Committing to Overhead: Proceed With Caution.
Back when SaaS was making its debut in the enterprise, I was a mid-level IT manager with a boss that was smart. It was a great experience working for him overall, and if not for external pressures, I might still be working on his team. One of the SaaS conversations we had was pretty relevant to today’s rush to public cloud. He looked around the room and asked “Why are we getting rid of our mainframes?” There was the standard joking about old dogs and new tricks, and then the more serious cost analysis. Finally he said “No, we’re getting rid of our mainframes because a couple of decades ago, someone in my position said ‘we’ll sign these contracts that create overhead for ever, and future IT managers will have to deal with it. We won’t consider what happens when the market turns and the overhead is fixed even though the organization is making less, we won’t consider that this overhead will cost millions over the years. We’ll take the route we like, and everyone moving forward will have to deal with it.” We all pondered, it was a pretty cynical way to look at a process that chose the only viable solution back in the day, but it had a kernel of truth in it. He waited a bit, then finished. “And that’s why we will not be using SaaS unless we have an exit strategy that covers all of the bases. We will not sign future IT managers on to overhead that we cannot determine is onerous or not. If we have a way to get our data into the system, a way to get our data out of the system, and proof that it is as secure as it is on our premises, then we will utilize SaaS to the maximum.” That was good reasoning then, it’s good reasoning now. Though cloud is much more forgiving in terms of getting your data in and out, his point about committing the future to a fixed overhead holds today. When you own the systems, delaying upgrades or consolidating servers is an option. Dropping support to save money is an option. There are all sorts of fiscal flexibility issues that cloud takes away from management when times get tough. Typical mainframe – the early years. Compliments of ComputerScienceLab.Com That’s not to say “public cloud is a bad thing”, it is to say that the needs of an enterprise are not the same as those of a start-up or small business. There are even valid reasons that international corporations have chosen not to take email to the cloud, though cloud based email is appealing to an organization that would need servers in multiple datacenters and administrators with extreme email chops. As with everything, consider the options and do what’s best for your organization. The buzz words are not why we all have jobs, solving problems for business is. Even if you feel about cloud as my boss did about SaaS, you still have cloud opportunities. Replication is a good one if the replication tool handles encryption and compression. Testing is a no-brainer if your test data is scrubbed first. And capacity planning is a big one. If you deploy a pilot to the cloud and get a reasonable estimation of what kind of throughput, server utilization, etc. the application will require, then you can move it in-house and right-size the environment based upon projections from the pilot. It won’t be perfect, but it’s better than many of the capacity planning systems out there today, particularly the “let’s turn it on, and then worry about capacity” model some of you are using. And for some organizations, tasks like email really can be shipped to the cloud (or a SaaS provider that claims to be a cloud), it just depends upon the legal and accountability standards your organization must or has chosen to implement. Though looking ahead, make a plan for getting out. It’s not about distrusting your provider, it is about risk management. Even if you love your provider today, they’re one purchase or upper management change away from being the biggest PITA you have to deal with every day. The best system is if you’re actually doing cloud, replicate your VMs back to HQ on a regular basis. This process is easy and gives you a fall-back. You don’t have to “get your data out of the cloud”, it will already be out if you need it. And like I’ve said elsewhere, for many of the compliance/security concerns, extend your existing infrastructure to the cloud where you can. No sense implementing two separate access control systems when you really only need one, only geographic location separates them. Just some things to keep in mind when moving. Sure it’s cheaper this month, and maybe even cheaper in the long haul (the vote is still very much out on that one), but it will cost you some financial flexibility, fix more of your budget into immobility. If that trade-off is good for you, then just make sure you have an exit plan, because sooner or later, keeping a cloud service will no longer be your first choice, or you’ll have moved on and it will be someone else’s.220Views0likes0Comments
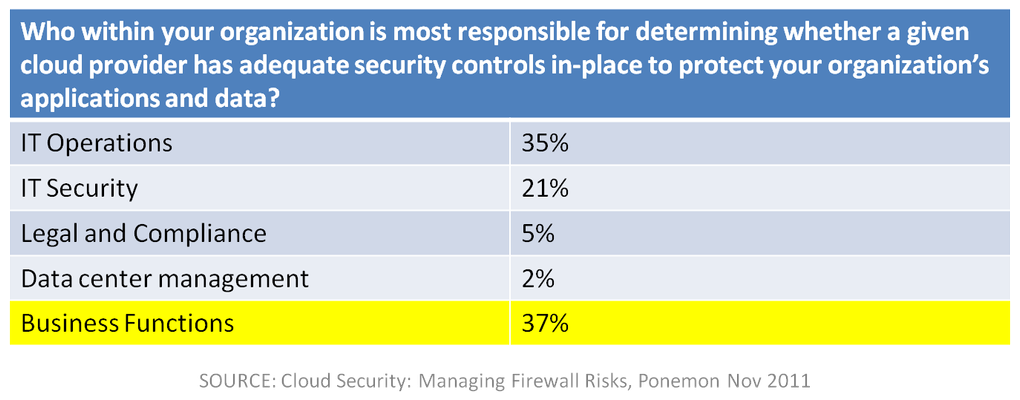
