The DevCentral Chronicles Volume 1, Issue 2
If you missed our initial issue of the DC Chronicles, check it out here. The Chronicles are intended to keep you updated on DevCentral happenings and highlight some of the cool articles you may have missed over the last month. Welcome. First up, 2018 will be the year that we publicly open up speaking proposals for our Agility conference this August. Historically, the presenters have been F5 employees or partners but this year, we’d love if you wanted to share your BIG-IP expertise, knowledge and mad-skillz to the greater F5 community. Review the info here and submit your proposal by Friday, Feb 9. Next up is our exciting new (and FREE!) Super-NetOps training program. The Super-NetOps curriculum teaches BIG-IP administrators how to standardize services and provide them through automation tool chains. For Network Operations Engineers you can learn new skills, improve collaboration and advance your career. For Network Managers and Architects, you can support digital transformation and improve operational practices. As Jason Rahm notes with his Lightboard Lessons: Why Super-NetOps, Super-NetOps is not a technology but an evolutionary journey. Already featuring two complete classes on integrating NetOps expertise into the benefits of a DevOps world, this training program is poised to help the NetOps professional take a well-deserved seat at the continuous deployment table. I’ve taken the training and it is amazing. Speaking of Lightboard Lessons, John Wagnon is going through the OWASP TOP 10 in his latest series and is already on number 5 of the list, Lightboard Lessons: OWASP Top 10 - Broken Access Control. The OWASP Top 10 is a list of the most common security risks on the Internet today and John has been lighting up each in some cool videos. If you want to learn about the OWASP TOP 10, start here and follow along. Interested in BIG-IP security? Then check out Chase Abbot’s Security Hardening F5's BIG-IP with SELinux. When a major release hits the street, documentation and digital press tends to focus on new or improved user features, seldom do underlying platform changes make the spotlight. Each BIG-IP release have plenty new customer-centric features but one unsung massive update is SELinux’s extensive enforcing mode policy across the architecture. Chase says that, BIG-IP and SELinux are no strangers, having coexisted since 2009, but comparing our original efforts to our current SELinux implementation is akin to having your kid's youth soccer team shoot penalties against David Seaman. Good one. Also filed under security for this edition is the Meltdown and Spectre Web Application Risk Management article by Nir Zigler. Nir talks about a simple setting that can reduce the attack surface with the “SameSite” Cookie Attribute. If you’re worried about those vulnerabilities, this is your article. This week, I’ll be at the F5 AFCEA West Tech Day on Wednesday Feb. 7 as part of the AFCEA West 2018 Conference in San Diego. A full day of technical sessions covering the challenges of DoD cloud adoption with a fun Capture the Flag challenge. Our friends at Microsoft Azure will also talk about solutions to address the complex requirements of a secure cloud computing architecture. There is a great article over on MSDN explaining how to Secure IaaS workloads for Department of Defense with Microsoft and F5. #whereisdevcentral Lastly, don’t forget to check out our Featured Member for February, Lee Sutcliffe, Lori’s take on #SOAD The State of Application Delivery 2018: Automation is Everywhere and the new F5 Editor Eclipse Plugin v2 which allows you to use the Eclipse IDE to manage iRules, iRules LX, iControl LX, and iApps LX development. You can stay engaged with @DevCentral by following us on Twitter, joining our LinkedIn Group or subscribing to our YouTube Channel. Look forward to hearing about your BIG-IP adventures. ps282Views0likes0Comments
Containers on the Rise
Insights from our 2017 State of Application Delivery survey. You can tell a lot about organizations use and adoption of technologies by how and where they want to deploy their app services. You may recall that app services is a big umbrella under which a variety of technologies actually lives. Load balancing (scale), acceleration (performance), and web app firewall (security) are all “app services”. That’s because they live, topologically, between a user (client) and an app (server). Requests and responses must flow through an app service. What that app service does is variable. It may modify it, strip things out or add things in. It may do nothing at all but keep an eye on it. But it does something that’s considered important to the success and security of that app, or else it wouldn’t be deployed. So when