Getting Started with iRules: Variables
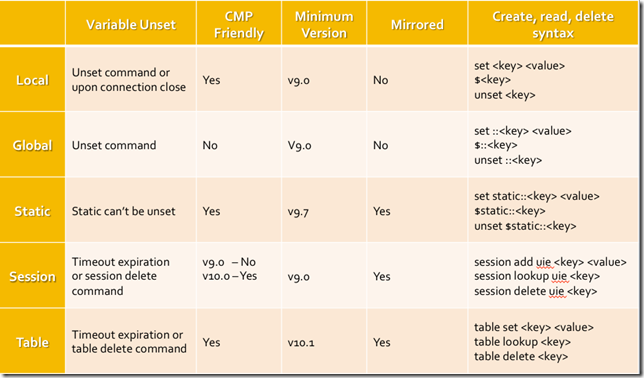
If you've been following along in this series, it's time to add another building block to the framework of what iRules are and can do. If you're new, it would behoove you to start at the beginning and catch up. So far we've covered introductions across the board for programming basics and concepts, F5 terminology and basic technology concepts, the core of what iRules are and why you'd use them, as well as a couple of cornerstone iRules concepts like events and priorities. All of these concepts are required to get a proper understanding of the base iRules infrastructure and functionality. Using those concepts as foundations we're going to add to the mix something that's integral to any programming language: variables. We'll cover a bit about what variables are, but also some iRules specific variables functionality and commentary. Things to look for in this article: What is a variable? How do I work with variables in my iRule? What types of variables are available to me in iRules? Is there a performance impact when using variables? When should I use variables? What is a variable? A variable, in simple terms, is a piece of data stored in memory. This is done usually with the notion of using that data again at some point, recalling it to make use of it later in your script. For instance if you want to store the hostname of an incoming connection so that you can reference that hostname on the response, or if you want to store the result of a given command, etc. those things would be stored in a variable. Every scripting language has variables of some form or another, and they're quite important in the grand scheme of things. Without them you'd be building static scripts to perform one off, iterative tasks. Variables are a large part of what allows dynamic programming to account for multiple conditions and use cases. Whether it's storing the data from a math operation to be compared against a desired result, or checking to see if a given condition has been met yet, variables are at the very core of just about everything in programming, and aren't something that we could live without in modern coding. The idea is simple, take a piece of data, whether it's a number or a string or...anything, and store it in memory with a unique name. Then, later, you can recall the value of that data by simply referencing the name you created to represent it. You can, of course, modify, or delete variables at will also. How do I work with variables in my iRule? There are two main functions when it comes to any variable: setting and retrieving. To set a variable in Tcl you simply use the set command and specify the desired value. This can be a static or dynamic value, such as an integer or the result of a command. The desired value is then stored in memory and associated with the variable name supplied. This looks like: #Basic variable creation in Tcl set integer 5 set hostname [HTTP::host] To retrieve the value associated with a given variable you simply reference that variable directly and you will get the resulting value. For instance "$integer" and "$hostname" would reference the values from the above example. Of course calling them by themselves won't do much good. Simple referring to a variable within your code will do pretty much nothing. You'll almost certainly be referencing the variables in relation to something or from another command. I.E.: #Basic variable reference to retrieve and use the value stored in memory if {$integer > 0) { log local0. "Host: $hostname" } What types of variables are available to me in iRules? This topic can creep in scope pretty darn quickly, given that variables are just a simple memory structure, and there are many different types of memory structures available to you via Tcl and iRules. From simple variables to arrays to tables and data groups, there are many ways to manage data in memory. For the purposes of this article, however, we're going to focus on the two main types of actual variables and leave the discussion of other data structures for later. There are two main types of variables in iRules, local and global. Local Variables All variables, unless otherwise specified, are created as local variables within an iRule. What does that mean? Well, a local variable means that it is assigned the same scope as the iRule that created it. All iRules are inherently connection based, and as such all local variables are connection based as well. This means that the connection dictates the memory space for a given iRule's local variables and data. For instance, if connection1 comes in and an iRule executes, creating 5 variables, those variables will only exist until connection1 closes and the connection is terminated on the BIG-IP. At that time the memory allocated to that flow will be freed up, and the variables created while processing that particular connection's iRule(s) will no longer be accessible. This is the case with all iRules and all variables created from within an iRule using the basic set command structure pictured above. Local variables are low cost, easy to use, you never have to worry about memory management with them, as they are automatically cleaned up when the connection terminates. It's important to remember that iRules as a whole, and the variables therein are connection bound. This can cause some confusion when people are expecting a more static state. Local variables will account for the vast majority of your variable usage within iRules. They're efficient, easy to use, and highly useful depending on the situation. These can be set directly as shown above but are also often the result of a command that provides output. There are also multiple ways to reference a variable within iRules. When using a command that directly affects the variable it is usually appropriate to leave the "$" off and reference the name directly, other times braces allow you to more clearly define the beginning and end of a variable name. Some examples would look like: #Standard variable reference log local0. "My host is $host" #Set variable to the output of a particular command using brackets [] set int [expr {5 + 8}] #Directly manipulating a variable's value means no "$", most times incr int #Bracing can allow you to deliniate between variable name and adjacent characters log local0. "Today's date is the ${int}th" Global Variables "Global variables" is a bit of a misnomer, actually. This is the general terminology used within most programming languages, including Tcl, for variables that exist outside of the local memory space. I.E., in the case of iRules, variables that exist beyond the constraints of a single connection. For instance, what if I want to store the IP address of my logging server, and have that always available, to every connection that comes through the BIG-IP, without having to re-set that variable every single time my iRule fires? That would be a global variable. Tcl has a mechanism for handling this, and it's relatively easy to use. Interestingly, though...we aren't using it. The global variable handling within Tcl requires a shared memory space, which in our world does something referred to as "demoting" from CMP. As you'll recall from the "Introduction to F5 Technology & Terms" article, CMP is Clustered Multi-Processing, and is the technology that allows us to distribute tasks within the BIG-IP to multiple cores in an efficient, scalable manner. Because of the requirements of the default Tcl global variable handling, making use of a global variable within Tcl forces any connection going through the Virtual to which the offending iRule is applied to be demoted from CMP, I.E. use only a single processing core, rather than all of them to process the traffic for that Virtual. This is a bad thing, and will severely limit performance. As such, we strongly recommend avoiding global variables in their traditional sense all together. But what about that log server address? There's still a definite need for long lived data to be stored in memory and available at will. It's for this purpose that we've included a new namespace within iRules called the "static" namespace. You can effectively set static global variable data in the static namespace without breaking CMP, and thereby not decreasing performance. To do so simply set up your static::varname variables, likely in RULE_INIT, since that special event only runs once at load time and static variables are global in scope, meaning they stay set until the configuration is reloaded. Once these variables are set you can call them like you would any other variable from within any iRule, and they will always be available. It looks something like this: #Set a static variable value, which will exist until config reload, living outside of the scope of any one particular iRule set static::logserver "10.10.1.145" #Reference that static variable just as you would any other variable from within any iRule log $static::logserver "This is a remote log message" For a more complete look at the different types of memory structures that you can access in iRules, I've included a handy dandy table to show memory structures by type along with some information about each, and an example of using that structure. We'll cover some of these in more detail in later installments of this series, but I want to make you aware of the different types of memory structures available. Note: There is a slight error in the table. It IS possible to unset static variables. Is there a performance impact when using variables? Running any command that isn't cached in any script has some cost associated with it, there's just no way around it. Variables in iRules happen to have a miniscule cost, generally speaking, so long as you're using them appropriately. The cost associated with a variable is in the creation process. It takes resources, albeit a very small amount, to store the desired data in memory and create a reference to that data to be used in the future. Accessing a variable is simply making a call to that reference, and as such doesn't have an additional cost. A common misunderstanding, however, is just what constitutes a variable within iRules, vs. a command or function that will perform a query. Many people see things like "HTTP::host" or "IP::client_addr" and, due to the format, assume it is a command or function and as such will cost CPU cycles to query the value and return it. This is not the case at all. These type of references are cached within TMM, so whether you call "HTTP::host" once or 100 times, you're not going to require more resources, as you're not performing a query to determine the hostname each time, rather just referencing a value that's already stored in memory. Think of these and many other similar commands