Controlling a Pool Members Ratio and Priority Group with iControl
A Little Background A question came in through the iControl forums about controlling a pool members ratio and priority programmatically. The issue really involves how the API’s use multi-dimensional arrays but I thought it would be a good opportunity to talk about ratio and priority groups for those that don’t understand how they work. In the first part of this article, I’ll talk a little about what pool members are and how their ratio and priorities apply to how traffic is assigned to them in a load balancing setup. The details in this article were based on BIG-IP version 11.1, but the concepts can apply to other previous versions as well. Load Balancing In it’s very basic form, a load balancing setup involves a virtual ip address (referred to as a VIP) that virtualized a set of backend servers. The idea is that if your application gets very popular, you don’t want to have to rely on a single server to handle the traffic. A VIP contains an object called a “pool” which is essentially a collection of servers that it can distribute traffic to. The method of distributing traffic is referred to as a “Load Balancing Method”. You may have heard the term “Round Robin” before. In this method, connections are passed one at a time from server to server. In most cases though, this is not the best method due to characteristics of the application you are serving. Here are a list of the available load balancing methods in BIG-IP version 11.1. Load Balancing Methods in BIG-IP version 11.1 Round Robin: Specifies that the system passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. This method works well in most configurations, especially if the equipment that you are load balancing is roughly equal in processing speed and memory. Ratio (member): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine within the pool. Least Connections (member): Specifies that the system passes a new connection to the node that has the least number of current connections in the pool. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. Observed (member): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (member), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (member): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Ratio (node): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine across all pools of which the server is a member. Least Connections (node): Specifies that the system passes a new connection to the node that has the least number of current connections out of all pools of which a node is a member. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node, or the fastest node response time. Fastest (node): Specifies that the system passes a new connection based on the fastest response of all pools of which a server is a member. This method might be particularly useful in environments where nodes are distributed across different logical networks. Observed (node): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (node), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (node): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Dynamic Ratio (node) : This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. Fastest (application): Passes a new connection based on the fastest response of all currently active nodes in a pool. This method might be particularly useful in environments where nodes are distributed across different logical networks. Least Sessions: Specifies that the system passes a new connection to the node that has the least number of current sessions. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current sessions. Dynamic Ratio (member): This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. L3 Address: This method functions in the same way as the Least Connections methods. We are deprecating it, so you should not use it. Weighted Least Connections (member): Specifies that the system uses the value you specify in Connection Limit to establish a proportional algorithm for each pool member. The system bases the load balancing decision on that proportion and the number of current connections to that pool member. For example,member_a has 20 connections and its connection limit is 100, so it is at 20% of capacity. Similarly, member_b has 20 connections and its connection limit is 200, so it is at 10% of capacity. In this case, the system select selects member_b. This algorithm requires all pool members to have a non-zero connection limit specified. Weighted Least Connections (node): Specifies that the system uses the value you specify in the node's Connection Limitand the number of current connections to a node to establish a proportional algorithm. This algorithm requires all nodes used by pool members to have a non-zero connection limit specified. Ratios The ratio is used by the ratio-related load balancing methods to load balance connections. The ratio specifies the ratio weight to assign to the pool member. Valid values range from 1 through 100. The default is 1, which means that each pool member has an equal ratio proportion. So, if you have server1 a with a ratio