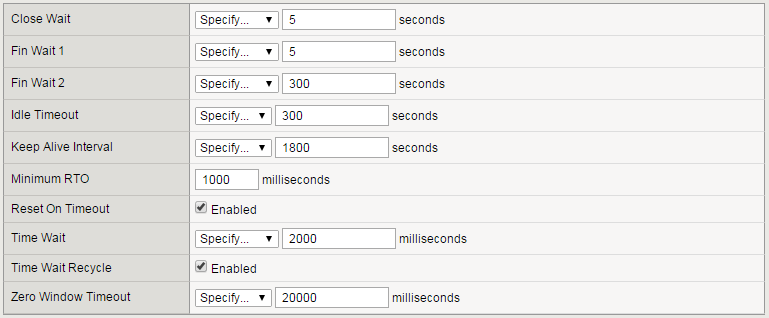
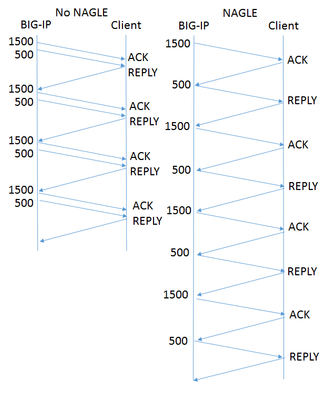
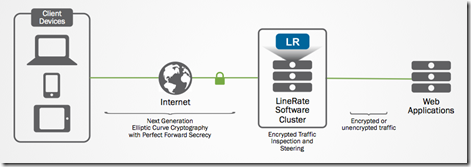
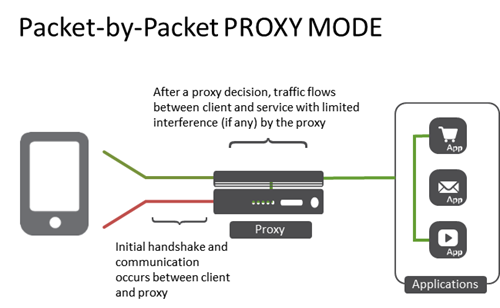
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/performance\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/performance\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1751557989989"}],"cachedText({\"lastModified\":\"1751557989989\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1751557989989"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1752585745251":{"__typename":"CachedAsset","id":"pages-1752585745251","value":[{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.MvpProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/mvp-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.AdvocacyProgram","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/advocacy-program","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp.NonCustomer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/non-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Customer","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-customer","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetInvolved","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.Learn","type":"COMMUNITY","urlPath":"/c/how-do-i/learn","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501996000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp.Community","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/community","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetInvolved.ContributeCode","type":"COMMUNITY","urlPath":"/c/how-do-i/get-involved/contribute-code","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.Learn.AboutIrules","type":"COMMUNITY","urlPath":"/c/how-do-i/learn/about-irules","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp.F5Support","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/f5-support","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI.GetHelp.SecurityIncident","type":"COMMUNITY","urlPath":"/c/how-do-i/get-help/security-incident","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752585745251,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1751557990837":{"__typename":"CachedAsset","id":"theme:customTheme1-1751557990837","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1751557989989","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1751557989989","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1751557989989","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1751557989071":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1751557989071","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1751557989989","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1751557989536":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1751557989536","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1751558010090","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1751558010090","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1751558010090","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1751558010090","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1751558010090":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1751558010090","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1751557989989","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1751557989989","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1751557989989","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:276364":{"__typename":"Conversation","id":"conversation:276364","topic":{"__typename":"TkbTopicMessage","uid":276364},"lastPostingActivityTime":"2025-04-29T14:28:51.157-07:00","solved":false},"User:user:355603":{"__typename":"User","uid":355603,"login":"Jibin_43310","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-2.svg?time=0"},"id":"user:355603"},"TkbTopicMessage:message:276364":{"__typename":"TkbTopicMessage","subject":"iRule Execution Tracing and Performance Profiling, Part 2","conversation":{"__ref":"Conversation:conversation:276364"},"id":"message:276364","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:276364","revisionNum":5,"uid":276364,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:355603"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1359},"postTime":"2017-12-04T17:00:00.000-08:00","lastPublishTime":"2025-04-29T14:27:46.691-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n In the last article we discussed some intriguing questions around iRules tracing and profiling. There are a lot we can do to facilitate iRules debugging and performance tuning, and we took the first step in BIG-IP v13.1. We are pleased to announce that iRules tracing and profiling feature is added to TMOS tool chain in this release. This feature enables both users and iRules infrastructure development team to broaden iRules functionality and application prospects. In this article we will describe the focal use cases and design principles of the feature; we will use examples to demonstrate how to use the feature. \n Use case and consideration \n Following are the major use model we target and the design principles we employ for the feature in this release: \n \n This feature is mostly used in debug environment. Execution tracing and performance tuning are part of development process. We envision that the most typical use case is users take to the tracing functionality when scripts are still in development. It is possible that the iRules are running on production systems, yet when users like to inspect performance issues, they take the scripts to lab environment to collect performance data, analyze bottleneck and experiment algorithm tuning. \n The solution needs to be non-intrusive. Tcl language has tracing constructs in its core infrastructure, for example trace command is a Tcl core command. Historically trace command is not supported by iRules. Although it is a viable option to reuse Tcl's trace command as the basic facility for the tracing feature, we make the choice that the feature does not require users to modify the script; instead, it is a passive observation solution: users configure the conditions and leave the script intact. This provides a smooth debugging experience: users can enable the feature, observe the result and adjust the feature configuration continuously. \n Graphical interface is not critical in the first release. Ideally the feature is presented in a GUI environment. We believe a command line interaction in the first release properly addresses the most critical use cases. \n Separate data collecting and data scoping. Tracing comes with high volume data, the deeper and wider the tracing goes, the more data are generated. In this release we focus on picking the right data (the \"occurrences\" presented in the last article) and delivering the data timely and securely. Providing tool chain to help users to mine the data is a logical next step. \n \n The Feature \n OK, now we are ready to present the feature. The audience of this article are familiar with BIG-IP and iRules, so let's have fun and jump to some examples. \n Example \n Here is a simple iRules script: \n ltm rule dc_1 {\n when CLIENT_ACCEPTED {\n if {[IP::remote_addr] eq \"10.10.10.2\"} {\n set the_one true\n } else {\n set the_one false\n }\n }\n when HTTP_REQUEST {\n if {$the_one} {\n HTTP::uri [string map {myPortal UserPortal} [HTTP::uri]]\n }\n }\n} \n Now issue the following TMSH commands to insert the tracer: \n tmsh create ltm rule-profiler dc_1_tracer event-filter add { CLIENT_ACCEPTED HTTP_REQUEST } vs-filter add { /Common/vs1 } publisher tracer_pub1\ntmsh modify ltm rule-profiler dc_1_tracer occ-mask { cmd cmd-vm event rule rule-vm var-mod }\ntmsh modify ltm rule-profiler dc_1_tracer state enabled \n \n The feature introduces a new TMSH configuration object, rule-profiler. There can be multiple rule-profiler objects, this facilitates difference tracing scenarios. Following attributes of rule-profiler are configured in the above TMSH commands: \n \n event-filter, the iRule events to trace; if not defined, all events are traced. \n vs-filter, the virtual servers to trace; if not defined, all virtual servers are traced. \n occ-mask, the occurrences to trace. The viable values are as explained in the last article. \n publisher, the syslog publisher to receive the tracing log. \n \n The user needs to enable the rule-profiler object after the configuration. Now the tracing facility is ready. We start the tracing on a running traffic by the following command: \n tmsh start ltm rule-profiler dc_1_tracer \n The lab setup for this example has publisher point to the local syslog and here is a partial capture of the output in /var/log/ltm (the color coding is for this article to describe the data): \n 1511494952932589,RP_EVENT_ENTRY,/Common/vs1,CLIENT_ACCEPTED,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,\n01511494952932622,RP_RULE_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 \n1511494952932625,RP_RULE_VM_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 \n1511494952932628,RP_CMD_VM_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 \n1511494952932630,RP_CMD_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 \n1511494952932633,RP_CMD_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0\n1511494952932636,RP_CMD_VM_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,\n01511494952932638,RP_VAR_MOD,/Common/vs1,the_one=true,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80 \n Now let us take a close look at the logs. \n Occurrence fields \n Each tracing occurrence, as defined by \"occ-mask\" attribute, dumps one line to the log file; there are 7 fields within each line: \n \n Timestamp - This is the TMM time stamp at the occurrence. The unit is micro second. \n Occurrence type - This is the type of the occurrence. It is corresponding to \"occ-mask\" attribute definition. The meaning of each occurrence is defined in the last article. \"RP\" stands for \"Rule Profiler\". \n Virtual server - This is the name of the virtual server on which the iRules are running. \n Occurrence value - This is the value of the corresponding occurrence. For example, the first log in the above snippet is at the entry occurrence of iRule event CLIENT_ACCEPTED. \n Process ID - This is the TMM process ID. \n Flow ID - This is the flow ID. \n Remote tuple - There are 3 fields, IP address, port and routing domain. \n Local tuple - There are 3 fields, IP address, port and routing domain. \n \n Stop Tracing \n User can stop the tracing by issuing this TMSH command: \n tmsh stop ltm rule-profiler <rule-profiler name> \n Tracer has a built-in timer, it stops tracing after 10 milliseconds. User can adjust it through the following command: \n tmsh modify ltm rule-profiler dc_1_tracer period <new value in ms> \n Bytecode \n As mentioned in the first article, the tracing feature supports bytecode tracing. Using the example above, add \"bytecode\" to \"occ-mask\": \n tmsh modify ltm rule-profiler dc_1_tracer occ-mask { bytecode cmd cmd-vm event rule rule-vm var-mod } \n With this addition, you will see the bytecode execution. But keep one thing in mind, you will see a lot more logging. \n 1511673715911247,RP_EVENT_ENTRY,/Common/vs1,CLIENT_ACCEPTED,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0, \n1511673715911273,RP_RULE_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911277,RP_RULE_VM_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911280,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911282,RP_CMD_BYTECODE,/Common/vs1,invokeStk1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911284,RP_CMD_VM_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911286,RP_CMD_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911288,RP_CMD_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,0 \n1511673715911291,RP_CMD_VM_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,0 \n1511673715911293,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911295,RP_CMD_BYTECODE,/Common/vs1,streq,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911296,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911298,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911300,RP_CMD_BYTECODE,/Common/vs1,storeScalarStk,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 \n1511673715911302,RP_VAR_MOD,/Common/vs1,the_one=true,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0 \n \n What's to come \n This article describes the TMSH commands to configure rule-profiler and how to interpret the tracing logs. Next article will talk about tips and tricks of using the tracing feature. \n Authors: Jibin Han, Bonny Rais \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"9074","kudosSumWeight":1,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:329158":{"__typename":"Conversation","id":"conversation:329158","topic":{"__typename":"TkbTopicMessage","uid":329158},"lastPostingActivityTime":"2024-05-07T10:06:04.501-07:00","solved":false},"User:user:129895":{"__typename":"User","uid":129895,"login":"Kin","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-4.svg?time=0"},"id":"user:129895"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMjkxNTgtYUR0a0V3?revision=5\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMjkxNTgtYUR0a0V3?revision=5","title":"speed.jpg","associationType":"TEASER","width":1000,"height":550,"altText":""},"TkbTopicMessage:message:329158":{"__typename":"TkbTopicMessage","subject":"Improve BIG-IP APM VPN speed with TLS dynamic record size","conversation":{"__ref":"Conversation:conversation:329158"},"id":"message:329158","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:329158","revisionNum":5,"uid":329158,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:129895"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":" ","introduction":"","metrics":{"__typename":"MessageMetrics","views":386},"postTime":"2024-05-01T05:00:00.045-07:00","lastPublishTime":"2024-05-07T10:06:04.501-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" After successfully setting up BIG-IP APM network access, and running it for sometime, you may be looking for ways to optimize VPN speed for your users. This article discusses one way you can do that. \n Feature Description \n Beginning in BIG-IP 12.1.0, the Client SSL profile includes a feature that enables dynamic record size in TLS. When applied to a F5 BIG-IP Access Policy Manager (APM) network access VPN TLS virtual server, this can improve VPN speeds for your users. It has been found that certain protocols, notably HTTP, show better client response times using this method. For more information on the Allow Dynamic Record Sizing setting down to the packet level, refer to the following resources \n \n The About dynamic record sizing section of the BIG-IP System: SSL Administration manual. \n Boosting TLS Performance with Dynamic Record Sizing on BIG-IP on DevCentral. \n SSL Profiles Part 11: TLS Optimization on DevCentral. \n \n Important: Dynamic record size is a TLS enhancement and does not apply to BIG-IP APM network access DTLS virtual servers. Do not enable dynamic record size on DTLS. \n When you want to optimize network performance, you must allocate time to tune each configuration to match the requirements specific to your environment. Additionally, note that configuration changes that improve performance may increase BIG-IP system resource (CPU, memory) usage. \n Testing dynamic record size on VPN speeds \n Having discussed the theory behind the feature, we will now perform tests to see how it affects VPN speeds. \n Network bandwidth can vary depending on many factors, for instance, peak vs non-peak hours. When more users are connected to a VPN, download speeds can decrease significantly. It is therefore important to establish a baseline network bandwidth and download speed at the beginning: \n Baseline AWS environment \n Windows Client (Seattle) -- VPN --> BIG-IP APM (Oregon) --local LAN--> Apache and iperf servers \n AWS environment: \n \n BIG-IP APM 17.1.0 VE on AWS (F5 BIG-IP VE - ALL modules, m5.xlarge, 1 Gbps, AWS) located in us-west-2 Oregon. Note: Ensure you use at least the recommended size (m5.xlarge) and at least 1Gbps on AWS to make sure there are no bandwidth and resource limits. \n Windows client in located in Seattle\n \n Using iperf3 to measure network bandwidth \n Using curl to download a 377MB apmclient.iso \n Optional: You can optionally test using the developer tools on your browser. I used firefox; as the results did not differ significantly from curl. They are not included in this article. \n \n \n \n Baseline test results \n These are measured with all default settings on BIG-IP APM and dynamic record sizing not enabled: \n curl download results \n Average download speed: 4950k \n C:\\Windows\\system32>curl -k -o null https://10.0.128.23/apmclient.iso % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 377M 100 377M 0 0 4950k 0 0:01:18 0:01:18 --:--:-- 4988k \n iperf3 results \n Network bandwidth: 4873 KB/sec \n c:\\Users\\klau\\Desktop\\iperf-3.1.3-win64>iperf3.exe -c 10.0.128.24 --get-server-output -i 1 -f K -R Connecting to host 10.0.128.24, port 5201 Reverse mode, remote host 10.0.128.24 is sending [ 4] local 10.0.128.31 port 61284 connected to 10.0.128.24 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-1.00 sec 4.33 MBytes 4434 KBytes/sec [ 4] 1.00-2.00 sec 4.67 MBytes 4785 KBytes/sec [ 4] 2.00-3.00 sec 4.86 MBytes 4977 KBytes/sec [ 4] 3.00-4.00 sec 4.77 MBytes 4878 KBytes/sec [ 4] 4.00-5.00 sec 4.72 MBytes 4834 KBytes/sec [ 4] 5.00-6.00 sec 4.78 MBytes 4898 KBytes/sec [ 4] 6.00-7.00 sec 4.87 MBytes 4989 KBytes/sec [ 4] 7.00-8.00 sec 4.81 MBytes 4925 KBytes/sec [ 4] 8.00-9.00 sec 4.71 MBytes 4823 KBytes/sec [ 4] 9.00-10.00 sec 4.82 MBytes 4934 KBytes/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 48.0 MBytes 4919 KBytes/sec 9 sender [ 4] 0.00-10.00 sec 47.6 MBytes 4873 KBytes/sec receiver Server output: [...] [ 5] 0.00-10.04 sec 48.0 MBytes 4900 KBytes/sec 9 sender \n Test 1: Enabling dynamic record size from baseline Comparing with baseline results after enabling dynamic record size \n \n \n \n \n \n Baseline: Dynamic record size disabled \n dynamic record size enabled \n Percentage improvement \n \n \n curl average download, k \n 4950 \n 5272 \n 6.51% \n \n \n iperf3 network bandwidth, KBytes/sec \n 4873 \n 5138 \n 5.44% \n \n \n \n \n While this may not appear to be too high on the AWS cloud, there is also received feedback from customers that they see greater improvements in environments, especially in cases where the end-to-end latencies increase. \n Implementation strategy and recommendations \n As you plan to introduce this in your environment, take note of the following recommendations: \n \n Every environment is unique Many factors can affect network performance. This can range from VLAN settings (For example. MTU), TCP settings, intermediate network device throttling, and so on. You must perform testing in your own environment before enabling the feature. \n Implement the feature incrementally for a selected group of users. There are different ways to do this. For example, use an iRule to redirect users based on a URL, to a separate virtual server using a different Client SSL profile that has the feature enabled. Refer to SSL::allow_dynamic_record_sizing on Clouddocs. \n Monitor BIG-IP system logs and resource usage After you enable dynamic record size, make sure that your BIG-IP system continues to function as expected by monitoring the following\n \n monitor /var/log/ltm and /var/log/apm log files \n monitor BIG-IP CPU and memory usage. For example, you can select Dashboard on the Configuration utility, generating a QKview and analyze it in iHealth and so on. For more information, refer to K71764661: Understanding BIG-IP CPU usage and K16419: Overview of BIG-IP memory usage \n \n \n Verify and analyze SSL statistics Use the tmsh command in K41057430: Enhanced SSL profile statistics and check for failures. The SSL Dynamic Record Sizes section should also indicate use of large record sizes. \n Boosting TLS Performance with Dynamic Record Sizing on BIG-IP \n \n Conclusion \n There are a variety of different ways to improve VPN speeds, and this article describes just one. For other options and considerations, refer to K31143831: VPN for business continuity | Chapter 5: Optimizing Network Access VPN. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7689","kudosSumWeight":2,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMjkxNTgtYUR0a0V3?revision=5\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:290743":{"__typename":"Conversation","id":"conversation:290743","topic":{"__typename":"TkbTopicMessage","uid":290743},"lastPostingActivityTime":"2023-12-01T01:45:03.680-08:00","solved":false},"User:user:193863":{"__typename":"User","uid":193863,"login":"Martin_Duke","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-4.svg?time=0"},"id":"user:193863"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1","title":"0151T000003d6kLQAQ.png","associationType":"BODY","width":769,"height":318,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1","title":"0151T000003d6kMQAQ.png","associationType":"BODY","width":768,"height":134,"altText":null},"TkbTopicMessage:message:290743":{"__typename":"TkbTopicMessage","subject":"Tuning the TCP Profile, Part One","conversation":{"__ref":"Conversation:conversation:290743"},"id":"message:290743","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:290743","revisionNum":1,"uid":290743,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:193863"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3926},"postTime":"2016-01-28T18:51:00.000-08:00","lastPublishTime":"2016-01-28T18:51:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" A few months ago I pointed out some problems with the existing F5-provided TCP profiles, especially the default one. Today I'll begin a pass through the (long) TCP profile to point out the latest thinking on how to get the most performance for your applications. We'll go in the order you see these profile options in the GUI. \n\n But first, a note about programmability: in many cases below, I'm going to ask you to generalize about the clients or servers you interact with, and the nature of the paths to those hosts. In a perfect world, we'd detect that stuff automatically and set it for you, and in fact we're rolling that out setting by setting. In the meantime, you can customize your TCP parameters on a per-connection basis using iRules for many of the settings described below, something I'll explain further where applicable. \n\n In general, when I refer to \"performance\" below, I'm referring to the speed at which your customer gets her data. Performance can also refer to the scalability of your application delivery due to CPU and memory limitations, and when that's what I mean, I'll say so. \n\n Timer Management \n\n \n\n The one here with a big performance impact is Minimum RTO. When TCP computes its Retransmission Timeout (RTO), it takes the average measured Round Trip Time (RTT) and adds a few standard deviations to make sure it doesn't falsely detect loss. (False detections have very negative performance implications.) But if RTT is low and stable that RTO may be too low, and the minimum is designed to catch known fluctuations in RTT that the connection may not have observed. \n\n Set Minimum RTO too low, and TCP may improperly enter congestion response and reduce the sending rate all the way down to one packet per round trip. Set it too high, and TCP sits idle when it ought to retransmit lost data. \n\n So what's the right value? Obviously, if you have a sense of the maximum RTT to your clients (which you can get with the ping command), that's a floor for your value. Furthermore, many clients and servers will implement some sort of Delayed ACK, which reduces ACK volume by sometimes holding them back for up to 200ms to see if it can aggregate more data in the ACK. RFC 5681 actually allows delays of up to 500ms, but this is less common. So take the maximum RTT and add 200 to 500 ms. \n\n Another group of settings aren't really about throughput, but to help clients and servers to close gracefully, at the cost of consuming some system resources. Long Close Wait, Fin Wait 1, Fin Wait 2, and Time Wait timers will keep connection state alive to make sure the remote host got all the connection close messages. Enabling Reset On Timeout sends a message that tells the peer to tear down the connection. Similarly, disabling Time Wait Recycle will prevent new connections from using the same address/port combination, making sure that the old connection with that combination gets a full close. \n\n The last group of settings keeps possibly dead connections alive, using system resources to maintain state in case they come back to life. Idle Timeout and Zero Window Timeout commit resources until the timer expires. If you set Keep Alive Interval to a value less than the Idle Timeout, then on the clientside BIG-IP will keep the connection alive as long as the client keeps responding to keepalive and the server doesn't terminate the connection itself. In theory, this could be forever! \n\n Memory Management \n\n \n\n In terms of high throughput performance, you want all of these settings to be as large as possible up to a point. The tradeoff is that setting them too high may waste memory and reduce the number of supportable concurrent connections. I say \"may\" waste because these are limits on memory use, and BIG-IP doesn't allocate the memory until it needs it for buffered data. Even so, the trick is to set the limits large enough that there are no performance penalties, but no larger. \n\n Send Buffer and Receive Window are easy to set in principle, but can be tricky in practice. For both, answer these questions: \n\n What is the maximum bandwidth (Bytes/second) that BIG-IP might experience sending or receiving? Out of all paths data might travel, what minimum delay among those paths is the highest? (What is the \"maximum of the minimums\"?) \n\n Then you simply multiply Bytes/second by seconds of delay to get a number of bytes. This is the maximum amount of data that TCP ought to have in flight at any one time, which should be enough to prevent TCP connections from idling for lack of memory. If your application doesn't involve sending or receiving much data on that side of the proxy, you can probably get away with lowering the corresponding buffer size to save on memory. For example, a traditional HTTP proxy's clientside probably can afford to have a smaller receive buffer if memory-constrained. \n\n There are three principles to follow in setting Proxy Buffer Limits: \n\n Proxy Buffer High should be at least as big as the Send Buffer. Otherwise, if a large ACK clears the send buffer all at once there may be less data available than TCP can send. Proxy Buffer Low should be at least as big as the Receive Window on the peer TCP profile (i.e. for the clientside profile, use the receive window on the serverside profile). If not, when the peer connection exits the zero-window state, new data may not arrive before BIG-IP sends all the data it has. Proxy Buffer High should be significantly larger than Proxy Buffer Low (we like to use a 64 KB gap) to avoid constant flapping to and from the zero-window state on the receive side. \n\n Obviously, figuring out bandwidth and delay before a deployment can be tricky. This is a place where some iRule mojo can really come in handy. The TCP::rtt and TCP::bandwidth* commands can give you estimates of both quantities you need, even though the RTT isn't a minimum RTT. Alternatively, if you've enabled cmetrics-cache in the profile, you can also obtain historical data for a destination using the ROUTE::cwnd* command, which is a good (possibly low) guess at the value you should plug into the send and receive buffers. \n\n You can then set buffer limits directly using TCP::sendbuf**, TCP::recvwnd**, and TCP::proxybuffer**. Getting this to work very well will be difficult, and I don't have any examples where someone worked it through and proved a benefit. But if your application travels highly varied paths and you have the inclination to tinker, you could end up with an optimized configuration. If not, set the buffer sizes using conservatively high inputs and carry on. \n\n *These iRule commands only supported in TMOS® version 12.0.0 and later. \n\n **These iRule commands only supported in TMOS® version 11.6.0 and later. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6818","kudosSumWeight":0,"repliesCount":6,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtMjc4MGlCQjA0NTQ5RDk4RkE2QTVD?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA3NDMtNTIzOWkyODU0MUMwMjE3NTg0REU0?