Two-Factor Authentication With Google Authenticator And APM
Introduction Two-factor authentication (TFA) has been around for many years and the concept far pre-dates computers. The application of a keyed padlock and a combination lock to secure a single point would technically qualify as two-factor authentication: “something you have,” a key, and “something you know,” a combination. Until the past few years, two-factor authentication in its electronic form has been reserved for high security environments: government, banks, large companies, etc. The most common method for implementing a second authentication factor has been to issue every employee a disconnected time-based one-time password hard token. The term “disconnected” refers to the absence of a connection between the token and a central authentication server. A “hard token” implies that the device is purpose-built for authentication and serves no other purpose. A soft or “software” token on the other hand has other uses beyond providing an authentication mechanism. In the context of this article we will refer to mobile devices as a soft tokens. This fits our definition as the device an be used to make phone calls, check email, surf the Internet, all in addition to providing a time-based one-time password. A time-based one-time password (TOTP) is a single use code for authenticating a user. It can be used by itself or to supplement another authentication method. It fits the definition of “something you have” as it cannot be easily duplicated and reused elsewhere. This differs from a username and password combination, which is “something you know,” but could be easily duplicated by someone else. The TOTP uses a shared secret and the current time to calculate a code, which is displayed for the user and regenerated at regular intervals. Because the token and the authentication server are disconnected from each other, the clocks of each must be perfectly in sync. This is accomplished by using Network Time Protocol (NTP) to synchronize the clocks of each device with the correct time of central time servers. Using Google Authenticator as a soft token application makes sense from many angles. It is low cost due to the proliferation of smart phones and is available from the “app store” free of charge on all major platforms. It uses an open standard (defined by RFC 4226), which means that it is well-tested, understood, secure. Calculation as you will later see is well-documented and relatively easy to implement in your language of choice (iRules in our case). This process is explained in the next section. This Tech Tip is a follow-up to Two-Factor Authentication With Google Authenticator And LDAP. The first article in this series highlighted two-factor authentication with Google Authenticator and LDAP on an LTM. In this follow-up, we will be covering implementation of this solution with Access Policy Manager (APM). APM allows for far more granular control of network resources via access policies. Access policies are rule sets, which are intuitively displayed in the UI as flow charts. After creation, an access policy is applied to a virtual server to provide security, authentication services, client inspection, policy enforcement, etc. This article highlights not only a two-factor authentication solution, but also the usage of iRules within APM policies. By combining the extensibility of iRules with the APM’s access policies, we are able to create virtually any functionality we might need. Note: A 10-user fully-featured APM license is included with every LTM license. You do not need to purchase an additional module to use this feature if you have less than 10 users. Calculating The Google Authenticator TOTP The Google Authenticator TOTP is calculated by generating an HMAC-SHA1 token, which uses a 10-byte base32-encoded shared secret as a key and Unix time (epoch) divided into a 30 second interval as inputs. The resulting 80-byte token is converted to a 40-character hexadecimal string, the least significant (last) hex digit is then used to calculate a 0-15 offset. The offset is then used to read the next 8 hex digits from the offset. The resulting 8 hex digits are then AND’d with 0x7FFFFFFF (2,147,483,647), then the modulo of the resultant integer and 1,000,000 is calculated, which produces the correct code for that 30 seconds period. Base32 encoding and decoding were covered in my previous Tech Tip titled Base32 Encoding And Decoding With iRules . The Tech Tip details the process for decoding a user’s base32-encoded key to binary as well as converting a binary key to base32. The HMAC-SHA256 token calculation iRule was originally submitted by Nat to the Codeshare on DevCentral. The iRule was slightly modified to support the SHA-1 algorithm, but is otherwise taken directly from the pseudocode outlined in RFC 2104. These two pieces of code contribute the bulk of the processing of the Google Authenticator code. The rest is done with simple bitwise and arithmetic functions. Triggering iRules From An APM Access Policy Our previously published Google Authenticator iRule combined the functionality of Google Authenticator token verification with LDAP authentication. It was written for a standalone LTM system without the leverage of APM’s Visual Policy Editor. The issue with combining these two authentication factors in a single iRule is that their functionality is not mutually exclusive or easily separable. We can greatly reduce the complexity of our iRule by isolating functionality for Google Authenticator token verification and moving the directory server authentication to the APM access policy. APM iRules differ from those that we typically develop for LTM. iRules assigned to LTM virtual server are triggered by events that occur during connection or payload handling. Many of these events still apply to an LTM virtual server with an APM policy, but do not have perspective into the access policy. This is where we enter the realm of APM iRules. APM iRules are applied to a virtual server exactly like any other iRule, but are triggered by custom iRule event agent IDs within the access policy. When the access policy reaches an iRule event, it will trigger the ACCESS_POLICY_AGENT_EVENT iRule event. Within the iRule we can execute the ACCESS::policy agent_id command to return the iRule event ID that triggered the event. We can then match on this ID string prior to executing any additional code. Within the iRule we can get and set APM session variables with the ACCESS::session command, which will serve as our conduit for transferring variables to and from our access policy. A visual walkthrough of this paragraph is shown below. iRule Trigger Process Create an iRule Event in the Visual Policy Editor Specify a Name for the object and an ID for the Custom iRule Event Agent Create an iRule with the ID referenced and assign it to the virtual server 1: when ACCESS_POLICY_AGENT_EVENT { 2: if { [ACCESS::policy agent_id] eq "ga_code_verify" } { 3: # get APM session variables 4: set username [ACCESS::session data get session.logon.last.username] 5: 6: ### Google Authenticator token verification (code omitted for brevity) ### 7: 8: # set APM session variables 9: ACCESS::session data set session.custom.ga_result $ga_result 10: } 11: } Add branch rules to the iRule Event which read the custom session variable and handle the result Google Authenticator Two-Factor Authentication Process Two-Factor Authentication Access Policy Overview Rather than walking through the entire process of configuring the access policy from scratch, we’ll look at the policy (available for download at the bottom of this Tech Tip) and discuss the flow. The policy has been simplified by creating macros for the redundant portions of the authentication process: Google Authenticator token verification and the two-factor authentication processes for LDAP and Active Directory. The “Google Auth verification” macro consists of an iRule event and 5 branch rules. The number of branch rules could be reduced to just two: success and failure. This would however limit our diagnostic capabilities should we hit a snag during our deployment, so we added logging for all of the potential failure scenarios. Remember that these logs are sent to APM reporting (Web UI: Access Policy > Reports) not /var/log/ltm. APM reporting is designed to provide per-session logging in the user interface without requiring grepping of the log files. The LDAP and Active Directory macros contain the directory server authentication and query mechanisms. Directory server queries are used to retrieve user information from the directory server. In this case we can store our Google Authenticator key (shared secret) in a schema attribute to remove a dependency from our BIG-IP. We do however offer the ability to store the key in a data group as well. The main portion of the access policy is far simpler and easier to read by using macros. When the user first enters our virtual server we look at the Landing URI they are requesting. A first time request will be sent to the “normal” logon page. The user will then input their credentials along with the one-time password provided by the Google Authenticator token. If the user’s credentials and one-time password match, they are allowed access. If they fail the authentication process, we increment a counter via a table in our iRule and redirect them back to an “error” logon page. The “error” logon page notifies them that their credentials are invalid. The notification makes no reference as to which of the two factors they failed. If the user exceeds the allowed number of failures for a specified period of time, their session will be terminated and they will be unable to login for a short period of time. An authenticated user would be allowed access to secured resources for the duration of their session. Deploying Google Authenticator Token Verification This solution requires three components (one optional) for deployment: Sample access policy Google Authenticator token verification iRule Google Authenticator token generation iRule (optional) The process for deploying this solution has been divided into four sections: Configuring a AAA server Login to the Web UI of your APM From the side panel select Access Policy > AAA Servers > Active Directory, then the + next to the text to create a new AD server Within the AD creation form you’ll need to provide a Name, Domain Controller, Domain Name, Admin Username, and Admin Password When you have completed the form click Finished Copy the iRule to BIG-IP and configure options Download a copy of the Google Authenticator Token Verification iRule for APM from the DevCentral CodeShare (hint: this is much easier if you “edit” the wiki page to display the source without the line numbers and formatting) Navigate to Local Traffic > iRules > iRule List and click the + symbol Name the iRule '”google_auth_verify_apm,” then copy and paste the iRule from the CodeShare into the Definition field At the top of the iRule there are a few options that need to be defined: lockout_attempts - number of attempts a user is allowed to make prior to being locked out temporarily (default: 3 attempts) lockout_period - duration of lockout period (default: 30 