F5 Distributed Cloud Services: API Security and Control
The previous article gave great coverage of API Discovery functionality on the F5 Distributed Cloud Services Web App and API Protection (XC WAAP) platform. This one gives an overview of what is available in terms of API control features. The XC WAAP platform provides a rich set of techniques to securely deliver applications and APIs. It goes beyond industry-standard features like WAF and DoS and introduces cutting-edge AI/ML technologies that significantly increase accuracy and decrease the number of false positives. The following paragraphs give an overview of available technologies and provide links to get started. Per API Request Analysis Per requests analysis name is self-explaining. The technique analyzes every single API call and extracts various metrics out of it such as request/response size, latency, etc. Based on observed data it builds a model that identifies a valid request structure for a particular API endpoint. Once the model is applied to the traffic it automatically catches any request that deviates from learned models and notifies a user. This approach is good to discover any per request-based threats. Getting started documentation Time-Series Anomaly Detection TS anomaly detection is somewhat similar to the previous mechanism but instead of looking into each API request, it monitors the traffic stream as a whole. Therefore, metrics of interest relate to the entire stream such as requests rate, errors, latency, and throughput. Then statistical algorithms detect the following types of anomalies: Unexpected spikes/drops Unexpected traffic patterns Such detection instantly notifies an administrator about any event that potentially means a service disruption. Whether it is a traffic drop caused by a misconfiguration or a traffic spike due to a DoS attack. Getting Started Documentation User Behavior Analysis Behavior analysis uses AI and ML to profile valid user behavior. It detects clear suspicious behavior based on WAF events, login failures, L7 policy violations, and other anomalous activity based on user behavioral aspects. Once enabled an administrator can observe a whole list of suspicious users in the HTTP load balancer app firewall dashboard. Getting started documentation Web Application Firewall As a platform with a mature security stack, the XC WAAP matches and exceeds all industry-standard features. In addition to that, it significantly simplifies the WAAP configuration. It only asks for application language, CMS, and web server type to set up the best level of protection for an application. Getting started documentation Service Policies Another name of the service policy is the L7 policy. When applied to a load balancer it allows to granularly define what traffic is allowed to a service and what is not in terms of L7 metrics such as hostname, method, path, or any other property available from a request. Service policy consists of rules that match a request by one or more metrics and then apply one of the following actions allow, deny or check next. Getting started documentation Rate Limiting Rate limiting protects an application or an API from excessive usage via limiting the rate of requests from a single user or client executed in a period of time. There is a variety of ways to identify a user: By IP address By cookie By HTTP Header By query string parameter The feature can limit the rate or total amount of requests which an entity is allowed to execute. Getting started documentation DoS Protection Similar to rate limiting DoS protection helps to keep service up and running under an excessive amount of traffic. However, opposite to rate limiting XC WAAP's DoS protection operates on L3/4 and deals with much higher volumes of traffic. Getting started documentation Allow/Deny Lists Self-explaining feature as well. Allows to set up lists of trusted and untrusted IP prefixes. Clients from trusted prefixes bypass all security checks. Clients from untrusted prefixes are simply blocked before any security check happens. Both lists support the expiration time setting. Meaning that rule continues to exist but isn't applied to the traffic after expiration time comes. That is handy to set up temporary rules e.g. for testing or security purposes. Getting started documentation Conclusion All security features above are available on top of the F5 Distributed Cloud Services HTTP load balancer. A combination of those provides reliable protection for an API and automatically supports it in up and running conditions.1.1KViews4likes2CommentsDeclarative Advanced WAF policy lifecycle in a CI/CD pipeline
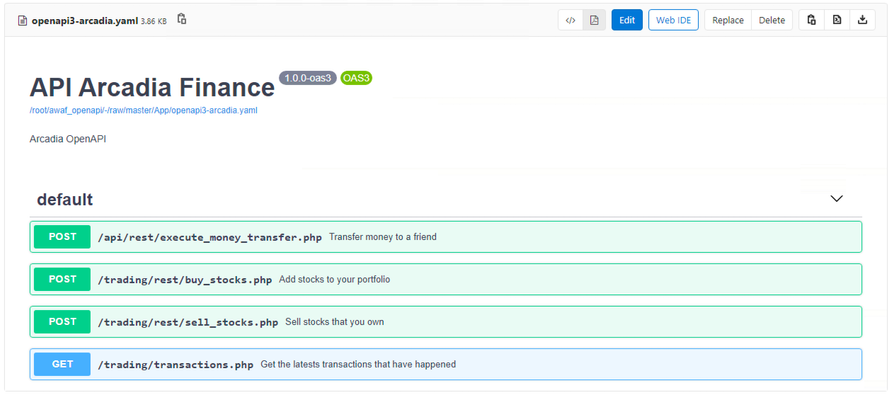
The purpose of this article is to show the configuration used to deploy a declarative Advanced WAF policy to a BIG-IP and automatically configure it to protect an API workload by consuming an OpenAPI file describing the application. For this experiment, a Gitlab CI/CD pipeline was used to deploy an API workload to Kubernetes, configure a declarative Adv. WAF policy to a BIG-IP device and tuning it by incorporating learning suggestions exported from the BIG-IP. Lastly, the F5 WAF tester tool was used to determine and improve the defensive posture of the Adv. WAF policy. Deploying the declarative Advanced WAF policy through a CI/CD pipeline To deploy the Adv. WAF policy, the Gitlab CI/CD pipeline is calling an Ansible playbook that will in turn deploy an AS3 application referencing the Adv.WAF policy from a separate JSON file. This allows the application definition and WAF policy to be managed by 2 different groups, for example NetOps and SecOps, supporting separation of duties. The following Ansible playbook was used; --- - hosts: bigip connection: local gather_facts: false vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxx" tasks: - name: Deploy AS3 API AWAF policy uri: url: "https://{{ bigip }}/mgmt/shared/appsvcs/declare" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxx body: "{{ lookup('file','as3_waf_openapi.json') }}" body_format: json validate_certs: no status_code: 200 The Advanced WAF policy 'as3_waf_openapi.json' was specified as follows: { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.2.0", "id": "Prod_API_AS3", "API-Prod": { "class": "Tenant", "defaultRouteDomain": 0, "arcadia": { "class": "Application", "template": "generic", "VS_API": { "class": "Service_HTTPS", "remark": "Accepts HTTPS/TLS connections on port 443", "virtualAddresses": ["xxxxx"], "redirect80": false, "pool": "pool_NGINX_API", "policyWAF": { "use": "Arcadia_WAF_API_policy" }, "securityLogProfiles": [{ "bigip": "/Common/Log all requests" }], "profileTCP": { "egress": "wan", "ingress": { "use": "TCP_Profile" } }, "profileHTTP": { "use": "custom_http_profile" }, "serverTLS": { "bigip": "/Common/arcadia_client_ssl" } }, "Arcadia_WAF_API_policy": { "class": "WAF_Policy", "url": "http://xxxx/root/awaf_openapi/-/raw/master/WAF/ansible/bigip/policy-api.json", "ignoreChanges": true }, "pool_NGINX_API": { "class": "Pool", "monitors": ["http"], "members": [{ "servicePort": 8080, "serverAddresses": ["xxxx"] }] }, "custom_http_profile": { "class": "HTTP_Profile", "xForwardedFor": true }, "TCP_Profile": { "class": "TCP_Profile", "idleTimeout": 60 } } } } } The AS3 declaration will provision a separate Administrative Partition ('API-Prod') containing a Virtual Server ('VS_API'), an Adv. WAF policy ('Arcadia_WAF_API_policy') and a pool ('pool_NGINX_API'). The Adv.WAF policy being referenced ('policy-api.json') is stored in the same Gitlab repository but can be downloaded from a separate location. { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ ] } The declarative Adv.WAF policy is referencing in turn the OpenAPI file ('openapi3-arcadia.yaml') that describes the application being protected. Executing the Ansible playbook results in the AS3 application being deployed, along with the Adv.WAF policy that is automatically configured according to the OpenAPI file. Handling learning suggestions in a CI/CD pipeline The next step in the CI/CD pipeline used for this experiment was to send legitimate traffic using the API and collect the learning suggestions generated by the Adv.WAF policy, which will allow a simple way to customize the WAF policy further for the specific application being protected. The following Ansible playbook was used to retrieve the learning suggestions: --- - hosts: bigip connection: local gather_facts: true vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxxx" tasks: - name: Get all Policy_key/IDs for WAF policies uri: url: 'https://{{ bigip }}/mgmt/tm/asm/policies?