we ask respondents to our State of Application Delivery surveys where and in what form factor they prefer to deploy those app services, it tells us something about where they’re deploying applications and with what kind of architecture they may be working. For example, this year (2017), we added “Containers” to the list of form factors for which respondents could select a preference. They could choose hardware, software (virtual appliances), containers, or the always popular “D. All of the above” option. For containers, we were pleasantly surprised to discover an existing preference that’s striking considering the age and maturity of the technology. In general, containers were preferred by 5% of respondents. When we filter that through the lens of “cloud-first” organizations, that jumps to 8%. Remember, that’s for app services, not apps. Which kind of implies that apps are already deployed in containers (or are about to be) and respondents want to deploy the appropriate app services in containers along with them. More surprising, perhaps, was that the largest role to express that preference was respondents in infrastructure and network roles. Twenty-nine percent (29%) of those who want containers self-identify as “infrastructure” or “network” professionals. As noted in an earlier blog about containers and usage habits, containers appears poised to explode on-premises, at least, given their broad applicability across application types and architectures. Rather than being relegated to supporting “emerging” application architectures like microservices, containers appear to be flourishing as a mechanism to gain portability and scalability of legacy (often called ‘monolithic’) applications as well. This, in itself, should not be surprising given the “legacy” use-case promoted by virtualization. One of more appealing aspects of virtualization (a category into which containers can be loosely included) is its ability to support aging apps within more modern network and infrastructure architectures. Containers are able to do this, as well, and are rapidly gaining the automation and orchestration supportive structure necessary to enable the same capabilities it took virtualization years to realize. While there’s certainly something to the argument that containers are better at enabling the real-time migration to and from off-premise cloud environments we’ve always been promised, it is more likely that the innate capabilities of the orchestration and automation frameworks surrounding containers and enabling efficient, on-demand scale are behind containers rapid rise across all IT concerns. Scale, today, is of major importance to not only IT but business, too. With digital transformation efforts – internal and external facing – driving new applications and services into production, it is inevitable that scale and security will rise to the fore of requirements for business success. Containers, for all their rough edges (and make no mistake, these fledgling systems certainly have them just as any tech in its infancy), are an appealing alternative to existing options. With a native affinity for API-driven integration with the various other systems and services in the data center necessary to scale applications, containers are indicative of a new mindset within the data center that’s driven by a focus on scale from the get-go, rather than as a bolt-on after-thought “if we need it.” It’s not just the ability to scale quickly and automatically; it’s the built-in assumption that you will and the support innate to the orchestration and scheduling systems that’s likely to propel containers higher and higher in the “preference for” category across all IT roles. Containers are rising. They’re not in ascendancy yet, but I don’t think I’d be crazy (or alone) to predict that it won’t be long before they will be.400Views0likes2CommentsThe State of Application Delivery - Webinar
Thursday, January 28, 2016 at 10:00 am Pacific Time, I will have the pleasure of joining Principal Technical EvangelistLori MacVittie and Business Intelligence DirectorCindy Borovickin a live webinar to review the results and key findings of our recent State of Application Deliveryreport. This webinar will provide insights on how emerging trends and technologies will impact application services in 2016. We’ll discuss thekey application services that organizations use today,cloud strategies that organizations prefer, and how organizations are addressing top security challenges. We’ll also talk about why SDN adoption remains low while the use of DevOps tools has become widespread. Updated Feb 1, 2016: see the video below for a recording of the webinar182Views0likes0CommentsState of Application Delivery 2015: If SDN is the answer what was the question?