value of “10” and server2 with a ratio value of “1”, server1 will get served 10 connections for every one that server2 receives. This can be useful when you have different classes of servers with different performance capabilities. Priority Group The priority group is a number that groups pool members together. The default is 0, meaning that the member has no priority. To specify a priority, you must activate priority group usage when you create a new pool or when adding or removing pool members. When activated, the system load balances traffic according to the priority group number assigned to the pool member. The higher the number, the higher the priority, so a member with a priority of 3 has higher priority than a member with a priority of 1. The easiest way to think of priority groups is as if you are creating mini-pools of servers within a single pool. You put members A, B, and C in to priority group 5 and members D, E, and F in priority group 1. Members A, B, and C will be served traffic according to their ratios (assuming you have ratio loadbalancing configured). If all those servers have reached their thresholds, then traffic will be distributed to servers D, E, and F in priority group 1. he default setting for priority group activation is Disabled. Once you enable this setting, you can specify pool member priority when you create a new pool or on a pool member's properties screen. The system treats same-priority pool members as a group. To enable priority group activation in the admin GUI, select Less than from the list, and in the Available Member(s) box, type a number from 0 to 65535 that represents the minimum number of members that must be available in one priority group before the system directs traffic to members in a lower priority group. When a sufficient number of members become available in the higher priority group, the system again directs traffic to the higher priority group. Implementing in Code The two methods to retrieve the priority and ratio values are very similar. They both take two parameters: a list of pools to query, and a 2-D array of members (a list for each pool member passed in). long [] [] get_member_priority( in String [] pool_names, in Common__AddressPort [] [] members ); long [] [] get_member_ratio( in String [] pool_names, in Common__AddressPort [] [] members ); The following PowerShell function (utilizing the iControl PowerShell Library), takes as input a pool and a single member. It then make a call to query the ratio and priority for the specific member and writes it to the console. function Get-PoolMemberDetails() { param( $Pool = $null, $Member = $null ); $AddrPort = Parse-AddressPort $Member; $RatioAofA = (Get-F5.iControl).LocalLBPool.get_member_ratio( @($Pool), @( @($AddrPort) ) ); $PriorityAofA = (Get-F5.iControl).LocalLBPool.get_member_priority( @($Pool), @( @($AddrPort) ) ); $ratio = $RatioAofA[0][0]; $priority = $PriorityAofA[0][0]; "Pool '$Pool' member '$Member' ratio '$ratio' priority '$priority'"; } Setting the values with the set_member_priority and set_member_ratio methods take the same first two parameters as their associated get_* methods, but add a third parameter for the priorities and ratios for the pool members. set_member_priority( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] priorities ); set_member_ratio( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] ratios ); The following Powershell function takes as input the Pool and Member with optional values for the Ratio and Priority. If either of those are set, the function will call the appropriate iControl methods to set their values. function Set-PoolMemberDetails() { param( $Pool = $null, $Member = $null, $Ratio = $null, $Priority = $null ); $AddrPort = Parse-AddressPort $Member; if ( $null -ne $Ratio ) { (Get-F5.iControl).LocalLBPool.set_member_ratio( @($Pool), @( @($AddrPort) ), @($Ratio) ); } if ( $null -ne $Priority ) { (Get-F5.iControl).LocalLBPool.set_member_priority( @($Pool), @( @($AddrPort) ), @($Priority) ); } } In case you were wondering how to create the Common::AddressPort structure for the $AddrPort variables in the above examples, here’s a helper function I wrote to allocate the object and fill in it’s properties. function Parse-AddressPort() { param($Value); $tokens = $Value.Split(":"); $r = New-Object iControl.CommonAddressPort; $r.address = $tokens[0]; $r.port = $tokens[1]; $r; } Download The Source The full source for this example can be found in the iControl CodeShare under PowerShell PoolMember Ratio and Priority.27KViews0likes3Comments
A Brief Introduction To External Application Verification Monitors