seconds) ga_code_form_field - name of HTML form field used in the APM logon page, this field is define in the "Logon Page" access policy object (default: ga_code_attempt) ga_key_storage - key storage method for users' Google Authenticator shared keys, valid options include: datagroup, ldap, or ad (default: datagroup) ga_key_ldap_attr - name of LDAP schema attribute containing users' key ga_key_ad_attr - name of Active Directory schema attribute containing users' key ga_key_dg - data group containing user := key mappings Click Finished when you’ve configured the iRule options to your liking Import sample access policy From the Web UI, select Access Policy > Access Profiles > Access Profiles List In the upper right corner, click Import Download the sample policy for Two-Factor Authentication With Google Authenticator And APM and extract the .conf from ZIP archive Fill in the New Profile Name with a name of your choosing, then select Choose File, navigate to the extracted sample policy and Open Click Import to complete the import policy The sample policy’s AAA servers will likely not work in your environment, from the Access Policy List, click Edit next to the imported policy When the Visual Policy Editor opens, expand the macro (LDAP or Active Directory auth) that describe your environment Click the AD Auth object, select the AD server from the drop-down that was defined earlier in the AAA Servers step, then click Save Repeat this process for the AD Query object Assign sample policy and iRule to a virtual server From the Web UI, select Local Traffic > Virtual Servers > Virtual Server List, then the create button (+) In the New Virtual Server form, fill in the Name, Destination address, Service Port (should be HTTPS/443), next select an HTTP profile and anSSL Profile (Client). Next you’ll add a SNAT Profile if needed, an Access Profile, and finally the token verification iRule Depending on your deployment you may want to add a pool or other network connectivity resources Finally click Finished At this point you should have a function virtual server that is serving your access policy. You’ll now need to add some tokens for your users. This process is another section on its own and is listed below. Generating Software Tokens For Users In addition to the Google Authenticator Token Verification iRule for APM we also wrote a Google Authenticator Soft Token Generator iRule that will generate soft tokens for your users. The iRule can be added directly to an HTTP virtual server without a a pool and accessed directly to create tokens. There are a few available fields in the generator: account, pre-defined secret, and a QR code option. The “account” field defines how to label the soft token within the user’s mobile device and can be useful if the user has multiple soft token on the same device (I have 3 and need to label them to keep them straight). A 10-byte string can be used as a pre-defined secret for conversion to a base32-encoded key. We will advise you against using a pre-defined key because a key known to the user is something they know (as opposed to something they have) and could be potentially regenerate out-of-band thereby nullifying the benefits of two-factor authentication. Lastly, there is an option to generate a QR code by sending an HTTPS request to Google and returning the QR code as an image. While this is convenient, this could be seen as insecure since it may wind up in Google’s logs somewhere. You’ll have to decide if that is a risk you’re willing to take for the convenience it provides. Once the token has been generated, it will need to be added to a data group on the BIG-IP: Navigate to Local Traffic > iRules > Data Group Lists Select Create from the upper right-hand corner if the data group does not yet exist. If it exists, just select it from the list. Name the data group “google_auth_keys” (data group name can be changed in the beginning section of the iRule) The type of data group will be String Type the “username” into the String field and paste the “Google Authenticator key” into the Value field Click Add and the username/key pair should appear in the list as such: user := ONSWG4TFOQYTEMZU Click Finished when all your username/key pairs have been added. Your user can scan the QR code or type it into their device manually. After they scan the QR code, the account name should appear along with the TOTP for the account. The image below is how the soft token appears in the Google Authenticator iPhone application: Once again, do not let the user leave with a copy of the plain text key. Knowing their key value will negate the value of having the token in the first place. Once the key has been added to the BIG-IP, the user’s device, and they’ve tested their access, destroy any reference to the key outside the BIG-IPs data group.If you’re worried about having the keys in plain text on the BIG-IP, they can be encrypted with AES or stored off-box in LDAP and only queried via secure connection. This is beyond the scope of this article, but doable with iRules. Code Google Authenticator Token Verification iRule for APM – Documentation and code for the iRule used in this Tech Tip Google Authenticator Soft Token Generator iRule – iRule for generating soft tokens for users Sample Access Policy: Two-Factor Authentication With Google Authenticator And APM – APM access policy Reference Materials RFC 4226 - HOTP: An HMAC-Based One-Time Password Algorithm RFC 2104 - HMAC: Keyed-Hashing for Message Authentication RFC 4648 - The Base16, Base32, and Base64 Data Encodings SOL3122: Configuring the BIG-IP system to use an NTP server using the Configuration utility – Information on configuring time servers Configuration Guide for BIG-IP Access Policy Manager – The “big book” on APM configurations Configuring Authentication Using AAA Servers – Official F5 documentation for configuring AAA servers for APM Troubleshooting AAA Configurations – Extra help if you hit a snag configuring your AAA server14KViews6likes28Comments
iRules Event Order
iRules is an event driven language. This has been discussed before, but to recap briefly, here’s what “Event Driven” means in iRules terms: iRules code is written inside event blocks. Those event blocks translate to times within the life-cycle of a connection to your LTM. By putting your code inside a given event block you are ensuring that it executes at a particular point in that transaction. I.E. HTTP_REQUEST code is executed once a request has been received, not before, so you’re safe to look for HTTP header info. SERVER_CONNECTED however isn’t fired until all the client side processing has been done and a load balancing decision is made, but before the actual data is sent to the chosen system. In this way we ensure granularity in the control of when and how your code is executed to allow you the absolute most control possible. It also allows for things to be highly efficient as we only have to execute the needed code each time, not the entire script. So now that we know what “Event Driven” means and how to use events to execute code precisely where we want to within the context of a connection, that leaves two burning questions. What events can I choose from? That is answered handily by the “Events” page in the iRules wiki. The other is: When does each event fire? I.E – what’s the overall order of events for a given connection? This has been something that’s a little harder to nail down as it takes a little bit of disclaimer work since not all events fire for every connection because some are based on given profiles, not to mention iRules is constantly changing. Keeping that in mind, though, I’ve put together a list of events in the order that they execute, checked it twice…then sent it off for PD approval (hey, I’m not an idiot). The below list has gotten the stamp of approval and I’m quite happy to finally get a documented order online as there have been many requests for this. Events are processed in a linear fashion so all CLIENT_ACCEPTED events in all iRules finish processing before the first HTTP_REQUEST event can fire. The linear order of this list is representative of that. Each event will not fire until all events above it have completed. Also, all events within one line, separated by slashes (/) execute at effectively the same time as far as the context of a connection is concerned. Please note that some of the events below are only executed under certain circumstances. For instance the AUTH_RESULT event only occurs if an AUTH command (such as AUTH::authenticate) completes to return results. iRules Event Order: RULE_INIT This is a global iRule event. It occurs once when the iRule is loaded into memory and does not continue to be processed for each subsequent request. Client Request Events - These events occur between the time the client connects to the LTM and the time the LTM makes a load balancing decision. At this point it has finished client data processing and is ready to connect to the chosen server but has not yet sent the data. These events are executed in a client-side context, meaning they behave as if you've used the clientside command with each of them. This means that local_addr type commands behave with the client in mind. This is where you have the opportunity to change the information a user is sending in before it makes it to the server for processing. URI re-writing, authentication and encryption offloading or inspection, server impersonation (acting like you’re a server to dig deeper into the transaction) – it all happens here. CLIENT_ACCEPTED CLIENTSSL_HANDSHAKE CLIENTSSL_CLIENTCERT HTTP_REQUEST / CACHE_REQUEST / RTSP_REQUEST / SIP_REQUEST / HTTP_CLASS_FAILED / HTTP_CLASS_SELECTED STREAM_MATCHED CACHE_UPDATE CLIENT_DATA / RTSP_REQUEST_DATA / HTTP_REQUEST_DATA – Only occur when collected data arrives AUTH_RESULT / AUTH_WANTCREDENTIAL – Only occur when authentication commands return LB_SELECTED / LB_FAILED / PERSIST_DOWN Server Request Events - These events take place after client request processing has finished, a destination has been chosen by the LTM, and the connection to the server is initiated. They happen before the client request is actually sent to the server. This is the end of the request process, which is followed by the first Server Response event. These events are executed in a server-side context. Much like the opposite of the above client-side events, these behave as if you’ve used the serverside command with each of them. SERVER_CONNECTED SERVER_SSL_HANDSHAKE HTTP_REQUEST_SEND / SIP_REQUEST_SEND Server Response Events - These events are triggered after the request has been sent to the server, the server has processed the request and the LTM receives a response from the server. These events are where you can access content generated by the server before it gets sent back to the client. Scrubbing out credit card information, server response manipulation, etc. – this is the place for it. CACHE_RESPONSE HTTP_RESPONSE / RTSP_RESPONSE / SIP_RESPONSE STREAM_MATCHED HTTP_RESPONSE_CONTINUE HTTP_RESPONSE_DATA / SERVER_DATA / RTSP_RESPONSE_DATA – Only occur when collected data arrives Disconnect Events - These are the events that represent the termination of a connection after all processing is completed. SERVER_CLOSED CLIENT_CLOSED This list is representative of iRules as they sit today. Keep in mind that the iRules language is continually evolving and changing, which may impact this list as well. I’ll do my best to keep it updated, because I think it’s a useful resource. Get the Flash Player to see this player. 20090331-iRulesEventOrder.mp32.8KViews4likes7CommentsAccessing TCP Options from iRules