as pre-populated variable data that you can use at will. When should I use variables? While the cost of creating variables is low, there still is some overhead associated with it. In iRules, due to the exorbitantly high rate of execution in some deployments, we tend to lean towards extreme efficiency mindedness. In this vein we recommend only using variables where they are actually necessary, rather than many programming practices which dictate to use them often as a means of keeping code tidy, even when not truly warranted. For instance, a common practice with many new iRule programmers is to do things like set host [HTTP::host] As I just explained above, however, this is completely unnecessary. Rather, it would be more efficient to simply re-use the HTTP::host command any time you need to reference this information. When it does make sense to use a variable, however, is when you are going to modify the data in some way. For instance log local0. "My lower case URI: [string tolower [HTTP::uri]]" The above will give you an all lowercase representation of the HTTP URI. This is a very common use case, and it is not abnormal to have the need to reference the lowercase version of the URI multiple times in a given iRule. While the HTTP::uri command is cached and will not incur additional overhead regardless of how many times you reference it, the string tolower command is not. As such, it would make sense in this case, assuming you're going to reference the lowercase URI at least 2 or more times, to create a variable and reference that: set loweruri [string tolower [HTTP::uri]] log local0. "My lower case URI: $loweruri" Effectively you want to use variables any time you are going to have to repeat any operation against a value that has a cost associated with it. Rather than repeat that operation multiple times and accumulate extra overhead it's better to perform the operation once, store the result, and reference the variable from there. That covers the basics of variables: What they are, how they work, when to use them and when not, which types you can make use of and how they'll affect your performance, if at all. Hopefully that allows you to approach your iRules with that much more confidence, understanding such a core piece of their makeup. In the next article we'll dig into control structures and operators.14KViews3likes3CommentsIntermediate iRules: Data-Groups
For this article in the Intermediate iRules series we’ll begin arming you with some knowledge on data-groups. As such, this article will endeavor to answer the following: What is a data-group? What is a class? What are the benefits of a data-group? What command(s) would I use to access data in a data-group? This will be a relatively high-level overview that walks through the basics of these constructs. There is much more to dig into out on DevCentral, but here’s a start: What is a data-group? A data-group is a particular type of memory structure within iRules. It is effectively a list in a key -> value pair format consisting of IP addresses/subnets, strings, or integers. You can have just a list of keys, or a list of matched keys and values in this unique structure. It’s unique and special in a couple of ways, but most obvious among them is that it is actually stored permanently as part of the configuration, rather than only existing as a part of an iRule, or in memory. This can be done either inline in the big-ip.conf, or as a separate file (known as an external data-group). Both function effectively the same for the purposes of our discussion here. Because it is stored on box and not solely in memory, data-groups are pre-populated with data before an iRule ever executes. This makes them ideal for stored lists of any sort, such as authorized IP ranges or URI redirection mappings and the like. This also means they are mirrored across all boxes in a cluster (or both in a pair) because they are effectively a config object. Modifying a data-group is simple as well, thanks to direct access via the CLI or GUI. You can add, modify or remove entries in a data-group without ever touching the iRule(s) referencing it, which makes it ideal for storing config bits or static info that may need to be updated from time to time. As long as the formatting of the data remains correct while you’re editing, there’s no real chance of breaking your iRule by modifying the data-group, since the code itself isn’t being touched. To that end, there are two ways to store data-groups, internal or external. For internal data-groups, the data set is stored in the bigip.conf file. For external data-groups, they are maintained in their own file and referenced from the data-group object. Very large data sets should be kept in external data-groups. The only (possibly) limiting factor about data-groups being a config object is that iRules can’t affect configuration objects directly. This means that while you can read, sort, and reference data-groups from within your iRule, you can’t actually modify them directly. If you want to update a data-group it has to be either done manually via the CLI/GUI, or scripted via TMSH or iControl. There is no direct iRules access for modifying the contents, making these a read-only data structure from iRules’ perspective. The config object would look like this (v11+, see the class command in the wiki for earlier versions): ltm data-group internal name_value_dg { records { name1 { data value1 } name2 { data "value2 with spaces" } } type string } What is a class? A class is exactly the same thing as a data-group. We have used the terms interchangeably for years, much to the chagrin and confusion of some users. We even called the command classwhile the structure is called “data-group”. Don’t let that confuse you, they are the same thing, and regardless of which you hear someone mention, they’re talking about the memory structure that I just described above. What are the benefits of a data-group? I mentioned before that one of the only drawbacks of data-groups is that they are read-only for all intents and purposes where iRules is concerned.That, however, is a tiny drawback in most cases when you consider the performance of data-groups. data-groups are far and away the most efficient memory structure with which to perform lookups past only a few entries. if/else and switch are fine to a point, but past about 10 items even the more efficient switch can’t keep up with the linear scaling of data-group lookups. Whether you’re storing 100 or 100,000 entries, queries are roughly the same thanks to the indexed, hashed format of data groups. This makes them far and away the best option for storing large lists of data as well as frequently performed queries that can be represented in a read-only fashion. The bottom line is: If you’re not updating the data in the list, and you’re dealing with more than a handful of items, be it strings, IPs or otherwise, data-groups are likely your best bet. They’re also resilient through failover, reboots, etc. unlike data structures without a disk based config object to back them up. Last, but in some cases not least at all, you can script the management of data-groups, especially external data-groups, via iControl. TMSH, etc. This makes it an ideal way to bulk load data or manage entries in the data structure externally. Just remember that you’ll have to re-instantiate the iRule for the changes to be recognized. What command(s) would I use to access data in a data-group? The command you’ll be using to access data-groups is the classcommand. In versions prior to 10 there were other commands (matchclass / findclass,) but as of v10 data-groups were completely overhauled to be more effective and higher performance, and the classcommand was born. It’s extremely powerful and has many permutations. I won’t attempt to go into all of them here, but you can see some basic matching examples here. When you combine the flexibility of the classcommand (full documentation here) with the performance and scalability of data-groups, you get some pretty powerful possibilities. Here are a couple examples from the wiki: when HTTP_REQUEST { if { [class match [IP::client_addr] equals "localusers_dg" ] } { COMPRESS::disable } } when HTTP_REQUEST { set app_pool [class match -value -- [HTTP::uri] starts_with app_class] if {$app_pool ne ""} { pool $app_pool } else { pool default_pool } } Data-Group Formatting Differences The format at the command line has changed over the years, please reference these articles for your particular version of TMOS v10 Data-Group Formatting Rules v11+ Data-Group Formatting Rules9.2KViews3likes3CommentsGetting Started with iRules: Control Structures & Operators
So far in the first several installments of this series we’ve talked about some solid introduction topics, from programming basics to F5 terminology to covering an introduction of what iRules is as a technology, how it works, and how to make use of it. These introductions are a solid stepping-stone to get people on the same page so that we can delve into iRules without losing people along the way, or so goes the theory. In the last couple of installments we moved past introductions and started talking about iRules proper, discussing events, which are a foundational piece of the iRules framework, and priorities. It’s important to understand events and the way iRules work within an event driven framework, so I highly suggest giving at least that installment, as well as the article on variables a read if you are new to the series. Building from those ideas we’re now going to cover control structures and operators, two more fundamental and important pieces of iRules that are integral to just about any iRules script that you may write. Combining these along with events will give you the basic framework for a logical flow within almost any iRule, with varying degrees of complexity, of course. Control Structures What is a control structure? A control structure is a logical statement that will allow you to make a comparison and, based on the result of that comparison, perform some set of actions. If you’ve done any form of scripting whatsoever you’ve used them, if, else, switch…etc. Whether this is checking to see if a value is equal to zero and then only executing a block of code if that is true, or determining whether or not an inbound IP address is in the allowed list before granting access to a restricted portion of your application, any decision you’re making within your iRule is made using control structures. Just like without events, you’d be unable to execute code at the proper moment in time, based on what’s happening with network flow; without control structures you wouldn’t be able to make logical separations in which code gets executed under certain circumstances which, obviously, is paramount to