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:290699":{"__typename":"Conversation","id":"conversation:290699","topic":{"__typename":"TkbTopicMessage","uid":290699},"lastPostingActivityTime":"2023-10-27T21:34:00.248-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA2OTktOTgxOGlDRkRBNENFMjMwQTg5NTRE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA2OTktOTgxOGlDRkRBNENFMjMwQTg5NTRE?revision=1","title":"0151T000003d6gfQAA.png","associationType":"BODY","width":622,"height":760,"altText":null},"TkbTopicMessage:message:290699":{"__typename":"TkbTopicMessage","subject":"Is TCP's Nagle Algorithm Right for Me?","conversation":{"__ref":"Conversation:conversation:290699"},"id":"message:290699","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:290699","revisionNum":1,"uid":290699,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:193863"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1496},"postTime":"2015-12-14T07:54:00.000-08:00","lastPublishTime":"2015-12-14T07:54:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Of all the settings in the TCP profile, the Nagle algorithm may get the most questions. Designed to avoid sending small packets wherever possible, the question of whether it's right for your application rarely has an easy, standard answer. \n\n What does Nagle do? \n\n Without the Nagle algorithm, in some circumstances TCP might send tiny packets. In the case of BIG-IP®, this would usually happen because the server delivers packets that are small relative to the clientside Maximum Transmission Unit (MTU). If Nagle is disabled, BIG-IP will simply send them, even though waiting for a few milliseconds would allow TCP to aggregate data into larger packets. \n\n The result can be pernicious. Every TCP/IP packet has at least 40 bytes of header overhead, and in most cases 52 bytes. If payloads are small enough, most of the your network traffic will be overhead and reduce the effective throughput of your connection. Second, clients with battery limitations really don't appreciate turning on their radios to send and receive packets more frequently than necessary. Lastly, some routers in the field give preferential treatment to smaller packets. If your data has a series of differently-sized packets, and the misfortune to encounter one of these routers, it will experience severe packet reordering, which can trigger unnecessary retransmissions and severely degrade performance. \n\n Specified in RFC 896 all the way back in 1984, the Nagle algorithm gets around this problem by holding sub-MTU-sized data until the receiver has acked all outstanding data. In most cases, the next chunk of data is coming up right behind, and the delay is minimal. \n\n What are the Drawbacks? \n\n The benefits of aggregating data in fewer packets are pretty intuitive. But under certain circumstances, Nagle can cause problems: \n\n \n\n In a proxy like BIG-IP, rewriting arriving packets in memory into a different, larger, spot in memory taxes the CPU more than simply passing payloads through without modification. If an application is \"chatty,\" with message traffic passing back and forth, the added delay could add up to a lot of time. For example, imagine a network has a 1500 Byte MTU and the application needs a reply from the client after each 2000 Byte message. In the figure at right, the left diagram shows the exchange without Nagle. BIG-IP sends all the data in one shot, and the reply comes in one round trip, allowing it to deliver four messages in four round trips. On the right is the same exchange with Nagle enabled. Nagle withholds the 500 byte packet until the client acks the 1500 byte packet, meaning it takes two round trips to get the reply that allows the application to proceed. Thus sending four messages takes eight round trips. This scenario is a somewhat contrived worst case, but if your application is more like this than not, then Nagle is poor choice. If the client is using delayed acks (RFC 1122), it might not send an acknowledgment until up to 500ms after receipt of the packet. That's time BIG-IP is holding your data, waiting for acknowledgment. This multiplies the effect on chatty applications described above. \n\n F5 Has Improved on Nagle \n\n The drawbacks described above sound really scary, but I don't want to talk you out of using Nagle at all. The benefits are real, particularly if your application servers deliver data in small pieces and the application isn't very chatty. More importantly, F5® has made a number of enhancements that remove a lot of the pain while keeping the gain: \n\n Nagle-aware HTTP Profiles: all TMOS HTTP profiles send a special control message to TCP when they have no more data to send. This tells TCP to send what it has without waiting for more data to fill out a packet. Autonagle: in TMOS v12.0, users can configure Nagle as \"autotuned\" instead of simply enabling or disabling it in their TCP profile. This mechanism starts out not executing the Nagle algorithm, but uses heuristics to test if the receiver is using delayed acknowledgments on a connection; if not, it applies Nagle for the remainder of the connection. If delayed acks are in use, TCP will not wait to send packets but will still try to concatenate small packets into MSS-size packets when all are available. [UPDATE: v13.0 substantially improves this feature.] One small packet allowed per RTT: beginning with TMOS® v12.0, when in 'auto' mode that has enabled Nagle, TCP will allow one unacknowledged undersize packet at a time, rather than zero. This speeds up sending the sub-MTU tail of any message while not allowing a continuous stream of undersized packets. This averts the nightmare scenario above completely. \n\n Given these improvements, the Nagle algorithm is suitable for a wide variety of applications and environments. It's worth looking at both your applications and the behavior of your servers to see if Nagle is right for you. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"4897","kudosSumWeight":2,"repliesCount":5,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yOTA2OTktOTgxOGlDRkRBNENFMjMwQTg5NTRE?revision=1\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:276572":{"__typename":"Conversation","id":"conversation:276572","topic":{"__typename":"TkbTopicMessage","uid":276572},"lastPostingActivityTime":"2023-09-26T15:17:52.572-07:00","solved":false},"User:user:172184":{"__typename":"User","uid":172184,"login":"Andrew_Ragone_2","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-2.svg?time=0"},"id":"user:172184"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzY1NzItMTUwaUI0RkEyOTgwNTFDRkYwMDY?revision=4\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzY1NzItMTUwaUI0RkEyOTgwNTFDRkYwMDY?revision=4","title":"0151T000003d6FtQAI.png","associationType":"BODY","width":471,"height":167,"altText":null},"TkbTopicMessage:message:276572":{"__typename":"TkbTopicMessage","subject":"Implementing ECC+PFS on LineRate (Part 1/3): Choosing ECC Curves and Preparing SSL Certificates","conversation":{"__ref":"Conversation:conversation:276572"},"id":"message:276572","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:276572","revisionNum":4,"uid":276572,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:172184"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":467},"postTime":"2014-09-02T11:27:00.000-07:00","lastPublishTime":"2023-09-26T15:17:52.572-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" (Editors note: the LineRate product has been discontinued for several years. 09/2023) --- \n Overview \n In case you missed it, Why ECC and PFS Matter: SSL offloading with LineRate details some of the reasons why ECC-based SSL has advantages over RSA cryptography for both performance and security. \n This article will generate all the necessary ECC certificates with the secp384r1 curve so that they may be used to configure an LineRate System for SSL Offload. \n Getting Started with LineRate \n In order to appreciate the advantages of SSL/TLS Offload available via LineRate as discussed in this article, let's take a closer look at how to configure SSL/TLS Offloading on a LineRate system. This example will implement Elliptical Curve Cryptography and Perfect Forward Secrecy. SSL Offloading will be added to an existing LineRate System that has one public-facing Virtual IP (10.10.11.11) that proxies web requests to a Real Server on an internal network (10.10.10.1). The following diagram demonstrates this configuration: \n Figure 1: A high-level implementation of SSL Offload \n Overall, these steps will be completed in order to enable SSL Offloading on the LineRate System: \n \n Generate a private key specifying the secp384r1 elliptic curve \n Obtain a certificate from a CA \n Configure an SSL profile and attach it to the Virtual IP \n \n Note that this implementation will enable only ECDHE cipher suites. ECDH cipher suites are available, but these do not implement the PFS feature. Further, in production deployments, considerations to implement additional types of SSL cryptography might be needed in order to allow backward compatibility for older clients. \n Generating a private key for Elliptical Curve Cryptography \n When considering the ECC curve to use for your environment, you may choose one from the currently available curves list in the LineRate documentation. It is important to be cognizant of the curve support for the browsers or applications your application targets using. Generally, the NIST P-256, P-384, and P-521 curves have the widest support. This example will use the secp384r1 (NIST P-384) curve, which provides an RSA equivalent key of 7680-bits. Supported curves with OpenSSL can be found by running the openssl ecparam -list_curves command, which may be important depending on which curve is chosen for your SSL/TLS deployment. \n Using OpenSSL, a private key is generated for use with ssloffload.lineratesystems.com. The ECC SECP curve over a 384-bit prime field (secp384r1) is specified: \n \n openssl ecparam -genkey -name secp384r1 -out ssloffload.lineratesystems.com.key.pem \n \n This command results in the following private key: \n \n -----BEGIN EC PARAMETERS----- \nBgUrgQQAIg==\n-----END EC PARAMETERS-----\n-----BEGIN EC PRIVATE KEY-----\nMIGkAgEBBDD1Kx9hghSGCTujAaqlnU2hs/spEOhfpKY9EO3mYTtDmKqkuJLKtv1P\n1/QINzAU7JigBwYFK4EEACKhZANiAASLp1bvf/VJBJn4kgUFundwvBv03Q7c3tlX\nkh6Jfdo3lpP2Mf/K09bpt+4RlDKQynajq6qAJ1tJ6Wz79EepLB2U40fC/3OBDFQx\n5gSjRp8Y6aq8c+H8gs0RKAL+I0c8xDo=\n-----END EC PRIVATE KEY----- \n \n Generating a Certificate Request (CSR) to provide the Certificate Authority (CA) \n After the primary key is obtained, a certificate