OpenSSL HeartBleed, CVE-2014-0160
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed The Heartbleed attack in OpenSSL 1.0.1 and beyond allows an attacker to get up to 64k of process data from a TLS heartbeat response. The 64k of data will quite often contain sensitive information such as keys or passwords. There are quite a few exploits in the wild already for this attack. F5 has analyzed this attack and we are pleased to say that BIG-IP data traffic using an SSL profile with default ciphers is not vulnerable to this attack. BIG-IP SSL profiles terminate the SSL traffic on the BIG-IP, so the malicious heartbeat never gets to your webservers. TLS heartbeats are not enabled on current versions of BIG-IP, so any virtual server protected by an SSL profile is not vulnerable. However, if you are not using the SSL termination capabilities of the BIG-IP, then the attack will pass directly through the BIG-IP and to the webservers. You may be vulnerable depending on the webservers you use. BIG-IP versions 11.5.0 and 11.5.1 do use OpenSSL 1.0.1 for the management GUI and are vulnerable to the attack. Versions of BIG-IP older than 11.5 are not vulnerable. F5 encourages using a private management network that is not connected to the internet. A hotfix is available for the management GUI. Get the latest updates on how F5 mitigates Heartbleed See the AskF5 solution for more information. A mitigation for virtual servers that do not use SSL termination If you are using a simple load balancing virtual server without an SSL profile, then the traffic is passing directly to your webservers. My great F5 colleagues and I have written an iRule that mitigates this vulnerability when the client sends a heartbeat. Since we haven't seen a valid client that sends heartbearts, we like this solution. If you have clients that do send valid heartbeats, then we have an iRule that watches for large heartbeat responses and kills the connection before they are sent to the client.1.6KViews0likes8CommentsSSL Heartbleed iRule update
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed For those of you tuning in to learn more about the OpenSSL Heartbleed vulnerability, here are more details about it and how F5 customers are protected.The iRule below mitigates the Heartbleed vulnerability forvirtual servers that do not use SSL termination. This iRule will find any heartbeat request from a client and close the connection immediately. We believe this is an effective mitigation because we have not seen any clients that send a valid heartbeat request, even if they do advertise heartbeat support. Most of the malicious clients we've seen don't bother to do a full TLS handshake; they start the handshake, then send the malicious heartbeat request. This iRule works even if someone writes a malicious client that negotiates the full SSL handshake then sends an encrypted heartbeat reqest. ############################################## # Name: heatbleed.c rejector irule. # Description: This irule is a tweak to https://devcentral.f5.com/s/articles/ssl-heartbleed-irule-update # Purpose: to block heartbleed requests. # - added check for 768 and 769 ( SSLv3 and TLSv1 ) # - Ensure r is a positive value. This only happens when there is no valid SSL record. # VERSION: 4 - 16.apr.14 ############################################## when CLIENT_ACCEPTED { TCP::collect set s 0 set r 0 } when CLIENT_DATA { set c [TCP::payload length] set i 0 while { $i < $c } { set b [expr {$c - $i}] if { $s } { # skipping payload if { $b >= $r } { set s 0 set i [expr {$i + $r}] } else { set r [expr {$r - $b}] set i [expr {$i + $b}] } } else { # parsing TLS record header if { $b < 5 } { break } binary scan [TCP::payload] @${i}cSS t v r set r [expr {$r & 0xFFFF}] set i [expr {$i + 5}] if { $t == 24 }{ switch -- $v { "768" - "769" - "770" - "771" - "772" { log local0. "Detected Heartbeat Request from [IP::remote_addr]. REJECTING!" reject } } } set s 1 } } TCP::release $i TCP::collect } If you have clients that do issue valid heartbeat requests,we have a server side iRule that will only pass valid short heartbeat responses at the cost of a small performance penalty.1KViews0likes11CommentsSSL Heartbleed server side iRule
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed For those of you tuning in to learn more about the OpenSSL Heartbleed vulnerability,here are more details about it and how F5 customers are protected.The iRule below mitigates the Heartbleed vulnerability forvirtual servers that do not use SSL termination. This iRule is very similar to the client iRule, except it watches the server responses searching for a heartbeat. If it sees one that is longer than 128 bytes, it rejects the connection. As TCP segments arrive, we pick out the TLS records, which are rarely aligned with the containing TCP segment. The current segment may contain zero or more TLS records. All we know for sure is that the first 5 bytes of the first segment is a TLS record header. In the presentation language of the TLSv1.2 protocol specification (RFC5246), a TLS record is called TLSPlaintext. Here’s the relevant presentation: struct { uint8 major; uint8 minor; } ProtocolVersion; enum { change_cipher_spec(20), alert(21), handshake(22), application_data(23), (255) } ContentType; struct { ContentType type; ProtocolVersion version; uint16 length; opaque fragment[TLSPlaintext.length]; } TLSPlaintext; The code will parse the first five bytes of TLSPlaintext, which includes the fields type, version and length. Because these are always unencrypted, we use these bytes to determine if the server is sending an exceptionally long heartbeat response message. If we see the attack, we log and reject the connection. If the attack is not seen, we must skip the fragment, then look for another record header. This script is almost identical to the client-side script we posted yesterday. But because there’s so much more data in a typical web server stream, this one will affect performance a bit more than the previous. The advantage here is that by examining the length of the heartbeat response, we can more reliably detect the attack, allowing non-attack heartbeats through. It was difficult to find an off-the-shelf client that would actually send benign heartbeat requests. We just scripted one up for testing purposes. Curl and other OpenSSL-based clients will typically run with the library’s default behavior, which is to advertise support for heartbeats, but never actually send them. If that’s true on your network, then use the client-side script we posted yesterday. If not, and you have valid uses of the client-side heartbeats, then use this