building a functional script. What different control structures are there? In iRules the main control structures you’ll be working with are “if”, “else”, “elseif”, “switch”, and “class”, which is a bit of a special case, but we’ll discuss how that works. Let’s go through a simple look at each of these available options: if The if statement is by far the commonly used and widely understood form of a logical control structure out there. It’s in every language I’ve ever seen, and makes sense to just about anyone without any form of explanation whatsoever. Quite simply, this statement says “only execute the below code if the statement contained results as true”. A quick example would be: if {[info exists $auth]} { pool auth_pool } else Else, in and of itself, isn’t really a control structure, but is rather an optional addition to the if statement. It allows you to make a logical separation between the two outcomes of an if statement. So logically the above example reads as “if the auth variable is set, send traffic to the pool named auth_pool”. But…what happens in this case if the auth variable isn’t set? Nothing, as it stands right now. If we want to change that, we can use the else statement to describe what we want to happen. For example: if {[info exists $auth]} { pool auth_pool } else { pool other_pool } elseif So now we can make a pretty solid logical statement based on a single comparison (does the auth variable exist, in the above example). What if, however, we want to be able to make multiple comparisons and act differently based on which outcome proves to be true? We need to create a multi-choice logical statement, which can be done a couple of ways. The first, likely most common way is with the elseif statement, which is also associated with the if structure. With an if/else statement you are saying “if x, do y else do z”. With an elseif clause you can effectively say, “if x do y, if not x but a do b”, etc. It sounds much more complex trying to spell it out than it actually is, an example is probably a simpler way of depicting how elseif fits in with if and else: if {[info exists $auth]} { pool auth_pool } elseif {[info exists $secondary]} { pool secondary_pool } else { default_pool } switch Having covered if, else, and elseif we’ve covered the most common control structures used in most cases. That does not, however, mean that they are necessarily the best choice in every case. They are widely used because they are widely known, but there’s another option that, in many cases, can prove superior in not only readability but also in all important performance. A switch statement can be used to replace an if, an if/else, an if/elseif chain, and more. It’s a very versatile, compact statement and it would behoove any would be iRuler to learn the ins and outs of bending switch statements to their will. The one big caveat with a switch statement is that while it supports multiple match options, it does so against a single comparison string. Taking a look at a basic switch statement that inspects the URI and acts based on the contents looks like this: switch [HTTP::uri] { “/app1” { pool http_pool } } This effectively says “Inspect the HTTP::uri variable, and if it is /app1, send traffic to the http_pool”. This is a pretty basic if statement. That, however, isn’t anywhere near all of what switch can do. What if you wanted to do multiple possible matches against the URI. I.E. “If the HTTP::uri is /app1, send to http_pool, if it is /app2, send to http_pool2, if it is /app3, send to http_pool3”. That would be simple with switch, and would look like: switch [HTTP::uri] { “/app1” { pool http_pool } “/app2” { pool http_pool2 } “/app3” { pool http_pool3 } } Note the lack of need for else or elseif statements, and the simple, clean logical flow. Last let’s look at a logical or statement, a particularly useful trick that you can perform with a switch statement. If your logic statement looks like “If the URI is /app1, /app2, or /app3, send to the http_pool”. The switch statement to satisfy that requirement would be as simple as: switch [HTTP::uri] { “/app1” – “/app2” – “/app3” { pool http_pool } } The dash after a switch statement allows it to fall through in a logical “or” fashion, making it easy to chain multiple match cases to go along with a single action, as above. Finally, with the switch statement, you can use glob-style pattern matching. switch -glob [HTTP::uri] { "*\\?*ghtml*" { #do work here } {*\?*ghtml*} { #do work here } } Where the pattern is something like *\?*ghtml* and you are using double quotes, note that string substitution occurs before processing the glob pattern argument, so two back slashes are required to escape the question mark. By using the curly braces, you avoid the string substitution and the glob pattern can be matched as expected. Which control structure is right for me? There is much more to learn about the ins and outs of the different control structures, but that should be enough to get you started. Now the tough choice – which to use? While there is not a hard and fast set of rules saying “this is when you must use x vs y”, there are some general guidelines to live by: If is the most commonly used for a reason. If you are doing 1-3 comparisons, if or if/else(if) are probably the most appropriate, and easiest to use and understand. If you are making 3-10 comparisons, you should likely be using a switch statement. They are higher performance, easier to read, and much simpler to debug, generally speaking. Past 10-15 entries, you should be using a data group and the class command, but we’ll cover more on that in another article. What should I keep in mind when setting up my structure? When building out your control structures it’s important, regardless of whether it’s a series of if/else comparisons or a switch statement, to do your best to order them for efficiency. By putting the most frequently matched items towards the top of the list you can improve efficiency dramatically. The deeper the match depth in the if/elseif chain or the switch statement the more comparisons need to be made before arriving at the match. Comparison Operators What is a comparison operator? A comparison operator (just operator for our purposes) is how you define what type of comparison you’re going to use when comparing two items. Every if or switch requires some kind of true/false result, and most of these will make use of a comparison of some sort. Deciding “if {$x eq $y}” or “if {$z > 5}” requires the use of such operators, as does just about any logical decision being made. As such, they’re exceedingly common and frequently used. What different comparison operators are there? The main comparison operators are: Operator Example equal “$x eq $y” or “$x == 5” not equal “$x ne $y” or “$x != 5” contains [HTTP::uri] contains “abc” starts_with [HTTP::uri] starts_with “/app1” ends_with [HTTP::path] ends_with “.jpg” There are obviously more (>, %lt;, >=, <=, etc) but the above are the most commonly used, generally speaking. Comparison operators aren’t iRules specific, so I won’t belabor all of them here. Suffice to say most commonly accepted comparison operators will work in Tcl, and if they work in Tcl they’ll work in iRules. What are the pros and cons of the different operators? The most important thing to remember when dealing with operators is “the more specific the better”. Always use equals when you can, use starts_with or ends_with over contains when you can, etc. The more specific the operator you’re using the less work that needs to be done to identify whether or not the comparison will return true or not. This is directly visible in a savings in CPU cycles, and as such is worth some thought when writing your iRules. There is also the notion of polymorphism to take into account but that has already been covered, and tends to be a more advanced concept, so if you’d like to read more please do, but we don’t need to cover it in any great detail here. That wraps up control structures and operators. Next week we’ll dig into delimiters, covering the different types available within iRules, the pros and cons, the situations in which you’d use each, and more.6.8KViews2likes4CommentsGetting Started with iRules: Delimiters
So far in this series we've covered introductions across the board for programming basics and concepts, F5 terminology and basic technology concepts, the core of what iRules are and why you'd use them, as well as cornerstone iRules concepts like events, control structures, and variables. In this article, we will add to the foundation with a detailed discussion on delimiters. Buckle up! Whitespace The primary (and oft overlooked) delimiter in tcl and iRules is whitespace. In tcl, basically everything is a command. Commands have names, options, and arguments. Whitespace (space or tab) is used to separate the command name and its options & arguments, which are simply strings. A newline or semicolon is used to terminate a command. In this example log local0. "iRule, Do you?" the components of the command when you break it down are: Command log local0. "iRule. Do you?" Command Name log Command Parameter local0. Command Parameter "iRule. Do you?" The space character is also used to separate the elements in a tcl list. Double Quotes Let's take a closer look at that last example. You might have noticed that the 2nd parameter above is a string consisting of multiple words separated by whitespace, but enclosed within double quotes. This is an example of grouping with double quotes. Everything between a pair of double quotes " ", including newlines and semicolons, are grouped and interpreted as a single contiguous string. When the enclosed string is evaluated, the enclosing quotes are discarded and any whitespace padding is preserved. A literal double-quote character can be included in a string delimited by double quotes if it is escaped with a backslash ( \" -- more on backslash substitution below). Variable substitutions are always performed within strings delimited by double quotes. Avoid using double quotes on already-contiguous alpha-numeric strings because that results in an extra trip through the interpreter to create an unnecessary grouping. However, even in contiguous strings, if using any characters besides alpha-numeric it's a good idea to enclose the entire string in quotes to force interpretation as a contiguous string. For example, one of the most commonly used iRules commands, HTTP::redirect, takes a fully qualified URL as an argument which should be double quoted: HTTP::redirect "http://host.domain.com/uri" Strings as operands in expressions must be surrounded by double quotes or braces to avoid being interpreted as mathematical functions. Square Brackets A nested command is delimited by square brackets [ ], which force in-line