request (CSR) can be created. Using OpenSSL again, the following command is issued filling out all relevant information in the successive prompts: \n \n openssl req -new -key ssloffload.lineratesystems.com.key.pem -out ssloffload.lineratesystems.com.csr.pem \n \n This results in the following CSR: \n \n -----BEGIN CERTIFICATE REQUEST----- \nMIIB3jCCAWQCAQAwga8xCzAJBgNVBAYTAlVTMREwDwYDVQQIEwhDb2xvcmFkbzET \nMBEGA1UEBxMKTG91aXN2aWxsZTEUMBIGA1UEChMLRjUgTmV0d29ya3MxGTAXBgNV \nBAsTEExpbmVSYXRlIFN5c3RlbXMxJzAlBgNVBAMTHnNzbG9mZmxvYWQubGluZXJh \ndGVzeXN0ZW1zLmNvbTEeMBwGCSqGSIb3DQEJARYPYS5yYWdvbmVAZjUuY29tMHYw \nEAYHKoZIzj0CAQYFK4EEACIDYgAEi6dW73/1SQSZ+JIFBbp3cLwb9N0O3N7ZV5Ie \niX3aN5aT9jH/ytPW6bfuEZQykMp2o6uqgCdbSels+/RHqSwdlONHwv9zgQxUMeYE \no0afGOmqvHPh/ILNESgC/iNHPMQ6oDUwFwYJKoZIhvcNAQkHMQoTCGNpc2NvMTIz \nMBoGCSqGSIb3DQEJAjENEwtGNSBOZXR3b3JrczAJBgcqhkjOPQQBA2kAMGYCMQCn \nh1NHGzigooYsohQBzf5P5KO3Z0/H24Z7w8nFZ/iGTEHa0+tmtGK/gNGFaSH1ULcC \nMQCcFea3plRPm45l2hjsB/CusdNo0DJUPMubLRZ5mgeThS/N6Eb0AHJSjBJlE1fI \na4s= \n-----END CERTIFICATE REQUEST----- \n \n Obtaining a Certificate from a Certificate Authority (CA) \n Rather than using a self-signed certificate, a test certificate is obtained from Entrust. Upon completing the certificate request and receiving it from Entrust, a simple conversion needs to be done to PEM format. This can be done with the following OpenSSL command: \n openssl x509 -inform der -in ssloffload.lineratesystems.com.cer -out ssloffload.lineratesystems.com.cer.pem \n This results in the following certificate: \n \n -----BEGIN CERTIFICATE----- \nMIIC5jCCAm2gAwIBAgIETUKHWzAKBggqhkjOPQQDAzBtMQswCQYDVQQGEwJVUzEW \nMBQGA1UEChMNRW50cnVzdCwgSW5jLjEfMB0GA1UECxMWRm9yIFRlc3QgUHVycG9z \nZXMgT25seTElMCMGA1UEAxMcRW50cnVzdCBFQ0MgRGVtb25zdHJhdGlvbiBDQTAe \nFw0xNDA4MTExODQ3MTZaFw0xNDEwMTAxOTE3MTZaMGkxHzAdBgNVBAsTFkZvciBU \nZXN0IFB1cnBvc2VzIE9ubHkxHTAbBgNVBAsTFFBlcnNvbmEgTm90IFZlcmlmaWVk \nMScwJQYDVQQDEx5zc2xvZmZsb2FkLmxpbmVyYXRlc3lzdGVtcy5jb20wdjAQBgcq \nhkjOPQIBBgUrgQQAIgNiAASLp1bvf/VJBJn4kgUFundwvBv03Q7c3tlXkh6Jfdo3 \nlpP2Mf/K09bpt+4RlDKQynajq6qAJ1tJ6Wz79EepLB2U40fC/3OBDFQx5gSjRp8Y \n6aq8c+H8gs0RKAL+I0c8xDqjgeEwgd4wDgYDVR0PAQH/BAQDAgeAMB0GA1UdJQQW \nMBQGCCsGAQUFBwMBBggrBgEFBQcDAjA3BgNVHR8EMDAuMCygKqAohiZodHRwOi8v \nY3JsLmVudHJ1c3QuY29tL0NSTC9lY2NkZW1vLmNybDApBgNVHREEIjAggh5zc2xv \nZmZsb2FkLmxpbmVyYXRlc3lzdGVtcy5jb20wHwYDVR0jBBgwFoAUJAVL4WSCGvgJ \nzPt4eSH6cOaTMuowHQYDVR0OBBYEFESqK6HoSFIYkItcfekqqozX+z++MAkGA1Ud \nEwQCMAAwCgYIKoZIzj0EAwMDZwAwZAIwXWvK2++3500EVaPbwvJ39zp2IIQ98f66 \n/7fgroRGZ2WoKLBzKHRljVd1Gyrl2E3BAjBG9yPQqTNuhPKk8mBSUYEi/CS7Z5xt \ndXY/e7ivGEwi65z6iFCWuliHI55iLnXq7OU= \n-----END CERTIFICATE----- \n \n Note that the certificate generation process is very familiar with Elliptical Curve Cryptography versus traditional cryptographic algorithms like RSA. Only a few differences are found in the generation of the primary key where an ECC curve is specified. \n Continue the Configuration \n Now that the certificates needed to configure Elliptical Curve Cryptography have been created, it is now time to configure SSL Offloading on LineRate. Part 2: Configuring SSL Offload on LineRate continues the demonstration of SSL Offloading by importing the certificate information generated in this article and getting the system up and running. \n In case you missed it, Why ECC and PFS Matter: SSL offloading with LineRate details some of the reasons why ECC-based SSL has advantages over RSA cryptography for both performance and security. \n \n (Editors note: the LineRate product has been discontinued for several years. 09/2023) \n Stay Tuned! \n Next week a demonstration on how to verify a correct implementation of SSL with ECC+PFS on LineRate will make a debut on DevCentral. The article will detail how to check for ECC SSL on the wire via WireShark and in the browser. In the meantime, take some time to download LineRate and test out its SSL Offloading capabilities. \n \n In case you missed any content, or would like to reference it again, here are the articles related to implementing SSL Offload with ECC and PFS on LineRate: \n \n Why ECC and PFS Matter: SSL offloading with LineRate \n Implementing ECC+PFS on LineRate (Part 1/3): Choosing ECC Curves and Preparing SSL Certificates \n Implementing ECC+PFS on LineRate (Part 2/3): Configuring SSL Offload on LineRate \n Implementing ECC+PFS on LineRate (Part 3/3): Confirming the Operation of SSL Offloading \n \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"7672","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzY1NzItMTUwaUI0RkEyOTgwNTFDRkYwMDY?revision=4\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:288587":{"__typename":"Conversation","id":"conversation:288587","topic":{"__typename":"TkbTopicMessage","uid":288587},"lastPostingActivityTime":"2023-06-07T12:26:42.629-07:00","solved":false},"User:user:171720":{"__typename":"User","uid":171720,"login":"Lori_MacVittie","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-10.svg?time=0"},"id":"user:171720"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctODU0N2kzMzI4MjUzMkExQjFFNTA5?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctODU0N2kzMzI4MjUzMkExQjFFNTA5?revision=1","title":"0151T000003d5yIQAQ.png","associationType":"BODY","width":2,"height":2,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctOTM5OWkyQjNDQzBFQTI3QjdFNjFE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctOTM5OWkyQjNDQzBFQTI3QjdFNjFE?revision=1","title":"0151T000003d5yKQAQ.png","associationType":"BODY","width":500,"height":308,"altText":null},"TkbTopicMessage:message:288587":{"__typename":"TkbTopicMessage","subject":"Back to Basics: The Many Modes of Proxies","conversation":{"__ref":"Conversation:conversation:288587"},"id":"message:288587","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:288587","revisionNum":1,"uid":288587,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2269},"postTime":"2013-12-09T07:47:00.000-08:00","lastPublishTime":"2013-12-09T07:47:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" The simplicity of the term \"proxy\" belies the complex topological options available. Understanding the different deployment options will enable your proxy deployment to fit your environment and, more importantly, your applications. \n\n \n\n It seems so simple in theory. A proxy is a well-understood concept that is not peculiar to networking. Indeed, some folks vote by proxy, they speak by proxy (translators), and even on occasion, marry by proxy. \n\n A proxy, regardless of its purpose, sits between two entities and performs a service. In network architectures the most common use of a proxy is to provide load balancing services to enable scale, reliability and even performance for applications. Proxies can log data exchanges, act as a gatekeeper (authentication and authorization), scan inbound and outbound traffic for malicious content and more. Proxies are a key strategic point of control in the data center because they are typically deployed as the go-between for end-users and applications. These go-between services are often referred to as virtual services, and for purposes of this blog that's what we'll call them. It's an important distinction because a single proxy can actually act in multiple modes on a per-virtual service basis. \n\n That's all pretty standard stuff. What's not simple is when you start considering how you want your proxy to act. Should it be a full proxy? A half proxy? Should it route or forward? There are multiple options for these components and each has its pros and cons. Understanding each proxy \"mode\" is an important step toward architecting a suitable solution for your environment as the mode determines the behavior of traffic as it traverses the proxy. \n\n Standard Virtual Service (Full Application Proxy) \n\n The standard virtual service provided by a full proxy fully terminates the transport layer connections (typically TCP) and establishes completely separate transport layer connections to the applications. This enables the proxy to intercept, inspect and ultimate interact with the data (traffic) as its flowing through the system. \n\n Any time you need to inspect payloads (JSON, HTML, XML, etc...) or steer requests based on HTTP headers (URI, cookies, custom variables) on an ongoing basis you'll need a virtual service in full proxy mode. \n\n \n\n A full proxy is able to perform application layer services. That is, it can act on protocol and data transported via an application protocol, such as HTTP. \n\n \n\n Performance Layer 4 Service (Packet by Packet Proxy) \n\n Before application layer proxy capabilities came into being, the primary model for proxies (and load balancers) was layer 4 virtual services. In this mode, a proxy can make decisions and interact with packets up to layer 4 - the transport layer. For web traffic this almost always equates to TCP. This is the highest layer of the network stack at which SDN architectures based on OpenFlow are able to operate. Today this is often referred to as flow-based processing, as TCP connections are generally considered flows for purposes of configuring network-based services. \n\n In this mode, a proxy processes each packet and maps it to a connection (flow) context. This type of virtual service is used for traffic that requires simple load balancing, policy network routing or high-availability at the transport layer. Many proxies deployed on purpose-built hardware take advantage of FPGAs that make this type of virtual service execute at wire speed. \n\n \n\n A packet-by-packet proxy is able to make decisions based on information related to layer 4 and below. It cannot interact with application-layer data. The connection between the client and the server is actually \"stitched\" together in this mode, with the proxy primarily acting as a forwarding component after the initial handshake is completed rather than as an endpoint or originating source as is the case with a full proxy. \n\n IP Forwarding Virtual Service (Router) \n\n For simple packet forwarding where the destination is based not on a pooled resource but simply on a routing table, an IP forwarding virtual service turns your proxy into a packet layer forwarder. \n\n A IP forwarding virtual server can be provisioned to rewrite the source IP address as the traffic traverses the service. This is done to force data to return through the proxy and is referred to as SNATing traffic. It uses transport layer (usually TCP) port multiplexing to accomplish stateful address translation. The address it chooses can be load balanced from a pool of addresses (a SNAT pool) or you can use an automatic SNAT capability. \n\n Layer 2 Forwarding Virtual Service (Bridge) \n\n For situations where a proxy should be used to bridge two different Ethernet collision domains, a layer 2 forwarding virtual service an be used. It can be provisioned to be an opaque, semi-opaque, or transparent bridge. Bridging two Ethernet domains is like an old timey water brigade. One guy fills a bucket of water (the client) and hands it to the next guy (the proxy) who hands it to the destination (the server/service) where it's thrown on the fire. The guy in the middle (the proxy) just bridges the gap (you're thinking what I'm thinking - that's where the term came from, right?) between the two Ethernet domains (networks). ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5326","kudosSumWeight":0,"repliesCount":3,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctODU0N2kzMzI4MjUzMkExQjFFNTA5?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODg1ODctOTM5OWkyQjNDQzBFQTI3QjdFNjFE?revision=1\"}"}}],"totalCount":2,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:276541":{"__typename":"Conversation","id":"conversation:276541","topic":{"__typename":"TkbTopicMessage","uid":276541},"lastPostingActivityTime":"2023-06-05T22:15:03.371-07:00","solved":false},"User:user:150108":{"__typename":"User","uid":150108,"login":"Brian_Talley_15","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-3.svg?time=0"},"id":"user:150108"},"TkbTopicMessage:message:276541":{"__typename":"TkbTopicMessage","subject":"LineRate and Redis pub/sub","conversation":{"__ref":"Conversation:conversation:276541"},"id":"message:276541","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:276541","revisionNum":2,"uid":276541,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:150108"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":302},"postTime":"2014-08-05T08:39:00.000-07:00","lastPublishTime":"2023-06-05T22:15:03.371-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Using the pre-installed Redis server on LineRate proxy, we can use pub/sub to push new configuration options and modify the layer 7 data path in real time. \n\n Background \n\n Each LineRate proxy has multiple data forwarding path processors; each of these processors runs an instance of the Node.js scripting engine. When a new HTTP request has to be processed, one of these script engines will process the request. Which actual script engine handles the request is not deterministic. A traditional approach to updating a script's configuration might be to embed an onRequest function in your script to handle an HTTP POST with new configuration options. However, given that only a single script engine will process this request, only the script running on that engine will 'see' the new options. Scripts running on any other engines will continue to use old options. Here we show you and easy way to push new options to all running processes. \n\n How to \n\n If you're not already familiar with Node.js and the LineRate scripting engine, you should check out the LineRate Scripting Developer's Guide. \n\n Let's jump into the Redis details. Redis is already installed and running on your LineRate proxy, so you can begin to use it immediately. \n\n If you're not familiar with the pub/sub concept, it's pretty straight-forward. The idea is that a publisher publishes a message on a particular channel and any subscribers that are subscribed to that same channel will receive the message. In this example, the message will be in JSON format. Be sure to take note of the fact that if your subscriber is not listening on the channel when a message is published, this message will never be seen by that subscriber. I've added some additional code that will store the published options in redis. Any time a subscriber connects, it will check for these values in redis and use them if they exist. This way, any subscriber will always use the most recently published options. \n\n Here is the code that will be added to the main script to handle the Redis subscribe function: \n\n \n // load the redis module\nvar redis = require(\"redis\");\n\n// create the subscriber redis client\nvar sub = redis.createClient(); \n\n// listen to and process 'message' events \nsub.on('message', function(channel, message) {\n // ...\n\n // get 'message' and store in 'opts'\n var opts = JSON.parse(message); \n\n // ...\n});\n\n// subscribe to the 'options' channel\nsub.subscribe('options');\n \n\n We can now insert these code pieces into a larger script that uses the options published in the options message. For example, you might want to use LineRate for it's ability to do HTTP traffic replication. You could publish an option called \"load\" that controls what percentage of requests get replicated. All script engines will 'consume' this message, update the load variable and immediately start replicating only the percentage of requests that you specified. It just so happens we have some code for this. See below in the section sampled_traffic_replication.js for a fully commented script that does sampled traffic replication using parameters received from Redis. \n\n It should also be mentioned that if you have multiple LineRate's all performing the same function, they can all subscribe to the same Redis server/channel and all take the appropriate action - all at the same time, all in real-time. \n\n Of course we need a way to actually publish new options to the 'options' channel. This could be done in myriad ways. I've included a fully commented Node.js script below called publish_config.js that prompts the user for the appropriate options on the command line and then publishes those options to the 'options' channel. \n\n Lastly, here's a sample proxy config snippet for LineRate that you would need: \n\n \n [...]\n\nvirtual-server vsPrimary\n attach vipPrimary default\n attach real-server group ...\n\nvirtual-server vsReplicate\n attach vipReplicate default\n attach real-server group ...\n\nvirtual-ip vipPrimary\n admin-status online\n ip address 192.0.2.10 80\n\nvirtual-ip vipReplicate\n admin-status online\n ip address 127.0.0.1 8080\n\n[...]\n \n\n sampled_traffic_replication.js \n\n \n \"use strict\";\n\nvar vsm = require('lrs/virtualServerModule');\nvar http = require('http');\nvar redis = require(\"redis\"),\n sub = redis.createClient();\n\n// define initial config options\nvar replicateOptions = {\n ip: '127.0.0.1',\n port: 8080,\n // Replicate every pickInterval requests\n // by default, don't replicate any traffic\n pickInterval: 0\n};\n\n// pubsub error handling\nsub.on(\"error\", function(err) {\n console.log(\"Redis subscribe Error: \" + err);\n});\n\n// if options already exist in redis, use them\nsub.on(\"ready\", function() {\n sub.get('config_options', function (err, reply) {\n if (reply !== null) {\n process_options(reply);\n }\n });\n // switch to subscriber mode to\n // listen for any published options\n sub.subscribe('options');\n});\n\nfunction process_options(opts) {\n opts = JSON.parse(opts);\n\n // only update config params if not null\n if (opts.virtual_server_ip) {\n replicateOptions.ip = opts.virtual_server_ip;\n }\n if (opts.virtual_server_port) {\n replicateOptions.port = opts.virtual_server_port;\n }\n\n // convert 'load' to 'pickInterval' for internal use\n if (opts.load) {\n // convert opts.load string to int\n opts.load = parseInt(opts.load, 10);\n if (opts.load === 0) {\n replicateOptions.pickInterval = opts.load;\n } else {\n replicateOptions.pickInterval = Math.round(1 / (opts.load / 100));\n }\n }\n\n console.log(\"Updated options: \" + JSON.stringify(replicateOptions));\n}\n\nvar tapServerRequest = function(servReq, servResp, options, onResponse) {\n\n // There is no built-in method to clone a request, so we must generate a new\n // request based on the existing request and send it to the replicate VIP\n var newReq = http.request({ host: options.ip,\n port: options.port,\n method: servReq.method,\n path: servReq.url},\n onResponse);\n servReq.bindHeaders(newReq);\n servReq.pipe(newReq);\n\n return newReq;\n}\n\n// Listen for config updates on 'options' channel\nsub.on('message', function(channel, message) {\n console.log(process.pid + ' Updating config(' + channel + ': ' + message);\n process_options(message);\n});\n\nvsm.on('exist', 'vsPrimary', function(vs) {\n console.log('Replicate traffic script installed on Virtual Server: ' + vs.id);\n\n var reqCount = 0;\n\n vs.on('request', function(servReq, servResp, cliReq) {\n var tapStart = Date.now();\n var to;\n var aborted = false;\n\n reqCount++;\n\n //\n // decide if request should be replicated; replicate if so\n //\n // be sure to handle \"0\" load scenario gracefully\n //\n if (replicateOptions.pickInterval && reqCount % replicateOptions.pickInterval == 0) {\n var newReq = tapServerRequest(servReq, servResp, replicateOptions, function(resp) {\n\n // a close event indicates an improper connection termination\n resp.on('close', function(err) {\n console.log('Replicated response error: ' + err);\n });\n resp.on('end', function(err) {\n console.log('Replicated response error:' + aborted);\n clearTimeout(to);\n });\n });\n\n //\n // if replicated request timer exceeds 500ms, abort the request\n //\n to = setTimeout(function() {\n aborted = true;\n newReq.abort();\n }, 500);\n }\n\n //\n // also send original request along the normal data path\n //\n servReq.bindHeaders(cliReq);\n servReq.pipe(cliReq);\n cliReq.on('response', function(cliResp) {\n cliResp.bindHeaders(servResp);\n cliResp.fastPipe(servResp);\n });\n });\n});\n \n\n publish_config.js \n\n \n \"use strict\";\n\nvar prompt = require('prompt');\nvar redis = require('redis');\n\n// note you might need Redis server connection\n// parameters defined here for use in createClient()\n// method.