Sometimes a Hack is Not a Hack, but We Should Still Worry
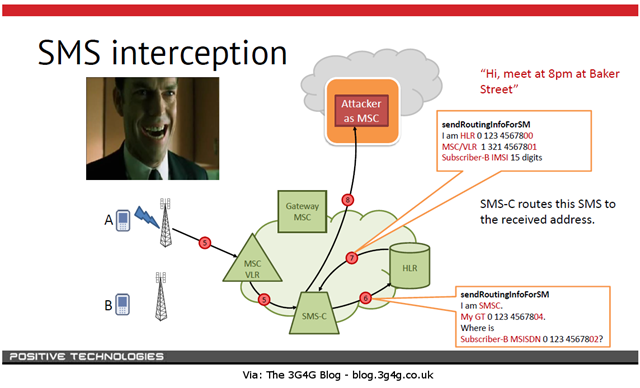
#LTEWS #Security I was at a roundtable discussion recently talking about security in the mobile carrier networks. During the discussion the recently announced SS7 signaling hack was introduced as an example. I would propose that this vulnerability is not a hack, but just poor design where trust is poorly assumed. Before you scream that I have my head stuck in the sand and I am ignoring a real threat that exists today for all mobile users, let me explain. The ‘hack’ in question depends on an agent to pose as a carrier wanting to interconnect with another established carrier for roaming and message forwarding capabilities. This is where the trust is involved. Interestingly, this is not as hard to do as one might think. With all the small carriers around the world and the MVNOs popping up like rabbits, it is hard to validate an entity with a 100% certainty. Once the trusted connection is established, now it is possible to send SS7 messages that can gain information that one should not normally have access to. There have been NO cases where an agent with malicious intent has been able to establish themselves to be in a position to send and receive SS7 information without establishing a trusted connection via a wrongly trusted, but legitimate processes. The reason I do not call this a hack, is that there is nothing technical about the method to gain access. This is purely social engineering. I can pose as a hedge fund and potentially gain some access to a larger financial company’s network infrastructure through a dedicated partner connection, but is that a ‘hack’? There are no software bugs, buffers to overflow, root access to obtain, or any other technical function that one thinks of when hacking to accomplish this compromise. So far, there have been NO instances reported or claimed of someone consciously and maliciously hacking or gaining information via the SS7 protocol. Now that I have THAT out of the way, let’s talk about the security in the current and future generation mobile networks, LTE. LTE uses a completely different model which uses an all-IP infrastructure and new protocols including Diameter, and protocols like SIP for new functions such as VoLTE. And we have our favorite attack vector, DNS, pervasively within the entire control plane infrastructure. LTE has major security concerns that need to be addressed because the traditionally closed control plane network is becoming exposed to the external (and hacker) community. SIP messages can be generated from one’s smart device and forwarded directly into the IMS infrastructure. DNS is used to forward messages from service function to service function within this previously closed network. It is possible that Diameter messaging can be exposed since it is easy for a malicious agent to hide their identity so it is impossible to find the source of the compromise via a fake origin ID. I wrote an introduction to this problem in an earlier blog post, Mobile Service Providers are missing a Key Security Issue - And it is not DNS. This is the time to take a close look at the security profile of the control plane network and determine what assurances can be put in place to prevent the malicious attacks that will certainly be forthcoming if nothing is done.285Views0likes0CommentsMobile Service Providers are missing a Key Security Issue - And it is not DNS
#MWC15 Barcelona is a great city, but with 100,000 people coming to the city for Mobile World Congress, it is expected that the criminals will come in force to prey upon these unwary travelers. When I travel, I am careful to protect myself from unsavory acts such as pickpocketing or physical attack. I avoid areas that may be dangerous and I take care to protect my personal belongings from theft such as keeping my wallet in my front pants pocket. But it is easy to become complacent and forget about possible ways to become a victim. When I am walking down a street, it is natural for me to have my phone out to look at the map for directions or use another service. My expensive smartphone is now out in the open for someone to run by and grab it. They will be gone before I even have a chance to react. Smartphone snatch and grab theft via The Times Mobile service providers are concerned about protecting their networks from DDoS attacks and intrusions that either degrade the performance of their network or expose sensitive information about them or their subscribers. One of the most common points of concern for the service providers is the DNS infrastructure. Every mobile operator has been hit by some DNS attack in the past, whether they are willing to admit it or not. Most service providers have implemented some level of protection against DNS attacks. But it is not only DNS that mobile service providers should be worried about. Many mobile operators have rolled out, or are rolling out Voice over LTE (VoLTE) services to deliver voice calls over the data network. To enable the VoLTE service, they