evaluation of the contents as a command. Everything between the brackets is evaluated as a command, and the interpreter rewrites the command in which it's nested by discarding the brackets and replacing everything between them with the result of the nested command. (If you've done any shell scripting, this is roughly equivalent to surrounding a command with backticks, although tcl allows multiple nesting.) In this example, the commands delimited by square brackets are evaluated and substituted into the log command before it is finally executed: log local0. "[IP::client_addr]:[TCP::client_addr] requested [HTTP::uri]" Strings contained within square brackets which are not valid tcl or iRule commands will generate an "undefined procedure" error when the interpreter attempts to interpret the string inside the brackets as a command. The use of square brackets for purposes besides forcing command evaluation requires escaping or backslash substitution. It's most optimal if you will be referring to the result of a command only once to use inline command substitution instead of saving the result of the command to a variable and substituting the variable. Backslash Substitution (Escaping) Backslash substitution is the practice of escaping characters that have special meaning ( $ {} [] " newline etc) by preceding them with a backslash. This example generates "undefined procedure: 0-9" error because the string "0-9" inside the [ ] is interpreted as a command: if { [HTTP::uri] matches_regex "[0-9]{2,3}"} { TCL error: undefined procedure: 0-9 while executing "[0-9] This example works as expected since the square brackets have been escaped: if { $uri matches_regex "\[0-9\]{2,3}" } { body } This example also works since the contents of the square brackets within the braces are not evaluated as a command (and it's also a bit more readable): if { $uri matches_regex {[0-9]{2,3}}}{ body } (The 2 approaches above are roughly equivalent performance-wise.) Another common use of backslash substitution is for line continuation: Continuing long commands on multiple lines. When a line ends with a backslash, the interpreter converts it and the newline following it and all whitespace at the beginning of the next line into a single space character, then evaluates the concatenated line as a single command: log local0. "[IP::client_addr]:[TCP::client_addr] requested [HTTP::uri] at [clock \ seconds]. Request headers were [HTTP::header names]. Method was [HTTP::method]" Backslash substitution, when required does not substantially affect performance one way or the other. Parentheses The most common use of parentheses ( ) in iRules is to perform negative comparisons. It's a common mistake to exclude the parentheses and unintentionally negate the first operand rather than the result of the comparison, which can result in the mysterious 'can't use non-numeric string as operand of "!"' error: If the first operand is non-numeric, the evaluation will fail, since a non-numeric value cannot be negated in the mathematical sense. Here's an example demonstrating the use of parentheses to properly perform a negative comparison. The following approach logs "no match", as expected, since $x is a string and not equal to 3: set x xxx if { !($x == 3) } { log "no match" } else { log "match } However, this (erroneous) approach results in the runtime error mentioned above: set x xxx if { !$x == 3 } { log "no match" } else { log "match" } TCL error: can't use non-numeric string as operand of "!" while executing "if { !$x == 3 } { log "no match" } else { log "match" }" Other uses for parentheses in iRules are for regular expression grouping of submatch expressions: regexp -inline (http://)(.*?)(\.)(.*?)(\.)(.*?) and to reference elements within an array: set array(element1) $val Braces And last but by no means least, braces are the most extensively used and perhaps least understood form of grouping in tcl and iRules. They can be confusing because they are used in a number of different contexts, but basically braces define a space-delimited list of one or more elements, or a newline delimited list of one or more commands. I'll try to give examples of each of the different ways braces are commonly used in iRules. Braces with Lists Lists in general are space delimited words enclosed in braces. Lists, like braces, may be nested. This example shows a list of 3 elements, each of which consists of a list of 2 elements: { { {ab} {cd} } { {ef} {gh} } { {ij} {kl} } } Braces with Subcommand Lists Some commands use braces to delimit lists of subcommands. The "when" command is a great example: In every iRule, braces are used to delimit all iRules events, encapsulating the list of commands that comprise the logic for each triggered event. The first line of each event declaration must end with an open brace, and the last line with a closing brace, like this: when HTTP_REQUEST { body } There are several other commands that use braces to group commands, such as switch: Syntax: switch condition body condition body Examples: switch { case1 { body } case2 { body } } or switch { case1 { body } case2 { body } } Braces with Parameter Lists Other commands use braces to define a parameter which is really a group of values - a list. The "string map" command, for example, requires a parameter containing the value pairs for substitution operations. The value pairs parameter is a list passed as a single parameter. Syntax: string map charMap string Example ("a" will be replaced by "x", "b" by "y", and "c" by "z"): string map {a x b y c z} aabbcc Braces with Parameter Lists and Subcommand Lists Combined And some commands use braces for both parameter lists and subcommand lists: Syntax: for start test next body Example: for {set x 0 } { x = 10 } { incr x } { body... ... } Nesting Braces Regardless of what context they are used in, multiple sets of braces can be nested. The innermost group will become an element of the next group out, and so on. All characters between the matching left and right brace are included in the group, including newlines, semicolons, and nested braces. The enclosing (i.e., outermost) braces are not included when the group is evaluated. There must be a matching close brace for every open brace -- even those enclosed in comments. Mismatched braces will generate a syntax error to that effect when you try to save the iRule. (Mismatches in other delimiters and invalid command syntax may also generate a mismatched braces error, so if you can't find mismatched braces, start commenting out lines without braces until the syntax check passes, then fix the problem in the last line you commented.) Special Cases for Using Braces You can also use braces to enclose strings, just as you would double quotes, but variables won't expand within them unless a command also inside the braces refers to them. Because of that difference, if you need to handle strings containing $, \, [], (), or other special characters, braces will work where double quotes won't. Braces may also be used to delimit variable names which are embedded into other strings, or which include characters other than letters, digits, and the underscore, enforcing the start and end boundaries of the variable name rather than relying on whitespace to do so. This example results in a runtime error since the end of the first variable name is unclear: set var1 111 set var2 222 log local0. "$var1xxx$var2" TCL error: can't read "var1xxx": no such variable while executing "log local0. "$var1xxx$var2"" But if you delimit the variable name in braces, it works: set var1 111 set var2 222 log local0. "${var1}xxx$var2" Returns: 111xxx222 Class names containing the dash character must be delimited by braces to ensure the class name is evaluated correctly. These are both valid class references: matchclass $::MyClass contains "Deb" matchclass ${::My-Class} contains "Deb" Forcing Variable Expansion within Braces If you want to use variables in the charMap value, you'll need to use a different way to pass a list to the string map command. As I mentioned above, variables aren't automatically expanded inside of braces. However, for some commands that accept a list as a parameter, it makes sense to pass variables to the command within a list, which is delimited by braces. To pass a list of expanded variables and/or literal strings, you can use an embedded "list" command to echo both the values of the variables and the literals into the enclosing command. This example shows how to pass a variable and a literal string as the charMap parameter to the "string map" command, substituting the string "NewName" wherever the string contained in $oldname is found in the HTTP Host header: Syntax: string map charMap string Example: string map [list $oldname NewName] [HTTP::host] Other Resources This article is by no means an exhaustive review of tcl delimiter use & optimization, but hopefully covers the basics well enough to get you started. Comments, corrections, & observations are welcome as always. Here are some additional resources you may want to check out: Summary of Tcl language syntax (tcl.tk) Summary of Tcl language syntax (sourceforge.net) Tcl Fundamentals Is white space significant in Tcl Quoting Hell Quoting Heaven! tcl list command If you have detailed questions about this or any other iRules questions, please ask! Join us for the next article in this series when we will cover logging and comments.4.5KViews2likes0CommentsGetting Started with iRules: Directing Traffic
