F5 Automated Backups - The Right Way
Hi all, Often I've been scouring the devcentral fora and codeshares to find that one piece of handywork that will drastically simplify my automated backup needs on F5 devices. Based on the works of Jason Rahm in his post "Third Time's the Charm: BIG-IP Backups Simplified with iCall" on the 26th of June 2013, I went ahead and created my own iApp that pretty much provides the answers for all my backup-needs. Here's a feature list of this iApp: It allows you to choose between both UCS or SCF as backup-types. (whilst providing ample warnings about SCF not being a very good restore-option due to the incompleteness in some cases) It allows you to provide a passphrase for the UCS archives (the standard GUI also does this, so the iApp should too) It allows you to not include the private keys (same thing: standard GUI does it, so the iApp does it too) It allows you to set a Backup Schedule for every X minutes/hours/days/weeks/months or a custom selection of days in the week It allows you to set the exact time, minute of the hour, day of the week or day of the month when the backup should be performed (depending on the usefulness with regards to the schedule type) It allows you to transfer the backup files to external devices using 4 different protocols, next to providing local storage on the device itself SCP (username/private key without password) SFTP (username/private key without password) FTP (username/password) SMB (using smbclient, with username/password) Local Storage (/var/local/ucs or /var/local/scf) It stores all passwords and private keys in a secure fashion: encrypted by the master key of the unit (f5mku), rendering it safe to store the backups, including the credentials off-box It has a configurable automatic pruning function for the Local Storage option, so the disk doesn't fill up (i.e. keep last X backup files) It allows you to configure the filename using the date/time wildcards from the tcl [clock] command, as well as providing a variable to include the hostname It requires only the WebGUI to establish the configuration you desire It allows you to disable the processes for automated backup, without you having to remove the Application Service or losing any previously entered settings For the external shellscripts it automatically generates, the credentials are stored in encrypted form (using the master key) It allows you to no longer be required to make modifications on the linux command line to get your automated backups running after an RMA or restore operation It cleans up after itself, which means there are no extraneous shellscripts or status files lingering around after the scripts execute I wasn't able to upload the iApp template to this article, so I threw it on pastebin: http://pastebin.com/YbDj3eMN Enjoy! Thomas Schockaert8.4KViews0likes79CommentsWhat is iCall?
tl;dr - iCall is BIG-IP’s event-based granular automation system that enables comprehensive control over configuration and other system settings and objects. The main programmability points of entrance for BIG-IP are the data plane, the control plane, and the management plane. My bare bones description of the three: Data Plane - Client/server traffic on the wire and flowing through devices Control Plane - Tactical control of local system resources Management Plane - Strategic control of distributed system resources You might think iControl (our SOAP and REST API interface) fits the description of both the control and management planes, and whereas you’d be technically correct, iControl is better utilized as an external service in management or orchestration tools. The beauty of iCall is that it’s not an API at all—it’s lightweight, it’s built-in via tmsh, and it integrates seamlessly with the data plane where necessary (via iStats.) It is what we like to call control plane scripting. Do you remember relations and set theory from your early pre-algebra days? I thought so! Let me break it down in a helpful way: P = {(data plane, iRules), (control plane, iCall), (management plane, iControl)} iCall allows you to react dynamically to an event at a system level in real time. It can be as simple as generating a qkview in the event of a failover or executing a tcpdump on a server with too many failed logins. One use case I’ve considered from an operations perspective is in the event of a core dump to have iCall generate a qkview, take checksums of the qkview and the dump file, upload the qkview and generate a support case via the iHealth API, upload the core dumps to support via ftp with the case ID generated from iHealth, then notify the ops team with all the appropriate details. If I had a solution like that back in my customer days, it would have saved me 45 minutes easy each time this happened! iCall Components Three are three components to iCall: events, handlers, and scripts. Events An event is really what drives the primary reason to use iCall over iControl. A local system event (whether it’s a failover, excessive interface or application errors, too many failed logins) would ordinarily just be logged or from a system perspective, ignored altogether. But with iCall, events can be configured to force an action. At a high level, an event is "the message," some named object that has context (key value pairs), scope (pool, virtual, etc), origin (daemon, iRules), and a timestamp. Events occur when specific, configurable, pre-defined conditions are met. Example (placed in /config/user_alert.conf) alert local-http-10-2-80-1-80-DOWN "Pool /Common/my_pool member /Common/10.2.80.1:80 monitor status down" { exec command="tmsh generate sys icall event tcpdump context { { name ip value 10.2.80.1 } { name port value 80 } { name vlan value internal } { name count value 20 } }" } Handlers Within the iCall system, there are three types of handlers: triggered, periodic, and perpetual. Triggered A triggered handler is used to listen for and react to an event. Example (goes with the event example from above:) sys icall handler triggered tcpdump { script tcpdump subscriptions { tcpdump { event-name tcpdump } } } Periodic A periodic handler is used to react to an interval timer. Example: sys icall handler periodic poolcheck { first-occurrence 2017-07-14:11:00:00 interval 60 script poolcheck } Perpetual A perpetual handler is used under the control of a deamon. Example: handler perpetual core_restart_watch sys icall handler perpetual core_restart_watch { script core_restart_watch } Scripts And finally, we have the script! This is simply a tmsh script moved under the /sys icall area of the configuration that will “do stuff" in response to the handlers. Example (continuing the tcpdump event and triggered handler from above:) modify script tcpdump { app-service none definition { set date [clock format [clock seconds] -format "%Y%m%d%H%M%S"] foreach var { ip port count vlan } { set $var $EVENT::context($var) } exec tcpdump -ni $vlan -s0 -w /var/tmp/${ip}_${port}-${date}.pcap -c $count host $ip and port $port } description none events none } Resources iCall Codeshare Lightboard Lessons on iCall Threshold violation article highlighting periodic handler7.4KViews2likes10Comments
Part 2: Monitoring the CPU usage of the BIG-IP system using a periodic iCall handler