SDN is a still simmering trend. It's not boiling over like cloud did in its early years but rather it's slowly, steadily continuing to move forward as more organizations evaluate, pilot and implement pockets of SDN within their organization. But it's not all rainbows and unicorns. A mere 8% of organizations in our State of Application Delivery 2015 reported having SDN deployed in production. Another 8% were in their initial implementation, but a whopping 43% had no plans to deploy at all. That's not all that different from an Information Week 2013 survey on SDN in which 33% of respondents indicated no plans to test SDN technologies. In fact it appears that SDN is actually losing ground. That may be because SDN has been, like every other emerging technology trend, hyped and washed and mutated until no one is really sure what it means. Is it about applications? Is about the network? Is it going to reduce my capital expenses or my operating expenses - or both? Just what is the question that SDN is supposed to be answering?? An Avaya-sponsored survey recently dug into the question and asked just what, exactly, was problem it was that IT professionals expected SDN to resolve. The answers indicated a good cross-section of both network and application-related challenges. The answers to various questions pointed to a complex set of problems involving both provisioning and management of a wide set of problems across applications and networks. This is at the heart of the SDN debate: what is SDN supposed to do for networks, for applications, and for the staff tasked with deploying and managing the delivery of both? And what role does programmability - a key component of SDN since its initial inception - play in achieving success? 69% of respondents in our State of Application Delivery 2015 survey state that API-enabled infrastructure was important to very important. When we narrowed down our questions and asked about data path programmability, 100% of those who agreed SDN was strategically salient said it was important. These are the types of questions we're (and that "we" includes me, personally) going to dive into, head first, at our fourth (and final) State of Application Delivery 2015 webinar. If you haven't signed up (or gotten the report) yet, you can do so here. You can also learn more about it (and other exciting application delivery related topics including security, cloud and DevOps) by following @f5networks.279Views0likes1CommentState of Application Delivery 2015: The answer was efficiency
When last we visited the State of Application Delivery 2015 we asked if SDN is the answer, what was the question? After taking live to the Internet for the last webinar in our series to discuss the insights we gleaned from our survey we determined that pretty much the answer was efficiency. You can check out some highlights from that webinar here. For some, SDN was about operational efficiency; about driving more stability and consistency out of the processes that push applications through the app deployment pipeline into production. For others, it was really about financial efficiency - the drive to lower capital expenditures. And for yet others it was about efficient use of time - speed - in getting apps to market faster. All had at their root this common theme - efficiency. IT and indeed businesses today are experiencing rapid and sometimes unexpected growth driven by demand for mobile applications and the introduction of things into the equation. All agree that IT is under incredible pressure to step up and become more fast, scalable and efficient in order to deliver the apps upon which business now relies in this new economy. SDN, like DevOps, is one of the ways in which organizations are looking to operationalize their networks using programmability to automate and orchestrate the processes that govern the production pipeline. Programmability is seen as a key component in general. A clear majority of organizations believe that all three faces of programmability - data path, APIs, and templatization - are important to operational strategies moving forward. As all three are at the heart of a clearly growing trend toward automation and orchestration of the entire data center and beyond (into cloud) we weren't surprised to see the emphasis put on programmability in general. Over the course of our webinar series on the State of Application Delivery 2015 we've seen interesting and sometimes surprising results (whodda thunk availability would win out over security as the most important application service?) and sometimes just validating results that match up with trends noted in the industry at large and by our own internal conversations with customers. We've delved deep into security, looking at the importance of DDoS protection as a means to ensure both security and availability, as well as looking into a growing interest to include subscription-based, managed services like DDoS protection and Web Application Firewalls into the corporate security portfolio. The State of Application Delivery 2015 represents our (and the industry's) first - but certainly not our last - look at the application services considered essential to business' strategy of delivering secure, fast, and available applications with increasing velocity and at lower costs. As we move into this year, we're already gathering the data to pull together our next edition of the State of Application Delivery, which will no doubt carry a similarly descriptive title like "State of Application Delivery 2016." In the meantime, while you're waiting expectantly, you can review the webinars or grab a copy of this year's report.210Views0likes0CommentsSoftware is Eating IT
