Advanced iRules: Tables
We’ve covered quite a bit of ground in the Getting Started with iRules and Intermediate iRules series. In this series, we’ll dive even deeper down the rabbit hole, starting with the table command. This article is a primer for the power of tables, but we actually have an entire 9 part series on the table command alone, so after reading this overview, I highly recommend you dig in to the meat of what tables can really do. What is a table? A table is somewhat similar to a data-group in that it is, at its core, a memory structure to contain lists. That’s about where the similarities end, though. Tables are stored in memory alone, which means they don’t have the config object backing that a data-group does, but that also makes them inherently more flexible. A table is a read/write memory structure that is maintained across connections, making it a solid contender for storing data that needs to be persistent, as opposed to connection based like normal iRules variables. Tables also allow a few extremely powerful concepts, namely sub tables and a built in timeout/lifetime structure. Both of these things add possibilities to what tables are capable of. Tables are also extremely efficient, much like data-groups, though on a slightly smaller scale given their more flexible nature. Tables make use of the session table within LTM, which is designed to handle every connection into or out of the device, and as such is very high performance. Table queries share this performance and can be a quick way to construct simple, persistent memory structures or more complex near DB like sets of sub-tables, depending on your needs. What are the benefits of a table? Tables are a high performance, highly scalable, persistent (non-connection bound), read/write data structure. That fact alone makes them unique within iRules and extremely powerful. There simply aren’t other things that fill that role. There are only a couple of ways to have read/write variable data across connections, and tables are by far the best option in almost every case. The ability to create what amounts to a mini database in memory from within your iRule is massively useful in many scenarios also. This is easy to do via subtables. You can create not just a flat list, but named lists to segregate data however you’d like. By doing so you can create relations and a relatively complex schema for data storage and accounting. Now add in the fact that there are configurable timeout and lifetime options, which means you’ll never have to worry about memory management or programmatic cleanup of a table, as things will time out as designed, and you’ve got another layer of usability and ease of use that is unique to tables. The bottom line is that tables are one of the more powerful, flexible features to hit iRules in quite a while. What command(s) would I use to access data in a table? To access tables, you make use of the table command, much like the class command to access data-groups. This command can also get quite complex quite fast, so I won’t attempt to cover all the possible permutations here. I’ll list a couple of simple examples, and give you a link to the full documentation. # Limit each client IP address to 20 concurrent connections when CLIENT_ACCEPTED { # Check if the subtable has over 20 entries if { [table keys -subtable connlimit:[IP::client_addr] -count] >= 20 } { reject } else { # Add the client IP:port to the client IP-specific subtable # with a max lifetime of 180 seconds table set -subtable connlimit:[IP::client_addr] [TCP::client_port] "" 180 } } when CLIENT_CLOSED { # When the client connection is closed, remove the table entry table delete -subtable connlimit:[IP::client_addr] [TCP::client_port] } As you can see tables are extremely powerful, and can add a powerful tool to your quiver for your future iRule endeavors. There are plenty of examples of using these powerful commands out on DevCentral, so there is no shortage of information to be found and code to be lifted for re-use if you scour Q&A and the Codeshare. In an attempt to keep this consumable I've not gone through the full list of command permutations or anywhere near the full possibilities. I'll leave discovering those things to the more advanced and/or eager iRulers, but suffice to say the possibilities are vast.6.5KViews5likes5Comments
Advanced iRules: Sideband Connections
With the release of BIG-IP version 11 there are many, many new features and capabilities to come up to sped on. Not the least of which are the additions and changes to the already powerful iRules infrastructure. iRules, as a whole, is an amazingly powerful, flexible technology. We've seen it used for thousands of things over the years, and it has solved problems that many people thought were beyond fixing. That being said, there are some new tricks being added that will, simply put, blow you away. One such feature is the concept of a sideband connection. This is one of the most exciting features in the entire v11 release for those of us that are true iRules zealots out there, as it's something that we've been asking to have for years now, and adds tremendous power to the already vast iRules toolbox. So what is a sideband connection you ask? Think of a sideband connection as a way to access the world outside of an iRule. With this functionality you can create a connection (TCP or UDP) to any outside resource you choose, send a custom formatted request, await a response if applicable, act on that response, etc. The sky is really the limit. If you've done any kind of socket programming this should start sounding pretty familiar. The concept is very similar, open, send, receive, process. By allowing you to reach out to surrounding applications, APIs, servers and even, if you're tricky enough, databases...the possibilities of what you can do within your iRule open up considerably. Curious what permissions someone is supposed to have but they're stored in your LDAP system? No problem. Want to query that custom HTTP based API with some information about the current connection before deciding where to load balance to? Sure, you can do that. So how does it work? What does it look like? Well, the commands are pretty simple, actually. In this article I'll briefly cover the four main commands that allow you to establish, communicate via, and manipulate sideband connections within iRules. Connect First is the connect command, which is the command used to initiate the connection for use. This is what reaches out, does whatever handshaking necessary and actually establishes the connection with whatever remote server you'll be interacting with. The connect command looks like this: connect [-protocol TCP|UDP] [-myport <port>] [-myaddr <addr>] [-tos <tos>] [-status <varname>] [-idle <s>] [-timeout <ms>] <destination> As you can see, there are a lot of options, but the structure itself is pretty logical. You're calling the connect command, obviously, and specifying how you want to connect (TCP vs UDP), where you're connecting to (IP & Port), and then giving some basic information about that connection, namely timeout, idle time, etc. Now that you have an established connection, you're probably going to want to send some data through it. When you're initiating the connection you'll normally also specify a variable that represents the resulting handle for later use. This looks like: set conn [connect -timeout 3000 -idle 30 -status conn_status vs_test] log local0. "Connect returns: <$conn> and conn status: <$conn_status>" Send The above will give you a variable named "$conn" that you can then pass traffic to, assuming the connection was initiated successfully. Once things are up and running and your variable is set you can make use of the send command to pass traffic to your