In this part series, you monitor the CPU usage of the BIG-IP system with a periodic iCall handler. The specific CPU statistics you want to monitor can be retrieved from either Unix or tmsh commands. For example, if you want to monitor the CPU usage of the tmm process, you can monitor the values from the output of the tmsh show sys proc-info tmm.0 command. An iCall script can iterate and retrieve a list of values from the output of a tmsh command. To display the fields available from a tmsh command that you can iterate from an iCall Tcl script, run the tmsh command with thefield-fmtoption. For example: tmsh show sys proc-info tmm.0 field-fmt You can then use a periodic iCall handler which runs an iCall script periodically every interval to check the value of the output of the tmsh command. When the value exceeds a configured threshold, you can have the script perform an action; for example, an alert message can be logged to the/var/log/ltmfile. The following describes the procedures: Creating an iCall script to monitor the required CPU usage values Creating a periodic iCall handler to run the iCall script once a minute 1. Creating an iCall script to monitor the required CPU usage values There are different Unix and tmsh commands available to display CPU usage. To monitor CPU usage, this example uses the following: tmsh show sys performance system detail | grep CPU: This displays the systemCPU Utilization (%). The script monitors CPU usage from theAveragecolumn for each CPU. tmsh show sys proc-info apmd: Monitors the CPU usage System Utilization (%) Last5-minsvalue of the apmd process. tmsh show sys proc-info tmm.0: Monitors the CPU usage System Utilization (%) Last5-minsvalue of the tmm process. This is the sum of the CPU usage of all threads of thetmm.0process divided by the number of CPUs over five minutes. You can display the number of TMM processes and threads started, by running different commands. For example: pstree -a -A -l -p | grep tmm | grep -v grep grep Start /var/log/tmm.start You can also create your own script to monitor the CPU output from other commands, such astmsh show sys cpuortmsh show sys tmm-info. However, a discussion on CPU usage on the BIG-IP system is beyond the scope of this article. For more information, refer toK14358: Overview of Clustered Multiprocessing (11.3.0 and later)andK16739: Understanding 'top' output on the BIG-IP system. You need to set some of the variables in the script, specifically the threshold values:cpu_perf_threshold, tmm.0_threshold, apmd_thresholdrespectively. In this example, all the CPU threshold values are set at 80%. Note that depending on the set up in your specific environment, you have to adjust the threshold accordingly. The threshold values also depend on the action you plan to run in the script. For example, in this case, the script logs an alert message in the/var/log/ltmfile. If you plan to log an emerg message, the threshold values should be higher, for example, 95%. Procedure Perform the following procedure to create the script to monitor CPU statistics and log an alert message in the/var/log/ltmfile when traffic exceeds a CPU threshold value. To create an iCall script, perform the following procedure: Log in to tmsh. Enter the following command to create the script in the vi editor: create sys icall script cpu_script 3. Enter the following script into the definition stanza of the editor. The 3 threshold values are currently set at 80%. You can change it according to the requirements in your environment. definition { set DEBUG 0 set VERBOSE 0 #CPU threshold in % from output of tmsh show sys performance system detail set cpu_perf_threshold 80 #The name of the process from output of tmsh show sys proc-info to check. The name must match exactly. #If you would like to add another process, append the process name to the 'process' variable and add another line for threshold. #E.g. To add tmm.4, "set process apmd tmm.0 tmm.4" and add another line "set tmm.4_threshold 75" set process "apmd tmm.0" #CPU threshold in % for output of tmsh show sys proc-info set tmm.0_threshold 80 set apmd_threshold 80 puts "\n[clock format [clock seconds] -format "%b %d %H:%M:%S"] Running CPU monitoring script..." #Getting average CPU output of tmsh show sys performance set errorcode [catch {exec tmsh show sys performance system detail | grep CPU | grep -v Average | awk {{ print $1, $(NF-4), $(NF-3), $(NF-1) }}} result] if {[lindex $result 0] == "Blade"} { set blade 1 } else { set blade 0 } set result [split $result "\n"] foreach i $result { set cpu_num "[lindex $i 1] [lindex $i 2]" if {$blade} {set cpu_num "Blade $cpu_num"} set cpu_rate [lindex $i 3] if {$DEBUG} {puts "tmsh show sys performance->${cpu_num}: ${cpu_rate}%."} if {$cpu_rate > $cpu_perf_threshold} { if {$DEBUG} {puts "tmsh show sys performance->${cpu_num}: ${cpu_rate}%. Exceeded threshold ${cpu_perf_threshold}%."} exec logger -p local0.alert "\"tmsh show sys performance\"->${cpu_num}: ${cpu_rate}%. Exceeded threshold ${cpu_perf_threshold}%." } } #Getting output of tmsh show sys proc-info foreach obj [tmsh::get_status sys proc-info $process] { if {$VERBOSE} {puts $obj} set proc_name [tmsh::get_field_value $obj proc-name] set cpu [tmsh::get_field_value $obj system-usage-5mins] set pid [tmsh::get_field_value $obj pid] set proc_threshold ${proc_name}_threshold set proc_threshold [set [set proc_threshold]] if {$DEBUG} {puts "tmsh show sys proc-info-> Average CPU Utilization of $proc_name pid $pid is ${cpu}%"} if { $cpu > ${proc_threshold} } { if {$DEBUG} {puts "$proc_name process pid $pid at $cpu% cpu. Exceeded ${proc_threshold}% threshold."} exec logger -p local0.alert "\"tmsh show sys proc-info\" $proc_name process pid $pid at $cpu% cpu. Exceeded ${proc_threshold}% threshold." } } } 4. Configure the variables in the script as needed and exit the editor by entering the following command: :wq! y 5. Run the following command to list the contents of the script: list sys icall script cpu_script 2. Creating a periodic iCall handler to run the iCall script once a minute Procedure Perform the following procedure to create the periodic handler that runs the script once a minute. To create an iCall periodic handler, perform the following procedure: Log in to tmsh Enter the following command to create a periodic handler: create sys icall handler periodic cpu_handler interval 60 script cpu_script 3. Run the following command to list the handler: list sys icall handler periodic cpu_handler 4. You can start and stop the handler by using the following command syntax: <start|stop> sys icall handler periodic cpu_handler Follow the /var/tmp/scriptd.out and /var/log/ltm file entries to verify your implementation is working correctly.2.5KViews1like0CommentsThird Time's the Charm: BIG-IP Backups Simplified with iCall
Backing up the BIG-IP Configuration is something I've written about a couple times (here and here) previously. Well, third time's the charm, thanks to the new iCall feature in the 11.4 release. This time, I've even wrapped in scp support to send the backup to a remote server! The great thing about this solution is the only thing required outside of tmsh is setting up the ssh keys. SSH Key Configuration 1. On Big_IP, create your keys [root@ltm1:Active:Standalone] config # ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: fd:d0:07:64:1d:f6:21:86:49:47:85:77:74:15:2c:36 root@ltm1.dc.local 2. copy the public key to your archive server [root@ltm1:Active:Standalone] config # scp /root/.ssh/id_rsa.pub jrahm@192.168.6.10:/var/tmp/id_rsa.pub-ltm1 jrahm@192.168.6.10's password: id_rsa.pub 3. Login to your server and append the public key to authorized keys, recommending not a root account! For my ubuntu installation, I have an encrypted home directory, so there are a couple extra steps to apply the authorized keys: 3a. Create a user-specific directory in /etc/ssh and change permissions/ownership sudo mkdir /etc/ssh/jrahm sudo chmod 755 /etc/ssh/jrahm sudo chown jrahm:jrahm /etc/ssh/jrahm 3b. Edit /etc/ssh/sshd_config to update authorized keys file: sudo vi /etc/ssh/sshd_config #update these two lines: AuthorizedKeysFile /etc/ssh/%u/authorized_keys PubkeysAuthentication yes 3c. Add your key to the user: sudo cat /var/tmp/id_rsa.pub-ltm1 >> /etc/ssh/jrahm/authorized_keys 3d. restart sshd on archive server sudo service ssh restart 4. Test login from BIG-IP to server (no password prompt, this is good!) [root@ltm1:Active:Standalone] config # ssh jrahm@192.168.6.10 Welcome to Ubuntu 12.04.2 LTS (GNU/Linux 3.2.0-23-generic x86_64) Last login: Mon Apr 1 15:15:22 2013 from 192.168.6.5 5. Test scp functionality: [root@ltm1:Active:Standalone] tmp # scp f5backup-ltm1.dc.local-20130326160303.tar.gz jrahm@192.168.6.10:/var/tmp/ f5backup-ltm1.dc.local-20130326160303.tar.gz Create the iCall Script iCall scripts are created in the vim editor much like tmsh scripts by (in the tmsh shell) calling create sys icall script <script name>. The skeleton looks like this: create script testme { app-service none definition { } description none events none } For this script, we only need to focus on the definition. There is no rocket science in this script at all, just setting date and file information, saving the archive, creating the tarball, zipping it up, and sending it off. sys icall script f5.config_backup.v1.0.0 { app-service none definition { #Set Current Date/Time for Filename set cdate [clock format [clock seconds] -format "%Y%m%d%H%M%S"] #Pull hostname from config for Filename set host [tmsh::get_field_value [lindex [tmsh::get_config sys global-settings] 0] hostname] #Create Temp Directory set tmpdir [exec mktemp -d /var/tmp/f5backup.XXXXXXXXXX] #Set Filename Root set fname "f5backup-$host-$cdate" #Export UCS tmsh::save /sys ucs $tmpdir/$fname #Create Backup exec tar cvzf /var/tmp/$fname.tar.gz -C $tmpdir . 