Back to Basics: The Many Modes of Proxies
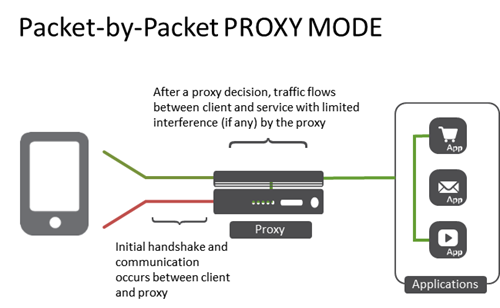
The simplicity of the term "proxy" belies the complex topological options available. Understanding the different deployment options will enable your proxy deployment to fit your environment and, more importantly, your applications. It seems so simple in theory. A proxy is a well-understood concept that is not peculiar to networking. Indeed, some folks vote by proxy, they speak by proxy (translators), and even on occasion, marry by proxy. A proxy, regardless of its purpose, sits between two entities and performs a service. In network architectures the most common use of a proxy is to provide load balancing services to enable scale, reliability and even performance for applications. Proxies can log data exchanges, act as a gatekeeper (authentication and authorization), scan inbound and outbound traffic for malicious content and more. Proxies are a key strategic point of control in the data center because they are typically deployed as the go-between for end-users and applications. These go-between services are often referred to as virtual services, and for purposes of this blog that's what we'll call them. It's an important distinction because a single proxy can actually act in multiple modes on a per-virtual service basis. That's all pretty standard stuff. What's not simple is when you start considering how you want your proxy to act. Should it be a full proxy? A half proxy? Should it route or forward? There are multiple options for these components and each has its pros and cons. Understanding each proxy "mode" is an important step toward architecting a suitable solution for your environment as the mode determines the behavior of traffic as it traverses the proxy. Standard Virtual Service (Full Application Proxy) The standard virtual service provided by a full proxy fully terminates the transport layer connections (typically TCP) and establishes completely separate transport layer connections to the applications. This enables the proxy to intercept, inspect and ultimate interact with the data (traffic) as its flowing through the system. Any time you need to inspect payloads (JSON, HTML, XML, etc...) or steer requests based on HTTP headers (URI, cookies, custom variables) on an ongoing basis you'll need a virtual service in full proxy mode. A full proxy is able to perform application layer services. That is, it can act on protocol and data transported via an application protocol, such as HTTP. Performance Layer 4 Service (Packet by Packet Proxy) Before application layer proxy capabilities came into being, the primary model for proxies (and load balancers) was layer 4 virtual services. In this mode, a proxy can make decisions and interact with packets up to layer 4 - the transport layer. For web traffic this almost always equates to TCP. This is the highest layer of the network stack at which SDN architectures based on OpenFlow are able to operate. Today this is often referred to as flow-based processing, as TCP connections are generally considered flows for purposes of configuring network-based services. In this mode, a proxy processes each packet and maps it to a connection (flow) context. This type of virtual service is used for traffic that requires simple load balancing, policy network routing or high-availability at the transport layer. Many proxies deployed on purpose-built hardware take advantage of FPGAs that make this type of virtual service execute at wire speed. A packet-by-packet proxy is able to make decisions based on information related to layer 4 and below. It cannot interact with application-layer data. The connection between the client and the server is actually "stitched" together in this mode, with the proxy primarily acting as a forwarding component after the initial handshake is completed rather than as an endpoint or originating source as is the case with a full proxy. IP Forwarding Virtual Service (Router) For simple packet forwarding where the destination is based not on a pooled resource but simply on a routing table, an IP forwarding virtual service turns your proxy into a packet layer forwarder. A IP forwarding virtual server can be provisioned to rewrite the source IP address as the traffic traverses the service. This is done to force data to return through the proxy and is referred to as SNATing traffic. It uses transport layer (usually TCP) port multiplexing to accomplish stateful address translation. The address it chooses can be load balanced from a pool of addresses (a SNAT pool) or you can use an automatic SNAT capability. Layer 2 Forwarding Virtual Service (Bridge) For situations where a proxy should be used to bridge two different Ethernet collision domains, a layer 2 forwarding virtual service an be used. It can be provisioned to be an opaque, semi-opaque, or transparent bridge. Bridging two Ethernet domains is like an old timey water brigade. One guy fills a bucket of water (the client) and hands it to the next guy (the proxy) who hands it to the destination (the server/service) where it's thrown on the fire. The guy in the middle (the proxy) just bridges the gap (you're thinking what I'm thinking - that's where the term came from, right?) between the two Ethernet domains (networks).1.9KViews0likes3Comments
The Drive Towards NFV: Creating Technologies to Meet Demand
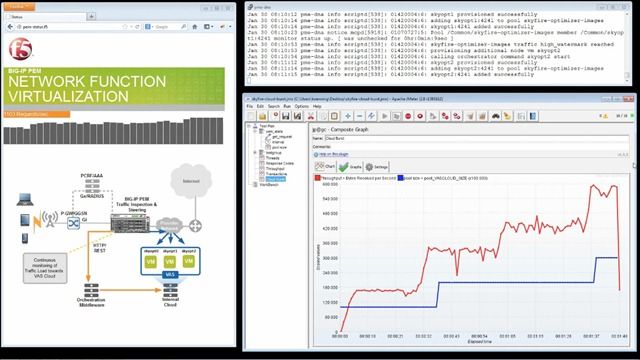
