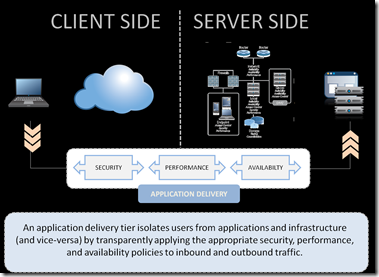
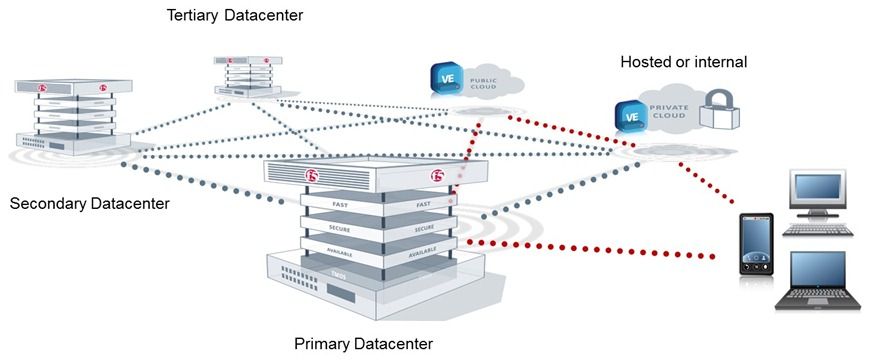
He Who Defends Everything Defends nothing… Right?
There has been much made in Information Technology about the military quote: “He Who Defends Everything Defends Nothing” – Originally uttered by Frederick The Great of Prussia. He has some other great quotes, check them out when you have a moment. The thing is that he was absolutely correct in a military or political context. You cannot defend every inch of ground or even the extent of a very long front with a limited supply of troops. You also cannot refuse to negotiate on all points in the political arena. The nature of modern representative government is such that the important things must be defended and the less important offered up in trade for getting other things you want or need. In both situations, demanding that everything be saved results in nothing being saved. Militarily because you will be defeated piecemeal with your troops spread out, and politically because your opponent has no reason to negotiate with you if you are not willing to give on any issue at all. But in high tech, things are a little more complex. That phrase is most often uttered to refer to defense against hacking attempts, and on the surface seems to fit well. But with examination, it does not suit the high-tech scenario at all. While defense in depth is important in datacenter defense, just in case someone penetrates your outer defenses. But we all know that there are one or two key choke-points that allow you to stop intruders who do not have inside help – your Internet connections. If those are adequately protected, the chances of your network being infiltrated, your website taken down, or any of a million other ugly outcomes are much smaller. The problem, in the 21st century, is the definition of “adequate”. Recent attacks have taken down firewalls previously assumed to be “adequate”, and the last several years have seen a couple of spectacular DNS vulnerabilities focusing on a primary function that had seriously seen little attention from attackers or security folks. In short, the entire face you present to the world is susceptible to attack. And at the application layer, attacks can slip through your outer defenses pretty easily. That’s why the future network defensive point for the datacenter will be a full proxy at the Strategic Point of Control where your network connects to the Internet. Keeping attacks from dropping your network requires a high-speed connection in front of all available resources. The Wikileaks attacks took out a few more than “adequate” firewalls, while the DNS vulnerabilities attacked DNS through its own protocol. A device in the strategic point of control between the Internet and your valuable resources needs to be able handle high-volume attacks and be resilient enough to respond to new threats be they at the protocol or application layers. It needs to be intelligent enough to compare user/device against known access allowances and quarantine the user appropriately if things appear fishy. It also needs to be adaptable enough to adapt to new attacks before they overwhelm the network. Zero day attacks by definition almost never have canned fixes available, so waiting for your provider to plug the hole is a delay that you might not be able to afford. That requires the ability for you to work in fixes and an environment that encourages the sharing of fixes – like DevCentral or a similar site. So that you can quickly solve the problem either by identifying the problem and creating a fix, or by downloading someone else’s fix and installing it. While an “official” solution might follow, and eventually the app will get patched, you are protected in the interim. You can defend everything by placing the correct tool at the correct location. You can manage who has access to what, from which devices, when, and how they authenticate. All while protecting against DOS attacks that cripple some infrastructures. That’s the direction IT needs to head. We spend far too many resources and far too much brainpower on defending rather than enabling. Time to get off the merry-go-round, or at least slow it down enough that you can return your focus to enabling the business and worry less about security. Don’t expect security concerns will ever go away though, because we can – and by the nature of the threats must – defend everything.1.8KViews0likes0CommentsDatabases in the Cloud Revisited
A few of us were talking on Facebook about high speed rail (HSR) and where/when it makes sense the other day, and I finally said that it almost never does. Trains lost out to automobiles precisely because they are rigid and inflexible, while population densities and travel requirements are highly flexible. That hasn’t changed since the early 1900s, and isn’t likely to in the future, so we should be looking at different technologies to answer the problems that HSR tries to address. And since everything in my universe is inspiration for either blogging or gaming, this lead me to reconsider the state of cloud and the state of cloud databases in light of synergistic technologies (did I just use “synergistic technologies in a blog? Arrrggghhh…). There are several reasons why your organization might be looking to move out of a physical datacenter, or to have a backup datacenter that is completely virtual. Think of the disaster in Japan or hurricane Katrina. In both cases, having even the mission critical portions of your datacenter replicated to the cloud would keep your organization online while you recovered from all of the other very real issues such a disaster creates. In other cases, if you are a global organization, the cost of maintaining your own global infrastructure might well be more than utilizing a global cloud provider for many services… Though I’ve not checked, if I were CIO of a global organization today, I would be looking into it pretty closely, particularly since this option should continue to get more appealing as technology continues to catch up with hype. Today though, I’m going to revisit databases, because like trains, they are in one place, and are rigid. If you’ve ever played with database Continuous Data Protection or near-real-time replication, you know this particular technology area has issues that are only now starting to see technological resolution. Over the last year, I have talked about cloud and remote databases a few times, talking about early options for cloud databases, and mentioning Oracle Goldengate – or praising Goldengate is probably more accurate. Going to the west in the US? HSR is not an option. The thing is that the options get a lot more interesting if you have Goldengate available. There are a ton of tools, both integral to database systems and third-party that allow you to encrypt data at rest these days, and while it is not the most efficient access method, it does make your data more protected. Add to this capability the functionality of Oracle Goldengate – or if you don’t need heterogeneous support, any of the various database replication technologies available from Oracle, Microsoft, and IBM, you can seamlessly move data to the cloud behind the scenes, without interfering with your existing database. Yes, initial configuration of database replication will generally require work on the database server, but once configured, most of them run without interfering with the functionality of the primary database in any way – though if it is one that runs inside the RDBMS, remember that it will use up CPU cycles at the least, and most will work inside of a transaction so that they can insure