new connection. Keep in mind that you're going to be sending raw data, which will require whatever protocol specific formatting may be necessary for whatever it is you're trying to send. Below you'll see the simple HTTP GET request we'll be sending, stored in the variable "$data" to keep things obvious, as well as the send command that is used to send that data through the connection we opened above. Note that the send command also allows you to specify a variable to contain the status of the send so that you can later verify that the send went through properly. set data "GET /mypage/myindex2.html HTTP/1.0\r\n\r\n" set send_info [send -timeout 3000 -status send_status $conn $data] Recv Now that you have a functioning connection and are sending data through it to some remote host, you're likely curious what that host is saying in response, I would imagine. There is a command for that too, naturally. With the recv command you're able to consume the data that is being returned from your open connection. There are also sub-commands like -peek and -eol. I'll get into more detail about these later, but here's the short version: The -peek flag allows you to instantly return any received data without unbuffering, to allow you to inspect a portion of the data before the recv command has completed collecting the response. The -eol command looks for an end-of-line character before terminating the recv. A basic recv looks like this, storing the data in a new variable: set recv_data [recv -timeout 3000 -status recv_status 393 $conn] Close At this point you'll be able to inspect whatever data was returned by parsing the $recv_data variable (though this variable name is up to you). Now that you've initiated a connection, sent data to it, and collected the response, the only thing left to do, unless you want to repeat the send/recv of course, is to close the connection. That is done quite simply with close command. No arguments or tricks here, just a simple termination of the connection: close $conn If you put it all together, a simple example iRule would look something like this: when HTTP_REQUEST { set conn [connect -timeout 3000 -idle 30 -status conn_status vs_test] log local0. "Connect returns: <$conn> and conn status: <$conn_status> " set conn_info [connect info -idle -status $conn] log local0. "Connect info: <$conn_info>" set data "GET /mypage/myindex2.html HTTP/1.0\r\n\r\n" set send_info [send -timeout 3000 -status send_status $conn $data] log local0. "Sent <$send_info> bytes and send status: <$send_status>" # This magically knows that we’re getting 393 bytes back set recv_data [recv -timeout 3000 -status recv_status 393 $conn] log local0. "Recv data: <$recv_data> and recv status: <$recv_status>" close $conn log local0. "Closed; conn info: <[connect info -status $conn]>" } So there you have it, a simple intro to how you can manipulate sideband connections via iRules. Keep in mind that the devil is, of course, in the details and it will take some practice to harness the power of these new commands, but the power is most definitely there for the taking. Feel free to ask any questions either here or in the iRules Q&A and also keep your eye on the wiki for the official command pages for the new v11 commands which will be coming soon.4.5KViews2likes11CommentsAdvanced iRules: Getting Started with iRules Procedures
As Colin so eloquently puts it in the procs overview on Clouddocs: "Ladies and gentlemen, procs are now supported in iRules!" Yes, the rumors are true. As of BIG-IP version 11.4, you can move all that repetitive code into functional blocks the Tcl language defines as procedures, or procs for short. If you program in any other languages, function support is not new. If you don't, maybe you've at some point built a macro in a Microsoft Office product to perform a repetitive task, such as substituting diapers for Dwight every time it was typed as Jim Halpert did in NBC's The Office. Anywho...now that we have them, what can you do with them? The biggest benefit is code re-use. If you have a particular set of commands that you use multiple times in one or more rules, it makes sense to code that once and just call that code block when necessary. Another benefit of using a procedure is having one source to document/troubleshoot/update when necessary. Where Do They Go, and How Do I Use Them? With few exceptions, code blocks must be place within the context of an event. Procedures join the short list of exceptions of code blocks or commands that live outside an event. There are two options for placing procs, in the iRule where it will be called, or in another iRule altogether. In this first example, the proc is local. rule encodeHTML { proc html_encode { str } { set encoded "" foreach char [split $str ""] { switch $char { "<" { append encoded "<" } ">" { append encoded ">" } "'" { append encoded "'" } {"} { append encoded """ } "&" { append encoded "&" } default { append encoded $char } } } return $encoded } when RULE_INIT { # iRule that calls the html_encode proc: set raw {some xss: < script > and sqli: ' or 1==1# "} log local0. "HTML encoded: [call html_encode $raw]" } } The proc definition is pretty basic, it receives a string and splits it up so it can encode characters matched in the switch statement, and otherwise leaves the characters alone. Notice, however, in the INIT event the new call command: [call html_encode $raw]. This is where the proc is invoked. Now, let's look at a remote proc. rule library { proc html_encode { str } { set encoded "" foreach char [split $str ""] { switch $char { "<" { append encoded "<" } ">" { append encoded ">" } "'" { append encoded "'" } {"} { append encoded """ } "&" { append encoded "&" } default { append encoded $char } } } return $encoded } } rule encodeHTML { when RULE_INIT { # iRule that calls the html_encode proc: set raw {some xss: < script > and sqli: ' or 1==1# "} log local0. "HTML encoded: [call library::html_encode $raw]" } } Notice the subtle change to the call command? Because the proc is in a remote irule, it is necessary to set that rule's name as the namespace of the proc being called. A couple of notes: I'd recommend starting a library of procedures and store that library in the common partition so all application owners from different partitions can use it. This works from partition x: [call library::proc_a], but I'd include the partition to be safe: [call /Common/library::proc_a]. If creating a library of procs, and one proc calls another proc in that library, make sure to explicitly define the namespace in that call. Example below. proc sequence {from to} { for {set lst {}} {$from <= $to} {incr from} { lappend lst $from } return $lst } proc knuth_shuffle lst { set j [llength $lst] for {set i 0} {$j > 1} {incr i;incr j -1} { set r [expr {$i+int(rand()*$j)}] set t [lindex $lst $i] lset lst $i [lindex $lst $r] lset lst $r $t } return $lst } proc shuffleIntSequence {x y} { return [call procs::knuth_shuffle [call procs::sequence $x $y]] } The shuffleIntSequence proc, which is called from another iRule, makes calls to two more procs, knuth_shuffle_lst and sequence. Without explicitly setting the namespace, the Tcl interpreter is expecting the call to sequence to be local to the iRule calling it, and it will fail. Use Cases There are already a couple procs out in the codeshare, and are referenced as well on a page on Clouddocs specifically for procedures. Logging, math functions, canned response pages, and more have been tossed around as ideas for procs. What else would you like to see?3.9KViews1like1Comment
Getting Started with iRules LX, Part 1: Introduction & Conceptual Overview
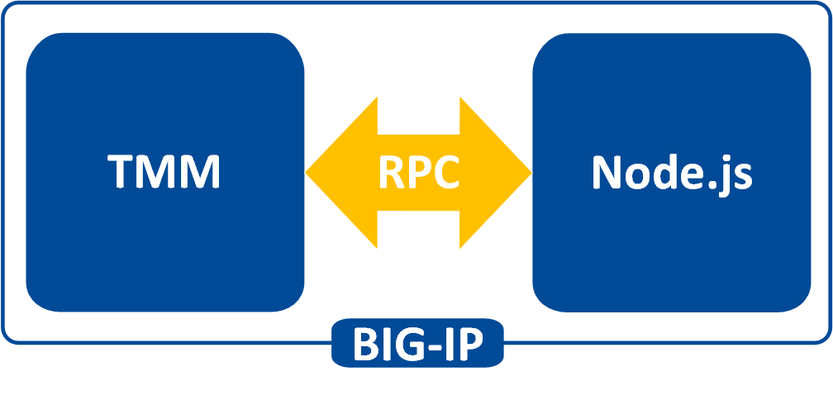