$select=name,id' method: GET headers: "Authorization": "Basic xxxxxxxxxxx" validate_certs: no status_code: 200 return_content: yes register: waf_policies - name: Extract Policy_key/ID of Arcadia_WAF_API_policy set_fact: Arcadia_WAF_API_policy_ID="{{ item.id }}" loop: "{{ (waf_policies.content|from_json)['items'] }}" when: item.name == "Arcadia_WAF_API_policy" - name: Export learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxxx" body: "{ \"inline\": \"true\", \"policyReference\": { \"link\": \"https://{{ bigip }}/mgmt/tm/asm/policies/{{ Arcadia_WAF_API_policy_ID }}/\" } }" body_format: json validate_certs: no status_code: - 200 - 201 - 202 - name: Get learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: GET headers: "Authorization": "Basic xxxxxxxxx" validate_certs: no status_code: 200 register: result - name: Print learning suggestions debug: var=result A sample learning suggestions output is shown below: "json": { "items": [ { "endTime": "xxxxxxxxxxxxx", "id": "ZQDaRVecGeqHwAW1LDzZTQ", "inline": true, "kind": "tm:asm:tasks:export-suggestions:export-suggestions-taskstate", "lastUpdateMicros": 1599953296000000.0, "result": { "suggestions": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "Check maximum number of parameters" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "No Host header in HTTP/1.1 request" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable enforcement of policy violation", "entity": { "name": "VIOL_REQUEST_MAX_LENGTH" }, "entityChanges": { "alarm": true, "block": true }, "entityType": "violation" } Incorporating the learning suggestions in the Adv.WAF policy can be done by simple copy&pasting the self-contained learning suggestions blocks into the "modifications" list of the Adv.WAF policy: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } Enhancing Advanced WAF policy posture by using the F5 WAF tester The F5 WAF tester is a tool that generates known attacks and checks the response of the WAF policy. For example, running the F5 WAF tester against a policy that has a "transparent" enforcement mode will cause the tests to fail as the attacks will not be blocked. The F5 WAF tester can suggest possible enhancement of the policy, in this case the change of the enforcement mode. An abbreviated sample output of the F5 WAF Tester: ................................................................ "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" } }, "summary": { "fail": 48, "pass": 0 } Changing the enforcement mode from "transparent" to "blocking" can easily be done by editing the same Adv. WAF policy file: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } A successful run will will be achieved when all the attacks will be blocked. ......................................... "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": true, "reason": "", "support_id": "17540898289451273964" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": true, "reason": "", "support_id": "17540898289451274344" } }, "system": "All systems" } }, "summary": { "fail": 0, "pass": 48 } Conclusion By adding the Advanced WAF policy into a CI/CD pipeline, the WAF policy can be integrated in the lifecycle of the application it is protecting, allowing for continuous testing and improvement of the security posture before it is deployed to production. The flexible model of AS3 and declarative Advanced WAF allows the separation of roles and responsibilities between NetOps and SecOps, while providing an easy way for tuning the policy to the specifics of the application being protected. Links UDF lab environment link. Short instructional video link.1.8KViews3likes1Comment
API Discovery and Auto Generation of Swagger Schema
APIDiscovery API discovery helps inlearning, searching,and identifying loopholes when app communicatesvia APIsespecially in a large micro-services ecosystem.After discovery, the systemanalyzesthe APIs, then will know how to secure the APIs from malicious requests. Customer Challenges With large ecosystems, integrations,and distributed microservices, there is a huge increase in the number of API attacks. Most of these API attacks authenticated users and are very hard to detect. Also, security controls for web apps are totally different than security controls for APIs. Customersincreased adoption of microservice architecture has increased the complexity of managing, debugging,and securingapplications. With microservices,all the traffic between apps is using REST/gRPC APIs that are multiplexed onthesame network port (eg. HTTP 443) and as a result, the network level security and connectivityisnot very usefulanymore. Withcustomers adoptinga multi-cloud strategy, services might be residing on different cloud/vpc, so customers need a uniform way to apply app-level policies which will enforce zero trust API security acrossservice-to-servicecommunication. Also,the SecOps team has an administrative overhead to manually track the changes toAPI’sin a multi-cloud environment.Dev/DevOps team needs an easier tool to debug the apps. Solution Description Volterra’s AI/ML learning engine uniquely discovers API endpoints used during aservice-to-servicecommunication. This feature provides users debugging capabilities for distributed apps that are deployed on a single cloud or across multiple clouds. API endpoints discovered could be used to create API-level security policy to enforce tighter service-to-service communication. Also, the swagger schema helps in analyzing and debugging the request logs.Secopscan download and use it for audit purposes. This also serves as an input to thethird-partytools. Step by step process to enable API discovery and auto-generation of swagger schema There are mainly three steps in enabling the API discovery and downloading the swagger schema: Step1 .Enabling the API discoverywhich is to create an app-type config. Step2 .Deploying an applicationon Kubernetes and creating the HTTP load balancer. Step3 .Observing an appthrough service mesh graph and HTTP load balancer dashboardwhich includes downloading of swagger schema. Let us seehowto configureonVoltConsole: Step 1 Create anapplication namespaceunder generalnamespace tab: General > My Namespaces > Add name space. Step 2 Next,we need to create an app type which is under the shared tab: Shared > AI&ML > Add app type Here, while creating a new apptype,we need to enable the API discovery feature and markup setting to learn from direct traffic. Save and exit. Step 3 Next,let'sgo to the app tab to deploy the app: App > Applications >Virtual K8s > Add virtual K8s While creating new virtual K8s, you give it a name and selectves-io-all-res as a virtual site.Save and exit.Wehave towait till the cluster status is ready. Next, we will have to download thekubeconfigfile for the virtual K8S cluster. Now, we will use theKubectlto deploy the applicationusing the below command: kubeconfig$YOURKUBECONFIGFILE apply -fkubenetes-manifest.yml–namespace $YOURNAMESPACE Step 4 Now, we can go to theVoltConsoleto go and check the status of this app. We will wait for the pods to become ready and once all the pods are ready, we can now create theload balancer(LB)for frontend service. Next, we give the LB aname andlabelthe HTTP LB asves-io/app_typeand value as default (which is the name of the app type). Provide the domain nameunder basic config. This guideprovides instructions on how to delegate your DNS domain to Volterra using theVoltConsole. Delegating the domain to Volterra enables Volterra to manage the domain and be the authoritative domain name server for the domain. Volterra checks the DNS domain configured in the virtual host and verifies that the tenant owns that domain. Step 5 Now select theoriginpool, andcreate a new poolwith theoriginserver type and name as below.Also, select the network on the site as vK8s network on site.Select the correct port number for the service and save & exit the configuration. Step 6 Now,let'snavigate to HTTP LB dashboard > security monitoring > API endpoints. Here you willsee all the API endpoints that are discovered on the HTTPLBand you can download the swagger right from the HTTP LB dashboard page. Step 7 Now ,letsnavigate to the service mesh graph where we can view the entire application micro-services and how they are connected, and how the east-west and north-south traffic is flowing. App Namespace -> Mesh -> Service Mesh-> API endpoints tab Step 8 Now,let'sclick on the