Intro to Load Balancing for Developers – The Algorithms
If you’re new to this series, you can find the complete list of articles in the series on my personal page here If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. Until then! Don.19KViews1like9Comments
Layer 4 vs Layer 7 DoS Attack
Not all DoS (Denial of Service) attacks are the same. While the end result is to consume as much - hopefully all - of a server or site's resources such that legitimate users are denied service (hence the name) there is a subtle difference in how these attacks are perpetrated that makes one easier to stop than the other. SYN Flood A Layer 4 DoS attack is often referred to as a SYN flood. It works at the transport protocol (TCP) layer. A TCP connection is established in what is known as a 3-way handshake. The client sends a SYN packet, the server responds with a SYN ACK, and the client responds to that with an ACK. After the "three-way handshake" is complete, the TCP connection is considered established. It is as this point that applications begin sending data using a Layer 7 or application layer protocol, such as HTTP. A SYN flood uses the inherent patience of the TCP stack to overwhelm a server by sending a flood of SYN packets and then ignoring the SYN ACKs returned by the server. This causes the server to use up resources waiting a configured amount of time for the anticipated ACK that should come from a legitimate client. Because web and application servers are limited in the number of concurrent TCP connections they can have open, if an attacker sends enough SYN packets to a server it can easily chew through the allowed number of TCP connections, thus preventing legitimate requests from being answered by the server. SYN floods are fairly easy for proxy-based application delivery and security products to detect. Because they proxy connections for the servers, and are generally hardware-based with a much higher TCP connection limit, the proxy-based solution can handle the high volume of connections without becoming overwhelmed. Because the proxy-based solution is usually terminating the TCP connection (i.e. it is the "endpoint" of the connection) it will not pass the connection to the server until it has completed the 3-way handshake. Thus, a SYN flood is stopped at the proxy and legitimate connections are passed on to the server with alacrity. The attackers are generally stopped from flooding the network through the use of SYN cookies. SYN cookies utilize cryptographic hashing and are therefore computationally expensive, making it desirable to allow a proxy/delivery solution with hardware accelerated cryptographic capabilities handle this type of security measure. Servers can implement SYN cookies, but the additional burden placed on the server alleviates much of the gains achieved by preventing SYN floods and often results in available, but unacceptably slow performing servers and sites. HTTP GET DoS A Layer 7 DoS attack is a different beast and it's more difficult to detect. A Layer 7 DoS attack is often perpetrated through the use of HTTP GET. This means that the 3-way TCP handshake has been completed, thus fooling devices and solutions which are only examining layer 4 and TCP communications. The attacker looks like a legitimate connection, and is therefore passed on to the web or application server. At that point the attacker begins requesting large numbers of files/objects using HTTP GET. They are generally legitimate requests, there are just a lot of them. So many, in fact, that the server quickly becomes focused on responding to those requests and has a hard time responding to new, legitimate requests. When rate-limiting was used to stop this type of attack, the bad guys moved to using a distributed system of bots (zombies) to ensure that the requests (attack) was coming from myriad IP addresses and was therefore not only more difficult to detect, but more difficult to stop. The attacker uses malware and trojans to deposit a bot on servers and clients, and then remotely includes them in his attack by instructing the bots to request a list of objects from a specific site or server. The attacker might not use bots, but instead might gather enough evil friends to launch an attack against a site that has annoyed them for some reason. Layer 7 DoS attacks are more difficult to detect because the TCP connection is valid and so are the requests. The trick is to realize when there are multiple clients requesting large numbers of objects at the same time and to recognize that it is, in fact, an attack. This is tricky because there may very well be legitimate requests mixed in with the attack, which means a "deny all" philosophy will result in the very situation the attackers are trying to force: a denial of service. Defending against Layer 7 DoS attacks usually involves some sort of rate-shaping algorithm that watches clients and ensures that they request no more than a configurable number of objects per time period, usually measured in seconds or minutes. If the client requests more than the configurable number, the client's IP address is blacklisted for a specified time period and subsequent requests are denied until the address has been freed from the blacklist. Because this can still affect legitimate users, layer 7 firewall (application firewall) vendors are working on ways to get smarter about stopping layer 7 DoS attacks without affecting legitimate clients. It is a subtle dance and requires a bit more understanding of the application and its flow, but if implemented correctly it can improve the ability of such devices to detect and prevent layer 7 DoS attacks from reaching web and application servers and taking a site down. The goal of deploying an application firewall or proxy-based application delivery solution is to ensure the fast and secure delivery of an application. By preventing both layer 4 and layer 7 DoS attacks, such solutions allow servers to continue serving up applications without a degradation in performance caused by dealing with layer 4 or layer 7 attacks.18KViews0likes3CommentsX-Forwarded-For Log Filter for Windows Servers
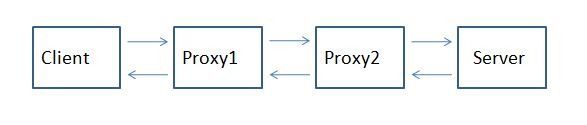