Background EAVs (External Application Verification) monitors are one of most useful and extensible features of the BIG-IP product line. They give the end user the ability to utilize the underlying Linux operating system to perform complex and thorough service checks. Given a service that does not have a monitor provided, a lot of users will assign the closest related monitor and consider the solution complete. There are more than a few cases where a TCP or UDP monitor will mark a service “up” even while the service is unresponsive. EAVs give us the ability to dive much deeper than merely performing a 3-way handshake and neglecting the other layers of the application or service. How EAVs Work An EAV monitor is an executable script located on the BIG-IP’s file system (usually under /usr/bin/monitors) that is executed at regular intervals by the bigd daemon and reports its status. One of the most common misconceptions (especially amongst those with *nix backgrounds) is that the exit status of the script dictates the fate of the pool member. The exit status has nothing to do with how bigd interprets the pool member’s health. Any output to stdout (standard output) from the script will mark the pool member “up”. This is a nuance that should receive special attention when architecting your next EAV. Analyze each line of your script and make sure nothing will inadvertently get directed to stdout during monitor execution. The most common example is when someone writes a script that echoes “up” when the checks execute correctly and “down” when they fail. The pool member will be enabled by the BIG-IP under both circumstances rendering a useless monitor. Bigd automatically provides two arguments to the EAV’s script upon execution: node IP address and node port number. The node IP address is provided with an IPv6 prefix that may need to be removed in order for the script to function correctly. You’ll notice we remove the “::ffff://” prefix with a sed substitution in the example below. Other arguments can be provided to the script when configured in the UI (or command line). The user-provided arguments will have offsets of $3, $4, etc. Without further ado, let’s take a look at a service-specific monitor that gives us a more complete view of the application’s health. An Example I have seen on more than one occasion where a DNS pool member has successfully passed the TCP monitor, but the DNS service was unresponsive. As a result, a more invasive inspection is required to make sure that the DNS service is in fact serving valid responses. Let’s take a look at an example: #!/bin/bash # $1 = node IP # $2 = node port # $3 = hostname to resolve [[ $# != 3 ]] && logger -p local0.error -t ${0##*/} -- "usage: ${0##*/} <node IP> <node port> <hostname to resolve>" && exit 1 node_ip=$(echo $1 | sed 's/::ffff://') dig +short @$node_ip $3 IN A &> /dev/null [[ $? == 0 ]] && echo “UP” We are using the dig (Domain Information Groper) command to query our DNS server for an A record. We use the exit status from dig to determine if the monitor will pass. Notice how the script will never output anything to stdout other than “UP” in the case of success. If there aren’t enough arguments for the script to proceed, we output the usage to /var/log/ltm and exit. This is a very simple 13 line script, but effective example. The Takeaways The command should be as lightweight and efficient as possible If the same result can be accomplished with a built-in monitor, use it EAV monitors don’t rely on the command’s exit status, only standard output Send all error and informational messages to logger instead of stdout or stderr (standard error) “UP” has no significance, it is just a series of character sent to stdout, the monitor would still pass if the script echoed “DOWN” Conclusion When I first discovered EAV monitors, it opened up a whole realm of possibilities that I could not accomplish with built in monitors. It gives you the ability to do more thorough checking as well as place logic in your monitors. While my example was a simple bash script, BIG-IP also ships with Perl and Python along with their standard libraries, which offer endless possibilities. In addition to using the built-in commands and libraries, it would be just as easy to write a monitor in a compiled language (C, C++, or whatever your flavor may be) and statically compile it before uploading it to the BIG-IP. If you are new to EAVs, I hope this gives you the tools to make your environments more robust and resilient. If you’re more of a seasoned veteran, we’ll have more fun examples in the near future.2KViews0likes7CommentsInvestigating the LTM TCP Profile: The Finish Line
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to the server-side connection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Deferred Accept Disabled by default, this option defers the allocation of resources to the connection until payload is received from the client. It is useful in dealing with three-way handshake DoS attacks, and delays the allocation of server-side resources until necessary, but delaying the accept could impact the latency of the server responses, especially if OneConnect is disabled. Bandwidth Delay This setting, enabled by default, specifies that the tcp stack tries to calculate the optimal bandwidth based on round-trip time and historical throughput. This product would then help determine the optimal congestion window without first exceeding the available bandwidth. Proxy MSS & Options These settings signal the LTM to only use the MSS and options negotiated with the client on the server-side of the connection. Disabled by