API endpoints tab, and we will see all the API endpoints discovered for the default app type. Now you can click on the Schema and then go to the PII& learned APIdata, andclick on the download button to download the swagger schema for each specific API endpoint. If we want to download the swagger schema for the entire application, then we go back to the API endpoints tab and download swagger as seen below: Conclusion With the increased attack surfaces with distributed microservices and other large ecosystems, having a feature such as API discovery andbeable to auto-generate the swagger file really helps in mitigating the malicious API attacks. This feature provides users debugging capabilities for distributed apps that are deployed on a single cloud or across multiple clouds. In addition,API endpoints discovered could be used to create API level security policy to enforce tighter service-to-service communication. The request logs are continuously analyzed to learn the schema for every learned API endpoint. The generated swagger schema could be downloaded through UI or Volterra API.SecOps can download and use it for audit purposesandDev/DevOps team can use to see the delta variables/path between differentversion.It can be used as input to otherthird-partytoolsand is less administrative overhead of managing the documents.2.6KViews2likes4CommentsL7 DoS Protection with NGINX App Protect DoS
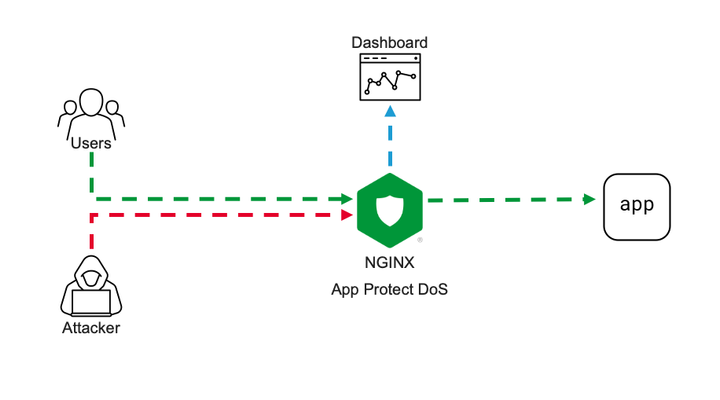
Intro NGINX security modules ecosystem becomes more and more solid. Current App Protect WAF offering is now extended by App Protect DoS protection module. App Protect DoS inherits and extends the state-of-the-art behavioral L7 DoS protection that was initially implemented on BIG-IPand now protects thousands of workloads around the world. In this article, I’ll give a brief explanation of underlying ML-based DDoS prevention technology and demonstrate few examples of how precisely it stops various L7 DoS attacks. Technology It is important to emphasize the difference between the general volumetric-based protection approach that most of the market uses and ML-based technology that powers App Protect DoS. Volumetric-based DDoS protection is an old and well-known mechanism to prevent DDoS attacks. As the name says, such a mechanism counts the number of requests sharing the same source or destination, then simply drops or applies rate-limiting after some threshold crossed. For instance, requests sourcing the same IP are dropped after 100 RPS, requests going to the same URL after 200 RPS, and rate-limiting kicks in after 500 RPS for the entire site. Obviously, the major drawback of such an approach is that the selection criterion is too rough. It can causeerroneous drops of valid user requests and overall service degradation. The phenomenon when a security measure blocks good requests is called a “false positive”. App Protect DoS implements much more intelligent techniques to detect and fight off DDoS attacks. At a high level, it monitors all ongoing traffic and builds a statistical model in other words a baseline in aprocesscalled “learning”. The learning process almost never stops, thereforea baseline automatically adjusts to the current web application layout, a pattern of use, and traffic intensity. This is important because it drastically reduces maintenance cost and reaction speed for the solution. There is no more need to manually customize protection configuration for every application or traffic change. Infinite learning produces a legitimate question. Why can’t the system learn attack traffic as a baseline and how does it detect an attack then? To answer this question let us define what a DDoS attack is. A DDoS attack is a traffic stream that intends to deny or degrade access to a service. Note, the definition above doesn’t focus on the amount of traffic. ‘Low and slow’ DDoS attacks can hurt a service as severely as volumetric do. Traffic is only considered malicious when a service level degrades. So, this means that attack traffic can become a baseline, but it is not a big deal since protected service doesn’t suffer. Now only the “service degradation” term separates us from the answer. How does the App Protect DoS measure a service degradation? As humans, we usually measure the quality of a web service in delays. The longer it takes to get a response the more we swear. App Protect DoS mimics human behavior by measuring latency for every single transaction and calculates the level of stress for a service. If overall stress crosses a threshold App Protect DoS declares an attack. Think of it; a service degradation triggers an attack signal, not a traffic volume. Volume is harmless if an application servermanages to respond quickly. Nice! The attack is detected for a solid reason. What happens next? First of all, the learning process stops and rolls back to a moment when the stress level was low. The statistical model of the traffic that was collected during peacetime becomes a baseline for anomaly detection. App Protect DoS keeps monitoring the traffic during an attack and uses machine learning to identify the exact request pattern that causes a service degradation. Opposed to old-school volumetric techniques it doesn’t use just a single parameter like source IP or URL, but actually builds as accurate as possible signature of entire request that causes harm. The overall number of parameters that App Protect DoS extracts from every request is in the dozens. A signature usually contains about a dozen including source IP, method, path, headers, payload content structure, and others. Now you can see that App Protect DoS accuracy level is insane comparing to volumetric vectors. The last part is mitigation. App Protect DoS has a whole inventory of mitigation tools including accurate signatures, bad actor detection, rate-limiting or even slowing down traffic across the board, which it usesto return service. The strategy of using those is convoluted but the main objective is to be as accurate as possible and make no harm to valid users. In most cases, App Protect DoS only mitigates requests that match specific signatures and only when the stress threshold for a service is crossed. Therefore, the probability of false positives is vanishingly low. The additional beauty of this technology is that it almost doesn’t require any configuration. Once enabled on a virtual server it does all the job "automagically" and reports back to your security operation center. The following lines present a couple of usage examples. Demo Demo topology is straightforward. On one end I have a couple of VMs. One of them continuously generates steady traffic flow simulating legitimate users. The second one is supposed to generate various L7 DoS attacks pretending to be an attacker. On the other end, one VM hosts a demo application and another one hosts NGINX with App Protect DoS as a protection tool. VM on a side runs ELK cluster to visualize App Protect DoS activity. Workflow of a demo aims to showcase a basic deployment example and overall App Protect DoS protection technology. First, I’ll configure NGINX to forward traffic to a demo application and App Protect DoS to apply for DDoS protection. Then a VM that simulates good users will send continuous traffic flow to App Protect DoS to let it learn a baseline. Once a baseline is established attacker VM will hit a demo app with various DoS attacks. While all this battle is going on our objective is to learn how App Protect DoS behaves, and that good user's experience remains unaffected. Similar to App Protect WAF App Protect DoS is implemented as a separate module for NGINX. It installs to a system as an apt/yum package. Then hooks into NGINX configuration via standard “load_module” directive. load_module modules/ngx_http_app_protect_dos_module.so; Once loaded protection enables under either HTTP, server, or location sections. Depending on what would you like to protect. app_protect_dos_enable [on|off] By default, App Protect DoS takes a protection configuration from a local policy file “/etc/nginx/BADOSDefaultPolicy.json” { "mitigation_mode" : "standard", "use_automation_tools_detection": "on", "signatures" : "on", "bad_actors" : "on" } As I mentioned before App Protect DoS doesn’t require complex config and only takes four parameters. Moreover, default policy covers most of the use cases therefore, a user only needs to enable App Protect DoS on a protected object. The next step is to simulate good users’ traffic to let App Protect DoS learn