F5 and Versafe: Because Mobility Matters
#F5 #security #cloud #mobile #context Context means more visibility into devices, networks, and applications even when they're unmanaged. Mobility is a significant driver of technology today. Whether it's mobility of applications between data center and cloud, web and mobile device platform or users from corporate to home to publicly available networks, mobility is a significant factor impacting all aspects of application delivery but in particular, security. Server virtualization, BYOD, SaaS, and remote work all create new security problems for data center managers. No longer can IT build a security wall around its data center; security must be provided throughout the data and application delivery process. This means that the network must play a key role in securing data center operations as it “touches” and “sees” all traffic coming in and out of the data center. -- Lee Doyle, GigaOM "Survey: SDN benefits unclear to enterprise network managers" 8/29/2013 It's a given that corporate data and access to applications need to be protected when delivered to locations outside corporate control. Personal devices, home networks, and cloud storage all introduce the risk of information loss through a variety of attack vectors. But that's not all that poses a risk. Mobility of customers, too, is a source of potential disaster waiting to happen as control over behavior as well as technology is completely lost. Industries based on consumers and using technology to facilitate business transactions are particularly at risk from consumer mobility and, more importantly, from the attackers that target them. If the risk posed by successful attacks - phishing, pharming and social engineering - isn't enough to give the CISO an ulcer, the cost of supporting sometimes technically challenged consumers will. Customer service and support has become in recent years not only a help line for the myriad web and mobile applications offered by an organization, but a security help desk, as well, as consumers confused by e-mail and web attacks make use of such support lines. F5 and Security F5 views security as a holistic strategy that must be able to dig into not just the application and corporate network, but into the device and application, as well as the networks over which users access both mobile and web applications. That's where Versafe comes in with its unique combination of client-side intelligent visibility and subscription-based security service. Versafe's technology employs its client-side visibility and logic with expert-driven security operations to ensure real-time detection of a variety of threat vectors common to web and mobile applications alike. Its coverage of browsers, devices and users is comprehensive. Every platform, every user and every device can be protected from a vast array of threats including those not covered by traditional solutions such as session hijacking. Versafe approaches web fraud by monitoring the integrity of the session data that the application expects to see between itself and the browser. This method isn’t vulnerable to ‘zero-day’ threats: malware variants, new proxy/masking techniques, or fraudulent activity originating from devices, locations or users who haven’t yet accumulated digital fraud fingerprints. Continuous Delivery Meets Continuous Security Versafe's solution can accomplish such comprehensive coverage because it's clientless,relying on injection into web content in real time. That's where F5 comes in. Using F5 iRules, the appropriate Versafe code can be injected dynamically into web pages to scan and detect potential application threats including script injection, trojans, and pharming attacks. Injection in real-time through F5 iRules eliminates reliance on scanning and updating heterogeneous endpoints and, of course, relying on consumers to install and maintain such agents. This allows the delivery process to scale seamlessly along with users and devices and reasserts control over processes and devices not under IT control, essentially securing unsecured devices and lines of communication. Injection-based delivery also means no impact on application developers or applications, which means it won't reduce application development and deployment velocity. It also enables real-time and up-to-the-minute detection and protection against threats because the injected Versafe code is always communicating with the latest, up-to-date security information maintained by Versafe at its cloud-based, Security Operations Center. User protection is always on, no matter where the user might be or on what device and doesn't require updating or action on the part of the user. The clientless aspect of Versafe means it has no impact on user experience. Versafe further takes advantage of modern browser technology to execute with no performance impact on the user experience, That's a big deal, because a variety of studies on real behavior indicates performance hits of even a second on load times can impact revenue and user satisfaction with web applications. Both the web and mobile offerings from Versafe further ensure transaction integrity by assessing a variety of device-specific and behavioral variables such as device ID, mouse and click patterns, sequencing of and timing between actions and continuous monitoring of JavaScript functions. These kinds of checks are sort of an automated Turing test; a system able to determine whether an end-user is really a human being - or a bot bent on carrying out a malicious activity. But it's not just about the mobility of customers, it's also about the mobility - and versatility - of modern attackers. To counter a variety of brand, web and domain abuse, Versafe's cloud-based 24x7x365 Security Operations Center and Malware Analysis Team proactively monitors for organization-specific fraud and attack scheming across all major social and business networks to enable rapid detection and real-time alerting of suspected fraud. EXPANDING the F5 ECOSYSTEM The acquisition of Versafe and its innovative security technologies expands the F5 ecosystem by exploiting the programmable nature of its platform. Versafe technology supports and enhances F5's commitment to delivering context-aware application services by further