default, enabling them doesn't allow the LTM to properly isolate poor TCP performance on one side of the connection nor does it enable the LTM to offload the client or server. The scenarios for these options are rare and should be utilized sparingly. Examples:troubleshooting performance problems isolated to the server, or if there is a special case for negotiating TCP options end to end. Appropriate Byte Counting Defined in RFC 3465, this option calculates the increase ot the congestion window on the number of previously unacknowledged bytes that each ACK covers. This option is enabled by default, and it is recommended for it to remain enabled. Advantages: more appropriately increases the congestion window, mitigates the impact of delayed and lost acknowledgements, and prevents attacks from misbehaving receivers. Disadvantages include an increase in burstiness and a small increase in the overall loss rate (directly related to the increased aggressiveness) Congestion Metrics Cache This option is enabled by default and signals the LTM to use route metrics to the peer for initializing the congestion window. This improves the initial slow-start ramp for previously encountered peers as the congestion information is already known and cached. If the majority of the client base is sourced from rapidly changing and unstable routing infrastructures, disabling this option ensures that the LTM will not use bad information leading to wrong behavior upon the initial connection. Conclusion This concludes our trip through the TCP profile, I hope you've enjoyed the ride. I'd like to thank the developers, UnRuleY in particular, for their help along the way. Update: This series is a decade+ old. Still relevant, but Martin Duke wrote a series of articles on the TCP profile as well with updates and considerations you should read up on as well.407Views0likes2CommentsInvestigating the LTM TCP Profile: ECN & LTR
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Extended Congestion Notification The extended congestion notification option available in the TCP profile by default is disabled. ECN is another option in TCP that must be negotiated at start time between peers. Support is not widely adopted yet and the effective use of this feature relies heavily on the underlying infrastructures handling of the ECN bits as routers must participate in the process. If you recall from the QoS tech tip, the IP TOS field has 8 bits, the first six for DSCP, and the final two for ECN. DSCP ECN Codepoints DSCP ECN Comments X X X X X X 0 0 Not-ECT X X X X X X 0 1 ECT(1) ECN-capable X X X X X X 1 0 ECT(0) ECN-capable X X X X X X 1 1 CE Congestion Experienced Routers implementing ECN RED (random early detection) will mark ECN-capable packets and drop Not-ECT packets (only under congestion and only by the policies configured on the router). If ECN is enabled, the presence of the ECE (ECN-Echo) bit will trigger the TCP stack to halve its congestion window and reduce the slow start threshold (cwnd and ssthresh, respectively...remember these?) just as if the packet had been dropped. The benefits of enabling ECN are reducing/avoiding drops where they normally would occur and reducing packet delay due to shorter queues. Another benefit is that the TCP peers can distinguish between transmission loss and congestion signals. However, due to the nature of this tightly integrated relationship between routers and tcp peers, unless you control the infrastructure or have agreements in place to its expected behavior, I wouldn't recommend enabling this feature as there are several ways to subvert ECN (you can read up on it in RFC 3168). Limited Transmit Recovery Defined in RFC 3042, Limited Transmit Recovery allows the sender to transmit new data after the receipt of the second duplicate acknowledge ifthe peer's receive windowallows for it and outstandingdata is less than the congestion window plus two segments. Remember that with fast retransmit,a retransmit occurs after the third duplicate acknolwedgement or after a timeout. The congestion window is not updated when LTR triggers a retransmission. Note also that if utilized with selective acknowledgements, LTR must not transmit unless the ack contains new SACK information. In the event of acongestion windowof three segments and one is lost, fast retransmit would never trigger since three duplicate acks couldn't be received. This would result in a timeout, which could be a penalty ofat least one second. Utilizing LTR can significantly reduce the number oftimeout basedretransmissions. This option is enabled by default in the profile.494Views0likes0CommentsInvestigating the LTM TCP Profile: Acknowledgements