script. ############################################## # Name: Server side block_heartbleed iRule. # Description: This irule will detect a long TLS heartbeat response # and reject the TCP connection. It uses TCP::collect and TCP::release # more efficiently, which results in a much lower performance # penalty compared with the previous version. # VERSION: 2 - 12.apr.14 ############################################## when SERVER_CONNECTED { set Debug 1 set HB_Size_Max 64 TCP::collect 5 } when SERVER_DATA { set Buf_Len [TCP::offset] set Skip_Len 0 set Collect_Len 0 while { $Collect_Len == 0 && $Buf_Len > 0 } { set Skip_Len 0 set Collect_Len 0 # Start of new Rec(s) binary scan [TCP::payload] cSS Rec_Type Version Rec_Len if { ($Rec_Type == 24) } { if { $Rec_Len > $HB_Size_Max } { if { $Debug > 0 } { log local0. [format "BIG HEARTBEAT len %i; conn reset" $Rec_Len $Rec_Len] } reject return } elseif { $Debug > 1 } { log local0. [format "HEARTBEAT len %i (%#x)" $Rec_Len $Rec_Len] } } TCP::release 5 incr Buf_Len -5 # From current buffer, release as much data as possible. if { $Rec_Len > 0 } { # Partial data. Prepare to passthru remainder, then collect next header. if { $Buf_Len < $Rec_Len } { TCP::release $Buf_Len incr Rec_Len -$Buf_Len set Skip_Len $Rec_Len set Collect_Len 5 } else { # Complete data. TCP::release $Rec_Len set Rec_Len 0 } } set Buf_Len [TCP::offset] # If buffer does not contain full next header, prepare to collect. if { $Buf_Len < 5 } { set Collect_Len 5 incr Collect_Len -$Buf_Len } if { $Collect_Len > 0 } { if { $Skip_Len > 0 } { TCP::collect $Collect_Len $Skip_Len } else { TCP::collect $Collect_Len } } } return } With this new iRule, you can be assured that your servers will not leak information.857Views0likes1CommentJune 2014 OpenSSL Vulnerabilities
On June 5 th 2014, the OpenSSL project released some new vulnerabilities on the tail of the heartbleed vulnerability. F5 fared pretty well through heartbleed because TLS terminating virtual servers were not affected and we even had the ability to stop heartbleed attacks against simple TCP virtual servers. The latest OpenSSL vulnerabilities are not quite as bad. This article will go into depth on 2 of the vulnerabilities and explain the others. Let’s start with the easy ones and progress up to the fun ones. CVE-2014-3470 Anonymous ECDH DoS attack If a server advertises anonymous elliptic curve Diffie-Hellman ciphers, a malicious client could crash the server. F5 BIG-IP does not support anonymous ECDH ciphers on the management interface nor for dataplane traffic so we are not vulnerable. We have created ID465805 to track this vulnerability. CVE-2014-0198 and CVE-2010-5298 SSL_MODE_RELEASE_BUFFERS SSL_MODE_RELEASE_BUFFERS is a special flag that will treat OpenSSL memory slightly differently. F5 does not use this flag and are not vulnerable to this issue. We have created ID465804 for tracking purposes. DTLS flaws This is where it gets fun. DTLS is rather new, but is essentially TLS over UDP instead of TCP. CVE-2014-0221 DTLS handshake flaw This flaw happens when a server sends a malicious handshake message to a client. BIG-IP does not by default contain any DTLS clients and is not vulnerable. If you are using BIG-IP as a DTLS client, F5 will be patching all older releases over time. ID465803 has been created. CVE-2014-0195 DTLS fragmentation issue This is more worrisome, but BIG-IPs are still not vulnerable. OpenSSL has a flaw that could allow remote code execution from a DTLS message fragmented across UDP messages. It’s easiest to illustrate the vulnerability. Here is a simple example of a 300 byte message spread across 3 DTLS fragments. 100 bytes are sent every message until we have a complete message. The flaw happens when OpenSSL allocates memory for the initial message. First, let’s start with the same initial fragmented message. OpenSSL allocates space for 300 bytes. You know where this is going, right? Next the attacker sends another fragment. This time, the attacker sends a fragment with a new 1000 byte length and 900 bytes of data. OpenSSL tries to write 900 bytes into the 200 bytes that are left in the buffer and bad things happen. F5 BIG-IP does not support DTLS for the management traffic, so BIG-IP is not vulnerable. This flaw does not exist in the dataplane NATIVE DTLS code so BIG-IP is not vulnerable. If you are using COMPAT ciphers (not the default on later versions of BIG-IP) then you may be vulnerable.. CVE-2014-0224 Change Cipher Spec message This is a great vulnerability. It’s got a lot of complicated elements and it’s not intuitive. We have to first start with a man in the middle of our infant TLS connection. The attack happens before the server certificate has been checked and the attacker never tries to impersonate the server so the users’ browser will not even pop up a warning for a bad certificate. The MITM watches as the client sends his CLIENT_HELLO message. He passes that unmodified to the server. At this point, the MITM sends a Change Cipher Spec message to both the client and the server. This is a simple message that tells the server and the client that all new messages should use a new cipher. This message usually happens after a renegotiation Sending a CCS message during the handshake is forbidden by the protocol, but OpenSSL has ignored it since OpenSSL 0.9.8. New code was introduced into OpenSSL 1.0.1 to lock the TLS pre-master secret when a CCS message is received. This pre-master secret is used to generate the session key. It should be decided randomly later in the handshake. Since the pre-master secret is now set at a predictable value, the MITM can guess the session key. He can continue passing all further messages between the client and the server, but since he has the session key, all traffic can be decrypted or even modified. OpenSSL fixed the problem in OpenSSL 1.0.1h by dropping the connection when an early CCS message is received. The only way to be vulnerable to CVE-2014-0224 is to have an OpenSSL 1.0.1 server and an OpenSSL 0.9.8 or higher client. BIG-IP 11.5.0 and 11.5.1 use OpenSSL 1.0.1 for the management interface, so we are vulnerable. We are tracking this with ID 465799 and will be releasing a patch shortly. For now, you should ensure your management interface is isolated to a private network. We will be releasing fixes for all supported BIG-IP versions over time to patch the vulnerable clients that may be on the BIG-IP. See SOL 15325 for more information. However, there is good news. Dataplane virtual severs configured to use TLS termination are not vulnerable to this attack (unless you are using COMPAT ciphers; not the