\n\nvar redis_client = redis.createClient();\n\nvar config_channel = 'options';\n\nvar schema = {\n properties: {\n virtual_server_ip: {\n description: 'Virtual Server IP',\n pattern: /^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}$/,\n message: 'Must be an IP address',\n required: false\n },\n virtual_server_port: {\n description: 'Virtual Server port number',\n pattern: /^[0-9]{1,5}$/,\n message: 'Must be an integer between 1 and 65535',\n require: false\n },\n load: {\n description: 'Percentage of load to replicate',\n pattern: /^[0-9]{1,3}$/,\n message: 'Must be an integer between 0 and 100',\n require: false\n }\n }\n};\n\nprompt.start();\n\nfunction get_info() {\n\n console.log('Enter values; leave blank to not update');\n\n prompt.get(schema, function (err, result) {\n\n if (err) {\n return prompt_error(err);\n }\n\n //\n // TODO: do some input validation here\n //\n\n var config = JSON.stringify(result)\n\n console.log('Sending: ' + config)\n\n // publish options via pub/sub\n redis_publish_message(config_channel, config);\n redis_client.end();\n\n });\n}\n\nfunction redis_publish_message(channel, message) {\n // publish\n redis_client.publish(channel,message);\n // also store JSON message in redis\n redis_client.set(\"config_options\", message)\n}\n\nfunction prompt_error(err) {\n console.log(err);\n return 1;\n}\n\n//main\nget_info();\n \n\n Additional Resources \n\n Download LineRate LineRate Scripting Developer's Guide LineRate solution articles LineRate DevCentral ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"9711","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:276503":{"__typename":"Conversation","id":"conversation:276503","topic":{"__typename":"TkbTopicMessage","uid":276503},"lastPostingActivityTime":"2023-06-05T22:12:47.459-07:00","solved":false},"TkbTopicMessage:message:276503":{"__typename":"TkbTopicMessage","subject":"Conditional high-res image serving with LineRate","conversation":{"__ref":"Conversation:conversation:276503"},"id":"message:276503","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:276503","revisionNum":2,"uid":276503,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:150108"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":182},"postTime":"2014-10-28T09:51:00.000-07:00","lastPublishTime":"2023-06-05T22:12:47.459-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" There is a vast array of screen sizes, resolutions and pixel densities out there. As someone who is serving content to users, how do you ensure that you're serving the best quality images to screens where it actually makes a difference? \n\n The problem: If you're serving standard resolution images to high pixel density screens (such as Apple Retina, iPhones, Samsung Galaxy and myriad other devices), user experience may suffer. If you're serving higher resolution images to lower quality screens, you're chewing up unnecessary bandwidth and increasing page load times to users who won't benefit. So you've decided you want to give your users the best user experience you can when it comes to images, how do you go about it? \n\n One solution is to maintain multiple copies of the image at various qualities and to conditionally serve the right quality depending on the client. \n\n The basic premise of the solution documented here is to use a cookie to signal the client's device pixel ratio to the server. Once we know the device pixel ratio, we can decide which version of an image to serve. The device pixel ratio isn't something that is normally sent from client to server, so we have to give it a little nudge. There are a couple of ways to accomplish this - this article details two methods well. \n\n If you're already using javascript, I'd recommend using the javascript method. If you're not, or you just want to avoid javascript for whatever reason, go with the CSS method. Either way, we'll assume that you've implemented this and that the cookie is named \"device-pixel-ratio\" and that the value is an integer. \n\n This script below will check if the request is for an image (ex. image1.png ). If it is, it will also check for the presence and value of the device-pixel-ratio cookie. If the value is greater than 1, the request will be re-written to request the high res image (ex. image1.png@2x ). \n\n Here's the script: \n\n 'use strict';\n\nvar vsm = require('lrs/virtualServerModule');\nvar url = require('url');\nvar cookie = require('cookie');\n\n// append this to image names for highres\nvar suffix = '@2x';\n\n// image types to check for highres\nvar ext = [\n '.jpg',\n '.jpeg',\n '.gif',\n '.png',\n '.webp'\n];\n\nvar request_callback = function (vs_object) {\n console.log('pixel_ratio script installed on Virtual Server: ' +\n vs_object.id);\n\n vs_object.on('request', function (servReq, servResp, cliReq) {\n\n // check header for device-pixel-ratio\n if ('Cookie' in servReq.headers) {\n var cookies = cookie.parse(servReq.headers.Cookie);\n console.log(cookies);\n if ('device-pixel-ratio' in cookies &&\n cookies['device-pixel-ratio'] > 1) {\n\n var u = url.parse(servReq.url);\n\n for (var i = 0; i < ext.length; i++) {\n if (u.pathname.slice(-ext[i].length) === ext[i]) {\n servReq.bindHeaders(cliReq);\n servReq.url = u.pathname + suffix + (u.search || '');\n break;\n }\n };\n\n }\n }\n\n cliReq();\n\n });\n};\n\nvsm.on('exist', 'vs_http', request_callback);\n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3257","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:284954":{"__typename":"Conversation","id":"conversation:284954","topic":{"__typename":"TkbTopicMessage","uid":284954},"lastPostingActivityTime":"2023-06-05T21:35:54.036-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNDg4OGlDNzY3QUQwRURDRjQ4QkZB?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNDg4OGlDNzY3QUQwRURDRjQ4QkZB?revision=2","title":"0151T000003d9HMQAY.png","associationType":"QUOTE","width":24,"height":21,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNzM1NGlBMTlENEIxNDlDRTBBNzQ5?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNzM1NGlBMTlENEIxNDlDRTBBNzQ5?revision=2","title":"0151T000003d9HNQAY.png","associationType":"QUOTE","width":24,"height":21,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=2","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=2","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=2","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=2","title":"0151T000003d4HvQAI.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=2","title":"0151T000003d4HwQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=2","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:284954":{"__typename":"TkbTopicMessage","subject":"2.5 bad ways to implement a server load balancing architecture","conversation":{"__ref":"Conversation:conversation:284954"},"id":"message:284954","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:284954","revisionNum":2,"uid":284954,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":395},"postTime":"2008-10-24T07:55:06.000-07:00","lastPublishTime":"2023-06-05T21:35:54.036-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" I'm in a bit of mood after reading a Javaworld article on server load balancing that presents some fairly poor ideas on architectural implementations. It's not the concepts that are necessarily wrong; they will work. It's the architectures offered as a method of load balancing made me do a double-take and say \"What?\" I started reading this article because it was part 2 of a series on load balancing and this installment focused on application layer load balancing. You know, layer 7 load balancing. Something we at F5 just might know a thing or two about. But you never know where and from whom you'll learn something new, so I was eager to dive in and learn something. I learned something alright. I learned a couple of bad ways to implement a server load balancing architecture. TWO LOAD BALANCERS? The first indication I wasn't going to be pleased with these suggestions came with the description of a \"popular\" load-balancing architecture that included two load balancers: one for the transport layer (layer 4) and another for the application layer (layer 7). In contrast to low-level load balancing solutions, application-level server load balancing operates with application knowledge. One popular load-balancing architecture, shown in Figure 1, includes both an application-level load balancer and a transport-level load balancer. Even the most rudimentary, entry level load balancers on the market today - software and hardware, free and commercial - can handle both transport and application layer load balancing. There is absolutely no need to deploy two separate load balancers to handle two different layers in the stack. This is a poor architecture introducing unnecessary management and architectural complexity as well as additional points of failure into the network architecture. It's bad for performance because it introduces additional hops and points of inspection through which application messages must flow. To give the author credit he does recognize this and offers up a second option to counter the negative impact of the \"additional network hops.