a good traffic pattern. I use a custom bash script that generates about 6-8 requests per second like an average surfing activity. While inspecting traffic and building a statistical model of good traffic App Protect DoS sends logs and metrics to Elasticsearch so we can monitor all its activity. The dashboard above represents traffic before/after App Protect DoS, degree of application stress, and mitigations in place. Note that the rate of client-side transactions matches the rate of server-side transactions. Meaning that all requests are passing through App Protect DoS and there are not any mitigations applied. Stress value remains steady since the backend easily handles the current rate and latency does not increase. Now I am launching an HTTP flood attack. It generates several thousands of requests per second that can easily overwhelm an unprotected web server. My server has App Protect DoS in front applying all its’ intelligence to fight off the DoS attack. After a few minutes of running the attack traffic, the dashboard shows the following situation. The attack tool generated roughly 1000RPS. Two charts on the left-hand side show that all transactions went through App Protect DoS and were reaching a demo app for a couple of minutes causing service degradation. Right after service stress has reached a threshold an attack was declared (vertical red line on all charts). As soon as the attack has been declared App Protect DoS starts to apply mitigations to resume the service back to life. As I mentioned before App Protect DoS tries its best not to harm legitimate traffic. Therefore, it iterates from less invasive mitigations to more invasive. During the first several seconds when App Protect DoS just detected an attack and specific anomaly signature is not calculated yet. App Protect DoS applies an HTTP redirect to all requests across the board. Such measure only adds a tiny bit of latency for a web browser but allows it to quickly filter out all not-so-intelligent attack tools that can’t follow redirects. In less than a minute specific anomaly signature gets generated. Note how detailed it is. The signature contains 11 attributes that cover all aspects: method, path, headers, and a payload. Such a level of granularity and reaction time is not feasible neither for volumetric vectors nor a SOC operator armed with a regex engine. Once a signature is generated App Protect DoS reduces the scope of mitigation to only requests that match the signature. It eliminates a chance to affect good traffic at all. Matching traffic receives a redirect and then a challenge in case if an attacker is smart enough to follow redirects. After few minutes of observation App Protect DoS identifies bad actors since most of the requests come from the same IP addresses (right-bottom chart). Then switches mitigation to bad actor challenge. Despite this measure hits all the same traffic it allows App Protect DoS to protect itself. It takes much fewer CPU cycles to identify a target by IP address than match requests against the signature with 11 attributes. From now on App Protect DoS continues with the most efficient protection until attack traffic stops and server stress goes away. The technology overview and the demo above expose only a tiny bit of App Protect DoS protection logic. A whole lot of it engages for more complicated attacks. However, the results look impressive. None of the volumetric protection mechanisms or even a human SOC operator can provide such accurate mitigation within such a short reaction time. It is only possible when a machine fights a machine.4.2KViews1like3Comments
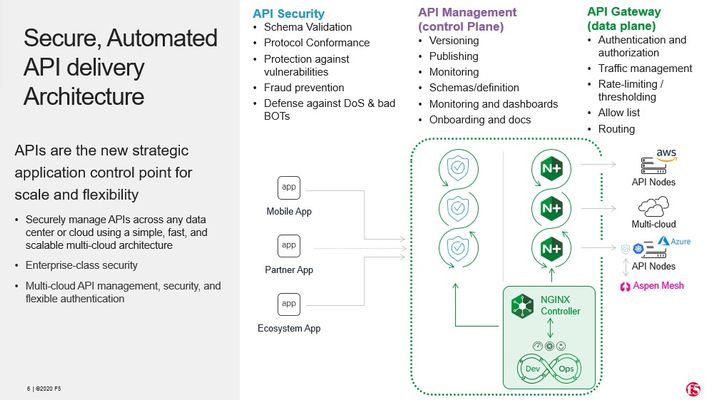
F5 powered API security and management
Editor's Note:The F5 Beacon capabilities referenced in this article hosted on F5 Cloud Services are planning a migration to a new SaaS Platform - Check out the latesthere. Introduction Application Programming Interfaces (APIs) enable application delivery systems to communicate with each other. According to a survey conducted by IDC, security is the main impediment to delivery of API-based services.Research conducted by F5 Labs shows that APIs are highly susceptible to cyber-attacks. Access or injection attacks against the authentication surface of the API are launched first, followed by exploitation of excessive permissions to steal or alter data that is reachable via the API.Agile development practices, highly modular application architectures, and business pressures for rapid development contribute to security holes in both APIs exposed to the public and those used internally. API delivery programs must include the following elements : (1) Automated Publishing of APIs using Swagger files or OpenAPI files, (2) Authentication and Authorization of API calls, (3) Routing and rate limiting of API calls, (4) Security of API calls and finally (5) Metric collection and visualization of API calls.The reference architecture shown below offers a streamlined way of achieving each element of an API delivery program. F5 solution works with modern automation and orchestration tools, equipping developers with the ability to implement and verify security at strategic points within the API development pipeline. Security gets inserted into the CI/CD pipeline where it can be tested and attached to the runtime build, helping to reduce the attack surface of vulnerable APIs. Common Patterns Enterprises need to maintain and evolve their traditional APIs, while simultaneously developing new ones using modern architectures. These can be delivered with on-premises servers, from the cloud, or hybrid environments. APIs are difficult to categorize as they are used in delivering a variety of user experiences, each one potentially requiring a different set of security and compliance controls. In all of the patterns outlined below, NGINX Controller is used for API Management functions such as publishing the APIs, setting up authentication and authorization, and NGINX API Gateway forms the data path.Security controls are addressed based on the security requirements of the data and API delivery platform. 1.APIs for highly regulated business Business APIs that involve the exchange of sensitive or regulated information may require additional security controls to be in compliance with local regulations or industry mandates.Some examples are apps that deliver protected health information or sensitive financial information.Deep payload inspection at scale, and custom WAF rules become an important mechanism for protecting this type of API. F5 Advanced WAF is recommended for providing security in this scenario. 2.Multi-cloud distributed API Mobile App users who are dispersed around the world need to get a response from the API backend with low latency.This requires that the API endpoints be delivered from multiple geographies to optimize response time.F5 DNS Load Balancer Cloud Service (global server load balancing) is used to connect API clients to the endpoints closest to them.In this case, F5 Cloud Services Essential App protect is recommended to offer baseline security, and NGINX APP protect deployed closer to the API workload, should be used for granular security controls. Best practices for this pattern are described here. 3.API workload in Kubernetes F5 service mesh technology helps API delivery teams deal with the challenges of visibility and security when API endpoints are deployed in Kubernetes environment. NGINX Ingress Controller, running NGINX App Protect, offers seamless North-South connectivity for API calls. F5 Aspen Mesh is used to provide East-West visibility and mTLS-based security for workloads.The Kubernetes cluster can be on-premises or deployed in any of the major cloud provider infrastructures including Google’s GKE, Amazon’s EKS/Fargate, and Microsoft’s AKS. An example for implementing this pattern with NGINX per pod proxy is described here, and more examples are forthcoming in the API Security series. 4.API as Serverless Functions F5 cloud services Essential App Protect offering SaaS-based security or NGINX App Protect deployed in AWS Fargate can be used to inject protection in front of serverless API endpoints. Summary F5 solutions can be leveraged regardless of the architecture used to deliver APIs or infrastructure used to host them.In all patterns described above, metrics and logs are sent to one or many of the following: (1) F5 Beacon (2) SIEM of choice (3) ELK stack.Best practices for customizing API related views via any of these visibility solutions will be published in the following DevCentral series. DevOps can automate F5 products for integration into the API CI/CD pipeline.As a result, security is no longer a roadblock to delivering APIs at the speed of business. F5 solutions are future-proof, enabling development teams to confidently pivot from one architecture to another. To complement and extend the security of above solutions, organizations can leverage the power of F5 Silverline Managed Services to protect their infrastructure against volumetric, DNS, and higher-level denial of service attacks.The Shape bot protection solutions can also be coupled to detect and thwart bots, including securing mobile access with its mobile SDK.790Views2likes0CommentsSecuring APIs with BigIP
