Telemetry streaming - One click deploy using Ansible
In this article we will focus on using Ansible to enable and install telemetry streaming (TS) and associated dependencies. Telemetry streaming The F5 BIG-IP is a full proxy architecture, which essentially means that the BIG-IP LTM completely understands the end-to-end connection, enabling it to be an endpoint and originator of client and server side connections. This empowers the BIG-IP to have traffic statistics from the client to the BIG-IP and from the BIG-IP to the server giving the user the entire view of their network statistics. To gain meaningful insight, you must be able to gather your data and statistics (telemetry) into a useful place.Telemetry streaming is an extension designed to declaratively aggregate, normalize, and forward statistics and events from the BIG-IP to a consumer application. You can earn more about telemetry streaming here, but let's get to Ansible. Enable and Install using Ansible The Ansible playbook below performs the following tasks Grab the latest Application Services 3 (AS) and Telemetry Streaming (TS) versions Download the AS3 and TS packages and install them on BIG-IP using a role Deploy AS3 and TS declarations on BIG-IP using a role from Ansible galaxy If AVR logs are needed for TS then provision the BIG-IP AVR module and configure AVR to point to TS Prerequisites Supported on BIG-IP 14.1+ version If AVR is required to be configured make sure there is enough memory for the module to be enabled along with all the other BIG-IP modules that are provisioned in your environment The TS data is being pushed to Azure log analytics (modify it to use your own consumer). If azure logs are being used then change your TS json file with the correct workspace ID and sharedkey Ansible is installed on the host from where the scripts are run Following files are present in the directory Variable file (vars.yml) TS poller and listener setup (ts_poller_and_listener_setup.declaration.json) Declare logging profile (as3_ts_setup_declaration.json) Ansible playbook (ts_workflow.yml) Get started Download the following roles from ansible galaxy. ansible-galaxy install f5devcentral.f5app_services_package --force This role performs a series of steps needed to download and install RPM packages on the BIG-IP that are a part of F5 automation toolchain. Read through the prerequisites for the role before installing it. ansible-galaxy install f5devcentral.atc_deploy --force This role deploys the declaration using the RPM package installed above. Read through the prerequisites for the role before installing it. By default, roles get installed into the /etc/ansible/role directory. Next copy the below contents into a file named vars.yml. Change the variable file to reflect your environment # BIG-IP MGMT address and username/password f5app_services_package_server: "xxx.xxx.xxx.xxx" f5app_services_package_server_port: "443" f5app_services_package_user: "*****" f5app_services_package_password: "*****" f5app_services_package_validate_certs: "false" f5app_services_package_transport: "rest" # URI from where latest RPM version and package will be downloaded ts_uri: "https://github.com/F5Networks/f5-telemetry-streaming/releases" as3_uri: "https://github.com/F5Networks/f5-appsvcs-extension/releases" #If AVR module logs needed then set to 'yes' else leave it as 'no' avr_needed: "no" # Virtual servers in your environment to assign the logging profiles (If AVR set to 'yes') virtual_servers: - "vs1" - "vs2" Next copy the below contents into a file named ts_poller_and_listener_setup.declaration.json. { "class": "Telemetry", "controls": { "class": "Controls", "logLevel": "debug" }, "My_Poller": { "class": "Telemetry_System_Poller", "interval": 60 }, "My_Consumer": { "class": "Telemetry_Consumer", "type": "Azure_Log_Analytics", "workspaceId": "<<workspace-id>>", "passphrase": { "cipherText": "<<sharedkey>>" }, "useManagedIdentity": false, "region": "eastus" } } Next copy the below contents into a file named as3_ts_setup_declaration.json { "class": "ADC", "schemaVersion": "3.10.0", "remark": "Example depicting creation of BIG-IP module log profiles", "Common": { "Shared": { "class": "Application", "template": "shared", "telemetry_local_rule": { "remark": "Only required when TS is a local listener", "class": "iRule", "iRule": "when CLIENT_ACCEPTED {\n node 127.0.0.1 6514\n}" }, "telemetry_local": { "remark": "Only required when TS is a local listener", "class": "Service_TCP", "virtualAddresses": [ "255.255.255.254" ], "virtualPort": 6514, "iRules": [ "telemetry_local_rule" ] }, "telemetry": { "class": "Pool", "members": [ { "enable": true, "serverAddresses": [ "255.255.255.254" ], "servicePort": 6514 } ], "monitors": [ { "bigip": "/Common/tcp" } ] }, "telemetry_hsl": { "class": "Log_Destination", "type": "remote-high-speed-log", "protocol": "tcp", "pool": { "use": "telemetry" } }, "telemetry_formatted": { "class": "Log_Destination", "type": "splunk", "forwardTo": { "use": "telemetry_hsl" } }, "telemetry_publisher": { "class": "Log_Publisher", "destinations": [ { "use": "telemetry_formatted" } ] }, "telemetry_traffic_log_profile": { "class": "Traffic_Log_Profile", "requestSettings": { "requestEnabled": true, "requestProtocol": "mds-tcp", "requestPool": { "use": "telemetry" }, "requestTemplate": "event_source=\"request_logging\",hostname=\"$BIGIP_HOSTNAME\",client_ip=\"$CLIENT_IP\",server_ip=\"$SERVER_IP\",http_method=\"$HTTP_METHOD\",http_uri=\"$HTTP_URI\",virtual_name=\"$VIRTUAL_NAME\",event_timestamp=\"$DATE_HTTP\"" } } } } } NOTE: To better understand the above declarations check out our clouddocs page: https://clouddocs.f5.com/products/extensions/f5-telemetry-streaming/latest/telemetry-system.html Next copy the below contents into a file named ts_workflow.yml - name: Telemetry streaming setup hosts: localhost connection: local any_errors_fatal: true vars_files: vars.yml tasks: - name: Get latest AS3 RPM name action: shell wget -O - {{as3_uri}} | grep -E rpm | head -1 | cut -d "/" -f 7 | cut -d "=" -f 1 | cut -d "\"" -f 1 register: as3_output - debug: var: as3_output.stdout_lines[0] - set_fact: as3_release: "{{as3_output.stdout_lines[0]}}" - name: Get latest AS3 RPM tag action: shell wget -O - {{as3_uri}} | grep -E rpm | head -1 | cut -d "/" -f 6 register: as3_output - debug: var: as3_output.stdout_lines[0] - set_fact: as3_release_tag: "{{as3_output.stdout_lines[0]}}" - name: Get latest TS RPM name action: shell wget -O - {{ts_uri}} | grep -E rpm | head -1 | cut -d "/" -f 7 | cut -d "=" -f 1 | cut -d "\"" -f 1 register: ts_output - debug: var: ts_output.stdout_lines[0] - set_fact: ts_release: "{{ts_output.stdout_lines[0]}}" - name: Get latest TS RPM tag action: shell wget -O - {{ts_uri}} | grep -E rpm | head -1 | cut -d "/" -f 6 register: ts_output - debug: var: ts_output.stdout_lines[0] - set_fact: ts_release_tag: "{{ts_output.stdout_lines[0]}}" - name: Download and Install AS3 and TS RPM ackages to BIG-IP using role include_role: name: f5devcentral.f5app_services_package vars: f5app_services_package_url: "{{item.uri}}/download/{{item.release_tag}}/{{item.release}}?raw=true" f5app_services_package_path: "/tmp/{{item.release}}" loop: - {uri: "{{as3_uri}}", release_tag: "{{as3_release_tag}}", release: "{{as3_release}}"} - {uri: "{{ts_uri}}", release_tag: "{{ts_release_tag}}", release: "{{ts_release}}"} - name: Deploy AS3 and TS declaration on the BIG-IP using role include_role: name: f5devcentral.atc_deploy vars: atc_method: POST atc_declaration: "{{ lookup('template', item.file) }}" atc_delay: 10 atc_retries: 15 atc_service: "{{item.service}}" provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" loop: - {service: "AS3", file: "as3_ts_setup_declaration.json"} - {service: "Telemetry", file: "ts_poller_and_listener_setup_declaration.json"} #If AVR logs need to be enabled - name: Provision BIG-IP with AVR bigip_provision: provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" module: "avr" level: "nominal" when: avr_needed == "yes" - name: Enable AVR logs using tmsh commands bigip_command: commands: - modify