What is iRules LX? When BIG-IP TMOS 12.1.0 released a couple weeks ago, Danny wrote an intro piece to a new feature called iRules LX. iRules LX is the next generation of iRules that allows you to programmatically extend the functionality of BIG-IP with Node.js. In this article series, you will learn the basics of what iRules LX is, some use cases, how the components fit together, troubleshooting techniques, and some introductory code solutions. What is Node.js ? Node.js provides an environment for running JavaScript independent of a web browser. With Node.js you can write both clients and servers, but it is mostly used for writing servers. There are 2 main componets to Node.js - Google v8 JavaScript Engine Node.js starts with the same open source JavaScript engine used in the Google Chrome web browser. v8 has a JIT complier that optimizes JavaScript code to allow it to run incrediable fast. It also has an optimizing complier that, during run time, further optimizes the code to increase the performance up to 200 times faster. LibUV Asynchronous I/O Library A JavaScript engine by itself would not allow a full set of I/O operations that are needed for a server (you dont want your web browser accessing the file system of computer after all). LubUV gives Node.js the capability to have those I/O operations. Because v8 is a single threaded process, I/O (which have the most latency) would normally be blocking; that is, the CPU would be doing nothing while waiting from a response of the I/O operation. LibUV allows for the v8 to continue running JavaScript while waiting for the response, maximizing the use of CPU cycles and providing great concurrency. Why Node.js? Some might ask "Why was Node.js chosen?" While there is more than one reason, the biggest factor is that you can use JavaScript. JavaScript has been a staple of web development for almost 2 decades and is a common skillset amongst developers. Also, Node.js has a vibrant community that not only contributes to the Node.js core itself, but also a plethora of people writing libraries (called modules). As of May 2016 there are over 280,000 Node.js modules available in the Node Package Manager (NPM) registry, so chances are you can find a library for almost any use case. An NPM client is included with distributions of Node.js. For more information about the specifics of Node.js on BIG-IP, please refer to AskF5 Solution ArticleSOL16221101. iRules LX Conceptual Operation Unlike iRules which has a TCL interpreter running inside the Traffic Management Micro-kernel (TMM), Node.js is running as a stand alone processes outside of TMM. Having Node.js outside of TMM is an advantage in this case because it allow F5 to keep the Node.js version more current than if it was integrated into TMM. In order to get data from TMM to the Node.js processes, a Remote Procedural Call (RPC) is used so that TMM can send data to Node.js and tell it what "procedure" to run. The conceptual model of iRules LX looks something like this - To make this call to Node.js , we still need iRules TCL. We will cover the coding much more extensively in a few days, so dont get too wrapped up in understanding all the new commands just yet. Here is an example of TCL code for doing RPC to Node.js - when HTTP_REQUEST { set rpc_hdl [ILX::init my_plugin my_extension] set result [ILX::call $rpc_hdl my_method $arg1] if { $result eq "yes" } { # Do something } else { # Do something else } } In line 2 you can see with the ILX::init command that we establish an RPC handle to a specific Node.js plugin and extension (more about those tomorrow). Then in line 3 we use the ILX::call command with our handle to call the method my_method (our "remote procedure") in our Node.js process and we send it the data in variable arg1 . The result of the call will be stored in the variable result . With that we can then evaluate the result as we do in lines 5-9. Here we have an example of Node.js code using the iRules LX API we provide - ilx.addMethod('my_method', function(req, res){ var data = req.params()[0]; <…ADDITIONAL_PROCESSING…> res.reply('<some_reply>'); }); You can see the first argument my_method in addMethod is the name of our method that we called from TCL. The second argument is our callback function that will get executed when we call my_method . On line 2 we get the data we sent over from TCL and in lines 3-5 we perform whatever actions we wish with JavaScript. Then with line 6 we send our result back to TCL. Use Cases While TCL programming is still needed for performing many of the tasks, you can offload the most complicated portions to Node.js using any number of the available modules. Some of the things that are great candidates for this are - Sideband connections -Anyone that has used sideband in iRules TCL knows how difficult it is to implement a protocol from scratch, even if it is only part of the protocol. Simply by downloading the appropriate module with NPM, you can easily accomplish many of the following with ease - Database lookups - SQL, LDAP, Memcached, Redis HTTP and API calls - RESTful APIs, CAPTCHA, SSO protocols such as SAML, etc. Data parsing - JSON - Parser built natively into JavaScript XML Binary protocols In the next installment we will be covering iRules LX configuration and workflow.3.4KViews0likes1CommentAdvanced iRules: Regular Expressions
A regular expression or regex for short is essentially a string that is used to describe or match a set of strings, according to certain syntax rules. Regular expressions ("REs") come in two basic flavors: extended REs ("ERE"s) and basic REs ("BREs"). For you unix heads out there, EREs are roughly the same as used by traditional egrep, while BREs are roughly those of the traditional ed. The TCL implementation of REs adds a third flavor, advanced REs ("AREs") which are basically EREs with some significant extensions. It is beyond the scope of this article to document the regular expression syntax. A great reference is included in the re_syntax document in the TCL Built-In Commands section of the TCL documentation. Regular Expression Examples So what does a regular expression look like? It can be as simple as a string of characters to search for an exact match to "abc" {abc} Or a builtin escape string that searches for all sequences of non-whitespace in a string {\S+} Or a set of ranges of characters that search for all three lowercase letter combinations {[a-z][a-z][a-z]} Or even a sequence of numbers representing a credit card number. {(?:3[4|7]\d{13})|(?:4\d{15})|(?:5[1-5]\d{14})|(?:6011\d{12})} For more information on the syntax, see the re_syntax manual page in the TCL documentation, you won't be sorry. Commands that support regular expressions In the TCL language, the following built in commands support regular expressions: regexp - Match a regular expression against a string regsub - Perform substitutions based on regular expression pattern matching lsearch - See if a list contains a particular element switch - Evaluate one of several scripts, depending on a given value iRules also has an operator to make regular expression comparisons in commands like "if", "matchclass" and "findclass" matches_regex - Tests if one string matches a regular expression. Think twice, no three times, about using Regular Expressions Regular expressions are fairly CPU intensive and in most cases there are faster, more efficient, alternatives available. There are the rare cases, such as the Credit Card scrubber iRule, that would be very difficult to implement with string searches. But, for most other cases, we highly suggest you search for alternate methods. The "switch -glob" and "string match" commands use a "glob style" matching that is a small subset of regular expressions, but allows for wildcards and sets of strings which in most cases will do exactly what you need. In every case, if you are thinking about using regular expressions to do straight string comparisons, please, please, please, make use of the "equals", "contains", "starts_with", and "ends_with" iRule operators, or the glob matching mentioned above. Not only will they perform significantly faster, they will do the exact same thing. Here's a comparative example: BAD: if { [regexp {bcd} "abcde"] } { BAD: if { "abcde" matches_regex "bcd" } { BETTER: if { [string match "*bcd*" "abcde"] } { BEST: if { "abcde" contains "bcd" } { A Performance Challenge: Scan vs Regex The scan and stringcommands will cover the majority of regex use cases, and as indicated above, will save significantly on system resources. Consider the following test where we use Tcl's time command to run a scanagainst an IP address 10,000 times, and then do that again only using the regexp command. % set ip "10.10.20.200" 10.10.20.200 % time { scan $ip {%d.