The Full-Proxy Data Center Architecture
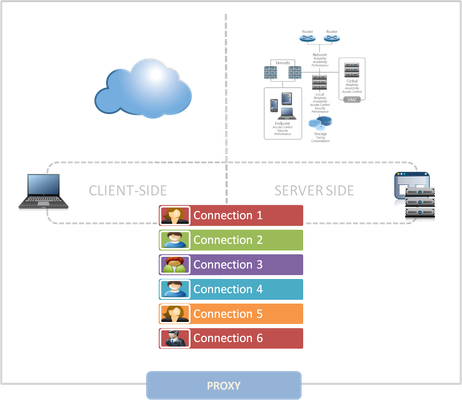
Why a full-proxy architecture is important to both infrastructure and data centers. In the early days of load balancing and application delivery there was a lot of confusion about proxy-based architectures and in particular the definition of a full-proxy architecture. Understanding what a full-proxy is will be increasingly important as we continue to re-architect the data center to support a more mobile, virtualized infrastructure in the quest to realize IT as a Service. THE FULL-PROXY PLATFORM The reason there is a distinction made between “proxy” and “full-proxy” stems from the handling of connections as they flow through the device. All proxies sit between two entities – in the Internet age almost always “client” and “server” – and mediate connections. While all full-proxies are proxies, the converse is not true. Not all proxies are full-proxies and it is this distinction that needs to be made when making decisions that will impact the data center architecture. A full-proxy maintains two separate session tables – one on the client-side, one on the server-side. There is effectively an “air gap” isolation layer between the two internal to the proxy, one that enables focused profiles to be applied specifically to address issues peculiar to each “side” of the proxy. Clients often experience higher latency because of lower bandwidth connections while the servers are generally low latency because they’re connected via a high-speed LAN. The optimizations and acceleration techniques used on the client side are far different than those on the LAN side because the issues that give rise to performance and availability challenges are vastly different. A full-proxy, with separate connection handling on either side of the “air gap”, can address these challenges. A proxy, which may be a full-proxy but more often than not simply uses a buffer-and-stitch methodology to perform connection management, cannot optimally do so. A typical proxy buffers a connection, often through the TCP handshake process and potentially into the first few packets of application data, but then “stitches” a connection to a given server on the back-end using either layer 4 or layer 7 data, perhaps both. The connection is a single flow from end-to-end and must choose which characteristics of the connection to focus on – client or server – because it cannot simultaneously optimize for both. The second advantage of a full-proxy is its ability to perform more tasks on the data being exchanged over the connection as it is flowing through the component. Because specific action must be taken to “match up” the connection as its flowing through the full-proxy, the component can inspect, manipulate, and otherwise modify the data before sending it on its way on the server-side. This is what enables termination of SSL, enforcement of security policies, and performance-related services to be applied on a per-client, per-application basis. This capability translates to broader usage in data center architecture by enabling the implementation of an application delivery tier in which operational risk can be addressed through the enforcement of various policies. In effect, we’re created a full-proxy data center architecture in which the application delivery tier as a whole serves as the “full proxy” that mediates between the clients and the applications. THE FULL-PROXY DATA CENTER ARCHITECTURE A full-proxy data center architecture installs a digital "air gap” between the client and applications by serving as the aggregation (and conversely disaggregation) point for services. Because all communication is funneled through virtualized applications and services at the application delivery tier, it serves as a strategic point of control at which delivery policies addressing operational risk (performance, availability, security) can be enforced. A full-proxy data center architecture further has the advantage of isolating end-users from the volatility inherent in highly virtualized and dynamic environments such as cloud computing . It enables solutions such as those used to overcome limitations with virtualization technology, such as those encountered with pod-architectural constraints in VMware View deployments. Traditional access management technologies, for example, are tightly coupled to host names and IP addresses. In a highly virtualized or cloud computing environment, this constraint may spell disaster for either performance or ability to function, or both. By implementing access management in the application delivery tier – on a full-proxy device – volatility is managed through virtualization of the resources, allowing the application delivery controller to worry about details such as IP address and VLAN segments, freeing the access management solution to concern itself with determining whether this user on this device from that location is allowed to access a given resource. Basically, we’re taking the concept of a full-proxy and expanded it outward to the architecture. Inserting an “application delivery tier” allows for an agile, flexible architecture more supportive of the rapid changes today’s IT organizations must deal with. Such a tier also provides an effective means to combat modern attacks. Because of its ability to isolate applications, services, and even infrastructure resources, an application delivery tier improves an organizations’ capability to withstand the onslaught of a concerted DDoS attack. The magnitude of difference between the connection capacity of an application delivery controller and most infrastructure (and all servers) gives the entire architecture a higher resiliency in the face of overwhelming connections. This ensures better availability and, when coupled with virtual infrastructure that can scale on-demand when necessary, can also maintain performance levels required by business concerns. A full-proxy data center architecture is an invaluable asset to IT organizations in meeting the challenges of volatility both inside and outside the data center. Related blogs & articles: The Concise Guide to Proxies At the Intersection of Cloud and Control… Cloud Computing and the Truth About SLAs IT Services: Creating Commodities out of Complexity What is a Strategic Point of Control Anyway? The Battle of Economy of Scale versus Control and Flexibility F5 Friday: When Firewalls Fail… F5 Friday: Platform versus Product3.9KViews1like1CommentInfrastructure Architecture: Whitelisting with JSON and API Keys
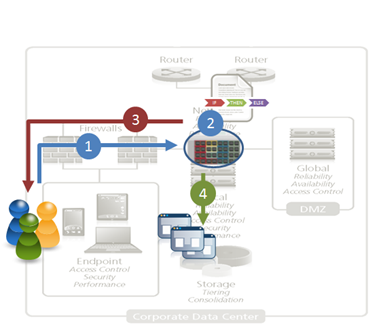
