Using CryptoNice as a Sanity-Checking Tool for Automated Application Deployments with Ansible
Any good automation pipeline should have some validation built in to perform sanity checks on what it should have done. This article describes how you can use CryptoNice as a simple and easy way of sanity checking the SSL/TLS configuration of your automated application deployments, by integrating CryptoNice into your pipeline directly after your automation solution has deployed the application. I am going to show a simple Ansible playbook that illustrates this point. The Ansible playbook deploys an application to a BIG-IP that resides in AWS, but it could be any BIG-IP on premises or in any cloud. After the deployment is complete, I use CryptoNice to validate that the application is reachable via TLS and that the deployed VIP is using best practices for SSL deployments. What Is CryptoNice? CryptoNice is both a command line tool and Python library that is developed by F5 Labs and is publicly available; it provides the ability to scan and report on the configuration of SSL/TLS for your internet or internal-facing web services. Built using the sslyze API and SSL, http-client, and DNS libraries, CryptoNice collects data on a given domain and performs a series of tests to check TLS configuration. You can get CryptoNice here:https://github.com/F5-Labs/cryptonice What Is Ansible? Ansible is an open-source software-provisioning, configuration-management, and application-deployment tool enabling infrastructure as code. It runs on many Unix-like systems, and can configure both Unix-like systems as well as Microsoft Windows and also F5 BIG-IPs. You can learn how to install Ansible here:https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html F5 publishes instructions on how to integrate the Ansible plugins here:https://clouddocs.f5.com/products/orchestration/ansible/devel/ In this article I use the published version 1 F5 Ansible plugin that uses the iControl REST API. If we take a look briefly under the hood here, this plugin is using an imperative API. As of today, F5 has a version 2 plugin in preview that focuses on managing F5 BIG-IP/BIG-IQ through declarative APIs such asAS3, DO, TS, and CFE. You can also check the version 2 plugin preview out on F5 Cloud Docs. I used a stock Ubuntu image as a basis for my Ansible server and followed the instructions for installing Ansible on Ubuntu, then followed the instructions for installing the F5 plugin for Ansible referenced above. You can take a look at the F5/Ansible 1.0 plugin that is published on the Ansible Galaxy Hub here:https://galaxy.ansible.com/f5networks/f5_modules For my demonstration, I also installed CryptoNice on the same server where Ansible and the F5 Ansible plugin are installed; at that point you are off to the races and you can build a simple Ansible script and begin to automate a BIG-IP. The F5 Ansible Module provides you with a great deal of programmability for the BIG-IP basic onboarding, WAF, APM, and LTM. The following is a great reference to give you an idea of the scope of capabilities with Ansible examples that this module provides. You can also automate the infrastructure creation if you so choose, meaning you could stand up a BIG-IP in AWS and then configure everything required to get the device onboarded, and then after that, configure traffic-management objects like VIPs/pools, etc. https://clouddocs.f5.com/products/orchestration/ansible/devel/modules/module_index.html For my test, I created a simple Ansible script that automates the creation of a VIP with an iRule to respond to http get requests. The example also associates a pool and pool members to the VIP to give you an idea of what a simple application deployment may look like. After that, I run a CryptoNice to test the quality of the SSL/TLS. My simple Ansible playbook looks like this: --- - name: Create a VIP, pool and pool members hosts: f5 connection: local vars: provider: password: notmypassword server: f5cove.me user: auser validate_certs: no server_port: 8443 tasks: - name: Create a pool bigip_pool: provider: "{{ provider }}" lb_method: ratio-member name: examplepool slow_ramp_time: 120 delegate_to: localhost - name: Add members to pool bigip_pool_member: provider: "{{ provider }}" description: "webserver {{ item.name }}" host: "{{ item.host }}" name: "{{ item.name }}" pool: examplepool port: '80' with_items: - host: 10.0.0.68 name: web01 - host: 10.0.0.67 name: web02 delegate_to: localhost - name: Create a VIP bigip_virtual_server: provider: "{{ provider }}" description: avip destination: 10.0.0.66 name: vip-1 irules: - responder pool: examplepool port: '443' snat: Automap profiles: - http - f5cove delegate_to: localhost - name: Create Ridirect bigip_virtual_server: provider: "{{ provider }}" description: avipredirect destination: 10.0.0.66 name: vip-1-redirect irules: - _sys_https_redirect port: '80' snat: None profiles: - http delegate_to: localhost - name: play cryptonice nicely hosts: 127.0.0.1 connection: local tasks: - pause: seconds: 30 - name: run cryptonice shell: "cryptonice f5cove.me" register: output - debug: var=output.stdout_lines My output from running the playbook looks like this: PLAY [Create a VIP, pool and pool members] ************************************************************************************************************************************************************************************************* TASK [Gathering Facts] ********************************************************************************************************************************************************************************************************************* ok: [1.2.3.4] TASK [Create a pool] *********************************************************************************************************************************************************************************************************************** ok: [1.2.3.4 -> localhost] TASK [Add members to pool] ***************************************************************************************************************************************************************************************************************** ok: [1.2.3.4 -> localhost] => (item={'host': '10.0.0.68', 'name': 'web01'}) ok: [1.2.3.4 -> localhost] => (item={'host': '10.0.0.67', 'name': 'web02'}) TASK [Create a VIP] ************************************************************************************************************************************************************************************************************************ changed: [1.2.3.4 -> localhost] TASK [Create Ridirect] ********************************************************************************************************************************************************************************************************************* ok: [1.2.3.4 -> localhost] PLAY [play cryptonice nicely] ************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ********************************************************************************************************************************************************************************************************************* ok: [localhost] TASK [pause] ******************************************************************************************************************************************************************************************************************************* Pausing for 30 seconds (ctrl+C then 'C' = continue early, ctrl+C then 'A' = abort) ok: [localhost] TASK [run cryptonice] ********************************************************************************************************************************************************************************************************************** changed: [localhost] TASK [debug] ******************************************************************************************************************************************************************************************************************************* ok: [localhost] => { "output.stdout_lines": [ "Pre-scan checks", "-------------------------------------", "Scanning f5cove.me on port 443...", "Analyzing DNS data for f5cove.me", "Fetching additional records for f5cove.me", "f5cove.me resolves to 34.217.132.104", "34.217.132.104:443: OPEN", "TLS is available: True", "Connecting to port 443 using HTTPS", "Queueing TLS scans (this might take a little while...)", "Looking for HTTP/2", "", "", "RESULTS", "-------------------------------------", "Hostname:\t\t\t f5cove.me", "", "Selected