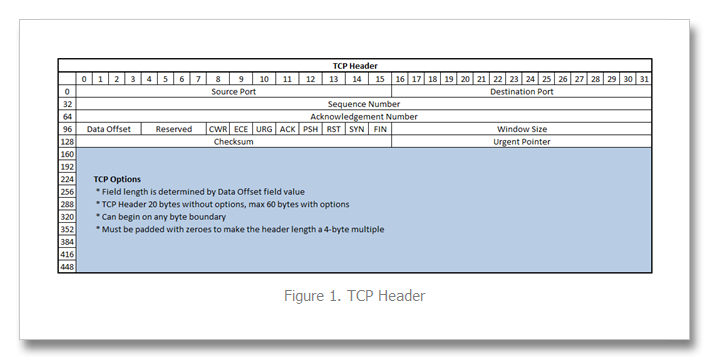
I’ve written several articles on the TCP profile and enjoy digging into TCP. It’s a beast, and I am constantly re-learning the inner workings. Still etched in my visual memory map, however, is the TCP header format, shown in Figure 1 below. Since 9.0 was released, TCP payload data (that which comes after the header) has been consumable in iRules via the TCP::payload and the port information has been available in the contextual commands TCP::local_port/TCP::remote_port and of course TCP::client_port/TCP::server_port. Options, however, have been inaccessible. But beginning with version 10.2.0-HF2, it is now possible to retrieve data from the options fields. Preparing the BIG-IP Prior to version 11.0, it was necessary to set a bigpipe database key with the option (or options) of interest: bigpipe db Rules.Tcpoption.settings [option, first|last], [option, first|last] In version 11.0 and forward, the DB keys are no more and you need to create a tcp profile with the these options defined, like so: ltm profile tcp tcp_opt { app-service none tcp-options "{option first|last} {option first|last}" } The option is an integer between 2 and 255, and the first/last setting indicates whether the system will retain the first or last instance of the specified option. Once that key is set, you’ll need to do a bigstart restart for it to take (warning: service impacting). Note also that the LTM only collects option data starting with the ACK of a connection. The initial SYN is ignored even if you select the first keyword. This is done to prevent a SYN flood attack (in keeping with SYN-cookies). A New iRules Command: TCP::option The TCP::option command has the following syntax: TCP::option get <option> v11 Additions/Changes: TCP::option set <option number> <value> <next|all> TCP::option noset <option number> Pretty simple, no? So now that you can access them, what fun can be had? Real World Scenario: Akamai In Akamai’s IPA and SXL product lines, they support client IP visibility by embedding a version number (one byte) and an IPv4 address (four bytes) as part of their overlay path feature in tcp option number 28. To access this data, we first set the database key: tmsh create ltm profile tcp tcp_opt tcp-options "{28 first}" Now, the iRule utilizing the TCP::option command: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt28 cH8 ver addr if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { scan $addr "%2x%2x%2x%2x" ip1 ip2 ip3 ip4 set optaddr "$ip1.$ip2.$ip3.$ip4" } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } The Akamai version should be one, so we log if not. Otherwise, we take the address (stored in the variable addr in hex) and scan it to get the decimal equivalents to build the address for inserting in the X-Forwarded-For header. Cool, right? Also cool—along with the new TCP::option command , an extension was made to the IP::addr command to parse binary fields into a dotted decimal IP address. This extension is also available beginning in 10.2.0-HF2, but extended in 11.0. Here’s the syntax: IP::addr parse [-ipv4 | -ipv6 [swap]] <binary field> [<offset>] So for example, if you had an IPv6 address in option 28 with a 1 byte offset, you would parse that like: log local0. "IP::addr parse IPv6 output: [IP::addr parse -ipv6 [TCP::option get 28] 1]" ## Log Result ## May 27 21:51:34 ltm13 info tmm[27207]: Rule /Common/tcpopt_test <CLIENT_ACCEPTED>: IP::addr parse IPv6 output: 2601:1930:bd51:a3e0:20cd:a50b:1cc1:ad13 But in the context of our TCP option, we have 5-bytes of data with the first byte not mattering in the context of an address, so we get at the address with this: set optaddr [IP::addr parse -ipv4 [TCP::option get 28] 1] This cleans up the rule a bit: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] } } } when HTTP_REQUEST { if { [info exists optaddr] } { HTTP::header insert "X-Forwarded-For" $optaddr } } No need to store the address in the first binary scan and no need for the scan command at all so I eliminated those. Setting a forwarding header is not the only thing we can do with this data. It could also be shipped off to a logging server, or used as a snat address (assuming the server had either a default route to the BIG-IP, or specific routes for the customer destinations, which is doubtful). Logging is trivial, shown below with the log command. The HSL commands could be used in lieu of log if sending off-box to a log server. when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "Client IP extracted from Akamai TCP option is $optaddr" } } } If setting the provided IP as a snat address, you’ll want to make sure it’s a valid IP address before doing so. You can use the TCL catch command and IP::addr to perform this check as seen in the iRule below: when CLIENT_ACCEPTED { set addrs [list \ "192.168.1.1" \ "256.168.1.1" \ "192.256.1.1" \ "192.168.256.1" \ "192.168.1.256" \ ] foreach x $addrs { if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "IP $x is invalid" } else { log local0. "IP $x is valid" } } } The output of this iRule: <CLIENT_ACCEPTED>: IP 192.168.1.1 is valid <CLIENT_ACCEPTED>: IP 256.168.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.256.1.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.256.1 is invalid <CLIENT_ACCEPTED>: IP 192.168.1.256 is invalid Adding this logic into a functional rule with snat: when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] if { [string length $opt28] == 5 } { binary scan $opt c ver if { $ver != 1 } { log local0. "Unsupported Akamai version: $ver" } else { set optaddr [IP::addr parse -ipv4 $opt28 1] if { [catch {IP::addr $x mask 255.255.255.255}] } { log local0. "$optaddr is not a valid address" snat automap } else { log local0. "Akamai inserted Client IP is $optaddr. Setting as snat address." snat $optaddr } } } Alternative TCP Option Use Cases The Akamai solution shows an application implementation taking advantage of normally unused space in TCP headers. There are, however, defined uses for several option “kind” numbers. The list is available here: http://www.iana.org/assignments/tcp-parameters/tcp-parameters.xml. Some options that might be useful in troubleshooting efforts: Opkind 2 – Max Segment Size Opkind 3 – Window Scaling Opkind 5 – Selective Acknowledgements Opkind 8 – Timestamps Of course, with tcpdump you get all this plus the context of other header information and data, but hey, another tool in the toolbox, right? Addendum I've been working with F5 SE Leonardo Simon on on additional examples I wanted to share here that uses option 28 or 253 to extract an IPv6 address if the version is 34 and otherwise extracts an IPv4 address if the version is 1 or 2. Option 28 when CLIENT_ACCEPTED { set opt28 [TCP::option get 28] binary scan $opt28 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt28 1] log local0. "opt28 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt28 1] log local0. "opt28 ipv4 address: $optaddr" } } Option 253 when CLIENT_ACCEPTED { set opt253 [TCP::option get 253] binary scan $opt253 c ver #log local0. "version: $ver" if { $ver == 34 } { set optaddr [IP::addr parse -ipv6 $opt253 1] log local0. "opt253 ipv6 address: $optaddr" } elseif { $ver == 1 || $ver == 2 } { set optaddr [IP::addr parse -ipv4 $opt253 1] log local0. "opt253 ipv4 address: $optaddr" } }17KViews2likes10CommentsPreventing Brute Force Password Guessing Attacks with APM - Part 1
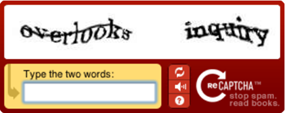
F5er and DevCentral community member ystephie is back with another great solution (check out her first solution here: BIG-IP APM Customized Logon Page), this time tackling brute force attacks utilizing customizations with the BIG-IP Access Policy Manager. This solution requires BIG-IP10.2.2 Hotfix 1 or later. Introduction Exposing applications or services to the Internet opens inherent security risks. BIG-IP Access Policy Manager (APM) provides edge authentication and access control services for applications, BIG-IP Edge Gateway provides secure SSL VPN services, and BIG-IP Application Security Manager (ASM) provides protection against a variety of attacks. In this series of APM deployment examples, we will cover a couple of techniques for protecting against brute force password-guessing attacks. We’ll start with examples where a CAPTCHA challenge is used to block automated password guessing attacks, followed by an example providing temporary account lockout after a configured number of authentication failures. CAPTCHA stands for Completely Automated Public Turing Test to Tell Computers and Humans Apart (quite a mouthful), but basically consists of a challenge that a human can pass but a computer program cannot. It is used to protect against bots, and in the examples here can help protect against an automated password guessing attack. We can take advantage of Google’s reCAPTCHA web service and APM’s flexible advanced customization to provide basic defense against automated password guessing attacks. In addition, we will play around with the general look of your logon page. With reCAPTCHA available as a web service, we’ll be incorporating the CAPTCHA challenge within the APM logon page via advanced customization. The JavaScript added to the logon page will request a challenge (image with distorted text) from the reCAPTCHA web service and display it within the page. We’ll then create a custom APM Access Policy where we validate the user’s CAPTCHA challenge answer against the same reCAPTCHA web service (using the APM HTTP Auth agent). The links below describe the Google reCAPTCHA service in greater detail: http://code.google.com/apis/recaptcha/intro.html http://code.google.com/apis/recaptcha/docs/display.html http://code.google.com/apis/recaptcha/docs/verify.html Initial Setup – Create a Google Account for the reCAPTCHA Project Sign up for Google’s reCAPTCHA project through http://www.google.com/recaptcha/whyrecaptcha. Fill in a domain name and jot down the private and public keys for we’ll be using them later. Device Wizard For the purpose of this example, we’ll be using the Network Access Setup Wizard for Remote Access option under Templates and Wizards -> Device Wizards shown in Figure 1. Select HTTP Authentication with the following setup. This is required to verify the CAPTCHA challenge answer from the user against the reCAPTCHA web service. Follow the steps in the wizard (AAA Server, Lease Pool, Network Access, and etc.) to get to the summary page shown below in Figure 2. Before clicking finished, enter the Visual Policy Editor (VPE) to make a few changes. Click on Logon Page and modify field 3 and 4 under Logon Page Agent with the following configuration and save. Note: The logon page agent will only parse and store POST parameters it knows about (that are defined here). We’ll be hiding these two new fields on the logon page via advanced customization later. You should add an Ad Auth after the success leg of HTTP Auth. In my examples, I will be using ADAuth but feel free to use any sort of additional authenticate. That way, you only need to check their credentials once we know for sure that this is a human user (passes the CAPTCHA challenge). Update the access policy by clicking Apply Access Policy and finish the Device Wizard. Advanced Customization Follow steps 1-3 under the section “Customize the Logon Page” in the BIG-IP APM-Customized Logon Page article. We’ll be replacing the auto-generated logon form with HTML that includes the username and password fields, along with some JavaScript that calls the reCAPTCHA service and includes the challenge within the page. Edit logon_en.inc file: remove this block of PHP code: <? //------------------------------------------------------------ foreach( $fields_settings as $field_settings ) { if( $field_settings["type"] != "none" ) { if( $GLOBALS["label_position"] == "above" ){ ?