DNS on the BIG-IP: IPv6 to IPv4 Translation
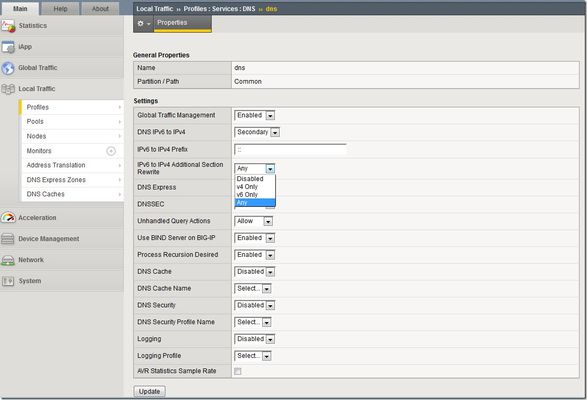
I've been writing some DNS articles over the past couple of months, and I wanted to keep the momentum going with a discussion on IPv6 translation. As a reminder, my first four articles are: Let's Talk DNS on DevCentral DNS The F5 Way: A Paradigm Shift DNS Express and Zone Transfers The BIG-IP GTM: Configuring DNSSEC The Address Space Problem I'm pretty sure all of you have heard about the problem of IPv4 address depletion, so I won't go too crazy on that. But, I did want to share one quick analogy of how the IPv4 address space relates to the IPv6 space. There are ~4 billion possible IPv4 addresses and ~3.4 x 10 38 IPv6 addresses. Sometimes when I see a comparison of large numbers like these, it's hard for me to grasp the magnitude of the difference. Here's the analogy that helped put this in perspective: if the entire IPv4 address space was a single drop of water, the IPv6 address space would be the equivalent of 68 times the entire volume of the world's oceans! I can't imagine ever needing more IP address space than that, but I guess we will see. As IPv4 address space is used up and new IP-enabled devices continue to hit the market, companies need to support and manage existing IPv4 devices and content while transitioning to IPv6. Just last week, ICANN announced that IPv4 addresses are nearing total exhaustion. Leo Vegoda, operational excellence manager at ICANN, said "Redistributing increasingly small blocks of IPv4 address space is not a sustainable way to grow the Internet. IPv6 deployment is a requirement for any network that needs to survive." As companies transition to IPv6, they still face a real issue of handling IPv4 traffic. Despite the need to move to IPv6, the fact is most Internet traffic today is still IPv4. Google has a really cool graph that tracks IPv6 adoption, and they currently report that only 3.5% of all Internet traffic is IPv6. You would think that the people who developed IPv6 would have made it backward compatible with IPv4 thus making the transition fairly easy and straightforward...but that's not true. This leaves companies in a tough spot. They need a services fabric that is flexible enough to handle both IPv4 and IPv6 at the same time. The good news is that the BIG-IP is the best in the business at doing just that. BIG-IP Configuration Let's say you built an IPv6 network and things are running smoothly within your own network...IPv6 talking to IPv6 and all is well. But remember that statistic I mentioned about most of the Internet traffic running IPv4? That creates a big need for your network to translate from IPv6 to IPv4 and back again. The BIG-IP can do this by configuring a DNS profile and assigning it to a virtual server. You can create this DNS profile by navigating to Local Traffic >> Profiles >> Services >> DNS and create/modify a DNS profile. There are several options to configure in the DNS profile, but for this article, we are just going to look at the DNS IPv6 to IPv4 translation part. Notice the three DNS IPv6 to IPv4 settings in the screenshot below: DNS IPv6 to IPv4, IPv6 to IPv4 Prefix, and IPv6 to IPv4 Additional Section Rewrite. The DNS IPv6 to IPv4 setting has four options. This setting specifies whether you want the BIG-IP to convert IPv6-formatted IP addresses to IPv4-formatted IP addresses. The options for DNS IPv6 to IPv4 are: Disabled: The BIG-IP does not map IPv4 addresses to IPv6 addresses. This is the default setting. Secondary: The BIG-IP receives an AAAA (IPv6) query and forwards the query to a DNS server. Only if the server fails to return a response does the BIG-IP system send an A (IPv4) query. If the BIG-IP system receives an A response, it prepends a 96-bit user-configured prefix to the record and forwards it to the client. Immediate: The BIG-IP system receives an AAAA query and forwards the query to a DNS server. The BIG-IP then forwards the first good response from the DNS server to the client. If the system receives an A response first, it prepends a 96-bit prefix to the record and forwards it to the client. If the system receives an AAAA response first, it simply forwards the response to the client. The system disregards the subsequent response from the DNS server. v4 Only: The BIG-IP receives an AAAA query, but forwards an A query to a DNS server. After receiving an A response from the server, the BIG-IP system prepends a 96-bit user-configured prefix to the record and forwards it to the client. Only select the v4 Only option if you know that all DNS servers are IPv4-only servers. When you select one of the options listed above (except the "Disabled" option), you must