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Delayed Acknowledgements The delayed acknowledgement was briefly mentioned back in the first tip in this series when we were discussing Nagle's algorithm (link above). Delayed acknowledgements are (most implementations, including the LTM) sent every other segment (note that this is not required. It can be stretched in some implementations) typically no longer than 100ms and never longer than 500ms. Disabling the delayed acknowledgement sends more packets on the wire as the ack is sent immediately upon receipt of a segment instead of beingtemporarily queuedto piggyback on a data segment. This drives up bandwidth utilization (even if the increase per session is marginal, consider the number of connections the LTM is handling) and requires additional processing resources to handle the additional packet transfers. F5 does not recommend disabling this option. Selective Acknowledgements Traditional TCP receivers acknowledge data cumulatively. In loss conditions, the TCP sender can only learn about a lost segment each round trip time, and retransmits of successfully received segments cuts throughput significantly. With Selective Acknowlegments (SACK, defined in RFC 2018) enabled, the receiver can send an acknowledgement informing the sender of the segments it has received. This enables the sender to retransmit only the missing segments. There are two TCP options for selective acknowledgements. Because SACK is not required, it must be negotiated at session startup between peers. First is the SACK-Permitted option, which has a two byte length and is negotiated in the establishment phase of the connection. It should not be set in a non-SYN segment. Second is the TCP SACK option, which has a variable length, but cannot exceed the 40 bytes available to TCP options, so the maximum blocks of data that can be selectively acknowledged at a time is four. Note that if your profile has theRFC 1323 High Performance extensions enabled (it is by default) the maximum blocks is limited to three. A block represents received bytes of data that are contiguous and isolated (data immediately prior and immediately after is missing). Each block is defined by two 32-bit unsigned integers in network byte order: the first integer stores the left edge (first sequence number) of the block and the second integer stores the right edge (sequence number immediately following the last sequence number of the block). This option is enabled in the default profile and F5 does not recommend disabling it. For a nice visual walkthrough on selective acknowledgements, check out this article at Novell. D-SACK The D-SACK option (RFC 2883) enables SACK on duplicate acknowledgements. Remember that a duplicate acknowledgement is sent when a receiver receives a segment out of order. This option, first available in LTM version 9.4, is disabled by default and is not recommended unless the remote peers are known to also support D-SACK. ACK on Push This optionsignals the LTM to immediately acknowledge a segment received with the TCP PUSH flag set, which will override the delayed acknowledgement mechanism, which acts like only having delayed ACKs during bulk transfers. The result is equivalent bulk transfer efficiency as if delayed acknowledgements were on but the same transaction rates as if delayed acknowledgements were off. This option is disabled in the default profile, but is enabled in the pre-configured tcp-lan-optimized profile.1KViews0likes0CommentsInvestigating the LTM TCP Profile: Slow Start
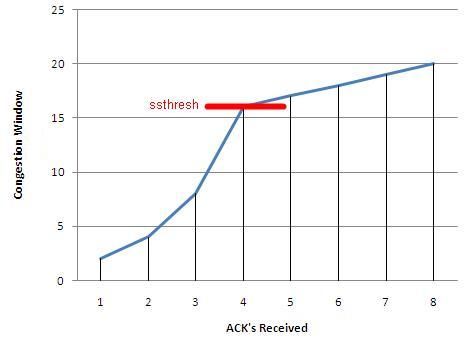
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. TCP Slow Start Refinedin RFC 3390, slow start is an optional setting that allows for the initial congestion window (cwnd) to be increased from one or two segments to between two and four segments. This refinement results in a larger upper bound for the initial window: If (MSS <= 1095 bytes) then win <= 4 * MSS; If (1095 bytes < MSS < 2190 bytes) then win <= 4380; If (2190 bytes <= MSS) then win <= 2 * MSS; The congestion window (cwnd) grows exponentially under slow start.After the handshake is completed and the connection has been established, the congestion windowis doubled after each ACK received.Once the congestion window surpasses the slow start threshold (ssthresh, set by the LTM and dependent onfactorslike the selected congestion algorithm), the tcp connection is converted to congestion avoidance mode and the congestion window grows linearly.Thisrelationship isrepresented in the following graph. Slow Start istriggered at the beginning of a connection (initial window), after an idle period in the connection (restart window), or after a retransmit timeout (loss window). Note that this setting in the profile only applies to the initial window. Some advantages of increasing the initial congestion window are eliminating the wait on timeout (up to 200ms) for receivers utilizing delayed acknowledgements and eliminating application turns for very short lived connections (such as short email messages, small web requests, etc). There are a few disadvantages as well, including higher retransmit rates in lossy networks. We'll dig a little deeper into slow startwhen we cover the congestion control algorithms. An excellent look at slow start in action can be found here.973Views0likes1CommentInvestigating the LTM TCP Profile: Quality of Service
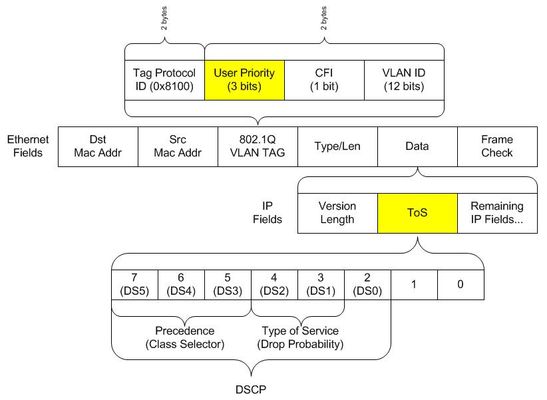