Software is eating the world. Everywhere you look there's an app for that. And I'm talking everywhere - including places and activities that maybe there shouldn't be an app for. No, I won't detail which those are. The Internet is your playground, I'm sure you can find examples. The point is that software is eating not just the world of consumers, but the world of IT. While most folks take this statement to mean that everything in IT is becoming software and the end of hardware is near, that's not really what it's saying. There has to be hardware somewhere, after all. Compute and network and storage resources don't come from the Stork, you know. No, it's not about the elimination of hardware but rather about how reliant on software we're becoming across all of IT. To put it succinctly, the future is software deploying software delivering software. Let me break that down now, because that's a lot of software. The first thing we note is that software is deploying, well, software. That software in turn is responsible for delivering software, a.k.a apps. And that's really what I mean when I say "software is eating IT". It's the inevitable realization that manual anything doesn't scale and to achieve that scale we need tools. In the case of IT that's going to be software. Software like Chef and Puppet, VMware and Cisco, OpenStack and OpenDaylight. Software that deploys. Software that automates and orchestrates the deployment of other things, including but not limited to, the apps transforming the world. What is that software deploying? More software, but not just the software we know as "apps" but the software responsible for hosting and delivering those apps. Infrastructure and platform software as well as the software that transports its data - every bit of someone's cat photo - from the database to their phablet, tablet or phone. The software that delivers apps. That's the lengthy list of application services that are responsible for the availability, performance and security of the software they deliver. The services so important to organizations they'd rather eat worms than go without. Those services are, in turn, delivering software. Software critical to business and front and center of just about every trend driving transformations in IT today. Go ahead, think of one - any one - trend that does not have at its core a focus on applications. I'll wait. See? It really is an application (software) world. And the impact of that being the case trickles down and across all of the business and IT. It means greater scale is required, operationally and humanly. It means faster time to market competing with the need for stability. It means increasing security risks balancing against performance and speed of provisioning. So into development we end with agile and continuous delivery and cloud. Down into operations and networking we find SDN and DevOps. It's everywhere. That's why the future is software (Chef, Puppet, Python, OpenStack, VMware, Cisco) deploying software (SDAS, VMs, as a service services) delivering software (apps, mobile apps, web apps, IoT apps) with a lot more automation, orchestration and scale than ever before. Operationalization. It's leaving IT a lean, mean app deployment and delivery machine. Which is exactly what business needs to get to market, remain competitive, and engage with the consumers that ultimately pay the bills. Productivity and profit are critical to business success and apps are key in the formula for improving both. Every initiative has to support those apps, which ultimately means everything is supportive of applications. Of their development, deployment and delivery. And that's why software is eating IT.280Views0likes0CommentsCloudy with a Chance of Security
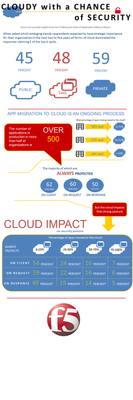
We found all manner of interesting practices and trends as it relates to cloud and security in our State of Application Delivery 2015 report. One of the more fascinating data points was a relationship between security posture and cloud adoption. That is, it appears that the more applications an organization migrates to the cloud, the less strict its security posture becomes. Really. I was a bit disturbed by that, too. At least at first. The reality is that simply asking about "applications in the cloud" isn't enough. It's perfectly reasonable to expect an organization that pays careful attention to application security (securing all three Cs) in the data center might not appear to be as careful if those applications move to a SaaS offering. Not because the attitude toward security has changed, mind you, but because there's no means for an organization to apply that level of scrutiny to a SaaS. They can't deploy a WAF inspect inbound requests and outbound responses, after all. But if those apps are migrating to an IaaS environment, where services like web application firewalls and application aware services can be deployed, then we're looking at a very different story. After all, if you can and choose not to, then you're purposefully degrading your security posture; hedging your bets that "in the cloud" is somehow safer than "in the data center." I'd guess that in the case of our results with respect to cloud and security practices, that there's some of both these scenarios (and probably some other ones, too) that explain the abandonment in security practices with increases in cloud presence that the data shows. Lesson learned: don't just ask about migration to "the cloud"; specifically dig in and ask whether an app is migrating to SaaS* or to IaaS or even to PaaS. That's important, because it has an impact on the amount and type of attention paid to