The Scariest Cloud Security Statistic You’ll See This Year
Who is most responsible for determining the adequacy of security in the cloud in your organization? Dome9, whom you may recall is a security management-as-a-service solution that aims to take the complexity out of managing administrative access to cloud-deployed servers, recently commissioned research on the subject of cloud computing and security from the Ponemon Institute and came up with some interesting results that indicate cloud chaos isn’t confined to just its definition. The research, conducted this fall and focusing on the perceptions and practices of IT security practitioners, indicated that 54% of respondents felt IT operations and infrastructure personnel were not aware of the risks of open ports in cloud computing environments. I found that hard to swallow. After all, we’re talking about IT practitioners. Surely these folks recognize the dangers associated with open ports on servers in general. But other data in the survey makes this a reasonable assumption, as 51% of respondents said leaving administrative server ports open in cloud computing environments was very likely or likely to expose the company to increased attacks and risks, with 19% indicating such events had already happened. Yet 30% of those surveyed claimed it was not likely or simply would not happen. At all. I remain wishing Ponemon had asked the same questions of the same respondents about similar scenarios in their own data center as I ‘m confident the results would be very heavily weighted toward the “likely or very likely to happen.” It may be time for a reminder of Hoff’s law: “If your security practices suck in the physical realm, you’ll be delighted by the surprising lack of change when you move to Cloud.” However, digging down into the data one begins to find the real answer to this very troubling statistic in the assignment of responsibility for security of cloud-deployed servers. It is, without a doubt, the scariest statistic with respect to cloud security I’ve seen all year, and it seems to say that for some organizations, at least, the cloud of Damocles is swinging mightily. If it doesn’t scare you that business functions are most cited as being ultimately responsible for determining adequacies of security controls in the cloud, it might frighten you to know that 54% of respondents indicated that IT operations and infrastructure personnel were not very or completely unknowledgeable with respect to the dangers inherent in open ports on servers in cloud computing environments – and that 35% of those organizations rely on IT operations to determine the adequacy of security in cloud deployments. While certainly IT security is involved in these decisions (at least one hopes that is the case) that the most responsibility is assigned to those least knowledgeable in the risks. That 19% of respondents indicated already experiencing an attack because of open ports on cloud-deployed servers is no longer such a surprising result of the study. CALL to ACTION The Ponemon study is very interesting in its results, and indicates that we’ve got a ways to go when it comes to cloud and security and increasing our comfort level combining the two. Cloud is a transformational and highly disruptive technology, and at times it may be transforming organizations in ways that are perhaps troubling – such as handing responsibility of security to business or non-security practitioners. Or perhaps it’s simply exposing weaknesses in current processes that should force change. Or it may be something we have to live with. It behooves IT security, then, to ensure it is finding ways to address the threats they know exist in the cloud through education of those responsible for ensuring it. It means finding tools like Dome9 to assist the less-security savvy in the organization with ensuring that security policies are consistently applied in cloud environments as well as in the data center. It may require new technology and solutions that are designed with the capability to easily replicate policies across multiple environments, to ensure that a standard level of security is maintained regardless of where applications are deployed. As cloud becomes normalized as part of the organization’s deployment options, the ability to effectively manage security, availability, and performance across all application deployments becomes critical. The interconnects (integration) between applications in an organization means that the operational risk of one is necessarily shared by others. Consistent enforcement of all delivery-related policies – security, performance, and availability – is paramount to ensuring the successful integration of cloud-based resources, systems, and applications into the IT organization’s operational processes. You can register to read the full report on Dome9’s web site. Related blogs & articles: The Corollary to Hoff’s Law Dome9: Closing the (Cloud) Barn Door171Views0likes0CommentsCopied Data. Is it a Replica, Snapshot, Backup, or an Archive?