also provide a prefix in the IPv6 to IPv4 Prefix field and make a selection from the IPv6 to IPv4 Additional Section Rewrite list. The IPv6 to IPv4 Prefix specifies the prefix to use for the IPv6-formatted IP addresses that the BIG-IP converts to IPv4-formatted IP addresses. The default is 0:0:0:0:0:0:0:0. The IPv6 to IPv4 Additional Section Rewrite allows improved network efficiency for both Unicast and Multicast DNS-SD responses. This setting has 4 options: Disabled: The BIG-IP does not perform additional rewrite. This is the default setting. V4 Only: The BIG-IP accepts only A records. The system prepends the 96-bit user-configured prefix (mentioned previously) to a record and returns an IPv6 response to the client. V6 Only: The BIG-IP accepts only AAAA records and returns an IPv6 response to the client. Any: The BIG-IP accepts and returns both A and AAAA records. If the DNS server returns an A record in the Additional section of a DNS message, the BIG-IP prepends the 96-bit user-configured prefix to the record and returns an IPv6 response to the client. Like any configuration change, I would recommend initial testing in a lab to see how your network performs with these settings. This one is pretty straightforward, though. Hopefully this helps with any hesitation you may have with transitioning to an IPv6 network. Go ahead and take advantage of that vast IPv6 space, and let the BIG-IP take care of all the translation work! Stay tuned for more DNS articles, and let me know if you have any specific topics you'd like to see. One final and related note: check out the F5 CGNAT products page to learn more about seamless migration to IPv6.2.7KViews0likes2Comments
F5 Friday: Thanks for calling... please press 1 for IPv6 or 2 for IPv4.
World IPv6 Day is June 8. We’re ready, how about you? World IPv6 day, scheduled for 8 June 2011, is a global-scale test flight of IPv6 sponsored by the Internet Society. On World IPv6 Day, major web companies and other industry players will come together to enable IPv6 on their main websites for 24 hours. The goal is to motivate organizations across the industry — Internet service providers, hardware makers, operating system vendors and web companies — to prepare their services for IPv6 to ensure a successful transition as IPv4 address space runs out. This is more than a marketing play to promote IPv6 capabilities, it’s a serious test to ensure that services are prepared to meet the challenge of a dual-stack environment of the kind that will be necessary to support the migration from IPv4 to IPv6. Such a migration is not a trivial task as it requires more than simply flipping a switch in the billions of components, applications and services that make up what we call “The Internet”. That’s because IPv6 shares basic concepts like routing, switching and internetworking communication with IPv4, but the technical bits that describe hosts, services and endpoints on the Internet and in the data center are different enough to make cross-protocol communication challenging. Supporting IPv6 is easy; supporting communication between IPv6 and IPv4 during such a massive migration is not. If you consider how tightly coupled not only routing and switching but applications and myriad security, acceleration, access and application-centric networking policies are to IP you start to see how large a task such a migration really will be. cloud computing hasn’t helped there by relying on IP address as the primary mechanism for identifying instances of applications as they are provisioned and decommissioned throughout the day. All that eventually needs to change, to be replaced with IPv6 compatible systems, components and management frameworks, and it’s not going to happen in a single day. FIRST THINGS FIRST The first step is simply to lay the foundation for services and core Internet communications to support IPv6, and that’s what World IPv6 Day is promoting – an IPv6 Internet with IPv6 capable services on the outside interacting with other IPv6 capable services and networking components and clients. In many ways, World IPv6 Day will illustrate the power of loose coupling, of service-oriented networking and architectures. Most organizations aren’t ready for the gargantuan task of migrating their data centers to IPv6, nor the investment that may be required in upgrading or replacing core infrastructure to support the new standard. The beautify of loose-coupling and translative gateways, however, is that they don’t have to – yet. As part of our participation in World IPv6 Day, F5’s IT team worked hard - and ate a whole lot of our own dog food - to ensure that users have a positive experience while browsing our sites from