need to have an IMS infrastructure in place to handle the SIP signaling to connect and monitor the VoLTE call status. Traditionally, before VoLTE, this IMS network has been closed and not accessible from the subscriber devices directly. Unfortunately, VoLTE changes that. VoLTE requires the smartphone to generate SIP messages to initiate a phone call. These SIP messages are sent to the IMS infrastructure intact. This means it is just a matter of time for malicious hacker to generate fake SIP messages that can reach the IMS services to deliver a DoS attack, obtain unauthorized services, or possibly even gain intelligence about the service provider’s subscribers or network configuration. Mobile service providers need to take a hard look at this portion of their network. They need to determine what needs to be in place in terms of security services such as an application-aware firewall, and/or DDoS protection solution to protect this newly exposed critical component of their infrastructure. Using a smartphone has changed my vulnerabilities and habits in the same way is VoLTE is forcing mobile service providers to re-inspect all aspects of their network as it changes the fundamental models that they have become accustomed to.262Views0likes0Comments
Back to Basics: The Many Faces of Load Balancing Persistence
Finally! It all makes sense now! Thanks to cloud and the very generic "sticky sessions", many more people are aware of persistence as it relates to load balancing. It's a critical capability of load balancing without which stateful applications (which is most of them including VDI, most web applications, and data analysis tools) would simply fail to scale. Persistence is, in general, like the many moods of Spock. They all look pretty much the same from the outside - ensure that a user, once connected, continues to be connected to the same application instance to ensure access to whatever state is stored in that instance. But though they act the same (and Spock's expression appears the same) deep down, where it counts, persistence is very different depending on how it's implemented. It requires different processing, different inspection, different data, even. Understanding these differences is important because each one has a different impact on performance. The Many Faces of Persistence There are several industry de facto standard types of persistence: simple, SSL, and cookie. Then there are more advanced forms of persistence: SIP, WTS, Universal and Hash. Generally speaking the de facto standard types of persistence are applicable for use with just about any web application. The more advanced forms of persistence are specific to a protocol or rely on a capability that is not necessarily standardized across load balancing services. Without further adieu, let's dive in! Simple Persistence Simple persistence is generally based on network characteristics, like source IP address. It can also include the destination port, to give the load balancer a bit more capacity in terms of simultaneously applications supported. Best practices avoid simple persistence to avoid reoccurrence of the mega-proxy problem which had a tendency to overwhelm application instances. Network load balancing uses a form of simple persistence. SSL Session ID Persistence SSL Session ID persistence became necessary when SSL was broadly accepted as the de facto means of securing traffic in flight for web applications. Because SSL sessions need to be established and are very much tied to a session between client and server, failing to "stick" SSL-secured sessions results in renegotiation of the session, which takes a noticeable amount of time and annoys end-users. To avoid unnecessary renegotiation, load balancers use the SSL Session ID to ensure sessions are properly routed to the application instance to which they first connected. Cookie Persistence Cookie persistence is a technique invented by F5 (shameless plug) that uses the HTTP cookie header to persist connections across a session. Most application servers insert a session id into responses that is used by developers to access data stored in the server session (shopping carts, etc... ). This value is used by load balancing services to enable persistence. This technique avoids the issues associated with simple persistence because the session id is unique. Universal Persistence Universal persistence is the use of any piece of data (network, application protocol, payload) to persist a session. This technique requires the load balancer to be able to inspect and ultimately extract any piece of data from a request or response. This technique is the basis for application-specific persistence solutions addressing popular applications like SIP, WTS, and more recently, VMware View. SIP, WTS, Username Persistence Session Initiation Protocol (SIP) and Windows Terminal Server (WTS) persistence are application-specific persistence techniques that use data unique to a session to persist connections. Username persistence is a similar technique designed to address the needs of VDI - specifically VMware View solutions - in which sessions are persisted (as one might expect) based on username. When a type of persistence becomes very commonly used it is often moved from being a customized, universal persistence implementation to a native, productized persistence profile. This improves performance and scalability by removing the need to inspect and extract the values used to persist sessions from the data flow and results in an application-specific persistence type, such as SIP or WTS. Hash Persistence Hash persistence is the use of multiple values within a request to enable persistence. To avoid problems with simple persistence, for example, a hash value may be created based on Source IP, Destination IP, Destination Port. While not necessarily unique to every session, this technique results in a more even distribution of load across servers. Non-unique value-based persistence techniques (simple, hash) are generally used with stateless applications or streaming content (video, audio) as a means to more evenly distribute load. Unique value-based persistence techniques (universal, application-specific, SSL ID) are generally used with stateful applications that depend on the client being connected to the same application instance through the session's life. Cookie persistence can be used with both techniques, provided the application is web based and uses HTTP headers for each request (Web Sockets breaks this technique).4.1KViews0likes1CommentF5 Friday: It’s a Data Tsunami for Service Providers
F5 introduces its Service Delivery Network to help service providers weather the storm. If you haven’t seen the video “Everything’s amazing, nobody’s happy” (Louis CK) go ahead and check it out. You won’t regret it, trust me. Especially the section where he’s talking about the impact of the need for instant gratification via mobile connectivity. Seriously. We’ve all done the same thing – complained, griped, and probably called our service provider names because an application or web site didn’t respond immediately. As in sub-second response time. Even though many of us are technically astute enough to recognize it probably wasn’t the service provider’s fault in the first place. Reality is that service providers are under increasing pressure not only to deliver excellent call quality as the number of folks relying on land lines rapidly fades into yet another “old timey” technology chapter in history, but also applications, services, and streaming video. A mobile phone is not just a phone, anymore. It’s a handheld, mobile entertainment device and a collaborative support network life-line. The result for service providers is a data tsunami. The vast amounts of bits and bytes flowing over their networks is incredible, and it’s growing by the day along with the number of users, applications, and uses for mobile devices. Consumer-oriented gadgets like the iPad are not just for play-time anymore, they’re quickly becoming standard connectivity methods for IT folks – so much so that even vendors are taking note and supporting it as an endpoint for corporate secure remote access solutions. The problem is that much of the content delivered via service provider networks to endpoints of all kinds is not owned by the service provider. It’s just “passing through”, as it were, and isn’t necessarily generating additional revenue. But it needs to be managed by the service provider, which increases OPEX and in some cases CAPEX as service providers scramble to scale along with the growth in data flowing to their customers. That results in a gap between ARPU (average revenue per user) and OPEX. And when you’re taking in less than you’re spending, well, you know that isn’t good. Service providers increase revenue by providing new services – usually in a subscription model. But current conditions and usage patterns are such that new services won’t necessarily raise the ARPU because what’s causing the increase in costs is simply data. Lots and lots of data. So if a service provider can’t necessarily offer new services such that they can equalize ARPU with OPEX, what can they do? Right. Decrease OPEX and CAPEX to bring it more in line with ARPU - hopefully lower to achieve a positive ARPU:costs ratio. THE SERVICE DELIVERY NETWORK That’s why F5 introduced its Service Delivery Network (SDN) specifically for service providers. By offering a unified traffic management platform that affords providers with intelligent and versatile policy-based control over all traffic, service providers have the ability to satisfy changing market needs profitably. The combination of subscriber, device, location and application awareness enables intelligent, centralized control over traffic resources to ensure that each service is delivered exactly as intended, protected from security threats, congestion, and failures. Combined with scalability and high-availability, F5 BIG-IP controllers enable service providers to lower CAPEX and OPEX while simultaneously supporting the “instant gratification” driven needs of their