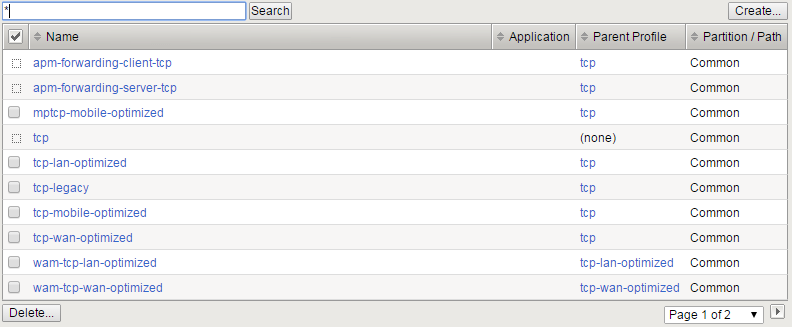
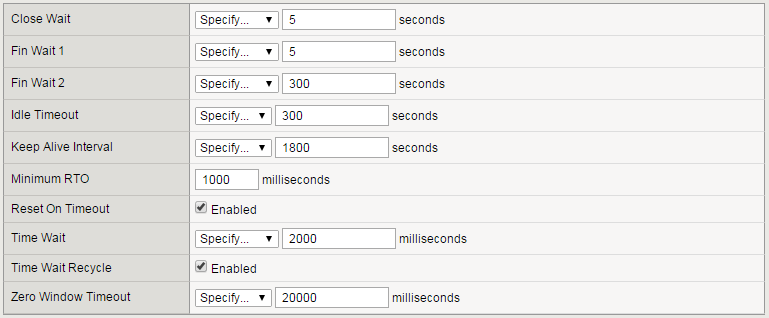
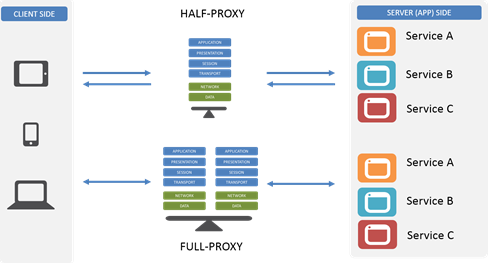
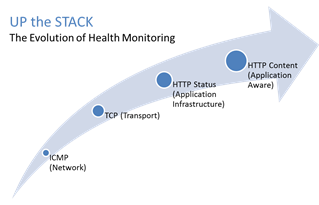
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/performance\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/performance\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1751557989989"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1751560861975":{"__typename":"CachedAsset","id":"pages-1751560861975","value":[{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.MvpProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/mvp-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.AdvocacyProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/advocacy-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp.NonCustomer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/non-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Customer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetInvolved","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.Learn","type":"COMMUNITY","urlPath":"/c/how-do-i/learn","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501996000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp.Community","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/community","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.ContributeCode","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/contribute-code","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.Learn.AboutIrules","type":"COMMUNITY","urlPath":"/c/how-do-i/learn/about-irules","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Support","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-support","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI.GetHelp.SecurityIncident","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/security-incident","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1751560861975,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1751557990837":{"__typename":"CachedAsset","id":"theme:customTheme1-1751557990837","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1751557989989","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1751557989989","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1751557989989","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1751557989071":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1751557989071","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1751557989989","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1751557989536":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1751557989536","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1751558010090","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1751558010090","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1751558010090","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1751558010090","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1751558010090","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1751557989989","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1751557989989","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1751557989989","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:280806":{"__typename":"Conversation","id":"conversation:280806","topic":{"__typename":"TkbTopicMessage","uid":280806},"lastPostingActivityTime":"2022-11-02T05:32:09.620-07:00","solved":false},"User:user:115030":{"__typename":"User","uid":115030,"login":"Rodrigo_Albuque","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-6.svg?time=0"},"id":"user:115030"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDcxMGlDOTQ2N0Q5Nzc2N0ZFMkNG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDcxMGlDOTQ2N0Q5Nzc2N0ZFMkNG?revision=1","title":"0151T000003l6RMQAY.png","associationType":"BODY","width":508,"height":54,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTExOTlpOUJENzBFMUQ4RjVGRjE4NQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTExOTlpOUJENzBFMUQ4RjVGRjE4NQ?revision=1","title":"0151T000003l6RWQAY.png","associationType":"BODY","width":1121,"height":587,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzkxM2lDRjM3NkU4NUExNUU1QkU2?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzkxM2lDRjM3NkU4NUExNUU1QkU2?revision=1","title":"0151T000003l6RlQAI.png","associationType":"BODY","width":777,"height":491,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDg1NmkyQkNGQjNEMTg3QTFDMkY0?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDg1NmkyQkNGQjNEMTg3QTFDMkY0?revision=1","title":"0151T000003l6RqQAI.png","associationType":"BODY","width":893,"height":212,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTEwNDVpNTI2MkQ3MzA5RUYwOTA1Ng?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTEwNDVpNTI2MkQ3MzA5RUYwOTA1Ng?revision=1","title":"0151T000003l6SPQAY.png","associationType":"BODY","width":779,"height":177,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjlpMEE5NUQxNjk3NTVDQjMxOA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjlpMEE5NUQxNjk3NTVDQjMxOA?revision=1","title":"0151T000003l6SeQAI.png","associationType":"BODY","width":523,"height":269,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNzI1MmlBRUMwMTFFNUZDRDg3NzI4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNzI1MmlBRUMwMTFFNUZDRDg3NzI4?revision=1","title":"0151T000003l6SjQAI.png","associationType":"BODY","width":258,"height":768,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIxNDVpMkE1MjA0MTdBMDc0OEFBMQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIxNDVpMkE1MjA0MTdBMDc0OEFBMQ?revision=1","title":"0151T000002dlPUQAY.png","associationType":"BODY","width":2356,"height":662,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTQ3M2kyOUQ5QzM4MjlEOTFCRjQz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTQ3M2kyOUQ5QzM4MjlEOTFCRjQz?revision=1","title":"0151T000002dlP1QAI.png","associationType":"BODY","width":1824,"height":394,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzc2NWkwMDcyRTUwNTI1MEQ1NTkz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzc2NWkwMDcyRTUwNTI1MEQ1NTkz?revision=1","title":"0151T000002dlP2QAI.png","associationType":"BODY","width":1848,"height":416,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjk1NWkyMTMwQThCMzlCMDdBMjRB?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjk1NWkyMTMwQThCMzlCMDdBMjRB?revision=1","title":"0151T000002dlPFQAY.png","associationType":"BODY","width":2510,"height":746,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIwNzNpOTRDRkQ1NzQ0MTBBNjE3Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIwNzNpOTRDRkQ1NzQ0MTBBNjE3Mw?revision=1","title":"0151T000002dlPKQAY.png","associationType":"BODY","width":2158,"height":864,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTk2aTA0ODgyQjVBMkFBQTM2OUQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTk2aTA0ODgyQjVBMkFBQTM2OUQ?revision=1","title":"0151T000002dlPPQAY.png","associationType":"BODY","width":2308,"height":468,"altText":null},"TkbTopicMessage:message:280806":{"__typename":"TkbTopicMessage","subject":"Troubleshooting high CPU utilisation on BIG-IP systems","conversation":{"__ref":"Conversation:conversation:280806"},"id":"message:280806","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280806","revisionNum":1,"uid":280806,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:115030"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":18099},"postTime":"2020-06-03T02:58:59.000-07:00","lastPublishTime":"2020-06-03T02:58:59.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Introduction This is not really a step-by-step troubleshooting guide. What I'm sharing here is the result of reverse engineering the kind of knowledge that led me to succeed on troubleshooting CPU issues during the time I worked for Engineering Services department at F5. Here's what I'll cover sequentially with a mix of what we should know and where to find the problem: Know what HyperThreading (HT) is Know how HT is used within F5 Find out if F5 box supports HyperThreading (HT) Know the difference between Forwarding plane (TMM) vs Control plane (Linux) CPU consumption Confirm if the problem is TMM or another daemon Where to look further when TMM CPU is high What if it's a control plane daemon? Learn how to interpret graphs High CPU in non-HT boxes High CPU in HT+ boxes Use scripts when necessary to collect real time data 1. Know what HyperThreading (HT) is Physical core, as the name implies, is a physical CPU core connected to mothership's socket Physical CPU core has several execution units (modules) capable of performing different tasks e.g. basic integer maths, another for more advanced maths, loading and storing data from/to memory, etc. HT uses 2 or more logical CPU cores to use execution units that are not being utilised by process A, so process B can use them if needed. When 2 programs want to use the same part of the physical core, then it's inevitable that one of them will have to wait The Operating System (OS) scheduler decides which process gets execution priority in this case This is when 2 (or more) actual physical cores would perform better as this limitation is not present i.e. 2 physical cores would be able to concurrently perform tasks using their own execution units 2. Know how HT is used within F5 Before BIG-IP v11.5.0 on systems with HyperThreading (HT) Technology, we would have: 1 TMM per logical core Each logical core processes both data plane (TMM) and control plane (Linux) tasks v11.5.0+ (affects only processors with HT Technology) Data plane (TMM) reside in even-numbered cores (0, 2, 4, etc) Control plane cores (Linux) reside in odd-numbered cores (1, 3, 5, etc) When TMM reaches 80% of actual CPU utilisation, odd-numbered cores limit control plane tasks so they can only use up to 20% of CPU capacity, allowing remaining to be used by overloaded forwarding plane (TMM). vCMP host must also be using v11.5.0+ or newer in order for guests to use HTSplit technology. We can disable it manually by issuing the following command: 3 Find out if your box supports HyperThreading (HT) The hardware boxes listed with HT+ in K14358, all support HyperThreading technology. Here's how to check the number of cores in a given BIG-IP box (this is a VIPRION C2200 chassis with 2250 blade installed): The above box is able to run 2 threads per physical core (Thread(s) per core) with a total of 10 physical cores (Core(s) per socket) and a total of 20 (logical) cores (CPU(s)). Here's the same output from a 3900 series box that does not support HT: The above box is able to run 1 thread per physical core (Thread(s) per core) with a total of 4 physical cores (Core(s) per socket) and a total of 4 cores (CPU(s)). 