default). BIG-IP queues the CCS message and does not set the pre-master secret like OpenSSL. If you are using straight TCP virtual servers, then the attack will be passed through directly to your SSL servers. You could use a variant of the heartbleed mitigation iRule to stop early CCS messages. My team hasn’t written this iRule yet; it only needs to watch for a CCS message before the initial handshake is completed. If it occurs, the connection should be dropped. This is how patched OpenSSL operates. I must point out there are some tools in existence that incorrectly claim that BIG-IP TLS virtual servers are vulnerable. The tools merely send a client HELLO message and then immediately send a CCS message. If the server does not shut down the connection, then the tool claims the server is vulnerable. Even though we are not vulnerable, F5 plans to change our behavior to match OpenSSL. This is currently being tracked as ID465908 and will be released in hotfixes over time. Conclusion The OpenSSL saga keeps going. Heartbleed has put a lot of scrutiny on the code. F5 will continue to watch for vulnerable code and patch as needed. I hope you enjoyed this deep dive into the latest OpenSSL vulnerabilities.359Views0likes2Comments
Heartbleed and Perfect Forward Secrecy
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed #heartbleed #PFS #infosec Last week was a crazy week for information security. That's probably also the understatement of the year. With the public exposure of Heartbleed, everyone was talking about what to do and how to do it to help customers and the Internet, in general, deal with the ramifications of such a pervasive vulnerability. If you still aren't sure, we have some options available, check them out here: The most significant impact on organizations was related to what amounts to the invalidation of the private keys used to ensure secure communications. Researchers found that not only did exploitation of the vulnerability result in the sharing of passwords or sensitive data, but the keys to the organization's kingdom. That meant, of course, that anyone who'd managed to get them could decrypt any communication they'd snatched over the past couple of years while the vulnerable versions of OpenSSL were in use. Organizations must not not only patch hundreds (or thousands) of servers, but they must also go through the process of obtaining new keys. That's not going to be simple - or cheap. That's all because of the way PKI (Public key infrastructure) works. Your private key. And like the One Ring, Gandalf's advice to Frodo applies to organizations: keep it secret; keep it safe. What Heartbleed did was to make that impossible. There's really no way to know for sure how many private keys were exposed, because the nature of the vulnerability was such that exploitation left no trail, no evidence, no nothing. No one knows just what was exposed, only what might have been exposed. And that is going to drive people to assume that keys were compromised because playing with a potentially compromised key is ... as insane as Gollum after years of playing with a compromised Ring. There's no debating this is the right course of action and this post is not about that anyway, not really. Post-mortem blogs and discussions are generally around how to prevent similar consequences in the future, and this is definitely that kind of post. Now, it turns out that in the last year or so (and conspiracy theorists will love this) support for PFS (Perfect Forward Secrecy) has been introduced by a whole lot of folks. Both Microsoft and Twitter introduced support for the protocol late last year, and many others have followed suit. PFS was driven by a desire for providers to protect consumer privacy from government snooping, but it turns out that PFS would have done that as well in the case of Heartbleed being exploited. Even though PFS relies on a single private key, just as current encryption mechanisms, what PFS (and even FS) do with that key means that even if the key is compromised, it's not going to open up the world to the attacker. PFS uses the private key to generate what are called ephemeral keys; that is, they're keys based on the original but unique to either the conversation or a few, selected messages within a conversation, depending on the frequency with which ephemeral keys are generated.That means you can't use the private key to decrypt communication that's been secured using an ephemeral key. They're only related, not the same, and cryptography is pretty unforgiving when it comes to even a single bit difference in the data. In cryptography, forward secrecy (also known as perfect forward secrecy or PFS [1] ) is a property of key-agreement protocols ensuring that a session key derived from a set of long-term keys will not be compromised if one of the long-term keys is compromised in the future. The key used to protect transmission of data must not be used to derive any additional keys, and if the key used to protect transmission of data was derived from some other keying material, that material must not be used to derive any more keys. Thus, compromise of a single key will permit access only to data protected by a single key. -- Wikipedia, Forward secrecy This is the scenario for which PFS was meant to shine: the primary key is compromised, yet if enabled, no conversations (or transactions or anything else) can be decrypted with that key. Similarly, if the key currently being used to encrypt communications is compromised, it can only impact the current communication - no one else. PFS has only recently begun being supported, more recently than Heartbleed has been in existence. But now that we know it does exist, and the very real threat of vulnerabilities that compromise consumer privacy and organizational confidentiality, we should take a look at PFS and how it might benefit us to put it in place - before we find out about the next bleeding organ.346Views0likes0Comments
Heartbleed: Network Scanning, iRule Countermeasures