an IPv6 device. That means you don’t have to press “1” for IPv6 or “2” for IPv4 as you do when communicating with organizations that supporting multiple languages. Like our own customers, we have an organizational reliance on IP addresses in the network and application infrastructure that thoroughly permeates throughout configurations and even application logic. But leveraging our own BIG-IP Local Traffic Manager (LTM) with IPv6 Gateway Module means we don’t have to perform a mass IPectomy on our entire internal infrastructure. Using the IPv6 gateway we’re able to maintain our existing infrastructure – all talking IPv4 – while providing IPv6 interfaces to Internet-facing infrastructure and clients. Both our corporate site (www.f5.com) and our community site (devcentral.f5.com) have been “migrated” to IPv6 and stand ready to speak what will one day be the lingua franca of the Internet. Granted, we had some practice at Interop 2011 supporting the Interop NOC IPv6 environment. F5 provided network and DNS translations and facilitated access and functionality for both IPv4 and IPv6 clients to resources on the Interop network. F5 also provided an IPv6 gateway to the www.interop.com website. Because organizations can continue to leverage IPv4 internally with an IPv6 gateway – and thus make no changes to its internal architecture, infrastructure, and applications – there is less pressure to migrate immediately, which can reduce the potential for introducing problems that cause downtime and outages. As Mike Fratto mentioned when describing Network Computing’s IPv6 enablement using BIG-IP: Like many other organizations, we have to migrate to IPv6 at some point, and this is the first step in the process--getting our public-facing servers ready. There is no rush to roll out massive changes, and by taking the transition in smaller bits, you will be able to manage the transition seamlessly. A planned, conscious effort to move to IPv6 internally in stages will reduce the overall headaches and inevitable outages caused by issues sure to arise during the process. F5 and IPv6 F5 BIG-IP supports IPv6 but more importantly its IPv6 Gateway Module supports efforts to present an IPv6 interface to the public-facing world while maintaining existing IPv4 based infrastructure. Deploying a gateway can provide the translation necessary to enable the entire organization to communicate with IPv6 regardless of IP version utilized internally. A gateway translates between IP versions rather than leveraging tunneling or other techniques that can cause confusion to IP-version specific infrastructure and applications. Thus if an IPv6 client communicates with the gateway and the internal network is still completely IPv4, the gateway performs a full translation of the requests bi-directionally to ensure seamless interoperation. This allows organizations to continue utilizing their existing investments – including network management software and packaged applications that may be under the control of a third party and are not IPv6 aware yet – but publicly move to supporting IPv6. Additionally, F5 BIG-IP Global Traffic Manager (GTM) handles IPv6 integration natively when answering AAAA (IPv6) DNS requests and includes a checkbox feature to reject IPv6 queries for Wide IPs that only have IPv4 addresses, which forces the client DNS resolver to re-request asking for the IPv4 address. This solves a common problem with deployment of dual stack IPv6 and IPv4 addressing. The operating systems try to query for an IPv6 address first and will hang or delay if they don’t get a rejection. GTM solves this problem by supporting both address schemes simultaneously. Learn More For Enterprises Controlling Your Migration to IPv6: A Gateway to Tomorrow IPv6—101: Introduction IPv6 - Bridging the Gap to Tomorrow For Service Providers Managing IPv6 in Service Provider Networks with BIG-IP Devices Service Provider Series: Managing the IPv6 Migration If you’ve got an IPv6-enabled device, give the participating sites on June 8 a try. While we’ll all learn a lot about IPv6 and any potential pitfalls with a rollout throughout the day just by virtue of the networking that’s always going on under the hood, without client participation it’s hard to gauge whether there’s more work to be done on that front. Even if your client isn’t IPv6 enabled, give these sites a try – they should be supporting both IPv6 and IPv4, and thus you should see no discernable difference when connecting. If you do, let us (or the site you’re visiting) know – it’s important for everyone participating in IPv6 day to hear about any unexpected issues or problems so we can all work to address them before a full IPv6 migration gets under way. You can also participate on DevCentral: Post your IPv6 questions and our DevCentral team members will do their best to answer them. Join our live roundtable podcast on June 8 at 11:00 a.m. (Pacific) to hear your IPv6 questions answered and get professional tips from F5's IPv6 expert guests. So give it a try and participate if you can, and make it a great day!220Views0likes1CommentF5 Friday: ‘IPv4 and IPv6 Can Coexist’ or ‘How to eat your cake and have it too’
