Solving for true-source IP with global load balancers in Google Cloud
Background Recently a customer approached us with requirements that may seem contradictory: true source IP persistence, global distribution of load balancers (LB's), TCP-only proxying, and alias IP ranges in Google Cloud. With the help of PROXY protocol support, we offered a straightforward solution that is worth documenting for others. Customer requirements We have NGINX WAF running on VM instances in Google Cloud Platform (GCP) We want to expose these to the Internet with aglobal load balancer We must know the true source IP of clients when traffic reaches our WAF We donot want so use an application (HTTP/S) load balancer in Google. i.e., we do not want to perform TLS decryption with GCP or use HTTP/HTTPS load balancing therefore, we cannot use X-Forwarded-For headers to preserve true source IP Additionally, we'd like to use Cloud Armor. How can we add on a CDN/DDoS/etc provider if needed? Let's solve for these requirements by finding the load balancer to use, and then how to preserve and use true source IP. Which load balancer type fits best? This guideoutlines our options for Google LB’s. Because our requirements includeglobal, TCP-only load balancing, we will choose the highlighted LB type of “Global external proxy Network Load Balancer”. Proxy vs Passthrough Notice that global LB’sproxytraffic. They do not preserve source IP address as apassthrough LB does. Global IP addresses are advertised from multiple, globally-distributed front end locations, using Anycast IP routing. Proxying from these locations allows traffic symmetry, but Source NAT causes loss of the original client IP address. I've added some comments into a Google diagram below to show our core problem here: PROXY protocol support with Google load balancers Google’s TCP LBdocumentationoutlines our challenge and solution: "By default, the target proxy does not preserve the original client IP address and port information. You can preserve this information by enabling the PROXY protocol on the target proxy." Without PROXY protocol support, we could only meet 2 out of 3 core requirements with any given load balancer type. PROXY protocol allows us to meet all 3 simultaneously. Setting up our environment in Google The script below configures a global TCP proxy network load balancer and associated objects. It is assumed that a VPC network, subnet, and VM instances exist already. This script assumes the VM’s are F5 BIG-IP devices, although our demo will use Ubuntu VM’s with NGINX installed. Both BIG-IP and NGINX can easily receive and parse PROXY protocol. # GCP Environment Setup Guide for Global TCP Proxy LB with Proxy Protocol. Credit to Tony Marfil, @tmarfil # Step 1: Prerequisites # Before creating the network endpoint group, ensure the following GCP resources are already configured: # # -A VPC network named my-vpc. # -A subnet within this network named outside. # -Instances ubuntu1 and ubuntu2 should have alias IP addresses configured: 10.1.2.16 and 10.1.2.17, respectively, both using port 80 and 443. # # Now, create a network endpoint group f5-neg1 in the us-east4-c zone with the default port 443. gcloud compute network-endpoint-groups create f5-neg1 \ --zone=us-east4-c \ --network=my-vpc \ --subnet=outside \ --default-port=443 # Step 2: Update the Network Endpoint Group # # Add two instances with specified IPs to the f5-neg1 group. gcloud compute network-endpoint-groups update f5-neg1 \ --zone=us-east4-c \ --add-endpoint 'instance=ubuntu1,ip=10.1.2.16,port=443' \ --add-endpoint 'instance=ubuntu2,ip=10.1.2.17,port=443' # Step 3: Create a Health Check # # Set up an HTTP health check f5-healthcheck1 that uses the serving port. gcloud compute health-checks create http f5-healthcheck1 \ --use-serving-port # Step 4: Create a Backend Service # # Configure a global backend service f5-backendservice1 with TCP protocol and attach the earlier health check. gcloud compute backend-services create f5-backendservice1 \ --global \ --health-checks=f5-healthcheck1 \ --protocol=TCP # Step 5: Add Backend to the Backend Service # # Link the network endpoint group f5-neg1 to the backend service. gcloud compute backend-services add-backend f5-backendservice1 \ --global \ --network-endpoint-group=f5-neg1 \ --network-endpoint-group-zone=us-east4-c \ --balancing-mode=CONNECTION \ --max-connections=1000 # Step 6: Create a Target TCP Proxy # # Create a global target TCP proxy f5-tcpproxy1 to handle routing to f5-backendservice1. gcloud compute target-tcp-proxies create f5-tcpproxy1 \ --backend-service=f5-backendservice1 \ --proxy-header=PROXY_V1 \ --global # Step 7: Create a Forwarding Rule # # Establish global forwarding rules for TCP traffic on port 80 & 443. gcloud compute forwarding-rules create f5-tcp-forwardingrule1 \ --ip-protocol TCP \ --ports=80 \ --global \ --target-tcp-proxy=f5-tcpproxy1 gcloud compute forwarding-rules create f5-tcp-forwardingrule2 \ --ip-protocol TCP \ --ports=443 \ --global \ --target-tcp-proxy=f5-tcpproxy1 # Step 8: Create a Firewall Rule # # Allow ingress traffic on specific ports for health checks with the rule allow-lb-health-checks. gcloud compute firewall-rules create allow-lb-health-checks \ --direction=INGRESS \ --priority=1000 \ --network=my-vpc \ --action=ALLOW \ --rules=tcp:80,tcp:443,tcp:8080,icmp \ --source-ranges=35.191.0.0/16,130.211.0.0/22 \ --target-tags=allow-health-checks # Step 9: Add Tags to Instances # # Tag instances ubuntu1 and ubuntu2 to include them in health checks. gcloud compute instances add-tags ubuntu1 --tags=allow-health-checks --zone=us-east4-c gcloud compute instances add-tags ubuntu2 --tags=allow-health-checks --zone=us-east4-c ## TO PULL THIS ALL DOWN: (uncomment the lines below) # gcloud compute firewall-rules delete allow-lb-health-checks --quiet # gcloud compute forwarding-rules delete f5-tcp-forwardingrule1 --global --quiet # gcloud compute forwarding-rules delete f5-tcp-forwardingrule2 --global --quiet # gcloud compute target-tcp-proxies delete f5-tcpproxy1 --global --quiet # gcloud compute backend-services delete f5-backendservice1 --global --quiet # gcloud compute health-checks delete f5-healthcheck1 --quiet # gcloud compute network-endpoint-groups delete f5-neg1 --zone=us-east4-c --quiet # # Then delete your VM's and VPC network if desired. Receiving PROXY protocol using NGINX We now have 2x Ubuntu VM's running in GCP that will receive traffic when we target our global TCP proxy LB's IP address. Let’s use NGINX to receive and parse the PROXY protocol traffic. When proxying and "stripping" the PROXY protocol headers from traffic, NGINX can append an additional header containing the value of the source IP obtained from PROXY protocol: server { listen 80 proxy_protocol; # tell NGINX to expect traffic with PROXY protocol server_name customer1.my-f5.com; location / { proxy_pass http://localhost:3000; proxy_http_version 1.1; proxy_set_header x-nginx-ip $server_addr; # append a header to pass the IP address of the NGINX server proxy_set_header x-proxy-protocol-source-ip $proxy_protocol_addr; # append a header to pass the src IP address obtained from PROXY protocol proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; # append a header to pass the src IP of the connection between Google's front end LB and NGINX proxy_cache_bypass $http_upgrade; } } Displaying true source IP in our web app You might notice above that NGINX is proxying to http://localhost:3000. I have a simple NodeJS app to display a page with HTTP headers: const express = require('express'); const app = express(); const port = 3000; // set the view engine to ejs app.set('view engine', 'ejs'); app.get('/', (req, res) => { const proxy_protocol_addr = req.headers['x-proxy-protocol-source-ip']; const source_ip_addr = req.headers['x-real-ip']; const array_headers = JSON.stringify(req.headers, null, 2); const nginx_ip_addr = req.headers['x-nginx-ip']; res.render('index', { proxy_protocol_addr: proxy_protocol_addr, source_ip_addr: source_ip_addr, array_headers: array_headers, nginx_ip_addr: nginx_ip_addr }); }) app.listen(port, () => { console.log('Server is listenting on port 3000'); }) For completeness, NodeJS is using the EJS template engine to build our page. The file views/index.ejs is here: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale-1"> <title>Demo App</title> </head> <body class="container"> <main> <h2>Hello World!