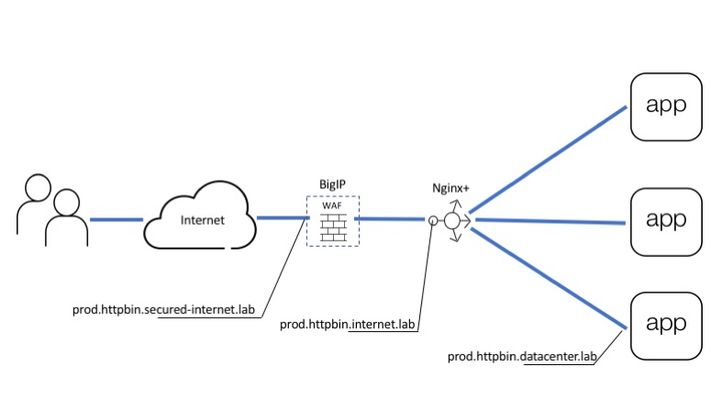
Introduction API servers respond to requests using the HTTP protocol, much like Web Servers. Therefore, API servers are susceptible to HTTP attacks in ways similar to Web Servers. Previous articles covered how to publish an API using the NGINX platform as an API management gateway. These APIs are still exposed to web attacks and defensive mechanisms are needed to defend the API against web attacks, denial of service, and Bots.The diagram below shows all the layers needed to deliver and defend APIs. BIGIP provides the protection and NGINX Plus provides API management. Picture 1. This article covers Advanced Web Application Firewall (AWAF) to protect against HTTP vulnerabilities Unified Bot Defense to protect against bots Behavioral Anomaly DoS Defense to prevent DoS attacks As shown in Picture 1, above BIG-IP goes in front of the API management gateway as an additional security gateway. The beauty of this approach is that BIG-IP can be initially deployed on the side while the API is being delivered to users through the NGINX Plus gateway directly. Once BIG-IP is configured to forward good requests to NGINX Plus and security policies are in place, BIG-IP can be brought into the traffic flow by simply changing the DNS records for "prod.httpbin.internet.lab" to point to BIG-IP instead of NGINX Plus. From this point on all calls will automatically arrive at BIG-IP for inspection and only those that pass all verifications will be forwarded to the next layer. Configuring Data Path Data path configuration for this use case is pretty common for BIG-IP which is historically a load balancer. It includes: Virtual Server (listens for API calls) SSL profile (defines SSL settings) SSL certificate and key (cryptographically identifies virtual server) Pool (destination for passed calls) Picture below shows how all of the configuration pieces work together. Picture 3. At first upload server certificate and key Setup SSL profile to use a certificate from the previous step Finally, create a virtual server and a pool to accept API calls and forward them to the backend From this point IG-IP accepts all requests which go to "prod.httpbin.secured-internet.lab" hostname and forwards them to API management gateway powered by NGINX Plus. Setting up WAF policy As you may already know every API starts from the OpenAPI file which describes all available endpoints, parameters, authentication methods, etc. This file contains all details related to API definition and it is widely used by most tools including F5's WAF for self-configuration. Imported OpenAPI file automatically configures policy with all API specific parameters as a list of allowed URLs, parameters, methods, and so on. Therefore WAF configuration narrows down to importing OpenAPI file and using policy template for API security. Create a policy Specify policy name, template, swagger file, virtual server and logging profile. API security template pre-configures WAF policy with all necessary violations and signatures to protect API backend. OpenAPI file introduces application-specific configuration to a policy as a list of allowed URLs, parameters, and methods. That is it. WAF policy is configured and assigned to the virtual server. Now we can test that only legitimate requests to allowed resources go through. For example request to URL which does not exist in the policy will be blocked: ubuntu@ip-10-1-1-7:~$ http -v https://prod.httpbin.secured-internet.lab/urldoesntexist GET /urldoesntexist HTTP/1.1 Accept: */* Accept-Encoding: gzip, deflate Connection: keep-alive Host: prod.httpbin.secured-internet.lab User-Agent: HTTPie/0.9.2 HTTP/1.1 403 Forbidden Cache-Control: no-cache Connection: close Content-Length: 38 Content-Type: application/json; charset=utf-8 Pragma: no-cache { "supportID": "1656927099224588298" } Request with SQL injection also blocked: Configuring Bot Defense Starting from BIG-IP release 14.1 proactive bot defense, web scraping, and bot detection features are combined under Bot Defense profile. Therefore current bot defense forms a unified tool to prevent all types of bots from accessing your web asset. Bot detection and mitigation mechanisms heavily rely on signatures and javascript (JS) based challenges. JS challenges run in a client browser and help to identify client type/malicious activities or apply mitigation by injecting a CAPTCHA or slowing down a client by making a browser perform a heavy calculation. Since this article is focused on protecting APIs it is important to note that JS challenges need to be used with caution in this case. Keep in mind that robots might be legitimate users for an API. However, robots similar to bots can not execute javascript. So when a robot receives JS it considers JS as API response. Such response does not align with what a robot expects and the application may break. If you know an API is serving automated processes avoid the use of JS-based challenges or test every JS-based feature in the staging environment first. Configuration to detect and handle many different types of Bots can be simplified by using any of the three pre-configured security modes: Relaxed (Challenge free, mitigates only 100% bad bots based on signatures ) Balanced (Let suspicious clients prove good behavior by executing JS challenges or solving CAPTCHA) Strict (Blocks all kinds of bots, verifies browsers, and collects device id from all clients) It is best to start with the relaxed template and tighten up the configuration as familiarity grows with the traffic that the API endpoints see. Once the profile is created assign it to the same virtual server at "Local Traffic ›› Virtual Servers : Virtual Server List ›› prod.httpbin.secured-internet.lab ›› Security" page. Such configuration performs bot detection based on data that is available in requests such as URL, user-agent, or header order. This mode is safe for all kinds of API users (browser-based or code-based robots) and you can see transaction outcome on "Security ›› Event Logs : Bot Defense : Bot Requests" page. If there are false positives you can adjust bot status or create a new trusted one for your robots through "Security ›› Bot Defense : Bot Signatures : Bot Signatures List". Setting Up DDoS Defense WAF and BOT defenses can detect requests with attack signatures or requests that are generated by malicious clients. However, attackers can send attacks composed of legitimate requests at a high scale, that can bring down an API endpoint. The following features present in the BIG-IP can be used to defeat Denial of Service attacks against API endpoints. Transaction per second (TPS) Based DoS Defense Stress Based DoS Defense Behavioral Anomaly Based DoS Defense Eviction Policies TPS-based DoS defense is the most straightforward protection mechanism. In this mode, BigIP measures requests rate for parameters such as Source IP, URL, Site, etc. In case the per minute rate becomes higher than the configured threshold then the attack gets triggered, and selected mitigation modes are applied to ‘all’ requests identified by the parameter. The stress-based mode works similarly to TPS, but instead of applying mitigation right after the threshold is crossed it only mitigates when the protected asset is under stress. This approach significantly reduces false positives. Behavioral anomaly detection (BADoS) mode offers the most advanced security and accuracy. This mode does not require the administrator to perform any configuration, other than turning the feature on. A machine learning algorithm is used to detect whether the protected asset is under attack or not. Another machine learning algorithm is used to baseline the traffic in peacetime. When the ‘attack detector algorithm’ identifies that the protected asset is under stress and non-responsive, then the second algorithm stops learning and looks for anomalies. Signatures matching these anomalies are automatically created. Anomalies discovered during attack time are likely nefarious and are eliminated from the traffic by application of dynamically discovered signatures. BADoS will automatically build a good traffic baseline, detect anomalies and stop them if the API endpoint is under stress. Conclusion F5 offers a multi-layered solution for protecting APIs, which is easy to configure.Please connect with me via comments and keep an eye on more articles in this series. Good luck!3.4KViews2likes2CommentsCloud Template for App Protect WAF