Migration is not going to happen overnight and it’s going to require simultaneous support for both IPv4 and IPv6 until both sides of the equation are ready. Making the switch from IPv4 to IPv6 is not a task anyone with any significant investment in infrastructure wants to undertake. The reliance on IP addresses of infrastructure to control, secure, route, and track everything from simple network housekeeping to complying with complex governmental regulations makes it difficult to simply “flick a switch” and move from the old form of addressing (IPv4) to the new (IPv6). This reliance is spread up and down the network stack, and spans not only infrastructure but the very processes that keep data centers running smoothly. Firewall rules, ACLs, scripts that automate mundane tasks, routing from layer 2 to layer 7, and application architecture are likely to communicate using IPv4 addresses. Clients, too, may not be ready depending on their age and operating system, which makes a simple “cut over” strategy impossible or, at best, fraught with the potential for techncial support and business challenges. IT’S NOT JUST SIZE THAT MATTERS The differences between IPv4 and IPv6 in addressing are probably the most visible and oft referenced change, as it is the length of the IPv6 address that dramatically expands the available pool of IP addresses and thus is of the most interest. IPv4 IP addresses are 32-bits long while IPv6 addresses are 128-bits long. But IPv6 addresses can (and do) interoperate with IPv4 addresses, through a variety of methods that allow IPv6 to carry along IPv4 addresses. This is achieved through the use of IPv4 mapped IPV6 addresses and IPv4 compatible IPv6 addresses. This allows IPv4 addresses to be represented in IPv6 addresses.185Views0likes2Comments
DevCentral Top5 02/04/2011
If your week has been anything like mine, then you’ve had plenty to keep you busy. While I’d like to think that your “busy” equates to as much time on DevCentral checking out the cool happenings while people get their geek on as mine does, I understand that’s less than likely. Fortunately, though, there is a mechanism by which I can distribute said geeky goodness for your avid assimilation. I give to you, the DC Top 5: iRuling the New FSE Crop http://bit.ly/f1JIiM Easily my favorite thing that happened this week was something I was fortunate enough to get to be a part of. A new crop of FSEs came through corporate this week to undergo a training boot camp that has been, from all accounts, a smashing success. A small part of this extensive readiness regimen was an iRules challenge issued unto the newly empowered engineers by yours truly. Through this means they were intended to learn about iRules, DevCentral, and the many resources available to them for researching and investigating any requirements and questions they may have. The results are in as of today and I have to say I’m duly impressed. I’ll post the results next week but, for now, here’s a taste of the challenge that was issued. Keep in mind these people range from a few weeks to maybe a couple months tops experience with F5, let alone iRules or coding in general, so this was a tall order. The gauntlet was laid down and the engineers answered, and answered with vigor. Stay tuned for more to come. Mitigate Java Vulnerabilities with iRules http://bit.ly/gbnPOe Jason put out a fantastic blog post this week showing how to thwart would be JavaScript abusing villains by way of iRules fu. Naturally I was interested so I investigated further. It turns out there was a vuln that cropped up plenty last week dealing with a specific string (2.2250738585072012e-308) that has a nasty habit of making the Java runtime compiler go into an infinite loop and, eventually, pack up its toys and go home. This is, as Jason accurately portrayed, “Not good.”