4 Know the difference between Forwarding plane (TMM) vs Control plane (Linux) CPU consumption 4.1 Confirming if it's TMM or Linux BIG-IP's forwarding plane is TMM. TMM is a daemon/process within Linux space. If tmm CPU usage is high, then we know high CPU utilisation is a forwarding plane issue. The other daemons are part of BIG-IP's control plane (e.g. bigd - monitoring daemon). In this example, both tmm (102.3%) and bigd (51.8%) are high here: If TMM CPU utilisation is high, we will need to troubleshoot CPU usage of internal TMM components. For other daemons, there are different places to look. For example, for bigd (monitoring daemon), we need to check BIG-IP's monitors. AskF5 has a nice how-to guide here. Here's a list of BIG-IP daemons. 4.2 TMM CPU utilisation or forwarding plane CPU utilisation Check tmsh show ltm virtual <virtual server name> to confirm if there is a particular virtual server eating up tmm CPU cycles: Check iRules Check tmsh sys tmm-info to see the breakdown of TMM cpu utilisation per tmm: 4.3 Linux CPU utilisation or data plane CPU utilisation For anything else apart from TMM, top output is your best friend for confirmation of which daemon is the culprit. tmsh show sys proc-info is also another command we can use to gather process specific CPU information. Here I'm checking bigd's monitoring daemon information: 5. Learn how to interpret graphs 5.1 High CPU in non-HT boxes The below graph is just an example taken from 3900 box that doesn't have HT split Because graphs are generated based on average cpu utilisation then we can assume that cpu utilisation is very high at times Because there is no HT-split the below cpu utilisation can be either due to TMM or due some other Linux daemon We can confirm using top command In the below graph it was due to both tmm and bigd to confirm normal usage we always try to match with other numbers in the graph (e.g. active connections, etc) Note: this is a graph as seen in qkview (Clicking on System > Support) which takes a snapshot of the system. It can then be uploaded to ihealth and is mostly used to sharing snapshot of BIG-IP systems with F5 support. However, the graph here is used for illustrative purposes to understand CPU utilisation as seen in graphs. 5.2 High CPU in HT+ boxes This other graph here was taken from a 4200 series box which has HT split enabled Notice that CPU cores 0, 2, 4 and 6 (tmm/data plane) show CPU at about 60% Cores 1, 3, 5 and 7 show very minimal CPU utilisation with some spikes Spikes can be due to AVR/ASM daemons described in K16469 and K15606 Or because TMM has reached 80% of cpu utilisation and is now using control plane's cores This is an example of mostly normal/regular cpu utilisation When HT is enabled and TMM cores use less than 80% of cpu, then data-plane cores remain mostly 'quiet'. 6. Use scripts when necessary to collect real time data Sometimes just by looking at the graphs and commands is not enough to determine why CPU is high. Here's an example of a script to collect real-time TMM/Linux CPU stats on BIG-IP every 60 seconds and copy output to /var/log/cpu-average.log top command output is also copied to /var/log/top-output.log: Output should be similar to this: The number after \"Counter64\" is the percentage value representing how busy each CPU core is. For example, TMM0.0 and TMM0.1 are both at 1% of capacity. We can add H to top command (e.g. top -Hcbn 1) in the script above to show the individual threads of a process, including TMM threads. When opening a support case with F5, it may be useful to include the full tmctl table as it contains roughly all raw data about everything we can possibly find on BIG-IP system. The below is an example of a script that collects all tmctl information every 5 seconds: Apart from knowing where to look, understanding the CPU usage pattern when it comes to our own organisation's production traffic is really important. It enables us to compare, for example, the number of active connections with a spike in CPU in the graphs to understand if the spike is related to a sudden and sharp increase in traffic. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7585","kudosSumWeight":6,"repliesCount":3,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDcxMGlDOTQ2N0Q5Nzc2N0ZFMkNG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTExOTlpOUJENzBFMUQ4RjVGRjE4NQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzkxM2lDRjM3NkU4NUExNUU1QkU2?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNDg1NmkyQkNGQjNEMTg3QTFDMkY0?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTEwNDVpNTI2MkQ3MzA5RUYwOTA1Ng?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjlpMEE5NUQxNjk3NTVDQjMxOA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNzI1MmlBRUMwMTFFNUZDRDg3NzI4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIxNDVpMkE1MjA0MTdBMDc0OEFBMQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTQ3M2kyOUQ5QzM4MjlEOTFCRjQz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMzc2NWkwMDcyRTUwNTI1MEQ1NTkz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtNjk1NWkyMTMwQThCMzlCMDdBMjRB?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEy","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtMTIwNzNpOTRDRkQ1NzQ0MTBBNjE3Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEz","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA4MDYtOTk2aTA0ODgyQjVBMkFBQTM2OUQ?revision=1\"}"}}],"totalCount":13,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:284798":{"__typename":"Conversation","id":"conversation:284798","topic":{"__typename":"TkbTopicMessage","uid":284798},"lastPostingActivityTime":"2013-11-07T18:50:46.000-08:00","solved":false},"User:user:171720":{"__typename":"User","uid":171720,"login":"Lori_MacVittie","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-10.svg?time=0"},"id":"user:171720"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:284798":{"__typename":"TkbTopicMessage","subject":"The Disadvantages of DSR (Direct Server Return)","conversation":{"__ref":"Conversation:conversation:284798"},"id":"message:284798","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:284798","revisionNum":1,"uid":284798,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":6031},"postTime":"2008-07-03T04:29:32.000-07:00","lastPublishTime":"2008-07-03T04:29:32.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" I read a very nice blog post yesterday discussing some of the traditional pros and cons of load-balancing configurations. The author comes to the conclusion that if you can use direct server return, you should. I agree with the author's list of pros and cons; DSR is the least intrusive method of deploying a load-balancer in terms of network configuration. But there are quite a few disadvantages missing from the author's list. Author's List of Disadvantages of DSR The disadvantages of Direct Routing are: Backend server must respond to both its own IP (for health checks) and the virtual IP (for load balanced traffic) Port translation or cookie insertion cannot be implemented. The backend server must not reply to ARP requests for the VIP (otherwise it will steal all the traffic from the load balancer) Prior to Windows Server 2008 some odd routing behavior could occur in In some situations either the application or the operating system cannot be modified to utilse Direct Routing. Some additional disadvantages: Protocol sanitization can't be performed. This means vulnerabilities introduced due to manipulation of lax enforcement of RFCs and protocol specifications can't be addressed. Application acceleration can't be applied. Even the simplest of acceleration techniques, e.g. compression, can't be applied because the traffic is bypassing the load-balancer (a.k.a. application delivery controller). Implementing caching solutions become more complex. With a DSR configuration the routing that makes it so easy to implement requires that caching solutions be deployed elsewhere, such as via WCCP on the router. This requires additional configuration and changes to the routing infrastructure, and introduces another point of failure as well as an additional hop, increasing latency. Error/Exception/SOAP fault handling can't be implemented. In order to address failures in applications such as missing files (404) and SOAP Faults (500) it is necessary for the load-balancer to inspect outbound messages. Using a DSR configuration this ability is lost, which means errors are passed directly back to the user without the ability to retry a request, write an entry in the log, or notify an administrator. Data Leak Prevention can't be accomplished. Without the ability to inspect outbound messages, you can't prevent sensitive data (SSN, credit card