Lightboard Lessons: BIG-IP Deployments in Azure Cloud
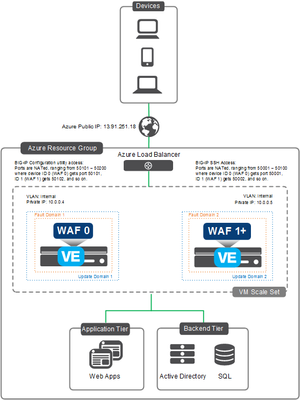
In this edition of Lightboard Lessons, I cover the deployment of a BIG-IP in Azure cloud. There are a few videos associated with this topic, and each video will address a specific use case. Topics will include the following: Azure Overview with BIG-IP BIG-IP High Availability Failover Methods Glossary: ALB = Azure Load Balancer ILB = Azure Internal Load Balancer HA = High Availability VE = Virtual Edition NVA = Network Virtual Appliance DSR = Direct Server Return RT = Route Table UDR = User Defined Route WAF = Web Application Firewall Azure Overview with BIG-IP This overview covers the on-prem BIG-IP with a 3-nic example setup. I then discuss the Azure cloud network and cloud components and how that relates to making a BIG-IP work in the Azure cloud. Things discussed include NICs, routes, network security groups, and IP configurations. The important thing to remember is that the cloud is not like on-prem regarding things like L2 and L3 networking components. This makes a difference as you assign NICs and IPs to each virtual machine in the cloud. Read more here on F5 CloudDocs for Azure BIG-IP Deployments. BIG-IP HA and Failover Methods The high availability section will review three different videos. These videos will discuss the failover methods for a BIG-IP cluster and how traffic can failover to the second device upon a failover event. I also discuss IP addressing options for the BIG-IP VIP/listeners and "why". Question: “Which F5 solution is right for me? Autoscaling or HA solutions?” Use these bullet points as guidance: Auto Scale Solution Ramp up/down time to consider as new instances come and go Dynamically adjust instance count based on CPU, memory, and throughput No failover, all devices are Active/Active Self-healing upon device failure (thanks to cloud provider native features) Instances are deployed with 1-NIC only HA Failover (non auto scale) No Ramp up/down time since no additional devices are "auto" scaling No dynamic scaling of the cluster, it will remain as two (2) instances Yes failover, UDRs and IP config will failover to other BIG-IP instance No self-healing, manual maintenance is required by user (similar to on-prem) Instances can be deployed with multiple NICs if needed HA Using API for Failover How do IP addresses and routes failover to the other BIG-IP unit and still process traffic with no layer 2 (L2) networking? Easy, API calls to the cloud. When you deploy an HA pair of BIG-IP instances in the Azure cloud, the BIG-IP instances are onboarded with various cloud scripts. These scripts help facilitate the moving of cloud objects by detecting failover events, triggering API calls to Azure cloud, and thus moving cloud objects (ex. Azure IPs, Azure route next-hops). Traffic now processes successfully on the newly active BIG-IP instance. Benefits of Failover via API: This is most similar to a traditional HA setup No ALB or ILB required VIPs, SNATs, Floating IPs, and managed routes (UDR) can failover to the peer SNAT pool can be used if port exhaustion is a concern SNAT automap is optional (UDR routes needed if SNAT none) Requirements for Failover via API: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 Mutli-NIC required Other things to know: BIG-IP pair will be active/standby Failover times are dependent on Azure API queue (30-90 seconds, sometimes longer) I have experienced up to 20 minutes to failover IPs (public IPs, private IPs) UDR route table entries typically take 5-10 seconds in my testing experience BIG-IP listener can be secondary private IP associated with NIC can be an IP within network prefix being routed to BIG-IP via UDR Read about the F5 GitHub Azure Failover via API templates. HA Using ALB for Failover This type of BIG-IP deployment in Azure requires the use of an Azure load balancer. This ALB sits in a Tier 1 position and acts as an Layer 4 (L4) load balancer to the BIG-IP instances. The ALB performs health checks against the BIG-IP instances with configurable timers. This can result in a much faster failover time than the "HA via API" method in which the latter is dependent on the Azure API queue. In default mode, the ALB has Direct Server Return (DSR) disabled. This means the ALB will DNAT the destination IP requested by the client. This results in the BIG-IP VIP/listener IP listening on a wildcard 0.0.0.0/0 or the NIC subnet range like 10.1.1.0/24. Why? Because ALB will send traffic to the BIG-IP instance on a private IP. This IP will be unique per BIG-IP instance and cannot "float" over without an API call. Remember, no L2...no ARP in the cloud. Rather than create two different listener IP objects for each app, you can simply use a network range listener or a wildcard. The video has a quick example of this using various ports like 0.0.0.0/0:443, 0.0.0.0/0:9443. Benefits of Failover via LB: 3-NIC deployment supports sync-only Active/Active or sync-fail Active/Standby Failover times depend on ALB health probe (ex. 5 sec) Multiple traffic groups are supported Requirements for Failover via LB: ALB and/or ILB required SNAT automap required Other things to know: BIG-IP pair will be active/standby or active/active depending on setup ALB is for internet traffic ILB is for