. Luckily though iRules is able to leap to the rescue once more, as is its nature. By digging through the HTTP::request variable, Jason was able to quickly and easily strip out any possibly harmful instances of this string in the request headers. For more details on the problem, the process and the solution, click the link and have a read. F5 Friday: ‘IPv4 and IPv6 Can Coexist’ or ‘How to eat your cake and have it too’ http://bit.ly/ejYYSW Whether it was the promise of eating cake or the timely topic of IPv4 trying to cling to its last moments of glory in a world hurtling quickly towards an IPv6 existence I don’t know, but this one drew me in. Lori puts together an interesting discussion, as is often the case, in her foray into the “how can these two IP formats coexist” arena. With the reality of IPGeddon acting as the stick, the carrot of switching to an IPv6 compatible lifestyle seems mighty tasty for most businesses that want to continue being operational once the new order sets in. Time is quickly running out, as are the available IPv4 addresses, so the hour is nigh for decisions to be made. This is a look at one way in which you can exist in the brave new world of 128-bit addressing without having to reconfigure every system in your architecture. It’s interesting, timely, and might just save you 128-bits worth of headaches. Deduplication and Compression – Exactly the same, but different http://bit.ly/h8q0OS There’s something that got passed over last week because of an absolute overabundance of goodness that I wanted to bring up this week, as I felt it warranted some further review and discussion. That is, Don’s look at Deduplication and Compression. Taking the angle of the technologies being effectively the same is an interesting one to me. Certainly they aren’t the same thing, right? Clearly one prevents data from being transmitted while the other minimizes the transmission necessary. That’s different, right? Still though, as I was reading I couldn’t help but find myself nodding in agreeance as Don laid out the similarities. Honestly, they really do accomplish the same thing, that is minimizing what must pass through your network, even though they achieve it by different means. So which should you use when? How do they play together? Which is more effective for your environment? All excellent questions, and precisely why this post found its way into the Top5. Go have a look for yourself. Client Cert Fingerprint Matching via iRules http://bit.ly/gY2M69 Continuing in the fine tradition of the outright thieving of other peoples’ code to mold into fodder for my writing, this week I bring to you an awesome snippet from the land down under. Cameron Jenkins out of Australia was kind enough to share his iRule for Client Cert Fingerprint matching with the team. I immediately pounced on it as an opportunity to share another cool example of iRules doing what they do best: making stuff work. This iRule shows off an interesting way to compare cert fingerprints in an attempt to verify a cert’s identity without needing to store the entirety of the cert and key. It’s also useful for restricting access to a given list of certs. Very handy in some situations, and a wickedly simple iRule to achieve that level of functionality. Good on ya, Cameron, and thanks for sharing. There you have it, another week, another 5 piece of hawesome from DevCentral. See you next time, and happy weekend. #Colin179Views0likes0CommentsApple iPad Pushing Us Closer to Internet Armageddon
Apple’s latest “i” hit over a million sales in the first 28 days it was available. Combine that with sales of other Internet-abled devices like the iPhone, Android, Blackberry, and other “smart” phones as well as the continued growth of Internet users in general (via cable and other broadband access technologies) and we are heading toward the impending cataclysm that is IPv4 address depletion. Sound like hyperbole? It shouldn’t. The depletion of IPv4 addresses is imminent, and growing closer every day, and it is that depletion that will cause a breakdown in the ability of consumers to access the myriad services offered via the Internet, many of which they have come to rely upon. The more consumers, the more devices, the more endpoints just exacerbates the slide toward what will be, if we aren’t careful, a falling out between IPv6-only consumers and IPv4-only producers and vice-versa that will cause a breakdown in communication that essentially can only be called “Internet Armageddon.”280Views0likes1CommentWindows Vista Performance Issue Illustrates Importance of Context
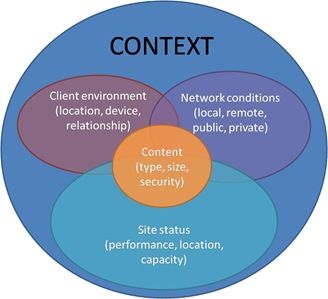