> <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="<? print( $field_settings["type"] ); ?>"><? print( $field_settings["caption"] ); ?></label><input type=<? print( $field_settings["type"] ); ?> name=<? print( $field_settings["name"] ); ?> class="credentials_input_<? print( $field_settings["type"] ); ?>" <? print( ( $field_settings["rw"] == 0 ? "disabled" : "" ) ); ?> value="<? print( $field_settings["value"] ); ?>" autocomplete="off"></td> </tr> <? }else{ ?> <tr> <td class="credentials_table_label_cell" ><? print( $field_settings["caption"] ); ?></td> <td class="credentials_table_field_cell"><input type="<? print( $field_settings["type"] ); ?>" name="<? print( $field_settings["name"] ); ?>" class="credentials_input_<? print( $field_settings["type"] ); ?>" <? print( ( $field_settings["rw"] == 0 ? "disabled" : "" ) ); ?> value="<? print( $field_settings["value"] ); ?>" autocomplete="off"></td> </tr> <? } } } //------------------------------------------------------------ ?> In its place, paste this second block of code. Make sure to replace the red text with your own information. <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="text">Username</label><input type=text name=username s="credentials_input_text" value="" autocomplete="off" autocapitalize="off"></td> </tr> <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="password">Password</label><input type=password =password class="credentials_input_password" value="" autocomplete="off" autocapitalize="off"></td> </tr> d colspan=2 class="credentials_table_unified_cell"> cript type="text/javascript" src="https://www.google.com/recaptcha/api/challenge?k=replace_with_your_public_key"> script> oscript> <iframe src="https://www.google.com/recaptcha/api/noscript?k=replace_with_your_public_key" height="300" width="500" frameborder="0"></iframe><br> <textarea name="recaptcha_challenge_field" rows="3" cols="40"> </textarea> <input type="hidden" name="recaptcha_response_field" value="manual_challenge"> noscript> td> > Apply the customizations to the policy with the following commands: b customization group <your policy name>_act_logon_page_ag action update b profile access <your policy name> generation action increment Extra Touches Currently the page should like like Figure 3. But we can easily customize this page. First, let us start by adding a helpful message before the CAPTCHA. Open the logon_en.inc file again and add some HTML like below. Place it between the <td...> tag and <script…> tag we added earlier. <td colspan=2 class="credentials_table_unified_cell"> <label for="text">Security Check<p>Enter <b>both words</b> below, <b>separated by a space</b>.</p></label> <script type="text/javascript" Edit this message as fits your organization. Don’t forget to update the access policy! The page now looks like Figure 4: The color scheme of the CAPTCHA may not work for every page so Google provides a few more templates shown in Figure 5. If you feel that you would like to do more customization, see the documentation found on this page -http://code.google.com/apis/recaptcha/docs/customization.html. <script type="text/javascript"> var RecaptchaOptions = { theme : 'theme_name' }; </script> To display a standard theme, add the following script into logon_en.inc anywhere before the <form> element where we inserted our code. Replace ‘theme_name’ with one of the above theme names. In Figure 6, I’m using the ‘white’ theme. Remember to update! More Extra Touches – Changing the Look of Your Page To customize the look of your page, click on your access profile- Access Policy -> Access Profiles -> <your access policy> -> Customization (third tab from the left on the top) -> general UI -> Find Customization. Feel free to make whatever changes you like, in Figure 7, I changed the color of the Header background color, and Form background color to #63919E and #94BBC2 respectively. Advanced Customization (Logon Page) Checklist When you copy and paste to a template file, it has the following formatting: logon_<language>.inc Set permissions using the following command chmod a+r logon_<language>.inc After editing, update with the following two commands b customization group <your policy name>_act_logon_page_ag action update b profile access <your policy name> generation action increment Final Notes Exposing applications or services to the Internet opens inherent security risks. APM can help by providing advanced authentication, authorization, and endpoint security checks. With a bit of customization you can integrate with web services such as the Google reCAPTCHA project to provide additional security layers. In our next example, we’ll build on this work to display the CAPTCHA only after the user has failed full authentication, to reduce the inconvenience of typing CATPCHA challenges. We’ll be demonstrating how to do an AD Query and use the bad password count attribute to determine when to show the CAPTCHA challenge. About the Author Stephanie is a summer intern at F5, heading back to school soon to continue her EECS degree at UC Berkeley, and has been having a blast creating interesting solutions for BIG-IP. Stephanie’s passion for engineering, and smile, is contagious.1.2KViews2likes5CommentsThese Are Not The Scrapes You're Looking For - Session Anomalies
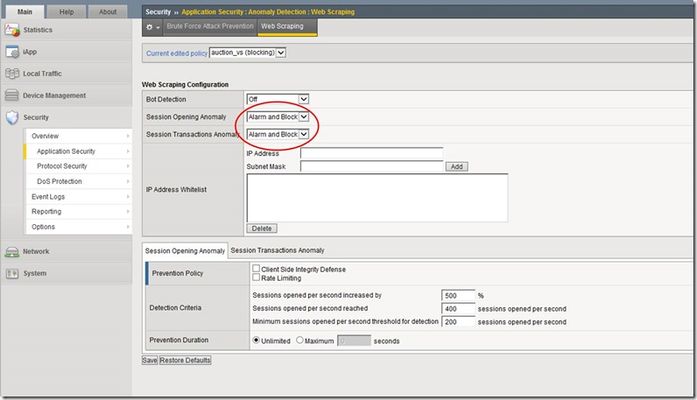
In my first article in this series, I discussed web scraping -- what it is, why people do it, and why it could be harmful. My second article outlined the details of bot detection and how the ASM blocks against these pesky little creatures. This last article in the series of web scraping will focus on the final part of the ASM defense against web scraping: session opening anomalies and session transaction anomalies. These two detection modes are new in v11.3, so if you're using v11.2 or earlier, then you should upgrade and take advantage of these great new features! ASM Configuration In case you missed it in the bot detection article, here's a quick screenshot that shows the location and settings of the Session Opening and Session Transactions Anomaly in the ASM. You'll find all the fun when you navigate to Security > Application Security > Anomaly Detection > Web Scraping. There are three different settings in the ASM for Session Anomaly: Off, Alarm, and Alarm and Block. (Note: these settings are configured independently...they don't have to be set at the same value) Obviously, if Session Anomaly is set to "Off" then the ASM does not check for anomalies at all. The "Alarm" setting will detect anomalies and record attack data, but it will allow the client to continue accessing the website. The "Alarm and Block" setting will detect anomalies, record the attack data, and block the suspicious requests. Session Opening Anomaly The first detection and prevention mode we'll discuss is Session Opening Anomaly. But before we get too deep into this, let's review what a session is. From a simple perspective, a session begins when a client visits a website, and it ends when the client leaves the site (or the client exceeds the session timeout value). Most clients will visit a website, surf around some links on the site, find the information they need, and then leave. When clients don't follow a typical browsing pattern, it makes you wonder what they are up to and if they are one of the bad guys trying to scrape your site. That's where Session Opening Anomaly defense comes in! Session Opening Anomaly defense checks for lots of abnormal activities like clients that don't accept cookies or process JavaScript, clients that don't scrape by surfing internal links in the application, and clients that create a one-time session for each resource they consume. These one-time sessions lead scrapers to open a large number of new sessions in order to complete their job quickly. What's Considered A New Session? Since we are discussing session anomalies, I figured we should spend a few sentences on describing how the ASM differentiates between a new or ongoing session for each client request. Each new client is assigned a "TS cookie" and this cookie is used by the ASM to identify future requests from the client with a known, ongoing session. If the ASM receives a client request and the request does not contain a TS cookie, then the ASM knows the request is for a new session. This will prove very important when calculating the values needed to determine whether or not a client is scraping your site. Detection There are two different methods used by the ASM to detect these anomalies. The first method compares a calculated value to a predetermined ceiling value for newly opened sessions. The second method considers the rate of increase of newly opened sessions. We'll dig into all that in just a minute. But first, let's look at the criteria used for detecting these anomalies. As you can see from the screenshot above, there are three detection criteria the ASM uses...they are: Sessions opened per second increased by: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second increases by a given percentage. The default setting is 500 percent. Sessions opened per second reached: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second is greater than or equal to this number. The default value is 400 sessions opened per second. Minimum sessions opened per second threshold for detection: This specifies that the ASM considers traffic to be an attack if the number of sessions opened per second is greater than or equal to the number specified. In addition, at least one of the "Sessions opened per second increased by" or "Sessions opened per second reached" numbers must also be reached. If the number of sessions opened per second is lower than the specified number, the ASM does not consider this traffic to be an attack even if one of the "Sessions opened per second increased by" or "Sessions opened per second" reached numbers was reached. The default value for this setting is 200 sessions opened per second. In addition, the ASM maintains two variables for each client IP address: a one-minute running average of new session opening rate, and a one-hour running average of new session opening rate. Both of these variables are recalculated every second. Now that we have all the basic building blocks. let's