</h2> <p>True source IP (the value of <code>$proxy_protocol_addr</code>) is <b><%= typeof proxy_protocol_addr != 'undefined' ? proxy_protocol_addr : '' %></b></p> <p>IP address that NGINX recieved the connection from (the value of <code>$remote_addr</code>) is <b><%= typeof source_ip_addr != 'undefined' ? source_ip_addr : '' %> </b></p> <p>IP address that NGINX is running on (the value of <code>$server_addr</code>) is <b><%= typeof nginx_ip_addr != 'undefined' ? nginx_ip_addr : '' %></b><p> <h3>Request Headers at the app:</h3> <pre><%= typeof array_headers != 'undefined' ? array_headers : '' %></pre> </main> </body> </html> Cloud Armor Cloud Armor is aneasy add-onwhen using Google load balancers. If required, an admin can: Create a Cloud Armor security policy Add rules (for example, rate limiting) to this policy Attach the policy to a TCP load balancer In this way “edge protection” is applied to your Google workloads with little effort. Our end result This small demo app shows that true source IP can be known to an application running on Google VM’s when using the Global TCP Network Load Balancer. We’ve achieved this using PROXY protocol and NGINX. We’ve used NodeJS to display a web page with proxied header values. Thanks for reading. Please reach out with any questions!229Views3likes4CommentsActive/Active load balancing examples with F5 BIG-IP and Azure load balancer
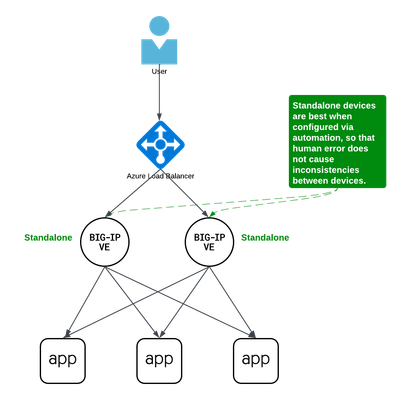
Background A couple years ago Iwrote an article about some practical considerations using Azure Load Balancer. Over time it's been used by customers, so I thought to add a further article that specifically discusses Active/Active load balancing options. I'll use Azure's standard load balancer as an example, but you can apply this to other cloud providers. In fact, the customer I helped most recently with this very question was running in Google Cloud. This article focuses on using standard TCP load balancers in the cloud. Why Active/Active? Most customers run 2x BIG-IP's in an Active/Standby cluster on-premises, and it's extremely common to do the same in public cloud. Since simplicity and supportability are key to successful migration projects, often it's best to stick with architectures you know and can support. However, if you are confident in your cloud engineering skills or if you want more than 2x BIG-IP's processing traffic, you may consider running them all Active. Of course, if your totalthroughput for N number of BIG-IP's exceeds the throughput thatN-1 can support, the loss of a single VM will leave you with more traffic than the remaining device(s) can handle. I recommend choosing Active/Active only if you're confident in your purpose and skillset. Let's define Active/Active Sometimes this term is used with ambiguity. I'll cover three approaches using Azure load balancer, each slightly different: multiple standalone devices Sync-Only group using Traffic Group None Sync-Failover group using Traffic Group None Each of these will use a standard TCP cloud load balancer. This article does not cover other ways to run multiple Active devices, which I've outlined at the end for completeness. Multiple standalone appliances This is a straightforward approach and an ideal target for cloud architectures. When multiple devices each receive and process traffic independently, the overhead work of disaggregating traffic to spread between the devices can be done by other solutions, like a cloud load balancer. (Other out-of-scope solutions could be ECMP, BGP, DNS load balancing, or gateway load balancers). Scaling out horizontally can be a matter of simple automation and there is no cluster configuration