For those that don't know what X-Forwarded-For is, then you might as well close your browser because this post likely will mean nothing to you… A Little Background Now, if you are still reading this, then you likely are having issues with determining the origin client connections to your web servers. When web requests are passed through proxies, load balancers, application delivery controllers, etc, the client no longer has a direct connection with the destination server and all traffic looks like it's coming from the last server in the chain. In the following diagram, Proxy2 is the last hop in the chain before the request hits the destination server. Relying on connection information alone, the server thinks that all connections come from Proxy2, not from the Client that initiated the connection. The only one in the chain here who knows who the client really is (as determined by it's client IP Address, is Proxy1. The problem is that application owners rely on source client information for many reasons ranging from analyzing client demographics to targeting Denial of Service attacks. That's where the X-Forwarded-For header comes in. It is non-RFC standard HTTP request header that is used for identifying the originating IP address of a client connecting to a web server through a proxy. The format of the header is: X-Forwarded-For: client, proxy1, proxy, … X-Forwarded-For header logging is supported in Apache (with mod_proxy) but Microsoft IIS does not have a direct way to support the translation of the X-Forwarded-For value into the client ip (c-ip) header value used in its webserver logging. Back in September, 2005 I wrote an ISAPI filter that can be installed within IIS to perform this transition. This was primarily for F5 customers but I figured that I might as well release it into the wild as others would find value out of it. Recently folks have asked for 64 bit versions (especially with the release of Windows 2008 Server). This gave me the opportunity to brush up on my C skills. In addition to building targets for 64 bit windows, I went ahead and added a few new features that have been asked for. Proxy Chain Support The original implementation did not correctly parse the "client, proxy1, proxy2,…" format and assumed that there was a single IP address following the X-Forwarded-For header. I've added code to tokenize the values and strip out all but the first token in the comma delimited chain for inclusion in the logs. Header Name Override Others have asked to be able to change the header name that the filter looked for from "X-Forwarded-For" to some customized value. In some cases they were using the X-Forwarded-For header for another reason and wanted to use iRules to create a new header that was to be used in the logs. I implemented this by adding a configuration file option for the filter. The filter will look for a file named F5XForwardedFor.ini in the same directory as the filter with the following format: [SETTINGS] HEADER=Alternate-Header-Name The value of "Alternate-Header-Name" can be changed to whatever header you would like to use. Download I've updated the original distribution file so that folks hitting my previous blog post would get the updates. The following zip file includes 32 and 64 bit release versions of the F5XForwardedFor.dll that you can install under IIS6 or IIS7. Installation Follow these steps to install the filter. Download and unzip the F5XForwardedFor.zip distribution. Copy the F5XForwardedFor.dll file from the x86\Release or x64\Release directory (depending on your platform) into a target directory on your system. Let's say C:\ISAPIFilters. Ensure that the containing directory and the F5XForwardedFor.dll file have read permissions by the IIS process. It's easiest to just give full read access to everyone. Open the IIS Admin utility and navigate to the web server you would like to apply it to. For IIS6, Right click on your web server and select Properties. Then select the "ISAPI Filters" tab. From there click the "Add" button and enter "F5XForwardedFor" for the Name and the path to the file "c:\ISAPIFilters\F5XForwardedFor.dll" to the Executable field and click OK enough times to exit the property dialogs. At this point the filter should be working for you. You can go back into the property dialog to determine whether the filter is active or an error occurred. For II7, you'll want to select your website and then double click on the "ISAPI Filters" icon that shows up in the Features View. In the Actions Pane on the right select the "Add" link and enter "F5XForwardedFor" for the name and "C:\ISAPIFilters\F5XForwardedFor.dll" for the Executable. Click OK and you are set to go. I'd love to hear feedback on this and if there are any other feature request, I'm wide open to suggestions. The source code is included in the download distribution so if you make any changes yourself, let me know! Good luck and happy filtering! -Joe13KViews0likes14CommentsThe Disadvantages of DSR (Direct Server Return)
I read a very nice blog post yesterday discussing some of the traditional pros and cons of load-balancing configurations. The author comes to the conclusion that if you can use direct server return, you should. I agree with the author's list of pros and cons; DSR is the least intrusive method of deploying a load-balancer in terms of network configuration. But there are quite a few disadvantages missing from the author's list. Author's List of Disadvantages of DSR The disadvantages of Direct Routing are: Backend server must respond to both its own IP (for health checks) and the virtual IP (for load balanced traffic) Port translation or cookie insertion cannot be implemented. The backend server must not reply to ARP requests for the VIP (otherwise it will steal all the traffic from the load balancer) Prior to Windows Server 2008 some odd routing behavior could occur in In some situations either the application or the operating system cannot be modified to utilse Direct Routing. Some additional disadvantages: Protocol sanitization can't be performed. This means vulnerabilities introduced due to manipulation of lax enforcement of RFCs and protocol specifications can't be addressed. Application acceleration can't be applied. Even the simplest