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Why QoS? First,let'sdefine QoS as it is implemented in the profile—the capability to apply an identifier to a specific type of traffic so the network infrastructure can treat it uniquely from other types.So now that we know what it is, why is it necessary?There are numerous reasons, but let’s again consider the remote desktop protocol.Remote users expect immediate response to their mouse and keyboard movements.If a large print job is released and sent down the wire and the packets hit the campus egress point towards the remote branch prior to the terminal server responses, the standard queue in a router will process the packets first in, first out, resulting in the user session getting delayed to the point human perception is impacted.Implementing a queuing strategy at the egress (at least) will ensure the higher priority traffic gets attention before the print job. QOS Options The LTM supports setting priority at layer 2 with Link QoS and at layer 3 with IP ToS.This can be configured on a pool, a virtual server’s TCP/UDP profile, and in an iRule.The Link QoS field is actually three bits within the vlan tag of an Ethernet frame, and the values as such should be between zero and seven.The IP ToS field in the IP packet header is eight bits long but the six most significant bits represent DSCP.This is depicted in the following diagram: The precedence level at both layers is low to high in terms of criticality: zero is the standard “no precedence” setting and seven is the highest priority.Things like print jobs and stateless web traffic can be assigned lower in the priority scheme, whereas interactive media or voice should be higher.RFC 4594 is a guideline for establishing DSCP classifications.DSCP, or Differentiated Services Code Point, is defined in RFC 2474.DSCP provides not only a method to prioritize traffic into classes, but also to assign a drop probability to those classes.The drop probability is high to low, in that a higher value means it will be more likely the traffic will be dropped.In the table below, the precedence and the drop probabilities are shown, along with their corresponding DSCP value (in decimal) and the class name.These are the values you’ll want to use for the IP ToS setting on the LTM, whether it is in a profile, a pool, or an iRule. You'll note, however, that the decimal used for IP::tos is a multiple of 4 of the actual DSCP value. The careful observer of the above diagram will notice that the DSCP bits are bit-shifted twice in the tos field, so make sure you use the multiple instead of the actual DSCP value. DSCP Mappings for IP::tos Command Precedence Type of Service DSCP Class DSCP Value IP::tos Value 0 0 none 0 0 1 0 cs1 8 32 1 1 af11 10 40 1 10 af12 12 48 1 11 af13 14 56 10 0 cs2 16 64 10 1 af21 18 72 10 10 af22 20 80 10 11 af23 22 88 11 0 cs3 24 96 11 1 af31 26 104 11 10 af32 28 112 11 11 af33 30 120 100 0 cs4 32 128 100 1 af41 34 136 100 10 af42 36 144 100 11 af43 38 152 101 0 cs5 40 160 101 11 ef 46 184 110 0 cs6 48 192 111 0 cs7 56 224 The cs classes are the original IP precedence (pre-dating DSCP) values.The assured forwarding (af) classes are defined in RFC 2597, and the expedited forwarding (ef) class is defined in RFC 2598.So for example, traffic in af33 will have higher priority over traffic in af21, but will experience greater drops than traffic in af31. Application As indicated above, the Link QoS and IP ToS settings can be applied globally to all traffic hitting a pool, or all traffic hitting a virtual to which the profile is applied, but they can also be applied specifically by using iRules, or just as cool, they can be retrieved to make a forwarding decision. In this example, if requests arrive marked as AF21 (decimal 18), forward the request to the platinum server pool, AF11 to the gold pool, and all others to the standard pool. when CLIENT_ACCEPTED { if { [IP::tos] == 72 } { pool platinum } elseif { [IP::tos] == 40 } { pool gold } else { pool standard } } In this example, set the Ethernet priority on traffic to the server to three if the request came from IP 10.10.10.10: when CLIENT_ACCEPTED { if { [IP::addr [IP::client_addr]/24 equals "10.10.10.0"] } LINK::qos serverside 3 } } Final Thoughts Note that by setting the Link QoS and/or IP ToS values you have not in any way guaranteed Quality of Service.The QoS architecture needs to be implemented in the network before these markings will be addressed.The LTM can play a role in the QoS strategy in that the marking can be so much more accurate and so much less costly than it will be on the router or switch to which it is connected.Knowing your network, or communicating with the teams that do, will go a long way to gaining usefulness out of these features.1.2KViews0likes6CommentsInvestigating the LTM TCP Profile: Timers
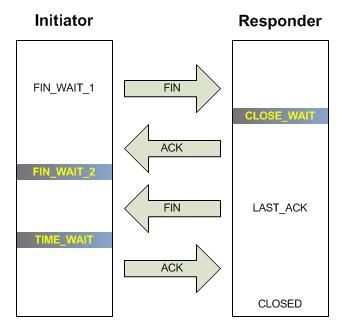