transaction integrity on the target database, so know your solution. Running inside the primary transaction is not necessary, and for many uses may not even be desirable, so if you want your commits to happen rapidly, something like Goldengate that spawns a separate transaction for the replica are a good option… Just remember that you then need to pay attention to alerts from the replication tool so that you don’t end up with successful transactions on the primary not getting replicated because something goes wrong with the transaction on the secondary. But for DBAs, this is just an extension of their daily work, as long as someone is watching the logs. With the advent of Goldengate, advanced database encryption technology, and products like our own BIG-IPWOM, you now have the ability to drive a replica of your database into the cloud. This is certainly a boon for backup purposes, but it also adds an interesting perspective to application mobility. You can turn on replication from your data center to the cloud or from cloud provider A to cloud provider B, then use VMotion to move your application VMS… And you’re off to a new location. If you think you’ll be moving frequently, this can all be configured ahead of time, so you can flick a switch and move applications at will. You will, of course, have to weigh the impact of complete or near-complete database encryption against the benefits of cloud usage. Even if you use the adaptability of the cloud to speed encryption and decryption operations by distributing them over several instances, you’ll still have to pay for that CPU time, so there is a balancing act that needs some exploration before you’ll be certain this solution is a fit for you. And at this juncture, I don’t believe putting unencrypted corporate data of any kind into the cloud is a good idea. Every time I say that, it angers some cloud providers, but frankly, cloud being new and by definition shared resources, it is up to the provider to prove it is safe, not up to us to take their word for it. Until then, encryption is your friend, both going to/from the cloud and at rest in the cloud. I say the same thing about Cloud Storage Gateways, it is just a function of the current state of cloud technology, not some kind of unreasoning bias. So the key then is to make sure your applications are ready to be moved. This is actually pretty easy in the world of portable VMs, since the entire VM will pick up and move. The only catch is that you need to make sure users can get to the application at the new location. There are a ton of Global DNS solutions like F5’s BIG-IP Global Traffic Manager that can get your users where they need to be, since your public-facing IPs will be changing when moving from organization to organization. Everything else should be set, since you can use internal IP addresses to communicate between your application VMs and database VMs. Utilizing a some form of in-flight encryption and some form of acceleration for your database replication will round out the solution architecture, and leave you with a road map that looks more like a highway map than an HSR map. More flexible, more pervasive.365Views0likes0CommentsTake a Peer To Lunch. Regularly.
#F5Networks There is a wealth of information out there, don’t forget to tap into it. Note: When I say “peers” and “lunch” throughout this blog, I am not only referring to IT management. No matter your position in the organization, gathering useful information is always a benefit. Though you’ll want management’s support for the bit where I suggest a two hour lunch. Some IT shops frown on that, even if it’s only occasionally. In many industries, it is all about word of mouth. I’m not talking about tech-savvy industries that have just rediscovered this truth since Social Media made it impossible for them to ignore, I’m talking about industries for whom it has always been about word of mouth… Take lawn care, child care, and household maintenance for example. In all three cases, most people will hesitate to invite a stranger into their home (or give them access to their children) without a recommendation of someone they trust. This has always been the case, and savvy business people in these markets tend to know that. Once you get into a social circle, it can do good things for your business, if you do a good job. We don’t hesitate to share our likes and dislikes with our friends – offline – and in case you missed it, we don’t hesitate to share some of our likes and dislikes online. The thing is that everyone is well served by this principal. While it is hard for a business to get started in such an environment, there is always someone who is willing to take a risk and hire without recommendations, and once they do, a good job can lead to more recommendations. Customers who want to be cautious get recommendations from friends in casual conversation, and don’t have to go hire someone they know little about. The trust of someone you trust is enough, in most cases, to settle your concerns. Yet most people don’t take this trend into the workplace. At least not in most businesses bigger than a startup. And that, IMO, is a mistake. I’ve heard people dismiss peer’s opinions as, well, opinionated. And of course they’re opinionated, but they’re also just like you – trying to solve problems for the business. The needs of one IT shop, even in a different industry, are often the needs of another. Particularly in regards to infrastructure items like databases, security, networking, and even the physical servers. When doing research into an area that is new for you or you are uncertain of, the first thing you should do is ask peers. Their advice – unlike analysts – is free, and it is forged in the same type of environment your advice would be. That makes it valuable in a way that most other advice is not. Will they have favorites? Yes. You chose product X for a reason. If that reason is satisfied completely by product X, then you’re going to have good things to say about it. If that reason is not though, you’ll have bad things to say about it. The same is true exactly for your peers. But the advice – if properly framed – is invaluable, because it’s based on actual production experience. So I would recommend that you take your local peers to lunch regularly, perhaps taking turns footing the bill, and make it a longer lunch. Not “longer than you usually take”, because Ramen between meetings is very quick, but along the lines of a couple of hours. It’s an investment in both networking and peer advice. Talking about things you’re looking into, without mentioning what the overall business project is, can offer up alternative views to the products you’re considering. And that can save both time and money. Will the advice always suit your needs? No. That’s why I recommend it as the first thing you should do, not the only thing. You still have to do research with your own department’s needs in mind, but if your peer Leia, whom you’ve grown to trust over many lunches says “That company Empire? Yeah, they’re unresponsive and after the sale, their reps are very hostile”, then you have information that much research just isn’t going to turn up, but is important to the decision making process. If nothing else, it gives you something to watch for when negotiating the IT contract for Alderon. And you’ll get lunch with peers, where you can share anecdotes, perhaps even make some life-long friends. Let’s face it, you’re not going to ask for and give advice for two hours solid, even if you only meet once a month (I recommend every two weeks, but that’s up to you). And no, I don’t recommend the big formal peer gatherings. A regular meeting with a small group will allow people to gradually let down their defenses and offer each other unfiltered advice. Finding peers is easy. You know who they are – or at least some of them who know some of them. I wouldn’t make the group too big, our Geek Lunch Crowd topped out at around 12, and we still missed some great conversation because at ten or so it starts to splinter along the length of the table. But finding ten people who share your job but in other organizations should be easy. They’re not exactly hiding, and if you don’t know anyone to start this with, ask coworkers for suggestions. Your business will be better served. I’ve seen these lunches answer vexing problems, serve up plenty of opinion, and offer an outlet for frustration with vendors, employers, contractors, and even family.340Views0likes0CommentsDNS Architecture in the 21st Century