numbers) from leaving the building. Connection Optimization functionality is lost. TCP multiplexing can't be accomplished in a DSR configuration because it relies on separating client connections from server connections. This reduces the efficiency of your servers and minimizes the value added to your network by a load balancer. There are more disadvantages than you're likely willing to read, so I'll stop there. Suffice to say that the problem with the suggestion to use DSR whenever possible is that if you're an application-aware network administrator you know that most of the time, DSR isn't the right solution because it restricts the ability of the load-balancer (application delivery controller) to perform additional functions that improve the security, performance, and availability of the applications it is delivering. DSR is well-suited, and always has been, to UDP-based streaming applications such as audio and video delivered via RTSP. However, in the increasingly sensitive environment that is application infrastructure, it is necessary to do more than just \"load balancing\" to improve the performance and reliability of applications. Additional application delivery techniques are an integral component to a well-performing, efficient application infrastructure. DSR may be easier to implement and, in some cases, may be the right solution. But in most cases, it's going to leave you simply serving applications, instead of delivering them. Just because you can, doesn't mean you should. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4025","kudosSumWeight":0,"repliesCount":4,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ3OTgtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}"}}],"totalCount":5,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286621":{"__typename":"Conversation","id":"conversation:286621","topic":{"__typename":"TkbTopicMessage","uid":286621},"lastPostingActivityTime":"2016-09-13T00:41:51.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1","title":"0151T000003d8I1QAI.jpg","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1","title":"0151T000003d8MMQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:286621":{"__typename":"TkbTopicMessage","subject":"HTTP Pipelining: A security risk without real performance benefits","conversation":{"__ref":"Conversation:conversation:286621"},"id":"message:286621","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286621","revisionNum":1,"uid":286621,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":4749},"postTime":"2009-04-02T03:30:40.000-07:00","lastPublishTime":"2009-04-02T03:30:40.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Everyone wants web sites and applications to load faster, and there’s no shortage of folks out there looking for ways to do just that. But all that glitters is not gold, and not all acceleration techniques actually do all that much to accelerate the delivery of web sites and applications. Worse, some actual incur risk in the form of leaving servers open to exploitation. A BRIEF HISTORY Back in the day when HTTP was still evolving, someone came up with the concept of persistent connections. See, in ancient times – when administrators still wore togas in the data center – HTTP 1.0 required one TCP connection for every object on a page. That was okay, until pages started comprising ten, twenty, and more objects. So someone added an HTTP header, Keep-Alive, which basically told the server not to close the TCP connection until (a) the browser told it to or (b) it didn’t hear from the browser for X number of seconds (a time out). This eventually became the default behavior when HTTP 1.1 was written and became a standard. I told you it was a brief history. This capability is known as a persistent connection, because the connection persists across multiple requests. This is not the same as pipelining, though the two are closely related. Pipelining takes the concept of persistent connections and then ignores the traditional request – reply relationship inherent in HTTP and throws it out the window. The general line of thought goes like this: “Whoa. What if we just shoved all the requests from a page at the server and then waited for them all to come back rather than doing it one at a time? We could make things even faster!” Tada! HTTP pipelining. In technical terms, HTTP pipelining is initiated by the browser by opening a connection to the server and then sending multiple requests to the server without waiting for a response. Once the requests are all sent then the browser starts listening for responses. The reason this is considered an acceleration technique is that by shoving all the requests at the server at once you essentially save the RTT (Round Trip Time) on the connection waiting for a response after each request is sent. WHY IT JUST DOESN’T MATTER ANYMORE (AND MAYBE NEVER DID) Unfortunately, pipelining was conceived of and implemented before broadband connections were widely utilized as a method of accessing the Internet. Back then, the RTT was significant enough to have a negative impact on application and web site performance and the overall user-experience was improved by the use of pipelining. Today, however, most folks have a comfortable speed at which they access the Internet and the RTT impact on most web application’s performance, despite the increasing number of objects per page, is relatively low. There is no arguing, however, that some reduction in time to load is better than none. Too, anyone who’s had to access the Internet via high latency links can tell you anything that makes that experience faster has got to be a Good Thing. So what’s the problem? The problem is that pipelining isn’t actually treated any differently on the server than regular old persistent connections. In fact, the HTTP 1.1 specification requires that a “server MUST send its responses to those requests in the same order that the requests were received.” In other words, the requests are return in serial, despite the fact that some web servers may actually process those requests in parallel. Because the server MUST return responses to requests in order that the server has to do some extra processing to ensure compliance with this part of the HTTP 1.1 specification. It has to queue up the responses and make certain responses are returned properly, which essentially negates the performance gained by reducing the number of round trips using pipelining. Depending on the order in which requests are sent, if a request requiring particularly lengthy processing – say a database query – were sent relatively early in the pipeline, this could actually cause a degradation in performance because all the other responses have to wait for the lengthy one to finish before the others can be sent back. Application intermediaries such as proxies, application delivery controllers, and general load-balancers can and do support pipelining, but they, too, will adhere to the protocol specification and return responses in the proper order according to how the requests were received. This limitation on the server side actually inhibits a potentially significant boost in performance because we know that processing dynamic requests takes longer than processing a request for static content. If this limitation were removed it is possible that the server would become more efficient and the user would experience non-trivial improvements in performance. Or, if intermediaries were smart enough to rearrange requests such that they their execution were optimized (I seem to recall I was required to design and implement a solution to a similar example in graduate school) then we’d maintain the performance benefits gained by pipelining. But that would require an understanding of the application that goes far beyond what even today’s most intelligent application delivery controllers are capable of providing. THE SILVER LINING At this point it may be fairly disappointing to learn that HTTP pipelining today does not result in as significant a performance gain as it might at first seem to offer (except over high latency links like satellite or dial-up, which are rapidly dwindling in usage). But that may very well be a good thing. As miscreants have become smarter and more intelligent about exploiting protocols and not just application code, they’ve learned to take advantage of the protocol to “trick” servers into believing their requests are legitimate, even though the desired result is usually malicious. In the case of pipelining, it would be a simple thing to exploit the capability to enact a layer 7 DoS attack on the server in question. Because pipelining assumes that requests will be sent one after the other and that the client is not waiting for the response until the end, it would have a difficult time distinguishing between someone attempting to consume resources and a legitimate request. Consider that the server has no understanding of a “page”. It understands individual requests. It has no way of knowing that a “page” consists of only 50 objects, and therefore a client pipelining requests for the maximum allowed – by default 100 for Apache – may not be seen as out of the ordinary. Several clients opening connections and pipelining hundreds or thousands of requests every second without caring if they receive any of the responses could quickly consume the server’s resources or available bandwidth and result in a denial of service to legitimate users. So perhaps the fact that pipelining is not really all that useful to most folks is a good thing, as server administrators can disable the feature without too much concern and thereby mitigate the risk