industry
51 TopicsOne Time Passwords via an SMS Gateway with BIG-IP Access Policy Manager
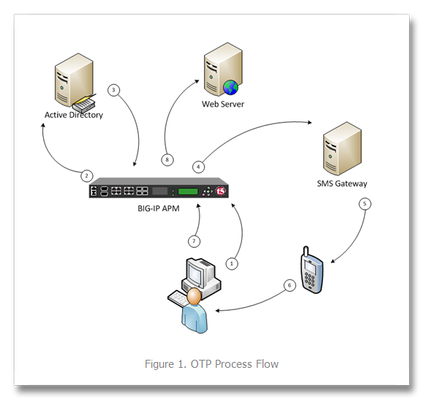
One time passwords, or OTP, are used (as the name indicates) for a single session or transaction. The plus side is a more secure deployment, the downside is two-fold—first, most solutions involve a token system, which is costly in management, dollars, and complexity, and second, people are lousy at remembering things, so a delivery system for that OTP is necessary. The exercise in this tech tip is to employ BIG-IP APM to generate the OTP and pass it to the user via an SMS Gateway, eliminating the need for a token creating server/security appliance while reducing cost and complexity. Getting Started This guide was developed by F5er Per Boe utilizing the newly released BIG-IP version 10.2.1. The “-secure” option for the mcget command is new in this version and is required in one of the steps for this solution. Also, this solution uses the Clickatell SMS Gateway to deliver the OTPs. Their API is documented at http://www.clickatell.com/downloads/http/Clickatell_HTTP.pdf. Other gateway providers with a web-based API could easily be substituted. Also, there are steps at the tail end of this guide to utilize the BIG-IP’s built-in mail capabilities to email the OTP during testing in lieu of SMS. The process in delivering the OTP is shown in Figure 1. First a request is made to the BIG-IP APM. The policy is configured to authenticate the user’s phone number in Active Directory, and if successful, generate a OTP and pass along to the SMS via the HTTP API. The user will then use the OTP to enter into the form updated by APM before allowing the user through to the server resources. BIG-IP APM Configuration Before configuring the policy, an access profile needs to be created, as do a couple authentication servers. First, let’s look at the authentication servers Authentication Servers To create servers used by BIG-IP APM, navigate to Access Policy->AAA Servers and then click create. This profile is simple, supply your domain server, domain name, and admin username and password as shown in Figure 2. The other authentication server is for the SMS Gateway, and since it is an HTTP API we’re using, we need the HTTP type server as shown in Figure 3. Note that the hidden form values highlighted in red will come from your Clickatell account information. Also note that the form method is GET, the form action references the Clickatell API interface, and that the match type is set to look for a specific string. The Clickatell SMS Gateway expects the following format: https://api.clickatell.com/http/sendmsg?api_id=xxxx&user=xxxx&password=xxxx&to=xxxx&text=xxxx Finally, successful logon detection value highlighted in red at the bottom of Figure 3 should be modified to response code returned from SMS Gateway. Now that the authentication servers are configured, let’s take a look at the access profile and create the policy. Access Profile & Policy Before we can create the policy, we need an access profile, shown below in Figure 4 with all default settings. Now that that is done, we click on Edit under the Access Policy column highlighted in red in Figure 5. The default policy is bare bones, or as some call it, empty. We’ll work our way through the objects, taking screen captures as we go and making notes as necessary. To add an object, just click the “+” sign after the Start flag. The first object we’ll add is a Logon Page as shown in Figure 6. No modifications are necessary here, so you can just click save. Next, we’ll configure the Active Directory authentication, so we’ll add an AD Auth object. Only setting here in Figure 7 is selecting the server we created earlier. Following the AD Auth object, we need to add an AD Query object on the AD Auth successful branch as shown in Figures 8 and 9. The server is selected in the properties tab, and then we create an expression in the branch rules tab. To create the expression, click change, and then select the Advanced tab. The expression used in this AD Query branch rule: expr { [mcget {session.ad.last.attr.mobile}] != "" } Next we add an iRule Event object to the AD Query OK branch that will generate the one time password and provide logging. Figure 10 Shows the iRule Event object configuration. The iRule referenced by this event is below. The logging is there for troubleshooting purposes, and should probably be disabled in production. 1: when ACCESS_POLICY_AGENT_EVENT { 2: expr srand([clock clicks]) 3: set otp [string range [format "%08d" [expr int(rand() * 1e9)]] 1 6 ] 4: set mail [ACCESS::session data get "session.ad.last.attr.mail"] 5: set mobile [ACCESS::session data get "session.ad.last.attr.mobile"] 6: set logstring mail,$mail,otp,$otp,mobile,$mobile 7: ACCESS::session data set session.user.otp.pw $otp 8: ACCESS::session data set session.user.otp.mobile $mobile 9: ACCESS::session data set session.user.otp.username [ACCESS::session data get "session.logon.last.username"] 10: log local0.alert "Event [ACCESS::policy agent_id] Log $logstring" 11: } 12: 13: when ACCESS_POLICY_COMPLETED { 14: log local0.alert "Result: [ACCESS::policy result]" 15: } On the fallback path of the iRule Event object, add a Variable Assign object as show in Figure 10b. Note that the first assignment should be set to secure as indicated in image with the [S]. The expressions in Figure 10b are: session.logon.last.password = expr { [mcget {session.user.otp.pw}]} session.logon.last.username = expr { [mcget {session.user.otp.mobile}]} On the fallback path of the AD Query object, add a Message Box object as shown in Figure 11 to alert the user if no mobile number is configured in Active Directory. On the fallback path of the Event OTP object, we need to add the HTTP Auth object. This is where the SMS Gateway we configured in the authentication server is referenced. It is shown in Figure 12. On the fallback path of the HTTP Auth object, we need to add a Message Box as shown in Figure 13 to communicate the error to the client. On the Successful branch of the HTTP Auth object, we need to add a Variable Assign object to store the username. A simple expression and a unique name for this variable object is all that is changed. This is shown in Figure 14. On the fallback branch of the Username Variable Assign object, we’ll configure the OTP Logon page, which requires a Logon Page object (shown in Figure 15). I haven’t mentioned it yet, but the name field of all these objects isn’t a required change, but adding information specific to the object helps with readability. On this form, only one entry field is required, the one time password, so the second password field (enabled by default) is set to none and the initial username field is changed to password. The Input field below is changed to reflect the type of logon to better queue the user. Finally, we’ll finish off with an Empty Action object where we’ll insert an expression to verify the OTP. The name is configured in properties and the expression in the branch rules, as shown in Figures 16 and 17. Again, you’ll want to click advanced on the branch rules to enter the expression. The expression used in the branch rules above is: expr { [mcget {session.user.otp.pw}] == [mcget -secure {session.logon.last.otp}] } Note again that the –secure option is only available in version 10.2.1 forward. Now that we’re done adding objects to the policy, one final step is to click on the Deny following the OK branch of the OTP Verify Empty Action object and change it from Deny to Allow. Figure 18 shows how it should look in the visual policy editor window. Now that the policy is completed, we can attach the access profile to the virtual server and test it out, as can be seen in Figures 19 and 20 below. Email Option If during testing you’d rather send emails than utilize the SMS Gateway, then configure your BIG-IP for mail support (Solution 3664), keep the Logging object, lose the HTTP Auth object, and configure the system with this script to listen for the messages sent to /var/log/ltm from the configured Logging object: #!/bin/bash while true do tail -n0 -f /var/log/ltm | while read line do var2=`echo $line | grep otp | awk -F'[,]' '{ print $2 }'` var3=`echo $line | grep otp | awk -F'[,]' '{ print $3 }'` var4=`echo $line | grep otp | awk -F'[,]' '{ print $4 }'` if [ "$var3" = "otp" -a -n "$var4" ]; then echo Sending pin $var4 to $var2 echo One Time Password is $var4 | mail -s $var4 $var2 fi done done The log messages look like this: Jan 26 13:37:24 local/bigip1 notice apd[4118]: 01490113:5: b94f603a: session.user.otp.log is mail,user1@home.local,otp,609819,mobile,12345678 The output from the script as configured looks like this: [root@bigip1:Active] config # ./otp_mail.sh Sending pin 239272 to user1@home.local Conclusion The BIG-IP APM is an incredibly powerful tool to add to the LTM toolbox. Whether using the mail system or an SMS gateway, you can take a bite out of your infrastructure complexity by using this solution to eliminate the need for a token management service. Many thanks again to F5er Per Boe for this excellent solution!6.6KViews0likes23CommentsUnix To PowerShell - Wc