It is interesting to me the number of variant Transformers that have been put out over the years, and the effect that has on those who like transformers. There are four different “Construction Devastator” figures put out over the years (there may be more, I know of four), and every Transformers collector or fan that I know – including my youngest son – want them all. That’s great marketing on the part of Hasbro, for certain, but it does mean that those who are trying to collect them are going to have a hard time of it, just because they were produced and then stopped, and all of them consist of seven or more parts. That’s a lot of things to go wrong. But still, it is savvy for Hasbro to recognize that a changed Transformer equates to more sales, even though it angers the diehard fans. As time moves forward, technology inevitably changes things. In IT that statement implies “at the speed of light”. Just like your laptop has been replaced with a newer model before you get it, and is “completely obsolete” within 18 months, so other portions of the IT field are quickly subsumed or consumed by changes. The difference is that IT is less likely to get caught up in the “new gadget” hype than the mass market. So while your laptop was technically outdated before it landed in your lap, IT knows that it is still perfectly usable and will only replace it when the warrantee is up (if you work for a smart company) or it completely dies on you (for a company pinching pennies). The same is true in every piece of storage, it is just that we don’t suffer from “Transformer Syndrome”. Old storage is just fine for our purposes, unless it actually breaks. Since you can just continue to pay annual licensing fees, there’s no such thing as “out of warrantee” storage unless you purchase very inexpensive, or choose to let it lapse. For the very highest end, letting it lapse isn’t an option, since you’re licensing the software. The same is true with how we back up and restore that data. Devastator, image courtesy of Gizmodo.com But even with a stodgy group like IT, who has been bitten enough times to know that we don’t change something unless there’s a darned good reason, eventually change does come. And it’s coming to backup and replication. There are a lot of people still differentiating between backups and replication. I think it’s time for us to stop doing so. What are the differences? Let’s take a look. Backups go to tape. Hello Virtual Tape Libraries, how are you? Backups are archival. Hello tiering, you allow us to move things to different storage types, and replicate them at different intervals, right? So all is correctly backed up for its usage levels? Replication is near-real-time. Not really. You’re thinking of Continuous Data Protection (CDP), which is gaining traction by app, not broadly. Replication goes to disk and that makes it much faster. See #1. VTL is fast too. Tape is slow. Right, but that’s a target problem, not a backup problem. VTLs are fast. Replication can do just the changes. Yeah, why this one ever became a myth, I’ll never know, but remember “incremental backups”? Same thing. I’m not saying they’re exactly the same – incremental replicas can be reverse applied so that you can take a version of the file without keeping many copies, and that takes work in a backup environment, what I AM saying is that once you move to disk (or virtual disk in the case of cloud storage), there isn’t really a difference worthy of keeping two different phrases. Tape isn’t dead, many of you still use a metric ton of it a year, but it is definitely waning, slowly. Meaning more and more of us are backing up or replicating to disk. Where did this come from? A whitepaper I wrote recently came back from technical review with “this is not accurate when doing backups”, and that got me to thinking “why the heck not?” If the reason for maintaining two different names is simply a people reason, while the technology is rapidly becoming the same mechanisms – disk in, disk out, then I humbly suggest we just call it one thing, because all maintaining two names and one fiction does is cause confusion. For those who insist that replicas are regularly updated, I would say making a copy or snapshotting them eliminates even that difference – you now have an archival copy that is functionally the same as a major backup. Add in an incremental snapshot and, well, we’re doing a backup cycle. With tiering, you can set policies to create snapshots or replicas on different timelines for different storage platforms, meaning that your tier three data can be backed up very infrequently, while your tier one (primary) storage is replicated all of the time. Did you see what I did there? The two are used interchangeably. Nobody died, and there’s less room for confusion. Of course I think you should use our ARX to do your tiering, ARX Cloud Extender to do your cloud connections, and take advantage of the built-in rules engine to help maintain your backup schedule. But the point is that we just don’t need two names for what is essentially the same thing any more. So let’s clean up the lingo. Since replication is more accurate to what we’re doing these days, let’s just call it replication. We have “snapshot” that is already associated with replication for point-in-time copies, which makes us able to differentiate between a regularly updated replica and a frozen-in-time “backup”. Words fall in and out of usage all of the time, let’s clean up the tech lingo and all get on the same language. No, no we won’t, but I’ve done my bit by suggesting it. And no doubt there are those confused by the current state of lingo that this will help to understand that yes, they are essentially the same thing, only archaic history keeps them separate. Or you could buy all three – replicate to a place where you can take a snapshot and then back up the snapshot (not as crazy as it sounds, I have seen this architecture deployed to get the backup process out of production, but I was being facetious). And you don’t need a ton of names. You replicate to secondary (tertiary) storage, then take a snapshot, then move or replicate the snapshot to a remote location – like the cloud or remote datacenter. Not so tough, and one term is removed from the confusion, inadvertently adding crispness to the other terms.251Views0likes0CommentsF5 Friday: CSG Case Study Shows Increased Performance, Less WAN Traffic With Dell and F5