of the feature being leveraged as an attack method against them. Pipelining as it is specified and implemented today is more of a security risk than it is a performance enhancement. There are, however, tweaks to the specification that could be made in the future that might make it more useful. Those tweaks do not address the potential security risk, however, so perhaps given that there are so many other optimizations and acceleration techniques that can be used to improve performance that incur no measurable security risk that we simply let sleeping dogs lie. IMAGES COURTESTY WIKIPEDIA COMMONS ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7772","kudosSumWeight":0,"repliesCount":5,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODY2MjEtNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}"}}],"totalCount":8,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:290793":{"__typename":"Conversation","id":"conversation:290793","topic":{"__typename":"TkbTopicMessage","uid":290793},"lastPostingActivityTime":"2019-04-25T11:03:37.000-07:00","solved":false},"User:user:193863":{"__typename":"User","uid":193863,"login":"Martin_Duke","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-4.svg?time=0"},"id":"user:193863"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3OTMtNjQ0OGk2MUYzQTk0QkQxMDlFNThE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3OTMtNjQ0OGk2MUYzQTk0QkQxMDlFNThE?revision=1","title":"0151T000003d6bgQAA.png","associationType":"BODY","width":792,"height":327,"altText":null},"TkbTopicMessage:message:290793":{"__typename":"TkbTopicMessage","subject":"Stop Using the Base TCP Profile!","conversation":{"__ref":"Conversation:conversation:290793"},"id":"message:290793","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:290793","revisionNum":1,"uid":290793,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:193863"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":4406},"postTime":"2015-10-14T15:34:00.000-07:00","lastPublishTime":"2015-10-14T15:34:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n\n [Update 1 Mar 2017: F5 has new built-in profiles in TMOS v13.0. Although the default profile settings still haven't changed, there is good news on that from as well.] \n\n If the customer data I've seen is any indication, the vast majority of our customers are using the base 'tcp' profile to configure their TCP optimization. This has poor performance consequences and I strongly encourage you to replace it immediately. \n\n What's wrong with it? \n\n The Buffers are too small. Both the receive and send buffers are limited to 64KB, and the proxy buffer won't exceed 48K . If the bandwidth/delay product of your connection exceeds the send or receive buffer, which it will in most of today's internet for all but the smallest files and shortest delays, your applications will be limited not by the available bandwidth but by an arbitrary memory limitation. \n\n The Initial Congestion Window is too small. As the early thin-pipe, small-buffer days of the internet recede, the Internet Engineering Task Force (see IETF RFC 6928) increased the allowed size of a sender's initial burst. This allows more file transfers to complete in single round trip time and allows TCP to discover the true available bandwidth faster. \n\n Delayed ACKs. The base profile enables Delayed ACK, which tries to reduce ACK traffic by waiting 200ms to see if more data comes in. This incurs a serious performance penalty on SSL, among other upper-layer protocols. \n\n What should you do instead? \n\n The best answer is to build a custom profile based on your specific environment and requirements. But we recognize that some of you will find that daunting! So we've created a variety of profiles customized for different environments. Frankly, we should do some work to improve these profiles, but even today there are much better choices than base 'tcp'. \n\n If you have an HTTP profile attached to the virtual, we recommend you use tcp-mobile-optimized. This is true even if your clients aren't mobile. The name is misleading! As I said, the default profiles need work. \n\n If you're just a bit more adventurous with your virtual with an HTTP profile, then mptcp-mobile-optimized will likely outperform the above. Besides enabling Multipath TCP (MPTCP) for clients that ask for it, it uses a more advanced congestion control (\"Illinois\") and rate pacing. We recognize, however, that if you're still using the base 'tcp' profile today then you're probably not comfortable with the newest, most innovative enhancements to TCP. So plain old tcp-mobile-optimized might be a more gentle step forward. \n\n If your virtual doesn't have an HTTP profile, the best decision is to use a modified version of tcp-mobile-optimized or mptcp-mobile-optimized. Just derive a profile from whichever you prefer and disable the Nagle algorithm. That's it! If you are absolutely dead set against modifying a default profile, then wam-tcp-lan-optimized is the next best choice. It doesn't really matter if the attached network is actually a LAN or the open internet. \n\n Why did we create a default profile with undesirable settings? \n\n That answer is lost in the mists of time. But now it's hard to change: altering the profile from which all other profiles are derived will cause sudden changes in customer TCP behavior when they upgrade. Most would benefit, and many may not even notice, but we try to not to surprise people. \n\n Nevertheless, if you want a quick, cheap, and easy boost to your application performance, simply switch your TCP profile from the base to one of our other defaults. You won't regret it. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3621","kudosSumWeight":1,"repliesCount":27,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3OTMtNjQ0OGk2MUYzQTk0QkQxMDlFNThE?revision=1\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:287270":{"__typename":"Conversation","id":"conversation:287270","topic":{"__typename":"TkbTopicMessage","uid":287270},"lastPostingActivityTime":"2013-03-08T03:02:59.000-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTUyNDhpNTA2MDlFQzY4ODZBMDk1MQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTUyNDhpNTA2MDlFQzY4ODZBMDk1MQ?revision=1","title":"0151T000003d5XPQAY.png","associationType":"BODY","width":292,"height":117,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMjM0MWlBRUZBN0JDODk0RkU3NjhG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMjM0MWlBRUZBN0JDODk0RkU3NjhG?revision=1","title":"0151T000003d5XQQAY.png","associationType":"BODY","width":417,"height":280,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ1MjBpRTc1MzM1REEwNjA5MTJGMg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ1MjBpRTc1MzM1REEwNjA5MTJGMg?revision=1","title":"0151T000003d5WCQAY.png","associationType":"BODY","width":65,"height":48,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ4OTVpQTFDQjhFRjc5QjQ2MzZFNQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ4OTVpQTFDQjhFRjc5QjQ2MzZFNQ?revision=1","title":"0151T000003d5WDQAY.png","associationType":"BODY","width":37,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEyODVpNEY3RjE3RTVGMEUyQzFFNg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEyODVpNEY3RjE3RTVGMEUyQzFFNg?revision=1","title":"0151T000003d5WEQAY.png","associationType":"BODY","width":40,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNTY1M2k2RUZBNkE3NERFMDA1QTFF?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNTY1M2k2RUZBNkE3NERFMDA1QTFF?revision=1","title":"0151T000003d5WFQAY.png","associationType":"BODY","width":39,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNDk2M2lBMTZGRkMxMkRBMTMzMEFB?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNDk2M2lBMTZGRkMxMkRBMTMzMEFB?revision=1","title":"0151T000003d5WGQAY.png","associationType":"BODY","width":42,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEzNDZpRDYzNkJCNkRENENBN0I1OA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEzNDZpRDYzNkJCNkRENENBN0I1OA?revision=1","title":"0151T000003d5WHQAY.png","associationType":"BODY","width":41,"height":38,"altText":null},"TkbTopicMessage:message:287270":{"__typename":"TkbTopicMessage","subject":"Back to Basics: Least Connections is Not Least Loaded","conversation":{"__ref":"Conversation:conversation:287270"},"id":"message:287270","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:287270","revisionNum":1,"uid":287270,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":4342},"postTime":"2013-01-02T08:08:00.000-08:00","lastPublishTime":"2013-01-02T08:08:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #webperf #ado When load balancing, \"least connections\" does not mean \"least loaded\" Performance is important, and that means it's important that our infrastructure support the need for speed. Load balancing algorithms are an integral piece of the performance equation and can both improve - or degrade - performance. That's why it's important to understand more about the algorithms than their general selection mechanism. Understanding that round robin is basically an iterative choice, traversing a list one by one is good - but understanding what that means in terms of performance and capacity on different types of applications and application workloads is even better. We last checked out \"fastest response time\" and today we're diving into \"least connections\" which, as stated above, does not mean \"least loaded.