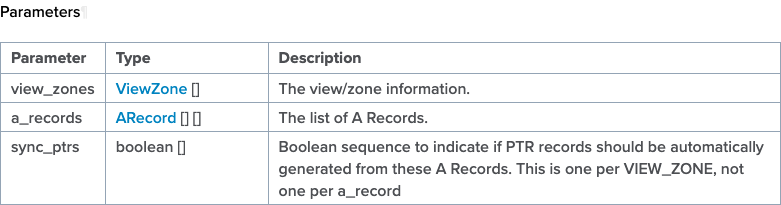
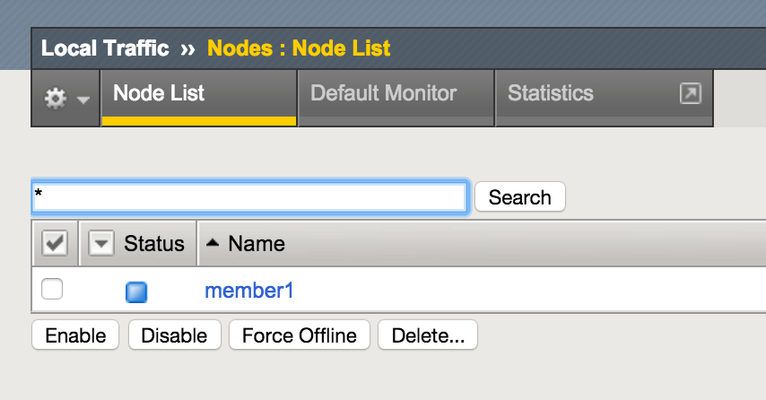
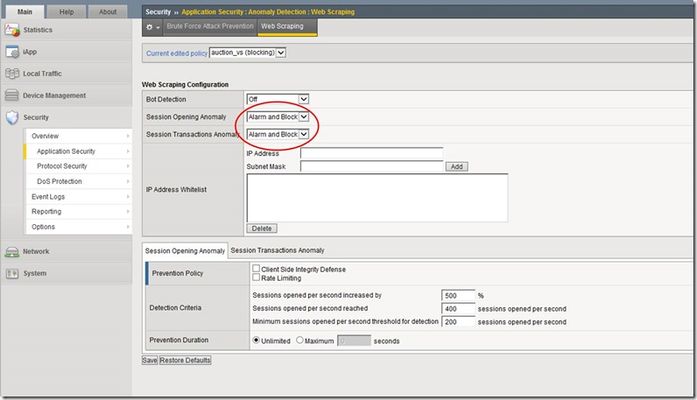
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/iControl\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/iControl\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/Pager/PagerLoadMore\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674562364"}],"cachedText({\"lastModified\":\"1752674562364\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674562364"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1752674579508":{"__typename":"CachedAsset","id":"pages-1752674579508","value":[{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501733000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1752674579508,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1752674563563":{"__typename":"CachedAsset","id":"theme:customTheme1-1752674563563","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1752674562364","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1752674562364","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1752674562364","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674558703":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1752674558703","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1752674560769":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1752674560769","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1752674562364","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1752674599735","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1752674599735","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1752674599735","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1752674599735","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1752674599735":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1752674599735","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1752674562364","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1752674562364","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1752674562364","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:284930":{"__typename":"Conversation","id":"conversation:284930","topic":{"__typename":"TkbTopicMessage","uid":284930},"lastPostingActivityTime":"2024-12-17T19:36:21.859-08:00","solved":false},"User:user:51154":{"__typename":"User","uid":51154,"login":"JRahm","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS01MTE1NC1uYzdSVFk?image-coordinates=0%2C0%2C1067%2C1067"},"id":"user:51154"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtMTAxMDFpOEY4QTY2NDAyMjlEODAxOA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtMTAxMDFpOEY4QTY2NDAyMjlEODAxOA?revision=1","title":"0EM1T000003Jj5t.png","associationType":"BODY","width":781,"height":205,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtNzAzMmlENkY2RTlDQjM5QzMyODYw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtNzAzMmlENkY2RTlDQjM5QzMyODYw?revision=1","title":"0EM1T000003Jj63.png","associationType":"BODY","width":348,"height":110,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtODg1NGlFOTlCNUFEN0ZCNjlFN0Ex?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtODg1NGlFOTlCNUFEN0ZCNjlFN0Ex?revision=1","title":"0EM1T000003Jj6D.png","associationType":"BODY","width":533,"height":137,"altText":null},"TkbTopicMessage:message:284930":{"__typename":"TkbTopicMessage","subject":"Managing ZoneRunner Resource Records with Bigsuds","conversation":{"__ref":"Conversation:conversation:284930"},"id":"message:284930","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:284930","revisionNum":1,"uid":284930,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1140},"postTime":"2021-09-23T10:54:35.000-07:00","lastPublishTime":"2021-09-23T10:54:35.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Over the last several years, there have been questions internal and external on how to manage ZoneRunner (the GUI tool in F5 DNS that allows you to manage DNS zones and records) resources via the REST interface. But that's a no can do with the iControl REST--it doesn't have that functionality. It was brought to my attention by one of our solutions engineers that a customer is using some methods in the SOAP interface that allows you to do just that...which was news to me! The things you learn... In this article, I'll highlight a few of the methods available to you and work on a sample domain in the python module bigsuds that utilizes the suds SOAP library for communication duties with the BIG-IP iControl SOAP interface. \n\n Test Domain & Procedure \n\n For demonstration purposes, I'll create a domain in the external view, dctest1.local, with the following attributes that mirrors nearly identically one I created in the GUI: \n\n Type: master Zone Name: dctest1.local. Zone File Name: db.external.dctest1.local. Options: allow-update from localhost TTL: 500 SOA: ns1.dctest1.local. Email: hostmaster.ns1.dctest1.local. Serial: 2021092201 Refresh: 10800 Retry: 3600 Expire: 604800 Negative TTL: 60 \n\n I'll also add a couple type A records to that domain: \n\n name: mail.dctest1.local., address: 10.0.2.25, TTL: 86400 name: www.dctest1.local., address: 10.0.2.80, TTL: 3600 \n\n After adding the records, I'll update one of them, changing the IP and the TTL: \n\n name: mail.dctest1.local., address: 10.0.2.110, ttl: 900 \n\n Then I'll delete the other one: \n\n name: www.dctest1.local., address: 10.0.2.80, TTL: 3600 \n\n And finally, I'll delete the zone: \n\n name: dctest1.local. \n\n ZoneRunner Methods \n\n All the methods can be found on Clouddocs in the ZoneRunner, Zone, and ResourceRecord method pages. The specific methods we'll use in our highlight real are: \n\n Management.ResourceRecord.add_a Management.ResourceRecord.delete_a Management.ResourceRecord.get_rrs Management.ResourceRecord.update_a Management.Zone.add_zone_text Management.Zone.get_zone_v2 Management.Zone.zone_exist \n\n With each method, there is a data structure that the interface expects. Each link above provides the details, but let's look at an example with the add_a method. The method requires three parameters, view_zones, a_records, and sync_ptrs, which the image of the table shows below. \n\n The boolean is just a True/False value in a list. The reason the list ( [] ) is there for all the attributes is because you can send a single request to update more than one zone, and add more than one record within each zone if desired. The data structure for view_zones and a_records is in the following two images. \n\n Now that we have an idea of what the methods require, let's take a look at some code! \n\n Methods In Action \n\n First, I import bigsuds and initialize the BIG-IP. The arguments are ordered in bigsuds for host, username, and password. If the default “admin/admin” is used, they are assumed, as is shown here. \n\n \nimport bigsuds\n\nb = bigsuds.BIGIP(hostname='ltm3.test.local')\n \n\n Next, I need to format the ViewZone data in a native python dictionary, and then I check for the existence of that zone. \n\n \nzone_view = {'view_name': 'external',\n 'zone_name': 'dctest1.local.'\n }\nb.Management.Zone.zone_exist([zone_view])\n\n# [0]\n \n\n Note that the return value, which should be a list of booleans, is a list with a 0. I’m guessing that’s either suds or the bigsuds implementation doing that, but it’s important to note if you’re checking for a boolean False. It’s also necessary to set the booleans as 0 or 1 as well when sending requests to BIG-IP with bigsuds. \n\n Now I will create the zone since it does not yet exist. From the add_zone_text method description on Clouddocs, note that I need to supply, in separate parameters, the zone info, the appropriate zone records, and the boolean to sync reverse records or not. \n\n \nzone_add_info = {'view_name': 'external',\n 'zone_name': 'dctest1.local.',\n 'zone_type': 'MASTER',\n 'zone_file': 'db.external.dctest1.local.',\n 'option_seq': ['allow-update { localhost;};']}\nzone_add_records = 'dctest1.local. 500 IN SOA ns1.dctest1.local. hostmaster.ns1.dctest1.local. 2021092201 10800 3600 604800 60;\\n' \\\n 'dctest1.local. 3600 IN NS ns1.dctest1.local.;\\n' \\\n 'ns1.dctest1.local. 3600 IN A 10.0.2.1;'\n\nb.Management.Zone.add_zone_text([zone_add_info],\n [[zone_add_records]],\n [0])\nb.Management.Zone.zone_exist([zone_view])\n\n# [1]\n \n\n Note that the strings here require a detailed understanding of DNS record formatting, the individual fields are not parameters that can be set like in the ZoneRunner GUI. But, I am confident there is an abundance of modules that manage DNS formatting in the python ecosystem that could simplify the data structuring. After creating the zone, another check to see if the zone exists results in a true condition. Huzzah! \n\n Now I’ll check the zone info and the existing records for that zone. \n\n \nzone = b.Management.Zone.get_zone_v2([zone_view])\nfor k, v in zone[0].items():\n print(f'{k}: {v}')\n\n# view_name: external\n# zone_name: dctest1.local.\n# zone_type: MASTER\n# zone_file: \"db.external.dctest1.local.\"\n# option_seq: ['allow-update { localhost;};']\n\nrrs = b.Management.ResourceRecord.get_rrs([zone_view])\nfor rr in rrs[0]:\n print(rr)\n\n# dctest1.local. 500 IN SOA ns1.dctest1.local. hostmaster.ns1.dctest1.local. 2021092201 10800 3600 604800 60\n# dctest1.local. 3600 IN NS ns1.dctest1.local.\n# ns1.dctest1.local. 3600 IN A 10.0.2.1\n \n\n Everything checks outs! Next I’ll create the A records for the mail and www services. I’m going to add a filter to only check for the mail/www services for printing to cut down on the lines, but know that they’re still there going forward. \n\n \na1 = {'domain_name': 'mail.dctest1.local.',\n 'ip_address': '10.0.2.25',\n 'ttl': 86400}\na2 = {'domain_name': 'www.dctest1.local.',\n 'ip_address': '10.0.2.80',\n 'ttl': 3600}\nb.Management.ResourceRecord.add_a(view_zones=[zone_view],\n a_records=[[a1, a2]],\n sync_ptrs=[0])\nrrs = b.Management.ResourceRecord.get_rrs([zone_view])\nfor rr in rrs[0]:\n if any(item in rr for item in ['mail', 'www']):\n print(rr)\n\n# mail.dctest1.local. 86400 IN A 10.0.2.25\n# www.dctest1.local. 3600 IN A 10.0.2.80\n \n\n Here you can see that I’m adding two records to the zone specified and not creating the reverse records (not included for brevity, but in prod would be likely). Now I’ll update the mail address and TTL. \n\n \nb.Management.ResourceRecord.update_a([zone_view],\n [[a1]],\n [[a1_update]],\n [0])\nrrs = b.Management.ResourceRecord.get_rrs([zone_view])\nfor rr in rrs[0]:\n if any(item in rr for item in ['mail', 'www']):\n print(rr)\n\n# mail.dctest1.local. 900 IN A 10.0.2.110\n# www.dctest1.local. 3600 IN A 10.0.2.80\n \n\n You can see that the address and TTL updated as expected. Note that with the update_/N/ methods, you need to provide the old and new, not just the new. Let’s get destruction and delete the www record! \n\n \nb.Management.ResourceRecord.delete_a([zone_view],\n [[a2]],\n [0])\nrrs = b.Management.ResourceRecord.get_rrs([zone_view])\nfor rr in rrs[0]:\n if any(item in rr for item in ['mail', 'www']):\n print(rr)\n\n# mail.dctest1.local. 900 IN A 10.0.2.110\n \n\n And your web service is now unreachable via DNS. Congratulations! But there’s more damage we can do: it’s time to delete the whole zone. \n\n \nb.Management.Zone.delete_zone([zone_view])\nb.Management.Zone.zone_exist([zone_view])\n\n# [0]\n \n\n And that’s a wrap! As I said, it’s been years since I have spent time with the iControl SOAP interface. It’s nice to know that even though most of what we do is done through REST, imperatively or declaratively, that some missing functionality in that interface is still alive and kicking via SOAP. H/T to Scott Huddy for the nudge to investigate this. Questions? Drop me a comment below. Happy coding! A gist of these samples is available on GitHub. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"8628","kudosSumWeight":2,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtMTAxMDFpOEY4QTY2NDAyMjlEODAxOA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtNzAzMmlENkY2RTlDQjM5QzMyODYw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODQ5MzAtODg1NGlFOTlCNUFEN0ZCNjlFN0Ex?revision=1\"}"}}],"totalCount":3,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282649":{"__typename":"Conversation","id":"conversation:282649","topic":{"__typename":"TkbTopicMessage","uid":282649},"lastPostingActivityTime":"2024-03-27T03:57:02.598-07:00","solved":false},"User:user:106220":{"__typename":"User","uid":106220,"login":"Joe_Pruitt","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0xMDYyMjAtUU1TTFdB?image-coordinates=0%2C0%2C1000%2C1000"},"id":"user:106220"},"TkbTopicMessage:message:282649":{"__typename":"TkbTopicMessage","subject":"Controlling a Pool Members Ratio and Priority Group with iControl","conversation":{"__ref":"Conversation:conversation:282649"},"id":"message:282649","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282649","revisionNum":1,"uid":282649,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:106220"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":29379},"postTime":"2012-02-17T10:20:51.000-08:00","lastPublishTime":"2012-02-17T10:20:51.