Troubleshooting high CPU utilisation on BIG-IP systems
Introduction This is not really a step-by-step troubleshooting guide. What I'm sharing here is the result of reverse engineering the kind of knowledge that led me to succeed on troubleshooting CPU issues during the time I worked for Engineering Services department at F5. Here's what I'll cover sequentially with a mix of what we should know and where to find the problem: Know what HyperThreading (HT) is Know how HT is used within F5 Find out if F5 box supports HyperThreading (HT) Know the difference between Forwarding plane (TMM) vs Control plane (Linux) CPU consumption Confirm if the problem is TMM or another daemon Where to look further when TMM CPU is high What if it's a control plane daemon? Learn how to interpret graphs High CPU in non-HT boxes High CPU in HT+ boxes Use scripts when necessary to collect real time data 1. Know what HyperThreading (HT) is Physical core, as the name implies, is a physical CPU core connected to mothership's socket Physical CPU core has several execution units (modules) capable of performing different tasks e.g. basic integer maths, another for more advanced maths, loading and storing data from/to memory, etc. HT uses 2 or more logical CPU cores to use execution units that are not being utilised by process A, so process B can use them if needed. When 2 programs want to use the same part of the physical core, then it's inevitable that one of them will have to wait The Operating System (OS) scheduler decides which process gets execution priority in this case This is when 2 (or more) actual physical cores would perform better as this limitation is not present i.e. 2 physical cores would be able to concurrently perform tasks using their own execution units 2. Know how HT is used within F5 Before BIG-IP v11.5.0 on systems with HyperThreading (HT) Technology, we would have: 1 TMM per logical core Each logical core processes both data plane (TMM) and control plane (Linux) tasks v11.5.0+ (affects only processors with HT Technology) Data plane (TMM) reside in even-numbered cores (0, 2, 4, etc) Control plane cores (Linux) reside in odd-numbered cores (1, 3, 5, etc) When TMM reaches 80% of actual CPU utilisation, odd-numbered cores limit control plane tasks so they can only use up to 20% of CPU capacity, allowing remaining to be used by overloaded forwarding plane (TMM). vCMP host must also be using v11.5.0+ or newer in order for guests to use HTSplit technology. We can disable it manually by issuing the following command: 3 Find out if your box supports HyperThreading (HT) The hardware boxes listed with HT+ in K14358, all support HyperThreading technology. Here's how to check the number of cores in a given BIG-IP box (this is a VIPRION C2200 chassis with 2250 blade installed): The above box is able to run 2 threads per physical core (Thread(s) per core) with a total of 10 physical cores (Core(s) per socket) and a total of 20 (logical) cores (CPU(s)). Here's the same output from a 3900 series box that does not support HT: The above box is able to run 1 thread per physical core (Thread(s) per core) with a total of 4 physical cores (Core(s) per socket) and a total of 4 cores (CPU(s)). 4 Know the difference between Forwarding plane (TMM) vs Control plane (Linux) CPU consumption 4.1 Confirming if it's TMM or Linux BIG-IP's forwarding plane is TMM. TMM is a daemon/process within Linux space. If tmm CPU usage is high, then we know high CPU utilisation is a forwarding plane issue. The other daemons are part of BIG-IP's control plane (e.g. bigd - monitoring daemon). In this example, both tmm (102.3%) and bigd (51.8%) are high here: If TMM CPU utilisation is high, we will need to troubleshoot CPU usage of internal TMM components. For other daemons, there are different places to look. For example, for bigd (monitoring daemon), we need to check BIG-IP's monitors. AskF5 has a nice how-to guide here. Here's a list of BIG-IP daemons. 4.2 TMM CPU utilisation or forwarding plane CPU utilisation Checktmsh show ltm virtual<virtual server name> to confirm if there is a particular virtual server eating up tmm CPU cycles: Check iRules Checktmsh sys tmm-infoto see the breakdown of TMM cpu utilisation per tmm: 4.3 Linux CPU utilisation or data plane CPU utilisation For anything else apart from TMM,topoutput is your best friend for confirmation of which daemon is the culprit. tmsh show sys proc-infois also another command we can use to gather process specific CPU information. Here I'm checking bigd's monitoring daemon information: 5. Learn how to interpret graphs 5.1 High CPU in non-HT boxes The below graph is just an example taken from 3900 box that doesn't have HT split Because graphs are generated based on average cpu utilisation then we can assume that cpu utilisation is very high at times Because there is no HT-split the below cpu utilisation can be either due to TMM or due some other Linux daemon We can confirm usingtopcommand In the below graph it was due to bothtmmandbigd to confirm normal usage we always try to match with other numbers in the graph (e.g. active connections, etc) Note: this is a graph as seen in qkview (Clicking on System > Support) which takes a snapshot of the system. It can then be uploaded to ihealth and is mostly used to sharing snapshot of BIG-IP systems with F5 support. However, the graph here is used for illustrative purposes to understand CPU utilisation as seen in graphs. 