It is amazing if you stop and think about it, how much we utilize DNS services, and how little we think about them. Every organization out there is running DNS, and yet there is not a ton of traction in making certain your DNS implementation is the best it can be. Oh sure, we set up a redundant pair of DNS servers, and some of us (though certainly not all of us) have patched BIND to avoid major vulnerabilities. But have you really looked at how DNS is configured and what you’ll need to keep your DNS moving along? If you’re looking close at IPv6 or DNSSEC, chances are that you have. If you’re not looking into either of these, you probably aren’t even aware that ISC – the non-profit responsible for BIND – is working on a new version. Or that great companies like Infoblox (fair disclosure, they’re an F5 partner) are out there trying to make DNS more manageable. With the move toward cloud computing and the need to keep multiple cloud providers available (generally so your app doesn’t go offline when a cloud provider does, but at a minimum for a negotiation tool), and the increasingly virtualized nature of our application deployments, DNS is taking on a new importance. In particular, distributed DNS is taking on a new importance. What a company with three datacenters and two cloud providers must do today, only ISPs and a few very large organizations did ten years ago. And that complexity shows no signs of slacking. While the technology that is required to operate in a multiple datacenter (whether those datacenters are in the cloud or on your premise) environment is available today, as I alluded to above, most of us haven’t been paying attention. No surprise with the number of other issues on our plates, eh? So here’s a quick little primer to give you some ideas to start with when you realize you need to change your DNS architecture. It is not all-inclusive, the point is to give you ideas you can pursue to get started, not teach you all that some of the experts I spent part of last week with could offer. In a massively distributed environment, DNS will have to direct users to the correct location – which may not be static (Lori tells me the term for this is “hyper-hybrid”) In a IPv6/IPv4 world, DNS will have to serve up both types of addresses, depending upon the requestor Increasingly, DNSSEC will be a requirement to play in the global naming game. While most orgs will go there with dragging feet, they will still go The failure of a cloud, or removal of a cloud from the list of options for an app (as elasticity contracts) will require dynamic changes in DNS. Addition will follow the same rules Multiple DNS servers in multiple locations will have to remain synched to cover a single domain. So the question is where do you begin if you’re like so many people and vaguely looked into DNSSEC or DNS for IPv6, but haven’t really stayed up on the topic. That’s a good question. I was lucky enough to get two days worth of firehose from a ton of experts – from developers to engineers configuring modern DNS and even a couple of project managers on DNS projects. I’ll try to distill some of that data out for you. Where it is clearer to use a concrete example or specific terminology, as almost always that example will be of my employer or a partner. From my perspective it is best to stick to examples I know best, and from yours, simply call your vendor and ask if they have similar functionality. Massively distributed is tough if you are coming from a traditional DNS environment, because DNS alone doesn’t do it. DNS load balancing helps, but so does the concept of a Wide IP. That’s an IP that is flexible on the back end, but static on the front end. Just like when load balancing you have a single IP that directs users to multiple servers, a Wide IP is a single IP address that directs people to multiple locations. A Wide IP is a nice abstraction to actively load balance not just between servers but between sites. It also allows DNS to be simplified when dealing with those multiple sites because it can route to the most appropriate instance of an application. Today most appropriate is generally defined by geographically closest, but in some cases it can include things like “send our high-value customers to a different datacenter”. There are a ton of other issues with this type of distribution, not the least of which is database integrity and primary sourcing, but I’m going to focus on the DNS bit today, just remember that DNS is a tool to get users to your systems like a map is a tool to get customers to your business. In the end, you still have to build the destination out. DNS that supports IPv4 and IPv6 both will be mandatory for the foreseeable future, as new devices come online with IPv6 and old devices persist with IPv4. There are several ways to tackle this issue, from the obvious “leave IPv4 running and implement v6 DNS” to the less common “implement a solution that serves up both”. DNSSEC is another tough one. It adds complexity to what has always been a super-simplistic system. But it protects your corporate identity from those who would try to abuse it. That makes DNSSEC inevitable, IMO. Risk management wins over “it’s complex” almost every time. There are plenty of DNSSEC solutions out there, but at this time DNSSEC implementations do not run BIND. The update ISC is working on might change that, we’ll have to see. The ability to change what’s behind a DNS name dynamically is naturally greatly assisted by the aforementioned Wide IPs. By giving a constant IP that has multiple variable IPs behind it, adding or removing those behind the Wide IP does not suffer the latency that DNS propagation requires. Elasticity of servers servicing a given DNS name becomes real simply by the existence of Wide IPs. Keeping DNS servers synched can be painful in a dynamic environment. But if the dynamism is not in DNS address responses, but rather behind Wide IPs, this issue goes away also. The DNS servers will have the same set of Name/address pairs that require changes only when new applications are deployed (servers is the norm for local DNS, but for Wide-IP based DNS, servers can come and go behind the DNS service with only insertion into local DNS, while a new application might require a new Wide-IP and configuration behind it). Okay, this got long really quickly. I’m going to insert an image or two so that there’s a graphical depiction of what I’m talking about, then I’m going to cut it short. There’s a lot more to say, but don’t want to bore you by putting it all in a single blog. You’ll hear from me again on this topic though, guaranteed. Related Articles and Blogs F5 Friday: Infoblox and F5 Do DNS and Global Load Balancing Right. How to Have Your (VDI) Cake and Deliver it Too F5 BIG-IP Enhances VMware View 5.0 on FlexPod Let me tell you Where To Go. Carrier Grade DNS: Not your Parents DNS Audio White Paper - High-Performance DNS Services in BIG-IP ... Enhanced DNS Services: For Administrators, Managers and Marketers The End of DNS As We Know It DNS is Like Your Mom F5 Video: DNS Express—DNS Die Another Day339Views0likes0CommentsWindow Coverings and Security