Decisions about routing at every layer require context A friend forwarded a blog post to me last week mainly because it contained a reference to F5, but upon reading it (a couple of times) I realized that this particular post contained some very interesting information that needed to be examined further. The details of the problems being experienced by the poster (which revolve around a globally load-balanced site that was for some reason not being distributed very equally) point to an interesting conundrum: just how much control over site decisions should a client have? Given the scenario described, and the conclusion that it is primarily the result of an over-eager client implementation in Windows Vista of a fairly obscure DNS-focused RFC, the answer to how much control a client should have over site decisions seems obvious: none. The problem (which you can read about in its full detail here) described is that Microsoft Vista, when presented with multiple A records from a DNS query, will select an address “which shares the most prefix bits with the source address is selected, presumably on the basis that it's in some sense "closer" in the network.” This is not a bad thing. This implementation was obviously intended to aid in the choice of a site closer to the user, which is one of the many ways in which application network architects attempt to improve end-user performance: reducing the impact of physical distance on the transfer of application data. The problem is, however, that despite the best intentions of those who designed IP, it is not guaranteed that having an IP address that is numerically close to yours means the site is physically close to you. Which kind of defeats the purpose of implementing the RFC in the first place. Now neither solution (choosing random addresses versus one potentially physically closer) is optimal primarily because neither option assures the client that the chosen site is actually (a) available and (b) physically closer. Ostensibly the way this should work is that the DNS resolution process would return a single address (the author’s solution) based on the context in which the request was made. That means the DNS resolver needs to take into consideration the potential (in)accuracy of the physical location when derived from an IP address, the speed of the link over which the client is making the request (which presumably will not change between DNS resolution and application request) and any other information it can glean from the client. The DNS resolver needs to return the IP address of the site that at the time the request is made appears best able to serve the user’s request quickly. That means the DNS resolver (usually a global load balancer) needs to be contextually aware of not only the client but the sites as well. It needs to know (a) which sites are currently available to serve the request and (b) how well each is performing and (c) where they are physically located. That requires collaboration between the global load balancer and the local application delivery mechanisms that serve as an intermediary between the data center and the clients that interact with it. Yes, I know. A DNS request doesn’t carry information regarding which service will be accessed. A DNS lookup could be querying for an IP address for Skype, or FTP, or HTTP. Therein lies part of the problem, doesn’t it? DNS is a fairly old, in technical terms, standard. It is service agnostic and unlikely to change. But providing even basic context would help – if the DNS resolver knows a site is unreachable, likely due to routing outages, then it shouldn’t return that IP address to the client if another is available. Given the ability to do so, a DNS resolution solution could infer service based on host name – as long as the site were architected in such a way as to remain consistent with such conventions. For example, ensuring that www.example.com is used only for HTTP, and ftp.example.com is only used for FTP would enable many DNS resolvers to make better decisions. Host-based service mappings, inferred or codified, would aid in adding the context necessary to make better decisions regarding which IP address is returned during a DNS lookup – without changing a core standard and potentially breaking teh Internets. The problem with giving the client control over which site it accesses when trying to use an application is that it lacks the context necessary to make an intelligent decision. It doesn’t know whether a site is up or down or whether it is performing well or whether it is near or at capacity. It doesn’t know where the site is physically located and it certainly can’t ascertain the performance of those sites because it doesn’t even know where they are yet, that’s why it’s performing a DNS lookup. A well-performing infrastructure is important to the success of any web-based initiative, whether that’s cloud-based applications or locally hosted web sites. Part of a well-performing infrastructure is having the ability to route requests intelligently, based on the context in which those requests are made. Simply returning IP addresses – and choosing which one to use – in a vacuum based on little or no information about the state of those sites is asking for poor performance and availability problems. Context is critical.212Views0likes1CommentWhat really breaks the "end-to-end nature of the Internet"