It is interesting to see what is happening in the petroleum industry over time. I won’t get into the political and social aspects of the industry or this will become a 200 page dissertation. What is interesting to me is how the petroleum industry has developed new technologies and uses these technologies in creative ways to gain more value from the resources that are available. Drilling has gone from the simple act of poking a hole in the ground using a tool, to the use of drilling fluids, ‘mud’, to optimize the drilling performance for specific situations, non-vertical directional drilling, where they can actually drill horizontally, and the use of fluids and gases to maximize the extraction of resources through a process called ‘fracking’. What the petroleum industry has done is looked for and created technologies to extract further value from known resources that would not have been available with the tools that were available to them. We see a similar evolution of the technologies used and value extracted by the communications service providers (CSPs). Looking back, CSPs usually delivered a single service such as voice over a dedicated physical infrastructure. Then, it became important to deliver data services and they added a parallel infrastructure to deliver the video content. As costs started to become prohibitive to continue to support parallel content delivery models, the CSPs started looking for ways to use the physical infrastructure as the foundation and use other technologies to drive both voice and data to the customer. Frame relay (FR) and asynchronous transfer mode (ATM) technologies were created to allow for the separation of the traffic at a layer 2 (network) perspective. The CSP is extracting more value from their physical infrastructure by delivering multiple services over it. Then, the Internet came and things changed again. Customers wanted their Internet access in addition to the voice and video services that they currently received. The CSPs evolved, yet again, and started looking at layer 3 (IP) differentiation and laid this technology on their existing FR and ATM networks. Today, mobile and fixed service providers are discovering that managing the network at the layer 3 level is no longer enough to deliver services to their customers, differentiate their offerings, and most importantly, support the revenue cost model as they continue to build and evolve their networks to new models such as 4G LTE wireless and customer usage patterns change. Voice services are not growing while data services are increasing at an explosive rate. Also, the CSPs are finding that much of their legacy revenue streams are being diverted to over-the-top providers that deliver content from the Internet and do not deliver any revenue or value to the CSP. There is Value in that Content The CSPs are moving up the OSI network stack and looking to find value in the layer 4 through 7 content and delivering services that enhance specific types of content and allow subscribers gain additional value through value added services (VAS) that can be targeted towards the subscribers and the content. This means that new technologies such as content inspection and traffic steering are necessary to leverage this function. Unfortunately, there is a non-trivial cost for the capability for the CSP to deliver content and subscriber aware services. These services require significant memory and computing resources. To offset these costs as well as introduce a more flexible dynamic network infrastructure that is able to adapt to new services and evolving technologies, a consortium of CSPs have developed the Network Functions Virtualization (NFV) technology working group. As I mentioned in a previous blog, NFV is designed to virtualize network functions such as the MME, SBC, SGSN/GGSN, and DPI onto an open hardware infrastructure using commercial, off-the-shelf (COTS) hardware. In addition, VAS solutions can leverage this architecture to enhance the customer experience. By using COTS hardware and using virtual/software versions of these functions, the CSP gains a cost benefit and the network becomes more flexible and dynamic. It is also important to remember that one of the key components of the NFV standard is to deliver a mechanism to manage and orchestrate all of these virtualized elements while tying the network elements more closely to the business needs of the operator. Since the services are deployed in a flexible and dynamic way, it becomes possible to deliver a mechanism to orchestrate the addition or removal of resources and services based on network analytics and policies. This flexibility allows operators to add and remove services and adjust capacity as needed without the need for additional personnel and time for coordination. An agile infrastructure enables operators to roll-out new services quicker to meet the evolving market demands, and also remove services, which are not contributing to the company’s bottom line or delivering a measurable benefit to the customer quality of experience, with minimal impact the the infrastructure or investment. Technology to Extract Content and Value Operators need to consider the four key elements to making the necessary application defined network (ADN) successful in an NFV-based architecture: Virtualization, Abstraction, Programmability, and Orchestration. Virtualization provides the foundation for that flexible infrastructure which allows for the standardization of the hardware layer as well as being one of the key enablers for the dynamic service provisioning. Abstraction is a key element because operators need to be able to tie their network services up into the application and business services they are offering to their customers – enabling their processes and the necessarily orchestration. Programmability of the network elements and the NFV infrastructure ensures that the components being deployed can not only be customized and successfully integrated into the network ecosystem, but adapted as the business needs and technology changes. Orchestration is the last key element. Orchestration is where operators will get some of their largest savings by being able to introduce and remove services quicker and broader through automating the service enablement on their network. This enables operators to adjust quicker to the changing market needs while “doing more with less”. As these CSPs look to introduce NFV into their architectures, they need to consider these elements and look for vendors which can deliver these attributes. I will discuss each of these features in more detail in upcoming blog posts. We will look at how these features are necessary to deliver the NFV vision and what this means to the CSPs who are looking to leverage the technologies and architectures surrounding the drive towards NFV. Ultimately, CSPs want a NFV orchestration system enabling the network to add and remove service capacity, on-demand and without human intervention, as the traffic ebbs and flows to those services. This allows the operator to be able to reduce their overall service footprint by re-using infrastructure for different services based upon their needs. F5 is combining these attributes in innovative ways to deliver solutions that enable them to leverage the NFV design. Demo of F5 utilizing NFV technologies to deliver an agile network architecture: Dynamic Service Availability through VAS bursting157Views0likes0CommentsIf apps incur technical debt then networks incur architectural debt