Note: While talking about this post with Lori during a break, it occurred to me that you might be thinking I meant “MS Windows”. Not this time, but that gives me another blog idea… And I’ll sneak in the windows –> Windows simile somewhere, no doubt. Did you ever ponder the history of simple things like windows? Really? They evolved from open spaces to highly complex triple-paned, UV resistant, crank operated monstrosities. And yet they serve basically the same purpose today that they did when they were just openings in a wall. Early windows were for ventilation and were only really practical in warm locales. Then shutters came along, which solved the warm/cold problem and kept rain off the bare wood or dirt floors, but weren’t very air tight. So to resolve that problem, a variety of materials from greased paper to animal hides were used to cover the holes while letting light in. This progression was not chronologically linear, it happened in fits and starts, with some parts of the world and social classes having glass windows long before the majority of people could afford it. When melted sand turned out to be relatively see-through though, the end was inevitable. Glass was placed into windows so the weather stayed mostly out while the sun came in. The ability to open windows helped to “air out” a residence or business on nice warm days, and closing them avoided excessive heat loss on cold days. At some point, screens came along that kept bugs and leaves out when they were open. Then artificial glass and double-paned windows came along, and now there are triple paned windows that you can buy with blinds built into the frame, that you can open fully, flip down, and clean the outside of without getting a ladder and taking a huge chunk of your day. Where are windows headed next? I don’t know. This development of seemingly unrelated things –screens and artificial glass and crankable windows – came about because people were trying to improve their environment. And that, when it comes down to it, is why we see advancement in any number of fields. In IT security, we have Web Application Firewalls to keep application-targeting attacks out, while we have SSL to keep connections secure, and we have firewalls to keep generic attacks out, while deploying anti-virus to catch anything that makes it through. And that’s kind of like the development of windows, screens, awnings or curtains… All layers built up through experience to tackle the problem of letting the good (sunshine) in, while keeping the bad (weather, dust, cold) out. Curtains even provide an adjustable filter for sunlight to come through. Open them to get more light in, close them to get less… Because there is a case where too much of a good thing can be bad. Particularly if your seat at the dining room table is facing the window and the window is facing directly east or west. We’re at a point in the evolution of corporate security where we need to deploy these various technologies together to do much the same with our public network that windows do with the outside. Filter out the bad in its various forms and allow the good in. Even have the ability to crank down on the good so we can avoid getting too much of a good thing. Utilizing an access solution to allow your employees access to the systems they require from anywhere or any device enables the business to do their job, while protecting against any old hacker hopping into your systems – it’s like a screen that allows the fresh air in, but filters out the pests. Utilizing a solution that can protect publicly facing applications from cross site scripting and SQL injection attacks is also high on the list of requirements – or should be. Even if you have policies to force your developers into checking for such attacks in all of their code, you still have purchased apps that might need exposing, or a developer might put in an emergency fix to a bug that wasn’t adequately security tested. It’s just a good idea to have this functionality in the network. That doesn’t even touch upon certification and audit reasons for running one, and they are perhaps the biggest drivers. Since I mentioned compliance, a tool that offers reporting is like when the sun shining in the window makes things too warm. You know when you need to shut the curtains – or tighten your security policy, as the case may be. XML firewalls are handy when you’re using XML as a communications method and want to make certain that a hacker didn’t mock up anything from an SQL Injection attack hidden in XML to an “XML bomb” type attack, and when combined with access solutions and web application firewalls, they’re another piece of our overall window(s) covering. If you’re a company whose web presence is of utmost importance, or one where a sizeable or important part of your business is conducted through your Internet connection, then DoS/DDoS protection is just plain and simply a good idea. Indeed, if your site isn’t available, it doesn’t matter why, so DDoS protection should be on the mandatory checklist. SSL encryption is a fact of life in the modern world, and another one of those pieces of the overall window(s) covering that allows you to communicate with your valid users but shut out the invalid or unwanted ones. If you have employees accessing internal systems, or customers making purchases on your website, SSL encryption is pretty much mandatory. If you don’t have either of those use cases, there are still plenty of good reasons to keep a secure connection with your users, and it is worth considering, if you have access to the technology and the infrastructure to handle it. Of course, it is even cooler if you can do all of the above and more on a single high-performance platform designed for application delivery and security. Indeed, a single infrastructure point that could handle these various tasks would be very akin to a window with all of the bells and whistles. It would keep out the bad, let in the good, and through the use of policies (think of them as cur tains) allow you to filter the good so that you are not letting too much in. That platform would be F5BIG-IPLTM, ASM, and APM. Maybe with some EDGE Gateways thrown in there if you have remote offices. All in one place, all on a single bit of purpose-built high-performance Application Delivery Network hardware. It is indeed worth considering. In this day and age, the external environment of the Internet is hostile, make certain you have all of the bits of security/window infrastructure necessary to keep your organization from being the next corporation to have to send data breach notifications out. Not all press is good press, and that’s one we’d all like to avoid. Review your policies, review your infrastructure, make sure you’re getting the most from your security architecture, and go home at the end of the day knowing you’re protecting corporate assets AND enabling business users. Because in the end, that’s all part of IT’s job. Just remember to go back and look it over again next year if you are one of the many companies who doesn’t have dedicated security staff watching this stuff. It’s an ugly Internet out there, you and your organization be careful…289Views0likes0CommentsIs it time for a new Enterprise Architect?