When time and performance mattered, CSG Content Direct turned to Dell and F5 to make their replication faster while reducing WAN utilization. We talk a lot in our blogs about what benefits you could get from an array of F5 products, so when this case study (pdf link) hit our inboxes, we thought you’d like to hear about what CSG’s Content Direct did get out of deploying F5 BIG-IPWOM. Utilizing tools by two of the premier technology companies in the world, Content Direct was able to decrease backup windows to as little as 5% of their previous time, and reduce traffic on the WAN significantly. At the heart of the problem was WAN performance that was inhibiting their replication to a remote datacenter and causing them to fall further and further behind. Placing a BIG-IP WOM between their Dell EqualLogic iSCSI devices, Content Direct was able to improve performance to the point that they are now able to meet their RPOs and RTOs with room for expansion. Since Content Direct already deployed F5 BIG-IP LTM, they were able to implement this solution by purchasing and installing F5 BIG-IP WAN Optimization Manager (WOM) on the existing BIG-IP hardware, eliminating the need for new hardware. The improvements that they saw while replicating iSCSI devices is in line with the improvements our testing has shown for NAS device replication also, making this case study a good examination of what you can expect from BIG-IP WOM in many environments. Since BIG-IP WOM supports a wide array of applications – from the major NAS vendors to the major database vendors – and includes offloading of encryption from overburdened servers, you can deploy it once and gain benefits at many points in your architecture. If you are sending a lot of data between two datacenters, BIG-IP WOM has help for your overburdened WAN connection. Check out our White Papers and Solution Profiles relevant to BIG-IP WOM for more information about how it might help, and which applications have been tested for improvement measurements. Of course BIG-IP WOM works on IP connections, and as such can improve many more scenarios than we have tested or even could reasonably test, but those applications tested will give you a feel for the amount of savings you can get when deploying BIG-IP WOM on your WAN. And if you are already a BIG-IP LTM customer, you can upgrade to include WOM without introducing a new device into your already complex network. Related Blogs: F5 Friday: Speed Matters F5 Friday: Performance, Throughput and DPS F5 Friday: A War of Ecosystems F5 Friday: IPv6 Day Redux F5 Friday: Spelunking for Big Data F5 Friday: The 2048-bit Keys to the Kingdom F5 Friday: ARX VE Offers New Opportunities F5 Friday: Eliminating the Blind Spot in Your Data Center Security ... F5 Friday: Gracefully Scaling Down F5 Friday: Data Inventory Control217Views0likes0CommentsDatabases in the Cloud Revisited
A few of us were talking on Facebook about high speed rail (HSR) and where/when it makes sense the other day, and I finally said that it almost never does. Trains lost out to automobiles precisely because they are rigid and inflexible, while population densities and travel requirements are highly flexible. That hasn’t changed since the early 1900s, and isn’t likely to in the future, so we should be looking at different technologies to answer the problems that HSR tries to address. And since everything in my universe is inspiration for either blogging or gaming, this lead me to reconsider the state of cloud and the state of cloud databases in light of synergistic technologies (did I just use “synergistic technologies in a blog? Arrrggghhh…). There are several reasons why your organization might be looking to move out of a physical datacenter, or to have a backup datacenter that is completely virtual. Think of the disaster in Japan or hurricane Katrina. In both cases, having even the mission critical portions of your datacenter replicated to the cloud would keep your organization online while you recovered from all of the other very real issues such a disaster creates. In other cases, if you are a global organization, the cost of maintaining your own global infrastructure might well be more than utilizing a global cloud provider for many services… Though I’ve not checked, if I were CIO of a global organization today, I would be looking into it pretty closely, particularly since this option should continue to get more appealing as technology continues to catch up with hype. Today though, I’m going to revisit databases, because like trains, they are in one place, and are rigid. If you’ve ever played with database Continuous Data Protection or near-real-time replication, you know this particular technology area has issues that are only now starting to see technological resolution. Over the last year, I have talked about cloud and remote databases a few times, talking about early options for cloud databases, and mentioning Oracle Goldengate – or praising Goldengate is probably more accurate. Going to the west in the US? HSR is not an option. The thing is that the options get a lot more interesting if you have Goldengate available. There are a ton of tools, both integral to database systems and third-party that allow you to encrypt data at rest these days, and while it is not the most efficient access method, it does make your data more protected. Add to this capability the functionality of Oracle Goldengate – or if you don’t need heterogeneous support, any of the various database replication technologies available from Oracle, Microsoft, and IBM, you can seamlessly move data to the cloud behind the scenes, without interfering with your existing database. Yes, initial