%d.%d.%d} a b c d} 10000 2.1713 microseconds per iteration % time {regexp {([0-9]{1,3})\.([0-9]{1,3})\.([0-9]{1,3})\.([0-9]{1,3})} $ip matched a b c d} 10000 34.2604 microseconds per iteration Two approaches, same result. The time to achieve that result? The scan command bests the regexp commandby far. I’ll save you the calculation…that’s a 93.7% reduction in processing time. 93.7 percent! Now, mind you, the difference between 2 and 34 microseconds will be negligible to an individual request’s response time, but in the context of a single system handling hundreds of thousands or even millions of request per second, the difference matters. A lot. Conclusion Regular expressions are available for those tricky situations where you just need to perform some crazy insane search like "string contains 123 but only if follows by "abc" or "def", or it contains a 5 digit number that is a valid US zip code". Also, if you need to find the exact location of a string within a string (for instance to replace one string for another), then regexp and regsubwill likely work for you (if a Stream Profile doesn't). So, in some cases, a regular expression is likely the only option. Just keep in mind that even multiple string and comparison tests are typically far more efficient than even the simplest regular expression, so use them wisely.3.4KViews1like1CommentAdvanced iRules: Binary Scan
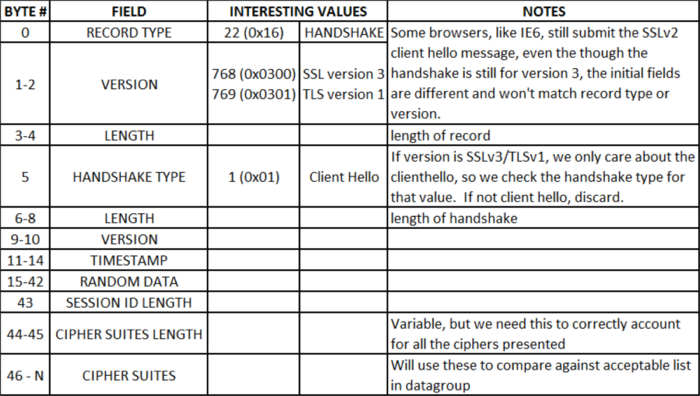
The binary scan command, like the scan command covered in this Advanced iRules series, parses strings. Only, as the adjective indicates, it parses binary strings. In this article, I’ll highlight the command syntax and a few of the format string options below. Check the man page for the complete list of format options. binary scan string formatString ?varName varName … ? c - The data is turned into count 8-bit signed integers and stored in the corresponding variable as a list. If count is *, then all of the remaining bytes in string will be scanned. If count is omitted, then one 8-bit integer will be scanned. S - The data is interpreted as count 16-bit signed integers represented in big-endian byte order. The integers are stored in the corresponding variable as a list. If count is *, then all of the remaining bytes in string will be scanned. If count is omitted, then one 16-bit integer will be scanned. H - The data is turned into a string of count hexadecimal digits in high-to-low order represented as a sequence of characters in the set "0123456789abcdef". The data bytes are scanned in first to last order with the hex digits being taken in high-to-low order within each byte. Any extra bits in the last byte are ignored. If count is *, then all of the remaining hex digits in string will be scanned. If count is omitted, then one hex digit will be scanned. Do the Research First! Before you can start mapping fields, you need to know where the delimiters are, and that takes a little research. In this example, I want to list out the cipher suites presented to the BIG-IP LTM by the browser (more on that later), so I’m going to decode the fields in an SSLv3/TLSv1 client hello message. I took a capture with Wireshark to find the field delineations, but you could also pull this information from RFC 2246 if you are so inclined. The table below shows the fields I’ll extract or skip over in the course of the iRule code. So why do I want to look at the cipher suites? I was contacted by a friend who wanted to increase security to 256-bit ciphers for those browsers that supported it, but would still allow users that don’t to connect as well so they could be redirected to an error page requesting they upgrade. With the cipher settings as they were, the unsupported browser (in this case, IE6) could connect, but the newer browsers connected at 128-bit as well instead of 256-bit. I later learned (courtesy of none other than hoolio) that I could use @STRENGTH in my cipher settings to force the capable browsers up, but for the benefit of demonstrating the use the binary string command, I’ll proceed with the iRule. Standard Behaviors I set up a clientssl profile with these cipher settings: “DEFAULT:!ADH:!EXPORT40:!EXP:!LOW”. Those settings result in my test browsers (Chrome 5, FF 3.6.4, IE 😎 all using the RC4-SHA 128-bit cipher. I used a simple iRule to display the information back to the client: when HTTP_REQUEST { set cipher_info "[SSL::cipher name]:[SSL::cipher bits]" HTTP::respond 200 content "$cipher_info" } Again, the easy (and better) fix here is to add strength to the cipher settings in the SSL profile like so: “DEFAULT:!ADH:!EXPORT40:!EXP:!LOW:@STRENGTH”, but instead I created an additional clientssl profile, adding not medium to the settings: “DEFAULT:!ADH:!EXPORT40:!EXP:!LOW:!MEDIUM”. Once I had that profile in place, work on the iRule could begin. Using Binary Scan Enough prep talk already, let me get to the good stuff! The iRule starts in CLIENT_ACCEPTED, disabling SSL and doing a TCP collect: when CLIENT_ACCEPTED { set lsec 0 SSL::disable TCP::collect } when CLIENT_DATA { if { ! [info exists rlen] } { binary scan [TCP::payload] cSS rtype sslver rlen #log local0. "SSL Record Type $rtype, Version: $sslver, Record Length: $rlen" # SSLv3 / TLSv1.0 if { $sslver > 767 && $sslver < 770 } { if { $rtype != 22 } { log local0. "Client-Hello expected, Rejecting. \ Src: [IP::client_addr]:[TCP::remote_port] -> \ Dst: [IP::local_addr]:[TCP::local_port]" reject return } As shown in the binary scan syntax, “c” grabs one byte and returns a signed integer, and “S” grabs two-bytes and returns a signed integer. The rest of the payload is thrown away. From table 1, we know the first three fields of SSLv3/TLSv1 client hello’s are one-byte, two-byte, two-byte, so a format string of cSS followed by three variable names takes care of the parsing. The clientssl profile doesn’t yet support TLS 1.1 or 1.2, so I’m only testing for SSLv3/TLSv1. The SSLv2 and earlier record format is different altogether, so the initial fields wouldn’t map this way anyway. This is true of IE6, which by default issues a SSLv2 client hello but supports SSLv3/TLSv1. Confused yet? Anyway, once the test for SSLv3/TLSv1 is complete, I then make sure the record type is a client hello, if not, no reason to continue. Once the verification is complete that this really is a client hello, there is a string (pun intended!) of binary scans to sort the rest of the details out: #Collect rest of the record if necessary if { [TCP::payload length] < $rlen } { TCP::collect $rlen #log local0. "Length is $len" } #skip record header and random data set field_offset 43 #set the offset binary scan [TCP::payload] @${field_offset}c sessID_len set field_offset [expr {$field_offset + 1 + $sessID_len}] #Get cipherlist length binary scan [TCP::payload] @${field_offset}S cipherList_len #log local0. "Cipher list length: $cipherList_len" #Get ciphers, separate into a list of elements set field_offset [expr {$field_offset + 2}] set cipherList_len [expr {$cipherList_len * 2}] binary scan [TCP::payload] @${field_offset}H${cipherList_len} cipherlist #log local0. "Cipher list: $cipherlist" I’m using the “@” symbol to skip bytes in the binary string. Also, the curly brackets are necessary to surround the variable name to distinguish your variable from the significance of the format string characters. In the first binary scan above, I’m skipping the record header and all the random data as I don’t need that information, but I do need the session ID length so I can set my offset properly to get to the cipher list. In the second binary scan, again I’m skipping (from original payload) the new offset and then storing another two-byte signed integer that tells me how long the cipher list is. From that information, I set a new offset, set the cipher list length (number of ciphers * 2, each cipher is two-bytes) and then perform the final binary scan to store the entire cipher list (in hex high->low characters, hence the “H” in the string format). The rest of the rule is processing that cipher list (thanks to Colin for some tcl-fu in the for loop below), and sending users to a different clientssl profile if any of the ciphers in the client hello list match the ciphers in a string datagroup you define, in this case, accepted_ciphers (values were four hex character pairs, like c005, 0088, etc). For browsers incapable of the higher security profile, they would be redirected to an error page instructing them to upgrade. set profile_select 0 for { set x 0 } { $x < $cipherList_len } { incr x 4 } { set start $x set end [expr {$x+3}] #Check cipher against 256-bit ciphers in accepted_ciphers data group if { [matchclass [string range $cipherlist $start $end] equals accepted_ciphers] } { #If 256-bit capable, select High Security profile set profile_select "SSL::profile clientssl_highSecurity" break } } #Set New Profile with eval since SSL::profile errors in CLIENT_ACCEPTED event if { $profile_select != 0 } { eval $profile_select #log local0. "Profile changed to High Security" } else { set lsec 1 } event CLIENT_DATA disable SSL::enable TCP::release } else { set lsec 1 event CLIENT_DATA disable SSL::enable TCP::release } } } Conclusion The rule is useless in production, but is a good teaching example on the use of binary scan. There are several good examples in the codeshare. Check out this tftp file server iRule (companion article for the tftp iRule), this one throws in a binary format to boot. Happy coding!3KViews2likes0CommentsGetting Started with iRules LX, Part 2: Configuration & Workflow
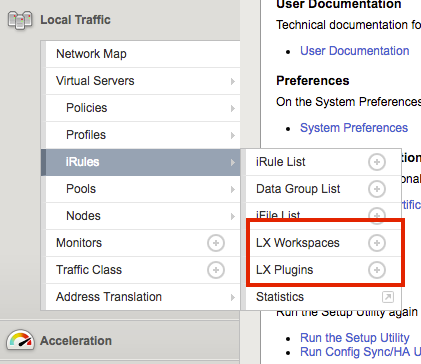
The previous article in this series covered the reasons for iRules LX and the conceptual operation. Now we need learn the new configurations items that iRules LX introduces. Since iRules LX has DevOps teams in mind, there is a slightly different workflow than standard iRules. Configuration Items LX Workspaces Our first new configuration item, LX Workspaces, provides a development and staging environment for your Node.js code and the TCL iRules that are used for iRules LX. The code can be authored and saved in the workspace without affecting the running code on the data plane. Workspaces can also be exported as TGZ files and then imported to another BIG-IP. This is especially useful to allow for development and testing on a BIG-IP in a lab/dev environment and then later installed onto a production BIG-IP. Both LX Workspaces and LX Plugins (which we will talk about later) can be found on your BIG-IP in the menu Local Traffic > iRules as shown here - When you select the + option to create a new workspace and give it a name, the workspace will look like this (except that it will be blank with no folders) - You can see in the screen shot that we have a rules folder. This folder will be created once you add an iRule and will always be named "rules". It can contain any number TCL iRules you create for the workspace. You also see the folder named dc_extension. This is an extension. Extensions An extension is folder of Node.js code within an LX Workspace. As we saw with the screenshot above, we had one extension named dc_extension. The extension folder can be given any valid Unix name (except rules), but the name will matter when it is time to start coding (more in tomorrow's article). If we expand the extension folder, we will see this - Each extension will have these files and folders to start off with. index.js - This file is the Node.js code that will eventually run on your BIG-IP. node_modules - This folder will contain node modules you install from NPM. package.json - This is the standard package.json file that is use to store various information and package dependencies about a Node.js program. LX Plugin An LX Plugin is the production code from the LX Workspace that is actively running on the data plane of the BIG-IP.You can see in this screenshot the settings of an LX Plugin - Also, each workspace extension is listed. Each extension has their own Node.js settings and if you click on an extension inside a LX Plugin you will see this - Workflow So now that we know our new configuration objects we need to follow a workflow to get iRules LX up and running. That workflow looks like this - Step 1: Write Code in LX Workspace The first step is to actually write the code you want in a LX Workspace. This would be both your Node.js code and the TCL iRules that would make the RPC calls to Node. Step 2: Load LX Workspace to an LX Plugin To load the workspace into the LX Plugin, you would create the LX Plugin and select the LX Workspace that you want to load into it - When you create the LX Plugin, the extensions will get loaded into a Node.js process(es) and the TCL iRules will be loaded in the TCL iRules menu with the rest of the iRules - You can see on the Partition/Path that this matches the LX Plugin we created. This works just like as if an iApp created the iRule. As such, you can not edit the iRule from here--you can only do it in the LX Workspace itself. Step 3: Load the TCL iRule to a Virtual Server At this point your TCL iRule can now be added to a virtual server - You will find your iRule under the Partition/Path for your LX Plugin. Move it over to the enabled section and you will be running iRules LX. Making Updates to iRules LX If you change code in the LX Workspace, that code will not be active until you reload it to the LX Plugin. An LX Workspace let's you know if the code in the workspace is different than that which is running in the LX Plugin with a status indicator - This indicator is yellow when the code is different. To reload the LX Workspace code into the LX Plugin, just click the Reload From Workspace button next to the indicator. When the code is in sync, the indicator will be green - Licensing and Provisioning iRules LX is licensed to all BIG-IP users in TMOS 12.1 (assuming you have a valid support contract). On new licenses (once that where generated after TMOS 12.1 released) iRules LX will be automatically licensed. If you have an older license and have upgraded to v12.1, you simply need to reactivate your license. This can be done online if your BIG-IP has internet access or manually. To use iRules LX, it must be provisioned. It is not turned on by default, so customers that are not using it do not need to worry about Node.js processes running on their BIG-IP. To provision it, browse over to the Resource Provisioning menu of your BIG-IP, check the box for iRules LX and give it a nominal level of resources - In the next article in this series, we will cover writing code for iRules LX.2.9KViews0likes1Comment
The table Command: Examples