securing that app. SaaS is more likely to be governed by an identity federation architecture that enables corporate oversight over access. IaaS is more likely to be protected by application layer security services but not traditional network security services (in the sense that the organization deploys and manages these services, of course cloud providers include these services, making them not only redundant but unnecessary). What we can, say, however, is that thanks to the migration of applications to cloud environments organizations certainly have less control over access to and security of those applications, whether intentional or not. The movement of apps toward the cloud has introduced fewer security practices on the part of the organization, and that might be a wee bit problematic. "Out of sight, out of mind" is not an appropriate attitude for information security, after all. I'll leave you with this infographic full of data related to cloud and security (and cloud security, I suppose) and a reminder that we have plenty more security-related (and application service-related, of course) data in the full report, which you can get here , along with archives of webinars exploring the data and concepts in more depth. If you're at RSA this week, feel free to stop by the F5 booth (it's the one with the big red ball ) and find out more about our full-stack approach to security, including apps "in the cloud". * I still maintain SaaS isn't really cloud computing, it's a hyper-scaled application on the Internet. We usually call those "apps", not "cloud". Call me Lori Quixote. It's my windmill, I'll tip at it if I want to.294Views0likes0CommentsA Series of Unfortunate (Delivery) Events
79% of new products miss their launch date. That was the conclusion of a CGT/Sopheon Survey in which the impact of such market misses were also explored. What it didn't dig into was the reason why so many products and projects miss their launch date. When we start digging into the details with respect to applications, we can find at least one causal factor in the delivery process, specifically that portion which focuses on the actual move into production, from which consumers (internal and external) are ultimately able to get their hands on the product they desire: your app. This is tied to a lexical misinterpretation (or perhaps misapplication) of the word "delivery" in "continuous delivery". Continuous delivery as used by developers and DevOps alike really means delivery to an application's penultimate destination. Not the ultimate destination, but its penultimate destination. That is, within most enterprises, production. Which means into the hands of the multiple operations' teams who are responsible for provisioning the resources necessary to move that app to its ultimate destination, which is of course the consumer. While continuous delivery efforts in development, closely tied to continuous integration, testing and build process automation, has stepped up in terms of being ready to go to production, there remain multiple obstacles in the production delivery process which have not stepped up. Here we find the bottlenecks inherent into the overarching "delivery" process, where slow manual processes and complexity continue to wreak havoc on delivery timelines and impede the timely delivery of applications into the hands of consumers. The problems in the production delivery process are similar to those that impede progress in development: handoffs between teams responsible for different tasks within the timeline, manual processes that introduce inconsistent and errors that must be found and fixed and even a failure to clearly define dependencies in a way that makes it possible to checklist the process and keep it moving forward. Continuous delivery addresses these issues within the development delivery process, but has not yet extended far beyond development and into the production delivery process. A recent DZone survey on Continuous Delivery indicates 22% of respondents had moved continuous delivery into production,focusing on infrastructure and another 57% want to do so. This desire and practice is further validated by the 28% of respondents in a Rackspace DevOps adoption report who have implemented infrastructure automation. But infrastructure is only one part of the production delivery process that must be considered, especially for new applications, as there are a multitude of other services in production that must be provisioned, configured and integrated in order to delivery an app to its ultimate destination. These services, traditionally delivered by network-hosted infrastructure, must also be included by continuous delivery practices if we are to achieve the faster time to market that 9 of 10 executives today feel pressured to realize (CA, Greasing the Gears of Innovation in the Application Economy). I/O (that's Infrastructure / Operations for the uninitiated) and network pros alike are well aware of the need for more agility (and the speed and consistency it brings) in the network. Their awareness of enablers like API-enabled infrastructure, app templates and programmability of the network in general is high and in our research, they place a great deal of importance on it whether they're a believer in DevOps or SDN or both. The stage is set (sorry, pun not intended) to move continuous delivery further down the delivery chain, from development into production, where it can continue to make a significant impact on organizational success in an application world. Continuous delivery shouldn't stop half-way to the goal of delivering apps to the consumers they're intended for.297Views0likes0CommentsBeyond Scalability: Achieving Availability