5.2 High CPU in HT+ boxes This other graph here was taken from a 4200 series box which has HT split enabled Notice that CPU cores 0, 2, 4 and 6 (tmm/data plane) show CPU at about 60% Cores 1, 3, 5 and 7 show very minimal CPU utilisation with some spikes Spikes can be due to AVR/ASM daemons described inK16469andK15606 Or because TMM has reached 80% of cpu utilisation and is now using control plane's cores This is an example of mostly normal/regular cpu utilisation When HT is enabled and TMM cores use less than 80% of cpu, then data-plane cores remain mostly 'quiet'. 6. Use scripts when necessary to collect real time data Sometimes just by looking at the graphs and commands is not enough to determine why CPU is high. Here's an example of a script to collect real-time TMM/Linux CPU stats on BIG-IP every 60 seconds and copy output to /var/log/cpu-average.log top command output is also copied to /var/log/top-output.log: Output should be similar to this: The number after "Counter64" is the percentage value representing how busy each CPU core is. For example, TMM0.0 and TMM0.1 are both at 1% of capacity. We can add H to top command (e.g. top -Hcbn 1) in the script above to show the individual threads of a process, including TMM threads. When opening a support case with F5, it may be useful to include the full tmctl table as it contains roughly all raw data about everything we can possibly find on BIG-IP system. The below is an example of a script that collects all tmctl information every 5 seconds: Apart from knowing where to look, understanding the CPU usage pattern when it comes to our own organisation's production traffic is really important. It enables us to compare, for example, the number of active connections with a spike in CPU in the graphs to understand if the spike is related to a sudden and sharp increase in traffic.15KViews6likes3Comments
Improve BIG-IP APM VPN speed with TLS dynamic record size
After successfully setting up BIG-IP APM network access, and running it for sometime, you may be looking for ways to optimize VPN speed for your users. This article discusses one way you can do that. Feature Description Beginning in BIG-IP 12.1.0, the Client SSL profile includes a feature that enables dynamic record size in TLS. When applied to a F5 BIG-IP Access Policy Manager (APM) network access VPN TLS virtual server, this can improve VPN speeds for your users. It has been found that certain protocols, notably HTTP, show better client response times using this method. For more information on the Allow Dynamic Record Sizing setting down to the packet level, refer to the following resources TheAbout dynamic record sizing section of the BIG-IP System: SSL Administration manual. Boosting TLS Performance with Dynamic Record Sizing on BIG-IP on DevCentral. SSL Profiles Part 11: TLS Optimizationon DevCentral. Important: Dynamic record size is a TLS enhancement and does not apply to BIG-IP APM network access DTLS virtual servers. Do not enable dynamic record size on DTLS. When you want to optimize network performance, you must allocate time to tune each configuration to match the requirements specific to your environment. Additionally, note that configuration changes that improve performance may increase BIG-IP system resource (CPU, memory) usage. Testing dynamic record size on VPN speeds Having discussed the theory behind the feature, we will now perform tests to see how it affects VPN speeds. Network bandwidth can vary depending on many factors, for instance, peak vs non-peak hours. When more users are connected to a VPN, download speeds can decrease significantly. It is therefore important to establish a baseline network bandwidth and download speed at the beginning: Baseline AWS environment Windows Client (Seattle) --VPN --> BIG-IP APM (Oregon) --local LAN-->Apache and iperf servers AWS environment: BIG-IP APM 17.1.0 VE on AWS (F5 BIG-IP VE - ALL modules, m5.xlarge, 1 Gbps, AWS) located in us-west-2 Oregon. Note: Ensure you use at least the recommended size (m5.xlarge) and at least 1Gbps on AWS to make sure there are no bandwidth and resource limits. Windows client in located in Seattle Using iperf3 to measure network bandwidth Using curl to download a 377MB apmclient.iso Optional: You can optionally test using the developer tools on your browser. I used firefox; as the results did not differ significantly from curl. They are not included in this article. Baseline test results These are measured with all default settings on BIG-IP APM and dynamic record sizing not enabled: curl download results Average download speed: 4950k C:\Windows\system32>curl -k -o null https://10.0.128.23/apmclient.iso % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 377M 100 377M 0 0 4950k 0 0:01:18 0:01:18 --:--:-- 4988k iperf3 results Network bandwidth: 4873 KB/sec c:\Users\klau\Desktop\iperf-3.1.3-win64>iperf3.exe -c 10.0.128.24 --get-server-output -i 1 -f K -R Connecting to host 10.0.128.24, port 5201 Reverse mode, remote host 10.0.128.24 is sending [ 4] local 10.0.128.31 port 61284 connected to 10.0.128.24 port 5201 [ ID] Interval Transfer Bandwidth [ 4] 0.00-1.00 sec 4.33 MBytes 4434 KBytes/sec [ 4] 1.00-2.00 sec 4.67 MBytes 4785 KBytes/sec [ 4] 2.00-3.00 sec 4.86 MBytes 4977 KBytes/sec [ 4] 3.00-4.00 sec 4.77 MBytes 4878 KBytes/sec [ 4] 4.00-5.00 sec 4.72 MBytes 4834 KBytes/sec [ 4] 5.00-6.00 sec 4.78 MBytes 4898 KBytes/sec [ 4] 6.00-7.00 sec 4.87 MBytes 4989 KBytes/sec [ 4] 7.00-8.00 sec 4.81 MBytes 4925 KBytes/sec [ 4] 8.00-9.00 sec 4.71 MBytes 4823 KBytes/sec [ 4] 9.00-10.00 sec 4.82 MBytes 4934 KBytes/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-10.00 sec 48.0 MBytes 4919 KBytes/sec 9 sender [ 4] 0.00-10.00 sec 47.6 MBytes 