2> /dev/null #Remove Temp Directory exec rm -rf $tmpdir #SSH settings exec scp /var/tmp/$fname.tar.gz jrahm@192.168.6.10:/var/tmp/ } description none events none } As you can probably surmise, an iCall script is pretty much a tmsh script, same Tcl / tmsh, just stored differently to be utilized by iCall handlers. Create the iCall Handler Since backups are typically run once a day, the handler we'll need is a periodic handler. There are several arguments you can set on a periodic handler: root@(ltm2)(cfg-sync Standalone)(Active)(/Common)(tmos)# create sys icall handler periodic testme ? Identifier: [object identifier] Specify a name for the handler item Properties: "{" Optional delimiter app-service arguments Specifies a set of name/value pairs to be passed in as data to the script for every execution description User defined explanation of the item first-occurrence Specifies the date and time of the first occurrence this handler should execute interval Specifies the number of seconds between each occurrence of this handler's automatic execution last-occurrence Specifies the date and time after which no more occurrences will execute script Specifies the handler's script to execute upon invocation status Manage the perpetual process by specifying active or inactive In my case, I only need to set the first-occurrence, the interval, and the script to call: sys icall handler periodic f5.config_backup.v1.0.0 { first-occurrence 2013-06-26:08:18:00 interval 360 script f5.config_backup.v1.0.0 } A normal interval would be once per day (86400), but since this is a test scenario, I set the interval low so I could see it happen at least twice. On the BIG-IP, notice that the temp directories are gone (but the archives remain, you can add a line to the script to clean up if you like) [root@ltm2:Active:Standalone] tmp # ls -las total 13100 8 drwxrwxrwt 6 root root 4096 Jun 26 08:23 . 8 drwxr-xr-x 21 root root 4096 Jun 20 09:41 .. 8 -rw-r--r-- 1 root root 718 Jun 24 09:59 audit.out 8 -rw-r--r-- 1 root root 1013 Jun 24 10:00 csyncd.out 4 -rw-r--r-- 1 root root 0 Jun 24 10:00 devmgmtd++.out 4 -rw-r--r-- 1 root root 0 Jun 24 09:59 evrouted.out 476 -rw-r--r-- 1 root root 478717 Jun 26 08:18 f5backup-ltm2.dc.local-20130626081800.tar.gz 476 -rw-r--r-- 1 root root 478556 Jun 26 08:23 f5backup-ltm2.dc.local-20130626082336.tar.gz 8 drwxr-xr-x 4 root root 4096 Jun 20 09:34 install And finally, the same files in place on my remote server: jrahm@u1204lts:/var/tmp$ ls -las total 2832 4 drwxrwxrwt 2 root root 4096 Jun 26 10:24 . 4 drwxr-xr-x 13 root root 4096 Mar 27 13:35 .. 468 -rw-r--r-- 1 jrahm jrahm 478717 Jun 26 10:18 f5backup-ltm2.dc.local-20130626081800.tar.gz 468 -rw-r--r-- 1 jrahm jrahm 478556 Jun 26 10:24 f5backup-ltm2.dc.local-20130626082336.tar.gz Going Further By this point in the article, you might been thinking..."Wait, the previous articles wrapped all that goodness in an iApp. What gives?" Well, I am not leaving you hanging--its' already in the iCall codeshare waiting for you! Stay tuned for future iCall articles, where I'll dive into some perpetual and triggered handler use cases.2.2KViews0likes12CommentsUsing iCall to monitor BIG-IP APM network access VPN
Introduction During peak periods, when a large number of users are connected to network access VPN, it is important to monitor your BIG-IP APM system's resource (CPU, memory, and license) usage and performance to ensure that the system is not overloaded and there is no impact on user experience. If you are a BIG-IP administrator, iCall is a tool perfectly suited to do this for you. iCall is a Tcl-based scripting framework that gives you programmability in the control plane, allowing you to script and run Tcl and TMOS Shell (tmsh) commands on your BIG-IP system based on events. For a quick introduction to iCall, refer to iCall - All New Event-Based Automation System. Overview This article is made up of three parts that describe how to use and configure iCall in the following use cases to monitor some important BIG-IP APM system statistics: Part 1: Monitoring access sessions and CCU license usage of the system using a triggered iCall handler Part 2: Monitoring the CPU usage of the system using a periodic iCall handler. Part 3: Monitoring the health of BIG-IP APM network access VPN PPP connections with a periodic iCall handler. In all three cases, the design consists of identifying a specific parameter to monitor. When the value of the parameter exceeds a configured threshold, an iCall script can perform a set of actions such as the following: Log a message to the /var/log/apm file at the appropriate severity: emerg: System is unusable alert: Action must be taken immediately crit: Critical conditions You may then have another monitoring system to pick up these messages and respond to them. Perform a remedial action to ease the load on the BIG-IP system. Run a script (Bash, Perl, Python, or Tcl) to send an email notification to the BIG-IP administrator. Run the tcpdump or qkview commands when you are troubleshooting an issue. When managing or troubleshooting iCall scripts and handler, you should take into consideration the following: You use the Tcl language in the editor in tmsh to edit the contents of scripts and handlers. For example: create sys icall script <name of script> edit sys icall script <name of script> The puts command outputs entries to the /var/tmp/scriptd.out file. For example: puts "\n[clock format [clock seconds] -format "%b %d %H:%M:%S"] Running script..." You can view the statistics for a particular handler using the following command syntax: show sys icall handler <periodic | perpetual | triggered> <name of handler> Series 1: Monitoring access sessions and CCU license usage with a triggered iCall handler You can view the number of currently active sessions and current connectivity sessions usage on your BIG-IP APM system by entering the tmsh show apm license command. You may observe an output similar to the following: -------------------------------------------- Global Access License Details: -------------------------------------------- total access sessions: 10.0M current active sessions: 0 current established sessions: 0 access sessions threshold percent: 75 total connectivity sessions: 2.5K current connectivity sessions: 0 connectivity sessions threshold percent: 75 In the first part of the series, you use iCall to monitor the number of current access sessions and CCU license usage by performing the following procedures: Modifying database DB variables to log a notification when thresholds are exceed. Configuring user_alert.conf to generate an iCall event when the system logs the notification. Creating a script to respond when the license usage reaches its threshold. Creating an iCall triggered handler to handle the