The intent of this getting started series was to be a journey through the basics of both iRules and programming concepts alike, bringing everyone up to speed on the necessary topics to tackle iRules in all their glory. Whether you’re a complete newbie to scripting or a seasoned veteran, we want everyone to be able to enjoy iRules equally, or at least as near as we can manage. As we wrap this series, it is our hope that it has been helpful to that end, and that you'll be eager to move on to intermediate topics in the next series. In this final entry in the series, we’re taking a look at what I think is likely the thing that many people believe is the primary if not one of the sole uses of iRules before they are indoctrinated into the iRuling ways: routing. That is, directing traffic to a particular location or in a given fashion based on … well, just about anything in the client request. Of course, this is only scratching the surface of what iRules is capable. Whether it's content manipulation, security, or authentication, there’s a huge amount that iRules can do beyond routing. That being said, routing and the various forms that it can take with a bit of lenience as to the traditional definition of the term, is a powerful function which iRules can provide. First of all, keep in mind that the BIG-IP platform is a full, bi-directional proxy, which means we can inspect and act upon any data in the transaction bound in either direction, ingress or egress. This means that we can technically affect traffic routing either from the client to the server or vice versa, depending on your needs. For simplicity’s sake, and because it’s the most common use case, let’s keep the focus of this article to only dealing with client-side routing, e.g. routing that takes place when a client request occurs, to determine the destination server to deliver the traffic to. Even looking at just this particular portion of the picture there are many options for routing from within iRules. Each of the following commands can change the flow of traffic through a virtual, and as such is something I’ll attempt to elucidate: pool node virtual HTTP::redirect reject drop discard As you can see there are some very different commands here, not all of them what you would consider traditional “routing” style commands, but each has a say in the outcome of where the traffic ends up. Let’s take a look at them in a bit more detail. pool The pool command is probably the most straight-forward, “bread and butter” routing command available from within iRules. The idea is very simple, you want to direct traffic, for whatever reason, to a given pool of servers. This simple command gets exactly that job done. Just supply the name of the pool you’d like to direct the traffic to and you’re done. Whether your criteria for allowing traffic to a given pool, or whether you’re trying to route traffic to one of several different pools based on client info or just about anything else, an iRule with a simple pool command will get you there. The pool command is the preferred method of simple traffic routing such as this because by using the pool construct you’re getting a lot of bang for your buck. The underlying infrastructure of monitors and reporting and such is a powerful thing, and shouldn’t be overlooked. There is, however, one other permutation of this command: pool [member []] Perhaps you don’t want to route to one of several pools, but instead want to route to a single pool but with more granularity. What if you don’t want to just route to the pool but to actually select which member inside the pool the traffic will be sent to? Easy enough, specify the “member” flag along with with the IP and port, and you’re set to go. This looks like: when CLIENT_ACCEPTED { if { [IP::addr [IP::client_addr] equals 10.10.10.10] } { pool my_pool } } when HTTP_REQUEST { if { [HTTP::uri] ends_with ".gif" } { if { [LB::status pool my_Pool member 10.1.2.200 80] eq "down" } { log "Server $ip $port down!" pool fallback_Pool } else { pool my_Pool member 10.1.2.200 80 } } } node So when directing traffic to a pool or a member in a pool, the pool command is the obvious choice. What if, however, you want to direct traffic to a server that may not be part of your configuration? What if you want to route to either a server not contained in a particular pool, whether that’s bouncing the request back out to some external server or to an off the grid type back-end server that isn’t a pool member yet? Enter the node command. The node command provides precisely this functionality. All you have to do is supply an IP address (and a port, if the desired port is different than the client-side destination port), and traffic is on its way. No pool member or configuration objects required. Keep in mind, of course, that because you aren’t routing traffic to an object within the BIG-IP statistics, connection information and status won’t be available for this connection. when HTTP_REQUEST { if { [HTTP::uri] ends_with ".gif" } { node 10.1.2.200 80 } } virtual The pool command routes traffic to a given pool, the node command to a particular node…it stands to reason that the virtual command would route traffic to the virtual of your choice, right? That is, in fact, precisely what the command does – allows you to route traffic from one virtual server to another within the same BIG-IP. That’s not all it does, though. This command allows for a massively complex set of scenarios, which I won’t even try to cover in any form of completeness. A couple of examples could be layered authentication, selective profile enabling, or perhaps late stage content re-writing post LB decision. Depending on your needs, there are two basic functions that this command provides. On is to add another level of flexibility to allow users to span multiple virtuals for a single connection. This command makes that easy, taking away the tricks the old timers may remember trying to perform to achieve something similar. Simply supply the name of whichever virtual you want to be the next stop for the inbound traffic, and you’re set. The other function is to return the name of the virtual server itself. If a virtual name is not supplied the command simply returns the name of the current VIP executing the iRule, which is actually quite useful in several different scenarios. Whether you’re looking to do virtual based rate limiting or use some wizardry to side-step SSL issues, the CodeShare has some interesting takes on how to make use of this functionality. when HTTP_REQUEST { # Send request to a new virtual server virtual my_post_processing_server } when HTTP_REQUEST { log local0. "Current virtual server name: [virtual name]" } HTTP::redirect While not something I would consider a traditional routing command, the redirection functionality within iRules has become a massively utilized feature and I’d be remiss in leaving it out, as it can obviously affect the outcome of where the traffic lands. While the above commands all affect the destination of the traffic invisibly to the user, the redirect command is more of a client-side function. It responds to the client browser indicating that the desired content is located elsewhere, by issuing an HTTP 302 temporary redirect. This can be hugely useful for many things from custom URIs to domain consolidation to … well, this command has been put through its paces in the years since iRules v9. Simple and efficient, the only required argument is a full URL to which the traffic will be routed, though not directly. Keep in mind that if you redirect a user to an outside URL you are removing the BIG-IP and as such your iRule(s) from the new request initiated by the client. when HTTP_RESPONSE { if { [HTTP::uri] eq “/app1?user=admin”} { HTTP::redirect "http://www.example.com/admin" } } reject The reject command does exactly what you’d expect: rejects connections. If there is some reason you’re looking to actively terminate a connection in a not so graceful but very immediate fashion, this is the command for you. It severs the given flow completely and alerts the user that their session has been terminated. This can be useful in preventing unwanted traffic from a particular virtual or pool, for weeding out unwanted clients all-together, etc. when CLIENT_ACCEPTED { if { [TCP::local_port] != 443 } { reject } } drop & discard These two commands have identical functionality. They do effectively the same thing as the reject command, that is, prevent traffic from reaching its intended destination but they do so in a very different manner. Rather than overtly refusing content, terminating the connection and as such alerting the client that the connection has been closed, the discard or drop commands are subtler. They simply do away with the affected traffic and leave the client without any status as to the delivery. This small difference can be very important in some security scenarios where it is far more beneficial to not notify an attacker that their attempts are being thwarted. when SERVER_CONNECTED { if { [IP::addr [IP::client_addr] equals 10.1.1.80] } { discard log local0. "connection discarded from [IP::client_addr]" } } Routing traffic is by no means the most advanced or glamorous thing that iRules can do, but it is valuable and quite powerful nonetheless. Combing advanced, full packet inspection with the ability to manipulate the flow of traffic leaves you with near endless options for how to deliver traffic in your infrastructure, and allows for greater flexibility with your deployments. This kind of fine grained control is part of what leads to a tailored user experience which is something that iRules can offer in a very unique and powerful way. Internal Virtual Server This isn't directly an iRules routing technology, though there are plenty of iRules entry points into this unique routing scenario on BIG-IP, so I thought I'd share. The internal virtual server is reachable only by configuration of an adapt profile on a standard virtual server. Once the configuration routing is place, events and commands related to content adaption (ICAP, though not required) are available to make decision on traffic manipulation and further routing. Check out the overview on AskF5.6.2KViews2likes1CommentIntermediate iRules: Iteration
In this article, we're going to cover loop control structures and how to gain efficiency therein. One of the things that makes iRules so powerful is the fact that it is effectively a full scripting language at your fingertips with which you can inspect and modify traffic in real time. As with any scripting language, TCL (which iRules is based on) makes use of different loop control structures to perform different tasks. These are usually used in more advanced iRules, but we'll take a look at a couple of simple examples for ease of reading. In the below examples we're going to be looking at a relatively simple situation. In both we're going to be taking a list of strings, domain names in this case, and cycling through that list one at a time, performing some given tasks on each item in the list. For & While Loops In the first examples, we use the for and whileoop. These loops are two of the most common loop structures around, and are used in many, many languages. While these examples certainly function, you'll notice there are many steps required to get to the point of actually performing the actions based on the data in question. These are the preferred loops in many languages as they are relatively robust and functional, and the difference in overhead is less important. But this is a bit expensive for iRules, unless there is an actual need. It ultimately doesn't matter if you use a for or while in this scenario, but for loops are far more common in the examples you'll find on DevCentral. when HTTP_REQUEST { set domains {bob.com ted.com domain.com} set countDomains [llength $domains] #for loop for {set i 0} { $i < $countDomains } {incr i} { set domain [lindex $domains $i] # This is slower } #while loop set i 0 while { $i < $countDomains } { set domain [lindex $domains $i] incr i } } If you do need the additional flexibility with these