\" INTRA-APPLICATION WORKLOADS The industry standard \"Least connections\" load balancing algorithm uses the number of current connections to each application instance (member) to make its load balancing decision. The member with the least number of active connections is chosen. Pretty simple, right? The premise of this algorithm is a general assumption that fewer connections (and thus fewer users) means less load and therefore better performance. That's operational axiom #2 at work - if performance decreases as load increases it stands to reason that performance increases as load decreases. That would be true (and in the early days of load balancing it was true) if all intra-application workloads required the same resources. Unfortunately, that's no longer true and the result is uneven load distribution that leads to unpredictable performance fluctuations as demand increases. Consider a simple example: a user logging into a system takes at least one if not more database queries to validate credentials and then update the system to indicate the activity. Depending on the nature of the application, other intra-application activities will require different quantities of resources. Some are RAM heavy, others CPU heavy, others file or database heavy. Furthermore, depending on the user in question, the usage pattern will vary greatly. One hundred users can be logged into the same system (requiring at a minimum ten connections) but if they're all relatively idle, the system will be lightly loaded and performing well. Conversely, another application instance may boast only 50 connections, but all fifty users are heavily active with database queries returning large volumes of data. The system is far more heavily loaded and performance may be already beginning to suffer. When the next request comes in, however, the load balancer using a \"least connections\" algorithm will choose the latter member, increasing the burden on that member and likely further degrading performance. The premise of the least connections algorithm is that the application instance with the fewest number of connections is the least loaded. Except, it's not. The only way to know which application instance is the least loaded is to monitor its system variables directly, gathering CPU utilization and memory and comparing it against known maximums. That generally requires either SNMP, agents, or other active monitoring mechanisms that can unduly tax the system in and of itself by virtue of consuming resources. This is a quandary for operations, because \"application workload\" is simply too broad a generalization. Certainly some applications are more I/O heavy than others, still others are more CPU or connection heavy. But all applications have both a general workload profile and an intra-application workload profile. Understanding the usage patterns - the intra-application workload profile - of an application is critical to being able to determine how best to not only choose a load balancing algorithm but specify any limitations that may provide better overall performance and use of capacity during execution. As always, being aware of the capabilities and the limitations of a given load balancing algorithm will assist in choosing one that is best able to meet the performance and availability requirements of an application (and thus the business). ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4313","kudosSumWeight":0,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTUyNDhpNTA2MDlFQzY4ODZBMDk1MQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMjM0MWlBRUZBN0JDODk0RkU3NjhG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ1MjBpRTc1MzM1REEwNjA5MTJGMg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTQ4OTVpQTFDQjhFRjc5QjQ2MzZFNQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEyODVpNEY3RjE3RTVGMEUyQzFFNg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNTY1M2k2RUZBNkE3NERFMDA1QTFF?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtNDk2M2lBMTZGRkMxMkRBMTMzMEFB?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODcyNzAtMTEzNDZpRDYzNkJCNkRENENBN0I1OA?revision=1\"}"}}],"totalCount":8,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:290743":{"__typename":"Conversation","id":"conversation:290743","topic":{"__typename":"TkbTopicMessage","uid":290743},"lastPostingActivityTime":"2023-12-01T01:45:03.680-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1","title":"0151T000003d6kLQAQ.png","associationType":"BODY","width":769,"height":318,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1","title":"0151T000003d6kMQAQ.png","associationType":"BODY","width":768,"height":134,"altText":null},"TkbTopicMessage:message:290743":{"__typename":"TkbTopicMessage","subject":"Tuning the TCP Profile, Part One","conversation":{"__ref":"Conversation:conversation:290743"},"id":"message:290743","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:290743","revisionNum":1,"uid":290743,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:193863"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3900},"postTime":"2016-01-28T18:51:00.000-08:00","lastPublishTime":"2016-01-28T18:51:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" A few months ago I pointed out some problems with the existing F5-provided TCP profiles, especially the default one. Today I'll begin a pass through the (long) TCP profile to point out the latest thinking on how to get the most performance for your applications. We'll go in the order you see these profile options in the GUI. \n\n But first, a note about programmability: in many cases below, I'm going to ask you to generalize about the clients or servers you interact with, and the nature of the paths to those hosts. In a perfect world, we'd detect that stuff automatically and set it for you, and in fact we're rolling that out setting by setting. In the meantime, you can customize your TCP parameters on a per-connection basis using iRules for many of the settings described below, something I'll explain further where applicable. \n\n In general, when I refer to \"performance\" below, I'm referring to the speed at which your customer gets her data. Performance can also refer to the scalability of your application delivery due to CPU and memory limitations, and when that's what I mean, I'll say so. \n\n Timer Management \n\n \n\n The one here with a big performance impact is Minimum RTO. When TCP computes its Retransmission Timeout (RTO), it takes the average measured Round Trip Time (RTT) and adds a few standard deviations to make sure it doesn't falsely detect loss. (False detections have very negative performance implications.) But if RTT is low and stable that RTO may be too low, and the minimum is designed to catch known fluctuations in RTT that the connection may not have observed. \n\n Set Minimum RTO too low, and TCP may improperly enter congestion response and reduce the sending rate all the way down to one packet per round trip. Set it too high, and TCP sits idle when it ought to retransmit lost data. \n\n So what's the right value? Obviously, if you have a sense of the maximum RTT to your clients (which you can get with the ping command), that's a floor for your value. Furthermore, many clients and servers will implement some sort of Delayed ACK, which reduces ACK volume by sometimes holding them back for up to 200ms to see if it can aggregate more data in the ACK. RFC 5681 actually allows delays of up to 500ms, but this is less common. So take the maximum RTT and add 200 to 500 ms. \n\n Another group of settings aren't really about throughput, but to help clients and servers to close gracefully, at the cost of consuming some system resources. Long Close Wait, Fin Wait 1, Fin Wait 2, and Time Wait timers will keep connection state alive to make sure the remote host got all the connection close messages. Enabling Reset On Timeout sends a message that tells the peer to tear down the connection. Similarly, disabling Time Wait Recycle will prevent new connections from using the same address/port combination, making sure that the old connection with that combination gets a full close. \n\n The last group of settings keeps possibly dead connections alive, using system resources to maintain state in case they come back to life. Idle Timeout and Zero Window Timeout commit resources until the timer expires. If you set Keep Alive Interval to a value less than the Idle Timeout, then on the clientside BIG-IP will keep the connection alive as long as the client keeps responding to keepalive and the server doesn't terminate the connection itself. In theory, this could be forever! \n\n Memory Management \n\n \n\n In terms of high throughput performance, you want all of these settings to be as large as possible up to a point. The tradeoff is that setting them too high may waste memory and reduce the number of supportable concurrent connections. I say \"may\" waste because these are limits on memory use, and BIG-IP doesn't allocate the memory until it needs it for buffered data. Even so, the trick is to set the limits large enough that there are no performance penalties, but no larger. \n\n Send Buffer and Receive Window are easy to set in principle, but can be tricky in practice. For both, answer these questions: \n\n What is the maximum bandwidth (Bytes/second) that BIG-IP might experience sending or receiving? Out of all paths data might travel, what minimum delay among those paths is the highest? (What is the \"maximum of the minimums\"?) \n\n Then you simply multiply Bytes/second by seconds of delay to get a number of bytes. This is the maximum amount of data that TCP ought to have in flight at any one time, which should be enough to prevent TCP connections from idling for lack of memory. If your application doesn't involve sending or receiving much data on that side of the proxy, you can probably get away with lowering the corresponding buffer size to save on memory. For example, a