internal traffic ALB has DSR disabled by default Failover times are much quicker than "HA via API" Times are dependent on Azure LB health probe timers Azure LB health probe can be tcp:80 for example (keep it simple) Backend pool members for ALB are the BIG-IP secondary private IPs BIG-IP listener can be wildcard like 0.0.0.0/0 can be network range associated with NIC subnet like 10.1.1.0/24 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Read about the F5 GitHub Azure Failover via ALB templates. HA Using ALB for Failover with DSR Enabled (Floating IP) This is a quick follow up video to the previous "HA via ALB". In this fourth video, I discuss the "HA via ALB" method again but this time the ALB has DSR enabled. Whew! Lots of acronyms! When DSR is enabled, the ALB will send the traffic to the backend pool (aka BIG-IP instances) private IP without performing destination NAT (DNAT). This means...if client requested 2.2.2.2, then the ALB will send a request to the backend pool (BIG-IP) on same destination 2.2.2.2. As a result, the BIG-IP VIP/listener will match the public IP on the ALB. This makes use of a floating IP. Benefits of Failover via LB with ALB DSR Enabled: Reduces configuration complexity between the ALB and BIG-IP The IP you see on the ALB will be the same IP as the BIG-IP listener Failover times depend on ALB health probe (ex. 5 sec) Requirements for Failover via LB: DSR enabled on the Azure ALB or ILB ALB and/or ILB required SNAT automap required Dummy VIP "healthprobe" to check status of BIG-IP on individual self IP of each instance Create one "healthprobe" listener for each BIG-IP (total of 2) VIP listener IP #1 will be BIG-IP #1 self IP of external network VIP listener IP #2 will be BIG-IP #2 self IP of external network VIP listener port can be 8888 for example (this should match on the ALB health probe side) attach iRule to listener for up/down status Example iRule... when HTTP_REQUEST { HTTP::respond 200 content "OK" } Other things to know: ALB is for internet traffic ILB is for internal traffic BIG-IP pair will operate as active/active Failover times are much quicker than "HA via API" Times are dependent on Azure LB health probe timers Backend pool members for ALB are the BIG-IP primary private IPs BIG-IP listener can be same IP as the ALB public IP can use different ports for different apps like 2.2.2.2:443, 2.2.2.2:8443 Read about the F5 GitHub Azure Failover via ALB templates. Also read about Azure LB and DSR. Auto Scale BIG-IP with ALB This type of BIG-IP deployment takes advantage of the native cloud features by creating an auto scaling group of BIG-IP instances. Similar to the "HA via LB" mentioned earlier, this deployment makes use of an ALB that sits in a Tier 1 position and acts as a Layer 4 (L4) load balancer to the BIG-IP instances. Azure auto scaling is accomplished by using Azure Virtual Machine Scale Sets that automatically increase or decrease BIG-IP instance count. Benefits of Auto Scale with LB: Dynamically increase/decrease BIG-IP instance count based on CPU and throughput If using F5 auto scale WAF templates, then those come with pre-configured WAF policies F5 devices will self-heal (cloud VM scale set will replace damaged instances with new) Requirements for Auto Scale with LB: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 ALB required SNAT automap required Other things to know: BIG-IP cluster will be active/active BIG-IP will be deployed with 1-NIC BIG-IP onboarding time BIG-IP VE process takes about 3-8 minutes depending on instance type and modules Azure VM Scale Set configured with 10 minute window for scale up/down window (ex. to prevent flapping) Take these timers into account when looking at full readiness to accept traffic BIG-IP listener can be wildcard like 0.0.0.0/0 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Licensing PAYG marketplace licensing can be used BIG-IQ license manager can be used for BYOL licensing Sorry, no video yet...a picture will have to do! Here's an example diagram of auto scale with ALB. Read about the F5 GitHub Azure Auto Scale via ALB templates. Auto Scale BIG-IP with DNS This type of BIG-IP deployment takes advantage of the native cloud features by creating an auto scaling group of BIG-IP instances. Unlike "HA via LB" mentioned earlier or "Auto Scale with ALB", this deployment makes use of DNS that acts as a method to distribute traffic to the auto scaling BIG-IP instances. This solution integrates with F5 BIG-IP DNS (formerly named GTM). And...since there is no ALB in front of the BIG-IP instances, this means you do not need SNAT automap on the BIG-IP listeners. In other words, if you have apps that need to see the real client IP and they are non-HTTP apps (can't pass XFF header) then this is one method to consider. Benefits of Auto Scale with DNS: Dynamically increase/decrease BIG-IP instance count based on CPU and throughput If using F5 auto scale WAF templates, then those come with pre-configured WAF policies F5 devices will self-heal (cloud VM scale set will replace damaged instances with new) ALB not required (cost savings) SNAT automap not required Requirements for Auto Scale with DNS: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 SNAT automap optional BIG-IP DNS (aka GTM) needs connectivity to each BIG-IP