loops, know that you have continue and breakat your disposal as well. The former will stop processing of the current loop, but move on to the next test condition, whereas the latter will exit the loop immediately and move on to the next line of code. It's also important to remember that these loops are blocking, so given the single-threaded nature of TMM, you really don't want to iterate through too many test cases before moving on. Unless of course you are trying to slow BIG-IP down for testing purposes, then, loop away! Foreach Loops This next example is logically similar. It accomplishes the same task in this case, and does so with less overhead. See how we have less variables to set, and less functions to perform for each loop iteration? While foreach is sometimes thought of as slightly less powerful or flexible than a for loop, it is markedly more efficient. As such, in cases where it will accomplish the task at hand, it is by far the preferred structure. when HTTP_REQUEST { set domains {bob.com ted.com domain.com} foreach domain $domains { # This is faster, and more elegant } } Looping as a Sleep Timer? Many moons ago someone asked in the forums (yes, we used to have forums) if there was a way to make iRules sleep for a period of time. I was relatively new to iRules but eager to help, so I weighed in that using a for loop with a massive counter would be the way to go. Colin quickly responded that that might not be the best idea, given the blocking nature of doing such a thing and the single threaded nature of TMM I mentioned above. At the time, there wasn't a great way, but you can accomplish this now with the aftercommand, which is non-blocking.1.9KViews2likes0CommentsGetting Started with iRules: Events & Priorities
As this series steams on we go deeper and deeper into what actually drives iRules as a technology. So far we have covered very basic concepts, from core programming ideas and F5 basic terminology through to what makes iRules unique and useful, when you’d make use of them, etc. This is all-important as a base of knowledge from which we can draw when speaking about the technology, but now it’s time to dig in deeper and start discussing the inner workings of iRules and what makes them tick. If you haven’t yet read the first three primer style introduction installments of this article series it is likely worth your time to at least peruse them to be sure you’re on the same page before delving into the rest of the series. In this installment, we’ll cover two core concepts within iRules: Events and Priorities. While we will eventually get to commands and different fun tricks that you can do with iRules, sure enough, it’s important to understand how iRules actually work first. I can think of no better starting place than events and our built in eventing structure. Events What is an event? iRules is an event driven language. What this means is that there is no freestanding code to be executed each time the script body as a whole is called. Rather code is placed under events, which act like containers, categorizing and separating the code within an iRule into logical sections. This is important to allow iRules to be truly network aware. When programming in a traditional scripting environment it is normal for the entirety of a script to be executed each time it is called. In a network based scripting environment however you ideally want sections of code to be called at specific moments within the connection flow. I.E. you want to look up an HTTP host name, want to do it after the connection is established, the handshake is performed and the appropriate headers are sent that contain the information you’re looking for, but before that request is sent off to the destination server. This means you have to have some way to understand and describe, in your code, that moment in time. There are many similar moments, such as when a connection is first established, when a server is selected for load balancing, when the connection is sent to that server, when a server responds, and so on. It is because of this that iRules is designed as an event driven language. Thanks to the flexibility of Tcl and our ability to easily modify it to our needs, we were able to extend it to understand a vast number of these moments within the session flow. It is those moments that we refer to as events. Rather than reading every packet that comes across the wire and waiting until you see the information that depicts the HTTP request has finally come across from the user, an iRules user can simply call the HTTP_REQUEST event and trust that the BIG-IP will execute the code contained within that event block at the appropriate moment. So, very simply, an “Event” when speaking about iRules is a Tcl command that we’ve added to iRules to describe specific moments within the session flow of a network connection, such as "CLIENT_ACCEPTED" and "HTTP_REQUEST" below. when CLIENT_ACCEPTED { if { [IP::client_addr] eq “192.168.1.1” } { drop } } when HTTP_REQUEST { log local0. “Host: [HTTP::host], Client IP: [IP::client_addr]” } What are the benefits of an event driven language? In addition to being able to accurately execute code at the specific time desired, which is important considering that often times information will be needed that is only available at specific points in the flow, an event driven language is also a large benefit to performance. In traditional programming when you make a call to a script the entire script body is executed. This means that if you have a 100 line script written in say Perl or Ruby (nothing against those languages, merely an example), every time that script is called all 100 lines will be executed, generally speaking. This is not true in iRules. With an iRule that is 100 lines long, but spread across 3 or 4 different events, only the specific code applied to each individual event is executed when that event occurs, rather than the entirety of the script. For instance, if you have a 100 line iRule with 50 lines in a request event and 50 lines in a response event, your BIG-IP is only executing 50 lines of code for every inbound request, rather than having to execute the entire rule. This may not seem like a massive savings, but keep in mind that everything when talking about network side scripting performance becomes more important than in traditional environments, because of the scale generally being discussed. While a traditional script may be executed several hundred times per second in a busy environment, an iRule may be executed several hundred thousand times per second, in a high traffic deployment. Another way of looking at this, perhaps, is that events themselves are the containers for the scripts being executed against the network. The iRule is a way of grouping those events into a logical container to express a function or segment of application or business logic that you wish to apply as a single object against your network traffic. What events are available? Events are broken down into protocols, with usually several events per supported protocol. Events will always follow a profile within BIG-IP, so you can largely correlate which available protocol profiles are available with which protocols have specific events called out within iRules. The list is wide-ranging and I won’t list it here, but it is available on DevCentral here (requires registration) for your perusal. From HTTP to SIP to DNS, most major protocols are represented in the listing and have specific iRules Events, and likely associated commands, designated to them. Keep in mind, however, that even if a particular protocol does not have events specifically set out for it you can accomplish almost anything with base TCP and UDP events and commands. With a strong understanding of iRules and the protocol in question it is entirely possible to parse and manipulate nearly anything passing across the wire with the commands and events already available within the TCP and UDP command sets. It’s also worth noting that particular events can be disabled for the duration of the connection with the event disable command. Be cautious when using this, as it will most certainly affect any other iRules applied to the same virtual. In which order do events fire? This is a question that gets asked time and time again on DevCentral and out in the field, and it is admittedly a bit difficult to answer. The way that events fire is largely based on the network flow through the proxy within BIG-IP. The proxy architecture within the BIG-IP is made up of a series of filters, each designed to perform specific functions, without getting into tedious detail. Each filter builds upon the last, I.E. the HTTP filter uses information drawn out of the session by the TCP filter, etc. Each of these filters has an associated set of iRules events that fire at that point in the session’s life cycle as well, when the connection is being interrogated or affected by the particular filter in question. As the connection is passed up the chain more and more specific filters fire, along with events to match, until finally the session is handed over from the client side of the proxy to the server side, and it traverses its way down the chain on that side. The return trip for responses follows a similar path with different filters, and as such events, in place; herein lies part of the problem with describing the order of events within an iRule. There is no static set of events that happen for every single connection. There may be a few specific events that always fire, such as CLIENT_ACCEPTED once per connection, but in general there is no set event structure that fires. The events that fire are dependent on the configuration of the virtual to which the iRule in question is applied. Because of this dynamic nature it is extremely hard to make a blanket statement about which events will fire in a given iRule, let alone event order. Given the entire config of a virtual server it is possible to determine which events will fire, and in which order, but that requires case by case information and analysis. Below are screenshots of iRule events graphed with visio and dot/graphviz, respectively, followed by links to the pdfs of the event flows from each project. This shows the way events relate given configuration and traffic considerations, and it is a good starting point for understanding event ordering. BIG-IP Event Order (Visio) BIG-IP Event Order (GraphViz) What happens if I have the same event in multiple iRules on a virtual server? Many people will have multiple iRules on a single virtual server, some of which will make use of like events. The question of what happens in such a case is often asked, or a user will want to know “Which CLIENT_ACCEPTED will fire first?” If you have a virtual server with multiple iRules all