\" One way to avoid additional network hops is to make use of the HTTP redirect directive. With the help of the redirect directive, the server reroutes a client to another location. Instead of returning the requested object, the server returns a redirect response such as 303. I found it interesting that the author cited an HTTP response code of 303, which is rarely returned in conjunction with redirects. More often a 302 is used. But it is valid, if not a bit odd. That's not the real problem with this one, anyway. The author claims \"The HTTP redirect approach has two weaknesses.\" That's true, it has two weaknesses - and a few more as well. He correctly identifies that this approach does nothing for availability and exposes the infrastructure, which is a security risk. But he fails to mention that using HTTP redirects introduces additional latency because it requires additional requests that must be made by the client (increasing network traffic), and that it is further incapable of providing any other advanced functionality at the load balancing point because it essentially turns the architecture into a variation of a DSR (direct server return) configuration. THAT\"S ONLY 2 BAD WAYS, WHERE'S THE .5? The half bad way comes from the fact that the solutions are presented as a Java based solution. They will work in the sense that they do what the author says they'll do, but they won't scale. Consider this: the reason you're implementing load balancing is to scale, because one server can't handle the load. A solution that involves putting a single server - with the same limitations on connections and session tables - in front of two servers with essentially the twice the capacity of the load balancer gains you nothing. The single server may be able to handle 1.5 times (if you're lucky) what the servers serving applications may be capable of due to the fact that the burden of processing application requests has been offloaded to the application servers, but you're still limited in the number of concurrent users and connections you can handle because it's limited by the platform on which you are deploying the solution. An application server acting as a cluster controller or load balancer simply doesn't scale as well as a purpose-built load balancing solution because it isn't optimized to be a load balancer and its resource management is limited to that of a typical application server. That's true whether you're using a software solution like Apache mod_proxy_balancer or hardware solution. So if you're implementing this type of a solution to scale an application, you aren't going to see the benefits you think you are, and in fact you may see a degradation of performance due to the introduction of additional hops, additional processing, and poorly designed network architectures. I'm all for load balancing, obviously, but I'm also all for doing it the right way. And these solutions are just not the right way to implement a load balancing solution unless you're trying to learn the concepts involved or are in a computer science class in college. If you're going to do something, do it right. And doing it right means taking into consideration the goals of the solution you're trying to implement. The goals of a load balancing solution are to provide availability and scale, neither of which the solutions presented in this article will truly achieve. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5626","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNDg4OGlDNzY3QUQwRURDRjQ4QkZB?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNzM1NGlBMTlENEIxNDlDRTBBNzQ5?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMTI2NzFpNUQ1REUwNUJBMTlBQjE4RA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtMzQ3MWk3Rjk5MTAzNUNGM0FEODk4?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5NTQtNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=2\"}"}}],"totalCount":8,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280218":{"__typename":"Conversation","id":"conversation:280218","topic":{"__typename":"TkbTopicMessage","uid":280218},"lastPostingActivityTime":"2023-01-31T16:30:02.641-08:00","solved":false},"User:user:321706":{"__typename":"User","uid":321706,"login":"PSilva","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0zMjE3MDYtMjE0NTFpRDA4NDA4QzE2MUZCREM5NA"},"id":"user:321706"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtOTc2MWk2Q0QzM0ZGRDE3RTdDMzMx?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtOTc2MWk2Q0QzM0ZGRDE3RTdDMzMx?revision=2","title":"0151T000003d5WfQAI.png","associationType":"BODY","width":24,"height":24,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQwNTRpRTgyRjVERDM5NUYzNjU2RQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQwNTRpRTgyRjVERDM5NUYzNjU2RQ?revision=2","title":"0151T000003d5WiQAI.png","associationType":"BODY","width":24,"height":24,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQ0OTlpMkZDNkJDRTZDNzE0MUIwOA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQ0OTlpMkZDNkJDRTZDNzE0MUIwOA?revision=2","title":"0151T000003d5WhQAI.png","associationType":"BODY","width":24,"height":24,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtNTcyMWlBODUwRjZEQTk3MTdCNUVD?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtNTcyMWlBODUwRjZEQTk3MTdCNUVD?revision=2","title":"0151T000003d5WlQAI.png","associationType":"BODY","width":24,"height":24,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTExNTFpQzk2QTBBRkZBM0NFRjcxNQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTExNTFpQzk2QTBBRkZBM0NFRjcxNQ?revision=2","title":"0151T000003d5WmQAI.png","associationType":"BODY","width":24,"height":24,"altText":null},"TkbTopicMessage:message:280218":{"__typename":"TkbTopicMessage","subject":"Inside Look - PCoIP Proxy for VMware Horizon View","conversation":{"__ref":"Conversation:conversation:280218"},"id":"message:280218","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280218","revisionNum":2,"uid":280218,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:321706"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":396},"postTime":"2013-06-21T11:57:00.000-07:00","lastPublishTime":"2023-01-31T16:30:02.641-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" I sit down with F5 Solution Architect Paul Pindell to get an inside look at BIG-IP's native support for VMware's PCoIP protocol. He reviews the architecture, business value and gives a great demo on how to configure BIG-IP. \n BIG-IP APM offers full proxy support for PC-over-IP (PCoIP), a leading virtual desktop infrastructure (VDI) protocol. F5 is the first to provide this functionality which allows organizations to simplify their VMware Horizon View architectures. Combining PCoIP proxy with the power of the BIG-IP platform delivers hardened security and increased scalability for end-user computing. In addition to PCoIP, F5 supports a number of other VDI solutions, giving customers flexibility in designing and deploying their network infrastructure. \n \n \n ps \n Related: \n \n F5 Friday: Simple, Scalable and Secure PCoIP for VMware Horizon View \n Solutions for VMware applications \n F5's YouTube Channel \n In 5 Minutes or Less Series (24 videos – over 2 hours of In 5 Fun) \n Inside Look Series \n Life@F5 Series \n \n Technorati Tags: vdi,PCoIP,VMware,Access,Applications,Infrastructure,Performance,Security,Virtualization,silva,video,inside look,big-ip,apm \n \n \n \n \n Connect with Peter: \n Connect with F5: \n \n \n \n \n \n \n \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"1337","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtOTc2MWk2Q0QzM0ZGRDE3RTdDMzMx?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQwNTRpRTgyRjVERDM5NUYzNjU2RQ?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTQ0OTlpMkZDNkJDRTZDNzE0MUIwOA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtNTcyMWlBODUwRjZEQTk3MTdCNUVD?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAyMTgtMTExNTFpQzk2QTBBRkZBM0NFRjcxNQ?revision=2\"}"}}],"totalCount":5,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1751557989989","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1751557989989","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1751557989989","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1751557989989","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1751557989989","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1751557989989","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1751557989989","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1751557989989","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1751557989989","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1751557989989","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1751557989989","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1751557989989","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1751557989989","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1751557989989","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1751557989989","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1751557989989","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1751557989989","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1751557989989","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1751557989989","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1751557989989","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1751557989989","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1751557989989","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1751557989989","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1751557989989":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1751557989989","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostRecent","tagName":"performance"},"buildId":"3XH0qYWYCnEYycuN5W4S8","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}