Application delivery infrastructure can be a valuable partner in architecting solutions …. AJAX and JSON have changed the way in which we architect applications, especially with respect to their ascendancy to rule the realm of integration, i.e. the API. Policies are generally focused on the URI, which has effectively become the exposed interface to any given application function. It’s REST-ful, it’s service-oriented, and it works well. Because we’ve taken to leveraging the URI as a basic building block, as the entry-point into an application, it affords the opportunity to optimize architectures and make more efficient the use of compute power available for processing. This is an increasingly important point, as capacity has become a focal point around which cost and efficiency is measured. By offloading functions to other systems when possible, we are able to increase the useful processing capacity of an given application instance and ensure a higher ratio of valuable processing to resources is achieved. The ability of application delivery infrastructure to intercept, inspect, and manipulate the exchange of data between client and server should not be underestimated. A full-proxy based infrastructure component can provide valuable services to the application architect that can enhance the performance and reliability of applications while abstracting functionality in a way that alleviates the need to modify applications to support new initiatives. AN EXAMPLE Consider, for example, a business requirement specifying that only certain authorized partners (in the integration sense) are allowed to retrieve certain dynamic content via an exposed application API. There are myriad ways in which such a requirement could be implemented, including requiring authentication and subsequent tokens to authorize access – likely the most common means of providing such access management in conjunction with an API. Most of these options require several steps, however, and interaction directly with the application to examine credentials and determine authorization to requested resources. This consumes valuable compute that could otherwise be used to serve requests. An alternative approach would be to provide authorized consumers with a more standards-based method of access that includes, in the request, the very means by which authorization can be determined. Taking a lesson from the credit card industry, for example, an algorithm can be used to determine the validity of a particular customer ID or authorization token. An API key, if you will, that is not stored in a database (and thus requires a lookup) but rather is algorithmic and therefore able to be verified as valid without needing a specific lookup at run-time. Assuming such a token or API key were embedded in the URI, the application delivery service can then extract the key, verify its authenticity using an algorithm, and subsequently allow or deny access based on the result. This architecture is based on the premise that the application delivery service is capable of responding with the appropriate JSON in the event that the API key is determined to be invalid. Such a service must therefore be network-side scripting capable. Assuming such a platform exists, one can easily implement this architecture and enjoy the improved capacity and resulting performance boost from the offload of authorization and access management functions to the infrastructure. 1. A request is received by the application delivery service. 2. The application delivery service extracts the API key from the URI and determines validity. 3. If the API key is not legitimate, a JSON-encoded response is returned. 4. If the API key is valid, the request is passed on to the appropriate web/application server for processing. Such an approach can also be used to enable or disable functionality within an application, including live-streams. Assume a site that serves up streaming content, but only to authorized (registered) users. When requests for that content arrive, the application delivery service can dynamically determine, using an embedded key or some portion of the URI, whether to serve up the content or not. If it deems the request invalid, it can return a JSON response that effectively “turns off” the streaming content, thereby eliminating the ability of non-registered (or non-paying) customers to access live content. Such an approach could also be useful in the event of a service failure; if content is not available, the application delivery service can easily turn off and/or respond to the request, providing feedback to the user that is valuable in reducing their frustration with AJAX-enabled sites that too often simply “stop working” without any kind of feedback or message to the end user. The application delivery service could, of course, perform other actions based on the in/validity of the request, such as directing the request be fulfilled by a service generating older or non-dynamic streaming content, using its ability to perform application level routing. The possibilities are quite extensive and implementation depends entirely on goals and requirements to be met. Such features become more appealing when they are, through their capabilities, able to intelligently make use of resources in various locations. Cloud-hosted services may be more or less desirable for use in an application, and thus leveraging application delivery services to either enable or reduce the traffic sent to such services may be financially and operationally beneficial. ARCHITECTURE is KEY The core principle to remember here is that ultimately infrastructure architecture plays (or can and should play) a vital role in designing and deploying applications today. With the increasing interest and use of cloud computing and APIs, it is rapidly becoming necessary to leverage resources and services external to the application as a means to rapidly deploy new functionality and support for new features. The abstraction offered by application delivery services provides an effective, cross-site and cross-application means of enabling what were once application-only services within the infrastructure. This abstraction and service-oriented approach reduces the burden on the application as well as its developers. The application delivery service is almost always the first service in the oft-times lengthy chain of services required to respond to a client’s request. Leveraging its capabilities to inspect and manipulate as well as route and respond to those requests allows architects to formulate new strategies and ways to provide their own services, as well as leveraging existing and integrated resources for maximum efficiency, with minimal effort. Related blogs & articles: HTML5 Going Like Gangbusters But Will Anyone Notice? Web 2.0 Killed the Middleware Star The Inevitable Eventual Consistency of Cloud Computing Let’s Face It: PaaS is Just SOA for Platforms Without the Baggage Cloud-Tiered Architectural Models are Bad Except When They Aren’t The Database Tier is Not Elastic The New Distribution of The 3-Tiered Architecture Changes Everything Sessions, Sessions Everywhere3.1KViews0likes0CommentsF5 Friday: Load Balancing MySQL with F5 BIG-IP