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" A Little Background A question came in through the iControl forums about controlling a pool members ratio and priority programmatically. The issue really involves how the API’s use multi-dimensional arrays but I thought it would be a good opportunity to talk about ratio and priority groups for those that don’t understand how they work. In the first part of this article, I’ll talk a little about what pool members are and how their ratio and priorities apply to how traffic is assigned to them in a load balancing setup. The details in this article were based on BIG-IP version 11.1, but the concepts can apply to other previous versions as well. Load Balancing In it’s very basic form, a load balancing setup involves a virtual ip address (referred to as a VIP) that virtualized a set of backend servers. The idea is that if your application gets very popular, you don’t want to have to rely on a single server to handle the traffic. A VIP contains an object called a “pool” which is essentially a collection of servers that it can distribute traffic to. The method of distributing traffic is referred to as a “Load Balancing Method”. You may have heard the term “Round Robin” before. In this method, connections are passed one at a time from server to server. In most cases though, this is not the best method due to characteristics of the application you are serving. Here are a list of the available load balancing methods in BIG-IP version 11.1. Load Balancing Methods in BIG-IP version 11.1 Round Robin: Specifies that the system passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. This method works well in most configurations, especially if the equipment that you are load balancing is roughly equal in processing speed and memory. Ratio (member): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine within the pool. Least Connections (member): Specifies that the system passes a new connection to the node that has the least number of current connections in the pool. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. Observed (member): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (member), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (member): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Ratio (node): Specifies that the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine across all pools of which the server is a member. Least Connections (node): Specifies that the system passes a new connection to the node that has the least number of current connections out of all pools of which a node is a member. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node, or the fastest node response time. Fastest (node): Specifies that the system passes a new connection based on the fastest response of all pools of which a server is a member. This method might be particularly useful in environments where nodes are distributed across different logical networks. Observed (node): Specifies that the system ranks nodes based on the number of connections. Nodes that have a better balance of fewest connections receive a greater proportion of the connections. This method differs from Least Connections (node), in that the Least Connections method measures connections only at the moment of load balancing, while the Observed method tracks the number of Layer 4 connections to each node over time and creates a ratio for load balancing. This dynamic load balancing method works well in any environment, but may be particularly useful in environments where node performance varies significantly. Predictive (node): Uses the ranking method used by the Observed (member) methods, except that the system analyzes the trend of the ranking over time, determining whether a node's performance is improving or declining. The nodes in the pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. This dynamic load balancing method works well in any environment. Dynamic Ratio (node) : This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. Fastest (application): Passes a new connection based on the fastest response of all currently active nodes in a pool. This method might be particularly useful in environments where nodes are distributed across different logical networks. Least Sessions: Specifies that the system passes a new connection to the node that has the least number of current sessions. This method works best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current sessions. Dynamic Ratio (member): This method is similar to Ratio (node) mode, except that weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the number of current connections per node or the fastest node response time. L3 Address: This method functions in the same way as the Least Connections methods. We are deprecating it, so you should not use it. Weighted Least Connections (member): Specifies that the system uses the value you specify in Connection Limit to establish a proportional algorithm for each pool member. The system bases the load balancing decision on that proportion and the number of current connections to that pool member. For example,member_a has 20 connections and its connection limit is 100, so it is at 20% of capacity. Similarly, member_b has 20 connections and its connection limit is 200, so it is at 10% of capacity. In this case, the system select selects member_b. This algorithm requires all pool members to have a non-zero connection limit specified. Weighted Least Connections (node): Specifies that the system uses the value you specify in the node's Connection Limitand the number of current connections to a node to establish a proportional algorithm. This algorithm requires all nodes used by pool members to have a non-zero connection limit specified. Ratios The ratio is used by the ratio-related load balancing methods to load balance connections. The ratio specifies the ratio weight to assign to the pool member. Valid values range from 1 through 100. The default is 1, which means that each pool member has an equal ratio proportion. So, if you have server1 a with a ratio value of “10” and server2 with a ratio value of “1”, server1 will get served 10 connections for every one that server2 receives. This can be useful when you have different classes of servers with different performance capabilities. Priority Group The priority group is a number that groups pool members together. The default is 0, meaning that the member has no priority. To specify a priority, you must activate priority group usage when you create a new pool or when adding or removing pool members. When activated, the system load balances traffic according to the priority group number assigned to the pool member. The higher the number, the higher the priority, so a member with a priority of 3 has higher priority than a member with a priority of 1. The easiest way to think of priority groups is as if you are creating mini-pools of servers within a single pool. You put members A, B, and C in to priority group 5 and members D, E, and F in priority group 1. Members A, B, and C will be served traffic according to their ratios (assuming you have ratio loadbalancing configured). If all those servers have reached their thresholds, then traffic will be distributed to servers D, E, and F in priority group 1. he default setting for priority group activation is Disabled. Once you enable this setting, you can specify pool member priority when you create a new pool or on a pool member's properties screen. The system treats same-priority pool members as a group. To enable priority group activation in the admin GUI, select Less than from the list, and in the Available Member(s) box, type a number from 0 to 65535 that represents the minimum number of members that must be available in one priority group before the system directs traffic to members in a lower priority group. When a sufficient number of members become available in the higher priority group, the system again directs traffic to the higher priority group. Implementing in Code The two methods to retrieve the priority and ratio values are very similar. They both take two parameters: a list of pools to query, and a 2-D array of members (a list for each pool member passed in). long [] [] get_member_priority( in String [] pool_names, in Common__AddressPort [] [] members ); long [] [] get_member_ratio( in String [] pool_names, in Common__AddressPort [] [] members ); \n \n\n \n\n The following PowerShell function (utilizing the iControl PowerShell Library), takes as input a pool and a single member. It then make a call to query the ratio and priority for the specific member and writes it to the console. \n\n \n\n \n function Get-PoolMemberDetails() { param( $Pool = $null, $Member = $null ); $AddrPort = Parse-AddressPort $Member; $RatioAofA = (Get-F5.iControl).LocalLBPool.get_member_ratio( @($Pool), @( @($AddrPort) ) ); $PriorityAofA = (Get-F5.iControl).LocalLBPool.get_member_priority( @($Pool), @( @($AddrPort) ) ); $ratio = $RatioAofA[0][0]; $priority = $PriorityAofA[0][0]; \"Pool '$Pool' member '$Member' ratio '$ratio' priority '$priority'\"; } \n\n \n\n Setting the values with the set_member_priority and set_member_ratio methods take the same first two parameters as their associated get_* methods, but add a third parameter for the priorities and ratios for the pool members. \n\n set_member_priority( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] priorities ); set_member_ratio( in String [] pool_names, in Common::AddressPort [] [] members, in long [] [] ratios ); \n\n The following Powershell function takes as input the Pool and Member with optional values for the Ratio and Priority. If either of those are set, the function will call the appropriate iControl methods to set their values. \n\n \n function Set-PoolMemberDetails() { param( $Pool = $null, $Member = $null, $Ratio = $null, $Priority = $null ); $AddrPort = Parse-AddressPort $Member; if ( $null -ne $Ratio ) { (Get-F5.iControl).LocalLBPool.set_member_ratio( @($Pool), @( @($AddrPort) ), @($Ratio) ); } if ( $null -ne $Priority ) { (Get-F5.iControl).LocalLBPool.set_member_priority( @($Pool), @( @($AddrPort) ), @($Priority) ); } } \n \n\n \n\n In case you were wondering how to create the Common::AddressPort structure for the $AddrPort variables in the above examples, here’s a helper function I wrote to allocate the object and fill in it’s properties. \n\n \n\n \n function Parse-AddressPort() { param($Value); $tokens = $Value.Split(\":\"); $r = New-Object iControl.CommonAddressPort; $r.address = $tokens[0]; $r.port = $tokens[1]; $r; } \n \n\n Download The Source \n\n The full source for this example can be found in the iControl CodeShare under PowerShell PoolMember Ratio and Priority. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"13857","kudosSumWeight":0,"repliesCount":3,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:287934":{"__typename":"Conversation","id":"conversation:287934","topic":{"__typename":"TkbTopicMessage","uid":287934},"lastPostingActivityTime":"2023-06-23T11:32:10.164-07:00","solved":false},"TkbTopicMessage:message:287934":{"__typename":"TkbTopicMessage","subject":"Self-Contained BIG-IP Provisioning with iRules and pyControl – Part 2","conversation":{"__ref":"Conversation:conversation:287934"},"id":"message:287934","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:287934","revisionNum":4,"uid":287934,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":350},"postTime":"2010-10-14T07:59:00.000-07:00","lastPublishTime":"2023-06-23T11:32:10.164-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" As I stated last week in Part 1, iRules work on the live data between client and server, and iControl works on the management plane out of band to collect information or to modify or create configuration objects. However, what if you could combine forces, wholly contained on your BIG-IP LTM? That’s the scenario I started tackling last week. In this second part, I’ll address the iRule and iControl components necessary to complete a provisioning task. \n \n Self-Contained BIG-IP Provisioning with iRules and pyControl - Part 1 \n \n The iRule code \n I’ll get the solution working prior to making it extensible and flashy. First thing I’ll do to enhance the test iRule from last week is to utilize the restful interface approach I used to access table information in this tech tip on Restful Access to BIG-IP Subtables - DevCentral . I want to pass an action, a pool name, and a pool member through the URL to the system. In this case, the action will be enable or disable, and the pool and pool member should be valid entries. In the event a pool or pool member is passed that is not valid, there is simple error checking in place, which will alert the client. Note also in the code below that I incorporated code from George’s basic auth tech tip. \n \n \n \n 1: when HTTP_REQUEST { \n 2: binary scan [md5 [HTTP::password]] H* password \n 3: \n 4: if { ([HTTP::path] starts_with \"/provision\") } { \n 5: if { [class lookup [HTTP::username] provisioners] equals $password } { \n 6: scan [lrange [split [URI::path [HTTP::uri]] \"/\"] 2 end-1] %s%s%s action pname pmem \n 7: if { [catch {[members $pname]} errmsg] && !($errmsg equals \"\")} { \n 8: if { [members -list $pname] contains \"[getfield $pmem \":\" 1] [getfield $pmem \":\" 2]\" } { \n 9: set pmstat1 [LB::status pool $pname member [getfield $pmem \":\" 1] [getfield $pmem \":\" 2]] \n 10: log local0. \"#prov=$action,$pname,$pmem\" \n 11: after 250 \n 12: set pmstat2 [LB::status pool $pname member [getfield $pmem \":\" 1] [getfield $pmem \":\" 2]] \n 13: HTTP::respond 200 content \"<html><body>Original Status<br />$pmem-$pmstat1<p>New Status<br />$pmem-$pmstat2</body></html>\" \n 14: } else { HTTP::respond 200 content \"$pmem not a valid pool member.\" } \n 15: } else { HTTP::respond 200 content \"$pname not a valid pool.