After a short break to get some major dental rework done, I return to you with my new, sore mouth for a round of “Maybe we should have…” discussions. In the nineties and early 21st century, positions were created in may organizations with titles like “chief architect” and often there was a group whose title were something like “IT Architect”. These people made decisions that impacted one or all subsidiaries of an organization, trying to bring standardization to systems that had grown organically and were terribly complex. They ushered in standards, shared code between disparate groups, made sure that AppDev and Network Ops and Systems Admins were all involved in projects that touched their areas. The work they did was important to the organization, and truly different than what had come before. Just like in the 20th century the concept of a “Commander of Army Group” became necessary because the armies being fielded were so large that you needed an overall commander to make sure the pieces were working together, the architect was there (albeit with far less power than an Army Group commander) to make sure all the pieces fit together. Through virtualization, they managed to keep the ball rolling, and direct things such that a commitment to virtualization was applied everywhere it made sense. Organizations without this role did much the same, but those with this role had a person responsible for making sure things moved along as smoothly as a major architecture change that impacts users, systems, apps, and networks can. Steve Martin in Little Shop of Horrors I worked on an enterprise architecture team for several years in the late 90s, and the work was definitely challenging, and often frustrating, but was a role (at least at the insurer I worked for) that had an impact on cutting waste out of IT and building a robust architecture in apps, systems, and networks. The problem was that network and security staff were always a bit distanced from architecture. A couple of companies whose architects I hung out with (Southwestern Bell comes to mind) had managed to drive deep into the decision making process for all facets of IT, but most of us were left with systems and applications being primary and having to go schmooze and beg to get influence in the network or security groups. Often we were seen as outsiders telling them what to do, which wasn’t the case at all. For the team we were on, if one subsidiary had a rocking security bit, we wanted it shared across the other subsidiaries so they would all benefit from this work the organization had already paid for. It was tough work, and some days you went home feeling as if you’d accomplished nothing. But when it all came together, it was a great job to have. You saw almost every project the organization was working on, you got to influence their decisions, and you got to see the project implemented. It was a fun time. Now, we face a scenario in networking and network architecture that is very similar to that faced by applications back then. We have to make increasingly complex networking decisions about storage, app deployment, load distribution, and availability. And security plays a critical role in all of these choices because if your platform is not secure, none of the applications running on it are. We use the term “Network architecture” a lot, and some of us even use it to describe all the possibilities – Internal, SaaS providers, cross-datacenter WAN, the various cloud application/platform providers, and cloud storage… But maybe it is time to create a position that can juggle all of these balls and get applications to the right place. This person could work with business units to determine needs, provide them with options about deployment that stress strengths and weaknesses in terms of their application, and make sure that each application lives in a “happy place” where all of its needs are met, and the organization is served by the locality. We here at F5, along with many other infrastructure vendors, are increasingly offering virtual versions of our products, in our case the goal is to allow you to extend the impact of our market leading ADC and File Virtualization appliances to virtualized and cloud environments. I won’t speak for other vendors about why they’re doing it, each has a tale to tell that I wouldn’t do justice to. But the point of this blog is that all of these options… In the cloud, or reserve capacity in the cloud? What impact does putting this application in the cloud have on WAN bandwidth? Can we extend our application firewall security functionality to protect this application if it is sent out to the cloud? Would an internal virtualized deployment be a better fit for the volume of in-datacenter database accesses that this particular application makes? Can we run this application from multiple datacenters and share the backend systems somehow, and if so what is the cost? These are the exact types of questions that a dedicated architect, specialized in deployment models, could ask and dig to find the answers to. It would be just like the other architecture team members, but more focused on getting the most out of where an application is deployed and minimizing the impacts of choices one application team makes upon everyone else. I think it’s time. A network architect worries mostly about the internal network, and perhaps some of the items above, we should use a different title. I know it’s been abused in the past, but extranet architect might be a good title. Since they would need to increasingly be able to interface with business units and explain choices and impacts, I think I prefer application locality architect… But that makes light of some of the more technical aspects of the job, like setting up load balancing in a cloud – or at least seeing to it that someone is. Like other architecture jobs, it would be a job of influence, not command. The role is to find the best solution given the parameters of the problem, and then sell the decision makers on why they are the right choice. But that role works well for all the other enterprise architect jobs, just takes a certain type of personality to get it done. Nothing new there, so knowledge of all of the options available would become the largest requirement… How costs of a cloud deployment at vendor X compare to costs of virtual deployment, what the impact of cloud-based applications are on the WAN (given application parameters of course), etc. There are a ton of really smart people in IT, so finding someone capable of digesting and utilizing all of that information may be easier than finding someone who can put up with “You may have the right solution, but for political reasons, we’re going to do this really dumb thing instead” with equanimity. And for those of you who already have a virtualization or cloud architect… Well that’s just a bit limiting if you have multiple platform choices and multiple deployment avenues. Just like there were application architects and enterprise architecture used their services, so would it be with this role and those specialized architects.286Views0likes1CommentMore Complexity, New Problems, Sounds Like IT!