look at how the ASM determines if a client is scraping your site. First Method: Predefined Ceiling Value This method uses the user-defined "minimum sessions opened per second threshold for detection" value and compares it to the one-minute running average. If the one-minute average is less than this number, then nothing else happens because the minimum threshold has not been met. But, if the one-minute average is higher than this number, the ASM goes on to compare the one-minute average to the user-defined "sessions opened per second reached" value. If the one-minute average is less than this value, nothing happens. But, if the one-minute average is higher than this value, the ASM will declare the client a web scraper. The following flowchart provides a pictorial representation of this process. Second Method: Rate of Increase The second detection method uses several variables to compare the rate of increase of newly opened sessions against user-defined variables. Like the first method, this method first checks to make sure the minimum sessions opened per second threshold is met before doing anything else. If the minimum threshold has been met, the ASM will perform a few more calculations to determine if the client is a web scraper or not. The "sessions opened per second increased by" value (percentage) is multiplied by the one-hour running average and this value is compared to the one-minute running average. If the one-minute average is greater, then the ASM declares the client a web scraper. If the one-minute average is lower, then nothing happens. The following matrix shows a few examples of this detection method. Keep in mind that the one-minute and one-hour averages are recalculated every second, so these values will be very dynamic. Prevention The ASM provides several policies to prevent session opening anomalies. It begins with the first method that you enable in this list. If the system finds this method not effective enough to stop the attack, it uses the next method that you enable in this list. The following screenshots show the different options available for prevention. The "Drop IP Addresses with bad reputation" is tied to Rate Limiting, so it will not appear as an option unless you enable Rate Limiting. Note that IP Address Intelligence must be licensed and enabled. This feature is licensed separately from the other ASM web scraping options. Here's a quick breakdown of what each of these prevention policies do for you: Client Side Integrity Defense: The system determines whether the client is a legal browser or an illegal script by sending a JavaScript challenge to each new session request from the detected IP address, and waiting for a response. The JavaScript challenge will typically involve some sort of computational challenge. Legal browsers will respond with a TS cookie while illegal scripts will not. The default for this feature is disabled. Rate Limiting: The goal of Rate Limiting is to keep the volume of new sessions at a "non-attack" level. The system will drop sessions from suspicious IP addresses after the system determines that the client is an illegal script. The default for this feature is also disabled. Drop IP Addresses with bad reputation: The system drops requests from IP addresses that have a bad reputation according to the system’s IP Address Intelligence database (shown above). The ASM will drop all request from any "bad" IP addresses even if they respond with a TS cookie. IP addresses that do not have a bad reputation also undergo rate limiting. The default for this option is disabled. Keep in mind that this option is available only after Rate Limiting is enabled. In addition, this option is only enforced if at least one of the IP Address Intelligence Categories is set to Alarm mode. Prevention Duration Now that we have detected session opening anomalies and mitigated them using our prevention options, we must figure out how long to apply the prevention measures. This is where the Prevention Duration comes in. This setting specifies the length of time that the system will prevent an attack. The system prevents attacks by rejecting requests from the attacking IP address. There are two settings for Prevention Duration: Unlimited: This specifies that after the system detects and stops an attack, it performs attack prevention until it detects the end of the attack. This is the default setting. Maximum <number of> seconds: This specifies that after the system detects and stops an attack, it performs attack prevention for the amount of time indicated unless the system detects the end of the attack earlier. So, to finish up our Session Opening Anomaly part of this article, I wanted to share a quick scenario. I was recently reading several articles from some of the web scrapers around the block, and I found one guy's solution to work around web scraping defense. Here's what he said: "Since the service conducted rate-limiting based on IP address, my solution was to put the code that hit their service into some client-side JavaScript, and then send the results back to my server from each of the clients. This way, the requests would appear to come from thousands of different places, since each client would presumably have their own unique IP address, and none of them would individually be going over the rate limit." This guy is really smart! And, this would work great against a web scraping defense that only offered a Rate Limiting feature. Here's the pop quiz question: If a user were to deploy this same tactic against the ASM, what would you do to catch this guy? I'm thinking you would need to set your minimum threshold at an appropriate level (this will ensure the ASM kicks into gear when all these sessions are opened) and then the "sessions opened per second" or the "sessions opened per second increased by" should take care of the rest for you. As always, it's important to learn what each setting does and then test it on your own environment for a period of time to ensure you have everything tuned correctly. And, don't forget to revisit your settings from time to time...you will probably need to change them as your network environment changes. Session Transactions Anomaly The second detection and prevention mode is Session Transactions Anomaly. This mode specifies how the ASM reacts when it detects a large number of transactions per session as well as a large increase of session transactions. Keep in mind that web scrapers are designed to extract content from your website as quickly and efficiently as possible. So, web scrapers normally perform many more transactions than a typical application client. Even if a web scraper found a way around all the other defenses we've discussed, the Session Transaction Anomaly defense should be able to catch it based on the sheer number of transactions it performs during a given session. The ASM detects this activity by counting the number of transactions per session and comparing that number to a total average of transactions from all sessions. The following screenshot shows the detection and prevention criteria for Session Transactions Anomaly. Detection How does the ASM detect all this bad behavior? Well, since it's trying to find clients that surf your site much more than other clients, it tracks the number of transactions per client session (note: the ASM will drop a session from the table if no transactions are performed for 15 minutes). It also tracks the average number of transactions for all current sessions (note: the ASM calculates the average transaction value every minute). It can use these two figures to compare a specific client session to a reasonable baseline and figure out if the client is performing too many transactions. The ASM can automatically figure out the number of transactions per client, but it needs some user-defined thresholds to conduct the appropriate comparisons. These thresholds are as follows: Session transactions increased by: This specifies that the system considers traffic to be an attack if the number of transactions per session increased by the percentage listed. The default setting is 500 percent. Session transactions reached: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number. The default value is 400 transactions. Minimum session transactions threshold for detection: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number, and at least one of the "Sessions transactions increased by" or "Session transactions reached" numbers was reached. If the number of transactions per session is lower than this number, the system does not consider this traffic to be an attack even if one of the "Session transactions increased by" or "Session transaction reached" numbers was reached. The default value is 200 transactions. The following table shows an example of how the ASM calculates transaction values (averages and individual sessions). We would expect that a given client session would perform about the same number of transactions as the overall average number of transactions per session. But, if one of the sessions is performing a significantly higher number of transactions than the average, then we start to get suspicious. You can see that session 1 and session 3 have transaction values higher than the average, but that only tells part of the story. We need to consider a few more things before we decide if this client is a web scraper or not. By the way, if the ASM knows that a given session is malicious, it does not use that session's transaction numbers when it calculates the average. Now, let's roll in the threshold values that we discussed above. If the ASM is going to declare a client as a web scraper using the session transaction anomaly defense, the session transactions must first reach the minimum threshold. Using our default minimum threshold value of 200, the only session that exceeded the minimum threshold is session 3 (250 > 200). All other sessions look good so far...keep in mind that these numbers will change as the client performs additional transactions during the session, so more sessions may be considered as their transaction numbers increase. Since we have our eye on session 3 at this point, it's time to look at our two methods of detecting an attack. The first detection method is a simple comparison of the total session transaction value to our user-defined "session transactions reached" threshold. If the total session transactions is larger than the threshold, the ASM will declare the client a web scraper. Our example would look like this: Is session 3 transaction value > threshold value (250 > 400)? No, so the ASM does not declare this client as a web scraper. The second detection method uses the "transactions increased by" value along with the average transaction value for all sessions. The ASM multiplies the average transaction value with the "transactions increased by" percentage to calculate the value needed for comparison. Our example would look like this: 90 * 500% = 450 transactions Is session 3 transaction value > result (250 > 450)? No, so the ASM does not declare this client as a web scraper. By the way, only one of these detection methods needs to be met for the ASM to declare the client as a web scraper. You should be able to see how the user-defined thresholds are used in these calculations and comparisons. So, it's important to raise or lower these values as you need for your environment. Prevention Duration In order to save you a bunch of time reading about prevention duration, I'll just say that the Session Transactions Anomaly prevention duration works the same as the Session Opening Anomaly prevention duration (Unlimited vs Maximum <number of> seconds). See, that was easy! Conclusion Thanks for spending some time reading about session anomalies and web scraping defense. The ASM does a great job of detecting and preventing web scrapers from taking your valuable information. One more thing...for an informative anomaly discussion on the DevCentral Security Forum, check out this conversation. If you have any questions about web scraping or ASM configurations, let me know...you can fill out the comment section below or you can contact the DevCentral team at https://devcentral.f5.com/s/community/contact-us.918Views2likes2CommentsInvestigating the LTM TCP Profile: Max Syn Retransmissions & Idle Timeout