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed I just spent the last two days writing “business-friendly” copy about Heartbleed. I think the result was pretty good and hey, it even got on the front page of f5.com so I guess I got that going for me. Then I wrote up some media stuff and sales stuff and blah, blah blah. But what I really wanted was to do talk tech. So let’s go! What’s Wrong with OpenSSL? The Heartbleed vulnerability only affects systems derived from, or using, the OpenSSL library. I have experience with the OpenSSL library. As one of F5’s SSL developers I spent a lot of time with OpenSSL before we basically abandoned it in our data plane path. Here are some examples of what’s wrong with OpenSSL from someone who spent hundreds of hours mired in its gore. OpenSSL does weird things for weird reasons. As Theo De Raadt points out in his small rant, the team’s decision to use their own malloc and free instead of trusting the OS by default was a tactical fuckup with major future impacts (Heartbleed). OpenSSL has dozens of different APIs with a lack of consistency between them. For some APIs, the caller frees the returned memory. In others, the API frees the memory itself. It’s not documented which is which and this results in lots of memory leaks or worse, double-frees. There are pointers opaque everywhere. A higher-level interface or language (even C++ instead of C) could provide lots of protection, but instead we’re stuck with pointers and a lack of good memory protection. Those are just three off the top of my head. The real meta-issue for OpenSSL is this: There is no real, commercial organization has any stake in maintaining the OpenSSL library. Other open source code bases typically have some very close commercial firm that has a significant interest in maintaining and improving the library. BSD has Apple. Linux has Ubuntu. Gecko has Mozilla. OpenSSL has nobody. The premier security firm, RSA, long ago forked off their own copy of the library (even hiring away its original development team) and thus they don’t put changes back upstream for OpenSSL. Why would they? Maybe you could say that OpenSSL has Adam Langley (from Google) on its side, so at least it’s got that going for it. In Dan Kaminsky’s analysis about the aftermath of Heartbleed, he says that Professor Matthew Green of Johns Hopkins University makes a great point: OpenSSL should be considered Critical Infrastructure. Therefore, it should be receiving critical infrastructure funding, which could enable code audits, static code analysis, fuzz-testing, and all the other processes and improvements it deserves. I agree: in spite of all its flaws, OpenSSL has become the most significant cryptographic library in the history of computing. Speaking of Kaminsky, if you are looking for the last time there was a vulnerability of this severity, you’d probably have to go back to CVE-2008-1447 - the DNS Cache Poisoning Issue (aka the "Kaminsky bug"). I wonder if he wishes he’d made a logo for it. Detecting Heartbleed Is it worth trying to detect Heartbleed moving forward? Heartbleed is so severe that there’s a possibility that nearly all vulnerable systems will get patched quickly and we’ll stop talking about it except in a historical sense. But until that happens, it is worthwhile to detect both vulnerable servers and Heartbleed probes. There’s been some debate about whether probing for Heartbleed is legal, since a successful probe will return up to 64K of server memory (and therefore qualifies as a hack). Regardless of the legality, there’s a Metasploit module for Heartbleed. For your browsers there’s also a Google Chrome extension and a Mozilla Firefox extension. In fact, here’s a whole list of Heartbleed testing tools. Scanning a network for Heartbleed using nmap I used the nmap engine script to scan my home network from an Ubuntu 13.04 client desktop. The script requires a relatively recent version (6.25) of nmap so I had to upgrade. Is it me or is it always more of a pain to upgrade on Ubuntu than it should be? Install Heartbleed nmap script Upgrade to nmap 6.45 Install Subversion (if libsnv_client load error) Install tls.lua NSE script and ssl-heartbleed.nse script. Run against your network like this: nmap -oN ./sslhb.out --script ssl-heartbleed --script-args vulns.showall -sV 192.168.5.0/24 On my home network I found one vulnerable server which I knew about and one which I didn’t! Nmap scan report for 192.168.5.23 Host is up, received syn-ack (0.00078s latency). PORT STATE SERVICE REASON VERSION 22/tcp open ssh syn-ack OpenSSH 6.1p1 Debian 4 (protocol 2.0) 80/tcp open http syn-ack Apache httpd 2.2.22 ((Ubuntu)) 443/tcp open ssl/http syn-ack Apache httpd 2.2.22 ((Ubuntu)) | ssl-heartbleed: | VULNERABLE: | The Heartbleed Bug is a serious vulnerability in the popular OpenSSL cryptographic software library. It allows for stealing information intended to be protected by SSL/TLS encryption. | State: VULNERABLE | Risk factor: High Scanning your network (home or otherwise) should hopefully be just as easy. I love nmap, so cool. Heartbleed iRule Countermeasures You probably don’t need an iRule. If you are using BIG-IP in front of HTTP servers, your applications are already protected because the native SSL code path for all versions isn’t vulnerable. Over 90% of the HTTPS applications fronted by BIG-IP are protected by its SSL code. However, there may be reasons that you might have BIG-IP doing simply layer 4 load balancing to a pool of HTTPS servers. A pool of servers with a security policy restricting private keys to origin server hosts. An ingress point for multi-tenant SSL sites (using SNI and different keys). A virtual ADC fronting a pool of virtualized SSL sites. If any of these cases apply to your organization, we have an iRule to help. While I was busy writing all the copy for Heartbleed, my long-time colleague and friend Jeff Costlow was on a team of heroes developing a se tof iRules to counter Heartbleed. Here’s the iRule to reject client connections that attempt to send a TLS heartbeat. No browsers or tools (such as curl) that we know of actually send TLS heartbeats at this time so this should be relatively safe. Client-side Heartbleed iRule: https://devcentral.f5.com/s/articles/ssl-heartbleed-irule-update And here’s a server-side iRule. It watches for HTTPS heartbeat responses from your server and discards any that look suspicious (over 128 bytes). Use this one if you have a client app that sends heartbeats. Server-side Heartbleed iRule: https://devcentral.f5.com/s/articles/ssl-heartbleed-server-side-irule Like I said, you probably don’t need to deploy them. But if you do I suggest making the slight tweaks you need to make them compatible with High-Speed logging. Notes on Patching Systems See F5 Solution 15159 All F5 users on 11.5.0 or 11.5.1 should patch their systems with F5 Heartbleed hotfix. Users on 11.4 or earlier are safe with the version they have. This includes the virtual edition, which is based on 11.3.0 HF1. See the Ask F5 solution for more information on patching. And don’t ignore internal systems A colleague of mine recently reminded me that after you get your externally-facing systems patched (and their certificates redeployed) you need to take care of