PowerShell is definitely gaining momentum in the windows scripting world but I still hear folks wanting to rely on unix based tools to get their job done. In this series of posts I’m going to look at converting some of the more popular Unix based tools to PowerShell. wc The Unix “wc” (word count) command will print the character, word, and newline counts for each file specified and a total line if more than one file is specified. This command is useful for quickly scanning a directory for small and large files or to quickly look at a file and determine it’s relative size. The Get-Content Cmdlet will return the number of characters in the full but not the number of lines and words. The following script will emulate the behavior of the Unix “wc” command with a few changes in the way parameters are supplied.3.2KViews0likes2Comments
RADIUS Load Balancing with iRules
What is RADIUS? “Remote Authentication Dial In User Service” or RADIUS is a very mature and widely implemented protocol for exchanging ”Triple A” or “Authentication, Authorization and Accounting” information. RADIUS is a relatively simple, transactional protocol. Clients, such as remote access server, FirePass, BIG-IP, etc. originate RADIUS requests (for example, to authenticate a user based on a user/password combination) and then wait for a response from the RADIUS server. Information is exchanged between a RADIUS client and server in the form of attributes. User-name, user-password, IP Address, port, and session state are all examples of attributes. Attributes can be in the format of text, string, IP address, integer or timestamp. Some attributes are variable in length, some are fixed. Why is protocol-specific support valuable? In typical UDP Load Balancing (not protocol-specific), there is one common challenge: if a client always sends requests with the same source port, packets will never be balanced across multiple servers. This behavior is the default for a UDP profile. To allow load balancing to work in this situation, using "Datagram LB" is the common recommendation or the use of an immediate session timeout. By using Datagram LB, every packet will be balanced. However, if a new request comes in before the reply for the previous request comes back from the server, BIG-IP LTM may change source port of that new request before forwards it to the server. This may result in an application not acting properly. In this later case, “Immediate timeout” must then be used. An additional virtual server may be needed for outbound traffic in order to route traffic back to the client. In short, to enable load balancing for RADIUS transaction-based traffic coming from the same source IP/source port, Datagram LB or immediate timeout should be employed. This configuration works in most cases. However, if the transaction requires more than 2 packets (1 request, 1 response), then, further BIG-IP LTM work is needed. An example where this is important occurs in RADIUS challenge/response handshakes, which require 4 packets: * Client ---- access-request ---> Server * Client <-- access-challenge --- Server * Client --- access-request ----> Server * Client <--- access-accept ----- Server For this traffic to succeed, all packets associated with the same transaction must be returned to the same server. In this case, custom layer 7 persistence is needed. iRules can provide the needed persistency. With iRules that understand the RADIUS protocol, BIG-IP LTM can direct traffic based on any attribute sent by client or persist sessions based on any attribute sent by client or server. Session management can then be moved to the BIG-IP, reducing server-side complexity. BIG-IP can provide almost unlimited intelligence in an iRule that can even re-calculate md5, modify usernames, detect realms, etc. BIG-IP LTM can also provide security at the application level of the RADIUS protocol, rejecting malformed traffic, denial of service attacks, or similar threats using customized iRules. Solution Datagram LB UDP profile or immediate timeout may be used if requests from client always use the same source IP/port. If immediate timeout is used, there should be an additional VIP for outbound traffic originated from server to client and also an appropriate SNAT (same IP as VIP). Identifier or some attributes can be used for Universal Inspection Engine (UIE) persistence. If immediate timeout/2-side-VIP technique are used, these should be used in conjunction with session command with "any" option. iRules 1) Here is a sample iRule which does nothing except decode and log some attribute information. This is a good example of the depth of fluency you can achieve via an iRule dealing with RADIUS. when RULE_INIT { array set ::attr_code2name { 1 User-Name 2 User-Password 3 CHAP-Password 4 NAS-IP-Address 5 NAS-Port 6 Service-Type 7 Framed-Protocol 8 Framed-IP-Address 9 Framed-IP-Netmask 10 Framed-Routing 11 Filter-Id 12 Framed-MTU 13 Framed-Compression 14 Login-IP-Host 15 Login-Service 16 Login-TCP-Port 17 (unassigned) 18 Reply-Message 19 Callback-Number 20 Callback-Id 21 (unassigned) 22 Framed-Route 23 Framed-IPX-Network 24 State 25 Class 26 Vendor-Specific 27 Session-Timeout 28 Idle-Timeout 29 Termination-Action 30 Called-Station-Id 31 Calling-Station-Id 32 NAS-Identifier 33 Proxy-State 34 Login-LAT-Service 35 Login-LAT-Node 36 Login-LAT-Group 37 Framed-AppleTalk-Link 38 Framed-AppleTalk-Network 39 Framed-AppleTalk-Zone 60 CHAP-Challenge 61 NAS-Port-Type 62 Port-Limit 63 Login-LAT-Port } } when CLIENT_ACCEPTED { binary scan [UDP::payload] cH2SH32cc code ident len auth \ attr_code1 attr_len1 log local0. "code = $code" log local0. "ident = $ident" log local0. "len = $len" log local0. "auth = $auth" set index 22 while { $index < $len } { set hsize [expr ( $attr_len1 - 2 ) * 2] switch $attr_code1 { 11 - 1 { binary scan [UDP::payload] @${index}a[expr $attr_len1 - 2]cc \ attr_value attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } 9 - 8 - 4 { binary scan [UDP::payload] @${index}a4cc rawip \ attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) =\ [IP::addr $rawip mask 255.255.255.255]" } 13 - 12 - 10 - 7 - 6 - 5 { binary scan [UDP::payload] @${index}Icc attr_value \ attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } default { binary scan [UDP::payload] @${index}H${hsize}cc \ attr_value attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } } set index [ expr $index + $attr_len1 ] set attr_len1 $attr_len2 set attr_code1 $attr_code2 } } when SERVER_DATA { binary scan [UDP::payload] cH2SH32cc code ident len auth \ attr_code1 attr_len1 log local0. "code = $code" log local0. "ident = $ident" log local0. "len = $len" log local0. "auth = $auth" set index 22 while { $index < $len } { set hsize [expr ( $attr_len1 - 2 ) * 2] switch $attr_code1 { 11 - 1 { binary scan [UDP::payload] @${index}a[expr $attr_len1 - 2]cc \ attr_value attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } 9 - 8 - 4 { binary scan [UDP::payload] @${index}a4cc rawip \ attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) =\ [IP::addr $rawip mask 255.255.255.255]" } 13 - 12 - 10 - 7 - 6 - 5 { binary scan [UDP::payload] @${index}Icc attr_value \ attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } default { binary scan [UDP::payload] @${index}H${hsize}cc \ attr_value attr_code2 attr_len2 log local0. " $::attr_code2name($attr_code1) = $attr_value" } } set index [ expr $index + $attr_len1 ] set attr_len1 $attr_len2 set attr_code1 $attr_code2 } } This iRule could be applied to many areas of interest where a particular value needs to be extracted. For example, the iRule could detect the value of specific attributes or realm and direct traffic based on that information. 