analytics global-settings { offbox-protocol tcp offbox-tcp-addresses add { 127.0.0.1 } offbox-tcp-port 6514 use-offbox enabled } - create ltm profile analytics telemetry-http-analytics { collect-geo enabled collect-http-timing-metrics enabled collect-ip enabled collect-max-tps-and-throughput enabled collect-methods enabled collect-page-load-time enabled collect-response-codes enabled collect-subnets enabled collect-url enabled collect-user-agent enabled collect-user-sessions enabled publish-irule-statistics enabled } - create ltm profile tcp-analytics telemetry-tcp-analytics { collect-city enabled collect-continent enabled collect-country enabled collect-nexthop enabled collect-post-code enabled collect-region enabled collect-remote-host-ip enabled collect-remote-host-subnet enabled collected-by-server-side enabled } provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" when: avr_needed == "yes" - name: Assign TCP and HTTP profiles to virtual servers bigip_virtual_server: provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" name: "{{item}}" profiles: - http - telemetry-http-analytics - telemetry-tcp-analytics loop: "{{virtual_servers}}" when: avr_needed == "yes" Now execute the playbook: ansible-playbook ts_workflow.yml Verify Login to the BIG-IP UI Go to menu iApps->Package Management LX. Both the f5-telemetry and f5-appsvs RPM's should be present Login to BIG-IP CLI Check restjavad logs present at /var/log for any TS errors Login to your consumer where the logs are being sent to and make sure the consumer is receiving the logs Conclusion The Telemetry Streaming (TS) extension is very powerful and is capable of sending much more information than described above. Take a look at the complete list of logs as well as consumer applications supported by TS over on CloudDocs: https://clouddocs.f5.com/products/extensions/f5-telemetry-streaming/latest/using-ts.html619Views3likes0Comments
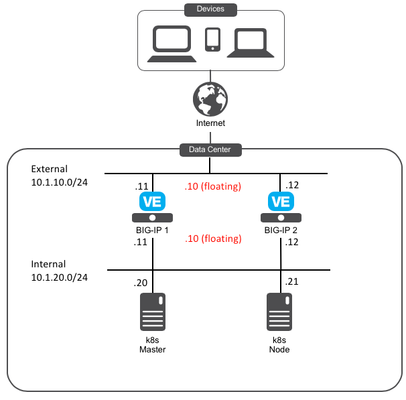
CIS and Kubernetes - Part 1: Install Kubernetes and Calico
Welcome to this series to see how to: Install Kubernetes and Calico (Part 1) Deploy F5 Container Ingress Services (F5 CIS) to tie applications lifecycle to our application services (Part 2) Here is the setup of our lab environment: BIG-IP Version: 15.0.1 Kubernetes component: Ubuntu 18.04 LTM We consider that your BIG-IPs are already setup and running: Licensed and setup as a cluster The networking setup is already done Part 1: Install Kubernetes and Calico Setup our systems before installing kubernetes Step1: Update our systems and install docker To run containers in Pods, Kubernetes uses a container runtime. We will use docker and follow the recommendation provided here As root on ALL Kubernetes components (Master and Node): # Install packages to allow apt to use a repository over HTTPS apt-get -y update && apt-get install -y apt-transport-https ca-certificates curl software-properties-common # Add Docker’s official GPG key curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - # Add Docker apt repository. add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" # Install Docker CE. apt-get -y update && apt-get install -y docker-ce=18.06.2~ce~3-0~ubuntu # Setup daemon. cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF mkdir -p /etc/systemd/system/docker.service.d # Restart docker. systemctl daemon-reload systemctl restart docker We may do a quick test to ensure docker run as expected: docker run hello-world Step2: Setup Kubernetes tools (kubeadm, kubelet and kubectl) To setup Kubernetes, we will leverage the following tools: kubeadm: the command to bootstrap the cluster. kubelet: the component that runs on all of the machines in your cluster and does things like starting pods and containers. kubectl: the command line util to talk to your cluster. As root on ALL Kubernetes components (Master and Node): curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF | tee /etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get -y update We can review which version of kubernetes is