of acceleration techniques, e.g. compression, can't be applied because the traffic is bypassing the load-balancer (a.k.a. application delivery controller). Implementing caching solutions become more complex. With a DSR configuration the routing that makes it so easy to implement requires that caching solutions be deployed elsewhere, such as via WCCP on the router. This requires additional configuration and changes to the routing infrastructure, and introduces another point of failure as well as an additional hop, increasing latency. Error/Exception/SOAP fault handling can't be implemented. In order to address failures in applications such as missing files (404) and SOAP Faults (500) it is necessary for the load-balancer to inspect outbound messages. Using a DSR configuration this ability is lost, which means errors are passed directly back to the user without the ability to retry a request, write an entry in the log, or notify an administrator. Data Leak Prevention can't be accomplished. Without the ability to inspect outbound messages, you can't prevent sensitive data (SSN, credit card numbers) from leaving the building. Connection Optimization functionality is lost. TCP multiplexing can't be accomplished in a DSR configuration because it relies on separating client connections from server connections. This reduces the efficiency of your servers and minimizes the value added to your network by a load balancer. There are more disadvantages than you're likely willing to read, so I'll stop there. Suffice to say that the problem with the suggestion to use DSR whenever possible is that if you're an application-aware network administrator you know that most of the time, DSR isn't the right solution because it restricts the ability of the load-balancer (application delivery controller) to perform additional functions that improve the security, performance, and availability of the applications it is delivering. DSR is well-suited, and always has been, to UDP-based streaming applications such as audio and video delivered via RTSP. However, in the increasingly sensitive environment that is application infrastructure, it is necessary to do more than just "load balancing" to improve the performance and reliability of applications. Additional application delivery techniques are an integral component to a well-performing, efficient application infrastructure. DSR may be easier to implement and, in some cases, may be the right solution. But in most cases, it's going to leave you simply serving applications, instead of delivering them. Just because you can, doesn't mean you should.5.7KViews0likes4CommentsBig-IP and ADFS Part 1 – “Load balancing the ADFS Farm”
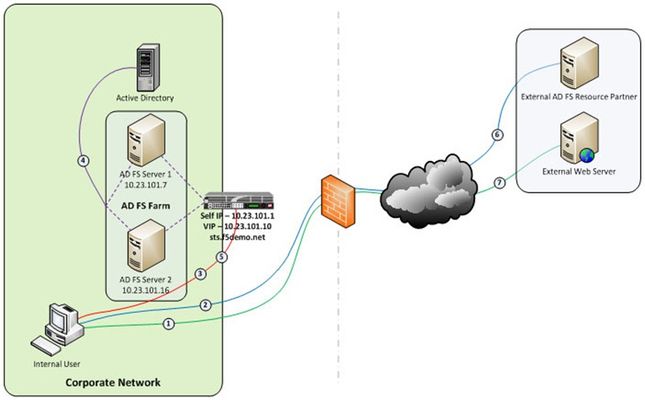
Just like the early settlers who migrated en masse across the country by wagon train along the Oregon Trail, enterprises are migrating up into the cloud. Well okay, maybe not exactly like the early settlers. But, although there may not be a mass migration to the cloud, it is true that more and more enterprises are moving to cloud-based services like Office 365. So how do you provide seamless, or at least relatively seamless, access to resources outside of the enterprise? Well, one answer is federation and if you are a Microsoft shop then the current solution is ADFS, (Active Directory Federation Services). The ADFS server role is a security token service that extends the single sign-on, (SSO) experience for directory-authenticated clients to resources outside of the organization’s boundaries. As cloud-based application access and federation in general becomes more prevalent, the role of ADFS has become equally important. Below, is a typical deployment scenario of the ADFS Server farm and the ADFS Proxy server farm, (recommended for external access to the internally hosted ADFS farm). Warning…. If the ADFS server farm is unavailable then access to federated resources will be limited if not completely inaccessible. To ensure high-availability, performance, and scalability the F5 Big-IP with LTM, (Local Traffic Manager), can be deployed to load balance the ADFS and ADFS Proxy server farms. Yes! When it comes to a load balancing and application delivery, F5’s Big-IP is an excellent choice. Just had to get that out there. So let’s get technical! Part one of this blog series addresses deploying and configuring the Big-IP’s LTM module for load balancing the ADFS Server farm and Proxy server farm. In part two I’m going to show how we can greatly simplify and improve this deployment by utilizing Big-IP’s APM, (Access Policy Manager) so stay tuned. Load Balancing the Internal ADFS Server Farm Assumptions and Product Deployment Documentation - This deployment scenario assumes an ADFS server farm has been installed and configured per the deployment guide including appropriate trust relationships with relevant claims providers and relying parties. In addition, the reader is assumed to have general administrative knowledge of the BIG-IP LTM module. If you want more information or guidance please check out F5’s support site, ASKF5. The following diagram shows a typical, (albeit simplified) process flow of the Big-IP load balanced ADFS farm. Client attempts to access the ADFS-enabled external resource; Client is redirected to the resource’s applicable federation service; Client is redirected to its organization’s internal federation service, (assuming the resource’s federation service is configured as trusted partner); The ADFS server authenticates the client to active directory; The ADFS server provides the client with an authorization cookie containing the signed security token and set of claims for the resource partner; The client connects to the resource partner federation service where the token and claims are verified. If appropriate, the resource partner provides the client with a new security token; and The client presents the new authorization cookie with included security token to the resource for access. VIRTUAL SERVER AND MEMBER POOL – A virtual server, (aka VIP) is configured to listen on port 443, (https). In the event that the Big-IP will be used for SSL bridging, (decryption and re-encryption), the public facing SSL certificate and associated