Introduction The LTM TCP profile has over thirty settings that can be manipulated to enhance the experience between client and server. Because the TCP profile is applied to the virtual server, the flexibility exists to customize the stack (in both client & server directions) for every application delivered by the LTM. In this series, we will dive into several of the configurable options and discuss the pros and cons of their inclusion in delivering applications. Nagle's Algorithm Max Syn Retransmissions & Idle Timeout Windows & Buffers Timers QoS Slow Start Congestion Control Algorithms Acknowledgements Extended Congestion Notification & Limited Transmit Recovery The Finish Line Quick aside for those unfamiliar with TCP: the transmission controlprotocol (layer4) rides on top of the internetprotocol (layer3) and is responsible for establishing connections between clients and servers so data can be exchanged reliably between them. Normal TCP communication consists of a client and a server, a 3-way handshake, reliable data exchange, and a four-way close. With the LTM as an intermediary in the client/server architecture, the session setup/teardown is duplicated, with the LTM playing the role of server to the client and client to the server. These sessions are completely independent, even though the LTM can duplicate the tcp source port over to the server side connection in most cases, and depending on your underlying network architecture, can also duplicate the source IP. Max Syn Retransmission This option specifies the maximum number of times the LTM will resend a SYN packet without receiving a corresponding SYN ACK from the server. The default value was four in versions 9.0 - 9.3, and is three in versions 9.4+. This option has iRules considerations with the LB_FAILED event. One of the triggers for the event is an unresponsive server, but the timeliness of this trigger is directly related to the max syn retransmission setting. The back-off timer algorithm for SYN packets effectively doubles the wait time from the previous SYN, so the delay grows excessive with each additional retransmission allowed before the LTM closes the connection: Retransmission Timers v9.0-v9.3 v9.4 Custom-2 Custom-1 Initial SYN 0s 0s 0s 0s 1st Retransmitted SYN 3s 3s 3s 3s 2nd Retransmitted SYN 6s 6s 6s NA 3rd Retransmitted SYN 12s 12s NA NA 4th Retransmitted SYN 24s NA NA NA LB_FAILED triggered 45s 21s 9s 3s Tuning this option down may result in faster response on your LB_FAILED trigger, but keep in mind the opportunity for false positives if your server gets too busy. Note that monitors are the primary means to ensure available services, but the max syn retransmission setting can assist. If the LB_FAILED event does trigger, you can check the monitor status in your iRule, and if the monitor has not yet been marked down, you can do so to prevent other new connections from waiting: when LB_FAILED { if { [LB::status pool [LB::server pool] member [LB::server addr] eq "up"] } { LB::down } } Idle Timeout The explanation of the idle timeout is fairly intuitive. This setting controls the number of seconds the connection remains idle before the LTM closes it. For most applications, the default 300 seconds is more than enough, but for applications with long-lived connections like remote desktop protocol, the user may want to leave the desk and get a cup of coffee without getting dumped but the administrators don't want to enable keepalives. The option can be configured with a numeric setting in seconds, or can be set to indefinite, in which case the abandoned connections will sit idle until a reaper reclaims them or services are restarted. I try to isolate applications onto their own virtual servers so I can maximize the profile settings, but in the case where a wildcard virtual is utilized, the idle timeout can be set in an iRule with the IP::idle_timeout command: when CLIENT_ACCEPTED { switch [TCP::local_port] { "22" { IP::idle_timeout 600 } "23" { IP::idle_timeout 600 } "3389" { IP::idle_timeout 3600 } default { IP::idle_timeout 120 } } If you look at the connection table, the current and the maximum (in parentheses) idle values are shown: b conn client 10.1.1.1 show all | grep –v pkts VIRTUAL 10.1.1.100:3389 <-> NODE any6:any CLIENTSIDE 10.1.1.1:36023 <-> 10.1.1.100:3389 SERVERSIDE 10.1.1.100:36023 <-> 10.1.1.50:3389 PROTOCOL tcp UNIT 1 IDLE 124 (3600) LASTHOP 1 00:02:0a:13:ef:80 Next week, we'll take a look at windows and buffers.1KViews1like1CommentRemote Authorization via Active Directory
A while back I wrote an article on remote authorization via tacacs+. I got a question in the comments yesterday about the same functionality with active directory. I hadn’t done anything with active directory outside of APM, so I wasn’t sure I could help. However, after reading up on a few solutions on askF5 (10929 and 11072 specifically), I gave it a shot and turns out it’s not so difficult at all. For more details on the roles themselves, reference the tacacs+ article. This tech tip will focus solely on defining the administrator and guest roles in the remoterole configuration on BIG-IP and setting up the active directory attributes. Mapping AD Attributes The attribute in the remoterole for active directory will look like this: memberOF=cn=<common name>, ou=<organizational unit>,dc=x,dc=y Let's break down the attribute string: The cn can be a single account, or a group. For example, jason.rahm (single account) or grp-Admins (security group) In the string, they’re represented as such: memberOF=cn=jason.rahm memberOF=cn=grp-Admins The ou is the organization unit where the cn is defined. It can be deeper than one level (So if the OU organization was IT->Ops and IT->Eng, the ou part of the string would like this: ou=Ops,ou=IT ou=Eng,ou=IT The dc is the domain component. So for a domain like devcentral.test, the dc looks like this dc=devcentral,dc=test Putting the examples all together, one attribute would look like this: memberOF=cn=grp-Admins,ou=Ops,ou=IT,dc=devcentral,dc=test Defining the Remote Role Configuration In tmsh, the remote-role configuration is under the auth module. The configuration options available to a specific role (defined under role-info) are shown below (tmos.auth.remote-role)# modify role-info add { F5Guest { ? Properties: "}" Close the left brace attribute Specifies the name of the group of remotely-authenticated users for whom you are configuring specific access rights to the BIG-IP system. This value is required. console Enables or disables console access for the specified group of remotely authenticated users. You may specify bpsh, disabled, tmsh or use variable substitution as describe in the help page. The default value is disabled. deny Enables or disables remote access for the specified group of remotely authenticated users. The default value is disable. line-order Specifies the order of the line in the file, /config/bigip/auth/remoterole. The LDAP and Active Directory servers read this file line by line. The order of the information is important; therefore, F5 recommends that you set the first line at 1000. This allows you, in the future, to insert lines before the first line. This value is required. role Specifies the role that you want to grant to the specified group of remotely authenticated users. The default value is no-access. The available roles and the corresponding number that you use to specify the role are: admin (0), resource-admin (20), user-manager (40), manager (100), application-editor (300), operator (400), guest (700), policy-editor (800) and no-access (900). user-partition Specifies the user partition to which you are assigning access to the specified group of remotely authenticated users. The default value is Common. With that syntax information and the AD attribute strings, I can define both roles: tmsh modify auth remote-role role-info add { F5Admins { attribute memberOF=cn=grp-F5Admins,ou=Groups,dc=devcentral,dc=test console enable line-order 1 role administrator user-partition all } } tmsh modify auth remote-role role-info add { F5Guests { attribute memberOF=cn=grp-F5Staff,ou=Groups,dc=devcentral,dc=test console disabled line-order 2 role guest user-partition all } } Next I confirm the settings took. tmsh show running-config /auth remote-role auth remote-role { role-info { F5Admins { attribute memberOF=cn=grp-F5Admins,ou=Groups,dc=devcentral,dc=test console enable line-order 1 role administrator user-partition all } F5Guests { attribute memberOF=cn=grp-F5Staff,ou=Groups,dc=devcentral,dc=test console disabled line-order 2 role guest user-partition all } } } Configure the BIG-IP to Use Active Directory Here I set the BIG-IP to use ldap authentication, defining my base-dn and the login attribute (samaccountname) and the user template (%s@devcentral.test). tmsh modify auth ldap system-auth login-attribute samaccountname search-base-dn dc=devcentral,dc=test servers add { 192.168.202.110 } user-template %s@devcentral.test And once again confirming the settings: tmsh show running-config /auth ldap system-auth auth ldap system-auth { login-attribute samaccountname search-base-dn dc=devcentral,dc=test servers { 192.168.202.110 } user-template %s@devcentral.test } Testing the Configuration For the test there are two users. test.user belongs the grp-F5Staff cn, and jason.rahm belongs to the grp-F5Admins cn. Therefore, test.user should have Guest access to the GUI and no access to the console, whereas jason.rahm should have Administrator access to the GUI and console access. Let’s see if that’s the case. Conclusion In this tech tip I walked through the steps required to configure remote authorization utilizing the BIG-IP remoterole configuration and Active Directory. I didn’t cover the custom attributes like the in tacacs+ article, but the same process applies, so if you’d rather define the roles within Active Directory that can be done as well.1KViews1like10CommentsBIG-IP APM - Customized Logon Page
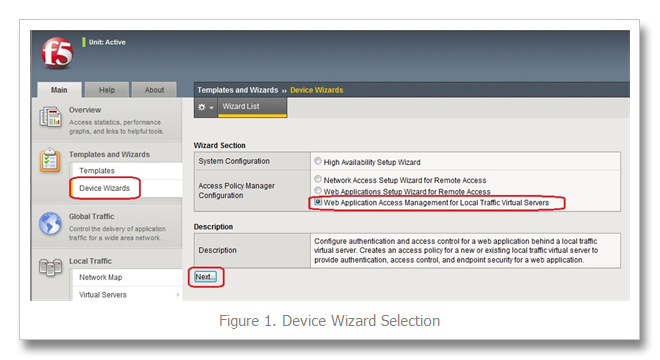