\" } \n 16: } else { HTTP::respond 401 WWW-Authenticate \"Basic realm=\\\"Secured Area\\\"\" } \n 17: \n 18: } \n 19: } \n \n \n \n I added the “after 250” command to give the pyControl script some time to receive the syslog event and process before checking the status again. This is strictly for display purposes back to the client. \n The pyControl code \n I already have the syslog listener in place, and now with the iRule passing real data, this is what arrives via syslog: \n \n <134>Oct 13 11:04:55 tmm tmm[4848]: Rule ltm_provisioning <HTTP_REQUEST>: #prov=enable,cacti-pool,10.10.20.200:80 \n \n Not really ready for processing, is it? So I need to manipulate the data a little to get it into manageable objects for pyControl. \n \n # Receive messages while True: data,addr = syslog_socket.recvfrom(1024) rawdata = data.split(' ')[-1] provdata = rawdata.split('=')[-1] dataset = provdata.split(',') dataset = map(string.strip, dataset) \n \n Splitting on whitespace removes all the syslog overhead, the I split again on the “=” sign to get the actual objects I need. Next, I split the data to eliminate the commons and create a list,and the finally, I strip any newline charcters (which happens to exist on the last element, the IP:port object). Now that I have the objects I need, I can go to work setting the enable/disable state on the pool members. Thankfully, the disable pool member pyControl code already exists in the iControl codeshare, I just need to do a little modification. None of the def’s need to change, so I added them as is. Because the arguments are coming from syslog and not from a command line, I have no need for the sys module, so I won’t import that. I do need to import string, though to strip the newline character in the map(string.strip, dataset) command above. The dataset object is a list and the elements are 0:action, 1:pool, 2:pool_member. pyControl expects the members to be a list, even if it’s only one member, which is true of this scenario. \n \n ### Process Pool, Pool Members, & Desired State ### POOL = dataset[1] members = [dataset[2]] sstate_seq = b.LocalLB.PoolMember.typefactory.create('LocalLB.PoolMember.MemberSessionStateSequence') sstate_seq.item = session_state_factory(b, members) \n session_objects = session_state_factory(b, members) \n if dataset[0] == 'enable': enable_member(b, session_objects) elif dataset[0] == 'disable': disable_member(b, session_objects) else: print \"\\nNo such action: \\\"dataset[0]\\\" \" \n \n More error checking here, if the action passed was enable/disable, I call the appropriate def, otherwise, I log to console. OK. Time to test it out! \n Results \n In this video, I walk through an example of enabling/disabling a pool member \n \n Provision Through iRules \n \n The Fine Print \n Obviously, there is risk with such a system. Allowing provisioning of your application delivery through the data plane can be a dangerous thing, so tread carefully. Also, customizing syslog and installing and running pyControl on box will not survive hotfixes and upgrades, so processes would need to be in place to ensure functionality going forward. Finally, I didn’t cover ensuring the pyControl script is running in the background and is started on system boot, but that is a step that would be required as well. For test purposes, I just ran the script on the console. \n Conclusion \n There is an abundance of valuable and helpful information on how to utilize the BIG-IP system, iRules, and iControl. Without too much work on my own, I was able to gather snippets of code here and there to deliver a self-contained provisioning system. The system is short on functionality (toggling pool members), but could be extended with a little elbow grease and MUCH error checking. For the full setup, check out the LTM Provisioning via iRules wiki entry in Advanced Design and Configuration wiki. \n \n Related Articles \n \n HTTP Basic Access Authentication iRule Style > DevCentral > F5 ... \n F5 DevCentral > Community > Group Details - Python iControl Library \n Getting Started with pyControl v2: Installing on Windows ... \n Getting Started with pyControl v2: Installing on Ubuntu Desktop ... \n Experimenting with pyControl on LTM VE > DevCentral > F5 ... \n Getting Started with pyControl v2: Understanding the TypeFactory ... \n Getting Started with pyControl v2: Constructor Changes ... \n LTM 9.4.2+: Custom Syslog Configuration > DevCentral > F5 ... \n LTM 9.4.2+ Custom Syslog errors when bpsh used - DevCentral - F5 ... \n Custom syslog-ng facility - DevCentral - F5 DevCentral > Community ... \n Customizing syslog-ng f_local0 filter - DevCentral - F5 DevCentral ... \n How to write iRule log statements to a custom log file, and rotate ... \n Syslog locally and remote with specific facility level ... \n DevCentral Wiki: Syslog NG Email Configuration \n \n \n Technorati Tags: F5 DevCentral,pyControl,iControl,iRules,syslog-ng,provisioning \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"8108","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280278":{"__typename":"Conversation","id":"conversation:280278","topic":{"__typename":"TkbTopicMessage","uid":280278},"lastPostingActivityTime":"2023-06-05T22:59:55.330-07:00","solved":false},"User:user:217977":{"__typename":"User","uid":217977,"login":"Tim_Rupp","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-9.svg?time=0"},"id":"user:217977"},"TkbTopicMessage:message:280278":{"__typename":"TkbTopicMessage","subject":"Getting started with Ansible","conversation":{"__ref":"Conversation:conversation:280278"},"id":"message:280278","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280278","revisionNum":2,"uid":280278,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:217977"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2961},"postTime":"2016-01-20T10:32:23.000-08:00","lastPublishTime":"2023-06-05T22:59:55.330-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Ansible is an orchestration and automation engine. It provides a means for you to automate the administration of different devices, from Linux to Windows and different special purpose appliances in-between. Ansible falls into the world of DevOps related tools. You may have heard of others that play in this area as well including. \n\n Chef Puppet Saltstack \n\n In this article I'm going to briefly skim the surface of what Ansible is and how you can get started using it. I've been toying around with it for some years now, and (most recently at F5) using it to streamline some development work I've been involved in. \n\n If you, like me, are a fan of dabbling with interesting tools and swear by the \"Automate all the Things!\" catch-phrase, then you might take an interest in Ansible. \n\n We're going to start small though and build upon what we learn. My goal here is to eventually bring you all to the point where we're doing some crazy awesome things with Ansible and F5 products. I'll also go into some brief detail on features of Ansible that make it relatively painless to interoperate with existing F5 products. Let's get started! \n\n So why Ansible? \n\n Any time that it comes to adopting some new technology for your everyday use, inevitably you need to ask yourself \"what's in it for me?\". Why not just use some custom shell scripts and pssh to do everything? Here are my reasons for using Ansible. \n\n It is agent-less The only dependencies (on the remote device) are SSH and python; and even python is not really a dependency The language that you \"do\" stuff in is YAML. No CS degree or programming language expertise is required (Perl, Ruby, Python, etc) Extending it is simple (in my opinion) Actions are idempotent Order of operations is well-defined and work is performed top-down \n\n Many of the original tools in the DevOps space were agent-based tools. This is a major problem for environments where it's literally (due to technology or politics) impossible to install an agent. Your SLA may prohibit you from installing software on the box. Or, you might legitimately not be able to install the software due to older libraries or other missing dependencies. Ansible has no agent requirement; a plus in my book. Most of the systems that you will come across can be, today, manipulated by Ansible. It is agent-less by design. \n\n Dependency wise you need to be able to connect to the machine you want to orchestrate, so it makes sense that SSH is a dependency. Also, you would like to be able to do higher-order \"stuff\" to a machine. That's where the python dependency comes into play. I say dependency loosely though, because Ansible provides a way to run raw commands on remote systems regardless of whether Python is installed. For professional Ansible development though, this method of orchestrating devices is largely not recommended except in very edge cases. \n\n Ansible's configuration language is YAML. If you have never seen YAML before, this is what it looks like \n\n \n - name: Deploy common hosts files settings\n hosts: all\n connection: ssh\n gather_facts: true\n \n tasks:\n - name: Install required packages\n apt:\n name: \"{{ item }}\"\n state: \"present\"\n with_items:\n - ntp\n - ubuntu-cloud-keyring\n - python-mysqldb \n\n YAML is generally composed of simple key/value pairs, lists, and dictionaries. Contrast this with the Puppet configuration language; a special DSL that resembles a real programming language. \n\n \n class sso {\n case $::lsbdistcodename {\n default: {\n $ssh_version = 'latest'\n }\n }\n \n class { '::sso':\n ldap_uri => $::ldap_uri,\n dev_env => true,\n ssh_version => $ssh_version,\n sshd_allow_groups => $::sshd_allow_groups,\n }\n} \n\n Or contrast this with Chef, in which you must know Ruby to be able to use. \n\n \n servers = search(\n :node,\n \"is_server:true AND chef_environment:#{node.chef_environment}\"\n).sort! do\n |a, b| a.name <=> b.name\nend\n \nbegin\n resources('service[mysql]')\nrescue Chef::Exceptions::ResourceNotFound\n service 'mysql'\nend\n \ntemplate \"#{mysql_dir}/etc/my.conf\" do\n source 'my.conf.erb'\n mode 0644\n variables :servers => servers, :mysql_conf => node['mysql']['mysql_conf']\n notifies :restart, 'service[mysql]'\nend \n\n In Ansible, work that is performed is idempotent. That's a buzzword. What does it mean? \n\n It means that an operation can be performed multiple times without changing the result beyond its initial application. If I try to add the same line to a file a thousand times, it will be added once and then will not be added again 999 times. Another example is adding user accounts. They would be added once, not many times (which might raise errors on the system). \n\n Finally, Ansible's workflow is well defined. Work starts at the top of a playbook and makes its way to the bottom. Done. End of story. There are other tools that have a declarative model. These tools attempt to read your mind. \"You declare to me how the node should look at the end of a run, and I will determine the order that steps should be run to meet that declaration.\" \n\n Contrast this with Ansible which only operates top-down. We start at the first task, then move to the second, then the third, etc. \n\n This removes much of the \"magic\" from the equation. Often times an error might occur in a declarative tool due specifically to how that tool arranges its dependency graph. When that happens, it's difficult to determine what exactly the tool was doing at the time of failure. \n\n That magic doesn't exist in Ansible; work is always top-down whether it be tasks, roles, dependencies, etc. You start at the top and you work your way down. \n\n Installation \n\n Let's now take a moment to install Ansible itself. Ansible is distributed in different ways depending on your operating system, but one tried and true method to install it is via pip ; the recommended tool for installing python packages. \n\n I'll be working on a vanilla installation of Ubuntu 15.04.2 (vivid) for the remaining commands. \n\n Ubuntu includes a pip package that should work for you without issue. You can install it via apt-get . \n\n \n sudo apt-get install python-pip python-dev \n\n Afterwards, you can install Ansible. \n\n \n sudo pip install markupsafe ansible==1.9.4 \n\n You might ask \"why not ansible 2.0\". Well, because 2.0 was just released and the community is busy ironing out some new-release bugs. I prefer to give these things some time to simmer before diving in. Lucky for us, when we are ready to dive in, upgrading is a simple task. \n\n So now you should have Ansible available to you. \n\n \nSEA-ML-RUPP1:~ trupp$ ansible --version\nansible 1.9.4\n configured module search path = None\nSEA-ML-RUPP1:~ trupp$ \n\n Your first playbook \n\n Depending on the tool, the body of work is called different things. \n\n Puppet calls them manifests Chef calls them recipes and cookbooks Ansible calls them plays and playbooks Saltstack calls them formulas and states \n\n They're all the same idea. You have a system configuration you need to apply, you put it in a file, the tool interprets the file and applies the configuration to the system. We will write a very simple playbook here to illustrate some concepts. It will create a file on the system. Booooooring. I know, terribly boring. We need to start somewhere though, and your eyes might roll back into your head if we were to start off with a more complicated example like bootstrapping a BIG-IP or dynamically creating cloud formation infrastructure in AWS and configuring HA pairs, pools, and injecting dynamically created members into those pools. \n\n So we are going to create a single file. We will call it site.yaml . Inside of that file paste in the following. \n\n \n- name: My first play\n hosts: localhost\n connection: local\n gather_facts: true\n \n tasks:\n - name: Create a file\n copy:\n dest: \"/tmp/test.txt\"\n content: \"This is some content\" \n\n This file is what Ansible refers