extending our visibility into the user and device domain. Its cloud-based, subscription service complements F5's IP Intelligence Service, which provides a variety of similar service-based data that augments F5 customers' ability to make context-aware decisions based on security and location data. Coupled with existing application security services such as web application and application delivery firewalls, Versafe adds to the existing circle of F5 application security services comprising user, network, device and application while adding brand and reputation protection to its already robust security service catalog. We're excited to welcome Versafe into the F5 family and with the opportunity to expand our portfolio of delivery services. More information on Versafe: Versafe Versafe | Anti-Fraud Solution (Anti Phishing, Anti Trojan, Anti Pharming) Versafe Identifies Significant Joomla CMS Vulnerability & Corresponding Spike in Phishing, Malware Attacks Joomla Exploit Enabling Malware, Phishing Attacks to be Hosted from Genuine Sites 'Eurograbber' online banking scam netted $47 million443Views0likes1CommentGoogle Gmail: The Lawn Darts of the Internet
This blog on the inadvertent sharing of Google docs led to an intense micro-conversation in the comments regarding the inadvertent sharing of e-mail. sensitive financial data, and a wealth of other private data that remained, well, not so private through that [cue scary music] deadly combination that makes security folks race for their torches and pitchforks: Google Apps and Gmail. [pause for laughter on my part. I can't say that without a straight face] Here's part of the "issue" "discovered" by the author: Closer examination of the spreadsheets, along with some online digging, indicated that a CNHI employee had most likely intended to share the reports and spreadsheets with an employee named Deirdre Gallagher. Instead, he or she typed in my Gmail address and handed me the keys to a chunk of CNHI’s Web kingdom, including the detailed financial terms for scores of Web advertising deals. [emphasis added] Many comments indicated deep displeasure with Google's e-mail functionality in terms of how it handles e-mail addresses. Other comments just seemed to gripe about Google Apps and its integration in general. "Dan" brought sanity to a conversation comprised primarily of technology finger-pointing, much of which blamed Google for people fat-fingering e-mail addresses, when he said: "The misuse of the technology can hardly be the fault of the providers." Thank you Dan, whoever you are. How insightful. How true. And how sad that most people won't - and don't - see it that way. Remember lawn darts? I do. If you're young enough you might not, because the company that manufactured and sold them stopped doing so in 1988 after they were sued when a child was tragically killed playing with them. But the truth is that a child was throwing the darts over the roof of a house at his playmate. He was misusing the lawn darts. The product was subsequently banned from sale in the US and Canada due to safety concerns. Because they were used in a way they were not intended to be used. After all, consider the millions of other children (myself included) who managed to play the game properly without ever earning so much as a scratch. The mosquito bites were more dangerous than the lawn darts when used correctly and with the proper amount of attention paid to what we were doing. This is not unlike the inadvertent sharing of Google docs. If I mistype an e-mail address, it's not the fault of my e-mail client when confidential launch plans find their way into an unintended recipients' inbox. That's my fault for not being more careful and paying attention to detail. In the aforementioned Google doc sharing escapade, Google's software did exactly what it was supposed to do: it e-mailed a copy of a Google doc to the e-mail address specified by the sender. Google has no way of knowing you meant to type "a" when you typed "o"; that's the responsibility of the individual and it's ridiculous to hold Google and its developers responsible for the intentional or unintentional mistakes of its users. Look, there are plenty of reasons to be concerned about storing sensitive corporate data on a remote server and/or in the cloud, Google or others. There are a lot of reasons to be concerned about privacy and information leaks in SaaS (Software as a Service) and Web 2.0 applications. THIS IS NOT ONE OF THEM. Those same documents could easily have been e-mailed to the wrong person, accidentally or purposefully, from someone's desktop. Mistyping e-mail addresses is not peculiar to GMail, or Hotmail, or Yahoo mail, or any other cloudware e-mail service. It's peculiar to people. Remember them? The ultimate security risk? Rather than claim this is some huge security hole (it is not) or point the finger of blame at Google for sending that e-mail, remember what your mother said about pointing... When you point one finger at Google for sending that e-mail, three fingers are pointing back at you.355Views0likes0CommentsWhy you still need layer 7 persistence
Tony Bourke of the Load Balancing Digest points out that mega proxies are largely dead. Very true. He then wonders whether layer 7 persistence is really all that important today, as it was largely implemented to solve the problems associated with mega-proxies - that is, large numbers of users coming from the same IP address. Layer 7 persistence is still applicable to situations where you may have multiple users coming from a single IP address (such as a small client base coming from a handful of offices, with each office using on public IP address), but I wonder what doing Layer 4 persistence would do to a major site these days. I’m thinking, not much. I'm going to say that layer 4 persistence would likely break a major site today. Layer 7 persistence is even more relevant today than it has been in the past for one very good reason: session coherence. Session coherence may not have the performance and availability ramifications of the mega-proxy problem, but it is essential to ensure that applications in a load-balanced environment work correctly. Where's F5? VMWorld Sept 15-18 in Las Vegas Storage Decisions Sept 23-24 in New York Networld IT