any internal systems that might be affected as well. Why? Let’s say you have an internal server running a recent version of Linux. And it uses a recent version of OpenSSL. Someone inside your organization (anyone) could send it Heartbleed probes and perhaps pick out passwords and browsing history (or bank records) or of course, the private keys in the system itself. It’s a privilege escalation problem. Conclusion If you need some less technical collateral to send to up your management chain about why your F5 systems are protecting your application from Heartbleed, here’s a link to that business-friendly copy: https://f5.com/solutions/mitigation/mitigating-openssl-heartbleed American computer scientist Gerald Weinberg once said, “If builders built buildings the way programmers wrote programs, the first woodpecker to come along would destroy civilization.” Heartbleed is one of those woodpeckers. We got lucky and had very limited exposure to it, so I guess we had that going for us. Hopefully you had limited exposure to it as well.345Views0likes2CommentsWhere you mitigate Heartbleed matters
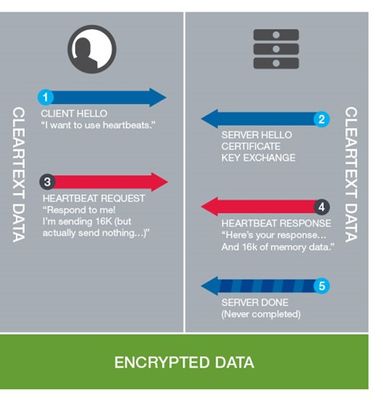
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed #heartbleed #infosec #SSL There are a variety of opinions on the seriousness of Heartbleed being put forth ranging from "it's not the end of the world" to "the sky is falling, duck and cover." Usually the former cites the relatively low percentage of sites impacted by Heartbleed, pegged at about 17% or 500,000 sites by Netcraft. The latter cite the number of consumers impacted, which is a way bigger number to be sure. Sites tracking the impact to users suggest many of the largest sites have potentially been impacted, translating into many millions of users. And then there’s the impact on gadgets and devices we might not immediately think of being vulnerable. A wide variety of smart phones, IP phones, switches and routers have been identified as being vulnerable. Home internet routers and that nifty system you had put in that lets you mess with your house’s temperature from any device, anywhere are likely impacted. With the Internet of Things connecting more and more devices it’s likely that list will only continue to grow. The growing consensus is that a plurality of the impacted devices will never be updated; leaving organizations that may interact with those devices vulnerable and in need of a mitigating solution that doesn’t rely on updates or changes to the device. There will be, as everyone scrambles to protect customers and consumers from Heartbleed, a variety of mitigating solutions offered up to address this pesky bug. Network devices will enable organizations with the visibility necessary to detect and reject requests attempting to exploit the vulnerability. There are a variety of points within the data path where solutions could be put into place to mitigate this (and similar) vulnerabilities. Thus customers must choose the most strategic point in the network at which to deploy their selected mitigation. To choose that point, organizations should ask how the exploit is detected by given solutions. To see why that's needful, consider how the attack works. How Heartbleed Works Heartbleed takes advantage of a missing length check in the OpenSSL code handling a relatively innocuous extension to the TSL/SSL protocol (defined in RFC 6520). It comprises two simple messages: a request and a response. The request can be sent be either the client or the server as a means to keep the connection alive. The sender ships off a HeartbeatMessage with a small amount of data, expecting the receiver to send back that same data. What's important about the protocol interaction is that whichever party sends the request determines the length of the response. The sender tells the receiver how much data it's sending - and thus how much should be returned. Now, the OpenSSL code should be making sure the length the attacker says he's sending is actually what's available. The code, however, does not. It simply trusts the sender and grabs whatever amount of data was specified out of memory. This is how an attacker can access data that's in memory and wind up with all sorts of sensitive data like passwords and private keys. Mitigation Options Because this exploit takes advantage of a vulnerability in encrypted communications, any mitigating solution must be in the path of that communication. That's a given. In that path are three points where this exploit can be mitigated: 1. Client. You can check the client operating system and device type and match that against known usage of the impacted OpenSSL versions. Once detected, the client can be rejected - preventing the offending request from ever being sent in the first place. Rejection of clients based on the possibility they might be an attacker can result in angry legitimate consumers, employees or partners, however. 2. On Request. Inspect client requests and upon discovery of a HeartbeatMessage, reject it. This prevents the request from being forwarding to vulnerable systems and servers. 3. On Response. Inspect responses and upon seeing a HeartbeatMessage response, check its length. If it's greater than a length you feel comfortable with, discard it. This method will prevent attackers from receiving sensitive data, but it should be noted that at the point of discovery, the server - and data - has already been compromised. Location in the Network Matters You have to be in communication path to implement these solutions. That means some solutions being put forth are architecturally misplaced to be able to completely mitigate this vulnerability. For example, the firewall landscape is bifurcating and separating inbound (application delivery) and outbound (next generation firewall) duties. That means while next-generation firewalls (NGFW) are capable of the inspection and interaction necessary to detect and mitigate Heartbleed on response, they generally only do so in the outbound use case. That's an important capability, but it won't catch inbound attempts, just outbound. Further complicating the situation is a growing delineation of security responsibilities between inbound and outbound in the firewall market. Growth and scale of security has led to separate inbound and outbound security solutions. NGFW are an outbound solution, generally positioned only as protection for corporate users. They’re intended to protect organizations from malware and malicious code entering the corporate data center by means of its employees accessing infected sites. They aren’t deployed in a position to protect servers and applications on