to as a Playbook. Inside of this playbook file we have a single Play (My first play). There can be multiple Plays in a Playbook. \n\n Let's explore what's going on here, as well as touch upon the details of the play itself. First, that Play. \n\n Our play is composed of a preamble that contains the following \n\n name hosts connection gather_facts \n\n The name is an arbitrary name that we give to our Play so that we will know what is being executed if we need to debug something or otherwise generate a reasonable status message. ALWAYS provide a name for your Plays, Tasks, everything that supports the name syntax. \n\n Next, the hosts line specifies which hosts we want to target in our Play. For this Play we have a single host; localhost . We can get much more complicated than this though, to include \n\n patterns of hosts groups of hosts groups of groups of hosts dynamically created hosts hosts that are not even real \n\n You get the point. \n\n Next, the connection line tells Ansible how to connect to the hosts. Usually this is the default value ssh . In this case though, because I am operating on the localhost, I can skip SSH altogether and simply say local . \n\n After that, I used the gather_facts line to tell Ansible that it should interrogate the remote system (in this case the system localhost) to gather tidbits of information about it. These tidbits can include the installed operating system, the version of the OS, what sort of hardware is installed, etc. \n\n After the preamble is written, you can see that I began a new block of \"stuff\". In this case, the tasks associated with this Play. Tasks are Ansible's way of performing work on the system. The task that I am running here is using the copy module. As I did with my Play earlier, I provide a name for this task. Always name things! After that, the body of the module is written. There are two arguments that I have provided to this module (which are documented more in the References section below) \n\n dest content \n\n I won't go into great deal here because the module documentation is very clear, but suffice it to say that dest is where I want the file written and content is what I want written in the file. \n\n Running the playbook \n\n We can run this playbook using the ansible-playbook command. For example. \n\n \nSEA-ML-RUPP1:~ trupp$ ansible-playbook -i notahost, site.yaml \n\n The output of the command should resemble the following \n\n \nPLAY [My first play] ******************************************************\n \nGATHERING FACTS ***************************************************************\nok: [localhost]\n \nTASK: [Create a file] *********************************************************\nchanged: [localhost]\n \nPLAY RECAP ********************************************************************\nlocalhost : ok=2 changed=1 unreachable=0 failed=0 \n\n We can also see that the file we created has the content that we expected. \n\n \nSEA-ML-RUPP1:~ trupp$ cat /tmp/test.txt\nThis is some content \n\n A brief aside on the syntax to run the command. Ansible requires that you specify an inventory file to provide hosts that it can orchestrate. In this specific example, we are not specifying a file. Instead we are doing the following \n\n Specifying an arbitrary string (notahost) Followed by a comma \n\n In Ansible, this is a short-hand trick to skip the requirement that an inventory file be specified. The comma is the key part of the argument. Without it, Ansible will look for a file called notahost and (hopefully) not find it; raising an error otherwise. \n\n The output of the command is shown next. The output is actually fairly straight-forward to read. It lists the PLAY s and TASK s that are running (as well as their names...see, I told you you wanted to have names). The status of the Tasks is also shown. This can be values such as \n\n changed ok failed skipped unreachable \n\n Finally, all Ansible Playbook runs end with a PLAY RECAP where Ansible will tell you what the status of the various plays on your hosts were. It is at this point where a Playbook will be considered successful or not. In this case, the Playbook was completely successful because there were not unreachable hosts nor failed hosts. \n\n Summary \n\n This was a brief introduction to the orchestration and automation system Ansible. \n\n There are far more complex subjects related to Ansible that I will touch upon in future posts. If you found this information useful, rate it as such. If you would like to see more advanced topics covered, videos demo'd, code samples written, or anything else on the subject, let me know in the comments below. \n\n Many organizations, both large and small, use DevOps tools like the one presented in this post. Ansible has several features, per design, that make it attractive to these organizations (such as being agent-less, and having minimum requirements). \n\n If you'd like to see crazy sophisticated examples of Ansible in use...well...we'll get there. You need to rate and comment on my posts though to let me know that you want to see more. \n\n References \n\n copy - Copies files to remote locations. — Ansible Documentation raw - Executes a low-down and dirty SSH command — Ansible Documentation Variables — Ansible Documentation ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"13466","kudosSumWeight":0,"repliesCount":12,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:280332":{"__typename":"Conversation","id":"conversation:280332","topic":{"__typename":"TkbTopicMessage","uid":280332},"lastPostingActivityTime":"2023-06-05T22:59:20.470-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMDdpMTM1MDFBRjU3NjI4RDRFNg?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMDdpMTM1MDFBRjU3NjI4RDRFNg?revision=2","title":"0151T000003d6l3QAA.png","associationType":"BODY","width":854,"height":446,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTc3OWk1RDBFOEZFNDU2MzE5MTNB?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTc3OWk1RDBFOEZFNDU2MzE5MTNB?revision=2","title":"0151T000003d6l4QAA.png","associationType":"BODY","width":1326,"height":1198,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItODcxMWk3NTFFMzdBRjc2MUNCOTI1?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItODcxMWk3NTFFMzdBRjc2MUNCOTI1?revision=2","title":"0151T000003d6l5QAA.png","associationType":"BODY","width":746,"height":432,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMzA1OGkyRkY4RTRCNTA1QzAxOUYz?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMzA1OGkyRkY4RTRCNTA1QzAxOUYz?revision=2","title":"0151T000003d6l6QAA.png","associationType":"BODY","width":672,"height":422,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItOTkyOWlDNDg1ODNDMUYyOURCMzAz?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItOTkyOWlDNDg1ODNDMUYyOURCMzAz?revision=2","title":"0151T000003d6l7QAA.png","associationType":"BODY","width":670,"height":488,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTQ0NDRpM0YzRDEzMkM5NEMxOTI5OA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTQ0NDRpM0YzRDEzMkM5NEMxOTI5OA?revision=2","title":"0151T000003d6l8QAA.png","associationType":"BODY","width":926,"height":764,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMTBpRDgxM0RBOUFGQTYyRDhCOQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMTBpRDgxM0RBOUFGQTYyRDhCOQ?revision=2","title":"0151T000003d6l9QAA.png","associationType":"BODY","width":916,"height":720,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjg0MGk1NjAyODZDRjIxRkE4RDI4?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjg0MGk1NjAyODZDRjIxRkE4RDI4?revision=2","title":"0151T000003d6lAQAQ.png","associationType":"BODY","width":648,"height":472,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjU4OGlGRjJFMTEzQTU2NjQxQ0Yx?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjU4OGlGRjJFMTEzQTU2NjQxQ0Yx?revision=2","title":"0151T000003d6lGQAQ.png","associationType":"BODY","width":934,"height":712,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNTI5MmkwMzMyNkU3NDhBQjk0RUFC?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNTI5MmkwMzMyNkU3NDhBQjk0RUFC?revision=2","title":"0151T000003d6lHQAQ.png","associationType":"BODY","width":936,"height":714,"altText":null},"TkbTopicMessage:message:280332":{"__typename":"TkbTopicMessage","subject":"Existing Ansible BIG-IP modules","conversation":{"__ref":"Conversation:conversation:280332"},"id":"message:280332","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:280332","revisionNum":2,"uid":280332,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:217977"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1769},"postTime":"2016-01-29T06:00:00.000-08:00","lastPublishTime":"2023-06-05T22:59:20.470-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Right around the time that I started at F5, I was at the pinnacle of my exposure to Ansible. So imagine my surprise when I saw BIG-IP modules in the Ansible core product! I immediately wanted to know which one of my colleagues I could go talk Ansible-fu with! \n\n I cracked open the source code, found the names of contributors, made haste to the corporate phone book to look up where they sat, and...wait a second... \n\n ...no entries in the phone book? \n\n ...that curious look in colleagues eyes that says \"I haven't the foggiest idea what you are talking about\". \n\n Then it hit me...the BIG-IP modules didn't originate at F5. \n\n Upon further investigation, it became clear to me that, indeed, we had no skin in this game. These modules originated from two enterprising individuals who I found on DevCentral, and I would be remiss to exclude their valuable contributions to the Ansible+F5 cause, so in this post I want to highlight those contributions and bring others up-to-speed on current Ansible+BIG-IP functionality. \n\n Credit where it is due \n\n As far as I can tell from perusing Ansible's git logs, the existing BIG-IP modules in Ansible are the work of Matt Hite and Serge van Ginderachter. Both are DevCentral contributors, and have had a presence in the Ansible community from (at least) 2013 when their modules landed in the tool. \n\n Among the modules that they had a hand in are \n\n bigip_facts bigip_node bigip_pool bigip_pool_member bigip_monitor_http bigip_monitor_tcp \n\n Since that time, I've seen even more folks step up to the plate with Ansible modules that will be making their appearance in upcoming releases. \n\n Well, I wanted to have a hand in this work too. I figured I had a perfect opportunity to help because, \n\n I had some background in Ansible I had access to unlimited BIG-IP technical resources \n\n It was only a question of how to get involved. \n\n And then, Matt posted this in a pull request (PR)... \n\n \n Unfortunately I don't have GTM to smoke test this with. Can you solicit some testers on the mailing list? \n \n\n And Serge followed with \n\n \n So same here, not tested as no GTM gear, but an offline code review. \n \n\n Bingo...I was in. \n\n If there's one area that I figured I could have the greatest impact, it's the area of technical resources. There is BIG-IP stuff all over the place at F5, and I sit next to, or at least near, many of the people who have knowledge of the products; far more advanced knowledge than I do. Many of those same people hang out and contribute on DevCentral. Paired with my knowledge of Ansible, I figured I could help test BIG-IP related PRs to validate their functionality beyond what a code review offered. \n\n So that's what I did (and what we're about to do). \n\n Before you begin \n\n If you were around for the earlier introductory article to Ansible that I posted a couple days ago, pull up a terminal to that machine. We need to install one more dependency that is common to all of the BIG-IP modules in Ansible; bigsuds . \n\n \n pip install bigsuds \n\n With that in place, you're ready to work with the Ansible modules. \n\n Additionally, I am going to be using a very minimal inventory file that just includes a single BIG-IP. You will want to adjust yours for your environment, but here is mine. \n\n \n [test] \n big-ip01.internal \n\n Note that the name above is available in my local DNS. If you only have an IP address to work with, you can just add that to your inventory file. \n\n For example \n\n \n[test]\n192.168.10.2 \n\n Also note that I included a line called [test] . In Ansible this is referred to as a group. We will be revisiting this in the future as we begin orchestrating multiple BIG-IPs. \n\n Let's dive in to some of Matt and Serge's BIG-IP modules! \n\n bigip_facts \n\n In Ansible, there is a pattern you often see over and over. This is the pattern of modules that provide information, and modules that change settings. For this tutorial I'll refer to them as, \n\n reader modules writer modules \n\n Without exception, reader modules are suffixed with an _facts string. While writer modules, are not. \n\n So, with that in mind...pop quiz! \n\n If I asked you whether the bigip_pool module was a reader module or a writer module, you would say...writer! If I asked you whether the bigip_pool_facts module was a reader module or a writer module, you would say...reader! \n\n The bigip_facts module will return to you a number of facts about the BIG-IP in question. Let's take a look. First, my playbook. \n\n \n- name: Test bigip_facts\n hosts: test\n connection: local\n \n tasks:\n - name: Get all of the facts from my BIG-IP\n bigip_facts:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n include: \"system_info\" \n\n And now, let's just run it to see what sort of output it generates. \n\n \nansible-playbook -i hosts site.yaml -vvvv \n\n You should be presented with information resembling the following. \n\n \nroot@debian:~# ansible-playbook -i hosts site.yaml -vvvv\nPLAY [Test bigip_facts] *******************************************************\nTASK: [Get all of the facts from my BIG-IP] ***********************************\n...