IPv6 was supposed to eliminate NAT (Network Address Translation). But in order to make the transition from IPv4 reasonable and less painful, it's being added to IPv6. It's intended use in being included in IPv6 is to create gateways that bridge between IPv6 and IPv4 while the transition occurs. The IETF is not thrilled however. It's description of how it feels about NAT and the necessity to include it make it sound like school-children forced to allow that kid to play in their game of kickball. And then they put him in far right field. And I mean far right field so it's obvious what they think of him. This Network World article describes NAT as "much maligned" and reminds us that purists hate it for breaking the end-to-end communication model on which the Internet was designed. From the article: NAT is deployed in routers, servers and firewalls, and it adds complexity and cost to enterprise networks. Internet purists hate NATs because they break the end-to-end nature of the Internet; this is the idea that any end user can communicate directly to another end user over the Internet without middle boxes altering their packets. I'm guessing purists hate a whole lot of technologies because there are a ton of other technologies and products that are essentially "middle boxes altering packets." The problem is I don't want any end user communicating directly with me. I want their packets inspected, sanitized, and thoroughly cleansed before they get anywhere near me. I want them altered or nuked into the ether, particularly if they're full of nastiness or hell-bent on destroying the delicate balance that is my desktop. Alteration of packets is a necessity to address protocol errors and perform all sorts of interesting application delivery functions. Alteration of packets is necessary to add caching control to web applications that are not written with caching in mind; it's necessary to rewrite URIs, and to protect sensitive data from escaping the confines of the data center. Alteration of packets by "middle boxes" (i.e. intermediaries or proxies) is a requirement for optimizing and securing application data. And more than just solving the lack of IPv4 problems, NAT has become a primary security mechanism for ensuring end users aren't directly reachable by external applications. Even if I had enough IPv4 addresses to put all the machines in my home on the public Internet, I wouldn't. That's just asking for trouble, especially when some of those machines are being used by teenagers whose idea of security is using "hotbutterfly99" as their username on HotMail or Yahoo. And there's not that much difference between those teenagers and many corporate employees. Geoff Huston, chief scientist at APNIC and an expert on IPv4 address depletion Huston says NATs are useful for addressing, packet filtering and other functions. He says the real problem with NATs is that they lack standards, and that is an area where the IETF can make improvements in NATs for IPv6. "The IETF's position of ignoring NATs some years back forced NAT software builders to exercise their own creativity when designing their version of NATs," Huston says. "This variation of NAT behavior is a far, far worse problem than NATs themselves." But it goes deeper than just a lack of standards and being "impure". When it comes down to it the root of the problem - what really breaks the end-to-end model of the Internet - is people. It's the nature of people to do things they shouldn't, to code applications without concern or regard for the bigger picture, to just outright make mistakes, and in some cases to be malicious and hell bent on destruction. So long as it's people writing applications and using the Internet, alteration of packets by "middle boxes" is going to be a requirement if we want to keep applications secure, fast, and available. Especially secure. Packets are going to continue to be altered when IPv6 is fully adopted whether NAT remains used or not, because people can't be upgraded to a new version that addresses our behavior, and we don't have a way to enforce a behavioral RFC on every Internet user in the world. Besides, given all the good that comes out of "middle boxes altering packets": optimization, scalability, application layer networking, acceleration, and of course, security, I'm just not convinced that NAT and other technologies breaking the end-to-end nature of the Internet is a bad thing after all.316Views0likes1CommentMaking the most of your IP address space with layer 7 switching