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. TCP Timers TCP sets several timers (not all documented here) for each connection, and decrements them either by the fast timer function every 200ms or by the slow timer function every 500ms. Several of the timers are dynamically calculated, but a few are static as well. We’ve already discussed the idle timeout setting, so today we’ll tackle the FIN_WAIT, CLOSE_WAIT, & TIME_WAIT settings. Reference these diagrams as you read through the timer settings below. The diagram on the left represents a standard tcp close, and the the one on the right represents a simultaneous close. FIN_WAIT There are actually two FIN_WAIT states, FIN_WAIT_1 and FIN_WAIT_2. In a standard close, the FIN_WAIT_1 state occurs when the initiator sends the initial FIN packet requesting to close the connection. The FIN_WAIT_2 state occurs when the initiator receives the acknowledgement to its FIN and prior to receiving the FIN from the responder. In a simultaneous close, both sides are initiators and send the FIN, creating the FIN_WAIT_1 state on both ends. Upon receiving a FIN before receiving the ACK from its FIN, it immediately transitions to the closing state. In the LTM TCP profile, the FIN_WAIT setting (in seconds) applies to both the FIN_WAIT and the CLOSING states, and if exceeded will enter the closed state. The default setting is five seconds. CLOSE_WAIT Whereas the FIN_WAIT states belong to the end of the connection initiating a close (called an active close), the CLOSE_WAIT state belongs to the end responding to a close request (called a passive close). The CLOSE_WAIT state occurs after a responder receives the initial FIN and returns an acknowledgement. If the responder does not receive an acknowledge from its FIN to the initiator before the timer is exceeded, the connection with enter the closed state. Like the FIN_WAIT state, the default setting is five seconds. TIME_WAIT The TIME_WAIT state occurs as part of the active close on the initiator side of the connection when the final FIN is received and acknowledged, or in the case of a simultaneous close, when the acknowledgment to its initial FIN is received. The default setting is 2000 milliseconds, so connections entering the TIME_WAIT state will enter the closed state after 2 seconds. TIME_WAIT Recycle This settingwhen enabled willsignal the LTM to reuse the connection when a SYN packet is received in the TIME_WAIT state. If disabled, a new connection will be established.1.3KViews0likes0CommentsInvestigating the LTM TCP Profile: Windows & Buffers
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to theserver-sideconnection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. TCP Windows The window field is a flow control mechanism built into TCP that limits the amount of unacknowledged data on the wire. Without the concept of a window, every packet sent would have to be acknowledged before sending another one, so the max transmission speed would be MaxSegmentSize / RoundTripTime. For example, my max MSS is 1490 (1472+28 for the ping overhead), and the RTT to ping google is 37ms. You can see below when setting the don't fragment flag the segment size where the data can no longer be passed. C:\Documents and Settings\rahm>ping -f www.google.com -l 1472 -n 2 Pinging www.l.google.com [74.125.95.104] with 1472 bytes of data: Reply from 74.125.95.104: bytes=56 (sent 1472) time=38ms TTL=241 Reply from 74.125.95.104: bytes=56 (sent 1472) time=36ms TTL=241 Ping statistics for 74.125.95.104: Packets: Sent = 2, Received = 2, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 36ms, Maximum = 38ms, Average = 37ms C:\Documents and Settings\rahm>ping -f www.google.com -l 1473 -n 2 Pinging www.l.google.com [74.125.95.104] with 1473 bytes of data: Packet needs to be fragmented but DF set. Packet needs to be fragmented but DF set. So the max transmission speed without windows would be 40.27 KB/sec. Not a terribly efficient use of my cable internet pipe. The window is a 16-bit field (offset 14 in the TCP header), so the max window is 64k (2^16=65536). RFC 1323 introduced a window scaling option that extends window sizes from a max of 64k to a max of 1G. This extension is enabled by default with the Extensions for High Performance (RFC 1323) checkbox in the profile. If we stay in the original window sizes, you can see that as latency increases, the max transmission speeds decrease significantly(numbers in Mb/s): TCP Max Throughput - Fast Ethernet Latency (RTT in ms) 0.1 1 10 100 Window Size 4k 73.605 24.359 3.167 0.327 8k 82.918 38.770 6.130 0.651 16k 88.518 55.055 11.517 1.293 32k 91.611 69.692 20.542 2.551 64k 93.240 80.376 33.775 4.968 Larger window sizes are possible, but remember the LTM is a proxy for the client and server, and must sustain connections for both sidesfor each connection the LTM is services.Increasing the max window size is a potential increase in the memory utilization per connection. The send buffer setting is the maximum amount of data the LTM will send before receiving an acknowledgement, and the receive window setting is the maximum size window the LTM will advertise. This is true for each side of the proxy. The connection speed can be quite different betweenthe client and the server, and this is where the proxy buffer comes in. Proxy Buffers For equally fast clients and servers, there is no need to buffer content between them. However, if the client or server falls behind in acknowledging data, or there are lossy conditions, the proxy will begin