configuration of database replication will generally require work on the database server, but once configured, most of them run without interfering with the functionality of the primary database in any way – though if it is one that runs inside the RDBMS, remember that it will use up CPU cycles at the least, and most will work inside of a transaction so that they can insure transaction integrity on the target database, so know your solution. Running inside the primary transaction is not necessary, and for many uses may not even be desirable, so if you want your commits to happen rapidly, something like Goldengate that spawns a separate transaction for the replica are a good option… Just remember that you then need to pay attention to alerts from the replication tool so that you don’t end up with successful transactions on the primary not getting replicated because something goes wrong with the transaction on the secondary. But for DBAs, this is just an extension of their daily work, as long as someone is watching the logs. With the advent of Goldengate, advanced database encryption technology, and products like our own BIG-IPWOM, you now have the ability to drive a replica of your database into the cloud. This is certainly a boon for backup purposes, but it also adds an interesting perspective to application mobility. You can turn on replication from your data center to the cloud or from cloud provider A to cloud provider B, then use VMotion to move your application VMS… And you’re off to a new location. If you think you’ll be moving frequently, this can all be configured ahead of time, so you can flick a switch and move applications at will. You will, of course, have to weigh the impact of complete or near-complete database encryption against the benefits of cloud usage. Even if you use the adaptability of the cloud to speed encryption and decryption operations by distributing them over several instances, you’ll still have to pay for that CPU time, so there is a balancing act that needs some exploration before you’ll be certain this solution is a fit for you. And at this juncture, I don’t believe putting unencrypted corporate data of any kind into the cloud is a good idea. Every time I say that, it angers some cloud providers, but frankly, cloud being new and by definition shared resources, it is up to the provider to prove it is safe, not up to us to take their word for it. Until then, encryption is your friend, both going to/from the cloud and at rest in the cloud. I say the same thing about Cloud Storage Gateways, it is just a function of the current state of cloud technology, not some kind of unreasoning bias. So the key then is to make sure your applications are ready to be moved. This is actually pretty easy in the world of portable VMs, since the entire VM will pick up and move. The only catch is that you need to make sure users can get to the application at the new location. There are a ton of Global DNS solutions like F5’s BIG-IP Global Traffic Manager that can get your users where they need to be, since your public-facing IPs will be changing when moving from organization to organization. Everything else should be set, since you can use internal IP addresses to communicate between your application VMs and database VMs. Utilizing a some form of in-flight encryption and some form of acceleration for your database replication will round out the solution architecture, and leave you with a road map that looks more like a highway map than an HSR map. More flexible, more pervasive.365Views0likes0CommentsIt’s Show Time
Ladies and gentleman. In tonight’s show the role of Application Delivery, normally played by Load Balancer will be replaced by ADC. We hope you enjoy the performance. I studied Theatre in college and have spent a good amount of time in and around the performing arts. The telling of a engaging story and the creativity, imagination and spontaneity of a great live performance is something I truly enjoy. Most of my life, when I think of the term performance, I think of the performing arts – acting, dancing, singing and the rest. When you pay good money for a show, you expect a great performance. Actors embodying the characters, musicians merged with their instruments, singers feeling every note, dancers moving to the tune. When we perform ourselves, we want to give it our all, have good energy, be prepared, engage our audience and tell a good story no matter if it’s vocal, musical or movement. And if we nail it, there’s no better feeling when you hit every note, lived the character or let the music take your body. With Method acting (Stanislavski/Strasberg/Actors Studio) you try to create, in yourself, the thoughts and feelings of the character and often rely on emotional memory to generate, for instance, tears. Remember how you felt when your first dog died. Hoffman, De Niro, Pacino and Baldwin are some that practice this technique. William Gillette, an actor/director/playwright in the late 1800’s talked about ‘The Illusion of the First Time.’ That, no matter how many times you’ve done this, you need to make it seem/feel as if it is the first time that the character has ever heard or encountered whatever is occurring. This gives true responses, reactions and behavior, within the character itself, to the many conflicts within the story. The other important facet to this is, it is the audience’s first time seeing it so an actor should not ‘telepath’ a response. Just what the heck does this all have to do with application delivery? As part of the 50 Ways to Use Your BIG-IP series, this week we cover performance. How the BIG-IP system helps improve performance and what are some of the variables that can impact the performance of an application. Again you may ask, what does acting have to do with application delivery? ‘Method’ application delivery might be things like caching and data deduplication – I know I’ve seen his before so let me pull from memory and deliver the content. What is this character user trying to accomplish and I can get them there. Session