Cipher Suite:\t\t ECDHE-RSA-AES128-GCM-SHA256", "Selected TLS Version:\t\t TLS_1_2", "", "Supported protocols:", "TLS 1.2:\t\t\t Yes", "TLS 1.1:\t\t\t Yes", "TLS 1.0:\t\t\t Yes", "", "TLS fingerprint:\t\t 29d29d15d29d29d21c29d29d29d29d930c599f185259cdd20fafb488f63f34", "", "", "", "CERTIFICATE", "Common Name:\t\t\t f5cove.me", "Issuer Name:\t\t\t R3", "Public Key Algorithm:\t\t RSA", "Public Key Size:\t\t 2048", "Signature Algorithm:\t\t sha256", "", "Certificate is trusted:\t\t False (Mozilla not trusted)", "Hostname Validation:\t\t OK - Certificate matches server hostname", "Extended Validation:\t\t False", "Certificate is in date:\t\t True", "Days until expiry:\t\t 29", "Valid From:\t\t\t 2021-02-12 23:28:14", "Valid Until:\t\t\t 2021-05-13 23:28:14", "", "OCSP Response:\t\t\t Successful", "Must Staple Extension:\t\t False", "", "Subject Alternative Names:", "\t f5cove.me", "", "Vulnerability Tests:", "No vulnerability tests were run", "", "HTTP to HTTPS redirect:\t\t False", "None", "", "RECOMMENDATIONS", "-------------------------------------", "HIGH - TLSv1.0 Major browsers are disabling TLS 1.0 imminently. Carefully monitor if clients still use this protocol. ", "HIGH - TLSv1.1 Major browsers are disabling this TLS 1.1 immenently. Carefully monitor if clients still use this protocol. ", "Low - CAA Consider creating DNS CAA records to prevent accidental or malicious certificate issuance.", "", "Scans complete", "-------------------------------------", "Total run time: 0:00:05.688562" ] } Note that after the playbook is complete, CryptoNice is telling me that I need to improve the quality of my SSL profile on my BIG-IP. As a result, I create a second SSL profile and Disable TLS 1.0 and 1.1. Upgrade the certificate from a 2048 bit key to a 4096 bit key. Make sure that the certificate bundle is configured correctly to ensure that the certificate is properly trusted. Create a cipher rule and group and use the following cipher string to improve the quality of the SSL connections: !EXPORT:!DHE+AES-GCM:!DHE+AES:ECDHE+AES-GCM:ECDHE+AES:RSA+AES-GCM:RSA+AES:-MD5:-SSLv3:-RC4:!3DES I then alter the playbook to reference the new SSL profile, and then re-run the Ansible playbook. Here is the relevant playbook snippet: - name: Create a VIP bigip_virtual_server: provider: "{{ provider }}" description: avip destination: 10.0.0.66 name: vip-1 irules: - responder pool: examplepool port: '443' snat: Automap profiles: - http - f5cove <change this to the new SSL Profile> delegate_to: localhost The resulting output from CryptoNice after running the playbook again to switch the SSL profile addresses all of the HIGH recommendations. TASK [debug] ********************************************************************************************************************************************************************** ok: [localhost] => { "output.stdout_lines": [ "Pre-scan checks", "-------------------------------------", "Scanning f5cove.me on port 443...", "Analyzing DNS data for f5cove.me", "Fetching additional records for f5cove.me", "f5cove.me resolves to 34.217.132.104", "34.217.132.104:443: OPEN", "TLS is available: True", "Connecting to port 443 using HTTPS", "Queueing TLS scans (this might take a little while...)", "Looking for HTTP/2", "", "", "RESULTS", "-------------------------------------", "Hostname:\t\t\t f5cove.me", "", "Selected Cipher Suite:\t\t ECDHE-RSA-AES256-GCM-SHA384", "Selected TLS Version:\t\t TLS_1_2", "", "Supported protocols:", "TLS 1.2:\t\t\t Yes", "", "TLS fingerprint:\t\t 2ad2ad0002ad2ad0002ad2ad2ad2adcb09dd549309271837f87ac5dad15fa7", "", "", "HTTP/2 supported:\t\t False", "", "", "CERTIFICATE", "Common Name:\t\t\t f5cove.me", "Issuer Name:\t\t\t R3", "Public Key Algorithm:\t\t RSA", "Public Key Size:\t\t 4096", "Signature Algorithm:\t\t sha256", "", "Certificate is trusted:\t\t True (No errors)", "Hostname Validation:\t\t OK - Certificate matches server hostname", "Extended Validation:\t\t False", "Certificate is in date:\t\t True", "Days until expiry:\t\t 88", "Valid From:\t\t\t 2021-04-13 00:55:09", "Valid Until:\t\t\t 2021-07-12 00:55:09", "", "OCSP Response:\t\t\t Successful", "Must Staple Extension:\t\t False", "", "Subject Alternative Names:", "\t f5cove.me", "", "Vulnerability Tests:", "No vulnerability tests were run", "", "HTTP to HTTPS redirect:\t\t False", "None", "", "RECOMMENDATIONS", "-------------------------------------", "Low - CAA Consider creating DNS CAA records to prevent accidental or malicious certificate issuance.", "", "Scans complete", "-------------------------------------", "Total run time: 0:00:05.638186" ] } Now you can see in the CryptoNice output that There are no trust issues with the certificate/certificate bundle. I have upgraded from 2048 bits to 4096 bit key length. I have disabled TLS1.0 and TLS1.1. The connection is handshaking with a more secure cryptographic algorithm. I no longer have any HIGH recommendations for improvement to the quality of TLS connection. Conclusion It is always best practice to perform a sanity check on the services that you create in your automation pipelines. This article describes using CryptoNice as part of a simple Ansible playbook to run an SSL/TLS sanity check on the application in order to improve the security of your application-delivery automation. Ultimately you should not just be checking the SSL/TLS; another good idea would be to introduce application-vulnerability scanners too as part of the automation pipeline.1.3KViews2likes1CommentManaging ZoneRunner Resource Records with Bigsuds
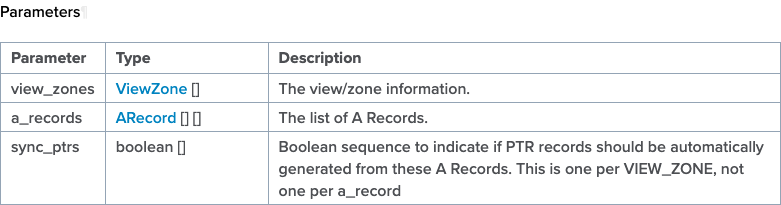
Over the last several years, there have been questions internal and external on how to manage ZoneRunner (the GUI tool in F5 DNS that allows you to manage DNS zones and records) resources via the REST interface. But that's a no can do with the iControl REST--it doesn't have that functionality. It was brought to my attention by one of our solutions engineers that a customer is using some methods in the SOAP interface that allows you to do just that...which was news to me! The things you learn... In this article, I'll highlight a few of the methods available to you and work on a sample domain in the python module bigsuds that utilizes the suds SOAP library for communication duties with the BIG-IP iControl SOAP interface. Test Domain & Procedure For demonstration purposes, I'll create a domain in the external view, dctest1.local, with the following attributes that mirrors nearly identically one I created in the GUI: Type: master Zone Name: dctest1.local. Zone File Name: db.external.dctest1.local. Options: allow-update from localhost TTL: 500 SOA: ns1.dctest1.local. Email: hostmaster.ns1.dctest1.local. Serial: 2021092201 Refresh: 10800 Retry: 3600 Expire: 604800 Negative TTL: 60 I'll also add a couple type A records to that domain: name: mail.dctest1.local., address: 10.0.2.25, TTL: 86400 name: www.dctest1.local., address: 10.0.2.80, TTL: 3600 After adding the records, I'll update one of them, changing the IP and the TTL: name: mail.dctest1.local., address: 10.0.2.110, ttl: 900 Then I'll delete the other one: name: www.dctest1.local., address: 10.0.2.80, TTL: 3600 And finally, I'll delete the zone: name: dctest1.local. ZoneRunner Methods All the methods can be found on Clouddocs in the ZoneRunner, Zone, and ResourceRecord method pages. The specific methods we'll use in our highlight real are: Management.ResourceRecord.add_a Management.ResourceRecord.delete_a Management.ResourceRecord.get_rrs Management.ResourceRecord.update_a Management.Zone.add_zone_text Management.Zone.get_zone_v2 Management.Zone.zone_exist With each method, there is a data structure that the interface expects. Each link above provides the details, but let's look at an example with the add_a method. The method requires three parameters, view_zones, a_records, and sync_ptrs, which the image of the table shows below. The boolean is just a True/False value in a list. The reason the list ( [] ) is there for all the attributes is because you can send a single request to update more than one zone, and addmore than one record within each zone if desired. The data structure for view_zones and a_records is in the following two images. Now that we have an idea of what the methods require, let's take a look at some code! Methods In Action First, I import bigsuds and initialize the BIG-IP. The arguments are ordered in bigsuds for host, username, and password. If the default “admin/admin” is used, they are assumed, as is shown here. import bigsuds b = bigsuds.BIGIP(hostname='ltm3.test.local') Next, I need to format the ViewZone data in a native python dictionary, and then I check for the existence of that zone. zone_view = {'view_name': 'external', 'zone_name': 'dctest1.local.' } b.Management.Zone.zone_exist([zone_view]) # [0] Note that the return value, which should be a list of booleans, is a list with a 0. I’m guessing that’s either suds or the bigsuds implementation doing that, but it’s important to note if you’re checking for a boolean False. It’s also necessary to set the booleans as 0 or 1 as well when sending requests to BIG-IP with bigsuds. Now I will create the zone since it does not yet exist. From the add_zone_text method description on Clouddocs, note that I need to supply, in separate parameters, the zone info, the appropriate zone records, and the boolean to sync reverse records or not. zone_add_info = {'view_name': 'external', 'zone_name': 'dctest1.local.', 'zone_type': 'MASTER', 'zone_file': 'db.external.dctest1.local.', 'option_seq': ['allow-update { localhost;};']} zone_add_records = 'dctest1.local. 