traditional HTTP proxy's clientside probably can afford to have a smaller receive buffer if memory-constrained. \n\n There are three principles to follow in setting Proxy Buffer Limits: \n\n Proxy Buffer High should be at least as big as the Send Buffer. Otherwise, if a large ACK clears the send buffer all at once there may be less data available than TCP can send. Proxy Buffer Low should be at least as big as the Receive Window on the peer TCP profile (i.e. for the clientside profile, use the receive window on the serverside profile). If not, when the peer connection exits the zero-window state, new data may not arrive before BIG-IP sends all the data it has. Proxy Buffer High should be significantly larger than Proxy Buffer Low (we like to use a 64 KB gap) to avoid constant flapping to and from the zero-window state on the receive side. \n\n Obviously, figuring out bandwidth and delay before a deployment can be tricky. This is a place where some iRule mojo can really come in handy. The TCP::rtt and TCP::bandwidth* commands can give you estimates of both quantities you need, even though the RTT isn't a minimum RTT. Alternatively, if you've enabled cmetrics-cache in the profile, you can also obtain historical data for a destination using the ROUTE::cwnd* command, which is a good (possibly low) guess at the value you should plug into the send and receive buffers. \n\n You can then set buffer limits directly using TCP::sendbuf**, TCP::recvwnd**, and TCP::proxybuffer**. Getting this to work very well will be difficult, and I don't have any examples where someone worked it through and proved a benefit. But if your application travels highly varied paths and you have the inclination to tinker, you could end up with an optimized configuration. If not, set the buffer sizes using conservatively high inputs and carry on. \n\n *These iRule commands only supported in TMOS® version 12.0.0 and later. \n\n **These iRule commands only supported in TMOS® version 11.6.0 and later. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6818","kudosSumWeight":0,"repliesCount":6,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282796":{"__typename":"Conversation","id":"conversation:282796","topic":{"__typename":"TkbTopicMessage","uid":282796},"lastPostingActivityTime":"2018-11-13T03:35:48.000-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTYtNjM1aTlFQTQ5Qjk5QTA5QTNFN0E?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTYtNjM1aTlFQTQ5Qjk5QTA5QTNFN0E?revision=1","title":"0151T000003d6dxQAA.png","associationType":"BODY","width":488,"height":263,"altText":null},"TkbTopicMessage:message:282796":{"__typename":"TkbTopicMessage","subject":"Three things your proxy can’t do unless it’s a full-proxy","conversation":{"__ref":"Conversation:conversation:282796"},"id":"message:282796","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282796","revisionNum":1,"uid":282796,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3020},"postTime":"2015-11-25T06:00:00.000-08:00","lastPublishTime":"2015-11-25T06:00:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Proxies are one of the more interesting (in my no-doubt biased opinion) “devices” in the network. They’re the basis for caching, load balancing, app security, and even app acceleration services. They’re also a bridge between dev and ops and the network, being commonplace to all three groups and environments in most data center architectures. \n\n But not all proxies are built on the same architectural principles, which means not all proxies are created equal. A large number of proxies are half-proxies while others are full-proxies, and the differences between them are what mean the difference between what you can and cannot do with them. In fact, there are three very important things you can do with a full-proxy that you can’t do with a regular old proxy. \n\n \n\n \n\n Before we jump into those three things, let’s review the differences between them, shall we? \n\n Half-Proxy \n\n Half-proxy is a description of the way in which a proxy, reverse or forward, handles connections. Basically it’s describing the notion that the proxy only mediates connections on the client side. So it only proxies half the communication between the client and the app. The most important thing to recognize about a half-proxy is that it has only one network stack that it shares across both client and server. \n\n Full-Proxy \n\n By contrast, a full-proxy maintains two distinct network stacks – one on the client side, one of the app side – and fully proxies both sides, hence the name. While a full-proxy can be configured to act like a half-proxy, its value is in its typical configuration, which is to maintain discrete connections to both the client and the server. \n\n It is this dual-stack approach that enables a full-proxy to provide capabilities that a half-proxy with its single network stack simply cannot. \n\n The Three Things \n\n A full-proxy completely understands the protocols for which it proxies and is itself both an endpoint and an originator for those protocols and connections. This also means the full-proxy can have its own TCP connection behavior for each network stack such as buffering, retransmits, and TCP options. With a full-proxy each connection is unique; each can have its own TCP connection behavior. This means that a client connecting to the full-proxy device would likely have different connection behavior than the full-proxy might use for communicating with servers. Full-proxies can look at incoming requests and outbound responses and can manipulate both if the solution allows it. \n\n #1 Optimize client side and server side \n\n Because it can maintain separate network stacks and characteristics, a full-proxy can optimize each side for its unique needs. The TCP options needed to optimize for performance on the client side’s lower-speed, higher-latency network connection – particularly when mobile devices are being served – are almost certainly very different than those needed to optimize for performance on the server side’s high-speed, low latency data center network connection. A full-proxy can optimize both at the same time and thus provide the best performance possible in all situations. A half-proxy, with its single network stack, is forced to optimize for the average of its connections, which certainly means one side or the other is left with less than optimal performance. \n\n #2 Act as a protocol gateway \n\n Protocol gateways are an important tool in the architect’s toolbox particularly when transitioning from one version of an application protocol to another, like HTTP/1 to HTTP/2 or SPDY. Because a full proxy maintains those two unique connections, it can accept HTTP/2 on the client side, for example, but speak HTTP/1 to the server (app). That’s because a full-proxy terminates the client connection (the proxy is the server) and initiatives a different connection to the server (the proxy is the client). The protocol used on the client side doesn’t restrict the choice of protocols on the server side. Realistically, any protocol transition that makes sense (and even those that don’t) can be managed with a full-proxy. A programmable full-proxy ensures that even if its an uncommon (and thus not universally supported) that you can code up a gateway yourself without expending effort on reinventing the proxy-wheel. \n\n #3 Terminate SSL/TLS \n\n Technically this is a specialized case of a protocol gateway but the ascendancy of HTTP/S (and the urgency with which we are encouraged to deploy SSL Everywhere and Encrypt All The Things) makes me treat this as its own case. Basically terminating SSL/TLS is a critical capability in modern and emerging architectures because of the need to inspect and direct HTTP-based traffic (like REST API calls) based on information within the HTTP protocol that would otherwise be invisible thanks to encryption. The ability to terminate SSL/TLS means the proxy becomes the secure endpoint to which clients connect (and ultimately trust). Termination means the proxy is responsible for decrypting requests and encrypting responses and is thus able to “see” into the messages and use the data therein to make routing and load balancing decisions. \n\n \n\n So the next time you’re looking at a proxy, don’t forget to find out whether it’s a full proxy or not. Because without a full-proxy, you’re limiting your ability to really take advantage of its capabilities and reaping the benefits it can offer modern and emerging application architectures. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5472","kudosSumWeight":1,"repliesCount":3,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTYtNjM1aTlFQTQ5Qjk5QTA5QTNFN0E?revision=1\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:287880":{"__typename":"Conversation","id":"conversation:287880","topic":{"__typename":"TkbTopicMessage","uid":287880},"lastPostingActivityTime":"2014-12-18T03:22:00.000-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTI4OTFpQjlERjM3MTg0RjM1NjQ2RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTI4OTFpQjlERjM3MTg0RjM1NjQ2RA?revision=1","title":"0151T000003d7gqQAA.png","associationType":"BODY","width":319,"height":205,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTM3NzZpODkyQUIwRjU4RDZDNEFGNQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTM3NzZpODkyQUIwRjU4RDZDNEFGNQ?revision=1","title":"0151T000003d7grQAA.png","associationType":"BODY","width":404,"height":236,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTAyMThpQjQ1QzY4MTJGQkVDOUI4Qw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTAyMThpQjQ1QzY4MTJGQkVDOUI4Qw?revision=1","title":"0151T000003d7gsQAA.png","associationType":"BODY","width":38,"height":39,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjE4MWk0RjFGQkYwNEVDN0UxNjQz?