private key must be installed on the BIG-IP and associated client SSL profile created. However, as will be discussed later SSL bridging is not the preferred method for this type of deployment. Rather, SSL tunneling, (pass-thru) will be utilized. ADFS requires Transport Layer Security and Secure Sockets Layer (TLS/SSL). Therefore pool members are configured to listen on port 443, (https). LOAD BALANCING METHOD – The ‘Least Connections (member)’ method is utilized. POOL MONITOR – To ensure the AD FS service is responding as well as the web site itself, a customized monitor can be used. The monitor ensures the AD FS federation service is responding. Additionally, the monitor utilizes increased interval and timeout settings. The custom https monitor requires domain credentials to validate the service status. A standard https monitor can be utilized as an alternative. PERSISTENCE – In this AD FS scenario, clients establish a single TCP connection with the AD FS server to request and receive a security token. Therefore, specifying a persistence profile is not necessary. SSL TUNNELING, (preferred method) – When SSL tunneling is utilized, encrypted traffic flows from the client directly to the endpoint farm member. Additionally, SSL profiles are not used nor are SSL certificates required to be installed on the Big-IP. In this instance Big-IP profiles requiring packet analysis and/or modification, (ex. compression, web acceleration) will not be relevant. To further boost the performance, a Fast L4 virtual server will be used. Load Balancing the ADFS Proxy Server Farm Assumptions and Product Deployment Documentation - This deployment scenario assumes an ADFS Proxy server farm has been installed and configured per the deployment guide including appropriate trust relationships with relevant claims providers and relying parties. In addition, the reader is assumed to have general administrative knowledge of the BIG-IP LTM module. If you want more information or guidance please check out F5’s support site, ASKF5. In the previous section we configure load balancing for an internal AD FS Server farm. That scenario works well for providing federated SSO access to internal users. However, it does not address the need of the external end-user who is trying to access federated resources. This is where the AD FS proxy server comes into play. The AD FS proxy server provides external end-user SSO access to both internal federation-enabled resources as well as partner resources like Microsoft Office 365. Client attempts to access the AD FS-enabled internal or external resource; Client is redirected to the resource’s applicable federation service; Client is redirected to its organization’s internal federation service, (assuming the resource’s federation service is configured as trusted partner); The AD FS proxy server presents the client with a customizable sign-on page; The AD FS proxy presents the end-user credentials to the AD FS server for authentication; The AD FS server authenticates the client to active directory; The AD FS server provides the client, (via the AD FS proxy server) with an authorization cookie containing the signed security token and set of claims for the resource partner; The client connects to the resource partner federation service where the token and claims are verified. If appropriate, the resource partner provides the client with a new security token; and The client presents the new authorization cookie with included security token to the resource for access. VIRTUAL SERVER AND MEMBER POOL – A virtual server is configured to listen on port 443, (https). In the event that the Big-IP will be used for SSL bridging, (decryption and re-encryption), the public facing SSL certificate and associated private key must be installed on the BIG-IP and associated client SSL profile created. ADFS requires Transport Layer Security and Secure Sockets Layer (TLS/SSL). Therefore pool members are configured to listen on port 443, (https). LOAD BALANCING METHOD – The ‘Least Connections (member)’ method is utilized. POOL MONITOR – To ensure the web servers are responding, a customized ‘HTTPS’ monitor is associated with the AD FS proxy pool. The monitor utilizes increased interval and timeout settings. "To SSL Tunnel or Not to SSL Tunnel” When SSL tunneling is utilized, encrypted traffic flows from the client directly to the endpoint farm member. Additionally, SSL profiles are not used nor are SSL certificates required to be installed on the Big-IP. However, some advanced optimizations including HTTP compression and web acceleration are not possible when tunneling. Depending upon variables such as client connectivity and customization of ADFS sign-on pages, an ADFS proxy deployment may benefit from these HTTP optimization features. The following two options, (SSL Tunneling and SSL Bridging) are provided. SSL TUNNELING - In this instance Big-IP profiles requiring packet analysis and/or modification, (ex. compression, web acceleration) will not be relevant. To further boost the performance, a Fast L4 virtual server will be used. Below is an example of the Fast L4 Big-IP Virtual server configuration in SSL tunneling mode. SSL BRIDGING – When SSL bridging is utilized, traffic is decrypted and then re-encrypted at the Big-IP device. This allows for additional features to be applied to the traffic on both client-facing and pool member-facing sides of the connection. Below is an example of the standard Big-IP Virtual server configuration in SSL bridging mode. Standard Virtual Server Profiles - The following list of profiles is associated with the AD FS proxy virtual server. Well that’s it for Part 1. Along with the F5 business development team for the Microsoft global partnership I want to give a big thanks to the guys at Ensynch, an Insight Company - Kevin James, David Lundell, and Lutz Mueller Hipper for reviewing and providing feedback. Stay tuned for Big-IP and ADFS Part 2 – “APM – An Alternative to the ADFS Proxy”. Additional Links: Big-IP and ADFS Part 2 – “APM–An Alternative to the ADFS Proxy” Big-IP and ADFS Part 3 - “ADFS, APM, and the Office 365 Thick Clients”4.9KViews0likes3CommentsPersistent and Persistence, What's the Difference?