2) This second iRule allows UDP Datagram LB to work with 2 factor authentication. Persistence in this iRule is based on "State" attribute (value = 24). Another great example of the kinds of things you can do with an iRule, and how deep you can truly dig into a protocol. when CLIENT_ACCEPTED { binary scan [UDP::payload] ccSH32cc code ident len auth \ attr_code1 attr_len1 set index 22 while { $index < $len } { set hsize [expr ( $attr_len1 - 2 ) * 2] binary scan [UDP::payload] @${index}H${hsize}cc attr_value \ attr_code2 attr_len2 # If it is State(24) attribute... if { $attr_code1 == 24 } { persist uie $attr_value 30 return } set index [ expr $index + $attr_len1 ] set attr_len1 $attr_len2 set attr_code1 $attr_code2 } } when SERVER_DATA { binary scan [UDP::payload] ccSH32cc code ident len auth \ attr_code1 attr_len1 # If it is Access-Challenge(11)... if { $code == 11 } { set index 22 while { $index < $len } { set hsize [expr ( $attr_len1 - 2 ) * 2] binary scan [UDP::payload] @${index}H${hsize}cc attr_value \ attr_code2 attr_len2 if { $attr_code1 == 24 } { persist add uie $attr_value 30 return } set index [ expr $index + $attr_len1 ] set attr_len1 $attr_len2 set attr_code1 $attr_code2 } } } Conclusion With iRules, BIG-IP can understand RADIUS packets and make intelligent decisions based on RADIUS protocol information. Additionally, it is also possible to manipulate RADIUS packets to meet nearly any application need. Contributed by: Nat Thirasuttakorn Get the Flash Player to see this player.2.7KViews0likes4CommentsUnix To PowerShell – Cut
PowerShell is definitely gaining momentum in the windows scripting world but I still hear folks wanting to rely on Unix based tools to get their job done. In this series of posts I’m going to look at converting some of the more popular Unix based tools to PowerShell. cut The Unix “cut” command is used to extract sections from each link of input. Extraction of line segments can be done by bytes, characters, or fields separated by a delimiter. A range must be provided in each case which consists of one of N, N-M, N- (N to the end of the line), or –M (beginning of the line to M), where N and M are counted from 1 (there is no zeroth value). For PowerShell, I’ve omitted support for bytes but the rest of the features is included. The Parse-Range function is used to parse the above range specification. It takes as input a range specifier and returns an array of indices that the range contains. Then, the In-Range function is used to determine if a given index is included in the parsed range. The real work is done in the Do-Cut function. In there, input error conditions are checked. Then for each file supplied, lines are extracted and processed with the given input specifiers. For character ranges, each character is processed and if it’s index in the line is in the given range, it is appended to the output line. For field ranges, the line is split into tokens using the delimiter specifier (default is a TAB). Each field is processed and if it’s index is in the included range, the field is appended to the output with the given output_delimiter specifier (which defaults to the input delimiter). The options to the Unix cut command are implemented with the following PowerShell arguments: Unix PowerShell Description FILE -filespec The files to process. -c -characters Output only this range of characters. -f -fields Output only these fields specified by given range. -d -delimiter Use DELIM instead of TAB for input field delimiter. -s -only_delimited Do not print lines not containing delimiters. --output-delimiter -output_delimiter Use STRING as the output deflimiter.2.6KViews0likes4Comments
The Challenges of SQL Load Balancing
#infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s.2.3KViews0likes1CommentIntroducing PoshTweet - The PowerShell Twitter Script Library
It's probably no surprise from those of you that follow my blog and tech tips here on DevCentral that I'm a fan of Windows PowerShell. I've written a set of Cmdlets that allow you to manage and control your BIG-IP application delivery controllers from within PowerShell and a whole set of articles around those Cmdlets. I've been a Twitter user for a few years now and over the holidays, I've noticed that Jeffrey Snover from the PowerShell team has hopped aboard the Twitter bandwagon and that got me to thinking... Since I live so much of my time in the PowerShell command prompt, wouldn't it be great to be able to tweet from there too? Of course it would! HTTP Requests So, last night I went ahead and whipped up a first draft of a set of PowerShell functions that allow access to the Twitter services. I implemented the functions based on Twitter's REST based methods so all that was really needed to get things going was to implement the HTTP GET and POST requests needed for the different API methods. Here's what I came up with. function Execute-HTTPGetCommand() { param([string] $url = $null); if ( $url ) { [System.Net.WebClient]$webClient = New-Object System.Net.WebClient $webClient.Credentials = Get-TwitterCredentials [System.IO.Stream]$stream = $webClient.OpenRead($url); [System.IO.StreamReader]$sr = New-Object System.IO.StreamReader -argumentList $stream; [string]$results = $sr.ReadToEnd(); $results; } } function Execute-HTTPPostCommand() { param([string] $url = $null, [string] $data = $null); if ( $url -and $data ) { [System.Net.WebRequest]$webRequest = [System.Net.WebRequest]::Create($url); $webRequest.Credentials = Get-TwitterCredentials $webRequest.PreAuthenticate = $true; $webRequest.ContentType = "application/x-www-form-urlencoded"; $webRequest.Method = "POST"; $webRequest.Headers.Add("X-Twitter-Client", "PoshTweet"); $webRequest.Headers.Add("X-Twitter-Version", "1.0"); $webRequest.Headers.Add("X-Twitter-URL", "http://devcentral.f5.com/s/poshtweet"); [byte[]]$bytes = [System.Text.Encoding]::UTF8.GetBytes($data); $webRequest.ContentLength = $bytes.Length; [System.IO.Stream]$reqStream = $webRequest.GetRequestStream(); $reqStream.Write($bytes, 0, $bytes.Length); $reqStream.Flush(); [System.Net.WebResponse]$resp = $webRequest.GetResponse(); $rs = $resp.GetResponseStream(); [System.IO.StreamReader]$sr = New-Object System.IO.StreamReader -argumentList $rs; [string]$results = $sr.ReadToEnd(); $results; } } Credentials Once those were completed, it was relatively simple to get the Status methods for public_timeline, friends_timeline, user_timeline, show, update, replies, and destroy going. But, for several of those services, user credentials were required. I opted to store them in a script scoped variable and provided a few functions to get/set the username/password for Twitter. $script:g_creds = $null; function Set-TwitterCredentials() { param([string]$user = $null, [string]$pass = $null); if ( $user -and $pass ) { $script:g_creds = New-Object System.Net.NetworkCredential -argumentList ($user, $pass); } else { $creds = Get-TwitterCredentials; } } function Get-TwitterCredentials() { if ( $null -eq $g_creds ) { trap { Write-Error "ERROR: You must enter your Twitter credentials for PoshTweet to work!"; continue; } $c = Get-Credential if ( $c ) { $user = $c.GetNetworkCredential().Username; $pass = $c.GetNetworkCredential().Password; $script:g_creds = New-Object System.Net.NetworkCredential -argumentList ($user, $pass); } } $script:g_creds; } The Status functions Now that the credentials were out of the way, it was time to tackle the Status methods. These methods are a combination of HTTP GETs and POSTs that return an array of status entries. For those interested in the raw underlying XML that's returned, I've included the $raw parameter, that when set to $true, will not do a user friendly display, but will dump the full XML response. This would be handy, if you want to customize the output beyond what I've done. #---------------------------------------------------------------------------- # public_timeline #---------------------------------------------------------------------------- function Get-TwitterPublicTimeline() { param([bool]$raw = $false); $results = Execute-HTTPGetCommand "http://twitter.com/statuses/public_timeline.xml"; Process-TwitterStatus $results $raw; } #---------------------------------------------------------------------------- # friends_timeline #---------------------------------------------------------------------------- function Get-TwitterFriendsTimeline() { param([bool]$raw = $false); $results = Execute-HTTPGetCommand "http://twitter.com/statuses/friends_timeline.xml"; Process-TwitterStatus $results $raw } #---------------------------------------------------------------------------- #user_timeline #---------------------------------------------------------------------------- function Get-TwitterUserTimeline() { param([string]$username = $null, [bool]$raw = $false); if ( $username ) { $username = "/$username"; } $results = Execute-HTTPGetCommand "http://twitter.com/statuses/user_timeline$username.xml"; Process-TwitterStatus $results $raw } #---------------------------------------------------------------------------- # show #---------------------------------------------------------------------------- function Get-TwitterStatus() { param([string]$id, [bool]$raw = $false); if ( $id ) { $results = Execute-HTTPGetCommand "http://twitter.com/statuses/show/" + $id + ".xml"; Process-TwitterStatus $results $raw; } } #---------------------------------------------------------------------------- # update #---------------------------------------------------------------------------- function Set-TwitterStatus() { param([string]$status); $encstatus = [System.Web.HttpUtility]::UrlEncode("$status"); $results = Execute-HTTPPostCommand "http://twitter.com/statuses/update.xml" "status=$encstatus"; Process-TwitterStatus $results $raw; } #---------------------------------------------------------------------------- # replies #---------------------------------------------------------------------------- function Get-TwitterReplies() { param([bool]$raw = $false); $results = Execute-HTTPGetCommand "http://twitter.com/statuses/replies.xml"; Process-TwitterStatus $results $raw; } #---------------------------------------------------------------------------- # destroy #---------------------------------------------------------------------------- function Destroy-TwitterStatus() { param([string]$id = $null); if ( $id ) { Execute-HTTPPostCommand "http://twitter.com/statuses/destroy/$id.xml", "id=$id"; } } You may notice the Process-TwitterStatus function. Since there was a lot of duplicate code in each of these functions, I went ahead and implemented it in it's own function below: function Process-TwitterStatus() { param([string]$sxml = $null, [bool]$raw = $false); if ( $sxml ) { if ( $raw ) { $sxml; } else { [xml]$xml = $sxml; if ( $xml.statuses.status ) { $stats = $xml.statuses.status; } elseif ($xml.status ) { $stats = $xml.status; } $stats | Foreach-Object -process { $info = "by " + $_.user.screen_name + ", " + $_.created_at; if ( $_.source ) { $info = $info + " via " + $_.source; } if ( $_.in_reply_to_screen_name ) { $info = $info + " in reply to " + $_.in_reply_to_screen_name; } "-------------------------"; $_.text; $info; }; "-------------------------"; } } } A few hurdles Nothing goes without a hitch and I found myself pounding my head at why my POST commands were all getting HTTP 417 errors back from Twitter. A quick search brought up this post on Phil Haack's website as well as this Google Group discussing an update in Twitter's services in how they react to the Expect 100 HTTP header. A simple setting in the ServicePointManager at the top of the script was all that was needed to get things working again. [System.Net.ServicePointManager]::Expect100Continue = $false; PoshTweet in Action So, now it's time to try it out. First you'll need to . source the script and then set your Twitter credentials. This can be done in your Twitter $profile file if you wish. Then you can access all of the included functions. Below, I'll call Set-TwitterStatus to update my current status and then Get-TwitterUserTimeline and Get-TwitterFriendsTimeline to get my current timeline as well as that of my friends. PS> . .\PoshTweet.ps1 PS> Set-TwitterCredentials PS> Set-TwitterStatus "Hacking away with PoshTweet" PS> Get-TwitterUserTimeline ------------------------- Hacking away with PoshTweet by joepruitt, Tue Dec 30, 12:33:04 +0000 2008 via web ------------------------- PS> Get-TwitterFriendsTimeline ------------------------- @astrout Yay, thanks! by mediaphyter, Tue Dec 30 20:37:15 +0000 2008 via web in reply to astrout ------------------------- RT @robconery: Headed to a Portland Nerd Dinner tonite - should be fun! http://bit.ly/EUFC by shanselman, Tue Dec 30 20:37:07 +0000 2008 via TweetDeck ------------------------- ... Things Left Todo As I said, this was implemented in an hour or so last night so it definitely needs some more work, but I believe I've got the Status methods pretty much covered. Next I'll move on to the other services of User, Direct Message, Friendship, Account, Favorite, Notification, Block, and Help when I've got time. I'd also like to add support for the "source" field. I'll need to setup a landing page for this library that is public facing so the folks at Twitter will add it to their system. Once I get all the services implemented, I'll more forward in formalizing this as an application and submit it for consideration. Collaboration I've posted the source to this set of functions on the DevCentral wiki under PsTwitterApi. You'll need to create an account to get to it, but I promise it will be worth it! Feel free to contribute and add to if you have the time. Everyone is welcome and encouraged to tear my code apart, optimize it, enhance it. Just as long as it get's better in the process. B-).1.7KViews0likes10Comments
The (hopefully) definitive guide to load balancing Lync Edge Servers with a Hardware Load Balancer
Having worked on a few large Lync deployments recently, I have realized that there is still a lot of confusion around properly architecting the network for load balancing Lync Edge Servers. Guidance on this subject has changed from OCS 2007 to OCS 2007 R2 and now to Lync Server 2010, and it's important that care is taken while planning the design. It's also important to know that although a certain architecture may seem to work, it could be very far from best practice. I'll explain what I mean by that below. The main purpose of Edge Services is to allow remote (whether they are corporate, anonymous, federated, etc) users to communicate with other external/internal users and vice versa. If you're looking to extend your Lync deployment to support communication with federated partners, public IM services, remote users and such, then you'll want to make sure you deploy your Edge Servers properly. This post will discuss some requirements and best practices for deploying Edge Servers, and then we'll go into some suggested architectures. For this discussion, let's assume that there are 3 device types within your DMZ; your firewall, your BIG-IP LTM, and your Lync Edge Server farm. Requirement 1: Your Edge Servers need at least 2 network interfaces; one or more dedicated to the external network, and one dedicated to the internal. The external and internal interfaces need to be on separate IP networks. The Edge Server will host 3 separate external services; Access, Web Conferencing, and Audio/Visual (A/V). If you plan on exposing all 3 services for remote users, you have a choice of using one IP for all 3 services on each server and differentiate them by TCP/UDP port value, or go with a separate IP for each service and use standard ports. Best Practice: This is more preference than best practice, but I like to use 3 separate IPs for these services. With alternative ports/port mapping, you can consolidate to a single IP, but unless you have a very specific reason for doing so, its best to stick with 3 separate IPs. You do burn more IPs by doing this, but you'll have to use non-standard ports for certain services if you use a single IP, and this could lead to issues with certain network devices that like certain traffic types on certain ports. Plus, troubleshooting, traffic statistics, logging are all cleaner if you are using 3 separate IPs. Requirement 2: Traffic that is load balanced to the Lync Edge servers needs to return through the load balancer. In other words, if the hardware load balancer sends traffic to an Edge Server, the return traffic from that Edge Server needs to flow back through the load balancer. There are 2 common ways to ensure that return traffic flows through the load balancer. You can… Use routing, and have the Edge Servers point to the load balancer as their default gateway. Enable SNAT on the load balancer, which rewrites the source IP of the connection to a local