the inbound path. Those that are can provide inbound protection but only on response, which means your servers have already been compromised. The right place to implement a mitigating solution is one that will afford you the choice of your mitigating solution - or allow all three, if you really want comprehensive coverage. It must be in the data path and have visibility into both the client and the server side of the equation. In most networks, that strategic point of control is the application delivery firewall. Using the right tool in the right place in the network means you can implement any (or all) of the three mitigating solutions in not only a one place, but in the most effective place. The right tool is not just one that has the right position in the network. It takes visibility and programmability to dig deeply into the network stack and find the data indicative of an attack – intentional or not. The right tool will be able to distinguish between client side and server side traffic and apply the applicable logic. The logic that detects Heartbleed on the client side is different than that of the server side. In the case of the client it must look for a specific message indicating a Heartbeat request or inspecting the client device environment itself. On the server side, it’s checking the size of the response. Each of these cases requires unique code. That means the right tool must have a programmatic environment that can execute with surgical-like precision the logic necessary at the right time – at the time of connection, on request and on response. The right tool, then, is positioned on the inbound path – in front of vulnerable services – and offers an event-driven, programmatic way to execute the right logic at the right time to detect vulnerable clients, malicious requests and responses carrying unauthorized sensitive data. An F5 ADC offers that event-driven, programmatic interface with iRules and is strategically positioned in the network to support all three mitigation solutions. Consider again how Heartbleed works and the three mitigation options: (1) Client. In most network architectures this means it is connecting to an application delivery controller (ADC) that provides load balancing services. When that ADC is F5, it also acts as an application delivery firewall (ADF) and can be programmatically controlled. That means it can inspect the request and, if it's vulnerable, reject the connection. (3) On Request. Because an ADC sits between the client and server and acts as a proxy, it sees every request and response. It can be programmatically instructed using iRules to inspect those requests and, upon finding a Heartbeat request message, can reject it. It is not necessary to decrypt the request to detect the Heartbeat message. (4) On Response. As noted, the strategic point of control in which an F5 ADC is deployed in the network means it sees every response, too. It can programmatically inspect responses and if found to be over a specified length, discard it to prevent the attacker from getting a hold of sensitive data. F5 suggests the "On Request" mitigation for dealing with Heartbleed. This approach minimizes the impact to clients and prevents legitimate requests from being rejected, and further assures that servers are not compromised. Customers have the option, of course, to implement any or all three of these options in order to protect their applications, customers and data as they see fit. F5 supports customer choices in every aspect of application delivery whether related to security, orchestration or architectural model. Action Items At this point, nearly a week after the exposure of Heartbleed, organizations should have a good handle on how it works and what the impact is to their business. There's no question the response to Heartbleed involves server patches and upgrades and the procurement of new keys, with consumer password change processes to come soon thereafter. In the meantime, servers (and thus customers) remain vulnerable. Organizations should be looking at putting into place a mitigation solution to protect both while longer-term plans are put into action. No matter which approach you choose, F5 has got you covered. [Edited: 11:11am PT with new graphic]322Views0likes0CommentsHeartbroken and then Redeemed
It has been over a month since Heartbleed. Remember that day when we found out that half the private keys on the Internet were each available for the price of just a few TLS heartbeat packets? I thought that in just a few news cycles the press would forget all about this. But no, the Heartbleed drama continues. And that’s a good thing. Bringing visibility to cryptography should mean a more secure Internet in the future. One of the reasons that Heartbleed is still in the news is because of researchers like Yngve Pettersen. Pettersen recently discovered, during a scan, hundreds of new internet hosts that appeared to be vulnerable to Heartbleed. It was especially confusing, because according to Pettersen, those hosts had previously tested negative. In his blog post of May 7, 2014, he called this set of “newly vulnerable” hosts “Heartbroken servers.” That’s kind of clever. But the hosts also exhibited a different characteristic that suggested they might be F5 equipment. Uh oh. Of course the tech press picked it up on a Friday. So it was an interesting weekend for all of us. We contacted Pettersen and he was kind enough to share his data with us. We double-checked all of the hosts – fortunately none of them appeared to be our devices. We alerted Pettersen with our findings. He re-ran his scan and the new results were sufficiently divergent to make him question the data of the original scan. He updated his blog entry not only removing reference to these “Heartbroken” hosts as F5 devices but also offering an apology to F5 and F5’s customers. We think that was awesome, gracious, and exactly the right thing to do. The underlying issue in all this is still very much worth investigation - to what extent is the Internet still vulnerable to Heartbleed? It is great that there are researchers like Pettersen who are trying to quantify the overall state of the vulnerability and to keep awareness high. He is to be commended for his efforts. I would be remiss if I didn’t close on the following point. Of the hundreds and hundreds of vulnerable servers found by Pettersen, not a single one was an F5 device. That’s pretty amazing, because (and most people don’t know this) a lot of the world’s SSL traffic is terminated at an F5 device. And they are all resistant to Heartbleed.227Views0likes0CommentsWat is Heartbleed?