The English language is one of the most expressive, and confusing, in existence. Words can have different meaning based not only on context, but on placement within a given sentence. Add in the twists that come from technical jargon and suddenly you've got words meaning completely different things. This is evident in the use of persistent and persistence. While the conceptual basis of persistence and persistent are essentially the same, in reality they refer to two different technical concepts. Both persistent and persistence relate to the handling of connections. The former is often used as a general description of the behavior of HTTP and, necessarily, TCP connections, though it is also used in the context of database connections. The latter is most often related to TCP/HTTP connection handling but almost exclusively in the context of load-balancing. Persistent Persistent connections are connections that are kept open and reused. The most commonly implemented form of persistent connections are HTTP, with database connections a close second. Persistent HTTP connections were implemented as part of the HTTP 1.1 specification as a method of improving the efficiency Related Links HTTP 1.1 RFC Persistent Connection Behavior of Popular Browsers Persistent Database Connections Apache Keep-Alive Support Cookies, Sessions, and Persistence of HTTP in general. Before HTTP 1.1 a browser would generally open one connection per object on a page in order to retrieve all the appropriate resources. As the number of objects in a page grew, this became increasingly inefficient and significantly reduced the capacity of web servers while causing browsers to appear slow to retrieve data. HTTP 1.1 and the Keep-Alive header in HTTP 1.0 were aimed at improving the performance of HTTP by reusing TCP connections to retrieve objects. They made the connections persistent such that they could be reused to send multiple HTTP requests using the same TCP connection. Similarly, this notion was implemented by proxy-based load-balancers as a way to improve performance of web applications and increase capacity on web servers. Persistent connections between a load-balancer and web servers is usually referred to as TCP multiplexing. Just like browsers, the load-balancer opens a few TCP connections to the servers and then reuses them to send multiple HTTP requests. Persistent connections, both in browsers and load-balancers, have several advantages: Less network traffic due to less TCP setup/teardown. It requires no less than 7 exchanges of data to set up and tear down a TCP connection, thus each connection that can be reused reduces the number of exchanges required resulting in less traffic. Improved performance. Because subsequent requests do not need to setup and tear down a TCP connection, requests arrive faster and responses are returned quicker. TCP has built-in mechanisms, for example window sizing, to address network congestion. Persistent connections give TCP the time to adjust itself appropriately to current network conditions, thus improving overall performance. Non-persistent connections are not able to adjust because they are open and almost immediately closed. Less server overhead. Servers are able to increase the number of concurrent users served because each user requires fewer connections through which to complete requests. Persistence Persistence, on the other hand, is related to the ability of a load-balancer or other traffic management solution to maintain a virtual connection between a client and a specific server. Persistence is often referred to in the application delivery networking world as "stickiness" while in the web and application server demesne it is called "server affinity". Persistence ensures that once a client has made a connection to a specific server that subsequent requests are sent to the same server. This is very important to maintain state and session-specific information in some application architectures and for handling of SSL-enabled applications. Examples of Persistence Hash Load Balancing and Persistence LTM Source Address Persistence Enabling Session Persistence 20 Lines or Less #7: JSessionID Persistence When the first request is seen by the load-balancer it chooses a server. On subsequent requests the load-balancer will automatically choose the same server to ensure continuity of the application or, in the case of SSL, to avoid the compute intensive process of renegotiation. This persistence is often implemented using cookies but can be based on other identifying attributes such as IP address. Load-balancers that have evolved into application delivery controllers are capable of implementing persistence based on any piece of data in the application message (payload), headers, or at in the transport protocol (TCP) and network protocol (IP) layers. Some advantages of persistence are: Avoid renegotiation of SSL. By ensuring that SSL enabled connections are directed to the same server throughout a session, it is possible to avoid renegotiating the keys associated with the session, which is compute and resource intensive. This improves performance and reduces overhead on servers. No need to rewrite applications. Applications developed without load-balancing in mind may break when deployed in a load-balanced architecture because they depend on session data that is stored only on the original server on which the session was initiated. Load-balancers capable of session persistence ensure that those applications do not break by always directing requests to the same server, preserving the session data without requiring that applications be rewritten. Summize So persistent connections are connections that are kept open so they can be reused to send multiple requests, while persistence is the process of ensuring that connections and subsequent requests are sent to the same server through a load-balancer or other proxy device. Both are important facets of communication between clients, servers, and mediators like load-balancers, and increase the overall performance and efficiency of the infrastructure as well as improving the end-user experience.4.7KViews0likes2CommentsThe Top 10, Top Predictions for 2012