Scaling MySQL just got a whole lot easier load balancing MySQL – any database, really – is not a trivial task. Generally speaking one does not simply round robin your way through a cluster of MySQL databases as a means to achieve scalability. It is databases, in fact, that have driven a wide variety of scalability patterns such as sharding and partitioning to achieve the ultimate goal of high-performance and scalability simultaneously. Unfortunately, most folks don’t architect their applications with scalability in mind. A single database is all that’s necessary at first, and because of the way in which the application interacts with the database, it doesn’t make sense to code in support for multiple database instances, such as is often implemented with a MySQL master-slave cluster. That’s because the application has to actually open a connection to the database in question. If you’re only starting with one database, you really can’t code in a connection to a separate instance. Eventually that application’s usage grows and the demands upon the database require a more scalable approach. Enter the MySQL master/slave relationship. A typical configuration is to maintain the master as the “write” database, i.e. all updates and/or inserts must use the master, while the slave instance is used as a “read only” instance. Obviously this means the application code must be changed to support this kind of functional sharding. Unless you leverage network server virtualization from a load balancing service capable of acting as a full-proxy at layer 7 (application) like BIG-IP. This solution leverages iRules to implement database load balancing. While this specific example is designed to perform the common functional sharding pattern of read-write separation for a master-slave MySQL cluster, the flexibility of iRules is such that other architectural solutions can easily be designed using the same basic functions. Location based sharding is another popular means of scaling databases, and using the GeoLocation capabilities of BIG-IP along with iRules to inspect and route database requests, it should be a fairly trivial architectural task to implement. The ability to further extend sharding or other distribution methodologies for scaling databases without modifying the application itself is a huge bonus for both developers and operations. By decoupling the application from the database, it provides a more flexibility set of scalability domains in which technology targeted scalability strategies can be leveraged independent of the other layers. This is an important facet of agile infrastructure architecture and should not be underestimated as a benefit of network server virtualization. MySQL Load Balancing Resources: MySQL Proxy iRule MySQL Proxy iApp (deployment package for BIG-IP v11) The Full-Proxy Data Center Architecture Infrastructure Scalability Pattern: Sharding Streams Infrastructure Scalability Pattern: Sharding Sessions Infrastructure Scalability Pattern: Partition by Function or Type IT as a Service: A Stateless Infrastructure Architecture Model F5 Friday: Platform versus Product At the Intersection of Cloud and Control… What is a Strategic Point of Control Anyway? All F5 Friday Posts on DevCentral Why Single-Stack Infrastructure Sucks2.4KViews0likes0CommentsThe Challenges of SQL Load Balancing
#infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s.2.1KViews0likes1CommentReactive, Proactive, Predictive: SDN Models
#SDN #openflow A session at #interop sheds some light on SDN operational models One of the downsides of speaking at conferences is that your session inevitably conflicts with another session that you'd really like to attend. Interop NY was no exception, except I was lucky enough to catch the tail end of a session I was interested in after finishing my own. I jumped into OpenFlow and Software Defined Networks: What Are They and Why Do You Care? just as discussion about an SDN implementation at CERN labs was going on, and was quite happy to sit through the presentation. CERN labs has implemented an SDN, focusing on the use of OpenFlow to manage the network. They partner with HP for the control plane, and use a mix of OpenFlow-enabled switches for their very large switching fabric. All that's interesting, but what was really interesting (to me anyway) was the answer to my question with respect to the rate of change and how it's handled. We know, after all, that there are currently limitations on the number of inserts per second into OpenFlow-enabled switches and CERN's environment is generally considered pretty volatile. The response became a discussion of SDN models for handling change. The speaker presented three approaches that essentially describe SDN models for OpenFlow-based networks: Reactive Reactive models are those we generally associate with SDN and OpenFlow. Reactive models are constantly adjusting and are in flux as changes are made immediately as a reaction to current network conditions. This is the base volatility management model in which there is a high rate of change in the location of end-points (usually virtual machines) and OpenFlow is used to continually update the location and path through the network to each end-point. The speaker noted that this model is not scalable for any organization and certainly not CERN. Proactive Proactive models anticipate issues in the network and attempt to address them before they become a real problem (which would require reaction). Proactive models can be based on details such as increasing utilization in specific parts of the network, indicating potential forthcoming bottlenecks. Making changes to the routing of data through the network before utilization becomes too high can mitigate potential performance problems. CERN takes advantage of sFlow and Netflow to gather this data. Predictive A predictive approach uses historical data regarding the performance of the network to adjust routes and flows periodically. This approach is less disruptive as it occurs with less frequency that a reactive model but still allows for trends in flow and data volume to inform appropriate routes. CERN uses a combination of proactive and predictive methods for managing its network and indicated satisfaction with current outcomes. I walked out with two takeaways. First was validation that a reactive, real-time network operational model based on OpenFlow was inadequate for managing high rates of change. Second was the use of OpenFlow as more of an operational management toolset than an automated, real-time self-routing network system is certainly a realistic option to address the operational complexity introduced by virtualization, cloud and even very large traditional networks. The Future of Cloud: Infrastructure as a Platform SDN, OpenFlow, and Infrastructure 2.0 Applying ‘Centralized Control, Decentralized Execution’ to Network Architecture Integration Topologies and SDN SDN is Network Control. ADN is Application Control. The Next IT Killer Is… Not SDN How SDN Is Defined Within ADN Architectures2KViews0likes0CommentsWhat is a Strategic Point of Control Anyway?