persistence might be another area. I remember you from an earlier meeting, remember that you were doing this particular thing and it made you happy or more productive. I remember that if users are requesting access from a particular geo-location, then send them to that data center. The illusion of the first time also connects well with application delivery via context. The ADC might have seen this user hundreds, maybe thousands of times, but this time, they are coming from a unrecognized network or from an unknown device and the ADC needs to make an instantaneous decision as to how best handle the request…since it is the first time…within this context. Just like a character, the ADC absorbs the information, processes it and answers with the best possible response at that moment. I can tell you, there have been a few times where I did forget my line but so immersed in the moment, that when I opened my mouth, the actual written words just came out. ADC’s need to perform at their best every moment of every day, not just 8 times a week on an Equity stage. They need to remember certain pieces of information but also, receive information for the very first time and make instantaneous, intelligent decisions. They need to adjust depending on the conditions and star in that strategic point of control within the data center stage. They don’t sign autographs, appear on the front page of the National Enquirer or show up at red carpet events, but can help deliver all the Tony, Grammy, Oscar, Emmy and Obie award(s) data. As a director/actor once said in one of my acting classes, a true artist is someone who cannot do anything else, but their craft…if there is anything else that you can do with your life, do it. Hello Internet circa 1995, I’m Peter. ps Resources: All “50 Ways” to use your BIG-IP system entries 50 Ways to Use Your BIG-IP: Performance Presentation Availability resources on DevCentral Availability Solutions on F5.com Security resources on DevCentral Security Solutions on F5.com Follow #50waystousebigip on Twitter206Views0likes0CommentsF5 Friday: F5 BIG-IP WOM Puts the Snap(py) in NetApp SnapMirror
Data replication is still an issue for large organizations and as data growth continues, those backup windows are getting longer and longer… With all the hype surrounding cloud computing and dynamic resources on demand for cheap you’d think that secondary and tertiary data centers are a thing of the past. Not so. Large organizations with multiple data centers – even those are evolving out of growth at remote offices – still need to be able to replicate and backup data between corporate owned sites. Such initiatives are often fraught with peril due to the explosive growth in data which, by all accounts, is showing no signs of slowing down any time soon. The reason this is problematic is because the pipes connecting those data centers are not expanding and doing so simply to speed up transfer rates and decrease transfer windows is cost prohibitive. It’s the same story as any type of capacity – expanding to meet periodic bursts results in idle resources, and idle resources are no longer acceptable in today’s cost conscious, waste-not want-not data centers. Organizations that have in place a NetApp solution for storage replication are in luck today, as F5 has a solution that can improve transfer rates by employing data reduction technologies: F5 BIG-IP WAN Optimization Module (WOM). One of the awesome advantages of WOM (and all F5 modules) over other solutions is that a BIG-IP module is a component of our unified application delivery platform. That’s an advantage because of the way in which BIG-IP modules interact with one another and are integrated with the rest of a dynamic data center infrastructure. The ability to leverage core functionality across a shared, high-speed internal messaging platform means context is never lost and interactions are optimized internally, minimizing the impact of chaining multiple point solutions together across the network. I could go on and on myself about and its benefits when employed to improve site-to-site transfer of big data, but I’ve got colleagues like Don MacVittie who are well-versed in telling that story so I’ll let him introduce this solution instead. Happy Replicating! NetApp’s SnapMirror is a replication technology that allows you to keep a copy of a NetApp storage system on a remote system over the LAN or WAN. While NetApp has built in some impressive compression technology, there is still room for improvement in the WAN space, and F5BIG- IPWOM picks up where SnapMirror leaves off. Specialized in getting the most out of your WAN connection, WOM (WAN Optimization Module) improves your SnapMirror performance and WAN connection utilization. Not just improves it, gives performance that, in our testing, shows a manifold increase in both throughput and overall performance. And since it is a rare WAN connection that is only transferring SnapMirror data, the other applications on that same connection will also see an impressive benefit. Why upgrade your WAN connection when you can get the most out of it at any throughput rating? Add in the encrypted tunneling capability of BIG-IP WOM and you are more fast, more secure, and more available. With the wide range of adjustments you can make to determine which optimizations apply to which data streams, you can customize your traffic to suit the needs of your specific usage scenarios. Or as we like to say, IT Agility, Your Way. You can find out more about how NetApp SnapMirror and F5 BIG-IP WOM work together by reading our solution profile. Related blogs & articles: Why Single-Stack Infrastructure Sucks F5 Friday: Microsoft and F5 Lync Up on Unified Communications F5 Friday: The 2048-bit Keys to the Kingdom All F5 Friday Posts on DevCentral F5 Friday: Elastic Applications are Enabled by Dynamic Infrastructure Optimizing NetApp SnapMirror with BIG-IP WAN Optimization Module Top-to-Bottom is the New End-to-End178Views0likes1CommentLet’s Rethink Our Views of Storage Before It Is Too Late.