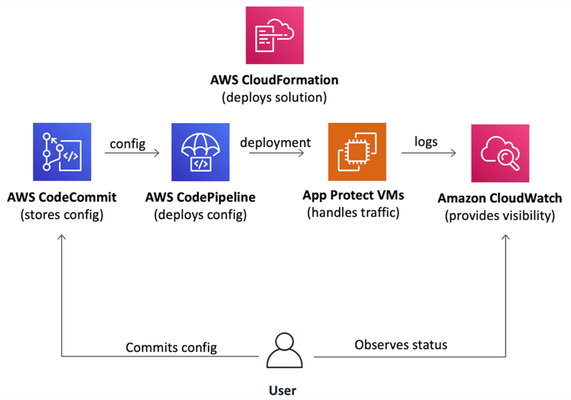
Introduction Everybody needs a WAF. However, when it gets to a deployment stage a team usually realizes that production-grade deployment going to be far more complex than a demo environment. In the case of a cloud deployment VPC networking, infrastructure security, VM images, auto-scaling, logging, visibility, automation, and many more topics require detailed analysis. Usually, it takes at least a few weeks for an average team to design and implement a production-grade WAF in a cloud. That is the one side of the problem. Additionally, cloud deployment best practices are the same for everyone, therefore most of well-made WAF deployments follow a similar path and become similar at the end. The statements above bring us to an obvious conclusion that proper WAF deployment can be templatized. So a team doesn’t spend time on deployment and maintenance but starts to use a WAF from day zero. The following paragraphs introduce a project that implements a Cloud Formation template to deploy production-grade WAF in AWS cloud just in a few clicks. Project (GitHub) On a high level, the project implements a Cloud Formation template that automatically deploys a production-grade WAF to AWS cloud. The template aims to follow cloud deployment best practices to set up a complete solution that is fully automated, requires minimum to no infrastructure management, therefore, allows a team to focus on application security. The following picture represents the overall solution structure. The solution includes a definition of three main components. Auto-scalingdata planebased on official NGINX App Protect AWS AMI images. Git repository as the source of data plane and securityconfiguration. Visibilitydashboards displaying the WAF health and security data. Therefore it becomes a complete and easy-to-use solution to protect applications whether they run in AWS or in any other location. Data Plane: Data plane auto-scales based on the amount of incoming traffic and uses official NGINX App Protect AWS AMIs to spin up new VM instances. That removes the operational headache and optimizes costs since WAF dynamically adjusts the amount of computing resources and charges a user on an as-you-go basis. Configuration Plane: Solution configuration follows GitOps principles. The template creates the AWS CodeCommit git repository as a source of forwarding and security configuration. AWS CodeDeploy pipeline automatically delivers a configuration across all data plane VMs. Visibility: Alongside the data plane and configuration repository the template sets up a set of visibility dashboards in AWS CloudWatch. Data plane VMs send logs and metrics to CloudWatch service that visualizes incoming data as a set of charts and tables showing WAF health and security violations. Therefore these three components form a complete WAF solution that is easy to deploy, doesn't impose any operational headache and provides handy interfaces for WAF configuration and visibility right out of the box. Demo As mentioned above, one of the main advantages of this project is the ease of WAF deployment. It only requires downloading the AWS CloudFormation template file from the project repository and deploy it whether via AWS Console or AWS CLI. Template requests a number of parameters, however, all they are optional. As soon as stack creation is complete WAF is ready to use. Template outputs contain WAF URL and pointer to configuration repository. By default the WAF responds with static page. As a next step, I'll put this cloud WAF instance in front of a web application. Similar to any other NGINX instance, I'll configure it to forward traffic to the app and inspect all requests with App Protect WAF. As mentioned before, all config lives in a git repo that resides in the AWS CodeCommit service. I'm adjusting the NGINX configuration to forward traffic to the protected application. Once committed to the repo, a pipeline delivers the change to all data plane VMs. Therefore all traffic redirects to a protected application (screenshot below is not of a real company, and used for demo purposes only). Similar to NGINX configuration App Protect policy resides in the same repository. Similarly, all changes reflect running VMs. Once the configuration is complete, a user can observe system health and security-related data via pre-configured AWS CloudWatch dashboards. Outline As you can see, the use of a template to deploy a cloud WAF allows to significantly reduce time spent on WAF deployment and maintenance. Handy interfaces for configuration and visibility turn this project into a boxed solution allowing a user to easily operate a WAF and focus on application security. Please comment if you find useful to have this kind of solution in major public clouds marketplaces. It is a community project so far, and we need as much feedback as possible to steer one properly. Feel free to give it a try and leave feedback here or at the project's git repository. P.S.: Take a look to another community project that contributes to F5 WAF ecosystem: WAF Policy Editor639Views3likes0CommentsSecuring GraphQL with Advanced WAF declarative policies
While REST has become the industry standard for designing Web APIs, GraphQL is rising in popularity as a more flexible and efficient alternative. Problem statement Similarly to REST, GraphQL is usually served over HTTP and is prone to the typical Web APIs security vulnerabilities, such as injection attacks, Denial of Service (DoS) attacks and abuse of flawed authorization. However, the mitigation strategies required to prevent a security breach of the GraphQL server must be specifically tailored to GraphQL. Unlike REST, where Web resources are identified by multiple URLs, GraphQL server operates on a single URL. Therefore, Web Application Firewalls (WAFs) configured to filter traffic based on URLs and query strings would not effectively protect GraphQL app. Instead, WAF policies for GraphQL must analyze and operate on the query level. In addition, GraphQL allows batching multiple queries in a single network call, which makes possible a batching attack specific to GraphQL. Proposed solution BIG-IP Advanced WAF has a number of features specifically designed for securing GraphQL APIs: A GraphQL Security Policy Template that enables quick deployment of GraphQL WAF policies A GraphQL Content Profile that groups all the relevant configurations relevant to GraphQL Support for the most common GraphQL use cases, where JSON payload is sent over POST (body) or GET (URL parameter) requests Native parsing of GraphQL enables the application of attack signature against each JSON field, with very low rate of false positives Protection against complexity-based Denial of Service attacks by allowing the configuration of a maximum depth of queries Support for enforcing the best practices of deployment GraphQL APIs with disabled introspection, which is the primary way for attackers to understand the API specification and tailor their attacks accordingly An option to control the number of allowed batched requests GraphQL-specific security violations allowing the fine tuning of the WAF policy Example configuration GraphQL configuration of the WAF policy can be done through the GUI or programatically, through the declarative policy model, allowing easy integration in automated environments that leverage, for example, CI/CD tools. As an example, below is a basic GraphQL declarative policy, demonstrating some of the features listed above: { "policy" : { "applicationLanguage" : "utf-8", "caseInsensitive" : false, "description" : "WAF Policy with GraphQL Profile", "enablePassiveMode" : false, "enforcementMode" : "blocking", "signature-settings": { "signatureStaging": false }, "filetypes" : [ { "allowed" : true, "checkPostDataLength" : true, "checkQueryStringLength" : true, "checkRequestLength" : true, "checkUrlLength" : true, "name" : "php", "performStaging" : true, "postDataLength" : 1000, "queryStringLength" : 1000, "requestLength" : 5000, "responseCheck" : false, "type" : "explicit", "urlLength" : 100 } ], "fullPath" : "/Common/waf_policy_withgraphql", "graphql-profiles" : [ { "attackSignaturesCheck" : true, "defenseAttributes" : { "allowIntrospectionQueries" : true, "maximumBatchedQueries" : 10, "maximumStructureDepth" : 10, "maximumTotalLength" : 100000, "maximumValueLength" : 10000, "tolerateParsingWarnings" : true }, "description" : "", "metacharElementCheck" : false, "name" : "graphql_profile" } ], "name" : "waf_policy_withgraphql", "protocolIndependent" : false, "softwareVersion" : "16.1.0", "template" : { "name" : "POLICY_TEMPLATE_GRAPHQL" }, "type" : "security", "urls" : [ { "attackSignaturesCheck" : true, "clickjackingProtection" : false, "description" : "", "disallowFileUploadOfExecutables" : false, "html5CrossOriginRequestsEnforcement" : { "enforcementMode" : "disabled" }, "isAllowed" : true, "mandatoryBody" : false, "method" : "*", "methodsOverrideOnUrlCheck" : false, "name" : "/graphql", "performStaging" : false, "protocol" : "https", "type" : "explicit", "urlContentProfiles" : [ { "contentProfile" : { "name" : "graphql_profile" }, "headerName" : "*", "headerOrder" : "default", "headerValue" : "*", "type" : "graphql" } ] } ] } } Conclusion As the adoption of GraphQL increases, so is the likelihood of emergence of security threats tailored for this (comparatively) new Web API technology. The features present in Advanced WAF enable a solid response against GraphQL-specific attacks, while allowing for integration in the most advanced CI/CD-driven environments. Other resources UDF lab: AWAF advanced security for GraphQL in CI/CD pipeline Many thanks to Serge Levin for his contribution to this article.2.2KViews3likes1CommentIntegrating NGINX Controller API Management with PingFederate to secure financial services API transactions
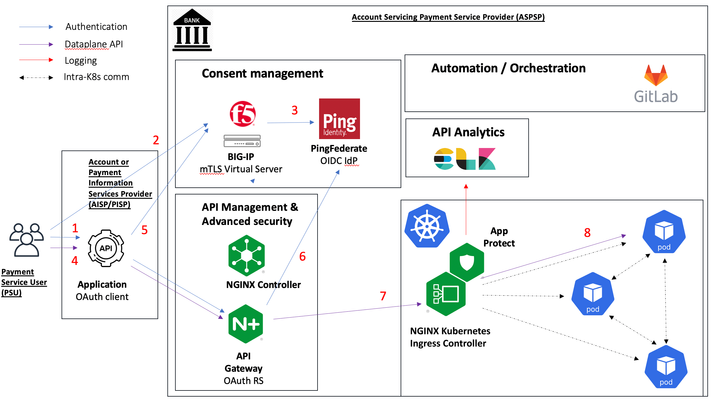
Introduction The previous article in the "Securing financial services APIs" series, "Using NGINX Controller API Management Module and NGINX App Protect to secure financial services API transactions", described a setup where NGINX Controller APIm, acting as an OAuth Resource Server, was using F5's APM as an OIDC IdP / OAuth Autorization Server in an OAuth/OIDC authentication flow. The current article explores the integration of NGINX Controller APIm with PingFederate, one of the market leading identity management solutions, in a similar setup. Ping Identity has partnered with OBIE (Open Banking Implementation Entity) the body responsible for UK Open Banking implementation as a response to EU's PSD2 directive and, as such, it acquired a front seat in the development of Open Banking initiative, one of the most mature examples of financial service API. Ping Identity technology is also Financial-Grade API (FAPI) compliant, supporting the features critical in ensuring higher security for financial API transactions, while maintaining seamless user experience and ease of configuration. Ping Identity's PDS2 & Open Banking technical solution guide can be found here, while this article focusses primarily on the ease of configuration of NGINX Controller APIm to interact with PingFederate solution in a basic financial services API scenario. Setup For demo purposes, as a backend banking application we used a server stub generated from UK Open Banking's OpenAPI spec deployed in a Kubernetes environment, having NGINX App Protect deployed on Kubernetes Ingress controller as an API WAF. The API Gateway and API Management function is implemented by NGINX API Gateway and NGINX Controller APIm, placed in front of the Kubernetes environment. The configuration of all the above (backend server, NAP/KIC and NGINX APIm) is managed through a CI/CD pipeline configured in Gitlab, simulating a modern application development environment. Authentication and API flow This demo is implementing the Authorization Code flow to enable a "domestic payment" transaction. Summarising the steps of the authentication and API flow (refer to the setup diagram above): 1. The user logs into the Third Party Provider application ("client") and creates a new funds transfer 2. The TPP application redirects the user to the OAuth Authorization Server / OIDC IdP - PingFederate 3. The user provides its credentials to PingFederate and gets access to the consent management screen where the required "payments" scope will be listed 4. If the user agrees to give consent to the TPP client to make payments out of his/her account, PingFederate will generate an authorization code (and an ID Token) and redirect the user to the TPP client 5. The TPP client exchanges the authorization code for an access token and attaches it as a bearer token to the /domestic-payments call sent to the API gateway 6. The API Gateway authenticates the access token by downloading the JSON Web Keys from PingFederate and grants conditional access to the backend application 7. The Kubernetes Ingress receives the API call and performs WAF security checks via NGINX App Protect 8. The API call is forwarded to the backend server pod NGINX APIm configuration In this scenario, NGINX APIm is performing the Resource Server OAuth role, where it downloads the JWKs from the OAuth Authorization Server / OIDC IdP (PingFederate) and checks the authenticity of the access token presented in the API call. Additionally, it may apply further checks to conditionally grant access to the application - in this demo it will check for the presence of the "payments" scope. The NGINX APIm configuration is straightforward and consists of two steps: 1. Configuring the IdP Go to Services => Identity Providers and click on Create identity Providers. Fill in the mandatory parameters Name, Environment and Type (JWT). Enter the JWKs URL location and the caching duration. 2. Configuring the OAuth authorization and conditional access criteria Go to Services =>APIs , select an API Definition and edit the associated Published API. Navigate to Routing and edit the Component to be protected, navigating to Security/Authentication. Select the previously created Identity Provider and optionally enable conditional access. As an example, access is granted if "payments" is one of the scopes found in the access token. Conclusion NGINX APIm offers a very simple yet granular way of configuring NGINX API Gateway as an OAuth Resource Server and allows the integration with an industry-leading IAM solution, PingFederate, to protect financial services API transactions. Links UDF lab environment link.756Views1like0CommentsProtecting gRPC based APIs with NGINX App Protect
gRPC support on NGINX Developed back in 2015, gRPC keeps attracting more and more adopters due to the use of HTTP/2.0 as efficient transport, tight integration with interface description language (IDL), bidirectional streaming, flow control, bandwidth effective binary payload, and a lot more other benefits. About two years ago NGINX started to support gRPC (link) as a gateway. However, the market quickly realized that (like any other gateway)it is subject to cyber-attacks and requires strong defense. As a response for such challenges, App Protect WAF for NGINX just released a compelling set of security features to defend gRPC based services. gRPC Security It is afact that App Protect for NGINX provides much more advanced security and performance than any ModSecurity based WAFs (most of the WAF market). Hence, even before explicit gRPC support, App Protect armory in conjunction with NGINX itself could protect web services from a wide variety of threats like: Injection attacks Sensitive data leakage OS Command execution Buffer Overflow Threat Campaigns Authentication attacks Denial-of-service and more (link) With gRPC support, App Protect provides an even deeper level of security. The newly added gRPC content profile allows to parse binary payload, make sure there is no malicious data, and ensures its structure conforms to interface definition (protocol buffers) (link). gRPC Profile Similar to JSON and XML profiles gRPC profile attaches to a subset of URLs and serves to define and enforce a payload structure. gRPC profile extracts application URLs and request/response structures from Interface Definition Language (IDL) file. IDL file is a mandatory part of every gRPC based application. Following policy listing