Around this time of year, almost everyone and their brother put out their annual predictions for the coming year. So instead of coming up with my own, I figured I’d simply regurgitate what many others are expecting to happen. Security Predictions 2012 & 2013 - The Emerging Security Threat – SANS talks Custom Malware, IPv6, ARM hacking and Social Media. Top 7 Cybersecurity Predictions for 2012 - From Stuxnet to Sony, a number of cyberattacks emerged in 2011 that experts have predicted for quite some time. Webroot’s top seven forecasts for the year ahead. Zero-day targets and smartphones are on this list. Top 8 Security Predictions for 2012 – Fortinet’s Security Predictions for 2012. Sponsored attacks and SCADA Under the Scope. Security Predictions for 2012 - With all of the crazy 2011 security breaches, exploits and notorious hacks, what can we expect for 2012? Websense looks at blended attacks, social media identity and SSL. Top 5 Security Predictions For 2012 – The escalating change in the threat landscape is something that drives the need for comprehensive security ever-forward. Firewalls and regulations in this one. Gartner Predicts 2012 – Special report addressing the continuing trend toward the reduction of control IT has over the forces that affect it. Cloud, mobile, data management and context-aware computing. 2012 Cyber Security Predictions – Predicts cybercriminals will use cyber-antics during the U.S. presidential election and will turn cell phones into ATMs. Top Nine Cyber Security Trends for 2012 – Imperva’s predictions for the top cyber security trends for 2012. DDoS, HTML 5 and social media. Internet Predictions for 2012 – QR codes and Flash TOP 15 Internet Marketing Predictions for 2012 – Mobile SEO, Social Media ROI and location based marketing. Certainly not an exhaustive list of all the various 2012 predictions including the doomsday and non-doomsday claims but a good swath of what the experts believe is coming. Wonder if anyone predicted that Targeted attacks increased four-fold in 2011. ps Technorati Tags: F5, cyber security, predictions, 2012, Pete Silva, security, mobile, vulnerabilities, crime, social media, hacks, the tube, internet, identity theft4.7KViews0likes1Comment
20 Lines or Less #1
Yesterday I got an idea for what I think will be a cool new series that I wanted to bring to the community via my blog. I call it "20 lines or less". My thought is to pose a simple question: "What can you do via an iRule in 20 lines or less?". Each week I'll find some cool examples of iRules doing fun things in less than 21 lines of code, not counting white spaces or comments, round them up, and post them here. Not only will this give the community lots of cool examples of what iRules can do with relative ease, but I'm hoping it will continue to show just how flexible and light-weight this technology is - not to mention just plain cool. I invite you to follow along, learn what you can and please, if you have suggestions, contributions, or feedback of any kind, don't hesitate to comment, email, IM, whatever. You know how to get a hold of me...please do. ;) I'd love to have a member contributed version of this once a month or quarter or ... whatever if you guys start feeding me your cool, short iRules. Ok, so without further adieu, here we go. The inaugural edition of 20 Lines or Less. For this first edition I wanted to highlight some of the things that have already been contributed by the awesome community here at DevCentral. So I pulled up the Code Share and started reading. I was quite happy to see that I couldn't even get halfway through the list of awesome iRule contributions before I found 5 entries that were neat, and under 20 lines (These are actually almost all under 10 lines of code - wow!) Kudos to the contributors. I'll grab another bunch next week to keep highlighting what we've got already! Cipher Strength Pool Selection Ever want to check the type of encryption your users are using before allowing them into your most secure content? Here's your solution. when HTTP_REQUEST { log local0. "[IP::remote_addr]: SSL cipher strength is [SSL::cipher bits]" if { [SSL::cipher bits] < 128 }{ pool weak_encryption_pool } else { pool strong_encryption_pool } } Clone Pool Based On URI Need to clone some of your traffic to a second pool, based on the incoming URI? Here you go... when HTTP_REQUEST { if { [HTTP::uri] starts_with "/clone_me" } { pool real_pool clone pool clone_pool } else { pool real_pool } } Cache No POST Have you been looking for a way to avoid sending those POST responses to your RAMCache module? You're welcome. when HTTP_REQUEST { if { [HTTP::method] equals "POST" } { CACHE::disable } else { CACHE::enable } } Access Control Based on IP Here's a great example of blocking unwelcome IP addresses from accessing your network and only allowing those Client-IPs that you have deemed trusted. when CLIENT_ACCEPTED { if { [matchclass [IP::client_addr] equals $::trustedAddresses] }{ #Uncomment the line below to turn on logging. #log local0. "Valid client IP: [IP::client_addr] - forwarding traffic" forward } else { #Uncomment the line below to turn on logging. #log local0. "Invalid client IP: [IP::client_addr] - discarding" discard } } Content Type Tracking If you're looking to keep track of the different types of content you're serving, this iRule can help in a big way. # First, create statistics profile named "ContentType" with following entries: # HTML # Images # Scripts # Documents # Stylesheets # Other # Now associate this Statistics Profile to the virtual server. Then apply the following iRule. # To view the results, go to Statistics -> Profiles - Statistics when HTTP_RESPONSE { switch -glob [HTTP::header "Content-type"] { image/* { STATS::incr "ContentType" "Images" } text/html { STATS::incr "ContentType" "HTML" } text/css { STATS::incr "ContentType" "Stylesheets" } *javascript { STATS::incr "ContentType" "Scripts" } text/vbscript { STATS::incr "ContentType" "Scripts" } application/pdf { STATS::incr "ContentType" "Documents" } application/msword { STATS::incr "ContentType" "Documents" } application/*powerpoint { STATS::incr "ContentType" "Documents" } application/*excel { STATS::incr "ContentType" "Documents" } default { STATS::incr "ContentType" "Other" } } } There you have it, the first edition of "20 Lines or Less"! I hope you enjoyed it...I sure did. If you've got feedback or examples to be featured in future editions, let me know. #Colin4.5KViews1like1CommentGot a SSN I can Borrow?