From mammoth hunting to military maneuvers to the datacenter, the key to success is control Recalling your elementary school lessons, you’ll probably remember that mammoths were large and dangerous creatures and like most animals they were quite deadly to primitive man. But yet man found a way to hunt them effectively and, we assume, with more than a small degree of success as we are still here and, well, the mammoths aren’t. Marx Cavemen PHOTO AND ART WORK : Fred R Hinojosa. The theory of how man successfully hunted ginormous creatures like the mammoth goes something like this: a group of hunters would single out a mammoth and herd it toward a point at which the hunters would have an advantage – a narrow mountain pass, a clearing enclosed by large rock, etc… The qualifying criteria for the place in which the hunters would finally confront their next meal was that it afforded the hunters a strategic point of control over the mammoth’s movement. The mammoth could not move away without either (a) climbing sheer rock walls or (b) being attacked by the hunters. By forcing mammoths into a confined space, the hunters controlled the environment and the mammoth’s ability to flee, thus a successful hunt was had by all. At least by all the hunters; the mammoths probably didn’t find it successful at all. Whether you consider mammoth hunting or military maneuvers or strategy-based games (chess, checkers) one thing remains the same: a winning strategy almost always involves forcing the opposition into a situation over which you have control. That might be a mountain pass, or a densely wooded forest, or a bridge. The key is to force the entire complement of the opposition through an easily and tightly controlled path. Once they’re on that path – and can’t turn back – you can execute your plan of attack. These easily and highly constrained paths are “strategic points of control.” They are strategic because they are the points at which you are empowered to perform some action with a high degree of assurance of success. In data center architecture there are several “strategic points of control” at which security, optimization, and acceleration policies can be applied to inbound and outbound data. These strategic points of control are important to recognize as they are the most efficient – and effective – points at which control can be exerted over the use of data center resources. DATA CENTER STRATEGIC POINTS of CONTROL In every data center architecture there are aggregation points. These are points (one or more components) through which all traffic is forced to flow, for one reason or another. For example, the most obvious strategic point of control within a data center is at its perimeter – the router and firewalls that control inbound access to resources and in some cases control outbound access as well. All data flows through this strategic point of control and because it’s at the perimeter of the data center it makes sense to implement broad resource access policies at this point. Similarly, strategic points of control occur internal to the data center at several “tiers” within the architecture. Several of these tiers are: Storage virtualization provides a unified view of storage resources by virtualizing storage solutions (NAS, SAN, etc…). Because the storage virtualization tier manages all access to the resources it is managing, it is a strategic point of control at which optimization and security policies can be easily applied. Application Delivery / load balancing virtualizes application instances and ensures availability and scalability of an application. Because it is virtualizing the application it therefore becomes a point of aggregation through which all requests and responses for an application must flow. It is a strategic point of control for application security, optimization, and acceleration. Network virtualization is emerging internal to the data center architecture as a means to provide inter-virtual machine connectivity more efficiently than perhaps can be achieved through traditional network connectivity. Virtual switches often reside on a server on which multiple applications have been deployed within virtual machines. Traditionally it might be necessary for communication between those applications to physically exit and re-enter the server’s network card. But by virtualizing the network at this tier the physical traversal path is eliminated (and the associated latency, by the way) and more efficient inter-vm communication can be achieved. This is a strategic point of control at which access to applications at the network layer should be applied, especially in a public cloud environment where inter-organizational residency on the same physical machine is highly likely. OLD SKOOL VIRTUALIZATION EVOLVES You might have begun noticing a central theme to these strategic points of control: they are all points at which some kind of virtualization – and thus aggregation – occur naturally in a data center architecture. This is the original (first) kind of virtualization: the presentation of many resources as a single resources, a la load balancing and other proxy-based solutions. When there is a one —> many (1:M) virtualization solution employed, it naturally becomes a strategic point of control by virtue of the fact that all “X” traffic must flow through that solution and thus policies regarding access, security, logging, etc… can be applied in a single, centrally managed location. The key here is “strategic” and “control”. The former relates to the ability to apply the latter over data at a single point in the data path. This kind of 1:M virtualization has been a part of datacenter architectures since the mid 1990s. It’s evolved to provide ever broader and deeper control over the data that must traverse these points of control by nature of network design. These points have become, over time, strategic in terms of the ability to consistently apply policies to data in as operationally efficient manner as possible. Thus have these virtualization layers become “strategic points of control”. And you thought the term was just another square on the buzz-word bingo card, didn’t you?1.1KViews0likes6CommentsThe Limits of Cloud: Gratuitous ARP and Failover
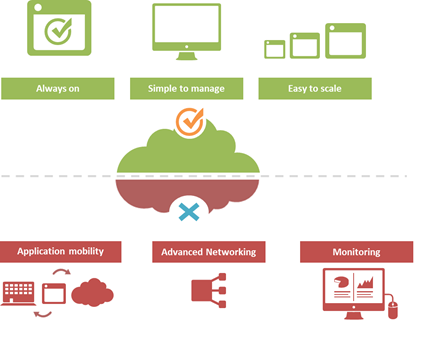
#Cloud is great at many things. At other things, not so much. Understanding the limitations of cloud will better enable a successful migration strategy. One of the truisms of technology is that takes a few years of adoption before folks really start figuring out what it excels at – and conversely what it doesn't. That's generally because early adoption is focused on lab-style experimentation that rarely extends beyond basic needs. It's when adoption reaches critical mass and folks start trying to use the technology to implement more advanced architectures that the "gotchas" start to be discovered. Cloud is no exception. A few of the things we've learned over the past years of adoption is that cloud is always on, it's simple to manage, and it makes applications and infrastructure services easy to scale. Some of the things we're learning now is that cloud isn't so great at supporting application mobility, monitoring of deployed services and at providing advanced networking capabilities. The reason that last part is so important is that a variety of enterprise-class capabilities we've come to rely upon are ultimately enabled by some