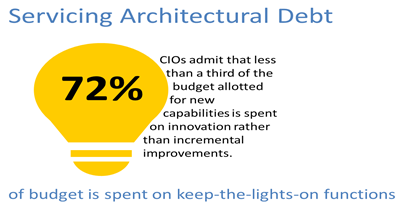
#devops #sdn #SDDC #cloud 72%. That's an estimate of how much of the IT budget is allocated to simply keeping the lights on (a euphemism for everything from actually keeping the lights on to cooling, heating, power, maintenance, upgrades, and day to day operations) in the data center. In a recent Forrester Research survey of IT leaders at more than 3,700 companies, respondents estimated that they spend an average 72% of the money in their budgets on such keep-the-lights-on functions as replacing or expanding capacity and supporting ongoing operations and maintenance, while only 28% of the money goes toward new projects. How to Balance Maintenance and IT Innovation This number will not, unfortunately, significantly improve without intentionally attacking it at its root cause: architectural debt. Data Center Debt The concept of "debt' is not a foreign one; we've all incurred debt in the form of credit cards, car loans and mortgages. In the data center, this concept is applied in much the same way as our more personal debt - as the need to "service" the debt over time. Experts on the topic of technical debt point out that this "debt' is chiefly a metaphor for the long-term repercussions arising from choices made in application architecture and design early on. Technical debt is a neologistic metaphor referring to the eventual consequences of poor software architecture and software development within a codebase. The debt can be thought of as work that needs to be done before a particular job can be considered complete. If the debt is not repaid, then it will keep on accumulating interest, making it hard to implement changes later on. Unaddressed technical debt increases software entropy. Wikipedia This conceptual debt also occurs in other areas of IT, particularly those in the infrastructure and networking groups, where architectural decisions have long lasting repercussions in the form of not only the cost to perform day-to-day operations but in the impact to future choices and operational concerns. The choice of a specific point product today to solve a particular pain point, for example, has an impact on future product choices. The more we move toward software-defined architectures - heavily reliant on integration to achieve efficiencies through automation and orchestration - the more interdependencies we build. Those interdependencies cause considerable complexity in the face of changes that must be made to support such a loosely coupled but highly integrated data center architecture. We aren't just maintaining configuration files and cables anymore, we're maintaining the equivalent of code - the scripts and methods used to integrated, automate and orchestrate the network infrastructure. Steve McConnell has a lengthy blog entry examining technical debt. The perils of not acknowledging your debt are clear: One of the important implications of technical debt is that it must be serviced, i.e., once you incur a debt there will be interest charges. If the debt grows large enough, eventually the company will spend more on servicing its debt than it invests in increasing the value of its other assets. Debt must be serviced, which is why the average organization dedicates so much of its budget to simply "keeping the lights on." It's servicing the architectural debt incurred by a generation of architectural decisions. Refinancing Your Architectural Debt In order to shift more of the budget toward the innovation necessary to realize the more agile and dynamic architectures required to support more things and the applications that go with them, organizations need to start considering how to shed its architectural debt. First and foremost, software-defined architectures like cloud, SDDC and SDN, enable organizations to pay down their debt by automating a variety of day-to-day operations as well as traditionally manual and lengthy provisioning processes. But it would behoove organizations to pay careful attention to the choices made in this process, lest architectural debt shift to the technical debt associated with programmatic assets. Scripts are, after all, a simple form of an application, and thus bring with it all the benefits and burdens of an application. For example, the choice between a feature-driven and an application-driven orchestration can be critical to the long-term costs associated with that choice. Feature-driven orchestration necessarily requires more steps and results in more tightly coupled systems than an application-driven approach. Loose coupling ensures easier future transitions and reduces the impact of interdependencies on the complexity of the overall architecture. This is because feature-driven orchestration (integration, really) is highly dependent on specific sets of API calls to achieve provisioning. Even minor changes in those APIs can be problematic in the future and cause compatibility issues. Application-driven orchestration, on the other hand, presents a simpler, flexible interface between provisioning systems and solution. Implementation through features can change from version to version without impacting that interface, because the interface is decoupled from the actual API calls required. Your choice of scripting languages, too, can have much more of an impact than you might think. Consider that a significant contributor to operational inefficiencies today stems from the reality that organizations have an L4-7 infrastructure comprised of not just multiple vendors, but a wide variety of domain specificity. That means a very disparate set of object models and interfaces through which such services are provisioned and configured. When automating such processes, it is important to standardize on a minimum set of environments. Using