Apparently, I can use my own name and your Social Security Number to get a job or buy a car and it is not an identity theft crime. Really. This is according to a recent Colorado Supreme Court ruling. They ruled that, ‘that using someone else’s Social Security number is not identity theft as long as you use your own name with it.’ Seriously. The case in question involved a man who used his real name but someone else’s Social Security number to obtain a car loan. The court said that since he used his real name, along with other identifiable pieces of information, he wasn’t trying to impersonate someone else. The SSN info was just the ‘lender’s’ requirement and not a ‘legal’ requirement. The defendant said that he fully intended to pay the loan back and wasn’t trying to avoid the bills. There was another case where a man used a fake SSN to get a job at a steel plant in Illinois. He presented a Social Security card with his name but a fake SSN. Since he didn’t know that the number was fake and belonged to another person, the US Supreme Court ruled that he also didn’t break any federal ID theft laws since he did not ‘knowingly’ use another person’s number. He just ‘borrowed’ it. He could have just written 9 random numbers that may or may not have been tied to someone’s identity or he could have bought it from a broker, not knowing it was either fake or stolen. These decisions contradicted previous rulings in Missouri, California, the Midwest, the Southeast and many other regions. It also left folks scratching their heads wondering just what were the courts thinking. Their logic is that, ‘(The suspect) claimed that the government could not prove that he knew that the numbers on the counterfeit documents were numbers assigned to other people….The question is whether the statute requires the government to show that the defendant knew that the ‘means of identification’ he or she unlawfully transferred, possessed, or used, in fact, belonged to ‘another person.’ We conclude that it does.’ I understand that there is a fine legal line between malicious intent and an uninformed accident but if you make up a number or obtain it by improper means, it’s still fake, false and fraudulent. I also understand that there are criminal organizations that prey on immigrants who might not fully understand the ramifications and are told that it is legitimate. We’ve all, at some point, been lured, duped or convinced that something we were obtaining was the real thing. We’re told with great conviction that it is authentic and because we want to believe, we do. When the truth is exposed, the ‘I didn’t know’ defense is obviously the most common and very well might be the honest answer. Maybe because I focus on Information Security and a bit skeptical myself, I also gotta believe that there’s that little nudge, intuition or feeling in your belly telling you that something isn’t right. I know because I’ve ignored that gut-check and got burned. Just because something is ‘not-illegal’ does not make it the right thing to do. I’m not claiming to be a Mr. Goody-Two-Shoes and have certainly made my fair share of mistakes along with doing things I know to be wrong, legal or not. I also know that always acting in the ‘proper’ way or doing the ‘right’ thing is difficult sometimes. That’s what makes us human. We might seek the easiest, least complicated and sometimes slightly unethical way of accomplishing something. Sometimes we have to break the law to ensure the safety of others – like speeding to the Emergency Room if your wife is giving birth or a person is bleeding to death – but those are extenuating circumstances and doesn’t necessarily cause harm to others; unless, of course, you run somebody over on the way to the hospital. There are victims with this SSN borrowing since the real person may not ever know that their information was used since it won’t show up on a credit report. The trouble starts when a loan or tax payment is missed and by then, it’s too late. The courts have had difficulty over the years trying to interpret certain laws as technology whizzes by but, at least in the States, our Social Security Number is one of our unique, primary identifiers and should be protected. Incidentally, BIG-IP ASM does have a cool feature called Data Guard that can mask sensitive data from being leaked from the web application. Data Guard helps protect against information leakage like the leakage of credit card or Social Security numbers. Instead of sending the actual data to the client, ASM can respond by replacing the sensitive data with asterisks, or block the response and sending out an alert. You can also decide what ASM should consider as sensitive: credit card numbers, Social Security numbers, or responses that contain a specific pattern. ps twitter: @psilvas4.4KViews0likes1CommentHTTP Pipelining: A security risk without real performance benefits
Everyone wants web sites and applications to load faster, and there’s no shortage of folks out there looking for ways to do just that. But all that glitters is not gold, and not all acceleration techniques actually do all that much to accelerate the delivery of web sites and applications. Worse, some actual incur risk in the form of leaving servers open to exploitation. A BRIEF HISTORY Back in the day when HTTP was still evolving, someone came up with the concept of persistent connections. See, in ancient times – when administrators still wore togas in the data center – HTTP 1.0 required one TCP connection for every object on a page. That was okay, until pages started comprising ten, twenty, and more objects. So someone added an HTTP header, Keep-Alive, which basically told the server not to close the TCP connection until (a) the browser told it to or (b) it didn’t hear from the browser for X number of seconds (a time out). This eventually became the default behavior when HTTP 1.1 was written and became a standard. I told you it was a brief history. This capability is known as a persistent connection, because the connection persists across multiple requests. This is not the same as pipelining, though the two are closely related. Pipelining takes the concept of persistent connections and then ignores the traditional request – reply relationship inherent