to maintain. The only limit to the number of BIG-IP's will be any limits of the cloud load balancer. The main disadvantage to this approach is the fear of misconfiguration by human operators. Often a customer is not confident that they can configure two separate devices consistently over time. This is why automation for configuration management is ideal. In the real world, it's also a reason customers consider our next approach. Clustering with a sync-only group A Sync-Only device group allows us to sync some configuration data between devices, but not fail over configuration objects in floating traffic groups between devices, as we would in a Sync-Failover group. With this approach, we can sync traffic objects between devices, assign them to Traffic Group None, and both devices will be considered Active. Both devices will process traffic, but changes only need to be made to a single device in the group. In the example pictured above: The 2x BIG-IP devices are in a Sync-Only group called syncGroup /Common partition isnotsynced between devices /app1 partition issynced between devices the /app1 partition has Traffic Group None selected the /app1 partition has the Sync-Only group syncGroup selected Both devices are Active and will process traffic received on Traffic Group None The disadvantage to this approach is that you can create an invalid configuration by referring to objects that are not synced. For example, if Nodes are created in/Common, they will exist on the device on which they were created, but not on other devices. If a Pool in /app1 then references Nodes from /Common, the resulting configuration will be invalid for devices that do not have these Nodes configured. Another consideration is that an operator must use and understand partitions. These are simple and should be embraced. However, not all customers understand the use of partitions and many prefer to use /Common only, if possible. The big advantage here is that changes only need to be made on a single device, and they will be replicated to other devices (up to 32 devices in a Sync-Only group). The risk of inconsistent configuration due to human error is reduced. Each device has a small green "Active" icon in the top left hand of the console, reminding operators that each device is Active and will process incoming traffic onTraffic Group None. Failover clustering using Traffic Group None Our third approach is very similar to our second approach. However, instead of a Sync-Only group, we will use a Sync-Failover group. A Sync-Failover group will sync all traffic objects in the default /Common partition, allowing us to keep all traffic objects in the default partition and avoid the use of additional partitions. This creates a traditional Active/Standby pair for a failover traffic group, and a Standby device will not respond to data plane traffic. So how do we make this Active/Active? When we create our VIPs in Traffic Group None, all devices will process traffic received on these Virtual Servers. One device will show "Active" and the other "Standby" in their console, but this is only the status for the floating traffic group. We don't need to use the floating traffic group, and by using Traffic Group None we have an Active/Active configuration in terms of traffic flow. The advantage here is similar to the previous example: human operators only need to configure objects in a single device, and all changes are synced between device group members (up to 8 in a Sync-Failover group). Another advantage is that you can use the/Common partition, which was not possible with the previous example. The main disadvantage here is that the console will show the word "Active" and "Standby" on devices, and this can confuse an operator that is familiar only with Active/Standby clusters using traffic groups for failover. While this third approach is a very legitimate approach and technically sound, it's worth considering if your daily operations and support teams have the knowledge to support this. Other