Get the latest updates on how F5 mitigates HeartbleedGet the latest updates on how F5 mitigates Heartbleed Heartbleed is nu al even in het nieuws en lijkt zijn impact nog steeds uit te breiden. Verschillende sites blijven updates versturen van de log-in handelingen om gebruikers gerust te stellen dat hun data veilig is. Andere sites melden dat ze slachtoffer zijn geworden, en dat een ander wachtwoord noodzakelijk is. Hoe serieus moeten we Heartbleed nemen? De meningen lopen uiteen van ‘gewoon weer een gat in de verdediging’ tot ‘dit is een revolutionair security-issue’. De gematigde reactie komt meestal voort uit de constatering dat ‘slechts’ 17 procent van de sites is geraakt. Maar er is ook nog de impact op gadgets en apparatuur die we snel over het hoofd zien. Heel veel smartphones, IP-telefoons, switches en routers worden aangemerkt als kwetsbaar. Internetrouters voor thuisgebruik en de hippe e-thermostaten zijn allemaal mogelijk slachtoffer. En terwijl het Internet of Things steeds meer apparatuur koppelt, wordt die lijst alleen maar langer. Veel van deze apparaten zullen niet worden geupdate, waardoor bedrijven die ermee werken en communiceren gevaar lopen. Zij hebben behoefte aan een beveiligingsoplossing die los staat van het wel of niet updaten van het apparaat zelf. Aangezien er veel aandacht voor is zullen de leveranciers haast over elkaar vallen met een passend aanbod om gebruikers te beschermen tegen Heartbleed. Netwerkapparatuur zal in stelling worden gebracht om verzoeken die gebruik maken van het lek te detecteren en tegen te houden. Er zijn verschillende plekken in het dataverkeer waar je dit lek en vergelijkbare kwetsbaarheden kunt tegenhouden. Bedrijven moeten het meest strategische punt kiezen in het netwerk. Om dat punt te bepalen, moet je je afvragen hoe en in welke situatie de kwetsbaarheid wordt gedetecteerd. Waarom dat van belang is, is het goed om te kijken naar hoe Heartbleed werkt. Werkwijze Heartbleed Heartbleed maakt gebruik van een ontbrekende lengte-controle in de OpenSSL code-afhandeling van een relatief onschuldige uitbreiding van het TSL/SSL protocol (gedefinieerd in RFC 6520). Het gaat om twee simpele berichten: een verzoek en een antwoord. Dit verzoek kan door zowel de client als de server worden verstuurd om de connectie in stand te houden. De verzender stuurt een HeartbeatMessage met een klein data-pakketje, in verwachting dat de ontvanger diezelfde data terugstuurt. Belangrijk hierbij is dat degene die het bericht verstuurt de omvang van het antwoord bepaalt. De verzender geeft aan de ontvanger door hoeveel dat hij verstuurt en hoeveel hij dus terug verwacht. De OpenSSL-code zou ervoor moeten zorgen dat de lengte die de aanvaller zegt te versturen daadwerkelijk beschikbaar is. Maar dat doet de code dus niet. Hij vertrouwt de verzender simpelweg en pakt gewoon de hoeveelheid data uit het geheugen. Op die manier kan een aanvaller toegang krijgen tot data in het geheugen en dus informatie als wachtwoorden en sleutels. Bescherming tegen Heartbleed Aangezien Heartbleed gebruik maakt van een kwetsbaarheid in versleutelde communicatiepaden moet de oplossing ook daarin worden gerealiseerd. Er zijn drie punten waar je dat kan doen. 1. Client - Je kunt het client OS en apparatuurtype controleren en dit afzetten tegen het bekende gebruik van de geraakt OpenSSL versies. Eenmaal gedetecteerd kan een client blijvend afgewezen worden, zodat het kwaadwillende verzoek sowieso niet gestuurd wordt. Echter, een client afwijzen omdat het mogelijk een kwaadwillende is, kan resulteren in boze, legitieme gebruikers, klanten of andere relaties. 2. Request - Inspecteer client-verzoeken en wijs het af, zodra een HeartbeatMessage wordt ontdekt. Dit voorkomt dat de verzoeken worden doorgestuurd naar kwetsbare systemen en servers. 