in HTTP and throws it out the window. The general line of thought goes like this: “Whoa. What if we just shoved all the requests from a page at the server and then waited for them all to come back rather than doing it one at a time? We could make things even faster!” Tada! HTTP pipelining. In technical terms, HTTP pipelining is initiated by the browser by opening a connection to the server and then sending multiple requests to the server without waiting for a response. Once the requests are all sent then the browser starts listening for responses. The reason this is considered an acceleration technique is that by shoving all the requests at the server at once you essentially save the RTT (Round Trip Time) on the connection waiting for a response after each request is sent. WHY IT JUST DOESN’T MATTER ANYMORE (AND MAYBE NEVER DID) Unfortunately, pipelining was conceived of and implemented before broadband connections were widely utilized as a method of accessing the Internet. Back then, the RTT was significant enough to have a negative impact on application and web site performance and the overall user-experience was improved by the use of pipelining. Today, however, most folks have a comfortable speed at which they access the Internet and the RTT impact on most web application’s performance, despite the increasing number of objects per page, is relatively low. There is no arguing, however, that some reduction in time to load is better than none. Too, anyone who’s had to access the Internet via high latency links can tell you anything that makes that experience faster has got to be a Good Thing. So what’s the problem? The problem is that pipelining isn’t actually treated any differently on the server than regular old persistent connections. In fact, the HTTP 1.1 specification requires that a “server MUST send its responses to those requests in the same order that the requests were received.” In other words, the requests are return in serial, despite the fact that some web servers may actually process those requests in parallel. Because the server MUST return responses to requests in order that the server has to do some extra processing to ensure compliance with this part of the HTTP 1.1 specification. It has to queue up the responses and make certain responses are returned properly, which essentially negates the performance gained by reducing the number of round trips using pipelining. Depending on the order in which requests are sent, if a request requiring particularly lengthy processing – say a database query – were sent relatively early in the pipeline, this could actually cause a degradation in performance because all the other responses have to wait for the lengthy one to finish before the others can be sent back. Application intermediaries such as proxies, application delivery controllers, and general load-balancers can and do support pipelining, but they, too, will adhere to the protocol specification and return responses in the proper order according to how the requests were received. This limitation on the server side actually inhibits a potentially significant boost in performance because we know that processing dynamic requests takes longer than processing a request for static content. If this limitation were removed it is possible that the server would become more efficient and the user would experience non-trivial improvements in performance. Or, if intermediaries were smart enough to rearrange requests such that they their execution were optimized (I seem to recall I was required to design and implement a solution to a similar example in graduate school) then we’d maintain the performance benefits gained by pipelining. But that would require an understanding of the application that goes far beyond what even today’s most intelligent application delivery controllers are capable of providing. THE SILVER LINING At this point it may be fairly disappointing to learn that HTTP pipelining today does not result in as significant a performance gain as it might at first seem to offer (except over high latency links like satellite or dial-up, which are rapidly dwindling in usage). But that may very well be a good thing. As miscreants have become smarter and more intelligent about exploiting protocols and not just application code, they’ve learned to take advantage of the protocol to “trick” servers into believing their requests are legitimate, even though the desired result is usually malicious. In the case of pipelining, it would be a simple thing to exploit the capability to enact a layer 7 DoS attack on the server in question. Because pipelining assumes that requests will be sent one after the other and that the client is not waiting for the response until the end, it would have a difficult time distinguishing between someone attempting to consume resources and a legitimate request. Consider that the server has no understanding of a “page”. It understands individual requests. It has no way of knowing that a “page” consists of only 50 objects, and therefore a client pipelining requests for the maximum allowed – by default 100 for Apache – may not be seen as out of the ordinary. Several clients opening connections and pipelining hundreds or thousands of requests every second without caring if they receive any of the responses could quickly consume the server’s resources or available bandwidth and result in a denial of service to legitimate users. So perhaps the fact that pipelining is not really all that useful to most folks is a good thing, as server administrators can disable the feature without too much concern and thereby mitigate the risk of the feature being leveraged as an attack method against them. Pipelining as it is specified and implemented today is more of a security risk than it is a performance enhancement. There are, however, tweaks to the specification that could be made in the future that might make it more useful. Those tweaks do not address the potential security risk, however, so perhaps given that there are so many other optimizations and acceleration techniques that can be used to improve performance that incur no measurable security risk that we simply let sleeping dogs lie. IMAGES COURTESTY WIKIPEDIA COMMONS4.3KViews0likes5Comments