considerations Source NAT (SNAT) It is almost always a requirement that you SNAT traffic when using Active/Active architecture, and this especially applies to the public cloud, where our options for other networking tricks are limited. If you have a requirement to see true source IPandneed to use multiple devices in Active/Active fashion, consider using Azure or AWS Gateway Load Balancer options. Alternative solutions like NGINX and F5 Distributed Cloud may also be worth considering in high-value, hard-requirement situations. Alternatives to a cloud load balancer This article is not referring to F5 with Azure Gateway Load Balancer, or to F5 with AWS Gateway Load Balancer. Those gateway load balancer solutions are another way for customers to run appliances as multiple standalone devices in the cloud. However, they typically requirerouting, not proxying the traffic (ie, they don't allow destination NAT, which many customers intend with BIG-IP). This article is also not referring to other ways you might achieve Active/Active architectures, such as DNS-based high availability, or using routing protocols, like BGP or ECMP. Note that using multiple traffic groups to achieve Active/Active BIG-IP's - the traditional approach on-prem or in private cloud - is not practical in public cloud, as briefly outlined below. Failover of traffic groups with Cloud Failover Extension (CFE) One option for Active/Standby high availability of BIG-IP is to use the CFE , which can programmatically update IP addresses and routes in Azure at time of device failure. Since CFE does not support Active/Active scenarios, it is appropriate only for failover of a single traffic group (ie., Active/Standby). Conclusion Thanks for reading! In general I see that Active/Standby solutions work for many customers, but if you are confident in your skills and have a need for Active/Active F5 BIG-IP devices in the cloud, please reach out if you'd like me to walk you through these options and explore any other possibilities. Related articles Practical Considerations using F5 BIG-IP and Azure Load Balancer Deploying F5 BIG-IP with Azure Cross-Region Load Balancer596Views2likes0CommentsInstalling and running iControl extensions in isolated GCP VPCs
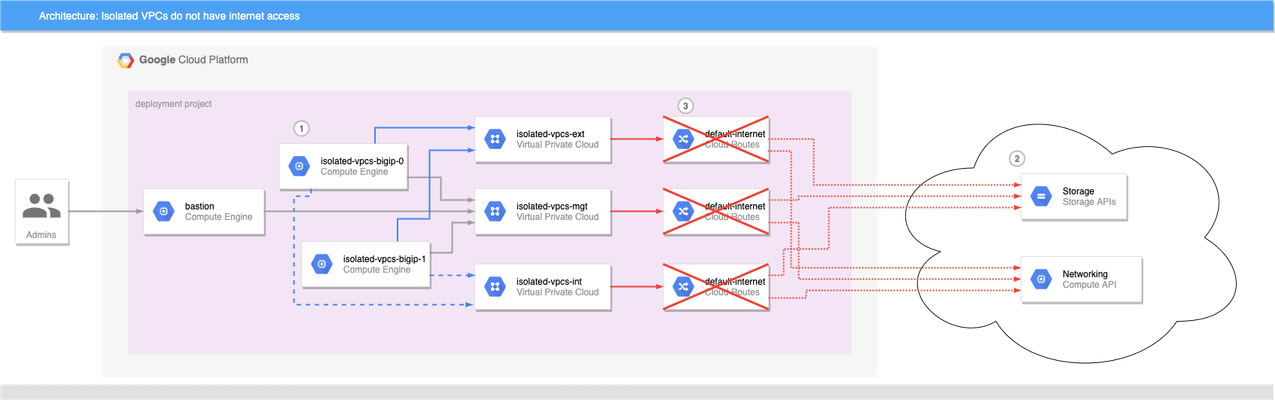
BIG-IP instances launched on Google Cloud Platform usually need access to the internet to retrieve extensions, install DO and AS3 declarations, and get to any other run-time assets pulled from public URLs during boot. This allows decoupling of BIG-IP releases from the library and extensions that enhance GCP deployments, and is generally a good thing. What if the BIG-IP doesn't have access to the Internet? Best practices for Google Cloud recommend that VMs are deployed with the minimal set of access requirements. For some that means that egress to the internet is restricted too: BIG-IP VMs do not have public IP addresses. A NAT Gateway or NATing VM is not present in the VPC. Default VPC network routes to the internet have been removed. If you have a private artifact repository available in the VPC, supporting libraries and onboarding resources could be added to there and retrieved during initialization as needed, or you could also create customized BIG-IP images that have the supporting libraries pre-installed (see BIG-IP image generator for details). Both those methods solve the problem of installing run-time components without internet access, but Cloud Failover Extension, AS3 Service Discovery, and Telemetry Streaming must be able to make calls to GCP APIs, but GCP APIs are presented as endpoints on the public internet. For example, Cloud Failover Extension will not function correctly out of the box when the BIG-IP instances are not able to reach the internet directly or via a NAT because the extension must have access to Storage APIs for shared-state persistence, and to Compute APIs to updates to network resources. If the BIG-IP is deployed without functioning routes to the internet, CFE cannot function as expected. Figure 