4873 KBytes/sec receiver Server output: [...] [ 5] 0.00-10.04 sec 48.0 MBytes 4900 KBytes/sec 9 sender Test 1: Enabling dynamic record size from baseline Comparing with baseline results after enabling dynamic record size Baseline: Dynamic record size disabled dynamic record size enabled Percentage improvement curl average download, k 4950 5272 6.51% iperf3 network bandwidth, KBytes/sec 4873 5138 5.44% While this may not appear to be too high on the AWS cloud, there is also received feedback from customers that they see greater improvements in environments, especially in cases where the end-to-end latencies increase. Implementation strategy and recommendations As you plan to introduce this in your environment, take note of the following recommendations: Every environment is unique Many factors can affect network performance. This can range from VLAN settings (For example. MTU), TCP settings, intermediate network device throttling, and so on. You must perform testing in your own environment before enabling the feature. Implement the feature incrementally for a selected group of users. There are different ways to do this. For example, use an iRule to redirect users based on a URL, to a separate virtual server using a different Client SSL profile that has the feature enabled. Refer to SSL::allow_dynamic_record_sizing on Clouddocs. Monitor BIG-IP system logs and resource usage After you enable dynamic record size, make sure that your BIG-IP system continues to function as expected by monitoring the following monitor /var/log/ltm and /var/log/apm log files monitor BIG-IP CPU and memory usage. For example, you can select Dashboard on the Configuration utility, generating a QKview and analyze it in iHealth and so on. For more information, refer to K71764661: Understanding BIG-IP CPU usage and K16419: Overview of BIG-IP memory usage Verify and analyze SSL statistics Use the tmsh command inK41057430: Enhanced SSL profile statistics and check for failures. The SSL Dynamic Record Sizes section should also indicate use of large record sizes. Boosting TLS Performance with Dynamic Record Sizing on BIG-IP Conclusion There are a variety of different ways to improve VPN speeds, and this article describes just one. For other options and considerations, refer to K31143831: VPN for business continuity | Chapter 5: Optimizing Network Access VPN.71Views2likes0CommentsIs TCP's Nagle Algorithm Right for Me?
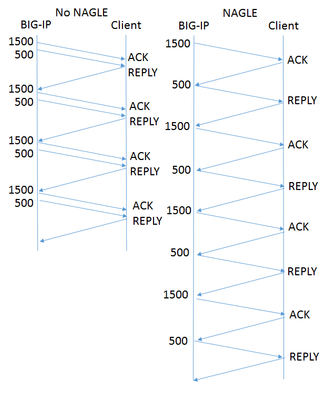
Of all the settings in the TCP profile, the Nagle algorithm may get the most questions. Designed to avoid sending small packets wherever possible, the question of whether it's right for your application rarely has an easy, standard answer. What does Nagle do? Without the Nagle algorithm, in some circumstances TCP might send tiny packets. In the case of BIG-IP®, this would usually happen because the server delivers packets that are small relative to the clientside Maximum Transmission Unit (MTU). If Nagle is disabled, BIG-IP will simply send them, even though waiting for a few milliseconds would allow TCP to aggregate data into larger packets. The result can be pernicious. Every TCP/IP packet has at least 40 bytes of header overhead, and in most cases 52 bytes. If payloads are small enough, most of the your network traffic will be overhead and reduce the effective throughput of your connection. Second, clients with battery limitations really don't appreciate turning on their radios to send and receive packets more frequently than necessary. Lastly, some routers in the field give preferential treatment to smaller packets. If your data has a series of differently-sized packets, and the misfortune to encounter one of these routers, it will experience severe packet reordering, which can trigger unnecessary retransmissions and severely degrade performance. Specified in RFC 896 all the way back in 1984, the Nagle algorithm gets around this problem by holding sub-MTU-sized data until the receiver has acked all outstanding data. In most cases, the next chunk of data is coming up right behind, and the delay is minimal. What are the Drawbacks? The benefits of aggregating data in fewer packets are pretty intuitive. But under certain circumstances, Nagle can cause problems: In a proxy like BIG-IP, rewriting arriving packets in memory into a different, larger, spot in memory taxes the CPU more than simply passing payloads through without modification. If an application is "chatty," with message traffic passing back and forth, the added delay could add up to a lot of time. For example, imagine a network has a 1500 Byte MTU and the application needs a reply from the client after each 2000 Byte message. In the figure at right, the left diagram shows the exchange without Nagle. BIG-IP sends all the data in one shot, and the reply comes in one round trip, allowing it to deliver four messages in four round trips. On the right is the same exchange with Nagle enabled. Nagle withholds the 500 byte packet until the client acks the 1500 byte packet, meaning it takes two round trips to get the reply that allows the application to proceed. Thus sending four messages takes eight round trips. This scenario is a somewhat contrived worst case, but if your application is more like this than not, then Nagle is poor choice. If the client is using delayed acks (RFC 1122), it might not send an acknowledgment until up to 500ms after receipt of the packet. That's time BIG-IP is holding your data, waiting for acknowledgment. This multiplies the effect on chatty applications described above. F5 Has Improved