Roadmap Sept 23 in Dallas Oracle Open World Sept 21-25 in San Francisco Storage Networking World Oct 13-16 in Dallas Storage Expo 2008 UK Oct 15-16 in London Storage Networking World Oct 27-29 in Frankfurt SESSION COHERENCE Layer 7 persistence is still heavily used in applications that are session sensitive. The most common example is shopping carts stored in the application server session, but it also increasingly important to Web 2.0 and interactive applications where state is important. Sessions are used to store that state and therefore Layer 7 persistence becomes important to maintaining that state in a load-balanced environment. It's common to see layer 7 persistence driven by JSESSIONID or PHPSESSIONID header variables today. It's a question we see in the forums here on DevCentral quite often. Many applications are rolled out, and then inserted into a load balanced environment, and subsequently break because sessions aren't shared across web application servers and the client isn't always routed to the same server or they come back "later" (after the connections have timed out) and expect the application to continue where they left it. If they aren't load balanced back to the same server, the session data isn't accessible and the application breaks. Application server sessions generally persist for hours as opposed to the minutes or seconds allowed for a TCP connection. Layer 4 (TCP) persistence can't adequately address this problem. Source port and IP address aren't always enough to ensure routing to the correct server because it doesn't persist once the connection is closed, and multiple requests coming from the same browser use multiple connections now, each with a different source port. That means two requests on the same page may not be load balanced to the same server, even though they both may require access to the application session data. These sites and applications are used for hours, often with long periods of time between requests, which means connections have often long timed out. Could layer 4 persistence work? Probably, but only if the time-out on these connections were set unreasonably high, which would consume a lot more resources on the load balancer and reduce its capacity significantly. And let's not forget SaaS (Software as a Service) sites like salesforce.com, where rather than mega-proxy issues cropping up we'd have lots-of-little-proxy issues cropping up as businesses still (thanks to IPv4 and the need to monitor Internet use) employ forward proxies. And SSL, too, is highly dependent upon header data to ensure persistence today. I agree with Tony's assessment that the mega proxy problem is largely a non-issue today, but session coherence is taking its place a one of the best reasons to implement layer 7 persistence over layer 4 persistence.354Views0likes1CommentCloud Computing: Will data integration be its Achilles Heel?
Wesley: Now, there may be problems once our app is in the cloud. Inigo: I'll say. How do I find the data? Once I do, how do I integrate it with the other apps? Once I integrate it, how do I replicate it? If you remember this somewhat altered scene from the Princess Bride, you also remember that no one had any answers for Inigo. That's apropos of this discussion, because no one has any good answers for this version of Inigo either. And no, a holocaust cloak is not going to save the day this time. If you've been considering deploying applications in a public cloud, you've certainly considered what must be the Big Hairy Question regarding cloud computing: how do I get at my data? There's very little discussion about this topic, primarily because at this point there's no easy answer. Data stored in the cloud is not easily accessible for integration with applications not residing in the cloud, which can definitely be a roadblock to adopting public cloud computing. Stacey Higginbotham at GigaOM had a great post on the topic of getting data into the cloud, and while the conclusion that bandwidth is necessary is also applicable to getting your data out of the cloud, the details are left in your capable hands. We had this discussion when SaaS (Software as a Service) first started to pick up steam. If you're using a service like salesforce.com to store business critical data, how do you integrate that back into other applications that may need it? Web services were the first answer, followed by integration appliances and solutions that included custom-built adapters for salesforce.com to more easily enable access and integration to data stored "out there", in the cloud. Amazon offers URL-based and web services access to data stored in its SimpleDB offering, but that doesn't help folks who are using Oracle, SQL Server, or MySQL offerings in the cloud. And SimpleDB is appropriately named; it isn't designed to be an enterprise class service - caveat emptor is in full force if you rely upon it for critical business data. RDBMS' have their own methods of replication and synchronization, but mirroring and real-time replication methods require a lot of bandwidth and very low latency connections - something not every organization can count on having. Of course you can always deploy custom triggers and services that automatically replicate back into the local data center, but that, too, is problematic depending on bandwidth availability and accessibility of applications and databases inside the data center. The reverse scenario is much more likely, with a daemon constantly polling the cloud computing data and pulling updates back into the data center. You can also just leave that data out there in the cloud, implement, or take advantage of if they exist, service-based access to the data and integrate it with business processes and applications inside the data center. You're relying on the availability of the cloud, the Internet, and all the infrastructure in between, but like the solution for integrating with salesforce.com and other SaaS offerings, this is likely the best of a set of "will have to do" options. The issue of data and its integration has not yet raised its ugly head, mostly because very few folks are moving critical business applications into the cloud and admittedly, cloud computing is still in its infancy. But even non-critical applications