network address as the traffic passes through the load balancer. In this case, the Edge Servers will believe that a local client generated the connection and send the responses back to that local address. So there are your two options, which I will refer to as Routing and SNATting. With Routing, your Edge Server will rely on its routing table to route the return traffic out through the load balancer. No obscuring of the source IP address will happen on the load balancer, but you will have to make sure your default gateway & routing tables are correct. With SNATting, you can ensure return traffic goes back through the load balancer and not have to worry about the routing table to take care of this. The drawback to SNATting is that the load balancer will obscure the source IP of the packet as it passes through the load balancer. I will explain below why the SNAT idea is less than ideal, primarily for A/V traffic. Best Practice: You can SNAT traffic to the Web Conferencing and Access services on the Edge Server, but do not SNAT traffic to the A/V Edge Services. By obscuring the client's IP Address when using SNAT, you limit the ability for the A/V Services to connect clients directly to each other, and this is important when clients try to set up peer 2 peer communication, such as a phone call. When using SNAT, The A/V services will not see the client's true IP, so the likelihood of the Edge Server being able to orchestrate the 2 clients to communicate directly with each other is reduced to nil. You'll force the A/V services to utilize its fallback method, in which the P2P traffic will actually have to use the A/V server as a proxy between the 2 clients. Now this 'proxy' fallback mode will still happen from time to time even when your not SNATting at the BIG-IP (for example, multiparty calls will always use 'proxy'), but when you can, its best to minimize the times that users have to leverage this fallback method. So even though SNATting connections to the A/V Edge Service will seem to work, it is far from desirable from a network perspective! FYI - Every load balanced service in a Lync Environment (including Lync FE's, Directors, etc) can be SNAT'ed except for the A/V Edge Service. Requirement 3: Certain connections will need to be load balanced to the Edge Services, while certain connections will need to be made directly to those Edge Services. Best Practice: Make sure clients can connect to the Virtual IP(s) that are load balancing the Edge Services, as well as make sure that clients can connect directly to the Edge Servers themselves. Typically users will hit the load balancer on their first incoming connection and get load balanced, but if a user gets invited to a media session that has started on an Edge Server, the invite they receive will point them directly to that server. NAT awareness was built into Lync 2010 to help in environments in which Edge Servers are deployed behind NATs. By enabling the NAT awareness, Edge Servers will refer clients to their respective NAT address in order to route the users in correctly. Do I need to use routable IPs on the external interface of my Edge Servers? Microsoft says you do, and I would recommend doing so if you can. I have worked on deployments where non-routable IPs are being used (leveraging NATs to allow direct access) and not run into any issues. Just be sure that the Edge Servers are aware of their NAT address. Best Practice: Suggested Deployment "DNAT in, SNAT out" on the Load Balancer ”DSNAT in, SNAT out” was derived from discussions with a certain MSFT engineer who helped me build this guidance. I’d love to give him credit (he knows Lync networking better than anyone I have ever talked to!!), but if named this person, his/her phone would never stop ringing for architecture guidance !!. Back to the subject, if you keep to "DNAT in, and SNAT out” for external-side Lync Edge traffic, your deployment will work! It sums it up very well! So you're ready to architect your Edge Server Deployment. Lets take all the information from above and build a deployment. Keep these things mind….. External Side of the Edge Servers -Plan for VIPs on your BIG-IP to load balance the 3 external services that your Edge Server Provides (Access, WebConferencing, A/V) -Plan for direct (non-load balanced) access to your Edge Servers by external clients -Plan a method to allow Edge Servers to make outbound connections (forwarding VIP or SNAT on BIG-IP) -Point the Edge Server's Default Gateway to the Self IP of the BIG-IP -Point the BIG-IP's Default Gateway to the Router -Do not SNAT traffic to the A/V Services on the Edge Servers If you use non-routable IPs on the external Interfaces of the Edge Servers, create a NAT on the BIG-IP for each Edge Server. Make sure the Edge Servers are aware of these NAT addresses so they can hand them out to clients who need to connect directly to Edge Server. Internal Side of the Edge Servers -Plan for VIPs on your BIG-IP to load balance ports 443, 3478, 5061, and 5062 on the internal interfaces of your Edge Servers -Plan for direct (non-load balanced) access to your Edge Servers -Make sure your Edge Servers have routes to the internal network(s) -You can SNAT traffic to the internal interface of the Edge Servers I'll leave you with an example of a fully supported configuration (i.e. using routable IP Addresses all around). Keep in mind, this is not the only way to architect this, but if you have the available public IP address space, this will work. Wow… so much for a short post. I welcome any and all feedback, and I promise to update this post with new information as it comes in. I'll also augment this post with more details & deployments as I find time to write them up, so check back for updates. This may even end up as a guide some day! Version 1.0 date 7/14/2011 Version 1.1 date 2/15/2011 - Fixed a few typos. Fixed some heinous formatting1.3KViews0likes8CommentsBig-IP and ADFS (SCRATCH THAT! Big-IP and SAML) with Office 365 – Part 5
The BIG-IP with APM has now become SAML, (claims) aware! “SAML” not “self-aware”. No need to start worrying about Skynet and Arnold Schwarzenegger kicking in your door, (except for you Sarah Connor). This is a good thing! If you need to federate your organization with Office 365, this is a very good thing. With the release of ver. 11.3, BIG-IP with APM, (Access Policy Manager) now includes full SAML support on the box. What does that mean? Well, rather than relying upon an external resource such as ADFS to issue or security tokens, (used to present/consume claims with a federation partner), the BIG-IP becomes the federation endpoint for the organization. Check out here for more information on federation. When it comes to Office 365, not only has the infrastructure required to federate your organization been dramatically reduced, the configuration required has been simplified. Available in our community codeshare forum is an iApp as well as guidance specifically designed for deploying the BIG-IP as a federation IdP, (identity provider) for Office 365. Now federating with Office 365 is as simple as answering a few questions and entering a few PowerShell commands to configure the Office 365 side. To gain a better understanding of how we arrived here, (replacing ADFS), as well as illustrating the benefit let’s take a look at the “Evolution of Solution”…development. Saying Goodbye to ADFS Ensuring a Highly Available Architecture Throughout this series, (links below), we’ve taken a look at how the F5 BIG-IP can add value and enhance to and ADFS, (Active Directory Federation Services). To get the ball rolling we looked at how the BIG-IP was able to provide for a highly-available and scalable ADFS infrastructure, (refer to Figure 1). This included ensuring the ADFS proxy farm, located in the perimeter network, as well as the internal ADFS farm was available and the traffic is optimized. BIG-IP enhancements to the ADFS federation process: • Intelligent traffic management • Advanced L7 health monitoring – (Ensures the ADFS service is responding) • Cookie-based persistence Enhancing Security and Streamlining ADFS Building upon the previous solution, (load balancing the ADFS and ADFS Proxy layers), we implemented APM, (Access Policy Manager), (refer to Figure 2). By implementing APM on the F5 appliance(s) we not only eliminated the need for these additional servers but, by implementing pre-authentication at