on Nagle The drawbacks described above sound really scary, but I don't want to talk you out of using Nagle at all. The benefits are real, particularly if your application servers deliver data in small pieces and the application isn't very chatty. More importantly, F5® has made a number of enhancements that remove a lot of the pain while keeping the gain: Nagle-aware HTTP Profiles: all TMOS HTTP profiles send a special control message to TCP when they have no more data to send. This tells TCP to send what it has without waiting for more data to fill out a packet. Autonagle:in TMOS v12.0, users can configure Nagle as "autotuned" instead of simply enabling or disabling it in their TCP profile. This mechanism starts out not executing the Nagle algorithm, but uses heuristics to test if the receiver is using delayed acknowledgments on a connection; if not, it applies Nagle for the remainder of the connection. If delayed acks are in use, TCP will not wait to send packets but will still try to concatenate small packets into MSS-size packets when all are available. [UPDATE:v13.0 substantially improves this feature.] One small packet allowed per RTT: beginning with TMOS® v12.0, when in 'auto' mode that has enabled Nagle, TCP will allow one unacknowledged undersize packet at a time, rather than zero. This speeds up sending the sub-MTU tail of any message while not allowing a continuous stream of undersized packets. This averts the nightmare scenario above completely. Given these improvements, the Nagle algorithm is suitable for a wide variety of applications and environments. It's worth looking at both your applications and the behavior of your servers to see if Nagle is right for you.1.2KViews2likes5CommentsStop Using the Base TCP Profile!
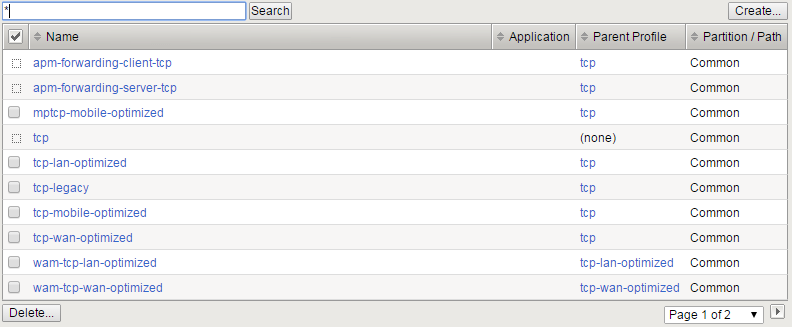
[Update 1 Mar 2017:F5 has new built-in profiles in TMOS v13.0. Although the default profile settings still haven't changed, there is good news on that from as well.] If the customer data I've seen is any indication, the vast majority of our customers are using the base 'tcp' profile to configure their TCP optimization. This haspoor performance consequencesand I strongly encourage you to replace it immediately. What's wrong with it? The Buffers are too small.Both the receive and send buffers are limited to 64KB, and the proxy buffer won't exceed 48K . If the bandwidth/delay product of your connection exceeds the send or receive buffer, which it will in most of today's internet for all but the smallest files and shortest delays, your applications will be limited not by the available bandwidth but by an arbitrary memory limitation. The Initial Congestion Window is too small.As the early thin-pipe, small-buffer days of the internet recede, the Internet Engineering Task Force (see IETFRFC 6928) increased the allowed size of a sender's initial burst. This allows more file transfers to complete in single round trip time and allows TCP to discover the true available bandwidth faster. Delayed ACKs.The base profile enables Delayed ACK, which tries to reduce ACK traffic by waiting 200ms to see if more data comes in. This incurs a serious performance penalty on SSL, among other upper-layer protocols. What should you do instead? The best answer is to build a custom profile based on your specific environment and requirements. But we recognize that some of you will find that daunting! So we've created a variety of profiles customized for different environments. Frankly, we should do some work to improve these profiles, but even today there are much better choices than base 'tcp'. If you have an HTTP profile attached to the virtual, we recommend you use tcp-mobile-optimized. This is trueeven if your clients aren't mobile. The name is misleading! As I said, the default profiles need work. If you're just a bit more adventurous with your virtual with an HTTP profile, then mptcp-mobile-optimizedwill likely outperform the above. Besides enabling Multipath TCP (MPTCP)for clients that ask for it, it uses a more advanced congestion control ("Illinois") and rate pacing. We recognize, however, that if you're still using the base 'tcp' profile today then you're probably not comfortable with the newest, most innovative enhancements to TCP. So plain old tcp-mobile-optimized might be a more gentle step forward. If your virtual doesn't have an HTTP profile, the best decision is to use a modified version of tcp-mobile-optimized or mptcp-mobile-optimized. Just derive a profile from whichever you prefer and disable the Nagle algorithm. That's it! If you are absolutely dead set against modifying a default profile, then wam-tcp-lan-optimized is the next best choice. It doesn't really matter if the attached network is actually a LAN or the open internet. Why did we create a default profile with undesirable settings? That answer is lost in the mists of time. But now it's hard to change: altering the profile from which all other profiles are derived will cause sudden changes in customer TCP behavior when they upgrade. Most would benefit, and many may not even notice, but we try to not to surprise people. Nevertheless, if you want a quick, cheap, and easy boost to your application performance, simply switch your TCP profile from the base to one of our other defaults. You won't regret it.3.6KViews1like27Comments
Back to Basics: Health Monitors and Load Balancing