Note: This solution is only applicable to version 10.x, version 11 doesn't use advCustHelp. The default logon page for the Access Policy Manager module is pretty basic, particularly so if only the minimal username and password is configured. However, APM is wildly flexible. In this tech tip, I’ll cover customizing the logon page by adding a dropdown box in addition to the standard username and password fields. Introduction Background Information The goal here is to provide access to multiple web applications behind APM through the use of an admin-defined dropdown menu and different LTM pools for each web application. We will be generating the list dynamically through the use of data groups so there will be no need to manually edit the iRule code each time an admin decides to add another option. Solution Overview Combining advanced customization, data groups, and iRules, we can dynamically generate html code for each key value pair in the data group. We simply add a session variable in the logon page through advanced customization and insert our html code, generated with iRules, through the session variable. The data group serves as a user friendly way of adding more applications as a layer of indirection. Create the Access Policy Before creating the custom logon page, an access policy needs to be defined. This can be done by utilizing the Device Wizards option under the Templates and Wizards main tab. Select Web Application Access Management for Local Traffic Virtual Servers as shown below in Figure 1. Follow the steps in the wizard (AAA server, virtual IP, pool info, etc) to get to the summary page shown below in Figure 2. Before clicking finished, enter the Visual Policy Editor to make a few changes. Immediately after the start box in the VPE, add an iRule Event as show in Figure 3. This will trigger the iRule event ACCESS_POLICY_AGENT_EVENT in the iRule featured later in this article. Make sure to assign an ID to the event before saving it (it's significant only in differentiating the use of multiple iRule events). Next, click on the Logon Page event in the VPE and add a text field immediately after the password field. Set the Post Variable Name and the Session Variable Name to ‘appname’. (The name is not significant but will need to match a statement in the HTML that will be replaced later in the article. This ensures that the logon page agent will know to expect appname as one of the POST parameters.) In the Logon Page Input Field #3 box, enter ‘Application’ and click save. See Figure 4 below for details. Note: The logon page agent will only parse and store POST parameters it knows about. Also, the 'Application' entry in Logon Page Input Field #3 is entered for the sake of completeness, but is technically unnecessary as the custom HTML will override this. Finally, update the access policy by clicking Apply Access Policy and finish the Device Wizard. Customize the Logon Page Now that the policy is created, login via ssh to the command line interface to complete several steps. 1. Change Directory into the specific policy’s logon directory: cd /config/customization/advanced/logon/<policy_name>_act_logon_page_ag (where <policy_name> is your policy name. devCenEx_act_logon_page_ag in this case.) 2. Make a copy of the tmp_logon_en.inc file (the name logon_en.inc is significant.) cp tmp_logon_en.inc logon_en.inc 3. Add group and world read permissions to the logon_en.inc file chmod a+r logon_en.inc 4. Edit and save the logon_en.inc file, replacing this PHP code with the HTML code below it. Notice that the label and select tags reference Applications and appname (respectively) from our Logon Page in Figure 4. PHP (remove) <? //------------------------------------------------------------ foreach( $fields_settings as $field_settings ) { if( $field_settings["type"] != "none" ) { if( $GLOBALS["label_position"] == "above" ){ ?> <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="<? print( $field_settings["type"] ); ?>"><? print( $field_settings["caption"] ); ?></label><input type=<? print( $field_settings["type"] ); ?> name=<? print( $field_settings["name"] ); ?> class="credentials_input_<? print( $field_settings["type"] ); ?>" <? print( ( $field_settings["rw"] == 0 ? "disabled" : "" ) ); ?> value="<? print( $field_settings["value"] ); ?>" autocomplete="off"></td> </tr> <? }else{ ?> <tr> <td class="credentials_table_label_cell" ><? print( $field_settings["caption"] ); ?></td> <td class="credentials_table_field_cell"><input type="<? print( $field_settings["type"] ); ?>" name="<? print( $field_settings["name"] ); ?>" class="credentials_input_<? print( $field_settings["type"] ); ?>" <? print( ( $field_settings["rw"] == 0 ? "disabled" : "" ) ); ?> value="<? print( $field_settings["value"] ); ?>" autocomplete="off"></td> </tr> <? } } } //------------------------------------------------------------ ?> Custom HTML (add) <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="text">Username</label> <input type=text name=username class="credentials_input_text" value="" autocomplete="off" autocapitalize="off"></td> </tr> <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="password">Password</label> <input type=password name=password class="credentials_input_password" value="" autocomplete="off" autocapitalize="off"></td> </tr> <tr> <td colspan=2 class="credentials_table_unified_cell" ><label for="text">Applications</label> <select name="appname"> %{session.custom.logon_opt} </select> </td> </tr> Note: The HTML above can be further customized if desired. The important section of code is: <select name>=”appname”> %{session.custom.logon_opt} </select> The POST variable was created in the Logon page and the session variable will be utilized in the iRule. UPDATE:As an alternative to replacing the php code with html as shown above, the javascript below can be added to the javascript section of the same file: function dropdown(){ var allTDs = document.getElementsByTagName('td'); for(i=0; i < allTDs.length; i++) { if(allTDs[i].innerHTML.indexOf('appname') > 0 && allTDs[i].innerHTML.indexOf('auth_form') == -1) { var replacetext = '<label for="text">Application</label><select name="appname" value="" autocomplete="off">%{session.custom.logon_opt}</select>'; allTDs[i].innerHTML = replacetext; } } } To ensure this javascript is run, insert the dropdown() function shown above in line 1 of the OnLoad() function defined in the same file. 5. Apply the customizations to the policy advCustHelp <your policy name> (The following two commands are included with instructions on updated the access policy when this command is run.) b customization group <your policy_name>_act_logon_page_ag action update b profile access <your policy name> generation action increment 6. Create a string class for the applications. The string should be the name of the application to be displayed in the Logon Page and the value should be the pool that hosts the applicable service. The resulting configuration of the class is shown entered below via bigpipe then via tmsh (See Figure 5 immediatedly after for the GUI entry for the class.) b class ExampleDataGroup '{ { "OWA" { "intranet-pool" } "Share Point" { "sharepoint-pool" } } }' tmsh create /ltm data-group ExampleDataGroup type string records add { "OWA" { data "intranet-pool" } "Share Point" { data "sharepoint-pool" } } 7. Create the iRule (via iRule editor, GUI, or tmsh) when ACCESS_POLICY_AGENT_EVENT { if {[ACCESS::policy agent_id] eq "GenHtml"} { set htmlstr "" # Pull data from the data group set keys [class names ExampleDataGroup] # log local0. "DATA GROUP:: $keys" foreach key $keys { # log local0. "KEY:: $key" # Add a new option in the drop down box for each key append htmlstr "<option value=\"$key\">$key</option>" } # log local0. "HTML STRING:: $htmlstr" # Using the session variable we inserted through advanced customization, # we can insert the html code we generated above ACCESS::session data set "session.custom.logon_opt" $htmlstr } } when ACCESS_ACL_ALLOWED { set appname [ACCESS::session data get "session.logon.last.appname"] # log local0. "appname:: $appname" set value [class search -value ExampleDataGroup equals $appname] # log local0. "value:: $value" if {[string length $value] > 0} { pool $value # log local0. "POOL:: $value" } } Note that the class name referenced in the iRule should match the actual class name (instead of ExampleDataGroup as shown above) 8. Finally, apply the iRule to the APM virtual server and the process is complete! tmsh modify /ltm virtual custom_dropdown_vs rules { custom_dropdown_iRule } Figure 6 below shows the resulting logon page from the customizations performed. This is just the surface of what can be done to customize the logon page. Many thanks to F5er ystephie for writing up the documentation steps for this solution. Related Articles DevCentral Wiki: BIG-IP Access Policy Manager (APM) Wiki Home Auto-launch Remote Desktop Sessions with APM > DevCentral > F5 ... NTLM/ Outlook Anywhere/ Big-IP APM - DevCentral - F5 DevCentral ... Web Application Login Integration with APM > DevCentral > F5 ... F5 Tutorial: BIG-IP APM with SecureAuth Set APM Cookies to HttpOnly - DevCentral - F5 DevCentral ... DevCentral Wiki: APM nested virtuals with APM - DevCentral - F5 DevCentral > Community ... Pete Silva - apm BigIp_VE_10.1.0 — APM module and Hypervisor Support - DevCentral ...1.5KViews1like10Comments
My Buddy Byron: Security iRules
So, I was having lunch with my buddy Byron, who is a fantabulous Sales Engineer here at F5. I know, the world sales sends shivers down my spine to, but trust me, he’s a sharp engineer. We do what most co-workers do at lunch, complain about the weather, the Seahawks, and of course… work. I forget how we got on the topic, but somehow we ended up in a rousing discussion around iRules and their usefulness. Both of us had gotten multiple requests around “Hey, what can iRules do to make me safer”? Luckily for us, Byron being the driven guy he is, took the time to create a fact sheet completely around security iRules. (Disclaimer: This has been slightly modified from original content) Fact Sheet: Security iRules The iRule The Solution Transparent Web App Bot Protection Block illegitimate requests from automated bots that bombard a contact form Distributed Apache Killer Deny application requests that cause a Web server Denial of Service (DoS) DNS Blackhole with iRules Prevent employees from accessing known bad websites at the DNS level Thwart Dictionary Attacks Restrict excessive login attempts using the Exponential Backoff algorithm SSL Renegotiation DOS attack Drop connections that renegotiate SSL sessions more than 5 times a minute So, what you have here are 5 iRules that in 5 minutes can help improve your security posture. Transparent Web Application Bot Protection: This iRule is rather cool alternative to CAPTCHA’s that can work well in situations. It also includes an admin interface iRule. That’s pretty shiny Distributed Apache Killer: We security folks are so lucky. It seems like every other month or so, another “Killer” comes out. The loic, hoic, D-A-K, all as deadly as a Drink Delivering Dalek DNS Blackhole: DNS is all the rage on the interwebs. Dan Kaminski has consistently preached on the importantly of DNS (much tech love/thank to Dan for his work), and rightfully so. The DNS blackhole iRule allows an admin to intercept requests to DNS and respond back with a DNS blocking page. Great application: Known malware sites, HR policy blocks, and of course world of warcraft. It doesn’t stop users from surfing via IP though (keep in mind) Thwart Dictionary Attacks: Brute Force.. it’s a brutal use of force to attempt to login. Attacker simply tries to login with every potential password that a user might choose. Given the time and cycles, they will succeed. So, what do we do? Limit a user to 3 attempts before locking them out for 5 minutes? That could work, but lets look at a more elegant weapon, for a more civilized age The exponential backoff algorithm determines the amount of time a user is locked out, based upon the number of times they failed login attempts during a window. It uses some nifty math to make it all happen. Ssl renegotiation dos attack: Ah the classics. SSL renegotiation was quite in fashion, until it was proven that you can DoS a server with ease from a single system, due to the processing expense of ssl renegotiation. While the F5 was a tougher nut to crack than a standard server, we wanted get out a mitigation quickly, just in case. I want to thank Byron for his great work on putting the document together! Have a great day all. Me and Byron at Lunch186Views1like0CommentsTen Steps to iRules Optimization