of the advanced networking techniques cloud simply does not support. Take gratuitous ARP, for example. Most cloud providers do not allow or support this feature which ultimately means an inability to take advantage of higher-level functions traditionally taken for granted in the enterprise – like failover. GRATUITOUS ARP and ITS IMPLICATIONS For those unfamiliar with gratuitous ARP let's get you familiar with it quickly. A gratuitous ARP is an unsolicited ARP request made by a network element (host, switch, device, etc… ) to resolve its own IP address. The source and destination IP address are identical to the source IP address assigned to the network element. The destination MAC is a broadcast address. Gratuitous ARP is used for a variety of reasons. For example, if there is an ARP reply to the request, it means there exists an IP conflict. When a system first boots up, it will often send a gratuitous ARP to indicate it is "up" and available. And finally, it is used as the basis for load balancing failover. To ensure availability of load balancing services, two load balancers will share an IP address (often referred to as a floating IP). Upstream devices recognize the "primary" device by means of a simple ARP entry associating the floating IP with the active device. If the active device fails, the secondary immediately notices (due to heartbeat monitoring between the two) and will send out a gratuitous ARP indicating it is now associated with the IP address and won't the rest of the network please send subsequent traffic to it rather than the failed primary. VRRP and HSRP may also use gratuitous ARP to implement router failover. Most cloud environments do not allow broadcast traffic of this nature. After all, it's practically guaranteed that you are sharing a network segment with other tenants, and thus broadcasting traffic could certainly disrupt other tenant's traffic. Additionally, as security minded folks will be eager to remind us, it is fairly well-established that the default for accepting gratuitous ARPs on the network should be "don't do it". The astute observer will realize the reason for this; there is no security, no ability to verify, no authentication, nothing. A network element configured to accept gratuitous ARPs does so at the risk of being tricked into trusting, explicitly, every gratuitous ARP – even those that may be attempting to fool the network into believing it is a device it is not supposed to be. That, in essence, is ARP poisoning, and it's one of the security risks associated with the use of gratuitous ARP. Granted, someone needs to be physically on the network to pull this off, but in a cloud environment that's not nearly as difficult as it might be on a locked down corporate network. Gratuitous ARP can further be used to execute denial of service, man in the middle and MAC flooding attacks. None of which have particularly pleasant outcomes, especially in a cloud environment where such attacks would be against shared infrastructure, potentially impacting many tenants. Thus cloud providers are understandably leery about allowing network elements to willy-nilly announce their own IP addresses. That said, most enterprise-class network elements have implemented protections against these attacks precisely because of the reliance on gratuitous ARP for various infrastructure services. Most of these protections use a technique that will tentatively accept a gratuitous ARP, but not enter it in its ARP cache unless it has a valid IP-to-MAC mapping, as defined by the device configuration. Validation can take the form of matching against DHCP-assigned addresses or existence in a trusted database. Obviously these techniques would put an undue burden on a cloud provider's network given that any IP address on a network segment might be assigned to a very large set of MAC addresses. Simply put, gratuitous ARP is not cloud-friendly, and thus it is you will be hard pressed to find a cloud provider that supports it. What does that mean? That means, ultimately, that failover mechanisms in the cloud cannot be based on traditional techniques unless a means to replicate gratuitous ARP functionality without its negative implications can be designed. Which means, unfortunately, that traditional failover architectures – even using enterprise-class load balancers in cloud environments – cannot really be implemented today. What that means for IT preparing to migrate business critical applications and services to cloud environments is a careful review of their requirements and of the cloud environment's capabilities to determine whether availability and uptime goals can – or cannot – be met using a combination of cloud and traditional load balancing services.1.1KViews1like0CommentsThe Stealthy Ascendancy of JSON
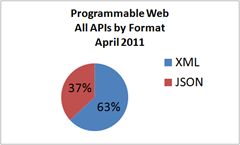
While everyone was focused on cloud, JSON has slowly but surely been taking over the application development world It looks like the debate between XML and JSON may be coming to a close with JSON poised to take the title of preferred format for web applications. If you don’t consider these statistics to be impressive, consider that ProgrammableWeb indicated that its “own statistics on ProgrammableWeb show a significant increase in the number of JSON APIs over 2009/2010. During 2009 there were only 191 JSON APIs registered. So far in 2010 [August] there are already 223!” Today there are 1262 JSON APIs registered, which means a growth rate of 565% in the past eight months, nearly catching up to XML which currently lists 2162 APIs. At this rate, JSON will likely overtake XML as the preferred format by the end of 2011. This is significant to both infrastructure vendors and cloud computing providers alike, because it indicates a preference for a programmatic model that must be accounted for when developing services, particularly those in the PaaS (Platform as a Service) domain. PaaS has yet to grab developers mindshare and it may be that support for JSON will be one of the ways in which that mindshare is attracted. Consider the results of the “State of Web Development 2010” survey from Web Directions in which developers were asked about their cloud computing usage; only 22% responded in the affirmative to utilizing cloud computing. But of those 22% that do leverage cloud computing, the providers they use are telling: PaaS represents a mere 7.35% of developers use of cloud computing, with storage (Amazon S3) and IaaS (Infrastructure as a Service) garnering 26.89% of responses. Google App Engine is the dominant PaaS platform at the moment, most likely owing to the fact that it is primarily focused on JavaScript, UI, and other utility-style services as opposed to Azure’s middle-ware and definitely more enterprise-class focused services. SaaS, too, is failing to recognize the demand from developers and the growing ascendancy of JSON. Consider this exchange on the Salesforce.com forums regarding JSON. Come on salesforce lets get this done. We need to integrate, we need this [JSON]. If JSON continues its steady rise into ascendancy, PaaS and SaaS providers alike should be ready to support JSON-style integration as its growth pattern indicates it is not going away, but is instead picking up steam. Providers able to support JSON for PaaS and SaaS will have a competitive advantage over those that do not, especially as they vie for the hearts and minds of developers which