supported with F5 Container Ingress Services here At the time of this article, the latest supported version is v1.13.4. We'll make sure to install this specific version with our following step apt-get install -qy kubelet=1.13.4-00 kubeadm=1.13.4-00 kubectl=1.13.4-00 kubernetes-cni=0.6.0-00 apt-mark hold kubelet kubeadm kubectl Install Kubernetes Step1: Setup Kubernetes with kubeadm We will follow the steps provided in the documentation here As root on the MASTER node (make sure to update the api server address to reflect your master node IP): kubeadm init --apiserver-advertise-address=10.1.20.20 --pod-network-cidr=192.168.0.0/16 Note: SAVE somewhere the kubeadm join command. It is needed to "assimilate" the node later. In my example, it looks like the following (YOURS WILL BE DIFFERENT): kubeadm join 10.1.20.20:6443 --token rlbc20.va65z7eauz89mmuv --discovery-token-ca-cert-hash sha256:42eca5bf49c645ff143f972f6bc88a59468a30276f907bf40da3bcf5127c0375 Now you should NOT be ROOT anymore. Go back to your non root user. Since i use Ubuntu, i'll use the default "ubuntu" user Run the following commands as highlighted in the screenshot above: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Step2: Install the networking component of Kubernetes The last step is to setup the network related to our k8s infrastructure. In our kubeadm init command, we used --pod-network-cidr=192.168.0.0/16 in order to be able to setup next on network leveraging Calico as documented here kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml You may monitor the deployment by running the command: kubectl get pods --all-namespaces After some time (<1 min), everything shouldhave a "Running" status. Make sure that CoreDNS started also properly. If everything is up and running, we have our master setup properly and can go to the node to setup k8s on it. Step3: Add the Node to our Kubernetes Cluster Now that the master is setup properly, we can assimilate the node. You need to retrieve the "kubeadmin join …" command that you received at the end of the "kubeadm init …" cmd. You must run the following command as ROOT on the Kubernetes NODE (remember that you got a different hash and token, the command below is an example): kubeadm join 10.1.20.20:6443 --token rlbc20.va65z7eauz89mmuv --discovery-token-ca-cert-hash sha256:42eca5bf49c645ff143f972f6bc88a59468a30276f907bf40da3bcf5127c0375 We can check the status of our node by running the following command on our MASTER (ubuntu user) kubectl get nodes Both component should have a "Ready" status. Last step is to setup Calico between our BIG-IPs and our Kubernetes cluster Setup Calico We need to setup Calico on our BIG-IPs and k8S components. We will setup our environment with the following AS Number: 64512 Step1: BIG-IPs Calico setup F5 has documented this procedure here We will use our self IPs on the internal network. Therefore we need to make sure of the following: The self IP has a portlock down setup to "Allow All" Or add a TCP custom port to the self IP: TCP port 179 You need to allow BGP on the default route domain 0 on your BIG-IPs. Connect to the BIG-IP GUI on go into Network > Route domain. Click on Route Domain "0" and allow BGP Click on "Update" Once this is done,connect via SSH and get into a bash shell on both BIG-IPs Run the following commands: #access the IMI Shell imish #Switch to enable mode enable #Enter configuration mode config terminal #Setup route bgp with AS Number 64512 router bgp 64512 #Create BGP Peer group neighbor calico-k8s peer-group #assign peer group as BGP neighbors neighbor calico-k8s remote-as 64512 #we need to add all the peers: the other BIG-IP, our k8s components neighbor 10.1.20.20 peer-group calico-k8s neighbor 10.1.20.21 peer-group calico-k8s #on BIG-IP1, run neighbor 10.1.20.12 peer-group calico-k8s #on BIG-IP2, run neighbor 10.1.20.11 peer-group calico-k8s #save configuration write #exit end You can review your setup with the command show ip bgp neighbors Note: your other BIG-IP should be identified with a router ID and have