bash, python, PERL and juju, for example, simply adds complexity and begins to fall under the Law of Software Entropy as described by Ivar Jacobson et al. in "Object-Oriented Software Engineering: A Use Case Driven Approach": The second law of thermodynamics, in principle, states that a closed system's disorder cannot be reduced, it can only remain unchanged or increased. A measure of this disorder is entropy. This law also seems plausible for software systems; as a system is modified, its disorder, or entropy, always increases. This is known as software entropy. Entropy is the antithesis of what we're trying to achieve with automation and orchestration, namely the acceleration of application deployment. Entropy impedes this goal, and causes the introduction of yet another set of systems requiring day-to-day operational attention. Other considerations include deciding which virtual overlay network will be your data center standard, as well as the choice of cloud management platform for data center orchestration. While such decisions seem, on the surface, to be innocuous, they are in fact significant contributors to the architectural debt associated with the data center architecture. Shifting to Innovation Every decision brings with it debt; that cannot be avoided. The trick is to reduce the interest payments, if you will, on that debt as a means to reduce its impact on the overall IT budget and enable a shift to funding innovation. Software-defined architectures are, in a way, the opportunity for organizations to re-finance their architectural debt. They cannot forgive the debt (unless you rip and replace) but these architectures and methodologies like devops can assist in reducing the operational expenses the organization is obliged to pay on a day-to-day basis. But it's necessary to recognize, up front, that the architectural choices you make today do, in fact, have a significant impact on the business' ability to take advantage of the emerging app economy. Consider carefully the options and weigh the costs - including the need to service the debt incurred by those options - before committing to a given solution. Your data center credit score will thank you for it.378Views0likes1Comment1024 Words: Why application focused networking is easy to say but really hard to do
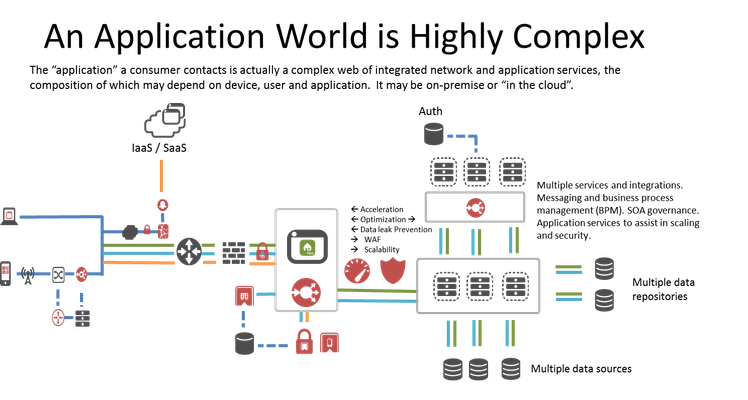
#devops #sdn The world of technology is shifting its center to applications. That means everything from operations to networking is trying to enable a more application-driven or application-aware or application-X model of delivering network and application services. While it looks elegant on a slide comprised of the three "tiers" of an application, the reality is that an application world is highly complex, massively integrated, and very confusing. Not to surprise you, but even this is greatly simplified. The complex web of interconnections that makes up the "middle" tier of an application can be so confusing it requires its own map, which architects often design and tack to walls to be able to see "the big picture" in much the same way DBAs will map out a particularly complex schema to understand the relationships between tables and objects and indexes. The resulting diagram of a real environment would be, by anyone's standards, unreadable in digital format. And that is why it's easy to say, but really super mega ultra hard to do.187Views0likes2CommentsiRules - Is There Anything You Can't Do?
Ex·ten·si·ble (in programming): Said of a system (e.g., program, file format, programming language, protocol, etc.) designed to easily allow the addition of new features at a later date. (from Dictionary.com) Whenever I attend a F5 customer or partner gathering, I always ask of those who use iRules, 'Do you deploy iRules due to BIG-IP not having a particular feature or because you need to solve a specific issue within your unique architecture?' Overwhelmingly, the answer is to address something exclusive to the environment. An iRule is a powerful and flexible feature of BIG-IP devices based on F5's exclusive TMOS architecture. iRules provide customers with unprecedented control to directly manipulate and manage any IP application traffic and enables administrators to customize how you intercept, inspect, transform, and direct inbound or outbound application traffic. iRules is an Event Drivenscripting language which means that you'll be writing code based off of specific Events that occur within the context of the connections being passed through the Virtual IP your iRule is applied to. There are many cool iRule examples on our DevCentral Community site like Routing traffic by URI and even instances where an iRule helped patch an Apache Zero-Day Exploit (Apache Killer) within hours of it being made public and well before the official Apache patch. An iRule was able to mitigate the vulnerability and BIG-IP customers who have Apache web servers were protected. Risk of exploit greatly diminished. Recently our own Joe Pruitt, Sr. Strategic Architect with the DevCentral team, wrote a cool iRule (and Tech Tip) to Automate Web Analytics. Analysis on the usage patterns of site visitors is critical for many organizations. It helps them determine how their website is being utilized and what adjustments are needed to make the experience as best as possible...among many other things. Joe's article discusses how to use an iRule to inject analytics code into HTML responses to enable the automation of analytics into your website software. Adding a certain piece of JavaScript code into each web page that you would like monitored is one option but what happens if the release criteria for application code requires testing and adding content to pages in production is not allowed or multiple products from multiple application groups reside on a given server or even when 3rd party code is present where you don't have access to all the source that controls page generation. If you have BIG-IP fronting your web application servers, then you can add Joe's iRule to inject client side JavaScript into the application stream without the application knowing about it. Joe uses Google Analytics as an example, but, according to Joe, it is fairly easy to replace the content of the "analytics" variable with the replacement code for any other service you might be using. Very cool indeed. So while iRules might not be able to make your coffee in the morning - unless of course it is a slew of IP enabled coffee machines - they can help organizations create extremely agile, flexible and secure environments. Like Oreos and Reese's, there have been a bunch of imitators but nothing is as good as the original. ps Related: Automated Web Analytics iRule Style Routing traffic by URI using iRule iRules | F5 DevCentral The F5 Guy » iRules – Transparent Header Modification F5′s iRules — My first look | Router Jockey iRules Videos Technorati Tags: f5,BIG-IP,iRules,Development,ADN,Monitoring / Management / Automation,Tech Tips,security,analytics,silva,devcentral Connect with Peter: Connect with F5:346Views0likes1CommentSDN: Network Scalability’s Secret Sauce