#webperf #ado Because every connection counts One of the truisms of architecting highly available systems is that you never, ever want to load balance a request to a system that is down. Therefore, some sort of health (status) monitoring is required. For applications, that means not just pinging the network interface or opening a TCP connection, it means querying the application and verifying that the response is valid. This, obviously, requires the application to respond. And respond often. Best practices suggest determining availability every 5 seconds or so. That means every X seconds the load balancing service is going to open up a connection to the application and make a request. Just like a user would do. That adds load to the application. It consumes network, transport, application and (possibly) database resources. Resources that cannot be used to service customers. While the impact on a single application may appear trivial, it's not. Remember, as load increases performance decreases. And no matter how trivial it may appear, health monitoring is adding load to what may be an already heavily loaded application. But Lori, you may be thinking, you expound on the importance of monitoring and visibility all the time! Are you saying we shouldn't be monitoring applications? Nope, not at all. Visibility is paramount, providing the actionable data necessary to enable highly dynamic, automated operations such as elasticity. Visibility through health-monitoring is a critical means of ensuring availability at both the local and global level. What we may need to do, however, is move from active to passive monitoring. PASSIVE MONITORING Passive monitoring, as the modifier suggests, is not an active process. The Load balancer does not open up connections nor query an application itself. Instead, it snoops on responses being returned to clients and from that infers the current status of the application. For example, if a request for content results in an HTTP error message, the load balancer can determine whether or not the application is available and capable of processing subsequent requests. If the load balancer is a BIG-IP, it can mark the service as "down" and invoke an active monitor to probe the application status as well as retrying the request to another available instance – insuring end-users do not see an error. Passive (inband) monitors are not binary. That is, they aren't simple "on" or "off" based on HTTP status codes. Such monitors can be configured to track the number of failures and evaluate failure rates against a configurable failure interval. When such thresholds are exceeded, the application can then be marked as "down". Passive monitors aren't restricted to availability status, either. They can also monitor for performance (response time). Failure to meet response time expectations results in a failure, and the application continues to be watched for subsequent failures. Passive monitors are, like most inline/inband technologies, transparent. They quietly monitor traffic and act upon that traffic without adding overhead to the process. Passive monitoring gives operations the visibility necessary to enable predictable performance and to meet or exceed user expectations with respect to uptime, without negatively impacting performance or capacity of the applications it is monitoring.2.8KViews1like2CommentsThree things your proxy can’t do unless it’s a full-proxy
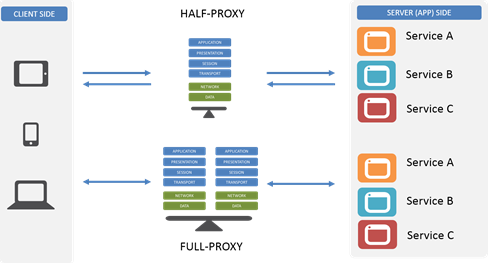
Proxies are one of the more interesting (in my no-doubt biased opinion) “devices” in the network. They’re the basis for caching, load balancing, app security, and even app acceleration services. They’re also a bridge between dev and ops and the network, being commonplace to all three groups and environments in most data center architectures. But not all proxies are built on the same architectural principles, which means not all proxies are created equal. A large number of proxies are half-proxies while others are full-proxies, and the differences between them are what mean the difference between what you can and cannot do with them. In fact, there are three very important things you can do with a full-proxy that you can’t do with a regular old proxy. Before we jump into those three things, let’s review the differences between them, shall we? Half-Proxy Half-proxy is a description of the way in which a proxy, reverse or forward, handles connections. Basically it’s describing the notion that the proxy only mediates connections on the client side. So it only proxies half the communication between the client and the app. The most important thing to recognize about a half-proxy is that it has only one network stack that it shares across both client and server. Full-Proxy By contrast, a full-proxy maintains two distinct network stacks – one on the client side, one of the app side – and fully proxies both sides, hence the name. While a full-proxy can be configured to act like a half-proxy, its value is in its typical configuration, which is to maintain discrete connections to both the client and the server. It is this dual-stack approach that enables a full-proxy to provide capabilities that a half-proxy with its single network stack simply cannot. The Three Things A full-proxy completely understands the protocols for which it proxies and is itself both an endpoint and an originator for those protocols and connections. This also means the full-proxy can have its own TCP connection behavior for each network stack such as buffering, retransmits, and TCP options. With a full-proxy each connection is unique; each can have its own TCP connection behavior. This means that a client connecting to the full-proxy device would likely have different connection behavior than the full-proxy might use