With version 10.1, we've given the session table some long-sought functionality, and revamped its iRules interface completely to give users a new, cleaner, full-featured way to keep track of global data. We are very proud to introduce the table command... Basics New Ways To Set Data New Ways To Alter Data Data Expiration Advanced Data Expiration Subtables Counting The Fine Print Examples In this last part of the series on the usage of the new table command, we discuss various examples of the use of the table command. Examples Now that we've covered all of the pieces of the table command, let's see some larger real-world uses of making them work together, not only simplfying existing iRules, but making new things possible. Limiting Connections To A VIP On the Counting page, we gave one powerful example iRule that would have been too bulky and/or unreliable to do before: limit a VIP to a certain number of connections. That example can be easily modified to limit those connections by IP address as well. If you compare it to this example when CLIENT_ACCEPTED { set tbl "connlimit:[IP::client_addr]" set key "[TCP::client_port]" if { [table keys -subtable $tbl -count] > 1000 } { event CLIENT_CLOSED disable reject } else { table set -subtable $tbl $key "ignored" 180 set timer [after 60000 -periodic { table lookup -subtable $tbl $key }] } } when CLIENT_CLOSED { after cancel $timer table delete -subtable $tbl $key } you can see that only the first two lines changed! We've gone from one global subtable to a subtable for each IP address. This is an example of the power of subtables and using them for scoping. Blocking DNSFlood Attacks This example to blacklist IPs if they make too many DNS queries per second, uses global arrays to keep track of the number of requests made in the current second, as well as the blacklist of IPs. when RULE_INIT { set ::maxquery 100 set ::holdtime 600 } when CLIENT_DATA { set srcip [IP::remote_addr] set curtime [clock second] if { [ info exists ::blacklist($srcip) ] } { if { $::holdtime > [expr ${curtime} - $::blacklist($srcip) ] } { drop return } unset ::blacklist($srcip) } if { [ info exists ::usertable(time,$srcip)] and $curtime == $::usertable(time,$srcip) } { incr ::usertable(freq,$srcip) if { $::usertable(freq,$srcip) > $::maxquery } { set ::blacklist($srcip) $curtime unset ::usertable(freq,$srcip) unset ::usertable(time,$srcip) drop return } } else { set ::usertable(freq,$srcip) 1 set ::usertable(time,$srcip) $curtime } } It has to do all of the work to remove old data from those arrays manually, so not only can that cause all those array entries to just accumulate in memory, but it demotes the VIP it gets attached to (because it uses global variables) . If we use the table command instead as shown in the following code, a lot of the complexity is handled by the system, so it's now cleaner, simpler, and CMP-compatible. A win all around! when RULE_INIT { set static::maxquery 100 set static::holdtime 600 } when CLIENT_DATA { set srcip [IP::remote_addr] if { [table lookup -subtable "blacklist" $srcip] != "" } { drop return } set curtime [clock second] set key "count:$srcip:$curtime" set count [table incr $key] table lifetime $key 2 if { $count > $static::maxquery } { table add -subtable "blacklist" $srcip "blocked" indef $static::holdtime table delete $key drop return } } Limiting POST Requests Per User Another example to limit POSTs per-user uses even more very tricky global array manipulation. when RULE_INIT { set ::windowSecs 10 } when HTTP_REQUEST { if { [HTTP::method] eq "POST" } { if { ![HTTP::header exists Authorization] } { HTTP::respond 401 return } set myUserID [getfield [b64decode [substr [HTTP::header "Authorization"] 6 end]] ":" 1] set myMaxRate [findclass $myUserID $::MaxPOSTRates3 " "] if { $myMaxRate ne "" }{ set currentTime [clock seconds] if { [info exists ::timestamp($myUserID)] } { set i [ expr $currentTime - $::timestamp($myUserID) ] if { $i > $::windowSecs } { set i $::windowSecs } while { $i > 0} { for {set j $::windowSecs} {$j > 0} {set j [expr $j - 1]} { set k [ expr $j - 1 ] set ::count($myUserID.$j) $::count($myUserID.$k) } set ::count($myUserID.0) 0 incr i -1 } set k 0 for {set i 0} { $i < $::windowSecs} {incr i} { incr k $::count($myUserID.$i) } if {$k < $myMaxRate } { incr ::count($myUserID.0) set ::timestamp($myUserID) $currentTime } else { HTTP::respond 302 Location http://asdf:44444/ } } else { for {set i 0} {$i < $::windowSecs} {incr i} { set ::count($myUserID.$i) 0 } set ::timestamp($myUserID) $currentTime set ::count($myUserID.0) 1 } } } } It can be very difficult to understand, to say nothing of trying to maintain or alter it. With the table command to do all of the heavy lifting for us, it becomes much simpler, lighter-weight, and CMP-compatible. when RULE_INIT { set static::windowSecs 10 } when HTTP_REQUEST { if { [HTTP::method] eq "POST" } { if { ! [HTTP::header exists Authorization] } { HTTP::respond 401 return } set myUserID [getfield [b64decode [substr [HTTP::header "Authorization"] 6 end]] ":" 1] set myMaxRate [findclass $myUserID $::MaxPOSTRates3 " "] if { $myMaxRate ne "" } { set reqnum [table incr "req:$myUserId"] set tbl "countpost:$myUserId" table set -subtable $tbl $reqnum "ignored" indef $static::windowSecs if { [table keys -subtable $tbl -count] > $myMaxRate } { HTTP::respond 302 Location http://asdf:44444/ return } } } } That's pretty impressive, if I do say so myself. And once again, because the table command will expire the entries automatically, there's no need to worry about old data taking up memory. We cannot wait to see all of the new (or old!) problems you solve with the help of the table command. Don't forget to show off your work in the iRules CodeShare!2.8KViews0likes4CommentsGetting Started with iRules LX, Part 3: Coding & Exception Handling
So far in this series, we have covered the conceptual overview, components, workflows, licensing and provisioning of iRules LX. In this article, we will actually get our hands wet with some iRules LX code! TCL Commands As mentioned in the first article, we still need iRules TCL to make a RPC to Node.js. iRules LX introduces three new iRules TCL commands - ILX::init - Creates a RPC handle to the plugin's extension. We will use the variable from this in our other commands. ILX::call - Does the RPC to the Node.js process to send data and receive the result (2 way communication). ILX::notify - Does an RPC to the Node.js process to send data only (1 way communication, no response). There is one caveat to the ILX::call and ILX::notify commands: you can only send 64KB of data. This includes overhead used to encapsulate the RPC so you will need to allow about 500B-1KB for the overhead. If you need to send more data you will need to create code that will send data over in chunks. TCL Coding Here is a TCL template for how we would use iRules LX. when HTTP_REQUEST { set ilx_handle [ILX::init "my_plgin" "ext1"] if {[catch {ILX::call $ilx_handle "my_method" $user $passwd} result]} { log local0.error "Client - [IP::client_addr], ILX failure: $result" # Send user graceful error message, then exit event return } # If one value is returned, it becomes TCL string if {$result eq 'yes'} { # Some action } # If multiple values are returned, it becomes TCL list set x [ lindex $result 0] set y [ lindex $result 1] } So as not to overwhelm you, we'll break this down to bite size chunks. Taking line 2 from above, we will use ILX::init command to create our RPC handle to extension ext1 of our LX plugin my_plugin and store it in the variable ilx_handle . This is why the names of the extensions and plugin matter. set ilx_handle [ILX::init "my_plgin" "ext1"] Next, we can take the handle and do the RPC - if {[catch {ILX::call $ilx_handle "my_method" $user $passwd} result]} { log local0.error "Client - [IP::client_addr], ILX failure: $result" # Send user graceful error message with whatever