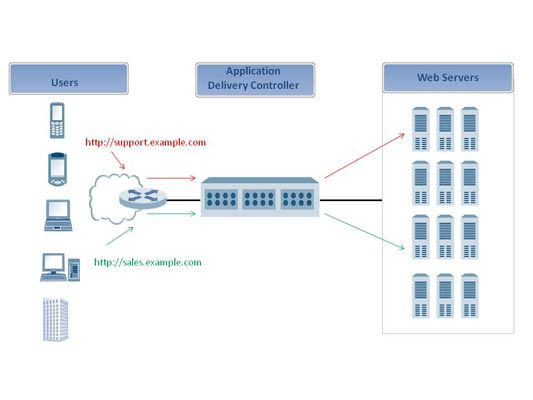
Organizations trying to make their presence known on the Internet today run into an interesting dilemma - there's just not enough IP addresses to go around. Long gone are the days when any old organization could nab a huge chunk of a Class A or even Class B network. Today they're relegated to a small piece of a Class C, which is often barely enough to run their business. This is especially true for smaller businesses who are lucky if they can get a /29 at a reasonable rate. While we wait for IPv6 to be fully adopted and solve most of this problem (a solution that seems to always be on the horizon but never fully realized) there is something you can do to resolve this situation, right now. That something is layer 7 - or URI - switching, which is the topic on which a reader wrote for help this morning. A reader asks... Using the iRule we can choose the pool based on the URI, but how to choose the pool based on URL. It's a great question! Choosing pools based on URI, i.e. URI switching, is something we talk a lot about, but we don't always talk about the other, less exciting HTTP headers upon which you can base your request routing decisions. Basically, we're talking about hosting support.example.com and sales.example.com on the same IP address (as far as the outside world is concerned) but physically deploying them on separate servers inside the organization/data center. Because both hosts appear in DNS entries to be the same IP address, we can use layer 7 switching to get the requests to the right host inside the organization. (On a side note this is a function made possible by "server virtualization", one of the umpteen types of virtualization out there today and supported by application delivery controllers and load balancers since, oh, the mid 1990s.) Using iRules you can route requests based on any HTTP header. You can also route requests based on anything in the payload, i.e. the application message/request, but right now we're just going to look at the HTTP header options, as there are more than enough to fill up this post today. What's cool about iRules is that you can switch on any HTTP header, and that includes custom headers, cookies, and even the HTTP version. If it's a header, you can choose a pool based on the value of the header. Here's a quick iRule solution to the problem of switching based on the host portion of a URL. The general flow of this iRule is: when HTTP_REQUEST { switch [string tolower [HTTP::host]] { "support" { pool pool_1 } "sales" { pool pool_2 } }} If you'd like to switch on, say, the HTTP request method, you could just replace the HTTP::host portion with HTTP::method and adjust the values upon which you are switching to "get" and "post" and "delete". iRules includes an HTTP class that makes it easy to retrieve the value of the most commonly accessed HTTP headers, such as host, path, method, and version. But you can use the HTTP::header method to extract any HTTP header you'd like. HTTP::host - Returns the value of the HTTP Host header. HTTP::cookie - Queries for or manipulates cookies in HTTP requests and responses. HTTP::is_keepalive - Returns a true value if this is a Keep-Alive connection. HTTP::is_redirect - Returns a true value if the response is a redirect. HTTP::method - Returns the type of HTTP request method. HTTP::password - Returns the password part of HTTP basic authentication. HTTP::path - Returns or sets the path part of the HTTP request. HTTP::payload - Queries for or manipulates HTTP payload information. HTTP::query - Returns the query part of the HTTP request. HTTP::uri - Returns or sets the URI part of the HTTP request. HTTP::username - Returns the username part of HTTP basic authentication. HTTP::version - Returns or sets the HTTP version of the request or response. Even if you have a plethora of IP addresses available, the ability to architect your application infrastructure is made even easier if you have the capability to perform layer 7 switching on HTTP requests. It allows you to make better use of resources and to optimize servers for specific type of content. A server serving up only images can be specifically configured for binary image content, while other servers can be better optimized to serve up HTML and other types of content. Whether you have enough IP addresses or not, there's something to be gained in the areas of efficiency and simplification of your application infrastructure using layer 7 switching. For a deeper dive into HTTP headers (and HTTP in general) check out the HTTP RFC specification Imbibing: Coffee312Views0likes0Comments