When I was in Radiographer (X-Ray Tech) training in the Army, we were told the cautionary tale of a man who walked into an emergency room with a hatchet in his forehead and blood everywhere. As the staff of the emergency room rushed to treat the man’s very serious head injury, his condition continued to degrade. Blood everywhere, people rushing to and fro, the XRay tech with a portable XRay machine trying to squeeze in while nurses and doctors are working hard to keep the patient alive. And all the frenzied work failed. If you’ve ever been in an ER where a patient dies – particularly one that dies of traumatic injuries rather than long-term illness – it is difficult at best. You want to save everyone, but some people just don’t make it. They’re too injured, or came to the ER too late, or the precise injury is not treatable in the time available. It happens, but no one is in a good mood about it, and everyone is wondering if they could have done something different. In US emergency rooms at least, it is very rare that a patient dies and the reason lies in failure of the staff to take some crucial step. There are too many people in the room, too much policy and procedure built up, to fail at that level. And part of that policy and procedure was teaching us the cautionary tale. You see, the tale wasn’t over with the death of the patient. The tale goes on to say that the coroner’s report said the patient died not of a head injury, but of bleeding to death through a knife wound in his back. The story ends with the warning not to focus on the obvious injury so exclusively that you miss the other things going on with the patient. It was a lesson well learned, and I used it to good effect a couple of times in my eight years in Radiography. Since the introduction of Hierarchical Storage Management (HSM) many years ago, the focus of many in the storage space is on managing the amount of data that is being stored on your system, optimizing access times and insuring that files are accessible to those who need them, when they need them. That’s important stuff, our users count upon us to keep their files safe and serve up their unstructured data in a consistent and reliable manner. At this stage of the game we have automated tiering such as that offered by F5’s ARX platform, we have remote storage for some data, we have cloud storage if there is overflow, there are backups, replications, snapshots, and even some cases of Continuous Data Protection… And all of these items focus on getting the data to users when they want in the most reliable manner possible. But, like our cautionary tale above, it is far too easy to focus on one piece of the puzzle and miss the rest. The rest is that tons of your unstructured data is chaff. Yes indeed, you’ve got some fine golden grains of wheat that you are protecting, but to do so, today it is a common misperception to feel that you have to protect the chaff too. It’s time for you to start pushing back, perhaps past time. The buildup of unnecessary files is costing the organization money and making it more difficult to manage the files that really are important to the day-to-day running of your organization. My proposal is simple. Tell business leaders to clean up their act. Only keep what is necessary, stop hoarding files that were of marginal use when created, and negligible or no use today. We have treated storage as an essentially unlimited resource for long enough, time to say “well yes, but each disk we add to the storage hierarchy increases costs to the organization”. Meet with business leaders and ask them to assign people to go through files. If your organization is like ones I’ve worked at, when someone leaves their entire user folder is kept, almost like a gravestone. Not necessarily touched, just kept. Most of those files aren’t needed at all, and it becomes obvious after a couple of months which those are. So have your business units clean up after themselves. I’ve said it before, I’ll say it again, IT is not in a position to decide what stays and what goes, only those deeply involved in the running of that bit of the business can make those calls. The other option is to use whatever storage tiering mechanism you have to shuffle them off to neverland, but again, do you want a system making permanent delete decisions about a file that may not have been touched in two years but (perhaps) the law requires you keep for seven? You can do it, but it will always much better to have users police their own area, if you can. While focused on availability of files, don’t forget to deal with deletion of unneeded information. And there is a lot of it out there, if the enterprises I’m familiar with are any indication. Recruit business leaders, maybe take them a sample that shows them just how outdated or irrelevant some of their unstructured data is “the football pool for the 1997 season… Is that necessary?” is a good one. Unstructured storage needs are going to continue to grow, mitigated by tiering, enhanced resource utilization, compression, and dedupe, but why bother deduping or even saving a file that was needed for a short time and is now just a waste of space? No, no it won’t be easy to recruit such help. The business is worried about tomorrow, not last year. But convincing them that this is a necessary step to saving money for more projects tomorrow is part of what IT management does. And if you can convince them, you’ll see a dramatic savings in space that might put off more drastic measures. If you can’t convince them, then you’ll need a way to “get rid of” those files without getting rid of them. Traditional archival storage or a Cloud Storage Gateway are both options in that case, but best to just recruit the help cleaning up the house.174Views0likes0CommentsLoad Balancing For Developers: Improving Application Performance With ADCs