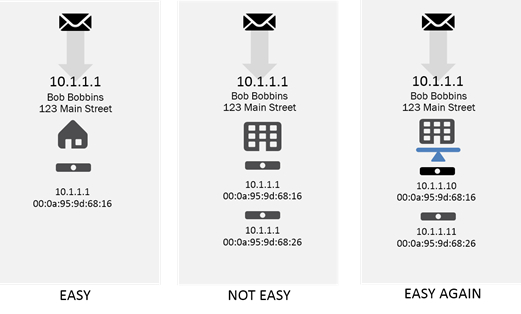
Scaling things seems like such a simple task, doesn’t it? Open a new checkout line. Call a new teller to the front. Hire another person. But under the covers in technology land, where networking standards rule the roost, it really isn’t as simple as just adding another “X”. Oh, we try to make it look that simple, but it’s not. Over the years we (as in the industry ‘we’) have come up with all sorts of interesting ways to scale systems and applications within the constraints that IP networking places upon us. One of those constraints is that physical (L2) and logical (L3) addresses have a one-to-one mapping. Oh, I know it looks like packets are routed based on IP address but really, they aren’t. They’re routed based on physical (MAC) addresses. And every switch (and router) keeps track of that mapping. 10.1.1.1? That goes to physical device A. 10.1.1.2? That goes to physical device B. That makes scalability a lot harder than you might think because horizontal scaling uses clusters of things, all with their own IP-MAC combination. After all, if a user makes a request to 10.0.0.1, it’s going to be mapped somewhere to a single, specific device. When you’re trying to distribute traffic across multiple devices (to scale) means somehow figuring out how to remap those associations. And while you could do that, it would totally destroy network performance and throughput. Think of the router like a building. When it’s a house it probably has one name (logical) and one address (physical). It’s easy to route to it, we know where it is. But if we’re trying to scale up housing, we might replace the house with an apartment building. Now we have one logical (names) going to the multiple physical (address). They can’t all share the same logical address. The post man can get to the right address, but can’t figure out how to find Bob to deliver the mail. So we add a bellman (proxy, load balancer, ADC) to the equation and give him the logical and physical address. All the apartments get their own physical and logical address (like “Apt 3”) and we ask the bellman to deliver the mail to not only Bob but Alice and Mary and Frank, too. We give the bellman a Virtual IP (VIP) address to represent the cluster of “things” (apartments). That’s how we mask the complexity of actually distributing load across multiple devices (servers, apps, instances). That user doesn’t talk directly to any app instance or server; it talks to the VIP, which in turn determines to which instance to forward the request. Because we’re sitting in the middle, we can exploit the one-to-one mapping between the physical and the logical by presenting ourselves as the endpoint and then distribute requests and traffic across a cluster to achieve really high scale of all sorts of things. The IP-MAC association is preserved and there’s no need for tricks to get around it. But (and you knew there was a but coming, didn’t you?) there are times when that one-to-one mapping thing gets in the way. After all, a VIP is still an IP, and it is constrained by the same one-to-one mapping requirement. So when you need to scale the VIP by adding more devices (cause your apartment building is really flourishing and one bellman just isn’t enough anymore), you run into the same problem as we just ran into when we tried to scale the app. To which node in the VIP cluster should traffic be routed? Who gets to hold the VIP address so the upstream router or switch knows where to send those packets? Turns out the solution is similar in nature, we have to go upstream to figure out how to fix it. Except upstream is a standard switch or router that expects –nay, it demands – a one-to-one mapping between physical (L2) and logical (L3) addresses. This is where SDN comes in handy and provides some secret (network) scalability sauce. One of the neat things about OpenFlow-based SDN is its use of OpenFlow and in particular the use of match/action programmability. Rather than hard-coding routes in the configuration, OpenFlow-enabled devices are able to programmatically consult a flow table that allows it to match attributes – like source IP address – with an action, like forwarding to a specific port or changing the destination MAC (physical) address. You see where I’m going with this, right? By taking advantage of this capability we can use an upstream, OpenFlow-enabled SDN switch to change the destination MAC (physical) address based on matching attributes. That means that we can work around that pesky one-to-one mapping problem that might prevent us from scaling out the bellman (proxy). But that’s not all we need. Scalability today is one part technical and another part operational. We can’t maintain operational efficiency if we have to manually adjust flow tables whenever we add (or remove) a proxy based on demand. So we need some magic, and that magic is programmability. Whenever the cluster changes (a proxy is added or removed) we need to be able to update the upstream (SDN) switch so it knows how to distribute traffic to the proxies. To do that, we use programmability to use the control-plane separation inherent in SDN and update the flow tables, keeping them accurate so traffic is directed appropriately automagically. So not only can we increase the size of the apartment building, but we can scale out the number of bellmen we need make sure