are going to use or create data, and that data will, invariably, become important or need to be accessed by folks in the organization, which means access to that data will - probably sooner rather than later - become a monkey on the backs of IT. The availability of and ease of access to data stored in the public cloud for integration, data mining, business intelligence, and reporting - all common enterprise application use of data - will certainly affect adoption of cloud computing in general. The benefits of saving dollars on infrastructure (management, acquisition, maintenance) aren't nearly as compelling a reason to use the cloud when those savings would quickly be eaten up by the extra effort necessary to access and integrate data stored in the cloud. Related articles by Zemanta SQL-as-a-Service with CloudSQL bridges cloud and premises Amazon SimpleDB ready for public use Blurring the functional line - Zoho CloudSQL merges on-site and on-cloud As a Service: The many faces of the cloud A comparison of major cloud-computing providers (Amazon, Mosso, GoGrid) Public Data Goes on Amazon's Cloud300Views0likes2CommentsGet Your Money for Nothing and Your Bots for Free
Cloning. Boomeranging. Trojan clouds. Start up CloudPassage takes aim at emerging attack surfaces but it’s still more about process than it is product. Before we go one paragraph further let’s start out by setting something straight: this is not a “cloud is insecure” or “cloud security – oh noes!” post. Cloud is involved, yes, but it’s not necessarily the source of the problem - that would be virtualization and processes (or a lack thereof). Emerging attack methods and botnet propagation techniques can just as easily be problematic for a virtualization-based private cloud as they are for public cloud. That’s because the problem isn’t with necessarily cloud, it’s with an underlying poor server security posture that is made potentially many times more dangerous by the ease with which vulnerabilities can be propagated and migrated across and between environments. That said, a recent discussion with a cloud startup called CloudPassage has given me pause to reconsider some of the ancillary security issues that are being discovered as a result of the use of cloud computing . Are there security issues with cloud computing? Yes. Are they enabled (or made worse) because of cloud computing models? Yes. Does that mean cloud computing is off-limits? No. It still comes down to proper security practices being extended into the cloud and potentially new architectural-based solutions for addressing the limitations imposed by today’s compute-on-demand-focused offerings. The question is whether or not proper security practices and processes can be automated through new solutions, through devops tools like Chef and Puppet, or require manual adherence to secure processes to implement. CLOUD SECURITY ISN’T the PROBLEM, IT’S THE WAY WE USE IT (AND WHAT WE PUT IN IT) We’ve talked about “cloud” security before and I still hold to two things: first, there is no such thing as “cloud” security and second, cloud providers are, in fact, acting on security policies designed to secure the networks and services they provide. That said, there are in fact several security-related issues that arise from the way in which we might use public cloud computing and it is those issues we need to address. These issues are not peculiar to public cloud computing per se, but some are specifically related to the way in which we might use – and govern – cloud computing within the enterprise. These emerging attack methods may give some credence to the fears of cloud security. Unfortunately for those who might think that adds another checkmark in the “con” list for cloud it isn’t all falling on the shoulders of the cloud or the provider; in fact a large portion of the problem falls squarely in the lap of IT professionals. CLONING One of the benefits of virtualization often cited is the ability to easily propagate a “gold image”. That’s true, but consider what happens when that “gold image” contains a root kit? A trojan? A bot-net controller? Trojans, malware, and viruses are just as easily propagated via virtualization as web and application servers and configuration. The bad guys make a lot of money these days by renting out bot-net controllers, and if they can enlist your cloud-hosted services in that endeavor to do most of the work for them, they’re making money for nothing and getting bots for free. Solution: Constant vigilance and server vulnerability management. Ensure that guest operating system images are free of vulnerabilities, hardened, patched, and up to date. Include identity management issues, such as accounts created for development that should not be active in production or those accounts assigned to individuals who no longer need access. BOOMERANGING Public cloud computing is also often touted as a great way to reduce the time and costs associated with development. Just fire up a cloud instance, develop away, and when it’s ready you can migrate that image into your data center production environment. So what if that image is compromised while it’s in the public cloud? Exactly – the compromised image, despite all your security measures, is now inside your data center, ready to propagate itself. Solution: Same as with cloning, but with additional processes that require a vulnerability scan of an image before its placed into the production environment, and vice-versa. SERVER VULNERABILITIES How the heck could an image in the public cloud be compromised, you ask? Vulnerabilities in the base operating system used to create the image. It is as easy as point and click to create a new server in a public cloud such as EC2, but that server – the operating system – may not be hardened, patched, or anywhere near secured when it’s created. That’s your job. Public cloud computing implies a shared customer-provider security model, one in which you, as the customer, must actively participate. “…the customer should assume responsibility and management of, but not limited to, the guest operating system.. and associated application software...” “it is possible for customers to enhance security and/or meet more stringent compliance requirements with the addition of… host based