code, then exit event return } You can see on line 3, we make the ILX::call to the extension by using our RPC handle, specifying the method my_method (our "remote procedure") and sending it one or more args (in this case user and passwd which we got somewhere else). In this example we have wrapped ILX::call in a catch command because it can throw an exception if there is something wrong with the RPC (Note: catch should actually be used on any command that could throw an exception, b64decode for example). This allows us to gracefully handle errors and respond back to the client in a more controlled manner. If ILX::call is successful, then the return of catch will be a 0 and the result of the command will be stored in the variable result . If ILX::call fails, then the return of catch will be a 1 and the variable result will contain the error message. This will cause the code in the if block to execute which would be our error handling. Assuming everything went well, we could now start working with data in the variable result . If we returned a single value from our RPC, then we could process this data as a string like so - # If one value is returned, it becomes TCL string if {$result eq 'yes'} { # Some action } But if we return multiple values from our RPC, these would be in TCL list format (we will talk more about how to return multiple values in the Node.js coding section). You could use lindex or any suitable TCL list command on the variable result - # If multiple values are returned, it becomes TCL list set x [ lindex $result 0] set y [ lindex $result 1] Node.js Coding On the Node.js side, we would write code in our index.js file of the extension in the workspace. A code template will load when the extension is created to give you a starting point, so you dont have to write it from scratch. To use Node.js in iRules LX, we provide an API for receiveing and sending data from the TCL RPC. Here is an example - var f5 = require('f5-nodejs'); var ilx = new f5.ILXServer(); ilx.addMethod('my_method', function (req, res) { // req.params() function is used to get values from TCL. Returns JS Array var user = req.params()[0]; var passwd = req.params()[1]; <DO SOMETHING HERE> res.reply('<value>'); // Return one value as string or number res.reply(['value1','value2','value3']); // Return multiple values with an Array }); ilx.listen(); Now we will run through this step-by-step. On line 1, you see we import the f5-nodejs module which provides our API to the ILX server. var f5 = require('f5-nodejs'); On line 3 we instantiate a new instance of the ILXServer class and store the object in the variable ilx . var ilx = new f5.ILXServer(); On line 5, we have our addMethod method which stores methods (our remote procedures) in our ILX server. ilx.addMethod('my_method', function (req, res) { // req.params() function is used to get values from TCL. Returns JS Array var user = req.params()[0]; var passwd = req.params()[1]; <DO SOMETHING HERE> res.reply('<value>'); // Return one value as string or number res.reply(['value1','value2','value3']); // Return multiple values with an Array }); This is where we would write our custom Node.js code for our use case. This method takes 2 arguments - Method name - This would be the name that we call from TCL. If you remember from our TCL code above in line 3 we call the method my_method . This matches the name we put here. Callback function - This is the function that will get executed when we make the RPC to this method. This function gets 2 arguments, the req and res objects which follow standard Node.js conventions for the request and response objects. In order to get our data that we sent from TCL, we must call the req.param method. This will return an array and the number of elements in that array will match the number of arguments we sent in ILX::call . In our TCL example on line 3, we sent the variables user and passwd which we got somewhere else. That means that the array from req.params will have 2 elements, which we assign to variables in lines 7-8. Now that we have our data, we can use any valid JavaScript to process it. Once we have a result and want to return something to TCL, we would use the res.reply method. We have both ways of using res.reply shown on lines 12-13, but you would only use one of these depending on how many values you wish to return. On line 12, you would put a string or number as the argument for res.reply if you wanted to return a single value. If we wished to return multiple values, then we would use an array with strings or numbers. These are the only valid data types for res.reply . We mentioned in the TCL result that we could get one value that would be a string or multiple values that would be a TCL list. The argument type you use in res.reply is how you would determine that. Then on line 16 we start our ILX server so that it will be ready to listen to RPC. ilx.listen(); That was quick a overview of the F5 API for Node.js in iRules LX. It is important to note that F5 will only support using Node.js in iRules LX within the provided API. A Real Use Case Now we can take what we just learned and actually do something useful. In our example, we will take POST data from a standard HTML form and convert it to JSON.In TCL we would intercept the data, send it to Node.js to transform it to JSON, then return it to TCL to replace the POST data with the JSON and change the Content-Type header - when HTTP_REQUEST { # Collect POST data if { [HTTP::method] eq "POST" }{ set cl [HTTP::header "Content-Length"] HTTP::collect $cl } } when HTTP_REQUEST_DATA { # Send data to Node.js set handle [ILX::init "json_plugin" "json_ext"] if {[catch {ILX::call $handle "post_transform" [HTTP::payload]} json]} { log local0.error "Client - [IP::client_addr], ILX failure: $json" HTTP::respond 400 content "<html>Some error page to client</html>" return } # Replace Content-Type header and POST payload HTTP::header replace "Content-Type" "application/json" HTTP::payload replace 0 $cl $json } In Node.js, would only need to load the built in module querystring to parse the post data and then JSON.stringify to turn it into JSON. 'use strict' var f5 = require('f5-nodejs'); var qs = require('querystring'); var ilx = new f5.ILXServer(); ilx.addMethod('post_transform', function (req, res) { // Get POST data from TCL and parse query into a JS object var postData = qs.parse(req.params()[0]); // Turn postData into JSON and return to TCL res.reply(JSON.stringify(postData)); }); ilx.listen(); Note: Keep in mind that this is only a basic example. This would not handle a POST that used 100 continue or mutlipart POSTs. Exception Handling iRules TCL is very forgiving when there is an unhanded exception. When you run into an unhandled runtime exception (such as an invalid base64 string you tried to decode), you only reset that connection. However, Node.js (like most other programming languages) will crash if you have an unhandled runtime exception, so you will need to put some guard rails in your code to avoid this. Lets say for example you are doing JSON.parse of some JSON you get from the client. Without proper exception handling any client could crash your Node.js process by sending invalid JSON. In iRules LX if a Node.js process crashes 5 times in 60 seconds, BIG-IP will not attempt to restart it which opens up a DoS attack vector on your application (max restarts is user configurable, but good code eliminates the need to change it). You would have to manually restart it via the Web UI or TMSH. In order to catch errors in JavaScript, you would use the try/catch statement. There is one caveat to this: code inside a try/catch statement is not optimized by the v8 complier and will cause a significant decrease in performance. Therefore, we should keep our code in