mail is delivered to the right apartment at the right time. It turns out that in large implementations – like those you might find in a service provider’s network – that this is a really handy thing to be able to do, especially as Network Functions Virtualization (NFV) takes hold and app services are increasingly delivered via virtual appliances. Scalability becomes critical by necessity; virtual appliances are increasing capacity at breakneck speed but still aren’t able to match their purpose-built hardware counterparts. Scale of “the network”, therefore, is key to keeping up with demand and keeping costs down. But to do that requires some magic, and that magic turns out to be SDN. You can dig even deeper into just such a solution by taking a gander at my colleague Christian Koenning’s blog right here on DevCentral, or go straight to the source and check out the iApp/iRule solution we’ve developed to automagically handle this scenario. Happy Scaling!251Views0likes0Comments
F5 BIG-IP OpenStack Integration Available For Download
Last week at the OpenStack Summit in Atlanta, F5 announced OpenStack support for the BIG-IP and BIG-IQ platforms. The first of these integrations, a BIG-IP OpenStack Neutron LBaaS plug-in, is now available for Developer use. The integration supports production ready use cases and provides a comprehensive OpenStack integration with F5’s Software Defined Application Services (SDAS). Why is F5 integrating with OpenStack? F5 has been working with the OpenStack community since 2012. As a OpenStack Foundation sponsor, F5 is excited about creating choice for cloud platform rollouts. We want to ensure that our customers have access to F5 built solutions when evaluating cloud platform integrations. As a result, F5 decided to add OpenStack support based on customer feedback and OpenStack production readiness. What is available for download and do I need a special license to use it? The OpenStack plug-ins are a package of Python scripts that help the OpenStack Controller integrate with the F5 BIG-IP and BIG-IQ platforms. As long as a customer has license for BIG-IP or the BIG-IQ solution, they can use these scripts. No separate license will be required to use the OpenStack plug-ins. The BIG-IP OpenStack Neutron LBaaS integration is now available for download. You can access the plug-in Read Me and get the package for the BIG-IP LBaaS plug-in driver/agent from this download location. The plug-in has been tested with OpenStack HAVANA Release. The LBaaS plug-in for BIG-IQ will be available later this summer.. F5 has also announced an upgrade to the BIG-IQ OpenStack Connector supporting the HAVANA release. The upgraded connector will be released as part of the BIG-IQ Early Access (EA) program later this month and will ship in the BIG-IQ release later this summer. Please contact your regional sales representative to get access via the BIG-IQ EA program. What does the BIG-IP LBaaS plug-in do? The F5 BIG-IP LBaaS plug-in for OpenStack allows Neutron, the networking component of OpenStack, to provision load balancing services on BIG-IP devices or virtual editions, either through the LBaaS API or through the OpenStack dashboard (Horizon). Supported provisioning actions include selecting an LB provider, load balancing method, defining health monitors, setting up Virtual IP addresses (VIP), and putting application instance member pools behind a VIP. This setup will allow F5 customers to seamlessly integrate BIG-IP SDAS into their OpenStack Neutron network layer and load balance their applications running in the OpenStack Nova compute environment. The APIs for the LBaaS plug-in are defined by the OpenStack community. The BIG-IP LBaaS plug-in supports the community API specification. F5 will enhance the plug-in when additional capabilities are defined in future versions of OpenStack. What Use Cases does the LBaaS plug-in support? The five example use cases described below help demonstrate the flexibility of F5’s support for OpenStack. The scenarios described below are production quality use cases, with detailed videos available on this OpenStack DevCentral Community and on F5’s YouTube Channel. Use Case 1: Extend an existing Data Center network into an OpenStack Cloud Video: https://devcentral.f5.com/s/videos/using-f5s-lbaas-plug-in-for-openstack-to-extend-your-data-center Summary: Here OpenStack is used as a cloud manager. Neutron is used to manage L3 subnets. Neutron will have pre-defined or static VLANS that will be shared with cloud tenants - there will be L3 subnets defined on those VLANs so guest instances can have IP allocations. Through LBaaS, F5 BIG-IP will be dynamically configured to provision appropriate VLANS as well as any L3 addresses needed to provide its service. Benefit: Extend the cloud using a vendor-neutral API specification (OpenStack Neutron LBaaS) to provide application delivery services via F5 BIG-IP. Use Case 2: Use F5 LBaaS to provision VLANs as a tenant virtualization technology – i.e. VLANs defined by the admin tenant for other tenants or by the tenant themselves. Video: https://devcentral.f5.com/s/videos/lbaas-plug-in-for-openstack-to-provision-vlans Summary: In this use case, tenants can securely extend their local networks into a shared OpenStack cloud. OpenStack is used as a cloud manager. Neutron will assign VLANS for a given tenant and will put L3 subnets on top of those dynamically provisioned VLANs - full L3 segmentation. F5 LBaaS will provision the VLANs as well as allocate L3 Subnets that might be needed. Benefit: This use case allows tenant networks to be extended beyond the OpenStack cloud to traditional and virtual networks with Layer 2 segmentation based on VLANs. Use Case 3: Software Defined Networking by using GRE/VXLAN as an overlay for tenant virtualization. Video: https://devcentral.f5.com/s/videos/lbaas-plug-in-for-openstack-using-gre-vxlan-for-tenant-virtualization Summary: In this scenario, an important component of Software Defined Networking, overlay networking in the form of either GRE or VXLAN, is used for tenant network virtualization. OpenStack will establish tunnels between compute nodes as the tenant's L2 network, then have L3 subnets built on top of those tunnels. BIG-IP will correctly