for communicating with servers. Full-proxies can look at incoming requests and outbound responses and can manipulate both if the solution allows it. #1 Optimize client side and server side Because it can maintain separate network stacks and characteristics, a full-proxy can optimize each side for its unique needs. The TCP options needed to optimize for performance on the client side’s lower-speed, higher-latency network connection – particularly when mobile devices are being served – are almost certainly very different than those needed to optimize for performance on the server side’s high-speed, low latency data center network connection. A full-proxy can optimize both at the same time and thus provide the best performance possible in all situations. A half-proxy, with its single network stack, is forced to optimize for the average of its connections, which certainly means one side or the other is left with less than optimal performance. #2 Act as a protocol gateway Protocol gateways are an important tool in the architect’s toolbox particularly when transitioning from one version of an application protocol to another, like HTTP/1 to HTTP/2 or SPDY. Because a full proxy maintains those two unique connections, it can accept HTTP/2 on the client side, for example, but speak HTTP/1 to the server (app). That’s because a full-proxy terminates the client connection (the proxy is the server) and initiatives a different connection to the server (the proxy is the client). The protocol used on the client side doesn’t restrict the choice of protocols on the server side. Realistically, any protocol transition that makes sense (and even those that don’t) can be managed with a full-proxy. A programmable full-proxy ensures that even if its an uncommon (and thus not universally supported) that you can code up a gateway yourself without expending effort on reinventing the proxy-wheel. #3 Terminate SSL/TLS Technically this is a specialized case of a protocol gateway but the ascendancy of HTTP/S (and the urgency with which we are encouraged to deploy SSL Everywhere and Encrypt All The Things) makes me treat this as its own case. Basically terminating SSL/TLS is a critical capability in modern and emerging architectures because of the need to inspect and direct HTTP-based traffic (like REST API calls) based on information within the HTTP protocol that would otherwise be invisible thanks to encryption. The ability to terminate SSL/TLS means the proxy becomes the secure endpoint to which clients connect (and ultimately trust). Termination means the proxy is responsible for decrypting requests and encrypting responses and is thus able to “see” into the messages and use the data therein to make routing and load balancing decisions. So the next time you’re looking at a proxy, don’t forget to find out whether it’s a full proxy or not. Because without a full-proxy, you’re limiting your ability to really take advantage of its capabilities and reaping the benefits it can offer modern and emerging application architectures.2.8KViews1like3Comments
iRule Execution Tracing and Performance Profiling, Part 2
In the last article we discussed some intriguing questions around iRules tracing and profiling. There are a lot we can do to facilitate iRules debugging and performance tuning, and we took the first step in BIG-IP v13.1. We are pleased to announce that iRules tracing and profiling feature is added to TMOS tool chain in this release. This feature enables both users and iRules infrastructure development team to broaden iRules functionality and application prospects. In this article we will describe the focal use cases and design principles of the feature; we will use examples to demonstrate how to use the feature. Use case and consideration Following are the major use model we target and the design principles we employ for the feature in this release: This feature is mostly used in debug environment. Execution tracing and performance tuning are part of development process. We envision that the most typical use case is users take to the tracing functionality when scripts are still in development. It is possible that the iRules are running on production systems, yet when users like to inspect performance issues, they take the scripts to lab environment to collect performance data, analyze bottleneck and experiment algorithm tuning. The solution needs to be non-intrusive. Tcl language has tracing constructs in its core infrastructure, for example trace command is a Tcl core command. Historically trace command is not supported by iRules. Although it is a viable option to reuse Tcl's trace command as the basic facility for the tracing feature, we make the choice that the feature does not require users to modify the script; instead, it is a passive observation solution: users configure the conditions and leave the script intact. This provides a smooth debugging experience: users can enable the feature, observe the result and adjust the feature configuration continuously. Graphical interface is not critical in the first release. Ideally the feature is presented in a GUI environment. We believe a command line interaction in the first release properly addresses the most critical use cases. Separate data collecting and data scoping. Tracing comes with high volume data, the deeper and wider the tracing goes, the more data are generated. In this release we focus on picking the right data (the "occurrences" presented in the last article) and delivering the data timely and securely. Providing tool chain to help users to mine the data