500 IN SOA ns1.dctest1.local. hostmaster.ns1.dctest1.local. 2021092201 10800 3600 604800 60;\n' \ 'dctest1.local. 3600 IN NS ns1.dctest1.local.;\n' \ 'ns1.dctest1.local. 3600 IN A 10.0.2.1;' b.Management.Zone.add_zone_text([zone_add_info], [[zone_add_records]], [0]) b.Management.Zone.zone_exist([zone_view]) # [1] Note that the strings here require a detailed understanding of DNS record formatting, the individual fields are not parameters that can be set like in the ZoneRunner GUI. But, I am confident there is an abundance of modules that manage DNS formatting in the python ecosystem that could simplify the data structuring. After creating the zone, another check to see if the zone exists results in a true condition. Huzzah! Now I’ll check the zone info and the existing records for that zone. zone = b.Management.Zone.get_zone_v2([zone_view]) for k, v in zone[0].items(): print(f'{k}: {v}') # view_name: external # zone_name: dctest1.local. # zone_type: MASTER # zone_file: "db.external.dctest1.local." # option_seq: ['allow-update { localhost;};'] rrs = b.Management.ResourceRecord.get_rrs([zone_view]) for rr in rrs[0]: print(rr) # dctest1.local. 500 IN SOA ns1.dctest1.local. hostmaster.ns1.dctest1.local. 2021092201 10800 3600 604800 60 # dctest1.local. 3600 IN NS ns1.dctest1.local. # ns1.dctest1.local. 3600 IN A 10.0.2.1 Everything checks outs! Next I’ll create the A records for the mail and www services. I’m going to add a filter to only check for the mail/www services for printing to cut down on the lines, but know that they’re still there going forward. a1 = {'domain_name': 'mail.dctest1.local.', 'ip_address': '10.0.2.25', 'ttl': 86400} a2 = {'domain_name': 'www.dctest1.local.', 'ip_address': '10.0.2.80', 'ttl': 3600} b.Management.ResourceRecord.add_a(view_zones=[zone_view], a_records=[[a1, a2]], sync_ptrs=[0]) rrs = b.Management.ResourceRecord.get_rrs([zone_view]) for rr in rrs[0]: if any(item in rr for item in ['mail', 'www']): print(rr) # mail.dctest1.local. 86400 IN A 10.0.2.25 # www.dctest1.local. 3600 IN A 10.0.2.80 Here you can see that I’m adding two records to the zone specified and not creating the reverse records (not included for brevity, but in prod would be likely). Now I’ll update the mail address and TTL. b.Management.ResourceRecord.update_a([zone_view], [[a1]], [[a1_update]], [0]) rrs = b.Management.ResourceRecord.get_rrs([zone_view]) for rr in rrs[0]: if any(item in rr for item in ['mail', 'www']): print(rr) # mail.dctest1.local. 900 IN A 10.0.2.110 # www.dctest1.local. 3600 IN A 10.0.2.80 You can see that the address and TTL updated as expected. Note that with the update_/N/ methods, you need to provide the old and new, not just the new. Let’s get destruction and delete the www record! b.Management.ResourceRecord.delete_a([zone_view], [[a2]], [0]) rrs = b.Management.ResourceRecord.get_rrs([zone_view]) for rr in rrs[0]: if any(item in rr for item in ['mail', 'www']): print(rr) # mail.dctest1.local. 900 IN A 10.0.2.110 And your web service is now unreachable via DNS. Congratulations! But there’s more damage we can do: it’s time to delete the whole zone. b.Management.Zone.delete_zone([zone_view]) b.Management.Zone.zone_exist([zone_view]) # [0] And that’s a wrap! As I said, it’s been years since I have spent time with the iControl SOAP interface. It’s nice to know that even though most of what we do is done through REST, imperatively or declaratively, that some missing functionality in that interface is still alive and kicking via SOAP. H/T to Scott Huddy for the nudge to investigate this. Questions? Drop me a comment below. Happy coding! A gist of these samples is available on GitHub.957Views2likes1CommentThese Are Not The Scrapes You're Looking For - Session Anomalies
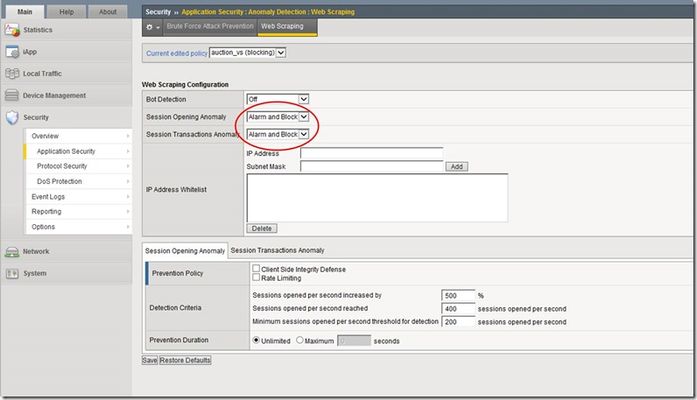
In my first article in this series, I discussed web scraping -- what it is, why people do it, and why it could be harmful. My second article outlined the details of bot detection and how the ASM blocks against these pesky little creatures. This last article in the series of web scraping will focus on the final part of the ASM defense against web scraping: session opening anomalies and session transaction anomalies. These two detection modes are new in v11.3, so if you're using v11.2 or earlier, then you should upgrade and take advantage of these great new features! ASM Configuration In case you missed it in the bot detection article, here's a quick screenshot that shows the location and settings of the Session Opening and Session Transactions Anomaly in the ASM. You'll find all the fun when you navigate to Security > Application Security > Anomaly Detection > Web Scraping. There are three different settings in the ASM for Session Anomaly: Off, Alarm, and Alarm and Block. (Note: these settings are configured independently...they don't have to be set at the same value) Obviously, if Session Anomaly is set to "Off" then the ASM does not check for anomalies at all. The "Alarm" setting will detect anomalies and record attack data, but it will allow the client to continue accessing the website. The "Alarm and Block" setting will detect anomalies, record the attack data, and block the suspicious requests. Session Opening Anomaly The first detection and prevention mode we'll discuss is Session Opening Anomaly. But before we get too deep into this, let's review what a session is. From a simple perspective, a session begins when a client visits a website, and it ends when the client leaves the site (or the client exceeds the session timeout value). Most clients will visit a website, surf around some links on the site, find the information they need, and then leave. When clients don't follow a typical browsing pattern, it makes you wonder what they are up to and if they are one of the bad guys trying to scrape your site. That's where Session Opening Anomaly defense comes in! Session Opening Anomaly defense checks for lots of abnormal activities like clients that don't accept cookies or process JavaScript, clients that don't scrape by surfing internal links in the application, and clients that create a one-time session for each resource they consume. These one-time sessions lead scrapers to open a large number of new sessions in order to complete their job quickly. What's Considered A New Session? Since we are discussing session anomalies, I figured we should spend a few sentences on describing how the ASM differentiates between a new or ongoing session for each client request. Each new client is assigned a "TS cookie" and this cookie is used by the ASM to identify future requests from the client with a known, ongoing session. If the ASM receives a client request and the request does not contain a TS cookie, then the ASM knows the request is for a new session. This will prove very important when calculating the values needed to determine whether or not a client is scraping your site. Detection There are two different methods used by the ASM to detect these anomalies. The first method compares a calculated value to a predetermined ceiling value for newly opened sessions. The second method considers the rate of increase of newly opened sessions. We'll dig into all that in just a minute. But first, let's look at the criteria used for detecting these anomalies. As you can see from the screenshot above, there are three detection criteria the ASM uses...they are: Sessions opened per second increased by: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second increases by a given