firewalls, host based intrusion detection/prevention, encryption and key management.” [emphasis added] -- Amazon Web Services: Overview of Security Processes (August 2010) Unfortunately, most public cloud provider’s terms of service prohibit actively scanning servers in the public cloud for such vulnerabilities. No, you can’t just run Nexxus out there, because the scanning process is likely to have a negative impact on the performance of other customers’ services shared on that hardware. So you’re left with a potentially vulnerable guest operating system – the security of which you are responsible for according to the terms of service but yet cannot adequately explore with traditional security assessment tools. Wouldn’t you like to know, after all, whether the default guest operating configuration allows or disallows null passwords for SSH? Wouldn’t you like to know whether vulnerable Apache modules – like python – are installed? Patched? Up to date? Catch-22, isn’t it? Especially if you’re considering migrating that image back into the data center at some point. IT’S STILL a CONTROL THING One aspect of these potential points of exploitation is that organizations can’t necessarily extend all the security practices of the data center into the public cloud. If an organization routinely scans and hardens server operating systems – even if they are virtualized – they can’t continue that practice into the cloud environment. Control over the topology (architecture) and limitations on modern security infrastructure – such components often are not capable of handling the dynamic IP addressing environment inherent in cloud computing – make deploying a security infrastructure in a public cloud computing environment today nearly impossible. Too, is a lack of control over processes. The notion that developers can simply fire up an image “out there” and later bring it back into the data center without any type of governance is, in fact, a problem. This is the other side of devops – the side where developers are being expected to step into operations and not only find but subsequently address vulnerabilities in the server images they may be using in the cloud. Joe McKendrick, discussing the latest survey regarding cloud adoption from CA Technologies, writes: The survey finds members of security teams top the list as the primary opponents for both public and private clouds (44% and 27% respectively), with sizeable numbers of business unit leaders/managers also sharing that attitude (23% and 18% respectively). Overall, 53% are uncomfortable with public clouds, and 31% are uncomfortable with private clouds. Security and control remain perceived barriers to the cloud. Executives are primarily concerned about security (68%) and poor service quality (40%), while roughly half of all respondents consider risk of job loss and loss of control as top deterrents. -- Joe McKendrick , “Cloud divide: senior executives want cloud, security and IT managers are nervous” Control, intimately tied to the ability to secure and properly manage performance and availability of services regardless of where they may be deployed, remains high on the list of cloud computing concerns. One answer is found in Amazon’s security white paper above – deploy host-based solutions. But the lack of topological control and inability of security infrastructure to deal with a dynamic environment (they’re too tied to IP addresses, for one thing) make that a “sounds good in theory, fails in practice” solution. A startup called CloudPassage, coming out of stealth today, has a workable solution. It’s host-based, yes, but it’s a new kind of host-based solution – one that was developed specifically to address the restrictions of a public cloud computing environment that prevent that control as well as the challenges that arise from the dynamism inherent in an elastic compute deployment. CLOUDPASSAGE If you’ve seen the movie “Robots” then you may recall that the protagonist, Rodney, was significantly influenced by the mantra, “See a need, fill a need.” That’s exactly what CloudPassage has done; it “fills a need” for new tools to address cloud computing-related security challenges. The need is real, and while there may be many other ways to address this problem – including tighter governance by IT over public cloud computing use and tried-and-true manual operational deployment processes – CloudPassage presents a compelling way to “fill a need.” CloudPassage is trying to fill that need with two new solutions designed to help discover and mitigate many of the risks associated with vulnerable server operating systems deployed in and moving between cloud computing environments. Its first solution – focused on server vulnerability management (SVM) - comprises three components: Halo Daemon The Halo Daemon is added to the operating system and because it is tightly integrated it is able to perform tasks such as server vulnerability assessment without violating public cloud computing terms of service regarding scanning. It runs silently – no ports are open, no APIs, there is no interface. It communicates periodically via a secured, message-based system residing in the second component: Halo Grid. Halo Grid The “Grid” collects data from and sends commands to the Halo Daemon(s). It allows for centralized management of all deployed daemons via the third component, the Halo Portal. Halo Portal The Halo Portal, powered by a cloud-based farm of servers, is where operations can scan deployed servers for vulnerabilities and implement firewalling rules to further secure inter and intra-server communications. Technically speaking, CloudPassage is a SaaS provider that leverages a small footprint daemon, integrated into the guest operating system, to provide centralized vulnerability assessments and configuration of host-based security tools in “the cloud” (where “the cloud” is private, public, or hybrid). The use of a message-based queuing-style integration system was intriguing. Discussions around how, exactly, Infrastructure 2.0 and Intercloud-based integration could be achieved have often come down to a similar thought: message-queuing based architectures. It will be interesting to see how well Cloud Passage’s Grid scales out and whether or not it can maintain performance