Scalability is only one of the factors that determine availability. Security and performance play a critical role in achieving the application availability demanded by business and customers alike. Whether the goal is to achieve higher levels or productivity or generate greater customer engagement and revenue the venue today is the same: applications. In any application-focused business strategy, availability must be the keystone. When the business at large is relying on applications to be available, any challenge that might lead to disruption must be accounted for and answered. Those challenges include an increasingly wide array of problems that cost organizations an enormous amount in lost productivity, missed opportunities, and damage to reputation. Today's applications are no longer simply threatened by overwhelming demand. Additional pressures in the form of attacks and business requirements are forcing IT professionals to broaden their views on availability to include security and performance. For example, a Kaspersky study[1] found that “61 percent of DDoS victims temporarily lost access to critical business information.” A rising class of attack known as “ransomware” has similarly poor outcomes, with the end result being a complete lack of availability for the targeted application. Consumers have a somewhat different definition of “availability” than the one found in text-books and scholarly articles. A 2012 EMA[2] study notes that “Eighty percent of Web users will abandon a site if performance is poor and 90% of them will hesitate to return to that site in the future” with poor performance designated as more than five seconds. The impact, however, of poor performance is the same as that of complete disruption: a loss of engagement and revenue. The result is that availability through scalability is simply not good enough. Contributing factors like security and performance must be considered to ensure a comprehensive availability strategy that meets expectations and ensures business availability. To realize this goal requires a tripartite of services comprising scalability, security and performance. Scalability Scalability is and likely will remain at the heart of availability. The need to scale applications and dependent services in response to demand is critical to maintaining business today. Scalability includes load balancing and failover capabilities, ensuring availability across the two primary failure domains – resource exhaustion and failure. Where load balancing enables the horizontal scale of applications, failover ensures continued access in the face of a software or hardware failure in the critical path. Both are equally important to ensuring availability and are generally coupled together. In the State of Application Delivery 2015, respondents told us the most important service – the one they would not deploy an application without – was load balancing. The importance of scalability to applications and infrastructure cannot be overstated. It is the primary leg upon which availability stands and should be carefully considered as a key criteria. Also important to scalability today is elasticity; the ability to scale up and down, out and back based on demand, automatically. Achieving that goal requires programmability, integration with public and private cloud providers as well as automation and orchestration frameworks and an ability to monitor not just individual applications but their entire dependency chain to ensure complete scalability. Security If attacks today were measured like winds we’d be looking at a full scale hurricane. The frequency, volume and surfaces for attacks have been increasing year by year and continues to surprise business after business after business. While security is certainly its own domain, it is a key factor in availability. The goal of a DDoS whether at the network or application layer is, after all, to deny service; availability is cut off by resource exhaustion or oversubscription. Emerging threats such as “ransomware” as well as existing attacks with a focus on corruption of data, too, are ultimately about denying availability to an application. The motivation is simply different in each case. Regardless, the reality is that security is required to achieve availability. Whether it’s protecting against a crippling volumetric DDoS attack by redirecting all traffic to a remote scrubbing center or ensuring vigilance in scrubbing inbound requests and data to eliminate compromise, security supports availability. Scalability may be able to overcome a layer 7 resource exhaustion attack but it can’t prevent a volumetric attack from overwhelming the network and making it impossible to access applications. That means security cannot be overlooked as a key component in any availability strategy. Performance Although performance is almost always top of mind for those whose business relies on applications, it is rarely considered with the same severity as availability. Yet it is a key component of availability from the perspective those who consume applications for work and for play. While downtime is disruptive to business, performance problems are destructive to business. The 8 second rule has long been superseded by the 5 second rule and recent studies support its continued dominance regardless of geographic location. The importance of performance to perceived availability is as real as scalability is to technical availability. 