making use of a particular event, there is no “first” or “last” occurrence of that event, it only happens once. To understand a bit more, first let me explain how iRules are stored and interpreted. iRules are not, for all intents and purposes, a dynamically interpreted language. That is, Tcl interpreter is not spun up every time a request comes into a virtual server with an iRule applied. This would be horribly inefficient. Instead, when an iRule is saved as part of a configuration, it is interpreted by the Tcl engine and pre-compiled down into what is known as “byte code”. This is a compiled state that breaks down most of the logic and commands within a given iRule so that at execution time it can very easily and efficiently be fired by the Tcl engine, in this case part of TMM. During this process the iRule is also effectively broken down and re-organized. The commands that are associated with each event within the iRule are removed from the context of that particular iRule and are instead associated with that event. Remember above where I mentioned the idea of events being tied to a particular filter in the proxy architecture, and that the events fire when those filters are called? This is why that concept is important. The commands you put under your HTTP_REQUEST events are all taken out of whichever iRules they were associated with and instead relegated to live under the event that is responsible for executing those commands. As such, there is no concept of multiple instances HTTP_REQUEST or CLIENT_ACCEPTED or SIP_RESPONSE or any other event occurring with a given virtual server. The session traffic proceeds up the chain, events fire, and commands are executed in that context, be it client or server. Regardless of how many iRules you have that call a given event, that event only ever fires once per connection/request, depending on the event. Even if you can’t have multiple instances of a given event executed from a particular virtual server, you can still control the order in which your iRules execute. This is done via the next concept we’ll cover, priorities. Priorities What are priorities? Priorities are an integer value associated with every iRule that determine the order in which iRules applied to a given virtual server execute, the lower the number, the higher the relative priority. I.E. an iRule with a priority of 1 would fire before an iRule with a priority of 900. If you want to ensure that the variable you’re setting in iRuleA exists when iRuleB executes, you’ll want to set priorities accordingly. How do I set priority? Every iRule has a priority, whether you set one or not. The system will implicitly set a priority value (500 is the default) to all iRules so that it can keep straight the order in which to execute commands at run time. This is done automatically when saving iRules without a specified priority. One nuance to this is that all iRules without an explicit priority ordered in the GUI will be prioritized top to bottom, even though they all share the implicit value. If, however, you want to set a specific priority, it is done so simply via the priority command. At the beginning of your iRule you can state “priority 100” to designate the priority for that iRule and, by association, all of the commands contained within. If you’re going to start setting specific priorities it is recommended to do so for all of your iRules, however, to be sure that the execution order you want is achieved. priority 100 when HTTP_REQUEST { if {[HTTP::host] eq “mydomain.com” } { set host [HTTP::host] } } Why does priority matter? In many cases, it doesn’t. The vast majority of iRules deployments that I’ve seen do not have specific priorities set. It can be useful, however, in cases where you want to ensure that a particular order of execution is achieved. A couple of possible examples may be if you’re passing particular information from one iRule to another, or want an iRule to act on a modified value of some sort. Whatever the reasons, it is likely that if you aren’t already looking for a way to set priority, you don’t need to worry about it. Can I supersede the session flow? First the simple answer: No. Now the explanation: People sometimes ask if they’re able to do things like act on a response before a request, view a load balancing decision as soon as the connection is established, or other things that are unnatural in regards to the flow of a session through the BIG-IP. This is not possible. By their very nature events occur based on the way traffic traverses the proxy, and no amount of priority will change that. You can absolutely ensure that iRuleA’s response event occurs before iRuleB’s response events, but you cannot force iRuleA’s response events to occur before iRuleB’s request events. You can achieve a similar effect with a couple of conditionals and variables, and this is the logic trick that I’d recommend to anyone who needs to mimic this behavior. Keep in mind that this immediately ceases to function effectively when you have multiple iRules on the virtual server, unless all of them are built with this in mind. Use caution, as this is absolutely risky. It is not, however, possible to alter the actual event structure or ordering. when HTTP_REQUEST { if { [info exists response_fired] } { unset response_fired ... } } when HTTP_RESPONSE { set response_fired 1 ... } Picking up what we’re laying down so far? Proceed to the next installment in this series, which will cover variables.6.4KViews1like6CommentsIntermediate iRules: Handling Lists
We've talked about variables in the Getting Started with iRules series, but we're going to cover specifically the list object type of variable. Most of the TCL commands for use in manipulating lists are available in iRules: list - Create a list split - Split a string into a proper Tcl list join - Create a string by joining together list elements concat - Join lists together llength - Count the number of elements in a list lindex - Retrieve an element from a list lrange - Return one or more adjacent elements from a list linsert - Insert elements into a list lreplace - Replace elements in a list with new elements lsort - Sort the elements of a list lsearch - See if a list contains a particular element The remaining documented list handling commands, lrepeat, lreverse, & dict, are not available within iRules. We’ll cover the commands from above that get the most traffic here on DevCentral. split split string ?splitChars? Returns a list created by splitting string at each character that is in the splitChars argument. Each element of the result list will consist of the characters from string that lie between instances of the characters in splitChars. Empty list elements will be generated if string contains adjacent characters in splitChars, or if the first or last character of string is in splitChars. If splitChars is an empty string then each character of string becomes a separate element of the result list. SplitChars defaults to the standard white-space characters. In this example, the split commandis used to separate the hours/minutes/seconds returned from the formatted clockcommand into separate list elements: % set caTime [clock format [clock seconds] -format {%H:%M:%S}] 10:38:30 % set l [split $caTime :] 10 38 30 join join string ?splitChars? The list argument must be a valid Tcl list. This command returns the string formed by joining all of the elements of list together with joinString separating each adjacent pair of elements. The joinString argument defaults to a space character. In this example, the user is building the IP address using the join commandand the “.” as the splitChar. foreach num $IPtmp { lappend IP [expr ($num + 0x100) % 0x100] } set ::attr_value1 [join $IP .] Using a TCL shell, the output follows: % set IPtmp { 0x8c 0xaf 0x55 0x44 } 0x8c 0xaf 0x55 0x44 % foreach num $IPtmp { lappend IP [expr ($num + 0x100) % 0x100] } % puts $IP 140 175 85 68 % set IP [join $IP .] 140.175.85.68 concat concat ?arg arg … ? This command joins each of its arguments together with spaces after trimming leading and trailing white-space from each of them. If all the arguments are lists, this has the same effect as concatenating them into a single list. It permits any number of arguments; if no args are supplied, the result is an empty string. Here’s an excellent example of the concat command, which joinsthe contents of a cookie with the values from LB::server and virtual name: HTTP::cookie insert path / name ltmcookie value [concat [virtual name] [LB::server]] using the TCL shell, need variables in place of the calls to [virtual name] and [LB::server]: % set virtual_name myVip myVip % set lb_server "myPool 10.10.10.10 443" myPool 10.10.10.10 443 % set ltmcookie_value [concat $virtual_name $lb_server] myVip myPool 10.10.10.10 443 lindex lindex list ?index … ? This command accepts a parameter, list, which it treats as a Tcl list. It also accepts zero or more indices into the list. The indices may be presented either consecutively on the command line, or grouped in a Tcl list and presented as a single argument. This example, from the same iRule as the concat example above, shows the extraction of the list elements into usable variables: set vipid [lindex [HTTP::cookie ltmcookie] 0] set poolid [lindex [HTTP::cookie ltmcookie] 1] set serverid [lindex [HTTP::cookie ltmcookie] 2] set portid [lindex [HTTP::cookie ltmcookie] 3] Using the cookie variable we set in the above concat example, we can now extract the list items: % set vipid [lindex $ltmcookie_value 0] myVip % set poolid [lindex $ltmcookie_value 1] myPool % set serverid [lindex $ltmcookie_value 2] 10.10.10.10 % set portid [lindex $ltmcookie_value 3] 443 Better to avoid the variables, but a good illustration none-the-less. Often you’ll see the split and lindex commands used together: set trimID [lindex [split [HTTP::cookie "JSESSIONID"] "!" ] 0] Stepping through that, you can see first the split occur, then the indexing: % set jsessionID_cookie "zytPJpxV0TnpssqZZRLBgsVMLhGS6M2ZNMZ622yCNvpv0gkpTwzn!956498630!-34852364" zytPJpxV0TnpssqZZRLBgsVMLhGS6M2ZNMZ622yCNvpv0gkpTwzn!956498630!-34852364 % set l [split $jsessionID_cookie !] zytPJpxV0TnpssqZZRLBgsVMLhGS6M2ZNMZ622yCNvpv0gkpTwzn 956498630 -34852364 % set jsessID [lindex $l 0] zytPJpxV0TnpssqZZRLBgsVMLhGS6M2ZNMZ622yCNvpv0gkpTwzn There is a shortcut command in iRules for the split and lindex command pairing called getfield. Note that whereas lindex begins at 0, getfield begins at 1. The example below shows a direct comparison: # lindex/split set trimID [lindex [split [HTTP::cookie "JSESSIONID"] "!"] 0] # getfield set trimID [getfield [HTTP::cookie "JSESSIONID"] "!" 1] Note that using iRules-specific commands might help readability, but doing so does require a jump from the Tcl virtual machine back over to TMM to process. In this case it's incredibility negligible, but if you are squeezing out every CPU cycle it's something to be aware of.3.3KViews1like0CommentsIntermediate iRules: catch