It is a very cool world we live in, where technology is concerned. We’re looking at a near future where your excess workload, be it applications or storage, can be shunted off to a cloud. Your users have more power in their hands than ever before, and are chomping at the bit to use it on your corporate systems. IBM recently announced a memory/storage breakthrough that will make Flash disks look like 5.25 inch floppies. While we can’t know what tomorrow will bring, we can certainly know that the technology will enable us to be more adaptable, responsive, and (yes, I’ll say it) secure. Whether we actually are or not is up to us, but the tools will be available. Of course, as has been the case for the last thirty years, those changes will present new difficulties. Enabling technology creates issues… Which create opportunity for emerging technology. But we have to live through the change, and deal with making things sane. In the near future, you will be able to send backup and replication data to the cloud, reducing your on-site storage and storage administration needs by a huge volume. You can today, in fact, with products like F5’s ARX Cloud Extender. You will also be able to grant access to your applications from an increasing array of endpoint devices, again, you can do it today, with products like F5’s ASM for VPN access and APM for application security, but recent surveys and events in the security space should be spurring you to look more closely into these areas. SaaS is cool again in many areas that it had been ruled out – like email – to move the expense of relatively standardized high volume applications out of the datacenter and into the hands of trusted vendors. You can get email “in the cloud” or via traditional SaaS vendors. That’s just some of the changes coming along, and guess who is going to implement these important changes, be responsible for making them secure, fast, and available? That would be IT. To frame the conversation, I’m going to pillage some of Lori’s excellent graphics and we’ll talk about what you’ll need to cover as your environment changes. I won’t use the one showing little F5 balls on all of the strategic points of control, but if we have one. First, the points of business value and cost containment possible on the extended datacenter network. Notice that this slide is couched in terms of “how can you help the business”. Its genius is that Lori drew an architecture and then inserted business-relevant bits into it, so you can equate what you do every day to helping the business. Next up is the actual Strategic Points of Control slide, where we can see the technological equivalency of these points. So these few points are where you can hook in to the existing infrastructure offer you enhanced control of your network – storage, global, WAN, LAN, Internet clients – by putting tools into place that will act upon the data passing through them and contain policies and programmability that give you unprecedented automation. The idea here is that we are stepping beyond traditional deployments, to virtualization, remote datacenters, cloud, varied clients, ever-increasing storage (and cloud storage of course), while current service levels and security will be expected to be maintained. That’s a tall order, and stepping up the stack a bit to put strategic points of control into the network helps you manage the change without killing yourself or implementing a million specialized apps, policies, and procedures just to keep order and control costs. At the Global Strategic Point of Control, you can direct users to a working instance of your application, even if the primary application is unavailable and users must be routed to a remote instance. At this same place, you can control access to restricted applications, and send unauthorized individuals to a completely different server than the application they were trying to access. That’s the tip of the iceberg, with load balancing to local strategic points of control being one of the other uses that is beyond the scope of this blog. The Local Strategic Point of Control offers performance, reliability, and availability in the guise of load balancing, security in the form of content-based routing and application security – before the user has hit the application server – and encryption of sensitive data flowing internally and/or externally, without placing encryption burdens on your servers. The Storage Strategic Point of Control offers up tiering and storage consolidation through virtual directories, heterogeneous security administration, and abstraction of the NAS heads. By utilizing this point of control between the user and the file services, automation can act across vendors and systems to balance load and consolidate data access. It also reduces management time for endpoint staff, as the device behind a mount/map point can be changed without impacting users. Remote site VPN extension and DMZ rules consolidation can happen at the global strategic point of control at the remote site, offering a more hands-off approach to satellite offices. Note that WAN Optimization occurs across the WAN, over the Local and global strategic points of control. Web Application Optimization also happens at the global or local strategic point of control, on the way out to the end point device. What’s not shown is a large unknown in cloud usage – how to extend the control you have over the LAN out to the cloud via the WAN. Some things are easy enough to cover by sending users to a device in your datacenter and then redirecting to the cloud application, but this can be problematic if you’re not careful about redirection and bookmarks. Also, it has not been possible for symmetric tools like WAN Optimization to be utilized in this environment. Virtual appliances like BIG-IP LTM VE are resolving that particular issue, extending much of the control you have in the datacenter out to the cloud. I’ve said before, the times are still changing, you’ll have to stay on top of the new issues that confront you as IT transforms yet again, trying to stay ahead of the curve. Related Blogs: Like Load Balancing WAN Optimization is a Feature of Application ... Is it time for a new Enterprise Architect? Virtual Infrastructure in Cloud Computing Just Passes the Buck The Cloud Computing – Application Acceleration Connection F5 Friday: Secure, Scalable and Fast VMware View Deployment Smart Energy Cloud? Sounds like fun. WAN Optimization is not Application Acceleration The Three Reasons Hybrid Clouds Will Dominate F5 Friday: BIG-IP WOM With Oracle Products Oracle Fusion Middleware Deployment Guides Introducing: Long Distance VMotion with VMWare Load Balancers for Developers – ADCs Wan Optimization Functionality Cloud Control Does Not Always Mean 'Do it yourself' Best Practices Deploying IBM Web Sphere 7 Now Available275Views0likes0CommentsUseful IT. Bringing Health Record Transfer into the 21st Century.
I read the Life as a Healthcare CIO blog on occasion, mostly because as a former radiographer, health care records integration and other non-diagnostic IT use in healthcare is a passing interest of mine. Within the last hospital I worked at the systems didn’t communicate – not even close, as in there was no effort to make them do so. This intrigues me, as since I’ve entered IT I have watched technology uptake in healthcare slowly ramp up at a great curve behind the rest of the business world. Oh make no mistake, technology has been in overdrive on the equipment used, but things like systems interoperability and utilizing technology to make doctors, nurses, and tech’s lives easier is just slower in the medical world. A huge chunk of the resistance is grounded in a very common sense philosophy. “When people’s lives are on the line you do not rush willy-nilly to the newest gadget.” No one in healthcare says it that way – at least not to my knowledge – but that’s the essence of what they think. I can think of a few businesses that could use that same mentality applied occasionally with a slightly different twist: “When the company’s viability is on the line…” but that’s a different blog. Even with this very common-sense resistance, there has been a steady acceleration of uptake in technology use for things like patient records and prescriptions. It has been interesting to watch, as someone on the outside with plenty of experience with the way hospitals worked and their systems were all silos. Healthcare IT is to be commended for things like electronic prescription pads and instant transfer of (now nearly all electronic) X-Rays to those who need them to care for the patient. Applying the “this can help with little impact on critical care” or even “this can help with positive impact on critical care and little risk of negative impact” viewpoint as a counter to the above-noted resistance has produced some astounding results. A friend of mine from my radiographer days is manager of a Cardiac Cath Lab, and talking with him is just fun. “Dude, ninety percent of the pups coming out of Radiology schools can’t set an exposure!” is evidence that diagnostic tools are continuing to take advantage of technology – in this case auto-detecting XRay exposure limits. He has more glowing things to say about the non-diagnostic growth of technology within any given organization. But outside the organization? Well that’s a completely different story. The healthcare organization wants to keep your records safe and intact, and rarely even want to let you touch them. That’s just a case of the “intact” bit. Some people might want their records to not contain some portion – like their blood alcohol level when brought to the ER – and some people might inadvertently lose some portion of the record. While they’re more than happy to send them on a referral, and willing to give you a copy if you’re seeking a second opinion, these records all have one archaic quality. Paper. If I want to buy a movie, I can go to netflix, sign up, and stream