\nok: [big-ip01.internal] => {\"ansible_facts\": {\"system_info\": {\"base_mac_address\": \"8A:83:8B:B1:AE:F7\",\n\"blade_temperature\": [], \"chassis_slot_information\": [], \"globally_unique_identifier\": \"8A:83:8B:B1:AE:F7\",\n\"group_id\": \"DefaultGroup\", \"hardware_information\": [{\"model\": \"Common KVM processor\", \"name\": \"cpus\",\n\"slot\": 0, \"type\": \"HARDWARE_BASE_BOARD\", \"versions\": [{\"name\": \"cache size\", \"value\": \"4096 KB\"}, {\"name\":\n\"cores\", \"value\": \"2\"}, {\"name\": \"cpu MHz\", \"value\": \"2199.994\"}]}],\n...\n\"os_version\": \"#1 SMP Mon Aug 11 19:54:07 PDT 2014\", \"platform\": \"Z100\", \"product_category\": \"Virtual Edition\",\n\"switch_board_part_revision\": null, \"switch_board_serial\": null, \"system_name\": \"Linux\"}, \"time\": {\"day\": 28,\n\"hour\": 22, \"minute\": 1, \"month\": 1, \"second\": 7, \"year\": 2016}, \"time_zone\": {\"gmt_offset\": -8,\n\"is_daylight_saving_time\": false, \"time_zone\": \"PST\"}, \"uptime\": 854}}, \"changed\": false}\nroot@debian:~# \n\n This module can output a lot of information that you can use in later tasks. Note that I just asked for the system_info facts, but there are a number of them that you can ask for, including \n\n address_class certificate client_ssl_profile device device_group interface key node pool rule self_ip software system_info traffic_group trunk virtual_address virtual_server vlan \n\n You can include multiple types of facts by separating them with a comma. For example \n\n \n- name: Test bigip_facts\n hosts: test\n connection: local\n \n tasks:\n - name: Get all of the facts from my BIG-IP\n bigip_facts:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n include: \"system_info,software,self_ip\" \n\n Returns facts representing the system_info , software , and self IPs. \n\n You can use the generated facts in later tasks by referencing their JSON keys. For example \n\n \n- name: Test bigip_facts\n hosts: test\n connection: local\n \n tasks:\n - name: Get all of the facts from my BIG-IP\n bigip_facts:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n include: \"system_info,software,self_ip\"\n \n - name: Mention the Self IP\n debug:\n msg: \"I have self IP {{ self_ip['/Common/net1'].address }}\"\n \n - name: Mention the software\n debug:\n msg: \"I have software version {{ software[0].version }}\" \n\n And the (truncated) output \n\n \n...\nTASK: [Mention the Self IP] ***************************************************\nok: [big-ip01.internal] => {\n \"msg\": \"I have self IP 10.2.2.2\"\n}\n \nTASK: [Mention the software] **************************************************\nok: [big-ip01.internal] => {\n \"msg\": \"I have software version 11.6.0\"\n}\n... \n\n bigip_node \n\n This module allows you to manipulate nodes in a BIG-IP. Nodes are logical objects on your BIG-IP that identify the IP address of a physical node on your network. In terms of what we can do with them with the existing BIG-IP modules, you can use this module to create nodes that you can later assign to pool members. \n\n First, let's show you the playbook that I'm going to run. \n\n \n- name: Node shenanigans\n hosts: test\n connection: local\n \n tasks:\n - name: Add a new node\n bigip_node:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n host: \"10.2.1.1\"\n name: \"member1\" \n\n This is a simple example of creating a node in my BIG-IP. As is probably apparent if I am going to be working with pools, I would want to create many nodes. I'll hold off on that until a future example, but hopefully this clarifies the point of how to create the object that we can later assign to pool members. \n\n Let's run it! \n\n \nansible-playbook -i hosts site.yaml \n\n And the output we should expect to see looks like this \n\n \nroot@debian:~# ansible-playbook -i hosts site.yaml\n \nPLAY [Node shenanigans] *******************************************************\n \nTASK: [Add a new node] ********************************************************\nchanged: [big-ip01.internal]\n \nPLAY RECAP ********************************************************************\nbig-ip01.internal : ok=1 changed=1 unreachable=0 failed=0\n \nroot@debian:~# \n\n Now, just to clarify what gets dropped where, and where these nodes can be used, let's first look at the Local Traffic > Nodes screen. \n\n \n\n Now, let's navigate over to the pool screen and try to create a new pool. On the new pool creation screen, we have the option of specifying members of that pool. If we click on Node List, well, look at that. Our new node. \n\n \n\n bigip_pool \n\n This module allows you to create pools on your BIG-IPs. To these pools we can later add pool members. With this and the bigip_pool_member module, you can control the basic load balancing functionality of the BIG-IP. \n\n First, just to prove that I have nothing up my BIG-IP sleeve, here's my current pool list. \n\n \n\n And now, for my playbook \n\n \n- name: Create a pool\n hosts: test\n connection: local\n \n tasks:\n - name: Create the pool1 pool\n bigip_pool:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n name: \"pool1\" \n\n With a wave of my magic wand... \n\n \nroot@debian:~# ansible-playbook -i hosts site.yaml\n \nPLAY [Create a pool] *******************************************************\n \nTASK: [Create the pool1 pool] ***********************************\n...\n \nchanged: [big-ip01.internal] => {\"changed\": true}\n \nPLAY RECAP ********************************************************************\nbig-ip01.internal : ok=1 changed=1 unreachable=0 failed=0\n \nroot@debian:~# \n\n ...and my pool list has been changed. \n\n \n\n The bigip_pool module has a number of other options that let you adjust settings of the pool. They are all documented on the module's page. \n\n bigip_pool_member \n\n With the bigip_pool_member module, you can manipulate the members of any of the pools on your BIG-IP. This module, in particular, is a crucial part of a rolling upgrade strategy that you may undertake when upgrading software on members of the pool. \n\n Consider the following scenario. \n\n Remove (or disable) the member from the pool Upgrade the member's software (you pick the software, but let's say Apache for example) Verify the software upgrade Add (or enable) the member back to the old pool, or, add the member to a new pool \n\n This module can be used for steps 1 and 4. Let's have a look at my playbook. \n\n \n- name: Pool member manipulation\n hosts: test\n connection: local\n \n tasks:\n - name: Drop members out of pool1\n bigip_pool_member:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n state: \"absent\"\n host: \"{{ item }}\"\n pool: \"pool1\"\n port: \"22\"\n with_items:\n - member1\n - member2\n \n - name: Intermediate processing\n debug:\n msg: \"Upgrade some software\"\n \n - name: More intermediate processing\n debug:\n msg: \"Install some configuration\"\n \n - name: Add member1 node back\n bigip_node:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n name: \"{{ item }}\"\n host: \"10.2.1.1\"\n state: \"present\"\n with_items:\n - member1\n \n - name: Add member2 node back\n bigip_node:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n name: \"{{ item }}\"\n host: \"10.2.1.2\"\n state: \"present\"\n with_items:\n - member2\n \n - name: Add member1 back to pool1\n bigip_pool_member:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n host: \"{{ item }}\"\n pool: \"pool1\"\n port: \"22\"\n state: \"present\"\n with_items:\n - member1\n \n - name: Add member2 to pool2\n bigip_pool_member:\n server: \"{{ inventory_hostname }}\"\n user: \"admin\"\n password: \"admin\"\n host: \"{{ item }}\"\n pool: \"pool2\"\n port: \"22\"\n state: \"present\"\n with_items:\n - member2 \n\n And before we run it, let's just take a peek at my current pools. \n\n \n\n As well as the members of pool1 \n\n \n\n And the members of pool2 \n\n \n\n Now, let's have a go at running the playbook. \n\n \nansible-playbook -i hosts site2.yaml \n\n After it runs, you should have output that resembles something like this. \n\n \nroot@debian:~# ansible-playbook -i hosts site.yaml\n \nPLAY [Pool member manipulation] ***********************************************\n \nTASK: [Drop members out of pool1] *********************************************\nchanged: [big-ip01.internal] => (item=member1)\nok: [big-ip01.internal] => (item=member2)\n \nTASK: [Intermediate processing] ***********************************************\nok: [big-ip01.internal] => {\n \"msg\": \"Upgrade some software\"\n}\n \nTASK: [More intermediate processing] ******************************************\nok: [big-ip01.internal] => {\n \"msg\": \"Install some configuration\"\n}\n \nTASK: [Add member1 node back] *************************************************\nchanged: [big-ip01.internal] => (item=member1)\n \nTASK: [Add member2 node back] *************************************************\nok: [big-ip01.internal] => (item=member2)\n \nTASK: [Add member1 back to pool1] *********************************************\nchanged: [big-ip01.internal] => (item=member1)\n \nTASK: [Add member2 to pool2] **************************************************\nok: [big-ip01.internal] => (item=member2)\n \nPLAY RECAP ********************************************************************\nbig-ip01.internal : ok=7 changed=3 unreachable=0 failed=0\n \nroot@debian:~# \n\n And your pool members should be different, check out the screenshots below. \n\n The pool list \n\n \n\n Members in pool1 \n\n \n\n Members in pool2 \n\n \n\n To Summarize \n\n BIG-IP would not have a presence in Ansible if it were not for Matt and Serge's initiative. \n\n Based on the work they started, I'm happy to assist with testing and contributing new modules moving forward. In my entirely too biased opinion, Ansible fits in well with the tools and products I work on. Perhaps it will also fit in well with your workflow. If we've piqued your interest, then the Ansible mailing list is a great place to ask more Ansible related questions and further solidify your understanding. \n\n If you liked this article and want to see more like it, rate it as such. Have comments? Questions? Something else? Leave a comment below! \n\n References \n\n http://docs.ansible.com/ansible/bigip_facts_module.html http://docs.ansible.com/ansible/bigip_node_module.html http://docs.ansible.com/ansible/bigip_pool_module.html http://docs.ansible.com/ansible/bigip_pool_member_module.html https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/ltm_configuration_guide_10_0_0/ltm_nodes.html#1188710 https://groups.google.com/forum/#!forum/ansible-project ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"16677","kudosSumWeight":0,"repliesCount":14,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMDdpMTM1MDFBRjU3NjI4RDRFNg?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTc3OWk1RDBFOEZFNDU2MzE5MTNB?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItODcxMWk3NTFFMzdBRjc2MUNCOTI1?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMzA1OGkyRkY4RTRCNTA1QzAxOUYz?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItOTkyOWlDNDg1ODNDMUYyOURCMzAz?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTQ0NDRpM0YzRDEzMkM5NEMxOTI5OA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItMTEyMTBpRDgxM0RBOUFGQTYyRDhCOQ?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjg0MGk1NjAyODZDRjIxRkE4RDI4?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNjU4OGlGRjJFMTEzQTU2NjQxQ0Yx?