event and run an iCall script Testing the implementation using logger 1. Modifying database variables to log a notification when thresholds are exceeded. The tmsh show apm license command displays the access sessions threshold percent and access sessions threshold percent values that you can configure with database variables. The default values are 75. For more information, refer to K62345825: Configuring the BIG-IP APM system to log a notification when APM sessions exceed a configured threshold. When the threshold values are exceeded, you will observe logs similar to the following in /var/log/apm: notice tmm1[<pid>]: 01490564:5: (null):Common:00000000: Global access license usage is 1900 (76%) of 2500 total. Exceeded 75% threshold of total license. notice tmm2[<pid>]: 01490565:5: 00000000: Global concurrent connectivity license usage is 393 (78%) of 500 total. Exceeded 75% threshold of total license. Procedure: Run the following commands to set the threshold to 95% for example: tmsh modify /sys db log.alertapmaccessthreshold value 95 tmsh modify /sys db log.alertapmconnectivitythreshold value 95 Whether to set the alert threshold at 90% or 95%, depends on your specific environment, specifically how fast the usage increases over a period of time. 2. Configuring user_alert.conf to generate an iCall event when the system logs the notification You can configure the /config/user_alert.conf file to run a command or script based on a syslog message. In this step, edit the user_alert.conf file with your favorite editor, so that the file contains the following stanza. alert <name> "<string in syslog to match to trigger event>" { <command to run> } For more information on configuring the /config/user_alert.conf file, refer to K14397: Running a command or custom script based on a syslog message. In particular, it is important to read the bullet points in the Description section of the article first; for example, the system may not process the user_alert.conf file after system upgrades. In addition, BIG-IP APM messages are not processed by the alertd SNMP process by default. So you will also have to perform the steps described in K51341580: Configuring the BIG-IP system to send BIG-IP APM syslog messages to the alertd process as well. Procedure: Perform the following procedure: Edit the /config/user_alert.conf file to match each error code and generate an iCall event named apm_threshold_event. Per K14397 Note: You can create two separate alerts based on both error codes or alternatively use the text description part of the log message common to both log entries to capture both in a single alert. For example "Exceeded 75% threshold of total license" # cat /config/user_alert.conf alert apm_session_threshold "01490564:" { exec command="tmsh generate sys icall event apm_threshold_event" } alert apm_ccu_threshold "01490565:" { exec command="tmsh generate sys icall event apm_threshold_event" } 2. Run the following tmsh command: edit sys syslog all-properties 3. Replace the include none line with the following: Per K51341580 include " filter f_alertd_apm { match (\": 0149[0-9a-fA-F]{4}:\"); }; log { source(s_syslog_pipe); filter(f_alertd_apm); destination(d_alertd); }; " 3. Creating a script to respond when the license usage reaches its threshold. When the apm session or CCU license usage exceeds your configured threshold, you can use a script to perform a list of tasks. For example, if you had followed the earlier steps to configure the threshold values to be 95%, you can write a script to perform the following actions: Log a syslog alert message to the /var/log/apm file. If you have another monitoring system, it can pick this up and respond as well. Optional: Run a tmsh command to modify the Access profile settings. For example, when the threshold exceeds 95%, you may want to limit users to one apm session each, decrease the apm access profile timeout or both. Changes made only affect new users. Users with existing apm sessions are not impacted. If you are making changes to the system in the script, it is advisable to run an additional tmsh command to stop the handler. When you have responded to the alert, you can manually start the handler again. Note: When automating changes to the system, it is advisable to err on the side of safety by making minimal changes each time and only when required. In this case, after the system reaches the license limit, users cannot login and you may need to take immediate action. Procedure: Perform the following procedure to create the iCall script: 1. Log in to tmsh. 2. Run the following command: create sys icall script threshold_alert_script 3. Enter the following in the editor: Note: The tmsh commands to modify the access policy settings have been deliberately commented out. Uncomment them when required. sys icall script threshold_alert_script { app-service none definition { exec logger -p local1.alert "01490266: apm license usage exceeded 95% of threshold set." #tmsh::modify apm profile access exampleNA max-concurrent-sessions 1 #tmsh::modify apm profile access exampleNA generation-action increment #tmsh::stop sys icall handler triggered threshold_alert_handler } description none events none } 4. Creating an iCall triggered handler to handle the event and run an iCall script In this step, you create a triggered iCall handler to handle the event triggered by the tmsh generate sys icall event command from the earlier step to run the script. Procedure: Perform the following: 1. Log in to tmsh. 2. Enter the following command to create the triggered handler. create sys icall handler triggered threshold_alert_handler script threshold_alert_script subscriptions add { apm_threshold_event { event-name apm_threshold_event } } Note: The event-name field must match the name of the event in the generate sys icall command in /config/user_alert.conf you configured in step 2. 3. Enter the following command to verify the configuration of the handler you created. (tmos)# list sys icall handler triggered threshold_alert_handler sys icall handler triggered threshold_alert_handler { script threshold_alert_script subscriptions { apm_threshold_event { event-name apm_threshold_event } } } 5. Testing the implementation using logger You can use theloggercommand to log test messages to the/var/log/apmfile to test your implementation. To do so, run the following command: Note: The message below must contain the keyword that you are searching for in the script. In this example, the keyword is01490564or01490565. logger -p local1.notice "01490564:5: (null):Common:00000000: Global access license usage is 1900 (76%) of 2500 total. Exceeded 75% threshold of total license." logger -p local1.notice "01490565:5: 00000000: Global concurrent connectivity license usage is 393 (78%) of 500 total. Exceeded 75% threshold of total license." Follow the /var/log/apm file to verify your implementation is working correctly.1.7KViews1like0CommentsiCall Triggers - Invalidating Cache from iRules
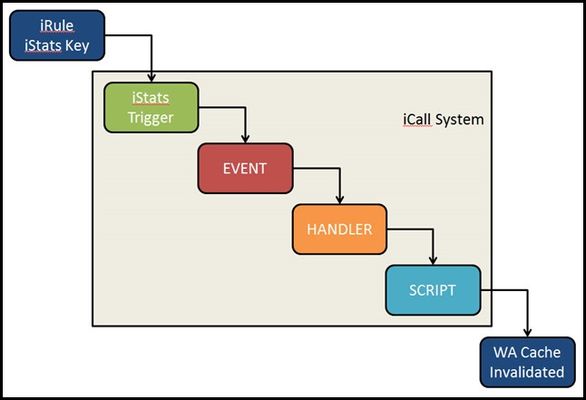