join the tunnel mesh with the other compute nodes in the overlay network then allocate any IP addresses it needs in order to provide its services. Here the BIG-IP's SDN gateway capabilities really come to light. The VIP can be placed on any kind of network. While the pool member can exist on one or multiple GRE or VXLAN tunnel networks. Benefit: This use case allows tenant networks to be extended beyond the OpenStack cloud to traditional and virtual networks with Layer 2 segmentation based on GRE or VXLAN overlays. Use Case 4: Use F5 as a network services proxy between tenant GRE or VXLAN. Video: https://devcentral.f5.com/s/videos/f5-lbaas-plug-in-for-openstack-as-a-network-services-proxy-between-tenant-gre-or-vxlan-tunnels Summary: In this use case, BIG-IP serves as a network services proxy between tenant VXLAN or GRE tenant network virtualization. Neutron manages the L2 tunnels and L3 subnets while F5 will provide appropriate LBaaS VIP services to other networks or other tunnels for: Inter-VM HA LB between VM Turn down specific VMs instead of turning off a complete service. Benefit: In this use case, the tenant may have multiple network services running on either Layer 2 VLANs or GRE/VXLAN tunnels. F5’s LBaaS agent acts as a proxy between these segments enabling inter-segment packet routing. Use Case 5: Using the BIG-IQ's connector to orchestrate load balancing and F5 iApps in an OpenStack Cloud. Video: https://devcentral.f5.com/s/videos/delivering-lbaas-in-openstack-with-f5s-big-iq Summary: In this use case, BIG-IQ serves as management and orchestration layer between OpenStack Neutron and BIG-IP. OpenStack Neutron communicates with BIG-IQ via the LBaaS integration. BIG-IQ orchestrates and provisions load balancing services on BIG-IP, further encapsulating the VIP placement business logic. Benefit: Cross-platform management and ability to define VIP placement policies based on business and infrastructure needs. What help is available when using F5’s OpenStack integrations? The BIG-IP plug-in is supported via the DevCentral OpenStack Community. You can post your questions in the OpenStack Questions and Answers section of the community. You can also use F5 Support services for issues with the iControl APIs and BIG-IP devices or virtual editions. One last time, where can I find the Read Me and the BIG-IP LBaaS plug-in driver/agent? Download the Read Me and the BIG-IP LBaaS plug-in driver/agent from this download location.471Views0likes1CommentMeasuring Management and Orchestration
Early (very early, in fact) in the rise of SDN there were many discussions around scalability. Not of the data plane, but of the control (management) plane. Key to this discussion was the rate at which SDN-enabled network devices, via OpenFlow, could perform “inserts”. That is, how many times per second/minute could the management plane make the changes necessary to adjust to the environment. It was this measurement that turned out to be problematic, with many well-respected networking pundits (respected because they are also professionals) noting that the 1000 inserts per second threshold was far too low for the increasingly dynamic environment in which SDN was purported to be appropriate. That was years ago, when virtualization was still the norm. Certainly the scalability of SDN solutions has likely increased, but so too has the environment. We’re now moving into environments where microservices and containers are beginning to dominate the application architecture landscape, characterized by more dynamism than even highly virtualized data centers. In some ways, that’s due to the differences between virtualization and containers that make it possible to launch a container in seconds where virtual machines took perhaps minutes. Thus the rate of change when microservices – and containers – are in play is going to have a significant impact on the network. Which brings us back to software-defined strategies like SDN. In an environment where containers are popping up and shutting down at what could be considered an alarming rate, there’s simply no way to manually keep up with the changes required to the network. The network must be enabled through the implementation of some kind of software-defined strategy. Which brings us to the need to measure management and orchestration capabilities. DevOps has, at its core, a pillar based on measurement. Measurement of KPI (Key Performance Indicators) relative to operations like MTTR (Mean Time to Recover) and Lead Time to Change. But it does not, yet, bring with it the requirement that we measure the rate at which we’re able to make changes – like those necessary to launch a container and add it to a load balancing pool to enable real-time scalability. Software-defined strategies tell us these tasks – making sure the network connections and routes are properly added or adjusted and adding a new container or VM to the appropriate load balancing pool – should be automated. The process of “scaling” should be orchestrated. And both should be measured. Operationally these are key metrics – and critical to determining how much “lead time” or “notice” is necessary to scale without disruption – whether that disruption is measured as performance degradations or failures to connect due to lack of capacity. This isn’t measuring for metrics’ sake – this is hard operational data that’s required in order to properly automate and orchestrate the processes used to scale dynamically. We need to measure management and orchestration; we need to include a “mean time to launch” as one of our operational metrics. If we don’t, we can’t figure out when we need to launch a new instance to dynamically scale to meet demand. And if we can’t dynamically scale, we have to do it manually. No one wants to do that. Which means, ultimately, that we must bring the network in to the DevOps fold. Whether as NetOps or NetDevOps or SDN, we need to start bringing in the management and orchestration capabilities of the network, particularly when it applies to those application-affine services that are impacted by changes to the application environment (like load balancing and app security).258Views0likes0CommentsDo you want SDN for network automation or automated networks?