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjE4MWk0RjFGQkYwNEVDN0UxNjQz?revision=1","title":"0151T000003d5TMQAY.png","associationType":"BODY","width":40,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEzMDdpM0Q2M0Q3QTQwQjZENjIyOQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEzMDdpM0Q2M0Q3QTQwQjZENjIyOQ?revision=1","title":"0151T000003d5TLQAY.png","associationType":"BODY","width":37,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtOTY2OGkyNkZFMUFDMzJBQ0QwQjA5?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtOTY2OGkyNkZFMUFDMzJBQ0QwQjA5?revision=1","title":"0151T000003d5TNQAY.png","associationType":"BODY","width":65,"height":48,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTY3NGk4QTAwQjYyMUFCMTE5NDcy?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTY3NGk4QTAwQjYyMUFCMTE5NDcy?revision=1","title":"0151T000003d5TQQAY.png","associationType":"BODY","width":39,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEyOTRpQkVFNjA5MEZDOEE4QTk1Ng?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEyOTRpQkVFNjA5MEZDOEE4QTk1Ng?revision=1","title":"0151T000003d5TRQAY.png","associationType":"BODY","width":42,"height":38,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjY5Mmk2RDcxNTYwOUNGNEY3MTE1?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjY5Mmk2RDcxNTYwOUNGNEY3MTE1?revision=1","title":"0151T000003d5TSQAY.png","associationType":"BODY","width":41,"height":38,"altText":null},"TkbTopicMessage:message:287880":{"__typename":"TkbTopicMessage","subject":"Back to Basics: Health Monitors and Load Balancing","conversation":{"__ref":"Conversation:conversation:287880"},"id":"message:287880","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:287880","revisionNum":1,"uid":287880,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2943},"postTime":"2012-11-21T05:52:00.000-08:00","lastPublishTime":"2012-11-21T05:52:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #webperf #ado Because every connection counts \n\n One of the truisms of architecting highly available systems is that you never, ever want to load balance a request to a system that is down. Therefore, some sort of health (status) monitoring is required. For applications, that means not just pinging the network interface or opening a TCP connection, it means querying the application and verifying that the response is valid. \n\n This, obviously, requires the application to respond. And respond often. Best practices suggest determining availability every 5 seconds or so. That means every X seconds the load balancing service is going to open up a connection to the application and make a request. Just like a user would do. \n\n That adds load to the application. It consumes network, transport, application and (possibly) database resources. Resources that cannot be used to service customers. While the impact on a single application may appear trivial, it's not. Remember, as load increases performance decreases. And no matter how trivial it may appear, health monitoring is adding load to what may be an already heavily loaded application. \n\n \n\n But Lori, you may be thinking, you expound on the importance of monitoring and visibility all the time! Are you saying we shouldn't be monitoring applications? \n\n Nope, not at all. Visibility is paramount, providing the actionable data necessary to enable highly dynamic, automated operations such as elasticity. Visibility through health-monitoring is a critical means of ensuring availability at both the local and global level. \n\n What we may need to do, however, is move from active to passive monitoring. \n\n PASSIVE MONITORING \n\n Passive monitoring, as the modifier suggests, is not an active process. The Load balancer does not open up connections nor query an application itself. Instead, it snoops on responses being returned to clients and from that infers the current status of the application. \n\n For example, if a request for content results in an HTTP error message, the load balancer can determine whether or not the application is available and capable of processing subsequent requests. If the load balancer is a BIG-IP, it can mark the service as \"down\" and invoke an active monitor to probe the application status as well as retrying the request to another available instance – insuring end-users do not see an error. \n\n Passive (inband) monitors are not binary. That is, they aren't simple \"on\" or \"off\" based on HTTP status codes. Such monitors can be configured to track the number of failures and evaluate failure rates against a configurable failure interval. When such thresholds are exceeded, the application can then be marked as \"down\". \n\n Passive monitors aren't restricted to availability status, either. They can also monitor for performance (response time). Failure to meet response time expectations results in a failure, and the application continues to be watched for subsequent failures. \n\n Passive monitors are, like most inline/inband technologies, transparent. They quietly monitor traffic and act upon that traffic without adding overhead to the process. \n\n Passive monitoring gives operations the visibility necessary to enable predictable performance and to meet or exceed user expectations with respect to uptime, without negatively impacting performance or capacity of the applications it is monitoring. \n\n \n\n \n\n \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3518","kudosSumWeight":1,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTI4OTFpQjlERjM3MTg0RjM1NjQ2RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTM3NzZpODkyQUIwRjU4RDZDNEFGNQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTAyMThpQjQ1QzY4MTJGQkVDOUI4Qw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjE4MWk0RjFGQkYwNEVDN0UxNjQz?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEzMDdpM0Q2M0Q3QTQwQjZENjIyOQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtOTY2OGkyNkZFMUFDMzJBQ0QwQjA5?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTY3NGk4QTAwQjYyMUFCMTE5NDcy?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtMTEyOTRpQkVFNjA5MEZDOEE4QTk1Ng?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODc4ODAtNjY5Mmk2RDcxNTYwOUNGNEY3MTE1?revision=1\"}"}}],"totalCount":9,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286177":{"__typename":"Conversation","id":"conversation:286177","topic":{"__typename":"TkbTopicMessage","uid":286177},"lastPostingActivityTime":"2009-07-30T04:07:59.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1","title":"0151T000003d7kjQAA.jpg","associationType":"BODY","width":170,"height":170,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1","title":"0151T000003d7ujQAA.jpg","associationType":"BODY","width":447,"height":108,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1","title":"0151T000003d8I1QAI.jpg","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1","title":"0151T000003d8MMQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:286177":{"__typename":"TkbTopicMessage","subject":"What is server offload and why do I need it?","conversation":{"__ref":"Conversation:conversation:286177"},"id":"message:286177","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286177","revisionNum":1,"uid":286177,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2900},"postTime":"2009-06-17T04:07:37.000-07:00","lastPublishTime":"2009-06-17T04:07:37.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" One of the tasks of an enterprise architect is to design a framework atop which developers can implement and deploy applications consistently and easily. The consistency is important for internal business continuity and reuse; common objects, operations, and processes can be reused across applications to make development and integration with other applications and systems easier. Architects also often decide where functionality resides and design the base application infrastructure framework. Application server, identity management, messaging, and integration are all often a part of such architecture designs. Rarely does the architect concern him/herself with the network infrastructure, as that is the purview of “that group”; the “you know who I’m talking about” group. And for the most part there’s no need for architects to concern themselves with network-oriented architecture. Applications should not need to know on which VLAN they will be deployed or what their default gateway might be. But what architects might need to know – and probably should know – is whether the network infrastructure supports “server offload” of some application functions or not, and how that can benefit their enterprise architecture and the applications which will be deployed atop it. WHAT IT IS Server offload is a generic term used by the networking industry to indicate some functionality designed to improve the performance or security of applications. We use the term “offload” because the functionality is “offloaded” from the server and moved to an application network infrastructure device instead. Server offload works because the application network infrastructure is almost always these days deployed in front of the web/application servers and is in fact acting as a broker (proxy) between the client and the server. Server offload is generally offered by load balancers and application delivery controllers. You can think of server offload like a relay race. The application network infrastructure device runs the first leg and then hands off the baton (the request) to the server. When the server is finished, the application