shows an example of referencing the IDL file from a gRPC profile. { "policy": { "name": "online-boutique-policy", "grpc-profiles": [ { "name": "hipstershop-grpc-profile", "defenseAttributes": { "maximumDataLength": 100, "allowUnknownFields": true }, "idlFiles": [ { "idlFile": { "$ref": "file:///hipstershop/demo.proto" }, "isPrimary": true } ] ...omitted... } ], ...omitted... } } gRPC profile references the IDL file to extract all required data to instantiate a positive security model. This means that all URLs and payload formats from it will be considered as valid and pass. To catch anomalies in the gRPC traffic, App Protect introduces three kinds of violations. Requests that don't match IDL trigger "VIOL_GRPC_MALFORMED" or "VIOL_GRPC_METHOD". Requests with unknown or longer than allowed fields cause "VIOL_GRPC_FORMAT" violation. In addition to the above checkups, App Protect looks up signatures or disallowed meta characters in gRPC data. Because of this, it protects applications from a wide variety of attacks that worked for plain HTTP traffic. The following listing gives an example of signatures and meta characters enforcement in gRPS profile (docs). "grpc-profiles": [ { "name": "online-boutique-profile", "attackSignaturesCheck": true, "signatureOverrides": [ { "signatureId": 200001213, "enabled": false }, { "signatureId": 200089779, "enabled": false } ], "metacharCheck": true, ...omitted... } ], Example Sandbox Here is an example of how to configure NGINX as a gRPC gateway and defend it with the App Protect. As a demo application, I use "Online Boutique" (link). This application consists of multiple micro-services that talk to each other in gRPC. The picture below represents the structure of entire application. Picture 1. I slightly modified the application deployment such that the frontend doesn't talk to micro-services directly but through NGINX gateway that proxies all calls. Picture 2. Before I jump to App Protect configuration, here is how NGINX config looks like for proxying gRPC services. http { include /etc/nginx/mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; include /etc/nginx/conf.d/upstreams.conf; server { server_name boutique.online; listen 443 http2 ssl; ssl_certificate /etc/nginx/ssl/nginx.crt; ssl_certificate_key /etc/nginx/ssl/nginx.key; ssl_protocols TLSv1.2 TLSv1.3; include conf.d/errors.grpc_conf; default_type application/grpc; app_protect_enable on; app_protect_policy_file "/etc/app_protect/conf/policies/online-boutique-policy.json"; app_protect_security_log_enable on; app_protect_security_log "/opt/app_protect/share/defaults/log_grpc_all.json" stderr; include conf.d/locations.conf; } } The listing above is self-explaining. NGINX virtual server "boutique.online" listens on port 443 for HTTP2 requests. Requests are routed to one of a micro-service from "upstreams.conf" based on the map defined in "locations.conf". Below are examples of these config files. $ cat conf.d/locations.conf upstream adservice { server 10.101.11.63:9555; } location /hipstershop.CartService/ { grpc_pass grpc://cartservice; } ...omitted... $ cat conf.d/uptsreams.conf location /hipstershop.AdService/ { grpc_pass grpc://adservice; } upstream cartservice { server 10.99.75.80:7070; } ...omitted... For instance, any call with URL starting from "/hipstershop.AdService" is routed to "adservice" upstream and so on. For more details on NGINX configuration for gRPC refer to this blog article or official documentation. App Protect is enabled on the virtual server. Hence, all requests are subject to inspection. Let's take a closer look at the security policy applied to the virtual server above. { "policy": { "name": "online-boutique-policy", "grpc-profiles": [ { "name": "online-boutique-profile", "idlFiles": [ { "idlFile": { "$ref": "https://raw.githubusercontent.com/GoogleCloudPlatform/microservices-demo/master/pb/demo.proto" }, "isPrimary": true } ] "associateUrls": true, "defenseAttributes": { "maximumDataLength": 10000, "allowUnknownFields": false }, "attackSignaturesCheck": true, "signatureOverrides": [ { "signatureId": 200001213, "enabled": true }, { "signatureId": 200089779, "enabled": true } ], "metacharCheck": true, } ], "urls": [ { "name": "*", "type": "wildcard", "method": "*", "$action": "delete" } ] } } The policy has one gRPC profile called "online-boutique-profile". Profile references IDL file for the demo application (similar to open API file reference) as a source of the application structure. "associateUrls: true" directive instructs App Protect to extract all possible URLs from IDL file and enforce parent profile on them. Notice URL section removes wildcard URL "*" from the policy to only allow URLs that are in IDL and therefore establish a positive security model. "defenseAttributes" directive enforces payload length and tolerance to unknown parameters. "attackSignaturesCheck" and "metaCharactersCheck" directives look for a malicious pattern in the entire request. Now let's see what does this policy block and pass. Experiments First of all, let's make sure that valid traffic passes. As an example, I construct a valid call to "Ads" micro-service based on IDL content below. syntax = "proto3"; package hipstershop; service AdService { rpc GetAds(AdRequest) returns (AdResponse) {} } message AdRequest { repeated string context_keys = 1; } Based on the definition above a valid call to the service should go to "/hipstershop.AdService/GetAds" URL and contain "context_keys" identifiers in a payload. I use the "grpcurl" tool to construct and send the call that passes. $ grpcurl -proto ../microservices-demo/pb/demo.proto -d '{"context_keys": "example"}' boutique.online:8443 hipstershop.AdService/GetAds { "ads": [ { "redirectUrl": "/product/2ZYFJ3GM2N", "text": "Film camera for sale. 50% off." }, { "redirectUrl": "/product/0PUK6V6EV0", "text": "Vintage record player for sale. 30% off." } ] } As you may note, the URL constructs out of package name, service name, and method name from IDL. Therefore it is expected that all calls which don't comply IDL definition will be blocked. A call to invalid service. $ curl -X POST -k --http2 -H "Content-Type: application/grpc" -H "TE: trailers" https://boutique.online:8443/hipstershop.DoesNotExist/GetAds <html><head><title>Request Rejected</title></head><body>The requested URL was rejected. Please consult with your administrator.<br><br>Your support ID is: 16472380185462165521<br><br><a href='javascript:history.back();'>[Go Back]</a></body></html> A call to an unknown service. Notice that the previous call got "html" response page when this one got a special "grpc" response. This happened because only valid URLs considered as type gRPC others are "html" by default. A call to an invalid method. $ curl -v -X POST -k --http2 -H "Content-Type: application/grpc" -H "TE: trailers" https://boutique.online:8443/hipstershop.AdService/DoesNotExist < HTTP/2 200 < content-type: application/grpc; charset=utf-8 < cache-control: no-cache < grpc-message: Operation does not comply with the service requirements. Please contact you administrator with the following number: 16472380185462166031 < grpc-status: 3 < pragma: no-cache < content-length: 0 A call with junk in the payload. curl -v -X POST -k --http2 -H "Content-Type: application/grpc" -H "TE: trailers" https://boutique.online:8443/hipstershop.AdService/GetAds -d@trash_payload.bin < HTTP/2 200 < content-type: application/grpc; charset=utf-8 < cache-control: no-cache < grpc-message: Operation does not comply with the service requirements. Please contact you administrator with the following number: 13966876727165538516 < grpc-status: 3 < pragma: no-cache < content-length: 0 All gRPC wise invalid calls are blocked. In the same way attack signatures are caught in gRPC payload ("alert() (Parameter)" signature). $ grpcurl -proto ../microservices-demo/pb/demo.proto -d '{"context_keys": "example"}' boutique.online:8443 hipstershop.AdService/GetAds { "ads": [ { "redirectUrl": "/product/2ZYFJ3GM2N", "text": "Film camera for sale. 50% off." }, { "redirectUrl": "/product/0PUK6V6EV0", "text": "Vintage record player for sale. 30% off." } ] } Conclusion With gRPC support App Protect provides even deeper controls for gRPC traffic along with all existing security inventory available for plain HTTP traffic. Keep in mind that this release only supports Unary gRPC traffic and doesn't support the server reflection feature. Refer to the official documentation for detailed information on gRPC support (link).1.8KViews2likes0Comments