buffering data. The proxy buffer high setting is the threshold at which the LTM stops advancing the receive window. The proxy buffer low setting is a falling trigger (from the proxy high setting) that will re-open the receive window once passed. Like the window, increasing the proxy buffer high setting will increase the potential for additional memory utilization per connection. Typically the clientside of a connection is slower than the serverside, and without buffering the data the client forces the server to slow down the delivery. Buffering the data on the LTM allows the server to deliver its data so it can move on to service other connections while the LTM feeds the data to the client as quickly as possible. This is also true the other way in a fast client/slow server scenario. Optimized profiles for the LAN & WAN environments With version 9.3, the LTMbegan shippingwith pre-configured optimized tcp profiles for the WAN & LAN environments. The send buffer and the receive window maximums are both set to the max non-scaled window size at 64k (65535), and the proxy buffer high is set at 131072. For the tcp-lan-optimized profile, the proxy buffer low is set at 98304 and for the tcp-wan-optimized, the proxy buffer low is set the same as the high at 131072. So for the LAN optimized profile, the receive window for the server is not opened until there is less than 98304 bytes to send to the client, whereas in the WAN optimized profile, the server receive window is opened as soon as any data is sent to the client. Again, this is good for WAN environments where the clients are typically slower. Conclusion Hopefully this has given some insight into the inner workings of the tcp window and the proxy buffers. If you want to do some additional research, I highly recommend the TCP/IP Illustrated volumes by W. Richard Stephens, and a very useful TCP tutorial at http://www.tcpipguide.com/.1.8KViews0likes3CommentsInvestigating the LTM TCP Profile: Max Syn Retransmissions & Idle Timeout
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to the server side connection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Max Syn Retransmission This option specifies the maximum number of times the LTM will resend a SYN packet without receiving a corresponding SYN ACK from the server. The default value was four in versions 9.0 - 9.3, and is three in versions 9.4+. This option has iRules considerations with the LB_FAILED event. One of the triggers for the event is an unresponsive server, but the timeliness of this trigger is directly related to the max syn retransmission setting. The back-off timer algorithm for SYN packets effectively doubles the wait time from the previous SYN, so the delay grows excessive with each additional retransmission allowed before the LTM closes the connection: Retransmission Timers v9.0-v9.3 v9.4 Custom-2 Custom-1 Initial SYN 0s 0s 0s 0s 1st Retransmitted SYN 3s 3s 3s 3s 2nd Retransmitted SYN 6s 6s 6s NA 3rd Retransmitted SYN 12s 12s NA NA 4th Retransmitted SYN 24s NA NA NA LB_FAILED triggered 45s 21s 9s 3s Tuning this option down may result in faster response on your LB_FAILED trigger, but keep in mind the opportunity for false positives if your server gets too busy. Note that monitors are the primary means to ensure available services, but the max syn retransmission setting can assist. If the LB_FAILED event does trigger, you can check the monitor status in your iRule, and if the monitor has not yet been marked down, you can do so to prevent other new connections from waiting: when LB_FAILED { if { [LB::status pool [LB::server pool] member [LB::server addr] eq "up"] } { LB::down } } Idle Timeout The explanation of the idle timeout is fairly intuitive. This setting controls the number of seconds the connection remains idle before the LTM closes it. For most applications, the default 300 seconds is more than enough, but for applications with long-lived connections like remote desktop protocol, the user may want to leave the desk and get a cup of coffee without getting dumped but the administrators don't want to enable keepalives. The option can be configured with a numeric setting in seconds, or can be set to indefinite, in which case the abandoned connections will sit idle until a reaper reclaims them or services are restarted. I try to isolate applications onto their own virtual servers so I can maximize the profile settings, but in the case where a wildcard virtual is utilized, the idle timeout can be set in an iRule with the IP::idle_timeout command: when CLIENT_ACCEPTED { switch [TCP::local_port] { "22" { IP::idle_timeout 600 } "23" { IP::idle_timeout 600 } "3389" { IP::idle_timeout 3600 } default { IP::idle_timeout 120 } } If you look at the connection table, the current and the maximum (in parentheses) idle values are shown: b conn client 10.1.1.1 show all | grep –v pkts VIRTUAL 10.1.1.100:3389 <-> NODE any6:any CLIENTSIDE 10.1.1.1:36023 <-> 10.1.1.100:3389 SERVERSIDE 10.1.1.100:36023 <-> 10.1.1.50:3389 PROTOCOL tcp UNIT 1 IDLE 124 (3600) LASTHOP 1 00:02:0a:13:ef:80 Next week, we'll take a look at windows and buffers.1.1KViews1like1Comment