percentage. The default setting is 500 percent. Sessions opened per second reached: This specifies that the ASM considers client traffic to be an attack if the number of sessions opened per second is greater than or equal to this number. The default value is 400 sessions opened per second. Minimum sessions opened per second threshold for detection: This specifies that the ASM considers traffic to be an attack if the number of sessions opened per second is greater than or equal to the number specified. In addition, at least one of the "Sessions opened per second increased by" or "Sessions opened per second reached" numbers must also be reached. If the number of sessions opened per second is lower than the specified number, the ASM does not consider this traffic to be an attack even if one of the "Sessions opened per second increased by" or "Sessions opened per second" reached numbers was reached. The default value for this setting is 200 sessions opened per second. In addition, the ASM maintains two variables for each client IP address: a one-minute running average of new session opening rate, and a one-hour running average of new session opening rate. Both of these variables are recalculated every second. Now that we have all the basic building blocks. let's look at how the ASM determines if a client is scraping your site. First Method: Predefined Ceiling Value This method uses the user-defined "minimum sessions opened per second threshold for detection" value and compares it to the one-minute running average. If the one-minute average is less than this number, then nothing else happens because the minimum threshold has not been met. But, if the one-minute average is higher than this number, the ASM goes on to compare the one-minute average to the user-defined "sessions opened per second reached" value. If the one-minute average is less than this value, nothing happens. But, if the one-minute average is higher than this value, the ASM will declare the client a web scraper. The following flowchart provides a pictorial representation of this process. Second Method: Rate of Increase The second detection method uses several variables to compare the rate of increase of newly opened sessions against user-defined variables. Like the first method, this method first checks to make sure the minimum sessions opened per second threshold is met before doing anything else. If the minimum threshold has been met, the ASM will perform a few more calculations to determine if the client is a web scraper or not. The "sessions opened per second increased by" value (percentage) is multiplied by the one-hour running average and this value is compared to the one-minute running average. If the one-minute average is greater, then the ASM declares the client a web scraper. If the one-minute average is lower, then nothing happens. The following matrix shows a few examples of this detection method. Keep in mind that the one-minute and one-hour averages are recalculated every second, so these values will be very dynamic. Prevention The ASM provides several policies to prevent session opening anomalies. It begins with the first method that you enable in this list. If the system finds this method not effective enough to stop the attack, it uses the next method that you enable in this list. The following screenshots show the different options available for prevention. The "Drop IP Addresses with bad reputation" is tied to Rate Limiting, so it will not appear as an option unless you enable Rate Limiting. Note that IP Address Intelligence must be licensed and enabled. This feature is licensed separately from the other ASM web scraping options. Here's a quick breakdown of what each of these prevention policies do for you: Client Side Integrity Defense: The system determines whether the client is a legal browser or an illegal script by sending a JavaScript challenge to each new session request from the detected IP address, and waiting for a response. The JavaScript challenge will typically involve some sort of computational challenge. Legal browsers will respond with a TS cookie while illegal scripts will not. The default for this feature is disabled. Rate Limiting: The goal of Rate Limiting is to keep the volume of new sessions at a "non-attack" level. The system will drop sessions from suspicious IP addresses after the system determines that the client is an illegal script. The default for this feature is also disabled. Drop IP Addresses with bad reputation: The system drops requests from IP addresses that have a bad reputation according to the system’s IP Address Intelligence database (shown above). The ASM will drop all request from any "bad" IP addresses even if they respond with a TS cookie. IP addresses that do not have a bad reputation also undergo rate limiting. The default for this option is disabled. Keep in mind that this option is available only after Rate Limiting is enabled. In addition, this option is only enforced if at least one of the IP Address Intelligence Categories is set to Alarm mode. Prevention Duration Now that we have detected session opening anomalies and mitigated them using our prevention options, we must figure out how long to apply the prevention measures. This is where the Prevention Duration comes in. This setting specifies the length of time that the system will prevent an attack. The system prevents attacks by rejecting requests from the attacking IP address. There are two settings for Prevention Duration: Unlimited: This specifies that after the system detects and stops an attack, it performs attack prevention until it detects the end of the attack. This is the default setting. Maximum <number of> seconds: This specifies that after the system detects and stops an attack, it performs attack prevention for the amount of time indicated unless the system detects the end of the attack earlier. So, to finish up our Session Opening Anomaly part of this article, I wanted to share a quick scenario. I was recently reading several articles from some of the web scrapers around the block, and I found one guy's solution to work around web scraping defense. Here's what he said: "Since the service conducted rate-limiting based on IP address, my solution was to put the code that hit their service into some client-side JavaScript, and then send the results back to my server from each of the clients. This way, the requests would appear to come from thousands of different places, since each client would presumably have their own unique IP address, and none of them would individually be going over the rate limit." This guy is really smart! And, this would work great against a web scraping defense that only offered a Rate Limiting feature. Here's the pop quiz question: If a user were to deploy this same tactic against the ASM, what would you do to catch this guy? I'm thinking you would need to set your minimum threshold at an appropriate level (this will ensure the ASM kicks into gear when all these sessions are opened) and then the "sessions opened per second" or the "sessions opened per second increased by" should take care of the rest for you. As always, it's important to learn what each setting does and then test it on your own environment for a period of time to ensure you have everything tuned correctly. And, don't forget to revisit your settings from time to time...you will probably need to change them as your network environment changes. Session Transactions Anomaly The second detection and prevention mode is Session Transactions Anomaly. This mode specifies how the ASM reacts when it detects a large number of transactions per session as well as a large increase of session transactions. Keep in mind that web scrapers are designed to extract content from your website as quickly and efficiently as possible. So, web scrapers normally perform many more transactions than a typical application client. Even if a web scraper found a way around all the other defenses we've discussed, the Session Transaction Anomaly defense should be able to catch it based on the sheer number of transactions it performs during a given session. The ASM detects this activity by counting the number of transactions per session and comparing that number to a total average of transactions from all sessions. The following screenshot shows the detection and prevention criteria for Session Transactions Anomaly. Detection How does the ASM detect all this bad behavior? Well, since it's trying to find clients that surf your site much more than other clients, it tracks the number of