are, after all, their core constituency. THE IMPACT What the steady rise of JSON should trigger for providers and vendors alike is a need to support JSON as the means by which services are integrated, invoked, and data exchanged. Application delivery, service-providers and Infrastructure 2.0 focused solutions need to provide APIs that are JSON compatible and which are capable of handling the format to provide core infrastructure services such as firewalling and data scrubbing duties. The increasing use of JSON-based APIs to integrate with external, third-party services continues to grow and the demand for enterprise-class service to support JSON as well will continue to rise. There are drawbacks, and this steady movement toward JSON has in some cases a profound impact on the infrastructure and architectural choices made by IT organizations, especially in terms of providing for consistency of services across what is likely a very mixed-format environment. Identity and access management and security services may not be prepared to handle JSON APIs nor provide the same services as it has for XML, which through long established usage and efforts comes with its own set of standards. Including social networking “streams” in applications and web-sites is now as common as including images, but changes to APIs may make basic security chores difficult. Consider that Twitter – very quietly – has moved to supporting JSON only for its Streaming API. Organizations that were, as well they should, scrubbing such streams to prevent both embarrassing as well as malicious code from being integrated unknowingly into their sites, may have suddenly found that infrastructure providing such services no longer worked: API providers and developers are making their choice quite clear when it comes to choosing between XML and JSON. A nearly unanimous choice seems to be JSON. Several API providers, including Twitter, have either stopped supporting the XML format or are even introducing newer versions of their API with only JSON support. In our ProgrammableWeb API directory, JSON seems to be the winner. A couple of items are of interest this week in the XML versus JSON debate. We had earlier reported that come early December, Twitter plans to stop support for XML in its Streaming API. --JSON Continues its Winning Streak Over XML, ProgrammableWeb (Dec 2010) Similarly, caching and acceleration services may be confused by a change from XML to JSON; from a format that was well-understood and for which solutions were enabled with parsing capabilities to one that is not. IT’S THE DATA, NOT the API The fight between JSON and XML is one we continue to see in a general sense. See, it isn’t necessarily the API that matters, in the end, but the data format (the semantics) used to exchange that data which matters. XML is considered unstructured, though in practice it’s far more structured than JSON in the sense that there are meta-data standards for XML that constrain security, identity, and even application formats. JSON, however, although having been included natively in ECMA v5 (JSON data interchange format gets ECMA standards blessing) has very few standards aside from those imposed by frameworks and toolkits such as JQuery. This will make it challenging for infrastructure vendors to support services targeting application data – data scrubbing, web application firewall, IDS, IPS, caching, advanced routing – to continue to effectively deliver such applications without recognizing JSON as an option. The API has become little more than a set of URIs and nearly all infrastructure directly related to application delivery is more than capable of handling them. It is the data, however, that presents a challenge and which makes the developers’ choice of formats so important in the big picture. It isn’t just the application and integration that is impacted, it’s the entire infrastructure and architecture that must adapt to support the data format. The World Doesn’t Care About APIs – but it does care about the data, about the model. Right now, it appears that model is more than likely going to be presented in a JSON-encoded format. JSON data interchange format gets ECMA standards blessing JSON Continues its Winning Streak Over XML JSON versus XML: Your Choice Matters More Than You Think I am in your HTTP headers, attacking your application The Web 2.0 API: From collaborating to compromised Would you risk $31,000 for milliseconds of application response time? Stop brute force listing of HTTP OPTIONS with network-side scripting The New Distribution of The 3-Tiered Architecture Changes Everything Are You Scrubbing the Twitter Stream on Your Web Site?871Views0likes0CommentsArchitecting Scalable Infrastructures: CPS versus DPS
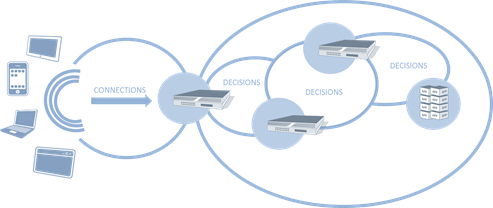
#webperf As we continue to find new ways to make connections more efficient, capacity planning must look to other metrics to ensure scalability without compromising performance. Infrastructure metrics have always been focused on speeds and feeds. Throughput, packets per second, connections per second, etc… These metrics have been used to evaluate and compare network infrastructure for years, ultimately being used as a critical component in data center design. This makes sense. After all, it's not rocket science to figure out that a firewall capable of handling 10,000 connections per second (CPS) will overwhelm a next hop (load balancer, A/V scanner, etc… ) device only capable of 5,000 CPS. Or will it? The problem with old skool performance metrics is they focus on ingress, not egress capacity. With SDN pushing a new focus on both northbound and southbound capabilities, it makes sense to revisit the metrics upon which we evaluate infrastructure and design data centers. CONNECTIONS versus DECISIONS As we've progressed from focusing on packets to sessions, from IP addresses to users, from servers to applications, we've necessarily seen an evolution in the intelligence of network components. It's not just application delivery that's gotten smarter, it's everything. Security, access control, bandwidth management, even routing (think NAC), has become much more intelligent. But that intelligence comes at a price: processing. That processing turns into latency as each device takes a certain amount of time to inspect, evaluate and ultimate decide what to do with the data. And therein lies the key to our conundrum: it makes a decision. That decision might be routing based or security based or even logging based. What the decision is is not as important as the fact that it must be made. SDN necessarily brings this key differentiator between legacy and next-generation infrastructure to the fore, as it's just software-defined but software-deciding networking. When a switch doesn't know what to do with a packet in SDN it asks the controller, which evaluates and makes a decision. The capacity of SDN – and of any modern infrastructure – is at least partially determined by how fast it can make decisions. Examples of decisions: URI-based routing (load balancers, application delivery controllers) Virus-scanning SPAM scanning Traffic anomaly scanning (IPS/IDS) SQLi / XSS inspection (web application firewalls) SYN flood protection (firewalls) BYOD policy enforcement (access control systems) Content scrubbing (web application firewalls) The DPS capacity of a system is not the same as its connection capacity, which is merely