is a logical next step. The Feature OK, now we are ready to present the feature. The audience of this article are familiar with BIG-IP and iRules, so let's have fun and jump to some examples. Example Here is a simple iRules script: ltm rule dc_1 { when CLIENT_ACCEPTED { if {[IP::remote_addr] eq "10.10.10.2"} { set the_one true } else { set the_one false } } when HTTP_REQUEST { if {$the_one} { HTTP::uri [string map {myPortal UserPortal} [HTTP::uri]] } } } Now issue the following TMSH commands to insert the tracer: tmsh create ltm rule-profiler dc_1_tracer event-filter add { CLIENT_ACCEPTED HTTP_REQUEST } vs-filter add { /Common/vs1 } publisher tracer_pub1 tmsh modify ltm rule-profiler dc_1_tracer occ-mask { cmd cmd-vm event rule rule-vm var-mod } tmsh modify ltm rule-profiler dc_1_tracer state enabled The feature introduces a new TMSH configuration object, rule-profiler. There can be multiple rule-profiler objects, this facilitates difference tracing scenarios. Following attributes of rule-profiler are configured in the above TMSH commands: event-filter, the iRule events to trace; if not defined, all events are traced. vs-filter, the virtual servers to trace; if not defined, all virtual servers are traced. occ-mask, the occurrences to trace. The viable values are as explained in the last article. publisher, the syslog publisher to receive the tracing log. The user needs to enable the rule-profiler object after the configuration. Now the tracing facility is ready. We start the tracing on a running traffic by the following command: tmsh start ltm rule-profiler dc_1_tracer The lab setup for this example has publisher point to the local syslog and here is a partial capture of the output in /var/log/ltm (the color coding is for this article to describe the data): 1511494952932589,RP_EVENT_ENTRY,/Common/vs1,CLIENT_ACCEPTED,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80, 01511494952932622,RP_RULE_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 1511494952932625,RP_RULE_VM_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 1511494952932628,RP_CMD_VM_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 1511494952932630,RP_CMD_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 1511494952932633,RP_CMD_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80,0 1511494952932636,RP_CMD_VM_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80, 01511494952932638,RP_VAR_MOD,/Common/vs1,the_one=true,18291,0x94558076344064,10.10.10.2,46052,0,10.10.10.160,80 Now let us take a close look at the logs. Occurrence fields Each tracing occurrence, as defined by "occ-mask" attribute, dumps one line to the log file; there are 7 fields within each line: Timestamp - This is the TMM time stamp at the occurrence. The unit is micro second. Occurrence type - This is the type of the occurrence. It is corresponding to "occ-mask" attribute definition. The meaning of each occurrence is defined in the last article. "RP" stands for "Rule Profiler". Virtual server - This is the name of the virtual server on which the iRules are running. Occurrence value - This is the value of the corresponding occurrence. For example, the first log in the above snippet is at the entry occurrence of iRule event CLIENT_ACCEPTED. Process ID - This is the TMM process ID. Flow ID - This is the flow ID. Remote tuple - There are 3 fields, IP address, port and routing domain. Local tuple - There are 3 fields, IP address, port and routing domain. Stop Tracing User can stop the tracing by issuing this TMSH command: tmsh stop ltm rule-profiler <rule-profiler name> Tracer has a built-in timer, it stops tracing after 10 milliseconds. User can adjust it through the following command: tmsh modify ltm rule-profiler dc_1_tracer period <new value in ms> Bytecode As mentioned in the first article, the tracing feature supports bytecode tracing. Using the example above, add "bytecode" to "occ-mask": tmsh modify ltm rule-profiler dc_1_tracer occ-mask { bytecode cmd cmd-vm event rule rule-vm var-mod } With this addition, you will see the bytecode execution. But keep one thing in mind, you will see a lot more logging. 1511673715911247,RP_EVENT_ENTRY,/Common/vs1,CLIENT_ACCEPTED,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0, 1511673715911273,RP_RULE_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911277,RP_RULE_VM_ENTRY,/Common/vs1,/Common/dc_1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911280,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911282,RP_CMD_BYTECODE,/Common/vs1,invokeStk1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911284,RP_CMD_VM_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911286,RP_CMD_ENTRY,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911288,RP_CMD_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,0 1511673715911291,RP_CMD_VM_EXIT,/Common/vs1,IP::remote_addr,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,0 1511673715911293,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911295,RP_CMD_BYTECODE,/Common/vs1,streq,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911296,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911298,RP_CMD_BYTECODE,/Common/vs1,push1,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911300,RP_CMD_BYTECODE,/Common/vs1,storeScalarStk,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0,2 1511673715911302,RP_VAR_MOD,/Common/vs1,the_one=true,18291,0x94558076344064,10.10.10.2,41772,0,10.10.10.160,80,0 What's to come This article describes the TMSH commands to configure rule-profiler and how to interpret the tracing logs. Next article will talk about tips and tricks of using the tracing feature. Authors:Jibin Han, Bonny Rais1.1KViews1like1CommentF5 Intelligent DNS – Optimizing the Mobile Core