auto scaled instance Other things to know: BIG-IP cluster will be active/active BIG-IP will be deployed with 1-NIC BIG-IP onboarding time BIG-IP VE process takes about 3-8 minutes depending on instance type and modules Azure VM Scale Set configured with 10 minute window for scale up/down window (ex. to prevent flapping) Take these timers into account when looking at full readiness to accept traffic BIG-IP listener can be wildcard like 0.0.0.0/0 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Licensing PAYG marketplace licensing can be used BIG-IQ license manager can be used for BYOL licensing Sorry, no video yet...a picture will have to do! Here's an example diagram of auto scale with DNS. Read about the F5 GitHub Azure Auto Scale via DNS templates. Summary That's it for now! I hope you enjoyed the video series (here in full on YouTube) and quick explanation. Please leave a comment if this helped or if you have additional questions. Additional Resources F5 High Availability - Public Cloud Guidance The Hitchhiker’s Guide to BIG-IP in Azure The Hitchhiker’s Guide to BIG-IP in Azure – “Deployment Scenarios” The Hitchhiker’s Guide to BIG-IP in Azure – “High Availability” The Hitchhiker’s Guide to BIG-IP in Azure – “Life Cycle Management”8.9KViews7likes7CommentsConfigure HA Groups on BIG-IP
Last week we talked about how HA Groups work on BIG-IP and this week we’ll look at how to configure HA Groupson BIG-IP. To recap, an HA group is a configuration object you create and assign to a traffic group for devices in a device group. An HA group defines health criteria for a resource (such as an application server pool) that the traffic group uses. With an HA group, the BIG-IP system can decide whether to keep a traffic group active on its current device or fail over the traffic group to another device when resources such as pool members fall below a certain level. First, some prerequisites: Basic Setup: Each BIG-IP (v13) is licensed, provisioned and configured to run BIG-IP LTM HA Configuration: All BIG-IP devices are members of a sync-failover device group and synced Each BIG-IP has a unique virtual server with a unique server pool assigned to it All virtual addresses are associated with traffic-group-1 To the BIG-IP GUI! First you go to System>High Availability>HA Group List>and then click the Create button. The first thing is to name the group. Give it a detailed name to indicate the object group type, the device it pertains to and the traffic group it pertains to. In this case, we’ll call it ‘ha_group_deviceA_tg1.’ Next, we’ll click Add in the Pools area under Health Conditions and add the pool for BIG-IP A to the HA Group which we’ve already created. We then move on to the minimum member count. The minimum member count is members that need to be up for traffic-group-1 to remain active on BIG-IP A. In this case, we want 3 out of 4 members to be up. If that number falls below 3, the BIG-IP will automatically fail the traffic group over to another device in the device group. Next is HA Score and this is the sufficient threshold which is the number of up pool members you want to represent a full health score. In this case, we’ll choose 4. So if 4 pool members are up then it is considered to have a full health score. If fewer than 4 members are up, then this health score would be lower. We’ll give it a default weight of 10 since 10 represents the full HA score for BIG-IP A. We’re going to say that all 4 members need to be active in the group in order for BIG-IP to give BIG-IP A an HA score of 10. And we click Add. We’ll then see a summary of the health conditions we just specified including the minimum member count and sufficient member count. Then click Create HA Group. Next, we go to Device Management>Traffic Groups>and click on traffic-group-1. Now, we’ll associate this new HA Group with traffic-group-1. Go to the HA Group setting and select the new HA Group from the drop-down list. And then select the Failover Method to Device with the Best HA Score. Click Save. Now we do the same thing for BIG-IP B. So again, go to System>High Availability>HA Group List>and then click the Create button. Give it a special name, click Add in the Pools area and select the pool you’ve already created for BIG-IP B. Again, for our situation, we’ll specify a minimum of 3 members to be up if traffic-group-1 is active on BIG-IP B. This minimum number does not have to be the same as the other HA Group, but it is for this example. Again, a default weight of 10 in the HA Score for all pool members. Click Add and then Create HA Group for BIG-IP B. And then, Device Management>Traffic Groups> and click traffic-group-1. Choose BIG-IP B’s HA Group and select the same Failover method as BIG-IP A – Based on HA Score. Click Save. Lastly, you would create another HA Group on BIG-IP C as we’ve done on BIG-IP A and BIG-IP B. Once that happens, you’ll have the same set up as this: As you can see, BIG-IP A has lost another pool member causing traffic-group-1 to failover and the BIG-IP software has chosen BIG-IP C as the next active device to host the traffic group because BIG-IP C has the highest HA Score based on the health of its pool. Thanks to our TechPubs group for the basis of this article and check out a video demo here. ps8.7KViews1like0Comments