and timeliness of configuration under heavier load, common concerns regarding queuing-based architectures. The second solution from CloudPassage is its Halo Firewall. The firewall is deployed like any other host-based firewall, but it can be managed via the Halo Daemon as well. One of the exciting facets of this firewall and the management method is that eliminates the need to “touch” every server upon which the firewall is deployed. It allows you to group-manage host-based firewalls in a simple way through the Halo Portal. Using a simple GUI, you can easily create groups, define firewall policies, and deploy to all servers assigned to the group. What’s happening under the covers is the creation of iptables code and a push of that configuration to all firewall instances in a group. What ought to make ops and security folks even happier about such a solution is that the cloning of a server results in the automatic update. The cloned server is secured automatically based on the group from which its parent was derived, and all rules that might be impacted by that addition to the group are automagically updated. This piece of the puzzle is what’s missing from most modern security infrastructure – the ability to automatically update / modify configuration based on current operating environment: context, if you will. This is yet another dynamic data center concern that has long eluded many: how to automatically identify and incorporate newly provisioned applications/virtual machines into the application delivery flow. Security, load balancing, acceleration, authentication. All these “things” that are a part of application delivery must be updated when an application is provisioned – or shut down. Part of the core problem with extended security practices into dynamic environments like cloud computing is that so many security infrastructure solutions are not Infrastructure 2.0 enabled and they are still tightly coupled to IP addresses and require a static network topology, something not assured in dynamically provisioned environments. CloudPassage has implemented an effective means by which at least a portion of the security side of application delivery concerns related to extreme dynamism can be more easily addressed. As of launch, CloudPassage supports Linux-based operating systems with plans to expand to Windows-based offerings in the future. CloudPassage Control, choice, and cost: The Conflict in the Cloud The Corollary to Hoff’s Law Infrastructure 2.0: Squishy Name for a Squishy Concept The Cloud Metastructure Hubub Does a Dynamic Infrastructure Need ARP for Applications? Shadowserver (realtime botnet stats) Don’t Conflate Virtual with Dynamic Attacks Cannot Be Prevented There Is No Such Thing as Cloud Security The Impact of Security on Infrastructure Integration Rational Survivability283Views0likes1CommentInside Look - F5 Mobile App Manager
I meet with WW Security Architect Corey Marshall to get an Inside Look and detailed demo of F5's Mobile App Manager. BYOD 2.0: Moving Beyond MDM. ps Related: F5's Feeling Alive with Newly Unveiled Mobile App Manager BYOD 2.0 – Moving Beyond MDM with F5 Mobile App Manager F5 MAM Overview F5 BYOD 2.0 Solution Empowers Mobile Workers Is BYO Already D? Will BYOL Cripple BYOD? Freedom vs. Control F5's YouTube Channel In 5 Minutes or Less Series (23 videos – over 2 hours of In 5 Fun) Inside Look Series Technorati Tags: f5,byod,smartphone,mobile,mobile device,saas,research,silva,security,compliance, video Connect with Peter: Connect with F5:268Views0likes0CommentsThe Future of Hybrid Cloud
You keep using that word. I do no think it means what you think it means... An interesting and almost ancillary point was made during a recent #cloudtalk hosted by VMware vCloud with respect to the definition of "hybrid" cloud. Sure, it implies some level of integration, but how much integration is required to be considered a hybrid cloud? The way I see it, there has to be some level of integration that supports the ability to automate something - either resources or a process - in order for an architecture to be considered a hybrid cloud. A "hybrid" anything, after all, is based on the premise of joining two things together to form something new. Simply using Salesforce.com and Ceridian for specific business functions doesn't seem to quality. They aren't necessarily integrated (joined) in any way to the corporate systems or even to processes that execute within the corporate environs. Thus, it seems to me that in order to truly be a "hybrid" cloud, there must be some level of integration. Perhaps that's simply at the process level, as is the case with SaaS providers when identity is federated as a means to reassert control over access as well as potentially provide single sign-on services. Similarly, merely launching a development or test application in a public IaaS environment doesn't really "join" anything, does it? To be classified as "hybrid" one would expect there be network or resource integration, via such emerging technologies as cloud bridges and gateways. The same is true internally with SDN and existing network technologies. Integration must be more than "able to run in the environment". There must be some level of orchestration and collaboration between the networking models in order to consider it "hybrid". From that perspective, the future of hybrid cloud seems to rely upon the existence of a number of different technological solutions: Cloud bridges Cloud gateways Cloud brokers SDN (both application layer and network layer) APIs (to promote the integration of networks and resources) Standards (such as SAML to enable the orchestration and collaboration at the application layer) Putting these technologies all together and you get what seems to be the "future" of a hybrid cloud: SaaS, IaaS, SDN and traditional technology integrated at some layer that enables both the business and operations to choose the right environment for the task at hand at the time they need it. In other words, our "network" diagrams of the future will necessarily need to extend beyond the traditional data center perimeter and encompass both SaaS and IaaS environments. That means as we move forward IT and operations needs to consider how such environments will fit into and with existing solutions, as well as how emerging solutions will enable this type of hybrid architecture to come to fruition. Yes, you did notice I left out PaaS. Isn't that interesting?248Views0likes0CommentsCollaborate in the Cloud