the perimeter and advanced features such as client-side checks, (antivirus validation, firewall verification, etc.), arguably provided for a more secure deployment. Additional BIG-IP enhancements to the ADFS federation process: •Enhanced Security •Variety of authentication methods •Client endpoint inspection •Multi-factor authentication •Improved User Experience •SSO across on-premise and cloud-based applications •Single-URL access for hybrid deployments •Simplified Architecture •Removes the ADFS proxy farm layer as well as the need to load balance the proxy farm Eliminating the ADFS Infrastructure Available with version 11.3, APM includes full SAML support. This allows the BIG-IP to not only authenticate the client connections with Active Directory, but act as the IdP or SP in the federation process. No longer will an organization be required to deploy an ADFS infrastructure for federation. Rather, the BIG-IP’s role as an application delivery controller is expanded out to include cloud-based resources, (including Office 365), as well as on-premise applications. Additional BIG-IP enhancements to the ADFS federation process: •Ability to act as IDP, (Identity Provider) for access to external claims-based resources including Office 365 •Act as service provider, (SP) to facilitate federated access to on-premise applications •Streamlined architecture, (no need for the ADFS architecture) •Simplified iApp deployment Figure 3 shows a typical Office 365 client access process utilizing APM and SAML. Additional Links: Big-IP APM as SAML 2.0 IdP from Microsoft Office 365 SAML Federation with the BIG-IP Big-IP and ADFS Part 1 – “Load balancing the ADFS Farm” Big-IP and ADFS Part 2 – “APM–An Alternative to the ADFS Proxy” Big-IP and ADFS Part 3 – “ADFS, APM, and the Office 365 Thick Clients” Big-IP and ADFS Part 4 – “What about Single Sign-Out?” BIG-IP Access Policy Manager (APM) Wiki Home - DevCentral Wiki Latest F5 Information F5 News Articles F5 Press Releases F5 Events F5 Web Media F5 Technology Alliance Partners F5 YouTube Feed1.1KViews0likes3CommentsCreating An iControl PowerShell Monitoring Dashboard With Google Charts
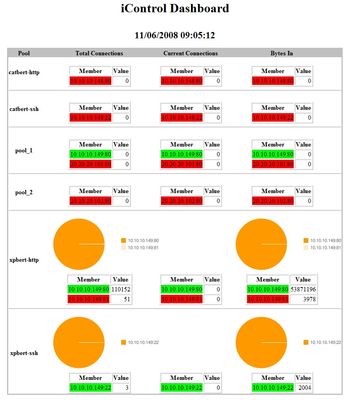
PowerShell is a very extensible scripting language and the fact that it integrates so nicely with iControl means you can do all sorts of fun things with it. In this tech tip, I'll illustrate how to use just a couple of iControl method calls (3 to be exact) to create a load distribution dashboard for you desktop (with a little help from the Google Chart API). Usage The arguments for this application are the address, username, and password for your BIG-IP. param ( $g_bigip = $null, $g_uid = $null, $g_pwd = $null ); The main control flow then looks for the input parameters and if they are not present, a usage message is displayed to the console indicating the required inputs. If the connection info is specified, then the standard Do-Initialize function is called which will look to see if the iControl Snapin is installed and the Initialize-F5.iControl cmdlet is called to initialize the connection to the BIG-IP. If an error occurs during the connection, then an error is logged and the application exits. function Write-Usage() { Write-Host "Usage: iControlDashboard.ps1 host uid pwd"; exit; } function Do-Initialize() { if ( (Get-PSSnapin | Where-Object { $_.Name -eq "iControlSnapIn"}) -eq $null ) { Add-PSSnapIn iControlSnapIn } $success = Initialize-F5.iControl -HostName $g_bigip -Username $g_uid -Password $g_pwd; return $success; } #------------------------------------------------------------------------- # Main Application Logic #------------------------------------------------------------------------- if ( ($g_bigip -eq $null) -or ($g_uid -eq $null) -or ($g_pwd -eq $null) ) { Write-Usage; } if ( Do-Initialize ) { Run-Dashboard } else { Write-Error "ERROR: iControl subsystem not initialized" Kill-Browser } Global Variables This appliction will make use of the Google Chart APIs to generate graphs and as such we need a browser to render it in. Since we will be interacting with another process (in this case Internet Explorer), it is probably a good idea to gracefully shutdown if an error occurs. A generic Exception Trap is created to log the error and shutdown the application properly. Trap [Exception] { Write-Host $("TRAPPED: " + $_.Exception.GetType().FullName); Write-Host $("TRAPPED: " + $_.Exception.Message); Kill-Browser Exit; } A few global variables are used to make the app more configurable. You can specify the title that comes up in the browsers header as well as the graph size for each report graph along with the chart type and polling interval. I opted for a pie chart but other options are available that may or may not be to your liking. At this point I go ahead and create a empty browser window and point it to the about:blank page giving us a context to manipulate the contents of the browser window. I make the window visible and set it to full screen theatermode. $g_title = "iControl PowerShell Dashboard"; $g_graphsize = "300x150"; $g_charttype = "p"; $g_interval = 5; $g_browser = New-Object -com InternetExplorer.Application; $g_browser.Navigate2("About:blank"); $g_browser.Visible = $true; $g_browser.TheaterMode = $true; Browser Control The following functions are to control the browser and the data going into it. The Refresh-Browser function takes as input the HTML to display. The Document object is then accessed from the InternetExplorer.Application object and from there we can access the DocumentElement. Then we set the InnerHTML to the input parameter $html_data and that is displayed in the browser window. #------------------------------------------------------------------------- # function Refresh-Browser #------------------------------------------------------------------------- function Refresh-Browser() { param($html_data); if ( $null -eq $g_browser ) { Write-Host "Creating new Browser" $g_browser = New-Object -com InternetExplorer.Application; $g_browser.Navigate2("About:blank"); $g_browser.Visible = $true; $g_browser.TheaterMode = $true; } $docBody = $g_browser.Document.DocumentElement.lastChild; $docBody.InnerHTML = $html_data; } #------------------------------------------------------------------------- # function Kill-Browser #------------------------------------------------------------------------- function Kill-Browser() { if ( $null -ne $g_browser ) { $g_browser.TheaterMode = $false; $g_browser.Quit(); $g_browser = $null; } } Main Application Loop The main logic for this application is a little infinite loop where we call the Get-Data function, refresh the browser with the newly acquired report, and sleep for the configured interval until the next poll occurs. function Run-Dashboard() { while($true) { #Write-Host "Requesting data..." $html_data = Get-Data; Refresh-Browser $html_data; Start-Sleep $g_interval; } } Generating the Report Here's where all the good stuff happens. The Get-Data function will make a few iControl calls (LocalLB.Pool.get_list(), LocalLB.PoolMember.get_all_statistics(), and LocalLB.PoolMember.get_object_status()) and from that generate a HTML report with charts generated with the Google Chart API. The local variable $html-data is used to store the resulting HTML data that will be sent to Internet Explorer for display and we start off the function by filling in the title and start of the report table. Then the three previously mentioned iControl calls are made and the resulting values are stored in local varables for later reference. The main loop here goes over each of the pools in the MemberStatisticsA local array variable. A few hash tables and counters are created and then we loop over each pool member for the current pool we are processing. Then entries are added to the local hash tables for total connections, current connections, bytes in, and status for later reference. Also a sum of all the values for those hash tables are stored so we can calculate percentages later on. At this point we will use the hash tables for generating the report. Each numeric value is calculated into a percent and chart variables are created to contain the data as well as the labels for the generated pie charts. Once all the number crunching has been performed the actual chart images are specified in the $chart_total, $chart_current, and $chart_bytes variables and the row in the report for the given pool is added to the $html_data variable. function Get-Data() { # TODO - get connection statistics $now = [DateTime]::Now; $html_data = "<html> <head> <title>$g_title</title> </head> <body> <center><h1>$g_title</h1><br/><h2>$now</h2></center> <center><table border='0' bgcolor='#C0C0C0'><tr><td><table border='0' cellspacing='0' bgcolor='#FFFFFF'>"; $html_data += " <tr bgcolor='#C0C0C0'><th>Pool</th><th>Total Connections</th><th>Current Connections</th><th>Bytes In</th></tr>"; $charts_total = ""; $charts_current = ""; $charts_bytes = ""; $PoolList = (Get-F5.iControl).LocalLBPool.get_list() | Sort-Object; $MemberStatisticsA = (Get-F5.iControl).LocalLBPoolMember.get_all_statistics($PoolList) $MemberObjectStatusAofA = (Get-F5.iControl).LocalLBPoolMember.get_object_status($PoolList); # loop over each pool $i = 0; foreach($MemberStatistics in $MemberStatisticsA) { $hash_total = @{}; $hash_current = @{}; $hash_bytes = @{}; $hash_status = @{}; $sum_total = 0; $sum_current = 0; $sum_bytes = 0; $PoolName = $PoolList[$i]; # loop over each member $MemberStatisticEntryA = $MemberStatistics.statistics; foreach($MemberStatisticEntry in $MemberStatisticEntryA) { $member = $MemberStatisticEntry.member; $addr = $member.address; $port = $member.port; $addrport = "${addr}:${port}"; $StatisticA = $MemberStatisticEntry.statistics; $total = Extract-Statistic $StatisticA "STATISTIC_SERVER_SIDE_TOTAL_CONNECTIONS" [long]$sum_total += $total; $hash_total.Add($addrport, $total); $current = Extract-Statistic $StatisticA "STATISTIC_SERVER_SIDE_CURRENT_CONNECTIONS" $sum_current += $current; $hash_current.Add($addrport, $current); $bytes = Extract-Statistic $StatisticA "STATISTIC_SERVER_SIDE_BYTES_IN" [long]$sum_bytes += $bytes; $hash_bytes.Add($addrport, $bytes); $color = Extract-Status $MemberObjectStatusAofA[$i] $member; $hash_status.Add($addrport, $color); } $chd_t = ""; $chd_c = ""; $chd_b = ""; $chl_t = ""; $chl_c = ""; $chl_b = ""; $chdl_t = ""; $chdl_c = ""; $chdl_b = ""; $tbl_t = ""; $tbl_c = ""; $tbl_b = ""; # enumerate the total connections foreach($k in $hash_total.Keys) { $member = $k; $v_t = $hash_total[$k]; $v_c = $hash_current[$k]; $v_b = $hash_bytes[$k]; $color = $hash_status[$k]; $div = $sum_total; if ($div -eq 0 ) { $div = 1; } $p_t = ($v_t/$div)*100; $div = $sum_current; if ($div -eq 0 ) { $div = 1; } $p_c = ($v_c/$div)*100; $div = $sum_bytes; if ($div -eq 0 ) { $div = 1; } $p_b = ($v_b/$div)*100; if ( $chd_t.Length -gt 0 ) { $chd_t += ","; $chd_c += ","; $chd_b += ","; } $chd_t += $p_t; $chd_c += $p_c; $chd_b += $p_b; if ( $chl_t.Length -gt 0 ) { $chl_t += "|"; $chl_c += "|"; $chl_b += "|"; $chdl_t += "|"; $chdl_c += "|"; $chdl_b += "|"; } $chl_t += "$member"; $chl_c += "$member"; $chl_b += "$member"; $chdl_t += "$member - $v_t"; $chdl_c += "$member - $v_c"; $chdl_b += "$member - $v_b"; #$alt_t += "($member,$v_t)"; #$alt_c += "($member,$v_c)"; #$alt_b += "($member,$v_b)"; $tbl_t += "<tr><td bgcolor='$color'>$member</td><td align='right'>$v_t</td></tr>"; $tbl_c += "<tr><td bgcolor='$color'>$member</td><td align='right'>$v_c</td></tr>"; $tbl_b += "<tr><td bgcolor='$color'>$member</td><td align='right'>$v_b</td></tr>"; } if ( $sum_total -gt 0 ) { $chart_total = "<img src='http://chart.apis.google.com/chart? chs=$g_graphsize &chd=t:$chd_t &cht=$g_charttype &chdl=$chl_t' alt='Total Connections for pool $PoolName' />"; } else { $chart_total = ""; } if ( $sum_current -gt 0 ) { $chart_current = "<img src='http://chart.apis.google.com/chart? chs=$g_graphsize &chd=t:$chd_c &cht=$g_charttype &chdl=$chl_c' alt='Current Connections for pool $PoolName' />"; } else { $chart_current = ""; } if ( $sum_bytes -gt 0 ) { $chart_bytes = "<img src='http://chart.apis.google.com/chart? chs=$g_graphsize &chd=t:$chd_b &cht=$g_charttype &chdl=$chl_b' alt='Incoming Bytes for pool $PoolName' />"; } else { $chart_current = ""; } if ( $i -gt 0 ) { $html_data += "<tr><td colspan='4'><hr/></td></tr>"; } $html_data += " <tr><th nowrap='nowrap'>$PoolName</th> <td valign='bottom'>$chart_total<br/> <center><table border='1'><tr><th>Member</th><th>Value</th></tr>$tbl_t</table> </td> <td valign='bottom'>$chart_current<br/> <center><table border='1'><tr><th>Member</th><th>Value</th></tr>$tbl_c</table> </td> <td valign='bottom'>$chart_bytes<br/> <center><table border='1'><tr><th>Member</th><th>Value</th></tr>$tbl_b</table> </td> </tr>"; $i++; } $html_data += "</table></td></tr></table></body></html>"; return $html_data; } Utility Functions It's always useful to extract common code into utility functions and this application is no exception. In here I've got a Convert-To64Bit function that takes the high and low 32 bits of a 64 bit number and does the math to convert them into a native 64 bit value. The Extract-Statistic function takes as input a Common.Statsistic Array along with a type to look for in that array. It loops over the array of Statistic values and returns the 64 bit value of the match, if one is found. And finally the Extract-Status function is used to look through the returned value from the LocalLB.PoolMember.get_object_status iControl method for a specific pool member. This function returns a color to display in the generated HTML table, green for good, red for bad. The only way a green will show up will be if both it's availability_status and enabled_status values are AVAILABILITY_STATUS_GREEN and ENABLED_STATUS_ENABLED respectively. function Convert-To64Bit() { param($high, $low); $low = [Convert]::ToString($low,2).PadLeft(32,'0') if($low.length -eq "64") { $low = $low.substring(32,32) } return [Convert]::ToUint64([Convert]::ToString($high,2).PadLeft(32,'0')+$low,2); } function Extract-Statistic() { param($StatisticA, $type); $value = -1; foreach($Statistic in $StatisticA) { if ( $Statistic.type -eq $type ) { $value = Convert-To64Bit $Statistic.value.high $Statistic.value.low; break; } } return $value; } function Extract-Status() { param($MemberObjectStatusA, $IPPortDefinition); $color = "#FF0000"; foreach($MemberObjectStatus in $MemberObjectStatusA) { if ( ($MemberObjectStatus.member.address -eq $IPPortDefinition.address) -and ($MemberObjectStatus.member.port -eq $IPPortDefinition.port) ) { $availability_status = $MemberObjectStatus.object_status.availability_status; $enabled_status = $MemberObjectStatus.object_status.enabled_status; if ( ($availability_status -eq "AVAILABILITY_STATUS_GREEN") -and ($enabled_status -eq "ENABLED_STATUS_ENABLED" ) ) { $color = "#00FF00"; } } } return $color; } Running The Application After running the application on the console, Internet Explorer will be created in Theater Mode (Full Screen) and will look something like this. My system is somewhat inactive so you'll see that some of the charts are missing. This was by design in that charts with no data are not very informative. Assuming you have traffic across all your pools, charts will be created. Extending This Application This application merely looks at load distribution and state for members within the pools. It would be trivial to change or extend the types of charts presented. iControl provides you with all the data you need to build your own monitoring dashboard regardless of the types of metrics you would like to keep an eye on. For the full application, check out the PsiControlDashboard entry in the iControl CodeShare Get the Flash Player to see this player. 20081106-iControlApps-15-iControlDashboard.mp3811Views0likes28CommentsTMG2F5 Series: Publishing Microsoft Exchange Using F5