try/catch to a minimum by putting only the functions that throw exceptions in the statement. Usually, any function that will take user provided input can throw. Note: The subject of code optimization with v8 is quite extensive so we will only talk about this one point. There are many blog articles about v8 optimization written by people much smarter than me. Use your favorite search engine with the keywords v8 optimization to find them. Here is an example of try/catch with JSON.parse - ilx.addMethod('my_function', function (req, res) { try { var myJson = JSON.parse(req.params()[0]) // This function can throw } catch (e) { // Log message and stop processing function console.error('Error with JSON parse:', e.message); console.error('Stack trace:', e.stack); return; } // All my other code is outside try/catch var result = ('myProperty' in myJson) ? true : false; res.reply(result); }); We can also work around the optimization caveat by hoisting a custom function outside try/catch and calling it inside the statement - ilx.addMethod('my_function', function (req, res) { try { var answer = someFunction(req.params()[0]) // Call function from here that is defined on line 16 } catch (e) { // Log message an stop processing function console.error('Error with someFunction:', e.message); console.error('Stack trace:', e.stack); return; } // All my other code is outside try/catch var result = (answer === 'hello') ? true : false; res.reply(result); }); function someFuntion (arg) { // Some code in here that can throw return result } RPC Status Return Value In our examples above, we simply stopped the function call if we had an error but never let TCL know that we encountered a problem. TCL would not know there was a problem until the ILX::call command reached it's timeout value (3 seconds by default). The client connection would be held open until it reached the timeout and then reset. While it is not required, it would be a good idea for TCL to get a return value on the status of the RPC immediately. The specifics of this is pretty open to any method you can think of but we will give an example here. One way we can accomplish this is by the return of multiple values from Node.js. Our first value could be some type of RPC status value (say an RPC error value) and the rest of the value(s) could be our result from the RPC. It is quite common in programming that make an error value would be 0 if everything was okay but would be a positive integer to indicate a specific error code. Here in this example, we will demonstate that concept. The code will verify that the property myProperty is presentin JSON data and put it's value into a header or send a 400 response back to the client if not. THe Node.js code - ilx.addMethod('check_value', function (req, res) { try { var myJson = JSON.parse(req.params()[0]) // This function can throw } catch (e) { res.reply(1); //<---------------------------------- The RPC error value is 1 indicating invalid JSON return; } if ('myProperty' in myJson){ // The myProperty property was present in the JSON data, evaluate its value var result = (myJson.myProperty === 'hello') ? true : false; res.reply([0, result]); //<-------------------------- The RPC error value is 0 indicating success } else { res.reply(2); //<-------------- The RPC error value is 2 indicating myProperty was not present } }); In the code above the first value we return to TCL is our RPC error code. We have defined 3 possible values for this - 0 - RPC success 1 - Invalid JSON 2 - Property "myProperty" not present in JSON One our TCL side we would need to add logic to handle this value - when HTTP_REQUEST { # Collect POST data if { [HTTP::method] eq "POST" }{ set cl [HTTP::header "Content-Length"] HTTP::collect $cl } } when HTTP_REQUEST_DATA { # Send data to Node.js set handle [ILX::init "json_plugin" "json_checker"] if {[catch [ILX::call $handle "check_value" [HTTP::payload]] json]} { log local0.error "Client - [IP::client_addr], ILX failure: $result" HTTP::respond 400 content "<html>Some error page to client</html>" return } # Check the RPC error value if {[lindex $json 0] > 0} { # RPC error value was not 0, there is a problem switch [lindex $json 0] { 1 { set error_msg "Invalid JSON"} 2 { set error_msg "myProperty property not present"} } HTTP::respond 400 content "<html>The following error occured: $error_msg</html>" } else { # If JSON was okay, insert header with myProperty value HTTP::header insert "X-myproperty" [lindex $json 1] } } As you can see on line 19, we check the value of the first element in our TCL list. If it is greater than 0 then we know we have a problem. We move on down further to line 20 to determine the problem and set a variable that will become part of our error message back to the client. Note:Keep in mind that this is only a basic example. This would not handle a POST that used 100 continue or mutlipart POSTs. In the next article in this series, we will cover how to install a module with NPM and some best practices.2.8KViews0likes2CommentsThe table Command: Subtables
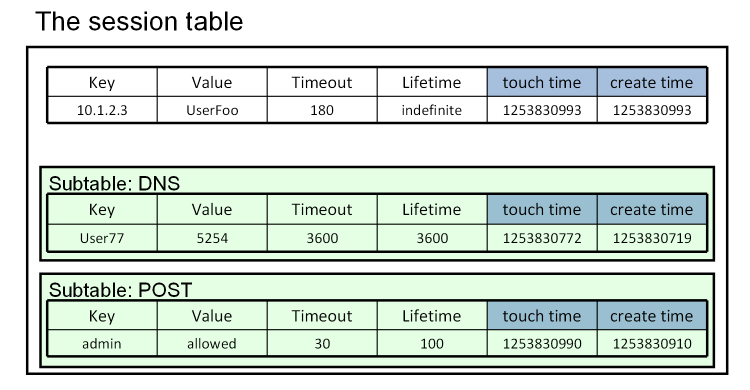
With version 10.1, we've given the session table some long-sought functionality, and revamped its iRules interface completely to give users a new, cleaner, full-featured way to keep track of global data. We are very proud to introduce the table command... Basics New Ways To Set Data New Ways To Alter Data Data Expiration Advanced Data Expiration Subtables Counting The Fine Print Examples In this sixth part of the series on the usage of the new table command, we discuss how you can create and manage subtables within the session table. Subtables Whew! Still with me? Good, because we're just now getting to some of best stuff. One of the most powerful changes to the session table in v10.1 is the concept of a subtable, which is simply a named set of entries. It lets you organize your entries in groups, and lets you act on those groups. A subtable is basically a table in and of itself, with some special abilities. Subtables only contain entries, though; you can’t nest subtables. Here's what they look like: They are trivial to use: every current table subcommand simply takes a -subtable <name> parameter. So you can do things like: table set -subtable $tbl $key $data table lookup -subtable $othertbl $key table delete -subtable $thirdtbl $key That's all there is to it! Doesn't look like much, does it? But this is very powerful stuff! Maybe you want a different set of data for each user, or for each client IP address, or for each virtual server? No problem! table set -subtable "$username" $key $data table add -subtable "[IP::client_addr]" $key $data table replace -subtable "[virtual]" $key $data Since you can name your subtables however you want, you can now have shared variables with any arbitrary scope! And there's an easy way to clean up: table delete -all -subtable "$username" will remove every entry in a subtable in one fell swoop. But wait! There's more! With subtables comes a new and long-desired ability: the ability to list or count the number of keys: table keys -subtable <name> [-count|-notouch] You’ll note that unlike all the other table subcommands, the subtable name is not optional here: there’s no way to use it on entries that aren’t in a subtable. Also note that by default, retrieving the list of keys will touch each one, but getting the count will never touch any entries. Isn't this AWESOME!?! This feature is going to simplify a lot of your iRules, and give you the ability to do things that simply weren't feasible before. I can't wait to see all the creative uses you come up with! That covers all of the new session table features. Now we'll cover some ways of putting everything together... Continue reading part seven in our series: Counting2.7KViews0likes5Comments