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODAzMzItNTI5MmkwMzMyNkU3NDhBQjk0RUFC?revision=2\"}"}}],"totalCount":10,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:289167":{"__typename":"Conversation","id":"conversation:289167","topic":{"__typename":"TkbTopicMessage","uid":289167},"lastPostingActivityTime":"2023-06-05T22:51:41.948-07:00","solved":false},"TkbTopicMessage:message:289167":{"__typename":"TkbTopicMessage","subject":"Getting Started with iControl: Working with the System","conversation":{"__ref":"Conversation:conversation:289167"},"id":"message:289167","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:289167","revisionNum":2,"uid":289167,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2360},"postTime":"2016-06-17T12:00:00.000-07:00","lastPublishTime":"2023-06-05T22:51:41.948-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" So far throughout this Getting Started with iControl series, we’ve worked our way through history, libraries, configuration object, and statistics. In this final article in the series, we’ll tackle a few system functions, namely system ntp and dns settings, and then generating a qkview. Some of the system functions are new functionality to iControl with the rest portal, as system calls are not available via soap. The rule of thumb here is if the system call is available in tmsh via the util branch, it’s available in the rest portal. \n\n \n System DNS Settings \n\n When setting up the BIG-IP, some functions require an active DNS configuration to perform lookups. In the GUI, this is configured by navigating to System->Configuration->Device->DNS. In tmsh, it’s configured by modifying the settings in /sys/dns. Note that there is not a create function here, as the DNS objects themselves already exist, whether or not you have configured them. Because of this, when updating these settings via iControl rest, you’ll use the PUT method. An example tmsh configuration for the DNS settings is below: \n\n \n[root@ltm3:Active:Standalone] config # tmsh list sys dns\nsys dns {\n name-servers { 10.10.10.2 10.10.10.3 }\n search { test.local }\n} \n\n This formatted in json looks like this: {\"nameServers\": [\"10.10.10.2\", \"10.10.10.3\"], \"search\": [\"test.local\"]} with a PUT to https://hostname/mgmt/tm/sys/dns. \n\n Powershell Python \n \n Powershell DNS Settings \n\n \n#----------------------------------------------------------------------------\nfunction Get-systemDNS()\n#\n# Description\n# This function retrieves the system DNS configuration\n#\n#----------------------------------------------------------------------------\n{\n$uri = \"/mgmt/tm/sys/dns\";\n$link = \"https://$Bigip$uri\";\n$headers = @{};\n$headers.Add(\"ServerHost\", $Bigip);\n\n$secpasswd = ConvertTo-SecureString $Pass -AsPlainText -Force\n$mycreds = New-Object System.Management.Automation.PSCredential ($User, $secpasswd)\n\n$obj = Invoke-RestMethod -Method GET -Headers $headers -Uri $link -Credential $mycreds\n\n Write-Host \"`nName Servers\";\n Write-Host \"------------\";\n $items = $obj.nameServers;\n for($i=0; $i -lt $items.length; $i++) {\n $name = $items[$i];\n Write-Host \"`t$name\";\n }\n\n Write-Host \"`nSearch Domains\";\n $items = $obj.search;\n for($i=0; $i -lt $items.length; $i++) {\n $name = $items[$i];\n Write-Host \"`t$name\";\n }\n Write-Host \"`n\"\n\n}\n\n#----------------------------------------------------------------------------\nfunction Set-systemDNS()\n#\n# Description\n# This function sets the system DNS configuration\n#\n#----------------------------------------------------------------------------\n{\n param(\n [array]$Servers,\n [array]$SearchDomains\n );\n $uri = \"/mgmt/tm/sys/dns\";\n $link = \"https://$Bigip$uri\";\n $headers = @{};\n $headers.Add(\"ServerHost\", $Bigip);\n $headers.Add(\"Content-Type\", \"application/json\");\n\n $obj = @{\n nameServers = $Servers\n search = $SearchDomains\n };\n $body = $obj | ConvertTo-Json\n$secpasswd = ConvertTo-SecureString $Pass -AsPlainText -Force\n$mycreds = New-Object System.Management.Automation.PSCredential ($User, $secpasswd)\n\n$obj = Invoke-RestMethod -Method PUT -Uri $link -Headers $headers -Credential $mycreds -Body $body;\n Get-systemDNS;\n\n} \n \n\n \n Python DNS Settings \n\n \ndef get_sys_dns(bigip, url):\n try:\n dns = bigip.get('%s/sys/dns' % url).json()\n print \"\\n\\n\\tName Servers:\"\n for server in dns['nameServers']:\n print \"\\t\\t%s\" % server\n print \"\\n\\tSearch Domains:\"\n for domain in dns['search']:\n print \"\\t\\t%s\\n\\n\" %domain\n\n except Exception, e:\n print e\n\n\ndef set_sys_dns(bigip, url, servers, search):\n servers = [x.strip() for x in servers.split(',')]\n search = [x.strip() for x in search.split(',')]\n payload = {}\n payload['nameServers'] = servers\n payload['search'] = search\n try:\n bigip.put('%s/sys/dns' % url, json.dumps(payload))\n get_sys_dns(bigip, url)\n except Exception, e:\n print e \n \n \n\n \n System NTP Settings \n\n NTP is another service that some functions like APM access require. In the GUI, the settings for NTP are configured in two places. First, the servers are configured in System->Configuration->Device->NTP. The timezone is configured on the System->Platform page. In tmsh, the settings are configured in /sys/ntp. Like DNS, these objects already exist, so the iControl rest method will be a PUT instead of a POST. An example tmsh configuration for the NTP settings is below: \n\n \n[root@ltm3:Active:Standalone] config # tmsh list sys ntp\nsys ntp {\n servers { 10.10.10.1 }\n timezone America/Chicago\n} \n\n This formatted in json looks like this: {\"servers\": [\"10.10.10.1\"], \"timezone\": \"America/Chicago\"} with a PUT to https://hostname/mgmt/tm/sys/ntp. \n\n Powershell Python \n \n Powershell NTP Settings \n\n \n#----------------------------------------------------------------------------\nfunction Get-systemNTP()\n#\n# Description\n# This function retrieves the system NTP configuration\n#\n#----------------------------------------------------------------------------\n{\n$uri = \"/mgmt/tm/sys/ntp\";\n$link = \"https://$Bigip$uri\";\n$headers = @{};\n$headers.Add(\"ServerHost\", $Bigip);\n\n$secpasswd = ConvertTo-SecureString $Pass -AsPlainText -Force\n$mycreds = New-Object System.Management.Automation.PSCredential ($User, $secpasswd)\n\n$obj = Invoke-RestMethod -Method GET -Headers $headers -Uri $link -Credential $mycreds\n\n Write-Host \"`nNTP Servers\";\n Write-Host \"------------\";\n $items = $obj.servers;\n for($i=0; $i -lt $items.length; $i++) {\n $name = $items[$i];\n Write-Host \"`t$name\";\n }\n\n Write-Host \"`nTimezone\";\n $item = $obj.timezone;\n Write-Host \"`t$item`n\";\n\n}\n\n#----------------------------------------------------------------------------\nfunction Set-systemNTP()\n#\n# Description\n# This function sets the system NTP configuration\n#\n#----------------------------------------------------------------------------\n{\n param(\n [array]$Servers,\n [string]$TimeZone\n );\n $uri = \"/mgmt/tm/sys/ntp\";\n $link = \"https://$Bigip$uri\";\n $headers = @{};\n $headers.Add(\"ServerHost\", $Bigip);\n $headers.Add(\"Content-Type\", \"application/json\");\n\n $obj = @{\n servers = $Servers\n timezone = $TimeZone\n };\n $body = $obj | ConvertTo-Json\n$secpasswd = ConvertTo-SecureString $Pass -AsPlainText -Force\n$mycreds = New-Object System.Management.Automation.PSCredential ($User, $secpasswd)\n\n$obj = Invoke-RestMethod -Method PUT -Uri $link -Headers $headers -Credential $mycreds -Body $body;\n Get-systemNTP;\n\n} \n \n\n \n Python NTP Settings \n\n \ndef get_sys_ntp(bigip, url):\n try:\n ntp = bigip.get('%s/sys/ntp' % url).json()\n print \"\\n\\n\\tNTP Servers:\"\n for server in ntp['servers']:\n print \"\\t\\t%s\" % server\n print \"\\n\\tTimezone: \\n\\t\\t%s\" % ntp['timezone']\n\n except Exception, e:\n print e\n\n\ndef set_sys_ntp(bigip, url, servers, tz):\n servers = [x.strip() for x in servers.split(',')]\n payload = {}\n payload['servers'] = servers\n payload['timezone'] = tz\n try:\n bigip.put('%s/sys/ntp' % url, json.dumps(payload))\n get_sys_ntp(bigip, url)\n except Exception, e:\n print e \n \n \n\n \n Generating a qkview \n\n Moving on from configuring some system settings to running a system task, we’ll now focus on a common operational task: running a qkview. In the GUI, this is done via System->Support. This is easy enough at the command line as well with the simple qkview command at the bash prompt, or via tmsh as show below: \n\n \n[root@ltm3:Active:Standalone] config # tmsh run util qkview\nGathering System Diagnostics: Please wait ...\nDiagnostic information has been saved in:\n/var/tmp/ltm3.test.local.qkview\nPlease send this file to F5 support. \n\n This formatted in json looks like this: {\"command\": \"run\"} with a POST to https://hostname/mgmt/tm/util/qkview. \n\n Powershell Python \n \n Powershell - Run a qkview \n\n \n#----------------------------------------------------------------------------\nfunction Gen-QKView()\n#\n# Description\n# This function generates a qkview on the system\n#\n#----------------------------------------------------------------------------\n{\n $uri = \"/mgmt/tm/util/qkview\";\n $link = \"https://$Bigip$uri\";\n $headers = @{};\n $headers.Add(\"serverHost\", $Bigip);\n $headers.Add(\"Content-Type\", \"application/json\");\n $secpasswd = ConvertTo-SecureString $Pass -AsPlainText -Force\n $mycreds = New-Object System.Management.Automation.PSCredential ($User, $secpasswd)\n\n $obj = @{\n command='run'\n };\n $body = $obj | ConvertTo-Json\n Write-Host (\"Running qkview...standby\")\n $obj = Invoke-RestMethod -Method POST -Uri $link -Headers $headers -Credential $mycreds -Body $body;\n Write-Host (\"qkview is complete and is available in /var/tmp.\")\n} \n \n\n \n Python - Run a qkview \n\n \ndef gen_qkview(bigip, url):\n payload = {}\n payload['command'] = 'run'\n try:\n print \"\\n\\tRunning qkview...standby\"\n qv = bigip.post('%s/util/qkview' % url, json.dumps(payload)).text\n if 'saved' in qv:\n print '\\tqkview is complete and available in /var/tmp.'\n except Exception, e:\n print e \n \n \n\n \n Going Further \n\n Now that you have a couple basic tasks in your arsenal, what else might you add? Here are a couple exercises for you to build your toolbox: \n\n Configure sshd, creating a custom security banner. Configure snmp Extend the qkview function to support downloading the qkview file generated. \n\n Resources \n\n All the scripts for this article are available in the codeshare under \"Getting Started with iControl Code Samples.\" ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"9882","kudosSumWeight":0,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282844":{"__typename":"Conversation","id":"conversation:282844","topic":{"__typename":"TkbTopicMessage","uid":282844},"lastPostingActivityTime":"2023-01-26T14:25:02.918-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI4NDQtMTQxNWk3MzNFNzAwM0IxNjRCRDBB?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI4NDQtMTQxNWk3MzNFNzAwM0IxNjRCRDBB?revision=2","title":"0151T000003d7prQAA.jpg","associationType":"BODY","width":96,"height":126,"altText":null},"TkbTopicMessage:message:282844":{"__typename":"TkbTopicMessage","subject":"64-bit numbers in perl","conversation":{"__ref":"Conversation:conversation:282844"},"id":"message:282844","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282844","revisionNum":2,"uid":282844,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:106220"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":513},"postTime":"2005-06-06T10:09:00.000-07:00","lastPublishTime":"2023-01-26T14:25:02.918-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n A question recently came up in the iControl forums about how to deal with the statistics returned by our iControl interfaces. In 9.0, we changed the interfaces to return true 64-bit values consisting of a structure of a low and high 32-bit value (this is due to the fact that there is a lack of support in the SOAP encoding specs, and some of the languages, for native 64-bit numbers). \n Our SDK samples show something like this: \n $low = $stat->{\"low\"};\n$high = $stat->{\"high\"};\n$value64 = ($high<<32)|$low; \n The question was asked, how come the value is truncated to a 32-bit number? I asked myself that same question as it worked for my build. After some digging, it turns out that perl needs to be compiled specifically to allow include support for 64-bit numbers. You can check your installation out by using the Config module \n use Config; \n($Config{use64bitint} eq 'define' || $Config{longsize} >= 8) && \n print \"Supports 64-bit numbers\\n\"; \n So, what do you do if you don't have control to rebuild your version of perl? Well, thanks to a user who pointed me this way, there exists a perl module to support large numbers. As long as you have the Math::BigInt package installed, you can use it as follows: \n use Math::BigInt; \n$low = $stat->{\"low\"};\n$high = $stat->{\"high\"};\n$value64 = Math::BigInt->new($high)->blsft(32)->bxor($low); \n Happy Coding! \n -Joe ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"1419","kudosSumWeight":0,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI4NDQtMTQxNWk3MzNFNzAwM0IxNjRCRDBB?revision=2\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:287315":{"__typename":"Conversation","id":"conversation:287315","topic":{"__typename":"TkbTopicMessage","uid":287315},"lastPostingActivityTime":"2023-01-26T14:22:27.122-08:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3","title":"0151T000003d46KQAQ.jpg","associationType":"BODY","width":800,"height":117,"altText":null},"TkbTopicMessage:message:287315":{"__typename":"TkbTopicMessage","subject":"BIG-IP Configuration Visualizer - iControl Style","conversation":{"__ref":"Conversation:conversation:287315"},"id":"message:287315","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:287315","revisionNum":3,"uid":287315,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:51154"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1517},"postTime":"2011-01-25T09:01:00.000-08:00","lastPublishTime":"2023-01-26T14:22:27.122-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" I posted almost two years ago to the day on a cool tool called BIG-IP Config Visualizer, or BCV, that one of our field engineers put together that utilizes a BIG-IP config parser and GraphViz to create images visualizing the relationship of configuration objects for a particular virtual server. Well, I’m here to report that another community user, Russell Moore, has taken that work to the next level. Rather than trying to figure out the nuances of configuration objects amongst all the versions of BIG-IP, he converted the script to utilize iControl! In this tech tip, I’ll walk through the installation steps necessary to get this tool off the ground. \n The Setup \n Install a few libraries and GraphViz via apt-get \n \n apt-get install libssl-dev libcrypt-ssleay-perl libio-socket-ssl-perl libgraph-writer-graphviz-perl \n \n Open a CPAN shell and install SOAP::Lite and Net::Netmask \n \n perl –MCPAN –e shell\n \n install SOAP::Lite \n install Net::Netmask \n \n \n \n After installing those libraries and tools, grab the BCV-iControl source from the codeshare, save it as an executable (bcv.pl on my system) and set these variables (I only changed the ones in bold type): \n \n #Declare CLI $vars my $vs1; my $new_dir = 'NO_DIR'; my $extension = 'NO_EXT'; my $ltm_host = \"172.16.99.5\"; my $ltm_port = '443'; my $user_id = \"admin\"; my $req_partition; my $user_password = \"admin\"; my $ltm_protocol = 'https'; my $path; my $dir; \n \n Finally, some command-line options: \n \n root@ubuntu:/home/jrahm# ./bcv.pl -h Thank you for using BIG-IP Configuration Visualizer (BCV 1.16.1-revisited with soap) -v <VS_NAME> this prints the specified virtual server and requires option -c. Default is to print all \n -c Specify the partition/container to look in for option -v \n -t <iControl host LTM> specify ltm_host IP we will connect to \n -d specifies a directory you want the images in. Has to be in Current working Directory: /home/jrahm Default is /img) \n -e Define image format options: svg, png (default is jpg) \n -help for help but you already found it \n \n The Payoff \n Now that all the legwork is complete, we can play! \n \n root@ubuntu:/home/jrahm# ./bcv.pl \n Please wait while we build some maps of your system. Retrieving SelfIPs in Partition: ** Common ** Mapping Partition: ** Common ** routes to gateways Mapping Partition: ** Common ** selfIPs and VLANs.. Mapping Partition: ** Common ** pools and iRule references to pools............ Mapping Partition: ** Common ** virtual servers and properties... Drawing VS: dc.hashtest which is 1 of 3 in Partition: Common Drawing VS: testvip1 which is 2 of 3 in Partition: Common Drawing VS: management_vip which is 3 of 3 in Partition: Common \n All drawings completed! They can be found in: /home/jrahm/img \n \n Taking a look at the virtual server I used for the hashing algorithm distribution tech tip: \n \n Conclusion \n Visual representations of configurations are incredibly helpful in identifying issues quickly. An interesting next step would be to track state of objects from iteration of the drawings, and build a page to include all the images. That would make a nice and cheap dashboard for application owners or operating centers. Any takers? Thanks to community user Russell Moore that took a great contributed tool and made it better with iControl! ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3516","kudosSumWeight":0,"repliesCount":12,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODczMTUtMTQ2NTNpQjJDQkU5RUU1OUU5NkU3OA?revision=3\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:279711":{"__typename":"Conversation","id":"conversation:279711","topic":{"__typename":"TkbTopicMessage","uid":279711},"lastPostingActivityTime":"2022-09-26T09:39:23.455-07:00","solved":false},"User:user:56738":{"__typename":"User","uid":56738,"login":"ltwagnon","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS01NjczOC0xNjM3OGk3QkQ0M0UxRDAzRDEzMDg3"},"id":"user:56738"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTIyMDlpQTJDMzRERDAxRjdBMEY4QQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTIyMDlpQTJDMzRERDAxRjdBMEY4QQ?revision=1","title":"0151T000003d5l2QAA.jpg","associationType":"BODY","width":796,"height":457,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTE4OTFpRTZCNTkyRkJEMEM0MUM5Rg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTE4OTFpRTZCNTkyRkJEMEM0MUM5Rg?revision=1","title":"0151T000003d5l3QAA.jpg","associationType":"BODY","width":438,"height":502,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjcyM2k1Q0ZDNjM0RjM5QTlGQ0I4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjcyM2k1Q0ZDNjM0RjM5QTlGQ0I4?revision=1","title":"0151T000003d5l4QAA.jpg","associationType":"BODY","width":854,"height":569,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjE1NWlDRERDRTAzMTE5NzIxNTdG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjE1NWlDRERDRTAzMTE5NzIxNTdG?revision=1","title":"0151T000003d5l5QAA.jpg","associationType":"BODY","width":951,"height":339,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMzk3OGlCMEIxOTgxODhEMjgyMzRE?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMzk3OGlCMEIxOTgxODhEMjgyMzRE?revision=1","title":"0151T000003d5l6QAA.jpg","associationType":"BODY","width":622,"height":441,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtOTM2MGk2QUFFODBGRDg2MDdEQThG?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtOTM2MGk2QUFFODBGRDg2MDdEQThG?revision=1","title":"0151T000003d5l7QAA.jpg","associationType":"BODY","width":877,"height":219,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTcxaUFCMTZGNjhDNTlBMENCRDY?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTcxaUFCMTZGNjhDNTlBMENCRDY?revision=1","title":"0151T000003d5l8QAA.jpg","associationType":"BODY","width":669,"height":442,"altText":null},"TkbTopicMessage:message:279711":{"__typename":"TkbTopicMessage","subject":"These Are Not The Scrapes You're Looking For - Session Anomalies","conversation":{"__ref":"Conversation:conversation:279711"},"id":"message:279711","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279711","revisionNum":1,"uid":279711,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:56738"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":1009},"postTime":"2013-05-29T06:00:00.000-07:00","lastPublishTime":"2013-05-29T06:00:00.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n In my first article in this series, I discussed web scraping -- what it is, why people do it, and why it could be harmful. My second article outlined the details of bot detection and how the ASM blocks against these pesky little creatures. This last article in the series of web scraping will focus on the final part of the ASM defense against web scraping: session opening anomalies and session transaction anomalies. These two detection modes are new in v11.3, so if you're using v11.2 or earlier, then you should upgrade and take advantage of these great new features! \n \n ASM Configuration \n \n In case you missed it in the bot detection article, here's a quick screenshot that shows the location and settings of the Session Opening and Session Transactions Anomaly in the ASM. You'll find all the fun when you navigate to Security > Application Security > Anomaly Detection > Web Scraping. There are three different settings in the ASM for Session Anomaly: Off, Alarm, and Alarm and Block. (Note: these settings are configured independently...they don't have to be set at the same value) \n Obviously, if Session Anomaly is set to \"Off\" then the ASM does not check for anomalies at all. The \"Alarm\" setting will detect anomalies and record attack data, but it will allow the client to continue accessing the website. The \"Alarm and Block\" setting will detect anomalies, record the attack data, and block the suspicious requests. \n \n \n \n \n Session Opening Anomaly \n \n The first detection and prevention mode we'll discuss is Session Opening Anomaly. But before we get too deep into this, let's review what a session is. From a simple perspective, a session begins when a client visits a website, and it ends when the client leaves the site (or the client exceeds the session timeout value). Most clients will visit a website, surf around some links on the site, find the information they need, and then leave. When clients don't follow a typical browsing pattern, it makes you wonder what they are up to and if they are one of the bad guys trying to scrape your site. That's where Session Opening Anomaly defense comes in! \n Session Opening Anomaly defense checks for lots of abnormal activities like clients that don't accept cookies or process JavaScript, clients that don't scrape by surfing internal links in the application, and clients that create a one-time session for each resource they consume. These one-time sessions lead scrapers to open a large number of new sessions in order to complete their job quickly. \n \n What's Considered A New Session? \n \n Since we are discussing session anomalies, I figured we should spend a few sentences on describing how the ASM differentiates between a new or ongoing session for each client request. Each new client is assigned a \"TS cookie\" and this cookie is used by the ASM to identify future requests from the client with a known, ongoing session. If the ASM receives a client request and the request does not contain a TS cookie, then the ASM knows the request is for a new session. This will prove very important when calculating the values needed to determine whether or not a client is scraping your site. \n \n Detection \n \n There are two different methods used by the ASM to detect these anomalies. The first method compares a calculated value to a predetermined ceiling value for newly opened sessions. The second method considers the rate of increase of newly opened sessions. We'll dig into all that in just a minute. But first, let's look at the criteria used for detecting these anomalies. As you can see from the screenshot above, there are three detection criteria the ASM uses...they are: \n Sessions opened per second increased by: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second increases by a given percentage. The default setting is 500 percent. Sessions opened per second reached: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second is greater than or equal to this number. The default value is 400 sessions opened per second. Minimum sessions opened per second threshold for detection: This specifies that the ASM considers traffic to be an attack if the number of sessions opened per second is greater than or equal to the number specified. In addition, at least one of the \"Sessions opened per second increased by\" or \"Sessions opened per second reached\" numbers must also be reached. If the number of sessions opened per second is lower than the specified number, the ASM does not consider this traffic to be an attack even if one of the \"Sessions opened per second increased by\" or \"Sessions opened per second\" reached numbers was reached. The default value for this setting is 200 sessions opened per second. \n In addition, the ASM maintains two variables for each client IP address: a one-minute running average of new session opening rate, and a one-hour running average of new session opening rate. Both of these variables are recalculated every second. \n \n Now that we have all the basic building blocks. let's look at how the ASM determines if a client is scraping your site. \n First Method: Predefined Ceiling Value \n This method uses the user-defined \"minimum sessions opened per second threshold for detection\" value and compares it to the one-minute running average. If the one-minute average is less than this number, then nothing else happens because the minimum threshold has not been met. But, if the one-minute average is higher than this number, the ASM goes on to compare the one-minute average to the user-defined \"sessions opened per second reached\" value. If the one-minute average is less than this value, nothing happens. But, if the one-minute average is higher than this value, the ASM will declare the client a web scraper. The following flowchart provides a pictorial representation of this process. \n \n \n \n \n Second Method: Rate of Increase \n The second detection method uses several variables to compare the rate of increase of newly opened sessions against user-defined variables. Like the first method, this method first checks to make sure the minimum sessions opened per second threshold is met before doing anything else. If the minimum threshold has been met, the ASM will perform a few more calculations to determine if the client is a web scraper or not. The \"sessions opened per second increased by\" value (percentage) is multiplied by the one-hour running average and this value is compared to the one-minute running average. If the one-minute average is greater, then the ASM declares the client a web scraper. If the one-minute average is lower, then nothing happens. The following matrix shows a few examples of this detection method. Keep in mind that the one-minute and one-hour averages are recalculated every second, so these values will be very dynamic. \n \n \n \n \n Prevention \n \n The ASM provides several policies to prevent session opening anomalies. It begins with the first method that you enable in this list. If the system finds this method not effective enough to stop the attack, it uses the next method that you enable in this list. The following screenshots show the different options available for prevention. The \"Drop IP Addresses with bad reputation\" is tied to Rate Limiting, so it will not appear as an option unless you enable Rate Limiting. Note that IP Address Intelligence must be licensed and enabled. This feature is licensed separately from the other ASM web scraping options. \n \n \n \n \n \n Here's a quick breakdown of what each of these prevention policies do for you: \n Client Side Integrity Defense: The system determines whether the client is a legal browser or an illegal script by sending a JavaScript challenge to each new session request from the detected IP address, and waiting for a response. The JavaScript challenge will typically involve some sort of computational challenge. Legal browsers will respond with a TS cookie while illegal scripts will not. The default for this feature is disabled. \n Rate Limiting: The goal of Rate Limiting is to keep the volume of new sessions at a \"non-attack\" level. The system will drop sessions from suspicious IP addresses after the system determines that the client is an illegal script. The default for this feature is also disabled. \n Drop IP Addresses with bad reputation: The system drops requests from IP addresses that have a bad reputation according to the system’s IP Address Intelligence database (shown above). The ASM will drop all request from any \"bad\" IP addresses even if they respond with a TS cookie. IP addresses that do not have a bad reputation also undergo rate limiting. The default for this option is disabled. Keep in mind that this option is available only after Rate Limiting is enabled. In addition, this option is only enforced if at least one of the IP Address Intelligence Categories is set to Alarm mode. \n \n Prevention Duration \n Now that we have detected session opening anomalies and mitigated them using our prevention options, we must figure out how long to apply the prevention measures. This is where the Prevention Duration comes in. This setting specifies the length of time that the system will prevent an attack. The system prevents attacks by rejecting requests from the attacking IP address. There are two settings for Prevention Duration: \n Unlimited: This specifies that after the system detects and stops an attack, it performs attack prevention until it detects the end of the attack. This is the default setting. Maximum <number of> seconds: This specifies that after the system detects and stops an attack, it performs attack prevention for the amount of time indicated unless the system detects the end of the attack earlier. \n \n So, to finish up our Session Opening Anomaly part of this article, I wanted to share a quick scenario. I was recently reading several articles from some of the web scrapers around the block, and I found one guy's solution to work around web scraping defense. Here's what he said: \"Since the service conducted rate-limiting based on IP address, my solution was to put the code that hit their service into some client-side JavaScript, and then send the results back to my server from each of the clients. This way, the requests would appear to come from thousands of different places, since each client would presumably have their own unique IP address, and none of them would individually be going over the rate limit.