Although predicted by some, Microsoft caused quite a stir last week by formally announcing the discontinuation of Forefront Threat Management Gateway. One of the primary use cases of TMG has been to externally publish Microsoft applications, and F5 has often co-existed in these environments. With the sunset of the TMG line, it's time to look at alternative technologies to replace the responsibilities of TMG, and the F5 gear that you already have in the network may be the best solution. I am putting together a 3 part blog series on leveraging F5 as a suitable (dare I say, better?) TMG replacement for your Exchange, Lync, and SharePoint deployments. This is the first post of the series, and will focus on using F5 to securely publish Exchange services. Architecture One of the most significant benefits of leveraging F5 to publish Exchange services is the consolidation of devices & simplification of the architecture. Enterprise customers leveraging TMG for publishing applications are often using F5 to provide the traffic management control to the TMG & application services, which means multiple devices and a tiered network. In a traditional F5/TMG deployment, traffic management and security responsibilities have often been split amongst devices like below…. As you can see, there are several tiers in the architecture, which leads to complexities in configuration and troubleshooting. By onboarding the publishing responsibilities onto the BIG-IP, customers can simplify the architecture by reducing the network segments and consolidating into an HA pair of BIG-IP devices. And more importantly, all without losing significant functionality. Now that we have a basic understanding of the architectural benefits of using F5, let’s dive deeper into some of the features and functionality that F5 will be providing when being used to publish Exchange Server. Traffic Management Yes, TMG does have basic server load balancing capabilities, however this has never been functionality that has met the needs of the enterprise customer. Even in the heyday of TMG, most enterprise customers opted to leverage a 3rd party technology, such as the BIG-IP LTM, to handle this workload. BIG-IP has been designed from the ground up (both hardware and software) to handle traffic management, and honestly, you won’t find similar performance nor features in any other solution. A critical piece of the Exchange network solution is providing high availability and scalability through load balancing, and the BIG-IPs application health awareness & load distribution engines deliver on the promise of making sure users & mail are consistently sent to Exchange servers that are alive and performing optimally. As enterprises move to multi-datacenter Exchange deployments, F5’s Global Traffic Manager (GTM) can provide the same load balancing and resiliency intelligence, but at the wide area level. Layer 3-7 Firewalling With roots in the firewall space, TMG has a history of providing layer 3/4 security, and over the last few years Microsoft added in application firewalling as well. BIG-IP LTM, an ICSA certified firewall, is a default-deny platform coupled with an advanced DDOS mitigation engine, making it extremely well suited to provide the layer3/4 defense perimeter. BIG-IP LTM also ships with content inspection & iRules, that allow administrators write basic filters to stop well known application layer attacks. Enterprises looking for a more advanced Web Application Firewall for Exchange can activate the Application Security Module (ASM), which ships with pre-built security policies for Outlook WebApp and ActiveSync. Server Optimization I hate to see this significant benefit of the solution overlooked, primarily because of the dividends it pays. Exchange Server makes use of SSL/TLS for a majority of the client access protocols, including Outlook Anywhere, Outlook WebApp, and Activesync. The server CPU cost of negotiating these SSL transactions is significant, and by offloading the SSL responsibilities to the BIG-IP LTM, enterprises can leave their Exchange servers to do what they do best, serve content. BIG-IP LTM also includes TCP optimizations and content caching which can significant decrease the load on the servers. By leveraging the optimization & offloading features in BIG-IP LTM, customers can decrease the load on the servers, allowing them to perform faster, and also possibly allowing them to go with a smaller farm of servers to serve the same amount of users. Perimeter Security Let’s face it, exposing domain joined servers (CAS, Hub) to anonymous connections is a bad idea, and this is probably one of the most compelling reasons to put TMG in front of your Exchange architecture. The good news is that F5's Access Policy Manager (APM), which is a software module for BIG-IP LTM, can provide an enhanced perimeter of security by making sure no user or connection reaches the CAS server until it has been authenticated and authorized. The APM engine is incredibly powerful and flexible, and new customer use cases are brought to our attention constantly. Client side certificate support, AD FS integration, client interrogation, single sign on, Active Directory attribute enforcement, are all features that APM supports in making sure the right level of privileges are granted the users that are authenticated before being sent to the CAS services. The Active Directory awareness that APM also provides has been instrumental in helping enterprises seamlessly upgrade from Exchange 2007 to Exchange 2010 without making any client side modifications at all. Acceleration Native BIG-IP LTM includes a set of acceleration technologies, such as caching and compression that provide benefit for Exchange deployments. Enterprises have the option of going a step further and leveraging advanced acceleration of Exchange by enabling the WebAccelerater Module (WAM) on top of their BIG-IP LTM to reach new levels of performance. WAM provides a set of acceleration technologies, such as browser optimization, deduplication & intelligent client side caching that enterprises with a large remote workforce, or multiple branch offices will want to take a look at. Administration 10+ network and access protocols can make it a challenge to deploy Exchange with the network optimally configured. Many of these protocols have different persistence, security, and acceleration profiles, and a configuration that may end up ‘working’ is still not the optimal solution. BIG-IP LTM’s wizard driven configuration menu, known as ‘iApp’, is designed to request the most basic system information from the Exchange administrator (Server IP addresses, hostnames, etc) and dynamically build the configuration on their behalf. The result is an optimal configuration that was simple and fast build, and much less prone to human error. Hardware Yes, the diagram above shows consolidating 5 TMG servers down to a single failover pair of BIG-IPs; and Yes, this is what we have often seen customers be able to do. To be honest, we’ve even seen customers go from much larger numbers of TMG servers to a single pair of BIG-IPs. BIG-IP is a special purpose platform with custom hardware built to provide advanced network services. Dedicated layer 2/3 chipsets, SSL and compression hardware, and specialized multi-core processing FPGAs are some of the pieces that allow BIG-IP LTM to manage and process network traffic at speeds and complexities not seen in typical server hardware. The others…. There are numerous other reasons to use F5 to publish Exchange, including 1. Single URL access, which gives the ability for Exchange administrators to give a single URL to all users, regardless of which device they will be using, or what protocol they will be connecting with. 2. Advanced Hosted & Hybrid Exchange deployment integration, that includes support for advertising a single point of client access and silently directing those users to their appropriate mail system. For customers migrating to/from hosted Exchange or Office 365, or moving forward with a long term hybrid solution, this removes the need to maintain different access URLs for the different mail systems. All of this integrates well with ADFS. 3. Integration with 3 rd party monitoring Solutions, including System Center Operations Manager, that in conjunction with BIG-IP provide fine grain detail about the Exchange system and user access. 4. Open APIs that allow for management & automation through tools such as PowerShell and System Center Orchestrator. 5. Multi-application support, which allows customers to leverage the same F5 investment across multiple application environments. The BIG-IPs providing publishing for Exchange can also provide the same benefits for SharePoint, Oracle, VMWare, etc….. I hope this post gives you some insight as to the benefits of using F5 to publish Exchange services. In light of the recent announcement regarding the future of TMG it’s time to consider alternatives, and F5 fits in well as a solution to provide network security, acceleration, and availability. All of the features described above are available in a lab edition of our virtual platform, allowing for customers to test the solution by running the BIG-IP as a virtual machine. Reach out to your F5 sales rep or F5 partner for information on access. If you want more information on F5’s solution for Exchange, check out our solution page.800Views0likes0Comments