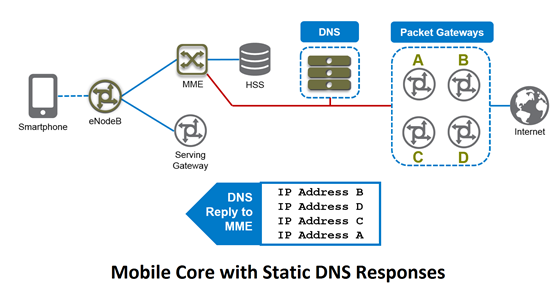
Martin J Brewer, Manager, DNS Product Management F5 has been very active in the service provider footprint for DNS, especially for high performance authoritative or caching resolver functions. In addition to those use cases, now F5 is able to augment them with what we call Intelligent DNS. In essence we’re taking our ability to use our monitoring functions (which are part of F5 BIG-IP GTM) and apply them so that DNS responses for DNS queries for the Mobile Core reflect the availability and health of the services which sit behind those DNS query names. Demo - Intelligent DNS for the Evolved Packet Core So what does this mean in real terms? With these optimizations, subscribers will benefit through increased service reliability and higher performance while Service Providers receive higher customer satisfaction. If subscribers are happy, you get loyalty and you see repeat users by making sure the service works optimally, every time. Perhaps first we need to talk about how a regular Mobile Core operates during connection setup for a core which uses static DNS. As you can see from the diagram, we have a simplified view of the core which is present in 3G and 4G network designs. On the left you’ll see the mobile device, or smartphone, and on the right you’ll see the Packet Gateways (PGWs) or Gateway GPRS Support Nodes (GGSNs). These are the gateways between the Service Provider core network and the internet and other IP services. Now for a device to get connectivity to the internet, it needs to initiate a connection. In 4G/LTE for example, this is performed through the Management Mobility Entity (MME). Now, you’ve probably seen in the Settings area on your smartphone that there’s a reference to an “APN” or Access Point Name. What that APN does is tell the network which service your device needs to establish a data connection. And that APN name is specified as a DNS name. So how does it work? That query ends up turning into a DNS request which is emitted by the MME so it can set up the connection. So it might look something like “apn.carrier.com” and once resolved by the DNS service inside the Mobile Core, it will resolve to an IP address, like 192.168.1.1. Now, the DNS service itself will pass not just one, but a complete list of all of the possible gateway addresses. Some DNS services might also randomize the order of the list so that the MME might spread the load on the PGWs. Sounds reasonable doesn’t it? Well, there are a few problems with that approach: What if the PGW unexpectedly went down? The DNS system has now directed the MME to an unreachable resource. Now it isn’t the end of the world, but it results in a delay in the connection setup and the MME times-out on the PGW that’s no longer in service. This impacts the customer experience and by extension, customer satisfaction. And remember, that until that PGW is removed from the DNS records, it will continue to serve bad DNS answers. To solve this, manual intervention is required, and that increases OpEx for the carrier. And the of course there’s the loading of those PGWs. Let’s take a look…. Just because the DNS service might have randomized the reply order to set some form of load distribution, this doesn’t equate to an even distribution in reality. Data sessions from mobile devices last anywhere from a few seconds to tens of hours, and the loading they place on the PGW is totally determined by how much data the client sends or receives. Placing additional capacity onto an already maxed PGW simply decreased connection speed for the mobile device and again, that leads to poor customer satisfaction. So isn’t there a better way? Using BIG-IP GTM with Intelligent DNS, the DNS service is made into a dynamic directory with intelligent answers based on service availability and loading. The big improvement is that BIG-IP is able to monitor services through a variety of real-time health checks. The system is highly customizable and allows a Mobile Core administrator the ability to use GTP Echo monitors (these are built right in to the BIG-IP GSLB engine) which check for active availability of the protocol that carries the data. They can also use External monitors which can factor in other parameters such as live loading information or consider environmental information, such as device temperature and equipment status. Using these optimizations, the DNS engine considers each IP address it monitors and assigns scores to each so that it may give an optimal reply for any given DNS query. Using this scoring mechanism, BIG-IP GTM can intelligently provide a single IP address as a reply to any given query based on its real-time feed of PGW availability and health. So what are the benefits? If a PGW fails unexpectedly, the BIG-IP Intelligent DNS service identifies the unavailability and stops providing DNS responses which contain that PGW’s IP address. Through loading data, the Intelligent DNS service provides answers for the most appropriate PGW in real-time. No longer will a subscriber be placed onto an overloaded PGW. All of this means there’s reduced OpEx through the automation of DNS records to service availability, together with an optimal user experience. Stop by the F5 Booth at Mobile World Congress in Barcelona from February 24 th through 27 th for a demonstration of F5 Intelligent DNS in action. We’re at hall 5 in booth 5G11.406Views1like0Comments