transactions per client session (note: the ASM will drop a session from the table if no transactions are performed for 15 minutes). It also tracks the average number of transactions for all current sessions (note: the ASM calculates the average transaction value every minute). It can use these two figures to compare a specific client session to a reasonable baseline and figure out if the client is performing too many transactions. The ASM can automatically figure out the number of transactions per client, but it needs some user-defined thresholds to conduct the appropriate comparisons. These thresholds are as follows: Session transactions increased by: This specifies that the system considers traffic to be an attack if the number of transactions per session increased by the percentage listed. The default setting is 500 percent. Session transactions reached: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number. The default value is 400 transactions. Minimum session transactions threshold for detection: This specifies that the system considers traffic to be an attack if the number of transactions per session is equal to or greater than this number, and at least one of the "Sessions transactions increased by" or "Session transactions reached" numbers was reached. If the number of transactions per session is lower than this number, the system does not consider this traffic to be an attack even if one of the "Session transactions increased by" or "Session transaction reached" numbers was reached. The default value is 200 transactions. The following table shows an example of how the ASM calculates transaction values (averages and individual sessions). We would expect that a given client session would perform about the same number of transactions as the overall average number of transactions per session. But, if one of the sessions is performing a significantly higher number of transactions than the average, then we start to get suspicious. You can see that session 1 and session 3 have transaction values higher than the average, but that only tells part of the story. We need to consider a few more things before we decide if this client is a web scraper or not. By the way, if the ASM knows that a given session is malicious, it does not use that session's transaction numbers when it calculates the average. Now, let's roll in the threshold values that we discussed above. If the ASM is going to declare a client as a web scraper using the session transaction anomaly defense, the session transactions must first reach the minimum threshold. Using our default minimum threshold value of 200, the only session that exceeded the minimum threshold is session 3 (250 > 200). All other sessions look good so far...keep in mind that these numbers will change as the client performs additional transactions during the session, so more sessions may be considered as their transaction numbers increase. Since we have our eye on session 3 at this point, it's time to look at our two methods of detecting an attack. The first detection method is a simple comparison of the total session transaction value to our user-defined "session transactions reached" threshold. If the total session transactions is larger than the threshold, the ASM will declare the client a web scraper. Our example would look like this: Is session 3 transaction value > threshold value (250 > 400)? No, so the ASM does not declare this client as a web scraper. The second detection method uses the "transactions increased by" value along with the average transaction value for all sessions. The ASM multiplies the average transaction value with the "transactions increased by" percentage to calculate the value needed for comparison. Our example would look like this: 90 * 500% = 450 transactions Is session 3 transaction value > result (250 > 450)? No, so the ASM does not declare this client as a web scraper. By the way, only one of these detection methods needs to be met for the ASM to declare the client as a web scraper. You should be able to see how the user-defined thresholds are used in these calculations and comparisons. So, it's important to raise or lower these values as you need for your environment. Prevention Duration In order to save you a bunch of time reading about prevention duration, I'll just say that the Session Transactions Anomaly prevention duration works the same as the Session Opening Anomaly prevention duration (Unlimited vs Maximum <number of> seconds). See, that was easy! Conclusion Thanks for spending some time reading about session anomalies and web scraping defense. The ASM does a great job of detecting and preventing web scrapers from taking your valuable information. One more thing...for an informative anomaly discussion on the DevCentral Security Forum, check out this conversation. If you have any questions about web scraping or ASM configurations, let me know...you can fill out the comment section below or you can contact the DevCentral team at https://devcentral.f5.com/s/community/contact-us.918Views2likes2CommentsMicrosoft Powershell with iControl
This component is not supported and we recommend reviewing Joel Newton's Powershell Module for iControlREST Code submission first. From the desk of Joe Pruitt (July 29, 2013) When we shipped DC4, we started looking at Windows PowerShell and how we could build some integration points with our products. The first pass was a set of PowerShell script files that we introduced in the PowerShell Labs section of DevCentral. No soon after we posted them, the requests started pouring in on when we would provide some native PowerShell CmdLets in addition to the function scripts. Well, I spent a little bit of time working some out and whipped out a good first rough draft. I've been holding on to these for a while now but figured they would do better out in the wild then trapped in a folder on my laptop. So, last night I posted an installer for the first release of the iControl CmdLets for PowerShell. Here's a step by step on getting up and running with the new bits. Download and install PowerShell from Microsoft Go to the PowerShell Labs page on DevCentral and select the "Download Now" link. This will download the Cmdlet installer. Run the iControlSnapInSetup.msi installer. This will install the SnapIn into the c:\program files\F5 Networks\iControlSnapIn directory. Start PowerShell from the Windows Start menu. Cd to c:\program files\F5 Networks\iControlSnapIn directory Dot Source the setup script (only once after the install) PS > . .\setupSnapIn.ps1) Load the SnapIn into the Runtime PS > Add-PSSnapIn iControlSnapIn Initialize the iControl connection with the Initialize-F5.iControl CmdLet PS > Initialize-F5.iControl -Hostname bigip_address -Credentials (Get-Credential) Run the Get-F5.iControlCommands CmdLet to list out all the available Cmdlets. PS > Get-F5.iControlCommands Try out some of the CmdLets PS > Get-F5.LTMPool Notes From the Legacy Download: Comment made 08-Jun-2016 by Patrik Jonsson Needed to add .Net 2.0 in add/remove windows features. Then it worked in Windows 10. The installation script should be changed to throw and error if the installutil file does not exist instead of quitting silently. Ken B Comment made 22-Jun-2016 by Ken B The problem I had getting this working was that I had to right-click the downloaded .zip file, properties, and click the "unblock" button on the General tab. Then I had to copy the files from the .zip to a folder under c:\Program Files\f5\icontrol. Then I ran PS As Administrator, then ran .\setupSnapIn.ps1, then I was *finally* able to run the "Add-PSSnapIn iControlSnapIn" command to get things going. Comment made 17-Jan-2017 by Joel Newton You can update the InstallPSSnapin.ps1 script to reference the .NET v4 install utility. Just replace the reference in setupSnapin.ps1 from $env:windir\Microsoft.Net\Framework${platform}\v2.0.50727\installUtil.exe to $env:windir\Microsoft.Net\Framework${platform}\v4.0.30319\installUtil.exe I don't believe there are any plans to replace the snapin with a module. My recommendation would be to use the REST API if possible. Comment made 05-Jul-2017 by Patrik Jonsson You can also use Joel's module: Powershell Module for the F5 LTM REST API Downloads: v11.00.00 Released August 10, 2013 v11.04.01 Released December 02, 2013 v11.05.00 Released February 18, 2014 v11.06.00 Released August 28, 2014 v12.01.00 Released May 09, 2016 v13.00.00 Released March 21, 2017 v13.01.00 Released November 11, 20175.5KViews2likes6CommentsDevCentral Relaunch Part Deux: Wiki Wiki...What?