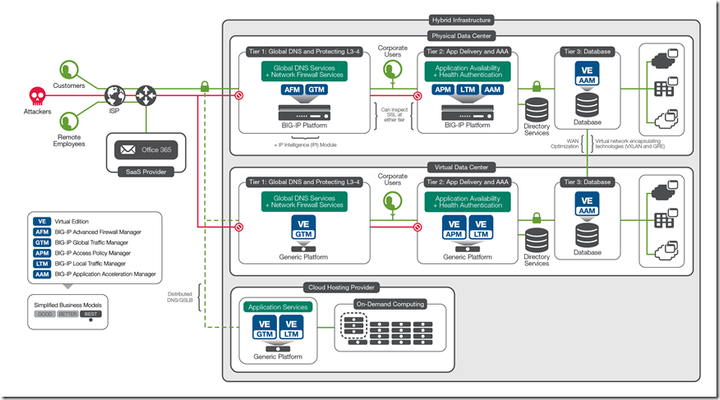
Employee collaboration and access to communication tools are essential for workplace productivity. Organizations are increasing their use of Microsoft Office 365, a subscription-based service that provides hosted versions of familiar Microsoft applications. Most businesses choose Exchange Online as the first app in Office 365 they adopt. The challenge with any SaaS application such as Office 365 is that user authentication is usually handled by the application itself, so user credentials are typically stored and managed in the cloud by the provider. The challenge for IT is to properly authenticate the employee (whether located inside or outside the corporate network) to a highly available identity provider (such as Active Directory). Authentication without complexity Even though Office 365 runs in a Microsoft-hosted cloud environment, user authentication and authorization are often accomplished by federating on premises Active Directory with Office 365. Organizations subscribing to Office 365 may deploy Active Directory Federation Services (ADFS) on premises, which then authenticates users against Active Directory. Deploying ADFS typically required organizations to deploy, manage, and maintain additional servers onsite, which can complicate or further clutter the infrastructure with more hardware. SAML (security assertion markup language) is often the enabler to identify and authenticate the user. It then directs the user to the appropriate Office 365 service location to access resources. SAML-enabled applications work by accepting user authentication from a trusted third party—an identity provider. In the case of Office 365, the BIG-IP platform acts as the identity provider. For example, when a user requests his or her OWA email URL via a browser using Office 365, that user is redirected to a BIG-IP logon page to validate the request. The BIG-IP system authenticates the user on behalf of Office 365 and then grants access. The Office 365 environment will recognize the individual and provide their unique Office 365 OWA email environment. The BIG-IP platform provides a seamless experience for Office 365 users and with the federated identity that the BIG-IP platform enables, the IT team is able to extend SSO capabilities to other applications. The benefit of using the BIG-IP platform to support Office 365 with SAML is that organizations can reduce the complexity and requirements of deploying ADFS. By default, when enabling Office 365, administrators need to authenticate those users in the cloud. If an IT administrator wants to use the corporate authentication mechanism, ADFS must be put into the corporate infrastructure. With the BIG-IP platform, organizations can support authentication to Office 365 and the ADFS requirement disappears, resulting in centralized access control with improved security. Secure collaboration Because email is a mission-critical application for most organizations, it is typically deployed on premises. Organizations using BIG-IP-enhanced Microsoft Exchange Server and Outlook can make it easier for people to collaborate regardless of their location. For example, if a company wanted to launch a product in Europe that had been successfully launched in the United States, it needs workers and contractors in both locations to be able to communicate and share information. In the past, employees may have emailed plain-text files to each other as attachments or posted them online using a web-based file hosting service. This can create security concerns since potentially confidential information is leaving the organization and being stored on the Internet without any protection or encryption. There are also concerns about ease of use for employees and how the lack of an efficient collaboration tool negatively impacts productivity. Internal and external availability 24/7 To solve these issues, many organizations move from the locally managed Exchange Server deployment to Microsoft Office 365. Office 365 makes it easier for employees to work together no matter where they are in the world. Employees connect to Office 365 using only a browser, and they don’t have to remember multiple usernames and passwords to access email, SharePoint, or other internal-only applications and file shares. In this scenario, an organization would deploy the BIG-IP platform in both the primary and secondary data centers. BIG-IP LTM intelligently manages all traffic across the servers. One pair of BIG-IP devices sits in front of the servers in the core network; another pair sits in front of the directory servers in the perimeter network. By managing traffic to and from both the primary and directory servers, the F5 devices ensure availability of Office 365—for both internal and external (federated) users. Ensuring global access To provide for global application performance and disaster recovery, organizations should also deploy BIG-IP GTM devices in the perimeter network at each data center. BIG-IP GTM scales and secures the DNS infrastructure, provides high-speed DNS query responses, and also reroutes traffic when necessary to the most available application server. Should an organization’s primary data center ever fail, BIG-IP GTM would automatically reroute all traffic to the backup data center. BIG-IP GTM can also load balance the directory servers across data centers to provide cross-site resiliency. The BIG-IP platform provides the federated identity services and application availability to allow organizations to make a quick migration to Office 365, ensuring users worldwide will always have reliable access to email, corporate applications, and data. ps Related: Leveraging BIG-IP APM for seamless client NTLM Authentication Enabling SharePoint 2013 Hybrid Search with the BIG-IP (SCRATCH THAT! Big-IP and SAML) with Office 365 Technorati Tags: office 365,o365,big-ip,owa,exchange,employee,collaborate,email,saml,adfs,silva,saas,cloud Connect with Peter: Connect with F5:243Views0likes0CommentsAsk the Expert – Why Identity and Access Management?