it (at least many of them) to watch. If I want my medical records transferred to a specialist so I can get treatment before my left eye oozes out of its socket, they have to be copied, verified, and mailed. If they’re short or my eye is on the verge of falling out right this instant, then they might be faxed. But the bulk of records are mailed. Even overnight is another day lost in the treatment cycle. Recently – the last couple of years – there has been a movement to replicate the records delivery process electronically. As time goes on, more and more of your medical records are being stored digitally. It saves room, time, and makes it easier for a doctor to “request” your record should he need it in a hurry. It also makes it easier to track accidental or even intentional changes in records. While it didn’t happen as often as fear-mongers and ambulance chasers want you to believe, of course there are deletions and misplacements in the medical records of the 300 million US citizens. An electronic system never forgets, so while something as simple as a piece of paper falling out of a record could forever change it, in electronic form that can’t happen. Even an intentional deletion can be “deleted” as in not show up, but still there, stored with your other information so that changes can be checked should the need ever arise. The inevitable off-shoot of electronic records is the ability to communicate them between hospitals. If you’re in the ER in Tulsa, and your normal doctor is in Manhattan, getting your records quickly and accurately could save your life. So it made sense that as the percentage of new records that were electronic grew, someone would start to put together a way to communicate them. No doubt you’re familiar with the debate about national health information databases, a centralized location for records is a big screaming target from many people’s perspectives, while it is a potentially life-saving technological advancement to others (they’re both right, but I think the infosec crowd has the stronger argument). But a smart group of people put together a project to facilitate doing electronically exactly what is being done today physically. The process is that the patient (or another doctor) requests the records be sent, they are pulled out, copied, mailed or faxed, and then a follow-up or “record received” communication occurs to insure that the source doctor got your records where they belong. Electronically this equates to the same thing, but instead of “selected” you get “looked up”, and instead of “mailed or faxed” you get “sent electronically”. There’s a lot more to it, but that’s the gist of The Direct Project. There are several reasons I got sucked into reading about this project. From a former healthcare worker’s perspective, it’s very cool to see non-diagnostic technology making a positive difference in healthcare, from a patient perspective, I would like the transfer of records to be as streamlined as possible, from the InfoSec perspective (I did a couple of brief stints in InfoSec), I like that it is not a massive database, but rather a “faster transit” mechanism, and from an F5 perspective, the possibilities for our gear to help make this viable were in my mind while reading. While Dr. Halamka has a lot of interesting stuff on his blog, this is one I followed the links and read the information about. It’s a pretty cool initiative, and what may seem very limiting in their scope assumptions holds true to the Direct Project’s idea of replacing the transfer mechanism and not creating a centralized database. While they’re not specifying formats to use during said transfer, they do list some recommended reading on that topic. What they do have is a registry of people who can receive records, and a system for transferring data over the wire. They worry about DNS-style health-care provider lookups, transfer protocols, and encryption, which is certainly a large enough chunk for them to bite off, and then they show how they fit into the larger nation-wide healthcare electronic records efforts going on. I hope they get it right, and the system they’re helping to build results in near-instantaneous secure records transfers, but many inventions are a product of the time and society in which they live, and even if The Direct Project fails, something like it will eventually succeed. If you’re in Healthcare IT, this is certainly a way to add value to the organization, and worth checking out. Meanwhile, I’m going to continue to delve into their work and the work of other organizations they’ve linked to and see if there isn’t a way F5 can help. After all, we can compress, dedupe, and encrypt communications on-the-wire, and the entire system is about on-the-wire communications, so it seems like a perfectly logical route to explore. Though the patient care guy in me will be reading up as much as the IT guy, because healthcare was a very rewarding field that seriously needed a bit more non-diagnostic technology when I was doing it.271Views0likes0CommentsWhen VDI Comes Calling
It is an interesting point/counterpoint to read up about Virtual Desktop Infrastructure (VDI) deployment or lack thereof. The industry definitely seems to be split on whether VDI is the wave of the future or not, what its level of deployment is, and whether VDI is more secure than traditional desktops. There seems to be very little consensus on any of these points, and yet VDI deployments keep rolling out. Meanwhile, many IT folks are worried about all of these “issues” and more. Lots more. Like where the heck to get started even evaluating VDI needs for a given organization. There’s a lot written about who actually needs VDI, and that is a good place to start. Contrary to what some would have you believe, not every employee should be dumped into VDI. There are some employees that will garner a lot more benefit from VDI than others, all depending upon work patterns, access needs, and software tools used. There are some excellent discussions of use cases out there, I won’t link to a specific one just because you’ll need to find one that suits your needs clearly, but searching on VDI use cases will get you started. Then the hard part begins. It is relatively easy to identify groups in your organization that share most of the same software and could either benefit, or at least not be harmed by virtualizing their desktop. Note that in this particular blog post I am ignoring application virtualization in favor of the more complete desktop virtualization. Just thought I’d mention that for clarity. The trick, once you’ve identified users that are generally the same, is to figure out what applications they actually use, what their usage patterns are (if they’re maxing out the CPU of a dedicated machine, that particular user might not be a great choice for VDI unless all the other users that share a server with them are low-usage), and how access from other locations than their desktop could help them to work better/smarter/faster. A plan to plan. I don’t usually blog about toolsets that I’ve never even installed, working at Network Computing Magazine made me leery of “reviews” by people who’ve never touched a product. But sometimes (like with Oracle DataGuard about a year ago), an idea so strikes to the heart of what enterprise IT needs to resolve a given problem than I think it’s worth talking about. Sometimes – like with DataGuard – lots of readers reap the benefits, sometimes – like with Cirtas – I look like a fool. That’s the risks of talking about toys you don’t touch though. That is indeed an introduction to products I haven’t touched . Centrix Software’s Workspace IQ and Lakeside Software’s Systrack Virtual Machine Planner are tools that can help you evaluate usage patterns, software actually run, and usage volumes. Software actually run is a good indicator of what the users actually need, because as everyone in IT knows, often software is installed and when it is no longer needed it is not removed. Usage patterns help you group VMs together on servers. The user that is active at night can share a VM with daytime users without any risk of oversubscription of the CPU or memory. Usage volumes also help you figure out who/how many users you can put on a server. For one group it may be very few heavy users, for another group it may be very many light users. And that’s knowledge you need to get started. It helps you scope the entire project, including licenses and servers, it helps you identify the groups that will have to be trained – and yes coddled – before, during, and shortly after the rollout is occurring, and it helps you talk with vendors about their product’s capabilities. One nice bit about Systrack VMP is that it suggests the correct VDI vendor for your environment. If it does that well, it certainly is a nice feature. These aren’t new tools by any means, but as more and more enterprises look into VDI, talking about solutions like this will give hapless architects and analysts who were just thrown into VDI projects a place to start looking at how to tackle a very large project. It wouldn’t hurt to read the blog over at Moose Logic either, specifically Top Ten VDI Mistakes entry. And when you’re planning for VDI, plan for the network too. There’s a lot more traffic on the LAN in a VDI deployment than there was before you started, and for certain (or maybe all) users you’re going to want high availability. We can help with that when the time comes, just hit DevCentral or our website and search for VDI. Hopefully this is a help to those of you who are put onto a VDI project and expected to deliver quickly. It’s not all there is out there by any stretch, but it can get you started. Related Articles and Blogs: Skills Drive Success It’s Time To Consider Human Capital Again. F5 Friday: In the NOC at Interop Underutilized F5 Friday: Are You Certifiable? SDN, OpenFlow, and Infrastructure 2.0264Views0likes0CommentsSSDs, Velocity and the Rate of Change.