Ever wondered whether to use switch or if/else? How about the effects of regular expressions? Or even what the overhead of variables are? We've come up with a list of the top 10 optimization techniques you can follow to write a healthier happier iRule. #1 - Use a Profile First This one seems obvious enough but we continually get questions on the forums about iRules that are already built into the product directly. iRules does add extra processing overhead and will be slower than executing the same features in native code. Granted, they won't be that slow, but any little bit you can save will help you in the long run. So, if you aren't doing custom conditional testing, let the profiles do the work. The following common features implemented in iRules can be handled by native profiles: HTTP header insert and erase HTTP fallback HTTP compress uri <exclude|include> HTTP redirect rewrite HTTP insert X-Forwarded-For HTTP ramcache uri <exclude|include|pinned> Stream profile for content replacement Class profile for URI matching. Even if you do need to do some conditional testing, several of the profiles such as the stream profile will allow you to enable/disable and control the expression directly from the iRule. #2 - A Little Planning Goes A Long Way iRules are fun and it is really easy to find yourself jumping right in and coding without giving proper thought to what you are trying to accomplish. Just like any software project, it will pay off in the long run if you come up with some sort of feature specification and try to determine the best way to implement it. Common questions you can ask yourself include: What are the protocols involved? What commands should I use to achieve the desired result? How can I achieve the desired result in the least amount of steps? What needs to be logged? Where and how will I test it? By taking a few minutes up front, you will save yourself a bunch of rewrites later on. #3 - Understand Control Statements Common control statements include if/elseif/else, switch, and the iRule matchclass/findclass commands with datagroups. The problem is that most of these do the same thing but, depending on their usage, their performance can vary quite a bit. Here are some general rules of thumb when considering which control statement to use: Always think: "switch", "data group", and then "if/elseif" in that order. If you think in this order, then in most cases you will be better off. Use switch for < 100 comparisons. Switches are fastest for fewer than 100 comparisons but if you are making changes to the list frequently, then a data group might be more manageable. Use data groups for > 100 comparisons. Not only will your iRule be easier to read by externalizing the comparisons, but it will be easier to maintain and update. Order your if/elseif's with most frequent hits at the top. If/elseif's must perform the full comparison for each if and elseif. If you can move the most frequently hit match to the top, you'll have much less processing overhead. If you don't know which hits are the highest, think about creating a Statistics profile to dynamically store your hit counts and then modify you iRule accordingly. Combine switch/data group/if's when appropriate. No one said you have to pick only one of the above. When it makes since, embed a switch in an if/elseif or put a matchclass inside a switch. User your operators wisely. "equals" is better than "contains", "string match/switch-glob" is better than regular expressions. The "equals" operator checks to see if string "a" is contained in string "b". If you are trying to do a true comparison, the overhead here is unnecessary - use the "equals" command instead. As for regular expressions, see #4. Use break, return, and EVENT::disable commands to avoid unnecessary iRule processing. Since iRules cannot be broken into procedures they tend to be lengthy in certain situations. When applicable use the "break", "return", or "EVENT::disable" commands to halt further iRule processing. Now, these are not set in stone but just general rules of thumb so use your best judgement. There will always be exceptions to the rule and it is best if you know the cost/benefits to make the right decision for you. #4 - Regex is EVIL! Regex's are cool and all, but are CPU hogs and should be considered pure evil. In most cases there are better alternatives. Bad when HTTP_REQUEST { if { [regex {^/myPortal} [HTTP::uri] } { regsub {/myPortal} [HTTP::uri] "/UserPortal" newUri HTTP::uri $newUri } Good when HTTP_REQUEST { if { [HTTP::uri] starts_with "/myPortal" } { set newUri [string map {myPortal UserPortal [HTTP::uri]] HTTP::uri $newUri } But sometimes they are a necessary evil as illustrated in the CreditCardScrubber iRule. In the cases where it would take dozens or more commands to recreate the functionality in a regular expression, then a regex might be your best option. when HTTP_RESPONSE_DATA { # Find ALL the possible credit card numbers in one pass set card_indices [regexp -all -inline -indices \ {(?:3[4|7]\d{2})(?:[ ,-]?(?:\d{5}(?:\d{1})?)){2}|(?:4\d{3})(?:[ ,-]?(?:\d{4})){3}|(?:5[1-5]\d{2})(?:[ ,-]?(?:\d{4})){3}|(?:6011)(?:[ ,-]?(?:\d{4})){3}} \ [HTTP::payload]] } #5 - Don't Use Variables The use of variables does incur a small amount of overhead that in some cases can be eliminated. Consider the following example where the value of the Host header and the URI are stored in variables and later are compared and logged. These take up additional memory for each connection. when HTTP_REQUEST { set host [HTTP::host] set uri [HTTP::uri] if { $host equals "bob.com" } { log "Host = $host; URI = $uri" pool http_pool1 } } Here is the exact same functionality as above but without the overhead of the variables. when HTTP_REQUEST { if { [HTTP::host] equals "bob.com" } { log "Host = [HTTP::host]; URI = [HTTP::uri]" pool http_pool1 } } You may ask yourself: "Self, who cares about a spare 30 bytes or so?" Well, for a single connection, it's likely no big deal but you need to think in terms of 100's of 1000's of connections per second. That's where even the smallest amount of overhead you can save will add up. Removing those variables could gain you a couple thousand connections per second on your application. And never fear, there is no more overhead in using the builtin commands like [HTTP::host] over a varable reference as both are just direct pointers to the data in memory. #6 - Use Variables Now that I've told you not to use variables, here's the case where using variables makes sense. When you need to do repetitive costly evaluations on a value and can avoid it by storing that evaluation in a variable, then by all means do so. Bad - Too many memory allocations when HTTP_REQUEST { if { [string tolower [HTTP::uri]] starts_with "/img" } { pool imagePool } elseif { ([string tolower [HTTP::uri]] ends_with ".gif") || ([string tolower [HTTP::uri]] ends_with ".jpg") } { pool imagePool } } Bad - The length of a variable name can actually consume more overhead due to the way TCL stores variables in lookup tables. when HTTP_REQUEST { set theUriThatIAmMatchingInThisiRule [string tolower [HTTP::uri]] if { $theUriThatIAmMatchingInThisiRule starts_with "/img" } { pool imagePool } elseif { ($theUriThatIAmMatchingInThisiRule ends_with ".gif") || ($theUriThatIAmMatchingInThisiRule ends_with ".jpg") } { pool imagePool } } Good - Keep your variables names to a handful of characters. when HTTP_REQUEST { set uri [string tolower [HTTP::uri]] if { $uri starts_with "/img" } { pool imagePool } elseif { ($uri ends_with ".gif") || ($uri ends_with ".jpg") } { pool imagePool } } #7 - Understand Polymorphism TCL is polymorphic in that variables can "morph" back and forth from data type to data type depending on how it is used. This makes loosly-typed languages like TCL easier to work with since you don't need to declare variables as a certain type such as integer or string but it does come at a cost. You can minimize those costs by using the correct operators on your data types. Use the correct operator for the correct type. Use eq,ne when comparing strings. Use ==,!= when comparing numbers Use [IP::addr] when comparing IP addresses. If you aren't careful, things may not be what they seem as illustrated below set x 5 if { $x == 5 } { } # evaluates to true if { $x eq 5 } { } # evaluates to true if { $x == 05 } { } # evaluates to true if { $x eq 05 } { } # evaluates to false #8 - Timing The timing iRule command is a great tool to help you eek the best performance out of your iRule. CPU cycles are stored on a per event level and you can turn "timing on" for any and all of your events. These CPU metrics are stored and can be retrieved by the bigpipe CLI, the administrative GUI, or the iControl API. The iRule Editor can take these numbers and convert them into the following statistics CPU Cycles/Request Run Time (ms)/Request Percent CPU Usage/Request Max Concurrent Requests Just make sure you turn those timing values off when you are done optimizing your iRule as that will have overhead as well! #9 - Use The Community DevCentral is a great resource whether you are just starting your first iRule or a seasoned veteran looking for advice on something you may have overlooked. The forums and wikis can be a life saver when trying to squeeze every bit of performance out of your iRule. #10 - Learn about the newest features Read the release documentation for new BIG-IP releases as we are constantly adding new functionalty to make your iRules faster. For instance, look for the upcoming "class" command to make accessing your data groups lightning fast. Conclusion Take these 10 tips with you when you travel down the road of iRule development and you will likley have a faster iRule to show for it. As always, if you have any tips that you've found to be helpful when optimizing your iRules, please pass them along and we'll add them to this list. Get the Flash Player to see this player. 20081030-iRulesOpt_TenSteps.mp31.3KViews1like2Comments