Good people of the DevCentral community, greetings! On the heels of Chase's relaunch post last week, now that we are live on the new platform, what you have come to know and love as the DevCentral Wiki no longer exists in its current format. Wait…What? Yes, you read that correctly. The wiki is no more. When we were scoping the platform transition effort, we wanted to look at not just what the DevCentral audience needs, but what makes the most sense from a documentation perspective. Given that most of the API documentation in the wiki is more along the lines of product reference than insight or tutorial, it made sense to transition that type of content away from the pages of DevCentral where it can (eventually) be more accurately and continually updated by the tech docs team rather than by the DevCentral team. For now, the new home for the API documentation is on Clouddocs at https://clouddocs.f5.com/api/. The astute observers among you who engage often in the wiki have likely noticed that some of the API namespaces have alreadytransitioned away toCloudDocs(here’s looking at you, iApps LX and BIG-IQ!) The following wiki namespaces have joined iApps LX and BIG-IQ on CloudDocs: iApps iHealth iControl REST iControl SOAP iRules iRules LX tmsh The remaining namespaces were decommissioned when the new site launched. However, we have identified content from those namespaces that get consistent traffic. Those pages will be converted and released as articles at some point in the near future. If something specific is of interest, please drop a comment below and I’ll prioritize it. Embedded Links and Bookmarks and Search Queries, Oh My! Relaunch is the beginning of a new journey, not a destination. We just landed in Kansas and are standing at the inception of the yellow brick road. As such, there are some things outside of our immediate control that might make things a challenge at first. Namely, finding your favorite API documentation by way of embedded links, bookmarks, and search. We have some limitations we’re working through, so outside of the individual API landing pages, your embedded links and bookmarks are unlikely to land properly. Also, search will take some time to rectify itself, but If you navigate directly to https://clouddocs.f5.com/api/, you should be able to quickly click through to your content. UPDATE - one of our former MVPs Michael Jenkins wrote a tampermonkey script to ease the pain with wiki links. Load this up in your tampermonkey browser extension and it'll rewrite the URL on the click event and send you over to clouddocs. The Sky is Not Falling I can hear the collective groan from all you power users. I get it. Your experience on DevCentral matters to me. And because I am as much a client as I am an owner of the DevCentral community, it is imperative to preserve what we have and make it available in the event that something currently in the wiki is critical to you but not necessarily to the community at large. If this is you, the wiki as it exists today is available as a download that you can keep on your system for reference. It will not be updated going forward, but it contains most of what was in the wiki at cutover earlier today. To Infinity, And Beyond! The pause button on our platform innovation has been activated for quite some time here at DevCentral. We’re excited to move forward, and we hope you enjoy the new platform and assist us in navigating the bumps common with all launch activities.1.9KViews2likes25CommentsGetting Started with iControl: Interface Taxonomy & Language Libraries
In part two of this article in the Getting Started with iControl series, we will cover the taxonomy for both the SOAP and REST iControl interfaces, that were discussed in theprevious article on iControl History, as well as introduce the language libraries we unofficially support on DevCentral. Note: This article published by Jason Rahm but co-authored with Joe Pruitt. Taxonomy The two interfaces were designed in different ways and with different goals. iControl SOAP was developed as a functional API behaving very similar to a Java or C++ class where you have interfaces and methods included within those interfaces. Interfaces roughly related to product features and for organization, those interfaces were then grouped into larger namespaces, or product modules. To get a little more specific, iControl SOAP implements a RPC (Remote Procedure Call) type model. To make use of the APIs, one just instantiated an instance of the interface and then used functional (create(), get_list(), ...) and accessor (get_*(), set_*(), ...) methods with it. iControl REST on the other hand, is based on a document model where documents are passed back and forth containing all the relevant information of the given object(s) in question. This interface makes use of the HTTP protocol's VERBs (GET, POST, PUT, PATCH, DELETE) for action and URIs (ie. /mgmt/tm/ltm/pool) for the objects you are manipulating. Instead using methods to perform actions, you use the associated HTTP VERB to trigger the action, the URI to denote the object, and the POST data or Query Parameters to indicated the objects details. iControl REST is currently modeled off of the tmsh shell which uses similar modules and interfaces from SOAP (with different abbreviations) in it's URI path. Module Interface Method iControl SOAP LocalLB Pool get_list() create() add_member() Networking SelfIP get_netmask() set_vlan() Module Sub-Module Component iControl REST ltm pool <pool name> net self <self name> Now for some simple examples using the SOAP and REST interfaces using python libraries. Don't worry if python's not your thing,we’ll cover some perl, powershell, java, and Node.jsas well in the following articles in this series. ### ignore SSL cert warnings >>> import ssl >>> ssl._create_default_https_context = ssl._create_unverified_context ### SOAP >>> import bigsuds >>> b_soap = bigsuds.BIGIP('172.16.44.15', 'admin', 'admin') >>> b_soap.LocalLB.Pool.get_list() ['/Common/myNewPool2'] ### REST >>> from f5.bigip import BigIP as f5 >>> b_rest = f5('172.16.44.15', 'admin', 'admin') >>> b_rest.ltm.pools.get_collection()[0].name u'myNewPool2' Note there really isn't much difference between the two iControl interfaces when it comes to the client code. This is the beauty of libraries, they mask the hard work! We'll dig into the code more in the next article. so don't worry too much about the code above just yet. Interfaces & Objects In the above section, we briefly outlined the high level taxonomy between module and interface. There are literally thousands of defined methods for the SOAP interface, all defined and published in theiControl wikion DevCentral. For the REST interface, you will want toreference the iControl REST wikias well, but you will really want to become intimate with thetmsh reference guide, as a solid understanding of how tmsh works will make a more favorable going. Language Libraries Raw SOAP payload is out of the question unless you enjoy pain, so a library is a given if using the SOAP interface. But even with REST, as easy as it is to interact with interface directly, the fact is if you aren’t using a library, you still have to create all your JSON documents and investigate and prepare all the payload requirements when manipulating or creating objects. When selecting SOAP or REST, the reality is if you’re going to build applications that utilize iControl, you’re definitely going to want to use a library. What is a Library? Depending on the language or languages you might use, a library can be called many things, such as a package, a wrapper, a module, a class, etc. But at it’s most basic meaning, a library is simply a collection of tools and/or functionality that abstracts some of the work required in understanding the underlying protocols and assists in getting things done faster. For example, if you are formatting an office document and changing the font size, color, family, and bolding it on select words throughout the doc, it could be painful to do this if you have to do it more than a few times. You could record a macro of these steps, and then for each subsequent task, replay that work via the macro so you only have to do it once. In a roundabout way, this is what libraries do for you as well. The common repetitive work is done for you, so you can focus on the business logic in your applications. What Libraries Are Available? There are several libraries available, some languages having more than one to support both iControl SOAP and iControl REST, and at least one (like python) that has several libraries for just the SOAP interface. To each his own, we like to expand the horizons around here and equip everyone for whatever language suits best for your needs and abilities. We could list out all the libraries here, but they are already documented on theprogrammability page in the wiki, at least the ones we are directly responsible for. Joe does a lot with PowerShell and Perl, and I with python, and we do have quite a few community members well versed in the .Net languages and python too, though there is some support for java and ruby as well. On Github I've seen aniControl wrapper for the Go language, and I seem to recall some love for PHP a while back. Now that we'rethrough the historyand some foundational information on the SOAP and REST interfaces, we can move on to actually building something! In the next article in this series, we'll jump into some code samples to highlight the pros and cons of working with SOAP and REST, as well as show you the differences among a few languages for each interface in accomplishing the same tasks.2.1KViews1like1CommentF5 Automation Toolchain: Upload the Components with BIGREST!