If you’ve never heard of my Load Balancing For Developers series, it’s a good idea to start here. There are quite a few installments behind us, and I’m not going to look back in this post any more than I must to make it readable without going back… Meaning there’s much more detail back there than I’ll relate here. Again after a lengthy sojourn covering other points of interest, I return to Load Balancing For Developers with a more holistic view – application performance. Lori has talked a bit about this topic, and I’ve talked about it in the form of Load Balancing benefits and algorithms, but I’d like to look more architecturally again, and talk about those difficult to uncover performance issues that web apps often face. You’re the IT manager for the company’s Zap-n-Go website, it has grown nearly exponentially since launch, and you’re the one responsible for keeping it alive. Lately it’s online, but your users are complaining of sluggishness. Following the advice of some guy on the Internet, you put a load balancer in about a year ago, and things were better, but after you put in a redundant data center and Global Load Balancing services, things started to degrade again. Time to rethink your architecture before your product gets known as Zap-N-Gone… Again. Thus far you have a complete system with multiple servers behind an ADC in your primary data center, and a complete system with multiple servers behind an ADC in your secondary data center. Failover tests work correctly when you shut down the primary web servers, and the database at the remote location is kept up to date with something like Data Guard for Oracle or Merge Replication Services for SQL Server. This meets the business requirement that the remote database is up-to-date except for those transactions in-progress at the moment of loss. This makes you highly HA, and if your ADCs are running as an HA pair and your Global DNS – Like our GTM product - is smart enough to switch when it notices your primary site is down, most users won’t even know they’ve been shoved off to the backup datacenter. The business is happy, you’re sleeping at night, all is well. Except that slowly, as usage for the site has grown, performance has suffered. What started as a slight lag has turned into a dragging sensation. You’ve put more web servers into the pool of available resources – or better yet, used your management tools (in the ADC and on your servers) to monitor all facets of web server performance – disk and network I/O, CPU and memory utilization. And still, performance lags. Then you check on your WAN connection and database, and find the problem. Either the WAN connection is overloaded, or the database is waiting long periods of time for responses from the secondary datacenter. If you have things configured so that the primary doesn’t wait for acknowledgment from the secondary database, then your problem might be even more sinister – some transactions may never get deposited in the secondary datacenter, causing your databases to be out of synch. And that’s a problem because you need the secondary database to be as up to date as possible, but buying more bandwidth is a monthly overhead expense, and sometimes it doesn’t help – because the problem isn’t always about bandwidth, sometimes it is about latency. In fact, with synchronous real-time replication, it is almost always about latency. Latency, for those who don’t know, is a combination of how far your connection must travel over the wire and the number of “bumps in the wire” that have been inserted. Not actually the number of devices, but the number and their performance. Each device that touches your data – packet inspection, load balancing, security, whatever the reason – adds time to the delivery window. So does traveling over the wires/fiber. Synchronous replication is very time sensitive. If it doesn’t hear back in time, it doesn’t commit the changes, and then the primary and secondary databases don’t match up. So you need to cut down the latency and improve the performance of your WAN link. Conveniently, your ADC can help. Out-of-the-box it should have TCP optimizations that cut down the impact of latency by reducing the number of packets going back and forth over the wire. It may have compression too – which cuts down the amount of data going over the wire, reducing the number of packets required, which improves the “apparent” performance and the amount of data on your WAN connection. They might offer more functionality than that too. And you’ve already paid for an HA pair – putting one in each datacenter – so all you have to do is check what they do “out of the box” for WAN connections, and then call your sales representative to find out what other functionality is available. F5 includes some functionality in our LTM product, and has more in our add-on WAN Optimization Module (WOM) that can be bought and activated on your BIG-IP. Other vendors have a variety of architectures to offer you similar functionality, but of course I work for and write for F5, so my view is that they aren’t as good as our products… Certainly check with your incumbent vendor before looking for other solutions to this problem. We have seen cases where replication was massively improved with WAN Optimization. More on that in the coming days under a different topic, but just the thought that you can increase the speed and reliability of transaction-based replication (and indeed, file/storage replication, but again, that’s another blog), and you as a manager or a developer do not have to do a thing to your code. That implies the other piece – that this method of improvement is applicable to applications that you have purchased and do not own the source code for. So check it out… At worst you will lose a few hours tracking down your vendor’s options, at best you will be able to go back to sleep at night. And if you’re shifting load between datacenters, as I’ve mentioned before, Long Distance vMotion is improved by these devices too. F5’s architecture for this solution is here – PDF deployment guide. This guide relies upon the WOM functionality mentioned above. And encryption is supported between devices. That means if you are not encrypting your replication, that you can start without impacting performance, and if you are encrypting, you can offload the work of encryption to a device designed to handle it. And bandwidth allocation means you can guarantee your replication has enough bandwidth to stay up to date by giving it priority. But you won’t care too much about that, you’ll be relaxing and dreaming of beaches and stock options… Until the next emergency crops up anyway.255Views0likes0CommentsSometimes, It Is Not The Pipe Size
You could, in theory, install 2 foot diameter pipes in your house to run water through. If you like a really forceful shower, or want your hot-tub to fill quickly, bigger pipes would be your first thought. Imagine your surprise if you had someone come in, and install huge pipes on the inside of your water meter, only to discover that you didn’t get a whole heck of a lot more water through them? You see, the meter is a choke point. As is the pipe leading up to your house. It’s not just the issue of the pipes internally, it is also the external environment and the gateway to your house that determines how much water you can move.159Views0likes0Comments