network infrastructure device gets to run another leg, and then the race is done as the response is sent back to the client. There are basically two kinds of server offload functionality: Protocol processing offload Protocol processing offload includes functions like SSL termination and TCP optimizations. Rather than enable SSL communication on the web/application server, it can be “offloaded” to an application network infrastructure device and shared across all applications requiring secured communications. Offloading SSL to an application network infrastructure device improves application performance because the device is generally optimized to handle the complex calculations involved in encryption and decryption of secured data and web/application servers are not. TCP optimization is a little different. We say TCP session management is “offloaded” to the server but that’s really not what happens as obviously TCP connections are still opened, closed, and managed on the server as well. Offloading TCP session management means that the application network infrastructure is managing the connections between itself and the server in such a way as to reduce the total number of connections needed without impacting the capacity of the application. This is more commonly referred to as TCP multiplexing and it “offloads” the overhead of TCP connection management from the web/application server to the application network infrastructure device by effectively giving up control over those connections. By allowing an application network infrastructure device to decide how many connections to maintain and which ones to use to communicate with the server, it can manage thousands of client-side connections using merely hundreds of server-side connections. Reducing the overhead associated with opening and closing TCP sockets on the web/application server improves application performance and actually increases the user capacity of servers. TCP offload is beneficial to all TCP-based applications, but is particularly beneficial for Web 2.0 applications making use of AJAX and other near real-time technologies that maintain one or more connections to the server for its functionality. Protocol processing offload does not require any modifications to the applications. Application-oriented offload Application-oriented offload includes the ability to implement shared services on an application network infrastructure device. This is often accomplished via a network-side scripting capability, but some functionality has become so commonplace that it is now built into the core features available on application network infrastructure solutions. Application-oriented offload can include functions like cookie encryption/decryption, compression, caching, URI rewriting, HTTP redirection, DLP (Data Leak Prevention), selective data encryption, application security functionality, and data transformation. When network-side scripting is available, virtually any kind of pre or post-processing can be offloaded to the application network infrastructure and thereafter shared with all applications. Application-oriented offload works because the application network infrastructure solution is mediating between the client and the server and it has the ability to inspect and manipulate the application data. The benefits of application-oriented offload are that the services implemented can be shared across multiple applications and in many cases the functionality removes the need for the web/application server to handle a specific request. For example, HTTP redirection can be fully accomplished on the application network infrastructure device. HTTP redirection is often used as a means to handle application upgrades, commonly mistyped URIs, or as part of the application logic when certain conditions are met. Application security offload usually falls into this category because it is application – or at least application data – specific. Application security offload can include scanning URIs and data for malicious content, validating the existence of specific cookies/data required for the application, etc… This kind of offload improves server efficiency and performance but a bigger benefit is consistent, shared security across all applications for which the service is enabled. Some application-oriented offload can require modification to the application, so it is important to design such features into the application architecture before development and deployment. While it is certainly possible to add such functionality into the architecture after deployment, it is always easier to do so at the beginning. WHY YOU NEED IT Server offload is a way to increase the efficiency of servers and improve application performance and security. Server offload increases efficiency of servers by alleviating the need for the web/application server to consume resources performing tasks that can be performed more efficiently on an application network infrastructure solution. The two best examples of this are SSL encryption/decryption and compression. Both are CPU intense operations that can consume 20-40% of a web/application server’s resources. By offloading these functions to an application network infrastructure solution, servers “reclaim” those resources and can use them instead to execute application logic, serve more users, handle more requests, and do so faster. Server offload improves application performance by allowing the web/application server to concentrate on what it is designed to do: serve applications and putting the onus for performing ancillary functions on a platform that is more optimized to handle those functions. Server offload provides these benefits whether you have a traditional client-server architecture or have moved (or are moving) toward a virtualized infrastructure. Applications deployed on virtual servers still use TCP connections and SSL and run applications and therefore will benefit the same as those deployed on traditional servers. I am wondering why not all websites enabling this great feature GZIP? 3 Really good reasons you should use TCP multiplexing SOA & Web 2.0: The Connection Management Challenge Understanding network-side scripting I am in your HTTP headers, attacking your application Infrastructure 2.0: As a matter of fact that isn't what it means ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"8771","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzE2OWlENjUwOEQ5ODA5NjNGNDMy?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTU5MzVpRkI5NjFBOTJCQzEyMzNBRg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYxNzctNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}"}}],"totalCount":10,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280535":{"__typename":"Conversation","id":"conversation:280535","topic":{"__typename":"TkbTopicMessage","uid":280535},"lastPostingActivityTime":"2017-08-10T10:00:26.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1","title":"0151T000003d9HYQAY.jpg","associationType":"BODY","width":171,"height":171,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1","title":"0151T000003d9HZQAY.png","associationType":"BODY","width":490,"height":326,"altText":null},"TkbTopicMessage:message:280535":{"__typename":"TkbTopicMessage","subject":"The Challenges of SQL Load Balancing","conversation":{"__ref":"Conversation:conversation:280535"},"id":"message:280535","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280535","revisionNum":1,"uid":280535,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2500},"postTime":"2012-04-02T04:31:00.000-07:00","lastPublishTime":"2012-04-02T04:31:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" #infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"11020","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtOTQ1MWkzQTA3MDRBMjI1MEUzNDQw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODA1MzUtNDg1OGlFRDZCOUNFNTc2MEU3MEMw?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1751557989989","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1751557989989","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1751557989989","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1751557989989","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1751557989989","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1751557989989","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1751557989989","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1751557989989","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1751557989989","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1751557989989","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1751557989989","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1751557989989","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1751557989989","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1751557989989","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1751557989989","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1751557989989","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1751557989989","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1751557989989","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1751557989989","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1751557989989","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1751557989989","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1751557989989","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1751557989989","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostViewed","tagName":"performance"},"buildId":"3XH0qYWYCnEYycuN5W4S8","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}