3. Response - Onderzoek antwoorden, en zodra er een HeartbeatMessage tussenzit, controleer de lengte. Als die groter is dan wenselijk of gebruikelijk, negeer het. Op die manier ontvangen aanvallers niet je data, maar zijn inmiddels je servers en data wel blootgesteld. De juiste plek om bescherming te implementeren is de plek die je een keuze biedt tussen verschillende oplossingen. Of op alledrie de punten als je echt helemaal dichtgetimmerd wil zijn. In de meeste gevallen zal de application delivery firewall of application delivery controller de meest strategische plek zijn. De juiste oplossing staat echter niet alleen op de juiste plek in het netwerk. Het zorgt ook voor zichtbaarheid en programmeerbaarheid van de netwerk-stack en is in staat data te vinden die wijzen op een lek, bewust of onbewust. Een goede tool maakt onderscheid in client en server verkeer en past de benodigde logica toe. De logica die Heartbleed aan de client-kant ontdekt is anders dan die aan de server-kant. In geval van de client moet het op zoek gaan naar een specfiek bericht gericht op een Heartbleed-verzoek, of de omgeving van het client-apparaat onderzoeken. Aan de server-kant moet het de grootte van de response controleren. Elk geval vraagt om zijn eigen, unieke code. De tool moet dus een programmeerbare omgeving hebben die zeer nauwkeurig de juiste logica kan toepassen op het juiste moment. Nu Heartbleed een goede week zijn slag slaat moeten organisaties redelijkerwijs zicht hebben op de impact binnen hun bedrijf. Uiteraard zijn server patches en upgrades noodzakelijk, en de toewijzing van nieuwe sleutels en wachtwoorden. Ondertussen blijven servers (en dus gebruikers) kwetsbaar. Bedrijven moeten dus direct in actie komen, terwijl er ook gewerkt moet worden aan een oplossing voor de langere termijn. Dit artikel is gepubliceerd: - Infosecurity magazine http://infosecuritymagazine.nl/2014/04/18/wat-is-heartbleed/ - Computable (including some nice comments and feedback by Gert Jan) http://www.computable.nl/artikel/opinie/netwerkbeheer/5058876/4480198/wat-is-heartbleed-en-hoe-bescherm-je-jezelf.html - BlogIt http://www.blogit.nl/wat-heartbleed-en-welke-methode-biedt-bescherming194Views0likes1CommentSSL Heartbleed 취약성: 영향과 대응책 (part 2)
(1부에서 계속) 그렇다면 클라우드는? 깊은 지식을 가지고 있는 독자라면 클라우드 컴퓨팅은 자신의 독자적인 Heartbleed 위협 프로파일을 가지고 있음을 눈치챘을 것이다. 그것은 사실이며, 특정 클라우드의 구축 상황에 따라 위협의 강도가 다르기 때문이다. 전형적인 LAMP 클라우드 사이트: 전형적인 클라우드 사이트는 Apache, MySQL 및 PhP가 구동되는 리눅스 배포 (보통 줄여서 LAMP라고 불린다) 인스턴스들을 포함하고 있다. 클라우드가 도입된 것이 상대적으로 최근의 현상이며 Heartbleed 취약성이 2년 전에 알려진 것과 시기가 겹치는 것을 생각할 때, 이런 클라우드 LAMP 사이트들이 가장 위험하다. F5 ADC 하드웨어를 가진 클라우드: 많은 고객들이 자신들의 클라우드 인스턴스들 앞 단에 F5의 하드웨어 플랫폼을 두고 있다. F5 ADC가 TCP 연결들을 병합하고, 공통 객체들을 캐시하고, 또한 당연한 일이지만 성능이 많이 요구되는 하드웨어 암호화 연산에 따른 부하를 덜어주기 때문에 효율성이 눈에 띄게 좋아진다. 이런 고객들은 F5가 SSL을 종료하므로 이미 보호되고 있다. 만약 당신이 이런 경우라면, 단순히 가상 서버들이 HTTPS의 암호화를 해제하지 않은 채내보내지 않도록 하기만 하면 된다. (아래 참조) F5 가상 ADC: 완전히 가상화된 클라우드에서는 F5 모듈도 가상 인스턴스이다. 근본적인 암호화 하드웨어 오프로드가 생기지 않으면, F5 모듈이 HTTPS 서버들을 위해 SSL을 종료하도록 하는 것이 덜 매력적일 것이다. 그러므로 하드웨어로 구축된 앞의 경우에 비해 Heartbleed 위험성이 높아진다. 그러나 이 경우도 F5 플랫폼이 방어를 제공할 수 있는데, 그 이유는 가상 ADC에 내재하는 SSL 스택의 소프트웨어가 Heartbleed에 취약하지 않으며 따라서 충분한 방어를 제공하기 때문이다. 다음 단계 기존 F5 고객들은 단순히 단일 솔루션을 읽고 자신이 보유한 F5 디바이스의 안전성을 재확인한 후, 자신이 현재 안전할 뿐 아니라 자신의 애플리케이션들이 지난 2년 동안 Heartbleed에 성공적으로 맞서왔음을 알고 두 다리 뻗고 자면 된다. 만약 도움이 필요할 경우, 아래의 F5에 연락하기를 클릭해서 F5 코리아에 연락을 취하면 된다. 만약 F5가 생소한 고객이라면, F5 코리아에 연락을 취해 현재와 미래의 위협으로부터 자신의 비즈니스를 보호할 것을 권장한다. F5에 연락하기 결론 미국의 컴퓨터 공학자인 제럴드 와인버그 (Gerald Weinberg)는 “만약 프로그래머들이 프로그램을 작성하는 것처럼 건축가들이 건물을 짓는다면, 이런 건축물을 찾는 첫 번째 딱따구리가 문명 전체를 파괴해버릴 것이다.”라고 말한 일이 있다. Heartbleed야말로 바로 그런 딱따구리라고 말할 수 있다. 하지만 좋은 소식은 F5 BIG-IP 디바이스들과 가상 인스턴스들이 벌써 인터넷에 널리 퍼져 있으며 그들이 담당하고 있는 HTTPS 애플리케이션들을 보호하고 있다는 것이다. 운영자들은 그렇게 방어되고 있음을 검증할 수 있으며, 보안 팀과 협력해 자신에 맞는 속도로 시스템을 업그레이드할 수 있다. 그리고 현재 보호받지 못하고 있는 사람들은 단순히 F5에 전화를 걸거나, F5의 시험용 버전을 이용해 보호를 받을 수 있다. * 현재 LTM에서 SSL 터미네이션을 하고 있는 경우, 11.5.0이나 11.5.1에서 디폴트 암호화를 COMPAT로 바꿔서 보안 F5 SSL 스택을 벗어나게 하지만 않았다면, 보호되고 있다. F5의 고객 중 이런 경우는 그 수가 매우 작은 것으로 판명되었다. 만약 11.5.0 또는 11.5.1을 사용 중이고 관리 인터페이스가 인터넷에 노출되었다면, 취약하다. BIG-IP 관리 인터페이스에는 OpenSSL 1.0.2이 사용된다. F5는 이런 구성을 권장하지 않는다. Heartbleed에 대해 질문이 있으신가요? F5 커뮤니티에 물어보세요. *F5의 끊임 없이 진화하는 커뮤니티에서 배우세요. 191개 국가의 13만 명이 넘는 뛰어난 사람들로 구성되어 있습니다.184Views0likes0Comments