iCall is BIG-IP's all new (as of BIG-IP version 11.4) event-based automation system for the control plane. Previously, I wrote up the iCall system overview, as well as an article on the use of a periodic handler for automating backups. This article will feature the use of the triggered iCall handler to allow a user to submit a http request to invalidate the cache served up for an application managed by the Application Acceleration Manager. Starting at the End Before we get to the solution, I'd like to address the use case for invalidating cache. In many cases, the team responsible for an application's health is not the network services team which is the typical point of access to the BIG-IP. For large organizations with process overhead in generating tickets, invalidating cache can take time. A lot of time. So the request has come in quite frequently..."How can I invalidate cache remotely?" Or even more often, "Can I invalidate cache from an iRule?" Others have approached this via script, and it has been absolutely possible previously with iRules, albeit through very ugly and very-not-recommended ways. In the end, you just need to issue one TMSH command to invalidate the cache for a particular application: tmsh::modify wam application content-expiration-time now So how do we get signal from iRules to instruct BIG-IP to run a TMSH command? This is where iCall trigger handlers come in. Before we hope back to the beginning and discuss the iRule, the process looks like this: Back to the Beginning The iStats interface was introduced in BIG-IP version 11 as a way to make data accessible to both the control and data planes. I'll use this to pass the data to the control plane. In this case, the only data I need to pass is to set a key. To set an iStats key, you need to specify : Class Object Measure type (counter, gauge, or string) Measure name I'm not measuring anything, so I'll use a string starting with "WA policy string" and followed by the name of the policy. You can be explicit or allow the users to pass it in a query parameter as I'm doing in this iRule below: when HTTP_REQUEST { if { [HTTP::path] eq "/invalidate" } { set wa_policy [URI::query [HTTP::uri] policy] if { $wa_policy ne "" } { ISTATS::set "WA policy string $wa_policy" 1 HTTP::respond 200 content "App $wa_policy cache invalidated." } else { HTTP::respond 200 content "Please specify a policy /invalidate?policy=policy_name" } } } Setting the key this way will allow you to create as many triggers as you have policies. I'll leave it as an exercise for the reader to make that step more dynamic. Setting the Trigger With iStats-based triggers, you need linkage to bind the iStats key to an event-name, wacache in my case. You can also set thresholds and durations, but again since I am not measuring anything, that isn't necessary. sys icall istats-trigger wacache_trigger_istats { event-name wacache istats-key "WA policy string wa_policy_name" } Creating the Script The script is very simple. Clear the cache with the TMSH command, then remove the iStats key. sys icall script wacache_script { app-service none definition { tmsh::modify wam application dc.wa_hero content-expiration-time now exec istats remove "WA policy string wa_policy_name" } description none events none } Creating the Handler The handler is the glue that binds the event I created in the iStats trigger. When the handler sees an event named wacache, it'll execute the wacache_script iCall script. sys icall handler triggered wacache_trigger_handler { script wacache_script subscriptions { messages { event-name wacache } } } Notes on Testing Add this command to your arsenal - tmsh generate sys icall event <event-name> context none</event-name> where event-name in my case is wacache. This allows you to troubleshoot the handler and script without worrying about the trigger. And this one - tmsh modify sys db log.evrouted.level value Debug. Just note that the default is Notice when you're all done troubleshooting.1.5KViews0likes6CommentsLightboard Lessons: iCall
In this episode of Lightboard Lessons, I give an introduction to iCall, the built-in event-based BIG-IP control-plane scripting engine. Resources iCall release article iCall Wiki iCall Codeshare iCall Triggers Example with iStats to Invalidate Cache iCall Periodic Example Pool Check to Disable Interface Older Whiteboard Wednesday on iCall1.5KViews0likes4CommentsYou Want Action on a Threshold Violation? Use iCall!
iCall has been around since the 11.4 release, yet there seems to be a prevailing gap in awareness of this amazing functionality in BIG-IP. A blog I wrote last year covers the overview of the iCall system, but in brief, it provides event-based automation. The events can be periodic (like cron functionality,) perpetual (watching for something like a file to appear in a directory,) or triggered by an alert (like a pool member failure.) Late last week I was at the mother ship (F5 Corporate in Seattle) and found this question in Q&A (paraphrased): What is a good method for toggling interface 1.1 if active pool members in a pool falls below 70%? My mind went immediately to iCall, as this is a perfect use case. It binds an event (a pool's active members falling below a threshold) to a task (disable an interface.) I didn't have time to flesh out the solution last week, but I dropped some (errant) code in the thread to point the original poster (Lee) down the right path. Flash forward to this week, and I was intrigued enough about the solution I thought I'd take a crack at making it work. Building Out the Solution Given that Lee set a threshold of 70% of active pool members, I figured a test pool of four members would be a good candidate since failing one member would be just over the threshold at 75% whereas failing a second member would take me to 50%. I suppose a pool of three members would have been equally fine, but I like to see that some failure doesn't force an accidental event. So I fired up my test BIG-IP device and a linux vm with several interface aliases and built a pool with four members. ltm pool pool4 { members { 192.168.101.10:80 { address 192.168.101.10 session monitor-enabled state up } 192.168.101.20:80 { address 192.168.101.20 session monitor-enabled state up } 192.168.101.21:80 { address 192.168.101.21 session monitor-enabled state up } 192.168.101.22:80 { address 192.168.101.22 session monitor-enabled state up } } monitor http } Next, I needed to build the iCall script. An iCall script is just a tmsh script stored in a specific section of the configuration. It's tcl just like tmsh. But what does the script need to do? Well, a few things: Define the pool of interest Set the total number of pool members Set the number of available members Do math Enable/Disable the interface based on the result of that math Steps 1, 4, & 5 are pretty self explanatory. In tmsh scripting, setting an interface (and most other tmsh-based commands) look nearly identical to the shell command. #tmsh tmsh modify /net interface 1.1 disabled #tmsh script tmsh::modify /net interface 1.1 disabled Where it gets tricky is figuring out how to get pool member data. This is where the tmsh::get_status and tmsh::get_field_value commands come into play. Everything is object based in tmsh, and it can be a little overwhelming to figure out how to address the objects. If you were to just run the commands below in a script, the resulting output (in /var/tmp/scriptd.out) shows you the nomenclature of the addressable objects in that data. set pn "/Common/pool4" set pooldata [tmsh::get_status /ltm pool $pn detail] puts $data #data set ltm pool pool4 { active-member-cnt 4 connq-all.age-edm 0 connq-all.age-ema 0 connq-all.age-head 0 connq-all.age-max 0 connq-all.depth 0 connq-all.serviced 0 connq.age-edm 0 connq.age-ema 0 connq.age-head 0 connq.age-max 0 connq.depth 0 connq.serviced 0 cur-sessions 0 members { 192.168.101.10:80 { addr 192.168.101.10 connq.age-edm 0 connq.age-ema 0 connq.age-head 0 connq.age-max 0 connq.depth 0 connq.serviced 0 cur-sessions 0 monitor-rule http (pool monitor) monitor-status up node-name 192.168.101.10 nodes { 192.168.101.10 { addr 192.168.101.10 cur-sessions 0 monitor-rule none monitor-status unchecked ...continued... So I get to the pool member data by first getting the pool data. And the data needed for pool member availability is the availability-state and the enabled-state from the pool member data (incomplete view of data shown below, but the necessary information is there.) members 192.168.101.22:80 { addr 192.168.101.22 monitor-rule http (pool monitor) monitor-status up node-name 192.168.101.22 nodes { 192.168.101.22 { addr 192.168.101.22 cur-sessions 0 monitor-rule none monitor-status unchecked name 192.168.101.22 session-status enabled status.availability-state unknown status.enabled-state enabled status.status-reason tot-requests 0 } } pool-name pool4 port 80 session-status enabled