\" \n This guy is really smart! And, this would work great against a web scraping defense that only offered a Rate Limiting feature. Here's the pop quiz question: If a user were to deploy this same tactic against the ASM, what would you do to catch this guy? I'm thinking you would need to set your minimum threshold at an appropriate level (this will ensure the ASM kicks into gear when all these sessions are opened) and then the \"sessions opened per second\" or the \"sessions opened per second increased by\" should take care of the rest for you. As always, it's important to learn what each setting does and then test it on your own environment for a period of time to ensure you have everything tuned correctly. And, don't forget to revisit your settings from time to time...you will probably need to change them as your network environment changes. \n \n \n Session Transactions Anomaly \n \n The second detection and prevention mode is Session Transactions Anomaly. This mode specifies how the ASM reacts when it detects a large number of transactions per session as well as a large increase of session transactions. Keep in mind that web scrapers are designed to extract content from your website as quickly and efficiently as possible. So, web scrapers normally perform many more transactions than a typical application client. Even if a web scraper found a way around all the other defenses we've discussed, the Session Transaction Anomaly defense should be able to catch it based on the sheer number of transactions it performs during a given session. The ASM detects this activity by counting the number of transactions per session and comparing that number to a total average of transactions from all sessions. The following screenshot shows the detection and prevention criteria for Session Transactions Anomaly. \n \n \n \n \n Detection \n \n How does the ASM detect all this bad behavior? Well, since it's trying to find clients that surf your site much more than other clients, it tracks the number of transactions per client session (note: the ASM will drop a session from the table if no transactions are performed for 15 minutes). It also tracks the average number of transactions for all current sessions (note: the ASM calculates the average transaction value every minute). It can use these two figures to compare a specific client session to a reasonable baseline and figure out if the client is performing too many transactions. The ASM can automatically figure out the number of transactions per client, but it needs some user-defined thresholds to conduct the appropriate comparisons. These thresholds are as follows: \n Session transactions increased by: This specifies that the system considers traffic to be an attack if the number of transactions per session increased by the percentage listed. The default setting is 500 percent. \n Session transactions reached: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number. The default value is 400 transactions. \n Minimum session transactions threshold for detection: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number, and at least one of the \"Sessions transactions increased by\" or \"Session transactions reached\" numbers was reached. If the number of transactions per session is lower than this number, the system does not consider this traffic to be an attack even if one of the \"Session transactions increased by\" or \"Session transaction reached\" numbers was reached. The default value is 200 transactions. \n The following table shows an example of how the ASM calculates transaction values (averages and individual sessions). \n \n \n We would expect that a given client session would perform about the same number of transactions as the overall average number of transactions per session. But, if one of the sessions is performing a significantly higher number of transactions than the average, then we start to get suspicious. You can see that session 1 and session 3 have transaction values higher than the average, but that only tells part of the story. We need to consider a few more things before we decide if this client is a web scraper or not. By the way, if the ASM knows that a given session is malicious, it does not use that session's transaction numbers when it calculates the average. \n Now, let's roll in the threshold values that we discussed above. If the ASM is going to declare a client as a web scraper using the session transaction anomaly defense, the session transactions must first reach the minimum threshold. Using our default minimum threshold value of 200, the only session that exceeded the minimum threshold is session 3 (250 > 200). All other sessions look good so far...keep in mind that these numbers will change as the client performs additional transactions during the session, so more sessions may be considered as their transaction numbers increase. \n Since we have our eye on session 3 at this point, it's time to look at our two methods of detecting an attack. \n The first detection method is a simple comparison of the total session transaction value to our user-defined \"session transactions reached\" threshold. If the total session transactions is larger than the threshold, the ASM will declare the client a web scraper. \n Our example would look like this: \n Is session 3 transaction value > threshold value (250 > 400)? No, so the ASM does not declare this client as a web scraper. \n \n The second detection method uses the \"transactions increased by\" value along with the average transaction value for all sessions. The ASM multiplies the average transaction value with the \"transactions increased by\" percentage to calculate the value needed for comparison. \n Our example would look like this: \n 90 * 500% = 450 transactions \n Is session 3 transaction value > result (250 > 450)? No, so the ASM does not declare this client as a web scraper. \n \n By the way, only one of these detection methods needs to be met for the ASM to declare the client as a web scraper. You should be able to see how the user-defined thresholds are used in these calculations and comparisons. So, it's important to raise or lower these values as you need for your environment. \n \n Prevention Duration \n In order to save you a bunch of time reading about prevention duration, I'll just say that the Session Transactions Anomaly prevention duration works the same as the Session Opening Anomaly prevention duration (Unlimited vs Maximum <number of> seconds). See, that was easy! \n \n Conclusion \n \n Thanks for spending some time reading about session anomalies and web scraping defense. The ASM does a great job of detecting and preventing web scrapers from taking your valuable information. One more thing...for an informative anomaly discussion on the DevCentral Security Forum, check out this conversation. \n \n If you have any questions about web scraping or ASM configurations, let me know...you can fill out the comment section below or you can contact the DevCentral team at https://devcentral.f5.com/s/community/contact-us. \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"18676","kudosSumWeight":2,"repliesCount":2,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTIyMDlpQTJDMzRERDAxRjdBMEY4QQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTE4OTFpRTZCNTkyRkJEMEM0MUM5Rg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjcyM2k1Q0ZDNjM0RjM5QTlGQ0I4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtNjE1NWlDRERDRTAzMTE5NzIxNTdG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMzk3OGlCMEIxOTgxODhEMjgyMzRE?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtOTM2MGk2QUFFODBGRDg2MDdEQThG?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzk3MTEtMTcxaUFCMTZGNjhDNTlBMENCRDY?revision=1\"}"}}],"totalCount":7,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:279110":{"__typename":"Conversation","id":"conversation:279110","topic":{"__typename":"TkbTopicMessage","uid":279110},"lastPostingActivityTime":"2022-08-26T13:46:47.988-07:00","solved":false},"User:user:216790":{"__typename":"User","uid":216790,"login":"Chase_Abbott","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0yMTY3OTAtTWtUZzVs?image-coordinates=508%2C89%2C1008%2C590"},"id":"user:216790"},"TkbTopicMessage:message:279110":{"__typename":"TkbTopicMessage","subject":"iControl Library For Java With Source","conversation":{"__ref":"Conversation:conversation:279110"},"id":"message:279110","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:279110","revisionNum":2,"uid":279110,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:216790"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3692},"postTime":"2019-06-21T13:52:24.000-07:00","lastPublishTime":"2022-08-26T13:46:47.988-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" Included are the binary distribution of the iControl library for Java and Apache Axis. These releases coincides through version BIG-IP, version 13.0.0. \n \n iControl Assembly for Java 11.3.0 \n iControl Assembly for Java 11.4.0 \n iControl Assembly for Java 11.4.1 \n iControl Assembly for Java 11.5.0 \n iControl Assembly for Java 11.6.0 \n iControl Assembly for Java 12.0.0 \n iControl Assembly for Java 12.1.0 \n iControl Assembly for Java 13.0.0 \n iControl Assembly for Java 13.1.0 \n \n The source distribution of the iControl library for Java with Apache Axis. These releases coincide through version BIG-IP, version 12.1.0. The source code for this project is no longer maintained but available at our at f5-icontrol-library-java repository on GitHub. \n \n iControl Assembly Java Source 11.4.0 (older release not available on Github) \n iControl Assembly Java Source 11.4.1 \n iControl Assembly Java Source 11.5.0 \n iControl Assembly Java Source 11.6.0 \n iControl Assembly Java Source 12.1.0 \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"992","kudosSumWeight":0,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1752674562364","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1752674562364","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1752674562364","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1752674562364","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1752674562364","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1752674562364","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1752674562364","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1752674562364","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1752674562364","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1752674562364","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1752674562364","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Pager/PagerLoadMore-1752674562364","value":{"loadMore":"Show More"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1752674562364","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1752674562364","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1752674562364","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1752674562364","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1752674562364","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1752674562364","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1752674562364","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1752674562364","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1752674562364","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1752674562364","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1752674562364","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1752674562364":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1752674562364","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostRecent","tagName":"iControl"},"buildId":"3XH0qYWYCnEYycuN5W4S8","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","shared_client_components_common_Pager_PagerLoadMore","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}