1: BIG-IP VMs 1 cannot reach public API endpoints 2 because routes to internet 3 are removed Given that constraint, how can we make CFE work in truly isolated VPCs where internet access is prohibited? Private Google Access Enabling Private Google Access on each VPC subnet that may need to access Google Cloud APIs changes the underlying SDN so that the CIDRs for restricted.googleapis.com (or private.googleapis.com † ) will be routed without going through the internet. When combined with a private DNS zone which shadows all googleapis.com lookups to use the chosen protected endpoint range, the VPC networks effectively have access for all GCP APIs. The steps to do so are simple: Enable Private Google Access on each VPC subnet where a GCP API call may be sourced. Create a Cloud DNS private zone for googleapis.com that contains two records: CNAME for *.googleapis.com that responds with restricted.googleapis.com. A record for restricted.googleapis.com that resolves to each host in 199.36.153.4/30. Create a custom route on each VPC network for 199.36.153.4/30 with next-hop set for internet gateway. With this configuration in place, any VMs that are attached to the VPC networks that are associated with this private DNS zone will automatically try to use 199.36.153.4/30 endpoints for all GCP API calls without code changes, and the custom route will allow Private Google Access to function correctly. Automating with Terraform and Google Cloud Foundation Toolkit ‡ While you can perform the steps to enable private API access manually, it is always better to have a repeatable and reusable approach that can be automated as part of your infrastructure provisioning. My tool of choice for infrastructure automation is Hashicorp's Terraform, and Google's Cloud Foundation Toolkit, a set of Terraform modules that can create and configure GCP resources. By combining Google's modules with my own BIG-IP modules, we can build a repeatable solution for isolated VPC deployments; just change the variable definitions to deploy to development, testing/QA, and production. Cloud Failover Example Figure 2: Private Google Access 1 , custom DNS 2 , and custom routes 3 combine to enable API access 4 without public internet access A fully-functional example that builds out the infrastructure shown in figure 2 can be found in my GitHub repo f5-google-bigip-isolated-vpcs. When executed, Terraform will create three network VPCs that lack the default-internet egress route, but have a custom route defined to allow traffic to restricted.googleapis.com CIDR. A Cloud DNS private zone will be created to override wildcard googleapis.com lookups with restricted.googleapis.com, and the private zone will be enabled on all three VPC networks. A pair of BIG-IPs are instantiated with CFE enabled and configured to use a dedicated CFE bucket for state management. An IAP-enabled bastion host with tinyproxy allows for SSH and GUI access to the BIG-IPs (See the repo's README for full details on how to connect). Once logged in to the active BIG-IP, you can verify that the instances do not have access to the internet, and you can verify that CFE is functioning correctly by forcing the active instance to standby. Almost immediately you can see that the other BIG-IP instance has become the active instance. Notes † Private vs Restricted access GCP supports two protected endpoint options; private and restricted. Both allow access to GCP API endpoints without traversing the public internet, but restricted is integrated with VPC Service Controls. If you need access to a GCP API that is unsupported by VPC Service Controls, you can choose private access and change steps 2 and 3 above to use private.googleapis.com and 199.36.153.8/30 instead. ‡ Prefer Google Deployment Manager? My colleague Gert Wolfis has written a similar article that focuses on using GDM templates for BIG-IP deployment. You can find his article at https://devcentral.f5.com/s/articles/Deploy-BIG-IP-on-GCP-with-GDM-without-Internet-access.335Views1like0Comments