status.availability-state available status.enabled-state enabled status.status-reason Pool member is available } Now that the data set is known, the script can be completed. Note that to get to particular state information bolded above, I just set those attributes against the member in the tmsh::get_field_value commands bolded below. The math part is simple, though to get floating point, the .0 is added to the $usable count variable in the expression. Logging statements and puts commands (sending data to /var/tmp/scriptd.out for debugging) added to the script for demonstration purposes. sys icall script poolCheck.v1.0.0 { app-service none definition { set pn "/Common/pool4" set total 0 set usable 0 foreach obj [tmsh::get_status /ltm pool $pn detail] { puts $obj foreach member [tmsh::get_field_value $obj members] { puts $member incr total if { [tmsh::get_field_value $member status.availability-state] == "available" && \ [tmsh::get_field_value $member status.enabled-state] == "enabled" } { incr usable } } } if { [expr $usable.0 / $total] < 0.7 } { tmsh::log "Not enough pool members in pool $pn, interface 1.3 disabled" tmsh::modify /net interface 1.3 disabled } else { tmsh::log "Enough pool members in pool $pn, interface 1.3 enabled" tmsh::modify /net interface 1.3 enabled } } description none events none } Now that the script is complete, I just need to create the handler. A triggered handler could be created to run the script every time a pool member alert happens (as configured in /config/user_alert.conf,) but for demo purposes I used a periodic handler with a 60 second interval. sys icall handler periodic poolCheck.v1.0.0 { first-occurrence 2014-09-16:11:00:00 interval 60 script poolCheck.v1.0.0 } Configuration complete, moving on to test! Testing the Solution To test, I activated the vm instance in my lab and validated that my BIG-IP interfaces and pool members were up. Then, I shut down one apache virtual ahead of the first period at 11:26, and since I had 75% availability the interface remained enabled. Next, I shut down the second apache virtual, dropping availability to 50%. At 11:27, the BIG-IP interface was deactivated. Finally, I re-enabled the apache virtuals and at the next period the BIG-IP interface was reactivated. Log files and ping test to that interface shown below. # Log Files Sep 16 11:25:43 Pool /Common/pool4 member /Common/192.168.101.21:80 monitor status down. Sep 16 11:26:00 Enough pool members in pool /Common/pool4, interface 1.3 enabled Sep 16 11:26:26 Pool /Common/pool4 member /Common/192.168.101.22:80 monitor status down. Sep 16 11:27:00 Not enough pool members in pool /Common/pool4, interface 1.3 disabled Sep 16 11:27:32 Pool /Common/pool4 member /Common/192.168.101.21:80 monitor status up. Sep 16 11:27:36 Pool /Common/pool4 member /Common/192.168.101.22:80 monitor status up. Sep 16 11:28:01 Enough pool members in pool /Common/pool4, interface 1.3 enabled # Ping Test to Interface 1.3 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Request timed out. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.205: Destination host unreachable. Reply from 10.10.10.5: bytes=32 time=1000ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 Reply from 10.10.10.5: bytes=32 time=1ms TTL=255 One note from this solution, don't rely on the GUI or CLI status of the interface (known tested versions in 11.5.x+. Bug 471860 catalogs the reporting issue on BIG-IP for the interface status. At boot time, if the interface is up it reports as ENABLED, but if you disable and then re-enable, it reports as DISABLED even though it will be up and passing traffic. Dig into iCall! iCall (and tmsh more generally) is tremendously powerful, take a look at several other use cases already in the iCall codeshare! This solution has been added to the codeshare as well.1.3KViews0likes3CommentsPart 3: Monitoring the health of BIG-IP APM network access PPP connections with a periodic iCall handler
In this part, you monitor the health of PPP connections on the BIG-IP APM system by monitoring the frequency of a particular log message in the/var/log/apmfile. In this log file, when the system is under high CPU load, you may observe different messages indicating users' VPN connections are disconnecting. For example: You observe multiple of the following messages where the PPP tunnel is started and closed immediately: Mar 13 13:57:57 hostname.example notice tmm3[16095]: 01490505:5: /Common/accessPolicy_policy:Common:ee6e0ce7: PPP tunnel 0x5604775f7000 (ID: 2c4507ea) started. Mar 13 13:57:57 hostname.example notice tmm3[16095]: 01490505:5: /Common/accessPolicy_policy:Common:ee6e0ce7: PPP tunnel 0x560478482000 (ID: acf63e47) closed. You observe an unusually high rate of log messages indicating users' APM sessions terminated due to various reasons in a short span of time. Mar 13 14:01:10 hostname.com notice tmm3[16095]: 01490567:5: /Common/AccessPolicy_policy:Common:a7cf25d9: Session deleted due to user inactivity. You observe an unusually high rate of log messages indicating different user apm session IDs are attempting to reconnect to network access, VPN. Mar 13 12:18:13 hostname notice tmm1[16095]: 01490549:5: /Common/AP_policy:Common:2c321803: Assigned PPP Dynamic IPv4: 10.10.1.20 ID: 033d0635 Tunnel Type: VPN_TUNNELTYPE_TLS NA Resource: /Common/AP_policy_na_res Client IP: 172.2.2.2 – Reconnect In this article, you monitor theReconnectmessage in the last example because it indicates that the VPN connection terminated and the client system still wants to reconnect. When this happens for several users and repeatedly, it usually indicates that the issue is not related to the client side. The next question is, what is an unusually high rate of reconnect messages, taking into account the fact that some reconnects may be due to reasons on the client side and not due to high load on the system. You can create a periodic iCall handler to run a script once every minute. Each time the script runs, it uses grep to find the total number of Reconnect log messages that happened over the last 3 minutes for example. When the average number of entries per minute exceeds a configured threshold, the system can take appropriate action. The following describes the procedures: Creating an iCall script to monitor the rate of reconnect messages Creating a periodic iCall handler to run the iCall script once a minute Testing the implementation using logger 1. Creating an iCall script to monitor the rate of reconnect messages The example script uses the following values: Periodic handler interval 1 minute: This runs the script once a minute to grep the number of reconnect messages logged in the last 3.0 minutes. Period 3.0 minutes: The script greps for the Reconnect messages logged in the last three minutes. Critical threshold value 4: When the average number of Reconnect messages per minute exceeds four or a total of 12 in the last three minutes, the system logs a critical message in the/var/log/apmfile. Alert threshold value 7: When the average number of Reconnect messages per minute exceeds seven or a total of 21 in the last three minutes, the system logs an alert message and requires immediate action. Emergency threshold 10: When the BIG-IP system is logging 10 Reconnect messages or more every minute for the last three minutes or a total of 30 messages, the system logs an emergency message, indicating the system is unusable. You should reconfigure these values at the top of the script according to the behavior and set up of your environment. By performing the count over an interval of three minutes or longer, it reduces the possibility of high number of reconnects due to one-off spikes. Procedure Perform the following procedure to create the script to monitor CPU statistics and log an alert message in the/var/log/ltmfile when traffic exceeds a CPU threshold value. To create an iCall script, perform the following procedure: Log in to tmsh. Enter the following command