a BGP state of "Active". The k8s node won't have a router ID since BGP hasn't already been setup on those nodes. Keep your BIG-IP SSH sessions open. We'll re-use the imish terminal once our k8s components have Calico setup Step2: Kubernetes Calico setup On the MASTER node (not as root), we need to retrieve the calicoctl binary curl -O -Lhttps://github.com/projectcalico/calicoctl/releases/download/v3.10.0/calicoctl chmod +x calicoctl sudo mv calicoctl /usr/local/bin We need to setup calicoctl as explained here sudo mkdir /etc/calico Create a file /etc/calico/calicoctl.cfg with your preferred editor (you'll need sudo privilegies). This file should contain the following apiVersion: projectcalico.org/v3 kind: CalicoAPIConfig metadata: spec: datastoreType: "kubernetes" kubeconfig: "/home/ubuntu/config" Note: you may have to change the path specified by the kubeconfig parameter based on the user you use to do kubectl command To make sure that calicoctl is properly setup, run the command calicoctl get nodes You should get a list of your Kubernetes nodes Now we can work on our Calico/BGP configuration as documented here On the MASTER node: cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPConfiguration metadata: name: default spec: logSeverityScreen: Info nodeToNodeMeshEnabled: true asNumber: 64512 EOF Note: Because we setup nodeToNodeMeshEnabled to True, the k8s node will receive the same config We may now setup our BIG-IP BGP peers. Replace the peerIP Value with the IP of your BIG-IPs cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: bgppeer-global-bigip1 spec: peerIP: 10.1.20.11 asNumber: 64512 EOF cat << EOF | calicoctl create -f - apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: bgppeer-global-bigip2 spec: peerIP: 10.1.20.12 asNumber: 64512 EOF Review your setup with the command: calicoctl get bgpPeer If you go back to your BIG-IP SSH connections, you may check that your Kubernetes nodes have a router ID now in your BGP configuration: imish show ip bgp neighbors Summary So far we have: Setup Kubernetes Setup Calico between our BIG-IPs and our Kubernetes cluster In the next article, we will setup F5 container Ingress Services (F5 CIS)4.1KViews1like1CommentInstalling and running iControl extensions in isolated GCP VPCs
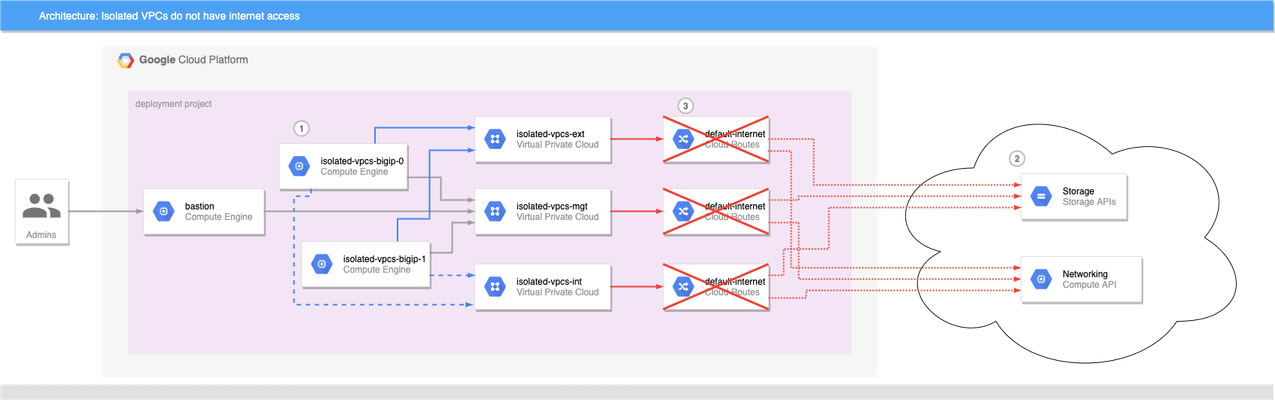
BIG-IP instances launched on Google Cloud Platform usually need access to the internet to retrieve extensions, install DO and AS3 declarations, and get to any other run-time assets pulled from public URLs during boot. This allows decoupling of BIG-IP releases from the library and extensions that enhance GCP deployments, and is generally a good thing. What if the BIG-IP doesn't have access to the Internet? Best practices for Google Cloud recommend that VMs are deployed with the minimal set of access requirements. For some that means that egress to the internet is restricted too: BIG-IP VMs do not have public IP addresses. A NAT Gateway or NATing VM is not present in the VPC. Default VPC network routes to the internet have been removed. If you have a private artifact repository available in the VPC, supporting libraries and onboarding resources could be added to there and retrieved during initialization as needed, or you could also create customized BIG-IP images that have the supporting libraries pre-installed (see BIG-IP image generator for details). Both those methods solve the problem of installing run-time components without internet access, but Cloud Failover Extension, AS3 Service Discovery, and Telemetry Streaming must be able to make calls to GCP APIs, but GCP APIs are presented as endpoints on the public internet. For example, Cloud Failover Extension will not function correctly out of the box when the BIG-IP instances are not able to reach the internet directly or via a NAT because the extension must have access to Storage APIs for shared-state persistence, and to Compute APIs to updates to network resources. If the BIG-IP is deployed without functioning routes to the internet, CFE cannot function as