82 percent of consumers in a UK study[3] believe website and application speed is crucial when interacting with a business. Applications suffering poor performance are abandoned, which has the same result as the application simply being inaccessible, namely a loss of productivity or revenue. After all, a consumer or employee can’t tell the difference between an app that’s simply taking a long time to respond and an app that’s suffered a disruption. There’s no HTTP code for that. Perhaps unsurprisingly a number of performance improving services have at their core the function of alleviating resource exhaustion. Offloading compute-intense functions like encryption and decryption as well as connection management can reduce the load on applications and in turn improve performance. These intertwined results are indicative of the close relationship between performance and scalability and indicate the need to address challenges with both in order to realize true availability. It's All About Availability Availability is as important to business as the applications it is meant to support. No single service can ensure availability on its own. It is only through the combination of all three services – security, scalability and performance – that true availability can be achieved. Without scalability, demand can overwhelm applications. Without security, attacks can eliminate access to applications. And without performance, end-users can perceive an application as unavailable even if it’s simply responding slowly. In an application world, where applications are core to business success and growth, the best availability strategy is one that addresses the most common challenges – those of scale, security and speed. [1] https://press.kaspersky.com/files/2014/11/B2B-International-2014-Survey-DDoS-Summary-Report.pdf [2] http://www.ca.com/us/~/media/files/whitepapers/ema-ca-it-apm-1112-wp-3.aspx [3] https://f5.com/about-us/news/press-releases/gone-in-five-seconds-uk-businesses-risk-losing-customers-to-rivals-due-to-sluggish-online-experience246Views0likes0CommentsState of Application Delivery 2015: Full-stack Security Confidence
Security is one the more prominent of the application service categories, likely due to its high profile impact. After all, if security fails, we all hear about it. The entire Internet. Forever. So when one conducts a survey on the state of application delivery (which is implemented using application services) you kinda have to include security. Which of course, we did. But when we asked questions about security we got down in the dirt. We asked the expected questions like what security services organizations were deploying (spoiler: it's a lot of them) and which ones they were planning on deploying. But we also asked some deeper, probing questions about web application security practices and their confidence in being able to withstand an application layer attack. We asked that question because reports and data all point to the same inescapable conclusion: application layer attacks are on the rise. What's perhaps more disturbing is that it's taken us (as in the industry at large) this long to pay more attention to it. Look back over the past 15 years of breaches and you'll find that nearly half of the biggest breaches (in terms of records exposed) were due to a web application compromise. So it's kind of an important topic and why it was both surprising and heartening to find that 92% of our customers were "confident to highly confident" in their ability to withstand such an attack. What makes them so confident? That's where the digging in the dirt paid off. Turns out there's a high correlation of specific web application security practices with level of confidence in withstanding an attack. You can read more about that here, in "Web App Security Practices of the Highly Confident." That doesn't mean that traditional attacks aren't still a problem. They are. You might recall that the DPS of a DDoS has doubled and what's more interesting is that a 2014 Neustar survey found that 55% of DDoS victims experienced "smokescreening - where criminals use DDoS attacks to distract IT staff while inserting malware to breach bank accounts and customer data" - with nearly 50% having malware/virus installed and 26% losing customer data. Which means it's a growing imperative that organizations feel highly confident about their ability to withstand not just an app layer attack, but a volumetric attack too - at the same time. With the staggering growth of bandwidth consumed by volumetric DDoS attacks, it's no surprise that experts and organizations alike are recognizing the need for a new approach to mitigating these attacks. The approach most often mentioned is a Hybrid DDoS Protection Architecture; one that combines the seemingly limitless bandwidth available to DDoS protection in the cloud that's needed to fend off an attack with an on-premise solution. One that, to be completely covered, continually stands guard against the inevitable app layer attacks. For even more insight into the current state of security and application delivery, check out the full "State of Application Delivery 2015" report. And while you're there grabbing the goods, you can sign up for our next webinar in the State of Application Delivery 2015 series focused on ... wait for it.... wait for it... you guessed it, security. Security: Mitigate DDoS Attacks Effectively with a Hybrid DDoS Protection Architecture DDoS threats are constantly evolving. While traditional attacks aimed at filling Internet pipes are still common, application-targeted attacks are becoming more prevalent. As attacks continue to grow in complexity and size, and span multiple vectors, organizations must evolve their defense. Learn how a hybrid DDoS protection architecture can help secure your business from today’s sophisticated attacks.211Views0likes0Comments