Michael Koyfman, Sr. Global Security Solution Architect, shares the access challenges organizations face when deploying SaaS cloud applications. Syncing data stores to the cloud can be risky so organizations need to utilize their local directories and assert the user identity to the cloud. SAML is a standardized way of asserting trust and Michael explains how BIG-IP can act either as an identity provider or a service provider so users can securely access their workplace tools. Integration is key to solve common problems for successful and secure deployments. ps Related: Ask the Expert – Are WAFs Dead? Ask the Expert – Why SSL Everywhere? Ask the Expert – Why Web Fraud Protection? Application Availability Between Hybrid Data Centers F5 Access Federation Solutions Inside Look - SAML Federation with BIG-IP APM RSA 2014: Layering Federated Identity with SWG (feat Koyfman) Technorati Tags: f5,iam,saas,saml,cloud,identity,access,security,silva,video,AAA Connect with Peter: Connect with F5:242Views0likes0CommentsCloudware and information privacy: TANSTAAFL
Ars Technica is reporting on a recent Pew study on cloud computing and privacy, specifically concerning remote data storage and the kind of data-mining performed on it by providers like Google, indicates that while consumers are concerned about the privacy of their data in the cloud, they still subject themselves to what many consider to be an invasion of privacy and misuse of data. 68 percent of respondents who said they'd used cloud services declared that they would be "very" concerned, and another 19 percent at least "somewhat" concerned, if their personal data were analyzed to provide targeted advertising. This, of course, is precisely what many Web mail services, such as Google's own Gmail, do—which implies that at least some of those who profess to be "very" concerned about the practice are probably nevertheless subjecting themselves to it. One wonders why those who profess to be very concerned about privacy and data-mining tactics used by cloudware providers would continue to use those services? One answer might lie in the confusing legalese of the EULA (end user license agreement) presented by corporations. Where's F5? VMWorld Sept 15-18 in Las Vegas Storage Decisions Sept 23-24 in New York Networld IT Roadmap Sept 23 in Dallas Oracle Open World Sept 21-25 in San Francisco Storage Networking World Oct 13-16 in Dallas Storage Expo 2008 UK Oct 15-16 in London Storage Networking World Oct 27-29 in Frankfurt It's necessary, of course, that the EULA be written using the language of the courts under which it will be enforced. But there are two problems with EULAs: first, they aren't really required to be read and second, even if they were really required to be read, they can't be easily understood by the vast majority of consumers. I'll be the first to admit I rarely read EULAs. They're long, filled with legalese speak, and they always come down to the same basic set of rules: it's our software, we don't make any guarantees, and oh, yeah, any rights not specifically listed (like the use of the data you use with our "stuff") are reserved for us. It's that last line that's the killer, by the way because just about everything falls under that particular clause in the EULA. Caveat emptor truly applies in the world of cloudware and online services. Buyer beware! You may be agreeing to all sorts of things you didn't intend. The argument against such privacy and security assurances for consumers is that they aren't paying for the service, therefore the provider needs some way to generate revenue to continue providing the service. That revenue is often generated by advertising and partnerships, but it's also largely provided by selling off personal information either directly gleaned from users or mined from their data. Which is what Google does with GMail. Enterprises, at least, are not only aware of but thoroughly understand the ramifications of storing their data "in the cloud". SaaS (Software as a Service) has had to provide proof positive that the data stored in their systems are the property of the consumer, that the data is not being used for data-mining or sharing purposes, and that security is in place to protect it from theft/viewing/etc... But in between the consumer and the enterprise markets lies the SMB, the small-medium business. Not quite financially able to afford a full data center and IT staff of their own, they often take advantage of cloudware services as a stop-gap measure. But in doing so, they put their business and data at risk, because they aren't necessarily using cloudware designed with businesses in mind, at least not from a data security perspective, and that means they are often falling under the more liberal end-user license agreement. All bets are off on the sanctity of their data. TANSTAAFL. There ain't no such thing as a free lunch, people, and that has never rang as true as it does in the world of cloudware and online services. If it's heralded as "free" that only means you aren't paying money for it, but you are bartering for the service; exchanging your personal information and data for the privilege of using that online service. In many cases folks weigh the value they receive from the "free" service against divulging personal information and data and make an informed choice to exchange that information for the service. When that's the case - the consumer or business is making an informed choice - it's all good. Everybody wins. Bartering is, after all, the oldest form of exchanging goods or services. And it's still used today. My grandmother paid her doctor three chickens for delivering my father, and that was in the mid 1900s, not that long ago at all. So exchanging personal information and access to your data for services is completely acceptable; just make sure you understand that's what you're doing - especially if you're a business.240Views0likes0Comments