expected. Figure 1: BIG-IP VMs 1 cannot reach public API endpoints 2 because routes to internet 3 are removed Given that constraint, how can we make CFE work in truly isolated VPCs where internet access is prohibited? Private Google Access Enabling Private Google Access on each VPC subnet that may need to access Google Cloud APIs changes the underlying SDN so that the CIDRs for restricted.googleapis.com (or private.googleapis.com † ) will be routed without going through the internet. When combined with a private DNS zone which shadows all googleapis.com lookups to use the chosen protected endpoint range, the VPC networks effectively have access for all GCP APIs. The steps to do so are simple: Enable Private Google Access on each VPC subnet where a GCP API call may be sourced. Create a Cloud DNS private zone for googleapis.com that contains two records: CNAME for *.googleapis.com that responds with restricted.googleapis.com. A record for restricted.googleapis.com that resolves to each host in 199.36.153.4/30. Create a custom route on each VPC network for 199.36.153.4/30 with next-hop set for internet gateway. With this configuration in place, any VMs that are attached to the VPC networks that are associated with this private DNS zone will automatically try to use 199.36.153.4/30 endpoints for all GCP API calls without code changes, and the custom route will allow Private Google Access to function correctly. Automating with Terraform and Google Cloud Foundation Toolkit ‡ While you can perform the steps to enable private API access manually, it is always better to have a repeatable and reusable approach that can be automated as part of your infrastructure provisioning. My tool of choice for infrastructure automation is Hashicorp's Terraform, and Google's Cloud Foundation Toolkit, a set of Terraform modules that can create and configure GCP resources. By combining Google's modules with my own BIG-IP modules, we can build a repeatable solution for isolated VPC deployments; just change the variable definitions to deploy to development, testing/QA, and production. Cloud Failover Example Figure 2: Private Google Access 1 , custom DNS 2 , and custom routes 3 combine to enable API access 4 without public internet access A fully-functional example that builds out the infrastructure shown in figure 2 can be found in my GitHub repo f5-google-bigip-isolated-vpcs. When executed, Terraform will create three network VPCs that lack the default-internet egress route, but have a custom route defined to allow traffic to restricted.googleapis.com CIDR. A Cloud DNS private zone will be created to override wildcard googleapis.com lookups with restricted.googleapis.com, and the private zone will be enabled on all three VPC networks. A pair of BIG-IPs are instantiated with CFE enabled and configured to use a dedicated CFE bucket for state management. An IAP-enabled bastion host with tinyproxy allows for SSH and GUI access to the BIG-IPs (See the repo's README for full details on how to connect). Once logged in to the active BIG-IP, you can verify that the instances do not have access to the internet, and you can verify that CFE is functioning correctly by forcing the active instance to standby. Almost immediately you can see that the other BIG-IP instance has become the active instance. Notes † Private vs Restricted access GCP supports two protected endpoint options; private and restricted. Both allow access to GCP API endpoints without traversing the public internet, but restricted is integrated with VPC Service Controls. If you need access to a GCP API that is unsupported by VPC Service Controls, you can choose private access and change steps 2 and 3 above to use private.googleapis.com and 199.36.153.8/30 instead. ‡ Prefer Google Deployment Manager? My colleague Gert Wolfis has written a similar article that focuses on using GDM templates for BIG-IP deployment. You can find his article at https://devcentral.f5.com/s/articles/Deploy-BIG-IP-on-GCP-with-GDM-without-Internet-access.335Views1like0Comments