the measure of how many new connections a second can be established (and in many cases how many connections can be simultaneously sustained). Such a measure is merely determining how optimized the networking stack of any given solution might be, as connections – whether TCP or UDP or SMTP – are protocol oriented and it is the networking stack that determines how well connections are managed. The CPS rate of any given device tells us nothing about how well it will actually perform its appointed tasks. That's what the Decisions Per Second (DPS) metric tells us. CONSIDERING BOTH CPS and DPS Reality is that most systems will have a higher CPS compared to its DPS. That's not necessarily bad, as evaluating data as it flows through a device requires processing, and processing necessarily takes time. Using both CPS and DPS merely recognizes this truth and forces it to the fore, where it can be used to better design the network. A combined metric helps design the network by offering insight into the real capacity of a given device, rather than a marketing capacity. When we look only at CPS, for example, we might feel perfectly comfortable with a topological design with a flow of similar CPS capacities. But what we really want is to make sure that DPS –> CPS (and vice-versa) capabilities were matched up correctly, lest we introduce more latency than is necessary into a given flow. What we don't want is to end up with is a device with a high DPS rate feeding into a device with a lower CPS rate. We also don't want to design a flow in which DPS rates successively decline. Doing so means we're adding more and more latency into the equation. The DPS rate is a much better indicator of capacity than CPS for designing high-performance networks because it is a realistic measure of performance, and yet a high DPS coupled with a low CPS would be disastrous. Luckily, it is almost always the case that a mismatch in CPS and DPS will favor CPS, with DPS being the lower of the two metrics in almost all cases. What we want to see is as close a CPS:DPS ratio as possible. The ideal is 1:1, of course, but given the nature of inspecting data it is unrealistic to expect such a tight ratio. Still, if the ratio becomes too high, it indicates a potential bottleneck in the network that must be addressed. For example, assume an extreme case of a CPS:DPS of 2:1. The device can establish 10,000 CPS, but only process at a rate of 5,000 DPS, leading to increasing latency or other undesirable performance issues as connections queue up waiting to be processed. Obviously there's more at play than just new CPS and DPS (concurrent connection capability is also a factor) but the new CPS and DPS relationship is a good general indicator of potential issues. Knowing the DPS of a device enables architects to properly scale out the infrastructure to remediate potential bottlenecks. This is particularly true when TCP multiplexing is in play, because it necessarily reduces CPS to the target systems but in no way impacts the DPS. On the ingress, too, are emerging protocols like SPDY that make more efficient use of TCP connections, making CPS an unreliable measure of capacity, especially if DPS is significantly lower than the CPS rating of the system. Relying upon CPS alone – particularly when using TCP connection management technologies - as a means to achieve scalability can negatively impact performance. Testing systems to understand their DPS rate is paramount to designing a scalable infrastructure with consistent performance. The Need for (HTML5) Speed SPDY versus HTML5 WebSockets Y U No Support SPDY Yet? Curing the Cloud Performance Arrhythmia F5 Friday: Performance, Throughput and DPS Data Center Feng Shui: Architecting for Predictable Performance On Cloud, Integration and Performance728Views0likes0CommentsInfrastructure 2.0 + Cloud + IT as a Service = An Architectural Parfait
Infrastructure 2.0 ≠ cloud computing ≠ IT as a Service. There is a difference between Infrastructure 2.0 and cloud. There is also a difference between cloud and IT as a Service. But they do go together, like a parfait. And everybody likes a parfait… The introduction of the newest member of the cloud computing buzzword family is “IT as a Service.” It is understandably causing some confusion because, after all, isn’t that just another way to describe “private cloud”? No, actually it isn’t. There’s a lot more to it than that, and it’s very applicable to both private and public models. Furthermore, equating “cloud computing” to “IT as a Service” does both a big a disservice as making synonyms of “Infrastructure 2.0” and “cloud computing.” These three [ concepts | models | technologies ] are highly intertwined and in some cases even interdependent, but they are not the same. In the simplest explanation possible: infrastructure 2.0 enables cloud computing which enables IT as a service. Now that we’ve got that out of the way, let’s dig in. ENABLE DOES NOT MEAN EQUAL TO One of the core issues seems to be the rush to equate “enable” with “equal”. There is a relationship between these three technological concepts but they are in no wise equivalent nor should be they be treated as such. Like SOA, the differences between them revolve primarily around the level of abstraction and the layers at which they operate. Not the layers of the OSI model or the technology stack, but the layers of a data center architecture. Let’s start at the bottom, shall we? INFRASTRUCTURE 2.0 At the very lowest layer of the architecture is Infrastructure 2.0. Infrastructure 2.0 is focused on enabling dynamism and collaboration across the network and application delivery network infrastructure. It is the way in which traditionally disconnected (from a communication and management point of view) data center foundational components are imbued with the ability to connect and collaborate. This is primarily accomplished via open, standards-based APIs that provide a granular set of operational functions that can be invoked from a variety of programmatic methods such as orchestration systems, custom applications, and via integration with traditional data center management solutions. Infrastructure 2.0 is about making the network smarter both from a management and a run-time (execution) point of view, but in the case of its relationship to cloud and IT as a Service the view is primarily focused on management. Infrastructure 2.0 includes the service-enablement of everything from routers to switches, from load balancers to application acceleration, from firewalls to web application security components to server (physical and virtual) infrastructure. It is, distilled to its core essence, API-enabled components. CLOUD COMPUTING Cloud computing is the closest to SOA in that it is about enabling operational services in much the same way as SOA was about enabling business services. Cloud computing takes the infrastructure layer services and orchestrates them together to codify an operational process that provides a more efficient means by which compute, network, storage, and security resources can be provisioned and managed. This, like Infrastructure 2.0, is an enabling technology. Alone, these operational services are generally discrete and are packaged up specifically as the means to an end – on-demand provisioning of IT services. Cloud computing is the service-enablement of operational services and also carries along the notion of an