If you've ever flown in earshot of a pilot or been handed a to-do list from your mommy or significant other, then you are quite familiar with eleventy billion step processes. I may be rounding up there a little. But that is similar to using an imperative approach to automation. The F5 Automation Toolchain, however, is a declarative approach to automation. You throw a big blob (technical term) of JSON data at the BIG-IP in a single declaration and BIG-IP does all the work for you. We will not use the components of the toolchain in this article, but we will get them all installed for use. Prerequisites In order to install the components of the toolchain, you need to download them first. You can find them in the releases of each respective repository on GitHub. I chose the latest release, but there are LTS versions as well if that’s important to your organization. f5-declarative-onboarding f5-appsvcs-extension f5-telemetry-streaming Process The upload and installation procedures are defined in each respective components clouddocs documentation. f5-declarative-onboarding f5-appsvcs-extension f5-telemetry-streaming The process is made super simple for you though: upload, install, verify. Upload To upload each component, you need to send the data to the /mgmt/shared/file-transfer/uploads endpoint in iControl REST. This puts the files in /var/config/rest/downloads on the BIG-IP host system. With the python BIGREST library, I’m using the following function to achieve this. def upload_file(obj, file_name): try: obj.upload(f"/mgmt/shared/file-transfer/uploads/", file_name) except Exception as e: print(f"Failed to upload the component due to {type(e).__name__}:\n") print(f"{e}") sys.exit() Install Installing each component requires a call to the /mgmt/shared/iapp/package-management-tasks endpoint with a JSON blob stating the INSTALL operation and the path to the component we uploaded. This is the function for this: def install_package(obj, file_name): try: data = {"operation": "INSTALL", "packageFilePath": f"/var/config/rest/downloads/{Path(file_name).name}"} obj.command("/mgmt/shared/iapp/package-management-tasks", data) except Exception as e: print(f"Failed to install the component due to {type(e).__name__}:\n") print(f"{e}") sys.exit() Verify Verification takes a little more customization as each is different and one of the component’s data format for the version is different as well. But the basic endpoint that needs to be queried to validate that the package is installed and available for service is /mgmt/shared/$component/info, where $component is updated accordingly like so: /mgmt/shared/declarative-onboarding/info /mgmt/shared/appsvcs/info /mgmt/shared/telemetry/info The function for verification: def verify_package(obj, file_name): component = Path(file_name).name if "f5-declarative-onboarding" in component: try: result = obj.load("/mgmt/shared/declarative-onboarding/info") if result.properties[0].get('version') in component: return True else: return False except RESTAPIError: return False elif "f5-appsvcs" in component: try: result = obj.load("/mgmt/shared/appsvcs/info") if result.properties.get('version') in component: return True else: return False except RESTAPIError: return False elif "f5-telemetry" in component: try: result = obj.load("/mgmt/shared/telemetry/info") if result.properties.get('version') in component: return True else: return False except RESTAPIError: return False else: return False Success! Putting it all together, when I run the script, I get the following feedback (venv) me@mine scripts % python toolchain_prep.py 10.0.2.26 admin admin Instantiating BIG-IP (host 10.0.2.26) Uploading packages Uploading f5-declarative-onboarding-1.20.0-2.noarch.rpm Uploading f5-appsvcs-3.27.0-3.noarch.rpm Uploading f5-telemetry-1.19.0-3.noarch.rpm Installing packages Installing f5-declarative-onboarding-1.20.0-2.noarch.rpm Installing f5-appsvcs-3.27.0-3.noarch.rpm Installing f5-telemetry-1.19.0-3.noarch.rpm Quick break to register packages... Verifying packages f5-declarative-onboarding-1.20.0-2.noarch.rpm installed and verified f5-appsvcs-3.27.0-3.noarch.rpm installed and verified f5-telemetry-1.19.0-3.noarch.rpm installed and verified ---complete--- The full source for this script is in the codeshare. Note that you'll need to be at least at version 1.3.3 of BIGREST for this to work. Conclusion You are now free to move about the cabin. And start declaring your BIG-IP configurations like a boss. And bonus news: the AS3 Configuration Converter, or ACC, was recently released and is available on GitHub. This takes the guess work out of converting your configuration to the proper AS3 declaration schema. Join us on DevCentral Connects this Thursday for a conversation with Ben Gordon on how to accomplish all this in VS Code.961Views1like0CommentsGetting Started with iControl: History
tl;dr - iControl provides access to BIG-IP management plane services through SOAP and REST API interfaces. The Early Days iControl started back in early 2000. F5 had 2 main products: BIG-IP and 3-DNS (later GTM, now BIG-IP DNS). BIG-IP managed the local datacenter's traffic, while 3-DNS was the DNS orchestrator for all the BIG-IP's in numerous data centers. The two products needed a way to communicate with each other to ensure they were making the right traffic management decisions respective to all of the products in the system. At the time, the development team was focused on developing the fastest running code possible and that idea found it's way into the cross product communication feature that was developed. The technology the team chose to use was the Common Object Request Broker Architecture (CORBA) as standardized by the Object Management Group (OMG). Coming hot off the heels of F5's first management product SEE-IT (which was another one of my babies), the dev team coined this internal feature as "LINK-IT" since it "linked" the two products together. With the development of our management, monitoring, and visualization product SEE-IT, we needed a way to get the data off of the BIG-IP. SEE-IT was written for Windows Server and we really didn't want to go down the route of integrating into the CORBA interface due to several factors. So, we wrote a custom XML provider on BIG-IP and 3-DNS to allow for configuration and statistic data to be retrieved and consumed by SEE-IT. It was becoming clear to me that automation and customization of our products would be beneficial to our customers who had been previously relying on our SNMP offerings. We now had 2 interfaces for managing and monitoring our devices: one purely internal (LINK-IT) and the other partially (XML provider). The XML provider was very specific to our SEE-IT products use case and we didn't see a benefit of trying to morph that so we looked back at LINK-IT to see what we could to do make that a publicly supported interface. We began work on documenting and packaging it into F5's first public SDK. About that time, a new standard was emerging for exchanging structured information. The Simple Object Access Protocol (SOAP), which allows for structured information exchange, was being developed but not fully ratified until version 1.2 in 2003. I had to choose to roll our own XML implementation or make use of this new proposed specification. There was risk as the specification was not a standard yet but I made the choice to go the SOAP route as I felt that picking a standard format would give us the best 3rd party software compatibility down the road. Our CORBA interface was built on a nice class model which I used as a basis for an SOAP/XML wrapper on top of that code. I even had a great code name for the interface: X-LINK-IT! For those who were around when I gave my "XML at F5" presentation to F5 Product Development, you may remember the snide comments going around afterwards about how XML was not a great technology and a big mistake supporting. Good thing I didn't listen to them... At this point in mid-2001, the LINK-IT SDK was ready to go and development of X-LINK-IT was well underway. Well, let's just say that Marketing didn't agree with our ingenious product naming and jumped in to VETO our internal code names for our public release. I'll give our Chief Marketer Jeff Pancottine credit for coining the term "iControl" which was explained to me as "Internet Control". This was the start of F5's whole Internet Controlled Architecture messaging by the way. So, LINK-IT and X-LINK-IT were dead and iControl CORBA and iControl SOAP were born. The Death of CORBA, All Hail SOAP The first version of the iControl SDK for CORBA was released on 5/25/2001 with the SOAP version trailing it by a few months. This was around the BIG-IP version 3 time frame. We chugged along for a few years through the BIG-IP version 4 life and then a big event occurred that was the demise for CORBA - well, it's actually 2 events. The first event was the full rewrite of the BIG-IP data plane when TMOS was introduced in BIG-IP, version 9 (we skipped from version 4 to version 9 for some reason that slips my mind). Since virtually the entire product was rewritten, the interfaces that were tied to the product features, would have to change drastically. We used this as an opportunity to look at the next evolution of iControl. Until this point, iControl SOAP was just a shim on top of CORBA and it had some performance issues so we worked at splitting them apart and having SOAP talk directly to our configuration engine. Now we had 2 interface stacks side by side. The second event was learning we only had 1 confirmed customer using the CORBA interface compared to the 100's using SOAP. Given that knowledge and now that BIG-IP and 3-DNS no longer used iControl CORBA to talk to each other, the decision was made to End of Life iControl CORBA with Version 9.0. But, iControl SOAP still used the CORBA IDL files for it's API definitions and documentation so fun trivia note: the same CORBA tools are still in place in today's iControl SOAP build tools that were there in version 3 of BIG-IP. I'm fairly sure that is the longest running component in our build system. The Birth of DevCentral I can't speak about iControl without mentioning DevCentral. We had our iControl SDK out but no where to directly support the developers using it. At that time, F5 was a "hardware" company and product support wasn't ready to support application developers. Not many know that DevCentral was created due to the popularity of iControl with our customer base and was born on a PC under my desk in 2003. I continued to help with DevCentral part time for a few years but in 2007 I decided to work full time on building our community and focusing 100% on DevCentral. It was about this time that we were pushing the idea of merging the application and infrastructure teams