subscribers. The unified and flexible BIG-IP platforms provide integration functions such as IPv4/6 translation, secure DNS traffic management (DNSSEC), TCP optimization, and integrated security to control operational and capital expenditures. Service-provider grade high-availability with fast failover improves uptime and maintains high levels of Quality of Service/Experience (QoS/QoE). Support for robust and message-based scalability of a wide variety of protocols seen primarily in service provider networks – SIP , Diameter – enables providers to more efficiently make use of resources in their network without compromising availability or quality. Our new Service Provider solution section of F5.com holds a wealth of information about the Service Delivery Network including case studies, deployment guides, white papers and solution profiles. All are specifically geared toward service providers with support for protocols and solutions for problems unique to service provider networks. If you’re a service provider, check it out. You won’t be disappointed. Related blogs & articles: Managing Large Scale, Carrier-Grade NAT with BIG-IP Products Service Delivery Networking Session Initiated Protocol Message-based Load Balancing F5 Friday: The 2048-bit Keys to the Kingdom All F5 Friday Posts on DevCentral Some Services are More Equal than Others Service Delivery Networking Presentation F5 Delivers Essential Solutions Enabling Service Providers to Cost Effectively Support Mobile Traffic Growth239Views0likes0Comments
20 Lines or Less #32 – Sip, Counters & Classes
What could you do with your code in 20 Lines or Less? That's the question I ask (almost) every week for the devcentral community, and every week I go looking to find cool new examples that show just how flexible and powerful iRules can be without getting in over your head. SIP topology hiding forward proxy http://devcentral.f5.com/s/wiki/default.aspx/iRules/SIP_topology_hiding_and_forward_proxy.html If you’re passing SIP traffic and want a way to mask the via & or from headers when passing traffic to the outside world, this might be just the rule you’ve been waiting for. It’s a cool look at using iRules for an off the wall issue with a non-HTTP protocol. This is a simplified version of the original iRule to cram it down to less than 21 lines, but the functionality is identical. Just a lot less comments and a few less variables being set. Good stuff. when SIP_REQUEST { set originator_ip [IP::remote_addr] node [IP::local_addr]:[TCP::local_port] } when SIP_REQUEST_SEND { set snat_ip [serverside {IP::local_addr}] set ip_map [list [findstr [SIP::header From] "@" 1 ">"] $snat_ip] SIP::header remove from SIP::header insert from "[string map $ip_map [SIP::header "From"]]" SIP::header remove via SIP::header insert via [string map $ip_map [SIP::header "Via"]] } when SIP_RESPONSE { set ip_map [list $snat_ip $originator_ip] SIP::header remove from SIP::header insert from "[string map $ip_map [SIP::header "From"]]" SIP::header remove via SIP::header insert via [string map $ip_map [SIP::header "Via"]] } CMP v10 Compatible counters using the session table http://devcentral.f5.com/s/wiki/default.aspx/iRules/CMP_v10_compatible_counters_using_the_session_table.html In this codeshare entry hoolio outlines two different ways to set up counters using the session table in v10. The benefit to this is that it’s fully CMP compliant which in certain systems will up performance considerably. It’s also much cooler because the second of the two examples packed into a single iRule shows how to make virtual specific variables for your counters, which is a trick I like a lot. I’m just highlighting the virtual specific version though Aaron showed you how to do both a virtual specific version and a global version in the original post, linked above. when HTTP_REQUEST { set vip [virtual name] set value [session lookup uie "${vip}_my_counter"] if {$value eq ""}{ session add uie "${vip}_my_counter" 0 } else { session add uie "${vip}_my_counter" [expr {$value + 1}] } } v10 Class matching http://devcentral.f5.com/s/Default.aspx?tabid=53&forumid=5&postid=86237&view=topic In version 10 iRules were given a whole new way to access data groups: the class command. The class command offers a host of new and powerful abilities and Aaron’s making use of one of them in this example. I want to dig into this more and see what other options there might be to achieve what he’s gunning for, but this one isn’t a bad one at all, so I thought I’d highlight it. # Loop through each class line for {set i 0} {$i < [class size my_dgl]} {incr i} { # Use scan to parse the two fields from the class scan [class element -name $i my_dgl] {%[^ ]%s} my_pattern my_value # Use string match to evaluate the pattern against the string if {[string match -nocase $my_pattern [HTTP::uri]]}{ # Found a match log local0. "Matched $my_pattern, using $my_value" break } } That’s it for this week. I’ll be out next week for vacation/holiday so check back the week after for more condensed iRule goodness! #Colin247Views0likes0Comments