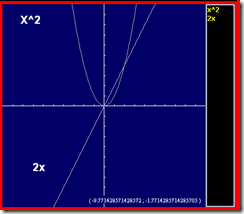
The rate of change in a mathematical equation can vary immensely based upon the equation and the inputs to the equation. Certainly the rate of change for f(x) = x^2 is a far different picture than the rate of change for f(x)=2x, for example. The old adage “the only constant is change” is absolutely true in high tech. The definition of “high” in tech changes every time something becomes mainstream. You’re working with tools and systems that even ten years ago were hardly imaginable. You’re carrying a phone that Alexander Graham Bell would not recognize – or know how to use. You have tablets with the power that was not so long ago only held by mainframes. But that change did not occur overnight. Apologies to iPhone fans, but all the bits Apple put together to produce the iPhone had existed before, Apple merely had the foresight to see how they could be put together in a way customers would love. The changes happen over time, and we’re in the midst of them, sometimes that’s difficult to remember. Sometimes that’s really easy to remember, as our brand-new system or piece of architecture gives us headaches. Depends upon the day. Image generated at Cool Math So what is coming of age right now? Well, SSDs for one. They’re being deployed in the numbers that were expected long ago, largely because prices have come down far enough to make them affordable. We offer an SSD option for some of our systems these days, and since the stability of our products is of tantamount to our customers’ interests, we certainly aren’t out there on the cutting edge with this development. They’re stable enough for mission critical use, and the uptick in sales reflects that fact. If you have a high-performance application that relies upon speedy database access, you might look into them. There are a lot of other valid places to deploy SSDs – Tier one for example – but a database is an easy win. If access times are impacting application performance, it is relatively easy to drop in an SSD drive and point the DB (cache or the whole DB) at them, speeding performance of every application that relies on that DBMS. That’s an equation that is pretty simple to figure out, even if the precise numbers are elusive. Faster disk access = faster database response times = faster applications. That is the same type of equation that led us to offer SSDs for some of our products. They sit in the network between data and the applications that need the data. Faster is better, assuming reliability, which after years of tweaking and incremental development, SSDs offer. Another place to consider SSDs is in your virtual environment. If you have twenty VMs on a server, and two of them have high disk access requirements, putting SSDs into place will lighten the load on the overall system simply by reducing the blocking time waiting for disk responses. While there are some starting to call for SSDs everywhere, remember that there were some who said cloud computing meant no one should ever build out a datacenter again also. The price of HDs has gone down with the price of SSDs pushing them from the top, so there is still a significant cost differential, and frankly, a lot of applications just don’t need the level of performance that SSDs offer. The final place I’ll offer up for SSDs is if you are implementing storage tiering such as that available through our ARX product. If you have high-performance NAS needs, placing an SSD array as tier one behind a tiering device can significantly speed access to the files most frequently used. And that acceleration is global to the organization. All clients/apps that access the data receive the performance boost, making it another high-gain solution. Will we eventually end up in a market where old-school HDDs are a thing of the past and we’re all using SSDs for everything? I honestly can’t say. We have plenty of examples in high-tech where as demand went down, the older technology started to cost more because margins plus volume equals profit. Tube monitors versus LCDs, a variety of memory types, and even big old HDDs – the 5.25 inch ones. But the key is whether SDDs can fulfill all the roles of HDDs, and whether you and I believe they can. That has yet to be seen, IMO. The arc of price reduction for both HDDs and SSDs plays in there also – if quality HDDs remain cheaper, they’ll remain heavily used. If they don’t, that market will get eaten by SSDs just because all other things being roughly equal, speed wins. It’s an interesting time. I’m trying to come up with a plausible use for this puppy just so I can buy one and play with it. Suggestions are welcome, our websites don’t have enough volume to warrant it, and this monster for laptop backups would be extreme – though it would shorten my personal backup window ;-). OCZ Technology 1 TB SSD. The Golden Age of Data Mobility? What Do You Really Need? Use the Force Luke. (Zzzaap) Don't Confuse A Rubber Stamp With Validation On Cloud, Integration and Performance Data Center Feng Shui: Architecting for Predictable Performance F5 Friday: Performance, Throughput and DPS F5 Friday: Performance Analytics–More Than Eye-Candy Reports Audio White Paper - High-Performance DNS Services in BIG-IP ... Analyzing Performance Metrics for File Virtualization263Views0likes0Comments