together - or at least getting them to talk more frequently. This was a precursor to the whole DevOps mentality so I'd like to think we were a bit ahead of the curve on that. Enter iControl REST In 2013, iControl was reaching it's teenage years and starting to show it's age a bit. While SOAP is still supported by all the major tool vendors, application development was shifting to richer browser-based apps. And with that, Representational State Transfer (REST) was gaining steam. REST defined a usage pattern for using browser based mechanisms with HTTP to access objects across the network with a JavaScript Object Notation (JSON) format for the content. To keep up with current technologies, the PD team at F5 developed the first REST/JSON interface in BIG-IP version 11.5 as Early Access and was made Generally Available in version 11.6. With the REST interface, more modern web paradigms could be supported and you could actually code to iControl directly from a browser! There were also additional interface based tools for developing and debugging built directly into the service to give service listings and schema definitions. At the time of this writing, F5 supports both of the main iControl interfaces (SOAP and REST) but are focusing all new energy on our REST platform for the future. For those who have developed SOAP integrations, have no fear as that interface is not going away. It will just likely not get all the new feature support that will be added into the REST interfaces over time. SDKs, Toolkits, and Libraries Through the years, I've developed several client libraries (.Net, PowerShell, Java) for iControl SOAP to assist with ramp-up time for initial development. There have also been numerous other language based libraries for languages like Ruby, PHP, and Python developed by the community and other development teams. Most recently, F5 has published the iControl library for Python which is available as part of our OpenStack integration. DevCentral is your place to for our API documentation where we update our wiki with API changes on each major release. And as time rolls on, we are adding REST support for new and existing products such as iWorkflow, BIG-IQ, and other products yet to be released that will include SDKs and other reference material. F5 has a strong commitment to our end users and their automation and integration projects with F5 technologies. Coming full circle, my current role is overseeing APIs and SDKs for standards, consistency, and completeness in our Programmability and Orchestration (P&O) team so keep a look out for future articles from me on our efforts on that front. And REST assured, we will continue to do all we can to help our customers move to new architectures and deployment models with programmability and automation with F5 technologies.3KViews1like1CommentMore Web Scraping - Bot Detection
In my last article, I discussed the issue of web scraping and why it could be a problem for many individuals and/or companies. In this article, we will dive into some of the technical details regarding bots and how the BIG-IP Application Security Manager (ASM) can detect them and block them from scraping your website. What Is A Bot? A bot is a software application that runs automated tasks and typically performs these tasks much faster than a human possibly could. In the context of web scraping, bots are used to extract data from websites, parse the data, and assemble it into a structured format where it can be presented in a useful form. Bots can perform many other actions as well, like submitting forms, setting up schedules, and connecting to databases. They can also do fun things like add friends to social networking sites like Twitter, Facebook, Google+, and others. A quick Internet search will show that many different bot tools are readily available for download free of charge. We won't go into the specifics of each vendor's bot application, but it's important to understand that they are out there and are very easy to use. Bot Detection So, now that we know what a bot is and what it does, how can we distinguish between malicious bot activity and harmless human activity? Well, the ASM is configured to check for some very specific activities that help it determine if the client source is a bot or a human. By the way, it's important to note that the ASM can accurately detect a human user only if clients have JavaScript enabled and support cookies. There are three different settings in the ASM for bot detection: Off, Alarm, and Alarm and Block. Obviously, if bot detection is set to "Off" then the ASM does not check for bot activity at all. The "Alarm" setting will detect bot activity and record attack data, but it will allow the client to continue accessing the website. The "Alarm and Block" setting will detect bot activity, record the attack data, and block the suspicious requests. These settings are shown in the screenshot below. Once you apply the setting for bot detection, you can then tune the ASM to begin checking for bots that are accessing your website. The bot detection utilizes four different techniques to detect and defend against bot activity. These include Rapid Surfing, Grace Interval, Unsafe Interval, and Safe Interval. Rapid Surfing detects bot activity by counting the client's page consumption speed. A page change is counted from the page load event to its unload event. The ASM configuration allows you to set a maximum number of page changes for a given time period (measured in milliseconds). If a page changes more than the maximum allowable times for the given time interval, the ASM will declare the client as a bot and perform the action that was set for bot detection (Off, Alarm, Alarm and Block). The default setting for Rapid Surfing is 5 page changes per second (or 1000 milliseconds). The Grace Interval setting specifies the maximum number of page requests the system reviews while it tries to detect whether the client is a human or a bot. As soon as the system makes the determination of human or bot it ends the Grace Interval and stops checking for bots. The default setting for the Grace Interval is 100 requests. Once the system determines that the client is valid, the system does not check the subsequent requests as specified in the Safe Interval setting. This setting allows for normal client activity to continue since the ASM has determined the client is safe (during the Grace Interval). Once the number of requests sent by the client reaches the value specified in the Safe Interval setting, the system reactivates the Grace Interval and begins the process again. The default setting for the Safe Interval is 2000 requests. This Safe Interval is nice because it lowers the processing overhead needed to constantly check every client request. If the system does not detect a valid client during the Grace Interval, the system issues and continues to issue the "Web Scraping Detected" violation until it reaches the number of requests specified in the Unsafe Interval setting. The Unsafe Interval setting specifies the number of requests that the ASM considers unsafe. Much like in the Safe Interval, after the client sends the number of requests specified in the Unsafe Interval setting, the system reactivates the Grace Interval and begins the process again. The default setting for the Unsafe Interval is 100 requests. The following figure shows the settings for Bot Detection and the values associated with each setting. Interval Timing The following picture shows a timeline of client requests and the intervals associated with each request. In the example, the first 100 client requests will fall into the Grace Interval, and during this interval the ASM will be determining whether or not the client is a bot. Let's say a bot is detected at client request 100. Then, the ASM will immediately invoke the Unsafe Interval and the next 100 requests will be issued a "Web Scraping Detected" violation. When the Unsafe Interval is complete, the ASM reverts back to the Grace Interval. If, during the Grace Interval, the system determines that the client is a human, it does not check the subsequent requests at all (during the Safe Interval). Once the Safe Interval is complete, the system moves back into the Grace Interval and the process continues. Notice that the ASM is able to detect a bot before the Grace Interval is complete (as shown in the latter part of the diagram below). As soon as the system detects a bot, it immediately moves into the Unsafe Interval...even if the Grace Interval has not reached its set threshold. Setting Thresholds As you can see from the timeline above, it's important to establish the correct thresholds for each interval setting. The longer you make the Grace Interval, the longer you give the ASM a chance to detect a bot, but keep in mind that the processing overhead can become expensive. Likewise, the Unsafe Interval setting is a great feature, but if you set it too high, your requesting clients will have to sit through a long period of violation notices before they can access your site again. Finally, the Safe Interval setting allows your users free and open access to your site. If you set this too low, you will force the system to cycle through the Grace Interval unnecessarily, but if you set it too high, a bot might have a chance to sneak past the ASM defense and scrape your site. Remember, the ASM does not check client requests at all during the Safe Interval. Also, remember the ASM does not perform web scraping detection on traffic from search engines that the system recognizes as being legitimate. If your web application has its own search engine, it's recommended that you add it to the system. Go to Security > Options > Application Security > Advanced Configuration > Search Engines and add it to the list (the ASM comes preconfigured with Ask, Bing, Google, and Yahoo already loaded). A Quick Test I loaded up a sample virtual web server (in this case it was a fictitious online auction site) and then configured the ASM to Alarm and Block bot activity on the site. Then, I fired up the iMacro plugin from Firefox to scrape the site. Using the iMacro plugin, I sent many client requests in a short amount of time. After several requests to the site, I received the response page shown below. You can see that the response page settings in the ASM are shown in the Firefox browser window when web scraping is detected. These settings can be adjusted in the ASM by navigating to Security > Application Security > Blocking > Response Pages. Well, thanks for coming back and reading about ASM bot detection. Be sure to swing by again for the final web scraping article where I will discuss session anomalies. I can't possibly think of anything that could be more fun than that!1.9KViews1like0Comments