to create the script in the vi editor: create sys icall script vpn_reconnect_script 3. Enter the following script into the definition stanza in the editor: This script counts the average number of entries/min the Reconnect message is logged in /var/log/apm over a period of 3 minutes. definition { #log file to grep errormsg set apm_log "/var/log/apm" #This is the string to grep for. set errormsg "Reconnect" #num of entries = grep $errormsg $apm_log | grep $hourmin | wc -l #When (num of entries < crit_threshold), no action #When (crit_threshold <= num of entries < alert_threshold), log crtitical message. #When (alert_threshold <= num of entries < emerg_threshold), log alert message. #When (emerg_threhold <= num of entries log emerg message set crit_threshold 4 set alert_threshold 7 set emerg_threshold 10 #Number of minutes to take average of. E.g. Every 1.0, 2.0, 3.0, 4.0... minutes set period 3.0 #Set this to 1 to log to /var/tmp/scriptd.out. Set to 0 to disable. set DEBUG 0 set total 0 puts "\n[clock format [clock seconds] -format "%b %e %H:%M:%S"] Running script..." for {set i 1} {$i <= $period} {incr i} { set hourmin [clock format [clock scan "-$i minute"] -format "%b %e %H:%M:"] set errorcode [catch {exec grep $errormsg $apm_log | grep $hourmin | wc -l} num_entries] if{$errorcode} { set num_entries 0 } if {$DEBUG} {puts "DEBUG: $hourmin \"$errormsg\" logged $num_entries times."} set total [expr {$total + $num_entries}] } set average [expr $total / $period] set average [format "%.1f" $average] if{$average < $crit_threshold} { if {$DEBUG} {puts "DEBUG: $hourmin \"$errormsg\" logged $average times on average. Below all threshold. No action."} exit } if{$average < $alert_threshold} { if {$DEBUG} {puts "DEBUG: $hourmin \"$errormsg\" logged $average times on average. Reached critical threshold $crit_threshold. Log Critical msg."} exec logger -p local1.crit "01490266: \"$errormsg\" logged $average times on average in last $period mins. >= critical threshold $crit_threshold." exit } if{$average < $emerg_threshold} { if {$DEBUG} {puts "DEBUG: $hourmin \"$errormsg\" logged $average times on average. Reached alert threshold $alert_threshold. Log Alert msg."} exec logger -p local1.alert "01490266: \"$errormsg\" logged $average times on average in last $period mins. >= alert threshold $alert_threshold." exit } if {$DEBUG} {puts "DEBUG: $hourmin \"$errormsg\" logged $average times on average in last $period mins. Log Emerg msg"} exec logger -p local1.emerg "01490266: \"$errormsg\" logged $average times on average in last $period mins. >= emerg threshold $emerg_threshold." exit } 4. Configure the variables in the script as needed and exit the editor by entering the following command: :wq! y 5. Run the following command to list the contents of the script: list sys icall script vpn_reconnect_script 2. Creating a periodic iCall handler to run the script In this example, you create the iCall handler to run the script once a minute. You can increase this interval to once every two minutes or longer. However, you should consider this value together with theperiodvalue of the script in the previous procedure to ensure that you're notified on any potential issues early. Procedure Perform the following procedure to create the periodic handler that runs the script once a minute. To create an iCall periodic handler, perform the following procedure: Log in to tmsh. Enter the following command to create a periodic handler: create sys icall handler periodic vpn_reconnect_handler interval 60 script vpn_reconnect_script 3. Run the following command to list the handler: list sys icall handler periodic vpn_reconnect_handler 4. You can start and stop the handler by using the following command syntax: <start|stop> sys icall handler periodic vpn_reconnect_handler 3. Testing the implementation using logger You can use theloggercommand to log test messages to the/var/log/apmfile to test your implementation. To do so, run the following command the required number of times to exceed the threshold you set: Note: The following message must contain the keyword that you are searching for in the script. In this case, the keyword is Reconnect. logger -p local1.notice "01490549:5 Assigned PPP Dynamic IPv4: 10.10.1.20 ID: 033d0635 Tunnel Type: VPN_TUNNELTYPE_TLS NA Resource: /Common/AP_policy_na_res Client IP: 172.2.2.2 - Reconnect" Follow the/var/tmp/scriptd.outand/var/log/apm file entries to verify your implementation is working correctly. Conclusion This article lists three use cases for using iCall to monitor the health of your BIG-IP APM system. The examples mainly log the appropriate messages in the log files. You can extend the examples to monitor more parameters and also perform different kinds of actions such as calling another script (Bash, Perl, and so on) to send an email notification or perform remedial action.1.3KViews1like5Comments
AWS Auto Scale Group to F5 BIG-IP via a webhook
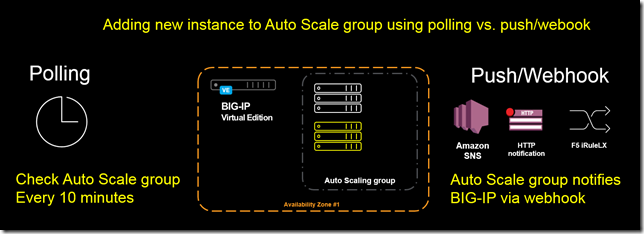
Polling vs. Pushing Traditionally a Networking Engineer/Operator makes configuration changes on a BIG-IP. In a cloud environment, like Amazon Web Services (AWS), we expect that the infrastructure will propagate the changes without the need for manual intervention. The following article describes how to use Amazon Web Services (AWS) Auto Scale and AWS Simple Notification Service (SNS) to trigger a dynamic update of a server pool on the F5 BIG-IP. A summary of the process will be; AWS Auto Scale group will notify AWS SNS of any changes, SNS will send a notification to an iRuleLX process on the BIG-IP that will trigger an update of the pool on the BIG-IP. TMOS has supported the ability to configure a pool from an AWS Auto Scale group since version 12.1.0. The updates are triggered by periodically polling the AWS API (default 10 minutes). The workflow is the following: BIG-IP contacts the AWS API to check for changes to an autoscale group BIG-IP updates pool with members from AWS Auto Scale group Wait 10 minutes In some cases you may want to trigger an update of a pool when an AWS Auto Scale group launches or terminates a new instance. Ideally something like (implemented later in this article) AWS Auto Scale Group changes Triggers notification to BIG-IP BIG-IP contacts the AWS API to check for changes to an Auto Scale group BIG-IP updates pool with members from AWS Auto Scale group This changes the workflow from a polling update to a push model. To make this work we’ll have to take advantage of a combination of F5 and AWS solutions. The following are a set of the leveraged technologies. Technologies Webhook This term refers to a mechanism to provide an alternative to polling for an update. A service will subscribe for notifications and when a notification is ready it will push the update back to the URL that was specified to receive the update. Common use-cases are used with services like GitHub / Slack for handling things like notification when code is committed and sending a message to a Slack channel. A precursor to the Slack example would have been an IRC bot. AWS Auto Scaling groups AWS Auto Scale Groups provide an option for an administrator to maintain a group of servers that can be dynamically scaled up or down. When changes are made to an AWS Auto Scale group an administrator can opt to send a notification to the AWS Simple Notification Service (SNS). AWS Simple Notification Service AWS SNS provides a mechanism for receiving events/topic notifications and sending messages to subscribers of those topics. SNS can send an e-mail notification or in the case of this article we will use HTTP/HTTPS to send a message to a BIG-IP. SNS requires that when you configure an HTTP/HTTPS message that you confirm via a subscription URL that is sent with the initial request. F5 iRuleLX iRuleLX offers the ability to extend the TCL based iRule and use a language like JavaScript to perform more advanced functionality. In this article we’ll use a 3 rd party Node.JS (JavaScript runtime) library to validate a SNS message. Something that would be challenging in TCL but easy in JavaScript. See also “Getting Started with iRules LX”. F5 iCall iCall provides the ability to trigger TMSH commands based on events. For the TMOS 12.1.0 AWS Auto Scale Group support the BIG-IP uses iCall to run a BASH script every 10 minutes. iCall can use other event triggers including an update to iStats. F5 iStats iStats provides the ability to create custom data counters (i.e. track usage of different SSL ciphers). For this article it will be used to trigger the update of the BIG-IP pool. This idea is taken from the following article. Step-by-step Now that we’ve reviewed the technologies involved let’s take a look at how to stich these together to make a dynamic solution. Create Auto Scale configuration Start by following the directions for Auto Scaling Application Servers in AWS. Create SNS Topic Create a unique topic that will be used only for the BIG-IP. Configure it to send either an HTTP/HTTPS request to an Elastic IP (public). This EIP will have the iRuleLX that will trigger the update. Create Auto Scale group Notification From the Auto Scale Notifications tab configure a notification to be sent on launch/terminate to the SNS topic that you previously created. Create iRuleLX iRuleLX has two components. A TCL script (a.k.a. plain old iRule) and JavaScript. The iRule part is the following. # # aws_sns_irule # # Receive SNS Message at a specific URI. # Capture POST data and send to iRuleLX process # When Notification message is received update iStats object # when HTTP_REQUEST { # only allow requests to specific/magic URI. SNS requests will originate from # AWS IP space. Ideally also use SSL. set magic_uri "/unicorns_and_rainbows_2016" # grab POST data from body of request if {[HTTP::method] eq "POST" && [HTTP::uri] eq $magic_uri }{ # Trigger collection for up to 1MB of data if {[HTTP::header "Content-Length"] ne "" && [HTTP::header "Content-Length"] <= 1048576}{ set content_length [HTTP::header "Content-Length"] } else { set content_length 1048576 } # Check if $content_length is not set to 0 if { $content_length > 0} { HTTP::collect $content_length } } else { # only accept POST requests reject } } when HTTP_REQUEST_DATA { # process POST body (JSON) set payload [HTTP::payload] set RPC_HANDLE [ILX::init aws_sns_plugin aws_sns_nodejs] set rpc_response [ILX::call $RPC_HANDLE process_aws_sns $payload] if { $rpc_response eq "Notification" } { log local0. "Updating AWS Auto Scale via webhook" ISTATS::set "AWS autoscale string erchen-autoscale-group" 1 } elseif { $rpc_response eq "Error"} { log local0. "Bad request" HTTP::respond 500 content "Error" return } HTTP::respond 200 content "Success" } The iRule code receives a POST request from SNS and sends the body of the request (JSON payload) to iRuleLX to process the payload. After processing the payload in iRuleLX it will update an iStats key that will be used to trigger an iCall script that invokes the BASH script that updates the BIG-IP pool. The JavaScript part (index.js) is the following. /* Import modules. * f5-nodejs: required * https: used to fetch subscription URL * sns-validator: used to verify SNS message */ var f5 = require('f5-nodejs'); var https = require('https'); var MessageValidator = require('sns-validator'), validator = new MessageValidator(); /* Create a new rpc server for listening to TCL iRule calls. */ var ilx = new f5.ILXServer(); ilx.addMethod('process_aws_sns', function(req, res) { /* parse message body as JSON. Error out if invalid */ try { var payload = JSON.parse(req.params(0)); } catch (err) { res.reply('Error'); return; } /* Use sns-validator to ensure valid SNS message */ validator.validate(payload, function(err, payload) { if (err) { console.error(err); res.reply('Error'); return; } /* in case of Subscription message. Send GET request. */ if (payload.Type == 'SubscriptionConfirmation') { console.log('Subscribing to SNS Topic'); console.log(payload.SubscribeURL); https.get(payload.SubscribeURL); } /* return SNS message Type */ res.reply(payload.Type); }); }); /* Start listening for ILX::call and ILX::notify events. */ ilx.listen(); The JavaScript code loads the “https” module for making a subscription request and the “sns-validator” module (use NPM to install) for validating the SNS message. When a message is received from the iRule it first parses the message into JSON and validates the message. Any errors are logged. In the case that the message includes a subscription request the BIG-IP will make a GET request to the URL that is embedded in the message. Modify iCall The iRule triggers an update by updating an iStats object. To reset the trigger you need to modify the iCall script to unset the iStats object. sys icall script autoscale { app-service none definition { exec /usr/libexec/aws/autoscale/aws-autoscale-pool-manager.sh exec istats remove "AWS autoscale string erchen-autoscale-group" } description none events none } This can be modified via TMSH running “edit /sys icall script autoscale”. Attach iRuleLX to Virtual Server Create a VIrtual Server that will host the webhook. You could dedicate a separate Virtual Server or allocate a non-standard port. For security you should utilize SSL, but for testing you can use a non-SSL VS. SNS needs to be able to communicate with a public IP. Make sure that you have an Elastic IP attached to the VS that you choose to use and an appropriate security group to allow communication. Create Subscription Now that you have the BIG-IP setup to receive a webhook you can go back into AWS SNS to create a subscription to the topic that you created earlier. Specify the Elastic IP / URI that you configured previously (i.e. http(s)://[Elastic IP]/[configured URI]). All Together Once everything has been plumbed together you can test it out by making a change to your Auto Scale group. The following are some sample logs of the initial subscription to the SNS Topic and receiving a notification from the Auto Scale group. Nov 23 07:08:49 ip-10-1-1-59 info sdmd[6129]: 018e0017:6: pid[27803] plugin[/Common/aws_sns_plugin.aws_sns_nodejs] Subscribing to SNS Topic Nov 23 07:08:49 ip-10-1-1-59 info sdmd[6129]: 018e0017:6: pid[27803] plugin[/Common/aws_sns_plugin.aws_sns_nodejs] https://sns.us-east-1.amazonaws.com/?Action=ConfirmSubscription&TopicArn=arn:aws:sns:us-east-1:XXX:trigger-f5-aws-autoscale-pool-manager&Token=XXX Nov 23 07:09:50 ip-10-1-1-59 info tmm[10437]: Rule /Common/aws_sns_plugin/aws_sns_irule : Updating AWS Auto Scale via webhook Nov 23 07:09:51 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Starting. Nov 23 07:09:52 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Using region us-east-1 Nov 23 07:09:52 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Using AutoScaling Url http://autoscaling.us-east-1.amazonaws.com Nov 23 07:09:52 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Updating pool : erchen-autoscale-group_pool with instances from Auto Scale Group : erchen-autoscale-group Nov 23 07:09:56 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Auto Scale Group : erchen-autoscale-group contains 2 instances Nov 23 07:09:56 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : erchen-autoscale-group : 10.1.20.210 10.1.20.105 Nov 23 07:09:56 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : erchen-autoscale-group_pool contains 1 instances Nov 23 07:09:56 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : erchen-autoscale-group_pool : 10.1.20.210 Nov 23 07:09:56 ip-10-1-1-59 notice logger: aws-autoscale-pool-manager.sh : Adding ip-10_1_20_105 with ip 10.1.20.105 to pool erchen-autoscale-group_pool Compared to the Auto Scale group log you can see that the BIG-IP picked up the change very quickly. Programmable Proxy Both AWS and F5 provide environments that are highly programmable. Please share your ideas on how you’re building a programmable proxy in AWS.747Views0likes0Comments