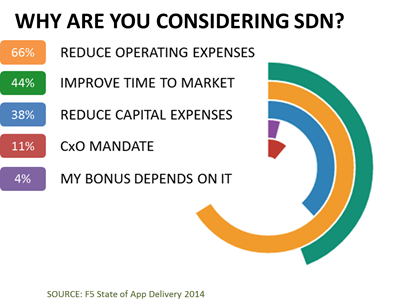
#SDN There is a difference... and it significantly impacts your strategy. When SDN made its mainstream debut at Interop in 2012, there was quite a bit of excitement tempered by the reality apparent to some folks that technical limitations would impact its applicability above layer 2-3 and, perhaps even at layers 2-3 depending on the network. But even then with all the hubbub over OpenFlow and commoditization of "the network" there were some of us who saw benefits in what SDN was trying to do around network automation. The general theory, of course, was that networks - bound by the tight coupling between control and data planes - were impeding the ability of networks to scale efficiently. Which is absolutely true. But while an OpenFlow-style SDN focuses on laying the foundation for an automated network - one that can, based on pre-defined and well understood rules, reroute traffic to meet application demands - the other more operationally focused style seeks to enable network automation. The former focuses on speeds and feeds of packets, the latter on speeds and feeds of process. The impact on the operational side of the network from the complexity inherent in a device by device configuration model means service velocity is not up to snuff to meet the demand for applications that would be created by the next generation of technologies. Basically, provisioning services in a traditional network model is slow, prone to error and not at all focused on the application. Network automation, through the use of open, standards-based APIs and other programmability features, enables automated provisioning of network services. A network automation goal for SDN addresses operational factors that cause network downtime, increase costs and generally suck up the days (and sometimes nights) of highly skilled engineers. Also complicating the matter is the reality that an OpenFlow-style SDN simply cannot scale to handle stateful network services. Those are stateful firewalls, application load balancing, web application firewalls, remote access, identity, web performance optimization, and more. These are the services that reside in the data path by necessity because they must have complete visibility into the data to perform their given functions. While an architectural model can be realized that addresses both stateless and stateful services by relying on service chaining, the complexity created by doing so may be just as significant as the complexity that was being addressed in the first place. So the question is, what do you really want out of SDN? What's the goal and how are you going to measure success? The answer should give you a clearer idea on which SDN strategy you should be considering.297Views0likes1Comment
BIG-IQ Grows UP [End of Life]
The F5 and Cisco APIC integration based on the device package and iWorkflow is End Of Life. The latest integration is based on the Cisco AppCenter named ‘F5 ACI ServiceCenter’. Visit https://f5.com/cisco for updated information on the integration. Today F5 is announcing a new F5® BIG-IQ™ 4.5. This release includes a new BIG-IQ component – BIG-IQ ADC. Why is 4.5 a big deal? This release introduces a critical new BIG-IQ component, BIG-IQ ADC. With ADC management, BIG-IQ can finally control basic local traffic management (LTM) policies for all your BIG-IP devices from a single pane of glass. Better still, BIG-IQ’s ADC function has been designed with the concept of “roles” deeply ingrained. In practice, this means that BIG-IQ offers application teams a “self-serve portal” through which they can manage load balancing of just the objects they are “authorized” to access and update. Their changes can be staged so that they don’t go live until the network team has approved the changes. We will post follow up blogs that dive into the new functions in more detail. In truth, there are a few caveats around this release. Namely, BIG-IQ requires our customer’s to be using BIG-IP 11.4.1 or above. Many functions require 11.5 or above. Customers with older TMOS version still require F5’s legacy central management solution, Enterprise Manager. BIG-IQ still can’t do some of the functions Enterprise Manager provides, such as iHealth integration and advanced analytics. And BIG-IQ can’t yet manage some advanced LTM options. Never-the-less, this release will an essential component of many F5 deployments. And since BIG-IQ is a rapidly growing platform, the feature gaps will be filled before you know it. Better still, we have big plans for adding additional components to the BIG-IQ framework over the coming year. In short, it’s time to take a long hard look at BIG-IQ. What else is new? There are hundreds of new or modified features in this release. Let me list a few of the highlights by component: 1. BIG-IQ ADC - Role-based central Management of ADC functions across the network · Centralized basic management of LTM configurations · Monitoring of LTM objects · Provide high availability and clustering support of BIG-IP devices and application centric manageability services · Pool member management (enable/disable) · Centralized iRules Management (though not editing) · Role-based management · Staging and manual of deployments 2. BIG-IQ Cloud - Enhanced Connectivity and Partner Integration · Expand orchestration and management of cloud platforms via 3rd party developers · Connector for VMware NSX and (early access) connector for Cisco ACI · Improve customer experience via work flows and integrations · Improve tenant isolation on device and deployment 3. BIG-IQ Device - Manage physical and virtual BIG-IP devices from a single pane of glass · Support for VE volume licensing · Management of basic device configuration & templates · UCS backup scheduling · Enhanced upgrade advisor checks 4. BIG-IQ Security - Centralizes security policy deployment, administration, and management · Centralized feature support for BIG-IP AFM · Centralized policy support for BIG-IP ASM · Consolidated DDoS and logging profiles for AFM/ASM · Enhanced visibility and notifications · API documentation for ASM · UI enhancements for AFM policy management My next blog will include a video demonstrating the new BIG-IQ ADC component and showing how it enhances collaboration between the networking and application teams with fine grained RBAC.794Views0likes3Comments