One of the often overlooked features of iRules is the ability to use dynamic variables in assignments. This can make for some interesting iRules, but it can also get you into trouble at runtime when your variables are not defined in the current configuration. This tech tip will illustrate how to take input from an HTTP request and use that as the criteria for which pool of servers the connection is sent to, all while maintaining runtime error checking using the TCL catchcommand. The pool command This command is used to assign a connection to a specified pool name (and optionally a specific pool member). pool Specifies the pool to which you want to send the traffic. pool ?member ??? Specifies a pool member to which you want to directly send the traffic. Typically, we see iRules written something like this (using hard-coded pool names). when HTTP_REQUEST { switch -glob [HTTP::uri] { "*.gif" - "*.jpg" - "*.png" { pool images_pool } "*.asp" { pool ms_app_pool } "*.jsp" { pool java_app_pool } } } When this iRule is created, the poolcommands are syntax checked and validated and since the pool name arguments are literals, the save logic will validate whether the given pools exist in the configuration. If they do not exist, a save error will occur and you will have to configure the pools before you save your iRule. In this case, no runtime exception will occur (unless you remove your pools out from under your iRule, that is). But, let's say you want to build a more dynamic solution that can expand over time. For this example, let's say that you want to allow your client to determine which pool of servers it is sent to. This could be the server specifying a pool name in an HTTP cookie, or simply appending it as a GET parameter on the URI. We'll use the later scenario for this example. For this example, we'll define the following GET parameters that can control pool direction. pool=name So an example URI could be: http://somedomain.com/somefile.ext?param1=val1&pool=pool_name¶rm2=val2... We will interrogate the URI's GET parameters in search of the "pool" parameter, extract the pool_name value and use that variable as the argument in the poolcommand. For newer versions of BIG-IP, one could use the URI::querycommand to extract values, but this implementation should work all the way back to BIG-IP v9.0. when HTTP_REQUEST { set namevals [split [HTTP::query] "&"] set pool_name "" for {set i 0} {$i < [llength $namevals]} {incr i} { set params [split [lindex $namevals $i] "="] set name [lindex $params 0] set val [lindex $params 1] switch $name { "pool" { set pool_name $val } } } if { "" ne $pool_name } { pool $pool_name } } What's wrong with this implementation? Nothing if your configuration has the given value in the $pool_name variable. What happens if that value doesn't exist in the configuration? catch The answer is that you will get a runtime error and the given connection will be broken. This is not an ideal solution and the simple use of the catchcommand can avoid runtime connection termination and allow the request to continue on through to a default pool of servers. The syntax for the catchcommand is as follows: catch script ?varName? The catchcommand may be used to prevent errors from aborting command interpretation. It calls the Tcl interpreter recursively to execute script, and always returns without raising an error, regardless of any errors that might occur while executing script. If script raises an error, catchwill return a non-zero integer value corresponding to the exceptional return code returned by evaluation of script. Tcl defines the normal return code from script evaluation to be zero (0), or TCL_OK. Tcl also defines four exceptional return codes: 1 (TCL_ERROR), 2 (TCL_RETURN), 3 (TCL_BREAK), and 4 (TCL_CONTINUE). Errors during evaluation of a script are indicated by a return code of TCL_ERROR. The other exceptional return codes are returned by the return, break, and continue commands and in other special situations as documented. Tcl packages can define new commands that return other integer values as return codes as well, and scripts that make use of the return -code command can also have return codes other than the five defined by Tcl. If the varName argument is given, then the variable it names is set to the result of the script evaluation. When the return code from the script is 1 (TCL_ERROR), the value stored in varName is an error message. When the return code from the script is 0 (TCL_OK), the value stored in resultVarName is the value returned from script. Solution The following iRule is the same as above, except that it makes use of exception handling in the dynamic pool assignment. when HTTP_REQUEST { set namevals [split [HTTP::query] "&"] set pool_name "" for {set i 0} {$i < [llength $namevals]} {incr i} { set params [split [lindex $namevals $i] "="] set name [lindex $params 0] set val [lindex $params 1] switch $name { "pool" { set pool_name $val } } } if { "" ne $pool_name } { if { [catch { pool $pool_name } ] } { log local0. "ERROR: Attempting to assign traffic to non-existant pool $pool_name" pool default_pool } } } Now, the control of which pool the connection is directed to is completely in the hands of the request URI. And in those rare situations where your app logic changes before the network configuration does, the connection will fallback to a default pool of servers, while logging the issue to the system log for later examination. Conclusion The ability to use dynamic variables greatly enhances the flexibility of what you can do with iRules commands. The catchcommand should be used around any iRule command that makes use of dynamic variables to catch any runtime errors that occur. In fact, if you so desire, you and nest catchcommands for a multi-layered exception handling solution.1.2KViews1like0CommentsIntermediate iRules: Evaluating Performance
Customers frequently ask, as poster CodeIT did: "I am wondering what the effect of writing more elaborate iRules will have on the F5’s memory and processor. Is there a way to predict the effect on the F5’s resources for a given rule and traffic load?" In this article, I'll show you how to collect and interpret iRule runtime statistics to determine whether one version of a rule is more efficient than another, or to estimate a theoretical maximum number of connections possible for an iRule running on your LTM. (Props to unRuleY, a1l0s2k9, citizenelah, Joe, acarandang, and stephengun for insightful posts on this topic.) Collecting Statistics To generate & collect runtime statistics, you can insert the command "timing on" into your iRule. When you run traffic through your iRule with timing enabled, LTM will keep track of how many CPU cycles are spent evaluating each iRule event. You can enable rule timing for the entire iRule, or only for specific events. To enable timing for the entire iRule, insert the "timing on" command at the top of the rule before the first "when EVENT_NAME" clause. Here's an example enabling timing for all events in a rule: rule my_fast_rule { timing on when HTTP_REQUEST { # Do some stuff } } To enable iRule timing for only a specific event, insert the "timing on" command between the "when EVENT_NAME" declaration and the open curly brace. Here's an example enabling timing for only a specific event: rule my_slow_rule { when HTTP_REQUEST timing on { # Do some other stuff } } (See the timing command documentation for more details on timing only selected events by toggling timing on & off.) With the timing command in place, each time the rule is evaluated, LTM will collect the timing information for the requested events. To get a decent average for each of the events, you'll want to run at least a couple thousand iterations of the iRule under the anticipated production load. For http traffic I generally do this with apache bench (ab) from the BIG-IP command line, though you can use netcat and other linux tools as well for non-http traffic. Viewing Statistics The statistics for your iRule (as measured in CPU cycles) may be viewed at the command line or console by running tmsh ltm rule rule_name show all The output includes totals for executions, failures & aborts along with minimum, average & maximum cycles consumed for each event since stats were last cleared. RULE rule_name +-> HTTP_REQUEST 729 total 0 fail 0 abort | Cycles (min, avg, max) = (3693, 3959, 53936) If you use the iRules Editor , you can instead view the same stats on the Statistics tab of the Properties dialog. (Double-click on the iRule in the left pane to open the Properties dialog.) Evaluating statistics Average cycles reported is the most useful metric of real-world performance, assuming a large representative load sample was evaluated. The maximum cycles reported is often very large since it includes some one-time and periodic system overhead. (More on that below.) The iRules Runtime Calculator Excel spreadsheet will calculate percentage of CPU load per iteration once you populate it with your clock speed and the statistics gathered with the "timing" command. (Clock speed can be found by running 'cat /proc/cpuinfo' at the command line.) Or if you are not a glutton for manual punishment, you can generate that spreadsheet automatically with iControl REST via the F5 Python SDK and the XlsxWriter module . Caveats Timing is intended to be used only as an optimization/debug tool, and does have a small impact on performance, so don't leave it turned on indefinitely. Timing functionality seems to exhibit a 70 - 100 cycle margin of error. Use average cycles for most analyses. Maximum cycles is not always an accurate indicator of actual iRule performance, as the very first call a newly edited iRule includes the cycles consumed for compile-time optimizations, which will be reflected in an inflated maximum cycles value. The simple solution to this is to wait until the first time the rule is hit, then reset the statistics. To reset statistics at the command line: tmsh ltm rule [rule_name | all] stats reset or "Reset Statistics" in the Statistics tab of the iRules Editor. However, maximum cycles is also somewhat inflated by OS scheduling overhead incurred at least once per tick, so the max value is often overstated even if stats are cleared after compilation. Resources timing command iRules Runtime Calculator Comparing iRule Control Statements IP Comparisons Testing Short walk through on what makes timing tick. Using python to test performance and insert resulting data in iRules headers Note: This article authored by Deb Allen, reprinted and updated here for inclusion in new article series.2.3KViews1like0Comments