:168, ack 1, win 14600, options [nop,nop,TS val 1609553998 ecr 1993497007], length 167: HTTP: GET / HTTP/1.1 Note that, as in the previous example, SYN sequence number sent by client to BIG-IP is different than the one BIG-IP sends to Server (3344434108 Vs 2235159701). Conclusion At this point only one part left to have a complete picture of BIG-IP's SYN Cookie countermeasure functioning, so in next article I finish this series giving details about expected logs when SYN Cookie is working in our device.2.9KViews0likes0Comments6. SYN Cookie: Hardware vs Software
Introduction Currently, you know the differences between LTM and AFM when talking about SYN Cookie capabilities and configuration. In this article I describe how SYN Cookie can perform its tasks using two different ways, in software or offloaded in hardware. The most important difference between these functioning modes is clearly the resource consuming. In hardware based platforms SYN Cookie is a countermeasure that will not consume extra memory nor CPU, while in software this task must be handled by TMM, so some load could be added comparing to normal operation. Hardware SYN Cookie If you have a hardware offloading capable platform and you configure SYN Cookie to work in hardware, the creation and validation of SYN Cookie challenges will be managed by dedicated FPGA (Programmable Field Array) or NSP (Neuron Search Processor) In a few words this means that SYN Cookie running in hardware basically allows you to forget about TCP SYN flood attacks. You do not have to care about it, if it is correctly configured, since BIG-IP will not only mitigate attack without impacting legitimate users, who will still access to application during the attack, but also no extra resources will be needed. The only handicap you have to take into account currently when hardware SYN Cookie is activated is that you cannot keep TCP options information. In order to keep this information you need to enable SYN Cookie in software and client connection need to activate TCP TS option (this is enabled by default in BIG-IP). See second article in this series for more details (SYN Cookie Operation). Neuron Platforms shipped with Neuron chip and running a TMOS version greater than 14, improve performance because this chip, which is directly connected to HSBe2, provide with extra functionalities to SYN Cookie. Neuron improves performance and solves limitations that you could find in HSBe2 only platforms when SYN Cookie is activated for wildcard virtual servers. A brief description of this limitation can be found in K50955355. Note that Neuron does not only offloads SYN Cookie tasks from software, if you have an AFM provisioned device you can take advantage of other features like extended whitelists and blacklists in hardware. However these article series are only focused on SYN Cookie. With this in mind the functioning of Neuron is simple, HSBe2 makes requests to Neuron when a TCP SYN reaches BIG-IP, and depending of the type of request Neuron then will create a SYN Cookie for the connection or it will validate SYN Cookie response presented by client. For example, as I showed in previous articles, when an ACK comes from a client then HSBe2 will ask Neuron if SYN Cookie is correct, then Neuron will response with the requested information, so TMM will know if it must drop or allow the connection through the datapath. SYN Cookie Neuron does not offload AFM Global SYN Cookie, it works for: LTM Global SYN Cookie Per VLAN SYN Cookie LTM Per Virtual SYN Cookie AFM Per Virtual SYN Cookie In order to enable SYN Cookie Neuron in your platform you need to activate the Turboflex profile for Security/Securityv1 (AFM) or ADC (LTM). There is many literature in AskF5 about Turboflex, but in a few words it allows you to group several related features to be accelerated in hardware. I will not give technical details about Neuron since it is not the intention of these article series. For troubleshooting issues with Neuron please raise a case to F5 Networks, so expert engineer can investigate it. Making internal changes to Neuron could lead to a worst result. Disabling SYN Cookie SYN Cookie is enabled by default in software and hardware, if we disable hardware SYN Cookie then software SYN Cookie comes into play. There is a DB key for disabling Hardware SYN Cookie in all contexts: tmsh list sys db pvasyncookies.enabled sys db pvasyncookies.enabled { value "false" } Of course, if the specific platform cannot offload SYN Cookie into hardware then above DB key has no effect. In this case software SYN Cookie is enabled by default. There is not such DB key for enabling/disabling software SYN Cookie as we have for hardware, instead, if you want to disable software SYN Cookie then you have different options depending on context that you can consult in table below. Remember that AFM SYN Cookie has precedence over LTM SYN Cookie, this means that if AFM SYN Cookie is configured and you want to disable completely SYN Cookie you need to disable both, AFM and LTM SYN Cookie. The simplest path to disable completely SYN Cookie assuming default config, that is, hardware SYN Cookie is enabled, it would be: Fig14. Disabling SYN Cookie In table below I summarize how to disable hardware and software SYN Cookie in each context for the different scopes. For AFM disabling SYN Cookie is quite easier, you just need to change DoS Device and DoS profiles TCP Half Open vector to 0/Infinite. Warnings It can be possible that SYN Cookie works in software in your device whilst you expected SYN Cookie working in hardware. Sometimes you end up in this situation due to a wrong configuration. Below I make a list of possible reasons that you can check: You have disabled autolasthop. This option must be enabled if you want to offload SYN Cookie into hardware (K16887). You have changed DB key connection.syncookies.algorithm manually. This key defines which algorithm is used for generating hash that is part of the SYN Cookie challenge (as I described in the first article of this series). When set a value of Hardware to this DB key the error detecting code used for validating the hash will be understood by both, software and hardware. If set to Software then it will only be understood by software. If your version also has the option ‘both’, this means that BIG-IP dynamically discovers which algorithm should be used rather than forcing to Software or Hardware. In summary, if virtual is configured for hardware SYN Cookie but algorithm is configured in software then hardware will inspect SYN Cookies, it will confirm it cannot validate them and then it will send it to TMM for validation. Until v14.1 SYN cookie hardware it is not recommended for protecting networks (wildcard virtual servers), this is because SYN Cookie will only protect a single flood network destination when flooding towards multiple network destination at a time. The other networks will be protected by software SYN cookie. This could cause unexpected extra CPU utilization. This is greatly improved in Neuron capable platforms. If there are collisions when SYN Cookie is configured in hardware you will still see non zero stats for software SYN Cookie. Also, these stats can increase due to validation of first challenges, when SYN Cookie is activated, and TMMs handles TCP SYN until it enables hardware to do it. This is expected and it does not mean that hardware SYN Cookie is not working. I will show examples in article dedicated to stats. In order to end up this section with clear ideas, remember that hardware SYN Cookie and hardware flow acceleration are two different concepts. Conclusion In this article you learnt how behaves SYN Cookie when working in software and hardware and the advantages or disadvantages. In next two articles I will show you how to troubleshoot SYN Cookie issues.1.4KViews0likes0Comments