API. In the case of cloud computing, this API serves as a framework through which specific operations can be accomplished in a push-button like manner. IT as a SERVICE At the top of our technology pyramid, as it is likely obvious at this point we are building up to the “pinnacle” of IT by laying more aggressively focused layers atop one another, we have IT as a Service. IT as a Service, unlike cloud computing, is designed not only to be consumed by other IT-minded folks, but also by (allegedly) business folks. IT as a Service broadens the provisioning and management of resources and begins to include not only operational services but those services that are more, well, businessy, such as identity management and access to resources. IT as a Service builds on the services provided by cloud computing, which is often called a “cloud framework” or a “cloud API” and provides the means by which resources can be provisioned and managed. Now that sounds an awful lot like “cloud computing” but the abstraction is a bit higher than what we expect with cloud. Even in a cloud computing API we are steal interacting more directly with operational and compute-type resources. We’re provisioning, primarily, infrastructure services but we are doing so at a much higher layer and in a way that makes it easy for both business and application developers and analysts to do so. An example is probably in order at this point. THE THREE LAYERS in the ARCHITECTURAL PARFAIT Let us imagine a simple “application” which itself requires only one server and which must be available at all times. That’s the “service” IT is going to provide to the business. In order to accomplish this seemingly simple task, there’s a lot that actually has to go on under the hood, within the bowels of IT. LAYER ONE Consider, if you will, what fulfilling that request means. You need at least two servers and a Load balancer, you need a server and some storage, and you need – albeit unknown to the business user – firewall rules to ensure the application is only accessible to those whom you designate. So at the bottom layer of the stack (Infrastructure 2.0) you need a set of components that match these functions and they must be all be enabled with an API (or at a minimum by able to be automated via traditional scripting methods). Now the actual task of configuring a load balancer is not just a single API call. Ask RackSpace, or GoGrid, or Terremark, or any other cloud provider. It takes multiple steps to authenticate and configure – in the right order – that component. The same is true of many components at the infrastructure layer: the APIs are necessarily granular enough to provide the flexibility necessary to be combined in a way as to be customizable for each unique environment in which they may be deployed. So what you end up with is a set of infrastructure services that comprise the appropriate API calls for each component based on the specific operational policies in place. LAYER TWO At the next layer up you’re providing even more abstract frameworks. The “cloud API” at this layer may provide services such as “auto-scaling” that require a great deal of configuration and registration of components with other components. There’s automation and orchestration occurring at this layer of the IT Service Stack, as it were, that is much more complex but narrowly focused than at the previous infrastructure layer. It is at this layer that the services become more customized and able to provide business and customer specific options. It is also at this layer where things become more operationally focused, with the provisioning of “application resources” comprising perhaps the provisioning of both compute and storage resources. This layer also lays the foundation for metering and monitoring (cause you want to provide visibility, right?) which essentially overlays, i.e. makes a service of, multiple infrastructure resource monitoring services. LAYER THREE At the top layer is IT as a Service, and this is where systems become very abstracted and get turned into the IT King “A La Carte” Menu that is the ultimate goal according to everyone who’s anyone (and a few people who aren’t). This layer offers an interface to the cloud in such a way as to make self-service possible. It may not be Infrabook or even very pretty, but as long as it gets the job done cosmetics are just enhancing the value of what exists in the first place. IT as a Service is the culmination of all the work done at the previous layers to fine-tune services until they are at the point where they are consumable – in the sense that they are easy to understand and require no real technical understanding of what’s actually going on. After all, a business user or application developer doesn’t really need to know how the server and storage resources are provisioned, just in what sizes and how much it’s going to cost. IT as a Service ultimately enables the end-user – whomever that may be – to easily “order” IT services to fulfill the application specific requirements associated with an application deployment. That means availability, scalability, security, monitoring, and performance. A DYNAMIC DATA CENTER ARCHITECTURE One of the first questions that should come to mind is: why does it matter? After all, one could cut out the “cloud computing” layer and go straight from infrastructure services to IT as a Service. While that’s technically true it eliminates one of the biggest benefits of a layered and highly abstracted architecture : agility. By presenting each layer to the layer above as services, we are effectively employing the principles of a service-oriented architecture and separating the implementation from the interface. This provides the ability to modify the implementation without impacting the interface, which means less down-time and very little – if any – modification in layers above the layer being modified. This translates into, at the lowest level, vender agnosticism and the ability to avoid vendor-lock in. If two components, say a Juniper switch and a Cisco switch, are enabled with the means by which they can be enabled as services, then it becomes possible to switch the two at the implementation layer without requiring the changes to trickle upward through the interface and into the higher layers of the architecture. It’s polymorphism applied to an data center operation rather than a single object’s operations, to put it in developer’s terms. It’s SOA applied to a data center rather than an application, to put it in an architect’s terms. It’s an architectural parfait and, as we all know, everybody loves a parfait, right? Related blogs & articles: Applying Scalability Patterns to Infrastructure Architecture The Other Hybrid Cloud Architecture The New Distribution of The 3-Tiered Architecture Changes Everything Infrastructure 2.0: Aligning the network with the business (and ... Infrastructure 2.0: As a matter of fact that isn't what it means Infrastructure 2.0: Flexibility is Key to Dynamic Infrastructure Infrastructure 2.0: The Diseconomy of Scale Virus Lori MacVittie - Infrastructure 2.0 Infrastructure 2.0: Squishy Name for a Squishy Concept Pay No Attention to the Infrastructure Behind the Cloudy Curtain Making Infrastructure 2.0 reality may require new standards The Inevitable Eventual Consistency of Cloud Computing Cloud computing is not Burger King. You can't have it your way. Yet.720Views0likes0Comments